Extracting Main Center Pattern from Road Networks Using Density-Based Clustering with Fuzzy Neighborhood

 ,
,
Abstract
:1. Introduction
2. Related Works
- The index-based method defines the city center by a simple or comprehensive indicator. For instance, Luscher and Weibel [39] extracted the city center from the topological datasets such as land cover and points of interest (POIs) with defined knowledge by participant experiments. Zhu and Sun [23] considered spatial proximity and attribute similarity in the delineation of city center from commercial land-use data. The index system is constructed according to the data source and the application, which always leads to different understandings of the “city center.”
- The density-based method mainly adopts a smooth density surface and the isolines to outline the center area. Hollenstein and Purves [25] explored the city cores through user-generated content and described the city cores using geo-referenced data with kernel density estimation (KDE). Yu et al. [22] provided a recognition method of a central business district (CBD) using the statistical aggregation of the socio-economic point data within network space. Yang et al. [24] proposed a commercial-intersection KDE, which combines road intersections with KDE to identify CBDs based on POIs. The density-based method is intuitive and the center areas are smooth, but it is difficult to determine the best bandwidth in the applications. Besides, there might be scattered areas due to the slightly higher density values than the threshold.
- The clustering-based method means that the data needs to be clustered first and then the boundary of the clusters is constructed using the convex hull, chi-shape, Delaunay triangle, Voronoi diagram, and so on. Yu et al. [40] analyzed the urban landscape pattern with an object-based method, in which urban objects were clustered by portioning Minimum Spanning Tree and then the clusters were delineated by the convex hull. Sun et al. [27] sought to combine the DBSCAN algorithm and Voronoi diagram to identify multiple city centers and delineate their precise boundaries from location-based social network data. Hu et al. [26] defined urban areas of interest (AOI) as the areas within a city that attract the attention of people, and a combination of DBSCAN and chi-shape was employed to identify AOI from the geo-tagged data. Gao et al. [34] used the same method to define the core regions and concluded that data-synthesis-driven approach has a clear advantage that it can be repeated for a wide field at flexible spatial scales.
3. Methods
3.1. Main Clusters Extraction
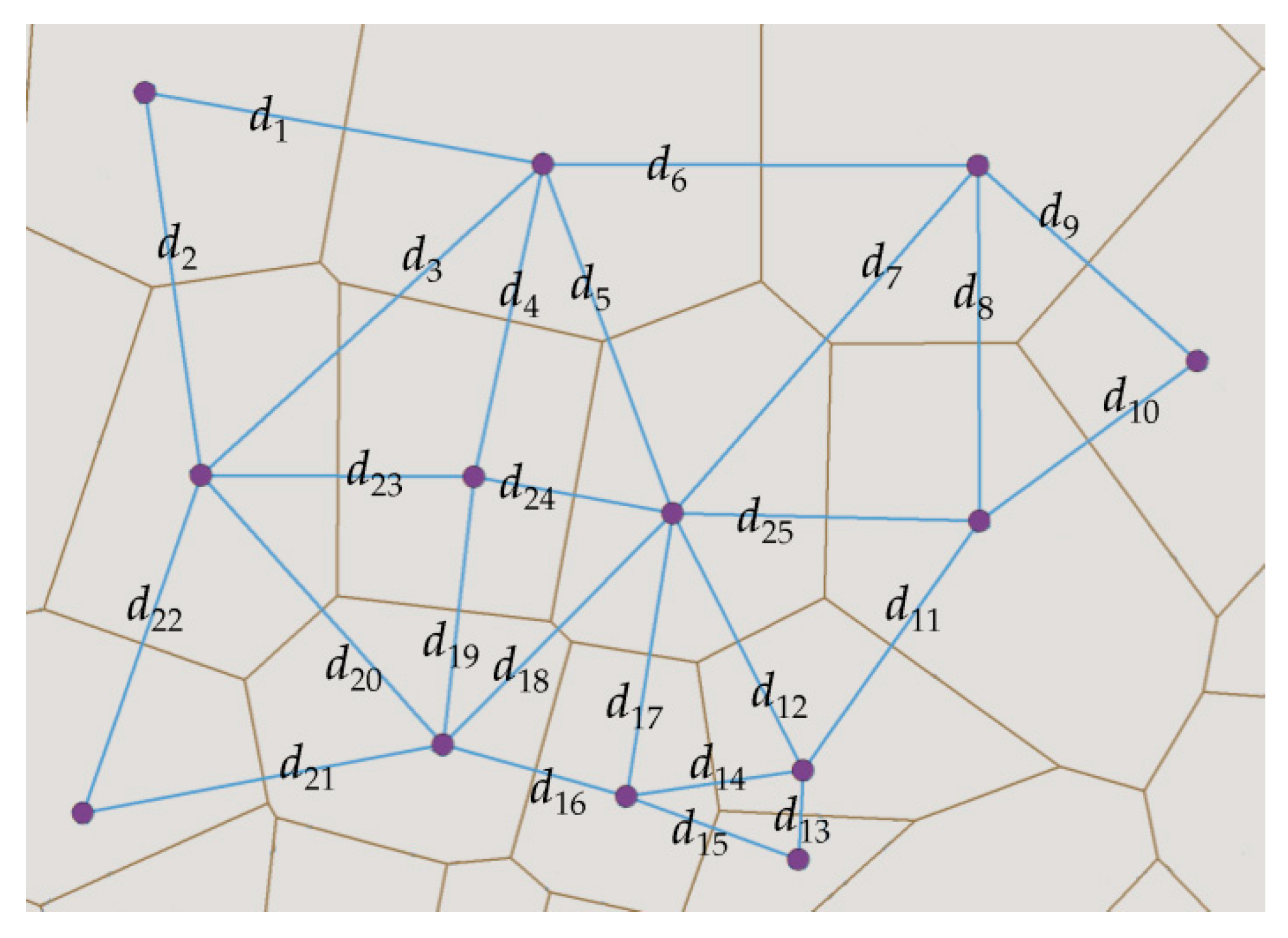
3.1.1. Basic Concepts of the DBCFN
3.1.2. Principle of the DBCFN
- Input the parameter MinPts and Eps, and calculate Mf and Cf of the points;
- Calculate parameter ε1 with a certain λ, and search for the core points;
- Search for the largest set of density-connected points with parameter ε2 from a core point;
- Repeat Step 3 until all core points have been visited, and allocate the points that have not been classified into any cluster as noise;
- Merge the clusters that share common points and record m; and
- If m is greater than M, then turn to Step 2 with the parameter λ + 1; else, break.
3.1.3. Parameters Setting
3.1.4. Comparison Analysis
3.2. Main Center Area Delineation
4. Experiments and Analysis
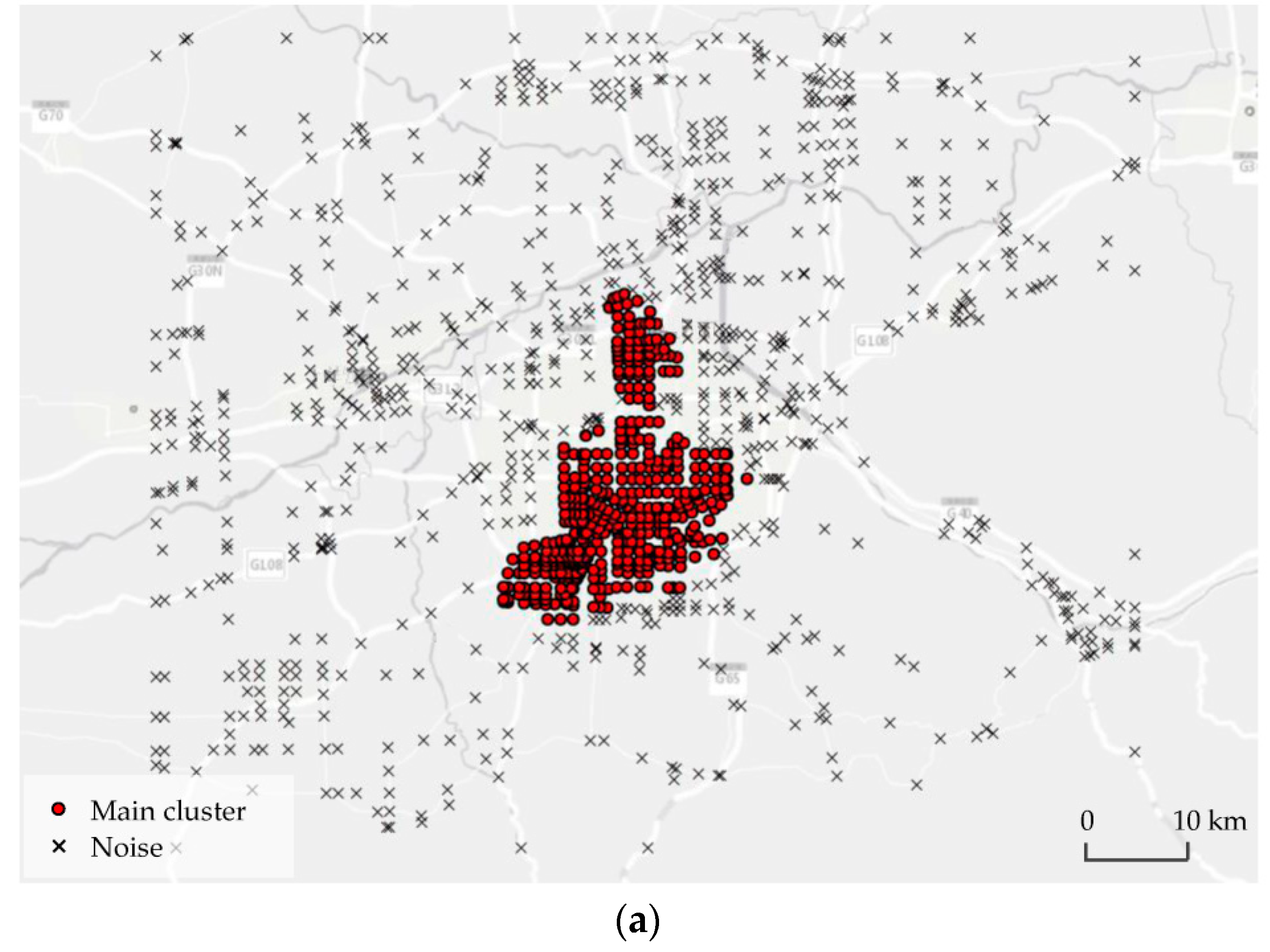
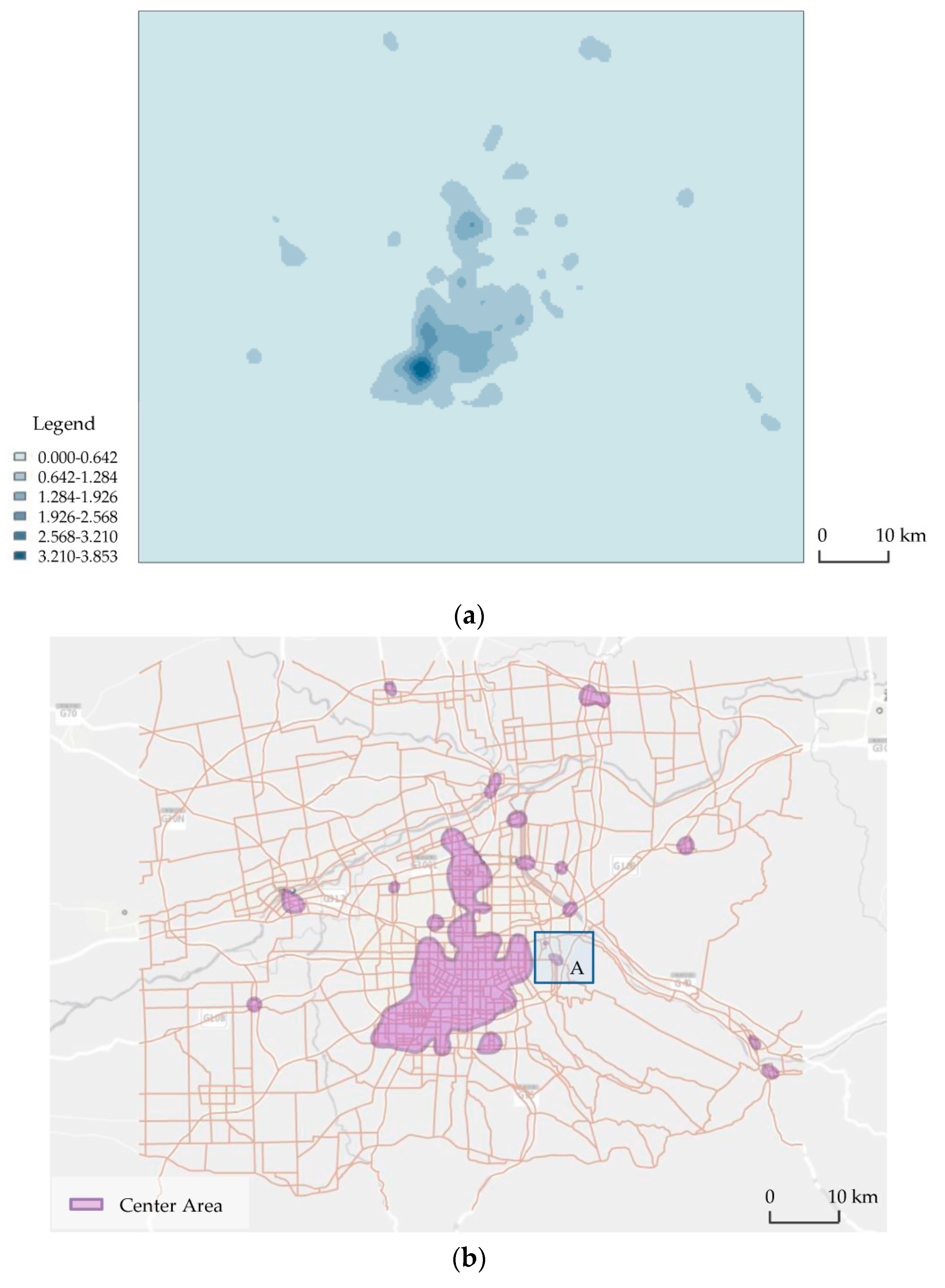
4.1. Case of the Monocentric City
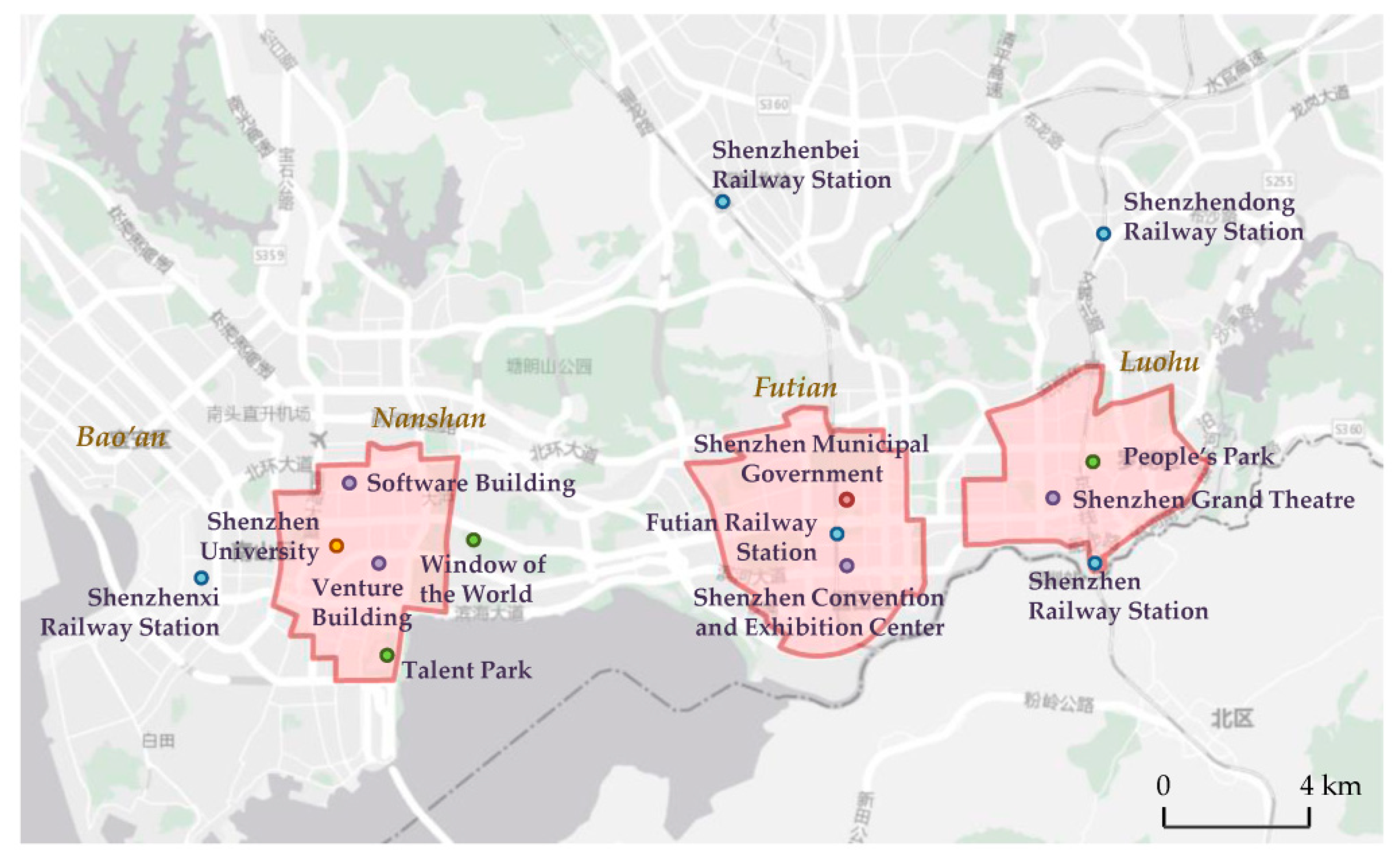
4.2. Case of the Polycentric City
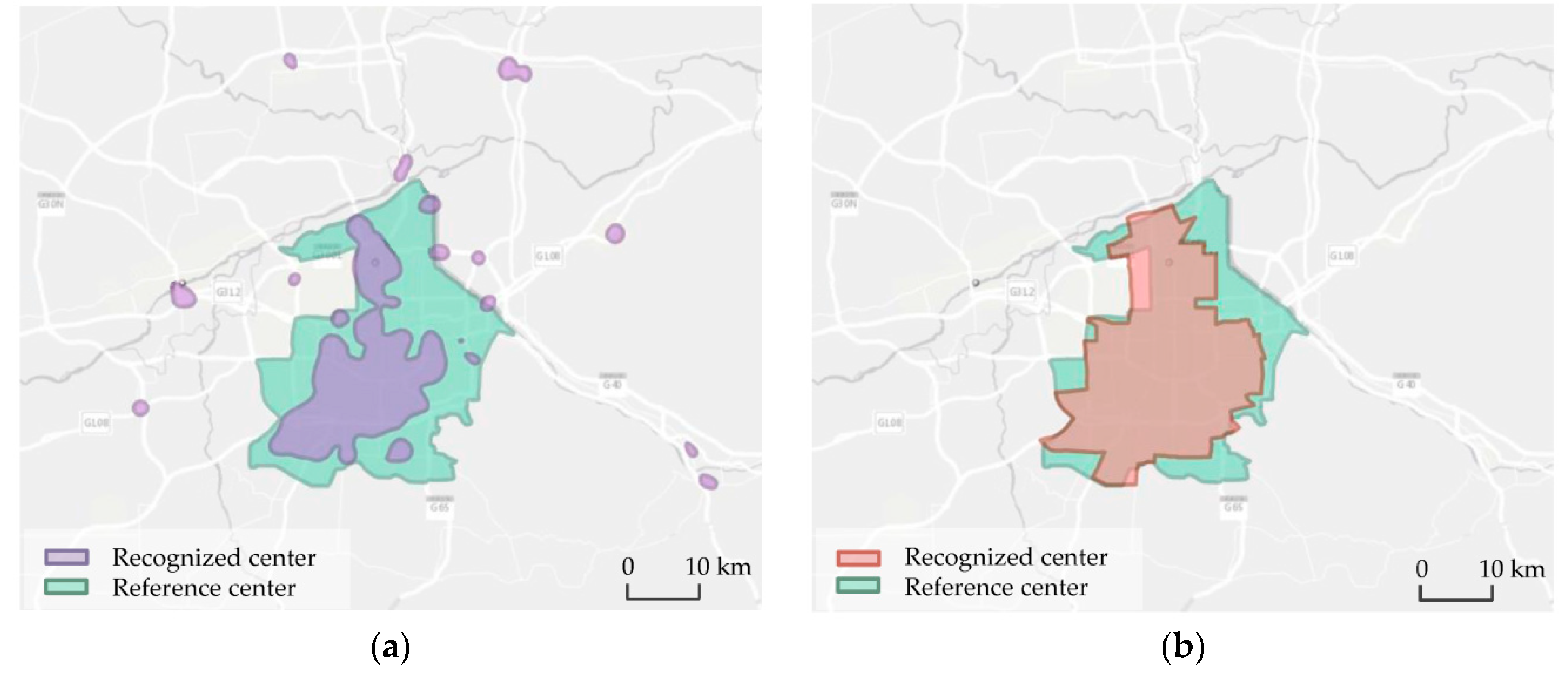
4.3. Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mackaness, W.; Edwords, G. The Importance of Modeling Pattern and Structure in Automated Map Generalization. In Proceedings of the Joint ISPRS/ICA Workshop on Multi-Scale Representations of Spatial Data, Ottawa, ON, Canada, 7–8 July 2002. [Google Scholar]
- Steiniger, S. Enabling Pattern Aware Automated Map Generalization. Ph.D. Thesis, University of Zurich, Zurich, Switzerland, 2007. [Google Scholar]
- Heinzle, F.; Anders, K.H. Characterizing Space via Pattern Recognition Techniques: Identifying Patterns in Road Networks. In Generalization of Geographic Information: Cartographic Modeling and Applications; Elsevier Ltd.: Amsterdam, The Netherlands, 2007; pp. 233–253. [Google Scholar]
- Zhang, Q. Modeling Structure and Patterns in Road Network Generalization. In Proceedings of the ICA Workshop on Generalization and Multiple Representation, Leicester, UK, 20–21 August 2004. [Google Scholar]
- Yang, B.; Luan, X.; Li, Q. An Adaptive Method for Identifying the Spatial Patterns in Road Networks. Comput. Environ. Urban Syst. 2010, 34, 40–48. [Google Scholar] [CrossRef]
- Gong, X.; Wu, F. A Typification Method for Linear Pattern in Urban Building Generalization. Geocarto Int. 2016, 33, 189–207. [Google Scholar] [CrossRef]
- Chaudhry, O.; Mackaness, W.A. Automatic identification of urban settlement boundaries for multiple representation databases. Comput. Environ. Urban Syst. 2008, 32, 95–109. [Google Scholar] [CrossRef]
- Marshall, S. Streets & Patterns; Spon Press: London, UK, 2005. [Google Scholar]
- Tian, J.; Song, Z.; Gao, F.; Zhao, F. Grid Pattern Recognition in Road Networks Using the C4.5 Algorithm. Cartogr. Geogr. Inf. Sci. 2016, 43, 266–282. [Google Scholar] [CrossRef]
- He, Y.; Ai, T.; Yu, W.; Zhang, X. A Linear Tessellation Model to Identify Spatial Pattern in Urban Street Networks. Int. J. Geogr. Inf. Sci. 2017, 31, 1541–1561. [Google Scholar] [CrossRef]
- Touya, G. A Road Network Selection Process Based on Data Enrichment and Structure Detection. Trans. GIS 2010, 14, 595–614. [Google Scholar] [Green Version]
- Savino, S.; Rumor, M.; Zanon, M.; Lissandron, L. Data Enrichment for Road Generalization through Analysis of Morphology in the Cargen Project. In Proceedings of the 13th ICA Workshop on Generalization and Multiple Representation, Zurich, Switzerland, 12–13 September 2010. [Google Scholar]
- Cui, X.; Wang, J.; Gong, X.; Wu, F. Roundabout Recognition Method Based on Improved Hough Transform in Road Networks. Acta Geod. Cartogr. Sin. 2018, 47, 1670–1679. [Google Scholar]
- Yang, B.; Luan, X.; Li, Q. Generating Hierarchical Strokes from Urban Street Networks Based on Spatial Pattern Recognition. Int. J. Geogr. Inf. Sci. 2011, 25, 2025–2050. [Google Scholar] [CrossRef]
- Heinzle, F.; Anders, K.H.; Sester, M. Pattern Recognition in Road Networks on the Example of Circular Road Detection. In Proceedings of the 4th Geographic Information Science, Münster, Germany, 20–13 September 2006; pp. 153–167. [Google Scholar]
- Tian, J.; Zhang, B.; Wu, D. A New Method for Identifying Radial Pattern in Vector Road Networks. Geomat. Inf. Sci. Wuhan Univ. 2013, 38, 1234–1238. [Google Scholar]
- Borruso, G. Network Density and the Delimitation of Urban Areas. Trans. GIS 2003, 7, 177–191. [Google Scholar] [CrossRef]
- Zhou, Q. Comparative Study of Approaches to Delineating Built-Up Areas Using Road Network Data. Trans. GIS 2016, 19, 848–876. [Google Scholar] [CrossRef]
- Murphy, R.E.; Vance, J.E. Delimiting the CBD. Econ. Geol. 1954, 30, 189–222. [Google Scholar] [CrossRef]
- Lowe, M. The Regional Shopping Centre in the Inner City: A Study of Retail-led Urban Regeneration. Urban Stud. 2005, 42, 449–470. [Google Scholar] [CrossRef]
- Redfearn, C. The Topography of Metropolitan Employment: Identifying Centres of Employment in a Polycentric Urban Area. J. Urban Econ. 2007, 61, 519–541. [Google Scholar] [CrossRef]
- Yu, W.; Ai, T.; Shao, S. The Analysis and Delimitation of Central Business District Using Network Kernel Density Estimation. J. Transp. Geogr. 2015, 45, 32–47. [Google Scholar] [CrossRef]
- Zhu, J.; Sun, Y. Building an Urban Spatial Structure from Urban Land Use Data: An Example Using Automated Recognition of the City Centre. ISPRS Int. J. Geo-Inf. 2017, 6, 122. [Google Scholar] [CrossRef]
- Yang, J.; Zhu, J.; Sun, Y.; Zhao, J. Delimitating Urban Commercial Central Districts by Combining Kernel Density Estimation and Road Intersections: A Case Study in Nanjing City, China. ISPRS Int. J. Geo-Inf. 2019, 8, 93. [Google Scholar] [CrossRef]
- Hollenstein, L.; Purves, R. Exploring Place through User-Generated Content: Using Flickr to Describe City Cores. J. Spat. Inf. Sci. 2010, 1, 21–48. [Google Scholar]
- Hu, Y.; Gao, S.; Janowicz, K.; Yu, B.; Li, W.; Prasad, S. Extracting and Understanding Urban Areas of Interest Using Geotagged Photos. Comput. Environ. Urban Syst. 2015, 54, 240–254. [Google Scholar] [CrossRef]
- Sun, Y.; Fan, H.; Li, M.; Zipf, A. Identifying the City Centre Using Human Travel Flows Generated From Location-Based Social Networking Data. Environ. Plann. B Plann. Des. 2016, 43, 480–498. [Google Scholar] [CrossRef]
- Jiang, B.; Liu, X. Scaling of Geographic Space from the Perspective of City and Field Blocks and Using Volunteered Geographic Information. Int. J. Geogr. Inf. Sci. 2012, 26, 215–229. [Google Scholar] [CrossRef]
- Porta, S.; Crucitti, P.; Latora, V. The Network Analysis of Urban Streets: A Primal Approach. Environ. Plan. B Plan. Des. 2006, 33, 705–725. [Google Scholar] [Green Version]
- Crucitti, P.; Latora, V.; Porta, S. Centrality measures in spatial networks of urban streets. Phys. Rev. E 2006, 73, 036125. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, B. A topological pattern of urban street networks: Universality and Peculiarity. Phys. A Stat. Mech. Its Appl. 2007, 384, 647–655. [Google Scholar] [CrossRef]
- Jiang, B.; Claramunt, C. A Structural Approach to the Model Generalization of an Urban Street Network. Geoinformatica 2004, 8, 157–171. [Google Scholar] [CrossRef]
- Liu, Q.; Deng, M.; Shi, Y.; Wang, J. A Density-Based Spatial Clustering Algorithm Considering both Spatial Proximity and Attribute Similarity. Comput. Geosci. 2012, 46, 296–309. [Google Scholar] [CrossRef]
- Gao, S.; Janowicz, K.; Montello, D.R.; Hu, Y.; Yang, J.; Mckenzie, G.; Ju, Y.; Gong, L.; Adams, B.; Yan, B. A Data-Synthesis-Driven Method for Detecting and Extracting Vague Cognitive Regions. Int. J. Geogr. Inf. Syst. 2017, 31, 1245–1271. [Google Scholar] [CrossRef]
- Lynch, K. The Image of the City; MIT Press: Cambridge, MA, USA, 1960. [Google Scholar]
- Le, T.; Abrahart, R.; Aplin, R.; Priestnall, G. Town Centre Modelling Based on Public Participation. In Proceedings of the CUPUM 05, Computers in Urban Planning and Urban Management—9th International Conference, London, UK, 29 June–1 July 2005. [Google Scholar]
- Montello, D.R.; Goodchild, M.F.; Gottsegen, J.; Fohl, P. Where‘s Downtown: Behavioral Methods for Determining Referents of Vague Spatial Queries. Spat. Cognit. Comput. 2003, 3, 185–204. [Google Scholar]
- Borruso, G.; Porceddu, A. A Tale of Two Cities: Density Analysis of CBD on Two Midsize Urban Areas in Northeastern Italy. In Geocomputation and Urban Planning; Springer: Berlin/Heidelberg, Germany, 2009; pp. 37–56. [Google Scholar]
- Lüscher, P.; Weibel, R. Exploiting Empirical Knowledge for Automatic Delineation of City Centres from Large-Scale Topographic Databases. Comput. Environ. Urban Syst. 2013, 37, 18–34. [Google Scholar] [CrossRef]
- Yu, B.; Shu, S.; Liu, H.; Song, W.; Wu, J.; Wang, L.; Chen, Z. Object-based Spatial Cluster Analysis of Urban Landscape Pattern Using Nighttime Light Satellite Images: A Case Study of China. Int. J. Geogr. Inf. Sci. 2014, 28, 2328–2355. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the KDD 1996, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Roberts, A. Integrating High Resolution Remote Sensing, GIS and Fuzzy Set Theory for Identifying Susceptibility Areas of Forest Insect Infestations. Int. J. Remote Sens. 2005, 26, 4809–4828. [Google Scholar]
- Cui, X.; Wang, J.; Gong, X.; Zhao, Y. Hotspot Area Recognition by Using Fuzzy Density Clustering and Bidirectional Buffer. Geomat. Inf. Sci. Wuhan Univ. 2019, 44, 84–91. [Google Scholar]
- Zadeh, L. Fuzzy Sets as a Basis for a Theory of Possibility. Fuzzy Sets Syst. 1978, 1, 3–28. [Google Scholar] [CrossRef]
- Nasibov, E.N.; Ulutagay, G. Robustness of Density-Based Clustering Methods with Various Neighborhood Relations. Fuzzy Sets Syst. 2009, 160, 3601–3615. [Google Scholar] [CrossRef]
- Chen, J.; Yan, C.; Zhao, R.; Zhao, X. Voronoi Neighbor-based Self- adaptive Clipping Model for Mobile Maps. Acta Geod. Cartogr. Sin. 2009, 38, 152–155. [Google Scholar]
- Galton, A.; Duckham, M. What Is the Region Occupied by a Set of Points? Lect. Notes Comput. Sci. 2006, 4197, 81–98. [Google Scholar]
- Montello, D.R.; Friedman, A.; Phillips, D.W. Vague Cognitive Regions in Geography and Geographic Information Science. Int. J. Geogr. Inf. Sci. 2014, 28, 1802–1820. [Google Scholar] [CrossRef]
- Heikinheimo, V.; Minin, E.D.; Tenkanen, H.; Hausmann, A.; Erkkonen, J.; Toivonen, T. User-generated geographic information for visitor monitoring in a national park: A comparison of social media data and visitor survey. ISPRS Int. J. Geo-Inf. 2017, 6, 85. [Google Scholar] [CrossRef]
- Keil, J.; Mocnik, F.-B.; Edler, D.; Dickmann, F.; Kuchinke, L. Reduction of map information regulates visual attention without affecting route recognition performance. ISPRS Int. J. Geo-Inf. 2018, 7, 469. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City | Method | Number of Polygons | Number of Holes | Boundary Extent |
|---|---|---|---|---|
| Xi’an | Contrast method | 18 | 0 | Within the city |
| Proposed method | 1 | 0 | Within the city | |
| Shenzhen | Contrast method | 45 | 2 | Beyond the city |
| Proposed method | 3 | 0 | Within the city |
| Algorithm | R | P | F1-score |
|---|---|---|---|
| Contrast method | 0.399 | 0.885 | 0.550 |
| Proposed method | 0.698 | 0.947 | 0.804 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, X.; Wang, J.; Wu, F.; Li, J.; Gong, X.; Zhao, Y.; Zhu, R. Extracting Main Center Pattern from Road Networks Using Density-Based Clustering with Fuzzy Neighborhood. ISPRS Int. J. Geo-Inf. 2019, 8, 238. https://doi.org/10.3390/ijgi8050238
Cui X, Wang J, Wu F, Li J, Gong X, Zhao Y, Zhu R. Extracting Main Center Pattern from Road Networks Using Density-Based Clustering with Fuzzy Neighborhood. ISPRS International Journal of Geo-Information. 2019; 8(5):238. https://doi.org/10.3390/ijgi8050238
Chicago/Turabian StyleCui, Xiaojie, Jiayao Wang, Fang Wu, Jinghan Li, Xianyong Gong, Yao Zhao, and Ruoxin Zhu. 2019. "Extracting Main Center Pattern from Road Networks Using Density-Based Clustering with Fuzzy Neighborhood" ISPRS International Journal of Geo-Information 8, no. 5: 238. https://doi.org/10.3390/ijgi8050238