
Forensic Audio and Voice Analysis: TV Series Reinforce False Popular Beliefs

 ,
, 
Abstract
:1. Introduction
1.1. Background and Goals
1.2. Some Landmarks in Forensic Voice Analysis
1.3. Forensic Voice Analysis and Voice Comparison in the World Today
1.4. Forensic Voice Comparison in France
2. Methods
2.1. Database Collection
- The episode, season number, and year of the first broadcast;
- Did the excerpt involve speaker identification?
- What methods were used?
- Was the analysis auditory and/or supported by visualizations of the signal?
- What type of visualizations were used;
- Was the display actually used or just decorative?
- Whether there was an explicit analogy with DNA;
- Whether there was an explicit analogy with fingerprints
2.2. Plausibility Ratings
3. Results
3.1. Database Analysis
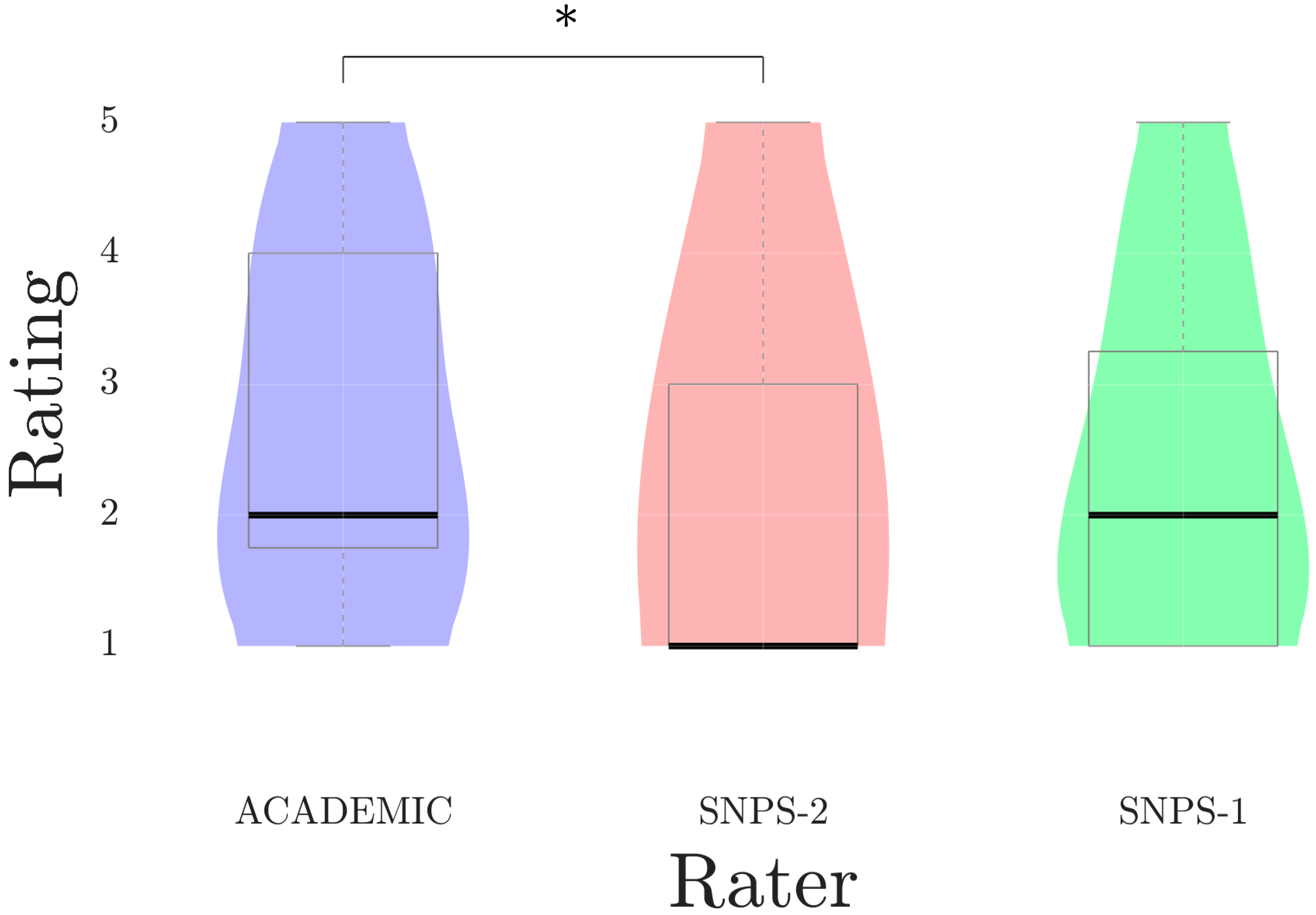
3.2. Plausibility Ratings
3.3. More on Aesthetics
3.4. Specialized Terminology
3.5. Lab Technicians
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | https://www.springfieldspringfield.co.uk/ (accessed on 23 January 2024). |
| 2 | https://programme-tv.nouvelobs.com/programme-tv/ (accessed on 23 January 2024). |
References
- Baranowski, Andreas M., Anne Burkhardt, Elisabeth Czernik, and Heiko Hecht. 2018. The CSI-education effect: Do potential criminals benefit from forensic TV series? International Journal of Law, Crime and Justice 52: 86–97. [Google Scholar] [CrossRef]
- Beugnet, Martine. 2022. The Gulliver effect: Screen size, scale and frame, from cinema to mobile phones. New Review of Film and Television Studies 20: 303–28. [Google Scholar] [CrossRef]
- Boë, Louis-Jean. 2000. Forensic voice identification in France. Speech Communication 31: 205–24. [Google Scholar] [CrossRef]
- Bolt, Richard H., Franklin S. Cooper, Edward E. David, Peter B. Denes, James M. Pickett, and Kenneth N. Stevens. 1969. Identification of a Speaker by Speech Spectrograms: How do scientists view its reliability for use as legal evidence? Science 166: 338–43. [Google Scholar] [CrossRef] [PubMed]
- Bolter, Jay David, and Richard A. Grusin. 1999. Remediation: Understanding New Media. Cambridge, MA: MIT Press. [Google Scholar]
- Bonastre, Jean-François. 2020. 1990–2020: Retours sur 30 ans d’échanges autour de l’identification de voix en milieu judiciaire. In 2e atelier Éthique et TRaitemeNt Automatique des Langues (ETeRNAL). Edited by Gilles Adda, Maxime Amblard and Karën Fort. pp. 38–47. Available online: https://aclanthology.org/2020.jeptalnrecital-eternal.5.pdf (accessed on 23 January 2024).
- Broeders, Ton. 2001. Forensic Speech and Audio Analysis Forensic Linguistics 1998 to 2001. Paper presented at the 13th INTERPOL Forensic Science Symposium, Lyon, France, October 16–19; pp. 54–84. [Google Scholar]
- Bull, Sofia. 2016. From crime lab to mind palace: Post-CSI forensics in Sherlock. New Review of Film and Television Studies 14: 324–44. [Google Scholar] [CrossRef]
- Call, Corey, Amy K. Cook, John D. Reitzel, and Robyn D. McDougle. 2013. Seeing is believing: The CSI effect among jurors in malicious wounding cases. Journal of Social, Behavioral, and Health Sciences 7: 52–66. [Google Scholar]
- Chion, Michel. 2003. Un art sonore, le cinéma: Histoire, esthétique, poétique. Paris: Cahiers du cinéma. [Google Scholar]
- Cooper, Glinda S., and Vanessa Meterko. 2019. Cognitive bias research in forensic science: A systematic review. Forensic Science International 297: 35–46. [Google Scholar] [CrossRef]
- De Jong-Lendle, Gea. 2022. Speaker Identification. In Language as Evidence. Edited by Victoria Guillén-Nieto and Dieter Stein. New York: Springer International Publishing, pp. 257–319. [Google Scholar] [CrossRef]
- Eatley, Gordon, Harry H. Hueston, and Keith Price. 2018. A Meta-Analysis of the CSI Effect: The Impact of Popular Media on Jurors’ Perception of Forensic Evidence. Politics, Bureaucracy, and Justice 5: 1–10. [Google Scholar]
- Ellis, John. 2006. Visible Fictions: Cinema, Television, Video (Nachdr.). London: Routledge. [Google Scholar]
- Ellis, Stanley. 1994. The Yorkshire Ripper enquiry: Part I. Forensic Linguistics 1: 197–206. [Google Scholar] [CrossRef]
- Gold, Erica, and Peter French. 2011. International Practices in Forensic Speaker Comparison. International Journal of Speech, Language and the Law 18: 293–307. [Google Scholar] [CrossRef]
- Gold, Erica, and Peter French. 2019. International practices in forensic speaker comparisons: Second survey. International Journal of Speech Language and the Law 26: 1–20. [Google Scholar] [CrossRef]
- Guiho, Mickaël. 2020. Willy Bardon condamné dans l’affaire Kulik: Les jurés expliquent leur décision. France 3 Hauts de France. Available online: https://france3-regions.francetvinfo.fr/hauts-de-france/somme/amiens/willy-bardon-condamne-affaire-kulik-jures-expliquent-leur-decision-1760827.html (accessed on 23 January 2024).
- Gully, Amelia, Philip Harrison, Vincent Hughes, Richard Rhodes, and Jessica Wormald. 2022. How Voice Analysis Can Help Solve Crimes. Frontiers for Young Minds 10: 702664. [Google Scholar] [CrossRef]
- Hoel, Aud Sissel. 2018. Operative Images. Inroads to a New Paradigm of Media Theory. In Image—Action—Space. Edited by Luisa Feiersinger, Kathrin Friedrich and Moritz Queisner. Berlin: De Gruyter, pp. 11–28. [Google Scholar] [CrossRef]
- Hudson, Toby, Gea de Jong, Kirsty McDougall, Philip Harrison, and Francis Nolan. 2007. F0 Statistics for 100 Young Male Speakers of Standard Southern British English. Paper presented at the 16th International Congress of Phonetic Sciences: ICPhS XVI, Saarbrücken, Germany, August 6–10; pp. 1809–12. Available online: https://api.semanticscholar.org/CorpusID:17550455 (accessed on 23 January 2024).
- Hudson, Toby, Kirsty McDougall, and Vincent Hughes. 2021. Forensic Phonetics. In The Cambridge Handbook of Phonetics, 1st ed. Edited by Rachael-Anne Knight and Jane Setter. Cambridge: Cambridge University Press, pp. 631–56. [Google Scholar] [CrossRef]
- Humble, Denise, Stefan R. Schweinberger, Axel Mayer, Tim L. Jesgarzewsky, Christian Dobel, and Romi Zäske. 2022. The Jena Voice Learning and Memory Test (JVLMT): A standardized tool for assessing the ability to learn and recognize voices. Behavior Research Methods 55: 1352–71. [Google Scholar] [CrossRef]
- Kersta, Lawrence G. 1962. Voiceprint Identification. Nature 196: 1253–57. [Google Scholar] [CrossRef]
- Kirby, David A. 2017. The Changing Popular Images of Science. Edited by Kathleen H. Jamieson, Dan M. Kahan and Dietram A. Scheufele. Oxford: Oxford University Press, vol. 1. [Google Scholar] [CrossRef]
- Le Saulnier, Guillaume. 2012. Ce que la fiction fait aux policiers. Réception des médias et identités professionnelles: Travailler 27: 17–36. [Google Scholar] [CrossRef]
- Mauriello, Thomas P. 2020. Public Speaking for Criminal Justice Professionals: A Manner of Speaking, 1st ed. Boca Raton: CRC Press. [Google Scholar]
- McDougall, Kirsty, Francis Nolan, and Toby Hudson. 2016. Telephone Transmission and Earwitnesses: Performance on Voice Parades Controlled for Voice Similarity. Phonetica 72: 257–72. [Google Scholar] [CrossRef]
- McGehee, Frances. 1937. The reliability of the identification of the human voice. The Journal of General Psychology 17: 249–71. [Google Scholar] [CrossRef]
- Morrison, Geoffrey S., and William C. Thompson. 2017. Assessing the admissibility of a new generation of forensic voice comparison testimony. Columbia Science and Technology Law Review 18: 326–434. [Google Scholar]
- Morrison, Geoffrey S., Farhan H. Sahito, Gaëlle Jardine, Djordje Djokic, Sophie Clavet, Sabine Berghs, and Caroline Goemans Dorny. 2016. INTERPOL survey of the use of speaker identification by law enforcement agencies. Forensic Science International 263: 92–100. [Google Scholar] [CrossRef] [PubMed]
- Nuance Communications. 2015. [White Paper]. The Essential Guide to Voice Biometrics. Available online: https://www.nuance.com/content/dam/nuance/en_us/collateral/enterprise/white-paper/wp-the-essential-guide-to-voice-biometrics-en-us.pdf (accessed on 23 January 2024).
- Rafter, Nicole. 2007. Crime, film and criminology: Recent sex-crime movies. Theoretical Criminology 11: 403–20. [Google Scholar] [CrossRef]
- Ratliff, Evan. 2022. Persona: The French Decepion [Audio podcast]. Pineapple Street Studios—Wondery. Available online: https://wondery.com/shows/persona/ (accessed on 23 January 2024).
- Ribeiro, Gianni, Jason M. Tangen, and Blake M. McKimmie. 2019. Beliefs about error rates and human judgment in forensic science. Forensic Science International 297: 138–47. [Google Scholar] [CrossRef] [PubMed]
- San Segundo, Eugenia, and Hermann Künzel. 2015. Automatic speaker recognition of spanish siblings: (Monozygotic and dizygotic) twins and non-twin brothers. Loquens 2: e021. [Google Scholar] [CrossRef]
- Sidtis, Diana, and Jody Kreiman. 2012. In the Beginning Was the Familiar Voice: Personally Familiar Voices in the Evolutionary and Contemporary Biology of Communication. Integrative Psychological and Behavioral Science 46: 146–59. [Google Scholar] [CrossRef] [PubMed]
- Smith, Peter Andrey. 2023. Can We Identify a Person from Their Voice? Digital Voiceprinting May Not Be Ready for the Courts. IEEE Spectrum, April 15. [Google Scholar]
- Solan, Lawrence M., and Peter M. Tiersma. 2003. Hearing Voices: Speaker Identification in Court. Hastings Law Journal 54: 373–435. [Google Scholar]
- Stevenage, Sarah V. 2018. Drawing a distinction between familiar and unfamiliar voice processing: A review of neuropsychological, clinical and empirical findings. Neuropsychologia 116: 162–78. [Google Scholar] [CrossRef] [PubMed]
- Trainum, James L. 2019. The CSI effect on cold case investigations. Forensic Science International 301: 455–60. [Google Scholar] [CrossRef] [PubMed]
- Villez, Barbara. 2005. Séries télé, visions de la justice, 1st ed. Paris: Presses universitaires de France. [Google Scholar]
- Villez, Barbara. 2014. Law and Order. New York Police Judiciaire. La Justice en Prime Time. Paris: Presses Universitaires de France. Available online: https://www.cairn.info/law-and-order-new-york-police-judiciaire--9782130594239.htm (accessed on 23 January 2024).
- Watt, Dominic, and Georgina Brown. 2020. Forensic phonetics and automatic speaker recognition. In The Routledge Handbook of Forensic Linguistics, 2nd ed. Edited by Malcolm Coulthard, Alison May and Rui Sousa-Silva. London: Routledge, pp. 400–15. [Google Scholar] [CrossRef]
- Watt, Dominic, Peter S. Harrison, and Lily Cabot-King. 2020. Who owns your voice? Linguistic and legal perspectives on the relationship between vocal distinctiveness and the rights of the individual speaker. International Journal of Speech Language and the Law 26: 137–80. [Google Scholar] [CrossRef]
- Yarmey, A. Daniel, A. Linda Yarmey, and Meagan J. Yarmey. 1994. Face and voice identifications in showups and lineups. Applied Cognitive Psychology 8: 453–64. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, Juan, Sara Ahmed, Danielius Visockas, and Cem Subakan. 2023. CommonAccent: Exploring Large Acoustic Pretrained Models for Accent Classification Based on Common Voice. Interspeech 2023: 5291–95. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features of Interest | Number of Excerpts (Out of 106) |
|---|---|
| Auditory identification of a speaker from an audio recording | 22 |
| Comparison of two recordings in order to identify the speaker | 42 |
| Audio signal is graphically represented | 65 |
| Superimposed waveforms | 5 |
| Comparison of two waveforms side by side | 4 |
| Decorative waveforms | 27 |
| Voice is compared to DNA | 0 |
| Voice is compared to fingerprints | 3 |
| Analysis of the speaker’s accent | 7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferragne, E.; Guyot Talbot, A.; Cecchini, M.; Beugnet, M.; Delanoë-Brun, E.; Georgeton, L.; Stécoli, C.; Bonastre, J.-F.; Fredouille, C. Forensic Audio and Voice Analysis: TV Series Reinforce False Popular Beliefs. Languages 2024, 9, 55. https://doi.org/10.3390/languages9020055
Ferragne E, Guyot Talbot A, Cecchini M, Beugnet M, Delanoë-Brun E, Georgeton L, Stécoli C, Bonastre J-F, Fredouille C. Forensic Audio and Voice Analysis: TV Series Reinforce False Popular Beliefs. Languages. 2024; 9(2):55. https://doi.org/10.3390/languages9020055
Chicago/Turabian StyleFerragne, Emmanuel, Anne Guyot Talbot, Margaux Cecchini, Martine Beugnet, Emmanuelle Delanoë-Brun, Laurianne Georgeton, Christophe Stécoli, Jean-François Bonastre, and Corinne Fredouille. 2024. "Forensic Audio and Voice Analysis: TV Series Reinforce False Popular Beliefs" Languages 9, no. 2: 55. https://doi.org/10.3390/languages9020055