A Deep Reinforcement Learning Algorithm for Smart Control of Hysteresis Phenomena in a Mode-Locked Fiber Laser

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
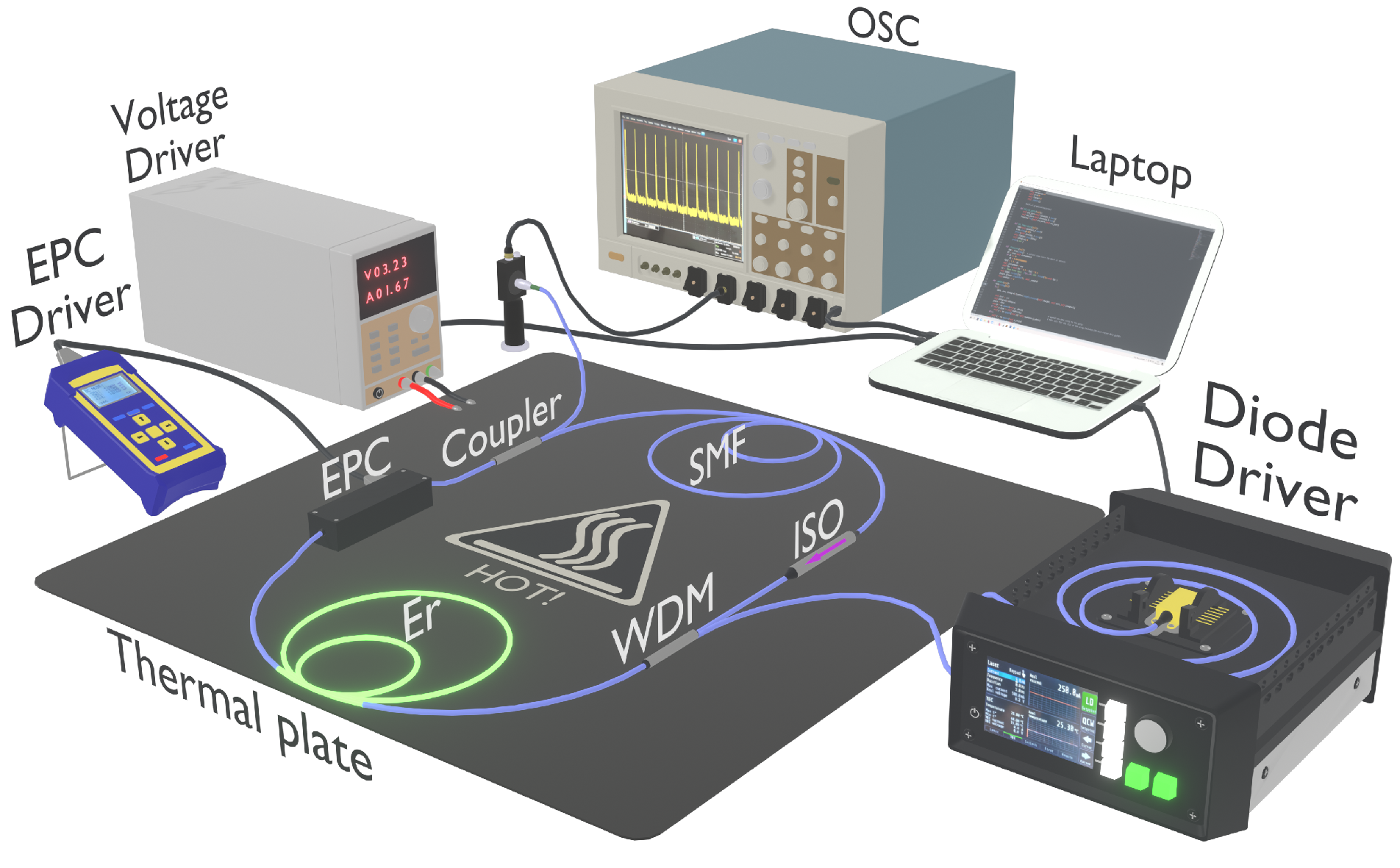
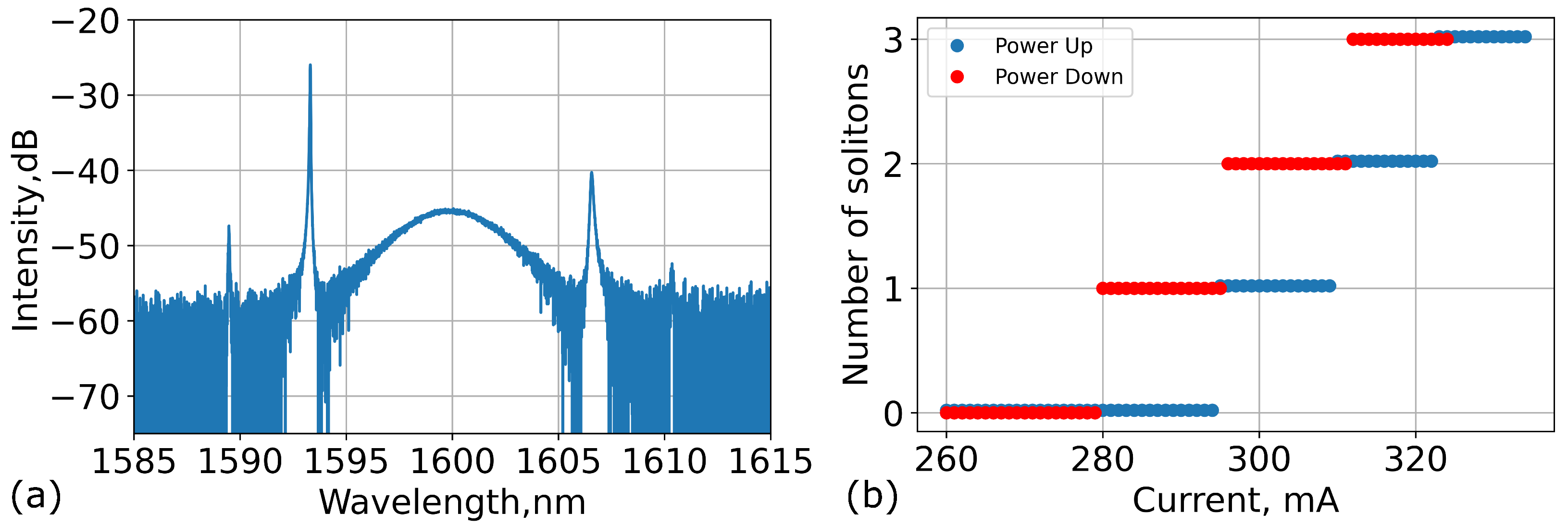
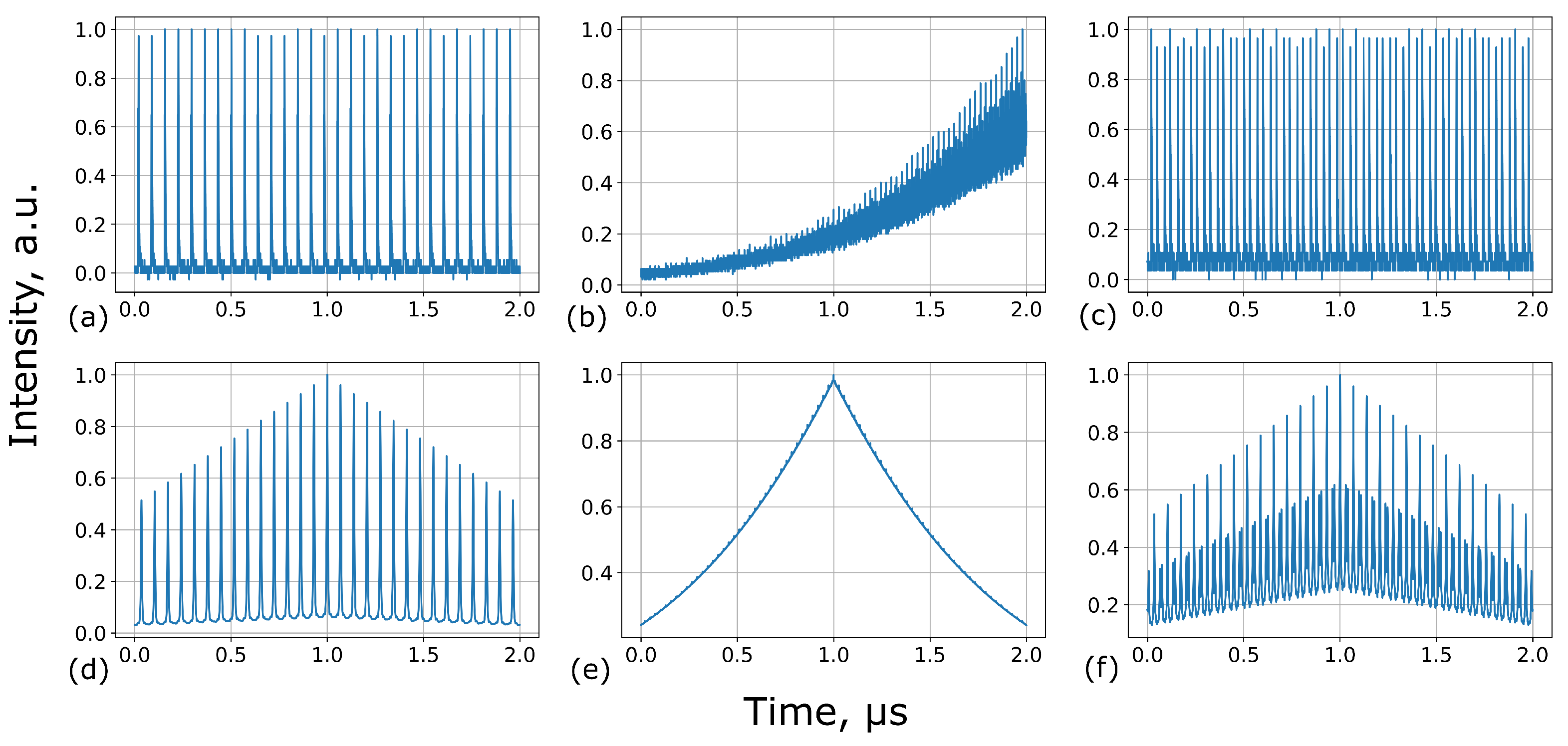
2. Experimental Setup
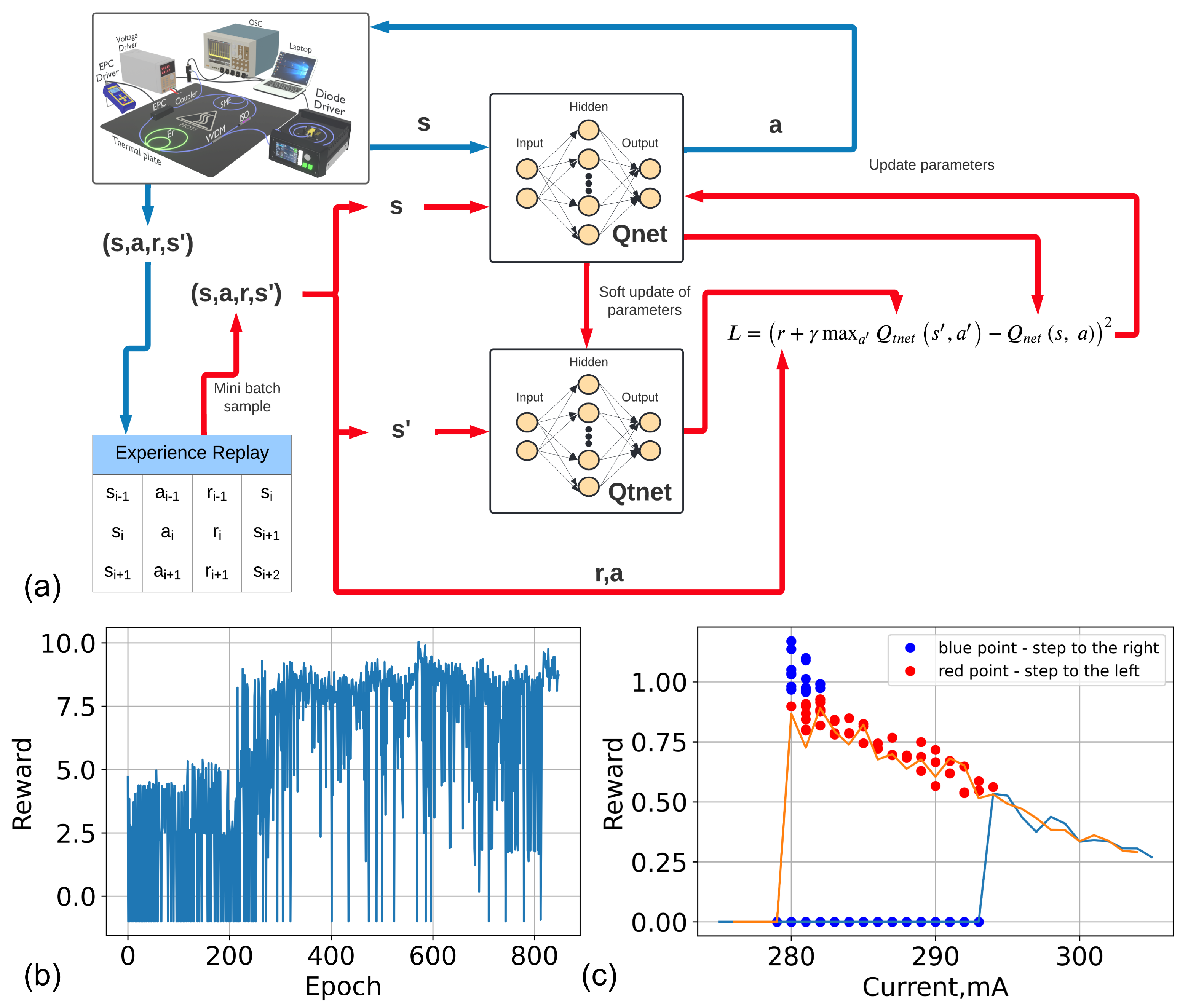
3. Reinforcement Learning
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Genty, G.; Salmela, L.; Dudley, J.M.; Brunner, D.; Kokhanovskiy, A.; Kobtsev, S.; Turitsyn, S.K. Machine learning and applications in ultrafast photonics. Nat. Photonics 2021, 15, 91–101. [Google Scholar] [CrossRef]
- Pu, G.; Yi, L.; Zhang, L.; Luo, C.; Li, Z.; Hu, W. Intelligent control of mode-locked femtosecond pulses by time-stretch-assisted real-time spectral analysis. Light Sci. Appl. 2020, 9, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, X.; Peng, J.; Boscolo, S.; Zhang, Y.; Finot, C.; Zeng, H. Intelligent breathing soliton generation in ultrafast fiber lasers. Laser Photonics Rev. 2022, 16, 2100191. [Google Scholar] [CrossRef]
- Kokhanovskiy, A.; Bednyakova, A.; Kuprikov, E.; Ivanenko, A.; Dyatlov, M.; Lotkov, D.; Kobtsev, S.; Turitsyn, S. Machine learning-based pulse characterization in figure-eight mode-locked lasers. Opt. Lett. 2019, 44, 3410–3413. [Google Scholar] [CrossRef] [PubMed]
- Andral, U.; Buguet, J.; Fodil, R.S.; Amrani, F.; Billard, F.; Hertz, E.; Grelu, P. Toward an autosetting mode-locked fiber laser cavity. JOSA B 2016, 33, 825–833. [Google Scholar] [CrossRef]
- Zibar, D.; Brusin, A.M.R.; de Moura, U.C.; Da Ros, F.; Curri, V.; Carena, A. Inverse system design using machine learning: The Raman amplifier case. J. Light. Technol. 2019, 38, 736–753. [Google Scholar] [CrossRef] [Green Version]
- Iegorov, R.; Teamir, T.; Makey, G.; Ilday, F. Direct control of mode-locking states of a fiber laser. Optica 2016, 3, 1312–1315. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.; Lin, W.; Tan, Y.J.; Cui, H.; Luo, Z.C.; Xu, W.C.; Luo, A.P. Pulses with switchable wavelengths and hysteresis in an all-fiber spatio-temporal mode-locked laser. Appl. Phys. Express 2020, 13, 022008. [Google Scholar] [CrossRef]
- Kuprikov, E.; Kokhanovskiy, A.; Kobtsev, S.; Turitysin, S. Exploiting hysteresis effect for electronic adjusting of fiber mode-locked laser. In Proceedings of the 2020 International Conference Laser Optics (ICLO), Saint Petersburg, Russia, 2–6 November 2020; IEEE: Piscataway, NJ, USA, 2020; p. 1. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Sun, C.; Kaiser, E.; Brunton, S.L.; Kutz, J.N. Deep reinforcement learning for optical systems: A case study of mode-locked lasers. Mach. Learn. Sci. Technol. 2020, 1, 045013. [Google Scholar] [CrossRef]
- Yan, Q.; Deng, Q.; Zhang, J.; Zhu, Y.; Yin, K.; Li, T.; Wu, D.; Jiang, T. Low-latency deep-reinforcement learning algorithm for ultrafast fiber lasers. Photonics Res. 2021, 9, 1493–1501. [Google Scholar] [CrossRef]
- Kuprikov, E.; Kokhanovskiy, A.; Serebrennikov, K.; Turitsyn, S. Deep reinforcement learning for self-tuning laser source of dissipative solitons. Sci. Rep. 2022, 12, 7185. [Google Scholar] [CrossRef] [PubMed]
- Tang, D.; Zhao, L.M.; Zhao, B.; Liu, A. Mechanism of multisoliton formation and soliton energy quantization in passively mode-locked fiber lasers. Phys. Rev. A 2005, 72, 043816. [Google Scholar] [CrossRef]
- Li, R.; Zou, J.; Li, W.; Wang, K.; Du, T.; Wang, H.; Sun, X.; Xiao, Z.; Fu, H.; Luo, Z. Ultrawide-space and controllable soliton molecules in a narrow-linewidth mode-locked fiber laser. IEEE Photonics Technol. Lett. 2018, 30, 1423–1426. [Google Scholar] [CrossRef]
- Komarov, A.; Komarov, K.; Sanchez, F. Quantization of binding energy of structural solitons in passive mode-locked fiber lasers. Phys. Rev. A 2009, 79, 033807. [Google Scholar] [CrossRef] [Green Version]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.; Sutton, R.S. A deeper look at experience replay. arXiv 2017, arXiv:1712.01275. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Gaskett, C.; Wettergreen, D.; Zelinsky, A. Q-learning in continuous state and action spaces. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Sydney, Australia, 6–10 December 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 417–428. [Google Scholar]
- Espeholt, L.; Soyer, H.; Munos, R.; Simonyan, K.; Mnih, V.; Ward, T.; Doron, Y.; Firoiu, V.; Harley, T.; Dunning, I.; et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1407–1416. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Freire, P.J.; Abode, D.; Prilepsky, J.E.; Costa, N.; Spinnler, B.; Napoli, A.; Turitsyn, S.K. Transfer Learning for Neural Networks-Based Equalizers in Coherent Optical Systems. J. Lightwave Technol. 2021, 39, 6733–6745. [Google Scholar] [CrossRef]
- Freire, P.J.; Spinnler, B.; Abode, D.; Prilepsky, J.E.; Ali, A.; Costa, N.; Schairer, W.; Napoli, A.; Ellis, A.D.; Turitsyn, S.K. Domain Adaptation: The Key Enabler of Neural Network Equalizers in Coherent Optical Systems. In Proceedings of the Optical Fiber Communication Conference (OFC) 2022, San Diego, CA, USA, 6–10 March 2022; p. Th2A.35. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kokhanovskiy, A.; Shevelev, A.; Serebrennikov, K.; Kuprikov, E.; Turitsyn, S. A Deep Reinforcement Learning Algorithm for Smart Control of Hysteresis Phenomena in a Mode-Locked Fiber Laser. Photonics 2022, 9, 921. https://doi.org/10.3390/photonics9120921
Kokhanovskiy A, Shevelev A, Serebrennikov K, Kuprikov E, Turitsyn S. A Deep Reinforcement Learning Algorithm for Smart Control of Hysteresis Phenomena in a Mode-Locked Fiber Laser. Photonics. 2022; 9(12):921. https://doi.org/10.3390/photonics9120921
Chicago/Turabian StyleKokhanovskiy, Alexey, Alexey Shevelev, Kirill Serebrennikov, Evgeny Kuprikov, and Sergey Turitsyn. 2022. "A Deep Reinforcement Learning Algorithm for Smart Control of Hysteresis Phenomena in a Mode-Locked Fiber Laser" Photonics 9, no. 12: 921. https://doi.org/10.3390/photonics9120921
APA StyleKokhanovskiy, A., Shevelev, A., Serebrennikov, K., Kuprikov, E., & Turitsyn, S. (2022). A Deep Reinforcement Learning Algorithm for Smart Control of Hysteresis Phenomena in a Mode-Locked Fiber Laser. Photonics, 9(12), 921. https://doi.org/10.3390/photonics9120921