
Maximum Likelihood Estimation of the I(2) Model under Linear Restrictions


Department of Economics and Institute for New Economic Thinking at the Oxford Martin School, University of Oxford, Oxford, OX1 3UQ, UK
Econometrics 2017, 5(2), 19; https://doi.org/10.3390/econometrics5020019
Submission received: 27 February 2017
/
Revised: 2 May 2017
/
Accepted: 8 May 2017
/
Published: 15 May 2017
(This article belongs to the Special Issue Recent Developments in Cointegration)
Abstract
:Estimation of the I(2) cointegrated vector autoregressive (CVAR) model is considered. Without further restrictions, estimation of the I(1) model is by reduced-rank regression (Anderson (1951)). Maximum likelihood estimation of I(2) models, on the other hand, always requires iteration. This paper presents a new triangular representation of the I(2) model. This is the basis for a new estimation procedure of the unrestricted I(2) model, as well as the I(2) model with linear restrictions imposed.
Keywords:
cointegration; I(2); vector autoregression; representation; maximum likelihood estimation; reduced rank regression; generalized least squaresJEL Classification:
C32; C51; C611. Introduction
The I(1) model or cointegrated vector autoregression (CVAR) is now well established. The model is developed in a series of papers and books (see, e.g., Johansen (1988), Johansen (1991), Johansen (1995a), Juselius (2006)) and generally available in econometric software. The I(1) model is formulated as a rank reduction of the matrix of ‘long-run’ coefficients. The Gaussian log-likelihood is estimated by reduced-rank regression (RRR; see Anderson (1951), Anderson (2002)).
Determining the cointegrating rank only finds the cointegrating vectors up to a rank-preserving linear transformation. Therefore, the next step of an empirical study usually identifies the cointegrating vectors. This may be followed by imposing over-identifying restrictions. Common restrictions, i.e., the same restrictions on each cointegrating vector, can still be solved by adjusting the RRR estimation; see Johansen and Juselius (1990) and Johansen and Juselius (1992). Estimation with separate linear restrictions on the cointegrating vectors, or more general non-linear restrictions, requires iterative maximization. The usual approach is based on so-called switching algorithms; see Johansen (1995b) and Boswijk and Doornik (2004). The former proposes an algorithm that alternates between cointegrating vectors, estimating one while keeping the others fixed. The latter consider algorithms that alternate between the cointegrating vectors and their loadings: when one is kept fixed, the other is identified. The drawback is that these algorithms can be very slow and occasionally terminate prematurely. Doornik (2017) proposes improvements that can be applied to all switching algorithms.
Johansen (1995c) and Johansen (1997) extend the CVAR to allow for I(2) stochastic trends. These tend to be smoother than I(1) stochastic trends. The I(2) model implies a second reduced rank restriction, but this is now more complicated, and estimation under Gaussian errors can no longer be performed by RRR. The basis of an algorithm for maximum likelihood estimation is presented in Johansen (1997), with an implementation in Dennis and Juselius (2004).
The general approach to handling the I(2) model is to create representations that introduce parameters that vary freely without changing the nature of the model. This facilitates both the statistical analysis and the estimation.
The contributions of the current paper are two-fold. First, we present the triangular representation of the I(2) model. This is a new trilinear formulation with a block-triangular matrix structure at its core. The triangular representation provides a convenient framework for imposing linear restrictions on the model parameters. Next, we introduce several improved estimation algorithms for the I(2) model. A simulation experiment is used to study the behaviour of the algorithms.
Notation
Let () be a matrix with full column rank . The perpendicular matrix () has . The orthogonal complement has with the additional property that . Define and . Then, is a orthogonal matrix, so .
The (thin) singular value decomposition (SVD) of is , where are orthogonal: , and W is a diagonal matrix with the ordered positive singular values on the diagonal. If rank, then the last singular values are zero. We can find from the SVD of the square matrix .
The (thin) QR factorization of with pivoting is , with orthogonal and R upper triangular. This pivoting is the reordering of columns of to better handle poor conditioning and singularity, and is captured in P, as discussed Golub and Van Loan (2013, §5.4.2).
The QL decomposition of A can be derived from the QR decomposition of : , so . J is the exchange matrix, which is the identity matrix with columns in reverse order: premultiplication reverses rows; postmultiplication reverses columns; and .
Let , then .
Finally, assigns the value of b to a.
2. The I(2) Model
The vector autoregression (VAR) with p dependent variables and lags:
for , and with fixed and given, can be written in equilibrium correction form as:
without imposing any restrictions. The I(1) cointegrated VAR (CVAR) imposes a reduced rank restriction on : rank; see, e.g., Johansen and Juselius (1990), Johansen (1995a).
With , the model can be written in second-differenced equilibrium correction form as:
The I(2) CVAR involves an additional reduced rank restriction:
where The two rank restrictions can be expressed more conveniently in terms of products of matrices with reduced dimensions:
where and are matrices. The second restriction needs rank s, so and are a . This requires that the matrices on the right-hand side of (2) and (3) have full column rank. The number of I(2) trends is .
The most relevant model in terms of deterministics allows for linearly trending behaviour: . Using the representation theorem of Johansen (1992) and assuming imply:
which restricts and links and ; we see that and .
2.1. The I(2) Model with a Linear Trend
The model (1) subject to the I(1) and I(2) rank restrictions (2) and (3) with , subject to (4) and (5) can be written as:
subject to:
where is , is and is . In this case, . Because is the leading term in (4), we can extend by introducing , so . Furthermore, has been extended to .
To see that (6) and (7) remains the same I(2) model, consider and insert :
Using the perpendicular matrix:
we see that the rank condition is unaffected:
A more general formulation allows for restricted deterministic and weakly exogenous variables and unrestricted variables :
where , and its lags are contained in ; this in turn, is subsumed under . The number of variables in is , so and always have the same dimensions. is unrestricted, which allows it to be concentrated out by regressing all other variables on :
To implement likelihood-ratio tests, it is necessary to count the number of restrictions:
defining . The restrictions on follow from the representation. Several representations of the I(2) model have been introduced in the literature to translate the implicit non-linear restriction (3) on into an explicit part of the model. These representations reveal the number of restrictions imposed on , as is shown below.
First, we introduce the new triangular representation.
2.2. The Triangular Representation
Theorem 1.
Consider the model:
with rank restrictions and where α is a matrix, β is , ξ is , η is . This can be written as:
where:
are full rank matrices. A is , and B is ; moreover, A, B and the nonzero blocks in W and V are freely varying. A and B are partitioned as:
where the blocks in A have columns respectively; for B, this is: ; . W and V are partitioned accordingly.
Proof.
Write , such that . Construct A and B as:
Now, and . and are full rank by design. Define :
is a full rank matrix. The zero blocks in V arise because, e.g., . Trivially:
is a full rank matrix. Both W and V are matrices. Because A and B are each orthogonal:
The QR decomposition shows that a full rank square matrix can be written as the product of an orthogonal matrix and a triangular matrix. Therefore, preserves the structure in when are lower triangular, as well as that in . This shows that (9) holds for any full rank A and B, and the orthogonality can be relaxed.
Therefore, any model with full rank matrices A and B, together with any that have the zeros as described above, satisfies the I(2) rank restrictions. We obtain the same model by restricting A and B to be orthogonal. ☐
When is restricted only by the I(2) condition: rank. Then, V varies freely, except for the zero blocks, and the I(2) restrictions are imposed through the trilinear form of (9). implies . Another way to have is ; in that case, .
The restrictions on the intercept (5) can be expressed as using , or for a vector v of length .
2.3. Obtaining the Triangular Representation
The triangular representation shows that the I(2) model can be written in trilinear form:
where A and B are freely varying, provided W and V have the appropriate structure.
Consider that we are given of an I(2) CVAR with rank indices and wish to obtain the parameters of the triangular representation. First compute , which can be done with the SVD, assuming rank s. From this, compute A and B:
Then, . Because satisfies the I(2) rank restriction, V will have the corresponding block-triangular structure.
It may be of interest to consider which part of the structure can be retrieved in the case where rank, but rank, while it should be s. This would happen when using I(1) starting values for I(2) estimation. The off anti-diagonal blocks of zeros:
can be implemented with two sweep operations:
The offsetting operations affect and only, so and are unchanged. However, we cannot achieve in a similar way, because it would remove the zeros just obtained. The block has dimension and represents the number of restrictions imposed on in the I(2) model. Similarly, the anti-diagonal block of zeros in W captures the restrictions on .
Note that the block can be made lower triangular. Write the column partition of V as , and use to replace by and by . When , the rightmost columns of L will be zero, and the corresponding columns of are not needed to compute . This part can then be omitted from the likelihood evaluation. This is an issue when we propose an estimation procedure in §4.2.1.
2.4. Restoring Orthogonality
Although A and B are freely varying, interpretation may require orthogonality between column blocks. The column blocks of A are in reverse order from B to make V and W block lower triangular. As a consequence, multiplication of V or W from either side by a lower triangular matrix preserves their structure. This allows for the relaxation of the orthogonality of A and B, but also enables us to restore it again.
To restore orthogonality, let , where are not orthogonal, but with block-triangular. Now, use the QL decomposition to get , with A orthogonal and L lower triangular. Use the QR decomposition to get , with B orthogonal and R upper triangular. Then, with the blocks of zeros in V preserved. must be adjusted accordingly. When is restricted, cannot be modified like this. However, we can still adjust to get and ; with similar adjustments to .
The orthogonal version is convenient mathematically, but for estimation, it is preferable to use the unrestricted version. We do not distinguish through notation, but the context will state when the orthogonal version is used.
2.5. Identification in the Triangular Representation
The matrices A and B are not identified without further restrictions. For example, rescaling and as in can be absorbed in V:
When is identified, remains freely varying, and we can, e.g., set . However, it is convenient to transform to , so that and correspond to and . This prevents part of the orthogonality, in the sense that and .
The following scheme identifies A and B, under the assumption that is already identified through prior restrictions.
- Orthogonalize to obtain .
- Choose s full rank rows from , denoted , and set . Adjust V accordingly.
- Do the same for .
- Set , and .
- .
The ordering of columns inside is not unique.
3. Relation to Other Representations
Two other formulations of the I(2) model that are in use are the so-called and representations. All representations implement the same model and make the rank restrictions explicit. However, they differ in their definitions of freely-varying parameters, so may facilitate different forms of analysis, e.g., asymptotic analysis, estimation or the imposition of restrictions. The different parametrizations may also affect economic interpretations.
3.1. Representation
Johansen (1997) transforms (8) into the -representation:
where is used to recover : . The parameters vary freely. If we normalize on and adjust accordingly, then , and:
We shall derive the representation. The first step is to define a transformation of :
This splits the p-variate systems into two independent parts. The first has any terms with leading knocked out, while the second has all leading ’s cancelled. The inverse transformation is given by:
The next step is to apply (13) to (8) to create two independent systems and insert in the ‘marginal’ equation:
where and are freely varying. Removing the transformation:
and introducing the additional parameters and completes the -representation (12). Table 1 provides definitions of the parameters that are used (cf. Johansen (1997, Tables 1 and 2)).
Proof.
Write , so . First, the system (9) is premultiplied by and subsequently with a lower triangular matrix L to create two independent subsystems. The matrix L and its inverse are given by:
where , cf. (14). Because , we have that , so . Furthermore: . The identity matrix can also be inserted directly in (9):
where and ☐
3.2. Representation
Paruolo and Rahbek (1999) and Paruolo (2000a) use the representation:
Here, vary freely. To derive the representation, use :
and insert in (8). The term with disappears because , so .
When is identified both and are unique, but not yet or . In the representation, the variable is also unique with chosen as and identified. Table 2 relates the , and triangular representations.
Proof.
Write and . Using the column partitioning if : . From (9):
☐
4. Algorithms for Gaussian Maximum Likelihood Estimation
Algorithms to estimate the Gaussian CVAR are usually alternating over sets of variables. In the cointegration literature, these are called switching algorithms, following Johansen and Juselius (1994).
The advantage of switching is that each step is easy to implement, and no derivatives are required. Furthermore, the partitioning circumvents the lack of identification that can occur in these models and which makes it harder to use Newton-type methods. The drawback is that progress is often slow, taking many iterations to converge. Occasionally, this will lead to premature convergence. Although the steps can generally be shown to be in a non-downward direction, this is not enough to show convergence to a stationary point. The work in Doornik (2017) documents the framework for the switching algorithms and also considers acceleration of these algorithms; both results are used here.
Johansen (1997, §8) proposes an algorithm based on the -representation, called -switching here. This is presented in detail in Appendix B. Two new algorithms are given next, the first based on the -representation, the second on the triangular representation. Some formality is required to describe the algorithms with sufficient detail.
4.1. -Switching Algorithm
The free parameters in the -representation (15) are with symmetric positive definite . The algorithm alternates between estimating given the rest and fixing . The model for given the other parameters is linear:
- To estimate , rewrite (15) as:where d replaces . Then, vectorize, using :Given , we can treat and d as free parameters to be estimated by generalized least squares (GLS). This will give a new estimate of .We can treat d as a free parameter in (16). First, when , has more parameters than . Second, when , then is reduced rank, and columns of are redundant. Orthogonality is recovered in the next step.
The RRR step is the same as used in Dennis and Juselius (2004) and Paruolo (2000b). However, the GLS step for is different from both. We have found that the specification of the GLS step can have a substantial impact on the performance of the algorithm.
For numerical reasons (see, e.g. Golub and Van Loan (2013, Ch.5)), we prefer to use the QR decomposition to implement OLS and RRR estimation rather than moment matrices. However, in iterative estimation, there are very many regressions, which would be much faster using precomputed moment matrices. As a compromise, we use precomputed ‘data’ matrices that are transformed by a QR decomposition. This reduces the effective sample size from T to . The regressions (16) and (17) can then be implemented in terms of the transformed data matrices; see Appendix A.
Usually, starting values of and are available from I(1) estimation. The initial is then obtained from the marginal equation of the -representation, (14a), written as:
RRR of on corrected for gives estimates of , and so, .
-switching algorithm:
To start, set , and choose starting values , tolerance and the maximum number of iterations. Compute from (18) and from (17). Furthermore, compute .
- 1.
- 2.
- Compute
- 3.
- Enter a line search for .The change in is and the line search find a step length with . Because only is varied, a GLS step is needed to evaluate the log-likelihood for each trial . The line search gives new parameters with corresponding .
- T.
- Compute the relative change from the previous iteration:Terminate if:Else increment k, and return to Step 1. ☐
The subscript c indicates that these are candidate values that may be improved upon by the line search. The line search is the concentrated version, so the I(2) equivalent to the LBeta line search documented in Doornik (2017). This means that the function evaluation inside the line search needs to re-evaluate all of the other parameters as changes. Therefore, within the line search, we effectively concentrate out all other parameters.
Normalization of prevents the scale from growing excessively, and it was found to be beneficial to normalize in the first iteration every hundredth or when the norm of gets large. Continuous normalization had a negative impact in our experiments. Care is required when normalizing: if an iteration uses a different normalization from the previous one, then the line search will only be effective if the previous coefficients are adjusted accordingly.
The algorithm is incomplete without starting values, and it is obvious that a better start will lead to faster and more reliable convergence. Experimentation also showed that this and other algorithms struggled more in cases with . To improve this, we generate two initial values, follow three iterations of the -switching algorithms, then select the best for continuation. The details are in Appendix C.
4.2. MLE with the Triangular Representation
We set . This tends to lead to slower convergence, but is required when both and are restricted. is kept unrestricted: fewer restrictions seem to lead to faster convergence. All regressions use the data matrices that are pre-transformed by an orthogonal matrix as described in Appendix A. In the next section, we describe the estimation steps that can be repeated until convergence.
4.2.1. Estimation Steps
Equation (9) provides a convenient structure for an alternating variables algorithm. We can solve three separate steps by ordinary or generalized least squares for the case with orthogonal A:
- B-step: estimate B, and fix at . The resulting model is linear in B:Estimation by GLS can be conveniently done as follows. Start with the Cholesky decomposition , and premultiply (20) by . Next take the QL decomposition of as with L lower diagonal and H orthogonal. Now, premultiply the transformed system by :which has the unit variance matrix. Because the structures of W and V are preserved, this approach can also be used in the next step.
- V-step: estimate , and fix . This is a linear model in , which can be solved by GLS as in the B step.
- A-step: estimate and fix at :This is the linear regression of on
The likelihood will not go down when making one update that consists of the three steps given above, provided V is full rank. If that does not hold, as noted at the end of §2.3, some part of or is not identified from the above expressions. To handle this, we make the following adjustments to steps 1 and 3:
- 1a.
- B-step: Remove the last columns from B, V and W, as they do not affect the log-likelihood. When iteration is finished, we can add columns of zeros back to W and V and the orthogonal complement of the reduced B to get a rectangular B.
- 3a.
- A-step: we wish to keep A invertible and, so, square during iteration. The missing part of is filled in with the orthogonal complement of the remainder of A after each regression. This requires re-estimation of by OLS.
4.2.2. Triangular-Switching Algorithm
The steps described in the previous section form the basis of an alternating variables algorithm:
Triangular-switching algorithm:
To start, set , and choose and the maximum number of iterations. Compute , , , and .
- 1.1
- B-step: obtain from .
- 1.2
- V step: obtain from .
- 1.3
- A step: obtain from .
- 1.4
- step: if necessary, obtain new from .
- 2...
- As steps 2,3,T from the -switching algorithm. In this case, the line search is over all of the parameters in . ☐
The starting values are taken as for the -switching algorithm; see Appendix C. This means that two iterations of -switching are taken first, using only restrictions on .
4.3. Linear Restrictions
4.3.1. Delta Switching
Estimation under linear restrictions on or of the form:
can be done by adjusting the GLS step in §4.1. However, estimation of is by RRR, which is not so easily adjusted for linear restrictions. Restricting requires replacing the RRR step by regression conditional on , which makes the algorithm much slower. Estimation under , which implies , is straightforward.
4.3.2. Triangular Switching
Triangular switching avoids RRR, and restrictions on or can be implemented by adjusting the B-step. In general, we can test restrictions of the form:
Such linear restrictions on the columns of A and B are a straightforward extension of the GLS steps described above.
Estimation without multi-cointegration is also feasible. Setting corresponds to in the triangular representation. This amounts to removing the last columns from . Boswijk (2010) shows that the test for has an asymptotic distribution.
Paruolo and Rahbek (1999) derives conditions for weak exogeneity in (15). They decompose this into three sub-hypotheses: , , . These restrictions, taking , where is the i-th column of , correspond to a zero right-hand side in a particular equation in the triangular representation. First is creating a row of zeros in . Next is , which extends the row of zeros. However, A must be full rank, so the final restriction must be imposed on V as , expressed as . Paruolo and Rahbek (1999) shows that the combined test for a single variable has an asymptotic distribution.
5. Comparing Algorithms
We have three algorithms that can be compared:
- The -switching algorithm, §4.1, which can handle linear restrictions on or .
- The triangular-switching algorithm proposed in §4.2.2. This can optionally have linear restrictions on the columns of A or B.
- The improved -switching algorithm, Appendix B, implemented to allow for common restrictions on .
These algorithms, as well as two pre-existing ones, have been implemented in Ox 7 Doornik (2013).
The comparisons are based on a model for the Danish data (five variables: log real money, log real GDP, log GDP deflator, and , , two interest rates); see Juselius (2006, §4.1.1). This has two lags in the VAR, with an unrestricted constant and restricted trend for the deterministic terms, i.e., specification . The sample period is 1973(3) to 2003(1). First computed is the I(2) rank test table.
Table 3 records the number of iterations used by each of the algorithms; this is closely related to the actual computational time required (but less machine specific). All three algorithms converge rapidly to the same likelihood value. Although switching takes somewhat fewer iterations, it tends to take a bit more time to run than the other two algorithms. The new triangular I(2) switching procedure is largely competitive with the new -switching algorithm.
To illustrate the advances made with the new algorithms, we report in Table 4 how the original -switching, as well as the CATS2 version of -switching performed. CATS2, Dennis and Juselius (2004), is a RATS package for the estimation of I(1) and I(2) models, which uses a somewhat different implementation of an I(2) algorithm that is also called -switching. The number of iterations of that CATS 2 algorithm is up to 200-times higher than that of the new algorithms, which are therefore much faster, as well as more robust and reliable.
6. A More Detailed Comparison
A Monte Carlo experiment is used to show the difference between algorithms in more detail. The first data generation process is the model for the Danish data, estimated with the I(1) and I(2) restrictions imposed. random samples are drawn from this, using, for each case, the estimated parameters and estimated residual variance assuming normality. The number of iterations and the progress of the algorithm is recorded for each sample. The maximum number of iterations was set to 10 000, , and all replications are included in the results.
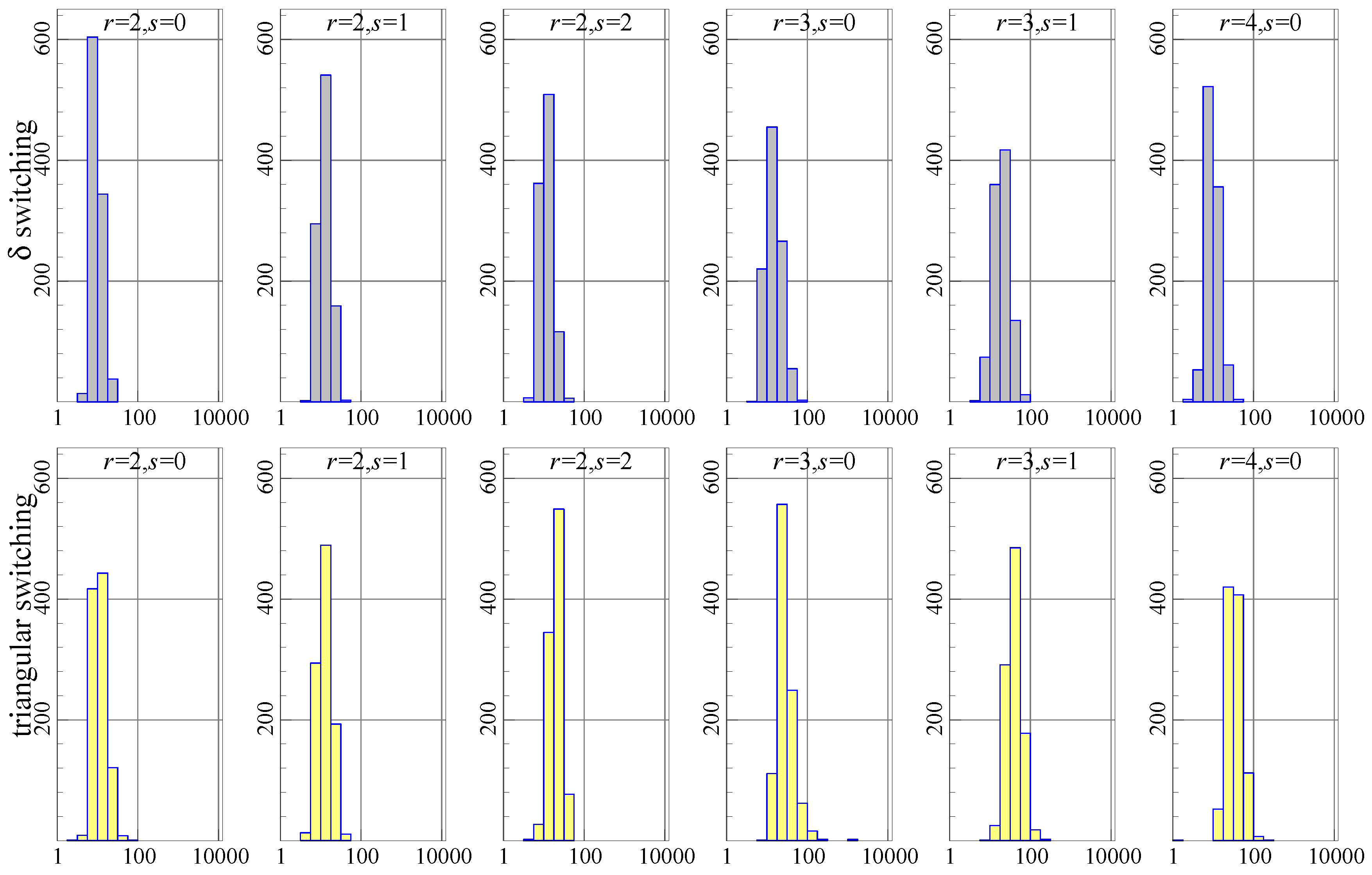
Figure 1 shows the histograms of the number of iterations required to achieve convergence (or 10,000). Each graph has the number of iterations (on a log 10 scale) on the horizontal axis and the count (out of 1000 experiments) represented by the bars and the vertical axis. Ideally, all of the mass is to the left, reflecting very quick convergence. The top row of histograms is for switching, the bottom row for triangular switching. In each histogram, the data generation process (DGP) uses the stated values, and estimation is using the correct values of .
The histograms show that triangular switching (bottom row) uses more iterations than switching (top row), in particular when . Nonetheless, the experiment using triangular switching runs slightly faster as measured by the total time taken (and switching is the slowest).
An important question is whether the algorithms converge to the same maximum. The function value that is maximized is:
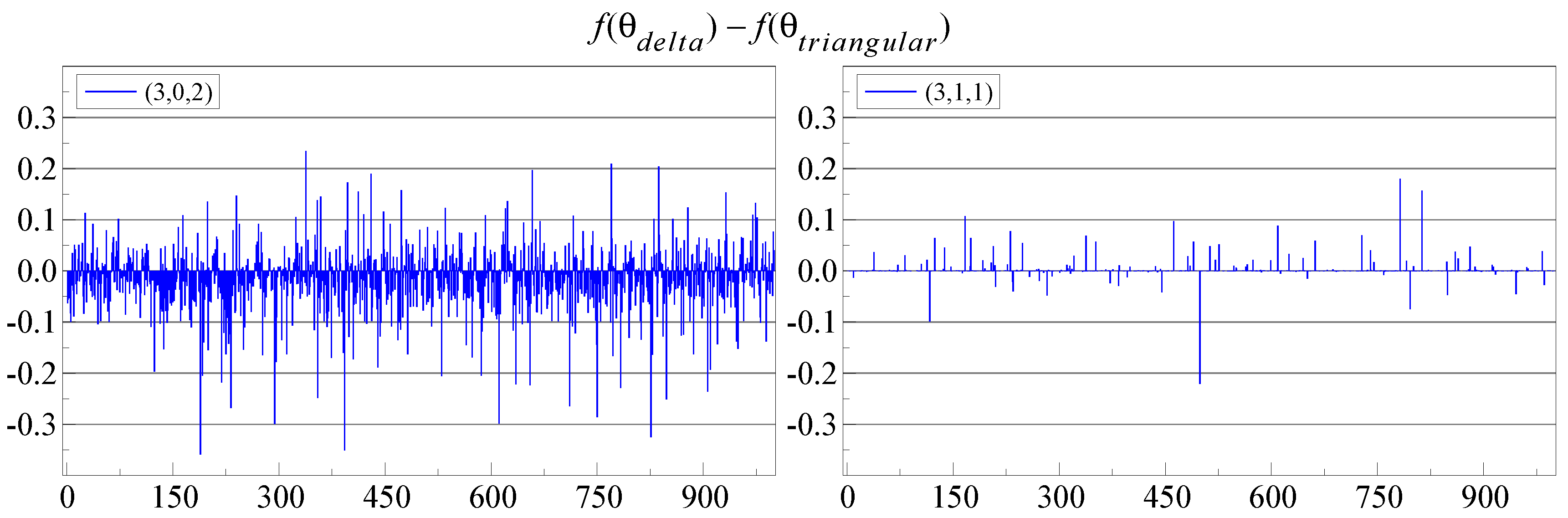
Out of 10,000 experiments, counted over all combinations that we consider, there is only a single experiment with a noticeable difference in . This happens for , and -switching finds a higher function value by almost . Because , the translates to a difference of three in the log-likelihoods.
A second issue of interest is how the algorithms perform when restrictions are imposed. The following restrictions are imposed on the three columns of with :
This specification identifies the cointegrating vectors and imposes two over-identifying restrictions. For this is accepted with a p-value of , while for , the p-value is using the model on the actual Danish data. Simulation is from the estimated restricted model.
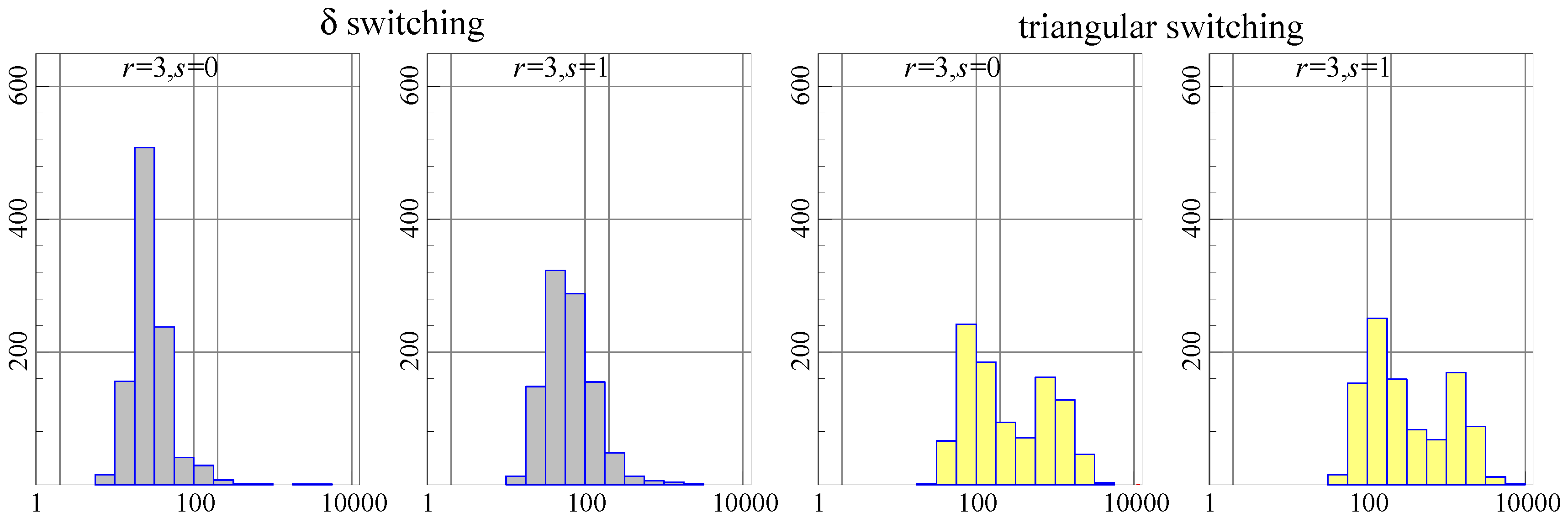
In terms of the number of iterations, as Figure 2 shows, -switching converges more rapidly in most cases. This makes triangular switching slower, but only by about –.
Figure 3 shows , so a positive value means that triangular switching obtained a lower log-likelihood. There are many small differences, mostly to the advantage of -switching when (right-hand plot), but to the advantage of triangular switching on the left, when . The latter case is also much more noisy.
6.1. Hybrid Estimation
To increase the robustness of the triangular procedure, we also consider a hybrid procedure, which combines algorithms as follows:
- standard starting values, as well as twenty randomized starting values, then
- triangular switching, followed by
- BFGS optimization (the Broyden-Fletcher, Goldfarb, and Shanno quasi-Newton method) for a maximum of 200 iterations, followed by
- triangular switching.
This offers some protection against false convergence, because BFGS is based on first derivatives combined with an approximation to the inverse Hessian.
More importantly, we add a randomized search for better starting values as perturbations of the default starting values. Twenty versions of starting values are created this way, and each is followed for ten iterations. Then, we discard half, merge (almost) identical ones and run another ten iterations. This is repeated until a single one is left.
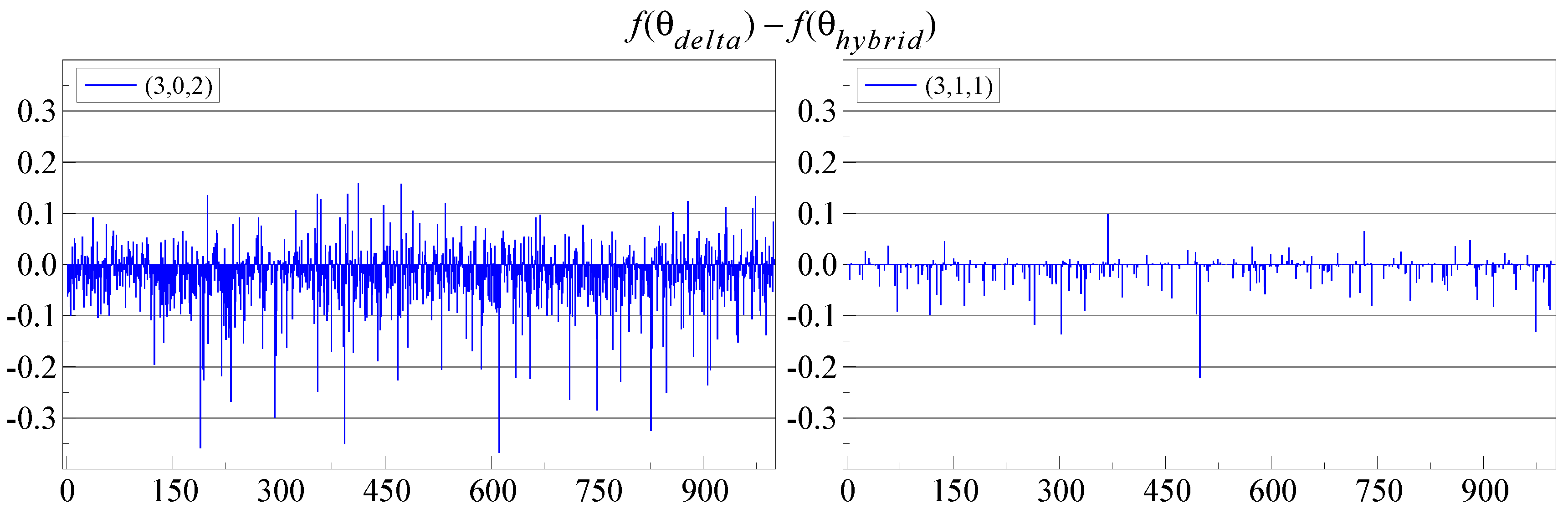
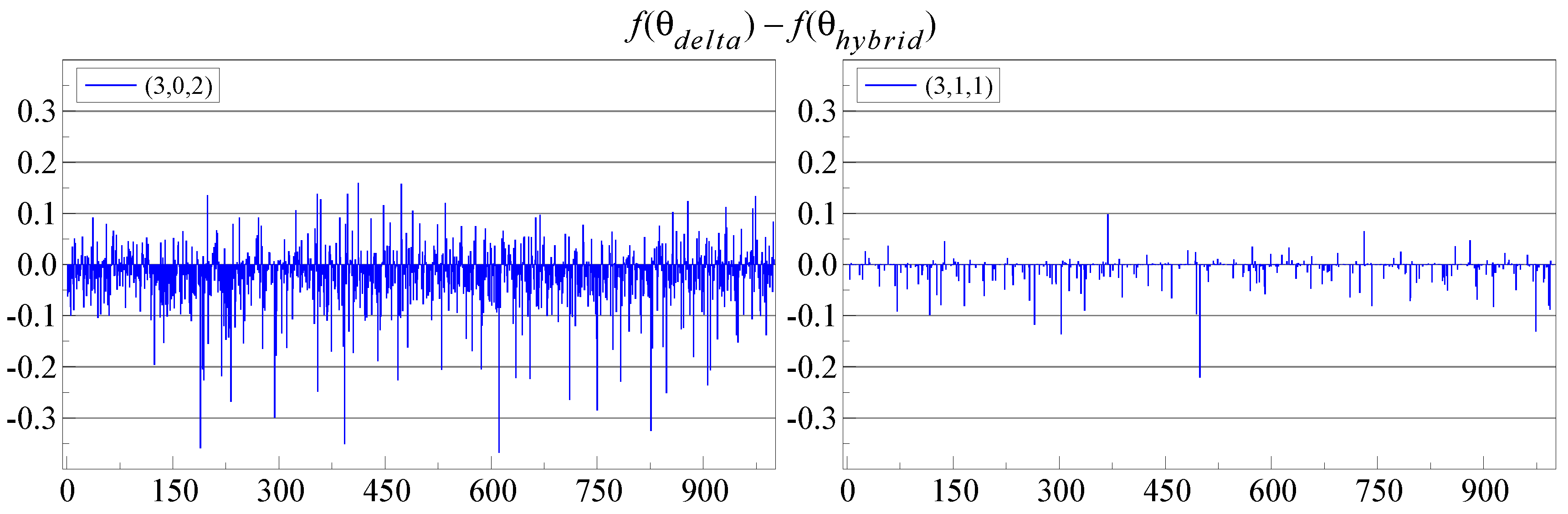
Figure 4 shows that this hybrid approach is an improvement: now, it is almost never beaten by switching. Of course, the hybrid approach is a bit slower again. The starting value procedure for switching could be improved in the same way.
7. Conclusions
We introduced the triangular representation of the I(2) model and showed how it can be used for estimation. The trilinear form of the triangular representation has the advantage that estimation can be implemented as alternating least squares, without using reduced-rank regression. This structure allows us to impose restrictions on (parts of) the A and B matrices, which gives more flexibility than is available in the and representations.
We also presented an algorithm based on the -representation and compared the performance to triangular switching in an application based on Danish data, as well as a parametric bootstrap using that data. Combined with the acceleration of Doornik (2017), both algorithms are fast and give mostly the same result. This will improve empirical applications of the I(2) model and facilitate recursive estimation and Monte Carlo analysis. Expressions for the computation of t-values of coefficients will be reported in a separate paper.
Because they are considerably faster than the previous generation, bootstrapping the I(2) model can now be considered, as Cavaliere et al. (2012) did for the I(1) model.
Acknowledgments
I am grateful to Peter Boswijk, Søren Johansen and Katarina Juselius for providing detailed comments as this paper was developing. Their suggestions have greatly improved the results presented here. Financial support from the Robertson Foundation (Award 9907422) and the Institute for New Economic Thinking (Grant 20029822) is gratefully acknowledged. All computations and graphs use OxMetrics and Ox, Doornik (2013).
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. Estimation Using the QR Decomposition
The data matrices in the I(2) model (8) are for .
Take the QR decomposition of as where Q is a orthogonal matrix and R a upper triangular matrix, while are the leading columns of Q and a upper triangular matrix. P is the orthogonal matrix that captures the column reordering. Then:
where is no longer triangular. Introduce:
where is , then:
Now, e.g., a regression of on for known :
has:
This is a regression of on . If such regressions need to be done often for the same Z’s, it is more efficient to do them in terms of the :
with estimated residual variance:
This regression has fewer ‘observations’, while at the same time avoiding the creation of moment matrices. Precomputed moment matrices would be faster, but not as good numerically. For recursive estimation, it is useful to be able to handle singular regressions because dummy variables can be zero over a subsample; this happens naturally in the QR approach. This approach needs to be adjusted when (A1) also has on the right-hand side, as happens for -switching in (A3).
Reduced Rank Regression
Let RRR denote reduced rank regression of on corrected for . Assume that have been transformed into using the QR decomposition described above. Concentrating out can be done by regression of on , with residuals . Form , and decompose using the Cholesky decomposition: .
We need to solve the matrix pencil:
Start by using the QR decomposition , :
The second line introduces ; the next line removes R; and the final line takes the SVD of . The eigenvalues are the squared singular values that are on the diagonal of , and the eigenvectors are .
When X is singular, as may be the case in recursive estimation, the upper triangular matrix R will have rows and columns that are zero at the bottom and end. These are the same on the left and right of the pencil, so they can be dropped. The resulting reduced dimension R is full rank, and we can set the corresponding rows in the eigenvectors to zero. When the regressors are singular, their corresponding coefficients in will be set to zero, just as in our regressions.
This approach differs somewhat from Doornik and O’Brien (2002) because of the different structure of as a consequence of the prior QR transformation.
Appendix B. Tau-Switching Algorithm
The algorithm of Johansen (1997, §8) is based on the -representation and involves three stages:
- The estimate of is obtained by GLS given all other parameters except . Johansen (1997, p. 451) shows the GLS expressions using second moment matrices. Define the orthogonal matrix , then using :The error term has variance , which is block diagonal. Given , (A2) is linear in and . The estimates of the latter are discarded.
- Given just , reduced-rank regression of corrected for on corrected for is used to estimate . Details are in Johansen (1997, p. 450).
- Given and , the remaining parameters can be obtained by GLS. The equivalence is used to write the conditional equation as:from which and are estimated by regression. Then, is estimated from the marginal equation:Together, they give and w. We always transform to set , adjusting and accordingly.
-switching algorithm:
To start, set , and choose starting values , tolerance and the maximum number of iterations. Compute from (18) and from (A3) and (A4). Furthermore, compute .
- 1.
- Get from (A2). Identify this as follows. Select the non-singular submatrix from with the largest volume, say M. We find M by using the first column pivots that are chosen by the QR decomposition of (Golub and Van Loan (2013, Algorithm 5.4.1) ). Set . Get by RRR; finally, get the remaining parameters from (A3) and (A4).
- 2...
- As steps 2,3,T from the -switching algorithm. ☐
The line search is only for the parameters in as part of it is set to a unit matrix every time. The function evaluation inside the line search needs to obtain all of the other parameters as changes.
This is the algorithm of Johansen (1997) except for the normalization of and the line search. The former protects the parameter values from exploding, while the latter improves convergence speed and makes it more robust. Removing is largely for convenience: it has little impact on convergence. The -switching algorithm is easily adjusted for common restrictions on in the form of . However, gets in the way of more general restrictions.
Appendix C. Starting Values
The first starting value procedure is:
- Set to their I(1) values (i.e., with full rank ).
- Take two iterations with the relevant switching algorithm subject to restrictions.
The second starting value procedure is:
- Get by RRR from the -representation using :
- Get by RRR from the -representation:
- Take two iterations with the relevant switching algorithm subject to restrictions.
Finally, choose the final starting values as those that have the highest function value.
References
- Anderson, Theodore W. 1951. Estimating linear restrictions on regression coefficients for multivariate normal distributions. Annals of Mathematical Statistics 22: 327–51, (Erratum in Annals of Statistics 8, 1980). [Google Scholar] [CrossRef]
- Anderson, Theodore W. 2002. Reduced rank regression in cointegrated models. Journal of Econometrics 106: 203–16. [Google Scholar] [CrossRef]
- Boswijk, H. Peter. 2010. Mixed Normal Inference on Multicointegration. Econometric Theory 26: 1565–76. [Google Scholar] [CrossRef]
- Boswijk, H. Peter, and Jurgen A. Doornik. 2004. Identifying, Estimating and Testing Restricted Cointegrated Systems: An Overview. Statistica Neerlandica 58: 440–65. [Google Scholar] [CrossRef]
- Cavaliere, Giuseppe, Anders Rahbek, and R.A.M. Taylor. 2012. Bootstrap Determination of the Co-Integration Rank in Vector Autoregressive Models. Econometrica 80: 1721–40. [Google Scholar]
- Dennis, Jonathan G., and Katarina Juselius. 2004. CATS in RATS: Cointegration Analysis of Time Series Version 2. Technical Report. Evanston: Estima. [Google Scholar]
- Doornik, Jurgen A. 2013. Object-Oriented Matrix Programming using Ox, 7th ed. London: Timberlake Consultants Press. [Google Scholar]
- Doornik, Jurgen A. 2017. Accelerated Estimation of Switching Algorithms: The Cointegrated VAR Model and Other Applications. Oxford: Department of Economics, University of Oxford. [Google Scholar]
- Doornik, Jurgen A., and R. J. O’Brien. 2002. Numerically Stable Cointegration Analysis. Computational Statistics & Data Analysis 41: 185–93. [Google Scholar] [CrossRef]
- Golub, Gen H., and Charles F. Van Loan. 2013. Matrix Computations, 4th ed. Baltimore: The Johns Hopkins University Press. [Google Scholar]
- Johansen, Søren. 1988. Statistical Analysis of Cointegration Vectors. Journal of Economic Dynamics and Control 12: 231–54, Reprinted in R. F. Engle, and C. W. J. Granger, eds. 1991. Long-Run Economic Relationships. Oxford: Oxford University Press, pp. 131–52. [Google Scholar] [CrossRef]
- Johansen, Søren. 1991. Estimation and Hypothesis Testing of Cointegration Vectors in Gaussian Vector Autoregressive Models. Econometrica 59: 1551–80. [Google Scholar] [CrossRef]
- Johansen, Søren. 1992. A Representation of Vector Autoregressive Processes Integrated of Order 2. Econometric Theory 8: 188–202. [Google Scholar] [CrossRef]
- Johansen, Søren. 1995a. Likelihood-based Inference in Cointegrated Vector Autoregressive Models. Oxford: Oxford University Press. [Google Scholar]
- Johansen, Søren. 1995b. Identifying Restrictions of Linear Equations with Applications to Simultaneous Equations and Cointegration. Journal of Econometrics 69: 111–32. [Google Scholar] [CrossRef]
- Johansen, Søren. 1995c. A Statistical Analysis of Cointegration for I(2) Variables. Econometric Theory 11: 25–59. [Google Scholar] [CrossRef]
- Johansen, Søren. 1997. Likelihood Analysis of the I(2) Model. Scandinavian Journal of Statistics 24: 433–62. [Google Scholar] [CrossRef]
- Johansen, Søren, and Katarina Juselius. 1990. Maximum Likelihood Estimation and Inference on Cointegration—With Application to the Demand for Money. Oxford Bulletin of Economics and Statistics 52: 169–210. [Google Scholar] [CrossRef]
- Johansen, Søren, and Katarina Juselius. 1992. Testing Structural Hypotheses in a Multivariate Cointegration Analysis of the PPP and the UIP for UK. Journal of Econometrics 53: 211–44. [Google Scholar] [CrossRef]
- Johansen, Søren, and Katarina Juselius. 1994. Identification of the Long-run and the Short-run Structure. An Application to the ISLM Model. Journal of Econometrics 63: 7–36. [Google Scholar] [CrossRef]
- Juselius, Katarina. 2006. The Cointegrated VAR Model: Methodology and Applications. Oxford: Oxford University Press. [Google Scholar]
- Paruolo, Paolo. 2000a. Asymptotic Efficiency of the Two Stage Estimator in I(2) Systems. Econometric Theory 16: 524–50. [Google Scholar] [CrossRef]
- Paruolo, Paolo. 2000b. On likelihood-maximizing algorithms for I(2) VAR models. Mimeo. Varese: Universitá dell’Insubria. [Google Scholar]
- Paruolo, Paolo, and Anders Rahbek. 1999. Weak exogeneity in I(2) VAR Systems. Journal of Econometrics 93: 281–308. [Google Scholar] [CrossRef]
Figure 1.
Comparison of algorithms: -switching (top row) and triangular-switching (bottom row). Simulating a range of . Number of iterations on the horizontal axis, count (out of 1000) on the vertical.
Figure 1.
Comparison of algorithms: -switching (top row) and triangular-switching (bottom row). Simulating a range of . Number of iterations on the horizontal axis, count (out of 1000) on the vertical.
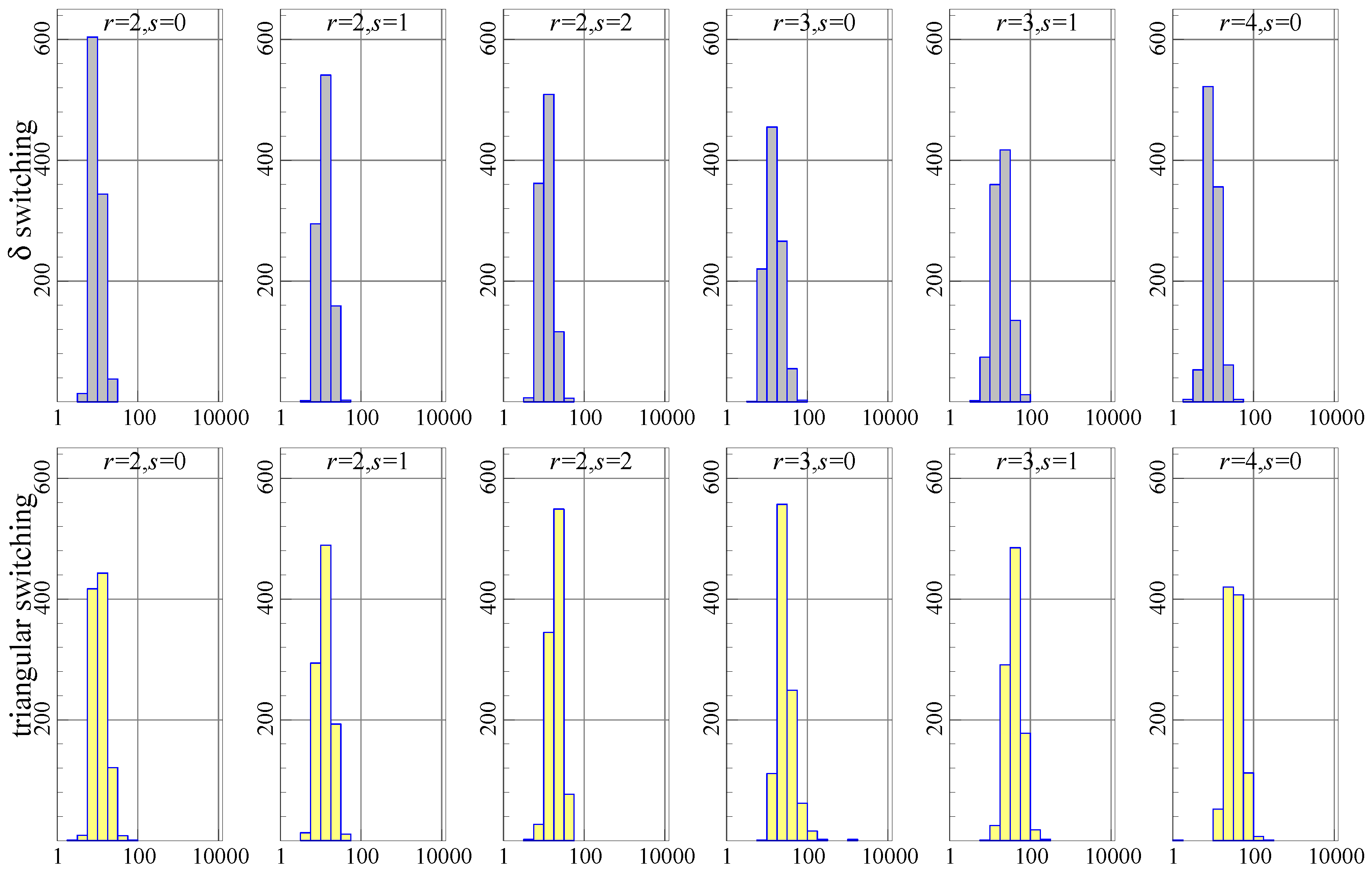
Figure 2.
Comparison of algorithms: -switching (left two) and triangular-switching (right two). Simulating a range of . Number of iterations on the horizontal axis, count (out of 1000) on the vertical.
Figure 2.
Comparison of algorithms: -switching (left two) and triangular-switching (right two). Simulating a range of . Number of iterations on the horizontal axis, count (out of 1000) on the vertical.
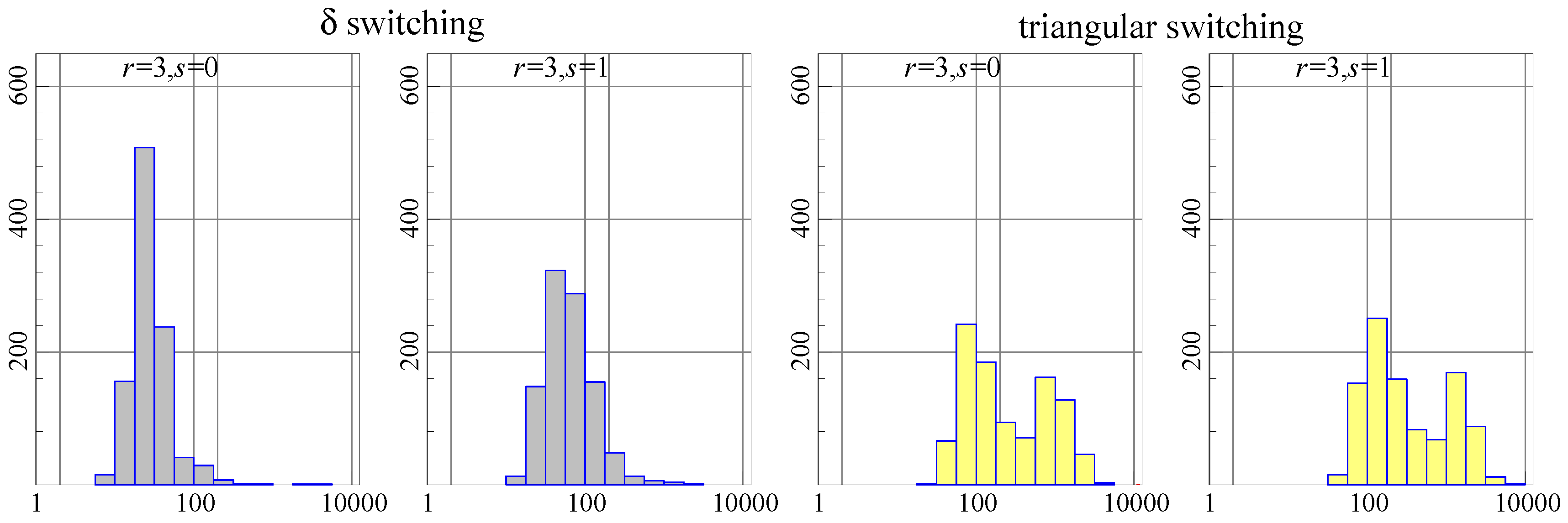
Figure 3.
-switching function value minus the triangular switching function value (vertical axis) for each replication (horizontal axis). Both starting from their default starting values. The labels are the cointegration indices .
Figure 3.
-switching function value minus the triangular switching function value (vertical axis) for each replication (horizontal axis). Both starting from their default starting values. The labels are the cointegration indices .
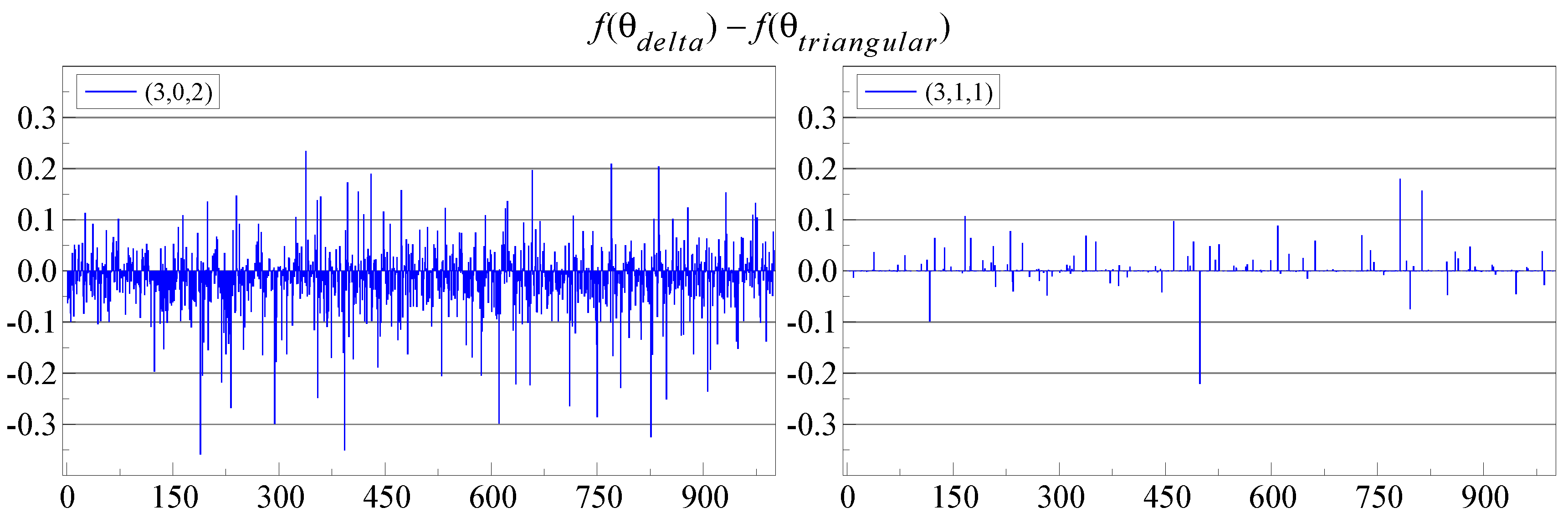
Figure 4.
-switching function value minus the hybrid triangular-switching function value (vertical axis) for each replication (horizontal axis).
Figure 4.
-switching function value minus the hybrid triangular-switching function value (vertical axis) for each replication (horizontal axis).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Definitions of the symbols used in the and representations of the I(2) model.
| Definition | Dimension | ||
|---|---|---|---|
| = | |||
| = | |||
| = | |||
| = | |||
| = | |||
| = | |||
| w | = | ||
| d | = | ||
| e | = | ||
Table 2.
Links between symbols used in the representations of the I(2) model, assuming and .
| = | |||
| = | |||
| = | |||
| = | |||
| = | |||
| = | |||
| = | |||
| = | |||
| = | |||
Table 3.
Estimation of all I(2) models by and triangular switching; all using the same starting value procedure. Number of iterations to convergence for .
Table 3.
Estimation of all I(2) models by and triangular switching; all using the same starting value procedure. Number of iterations to convergence for .
| r | Switching | Switching | Triangular Switching | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 3 | 2 | 1 | 4 | 3 | 2 | 1 | 4 | 3 | 2 | 1 | |
| 1 | 19 | 25 | 36 | 34 | 15 | 24 | 37 | 30 | 31 | 31 | 39 | 32 |
| 2 | 18 | 32 | 25 | 18 | 32 | 34 | 22 | 27 | 50 | |||
| 3 | 37 | 23 | 42 | 38 | 50 | 59 | ||||||
| 4 | 29 | 28 | 85 | |||||||||
Table 4.
Estimation of all I(2) models by old versions of switching. Number of iterations to convergence for .
Table 4.
Estimation of all I(2) models by old versions of switching. Number of iterations to convergence for .
| r | Old Switching | CATS2 Switching | ||||||
|---|---|---|---|---|---|---|---|---|
| 4 | 3 | 2 | 1 | 4 | 3 | 2 | 1 | |
| 1 | 126 | 198 | 338 | 201 | 5229 | 8329 | 8516 | 5371 |
| 2 | 79 | 211 | 229 | 7234 | 709 | 861 | ||
| 3 | 483 | 237 | 550 | 432 | ||||
| 4 | 4851 | 5771 | ||||||
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Doornik, J.A. Maximum Likelihood Estimation of the I(2) Model under Linear Restrictions. Econometrics 2017, 5, 19. https://doi.org/10.3390/econometrics5020019
AMA Style
Doornik JA. Maximum Likelihood Estimation of the I(2) Model under Linear Restrictions. Econometrics. 2017; 5(2):19. https://doi.org/10.3390/econometrics5020019
Chicago/Turabian StyleDoornik, Jurgen A. 2017. "Maximum Likelihood Estimation of the I(2) Model under Linear Restrictions" Econometrics 5, no. 2: 19. https://doi.org/10.3390/econometrics5020019
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.