1. Introduction
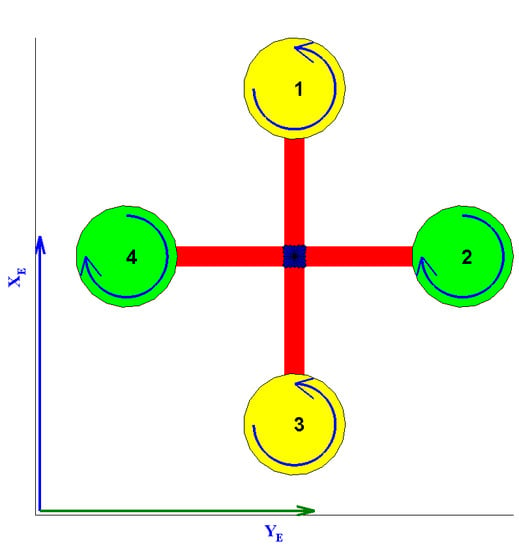
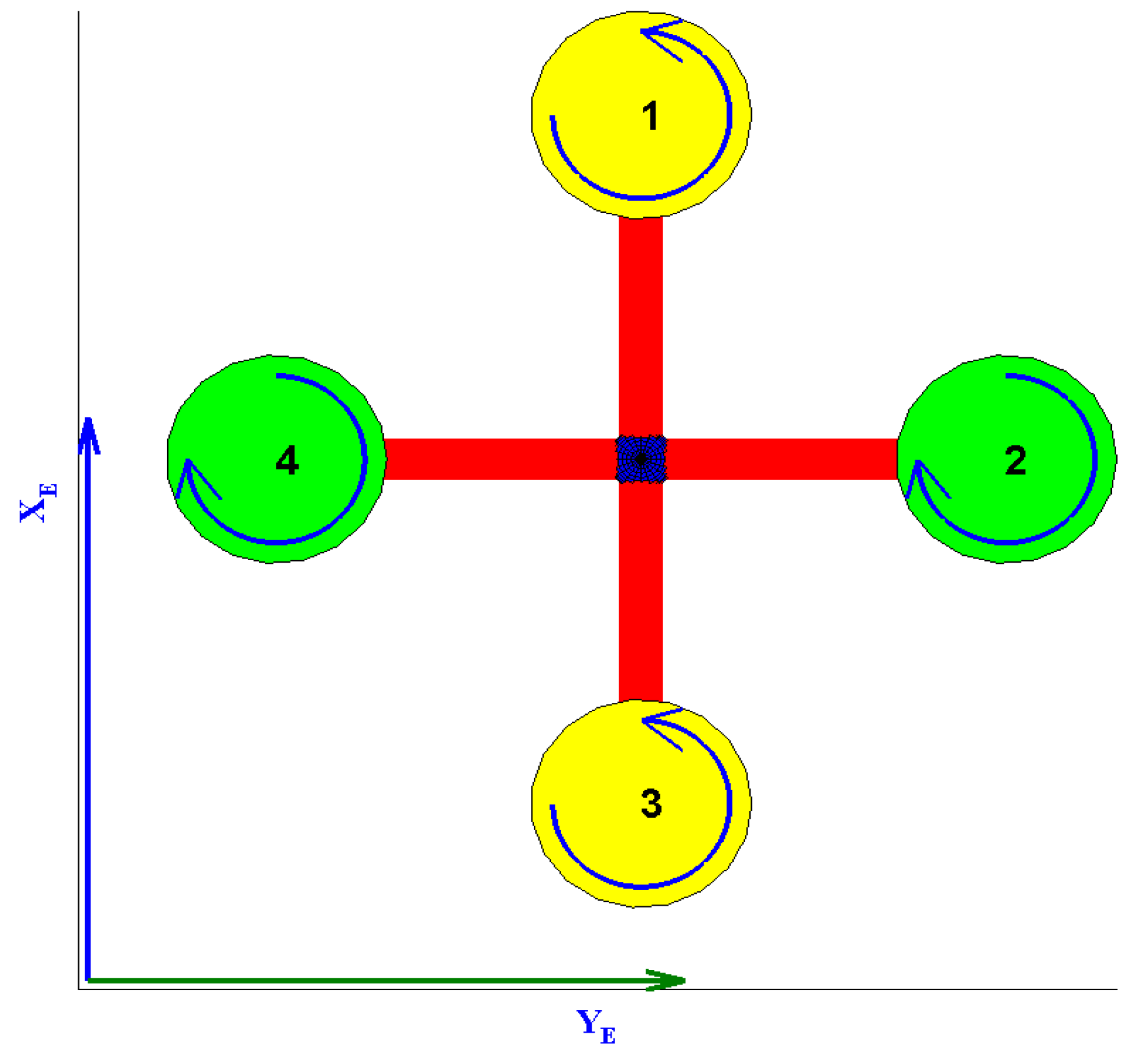
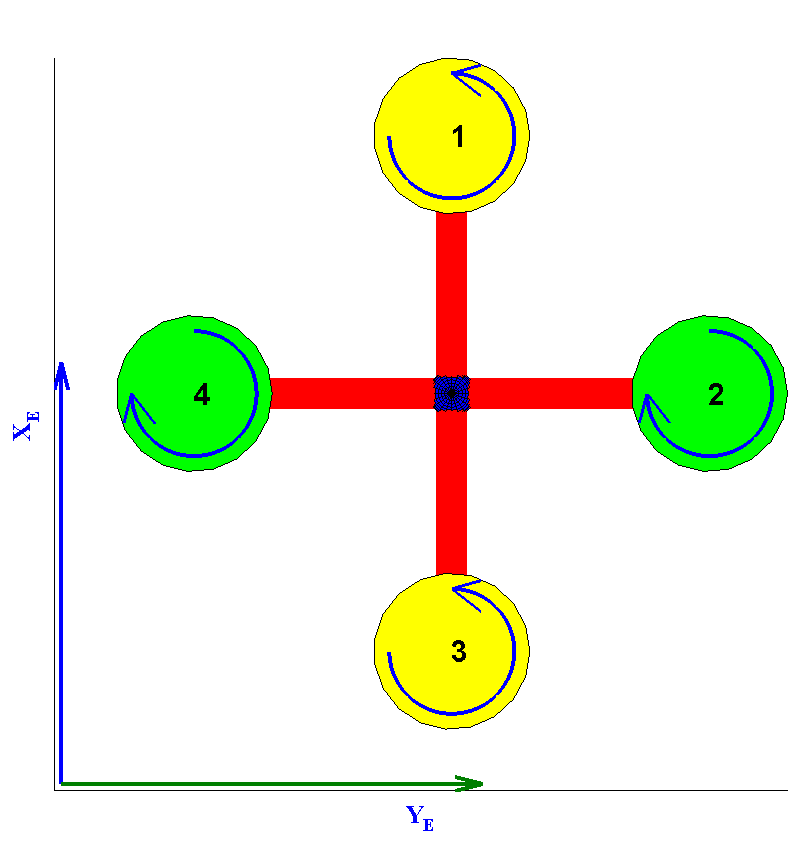
A quadrotor helicopter platform (often just called a quadrotor) is an under-actuated helicopter with two pairs of rotors in a cross-configuration capable of spinning at different angular velocities in order to achieve translational and rotational motion. Rotor pair
spins in one direction, while the pair
spins in the opposite (see
Figure 1).
The different motions the quadrotor can perform are: (a) vertical motion: simultaneous change in rotor speed; (b) roll motion: imbalance in the rotor speed of pair ; (c) pitch motion: imbalance in the rotor speed of pair ; (d) yaw motion: imbalance between all rotors.
Quadrotors have gained popularity as research platforms because of their simplicity of design and low cost of manufacturing. Because they are challenging vehicles to control, wherever operated in an indoor environment or in the open field, they serve as great platforms for research. They also possess many advantages over standard helicopters in terms of safety and efficiency at small sizes [
1]. There are many applications for a quadrotor platform, both in the military and the civil sectors, which are summarized quite extensively in [
2,
3,
4,
5,
6].
To enable autonomous operations of a quadrotor, the research community typically focuses on the following aspects of the quadrotor: kinematics and dynamics of the vehicle; trajectory generation (path planning); guidance, navigation and control.
The focus of this paper is to synthesize a nonlinear model predictive control law for tracking a trajectory to be followed by a quadrotor. The applications are typically way-point navigation and tracking certain agile maneuvers [
7,
8,
9,
10]. Since the quadrotor can only generate forces normal to the plane that contains the rotors, the translational and rotational dynamics are significantly coupled. This restricts the quadrotor from performing certain maneuvers [
11] that are possible with a fixed wing aircraft and the more conventional helicopter. In what follows, some key works relevant to these topics are summarized, and the layout of the paper is outlined.
A significant amount of research has been performed in the area of trajectory generation and constrained control of unmanned vehicles that apply to quadrotors alike. The work in [
12,
13] discusses the generation of trajectories for robots, wherein a spline interpolation method is used to solve a minimum time optimization problem, while staying under torque and velocity constraints. The work in [
14] also used a spline interpolation method to generate optimal-time trajectories and applied it to a micro-quadrotor. For reference trajectory generation, [
7] develops the governing equations of motion and describes the trajectories as algebraic functions of a flat output: outputs that can express the states and inputs of the system in terms of its outputs and their derivatives [
15]. This approach facilitates the automatic trajectory generation for the system. In [
9], trajectories are generated by designing a sequence of controllers to drive the system to a desired goal state. The works in [
1,
16] discuss the design of safe, aggressive maneuvers and control for a back flip trajectory. The work in [
17] constructed a dynamically feasible, desired speed profile for a given sequence of waypoints. The authors in [
18,
19] worked on trajectory generation for quadrotors by implementing dynamic constraints to an optimal control method and verified the existence of optimal trajectories. The work in [
20] addresses the problem of quadrotor trajectory generation and tracking while carrying a suspended payload. They solved this by developing an optimal controller based on the dynamic programming technique: breaking down a problem into several sub-problems. It should be recognized that translational control of the quadcopter is very strongly coupled with the rigid body rotation especially for the longitudinal and lateral motion. The stability of such platforms has been studied, and some notable techniques that address the stability by separating the fast and slow dynamics can be found in [
21,
22].
Virtually every possible control technique, linear control, such as PID and linear quadratic methods, robust linear control and nonlinear control [
23,
24] techniques, such as adaptive control, iterative learning control [
25], neural networks [
26], sliding mode, among others, have been tried and tested in simulations and on actual flying test platforms. Since the quadrotor can only produce bounded forces and that too only along one direction, the platform is input constrained. All of the earlier mentioned control techniques apply the input constraints post-facto, while model predictive control (MPC) provides a framework to impose input constraints as part of the control synthesis. Since the quadrotor is also constrained in operation in state-space, the platform essentially is state and input constrained. These state and input constraints along with goal states, as well as trajectory constraints (equality and inequality) can all be effectively integrated into the MPC framework. The work in [
27] looked into the nonlinear model predictive tracking control (NMPTC) technique and applied it to generate trajectories to unmanned rotorcraft while staying under input and state constraints.
This paper focuses on the development of the nonlinear model predictive control (NMPC) formulation to derive an optimal controller subject to input, state and output constraints. This is accomplished by formulating the nonlinear system dynamics using a state-dependent coefficient (SDC) form, which allows the representation of the system in a pseudo-linear form. The performance of this controller is illustrated via candidate simulations for tracking aggressive reference trajectories in the presence of high frequency disturbances in the roll and pitch channels.
The rest of the paper is organized as follows. A brief overview of the governing equations of motion is first presented. This is followed by elaborating the MPC technique for a linearized quadrotor model (about the hover equilibrium) for the sake of completeness. The SDC form of the nonlinear quadrotor model is presented next, which highlights key differences in the presented model from those in other comparable works. Following this, the state-dependent Riccati equation (SDRE) approach to deriving a nonlinear sub-optimal controller is presented that uses the aforementioned SDC form. The nonlinear model predictive controller (NMPC) is developed using a discretized form (sampled-data form) of the SDC model. The boundedness of the trajectory tracking errors is shown for the NMPC, and simulation results are presented that compare the performance of linear and nonlinear MPC techniques, highlighting key areas where the nonlinear controller performs better. The simulation results correspond to representative maneuver scenarios. Finally, a brief summary of the work and conclusions thereof are presented.
2. Mathematical Model of the Quadrotor
Let
denote the Earth-fixed inertial frame and
the body-fixed frame, whose origin
is at the center of mass of the quadrotor. The inertial position of the quadrotor is defined by
and the attitude by the Euler angles: roll, pitch and yaw (
).
is the direction cosine matrix representing the inertial to body frame transformation.
is the inertial velocity of the quadrotor expressed in the body frame components, and
is the angular velocity expressed in the body frame components. Neglecting the aerodynamic and gyroscopic effects, the quadrotor model can be shown as [
28]:
where
,
, and:
The constants in the equation denote the acceleration due to gravity, the mass and moment of inertia of the quadrotor, respectively. The body axes are assumed oriented along the principal axes without loss of any generality, and hence, the moment of inertia matrix is a diagonal matrix, . T and represent the total thrust and torques about the body axes of the quadrotor.
In addition, the relations between the total thrust (
T), torque (
) components and the individual rotor thrusts
can be expressed as:
where
L is the distance from the rotor to the center of gravity (CG) of the quadrotor and
c is a constant that relates the rotor angular momentum to the rotor thrust (normal force). Combining Equations (
1) and (
3), a more comprehensive model can be written as:
Let
and
. Equation (
4) can be compactly written as:
Given the nature of the quadrotor, the range of operation of the vehicle is restricted as shown below. At a pitch angle of
, the matrix
in Equation (
2) becomes singular.
Actuator dynamics for each rotor is assumed to be a first order system [
29]:
where
denotes the commanded value for rotor lift (thrust) and
denotes the first order actuator time constant (assumed the same for all of the rotors). Actuator dynamics is ignored for prediction, but is used for state propagation.
3. Linear Model Predictive Control of a Quadrotor
This section summarizes the model predictive control (MPC) algorithm for the sake of completeness. MPC, which can also be called receding horizon control (RHC), is a technique in which a mathematical model of a system is used to solve a finite, moving horizon, closed loop optimal control problem [
30] by using the current states of the system [
31]. MPC is able to take into account the physical and mechanical limitations of the plant during the design process [
32] and predict a number of future outputs of the system (called the prediction horizon), in order to formulate an optimal controller effort to bring the system to a desired state given a reference trajectory.
This optimization problem is solved at each sampling interval for the specified prediction horizon, but only the first step of the solution to the optimization problem is applied to the system until the next sampling interval. This routine is repeated for all subsequent time intervals (see [
33]). In the following section, the MPC technique as applied to a linear system (LMPC) is elaborated.
3.1. Plant Model and Prediction Horizon
Given the nonlinear system of the form:
where
are the system states,
are the system inputs and
are the system outputs as functions of time
t. In general
and
.
and
are vector valued functions in
. Note, the combined quadrotor governing equations of motion (Equation (
4)) constitute such a nonlinear dynamic system where
and
. This system can be linearized about a desired operating point, such as “hover”. The values of the states and the controls for such an operating point will be denoted as the ordered pair,
. The equivalent discretized linear system assuming a sampling interval
can be summarized as follows,
where
k is the current sample,
,
,
is the state matrix,
is the input matrix,
is the output matrix and
is the input feedforward matrix. The equilibrium control input in the case of “hover” is
.
The objective of the linear MPC is to drive the system towards a desired state. Based on the model of Equation (
9) [
34], the controller predicts the future states progression as a function of current states and future inputs:
where
. Thus, the standard prediction equations can be written as,
where,
Since
in most applications, it is assumed for the rest of the analysis:
The terminal state and output are given by:
where:
3.2. Controller Design
The MPC algorithm requires the use of an objective function in its control formulation in order to calculate the optimal solution at each sampling interval. It must be chosen in a way such that the predicted outputs, derived from the prediction horizon
N (Equation (
11)), are driven to a desired state or track a desired trajectory
, while at the same time, it should minimize the controller effort
required [
35]. For the quadrotor scenario, the penalty function penalizes the norm of the difference between the current output states and the desired trajectory and the norm of actuator inputs. It is of the form:
It is important to note that usually, the reference trajectory
is known in advance. Furthermore,
is defined as:
This implies that the controller is able to predict a series of adequate inputs that will drive the system towards the desired goal. In the quadratic form of (Equation (
13)), the term
and
are defined as:
where
,
and
are all diagonal, and they satisfy
,
and
.
is chosen based on the solution to the discrete algebraic Riccati equation using
.
is set equal to
. With proper substitution, it follows that,
Quadratic programming: Since the cost function from Equation (
14) is of quadratic form, a quadratic programming (QP) method can be used to solve the optimization problem [
36]. The idea behind QP is to minimize the quadratic function
in Equation (
14) by looking for a feasible search direction
.
Input and state constraint handling: Special attention is given to the constraint handling capabilities of the MPC problem formulation now that the objective function has been specified (Equation (
14)). In the case of the quadrotor, it is necessary to constrain both the total thrust force of each rotor and restrict the magnitude of the angles in order to stay within the limits allowed by the Euler angles’ formulation discussed previously.
3.3. Input Constraints
It is necessary to constrain the maximum force each rotor is able to deliver in order to make the quadrotor perform in such a way that it resembles a more realistic physical model. The forces need to be within some lower bound
and some upper bound
,
for
. However, the MPC problem is solved to obtain the perturbation controls since the model employed is the linearized dynamics about the equilibrium point. Since,
, it can be seen that
. Alternately,
. These constraints can be expressed in matrix form as follows:
where
is an
identity matrix. After proper arrangement, the input constraint can be represented as:
where:
3.4. Output and State Constraints
It is also of high importance to limit the angles so that no kinematic singularities are encountered due to the limitations in the model description. In the case of the quadrotor, the angles need to be within the bounds specified by Equation (
6). If a particular output, such as the pitch angle,
needs to be constrained, the corresponding output is defined as
. The constraints are represented as
for
, where
and
are the upper and lower bounds for the output variables. Since
,
. Thus,
. It can be represented in matrix form as:
With proper arrangement and substitution of
from (
12), the constraints can be expressed in terms of
as:
where:
3.5. Combined Input and Output State Constraints
Both the input and output variable constraints can be integrated into one equation as shown below.
where
is a matrix containing both input and output variable constraints and:
3.6. Stability of Unconstrained Linear MPC
Without loss of generality, an “informal” proof of stability will be given only for the regulator case. For trajectory tracking problems, an error system can always be constructed with the new state being . With the proper feed-forward input, the new system would be of the same form as the regulator.
The cost function in Equation (
14) can be simplified respectively as:
Assuming there are no constraints present on the inputs or states, the optimal control
can be determined by setting
, i.e.,
Additionally, the control input
can be extracted as follows.
Combining Equations (
23) and (
24),
can be simplified.
where:
According to [
37], if
in Equation (
22) satisfies the following inequality:
for some
, then the system of Equation (
9) driven by control
of Equation (
24) is stable (note, the input feedforward matrix
).
The optimal cost
satisfies the following monotonicity condition:
where
N denotes the prediction horizon and
,
represent the optimal control derived from minimizing their respective cost functions. Imagine a new control input
by using
up to time
and
; the cost for this control would be:
Since
is optimal and denoting
, the following applies:
thus proving the cost monotonicity condition. From the cost monotonicity condition, the following non-increasing sequence can be obtained:
Since a non-increasing sequence bounded from below converges to a constant,
, and hence,
as
. Thus,
which leads to the following equation:
It is proven in [
38] that if
is observable, then:
is observable for any
. Thus, the only solution that could guarantee this is the trivial solution
. Hence, system Equation (
9), driven by control
of Equation (
24) by minimizing the quadratic cost Equation (
22), is stable. Back to our control law design, if a
is carefully selected such that
is the solution of the Discrete Algebraic Riccati Equation (DARE), thus automatically satisfying the Equation (
27), the optimal control given by Equation (
25) asymptotically stabilizes system Equation (
9). Since full state feedback is assumed for this problem (
), this can be easily accomplished.
3.7. Stability of Constrained Linear MPC
Again without loss of generality, only stability for the regulator case is considered here. To guarantee the same monotonicity condition as Equation (
28), it must be guaranteed that the system is feasible. The following linear matrix inequalities (LMI) are constructed for this purpose. There must exist a set of
that satisfies the following conditions:
It should be noted here that
needs to be full rank. Since the constraints contain constant terms, this condition only needs to be checked just once at the beginning. After obtaining a suitable
from the above LMI,
is obtained by solving the following optimization problem:
subject to Equations (34)–(39).
The solution to the above-mentioned optimization problem yields
,
The same proof of asymptotic stability from the unconstrained case can then be used here once the feasible control action is determined. Thus, system Equation (
9) driven by control Equation (40) subject to constraints Equation (
21) is stable. Note, the stability of such platforms with coupled fast and slow dynamics has been studied extensively by other researchers, and some notable techniques, such as singular perturbation control can be found in [
21,
22]. In the present context, the translational control in the horizontal plane (forward and lateral directions) can only be affected by the pitch and roll angles. Thus, it is imperative for the quadrotor platform to have a very robust pitch and roll control. In our present work, we do not explicitly address this time scale decomposition, since the closed loop system is guaranteed stable with an appropriate choice of the weighting matrices. Robustness could be improved by further turning these weighting matrices.
4. Nonlinear Model Predictive Control Formulation
In this section, the procedure to develop the nonlinear model predictive controller (NMPC) is elaborated. The essential idea is to utilize the state-dependent coefficient (SDC) factorization [
39] of the nonlinear dynamics. A state space representation of the quadrotor is obtained, where each of its system matrices are now expressed as functions of the current state [
40]. Consider a dynamic system as in Equation (
8). The NMPC formulation involves transforming the nonlinear system into the following state space form,
where
is the state vector,
is the input vector,
is the output vector and
,
,
and
are the pseudo-linear system matrices in the SDC form, as well as the pairs
and
are stabilizable and detectable
, respectively. It is important to note that this representation of
,
,
and
is not unique in general, except for a scalar system. Different state-dependent coefficient matrices can be obtained from the equations of motion, and a solution to the optimization problem may or may not exist. However, a particular factorization (shown later) is derived here. The discrete-time equivalent of Equation (41) is obtained by using a zero-order-hold (ZOH) with a specified sample time. Let the discrete-time equivalent of the system be of the following form:
where
and
are discrete approximations of the continuous
and
, respectively.
From the description of the quadrotor, it can be seen that
and
(a constant matrix). Since Equation (42) is of the pseudo-linear form, the system matrices can be considered to be constants for each sampling interval, i.e.,
with
. It should be noted that in Equation (41), the first term
vanishes if
. For the quadrotor case (Equation (
5)),
does not completely vanish when
. Thus, a slight change is needed in Equation (41) to account for this. The quadrotor system will be transformed into the form:
where
represents the constant force term that is required to balance the weight of the quadrotor. It is assumed that the quadrotor starts from an initial equilibrium state. The new control design then focuses on the synthesis of
. Clearly, when
, for the “hover” equilibrium case,
, since
. One possible way to factorize the equations of motion into the SDC form is presented in Equation (
44).
where:
and
is the same as in Equation (
4). One issue that arises from this SDC form is that the term like
does not exist when
. To prevent this from happening, the first three terms of Taylor series expansions of
,
,
and
are used here to provide a close approximation (in reality, the approximations only differ from their true values
at most in the range of
). By doing this,
can be expressed as shown in Equation (45).
Considering the specific aspects of the quadrotor as detailed above, the discretized system for the derivation of the NMPC is summarized below:
where the fact that for this system,
(a constant matrix) is used. Following the same approach as outlined for the linear MPC, we arrive at the
N step state prediction equations (similar to Equation (
12)):
where,
Similarly, the terminal state and output is given by:
where:
The nonlinear MPC uses the same algorithm as the linear MPC to calculate the solution to the minimization of the cost function outlined in Equation (
13). The main difference between the linear and nonlinear version of the MPC is that now, the objective function depends on the current states of the system and needs to be calculated at the start of each sample interval. The objective function Equation (
14) then becomes:
As with the linear case,
is chosen based on the solution to the discrete algebraic Riccati equation using:
and
is set equal to
. This calculation is performed at each sample instant as opposed to just once, which was the case in the linear control law derivation.
The cost function is seen to be quasi-quadratic, and the regular quadratic programming method is used to solve for the control (Equation (48)). Similar to Equation (
21), the input and output variable constraints are integrated into one equation of the form:
where
is a matrix containing both input and output variable constraints and:
where,
Note, the inequality in Equation (50) needs to be checked at the start of every new prediction. Alternately, the feasibility of the solution to the LMIs for NMPC needs to be evaluated at every new prediction.
5. Stability of Nonlinear Model Predictive Control Solution
In this section, the stability of the closed loop system with the NMPC solution from minimizing the cost function in Equation (48) subject to the input and state constraints in Equation (50), when applied to the dynamics in Equation (
1), is shown. It is shown that the control scheme when applied to the quadrotor model results in bounded tracking errors, while guaranteeing internal stability. The bounded stability is shown for a general class of nonlinear systems representative of the application under consideration. Consider the nonlinear system:
with the definition of the state and control variables to be the same as what was discussed in earlier sections. The mappings
and
are sufficiently smooth. A pseudo-linear description of Equation (51) is the pair
, such that,
Since the control implementation essentially renders the closed loop system to be a sampled-data system, the stability problem is addressed by first considering the unconstrained sampled-data NMPC for the SDC system in Equation (52). The constrained sampled-data NMPC is considered later.
5.1. Stability of Unconstrained Sampled-Data NMPC Based on the SDC System
Assumptions:
is point-wise controllable. Thus, , i.e., , such that
is point-wise Hurwitz.
is obtained as a solution to a state-dependent Riccati equation using the system matrices in the SDC form. The control law is thus expressed as,
is an admissible reference state trajectory, i.e., satisfies the governing equations of motion, as well as the state constraints.
The reference control inputs obtained from Equation (51) together with and satisfy the control constraints discussed previously.
The solution is feasible for the given predictive horizon.
In this section, following a similar approach reported in [
41], it will be first shown that for an appropriate sample time
, the ZOH control, computed as:
when applied to the nonlinear system in Equation (51) results in bounded trajectory tracking errors, i.e.,
,
for
, where
. For the rest of the discussion,
and
will be simply written as
and
.
For
, the frozen in time SDC representation for the system is considered; thus, the states evolve as,
At the next sampling interval
,
is replaced with
measured from the original system Equation (52), and the same process starts over again. To avoid potential ambiguities, the solution of differential Equation (54) at the end of the interval, namely the value of
as
, is denoted as
. Note, the control input
is constant during the interval
. Under the assumptions stated earlier, the control for Equation (54) will stabilize the original system Equation (52) provided the control law given by Equation (53) will achieve uniformly globally asymptotic stability (UGAS) for System (51). It should be noted here that this algorithm is merely a sampled-data implementation of Equation (53). The work in [
41] proved the stability of sampled-data control based on SDC provided that
obtained from Equation (49) converges to a constant matrix; in other words,
exists. However, the convergence of
is hard, if not impossible to guarantee. Here, an alternative proof with a different, albeit restrictive assumption, is given. Without loss of generality, only the stability of the system for the regulator case, meaning
at all times, is proven. Firstly,
since
dictates
, which makes it trivial. With a constant input
during time interval
,
is obtained from the following:
and obtain
from:
The control input
is designed based on (56), such that:
It should be noted that such an input
will always exist since the system in Equation (52) is assumed point-wise controllable. The local truncation error (between the true nonlinear system and the discretized pseudo-linear system subject to the ZOH control law) at the end of the time interval is defined as:
Define a term
as:
By taking the limit of
when
, the following is obtained:
⇒
. A stabilizing
dictates
. From all of this, it can be concluded that:
Thus,
, which ensures the corresponding
. This leads to:
Combined with Equation (57), one can then easily deduce that which means that the system would progress successively as, . Therefore, one can conclude that , which guarantees that a control law designed based on Equation (54) will stabilize the original system described by Equation (51). Thus, it is shown that the sampled-data ZOH controller based on the pseudo-linear representation in Equation (52) also ensures that the states of the true nonlinear system stay close to the states evolving based on Equation (52). The next section focuses on the constrained sampled-data NMPC based on the SDC system.
5.2. Stability of Constrained Sampled-Data NMPC Based on SDC System
The only difference between the constrained sampled-data NMPC and constrained linear MPC is that the feasibility of the system needs to be checked at the start of every sampling interval. For simplicity, the brackets will be replaced as subscripts to indicate that the dependence on
,
would be written as
. Similarly for each
, there must exist a set of
that satisfy the following conditions:
After obtaining a suitable
from the above LMI,
is obtained by doing the following optimization:
subject to the conditions specified in Equations (58)–(63). Upon solving the optimization problem,
can be obtained by:
6. Simulation Results
In the preceding sections, two methods for generating control laws to track trajectories for a quadrotor with state and input constraints were discussed. All of the simulations were performed on a Fujitsu America i7 Laptop with 8 GB RAM and a 2.8-GHz processor running MATLAB R2016a. For all of the cases considered, there was always a converged optimization solution. The simulation had a provision to bypass the optimization if it exceeded the default maximum number of function evaluations and continue to use the previous converged solution. However, such a scenario was not encountered for the cases considered. The parameters used in the simulations are described in
Appendix A.
For the linear case, the six degrees of freedom equations of motion were linearized, and the MPC algorithm was implemented, which optimized the actuator effort based on the constraints imposed. For all of the simulation results, the initial equilibrium condition was that of a hover. The quadrotor model (
5) is linearized at a certain hover position denoted as
, in which
is any constant position. The input
needed to maintain the hover position is
. Furthermore,
where the
and
matrix is the same as in Equation (
4). The linear MPC control actions are obtained using the matrices given above that optimize Equation (
13) subject to constraints Equation (
21).
For the nonlinear case, the control laws are derived using the system matrices described in
Section 4 that optimize the cost in Equation (48) subject to the constraints in Equation (50).
For both cases, the true system dynamics presented in Equation (51) along with the first order actuator dynamics for the rotor thrusts is simulated. Three different reference trajectories are generated to evaluate the effectiveness of the control laws: (a) helical, (b) spherical spiral and (c) straight line segments. The control input bounds are set as and . The control horizon is chosen as .
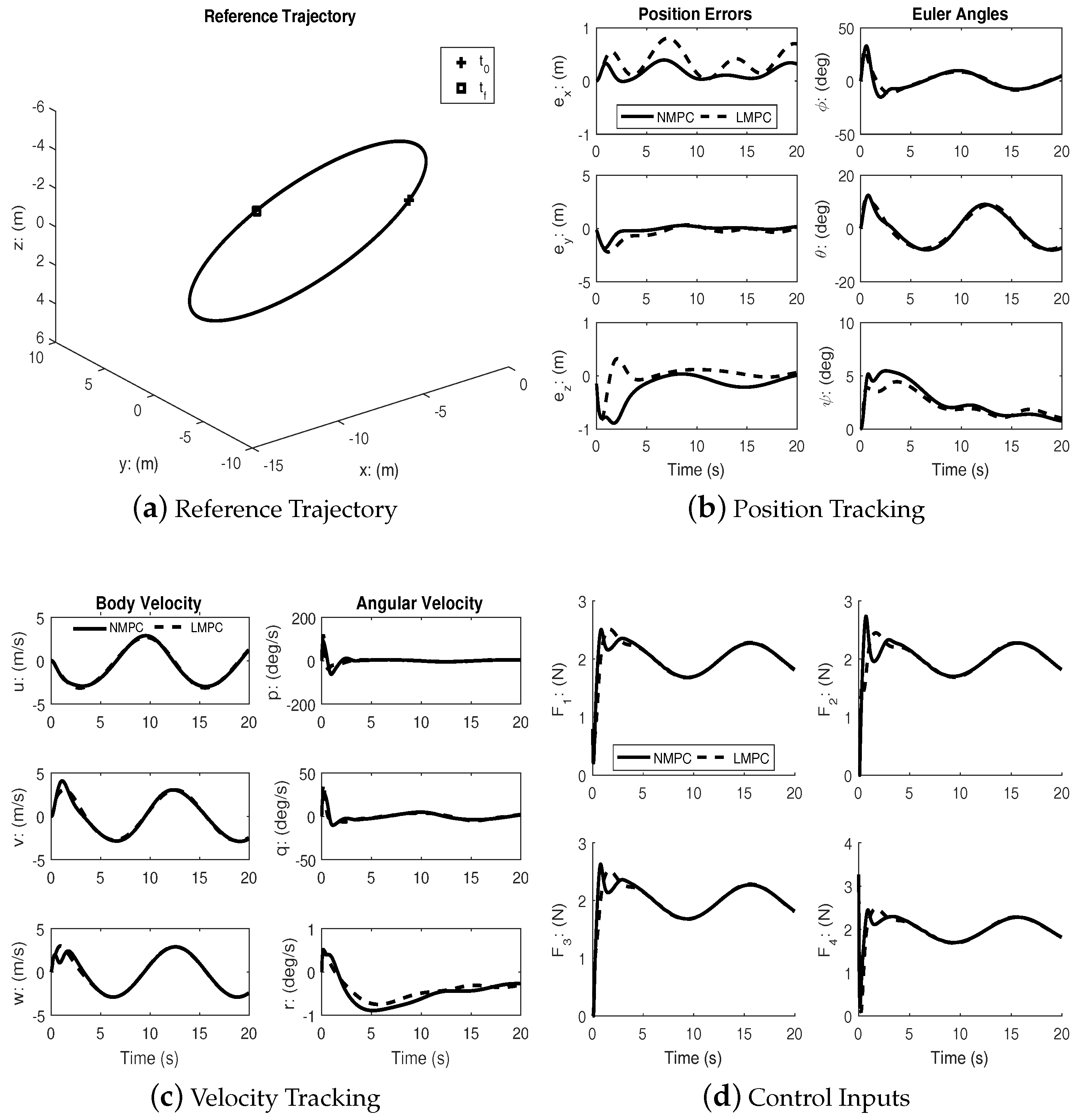
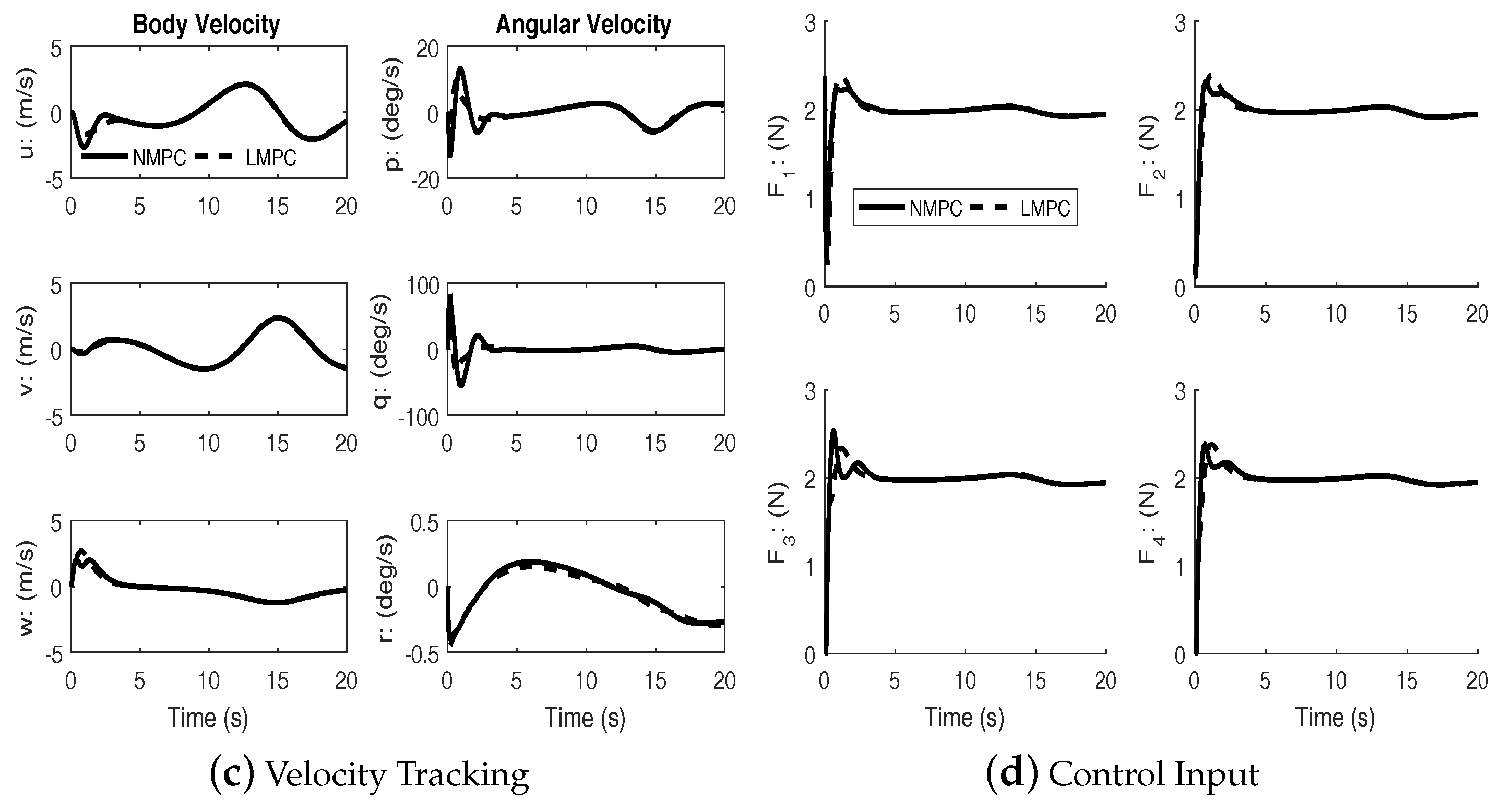
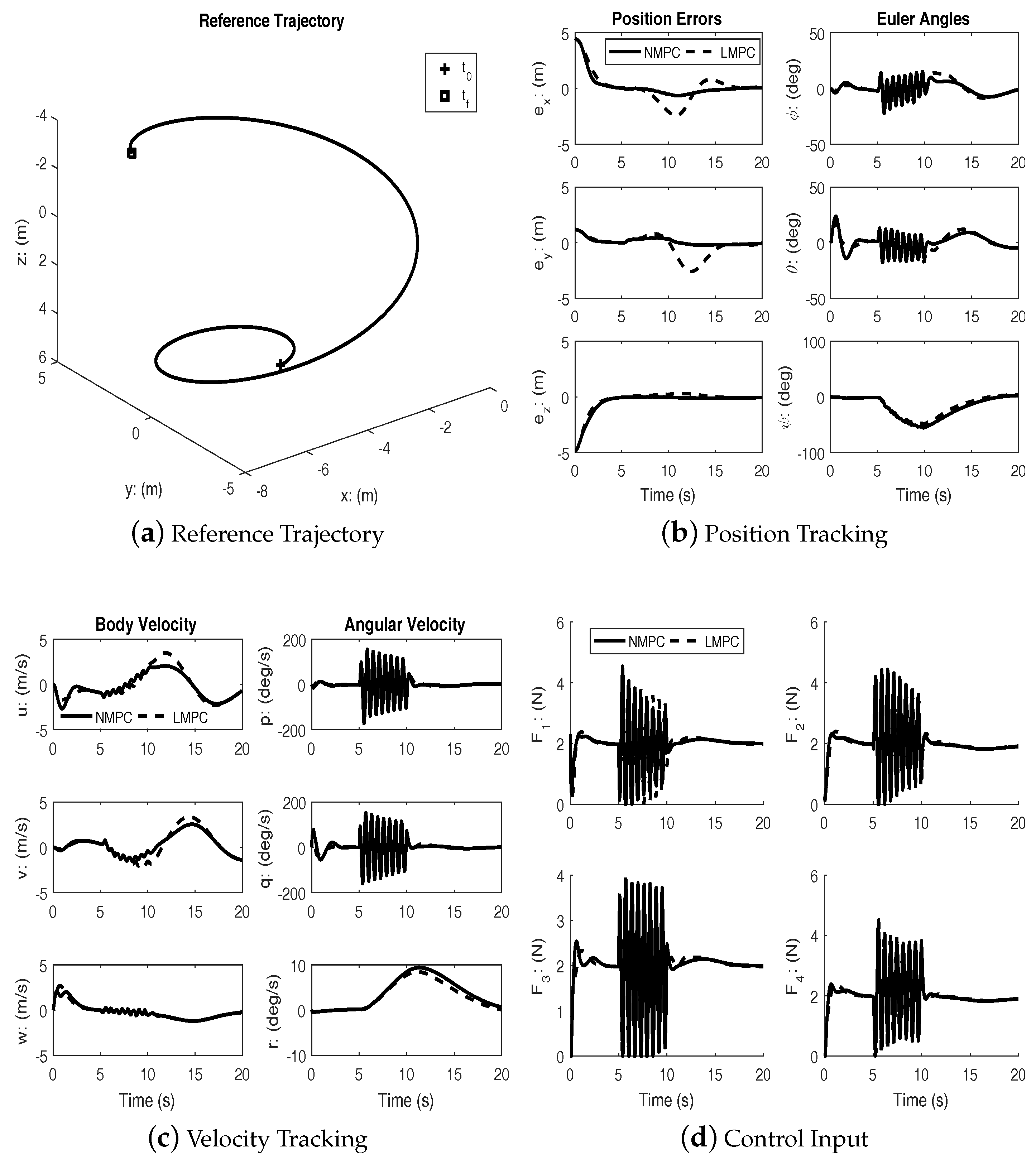
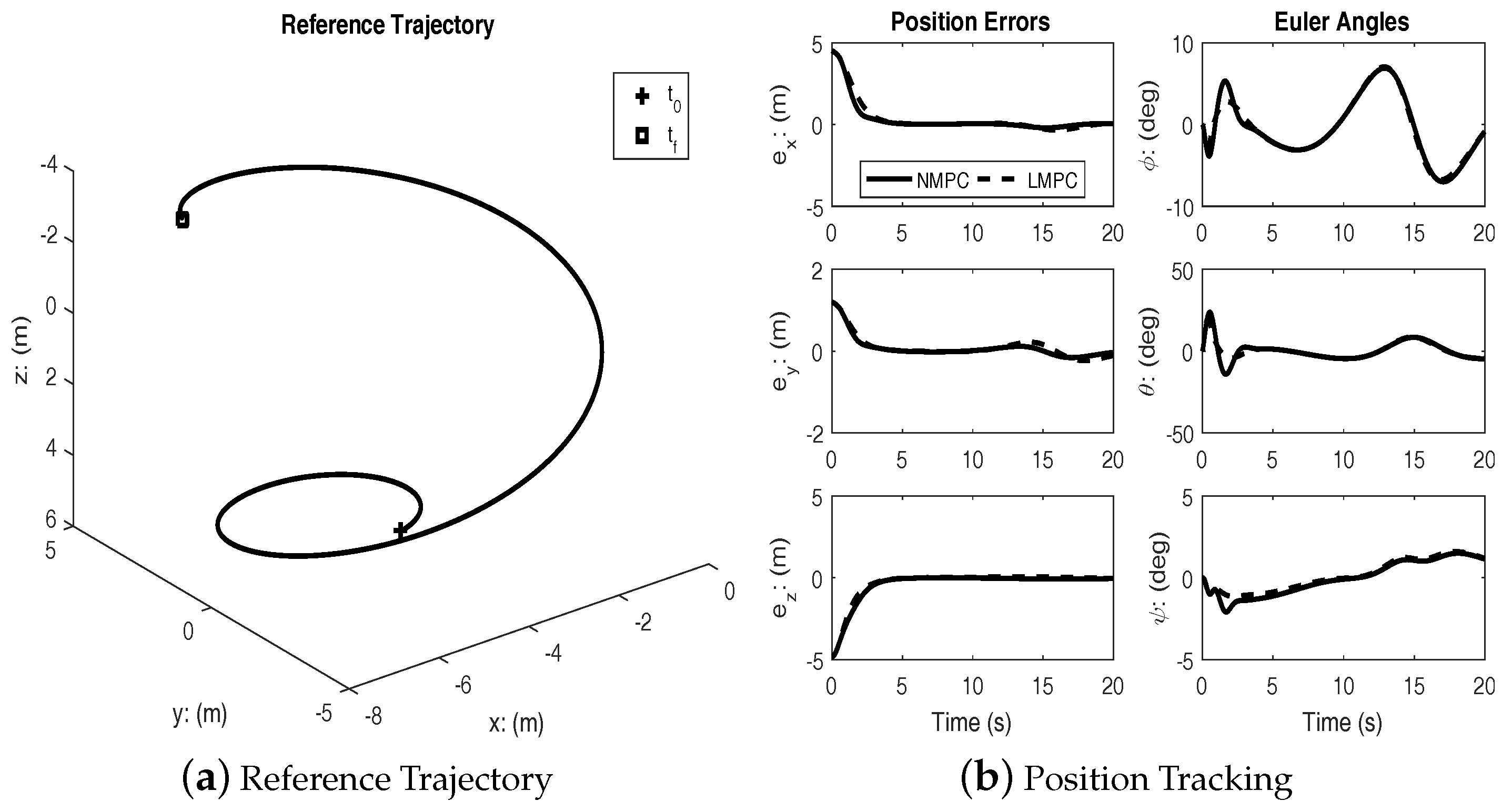
Figure 2 shows the reference trajectory and the tracking errors for both the linear and the nonlinear MPC cases. It can be seen that both controllers achieve good tracking; however, the transient response of the nonlinear MPC is better. Clearly, from
Figure 2b, the speed of response with regards to tracking the position errors is much better for the nonlinear MPC.
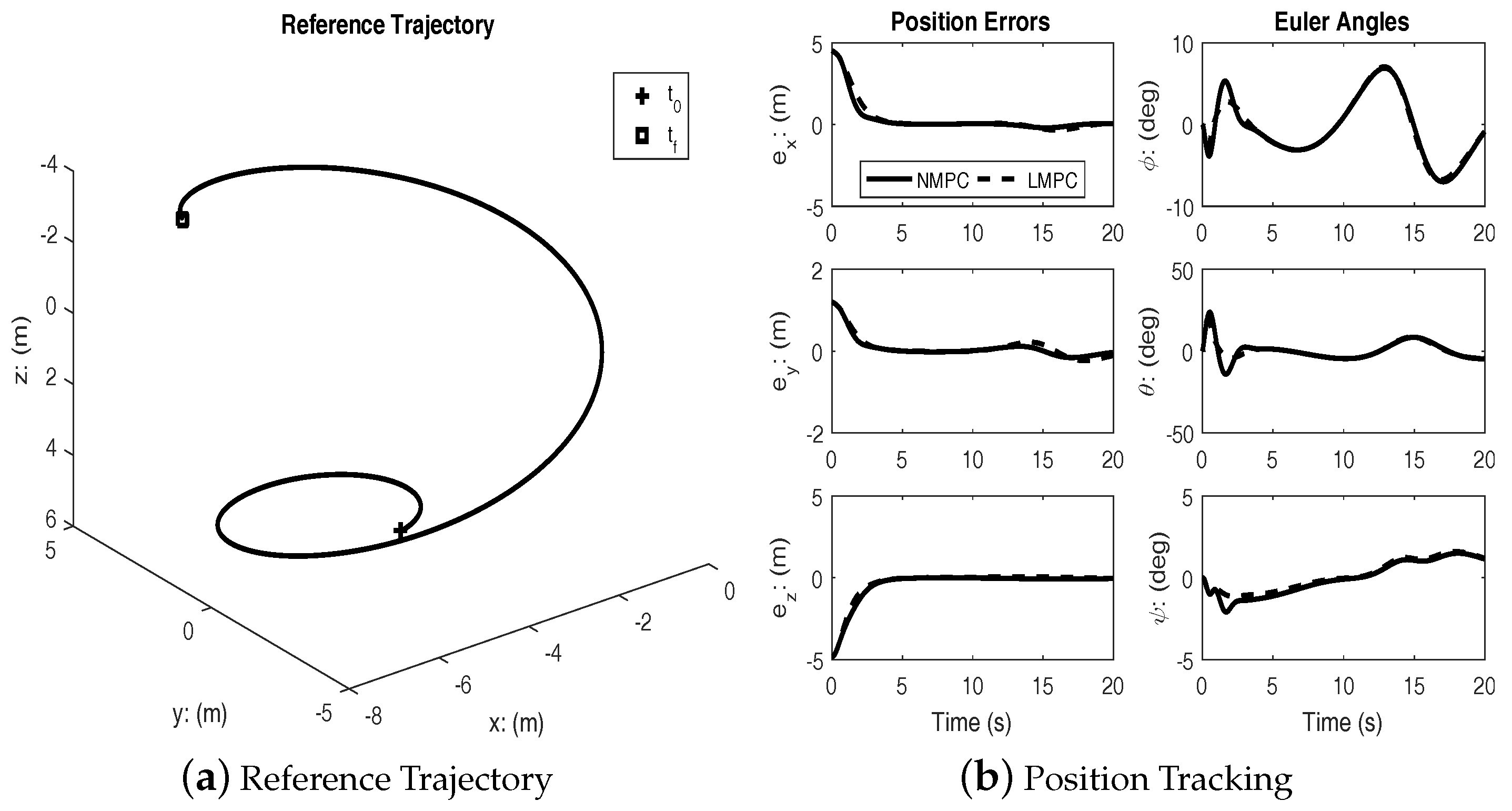
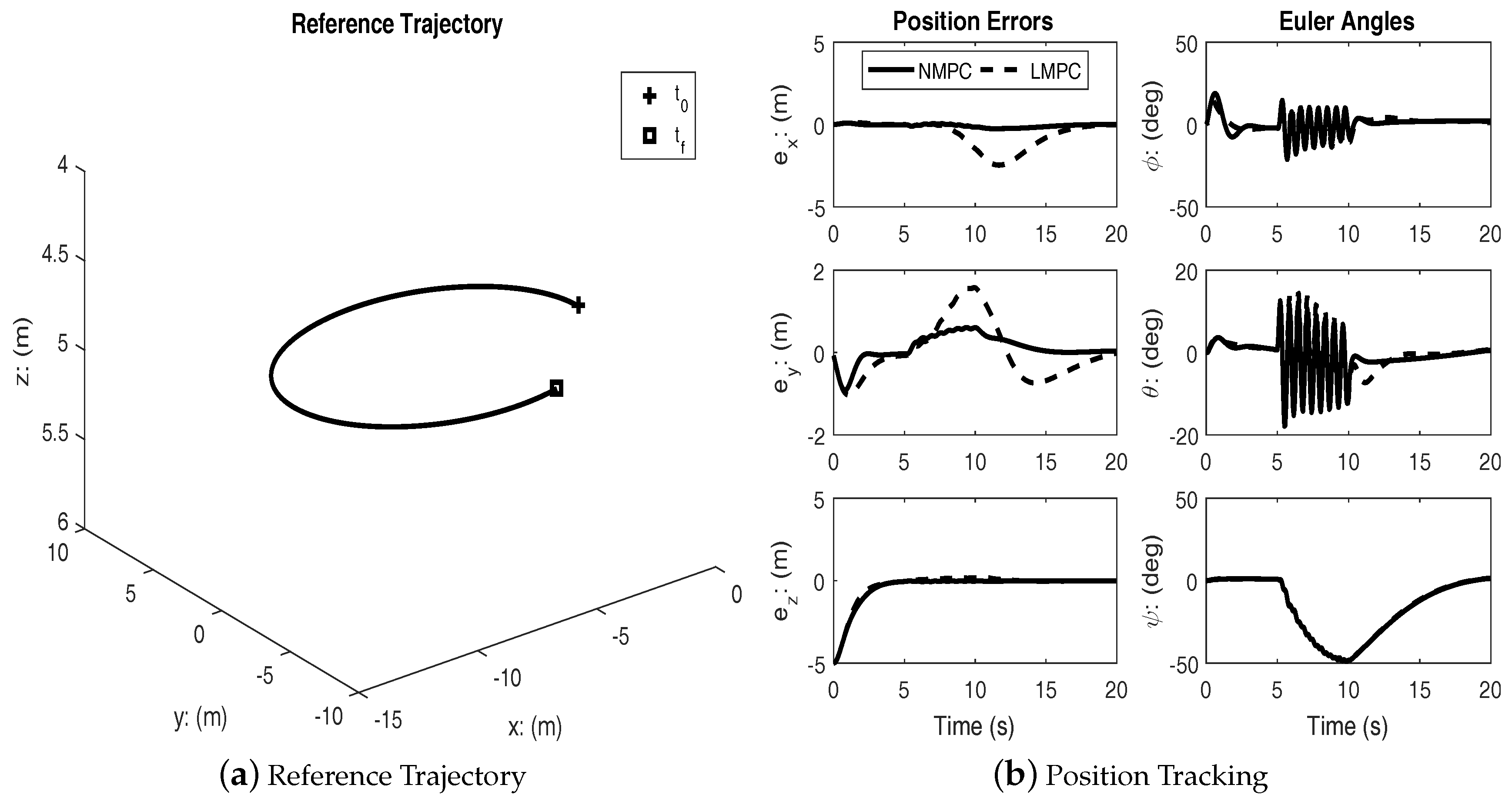
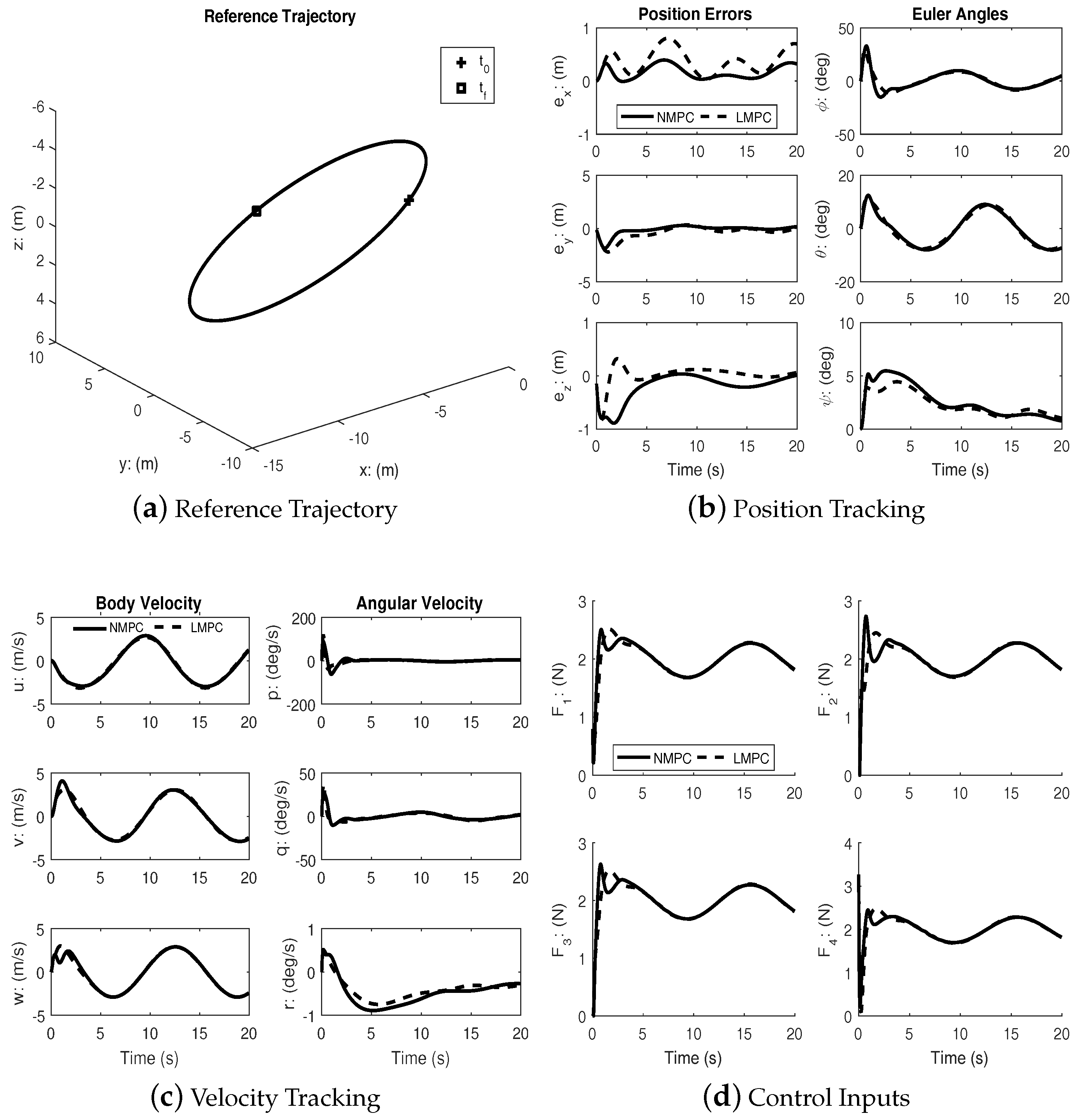
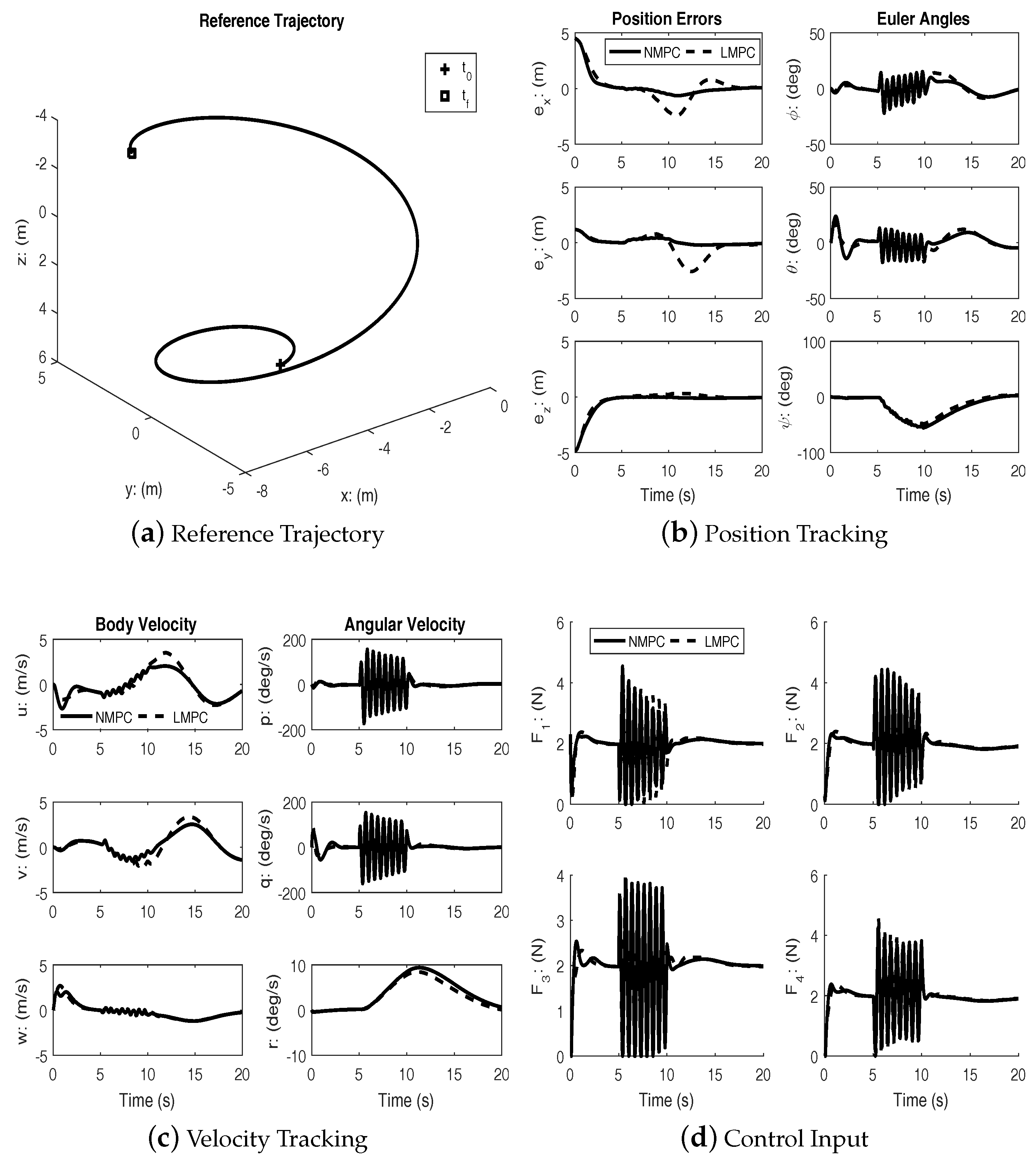
Figure 3 shows the results of tracking a spherical spiral trajectory. As with the previous case, both controllers achieve successful tracking.
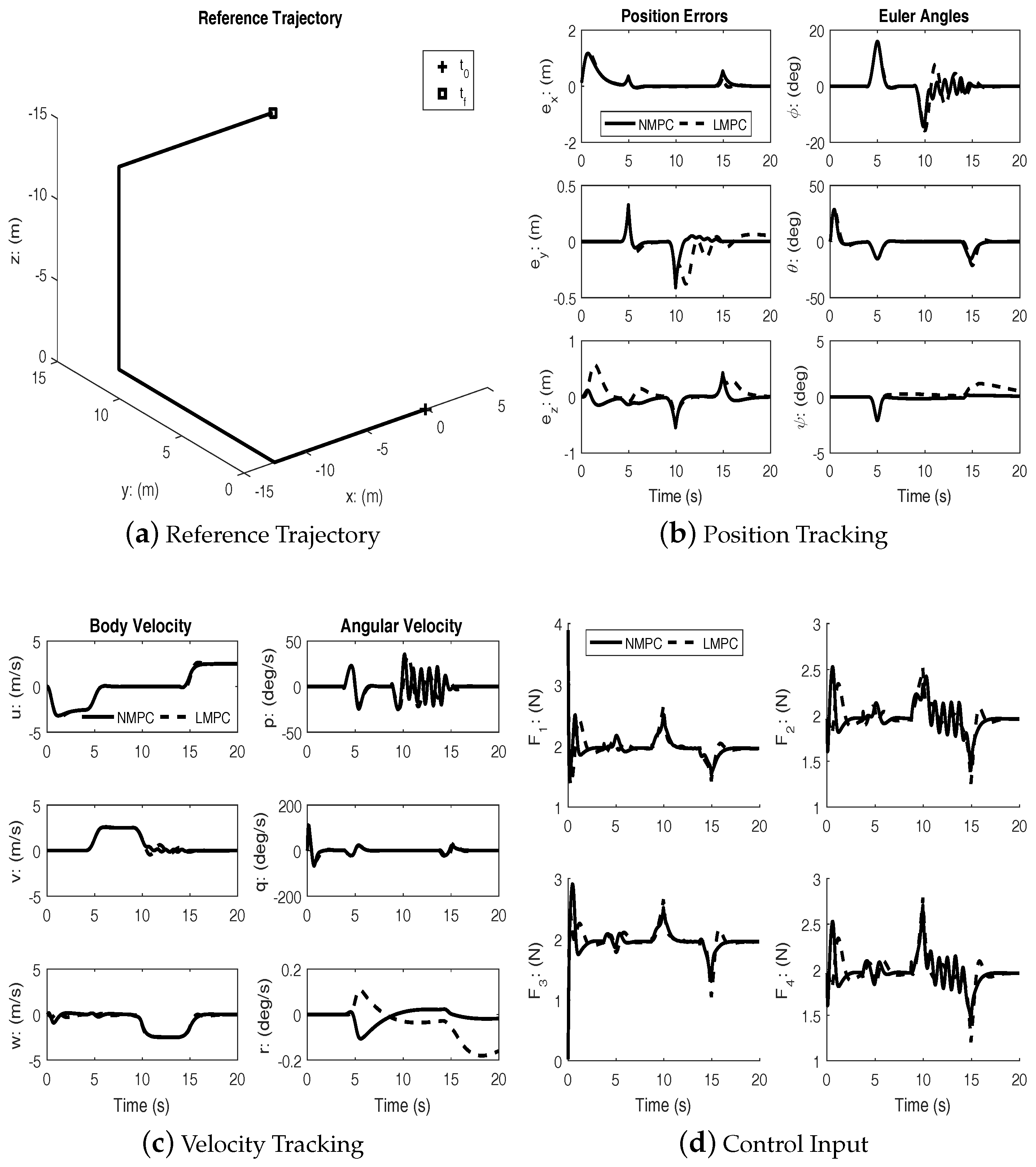
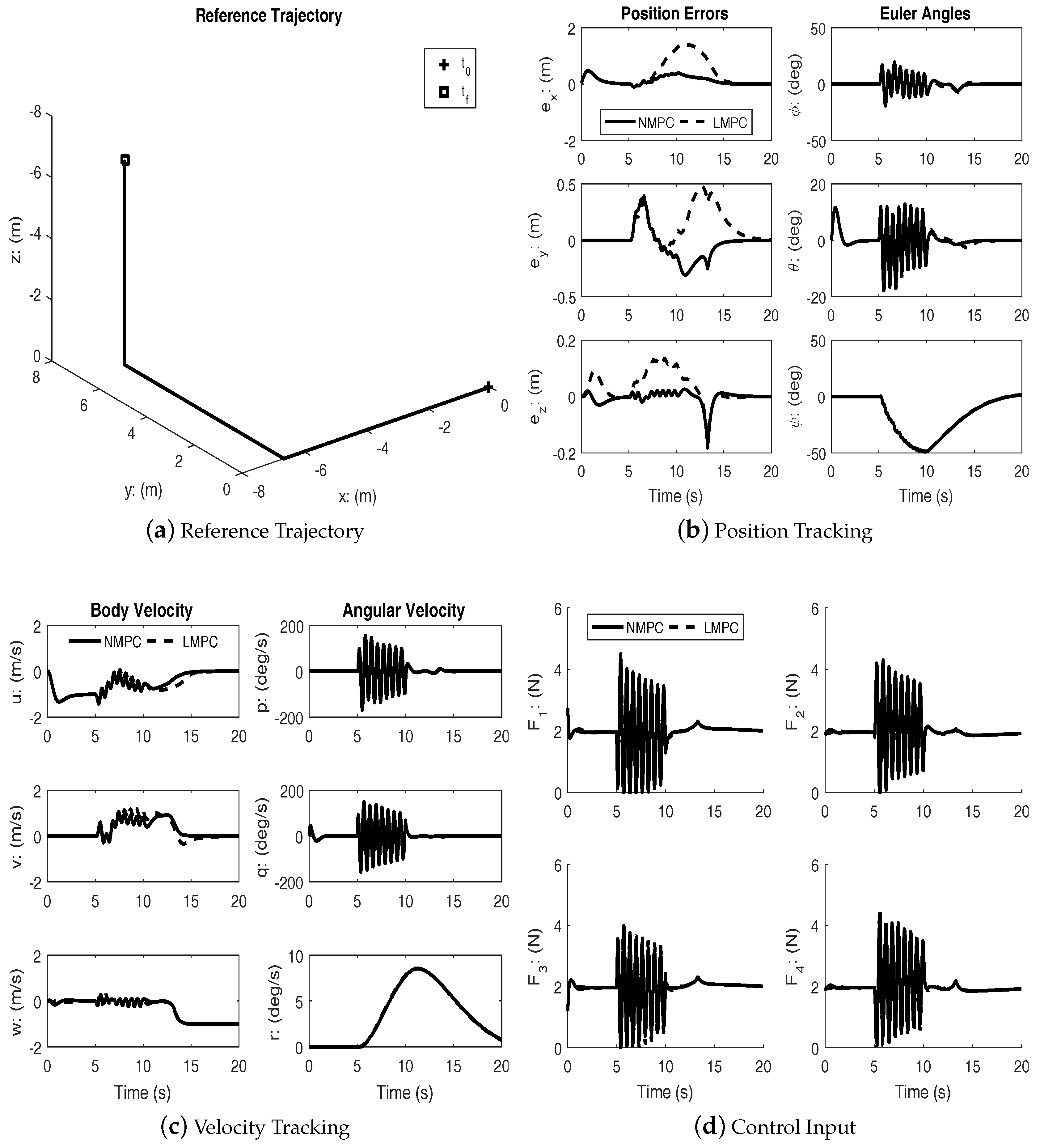
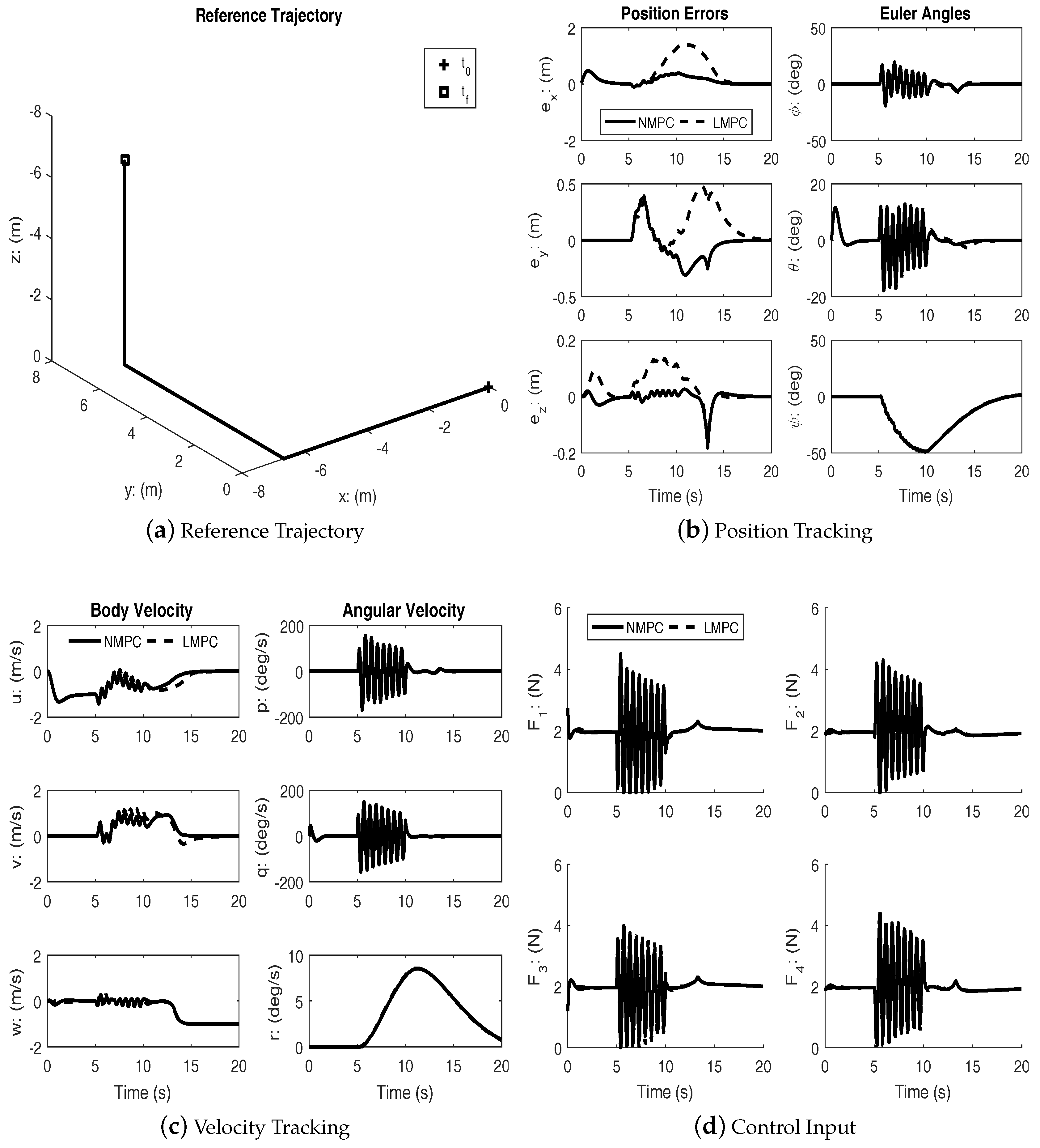
Figure 4 shows the results of tracking a straight line trajectory segment between two way points. As with the previous cases, both controllers achieve successful tracking. In this case, too, the superior transient performance of the nonlinear MPC is clearly seen. Additional studies show that the nonlinear MPC is able to track the trajectories even with a shorter prediction horizon.
Table 1 showed the average root mean square (RMS) of position tracking errors of different prediction horizons. It can be seen that NMPC has better tracking performances in terms of position tracking.
Table 2 showed the average control effort used in each tracking scenarios for different control horizons. In all three cases, NMPC is able to achieve better tracking with less control effort.
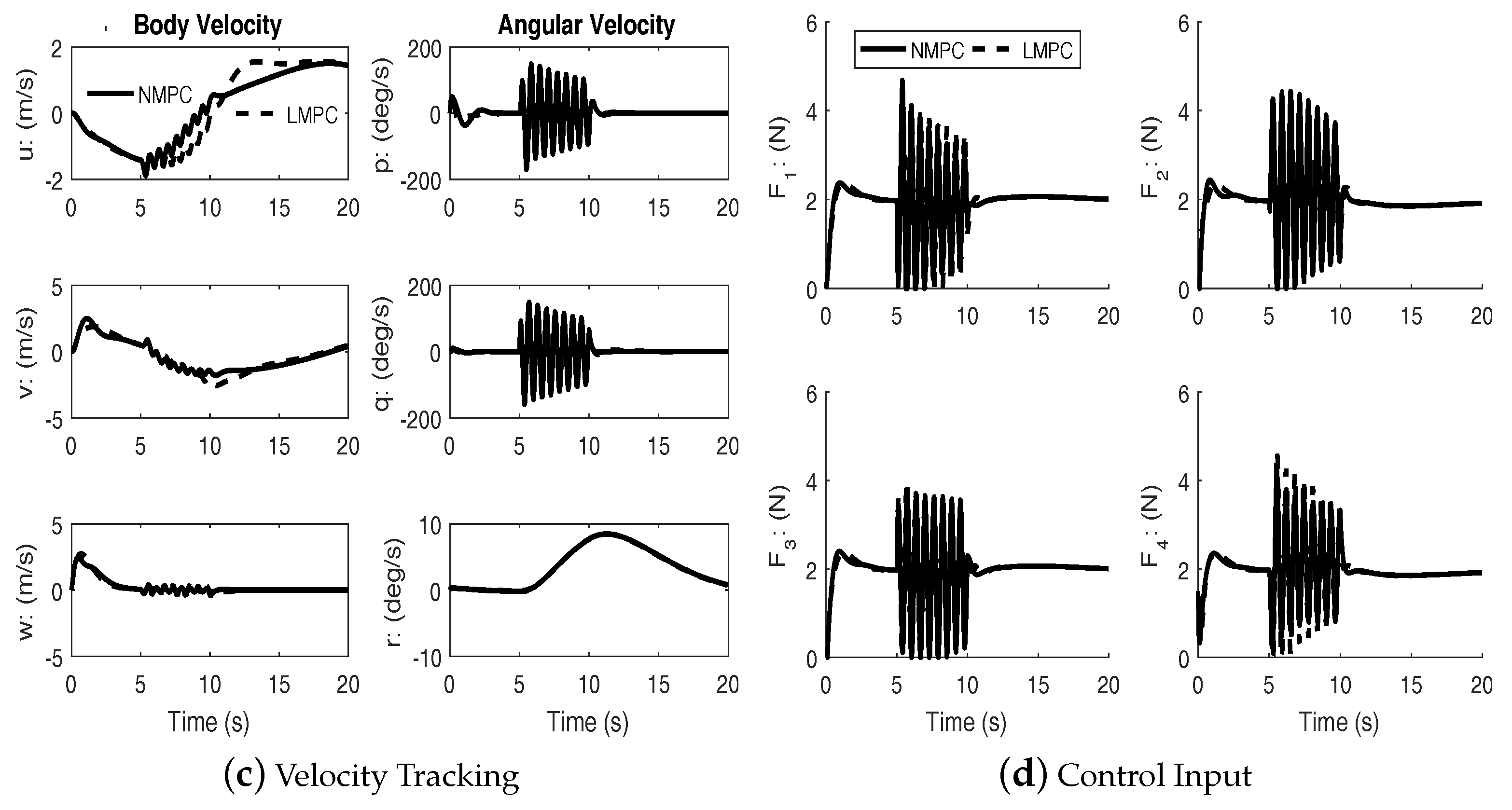
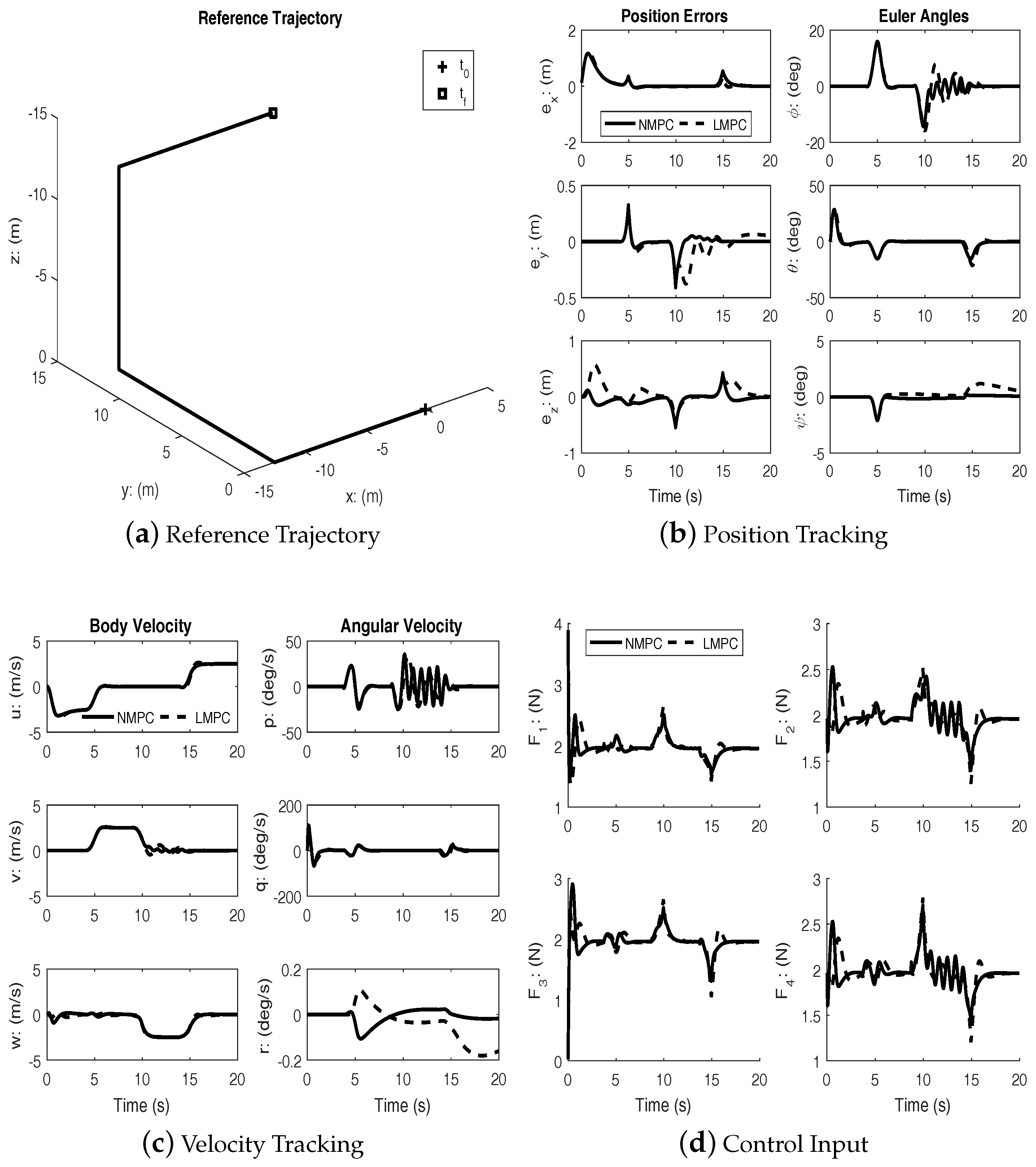
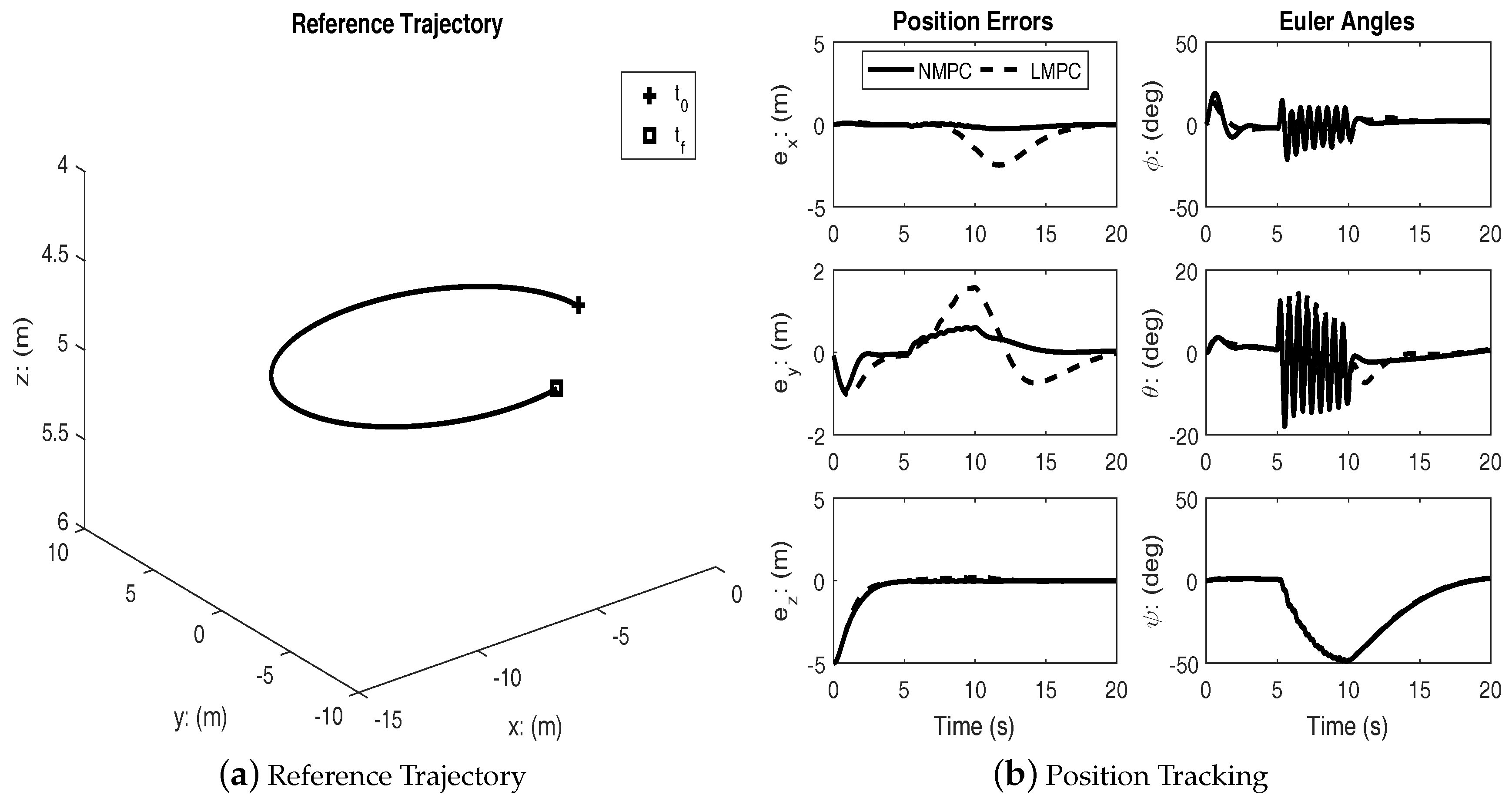
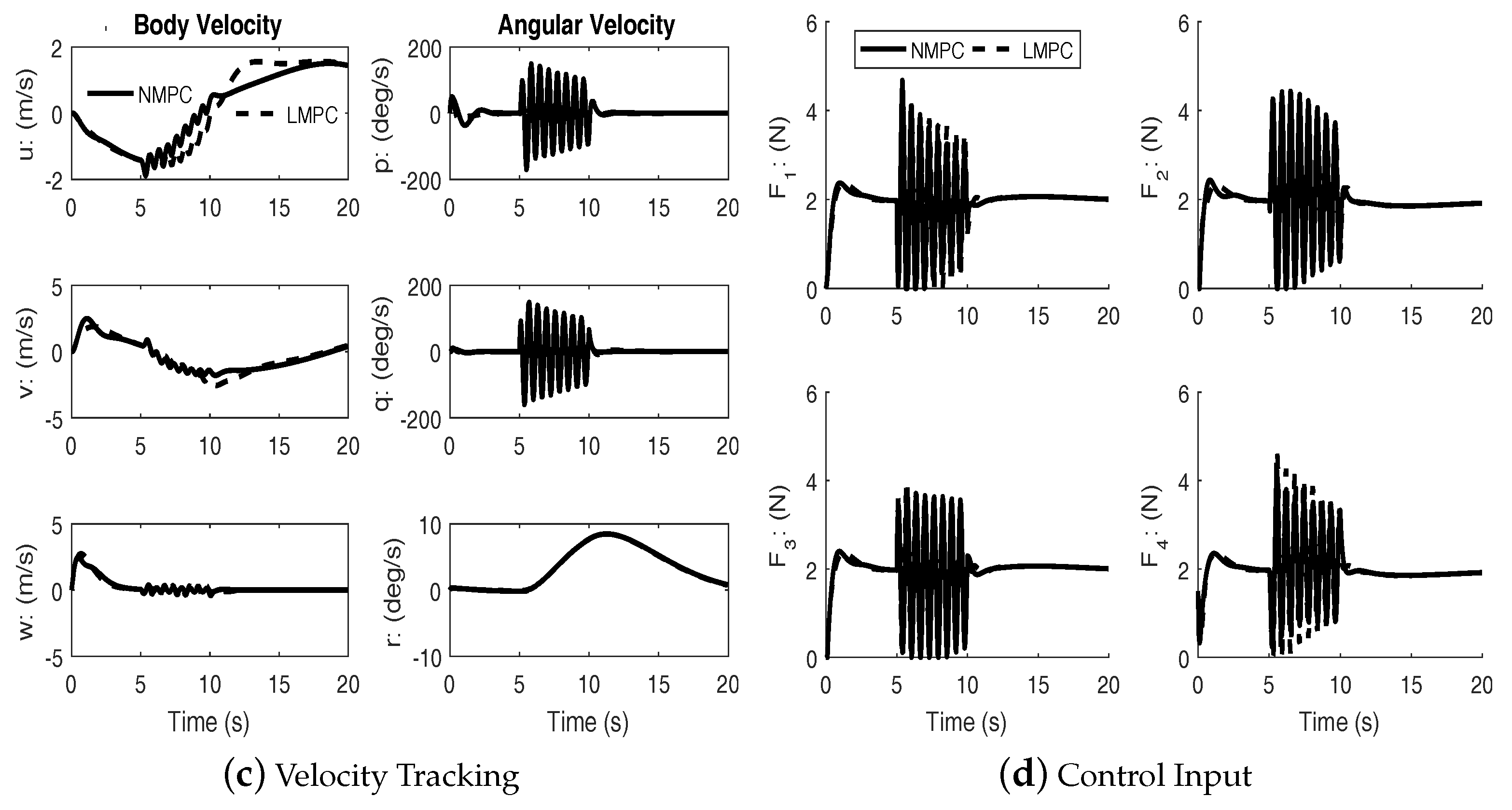
Nonlinear Model Predictive Control with Disturbance
In order to further assess the effectiveness of the NMPC scheme, simulations were performed with simultaneous high frequency disturbance torques injected in the roll and pitch channels. The disturbances are two exponentially decaying sinusoidal functions:
during
.
Figure 5,
Figure 6 and
Figure 7 show the performance of linear and nonlinear MPC subject to disturbance. The disturbance is used to approximate the effects of wind during typical outdoor flight conditions.
Under disturbances, linear MPC and nonlinear MPC both performed well with an acceptable amount of tracking errors and kept the input within bounds. It can be seen from the figures that the nonlinear MPC significantly out-performs the linear MPC with regards to transient performance.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}