(1) The process requirements for equipment processing in a group are the same.
(2) Equipment types within the group should be identical or equipment within the group should be able to process the same type of product.
(3) In order for workers to operate the control device, the grouping device must be an adjacent device, and the area constructed by the grouping device cannot enclose other grouped devices or ungrouped devices inside the region.
(4) The processing capacity generated by the equipment group should match the processing capacity required by the processing task.
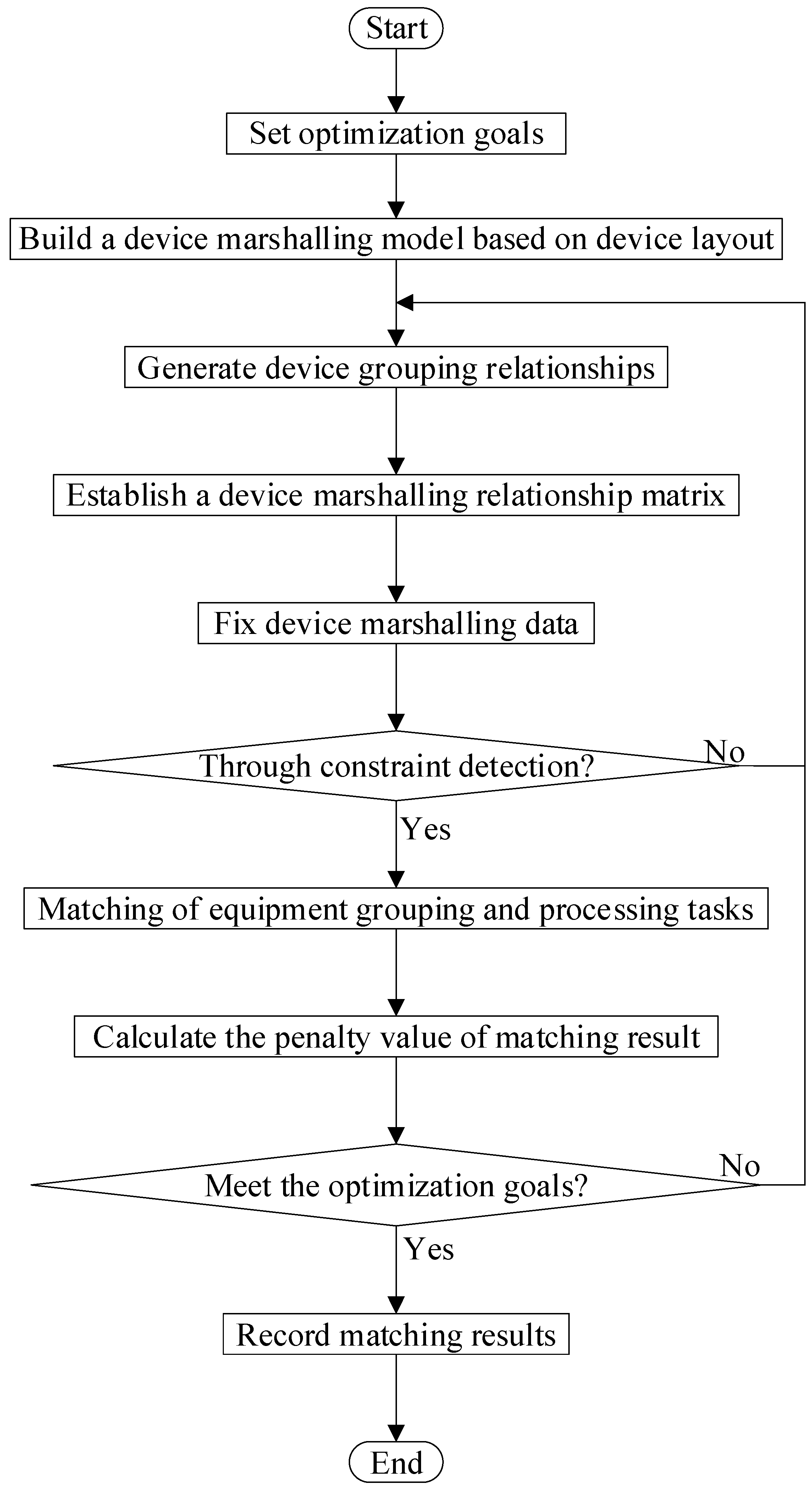
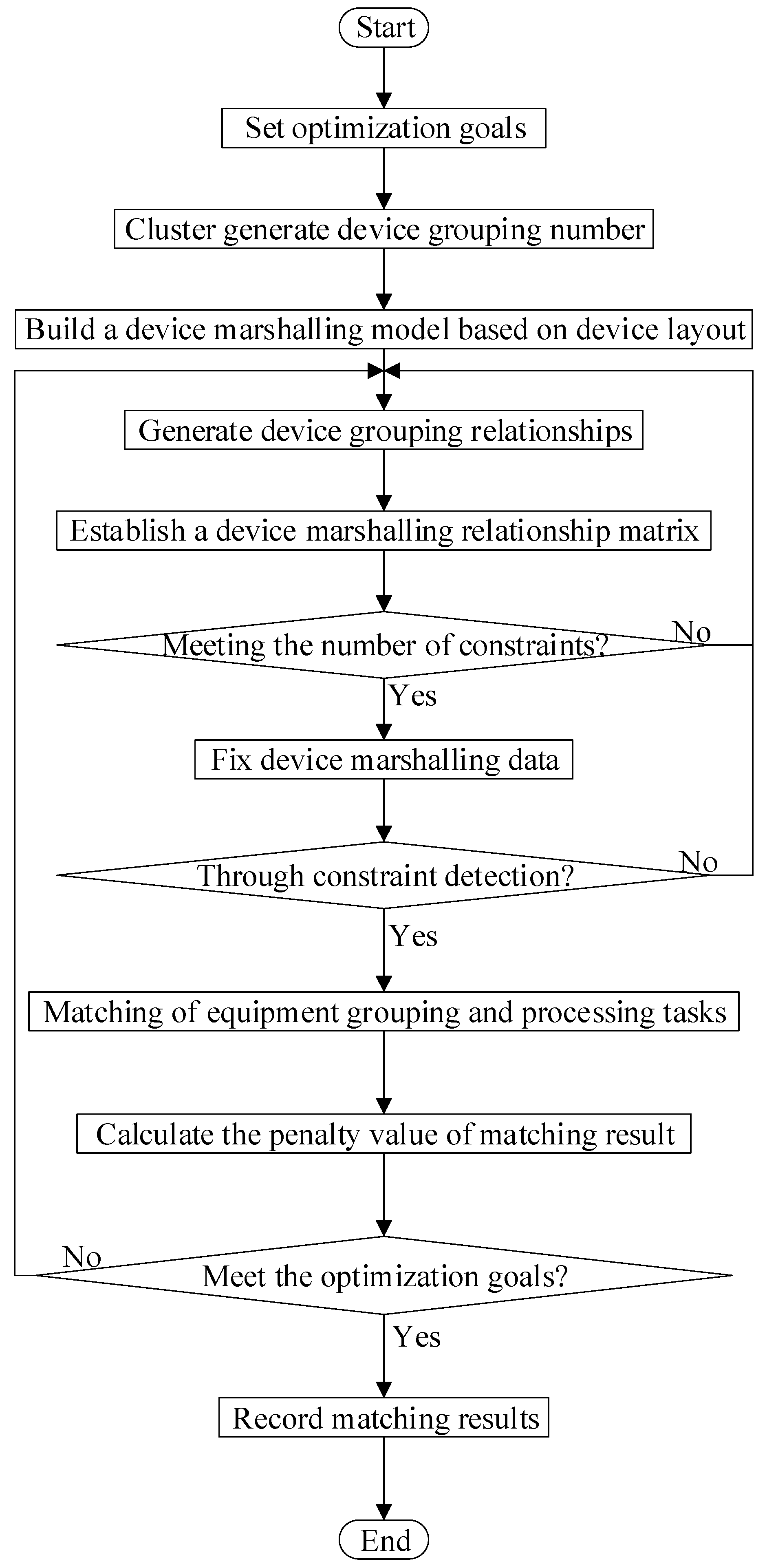
2.1. Equipment Marshalling Process
The flow of the bonding device grouping method based on the processing task [
13] matching semiconductor package line is as shown in
Figure 1 below:
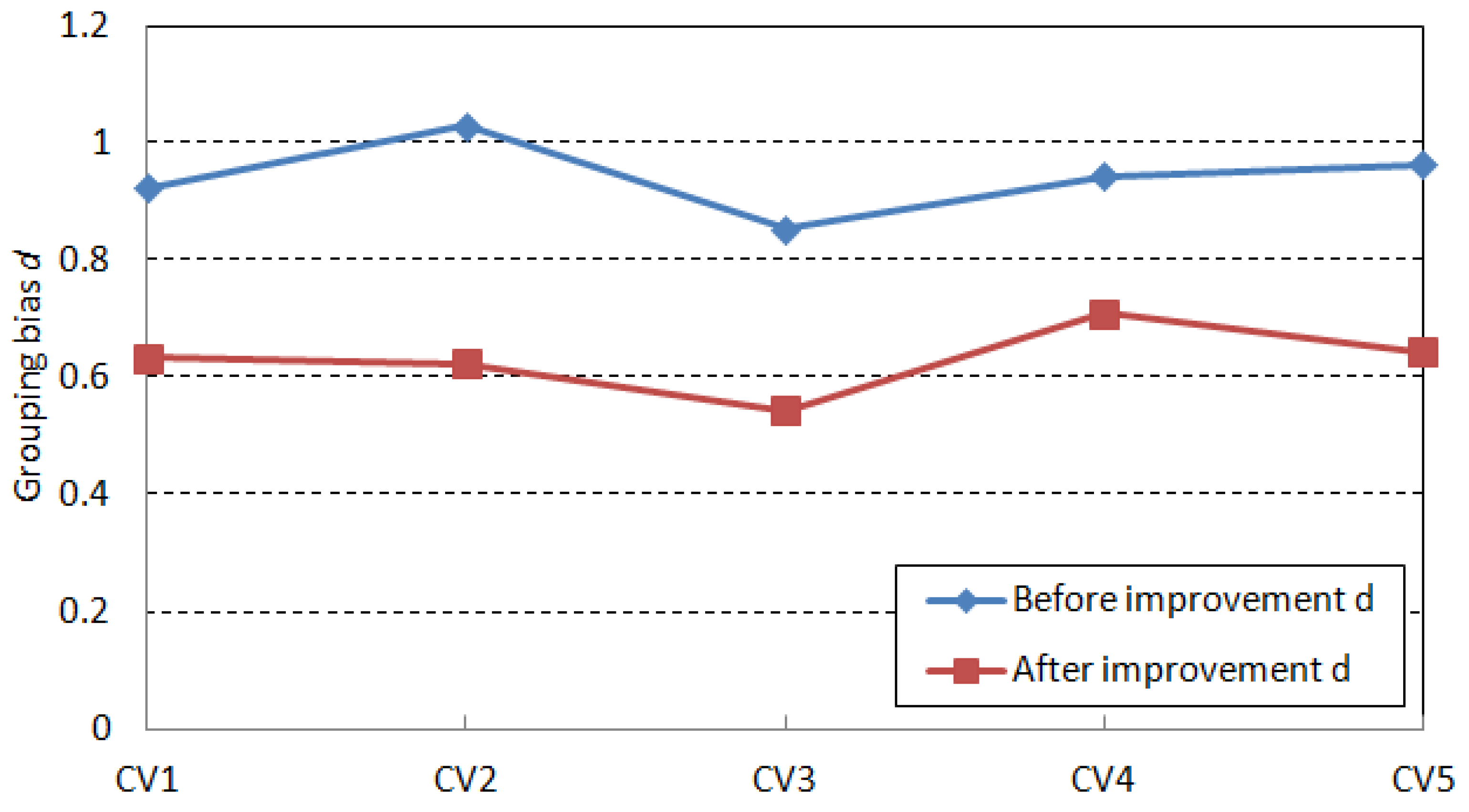
Step 1: The minimum penalty value obtained by equipment grouping to provide capacity and processing task demand capacity matching is the optimization goal of equipment grouping.
Semiconductor manufacturing mainly consists of three phases: chip design, front wafer fabrication, and back-end packaging testing. The process of semiconductor package testing is dicing, loading, bonding, plastic sealing, deflashing, electroplating, printing, cutting, molding, visual inspection, finished product testing, packaging, and shipping. Semiconductor manufacturing is a dynamic and continuous process, so the time-limited cost of the bonding process segment cannot be derived separately. The utilization rate of the equipment can only be measured by considering the difference in the capacity of the equipment provided by the difference between the capacity provided and the capacity required.
Insufficient capacity is provided by the equipment group matching the processing task
.
Capacity redundancy is provided by the device group that matches the processing task
.
indicates the equipment capacity required for the processing task . indicates the processing capability of the equipment group matched by the processing task where can provide, .
The punishment sum of equipment grouping and processing tasks.
indicates the penalty for the capacity of the processing task indicates the redundancy penalty for capacity of the processing task .
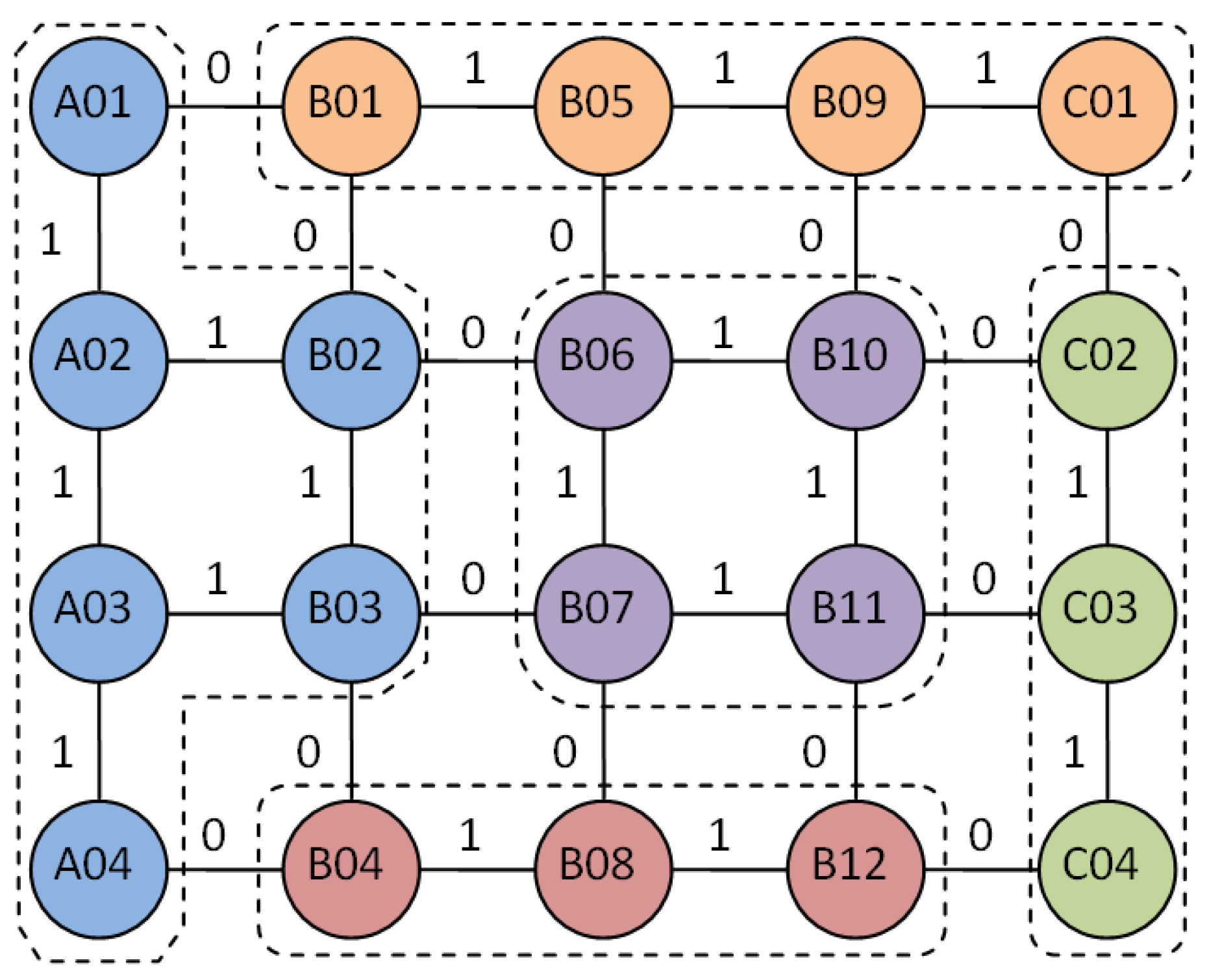
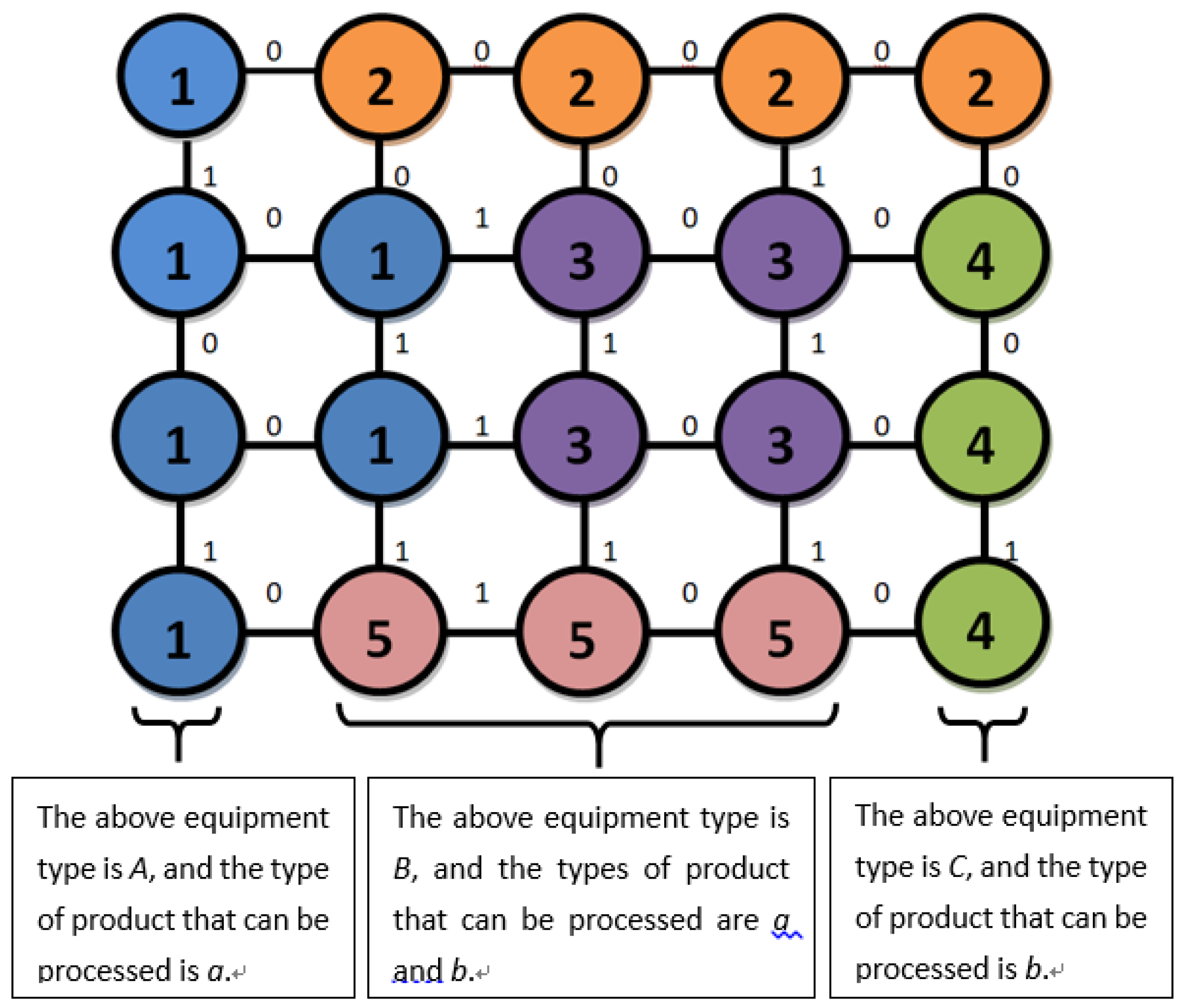
Step 2: Using graph theory to simplify the representation of a device as a node on a two-dimensional plane [
14], abstracting all device points of this process into
rows and
columns of device matrices.
represents a device of the
row and the
column.
Step 3: All devices are connected by wires to form a network structure with device as node [
15]. As shown in
Figure 2, the association coefficient between the devices is randomly generated and represented by 0 and 1. The “0” indicates no association between the devices, i.e., the two devices are not in one group, and the “1” indicates the existence of an association, i.e., the two devices are edited in a group [
16,
17].
Step 4: According to the association coefficient between the devices, the device grouping row association matrix and the column association matrix are established by using the adjacency matrix, and the temporary device grouping is established.
The correlation matrix
between rows is as shown in Equation (5), and
represents the row correlation coefficient between the
row and the
device of the
column. When
is “1”, it means that two adjacent devices are associated and can be grouped together. On the contrary,
takes “0” to indicate no association. The correlation matrix
between the columns is as shown in Equation (6).
The associated device is grouped into a device group by the generated row and column association matrix. A temporary group number is assigned to indicate the group number of the device group. represents the maximum group number for all groups.
Step 5: Correct the group association relationship. The temporary coding matrix of equipment grouping obtained in Step 4 may have a condition that conforms to the grouping rules but does not meet the actual grouping requirements. Therefore, it is necessary to correct the grouping relationship by employing the line scan and the column scan detection using the temporary group number of each group identification in Step 4.
Line detection starts from the 1st line and detects the
nth line stop. It is necessary to check whether the correlation coefficient of each line is correct. According to the Equation (7), if the device group number
of the
row and the
column is equal to the device group number
of the
row and the
column, the device row association relationship
is “1”. If it is “0”, it should be set to “1”.
Column detection starts from the 1st column and detects the
column stop. It is necessary to check whether the correlation coefficient of each column is correct. According to the Equation (8), if the device group number
of the
column and the
row is equal to the device group number
of the
column and the
row, the device column association relationship
is “1”. If it is “0”, it should be set to “1”.
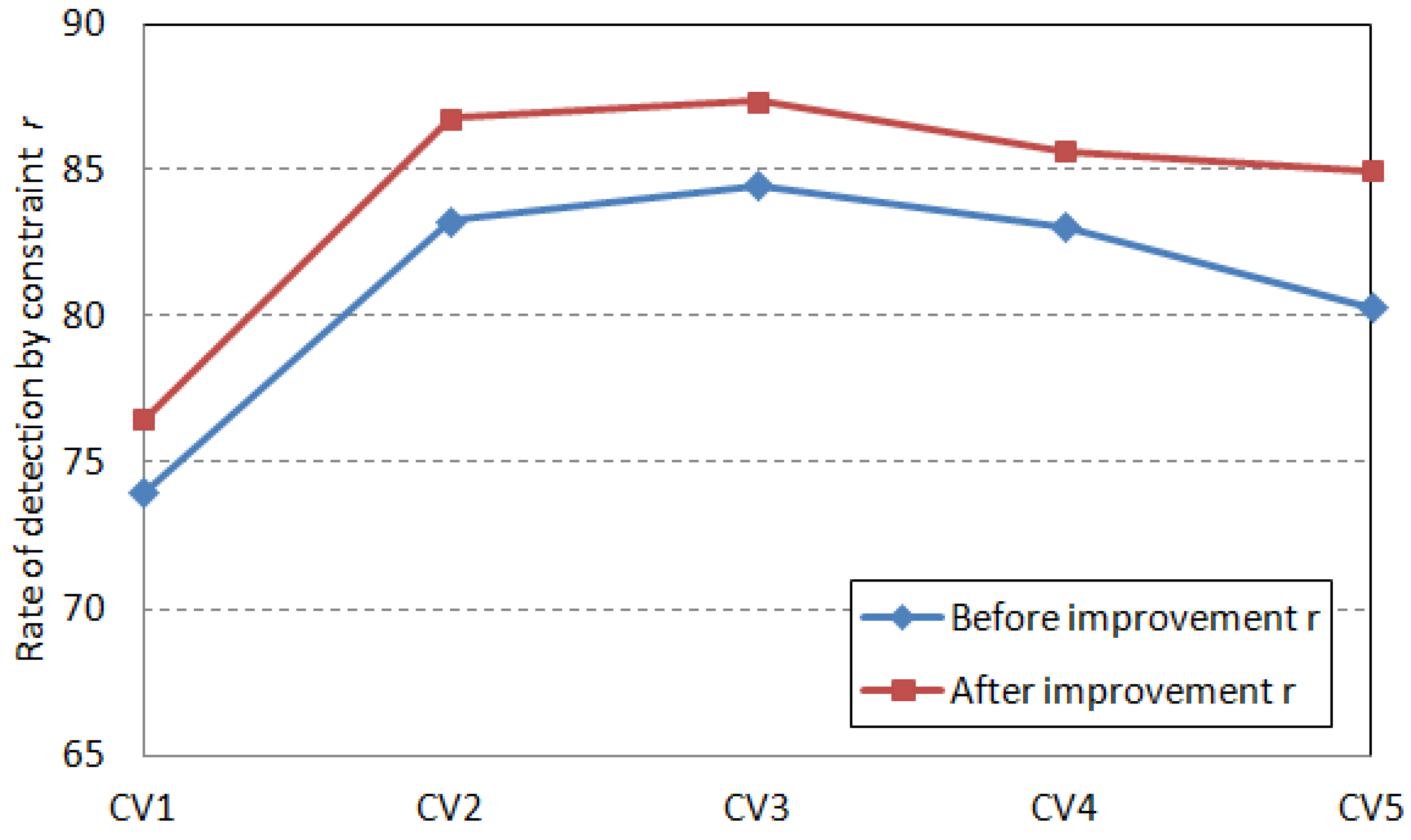
Step 6: Closed position constraint refers to a device group or other device group that does not belong to this group is included in a two-dimensional plane. Such a completely enclosed relationship can be understood as a closed position. Constraint detection of device grouping. Constraint detection is divided into device group closed position relationship constraint detection and device type and processing type matching constraint detection. If any constraint detection fails, the grouping result is invalid, and the grouping step returns to Step 3.
(1) Constraint detection of closed position relationship by equipment grouping
The enclosed area formed by the grouping device cannot contain devices that do not belong to the device group, nor can it contain another independent device group. If such a grouping situation exists, the jurisdiction of the two equipment group managers overlaps, causing confusion in the production management organization.
To determine whether the device is completely in the closed range of the grouping, it is necessary to perform row detection and column detection according to the grouping relationship in the device grouping matrix . If it is detected that a closed area formed in a device group contains devices that are not in this group, it is considered that the device grouping is unreasonable, and the temporary device grouping needs to be re-established. This inspection process needs to determine whether the grouping result is reasonable based on the results of the row and column test.
When the grouping information of the group to which the device of the
row and the
column belong is the same as the grouping number of the
group,
is equal to “1”, otherwise it is equal to “0”.
indicates whether the
row of the
device group contains devices that do not belong to the
group. When the value is “1”, it means the device is not included, and when it is “0”, it means that it contains equipment that does not belong to the
group.
indicates the result of row detection by the
device group. The value of
is “0”, indicating that the
device group has detected that there are
grouped devices in a certain device after the line detection.
indicates the result of column detection by the
device group. If
is “0”, it indicates that the
device group is detected by column and there is a
group device in a column device.
indicates whether the closed area of the
equipment group contains equipment that is not in this group. If
is “0”, it indicates that the
row detection result of the
device group and the
column detection result simultaneously determine the device having the
group in the group.
indicates that the device grouping result satisfies the device location constraint. When all device groupings constitute a closed area, none of the non-grouped devices are included, and
is equal to “1”.
(2) Constraint detection matching device type and processing type
The processed product type is represented by
, a total of
product types. The device type is represented by
, which is a total of
device types. The relationship matrix
whose product type matches the device type can be expressed as Equation (13). When
is “1”, the product type matches the device type. If it is “0”, the two do not match.
The matching relationship matrix
between the device and the device type is as shown in Equation (14).
indicates the matching relationship between device type and device.
equals “1” to indicate that the device matches the device type. If it is “0”, the device does not match the device type.
indicates that the device and product type matching relationship matrix is as shown in Equation (15), which is obtained by multiplying the product of
and
.
For the device group , the device set contained in the group is represented by . If and product type are grouped for any device, and is included in and belongs to , the device grouping matches the device type and the processed product type matching constraint. If the constraint is not met, it is necessary to return to Step 3 to re-establish the correlation coefficient between the devices.
Step 7: Matching of equipment grouping and processing tasks
(1) Capacity provided by equipment grouping
The processing speed matrix
is constructed according to the relationship matrix
where the device matches the product type.
is defined as the processing speed of the
type product by the device in the
row and the
column.
A matrix is constructed based on product type to provide capacity matrix
, where
indicates that the equipment group
produces the processing capacity of the
type product,
.
(2) Demand capacity of processing tasks
The processing task set is represented by ,. represents the processing task, the product type of the processing task is represented by , and the product type set constituting the processing task is represented by , . The set of processing tasks for product type is represented by ,, and , indicates the demand capacity of the processing task, and the processing task demand capacity set is represented by ,.
(3) Equipment grouping matching the processing task
The total number of production equipment marshalling should be greater than or equal to the total number of tasks to be assigned . The number of selectable device groups corresponding to the product type should be greater than or equal to the number of tasks in the processing task set whose product type is .
The matrix matching the processing task demand ability and the equipment group capability is represented by . . indicates the processing capacity of the equipment group, indicates the demand capacity of the processing task. The processing tasks are assigned to the equipment group. It is necessary to sort the processing task according to the descending order of the required task capacity . Then it is necessary to obtain the sorted device task collection queue and the product type sequence corresponding to .
According to the relationship matrix
matched by the device and the product type, the device group capable of processing the product is selected by the product type of the processing task, and the matching relationship matrix
of the device grouping and the product type are constructed.
The element in the matrix indicates the matching relationship between product type and device grouping. Its value of “1” means that the device group contains the device that satisfies the matching relationship between the device type and the product type.
When the device group is not assigned a task in the initial state, all is 1. The processing product type is and processing task is . Selected device grouping is set as , and each device group is calculated in . The processing capacity and the established corresponds to the equipment group capacity set ,. is the processing capability of equipment group to produce type products. When is not an empty set, the processing task should be assigned to . The device group with the largest processing capability in the set is represented by ,. The task is matched to the device group , where , and the row corresponding to the in the matrix corresponds to , indicating that the device group was assigned tasks. When the next task matches, the device group no longer participates in the matching of devices and tasks. After all the processing tasks are matched, the device group capability matching set and the device group matching set are matched with and . Then, according to the order of the original processing task the equipment group matching set matching the order of the processing tasks is obtained, . The processing task requirement capability and the device group capability matching set corresponding to the device group matching set are obtained.
Step 8: The optimization goal of device grouping is the penalty value minimum for device grouping and processing tasks. If the optimization range is satisfied, the temporary grouping result is saved. If the requirement is not met, the process returns to Step 3 until the maximum number of iterations is reached, and the grouping corresponding to the minimum penalty value is stopped as the final grouping result.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}