1. Introduction
Volatility forecasting is crucial for many investment decisions, such as asset allocation and risk management. This paper presents empirical results on volatility forecasting of a stochastic process with asymmetries and discontinuities in the return and volatility processes, highlighting the importance of incorporating these effects into the forecasting model itself. Moreover, a methodology for separating realized volatility into quarter variances and for estimating volatility jumps is introduced.
Asymmetries, discontinuities and memory properties in the data-generating process for asset returns are known stylized facts. Specifically, these are also known as the volatility leverage and feedback effects that induce skewness, infrequent jumps that induce fat tails and volatility persistence representing the process memory. The existence of these effects poses challenges for obtaining accurate volatility forecasts and requires models that can take into account all of those empirical features. Capturing volatility persistence, the popular heterogeneous autoregressive realized volatility model (
) of [
1], which is based on an approximation of long-run volatility components, performs surprisingly well in out-of-sample forecast evaluations.
The realized volatility, advocated by, among others, [
2] and [
3], consistently estimates the integrated volatility of the return process under the assumption that it follows a continuous semimartingale. Realized volatility is based on the notion of increasing sampling frequency and is generally considered an accurate proxy for the latent true volatility. These kinds of non-parametric estimates are particularly suited for forecasting, as jump information can be extracted directly from the data, and volatility persistence, leverage and feedback effects can be modeled parsimoniously in the framework of a simple regression.
Evidence of the leverage effect with high frequency data has been advanced by Bollerslev, T.
et al. [
4], who analyzed sign asymmetries of high frequency returns and their impact on future volatility. This paper presents new evidence of leverage effects by using high frequency data of the S & P500 Index. To the prior literature, it adds the consideration of a separate leverage effect generated by both the jump and the continuous components of the return process.
The main empirical contribution of this paper is the finding of a superior forecasting performance when the jumps in returns are isolated from the corresponding continuous component. While the previous papers separated jump variation and continuous variation, as proposed by Andersen, T.G.
et al. [
5], here, we disentangle the jump size from the continuous return at the intraday level and include it in the prediction model. With this approach, on top of improving forecasting performance, we could also interpret any effect of return jumps on future volatility as a jump leverage effect. As in [
1], we include in the forecasting model the long memory of volatility considering heterogeneous autoregressive (
) components and, as in [
6], the continuous leverage effect through lagged negative returns generated from continuous components.
Further, as in [
7], we find that the best forecasting model includes “downside risks,” which are volatilities generated by negative intraday returns. The realized variance is in fact also disentangled into continuous signed semi-variations and jump signed semi-variations, as a way to capture separate dynamics of negative intraday returns with respect to positive intraday returns. The leverage effect in forecasting realized volatility has been considered by both Corsi, F. and Renò, R. [
6] and Patton, A.J. and Sheppard, K. [
7] in a similar framework. These papers are the most closely related to our study. However, the methodology to assess it differs as we disentangle jump size from both return and volatility, and we also separate both jump variation and continuous variation into semi-variances. Particularly relevant for our analysis of return jumps and asymmetries between jump components is the methodology to detect intraday return jumps proposed by Lee, S.S. and Mykland, P.A. [
8].
Methodologically, using the return jump detection methodology of [
8], we derive a complete decomposition of the realized variance into four quarter variances, two signed jump variations and two signed continuous variations. To our knowledge, a complete linear decomposition of the realized variance into quarter variances is new in the literature. The work in [
9] proposed the decomposition of the realized variance into semi-variances, while Patton, A.J. and Sheppard, K. [
7] proposed a different method of estimating signed jump semi-variances, but together with the continuous variation, they do not sum to the total realized variance. Moreover, we propose a jump identification method for the quadratic variation based on auxiliary inference. As the return may jump, the quadratic variation may also jump if the underlying data-generating process is a double jump stochastic process. These are the two methodological contributions of this paper.
The literature on jump detection and realized volatility forecasting has become very rich in the last 10 years. Focusing on return jumps, Dumitru, A.M. and Urga, G. [
10] performed an extensive Monte Carlo study of the performance of nine methods to detect jumps. They find that the methodology used in this paper based on [
8] performs better than the alternatives and is more robust to microstructure noise. In this paper, we ignore microstructure noise and do not compare the performance of jump detection procedures, but rather, we compare the performance of volatility forecasting models that are based on the chosen jump detection methodology introduced in [
8].
1Using a different jump test, Huang, X. and Tauchen, G. [
12] studied the power of their jump detection test statistics and presented evidence of daily jump frequency in the S & P500 financial market. They found that for the S & P500 Index futures, the contribution of jump variation to total variation is between 4.4% and 4.6% for the time period from 1997 to 2003. The work in [
13] used ultra-high frequency data (tick-by-tick) to study the contribution of jump variation to total variation for a large set of securities. Their jump variation is estimated as the difference between total variation and continuous variation, with the two components, in turn, estimated by pre-averaged returns in a local neighborhood to be robust to noise and outliers. They found that jump variation estimated with ultra-high frequency data is of an order of magnitude lower than jump variation estimated with five minute price data. In this paper, we sample at five minutes to smooth microstructure noise, and unlike the previous paper, using a high-frequency jump test, we are able to estimate jump variation directly from the return jump size instead of resorting to the daily difference of estimated total and continuous variation. With this method of estimating jump variation, we find the contribution of jump variation to be in line with [
12]
2. As pointed out in [
13], with a higher sampling frequency, the jump variation magnitude may be different, and the estimates of jump variation based on five minute data may capture variation in liquidity. We do not aim to justify jumps and study microstructure noise effects, but rather, compare the out-of-sample forecasting performance of an imperfect proxy, such as the realized volatility.
Using daily price data, Jacquier, E. and Okou, C. [
14] separated jump from continuous variation to predict future excess returns. Their paper is related to the intertemporal capital asset pricing literature. They found evidence of past continuous variation having a longer lasting effect in pricing than jump variation. While focusing on volatility forecasting, we find that continuous variation is the driving factor for the persistence in volatility. In contrast, the effect of jumps is short-lived. This is in line with the finding of [
14].
The remainder of the paper is organized as follows.
Section 2 presents realized estimators used in the analysis, the continuous time framework on which the estimates are based and the methodology to disentangle continuous and jump components from both return and volatility processes.
Section 3 presents the data used in the empirical analysis and the candidate forecasting models.
Section 4 contains evidence of the leverage and jump effects and presents estimation results and the out-of-sample forecasting performance evaluation. Finally,
Section 5 concludes.
2. Theoretical Framework
The underlying framework for the empirical analysis is based on a double jump-diffusion data-generating process. This stochastic process features a continuous sample path component and occasional jumps in both return and volatility dynamics. The framework was first laid down by Duffie, D.
et al. [
15]. The empirical analysis of this class of models can be found in [
16,
17,
18,
19,
20]. Generally, the previous results support jumps in volatility, as well as jumps in returns for speculative prices. Let
denote the logarithmic asset price at time
t, for
. In stochastic differential equation form, the price and volatility processes are
where
is a bivariate standard Brownian motion,
is a bivariate count process and
represents the size of the jumps in return and in volatility if a count occurs at time
t3. The mean of the variance Equation (
2) is characterized by a long-run level parameter
θ and a mean-reverting parameter
ϑ. Moreover, the process is restricted to be non-negative.
This framework allows the generation of the contemporaneous leverage or volatility feedback effects through the correlation between the continuous components, as well as through the correlation between the jump components that may be both in the time and in the size of the jumps.
Following the theory of quadratic variation, the volatility of the price process is estimated with the realized volatility from high frequency data. Below, we present the estimators for volatility and jump components used in the analysis.
2.1. Return Volatility and Jumps
Let
be the discretely-sampled
i-th intraday return for day
t. In the presence of jumps in return, the realized variance,
, introduced by Andersen, T.G.
et al. [
2] and Andersen, T.G.
et al. [
21], captures both continuous and jump components of the quadratic variation:
The bi-power variation, introduced by [
22], is instead a consistent estimator for the continuous component only:
where
=
, with
denoting the gamma function.
The work in [
23] and [
8] proposes detecting intraday jumps using the ratio between intraday returns and estimated spot volatility. We follow more closely the methodology of [
8], and in particular, we test the presence of intraday jumps with the statistics
where the expression contains in the denominator the estimates of the spot volatility as the average bi-power variation over a period with
K observations. Lee, S.S.
et al. [
8] suggests using
, respectively, with return sampled at frequencies of 60, 30, 15 and 5 minutes. Under the null of no intraday jump, the test statistics
follow a normal distribution (with variance
).
In order to select the rejection region for the test statistics
, Lee, S.S.
et al. [
8] propose to look at the asymptotic distribution of maxima of the test statistics. As the sampling frequency tends to zero, under the null of no jumps between time
and
, the absolute value of
converges to a Gumbel distribution:
where
ζ has a standard Gumbel distribution,
,
and
n is the number of observations for each period
t. We reject the null of no jump at time
if
such that
,
i.e.,
, with
α being the significance level
4.
The test is able to detect the jump arrival time
for each day
t, where
j denotes the presence of a jump. Moreover, the jump size is computed as
consequently, the jump size for the day
t is
where
is the total number of significant jumps for day
t, and the jump-adjusted daily return is
With this methodology to identify intraday jumps, it is possible to directly estimate the jump variation,
i.e., the quadratic variation of return jumps. We follow [
25] and estimate the quadratic variation due to the continuous and the jump components respectively as
where
is the contribution to the quadratic variation of each intraday jump
, with
and
. We find that the daily jump variation identified with this methodology is highly correlated with more traditional methods to identify jump variation that primarily take the positive differences between
and
.
2.2. Downside Continuous and Jump Variation
To capture the sign asymmetry of the volatility process, the continuous variation and jump variation are decomposed using signed intraday returns. The work in [
9] introduced a new estimator that captures the quadratic variation due to signed returns, termed realized semi-variance. In a similar way, the continuous variation and jumps variation can both be decomposed into signed semi-variations by using the test of [
8]. This represents the main advantage of the test, as it is able to identify the sign and the timing of intraday jumps. If jump variation is instead identified by means of significant
, as normally done in the previous literature, no information is available about the sign or timing of intraday jumps, and therefore, we are not able to disentangle jump or continuous semi-variations.
The realized semi-variances of [
9] are defined as
We estimate the jump semi-variances in a similar fashion by using signed intraday jumps:
where
for
and
Consequently, the continuous semi-variances are estimated by
The realized variance is decomposed into quarter variances, and this decomposition is complete as
,
and
. To study the volatility feedback effect, a particular focus is on the downside continuous variation and jump variation captured by
and
, respectively, as Patton, A.J. and Sheppard, K. [
7] show that negative semi-variances are more informative than positive semi-variances for forecasting future volatility. These quantities are used in the empirical analysis of the following sections.
2.3. Volatility Jumps
The estimation of volatility jumps is a prominent topic of research (see [
20]). The difficulty in estimating volatility jumps is due to the model misspecification of the jump process coupled with the fact that volatility is a latent quantity. Here, we consider a methodology to estimate the size of (continuous) volatility jumps without imposing assumptions on its distribution while we assume that the realized variance estimate (continuous variation given in Equation (
11)) is the true variance, as is standard practice in the realized variance literature.
We consider an auxiliary first order autoregressive
model on the first difference of continuous variation with the variance of continuous variation following generalized autoregressive conditional heteroskedasticity
dynamics. This choice is motivated empirically and theoretically. The
on the changes in continuous volatility is a natural discrete approximation of the volatility process in Equation (
2) without the volatility jump component, with the
approximating the volatility mean and the
equation capturing the volatility of volatility. Empirically, it fits very well with the continuous variation sample series by excluding extreme values. It is specified as
with stationarity constraint
,
and non-negativity constraints on
:
. The jump in volatility is estimated as
where
denotes the
quantile of the standard normal distribution, and the indicator for the timing of volatility jumps is given by
.
5 Intuitively, in the absence of volatility jumps, the auxiliary model approximates the true volatility dynamics. However, in the presence of large jumps, the auxiliary model is not able to fit the data, and large residuals from the model fit represent contributions of volatility jumps.
At this point, it is worth reiterating that the estimated volatility jumps are in fact jumps of the continuous variation, where the continuous variation is an estimate of the variance process without return jumps. Given the double-jump process as the data-generating process, the continuous variation may well jump itself, even without jumps in the return process. The combination of the terms “jumps in continuous variation” may sound paradoxical. Therefore, the term “volatility jumps” instead of “jumps in continuous variation” is used.
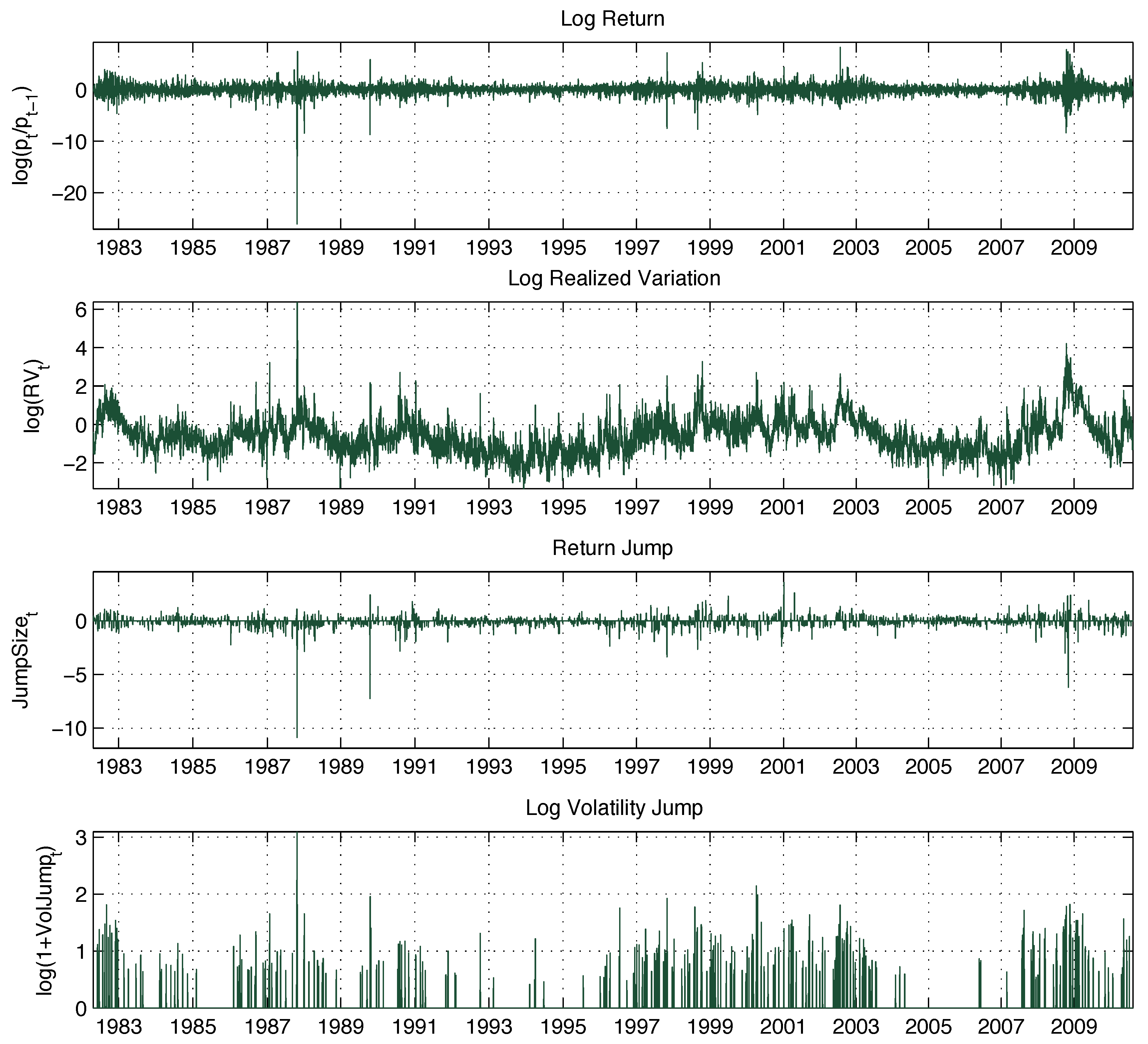
4. Empirical Evidence
4.1. Leverage Effect, Volatility Feedback Effect and Persistence
Leverage and volatility feedback effects are commonly studied by means of correlations. The work in [
4] provides exhaustive evidence of the leverage effect at high frequency by studying cross-correlations among return and volatility series for a horizon spanning several days. Exploiting the methodology we use to disentangle the continuous and jump components of return and volatility dynamics, we present new evidence of leverage and volatility feedback effects arising from both continuous and jump components. Moreover, we use signed intraday returns to capture sign asymmetries.
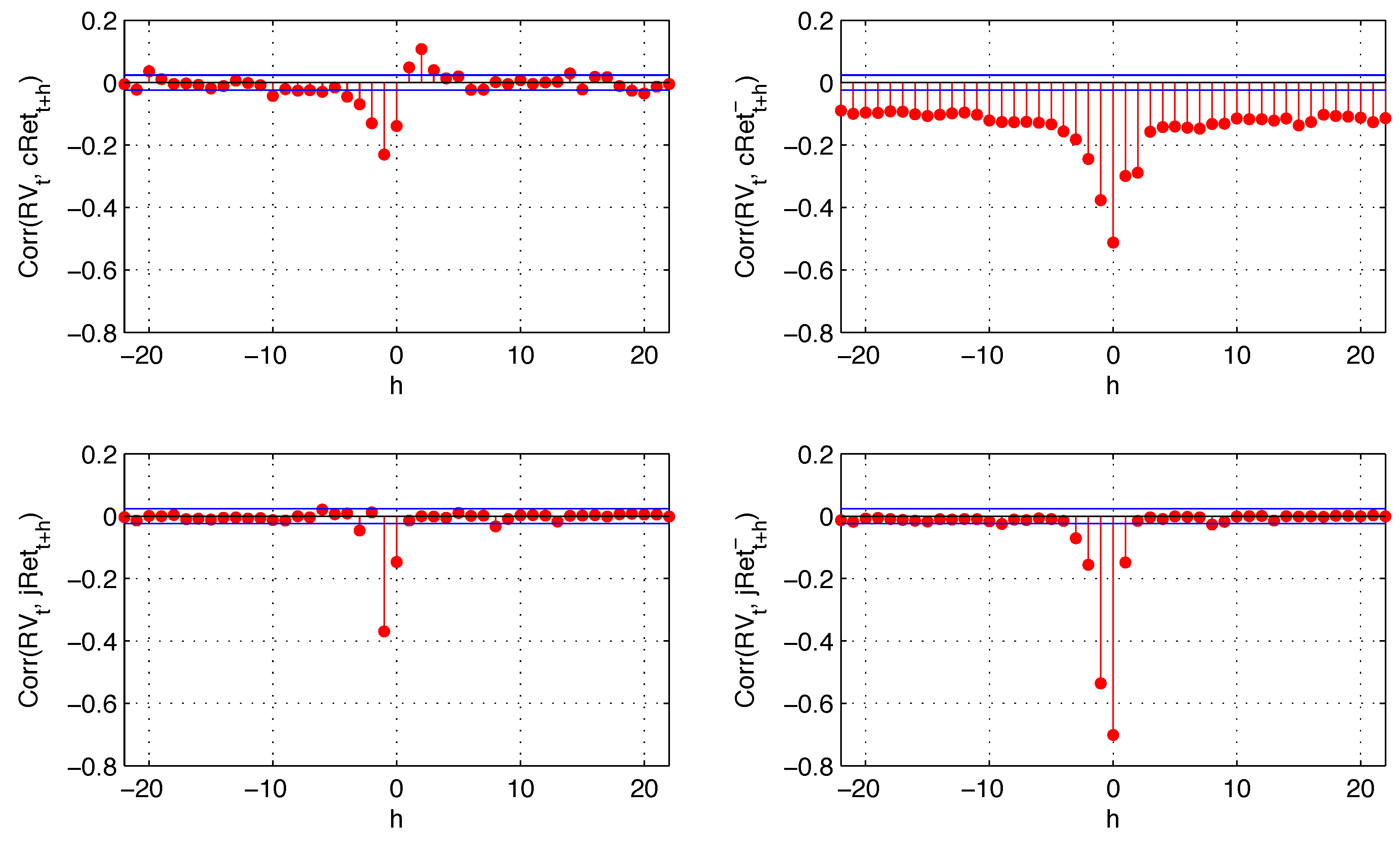
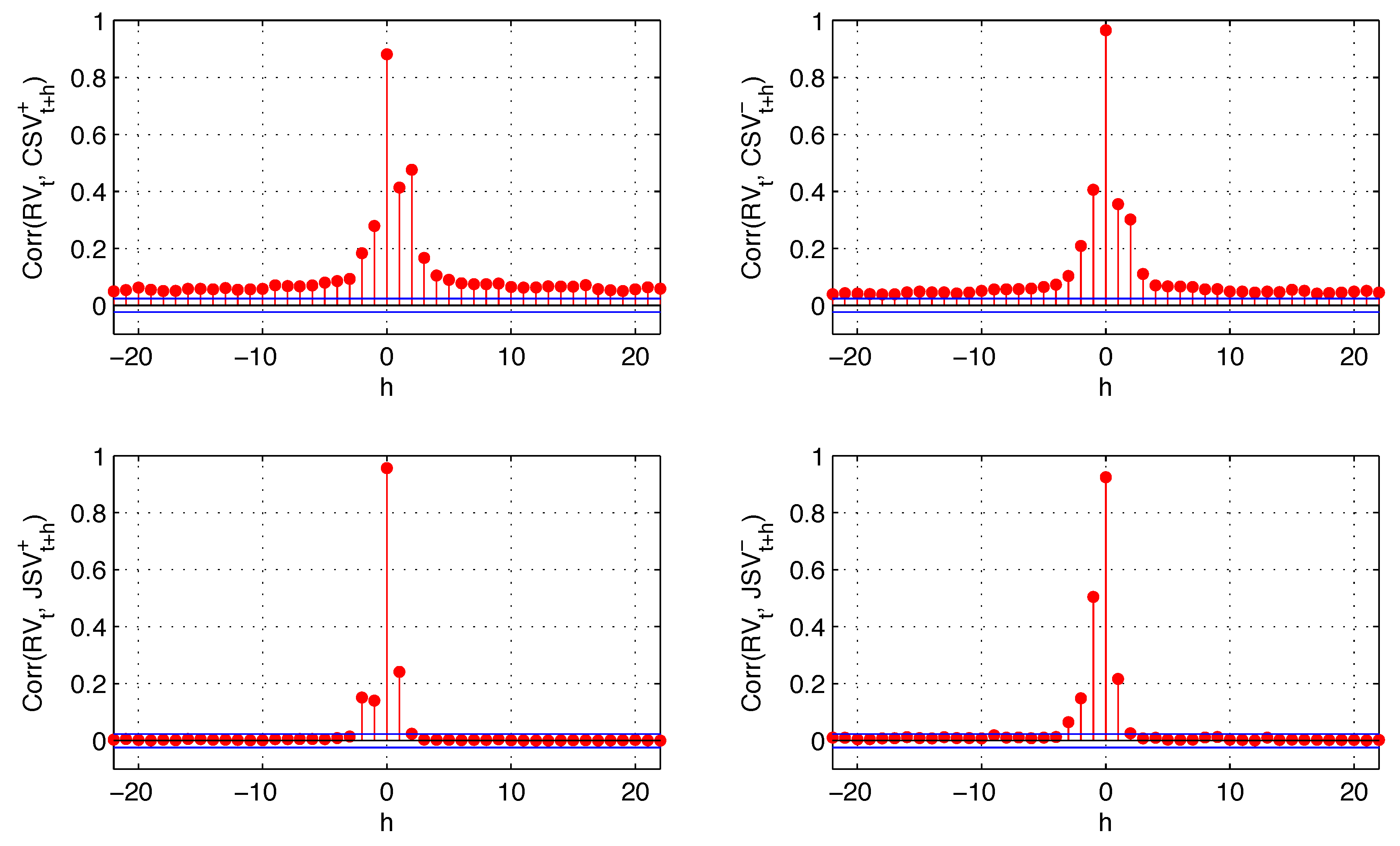
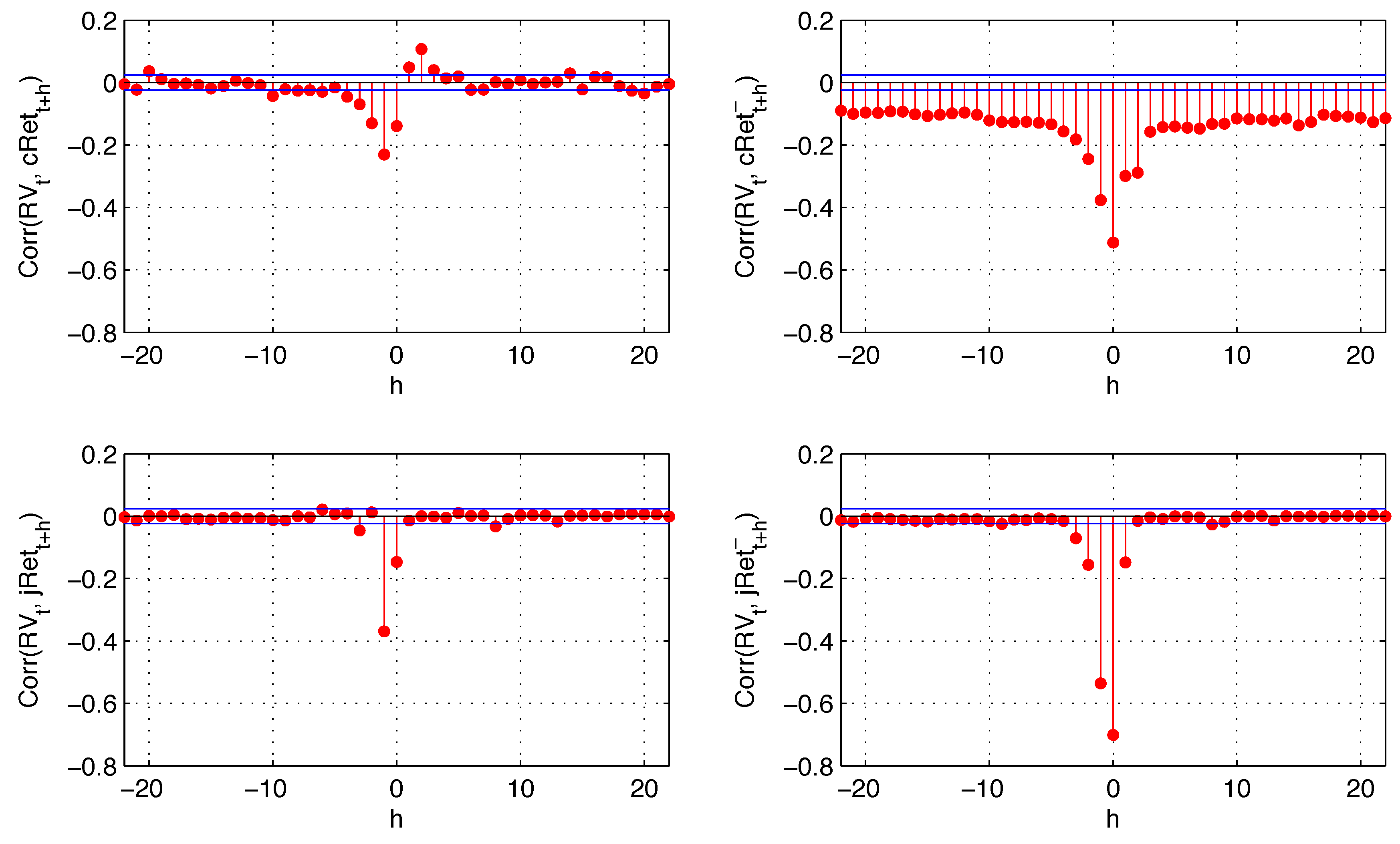
Figure 4 reports cross-correlations among different components of the return and realized variance as evidence of leverage and volatility feedback effects.
As in [
4], the leverage effect (negative correlation between
and
) is significant for prolonged days, while there is no clear evidence of a volatility feedback effect (negative correlation between
and
). The sign asymmetry of the leverage effect becomes evident as negative returns generate most of the negative correlation of return and lagged variance (see top right plot,
Figure 4), and the magnitude of this effect is higher than the positive correlation between positive returns and realized variance. We also observe a negative correlation between realized variance and future negative returns. However, this correlation is smaller in absolute value than the positive correlation of realized variance and positive future returns (cross-correlations with positive intraday return components are not plotted in order to save space). Therefore, it is insufficient to generate the sign asymmetry for the volatility feedback effect. In other words, while negative returns have a higher impact on future variance than positive returns (leverage effect), the variance does not have a higher impact on future negative returns than it does on future positive returns (no volatility feedback effect).
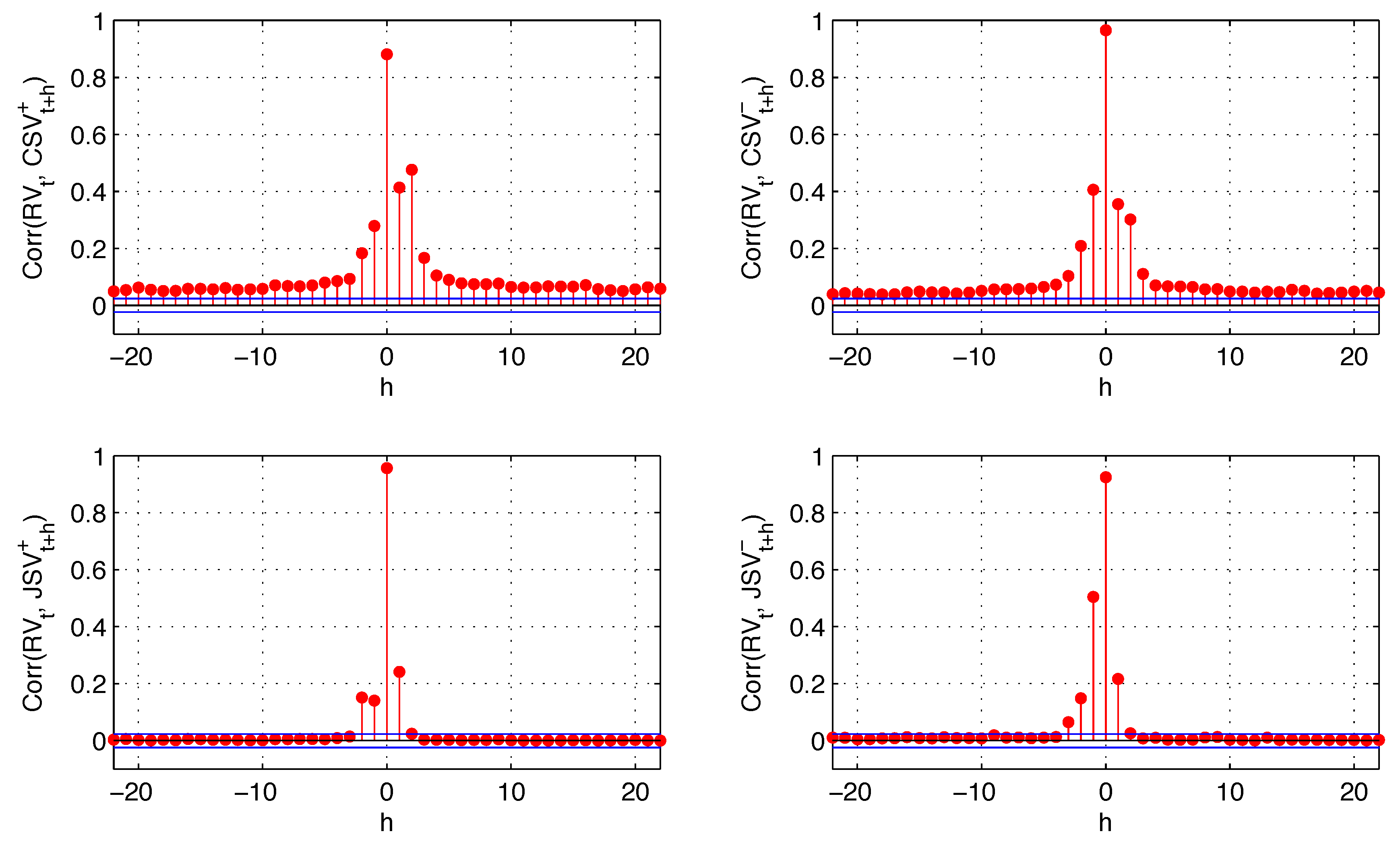
The persistence in volatility is also examined. It is well known that volatility is autocorrelated for a prolonged period of time. Evidence is found in [
30] for the S & P500 stock index. Models to capture the persistence in conditional volatility have been proposed in their early stage by Engle, R.F. and Bollerslev, T. [
31] and Baillie, R.T.
et al. [
32]. This autocorrelation is one of the drivers of the volatility feedback effect. The interpretation is that when an increase in volatility is associated with an expectation of higher future volatility, market participants may discount this information, resulting in an immediate drop in stock prices. We find that the persistence in volatility is mainly generated by the continuous component of the return variation. Jump variation has an effect on realized variance, as well, but this effect is short lived. The cross-correlations of realized variance with continuous variation and with jump variation are reported in
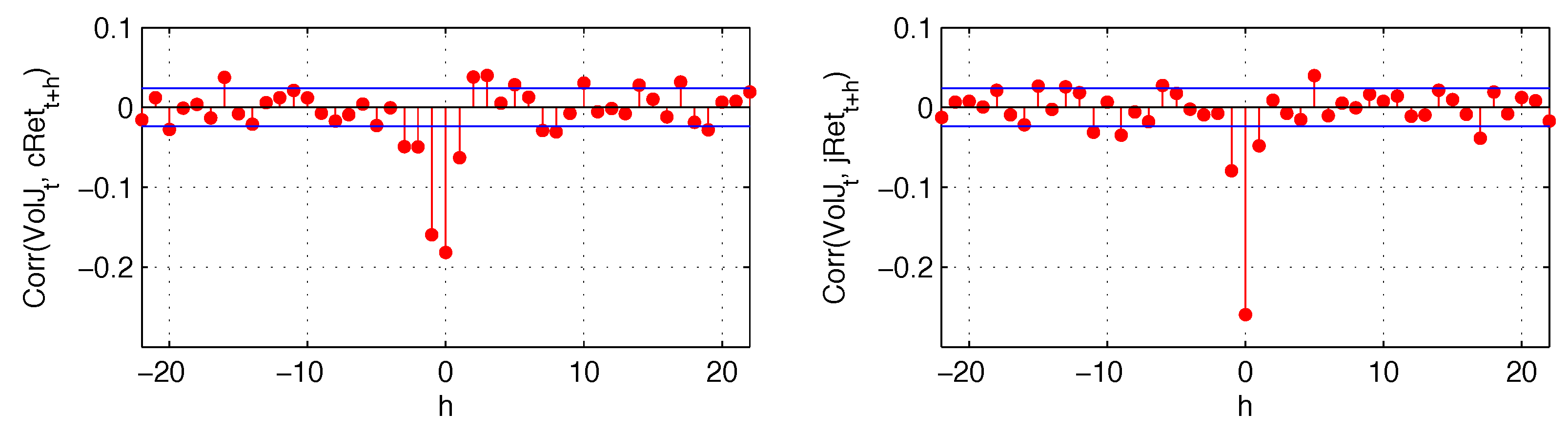
Figure 5.
The quarter variances represent different sources of risk: positive and negative quarter variances represent “good” and “bad” risks, while continuous and jump quarter variances represent “expected” and “unexpected” risks. At a short horizon, they all have an impact on future volatility when they happen, while the persistence of this effect is mainly due to expected risks.
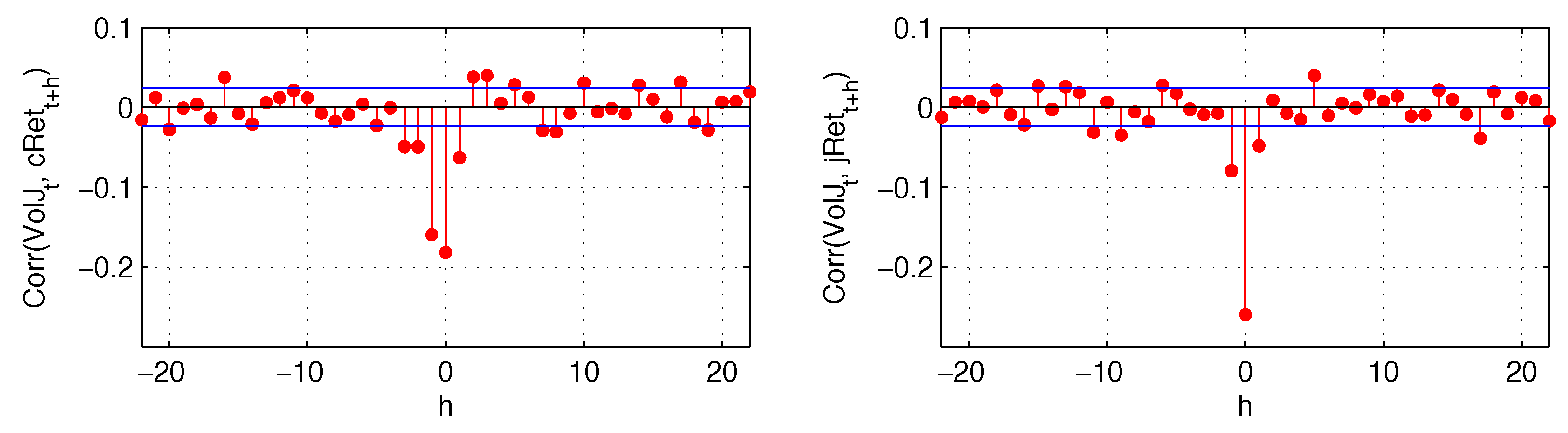
Finally, in
Figure 6, we analyze the cross-correlation of both continuous and jump returns with the estimated volatility jumps. Both of those components are negatively and contemporaneously correlated with volatility jumps, with correlation between the two jump components reaching almost
. Continuous and jump returns also have a short-lived impact on future volatility jumps. These results suggest that the leverage effect is also transmitted to the jump part of the variance. Consequently, the realized variance that we forecast consists of both continuous variation and jump variation, with the continuous variation not readjusted for volatility jumps.
4.2. In-Sample Analysis
Estimation results of the proposed forecasting models are discussed in this section. The in-sample evaluations are based on different horizons. The regression results of the candidate models are reported in
Table 2, for horizons of 1, 5, 15 and 22 days. For multi-period forecasts, the predicted variable is the cumulative average log realized variance between time
t and
.
In order to check the stability of the coefficients, regressions are run for different overlapping subsamples. As the full sample period is relatively long, consisting of more than 28 years, it is likely that structural breaks have occurred. This seems to be the case, as some coefficients estimated by including data for the initial eight years, from 1982 to 1989 (the forecasts are relative to the period 1990 to 1997), appear to differ from those estimated by using data starting from 1990. Conversely, the coefficients associated with the model for the last 20 years are relatively stable.
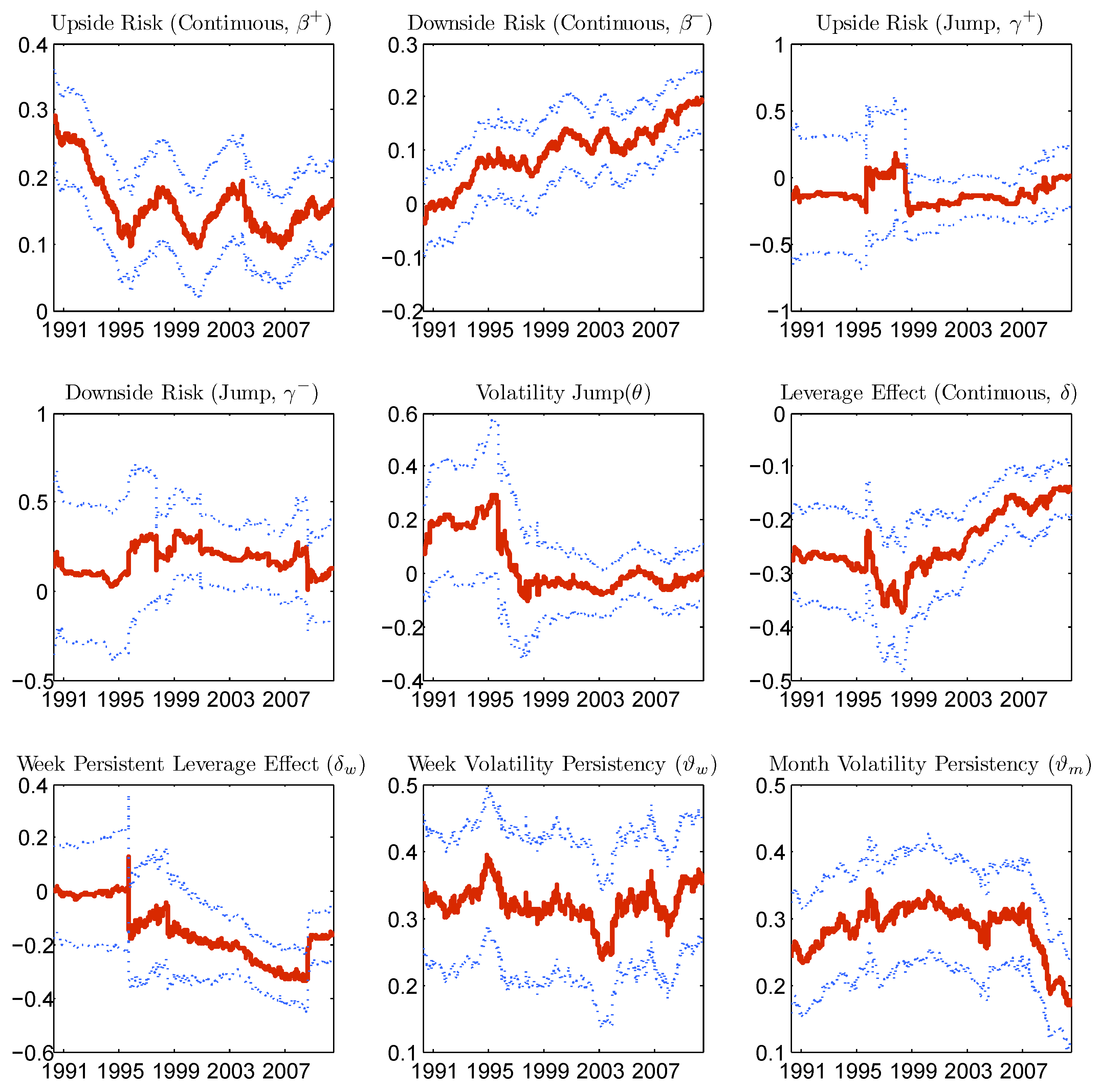
Figure 7 reports the estimated coefficients of one period forecast of Model (28) with rolling subsamples of 2000 observations (corresponding to almost eight years).
With an in-depth inspection, the difference of the coefficient estimates for the initial subsamples from those of the remaining subsamples is mainly caused by the market crash of October 1987. The sample period is therefore reduced, and the results of the in-sample analysis contained in
Table 2 are relative to the subperiod from 4 January 1988 to 6 August 2010
7. By contrast, the out-of-sample evaluations of the next sections, as they are performed using rolling forecasts, will be based on the whole sample period. Volatility jumps have a marginal power to forecast the one period ahead volatility only with the initial subsamples, which contain the market crash data, while for the remaining subsamples, they do not add further value. This indicates that volatility jumps are useful for forecasting during extremely agitated periods.
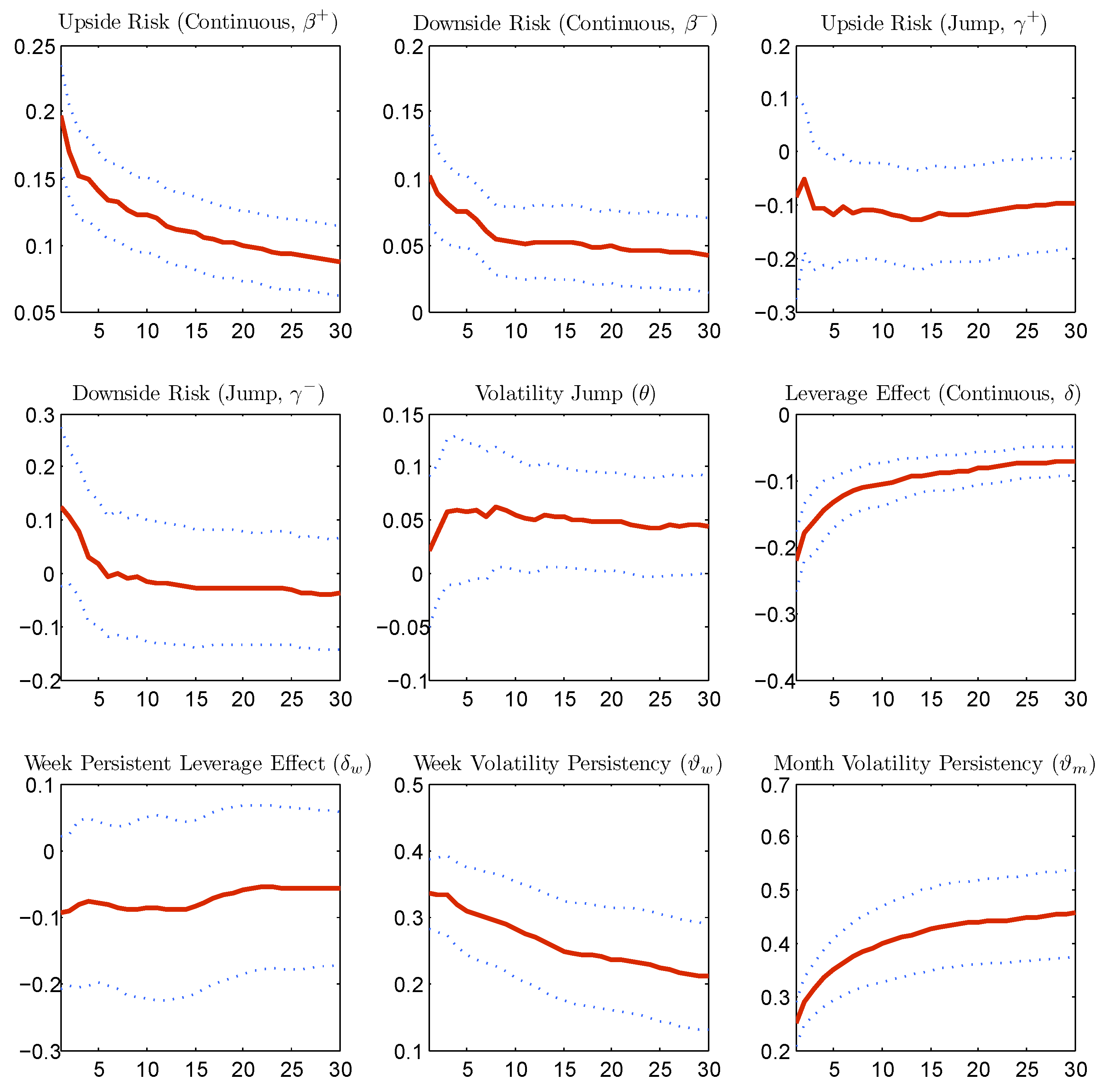
To check the stability of the estimates for different forecasting horizons,
Figure 8 reports the estimated coefficients for forecasting horizons ranging from one day to 30 days. The estimated parameters appear to be well behaved. The major differences between the coefficients for the different forecasting horizons lie in the horizon of one to five days, while after five days, all of the estimates of the coefficients are stable. This stability is due to the fact that we predict the average cumulative variance over multiple periods.
The following results from the estimation are worthy of comment. “Bad risks” have a significant impact on future volatility. In fact, both continuous and jump downside quarter variances increase future realized variance. However, when “good risks” are disentangled into upside continuous and jump quarter variances, a striking difference emerges. The effect of upside continuous variance on future volatility is still positive and statistically significant, but that of the upside jump variance is on average negative and negligible. This may well answer the critique advanced by Corsi, F.
et al. [
24], as they argue that influential studies, such as [
5] and [
33], among others, find a negative or null impact of jumps (more appropriately jump variation) on future volatility, while economic theory suggests the opposite. In fact, one needs to distinguish between downside and upside jumps. Future volatility is indeed increasing with downside jump variation, as jump variations are likely associated with an increase in uncertainty on fundamental values. However, the effect of upside jump variation does not necessarily increase future volatility. This would be consistent with the economic model of [
34]. Intuitively, a positive jump is associated with the occurrence of good news, as well as the expectation of higher future returns. The effect of the latter is able to offset the effect of an increasing uncertainty. The future volatility given the occurrence of a positive jump is therefore lower than the one associated with the occurrence of a negative jump.
Consistent with the leverage effect, both continuous and jump components of the return have a significant impact on future volatility. As mentioned previously, the persistence in leverage effect is captured mainly by the continuous component. In fact, as the forecasting horizon increases, the leverage effect generated by past jumps becomes less statistically significant. On the contrary, either coefficients associated with the negative continuous return over the past day and over the past week remain statistically significant even for longer forecasting horizons.
Concerning long memory features, the persistence parameters associated with the one week and the one month realized variance terms are both highly statistically significant for all horizons. Ultimately, jumps in volatility (continuous variation) do not appear to be statistically significant. Given that volatility jumps are present during extremely agitated periods, their null forecasting performance on the short horizon is due to the fact that only a few volatility jumps are identified for the sample period under investigation. There are in fact volatility jumps for only 3.6% of the sample days.
Finally, by examining the (in-sample) performance of the simplified Model (29) in comparison with that of the full model, the losses in accuracy that occur for the simplified model are negligible based on the adjusted .
4.3. Out-of-Sample Forecasting Performance
The methodology used to assess the forecasting performance of the proposed models is presented in this section. The analysis is based on the out-of-sample predictive accuracy of these models in comparison to the Model (26). The predicted variable is the cumulative average log realized variance between time t and . For predictions of horizons , a “direct method” is employed, that is the model specifies only the relation between and the regressors at time t. The evaluation of the performance is done recursively with rolling windows. The forecasting horizons considered are .
The recursive procedure is applied as follows: The forecasts are generated by using an in-sample estimation window of 2000 observations, corresponding to about eight years, starting from 28 April 1982. For
, the performance is evaluated on 5040 out-of-sample data points, corresponding to about 20 years. The forecasting performance is based on the
function of the log realized variance forecasts and the negative
loss function:
The
is a symmetric loss function, while
is asymmetric. The work in [
35] shows that the
loss function is robust to noise in the volatility proxy, as volatility forecasts represent a case where the true values are not observable. Moreover, this function has certain optimal properties in that it is less sensitive to large observations by more heavily penalizing under-predictions than over-predictions. It is therefore more suited to yield model rankings in the presence of imperfect proxies.
To test for the superior forecasting performance of the proposed models over the benchmark
model, the [
36] test is employed. The asymptotic variance of the loss differential (of each model and the
model) is estimated with Newey-West
consistent sample variance, as suggested by Giacomini, R.
et al. [
37]. The work in [
38] shows that in the presence of nested models, the distribution of the Diebold-Mariano test statistics for mean square error losses, under the null, can be nonstandard. Therefore, the test of forecasting performance for mean square error losses is based on the [
39] test statistic, which appropriately corrects the loss differential.
Table 3 reports the test statistics under the null of equal forecasting performance for each model pair. A positive value represents the superior average forecasting performance of the proposed model with respect to the
.
At the 99% confidence level, the proposed models outperform the base model for forecasting horizons of one day and five days. For longer forecasting horizons, overall, the models also perform well, with the reduced model (Equation (
29)) achieving surprisingly high performance. Based on the
loss function, the out-performance of the full Model (28) compared to the
model is only weakly statistically significant. This is a warning signal that Model (28) is probably over-parametrized, although as shown in the next section, outperforming the benchmark
model in forecasting long-run volatility seems to be a difficult task.
4.4. Model Confidence Set
The
model in logarithmic form generally has a good out-of-sample forecasting performance. In an attempt to raise the bar, other reference models recently proposed in the literature are considered. First, we test the performance of the
model for the realized variance, which yielded the lowest forecasting power among all of the candidate models when evaluated on the loss functions Equations (
30) and (
31). Then, we investigate the accuracy of the variance forecasts for several models involving two model specifications of [
5] (Equation (13), p. 709, and Equation (28), p. 715), named
and
, respectively, which explicitly take into account continuous and jump variation; two specifications proposed by Patton, A.J. and Sheppard, K. [
7] (Equation (19), p. 16, and Equation (17), p. 13, without upside semi-variance) based on upside and downside variances, one with complete decomposition into quarter variances and the other with a downside quarter variance only for the daily component; and two models of [
6] (Equation 2.4, p. 8, and
Table 3, p. 16) that add the leverage effect, named
and
, respectively. Finally, simple and commonly-used models are also taken into account. These are an autoregressive model on the daily log realized variance component only and an exponential smoothing model. The last is popularly used by risk practitioners (see [
40]) and is specified as
with parameter
α optimized for each rolling window following
All of the models (except the
) are evaluated on log realized variance. They are also estimated on the same rolling window and evaluated on the same out-of-sample data points. It is also worth mentioning that jump detection and quarter variance estimation are executed in the same way as described in this article.
8In order to evaluate forecasts of those models, the model confidence set (
) methodology of [
41] and [
42] is the most well suited. The comparison is done among a set of models, as pairwise comparisons would not be appropriate. The methodology allows the models to be ranked based on a given loss function, and it gives an indication of whether the forecast performances are significantly different. Out of the surviving models in the confidence set, the interpretation is that they have equal predictive ability, and they yield the best forecasts given a confidence level.
The model confidence set approach allows the user to specify different criteria to establish equal forecasting performance for the model set and subsets. We use both the “range” statistic and the “semi-quadratic” statistic:
where
is the mean loss differential between each pair combination of models, with
k and
s denoting each model.
Table 4 reports the model confidence set and the selected models at the classic 5% and 10% significance levels. The model confidence set
p-value is obtained through a block bootstrap procedure. An autoregressive process is estimated for each
, the loss differential between each model
k and
s and the lag length, for it is determined by Akaike information criteria, as suggested by Hansen, P.R.
et al. [
41]. The block length for the bootstrap procedure is then fixed as the maximum lag length among
, and it varies between nine and 30 depending on the forecasting horizon and the loss function used. Five thousand bootstrap repetitions are used to compute the test statistics. The model confidence set
p-value obtained by using the semi-quadratic test statistics is less conservative than the one obtained by using the range statistics. The surviving model set after using the semi-quadratic test statistic is therefore larger than the set obtained by using the range test statistic.
Overall, the best forecasting models for all different horizons are the candidate Models (28) and (29) and the two
models proposed by Corsi, F.
et al. [
6], which take into account past negative return without disentangling return jump size. The reduced model of Equation (
29) achieved equal forecasting performance, compared to the
model, with a lower model complexity (four variables less). Jumps in return indeed substantially improve the forecasting performance, while volatility jumps are infrequent and have a minor effect on future realized variance. For the one period ahead forecast, the full Model (28), which includes volatility jumps, does not survive based on the
loss function. However, it does survive based on the
loss function. This is due to the fact that by adding volatility jumps, the model tends to produce marginally less conservative forecasts of volatility. The
loss, since it less heavily penalizes over-predictions than under-predictions, still selects this model. Finally and not surprisingly, the best forecasting models are the ones that include the leverage effect.
The following considerations can be pointed out for the simplest models: for long horizons, the simple model is hard to beat. As has already been shown in the literature, the autoregressive model that takes only the daily component into account is not selected for any forecasting horizon and loss function used, pointing to the importance of correctly modeling long memory. Moreover, the exponential smoothing model, often used in practice, is clearly outperformed.
5. Conclusions
This paper analyzed the performance of volatility forecasting models that take into account downside risk, jumps and the leverage effect. The volatility forecasting model proposed consists of the following ingredients: First, the timing and the size of intraday return jumps is estimated based on the jump test of [
8]. Second, jump variation and continuous variation are disentangled into signed quarter variances using signed intraday returns. Finally, the size of jumps in volatility is also estimated with inference based on an auxiliary
model. The best candidate model for forecasting realized variance must simultaneously take into account return jumps, “good” and “bad” risks, leverage effect and strong volatility persistence (
i.e., long memory).
The model is motivated by the overwhelming empirical evidence of asymmetries in financial time series. We show that correlation asymmetries are present for both continuous and jump components among return and volatility. Moreover, asymmetries exist not only in size, but also in sign, justifying the use of quarter variances in forecasting volatility. Finally, the persistence of the volatility leverage effect is mostly due to the continuous returns.
The forecasting model is very simple to implement, as it is based on the parsimonious framework. The gain over the base in terms of out-of-sample forecasting power is substantial, and this is especially true for short and mid- forecasting horizons. However, for an accurate identification of jumps and the estimation of the jump size, the availability of high frequency data is required. In fact, the empirical analysis is based on a long history of high frequency S & P500 Futures data. When enough high frequency data are available, the effort of estimating return jumps and signed quarter variances is compensated with generally better predictions of future volatility.
Considering that synthetic instruments with financial market implied volatility (e.g., VIX index) as the underlying asset have existed for decades and that the use of the realized volatility itself as a market index is also becoming popular, the methodology proposed can be applied directly to construct profitable trading strategies that apply leading indicators based on quarter variances and jumps. In such applications, given the need for a long history of data and the possible presence of structural breaks, the forecasting model must be re-trained often to obtain accurate predictions. In this article, for example, for the out-of-sample forecast performance evaluation, we re-estimated the model every day using a rolling window strategy. Moreover, depending on the investment horizon and the economic objective of the trading strategy, for instance a minimum return strategy within a period of time or a “no-big loss” strategy, the forecasting model can be selected based on variants of the “MSE” or “QLIKE” loss functions used in this paper or other direct economic evaluation methods.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}