A Hybrid of Differential Evolution and Genetic Algorithm for the Multiple Geographical Feature Label Placement Problem



Abstract
:1. Introduction
2. Candidate-Position Generation and Quality Evaluation Model
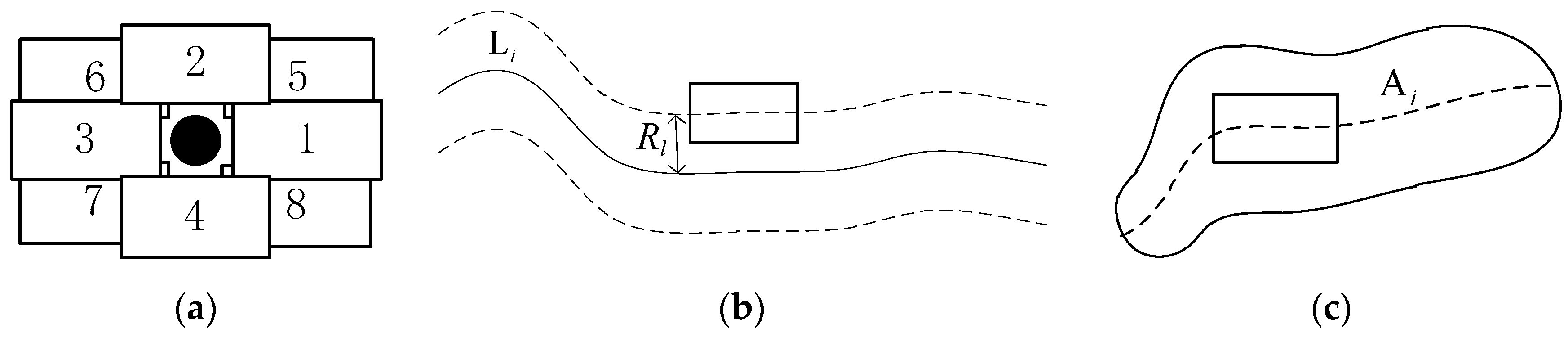
2.1. Candidate-Position Generation
2.2. Quality Metric
3. Label Placement Model of DDEGA
3.1. A Hybrid Algorithm of Discrete Differential Evolution and Genetic Algorithm
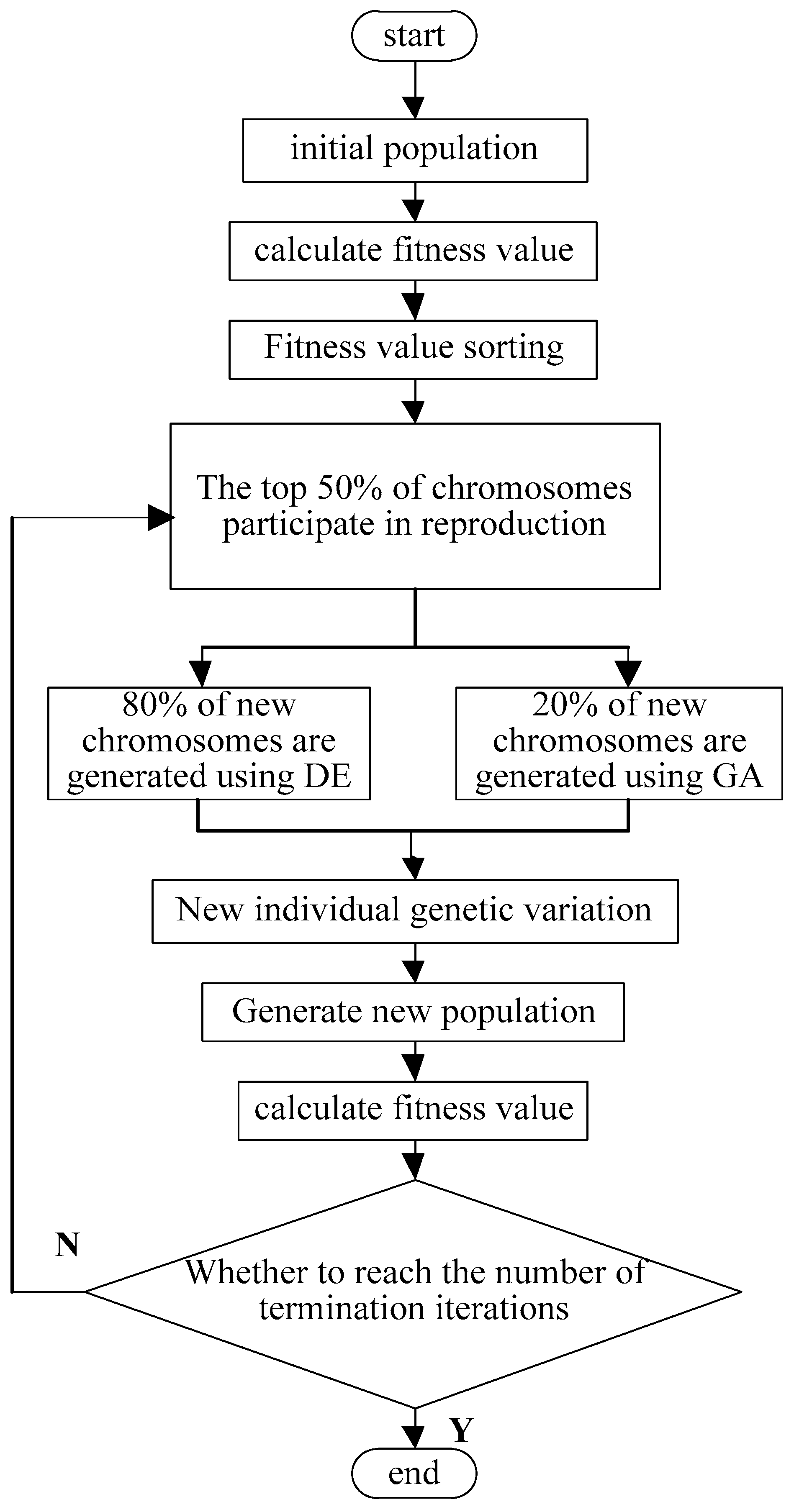
3.2. DDEGA Process
3.2.1. Initial Population Generation and Coding
3.2.2. Fitness Function
3.2.3. Selection Operation
3.2.4. Variation and Crossover
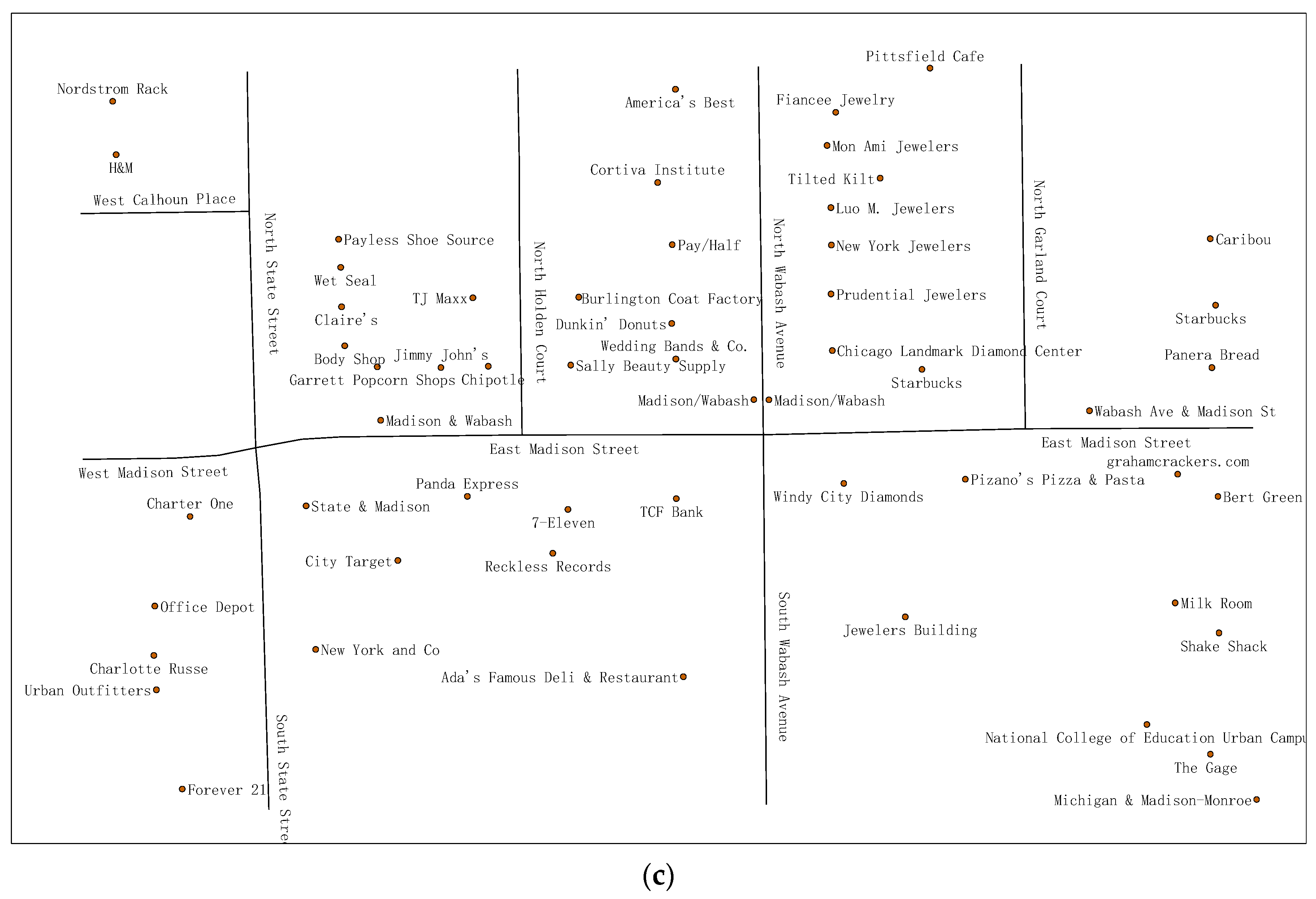
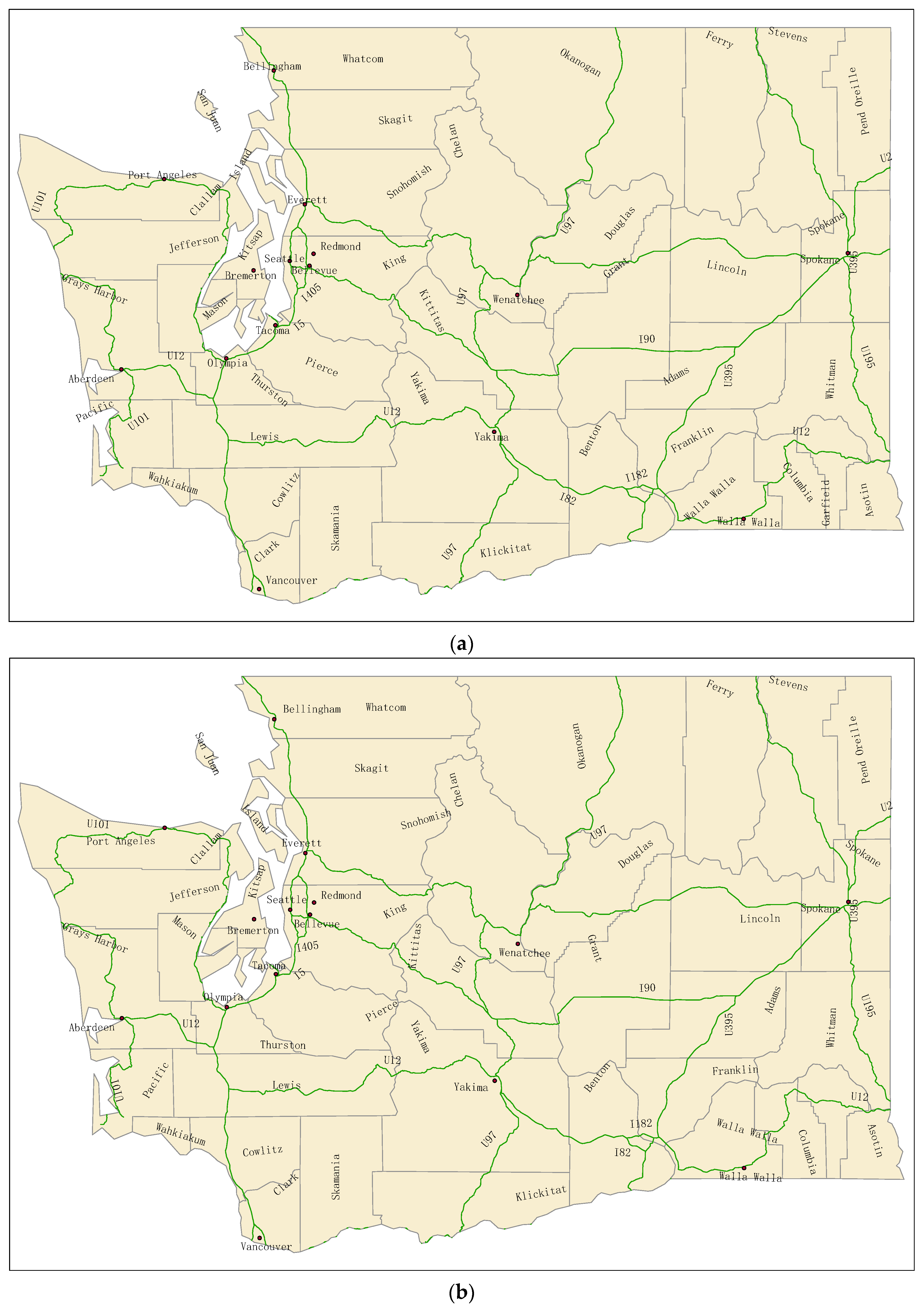
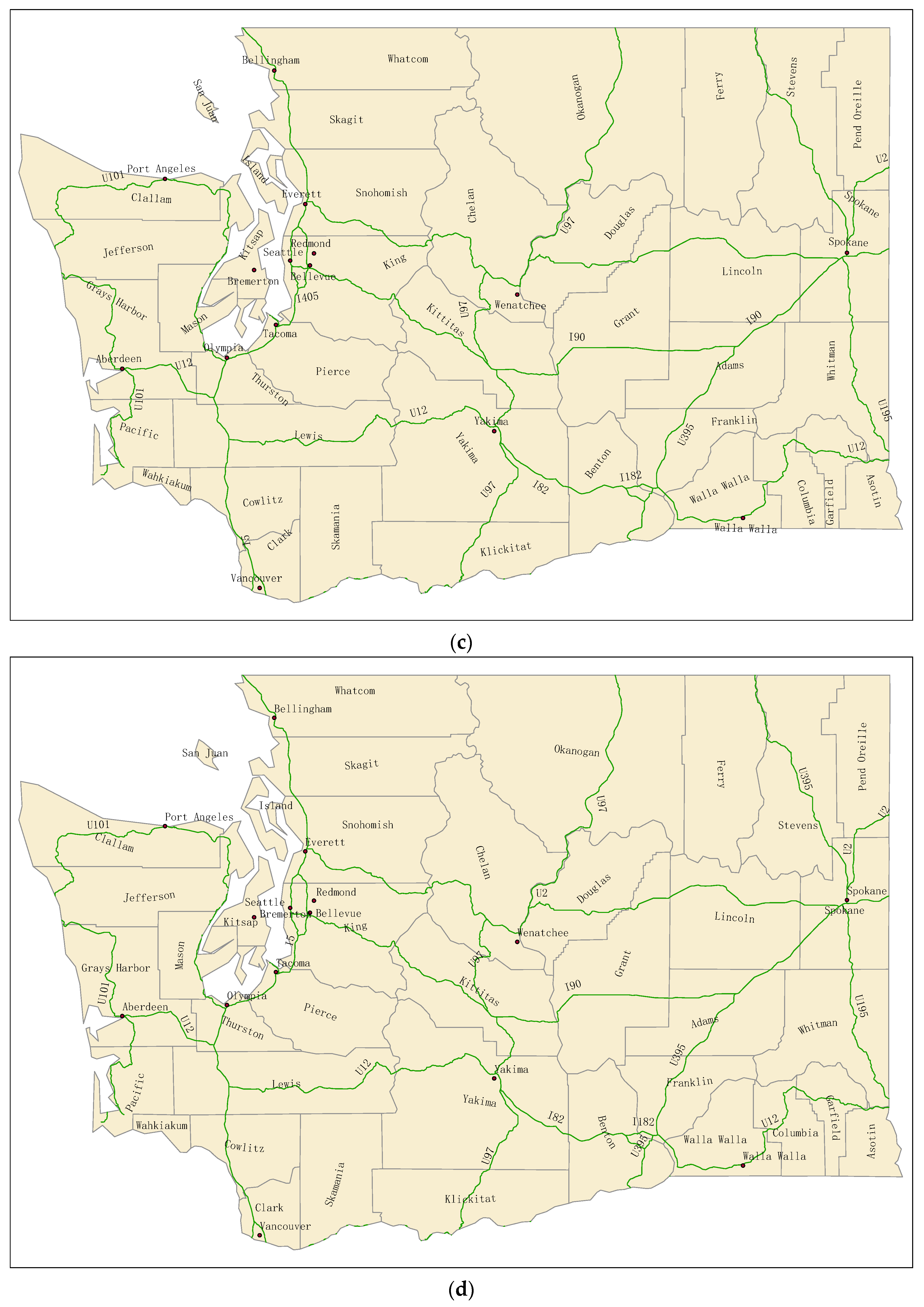
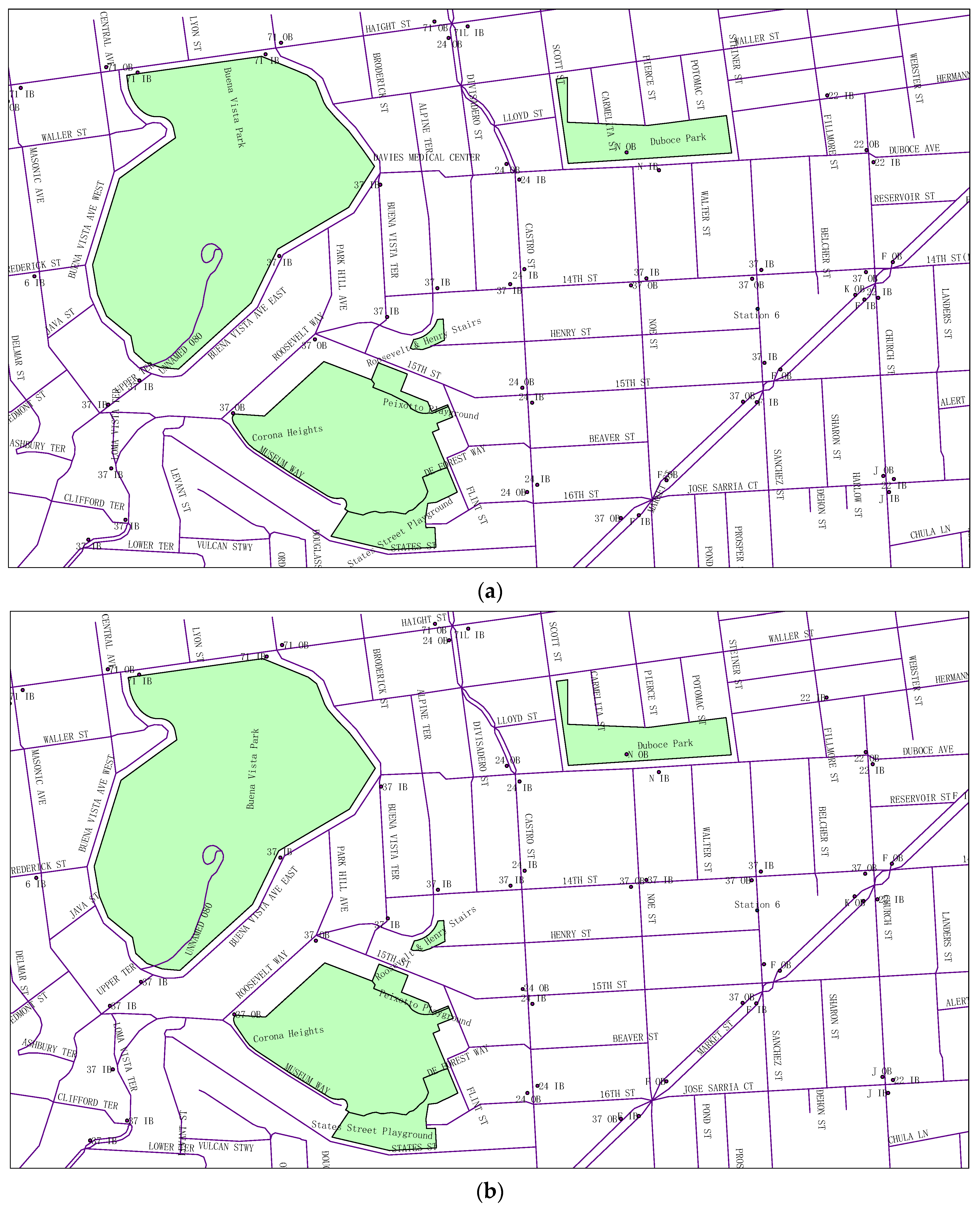
4. Experimental Results
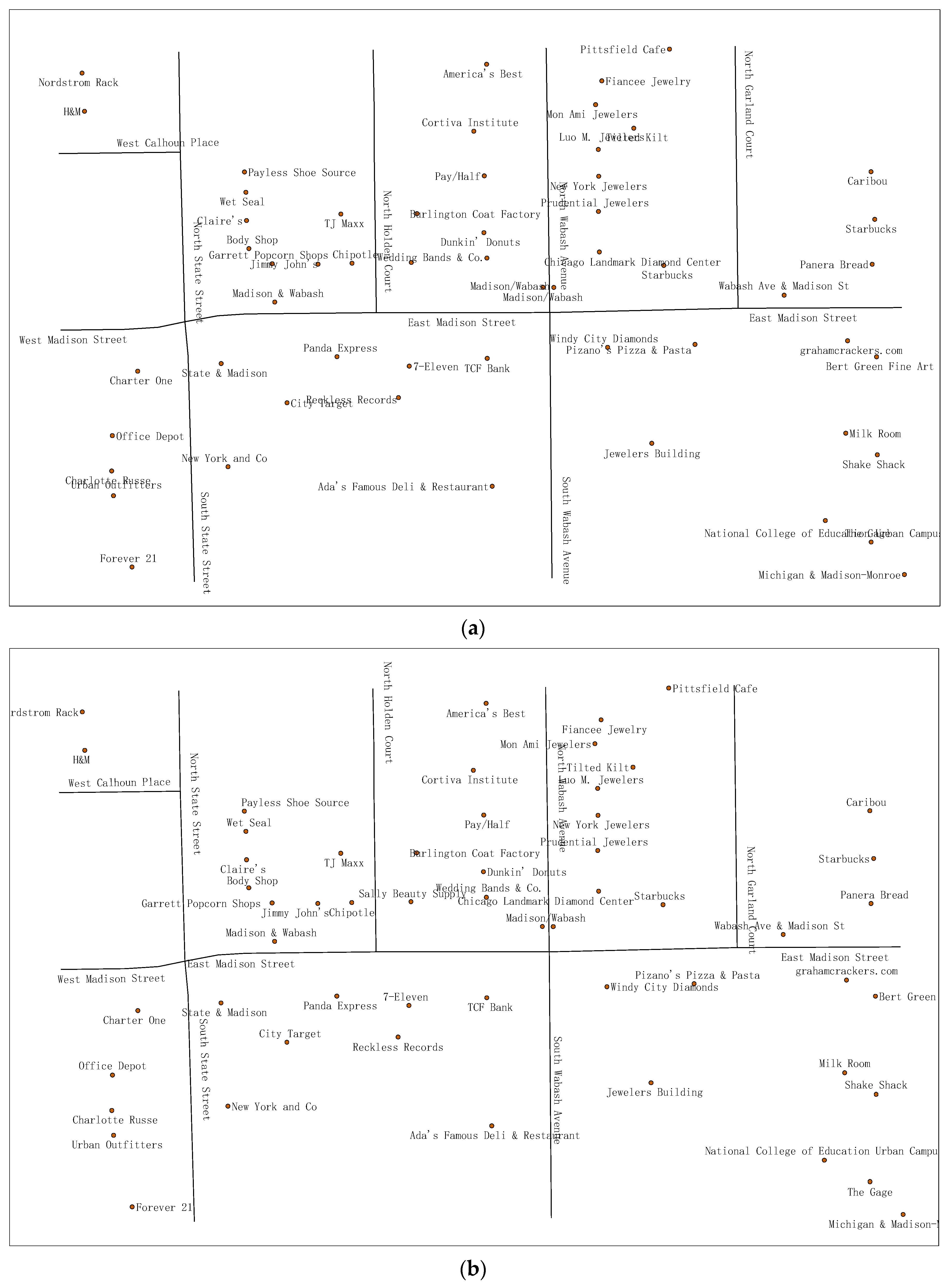
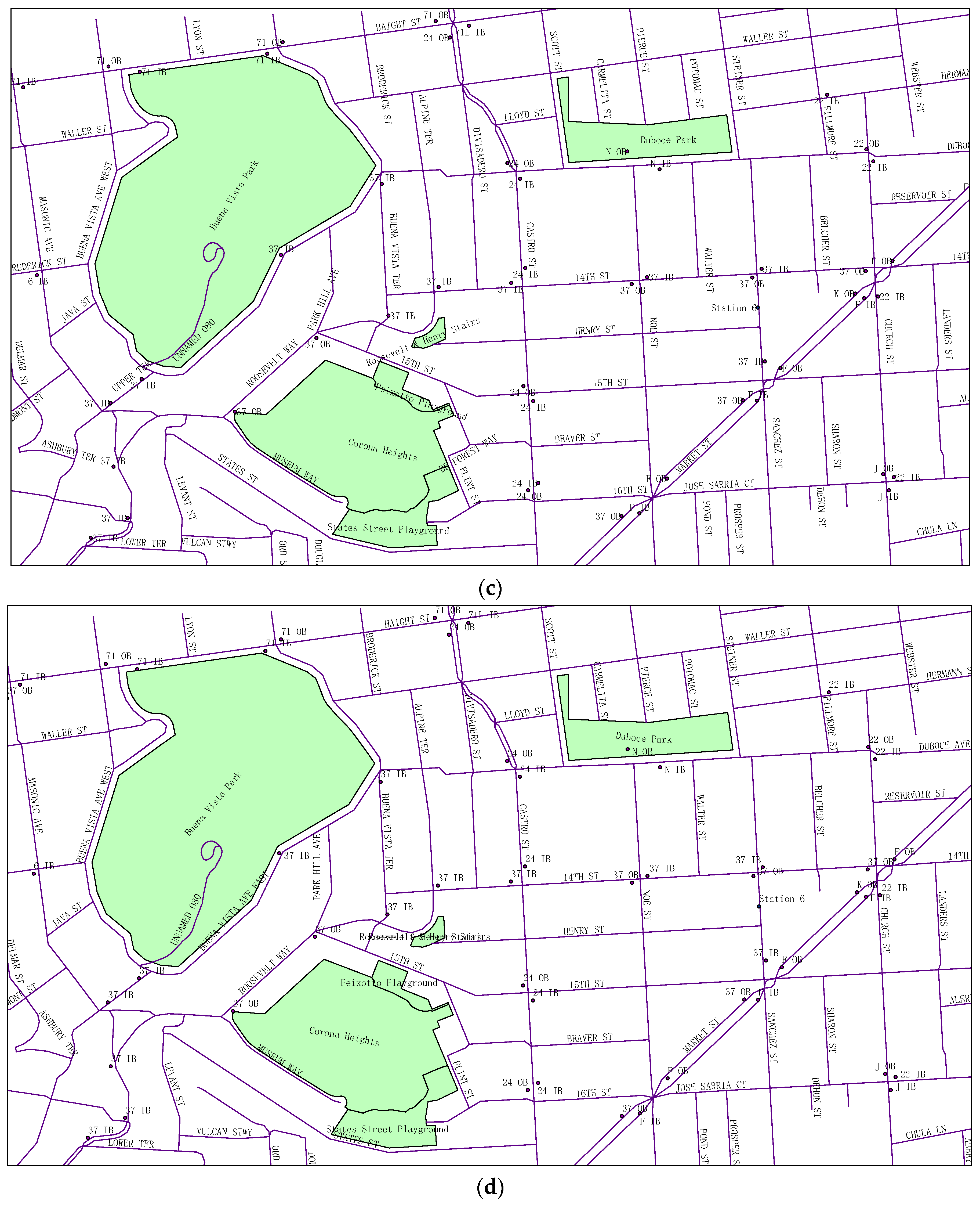
4.1. Label Placement Experiment Using DDEGA
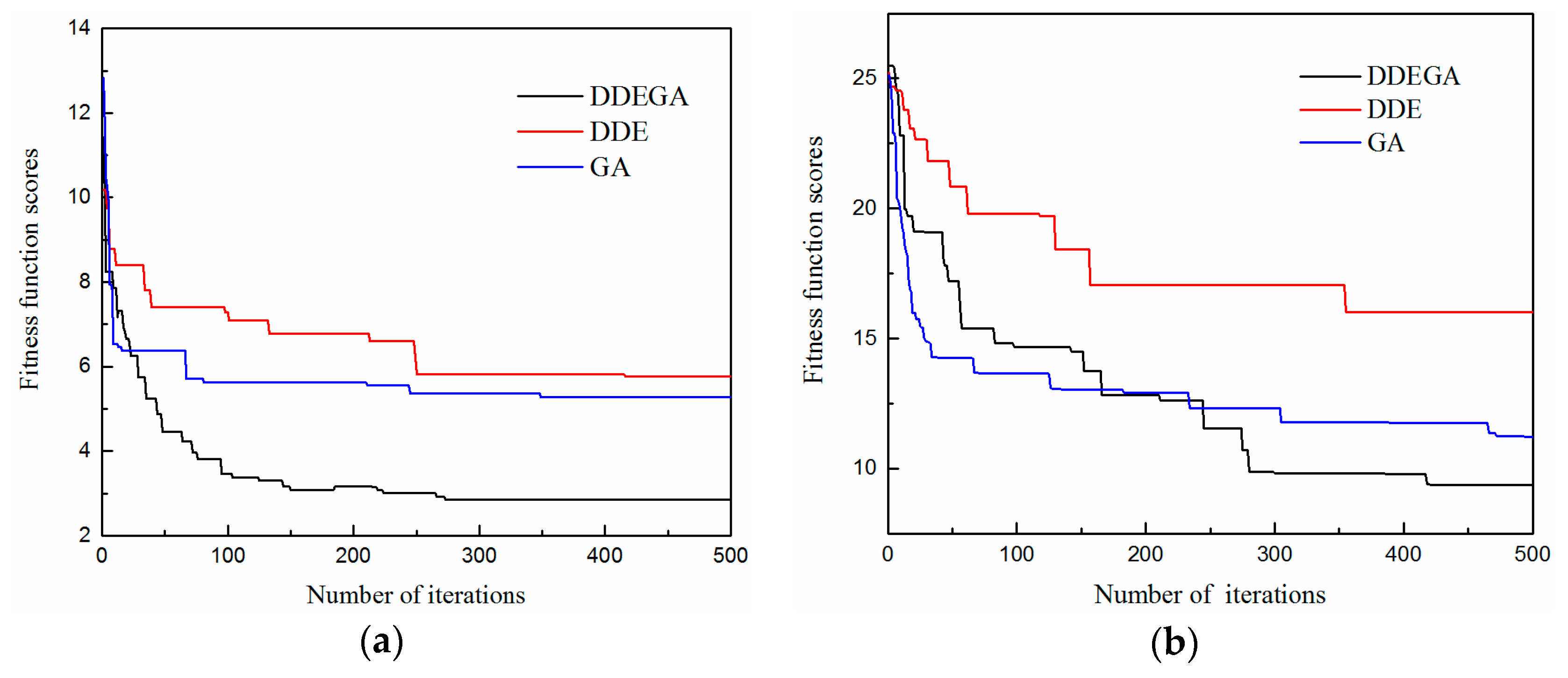
4.2. Experimental Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Schrijver, A. Combinatorial Optimization: Polyhedra and Efficiency; Springer: Berlin/Heidelberg Germany, 2004; Volume 27, pp. 153–159. [Google Scholar]
- Yoeli, P. The Logic of Automated Map Lettering. Cartogr. J. 1972, 9, 99–108. [Google Scholar] [CrossRef]
- Imhof, E. Positioning Names on Maps. Am. Cartogr. 1975, 2, 128–144. [Google Scholar] [CrossRef]
- Marks, J.; Shieber, S. The Computational Complexity of Cartographic Label Placement; Technical Report TR-05-91; Harvard University: Cambridge, MA, USA, 1991; pp. 5–91. [Google Scholar]
- Formann, M.; Wagner, F. A packing problem with applications to lettering of maps. In Proceedings of the Seventh Annual Symposium on Computational Geometry, North Conway, NH, USA, 10–12 June 1991; pp. 281–288. [Google Scholar]
- Zoraster, S. Practical Results Using Simulated Annealing for Point Feature Label Placement. Cartogr. Geogr. Inf. Syst. 1997, 24, 228–238. [Google Scholar] [CrossRef]
- Mauri, G.; Ribeiro, G.M.; Lorena, L.A.N. A new mathematical model and a Lagrangean decomposition for the point-feature cartographic label placement problem. Comput. Oper. Res. 2010, 37, 2164–2172. [Google Scholar] [CrossRef]
- Marín, A.; Pelegrín, M. Towards unambiguous map labeling-Integer programming approach and heuristic algorithm. Expert Syst. Appl. 2018, 98, 221–241. [Google Scholar] [CrossRef]
- Gomes, S.P.; Ribeiro, G.M.; Lorena, L.A.N. Dispersion for the point-feature cartographic label placement problem. Expert Syst. Appl. 2013, 40, 5878–5883. [Google Scholar] [CrossRef]
- Cravo, G.L.; Ribeiro, G.M.; Lorena, L.A.N. A greedy randomized adaptive search procedure for the point-feature cartographic label placement. Comput. Geosci. 2008, 34, 373–386. [Google Scholar] [CrossRef]
- Verner, O.V.; Wainwright, R.L.; Schoenefeld, D.A. Placing text labels on maps and diagrams using genetic algorithms with masking. INFORMS J. Comput. 1997, 9, 266–275. [Google Scholar] [CrossRef]
- Azamathulla, H.M.; Wu, F.C.; Ab Ghani, A.; Narulkar, S.M.; Zakaria, N.A.; Chang, C.K. Comparison between genetic algorithm and linear programming approach for real time operation. J. Hydro-Environ. Res. 2008, 2, 172–181. [Google Scholar] [CrossRef]
- Li, L.; Zhang, H.; Zhu, H.; Kuai, X.; Hu, W. A Labeling Model Based on the Region of Movability for Point-Feature Label Placement. ISPRS Int. J. Geo-Inf. 2016, 5, 159. [Google Scholar] [CrossRef]
- Yamamoto, M.; Lorena, L.A.N. A Constructive Genetic Approach to Point-Feature Cartographic Label Placement. Metaheuristics Prog. Real Probl. Solv. 2005, 32, 287–302. [Google Scholar] [CrossRef]
- Gomes, S.P.; Lorena, L.A.N.; Ribeiro, G.M. A Constructive Genetic Algorithm for Discrete Dispersion on Point Feature Cartographic Label Placement Problems. Geogr. Anal. 2016, 48, 43–58. [Google Scholar] [CrossRef]
- Doerschler, J.S.; Freeman, H. A rule-based system for dense-map name placement. Commun. ACM 1992, 35, 68–79. [Google Scholar] [CrossRef]
- Wolff, A.; Knipping, L.; Kreveld, M.v.; Strijk, T.; Agarwal, P.K. A Simple and Efficient Algorithm for High-Quality Line Labeling; Technical Report UU-CS-2001-44; Department of Computer Science, Utrecht University: Utrecht, The Netherlands, 1997; Volume 11, pp. 146–150. [Google Scholar]
- Sun, S.; Zhao, H.; Fang, J.; Cheng, Z.; Zhao, Y. A pratical Method for Line Labeling. In Proceedings of the 18th International Conference on Geoinformatics: GIScience in Change, Peking University, Beijing, China, 18–20 June 2010; pp. 18–20. [Google Scholar]
- Wu, C.; Ding, Y.; Zhou, X.; Lu, G. A grid algorithm suitable for line and area feature label placement. Environ. Earth Sci. 2016, 75, 1368. [Google Scholar] [CrossRef]
- Pfefferkorn, C.; Burr, D.; Harrison, D.; Heckman, B. A Cartographic Expert System. In Proceedings of the Seventh International Symposium on Autocarto, Falls Church, VA, USA, 11–14 March 1985; pp. 399–407. [Google Scholar]
- Ahn, J.; Freeman, H. A Program for Automatic Name Placement. Cartogr. Int. J. Geogr. Inf. Geovis. 1984, 21, 101–109. [Google Scholar] [CrossRef]
- Rylov, M.; Reimer, A. A Practical Algorithm for the External Annotation of Area Features. Cartogr. J. 2016, 54, 61–76. [Google Scholar] [CrossRef]
- Edmondson, S.; Christensen, J.; Marks, J.; Shieber, S. A General Cartographic Labelling Algorithm. Cartogr. Int. J. Geogr. Inf. Geovis. 1996, 33, 13–24. [Google Scholar] [CrossRef] [Green Version]
- Kakoulis, K.G.; Tollis, I.G. A unified approach to automatic label placement. Int. J. Comput. Geom. Appl. 2003, 13, 23–59. [Google Scholar] [CrossRef]
- Zhang, Q.; Harrie, L. Placing Text and Icon Labels Simultaneously: A Real-Time Method. Cartogr. Geogr. Inf. Sci. 2006, 33, 53–64. [Google Scholar] [CrossRef]
- Price, K.V.; Storn, R.M.; Lampinen, J.A. Differential Evolution: A Practical Approach to Global Optimization; Springer: Berlin/Heidelberg Germany, 2005; Volume 141. [Google Scholar]
- Jia, L.Y.; He, J.X.; Zhang, C.; Gong, W.Y. Differential evolution with controlled search direction. J. Cent. South Univ. 2012, 19, 3516–3523. [Google Scholar] [CrossRef]
- Ebinger, L.R.; Goulette, A.M. Automated Name Palcement in a Non-Interactive Environment. Available online: https://pdfs.semanticscholar.org/114f/ab94f3b7c96cf1992cf66f171828ed310966.pdf (accessed on 12 April 2019).
- Klau, G.W.; Mutzel, P. Optimal labeling of point features in rectangular labeling models. Math. Program. 2003, 94, 435–458. [Google Scholar] [CrossRef]
- Ribeiro, G.M.; Lorena, L.A.N. Column generation approach for the point-feature cartographic label placement problem. J. Comb. Optim. 2008, 15, 147–164. [Google Scholar] [CrossRef]
- Alvim, A.C.F.; Taillard, É.D. POPMUSIC for the point feature label placement problem. Eur. J. Oper. Res. 2009, 192, 396–413. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution–A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- What Is the Maplex Label Engine? Available online: http://desktop.arcgis.com/zh-cn/arcmap/10.3/map/working-with-text/what-is-maplex-.htm (accessed on 10 April 2019).
- Gomarasca, M.A. Elements of Cartography; Springer: Dordrecht, The Netherlands, 2009; pp. 19–77. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
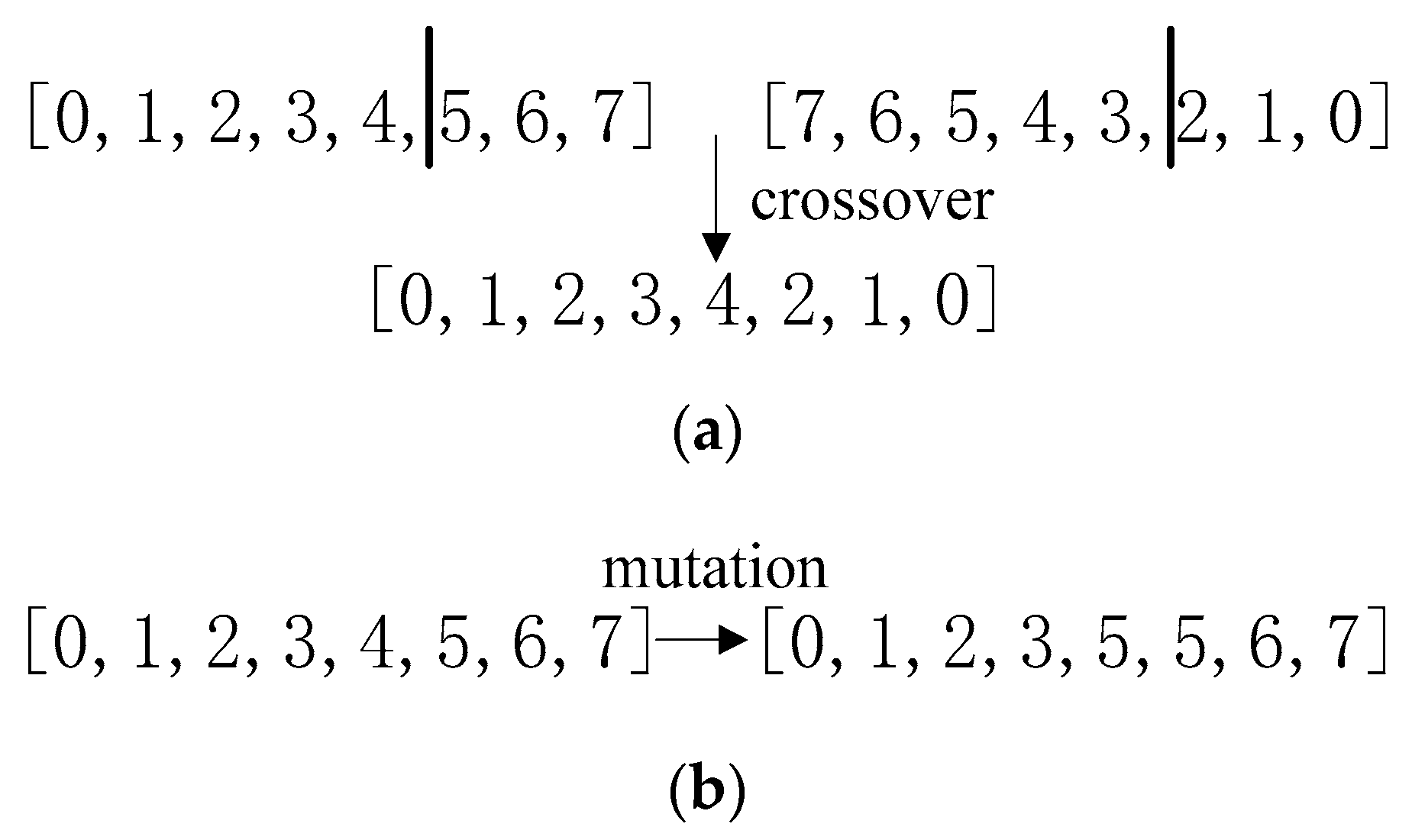{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Total number of labels of the map | |
| Score of label conflict factor for the ith label, | |
| Score of label conflict factor of the map | |
| Number of overlaps between the th label and the other labels | |
| Score of label-feature conflict factor for the th label | |
| Score of label-feature conflict factor of the map | |
| Number of overlaps between the th label and other features | |
| Number of the label rectangles on the map | |
| Score of label non-ambiguity factor for the th label | |
| Score of label non-ambiguity factor of the map | |
| Minimum Euclidean distance between the th label rectangle and the center of the line feature or the center of the skeleton line of the area feature | |
| The maximum Euclidean distance between the label and the center of the line feature or the center of the skeleton line of the area feature | |
| Score of label priority factor for the th label | |
| Score of label priority factor on the map | |
| The angle between the line of the center of label rectangle and point feature with the horizontal line | |
| Score of quality evaluation for the th label | |
| Score of the th factor, | |
| Weight of each impact factor | |
| Score of quality evaluation for the cartographic label placement |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, F.; Deng, J.; Li, S.; Deng, H. A Hybrid of Differential Evolution and Genetic Algorithm for the Multiple Geographical Feature Label Placement Problem. ISPRS Int. J. Geo-Inf. 2019, 8, 237. https://doi.org/10.3390/ijgi8050237
Lu F, Deng J, Li S, Deng H. A Hybrid of Differential Evolution and Genetic Algorithm for the Multiple Geographical Feature Label Placement Problem. ISPRS International Journal of Geo-Information. 2019; 8(5):237. https://doi.org/10.3390/ijgi8050237
Chicago/Turabian StyleLu, Fuyu, Jiqiu Deng, Shiyu Li, and Hao Deng. 2019. "A Hybrid of Differential Evolution and Genetic Algorithm for the Multiple Geographical Feature Label Placement Problem" ISPRS International Journal of Geo-Information 8, no. 5: 237. https://doi.org/10.3390/ijgi8050237
APA StyleLu, F., Deng, J., Li, S., & Deng, H. (2019). A Hybrid of Differential Evolution and Genetic Algorithm for the Multiple Geographical Feature Label Placement Problem. ISPRS International Journal of Geo-Information, 8(5), 237. https://doi.org/10.3390/ijgi8050237