Vehicle Object Detection in Remote Sensing Imagery Based on Multi-Perspective Convolutional Neural Network

Abstract
:1. Introduction
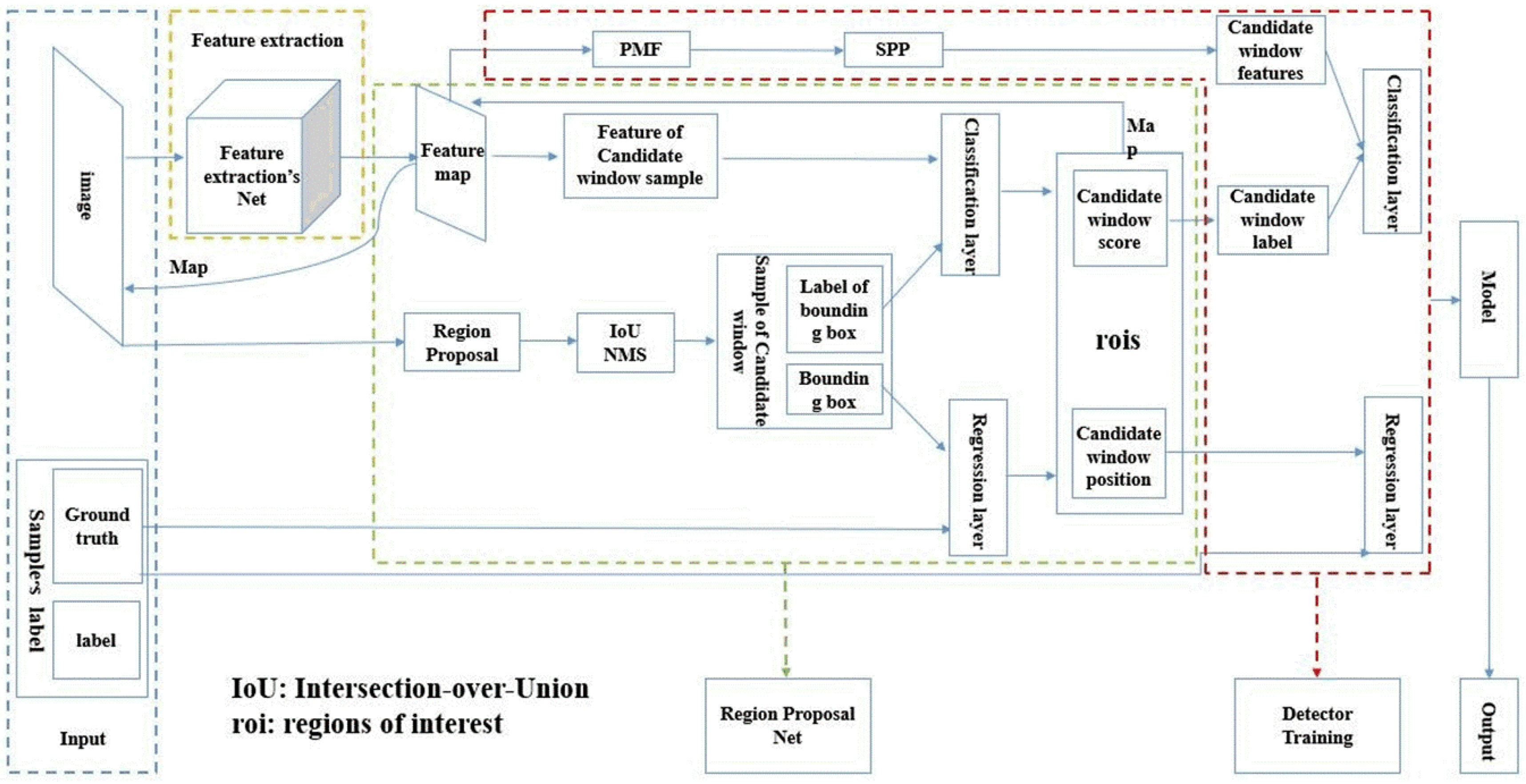
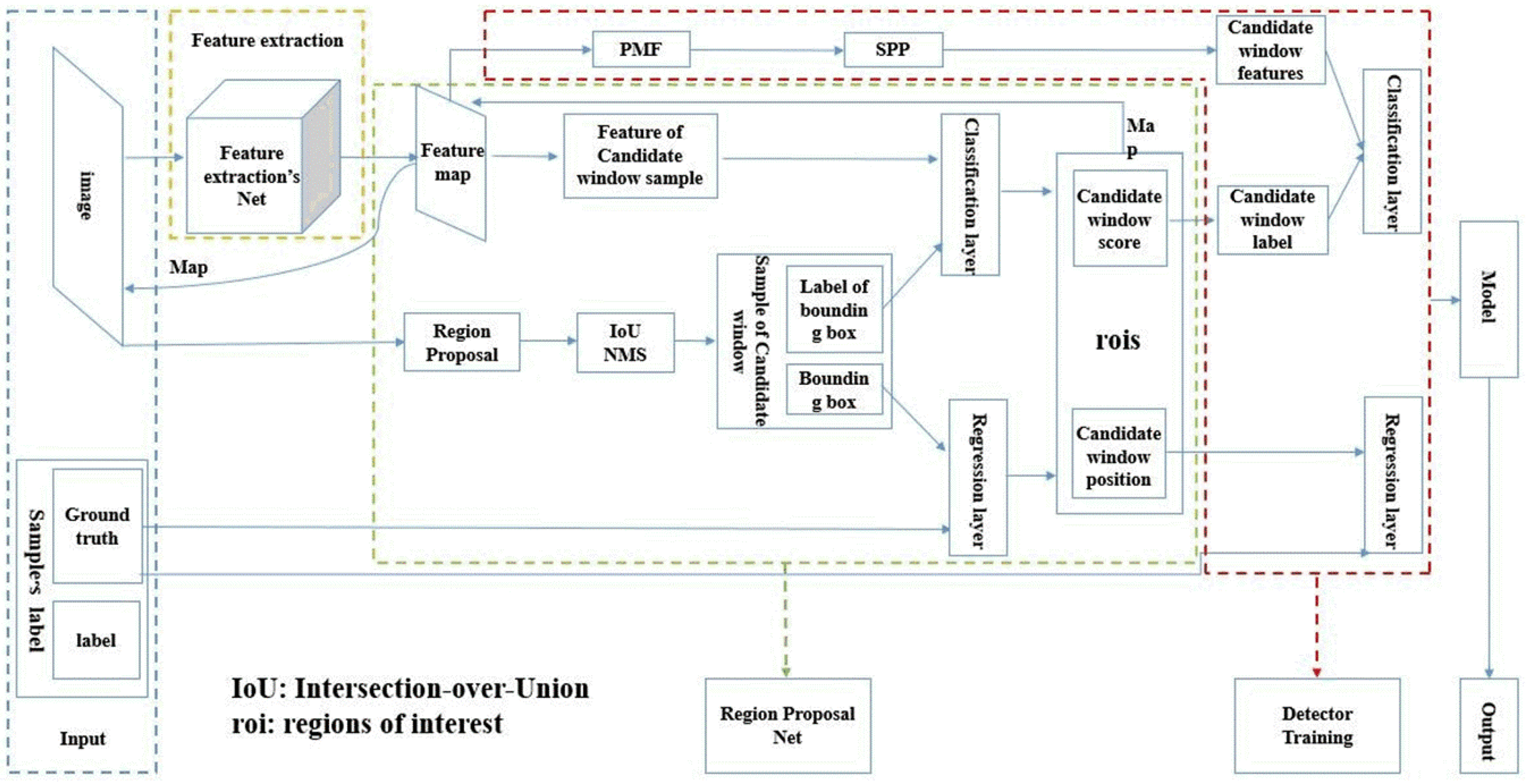
2. Object Detection Based on Faster R-CNN
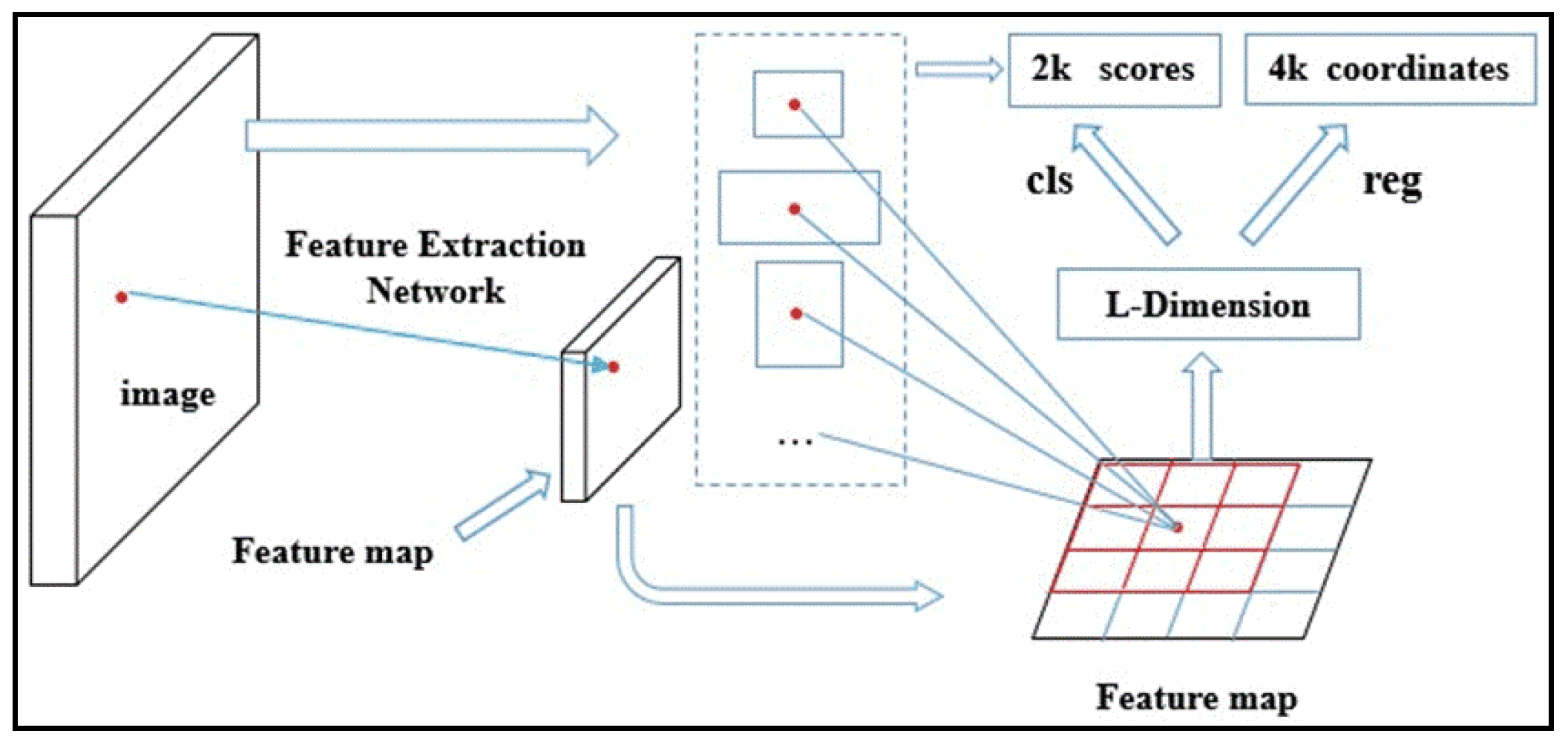
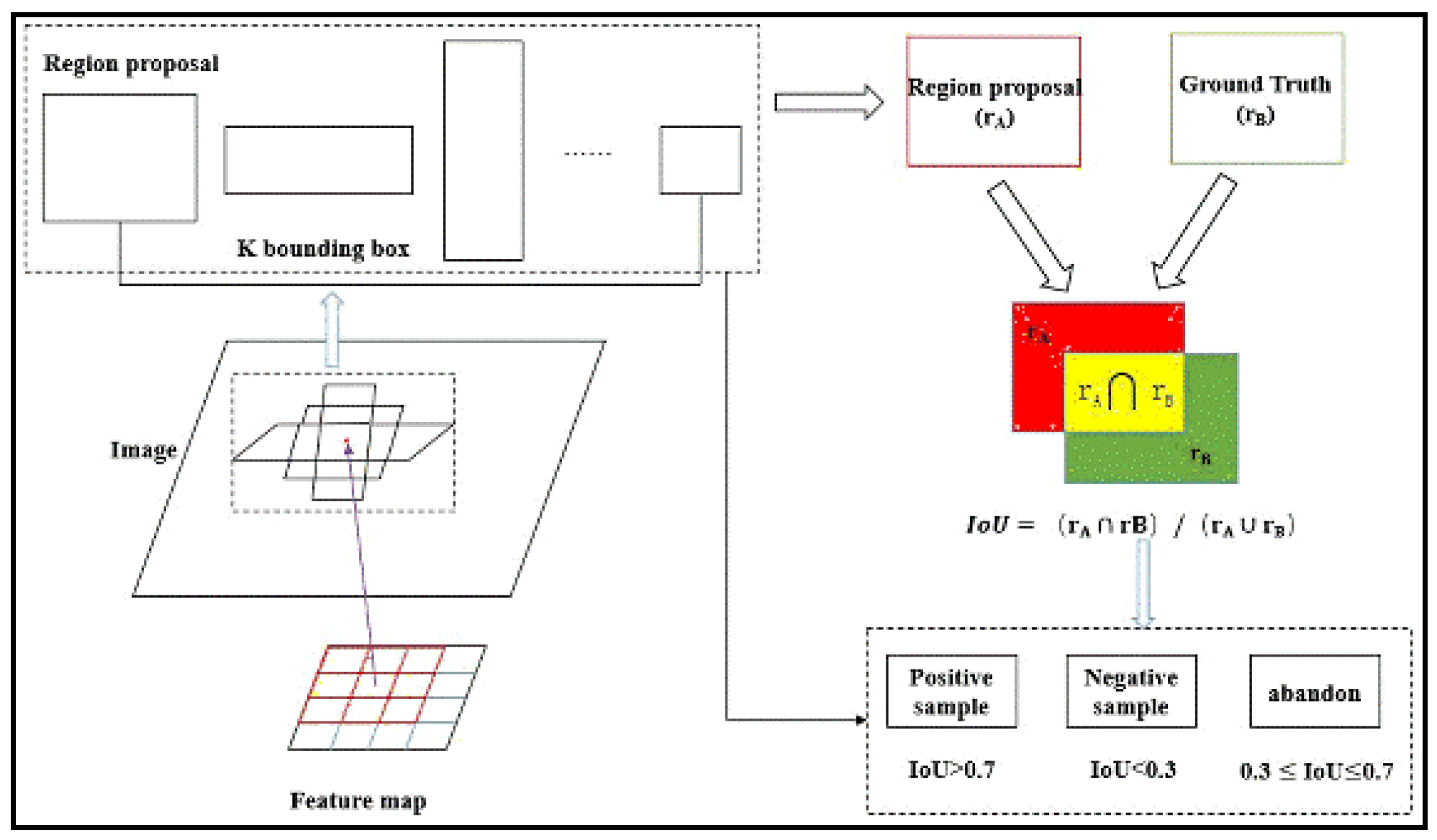
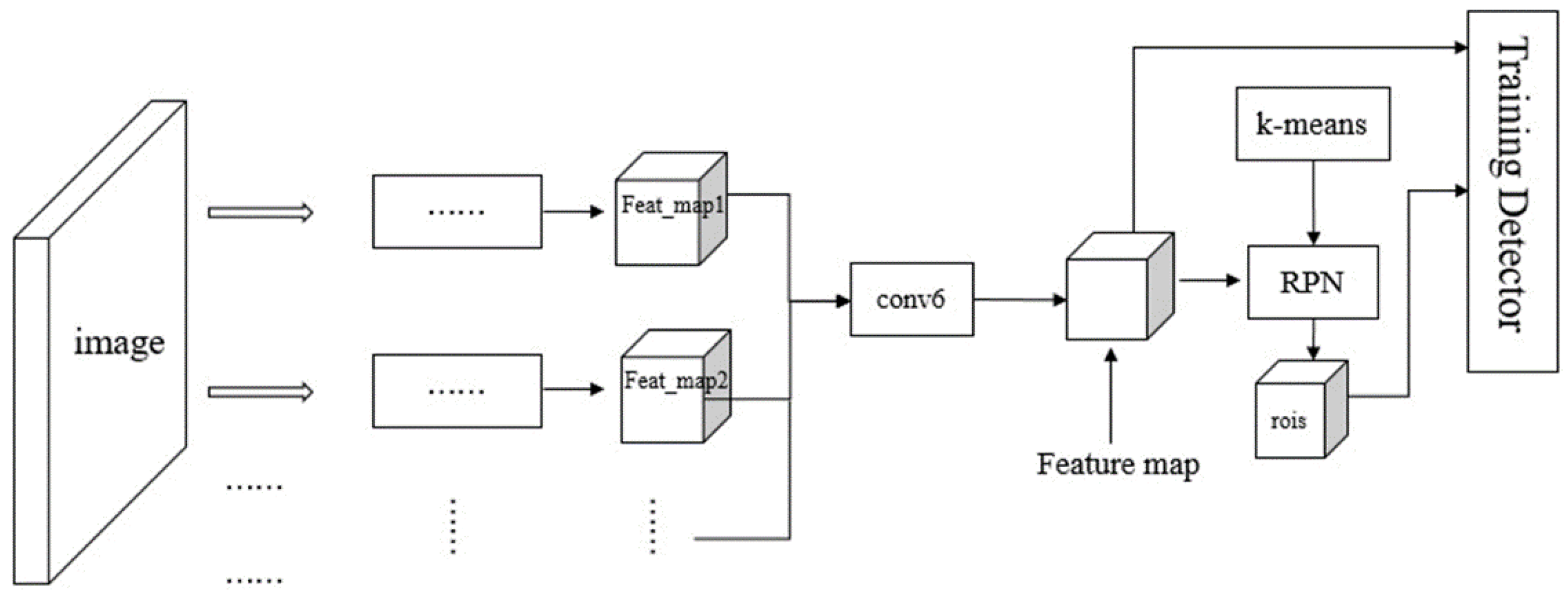
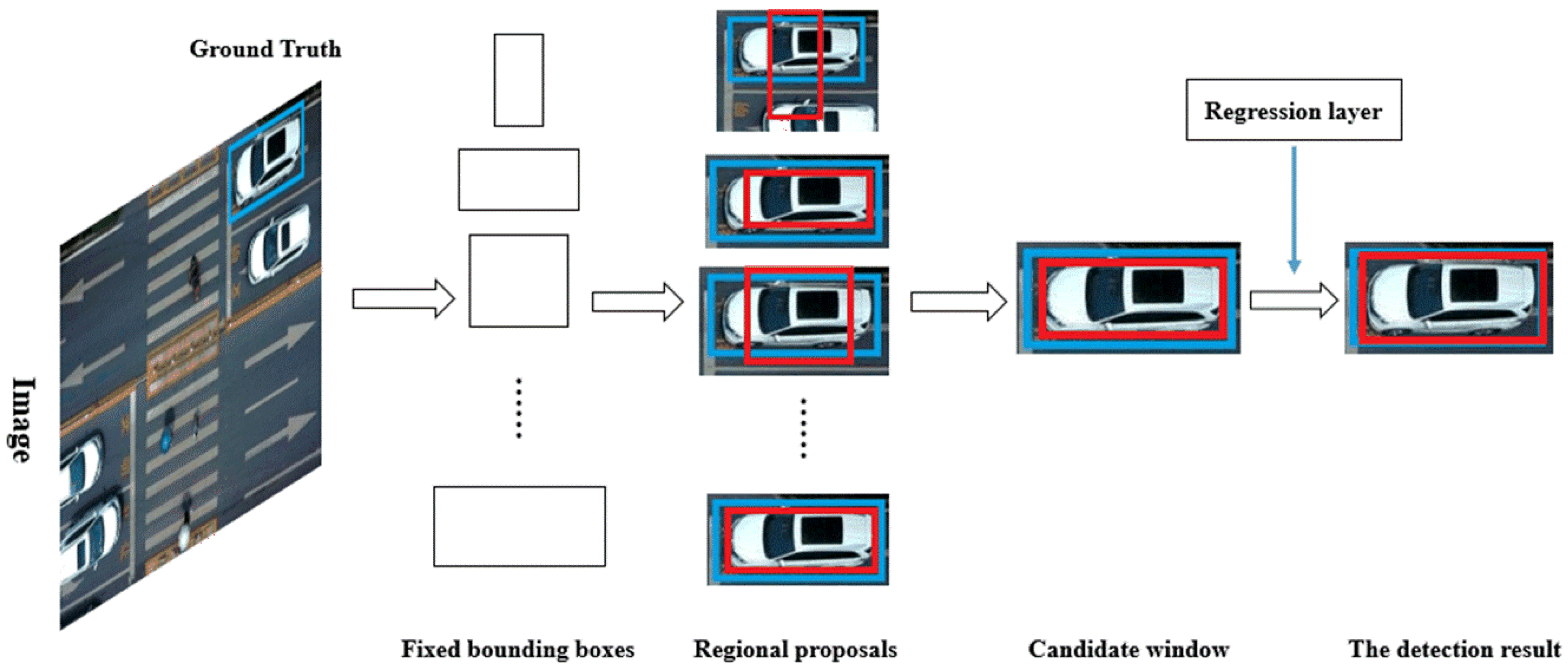
2.1. Region Proposal Networks
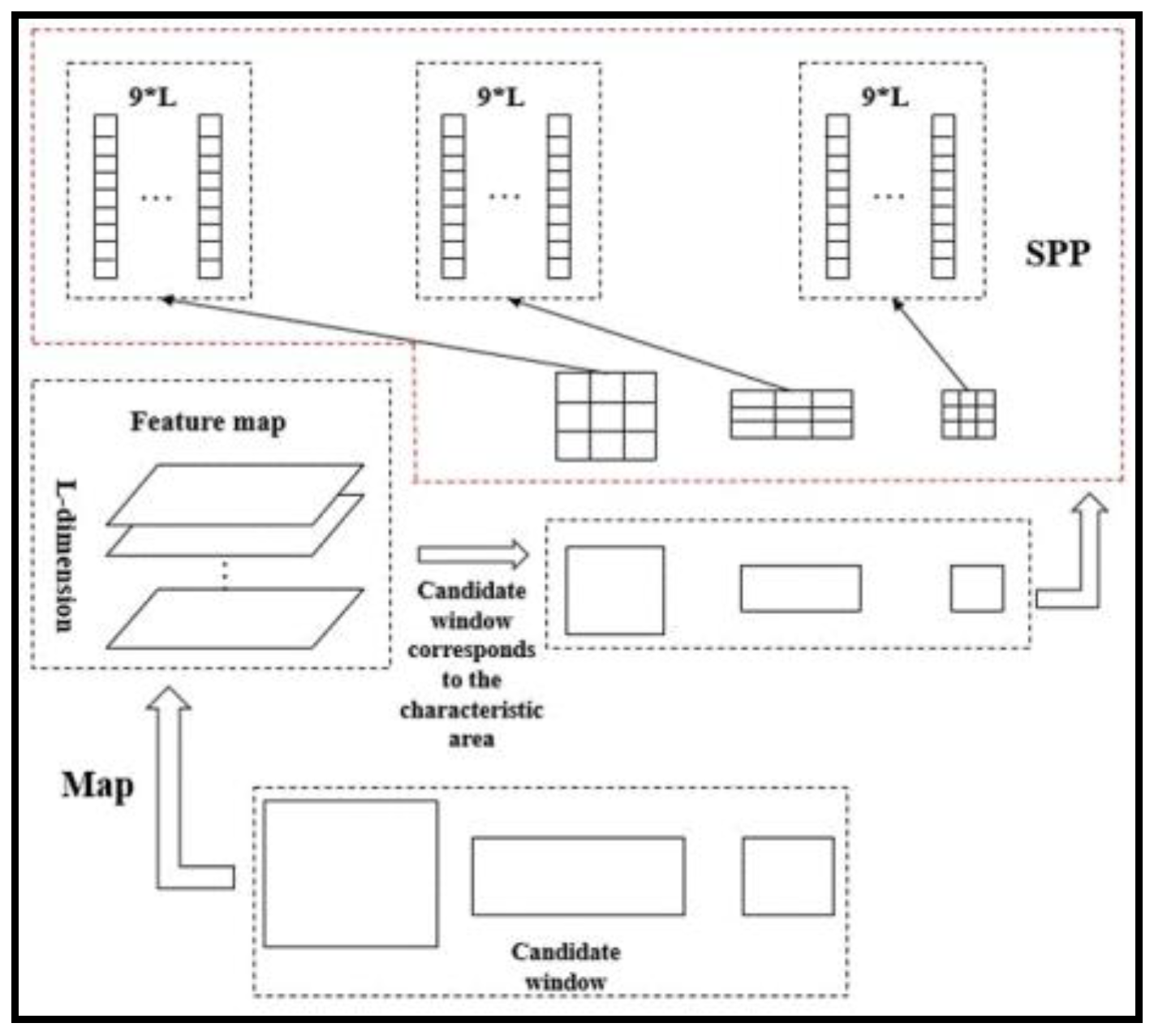
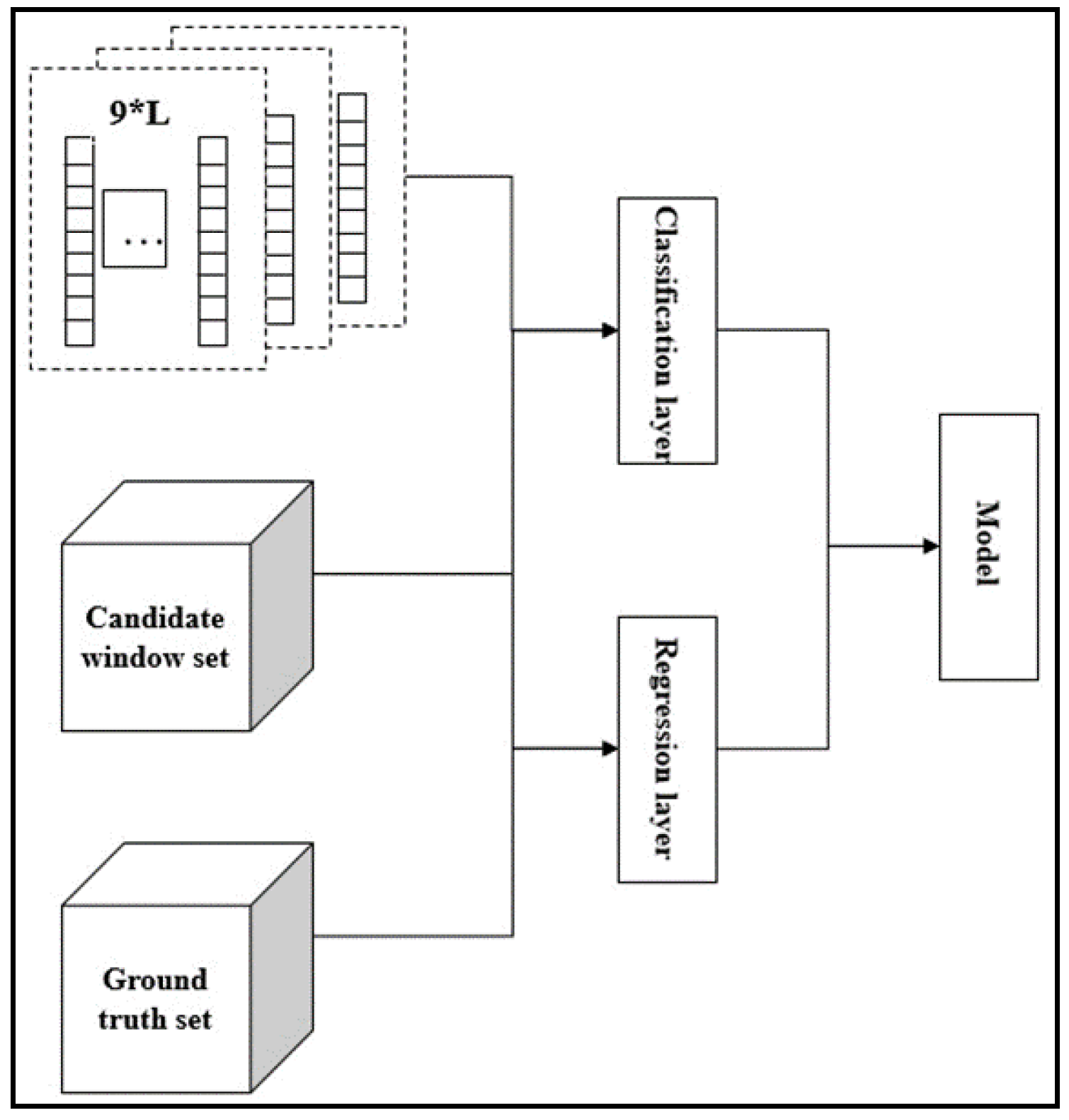
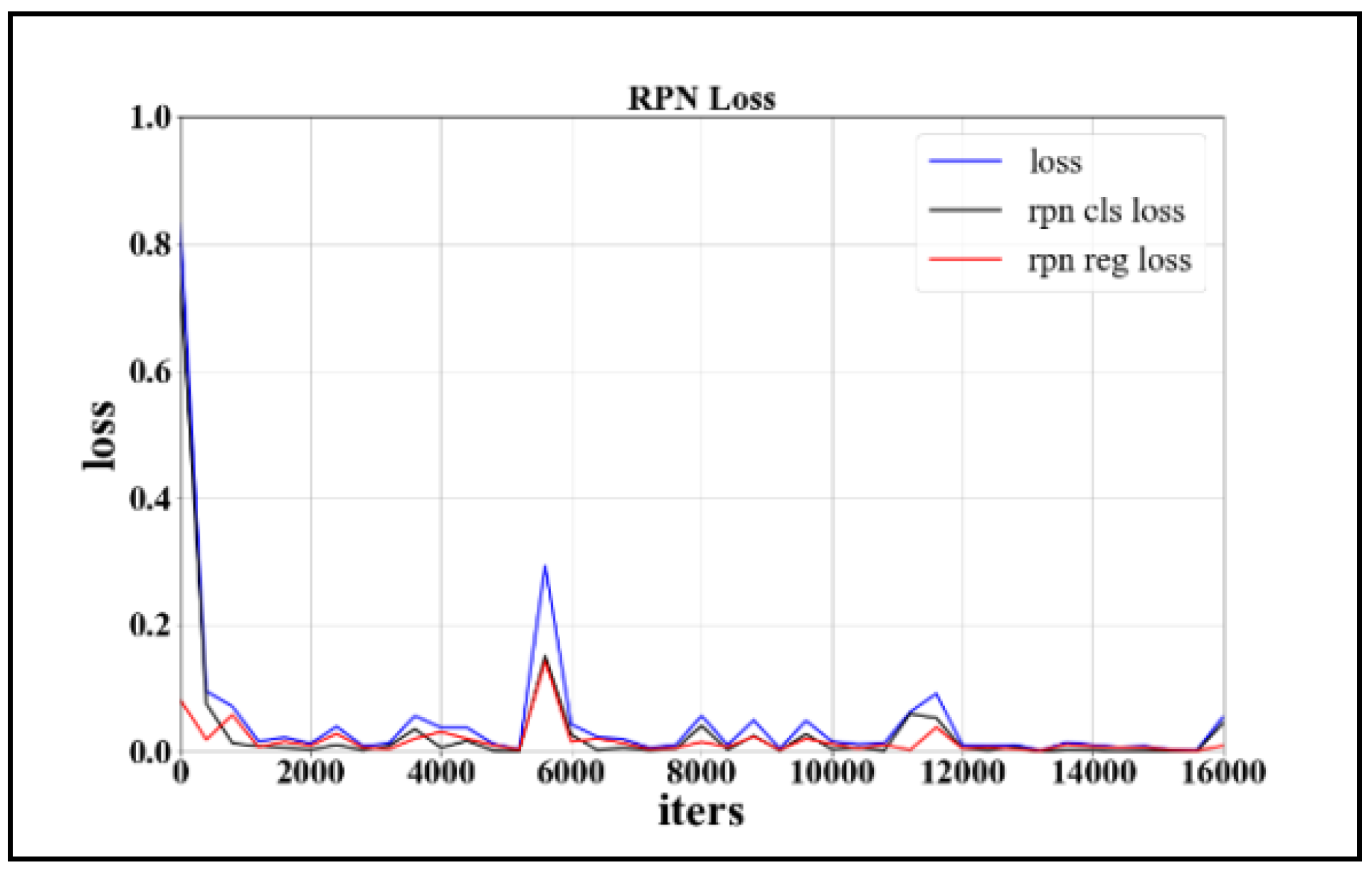
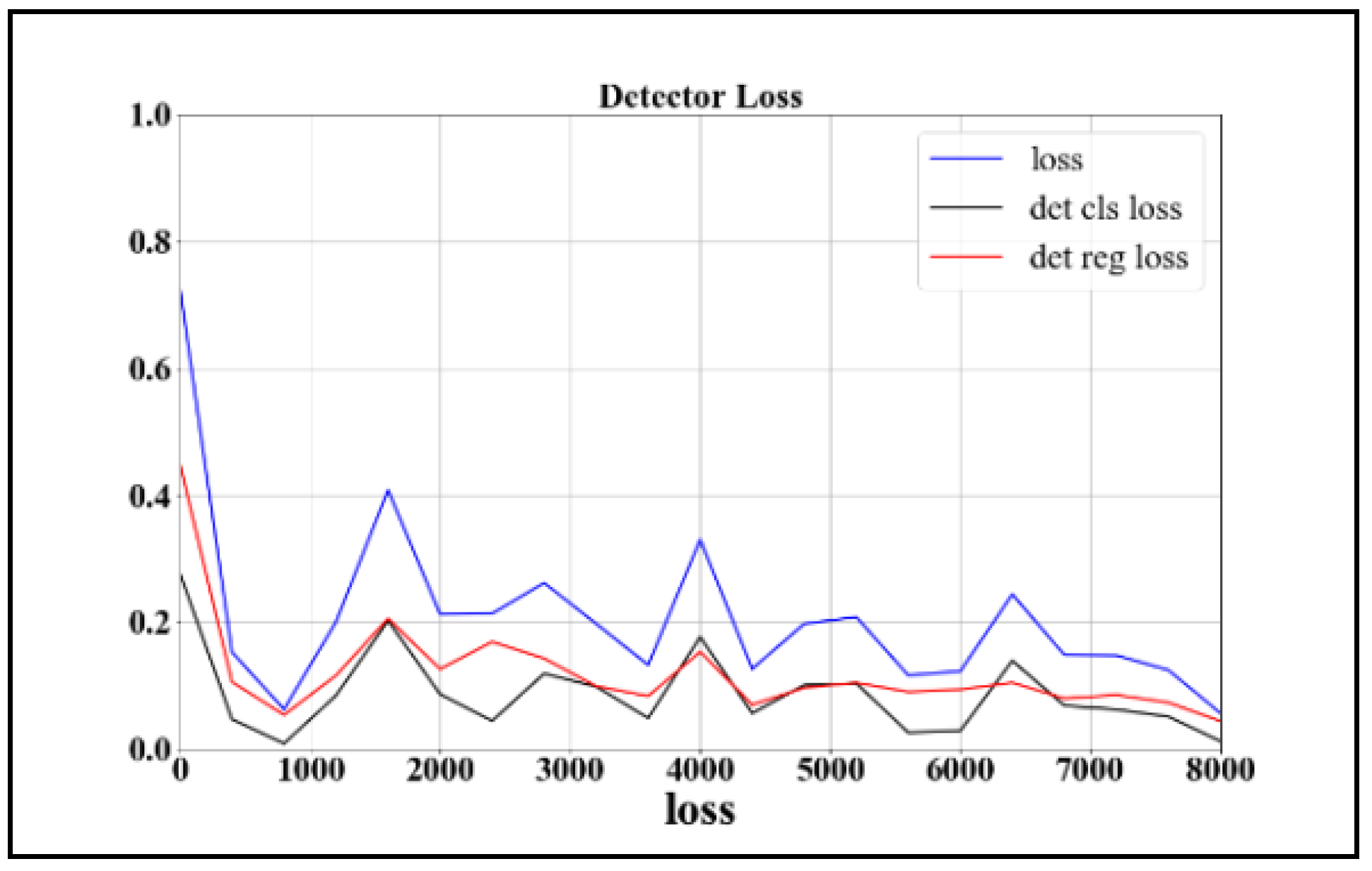
2.2. Training of the Detector
3. Multi-Perspective Convolutional Neural Network
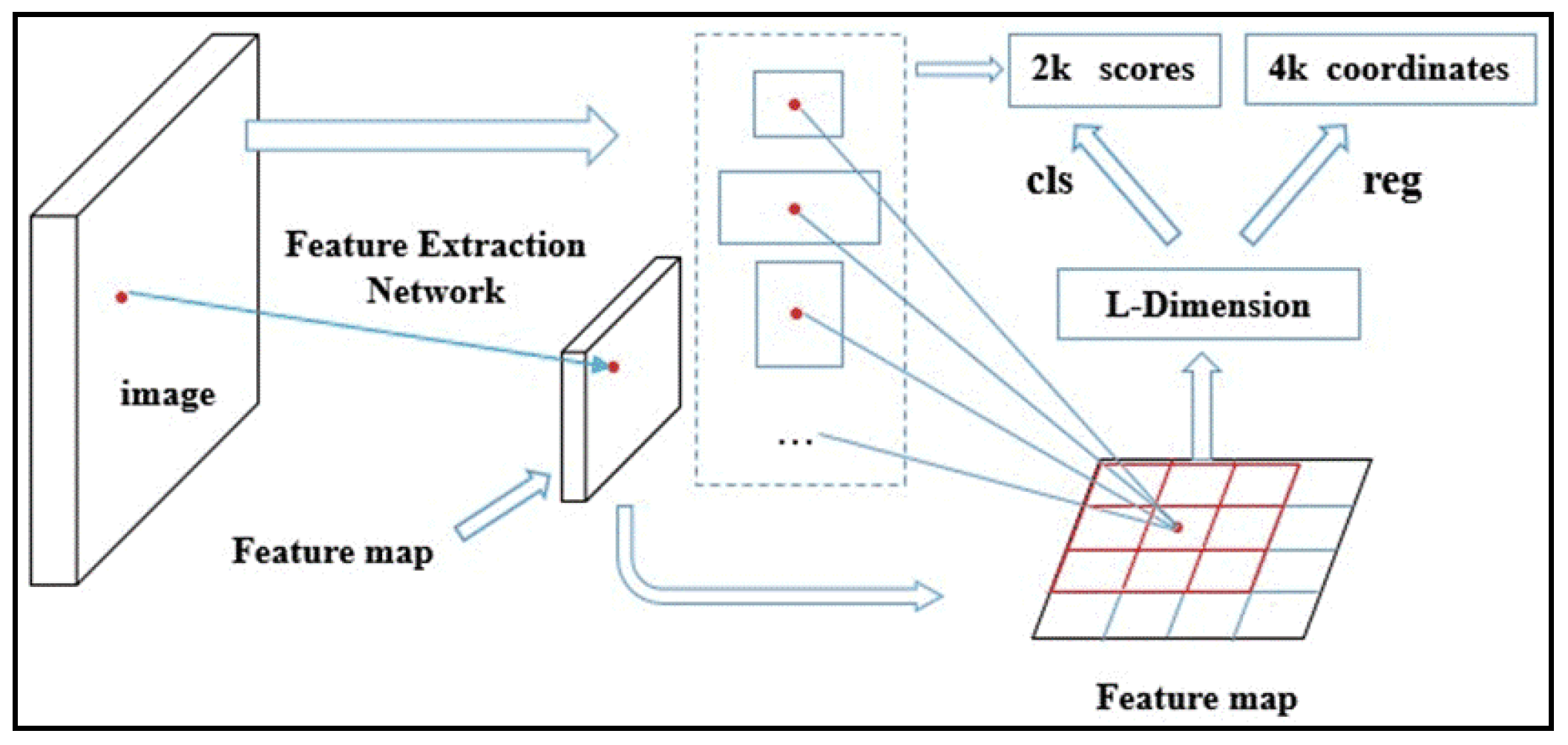
3.1. Feature Extraction Network
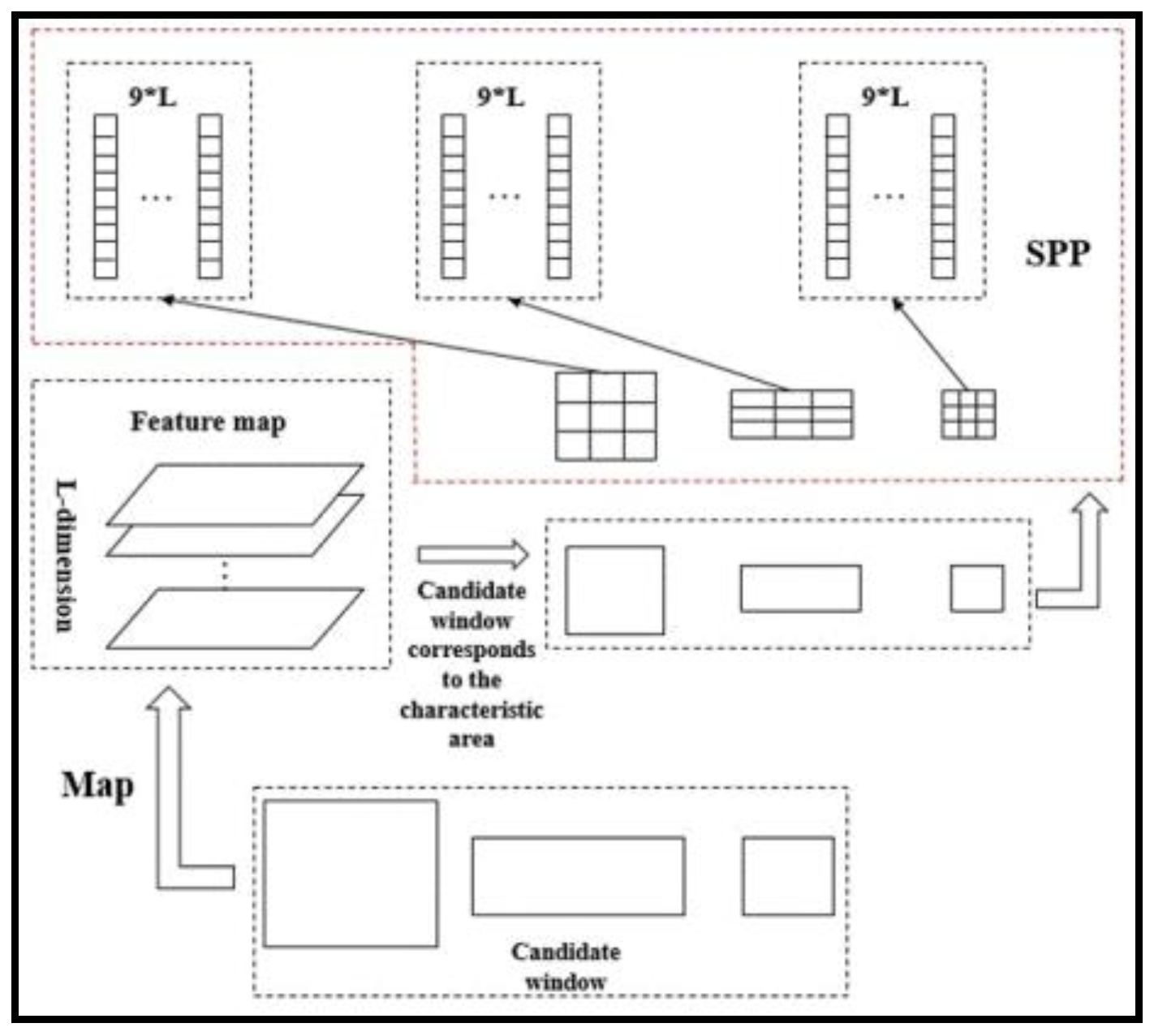
3.2. Obtain Region Proposals
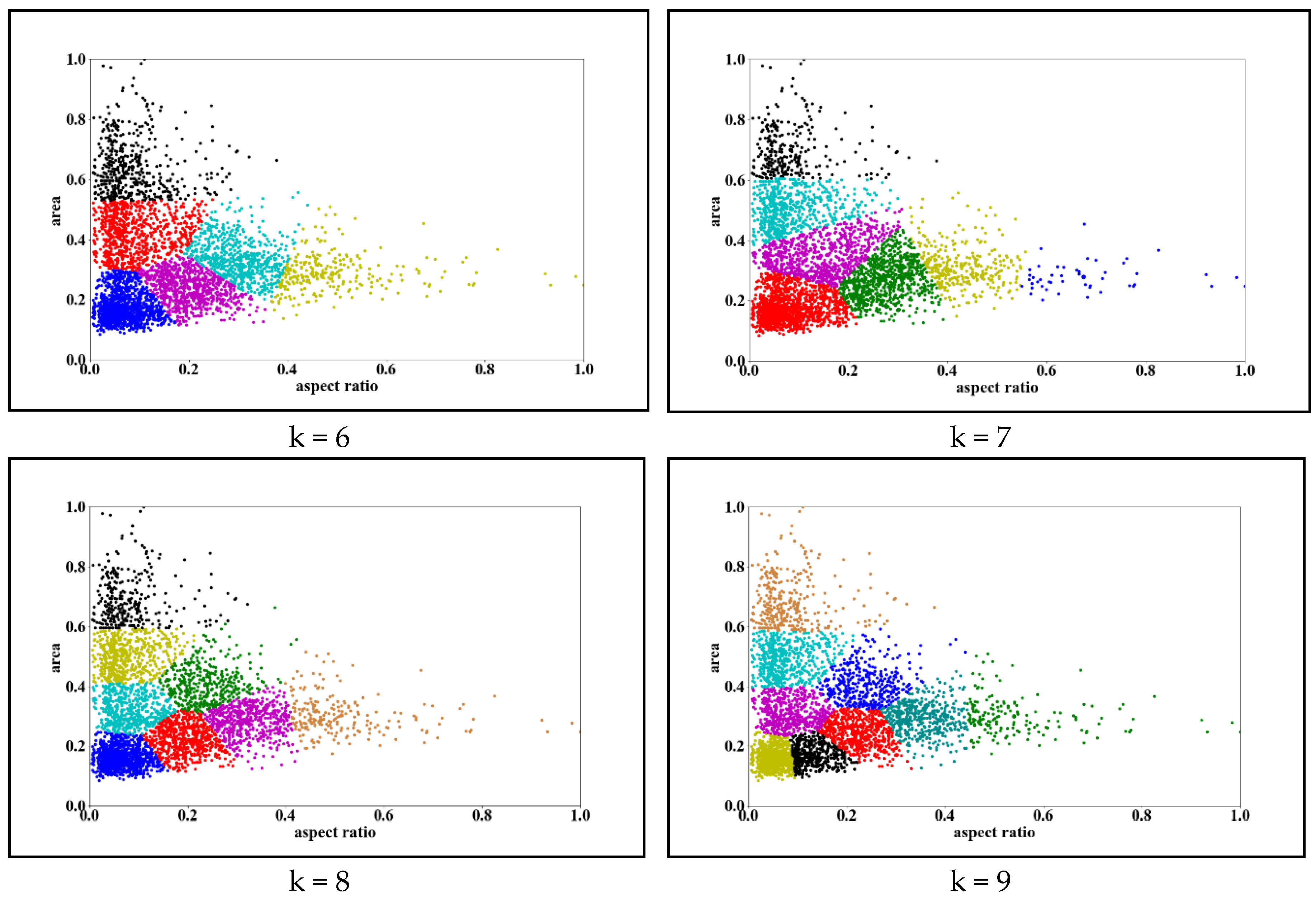
3.3. Performance Analysis of Multi-Perspective Convolutional Network
4. Experiment and Verification
4.1. Experimental Dataset
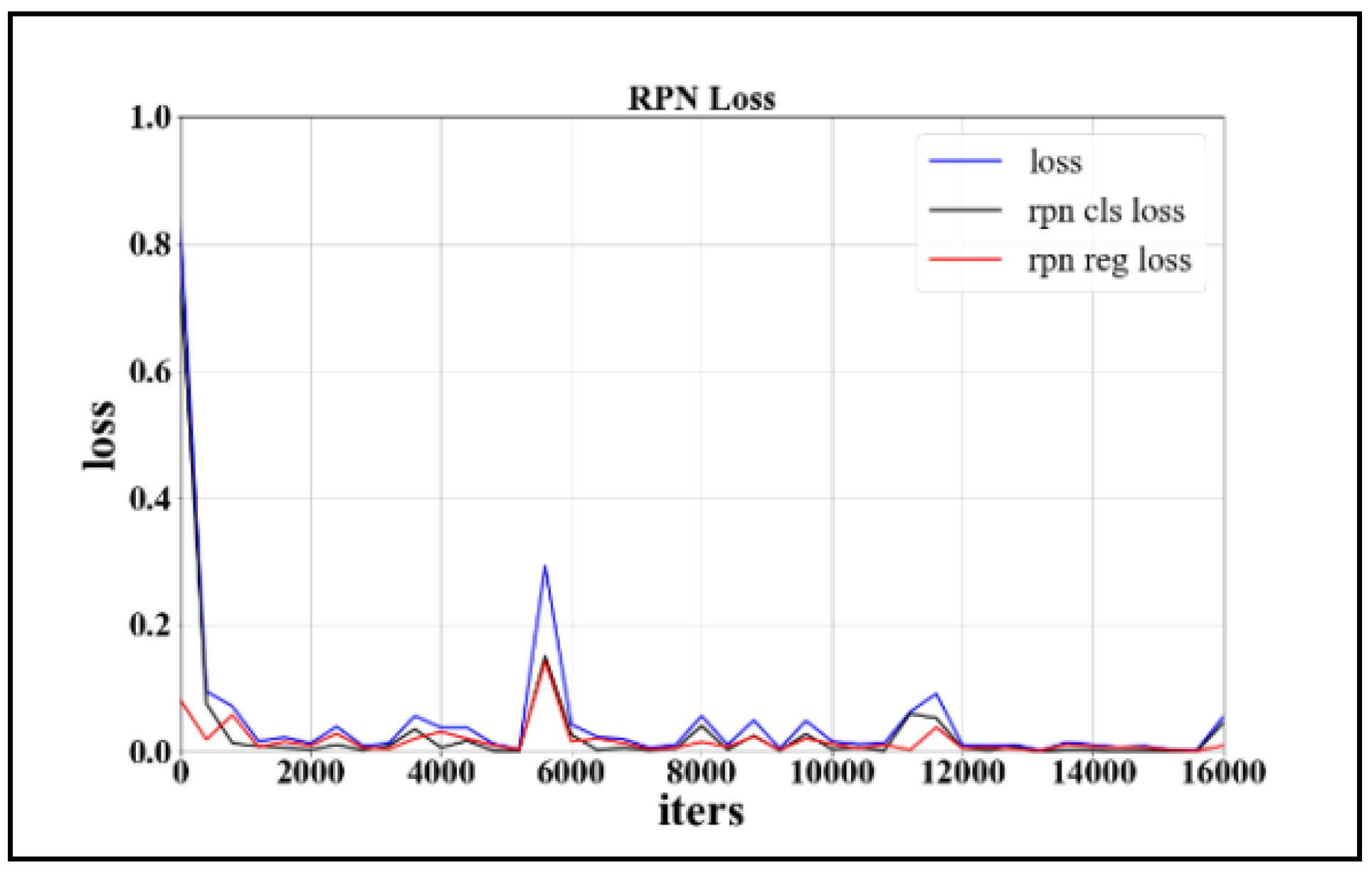
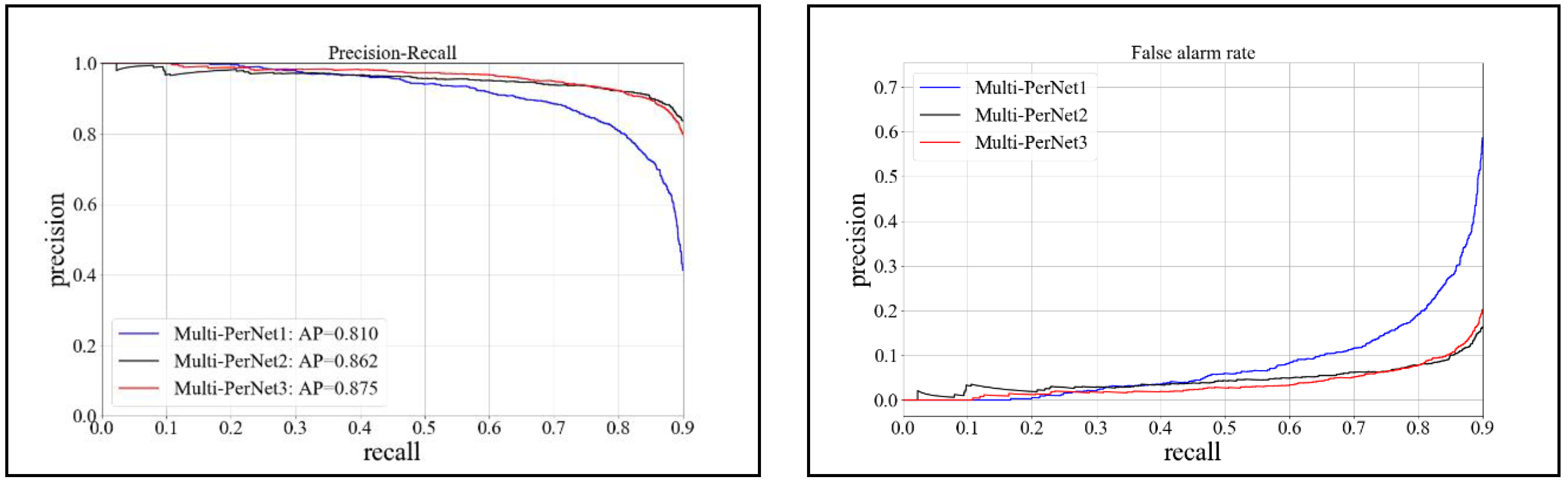
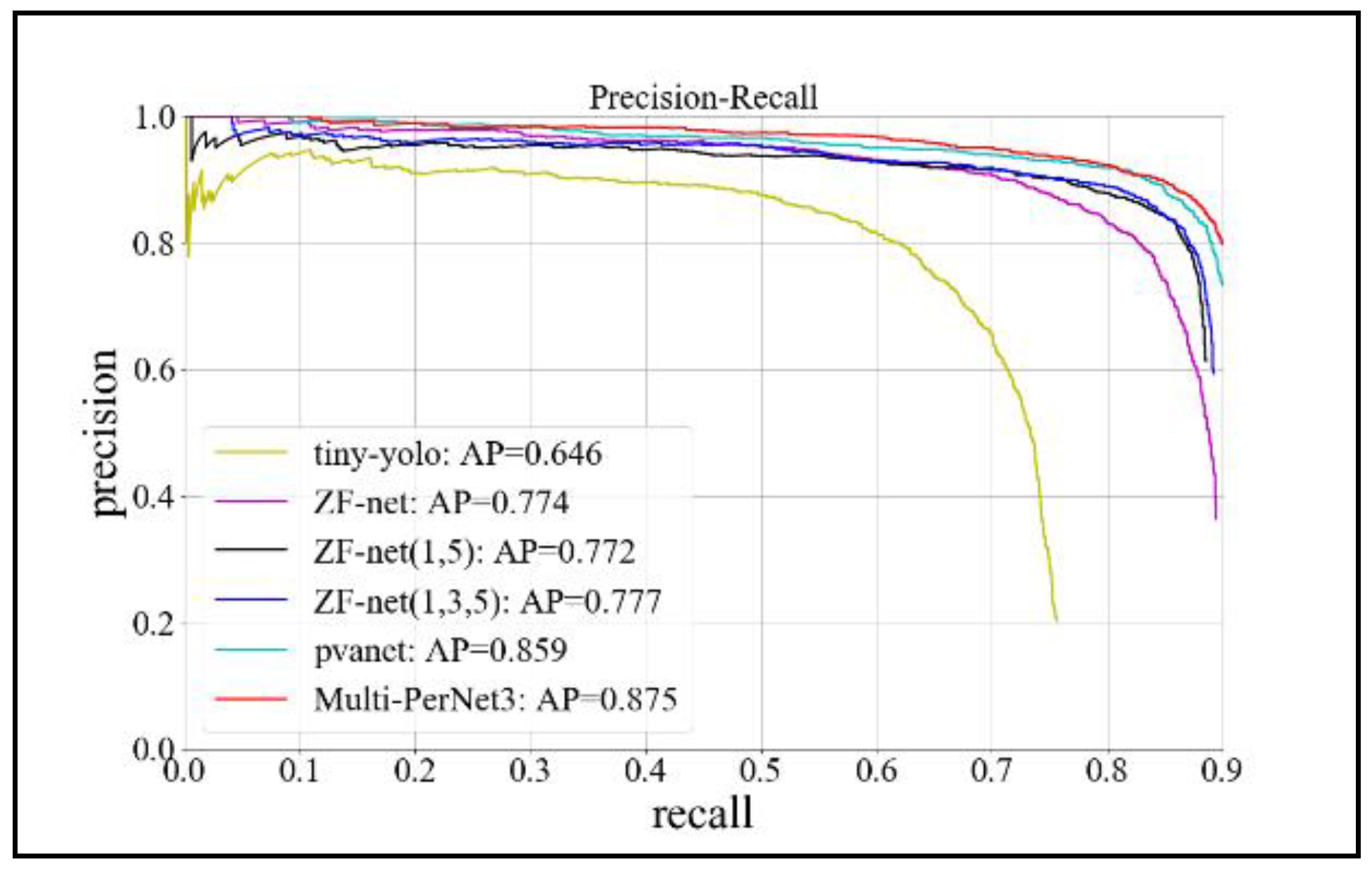
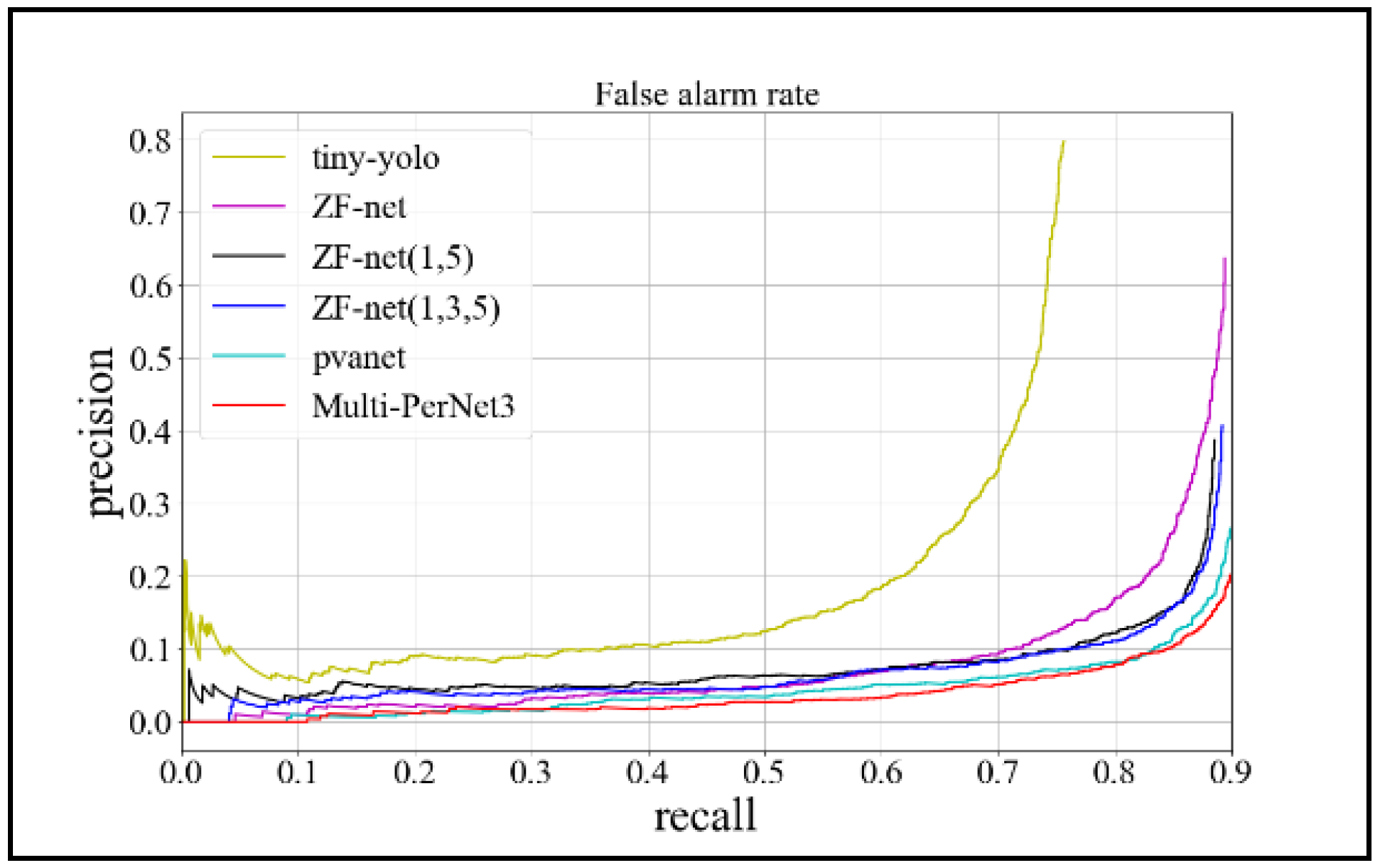
4.2. Evaluation of Test Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, Z.A. Study on Harbor Target Recognition in High Resolution Optical Remote Sensing Image; University of Science and Technology of China: Hefei, China, 2005. [Google Scholar]
- Zhen, L.; Tao, F.; Hong, H.; Li, D. Rotation invariant object detection of remotely sensed images based on Texton Forest and Hough Voting. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1206–1217. [Google Scholar]
- Wang, H. Improvement of the recognition probability about camouflage target based on BP neural network. Spectrosc. Spectr. Anal. 2010, 30, 3316–3319. [Google Scholar]
- Duan, S.; Li, J.-H.; Xu, W.-P.; Liu, X.; Shang, Z.-E. Moving object detection algorithm based on match time. Compet. Eng. 2013, 39, 192–195. [Google Scholar]
- Alba-Flores, R. Evaluation of the Use of High—Resolution Satellite Imagery in Transportation Applications; Department of Electrical and Computer Engineering, University of Minnesota: Duluth, MN, USA, 2005. [Google Scholar]
- Li, Y.; Peng, J. Feature Extraction of the Harbor Target and Its Recognition. J. Huazhong Univ. Sci. Technol. 2001, 29, 10–12. [Google Scholar]
- Zeng, J.; Fu, J.; Fu, X. Aircraft target recognition in remote sensing images based on distribution of the feature points and invariant moments. J. Image Gr. 2014, 19, 593–603. [Google Scholar]
- Qi, S.; Ma, J.; Lin, J.; Li, Y.; Tian, J. Unsupervised ship detection based on saliency and s-hog descriptor from optical satellite images. Geosci. Remote Sens. Lett. 2015, 12, 1451–1455. [Google Scholar]
- Huang, J.; Jiang, Z.; Zhang, H.; Yao, Y. Ship detection in remote sensing images using convolutional neural networks. J. Beijing Univ. Aeronaut. Astronaut. 2017, 43, 1–7. [Google Scholar]
- Yao, X.; Wan, L.; Huo, H. Airplane object detection in high resolution remote sensing imagery based on multi-structure convolutional neural network. Comput. Eng. 2017, 43, 259–267. [Google Scholar]
- Uijlings, J.R.; Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. IEEE Conf. Comput. Vis. Pattern Recognit. 2014, 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. IEEE Int. Conf. Comput. Vis. 2015, 1440–1448. Available online: http://openaccess.thecvf.com/content_iccv_2015/papers/Girshick_Fast_R-CNN_ICCV_2015_paper.pdf (accessed on 19 June 2018).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. IEEE Conf. Comput. Vis. Pattern Recognit. 2014, 8689, 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. 2015. Available online: https://arxiv.org/pdf/1409.1556.pdf (accessed on 19 June 2018).
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Shang, W.; Almeida, D.; Almeida, D.; Lee, H. Understanding and improving convolutional neural networks via concatenated rectified linear units. Int. Conf. Int. Mach. Learn. 2016, 48, 2217–2225. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. IEEE Conf. Comput. Vis. Pattern Recognit. 2016, 770–778. [Google Scholar] [CrossRef]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. HyperNet: Towards accurate region proposal generation and joint object detection. IEEE Conf. Comput. Vis. Pattern Recognit. 2016, 845–853. [Google Scholar] [CrossRef]
- Kim, K.H.; Hong, S.; Roh, B.; Cheon, Y.; Park, M. PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection. 2016. Available online: https://arxiv.org/abs/1608.08021 (accessed on 19 June 2018).
- Jie, D.; Hiromitsu, Y.; Hamid Reza, P.; Yunus, A.; Song, X.; Xu, Y.; Zhu, Z. An integrated artificial neural network model for the landslide susceptibility assessment of Osado Island, Japan. J. Nat. Hazards 2015, 78, 1749–1776. [Google Scholar]
- Jie, D.; Kuan-Tsung, C.; Shuisen, C.; Yunus, A.P.; Liu, J.-K.; Xia, H.; Zhu, Z. Automatic Case-Based Reasoning Approach for Landslide Detection: Integration of Object-Oriented Image Analysis and a Genetic Algorithm. J. Remote Sens. 2015, 7, 4318–4342. [Google Scholar] [Green Version]
- Jie, D.; Xia, L.; Yunus, A.P.; Paudel, U.; Chang, K.-T.; Zhu, Z.; Pourghasemi, H.R. Automatic detection of sinkhole collapses at finer resolutions using a multi-component remote sensing approach. J. Nat. Hazards 2015, 78, 1021–1044. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. Unified multi-scale deep convolutional neural network for fast object detection. Eur. Conf. Comput. 2016, 354–370. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. 2016. Available online: http://openaccess.thecvf.com/content_cvpr_2017/papers/Redmon_YOLO9000_Better_Faster_CVPR_2017_paper.pdf (accessed on 19 June 2018).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Centroid | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| Normalized area | 0.34 | 0.23 | 0.21 | 0.07 | 0.07 | 0.19 | 0.07 | 0.53 | 0.08 |
| Normalized aspect ratio | 0.30 | 0.45 | 0.21 | 0.30 | 0.51 | 0.30 | 0.15 | 0.30 | 0.67 |
| Area | 14,133 | 9692 | 8949 | 2941 | 2942 | 8009 | 2720 | 22,135 | 3190 |
| Aspect ratio | 1.0 | 1.5 | 0.7 | 1.0 | 1.7 | 1.0 | 0.5 | 1.0 | 2.3 |
| Resolution | Image Size | Number of Images | Number of Objects | Number of Training Samples |
|---|---|---|---|---|
| 0.6 m | Max: 734 × 464 Min: 151 × 105 | 1000 | 4300 | 500 |
| Convolutional Layer | Conv1 | Conv2 | Conv3 | Conv4 | Conv5 | Conv6 |
|---|---|---|---|---|---|---|
| Convolution kernel size | 9 × 9 | 7 × 7 | 5 × 5 | 3 × 3 | null | null |
| 7 × 7 | 5 × 5 | 3 × 3 | 3 × 3 | 3 × 3 | 3 × 3 | |
| 5 × 5 | 3 × 3 | 3 × 3 | 3 × 3 | null | null | |
| Stride | 2 | 2 | 2 | 1 | null | null |
| 2 | 2 | 1 | 1 | 1 | 1 | |
| 2 | 2 | 1 | 1 | null | null | |
| pad | 4 | 3 | 2 | 1 | null | null |
| 3 | 2 | 1 | 1 | 1 | 1 | |
| 2 | 1 | 1 | 1 | null | null | |
| Number of convolution kernels | 96 | 256 | 384 | 256 | null | null |
| 96 | 256 | 384 | 256 | 256 | 256 | |
| 96 | 256 | 384 | 256 | null | null |
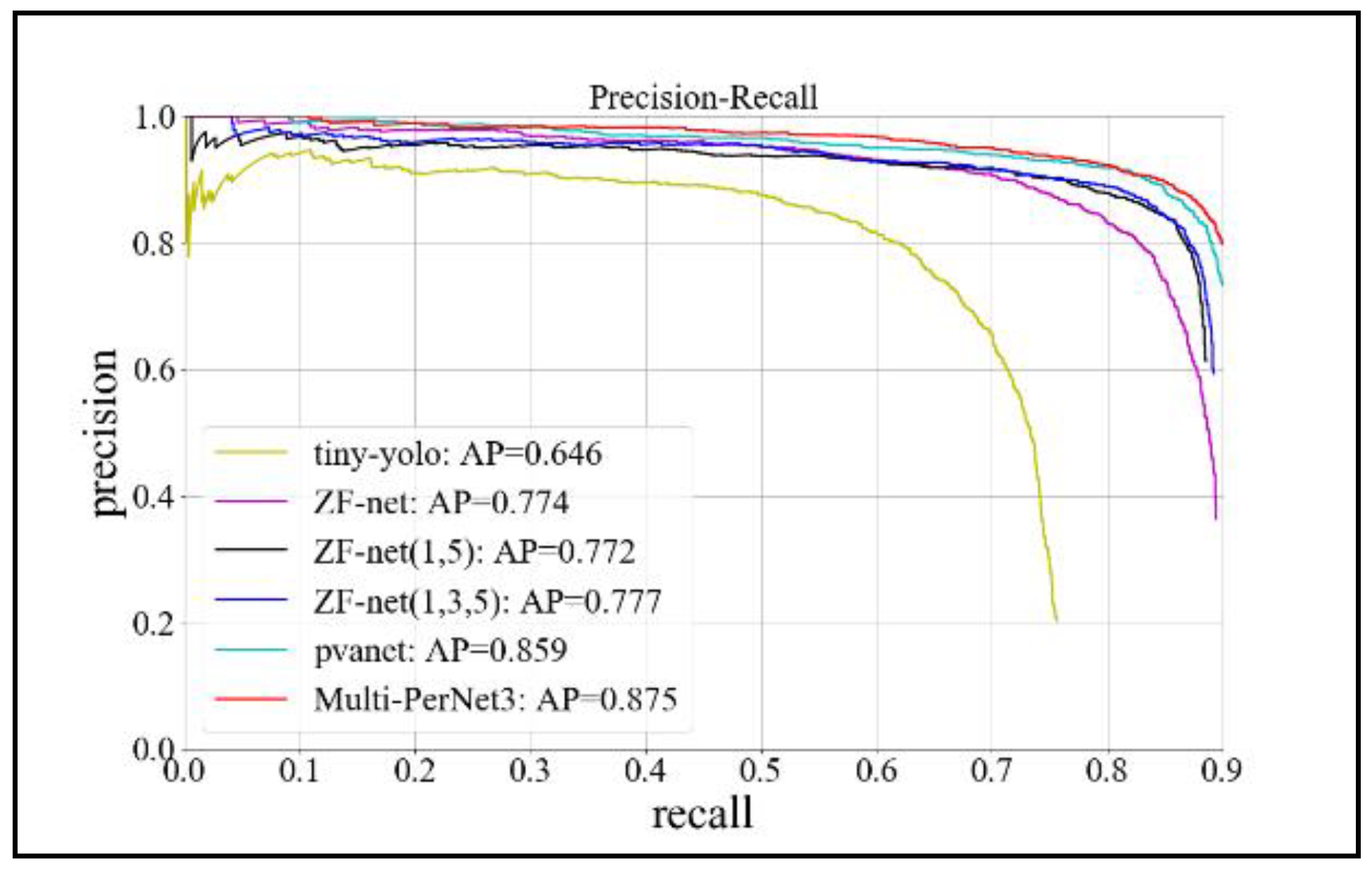
| Framework | Network Structure | Detection Accuracy (AP) | Model Size | Time/Sheet | Recall | False-Alarmate |
|---|---|---|---|---|---|---|
| Yolo [26,27] | tiny-yolo | 0.646 | 63 M | 0.01 s | Max: 0.757 | 0.797 |
| 0.757 | 0.797 | |||||
| Faster R-CNN [15] | ZF-net | 0.774 | 224 M | 0.06 s | Max: 0.894 | 0.637 |
| 0.894 | 0.637 | |||||
| ZF-net (1, 5 joint) | 0.772 | 240 M | 0.08 s | Max: 0.886 | 0.387 | |
| 0.886 | 0.387 | |||||
| ZF-net (1, 3, 5 joint) | 0.777 | 244 M | 0.08 s | Max: 0.892 | 0.407 | |
| 0.892 | 0.407 | |||||
| PVANet | 0.859 | 366 M | 0.053 s | Max: 0.952 | 0.701 | |
| 0.9 | 0.267 | |||||
| Multi-PerNet3 | 0.875 | 288 M | 0.062 s | Max: 0.912 | 0.328 | |
| 0.9 | 0.2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, C.; Li, W.; Lin, Z. Vehicle Object Detection in Remote Sensing Imagery Based on Multi-Perspective Convolutional Neural Network. ISPRS Int. J. Geo-Inf. 2018, 7, 249. https://doi.org/10.3390/ijgi7070249
Yang C, Li W, Lin Z. Vehicle Object Detection in Remote Sensing Imagery Based on Multi-Perspective Convolutional Neural Network. ISPRS International Journal of Geo-Information. 2018; 7(7):249. https://doi.org/10.3390/ijgi7070249
Chicago/Turabian StyleYang, Chenxi, Wenjing Li, and Zhiyong Lin. 2018. "Vehicle Object Detection in Remote Sensing Imagery Based on Multi-Perspective Convolutional Neural Network" ISPRS International Journal of Geo-Information 7, no. 7: 249. https://doi.org/10.3390/ijgi7070249
APA StyleYang, C., Li, W., & Lin, Z. (2018). Vehicle Object Detection in Remote Sensing Imagery Based on Multi-Perspective Convolutional Neural Network. ISPRS International Journal of Geo-Information, 7(7), 249. https://doi.org/10.3390/ijgi7070249