Techniques and Challenges of Data Centric Storage Scheme in Wireless Sensor Network


Abstract
:1. Introduction
2. Taxonomy and Design Drivers
2.1. Multi-Dimensional Attribute
2.2. Range versus Point Queries
2.3. Similarity Search
2.4. Data Aggregation
2.5. Non-Uniformity of Sensor Network Field
2.6. Multi-Replication
2.7. Load Balancing
3. DCS Scheme Families
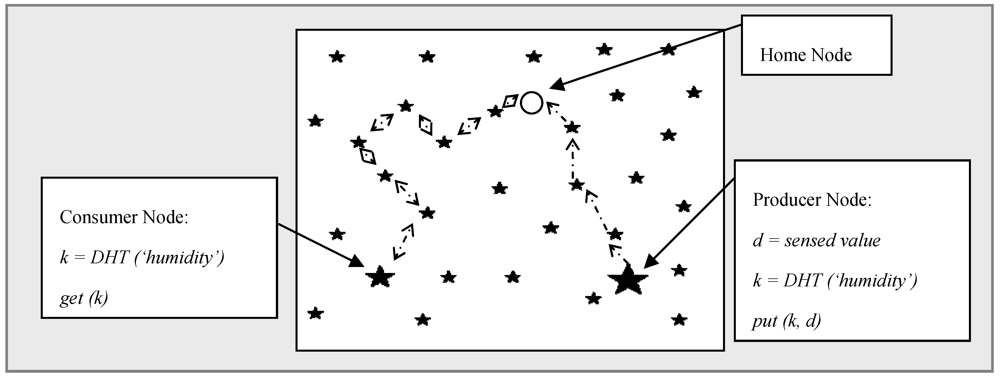
3.1. Geographic Hash Table
 ’. A producer node senses a value and forwards it to home node denoted by ‘
’. A producer node senses a value and forwards it to home node denoted by ‘  ’. In turn, another consumer node uses the same hash function and retrieves the stored data from the home node. When storing data, represented by ‘
’. In turn, another consumer node uses the same hash function and retrieves the stored data from the home node. When storing data, represented by ‘  ’, the producer node sends data to the target node and in the retrieval process, denoted by ‘
’, the producer node sends data to the target node and in the retrieval process, denoted by ‘  ’, the query is first forwarded to the home node and replies are then sent back to consumer.
’, the query is first forwarded to the home node and replies are then sent back to consumer.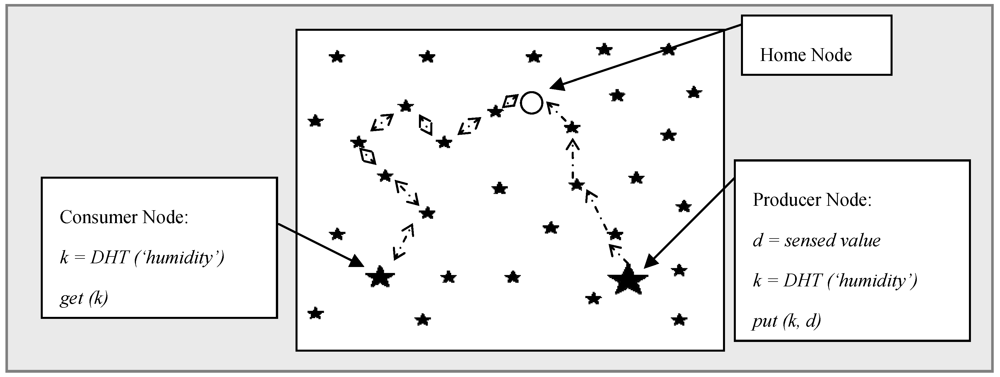
3.2. Similarity Data Storage (SDS)
 , where δxi,j = (IDj − IDi)%nx and δyi,j = (IDj − IDi)/nx. A head node in a zone is responsible for communication with other zones. All other nodes inside a zone are connected with the head node.
, where δxi,j = (IDj − IDi)%nx and δyi,j = (IDj − IDi)/nx. A head node in a zone is responsible for communication with other zones. All other nodes inside a zone are connected with the head node.3.3. Similarity Search Algorithm
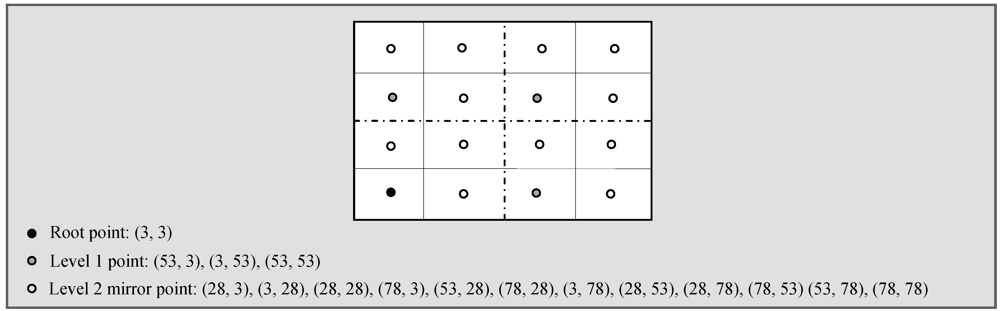
 . So, the number of levels l is defined by: l = log4
. So, the number of levels l is defined by: l = log4  . The entire data range of an event is referred to by R where RL and RU, respectively, denote the lower bound and upper bound. R is divided into n equal sub-ranges each being equal to r i.e., n.r = R. So, the data sub-range for which IID is responsible is defined as
. The entire data range of an event is referred to by R where RL and RU, respectively, denote the lower bound and upper bound. R is divided into n equal sub-ranges each being equal to r i.e., n.r = R. So, the data sub-range for which IID is responsible is defined as  . Figure 2 illustrates level 1 and level 2 assuming that the data range R of an event is (0, 1). Detected events are mapped to a particular segment if the event falls in the range of that cell. Two parameters
. Figure 2 illustrates level 1 and level 2 assuming that the data range R of an event is (0, 1). Detected events are mapped to a particular segment if the event falls in the range of that cell. Two parameters  are used to record the minimum and maximum values of each segment. Initially these two parameters are set to 0. When data is inserted into an index node, the values are updated accordingly. For example, if a sensor detects an event with a value of 0.2 then the data is sent to I0 as it belongs to the range [0, 0.25] and both parameters of this cell will be updated to
are used to record the minimum and maximum values of each segment. Initially these two parameters are set to 0. When data is inserted into an index node, the values are updated accordingly. For example, if a sensor detects an event with a value of 0.2 then the data is sent to I0 as it belongs to the range [0, 0.25] and both parameters of this cell will be updated to  . Being a mini-repository of an entire distributed database, each sensor has knowledge of its local data and hence lacks global knowledge of the entire sensor database. The distributed nature of the data throughout the sensor network is one of the major challenges when processing similarity search queries. To overcome this challenge, the adjacent index nodes in SSA along the Hilbert curve have data of similar values and thereby avoid the need to collect data from all of the sensors in the network. This data mapping based on the concept of the Hilbert curve is simple and easy to implement. However, when storing multidimensional attributes it is not clear whether SSA maintains a separate Hilbert curve or not and in this case how it responds to the multidimensional queries.
. Being a mini-repository of an entire distributed database, each sensor has knowledge of its local data and hence lacks global knowledge of the entire sensor database. The distributed nature of the data throughout the sensor network is one of the major challenges when processing similarity search queries. To overcome this challenge, the adjacent index nodes in SSA along the Hilbert curve have data of similar values and thereby avoid the need to collect data from all of the sensors in the network. This data mapping based on the concept of the Hilbert curve is simple and easy to implement. However, when storing multidimensional attributes it is not clear whether SSA maintains a separate Hilbert curve or not and in this case how it responds to the multidimensional queries. 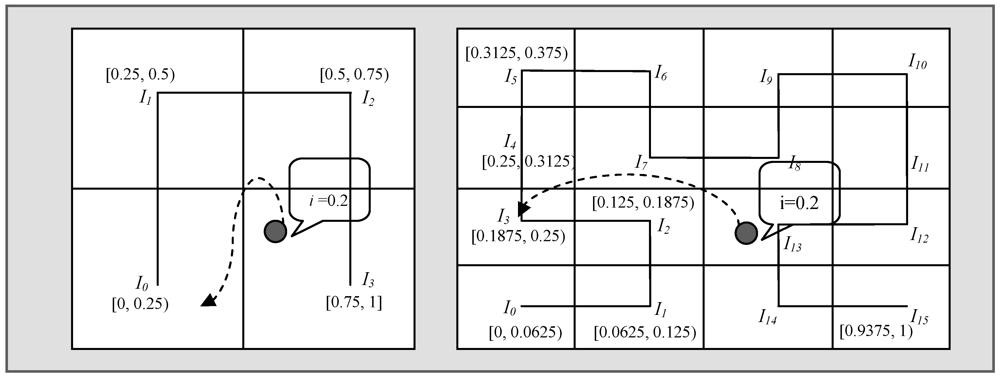
3.4. Dynamic Load Balancing
 and
and  (1)
(1) 3.5. Load Balanced Data-Centric Storage
 (2)
(2) sensors. This time it considers only the sensors in
sensors. This time it considers only the sensors in  . This process continues until H receives q acknowledgements or exhausts sensors within the perimeter. Apart from this QoS, the authors also include non-uniform hashing that can be used to balance the load even in non-uniform distribution such as a Gaussian distribution of sensor nodes in a network. In such a non-uniform WSN, LB-DCS applies two distributed protocols, referred to as proactive (Broadcast) and reactive (Stripes and Fatstripes), to compute the density approximation f of each zone. The density approximation is used to bias the hash function enabling the distribution of target co-ordinate pairs for storage according to the network distribution. For non-uniform hashing, the Rejection Method [26] has been used in LB-DCS.
. This process continues until H receives q acknowledgements or exhausts sensors within the perimeter. Apart from this QoS, the authors also include non-uniform hashing that can be used to balance the load even in non-uniform distribution such as a Gaussian distribution of sensor nodes in a network. In such a non-uniform WSN, LB-DCS applies two distributed protocols, referred to as proactive (Broadcast) and reactive (Stripes and Fatstripes), to compute the density approximation f of each zone. The density approximation is used to bias the hash function enabling the distribution of target co-ordinate pairs for storage according to the network distribution. For non-uniform hashing, the Rejection Method [26] has been used in LB-DCS.3.6. Tug-of-War
 per unit interval is defined by:
per unit interval is defined by:
 (3)
(3) (4)
(4) is minimized by the following value of r:
is minimized by the following value of r: (5)
(5) and the optimal value of r is defined by:
and the optimal value of r is defined by:
 (6)
(6) (7)
(7) (8)
(8)3.7. Quadratic Adaptive Replication
3.8. Double Rulings
3.9. Distributed Erasure Coding in DCS
3.10. Distributed Index for Features
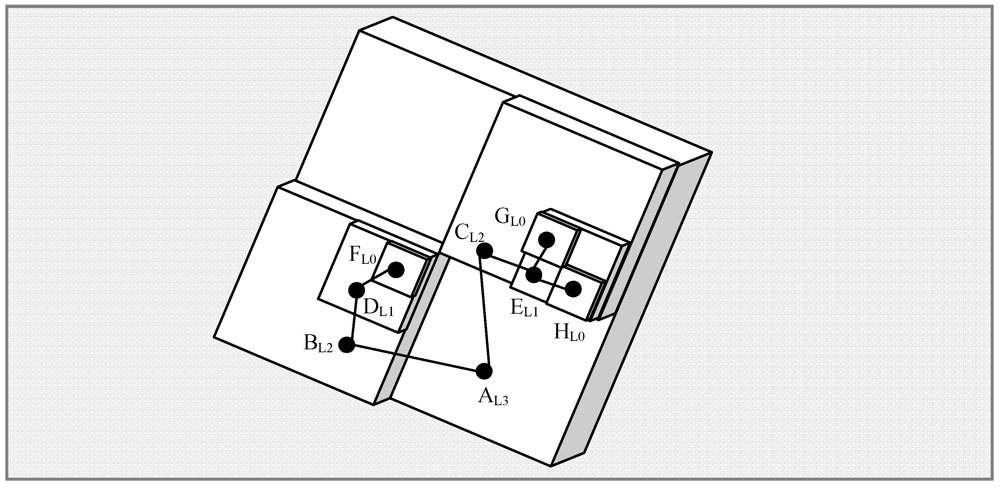
 , where h is the number of levels) and 1 (
, where h is the number of levels) and 1 (  ). Suppose that an event has been found in the vicinity of geographical co-ordinates (7.5, 4.5) with an attribute value of 8. For the time being, it is assumed that nothing is known a priori about the expected distribution of the attribute except that it always falls in the range [0~8]. The hash for the key “attribute:0:8” will return a location somewhere in the bounding box defined by the corner (7, 4) and (8, 5). So, a message containing the string “attribute”, the co-ordinates (7.5, 4.5) and the value 8 will be sent to leaf-level (level 0) index node, say
). Suppose that an event has been found in the vicinity of geographical co-ordinates (7.5, 4.5) with an attribute value of 8. For the time being, it is assumed that nothing is known a priori about the expected distribution of the attribute except that it always falls in the range [0~8]. The hash for the key “attribute:0:8” will return a location somewhere in the bounding box defined by the corner (7, 4) and (8, 5). So, a message containing the string “attribute”, the co-ordinates (7.5, 4.5) and the value 8 will be sent to leaf-level (level 0) index node, say  . Since, bfact = 2, the level 0 leaf index node will forward a histogram containing a count for values 7~8 to a level 1 index
. Since, bfact = 2, the level 0 leaf index node will forward a histogram containing a count for values 7~8 to a level 1 index  covering the region (6, 4) to (8, 6). The level 1 node will then forward a histogram containing counts for values 4~8 to a level 2 node,
covering the region (6, 4) to (8, 6). The level 1 node will then forward a histogram containing counts for values 4~8 to a level 2 node,  covering the region (4, 4) to (8, 8). This process continues until the value is forwarded to node
covering the region (4, 4) to (8, 8). This process continues until the value is forwarded to node  covering the entire network bounded by (0, 0) and (8, 8).
covering the entire network bounded by (0, 0) and (8, 8). 3.11. Practical Data-Centric Storage
 (9)
(9) 3.12. Hierarchical Voronoi Graph Based Routing

3.13. Data Storage and Range Query for Multidimensional Attribute

 (10)
(10) 
 (11)
(11) 



 (12)
(12) 









4. Classification Based on Taxonomy and Design Drivers
4.1. Range Query

4.2. Similarity Search
 (13)
(13) | Attribute | Keywords | Weight |
|---|---|---|
| Object | Car, Plane, Truck, etc. | 0.3 |
| Model | F-16, F-17, etc. | 0.2 |
| Color | Red, Purple, etc | 0.1 |
| Direction | North, South, etc | 0.1 |
| Division | Air-Force, etc. | 0.1 |
| Pressure | Integer | 0.1 |
| Speed | Float | 0.1 |
| .. | .. | .. |



 .
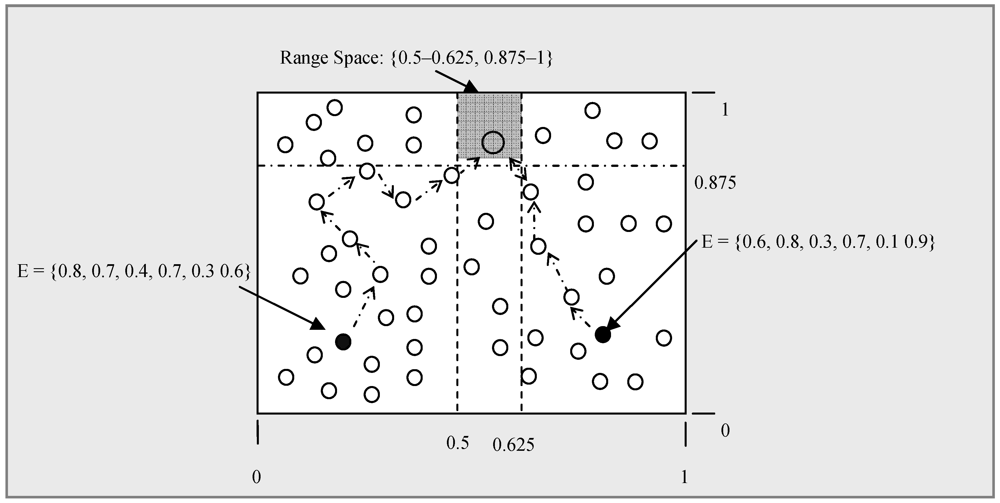
.- Case 1: IT is non-empty and vIT s is the most similar local data in IT.
- ○ Sub-case 1: If vIT s is larger than vq, then all data in IT+1 must be even greater than vq. But in IT-1 there may be a
![Jsan 01 00059 i064]() that is closer to vq.
that is closer to vq. - ○ Sub-case 2: If vIT s is smaller than vq, then all data in IT-1 must not be more similar to
![Jsan 01 00059 i065]() than vIT s is. But in IT+1 there may be a vIT+1 s that is closer to vq.
than vIT s is. But in IT+1 there may be a vIT+1 s that is closer to vq.
- Case 2: IT is empty (i.e., no data stored). vq has to be sent to both neighbors (i.e., IT−1 and IT+1) of IT to find the most similar data.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4.3. Data Aggregation
4.4. Sensor Network Field Non-Uniformity
4.5. Multi-Replication
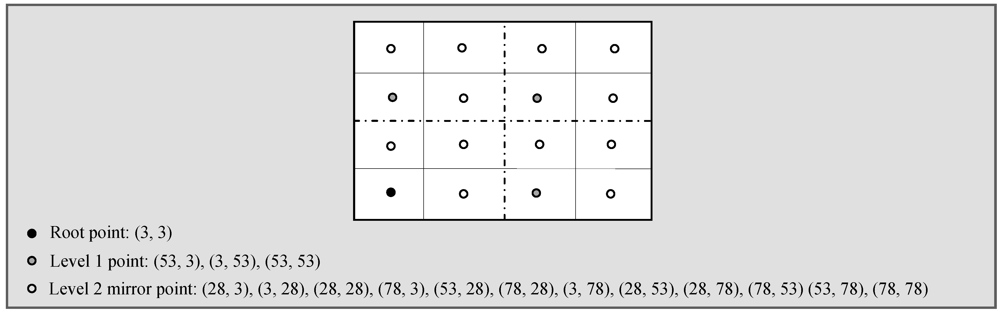
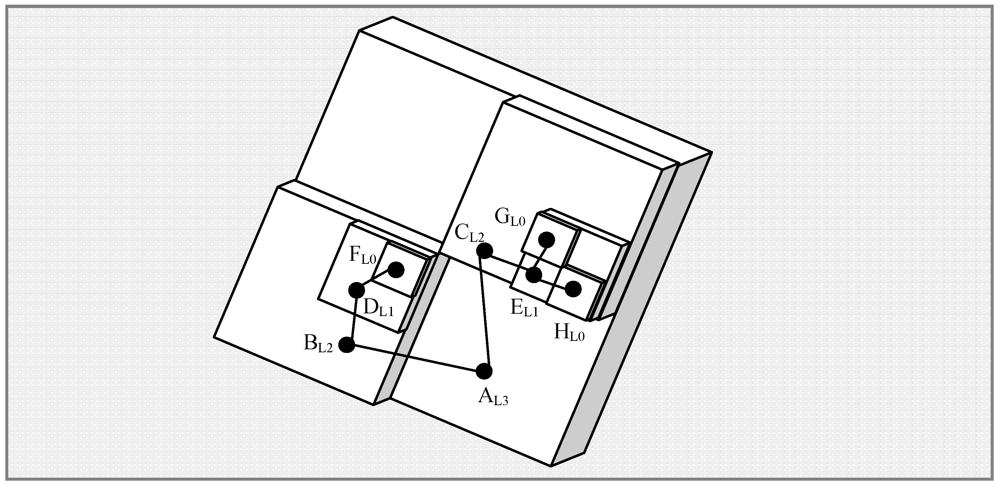
 from
from  . In the retrieval phase, GHT needs to forward queries to all mirror images. The query is first sent to the root node, which then forwards it to all mirror images in level 1 and then level 1 nodes forward this query to level 2 mirror images. This again increases the retrieval cost to
. In the retrieval phase, GHT needs to forward queries to all mirror images. The query is first sent to the root node, which then forwards it to all mirror images in level 1 and then level 1 nodes forward this query to level 2 mirror images. This again increases the retrieval cost to  from . Table 3 shows a summary of multi-replication DCS schemes based on their functionalities.
from . Table 3 shows a summary of multi-replication DCS schemes based on their functionalities.| Schemes | Policy | RoutingAmong Replica Nodes | Remark | |
|---|---|---|---|---|
| 1 | SR-GHT [1] | Hierarchical Grid Replication Mechanism (4d) | Recursive Hierarchical | As data never replicated to all nodes, basic data lost problem exists |
| 2 | SDS [19] | Head node stores copy of all client data | N/A | Single point of head zone failure. Head zone energy depletes quicker than others |
| 3 | ToW [27] | Hierarchical Grid Replication Mechanism (4d) | Combing | Extends SR-GHT by adding two modes of operation. It inherits drawbacks from SR-GHT |
| 4 | SSA [22] | Create mirror of index node using Mirror Hilbert Curve & Mirror Mapping Function | Not Specified | It doesn’t explain how data would be mirrored rather just a proposal is mentioned by couple of lines |
| 5 | RDCS [36] | Each zone has at most one replica node of mirror node | GPSR | Selection of mirror node is not specified clearly. |
| 6 | QAR [16] | Hierarchical Grid Replication Mechanism with Quadratic Evolution (d2) | Combing | Inherits drawbacks from SR-GHT |
| 6 | Double Rulings [28] | Stores data replica at a curve instead of one or multiple isolated sensors | Greedy Routing on a Curve | Can only employ 2 global replicas while tow and qar are adaptable to traffic load with multiple replicas |
| 7 | Dynamic Random Replication [41] | Replicate data in randomly selected set of data replication nodes | Minimum Spanning Tree | Two major limitations: static WSN and consideration of homogenous spatial applications |
 , where app is the application’s name and epoch is a shared time identifier employed to change replicas over time. The paper demonstrates that by placing a replica node randomly in the network it is possible to outperform ToW, QAR and GHT. Also by changing replication nodes over time it is possible to equalize the energy burdens across the network and hence a 60% improvement in network lifetime may be possible. However, the wireless network in the model is assumed to be static and the application is considered to be spatially homogenous.
, where app is the application’s name and epoch is a shared time identifier employed to change replicas over time. The paper demonstrates that by placing a replica node randomly in the network it is possible to outperform ToW, QAR and GHT. Also by changing replication nodes over time it is possible to equalize the energy burdens across the network and hence a 60% improvement in network lifetime may be possible. However, the wireless network in the model is assumed to be static and the application is considered to be spatially homogenous.4.6. Load Balancing
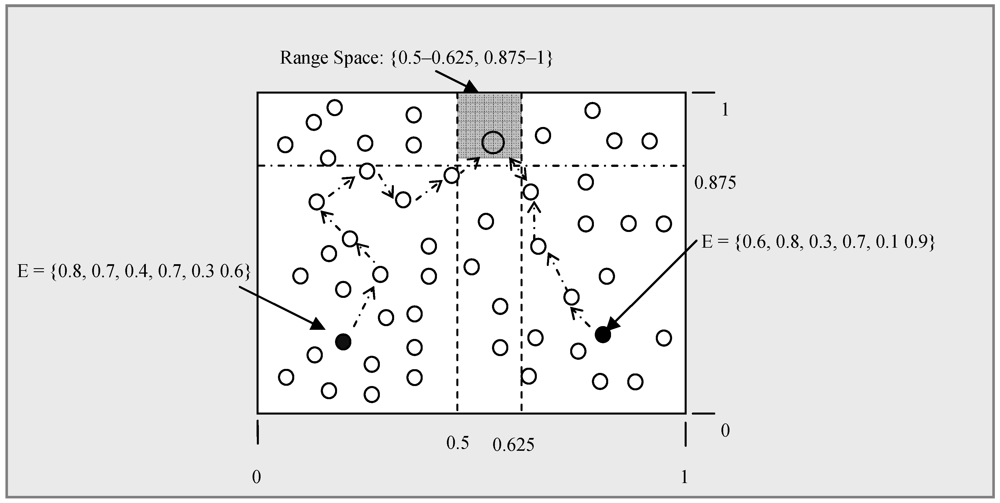
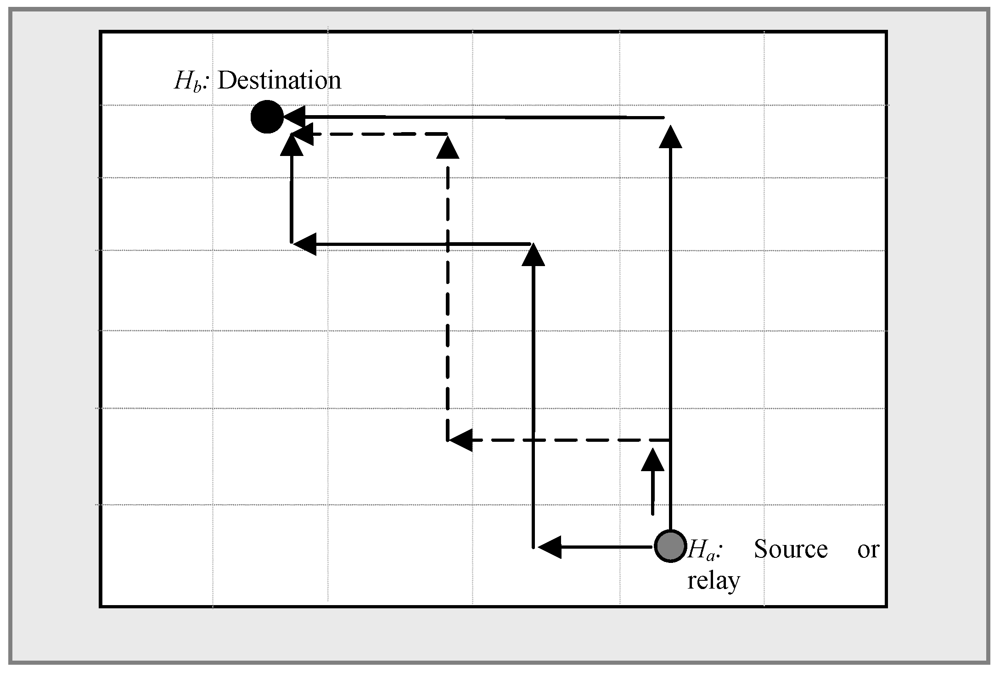
 and forwards this status to its neighbor zones periodically. In routing load balancing instead of routing packets using one specific route, SDS calculates more than one shortest route between a source or relay and destination. This reduces congestion in any specific route. The calculated shortest path between Ha (Xa, Ya) and Hb (Xb, Yb), as shown in Figure 7, is not unique. For simplification let us consider |Xa – Xb| = |Ya – Yb| and then the maximum number of inflexion points in the horizontal and vertical routing process is C = |Xa – Xb|∙C. The number of choices in choosing j inflexion points among C is
and forwards this status to its neighbor zones periodically. In routing load balancing instead of routing packets using one specific route, SDS calculates more than one shortest route between a source or relay and destination. This reduces congestion in any specific route. The calculated shortest path between Ha (Xa, Ya) and Hb (Xb, Yb), as shown in Figure 7, is not unique. For simplification let us consider |Xa – Xb| = |Ya – Yb| and then the maximum number of inflexion points in the horizontal and vertical routing process is C = |Xa – Xb|∙C. The number of choices in choosing j inflexion points among C is  , which is equivalent to the problem of putting C ball into j boxes. There are 2j possible routes for each choice with j inflexion points, hence the maximum number of possible shortest routes between Ha and Hb is
, which is equivalent to the problem of putting C ball into j boxes. There are 2j possible routes for each choice with j inflexion points, hence the maximum number of possible shortest routes between Ha and Hb is  . When two nodes frequently communicate to each other, each query issuer randomly chooses one at each time from the list of all the shortest paths calculated.
. When two nodes frequently communicate to each other, each query issuer randomly chooses one at each time from the list of all the shortest paths calculated.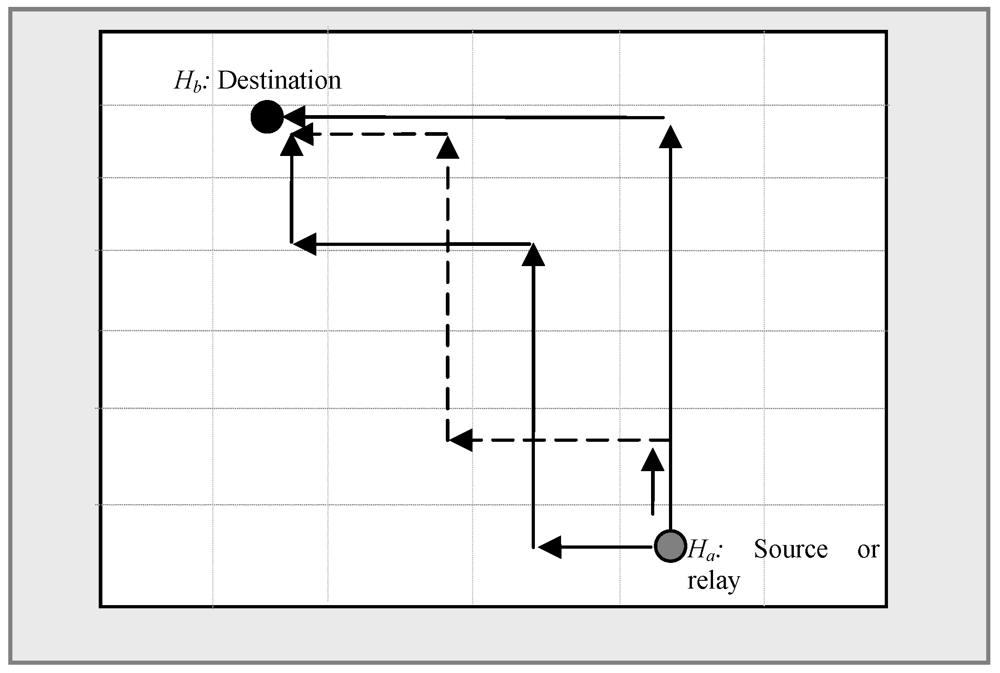
 (14)
(14)  .
. and
and  to calculate the density in each region and the final approximation based on the first computation, respectively. Here, wij is the density estimated by the sentinel for the i, j region and m is the number of neighbors in this region. In two situations referred to as false zeroes and over reporting, d ' i,j might give a misleading density estimation value. A region with sparse nodes near the watch point or a concentration of nodes near the border may report a zero or very low density representing false zeroes. In another situation, a region with a high concentration of nodes near a watch point and sparse nodes near borders may report a higher density than normal representing over reporting. To overcome these situations the final approximation di,j is computed as a weighted mean of the approximation computed in the first step for region ij. Table 4 shows a summary of load balancing DCS schemes based on their functionalities.
to calculate the density in each region and the final approximation based on the first computation, respectively. Here, wij is the density estimated by the sentinel for the i, j region and m is the number of neighbors in this region. In two situations referred to as false zeroes and over reporting, d ' i,j might give a misleading density estimation value. A region with sparse nodes near the watch point or a concentration of nodes near the border may report a zero or very low density representing false zeroes. In another situation, a region with a high concentration of nodes near a watch point and sparse nodes near borders may report a higher density than normal representing over reporting. To overcome these situations the final approximation di,j is computed as a weighted mean of the approximation computed in the first step for region ij. Table 4 shows a summary of load balancing DCS schemes based on their functionalities.| Functionalities | Schemes | Method Used |
|---|---|---|
| Intra-Zone Load Balance | DLB [23] | Cover-up Scheme |
| Inter-Zone Load Balance | SDS [19] | Measuring Storage Usage Status (  ) ) |
| DLB [23] | Extended Grid (Cover up grid) | |
| HVGR [33] | Proportional Assignment of Storage Task to Regions | |
| LB-DCS [24] | Sampling Density, Broadcast, Stripes, FatStripes | |
| KDDCS [42] | Weighted Split Median | |
| Routing Load Balance | SDS [19] | Distributing Routing Load to All Possible Routes Equals to  |
4.7. Routing Algorithm
| Routing Algorithm | Schemes | |
|---|---|---|
| Point-to-Point Routing | GPSR | MDA [35], GHT [1], DLB [23], DIM [13], D-GHT [43], LB-DCS [24], Q-NIGHT [25], SSA [22], Tug-of-War [27], RDCS [36] |
| Logical Stateless Routing (LSR) | KDDCS [42] | |
| CAR-POOLING | SDS [19] | |
| COMBING | Tug-of-War [27] | |
| Recursive Hierarchical Routing | SR-GHT [1] | |
| Tree Based Hierarchical Routing | GPSR | DIFS [30], DIM [13] |
| PATH BASED TREE STRUCTURE | PathDCS [32] | |
| HIERARCHICAL VORONOI GRAPH BASED ROUTING | HVGR [33] | |
| VPCR | GEM [44] | |
5. Conclusion
| Title | Routing Category | Dimension (attribute) | Range vs. Point Query | Data Aggregation | Similarity Search | Multi Replication | Load Balance | |
|---|---|---|---|---|---|---|---|---|
| 1 | Geographic Hash Table (GHT) [1] | Point-to-PointRouting | Single | Point | No | No | No | No |
| 2 | Data Storage and Range Query Mechanism for Multi-dimensional Attributes. [35] | Point-to-PointRouting | Multi | Range | No | No | No | No |
| 3 | Distributed Spatial-Temporal Data Storage Scheme. [19] | Point-to-PointRouting | Multi | Range | No | Yes | No | Yes |
| 4 | Load Balanced and Efficient Hierarchical Data-Centric Storage. [33] | Point-to-Point Routing | Single | Point | No | No | No | Yes |
| 5 | Dynamic Load Balancing Approach [23] | Point-to-Point Routing | Single | Point | No | No | No | Yes |
| 6 | Load Balanced Data-Centric Storage (LB-DCS) [24] | Point-to-Point Routing | Single | Point | No | No | No | Yes |
| 7 | Tug-of-War [27] | Point-to-Point Routing | Single | Point | No | No | Yes | No |
| 8 | Efficient Mechanism for Similarity Search [22] | Point-to-Point Routing | Single | Both | No | Yes | No | Yes |
| 9 | DIFS: A Distributed Index for Features in Sensor Network [30] | DCS Based on Tree-Structure | Single | Range | No | No | No | No |
| 10 | PathDCS [32] | DCS Based on Tree-Structure | Single | Point | No | No | No | No |
| 11 | DIM [13] | DCS Based on Tree-Structure | Multi | Both | No | No | No | No |
| 12 | GEM [44] | DCS Based on Tree-Structure | Single | Range | No | No | No | No |
| 13 | KDDCS [42] | DCS Based on Tree-Structure | Single | Range | No | No | No | Yes |
| 14 | RDCS [36] | Point-to-Point Routing | Single | Range | Yes | No | No | No |
| 15 | Modeling Data Aggregation [38] | Point-to-Point Routing | Single | N/A | Yes | No | Yes | No |
References
- Ratnasamy, S.; Karp, B.; Yin, L.; Yu, F.; Estrin, D.; Govindan, R.; Shenker, S. GHT: A Geographic Hash Table for Data-centric Storage. In Proceedings of the 1st ACM International Workshop on Wireless Sensor Networks and Applications, Atlanta, GA, USA, 28 September 2002; pp. 78–87.
- Campobello, G.; Leonardi, A.; Palazzo, S. A Novel Reliable and Energy-Saving Forwarding Technique for Wireless Sensor Networks. In Proceedings of the Tenth ACM international Symposium on Mobile Ad Hoc Networking and Computing, New Orleans, LA, USA, 18-21 May 2009; pp. 269–278.
- Pottie, G.J.; Kaiser, W.J. Wireless integrated network sensors. Commun. ACM 2000, 43, 51–58. [Google Scholar] [CrossRef]
- Saroiu, S.; Gummadi, P.K.; Gribble, S.D. A Measurement Study of Peer-to-Peer File Sharing Systems. In Proceedings of the Multimedia Computing and Networking (MMCN), San Jose, CA, USA, January 2002; pp. 152–157.
- Yao, Y.; Tang, X.; Lim, E.-P. In-Network Processing of Nearest Neighbor Queries for Wireless Sensor Networks. In Proceedings of the 11th International Conference on Database Systems for Advanced Applications, Singapore, 12–15 April 2006; pp. 35–49.
- Szewczyk, R.; Polastre, J.; Mainwaring, A.; Culler, D. Lessons from a Sensor Network Expedition. In Proceedings of European Workshop Wireless Sensor Network, Berlin, Germany, 19-21 January 2004; pp. 307–322.
- Intanagonwiwat, C.; Govindan, R.; Estrin, D. Directed Diffusion: A Scalable and Robust Communication Paradigm for Sensor Networks. In Proceedings of the 6th Annual International Conference on Mobile Computing and Networking, Boston, MA, USA, 6-11 August 2000; pp. 56–67.
- Zhang, W.; Cao, G.; Porta, T.L. Data dissemination with ring-based index for wireless sensor networks. IEEE Trans. Mob. Comput. 2007, 6, 832–847. [Google Scholar] [CrossRef]
- Madden, S.R.; Franklin, M.J.; Hellerstein, J.M.; Hong, W. TinyDB: An acquisitional query processing system for sensor networks. ACM Trans. Database Syst. 2005, 30, 122–173. [Google Scholar] [CrossRef]
- Ye, F.; Luo, H.; Cheng, J.; Lu, S.; Zhang, L. A Two-tier Data Dissemination Model for Large-scale Wireless Sensor Networks. In Proceedings of the 8th Annual International Conference on Mobile Computing and Networking, Atlanta, GA, USA, 23-26 September 2002; pp. 148–159.
- Ye, F.; Zhong, G.; Lu, S.; Zhang, L. Gradient broadcast: A robust data delivery protocol for large scale sensor networks. Wirel. Netw. 2005, 11, 285–298. [Google Scholar] [CrossRef]
- Langendoen, K. Medium access control in wireless sensor networks. Medium Access Control Wirel. Netw. 2008, 2, 535–560. [Google Scholar]
- Li, X.; Kim, Y.J.; Govindan, R.; Hong, W. Multi-dimensional Range Queries in Sensor Networks. In Proceedings of the 1st International Conference on Embedded Networked Sensor Systems, Los Angeles, CA, USA, 5-7 November 2003; pp. 63–75.
- Ganesan, D.; Estrin, D.; Heidemann, J. DIMENSIONS: Why do we need a new data handling architecture for sensor networks? ACM SIGCOMM Comput. Commun. Rev. 2003, 33, 143–148. [Google Scholar] [CrossRef]
- Ganesan, D.; Cerpa, A.; Ye, W.; Yu, Y.; Zhao, J.; Estrin, D. Networking issues in wireless sensor networks. J. Parallel Distrib. Comput. 2004, 64, 799–814. [Google Scholar] [CrossRef]
- Rumín, Á.C.; Pascual, M.U.; Ortega, R.R.; López, D.L. Data centric storage technologies: Analysis and enhancement. Sensors 2010, 10, 3023–3056. [Google Scholar] [CrossRef]
- Chatzigiannakis, I.; Kinalis, A.; Nikoletseas, S. An Adaptive Power Conservation Scheme for Heterogeneous Wireless Sensor Networks with Node Redeployment. In Proceedings of the Seventeenth Annual ACM Symposium on Parallelism in Algorithms and Architectures, Las Vegas, NV, USA, 17-20 July 2005; pp. 96–105.
- Shih, K.P.; Wang, S.S.; Chen, H.C.; Yang, P.H. CollECT: Collaborative event detection and tracking in wireless heterogeneous sensor networks. Comput. Commun. 2008, 31, 3124–3136. [Google Scholar] [CrossRef]
- Shen, H.; Zhao, L.; Li, Z. A distributed spatial-temporal similarity data storage scheme in wireless sensor networks. IEEE Trans. Mob. Comput. 2011, 10, 982–996. [Google Scholar] [CrossRef]
- Rowstron, A.I.T.; Druschel, P. Pastry: Scalable, Decentralized Object Location,and Routing for Large-Scale Peer-to-Peer Systems. In Proceedings of the IFIP/ACM International Conference on Distributed Systems Platforms, Heidelberg, Germany, 12-16 November 2001; pp. 329–350.
- Karp, B.; Kung, H.T. GPSR: Greedy Perimeter Stateless Routing for Wireless Networks. In Proceedings of the 6th Annual International Conference on Mobile Computing and Networking, Boston, MA, USA, 6-11 August 2000; pp. 243–254.
- Chung, Y.-C.; Su, I.F.; Lee, C. An efficient mechanism for processing similarity search queries in sensor networks. Inf. Sci. 2011, 181, 284–307. [Google Scholar] [CrossRef]
- Liao, W.-H.; Shih, K.-P.; Wu, W.-C. A grid-based dynamic load balancing approach for data-centric storage in wireless sensor networks. Comput. Electr. Eng. 2010, 36, 19–30. [Google Scholar] [CrossRef]
- Albano, M.; Chessa, S.; Nidito, F.; Pelagatti, S. Dealing with nonuniformity in data centric storage for wireless sensor networks. IEEE Trans. Parallel Distrib. Syst. 2011, 22, 1398–1406. [Google Scholar] [CrossRef]
- Albano, M.; Chessa, S.; Nidito, F.; Pelagatti, S. Q-NiGHT: Adding QoS to Data Centric Storage in Non-Uniform Sensor Networks. In Proceedings of the 2007 International Conference on Mobile Data Management, Mannheim, Germany, 7-11 May 2007; pp. 166–173.
- Von Neumann, J. Various techniques used in connection with random digits. Appl. Math Ser. 1951, 12, 36–38. [Google Scholar]
- Joung, Y.-J.; Huang, S.-H. Tug-of-War: An Adaptive and Cost-Optimal Data Storage and Query Mechanism in Wireless Sensor Networks. Lect. Note. Comput. Sci. 5067, 237–251. [Google Scholar]
- Sarkar, R.; Zhu, X.; Gao, J. Double Rulings for Information Brokerage in Sensor Networks. In Proceedings of the 12th Annual International Conference on Mobile Computing and Networking, Los Angeles, CA, USA, 24-29 September 2006; pp. 286–297.
- Albano, M.; Chessa, S. Distributed Erasure Coding in Data Centric Storage for Wireless Sensor Networks. In Proceedings of the IEEE Symposium on Computers and Communications, (ISCC 2009), Sousse, Tunisia, 5-8 July 2009; pp. 22–27.
- Greenstein, B.; Estrin, D.; Govindan, R.; Ratnasamy, S.; Shenker, S. DIFS: A Distributed Index for Features in Sensor Networks. In Proceedings of the First IEEE International Workshop on Sensor Network Protocols and Applications, Anchorage, AK, USA, 11 May 2003; pp. 163–173.
- Finkel, R.A.; Bentley, J.L. Quad trees a data structure for retrieval on composite keys. Acta Informa. 1974, 4, 1–9. [Google Scholar] [CrossRef]
- Ee, C.T.; Ratnasamy, S.; Shenker, S. Practical Data-centric Storage. In Proceedings of the 3rd Conference on Networked Systems Design & Implementation, San Jose, CA, USA, April 2006; 3, pp. 24–24.
- Yao, Z.; Yan, C.; Ratnasamy, S. Load Balanced and Efficient Hierarchical Data-Centric Storage in Sensor Networks. In Proceedings of the 5th Annual IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks, San Francisco, CA, USA, June 2008; pp. 560–568.
- Zhao, Y.; Li, B.; Zhang, Q.; Chen, Y.; Zhu, W. Efficient Hop ID based Routing for Sparse Ad Hoc Networks. In Proceedings of the 13th IEEE International Conference on Network Protocols, Boston, MA, USA, 6-9 November 2005; pp. 179–190.
- Liao, W.H.; Chen, C.C. Data storage and range query mechanism for multi-dimensional attributes in wireless sensor networks. Communications 2010, 4, 1799–1808. [Google Scholar]
- Ghose, A.; Grossklags, J.; Chuang, J. Resilient Data-Centric Storage in Wireless Ad-Hoc Sensor Networks. In Proceedings of the 4th International Conference on Mobile Data Management, Melbourne, Australia, 21-24 January 2003; pp. 45–62.
- Shen, H.; Li, T.; Schweiger, T. An Efficient Similarity Searching Scheme Based on Locality Sensitive Hashing. In Proceedings of the 3rd International Conference on Digital Telecommunications (ICDT); Bucharest, Romania: 29 June-5 July 2008.
- Cuevas, A.; Uruena, M.; Cuevas, R.; Romeral, R. Modelling data-aggregation in multi-replication data centric storage systems for wireless sensor and actor networks. Communications 2011, 5, 1669–1681. [Google Scholar]
- Amato, G.; Baronti, P.; Chessa, S. MaD-WiSe: Programming and Accessing Data in a Wireless Sensor Networks. In Proceedings of the International Conference on Computer as a Tool, (EUROCON 2005), Beograd, Yugoslavia, 21-24 November 2005; 2, pp. 1846–1849.
- Madden, S.; Franklin, M.J.; Hellerstein, J.M.; Hong, W. TAG: A tiny AGgregation service for ad-hoc sensor networks. SIGOPS Oper. Syst. Rev. 2002, 36, 131–146. [Google Scholar] [CrossRef]
- Cuevas, A.; Uruena, M.; de Veciana, G. Dynamic Random Replication for Data Centric Storage. In Proceedings of the 13th ACM international Conference on Modeling, Analysis, and Simulation of Wireless and Mobile Systems, Bodrum, Turkey, 17-21 October 2010; pp. 393–402.
- Aly, M.; Pruhs, K.; Chrysanthis, P.K. KDDCS: A Load-Balanced In-Network Data-Centric Storage Scheme for Sensor Networks. In Proceedings of the 15th ACM International Conference on Information and Knowledge Management, Arlington, VA, USA, 6-11 November 2006; pp. 317–326.
- Thang Nam, L.; Wei, Y.; Xiaole, B.; Dong, X. A Dynamic Geographic Hash Table for Data-centric Storage in Sensor Networks. In Proceedings of the Wireless Communications and Networking Conference, (WCNC 2006), Las Vegas, NV, USA, 3-6 April 2006; 4, pp. 2168–2174.
- Newsome, J.; Song, D. GEM: Graph EMbedding for Routing and Data-Centric Storage in Sensor Networks without Geographic Information. In Proceedings of the 1st International Conference on Embedded Networked Sensor Systems, Los Angeles, CA, USA, 5-7 November 2003; pp. 76–88.
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Ahmed, K.; Gregory, M.A. Techniques and Challenges of Data Centric Storage Scheme in Wireless Sensor Network. J. Sens. Actuator Netw. 2012, 1, 59-85. https://doi.org/10.3390/jsan1010059
Ahmed K, Gregory MA. Techniques and Challenges of Data Centric Storage Scheme in Wireless Sensor Network. Journal of Sensor and Actuator Networks. 2012; 1(1):59-85. https://doi.org/10.3390/jsan1010059
Chicago/Turabian StyleAhmed, Khandakar, and Mark A. Gregory. 2012. "Techniques and Challenges of Data Centric Storage Scheme in Wireless Sensor Network" Journal of Sensor and Actuator Networks 1, no. 1: 59-85. https://doi.org/10.3390/jsan1010059