
Variable Selection for Fault Detection Based on Causal Discovery Methods: Analysis of an Actual Industrial Case

 , , , ,
, , , ,  , ,
, , 
Abstract
:1. Introduction
- a benchmark case, where the procedures are used to evaluate some simulated faults of the Tennessee-Eastman process.
- a real industrial case, where the procedures are applied to actual industrial measurement datasets extracted from an oil and gas processing plant, with the objective to detect sensor faults reported by the operator.
2. Theoretical Background
2.1. Mutual Information and Entropy
2.2. Conditional Mutual Information
2.3. Conditional Independence and Causality
2.4. Approaches
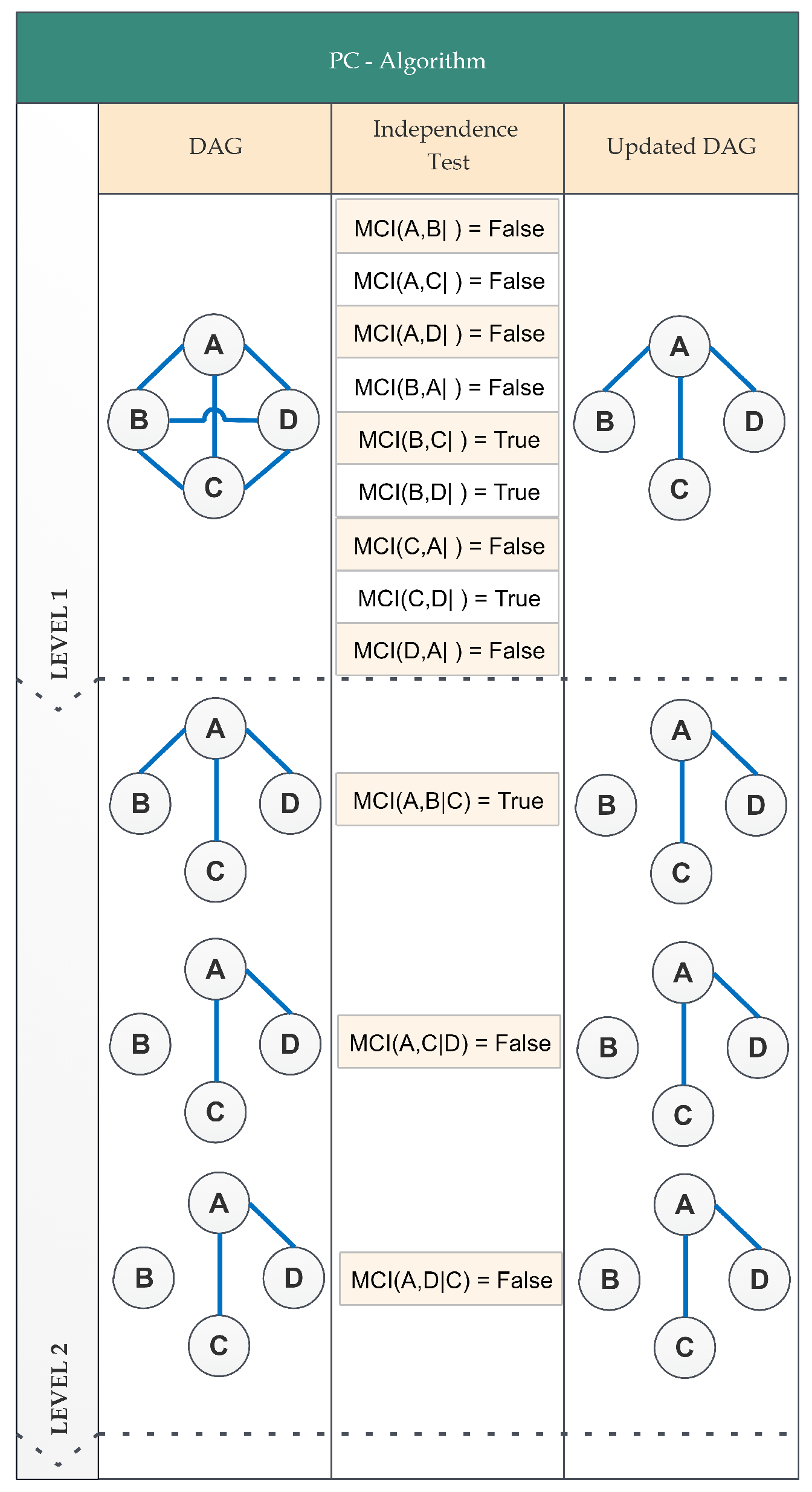
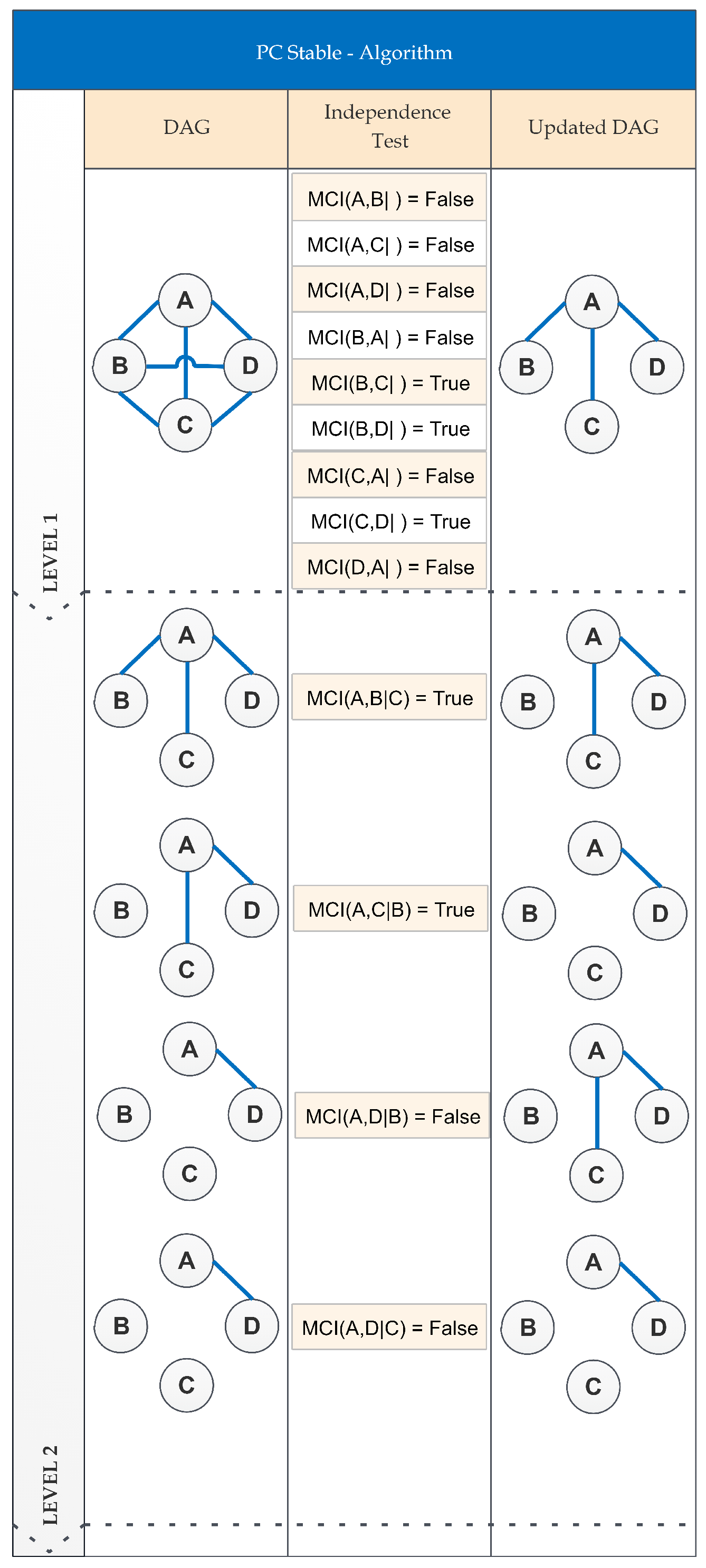
2.4.1. PC-Stable Algorithm

2.4.2. PCMCI Algorithm
- Estimate the parents for every variable using the PC-Stable algorithm.
- Using the estimated set of parents, perform a novel independence test called momentary conditional independence (MCI), where given the variable pair :
3. Case Studies
3.1. Benchmark Case: Tennessee-Eastman Process
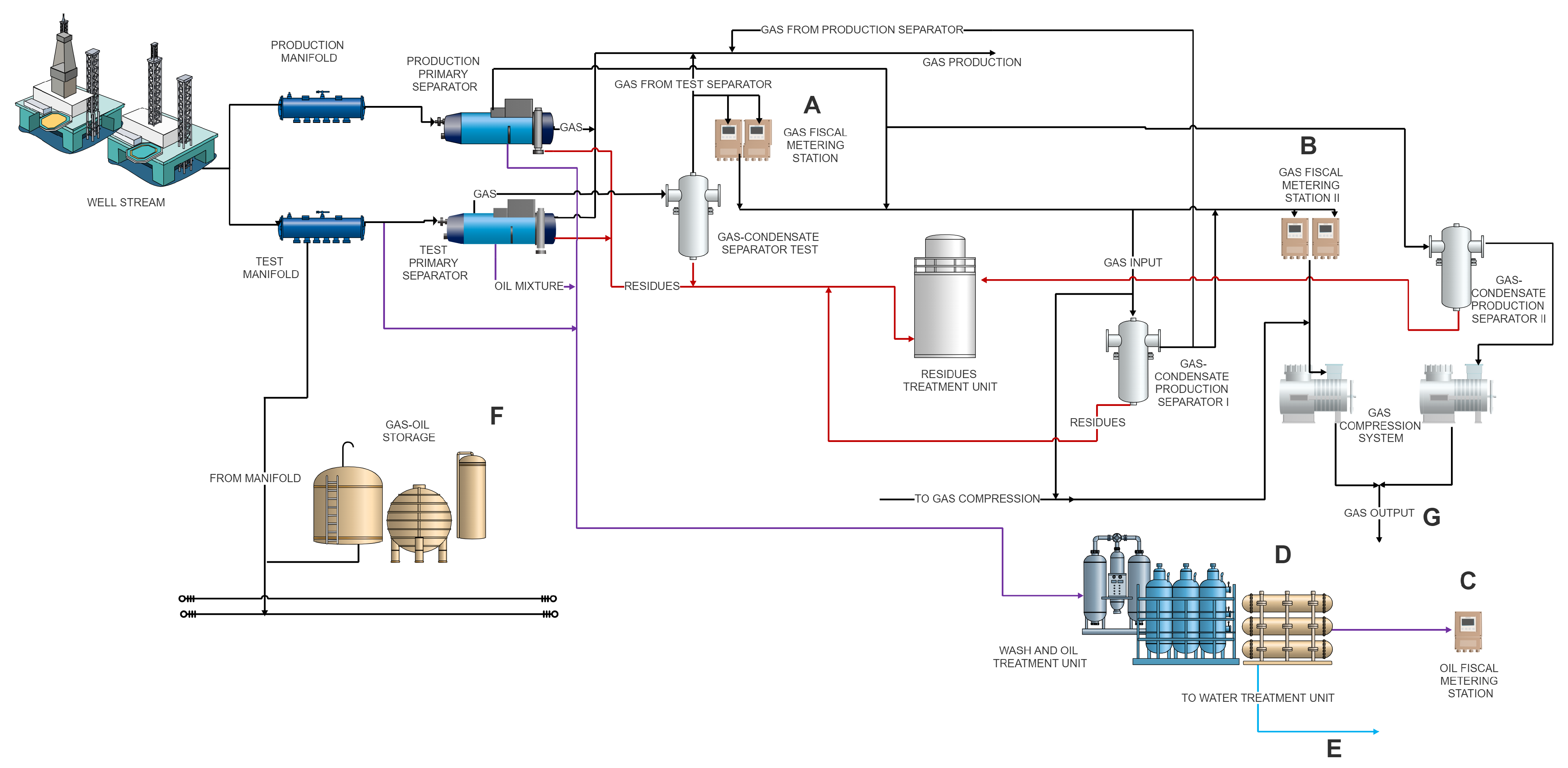
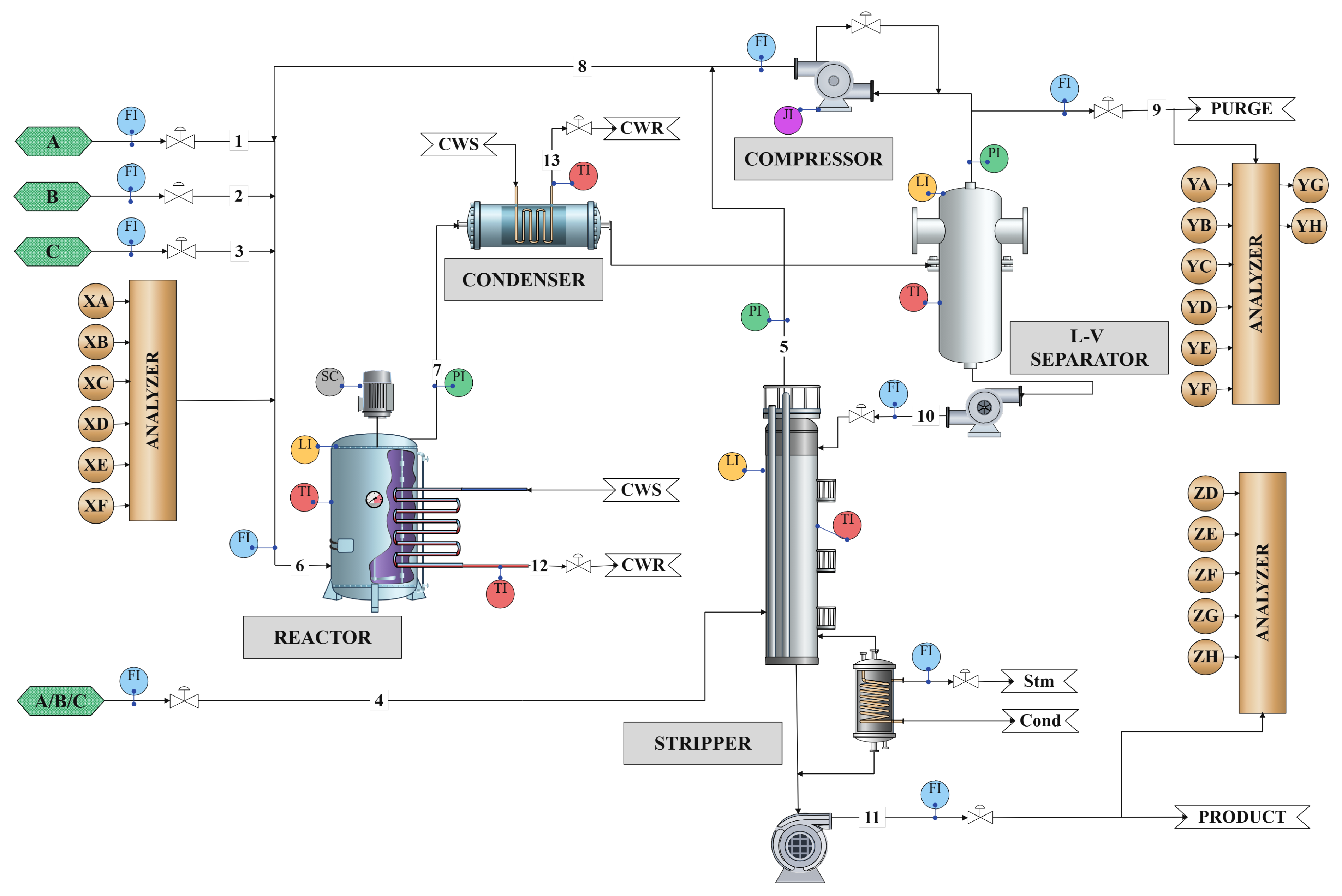
3.2. Real Industrial Case: Oil and Gas Fiscal Metering Station
3.3. Methodology
4. Results
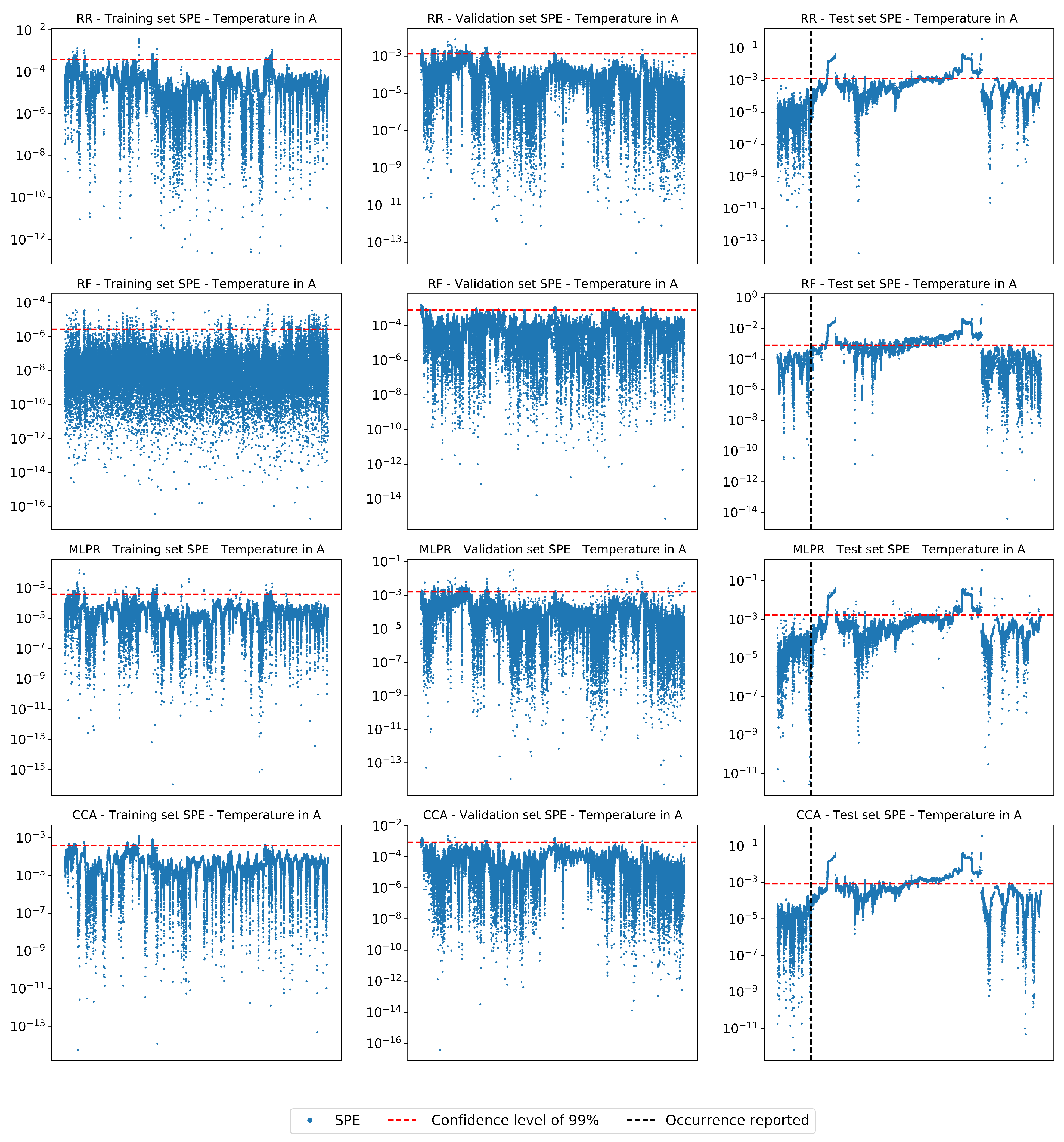
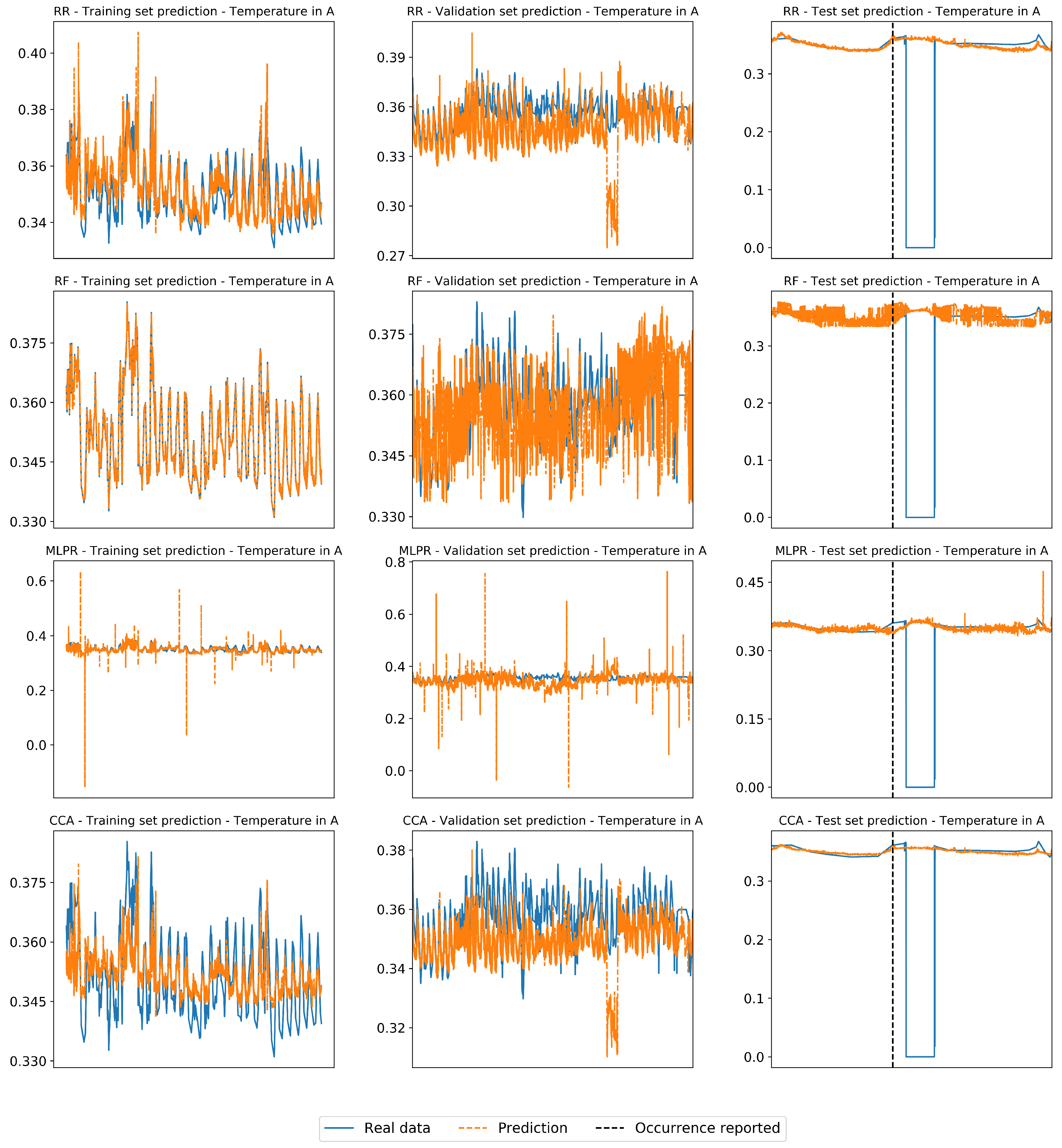
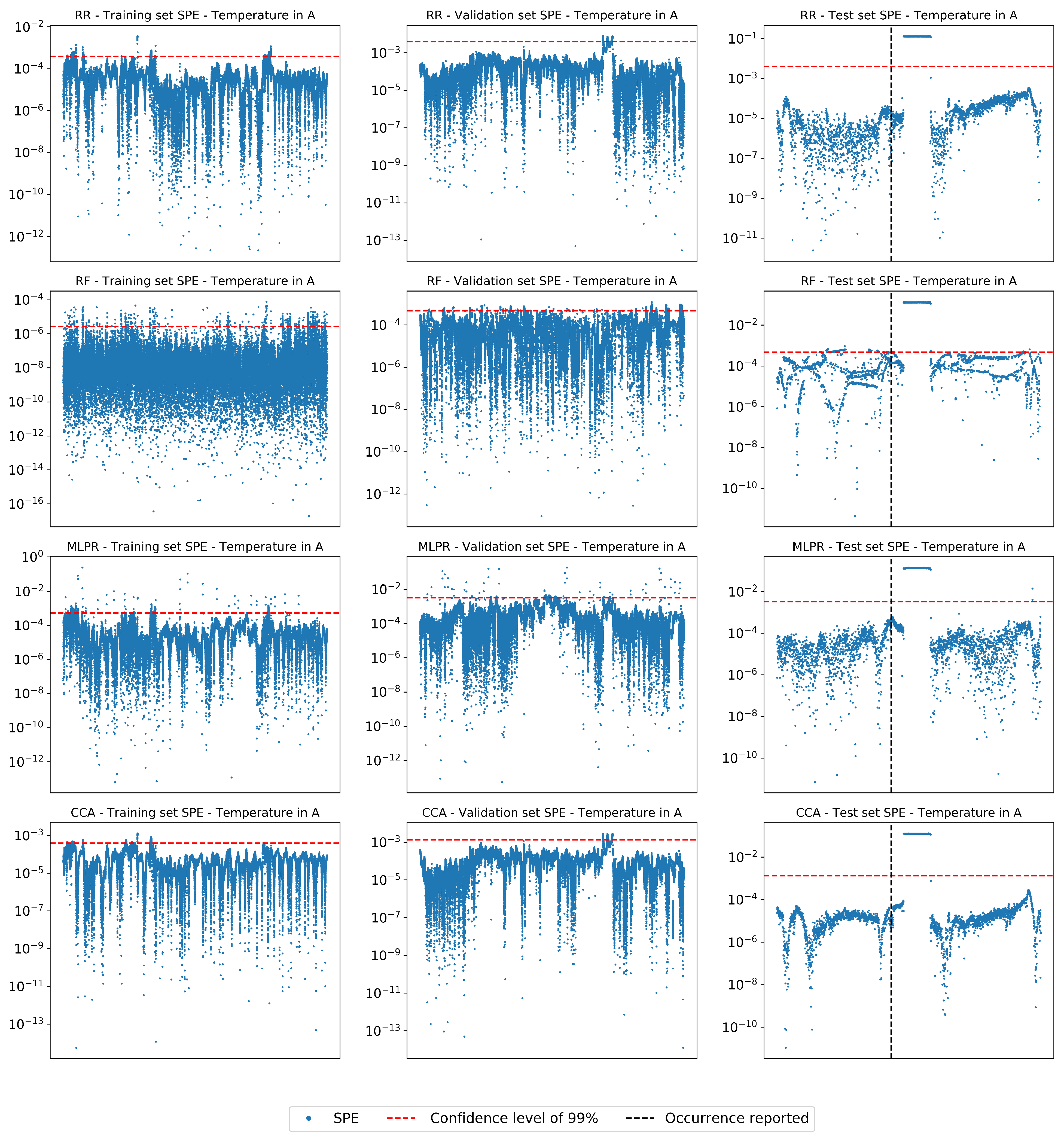
4.1. Performance on Real Industrial Case
4.2. Performance on Benchmark Case
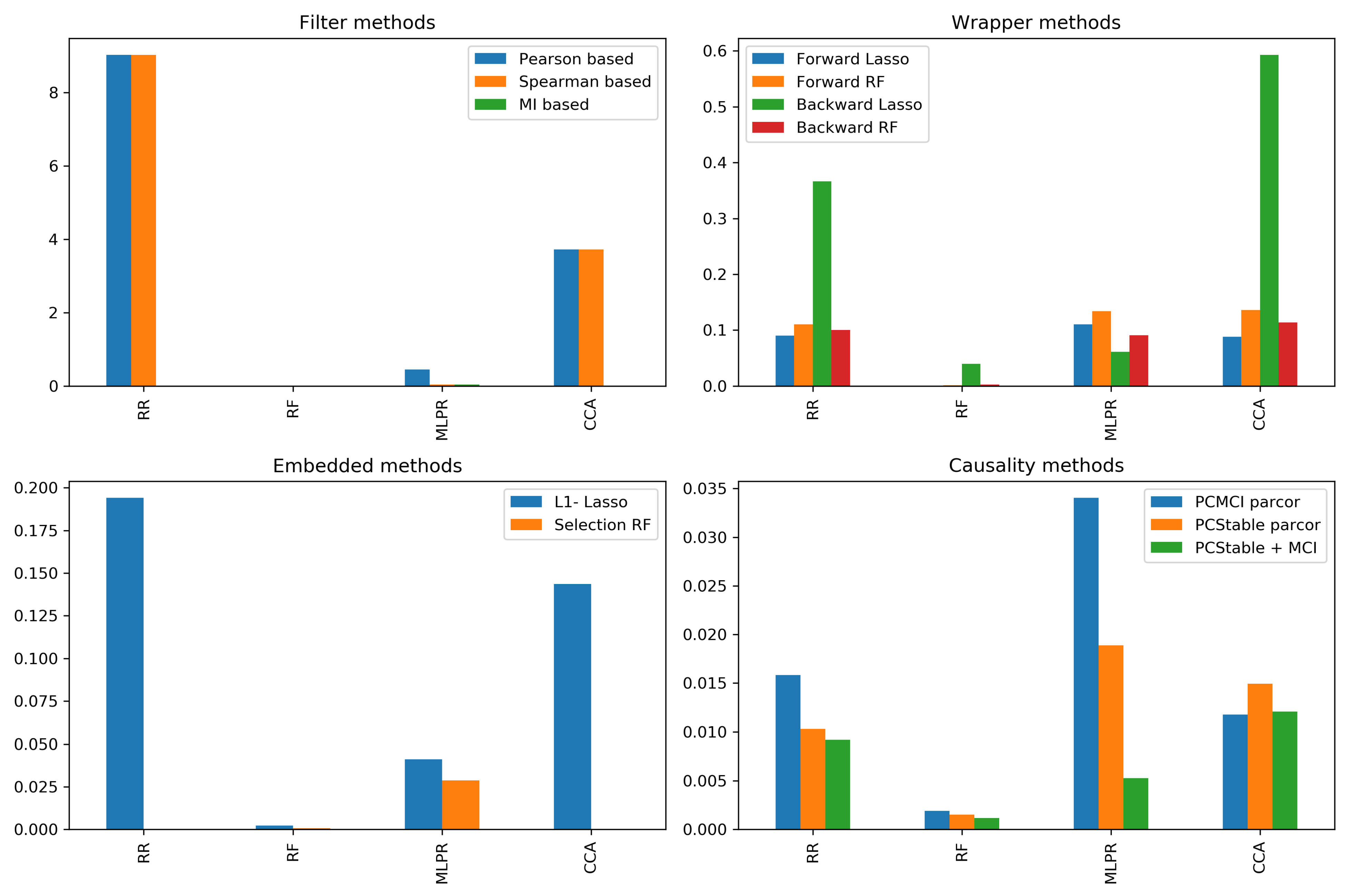
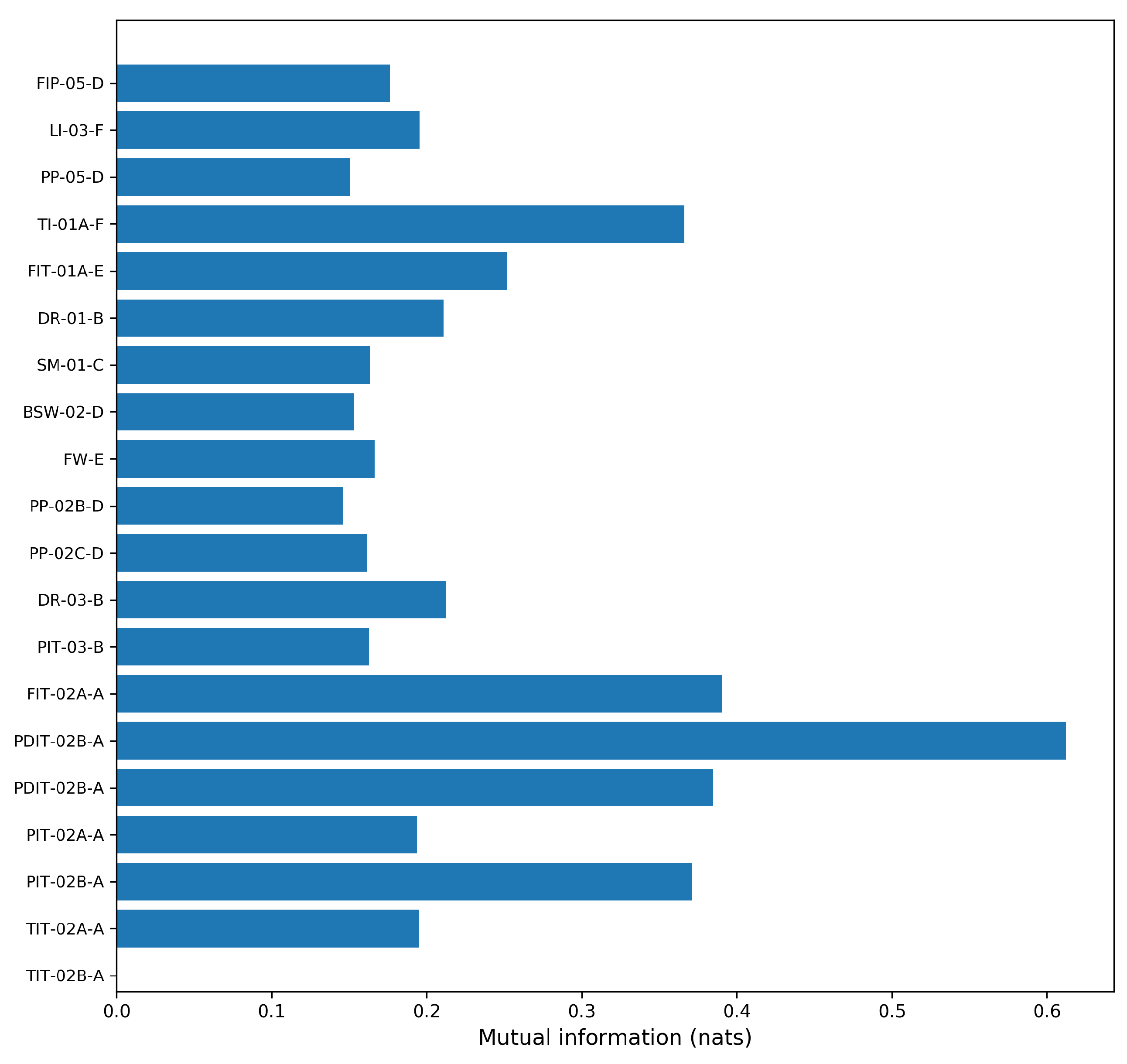
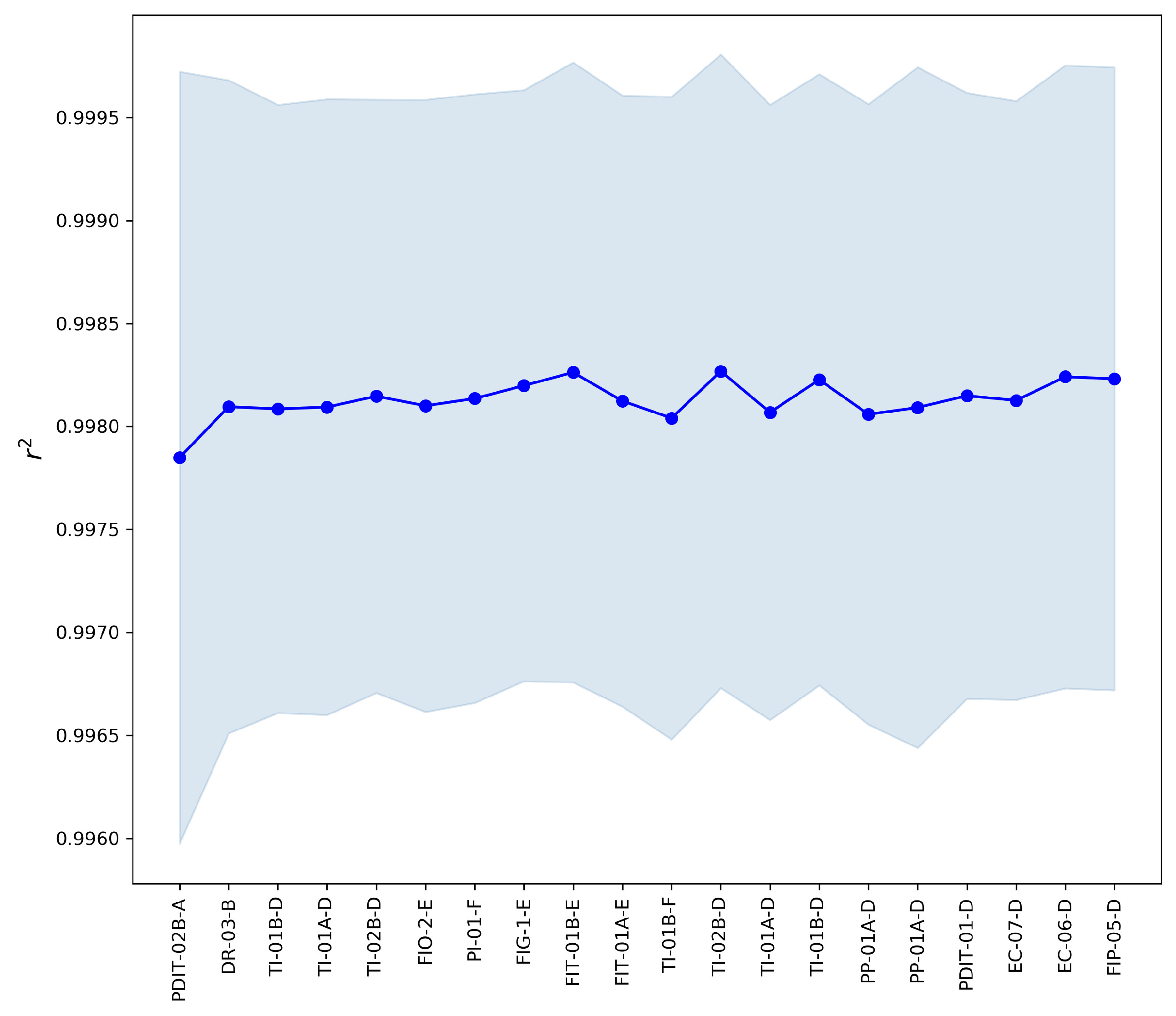
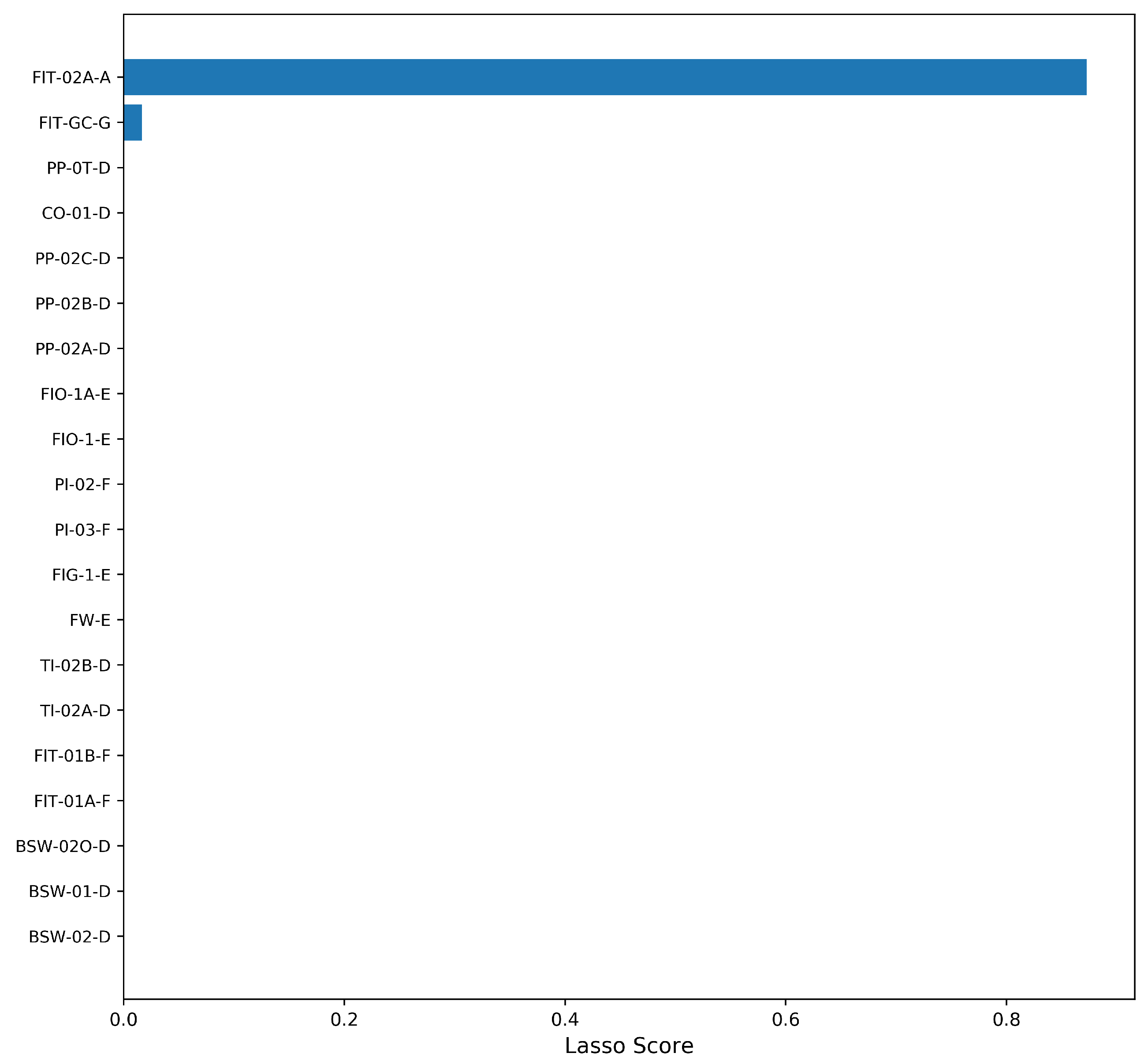
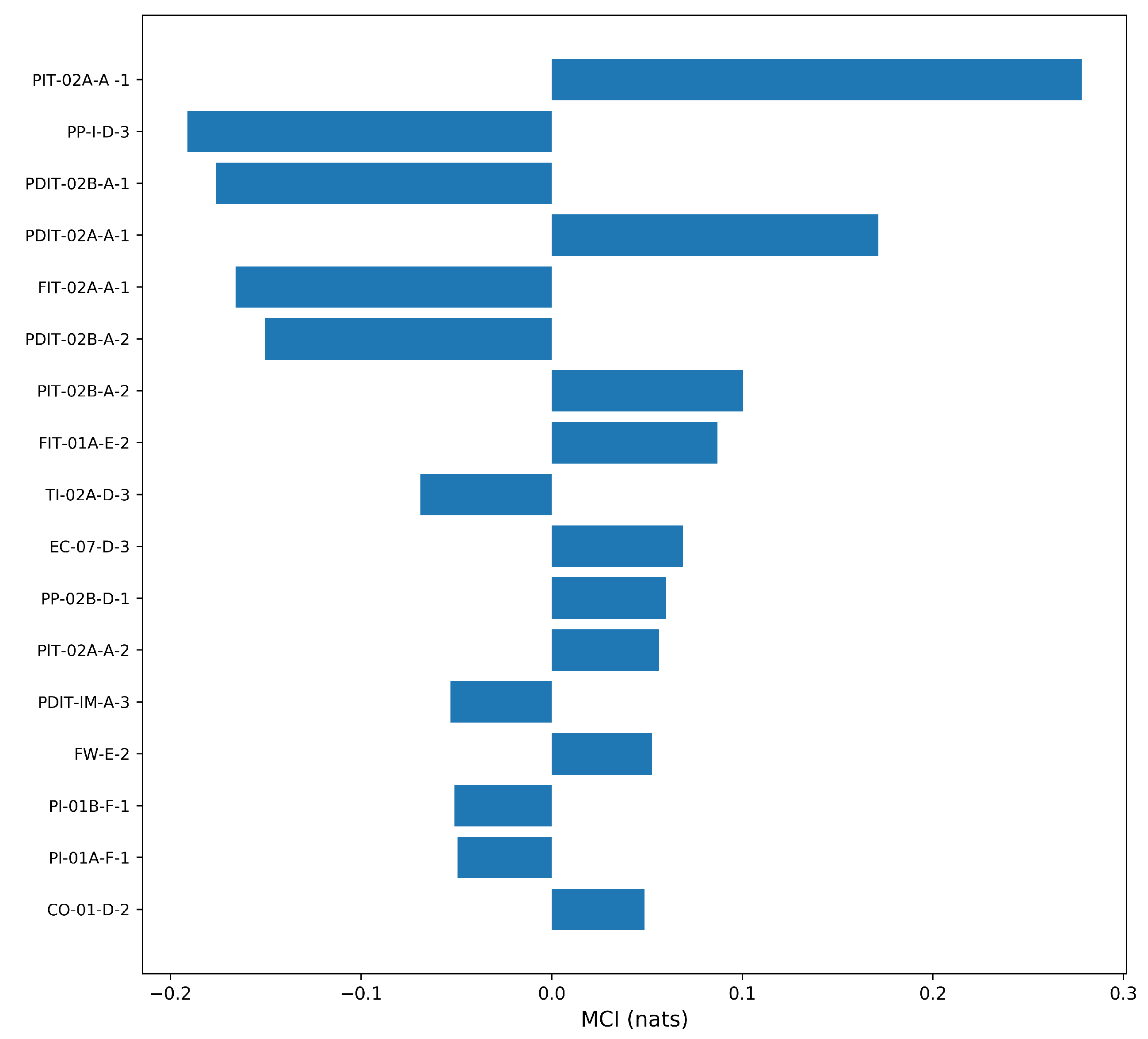
4.3. Analysis of Selected Variables
4.4. Final Considerations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MI | Mutual information |
| JMI | Joint mutual information |
| CMI | Conditional mutual information |
| DMI | Dynamic mutual information |
| TE | Transfer entropy |
| Probability density function | |
| DAG | Directed acyclic graph |
| TEP | Tennessee Eastman process |
| SPE | Square prediction error |
| PCA | Principal components analysis |
| FDR | Fault detection rate |
| FAR | False alarm rate |
| RF | Random Forest |
| RR | Ridge regression |
| MLPR | Multi-layer perceptron regressor |
| CCA | Canonical correlation analysis |
| MCI | Mutual conditional independence |
| PFD | Process flow diagram |
| MAE | Mean absolute error |
Appendix A
Appendix A.1. PC Algorithm and PC-Stable Algorithm


Appendix A.2. Tennessee Eastman Process


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measured Variable ID | Description |
|---|---|
| F1 | Feed flow component A (stream 1) in kscmh |
| F2 | Feed flow component D (stream 2) in kg/h |
| F3 | Feed flow component E (stream 3) in kg/h |
| F4 | Feed flow components A/B/C (stream 4) in kscmh |
| F5 | Recycle flow to reactor from separator (stream 8) in kscmh |
| F6 | Reactor feed rate (stream 6) in kscmh |
| P7 | Reactor pressure in kPa gauge |
| L8 | Reactor level |
| T9 | Reactor temperature in °C |
| F10 | Purge flow rate (stream 9) in kscmh |
| T11 | Separator temperature in °C |
| L12 | Separator level |
| P13 | Separator pressure in kPa gauge |
| F14 | Separator underflow in liquid phase (stream 10) in m³/h |
| L15 | Stripper level |
| P16 | Stripper pressure in kPa gauge |
| F17 | Stripper underflow (stream 11) in m³/h |
| T18 | Stripper temperature in °C |
| F19 | Stripper steam flow in kg/h |
| J20 | Compressor work in kW |
| T21 | Reactor cooling water outlet temperature in °C |
| T22 | Condenser cooling water outlet temperature in °C |
| XA | Concentration of A in reactor feed (stream 6) in mol% |
| XB | Concentration of B in reactor feed (stream 6) in mol% |
| XC | Concentration of C in reactor feed (stream 6) in mol% |
| XD | Concentration of D in reactor feed (stream 6) in mol% |
| XE | Concentration of E in reactor feed (stream 6) in mol% |
| XF | Concentration of F in reactor feed (stream 6) in mol% |
| YA | Concentration of A in purge (stream 9) in mol% |
| YB | Concentration of B in purge (stream 9) in mol% |
| YC | Concentration of C in purge (stream 9) in mol% |
| YD | Concentration of D in purge (stream 9) in mol% |
| YE | Concentration of E in purge (stream 9) in mol% |
| YF | Concentration of F in purge (stream 9) in mol% |
| YG | Concentration of G in purge (stream 9) in mol% |
| YH | Concentration of H in purge (stream 9) in mol% |
| ZD | Concentration of D in stripper underflow (stream 11) in mol% |
| ZE | Concentration of E in stripper underflow (stream 11) in mol% |
| ZF | Concentration of F in stripper underflow (stream 11) in mol% |
| ZG | Concentration of G in stripper underflow (stream 11) in mol% |
| ZH | Concentration of H in stripper underflow (stream 11) in mol% |
| Manipulated Variable ID | Description |
|---|---|
| MV1 | Valve position feed component D (stream 2) |
| MV2 | Valve position feed component E (stream 3) |
| MV3 | Valve position feed component A (stream 1) |
| MV4 | Valve position feed components A/B/C (stream 4) |
| MV5 | Valve position compressor recycle |
| MV6 | Purge valve position (stream 9) |
| MV7 | Valve position underflow separator (stream 10) |
| MV8 | Valve position underflow stripper (stream 11) |
| MV9 | Valve position stripper steam |
| MV10 | Valve position cooling water outlet of reactor |
| MV11 | Valve position cooling water outlet of separator |
| MV12 | Rotation speed of reactor agitator |
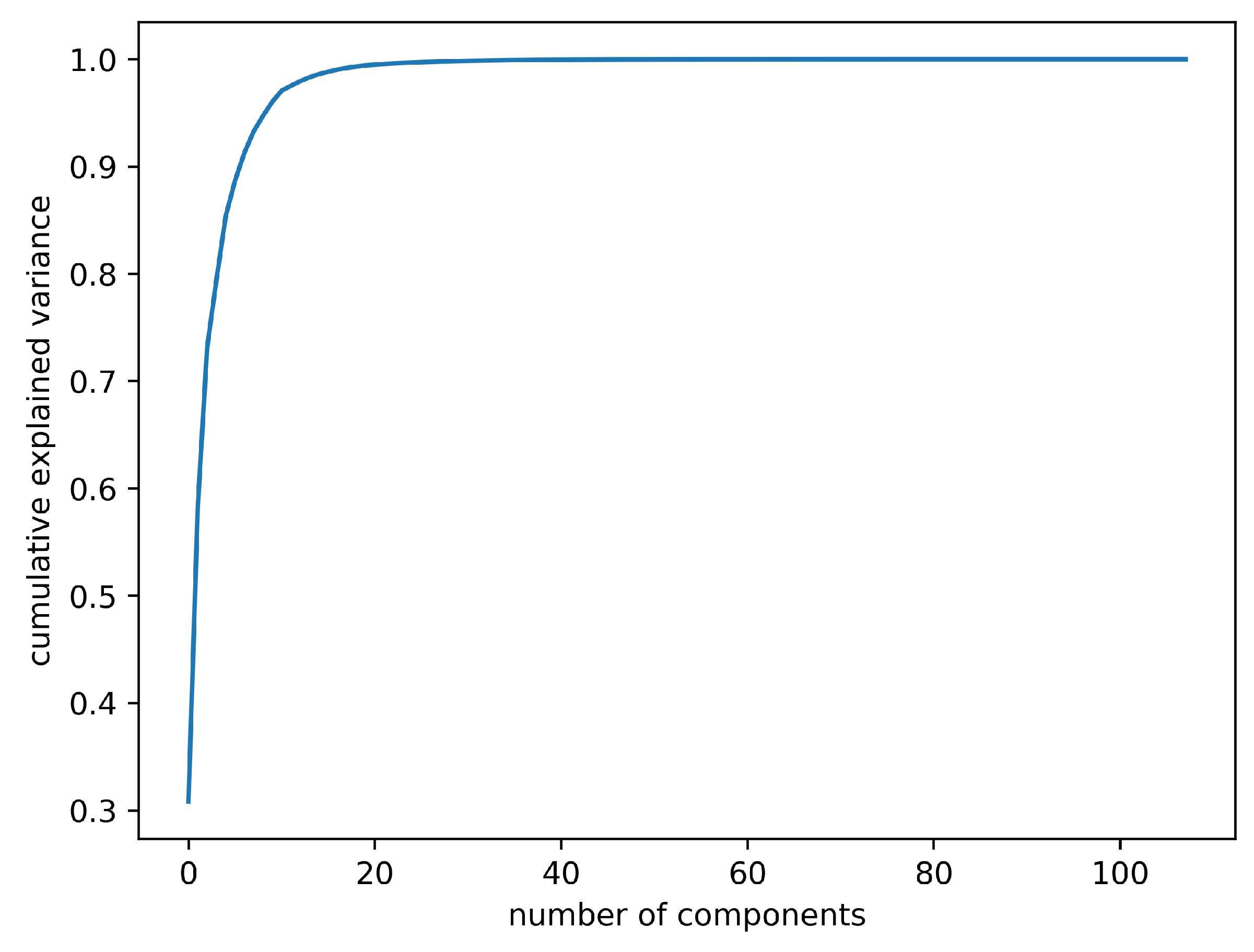
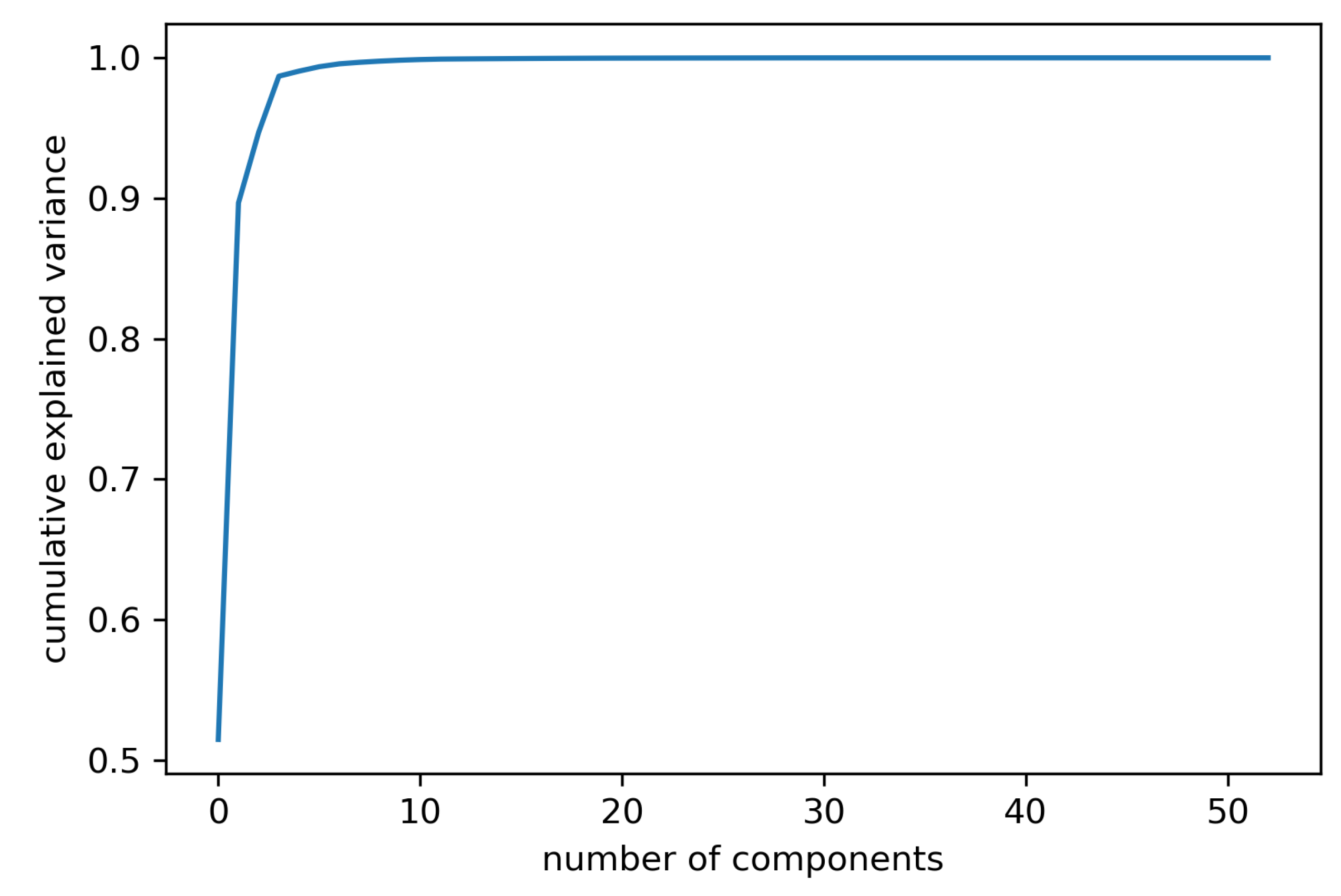
Appendix A.3. Principal Component Analysis in Case Studies


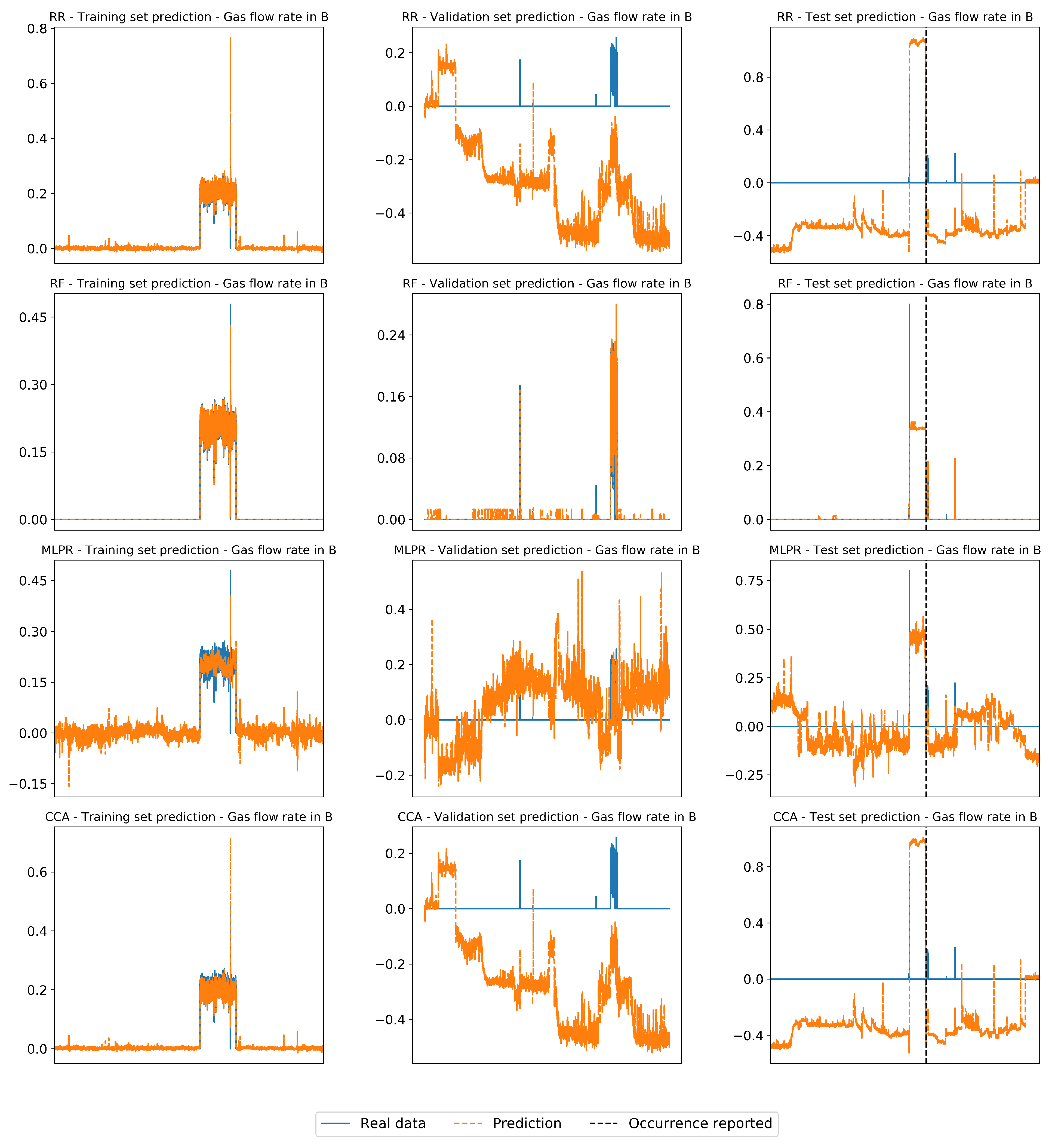
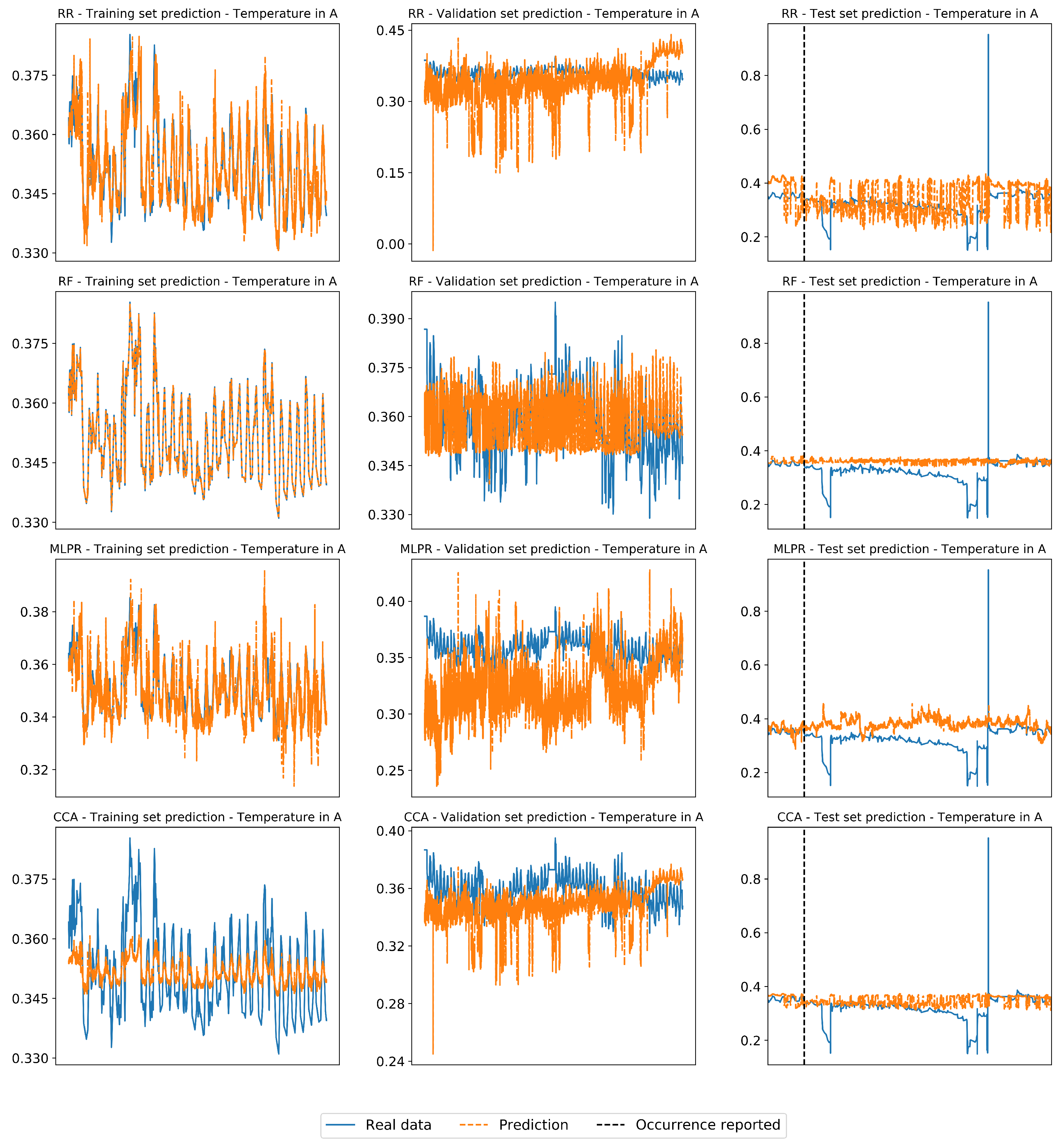
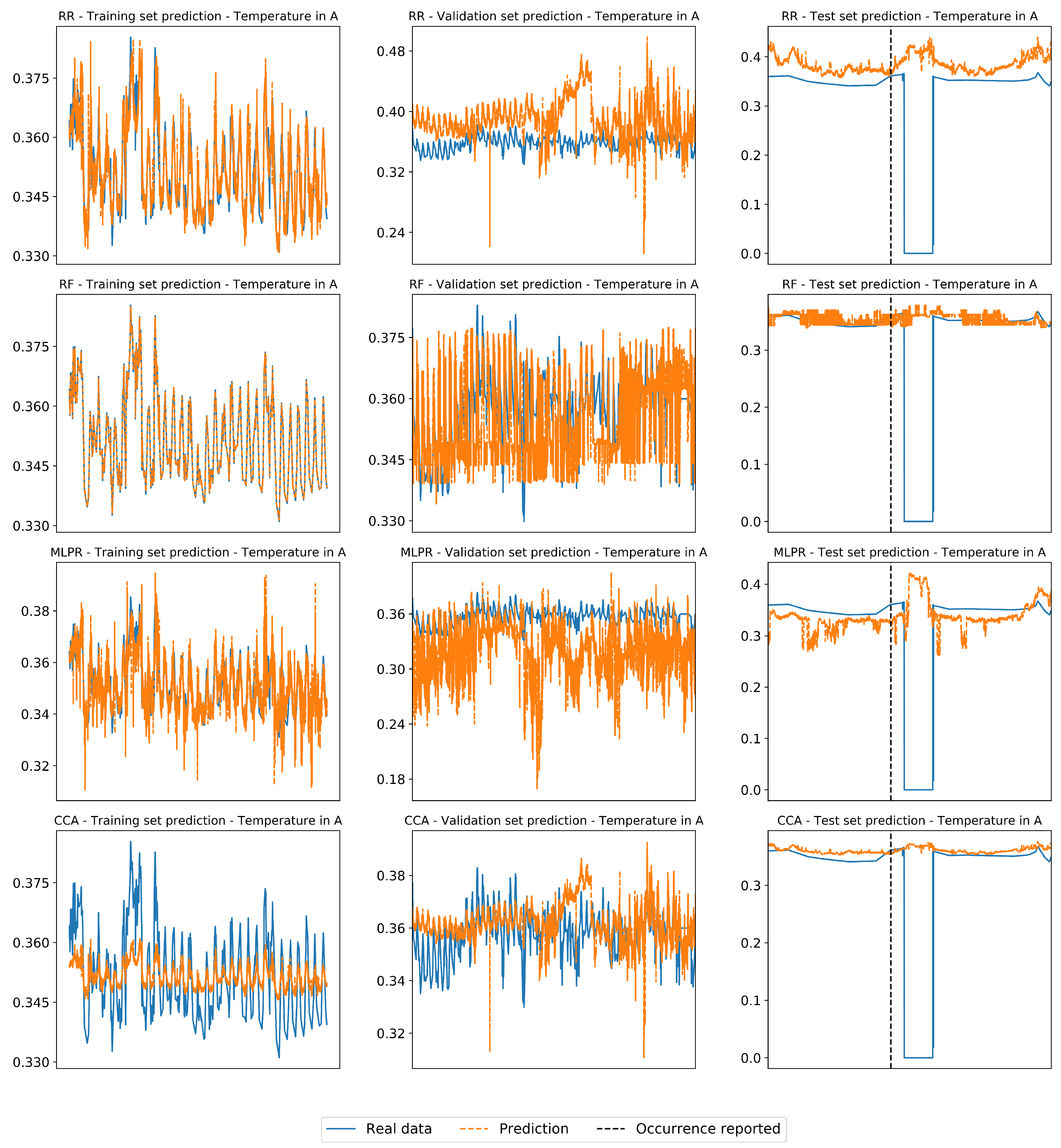
Appendix A.4. Regressors Prediction of Reference Scenarios in Real Industrial Case



Appendix A.5. Selected Subsets in Fault Detection F-I Scenario




Appendix A.6. Variables and Tags of the Real Industrial Case
| Variable | Tag | Plant Section | Variable | Tag | Plant Section |
|---|---|---|---|---|---|
| Gas flow rate in processing 05 | FIP-05-D | D | Temperature of water output in cooler 02B | TI-02B-D | D |
| Level Tank 03 | LI-03-F | F | Temperature of water output in cooler 02A | TI-02A-D | D |
| Pump pressure 05 in oil transfer | PP-05-D | D | Flow rate in transfer oil 01B | FIT-01B-F | F |
| Temperature in treatment tank 01A | TI-01A-F | F | Flow rate in transfer oil 01A | FIT-01A-F | F |
| Flow rate for water treatmente 01A | FIT-01A-E | E | BSW in treatment tank outlet 02 | BSW-02O-D | D |
| Density in gas fiscal meter 01 | DR-01-A | A | BSW in treatment tank 01 | BSW-01-D | D |
| Specific mass in oil fiscal meter 01 | SM-01-C | C | Density in gas fiscal meter 03 | DR-03-B | B |
| BSW in treatment tank 02 | BSW-02-D | D | Temperature of oil output in cooler 01B | TI-01B-D | D |
| Flow of water treated | FW-E | E | Temperature of oil output in cooler 01A | TI-01A-D | D |
| Pump pressure 02B | PP-02B-D | D | Temperature of oil input in heat exchanger 02B | TI-02B-D | D |
| Pump pressure 02C | PP-02C-D | D | Oil flow rate 2 | FIO-2-E | E |
| Density in gas fiscal meter 03 | DR-03-A | A | Tank Pressure 01 | PI-01-F | F |
| Static pressure in gas fiscal meter 03 | PIT-03-B | B | Flow rate for water treatmente 01B | FIT-01B-E | E |
| Flow rage in gas fiscal meter 02A | FIT-02A-A | A | Temperature in treatment tank 01B | TI-01B-F | F |
| Pressure differential in gas fiscal meter 02A | PDIT-02A-A | A | Temperature of oil output in heat exchanger 01B | TI-02B-D | D |
| Pressure differential in gas fiscal meter 02B | PDIT-02B-A | A | Temperature of oil input in heat exchanger 01A | TI-01A-D | D |
| Static pressure in gas fiscal meter 02A | PIT-02A-A | A | Temperature of oil input in heat exchanger 01B | TI-01B-D | D |
| Static pressure in gas fiscal meter 02B | PIT-02B-A | A | Pump pressure 01B in oil transfer | PP-01B-D | D |
| Temperature in gas fiscal meter 02A | TIT-02A-A | A | Pump pressure 01A in oil transfer | PP-01A-D | D |
| Temperature in gas fiscal meter 02B | TIT-02B-A | A | Pressure differential in oil treatment tank 01 | PDIT-01-D | D |
| Gas flow rate | FIT-GC-G | G | Electric current in pump 07 | EC-07-D | D |
| Pump pressure in oil transfer | PP-0T-D | D | Electric current in pump 06 | EC-06-D | D |
| Controller output in wash tank 01 | CO-01-D | D | Flow injection in treament equipment 05 | FIP-05-D | D |
| Pump pressure 02A | PP-02A-D | D | Pump pressure for injection in Section D | PP-I-D | D |
| Oil flow rate 1A | FIO-1A-E | E | Pressure differential in importation gas | PDIT-IM-A | A |
| Oil flow rate 1 | FIO-1-E | E | Pressure in treatment tank 01B | PI-01B-F | F |
| Tank Pressure 02 | PI-02-F | F | Pressure in treatment tank 01A | PI-01A-F | F |
| Tank Pressure 03 | PI-03-F | F | Controller output in wash tank 01 | CO-01-D | D |
| Gas flow rate 1 | FIG-1-E | E |
References
- Jiang, Q.; Yan, X.; Huang, B. Review and Perspectives of Data-Driven Distributed Monitoring for Industrial Plant-Wide Processes. Ind. Eng. Chem. Res. 2019, 58, 12899–12912. [Google Scholar] [CrossRef]
- Yuan, Z.; Qin, W.; Zhao, J. Smart Manufacturing for the Oil Refining and Petrochemical Industry. Engineering 2017, 3, 179–182. [Google Scholar] [CrossRef]
- Blum, A.L.; Langley, P. Selection of relevant features and examples in machine learning. Artif. Intell. 1997, 97, 245–271. [Google Scholar] [CrossRef] [Green Version]
- Rauber, T.W.; Boldt, F.A.; Munaro, C.J. Feature selection for multivariate contribution analysis in fault detection and isolation. J. Frankl. Inst. 2020, 357, 6294–6320. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Ghosh, K.; Ramteke, M.; Srinivasan, R. Optimal variable selection for effective statistical process monitoring. Comput. Chem. Eng. 2014, 60, 260–276. [Google Scholar] [CrossRef]
- Reunanen, J. Overfitting in Making Comparisons Between Variable Selection Methods. J. Mach. Learn. Res. 2003, 3, 1371–1382. [Google Scholar]
- Sun, Y.; Babbs, C.; Delp, E. A Comparison of Feature Selection Methods for the Detection of Breast Cancers in Mammograms: Adaptive Sequential Floating Search vs. Genetic Algorithm. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 1–4 September 2005; pp. 6532–6535. [Google Scholar] [CrossRef]
- Alexandridis, A.; Patrinos, P.; Sarimveis, H.; Tsekouras, G. A two-stage evolutionary algorithm for variable selection in the development of RBF neural network models. Chemom. Intell. Lab. Syst. 2005, 75, 149–162. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Society. Ser. B (Methodological) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zong, Y.B.; Jin, N.D.; Wang, Z.Y.; Gao, Z.K.; Wang, C. Nonlinear dynamic analysis of large diameter inclined oil–water two phase flow pattern. Int. J. Multiph. Flow 2010, 36, 166–183. [Google Scholar] [CrossRef]
- Sugumaran, V.; Muralidharan, V.; Ramachandran, K.I. Feature selection using Decision Tree and classification through Proximal Support Vector Machine for fault diagnostics of roller bearing. Mech. Syst. Signal Process. 2007, 21, 930–942. [Google Scholar] [CrossRef]
- Koller, D.; Sahami, M. Toward optimal feature selection. In Proceedings of the 13th International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; pp. 284–292. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [Green Version]
- Vergara, J.R.; Estévez, P.A. A review of feature selection methods based on mutual information. Neural Comput. Appl. 2014, 24, 175–186. [Google Scholar] [CrossRef]
- Tourassi, G.D.; Frederick, E.D.; Markey, M.K.; Floyd, C.E. Application of the mutual information criterion for feature selection in computer-aided diagnosis. Med. Phys. 2001, 28, 2394–2402. [Google Scholar] [CrossRef] [PubMed]
- Lucke, M.; Mei, X.; Stief, A.; Chioua, M.; Thornhill, N.F. Variable Selection for Fault Detection and Identification based on Mutual Information of Alarm Series ⁎⁎Financial support is gratefully acknowledged from the Marie Skodowska Curie Horizon 2020 EID-ITN project PROcess NeTwork Optimization for efficient and sustainable operation of Europe’s process industries taking machinery condition and process performance into account PRONTO, Grant agreement No 675215. IFAC-PapersOnLine 2019, 52, 673–678. [Google Scholar] [CrossRef]
- François, D.; Rossi, F.; Wertz, V.; Verleysen, M. Resampling methods for parameter-free and robust feature selection with mutual information. Neurocomputing 2007, 70, 1276–1288. [Google Scholar] [CrossRef] [Green Version]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Huang, J.; Cai, Y.; Xu, X. A hybrid genetic algorithm for feature selection wrapper based on mutual information. Pattern Recognit. Lett. 2007, 28, 1825–1844. [Google Scholar] [CrossRef]
- Mielniczuk, J.; Teisseyre, P. Stopping rules for mutual information-based feature selection. Neurocomputing 2019, 358, 255–274. [Google Scholar] [CrossRef]
- Frénay, B.; Doquire, G.; Verleysen, M. Is mutual information adequate for feature selection in regression? Neural Netw. 2013, 48, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Bennasar, M.; Hicks, Y.; Setchi, R. Feature selection using Joint Mutual Information Maximisation. Expert Syst. Appl. 2015, 42, 8520–8532. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Zhang, Y.; Zhang, Y.; Liu, H. Feature selection based on conditional mutual information: Minimum conditional relevance and minimum conditional redundancy. Appl. Intell. 2019, 49, 883–896. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, X.; Zhang, Y. Feature selection based on weighted conditional mutual information. Appl. Comput. Inf. 2020. ahead-of-print. [Google Scholar] [CrossRef]
- Liang, J.; Hou, L.; Luan, Z.; Huang, W. Feature Selection with Conditional Mutual Information Considering Feature Interaction. Symmetry 2019, 11, 858. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Sun, J.; Liu, L.; Zhang, H. Feature selection with dynamic mutual information. Pattern Recognit. 2009, 42, 1330–1339. [Google Scholar] [CrossRef]
- Granger, C.W.J. Investigating Causal Relations by Econometric Models and Cross-spectral Methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Runge, J.; Heitzig, J.; Marwan, N.; Kurths, J. Quantifying causal coupling strength: A lag-specific measure for multivariate time series related to transfer entropy. Phys. Rev. E 2012, 86, 061121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Wyner, A. A definition of conditional mutual information for arbitrary ensembles. Inf. Control 1978, 38, 51–59. [Google Scholar] [CrossRef] [Green Version]
- Runge, J. Quantifying information transfer and mediation along causal pathways in complex systems. Phys. Rev. E 2015, 92, 062829. [Google Scholar] [CrossRef] [Green Version]
- Runge, J. Causal network reconstruction from time series: From theoretical assumptions to practical estimation. Chaos Interdiscip. J. Nonlinear Sci. 2018, 28, 075310. [Google Scholar] [CrossRef] [PubMed]
- Runge, J.; Heitzig, J.; Petoukhov, V.; Kurths, J. Escaping the Curse of Dimensionality in Estimating Multivariate Transfer Entropy. Phys. Rev. Lett. 2012, 108, 258701. [Google Scholar] [CrossRef]
- Spirtes, P.; Glymour, C.; Scheines, R. Causation, Prediction, and Search; MIT: Cambridge, MA, USA, 1993. [Google Scholar] [CrossRef]
- Colombo, D.; Maathuis, M.H. Order-Independent Constraint-Based Causal Structure Learning. J. Mach. Learn. Res. 2014, 15, 3921–3962. [Google Scholar]
- Le, T.D.; Hoang, T.; Li, J.; Liu, L.; Liu, H.; Hu, S. A Fast PC Algorithm for High Dimensional Causal Discovery with Multi-Core PCs. IEEE/ACM Trans. Comput. Biol. Bioinf. 2019, 16, 1483–1495. [Google Scholar] [CrossRef] [Green Version]
- Runge, J.; Nowack, P.; Kretschmer, M.; Flaxman, S.; Sejdinovic, D. Detecting and quantifying causal associations in large nonlinear time series datasets. Sci. Adv. 2019, 5. [Google Scholar] [CrossRef] [Green Version]
- Zarebavani, B.; Jafarinejad, F.; Hashemi, M.; Salehkaleybar, S. cuPC: CUDA-Based Parallel PC Algorithm for Causal Structure Learning on GPU. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 530–542. [Google Scholar] [CrossRef] [Green Version]
- Downs, J.J.; Vogel, E.F. A plant-wide industrial process control problem. Comput. Chem. Eng. 1993, 17, 245–255. [Google Scholar] [CrossRef]
- Chiang, L.H.; Russell, E.L.; Braatz, R.D. Fault Detection and Diagnosis in Industrial Systems; Advanced Textbooks in Control and Signal Processing; Springer: London, UK, 2001. [Google Scholar] [CrossRef]
- Clavijo, N.; Melo, A.; Câmara, M.M.; Feital, T.; Anzai, T.K.; Diehl, F.C.; Thompson, P.H.; Pinto, J.C. Development and Application of a Data-Driven System for Sensor Fault Diagnosis in an Oil Processing Plant. Processes 2019, 7, 436. [Google Scholar] [CrossRef] [Green Version]
- Heaton, J. Introduction to Neural Networks for Java, 2nd ed.; Heaton Research, Inc.: St. Louis, MO, USA, 2008; Volume 1. [Google Scholar]
- Boger, Z.; Guterman, H. Knowledge extraction from artificial neural network models. In Proceedings of the Computational Cybernetics and Simulation 1997 IEEE International Conference on Systems, Man, and Cybernetics, Orlando, FL, USA, 15–17 October 1997; Volume 4, pp. 3030–3035. [Google Scholar] [CrossRef]
- Blum, A. Neural Networks in C++: An Object-Oriented Framework for Building Connectionist Systems, 1st ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1992. [Google Scholar]
- Sheela, K.G.; Deepa, S.N. Review on Methods to Fix Number of Hidden Neurons in Neural Networks. Math. Probl. Eng. 2013, 2013, 425740. [Google Scholar] [CrossRef] [Green Version]
- Bircanoğlu, C.; Arıca, N. A comparison of activation functions in artificial neural networks. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Pomerat, J.; Segev, A.; Datta, R. On Neural Network Activation Functions and Optimizers in Relation to Polynomial Regression. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 6183–6185. [Google Scholar] [CrossRef]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How Many Trees in a Random Forest? In Machine Learning and Data Mining in Pattern Recognition; Perner, P., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 154–168. [Google Scholar] [CrossRef]
- Probst, P.; Boulesteix, A.L. To tune or not to tune the number of trees in random forest. J. Mach. Learn. Res. 2017, 18, 6673–6690. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Kleiner, A.; Talwalkar, A.; Sarkar, P.; Jordan, M.I. A scalable bootstrap for massive data. J. R. Stat. Soc. Ser. B Stat. Methodol. 2014, 76, 795–816. [Google Scholar] [CrossRef] [Green Version]
- Ku, W.; Storer, R.H.; Georgakis, C. Disturbance detection and isolation by dynamic principal component analysis. Chemom. Intell. Lab. Syst. 1995, 30, 179–196. [Google Scholar] [CrossRef]
- Chen, J.; Liu, K.C. On-line batch process monitoring using dynamic PCA and dynamic PLS models. Chem. Eng. Sci. 2002, 57, 63–75. [Google Scholar] [CrossRef]
- Lee, C.; Choi, S.W.; Lee, I.B. Sensor fault identification based on time-lagged PCA in dynamic processes. Chemom. Intell. Lab. Syst. 2004, 70, 165–178. [Google Scholar] [CrossRef]
- Russell, E.L.; Chiang, L.H.; Braatz, R.D. Fault detection in industrial processes using canonical variate analysis and dynamic principal component analysis. Chemom. Intell. Lab. Syst. 2000, 51, 81–93. [Google Scholar] [CrossRef]
- Rato, T.J.; Reis, M.S. Fault detection in the Tennessee Eastman benchmark process using dynamic principal components analysis based on decorrelated residuals (DPCA-DR). Chemom. Intell. Lab. Syst. 2013, 125, 101–108. [Google Scholar] [CrossRef]
- Chiang, L.H.; Braatz, R.D. Process monitoring using causal map and multivariate statistics: Fault detection and identification. Chemom. Intell. Lab. Syst. 2003, 65, 159–178. [Google Scholar] [CrossRef]
- Shu, Y.; Zhao, J. Data-driven causal inference based on a modified transfer entropy. Comput. Chem. Eng. 2013, 57, 173–180. [Google Scholar] [CrossRef]
- Yu, W.; Yang, F. Detection of Causality between Process Variables Based on Industrial Alarm Data Using Transfer Entropy. Entropy 2015, 17, 5868–5887. [Google Scholar] [CrossRef] [Green Version]
- Khosravani, M.R.; Nasiri, S.; Weinberg, K. Application of case-based reasoning in a fault detection system on production of drippers. Appl. Soft Comput. 2019, 75, 227–232. [Google Scholar] [CrossRef]








| Fault Number | Process Variable | Type | Monitored Variable |
|---|---|---|---|
| IDV(1) | A/C feed ratio, B composition constant | Step | XMEAS(23) |
| IDV(5) | Condenser cooling water inlet temperature | Step | XMEAS(22) |
| Variable Type | Number of Measurements |
|---|---|
| Flow rate | 40 |
| Temperature | 11 |
| Controller output | 2 |
| Differential pressures | 8 |
| Pressures | 21 |
| Levels | 2 |
| Relative density | 9 |
| BSW (water content) | 6 |
| Electric current | 9 |
| Valve aperture | 4 |
| Fault | Training Set Size (Points) | Validation Set Size (Points) | Test Set Size (Points) | Monitored Variable |
|---|---|---|---|---|
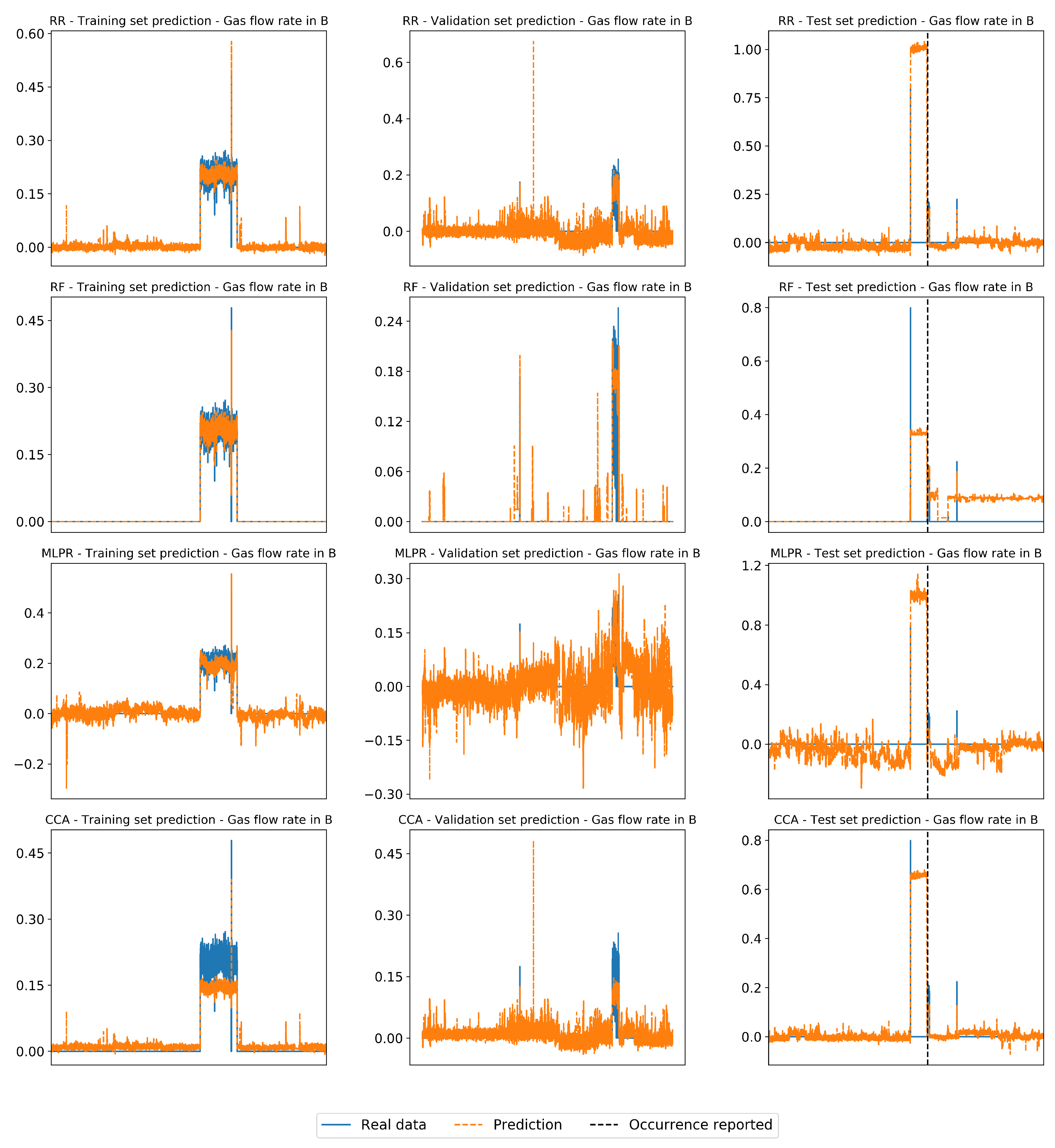
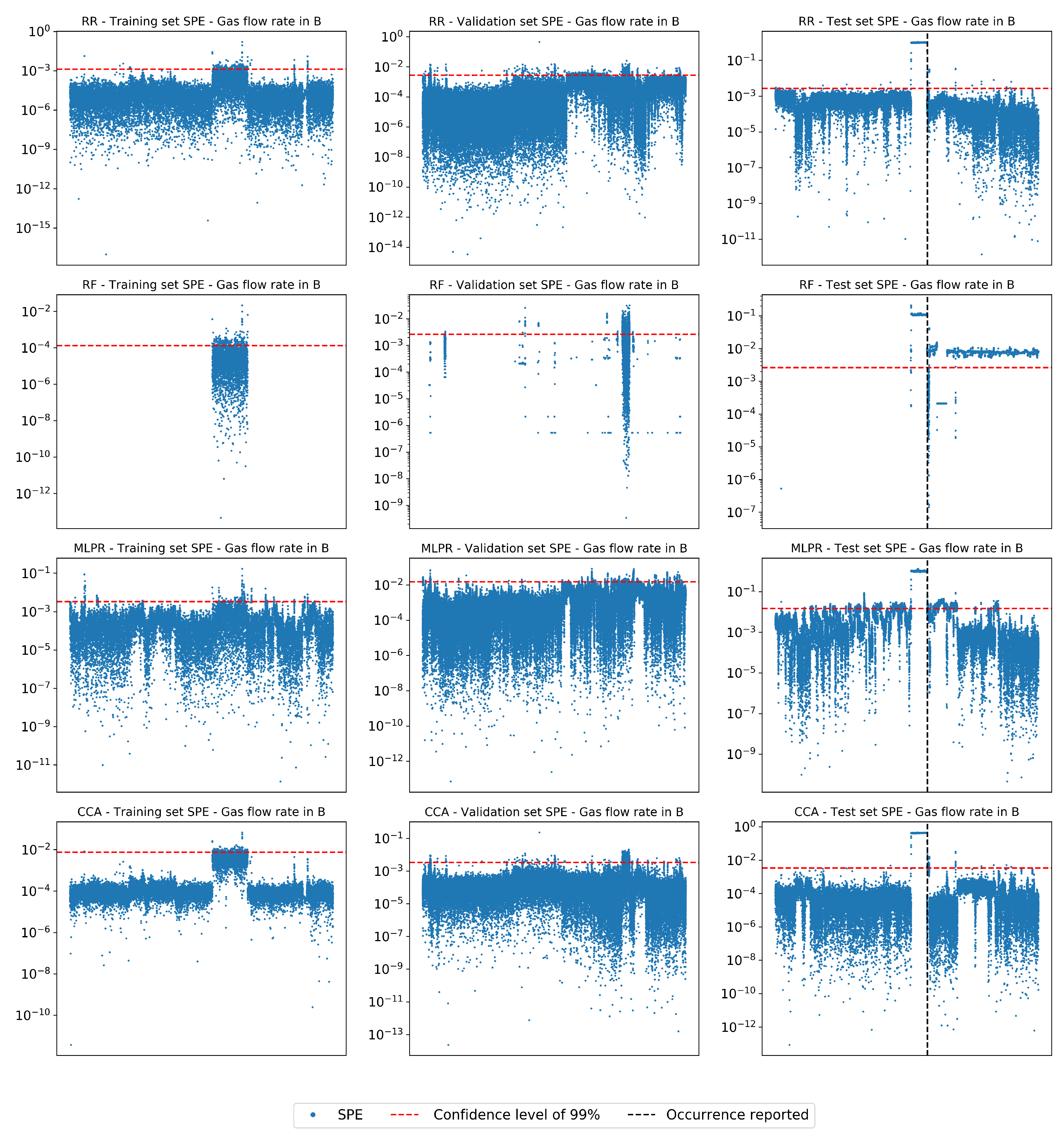
| F-I | 20,161 | 120,056 | 42,660 | Gas flow rate in B |
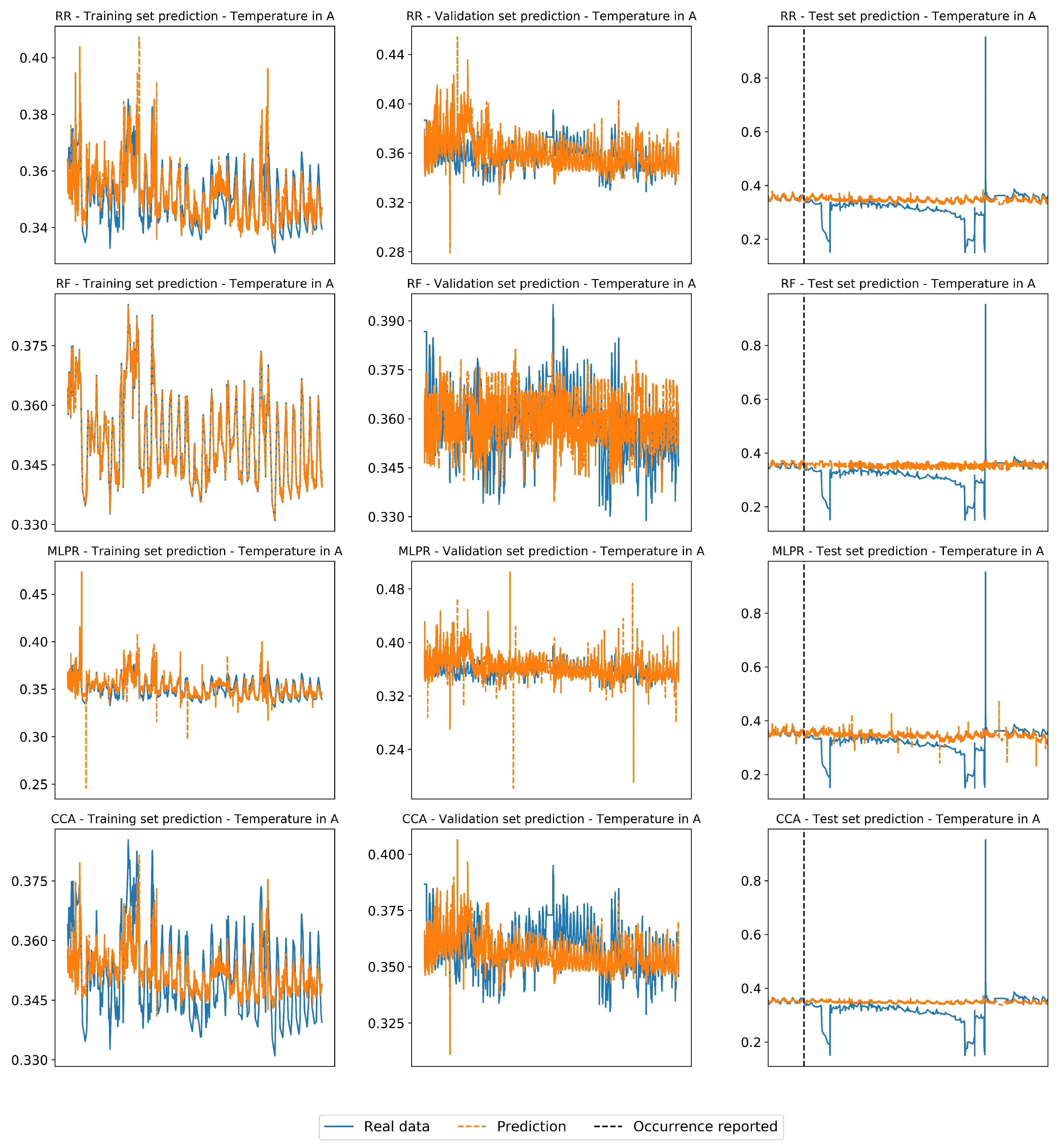
| F-II | 44,581 | 106,620 | 41,760 | Gas temperature in A |
| F-III | 44,581 | 74,727 | 2880 | Gas temperature in A |
| Variable Selection Method | Class of Method |
|---|---|
| Pearson correlation-based | Filter |
| Spearman correlation-based | Filter |
| Mutual information-based | Filter |
| Forward feature elimination (Lasso) | Wrapper |
| Forward feature elimination (Random Forest) | Wrapper |
| Backward feature elimination (Lasso) | Wrapper |
| Backward feature elimination (Random Forest) | Wrapper |
| L1-Regularization Lasso-based | Embedded |
| Random Forest importance-based | Embedded |
| PCMCI (partial correlation) | Filter |
| PCStable (partial correlation) | Filter |
| PCStable (partial correlation) + | |
| MCI (conditional mutual information) | Filter |
| Regressor | Hyperameter Heuristics |
|---|---|
| Canonical correlation analysis (CCA) |
|
| Ridge regression (RR) |
|
| Multilayer perceptron regressor (MLPR) |
|
| Random forest regressor (RF) |
|
| Fault | Regressor | FDR (%) | FAR (%) | Training Set | Validation Set | Test Set |
|---|---|---|---|---|---|---|
| F-I | RR | 0.0 | 10.71 | 0.99 | −186.93 | −690.37 |
| RF | 8.4 | 10.42 | 0.99 | 0.96 | −24.26 | |
| MLPR | 0.0 | 10.59 | 0.95 | −23.69 | −78.41 | |
| CCA | 0.0 | 10.60 | 0.99 | −170.23 | −635.27 | |
| F-II | RR | 3.98 | 0.0 | 0.88 | −21.76 | −1.78 |
| RF | 59.4 | 0.0 | 1.0 | −0.34 | −0.95 | |
| MLPR | 10.96 | 0.0 | 0.76 | −19.07 | −2.31 | |
| CCA | 21.53 | 0.0 | 0.43 | −2.79 | −0.40 | |
| F-III | RR | 51.47 | 11.0 | 0.88 | −20.28 | −0.61 |
| RF | 63.04 | 7.29 | 1.0 | −0.14 | −0.18 | |
| MLPR | 8.87 | 0.0 | −1.41 | −185.67 | −1.09 | |
| CCA | 63.44 | 0.3 | 0.43 | −0.51 | −0.22 |
| Variable Selection Method | Fault | Regressor | FDR (%) | FAR (%) | Training Set | Training Set | Training Set |
|---|---|---|---|---|---|---|---|
| Pearson-based | F-I | RR | 0.0 | 0.02 | 0.85 | −153700 | −379953 |
| RF | 9.1 | 0.03 | 0.99 | 0.71 | 0.709 | ||
| MLPR | 0.0 | 0.0 | 0.64 | −377 | −928.18 | ||
| CCA | 0.0 | 0.03 | 0.54 | −63786 | −63786 | ||
| F-II | RR | 1.9 | 8.12 | 0.79 | −41.74 | −11.26 | |
| RF | 74.5 | 0.0 | 0.99 | 0.04 | −0.69 | ||
| MLPR | 0.0 | 0.0 | 0.19 | −121.6 | −1.32 | ||
| CCA | 1.9 | 8.24 | 0.79 | −42.74 | −11.67 | ||
| F-III | RR | 63.4 | 0.0 | 0.79 | −22.59 | −0.30 | |
| RF | 63.4 | 23.14 | 0.99 | −0.35 | −0.23 | ||
| MLPR | 63.4 | 0.0 | 0.68 | 0.32 | 0.32 | ||
| CCA | 63.4 | 0.0 | 0.79 | −22.84 | −0.30 | ||
| Spearman based | F-I | RR | 0.0 | 0.01 | 0.83 | −85700 | −241433 |
| RF | 6.1 | 0.05 | 0.98 | 0.78 | 0.512 | ||
| MLPR | 9.8 | 0.02 | 0.96 | −2.31 | −6.061 | ||
| CCA | 0.0 | 0.03 | 0.54 | −26281 | −63786 | ||
| F-II | RR | 2.2 | 6.95 | 0.72 | −40.41 | −11.02 | |
| RF | 78.5 | 0.0 | 0.99 | 0.08 | −0.47 | ||
| MLPR | 4.9 | 0.0 | 0.78 | −35.79 | −0.64 | ||
| CCA | 1.97 | 8.24 | 0.79 | −42.74 | −11.72 | ||
| F-III | RR | 60.6 | 0 | 0.68 | −18.42 | −0.12 | |
| RF | 63.4 | 16.47 | 0.98 | −0.19 | −0.21 | ||
| MLPR | 63.4 | 0.16 | 0.57 | −214.65 | −2.74 | ||
| CCA | 63.4 | 0.0 | 0.79 | −22.84 | −0.31 | ||
| Mutual information-based | F-I | RR | 11.0 | 10.51 | 0.99 | 0.69 | −411.87 |
| RF | 28.4 | 10.43 | 0.99 | 0.99 | −32.64 | ||
| MLPR | 12.1 | 10.42 | 0.90 | −2.66 | −38.65 | ||
| CCA | 9.1 | 10.61 | 0.97 | 0.81 | −350.76 | ||
| F-II | RR | 6.9 | 0.0 | 0.56 | −244.78 | −8.21 | |
| RF | 78.4 | 3.05 | 0.99 | −0.04 | −0.83 | ||
| MLPR | 10.7 | 0.0 | 0.43 | −11.15 | −0.15 | ||
| CCA | 26.8 | 0.0 | 0.20 | −14.72 | −1.26 | ||
| F-III | RR | 63.4 | 0.0 | 0.56 | −64.56 | −1.47 | |
| RF | 63.4 | 0.0 | 0.99 | −0.25 | −0.21 | ||
| MLPR | 63.4 | 0.0 | 0.75 | −26.28 | −0.41 | ||
| CCA | 63.4 | 0.0 | 0.20 | −2.12 | −0.32 |
| Variable Selection Method | Fault | Regressor | FDR (%) | FAR (%) | Training Set | Training Set | Training Set |
|---|---|---|---|---|---|---|---|
| Forward feature elimination (Lasso) | F-I | RR | 0.4 | 11.43 | 0.98 | −15.90 | −1506.12 |
| RF | 8.6 | 10.42 | 0.99 | 0.99 | −28.19 | ||
| MLPR | 0.0 | 10.52 | 0.99 | −25.00 | −268.13 | ||
| CCA | 0.3 | 11.45 | 0.98 | −15.49 | −1535 | ||
| F-II | RR | 5.4 | 11.93 | 0.80 | −23.24 | −7.70 | |
| RF | 57.1 | 0.0 | 0.99 | −0.33 | −0.56 | ||
| MLPR | 5.2 | 10.28 | 0.65 | −13.90 | −2.34 | ||
| CCA | 5.3 | 11.53 | 0.70 | −10.22 | −2.18 | ||
| F-III | RR | 63.4 | 0.0 | 0.80 | −3.71 | −0.19 | |
| RF | 63.4 | 6.62 | 0.99 | −0.25 | −0.21 | ||
| MLPR | 63.4 | 0.0 | 0.47 | −8.21 | 0.05 | ||
| CCA | 63.4 | 0.0 | 0.70 | −1.21 | −0.16 | ||
| Forward feature elimination (Random Forest) | F-I | RR | 8.0 | 10.50 | 0.98 | −29.41 | −876.13 |
| RF | 23.7 | 10.43 | 0.99 | 0.97 | −38.19 | ||
| MLPR | 7.4 | 0.78 | 0.89 | −46.03 | −59.49 | ||
| CCA | 10.9 | 10.5 | 0.94 | −46.71 | −1268 | ||
| F-II | RR | 19.68 | 4.58 | 0.71 | −2.17 | −1.85 | |
| RF | 68.57 | 0.0 | 0.99 | −1.03 | −1.31 | ||
| MLPR | 11.15 | 3.31 | 0.47 | −4.31 | −0.16 | ||
| CCA | 31.60 | 0.31 | 0.57 | −0.12 | −1.08 | ||
| F-III | RR | 63.4 | 0.0 | 0.71 | −128.02 | −2.01 | |
| RF | 63.4 | 0.0 | 0.99 | −1.25 | −0.22 | ||
| MLPR | 63.4 | 0.0 | 0.52 | −182.21 | −0.48 | ||
| CCA | 63.4 | 0.0 | 0.54 | −35.93 | −0.85 | ||
| Backward feature elimination (Lasso) | F-I | RR | 0.0 | 0.0 | 0.31 | −424 | −247.82 |
| RF | 0.3 | 2.41 | 0.99 | −6.88 | −38.04 | ||
| MLPR | 0.0 | 0.06 | −0.01 | −9.57 | −23.18 | ||
| CCA | 0.0 | 0.0 | 0.22 | −1106 | −611.13 | ||
| F-II | RR | 21.5 | 24.51 | 0.75 | −20.72 | −4.21 | |
| RF | 60.5 | 0.0 | 0.99 | −1.84 | −0.73 | ||
| MLPR | 11.4 | 0.0 | −1.05 | −23.98 | −0.43 | ||
| CCA | 21.4 | 25.51 | 0.70 | −34.81 | −7.81 | ||
| F-III | RR | 63.4 | 1.60 | 0.75 | −9.94 | −0.76 | |
| RF | 63.4 | 0.0 | 0.99 | −1.28 | −0.23 | ||
| MLPR | 63.4 | 0.0 | 0.01 | −28.34 | −0.75 | ||
| CCA | 63.4 | 1.60 | 0.70 | −17.06 | −1.01 | ||
| Backward feature elimination (Random Forest) | F-I | RR | 0.0 | 0.14 | 0.91 | −27.23 | −25.16 |
| RF | 10.4 | 0.08 | 0.99 | 0.78 | 0.66 | ||
| MLPR | 0.0 | 0.03 | 0.76 | −20.81 | −66.90 | ||
| CCA | 0.0 | 0.15 | 0.89 | −35.51 | −30.75 | ||
| F-II | RR | 4.9 | 14.47 | 0.79 | −24.14 | −8.20 | |
| RF | 68.2 | 0.0 | 0.99 | −0.16 | −0.67 | ||
| MLPR | 1.5 | 0.0 | 0.19 | −22.97 | −0.05 | ||
| CCA | 5.8 | 14.38 | 0.78 | −28.84 | −10.25 | ||
| F−III | RR | 63.4 | 0.0 | 0.79 | −7.31 | −0.33 | |
| RF | 63.4 | 18.34 | 0.99 | −0.48 | −0.18 | ||
| MLPR | 63.4 | 53.36 | 0.35 | −24.15 | −1.51 | ||
| CCA | 63.4 | 0.0 | 0.78 | −8.67 | −0.36 |
| Variable Selection Method | Fault | Regressor | FDR (%) | FAR (%) | Training Set | Training Set | Training Set |
|---|---|---|---|---|---|---|---|
| L1-regularization (Lasso) | F-I | RR | 0.0 | 0.02 | 0.91 | −94.52 | −189.52 |
| RF | 0.7 | 0.07 | 0.99 | 0.76 | 0.71 | ||
| MLPR | 0.0 | 1.55 | 0.88 | −4.75 | −19.70 | ||
| CCA | 0.0 | 0.02 | 0.84 | −51.24 | −96.02 | ||
| F-II | RR | 7.6 | 12.28 | 0.81 | −51.27 | −19.62 | |
| RF | 58.9 | 0.0 | 0.99 | −0.26 | −0.51 | ||
| MLPR | 44.35 | 4.71 | 0.79 | −5.64 | −2.46 | ||
| CCA | 7.8 | 12.30 | 0.81 | −52.98 | −52.98 | ||
| F-III | RR | 63.7 | 1.36 | 0.81 | −9.39 | −0.37 | |
| RF | 63.4 | 0.0 | 0.99 | −0.71 | −0.21 | ||
| MLPR | 63.4 | 0.0 | 0.04 | −21.32 | −0.41 | ||
| CCA | 63.7 | 1.28 | 0.81 | −9.76 | −0.38 | ||
| Random forest importances | F-I | RR | 0.0 | 0.12 | 1.0 | 1.0 | 1.0 |
| RF | 0.3 | 0.08 | 0.99 | 0.99 | 0.94 | ||
| MLPR | 0.0 | 11.60 | 0.89 | −2.65 | −15.78 | ||
| CCA | 81.1 | 0.20 | 1.0 | 1.0 | 1.0 | ||
| F-II | RR | 0.6 | 0.0 | 1.0 | 0.99 | 0.99 | |
| RF | 69.2 | 0.0 | 0.99 | 0.99 | 0.12 | ||
| MLPR | 0.0 | 0.0 | −0.97 | −1257 | −3.59 | ||
| CCA | 26.1 | 17.58 | 1.0 | 1.0 | 1.0 | ||
| F-III | RR | 63.4 | 0.0 | 1.0 | 0.99 | 0.99 | |
| RF | 63.4 | 2.23 | 0.99 | 0.99 | 0.01 | ||
| MLPR | 0.0 | 0.0 | 0.82 | −335.12 | −3.09 | ||
| CCA | 63.4 | 0.80 | 1.0 | 1.0 | 1.0 |
| Variable Selection Method | Fault | Regressor | FDR (%) | FAR (%) | Training Set | Training Set | Training Set |
|---|---|---|---|---|---|---|---|
| PCMCI (Partial corellation) | F-I | RR | 11.1 | 10.36 | 0.98 | 0.21 | −218.91 |
| RF | 15.4 | 10.76 | 0.99 | 0.85 | −33.96 | ||
| MLPR | 38.1 | 21.02 | 0.91 | −2.31 | −237.33 | ||
| CCA | 66.4 | 10.41 | 0.86 | 0.61 | −92.75 | ||
| F-II | RR | 0.0 | 0.0 | 0.74 | −439.89 | −3.41 | |
| RF | 79.7 | 0.0 | 0.99 | −0.82 | −0.97 | ||
| MLPR | 0.7 | 18.04 | 0.05 | −105.12 | −7.64 | ||
| CCA | 44.7 | 0.0 | 0.01 | −0.50 | −0.44 | ||
| F-III | RR | 42.2 | 0.08 | 0.75 | −312.6 | −4.03 | |
| RF | 63.4 | 0.0 | 0.99 | −0.36 | −0.21 | ||
| MLPR | 4.3 | 2.04 | 0.40 | −1311 | −20.17 | ||
| CCA | 63.4 | 0.0 | 0.02 | −0.57 | −0.11 | ||
| PCStable (Partial correlation) | F-I | RR | 1.1 | 10.61 | 0.98 | 0.60 | −187.87 |
| RF | 3.8 | 10.85 | 0.99 | 0.90 | −27.37 | ||
| MLPR | 0.4 | 10.45 | 0.95 | −0.02 | −81.35 | ||
| CCA | 10.5 | 10.51 | 0.85 | 0.47 | −84.97 | ||
| F-II | RR | 8.67 | 0.0 | 0.55 | −15.23 | −0.61 | |
| RF | 74.9 | 0.0 | 0.99 | −0.40 | −0.75 | ||
| MLPR | 0.0 | 0.0 | 0.40 | −501.12 | −4.95 | ||
| CCA | 34.1 | 0.0 | 0.01 | −0.89 | −0.44 | ||
| F-III | RR | 63.4 | 0.08 | 0.55 | −45.23 | −0.60 | |
| RF | 63.3 | 10.36 | 0.99 | −1.23 | −0.25 | ||
| MLPR | 63.4 | 0.0 | 0.37 | −9.96 | −0.67 | ||
| CCA | 63.9 | 1.12 | 0.01 | −0.85 | −0.11 | ||
| PCStable (Partial correlation) + MCI (Conditional mutual information) | F-I | RR | 10.1 | 10.56 | 0.98 | 0.68 | −275.59 |
| RF | 10.38 | 10.86 | 0.99 | 0.90 | −26.26 | ||
| MLPR | 10.4 | 10.47 | 0.97 | 0.80 | −498.66 | ||
| CCA | 13.9 | 10.51 | 0.92 | 0.60 | −158.31 | ||
| F-II | RR | 28.8 | 0.0 | 0.57 | −0.55 | −0.31 | |
| RF | 61.3 | 0.0 | 0.99 | −0.06 | −0.07 | ||
| MLPR | 21.7 | 0.1 | 0.62 | −0.93 | −0.28 | ||
| CCA | 49.3 | 0.0 | 0.42 | −0.02 | −0.35 | ||
| F-III | RR | 63.4 | 0.0 | 0.57 | −2.97 | −0.17 | |
| RF | 63.7 | 9.78 | 0.99 | −0.24 | −0.18 | ||
| MLPR | 63.4 | 0.0 | 0.37 | −5.62 | −0.18 | ||
| CCA | 63.4 | 0.0 | 0.45 | −1.13 | −1.14 |
| Variable Selection Method | Fault | Regressor | FDR (%) | FAR (%) | Training Set | Training Set | Training Set |
|---|---|---|---|---|---|---|---|
| Without variable selection procedure | IDV(1) | RR | 48.63 | 1.25 | 0.35 | 0.28 | 0.77 |
| RF | 75.23 | 0.0 | 0.94 | 0.61 | 0.37 | ||
| MLPR | 37.43 | 0.62 | −996.67 | −1162.42 | −332.96 | ||
| CCA | 73.94 | 1.56 | 0.01 | 0.01 | −0.04 | ||
| IDV(5) | RR | 99.0 | 0.62 | 0.68 | 0.66 | −152.75 | |
| RF | 41.99 | 0.0 | 0.91 | 0.65 | 0.55 | ||
| MLPR | 26.93 | 0.62 | −845.53 | −873.52 | −1085.37 | ||
| CCA | 45.31 | 0.62 | 0.01 | 0.01 | −0.09 | ||
| Mutual information-based | IDV(I) | RR | 44.07 | 0.62 | 0.23 | 0.19 | 0.77 |
| RF | 61.49 | 0.0 | 0.98 | 0.58 | 0.31 | ||
| MLPR | 88.46 | 1.25 | −0.78 | −0.82 | −0.54 | ||
| CCA | 61.08 | 1.25 | −0.34 | −0.52 | 0.14 | ||
| IDV(5) | RR | 99.0 | 1.25 | 0.60 | 0.6 | −389.82 | |
| RF | 24.0 | 0.0 | 0.91 | 0.62 | 0.49 | ||
| MLPR | 23.62 | 0.94 | −769.7 | −760.7 | −886.25 | ||
| CCA | 30.75 | 0.94 | 0.06 | 0.06 | −1.06 | ||
| Forward feature elimination (Lasso) | IDV(I) | RR | 24.52 | 1.56 | 0.32 | 0.28 | 0.84 |
| RF | 61.91 | 0.0 | 0.91 | 0.59 | 0.41 | ||
| MLPR | 72.28 | 0.62 | −183.4 | −212.14 | −171.64 | ||
| CCA | 41.99 | 0.94 | 0.24 | 0.18 | 0.72 | ||
| IDV(5) | RR | 44.89 | 1.25 | 0.53 | 0.52 | 0.71 | |
| RF | 44.75 | 0.0 | 0.91 | 0.62 | 0.61 | ||
| MLPR | 29.22 | 0.62 | −201.32 | −205.56 | −110.87 | ||
| CCA | 56.17 | 0.94 | 0.37 | 0.37 | 0.44 | ||
| L1-regularization (Lasso) | IDV(I) | RR | 32.06 | 1.25 | 0.33 | 0.28 | 0.87 |
| RF | 84.54 | 0.0 | 0.93 | 0.64 | 0.32 | ||
| MLPR | 97.30 | 1.56 | −27.59 | −30.59 | −103.89 | ||
| CCA | 83.12 | 0.94 | 0.06 | -0.04 | 0.44 | ||
| IDV(5) | RR | 46.95 | 0.94 | 0.54 | 0.54 | 0.64 | |
| RF | 61.84 | 0.0 | 0.92 | 0.65 | 0.53 | ||
| MLPR | 80.99 | 2.19 | −99.74 | −100.12 | −360.55 | ||
| CCA | 61.13 | 0.31 | 0.39 | 0.38 | 0.39 | ||
| PCStable (Partial correlation) + MCI (Conditional mutual information) | IDV(I) | RR | 32.06 | 1.25 | 0.33 | 0.28 | 0.87 |
| RF | 84.54 | 0.0 | 0.93 | 0.60 | 0.32 | ||
| MLPR | 97.30 | 1.56 | −27.59 | −30.59 | −103.89 | ||
| CCA | 83.12 | 0.94 | 0.06 | −0.04 | 0.44 | ||
| IDV(5) | RR | 46.95 | 0.94 | 0.54 | 0.54 | 0.64 | |
| RF | 61.84 | 0.0 | 0.92 | 0.65 | 0.53 | ||
| MLPR | 80.99 | 2.19 | −99.74 | −100.12 | −360.55 | ||
| CCA | 61.13 | 0.31 | 0.39 | 0.38 | 0.39 |
| Variable Selection Method | Class | CPU Time (s) |
|---|---|---|
| Mutual information-based | Filter | 138 |
| Forward feature elimination (Lasso) | Wrapper | 720 |
| L1-regularization (Lasso) | Embedded | 43 |
| PCMCI (Partial correlation) | Filter (causal) | 1403 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Clavijo, N.; Melo, A.; Soares, R.M.; Campos, L.F.d.O.; Lemos, T.; Câmara, M.M.; Anzai, T.K.; Diehl, F.C.; Thompson, P.H.; Pinto, J.C. Variable Selection for Fault Detection Based on Causal Discovery Methods: Analysis of an Actual Industrial Case. Processes 2021, 9, 544. https://doi.org/10.3390/pr9030544
Clavijo N, Melo A, Soares RM, Campos LFdO, Lemos T, Câmara MM, Anzai TK, Diehl FC, Thompson PH, Pinto JC. Variable Selection for Fault Detection Based on Causal Discovery Methods: Analysis of an Actual Industrial Case. Processes. 2021; 9(3):544. https://doi.org/10.3390/pr9030544
Chicago/Turabian StyleClavijo, Nayher, Afrânio Melo, Rafael M. Soares, Luiz Felipe de O. Campos, Tiago Lemos, Maurício M. Câmara, Thiago K. Anzai, Fabio C. Diehl, Pedro H. Thompson, and José Carlos Pinto. 2021. "Variable Selection for Fault Detection Based on Causal Discovery Methods: Analysis of an Actual Industrial Case" Processes 9, no. 3: 544. https://doi.org/10.3390/pr9030544
APA StyleClavijo, N., Melo, A., Soares, R. M., Campos, L. F. d. O., Lemos, T., Câmara, M. M., Anzai, T. K., Diehl, F. C., Thompson, P. H., & Pinto, J. C. (2021). Variable Selection for Fault Detection Based on Causal Discovery Methods: Analysis of an Actual Industrial Case. Processes, 9(3), 544. https://doi.org/10.3390/pr9030544