6.1. Morphological Integration
Stammers and Deuchar [
17] (p. 635) report on the use of three transcribed conversations
7 from the Bangor
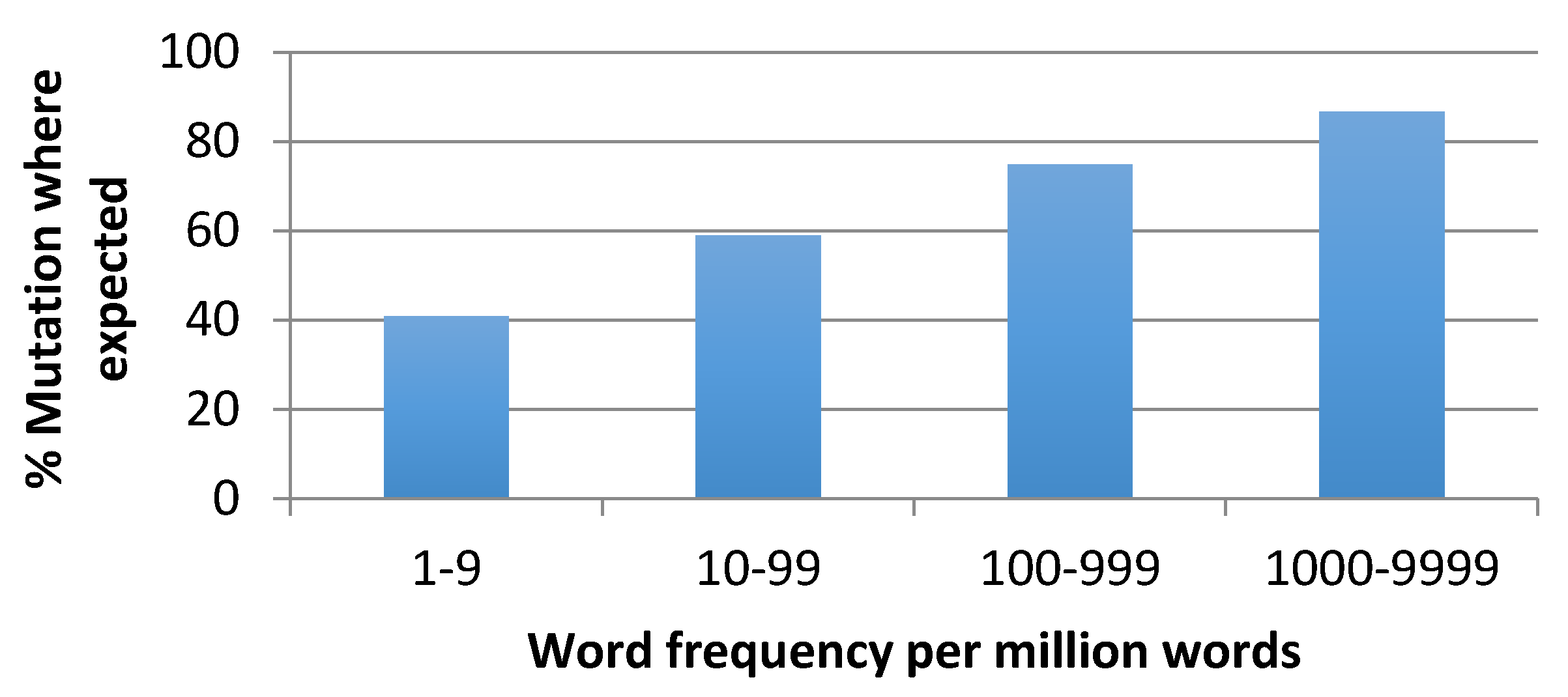
Siarad corpus. All verbs from these transcripts that were of English origin were extracted and classified as morphologically integrated in Welsh or not. There was a total of 184 tokens or 80 types
8. Of these 184 tokens, 179 (97.3%) were morphologically integrated by means of a Welsh derivational suffix. For Poplack and Meechan [
1], this fact would presumably lead them to categorize these 179 tokens as borrowings. Of course, if we look at the frequency of occurrence of these items they are far from uniform, including highly frequent loans found in the Welsh dictionary like
trio ‘try’ (5 tokens),
ffonio ‘phone’ (6 tokens) as well as low frequency verbs not found in any Welsh dictionary such as
stare-io ‘stare’ (1 token) and
freak-o (1 token). But this information about frequency would not be important for Poplack, who has argued elsewhere
9 that integration is abrupt
10 and that there is no relation with frequency
11 in their French-English data. For Myers-Scotton, the decision to draw the line between code-switching and borrowing would in contrast be based on frequency of usage rather than on the uniform morphological integration which we have discovered using our first test. We assume this would be considered by Myers-Scotton to be a central type of integration (see above), which would affect all donor-language items equally, regardless of any distinction drawn between code-switching and borrowing by investigators.
6.2. Syntactic Integration
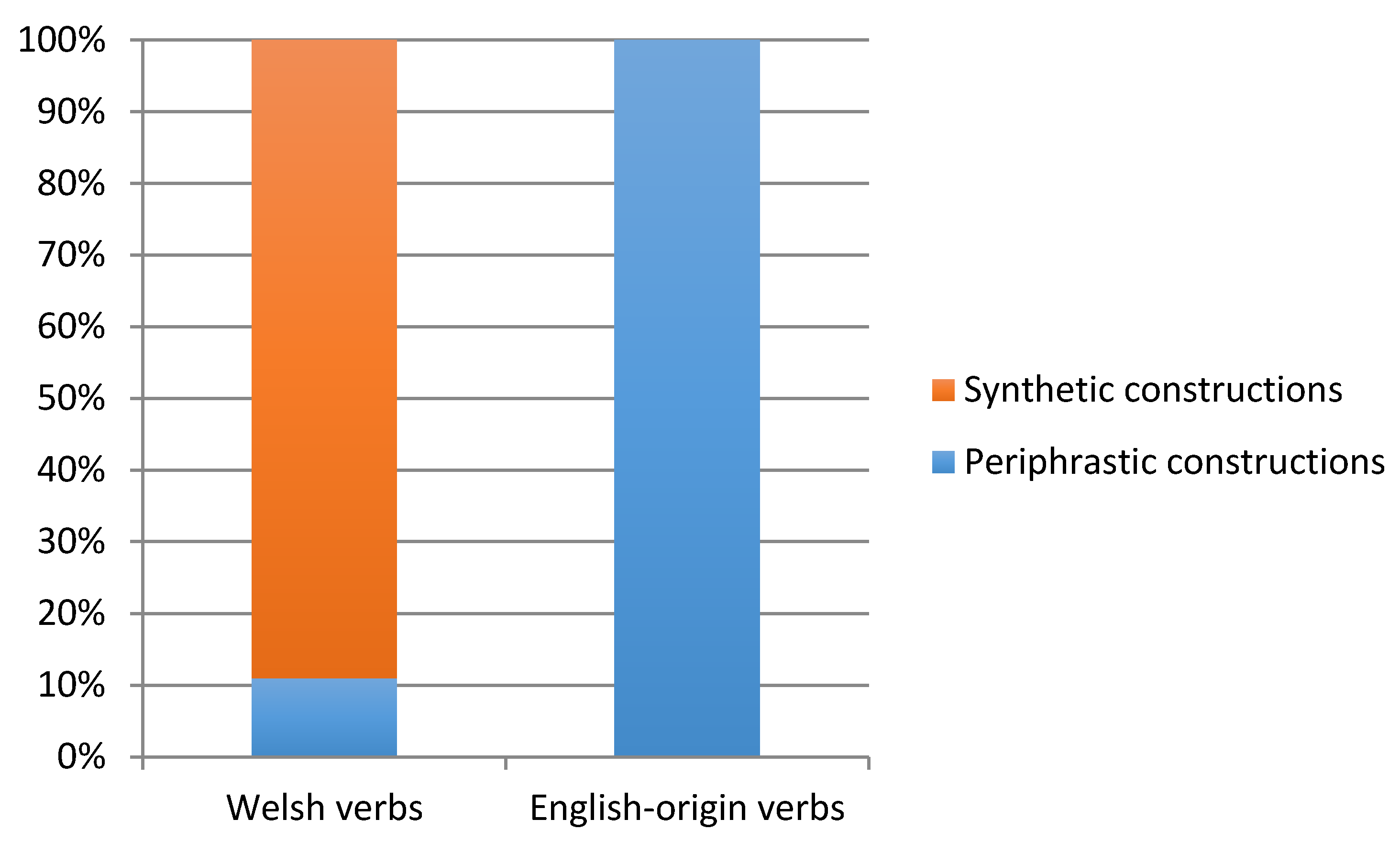
One way of examining the syntactic integration of English-origin verbs was reported by Stammers in his comparison of their occurrence in synthetic
versus periphrastic constructions with the distribution of native Welsh verbs in those two types of construction [
11] (p. 82). Examples of the two types were given in (3) and (4) above. Stammers [
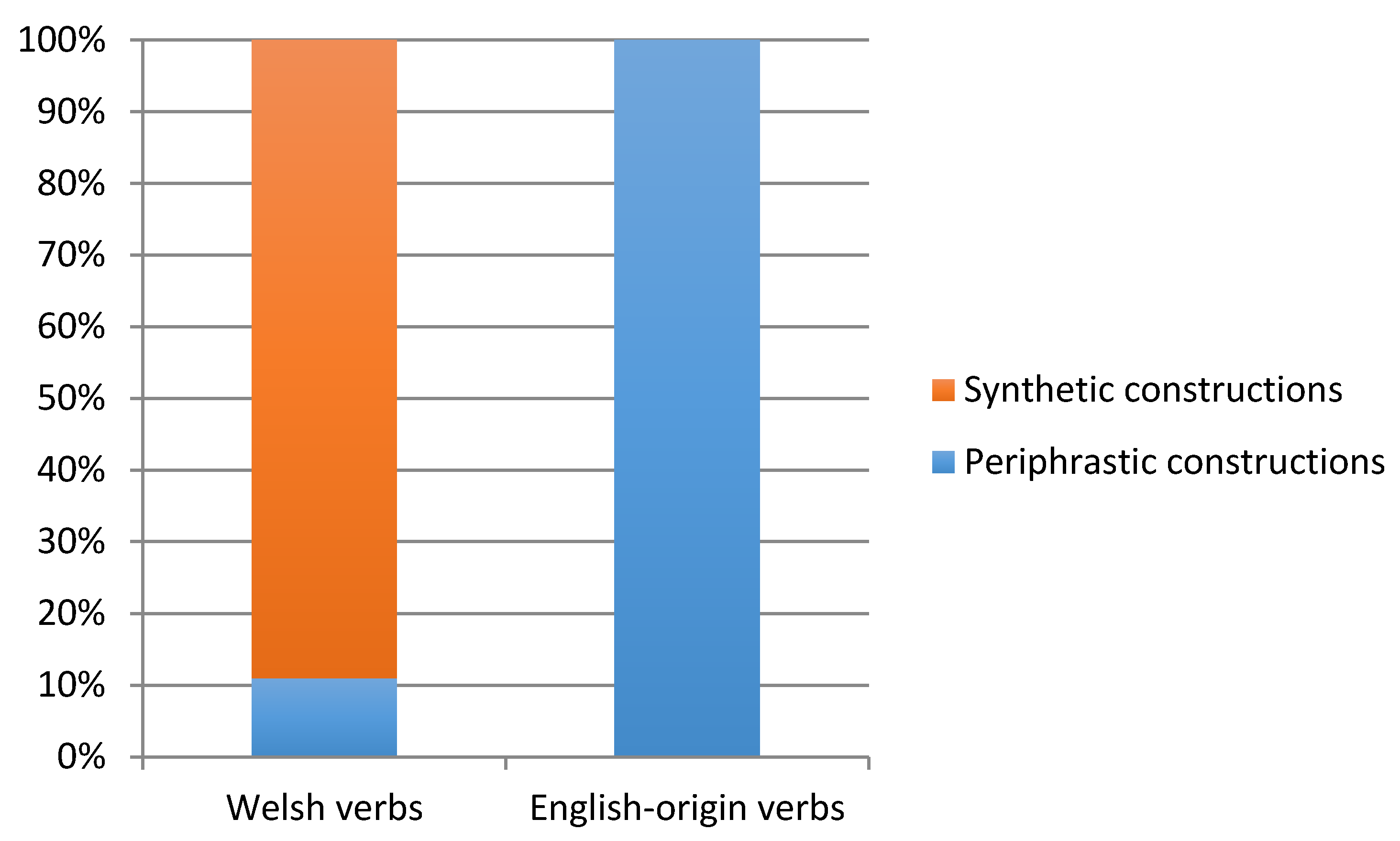
11] extracted all English-origin verbs from finite clauses in the three transcripts used in the previous analysis, ending up with 111 tokens. Their distribution in verbal constructions was compared with a sample of 300 tokens of native Welsh verbs. As shown in
Figure 1, 11% of native Welsh verb tokens appeared in synthetic constructions, compared with no English-origin verbs whatsoever, since 100% of the English-origin verbs appeared in periphrastic constructions. Stammers [
11] considered the possibility that this dramatic difference might be due to the small size of his sample, so he went on to investigate a large sample of both English-origin and native verbs. He searched the entire Siarad corpus for all tokens of English-origin verbs in synthetic constructions, and found 35. He estimated that “35 tokens of synthetic constructions represents approximately 1.3% of all English-origin main verb finite clauses in the corpus” Stammers [
11] (p. 88), in contrast with the results of a larger sample of 1082 tokens of which 12.6% were in synthetic as opposed to periphrastic constructions. He concluded that the distribution of native Welsh and English-origin verbs in syntactic constructions is not identical, so we may guess that this would lead Poplack and colleagues to conclude that the English-origin verbs cannot unequivocally be considered to be borrowings.
Table 2 summarizes the results of our tests of linguistic integration so far. As it shows, the English-origin verbs are almost all integrated according to the morphological test, whereas none are integrated according to the syntactic test. This suggests that identifying linguistic integration, which is crucial for Poplack and Meechan’s definition of borrowing, may depend on the test one uses and therefore is not an unproblematic criterion.
Perhaps the problem is that neither of the first two sets uses a sufficiently sensitive measure of linguistic integration. With the third test, however, we made use of a morphophonological process found in Welsh, soft mutation, to investigate the integration of English verbs into Welsh in a more subtle manner.
6.3. Morphophonological Integration
Soft mutation is a variable morphophonological process which affects certain consonants in the initial position of words in specific environments, for example following prepositions. Initial voiceless stops become voiced and voiced stops becoming fricatives, as outlined by Stammers [
11] (p. 89) and Stammers and Deuchar [
17] (p. 638).
Table 3 below shows the changes that are undergone in word-initial consonants when they are subject to soft mutation. Soft mutation, unlike derivational morphology described above, is not one of the morphosyntactic phenomena which Myers-Scotton would predict to come from the matrix language (she would presumably class it as a ‘peripheral’ process), and hence it might be accepted by proponents of all approaches as a possible measure of linguistic integration.
Stammers and Deuchar [
17] (p. 638) distinguish between lexically and syntactically triggered mutation. They state that “in lexically triggered soft mutation, the non-finite verb is directly preceded by a preposition, clitic or other particle causing soft mutation”. They give an example (reproduced as example (11) below) where the preverbal particle
i (translated as ‘to’ in English) triggers soft mutation of the initial consonant of the following verb
costio, which becomes
gostio.
| 11. | WELL | mae | mynd | i | gosti | pres |
| | well | be.3s.PRES | go.NONFIN | to | cost.NONFIN | money |
| | ‘well, it’s going to cost money’ | (fusser 6) |
| | Stammers and Deuchar [17] (p. 638), example (10) | |
Other environments involving lexically triggered mutation include where the non-finite verb is preceded by a second person or third person masculine possessive pronoun, the preposition am (‘for/about’), ar (‘on/about to’), gan (‘by/while/with’).
According to Stammers and Deuchar [
17], in syntactically triggered soft mutation the non-finite verb is expected to mutate because of its position in the clause following the grammatical subject. This is illustrated in example (12) below:
| 12. | wnest | ti | drio? |
| | do.2s.past | pron.2s | try.nonfin |
| | ‘did you try?’ | (stammers 5) |
| Stammers and Deuchar [17] (p. 639), example (14) |
As they explain, the verb
drio in example (12) is actually a mutated version of
trio (‘try’). Stammers and Deuchar provide additional examples of environments for mutation, including one where mutation does not apply as expected. Although soft mutation is the most robust mutation type in Welsh (
cf. Comrie) [
18] (p. 81) its application is still subject to variation even in Welsh words. (
cf. Ball and Müller) [
19] (p. 256). This variation is advantageous for our analysis since it provides us with a fine-grained measure to compare the integration of English-origin verbs with the level of mutation found in native Welsh verbs, following the methodology advocated by Poplack and Meechan [
1].
Stammers and Deuchar [
17] describe how verbs used in Welsh periphrastic constructions can be divided into three categories: (1) native Welsh; (2) English-origin verbs listed in a dictionary of Welsh (‘listed’, e.g., in Thomas [
20]) and (3) English-origin verbs not listed in a dictionary of Welsh (‘unlisted’). The following are examples of verbs
13 in the three categories:
- (I)
Native Welsh verbs: Regular native verbs ending with the -(i)o suffix, e.g., cofio (to remember), defnyddio (to use), cwyno (to complain), pwyso (to push), cneifio (to shear), treiglo (to mutate), twtio (to tidy).
- (II)
Listed English-origin verbs: Verbs of English origin ending with the -(i)o suffix and found listed in a dictionary of Welsh, e.g., trio (to try), cario (to carry), clirio (to clear), dreifio (to drive), clariffeio (to clarify), pinsio (to pinch), bargeinio (to bargain), manejio (to manage), tsiecio (to check), cidnapio (to kidnap).
- (III)
Unlisted English-origin verbs: Verbs of English origin ending with the -(i)o suffix but not found listed in any dictionary of Welsh, e.g., TEXT-io, DOWNLOAD-io, BRIEF-io, QUOTE-io, BULK-io, CONNECT-io, BABYSIT-io, DECORATE-io, CONCENTRATE-io, MOLLYCODDLE-io, POWER-WALK-io.
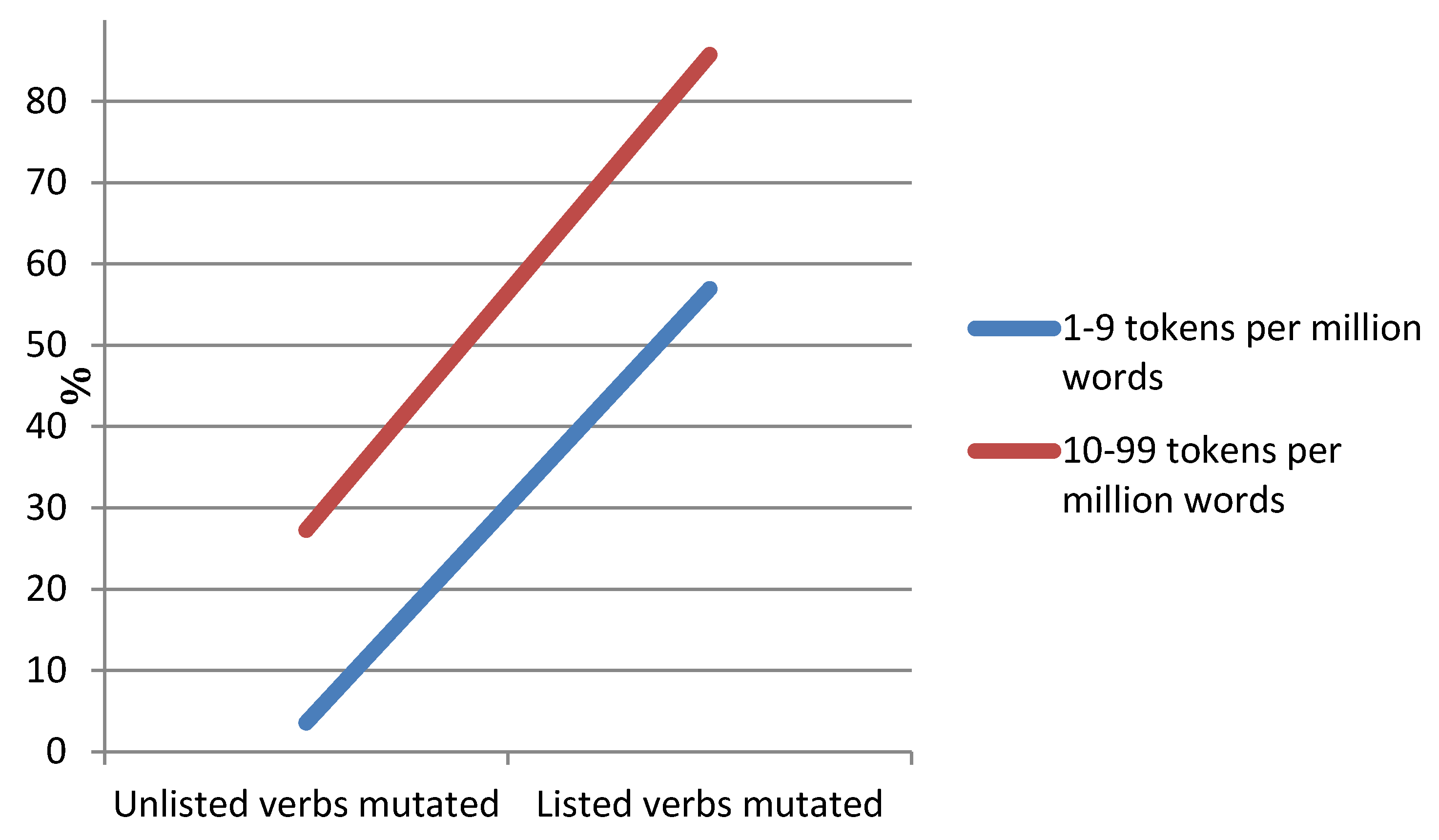
Note that these last two categories are distinguished here in their orthographic representation, following the conventions used in transcribing the corpus. The reason for distinguishing not only between Welsh-origin and English-origin verbs but also between ‘listed’ and ‘unlisted’ English verbs in an analysis of linguistic integration is that it allowed us to determine whether in addition to frequency, there is a factor of ‘listedness’ which influences linguistic integration (
cf. Muysken) [
22] (p. 71). The analysis involved extracting all of the non-finite verb tokens found in the
Siarad corpus that (i) ended in the -
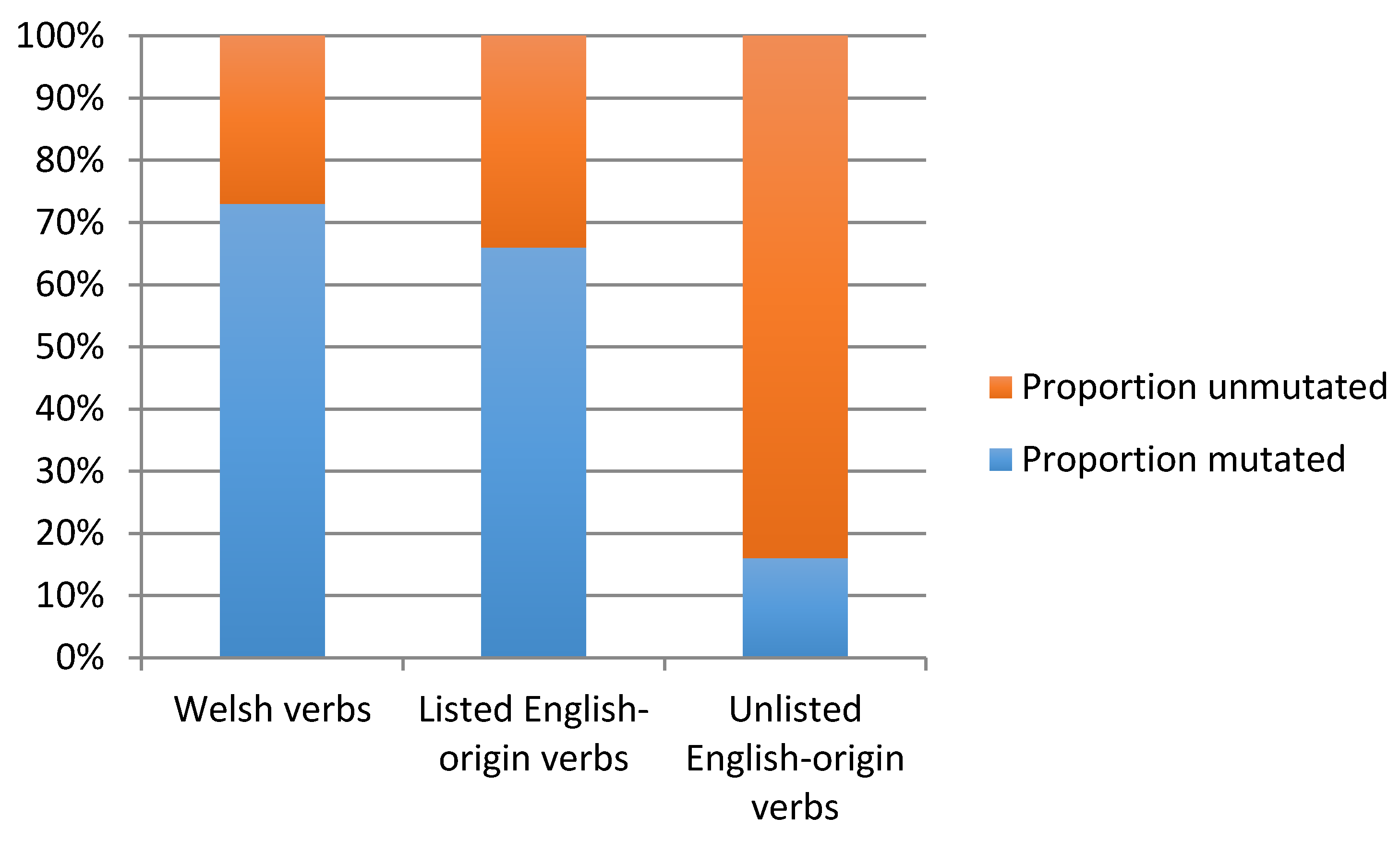
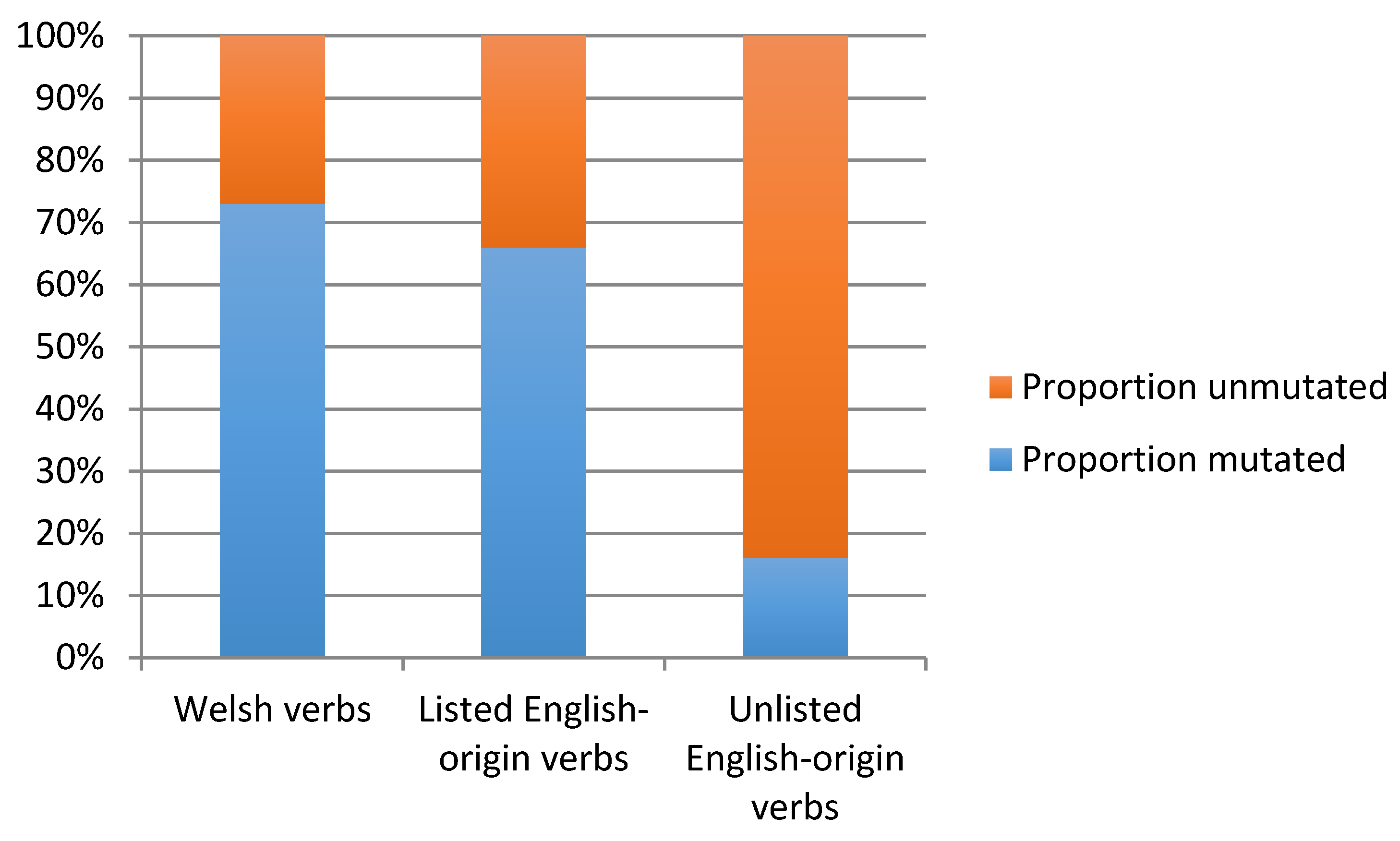
(i)o verbalising suffix; (ii) began with a consonant susceptible to soft mutation (subject to certain exclusions); and (iii) occurred in an environment where soft mutation could be expected to apply. Each of a total of 506 tokens was classified according to whether or not mutation actually applied.
The 506 tokens identified for the analysis (159 types) were an exhaustive selection of tokens of regular verbs meeting the criteria for mutation to occur and ending with the -
(i)o suffix. This means that each began with a consonant which was subject to mutation, and each occurred in an environment where mutation was predicted to occur. For each token, we noted whether or not mutation had actually occurred. One-hundred forty-three tokens of native verbs were identified, or 44 types, of which an example is
defnyddio (to use; either occurring with an initial [d] or in its mutated form with an initial fricative [ð] as
ddefnyddio). 302 tokens of listed English-origin verb were identified, or 81 types, of which an example is
trio (either occurring with an initial voiceless stop [t] or in its mutated form with an initial voiced stop [d] as
drio, and an example of an unlisted English-origin verb from the 61 tokens (34 types) found is COPE
-io (either occurring with an initial voiceless stop [k] or in its mutated form with an initial voiced stop [ɡ] as GOPE-
io). The results of our mutation analysis are shown in
Figure 2.
Figure 2 shows that there are differences between the three categories of verbs in terms of their behaviour in environments where mutation is expected. Native Welsh verbs show a 73% rate of mutation in environments where this is expected while English-origin verbs not listed in the dictionary show the reverse pattern: an 84% rate of non-mutation in environments where it is expected. The intermediate category of English-origin verbs found in the dictionary shows an intermediate pattern: The majority of tokens (66%) are mutated, meaning that they pattern more like the native Welsh verbs than the English-origin verbs not in the dictionary. These results show that integration measured in this way is not ‘abrupt’ as suggested by Poplack and Dion [
21] but that listed English-origin verbs are considerably more integrated than unlisted English-origin verbs.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}