Traffic Command Gesture Recognition for Virtual Urban Scenes Based on a Spatiotemporal Convolution Neural Network

Abstract
:1. Introduction
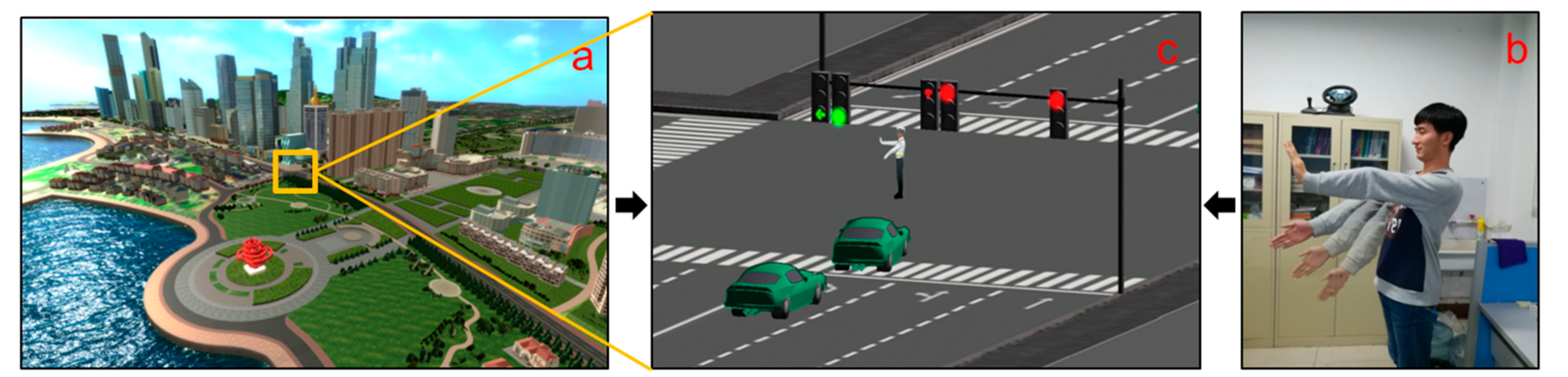
- We built a virtual traffic interaction environment with virtual reality technology. Users can have interactions between their actions and the objects in the virtual traffic environment through a communication interface, experiencing and interacting with “real traffic crossroads.”
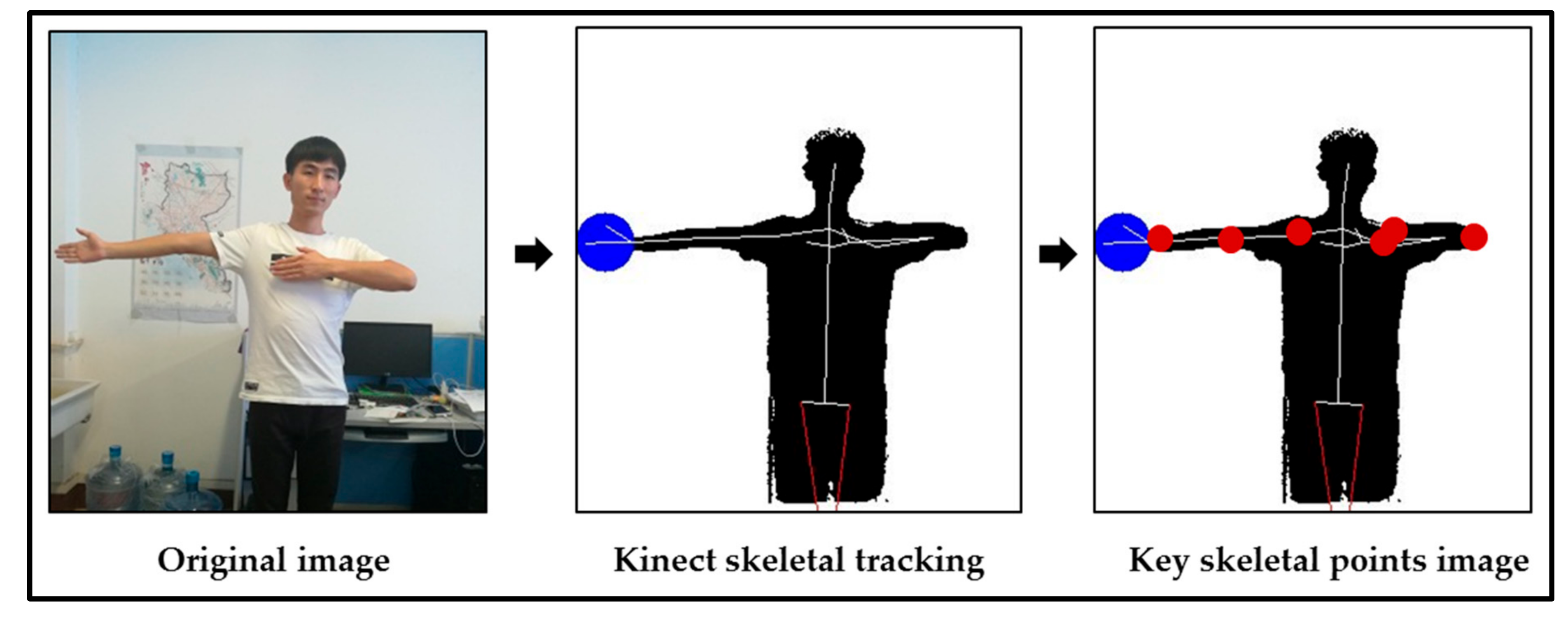
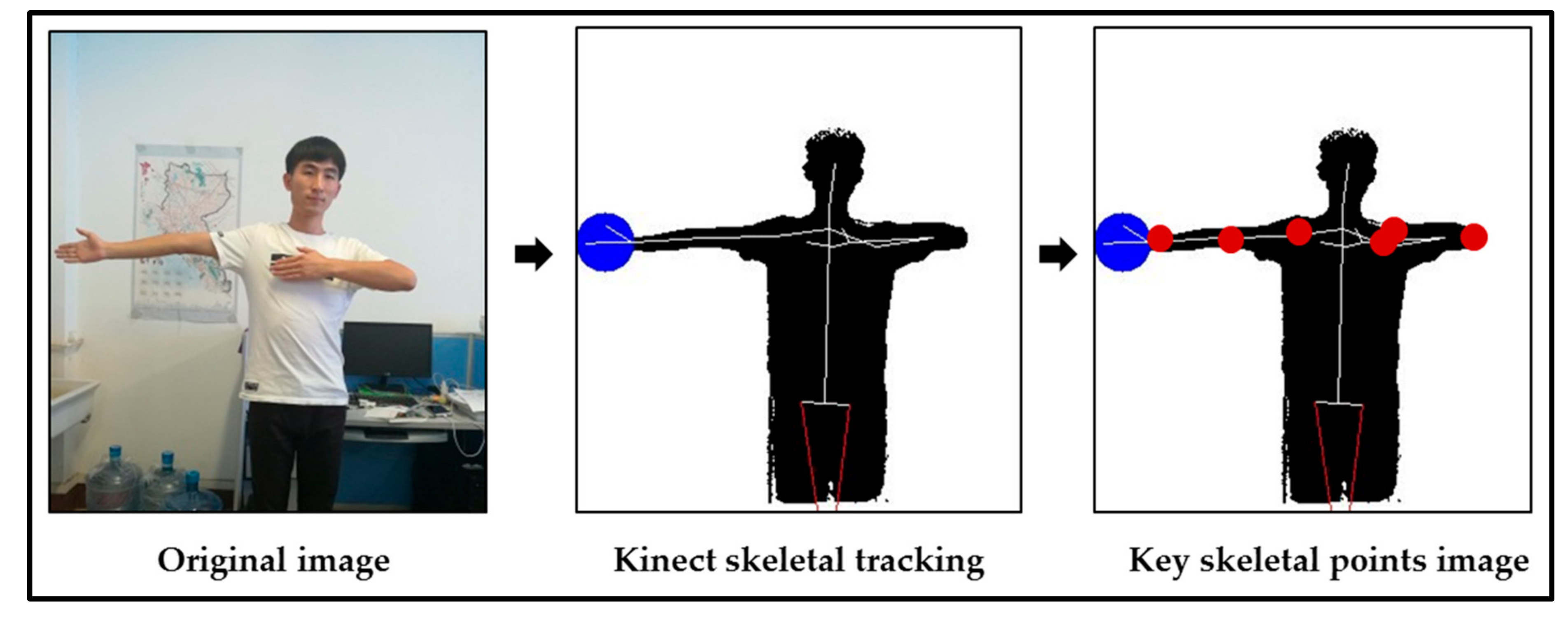
- We created a TPCGS dataset. The dataset uses depth trajectory data based on skeleton points. Compared with the video stream, the depth trajectory data features are more precise. The dataset provides a new means of identifying traffic police command gestures.
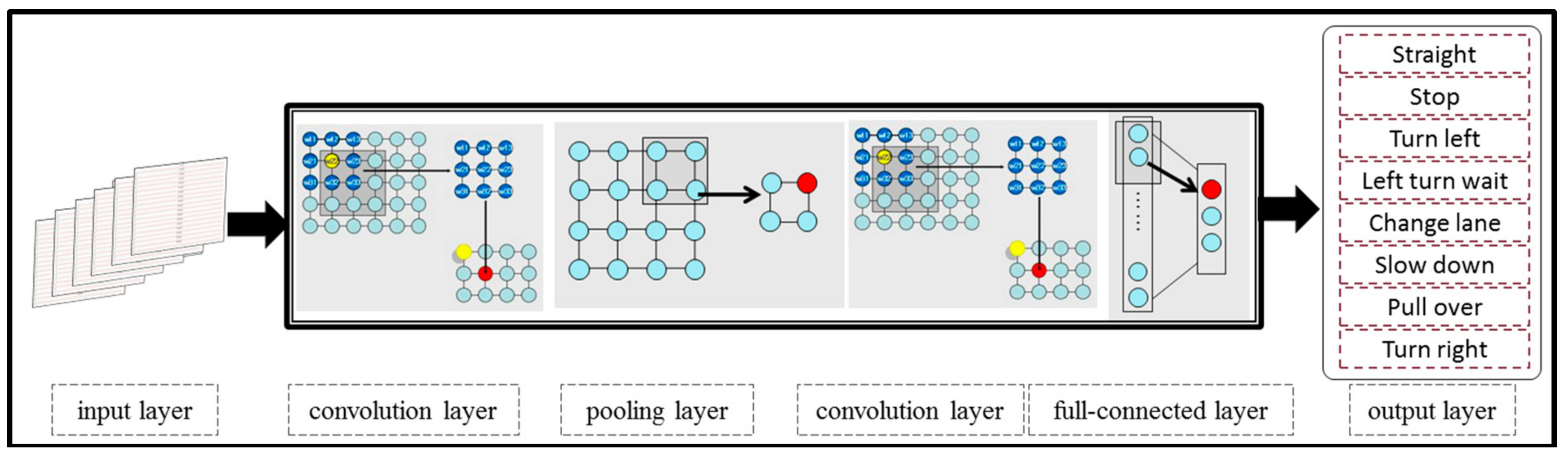
- The ST-CNN model performs convolution operations on 3D position data well and has strong portability. A convolution kernel extracts temporal features of the skeleton point positional information from consecutive frames and extracts spatial features from the relationship between multiple skeleton points.
2. Related Work
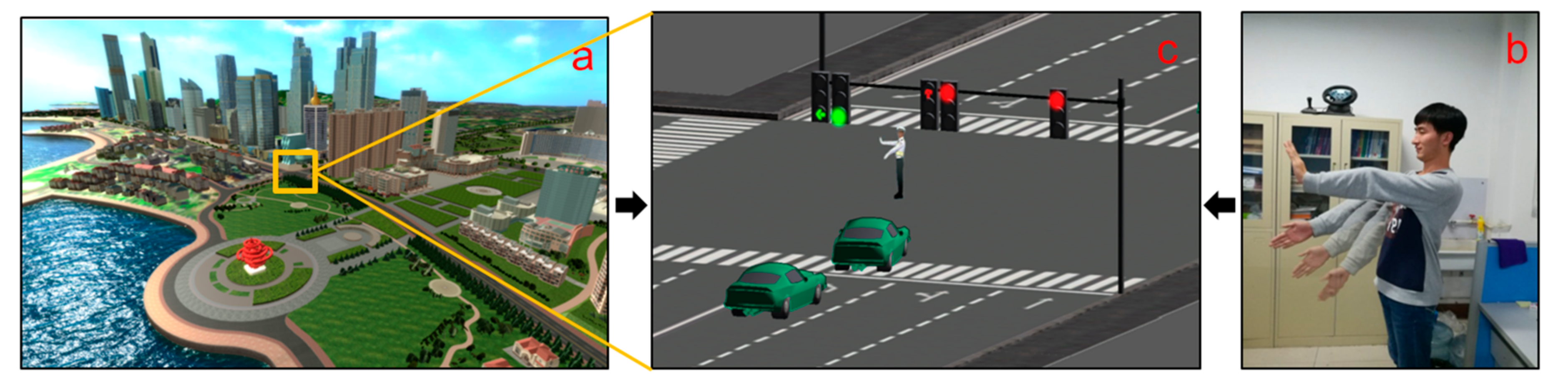
3. Virtual Urban Traffic Environment
4. The TPCGS Dataset
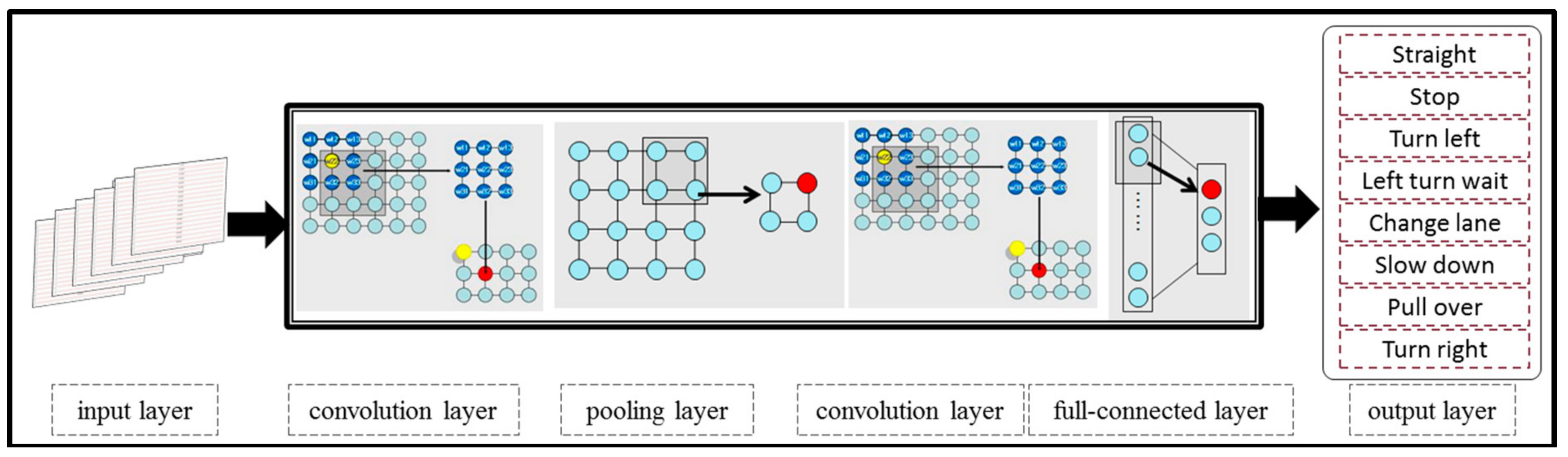
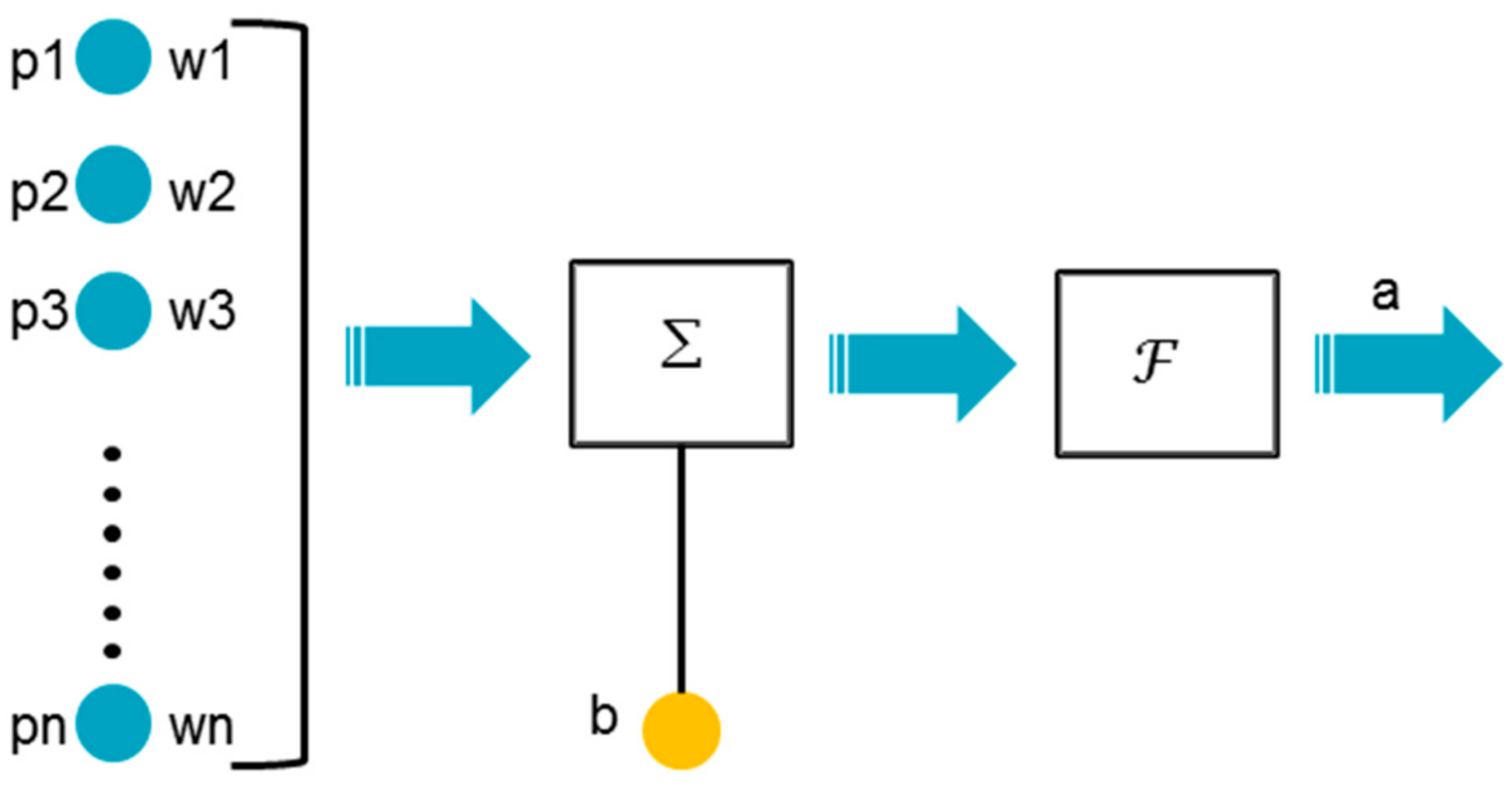
5. A Novel Spatiotemporal Convolution Neural Network Model
6. Experiments
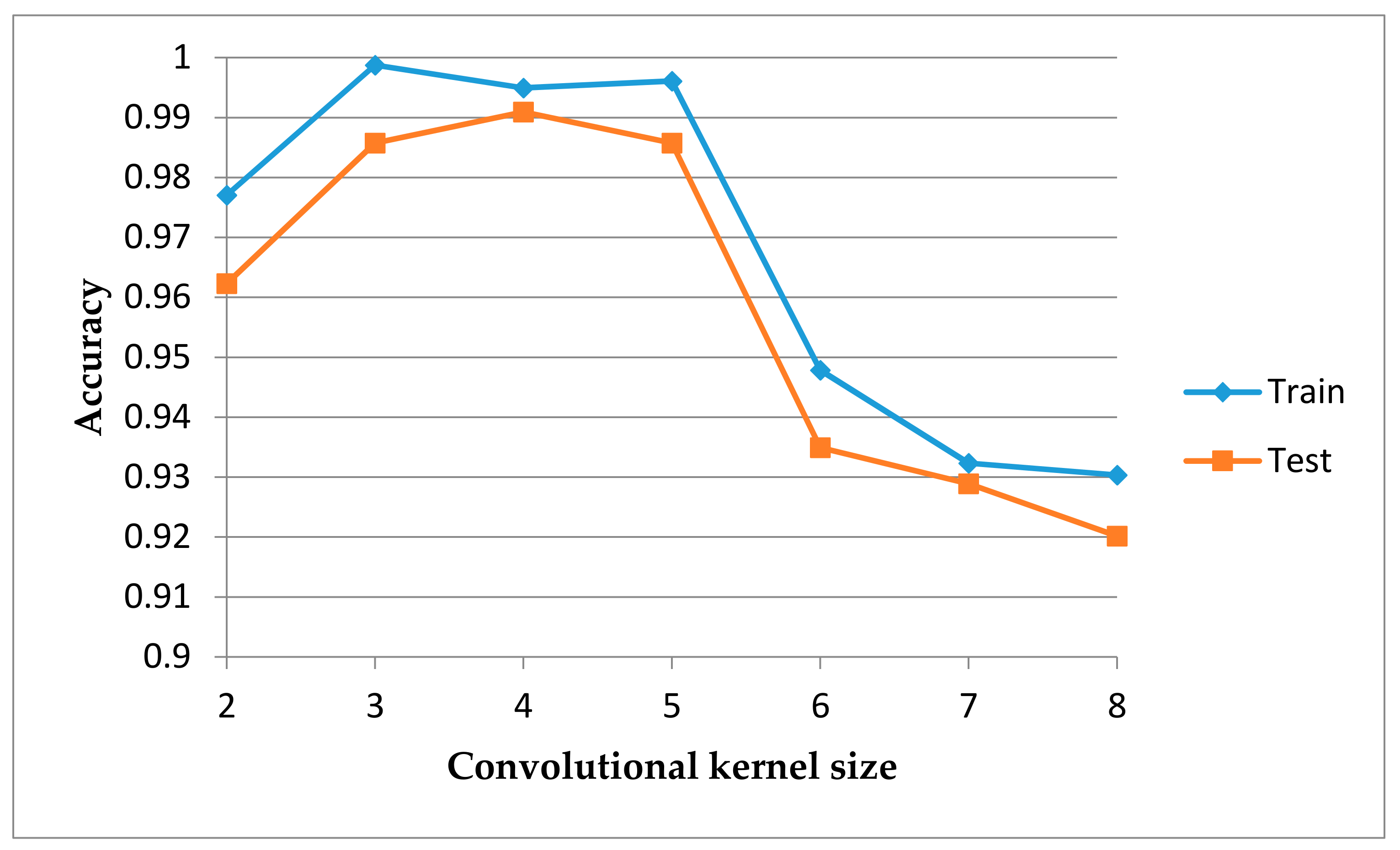
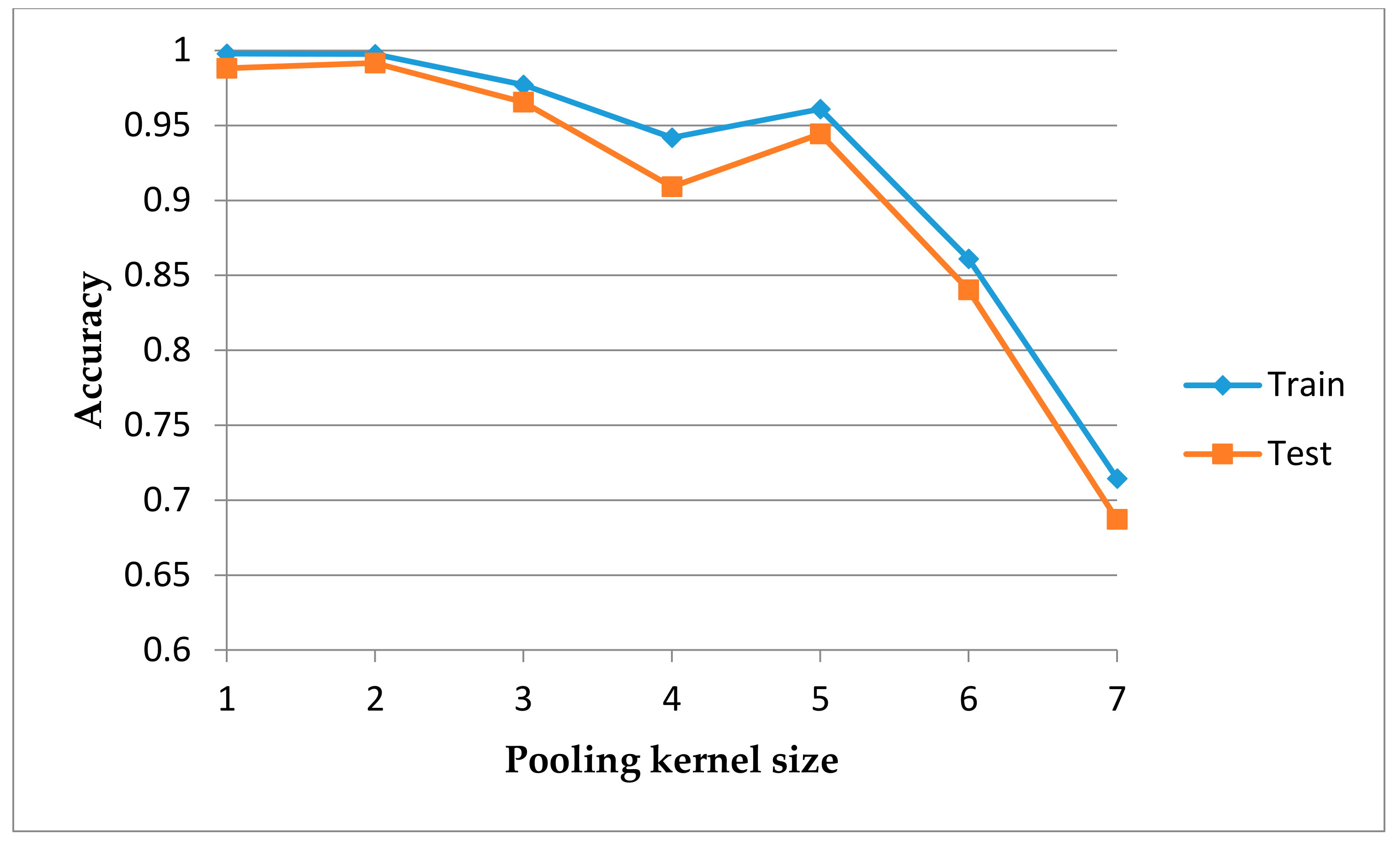
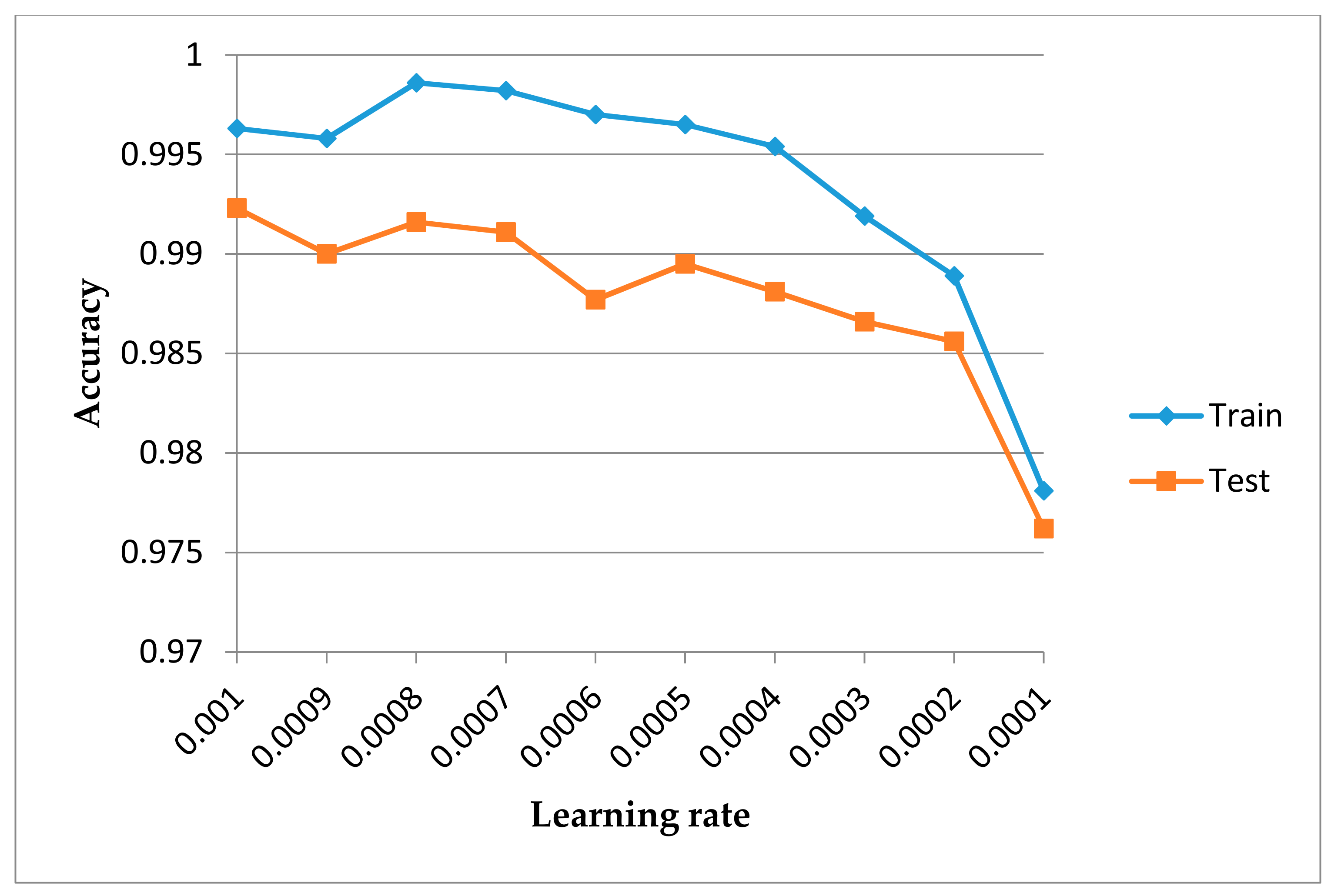
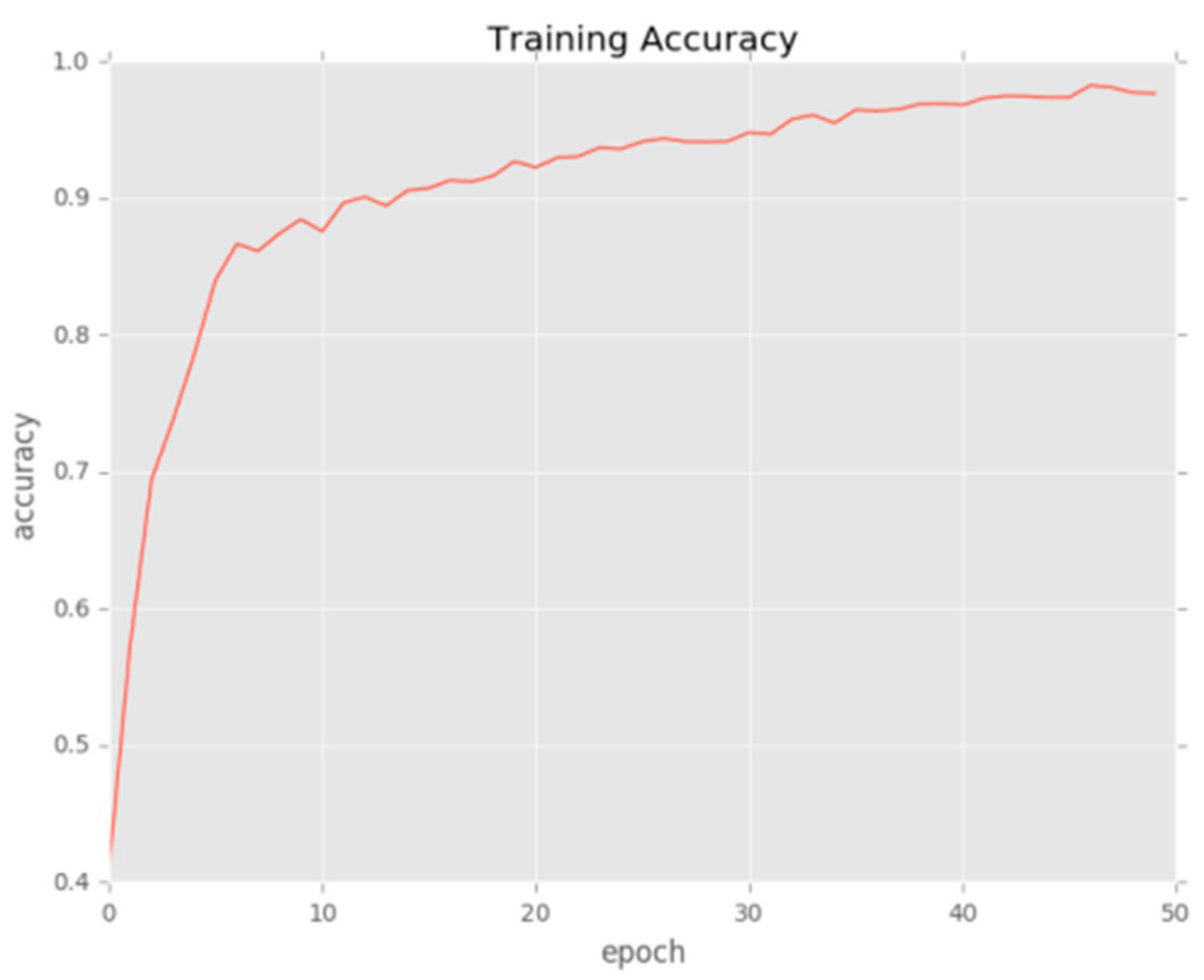
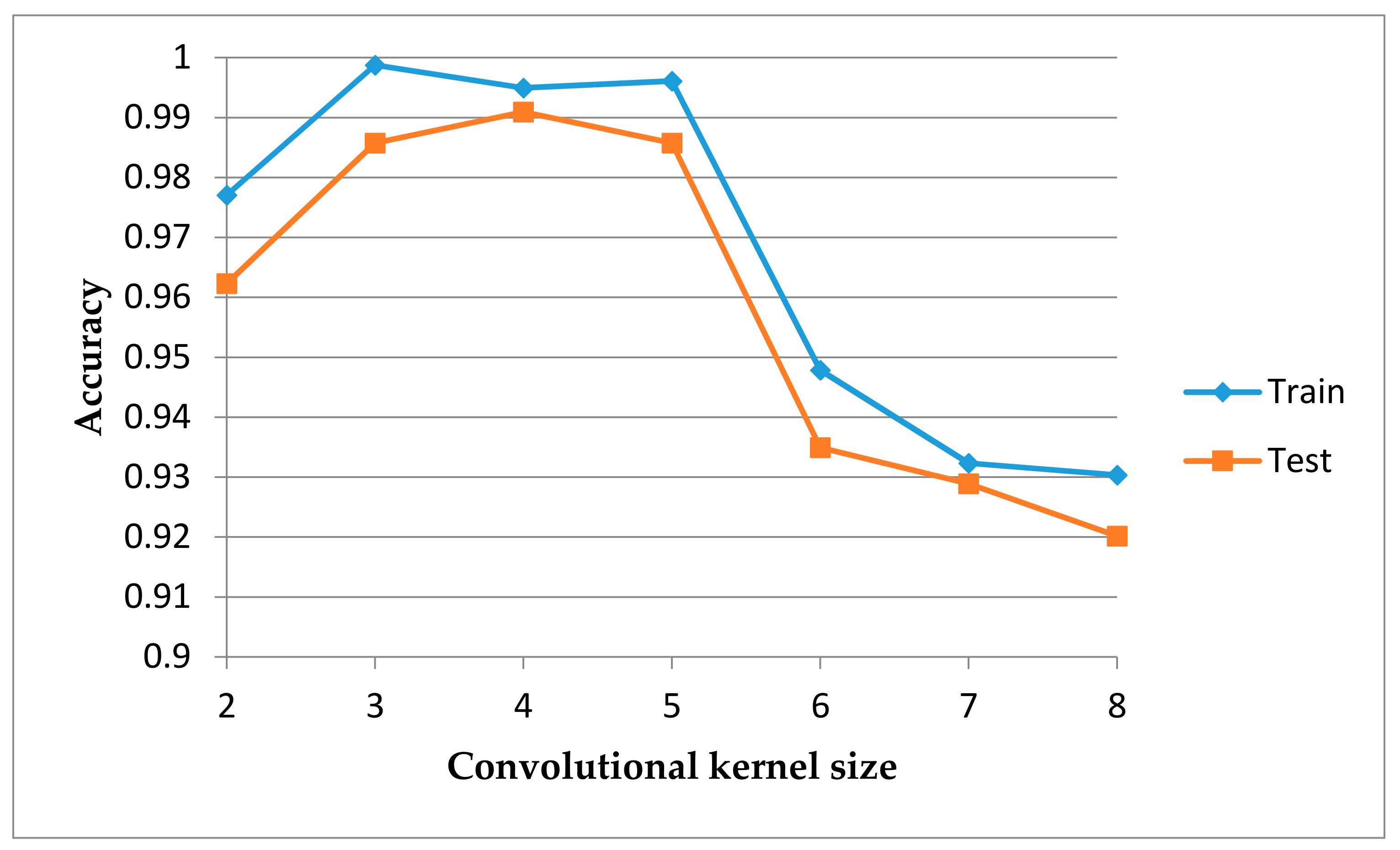
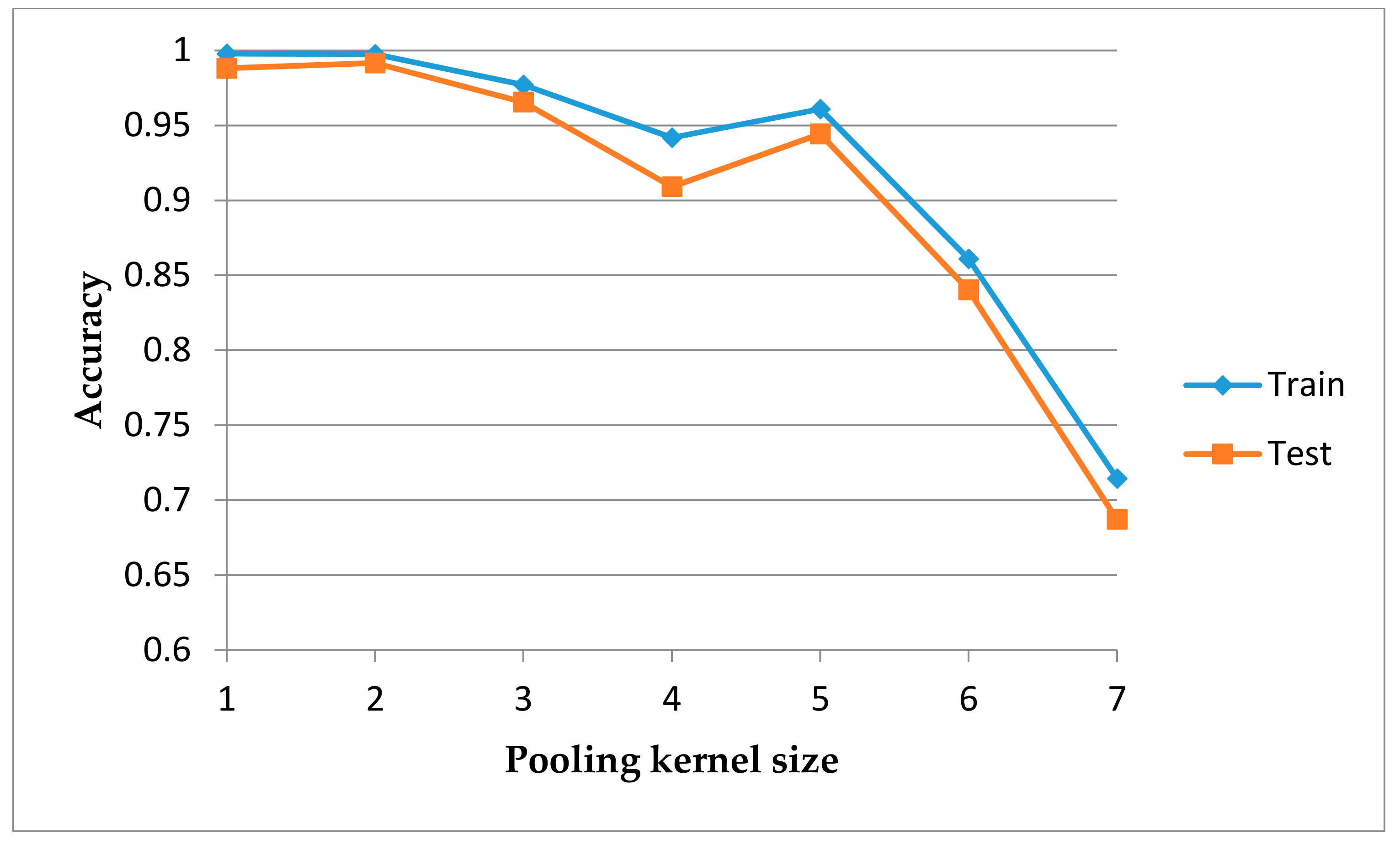
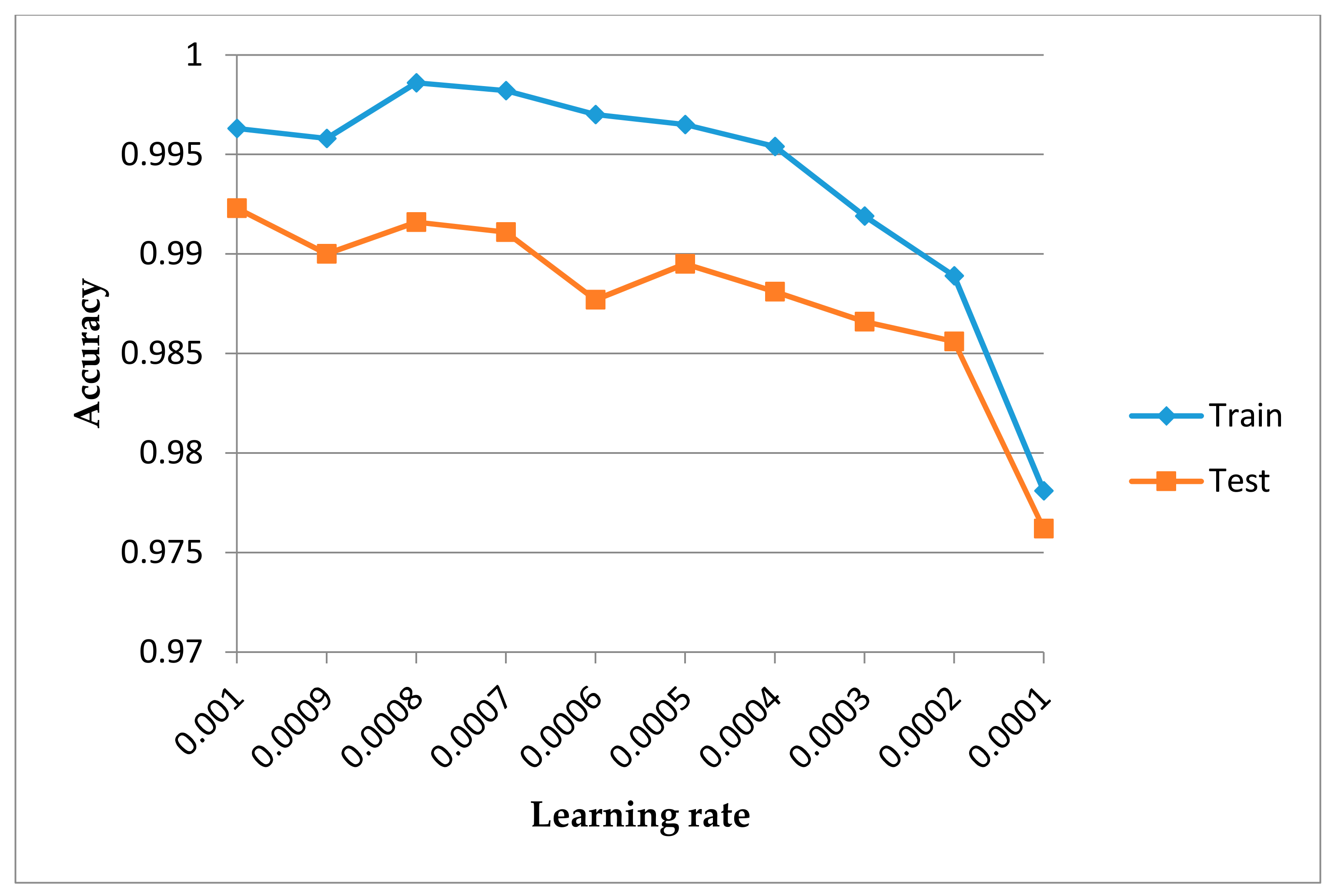
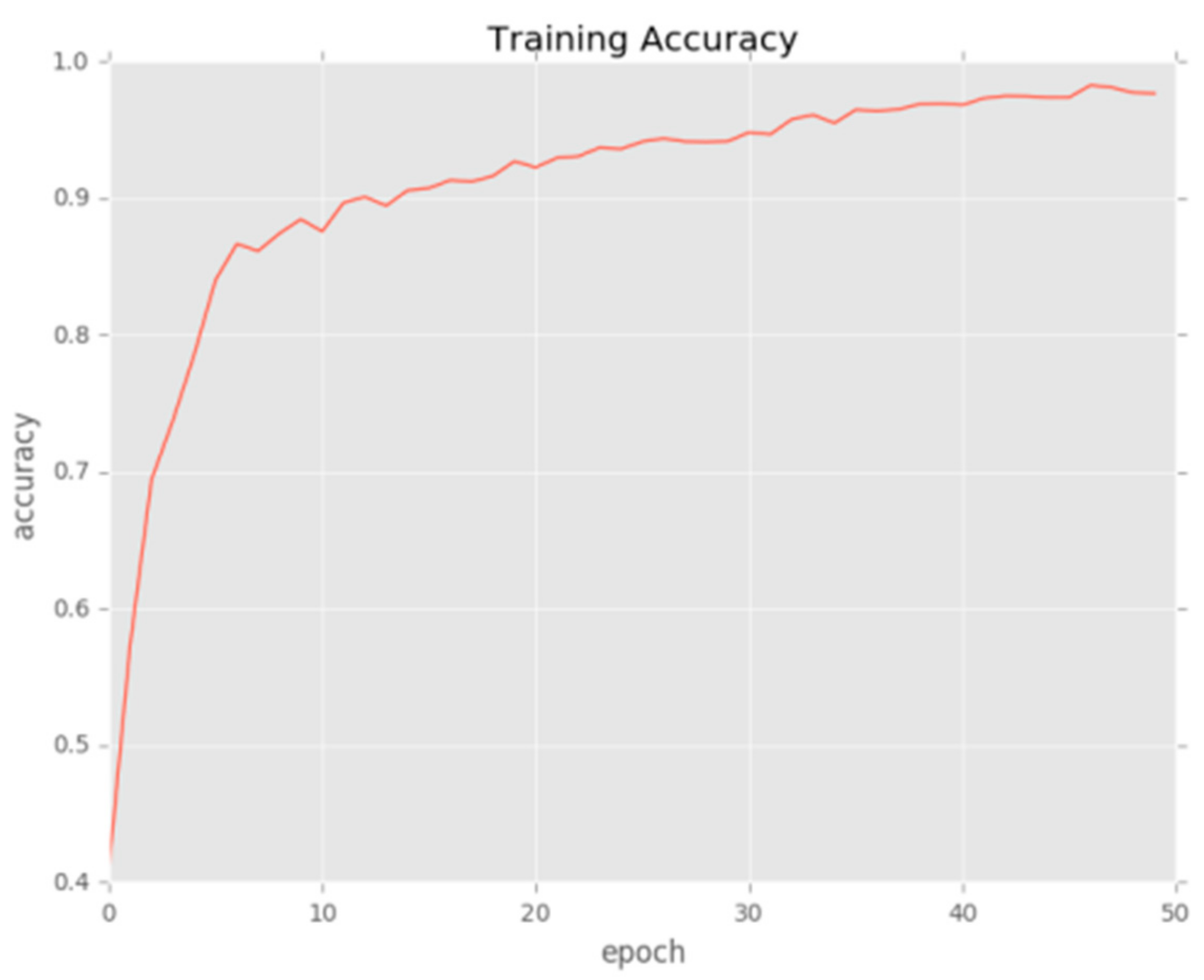
6.1. Data Preprocessing and Experimental Setup
6.2. Results
7. Conclusions and Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Li, X.; Lv, Z.; Hu, J.; Zhang, B.; Yin, L.; Zhong, C.; Wang, W.; Feng, S. Traffic management and forecasting system based on 3D GIS. In Proceedings of the 2015 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Shenzhen, China, 4–7 May 2015; pp. 991–998. [Google Scholar]
- Lin, H.; Chen, M.; Lu, G. Virtual geographic environment: A workspace for computer-aided geographic experiments. Ann. Assoc. Am. Geogr. 2013, 103, 465–482. [Google Scholar] [CrossRef]
- Song, X.; Xie, Z.; Xu, Y.; Tan, G.; Tang, W.; Bi, J.; Lie, X. Supporting real-world network-oriented mesoscopic traffic simulation on GPU. Simul. Model. Pract. Theory 2017, 74, 46–63. [Google Scholar] [CrossRef]
- Yang, X.; Li, S.; Zhang, Y.; Su, W.; Zhang, M.; Tan, G.; Zhang, Q.; Zhou, D.; Wei, X. Interactive traffic simulation model with learned local parameters. Multimedia Tools Appl. 2017, 76, 9503–9516. [Google Scholar] [CrossRef]
- Rautaray, S.S.; Agrawal, A. Vision based hand gesture recognition for human computer interaction: A survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Wang, B.; Yuan, T. Traffic Police Gesture Recognition Using Accelerometer. In Proceedings of the IEEE Sensors Conference, Lecce, Italy, 26–29 October 2008; pp. 1080–1083. [Google Scholar]
- Le, Q.K.; Pham, C.H.; Le, T.H. Road traffic control gesture recognition using depth images. IEEK Trans. Smart Process. Comput. 2012, 1, 1–7. [Google Scholar]
- Kela, J.; Korpipää, P.; Mäntyjärvi, J.; Kallio, S.; Savino, G.; Jozzo, L.; Di Marca, S. Accelerometer-based gesture control for a design environment. Pers. Ubiquitous Comput. 2006, 10, 285–299. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Oneata, D.; Verbeek, J.; Schmid, C. A robust and efficient video representation for action recognition. Int. J. Comput. Vis. 2016, 119, 219–238. [Google Scholar] [CrossRef] [Green Version]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Li, Q.; Qiu, Z.; Yao, T.; Mei, T.; Rui, Y.; Luo, J. Action Recognition by Learning Deep Multi-Granular Spatio-Temporal Video Representation. In Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, New York, NY, USA, 6–9 June 2016; pp. 159–166. [Google Scholar]
- Mitra, S.; Acharya, T. Gesture recognition: A survey. IEEE Trans. Syst. Man Cybern. 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Raheja, J.L.; Chaudhary, A.; Singal, K. Tracking of Fingertips and Centers of Palm Using Kinect. In Proceedings of the IEEE 2011 Third International Conference on Computational Intelligence, Modelling and Simulation (CIMSiM), Chennai, India, 14–16 December 2011; pp. 248–252. [Google Scholar]
- Liu, Y.; Wang, X.; Yan, K. Hand gesture recognition based on concentric circular scan lines and weighted K-nearest neighbor algorithm. Multimedia Tools Appl. 2016, 77, 209–233. [Google Scholar] [CrossRef]
- Wang, X.; Yan, K. Immersive human–computer interactive virtual environment using large-scale display system. Future Gener. Comput. Syst. 2017. [Google Scholar] [CrossRef]
- Wang, X.; Wang, J.; Yan, K. Gait recognition based on Gabor wavelets and (2D) 2PCA. Multimedia Tools Appl. 2017. [Google Scholar] [CrossRef]
- Fujiyoshi, H.; Lipton, A. J.; Kanade, T. Real-time human motion analysis by image skeletonization. IEICE Trans. Inf. Syst. 2004, 87, 113–120. [Google Scholar]
- Chaudhry, R.; Ravichandran, A.; Hager, G.; Vidal, R. Histograms of oriented optical flow and binet-cauchy kernels on nonlinear dynamical systems for the recognition of human actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 1932–1939. [Google Scholar]
- Yang, J.; Xu, Y.; Chen, C.S. Human action learning via hidden Markov model. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 1997, 27, 34–44. [Google Scholar] [CrossRef]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR 2004), Cambridge, UK, 23–26 August 2004; Volume 3, pp. 32–36. [Google Scholar]
- Yu, K.; Xu, W.; Gong, Y. Deep Learning with Kernel Regularization for Visual Recognition. In Proceedings of the Advances in Neural Information Processing Systems, Whistler, BC, Canada, 11 December 2009; pp. 1889–1896. [Google Scholar]
- Jiang, W.; Yin, Z. Human activity recognition using wearable sensors by deep convolutional neural networks. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1307–1310. [Google Scholar]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the IJCAI 2015, Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. [Google Scholar]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Lee, S.M.; Yoon, S.M.; Cho, H. Human activity recognition from accelerometer data using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 13–16 February 2017; pp. 131–134. [Google Scholar]
- Lv, Z.; Li, X.; Zhang, B.; Wang, W.; Zhu, Y.; Hu, J.; Feng, S. Managing big city information based on WebVRGIS. IEEE Access 2016, 4, 407–415. [Google Scholar] [CrossRef]
- Livingston, M.A.; Sebastian, J.; Ai, Z.; Decker, J.W. Performance measurements for the Microsoft Kinect skeleton. In Proceedings of the 2012 IEEE Virtual Reality Short Papers and Posters (VRW), Costa Mesa, CA, USA, 4–8 March 2012; pp. 119–120. [Google Scholar]
- Raheja, J.L.; Minhas, M.; Prashanth, D.; Shahb, T.; Chaudhary, A. Robust gesture recognition using Kinect: A comparison between DTW and HMM. Optik-Int. J. Light Electron Opt. 2015, 126, 1098–1104. [Google Scholar] [CrossRef]
- Zhu, Y.; Chen, W.; Guo, G. Fusing spatiotemporal features and joints for 3D action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 486–491. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3D skeletons as points in a lie group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Bau, O.; Mackay, W.E. OctoPocus: A dynamic guide for learning gesture-based command sets. In Proceedings of the 21st Annual ACM Symposium on User Interface Software and Technology, Monterey, CA, USA, 19–22 October 2008; pp. 37–46. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Output Unit (n−2) | Output Unit (n−1) | Output Unit (n) | Result |
|---|---|---|---|
| a | b | c | Action c |
| a | a | b | Action a |
| a | b | a | Action a |
| a | b | b | Action b |
| a | a | a | Action a |
| Action | Straight | Stop | Turn_Left | Turn_Left_Waiting |
|---|---|---|---|---|
| Test dataset accuracy (%) | 97.2 | 96.5 | 95.0 | 98.3 |
| Real-time test accuracy (%) | 90.3 | 94.6 | 85.4 | 93.3 |
| Action | Change_Lane | Slow_Down | Pull_Over | Turn_Right |
| Test dataset accuracy (%) | 94.8 | 98.5 | 96.5 | 96.6 |
| Real-time test accuracy (%) | 95.1 | 88.5 | 98.5 | 98.3 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, C.; Zhang, Y.; Wang, A.; Wang, Y.; Chen, G. Traffic Command Gesture Recognition for Virtual Urban Scenes Based on a Spatiotemporal Convolution Neural Network. ISPRS Int. J. Geo-Inf. 2018, 7, 37. https://doi.org/10.3390/ijgi7010037
Ma C, Zhang Y, Wang A, Wang Y, Chen G. Traffic Command Gesture Recognition for Virtual Urban Scenes Based on a Spatiotemporal Convolution Neural Network. ISPRS International Journal of Geo-Information. 2018; 7(1):37. https://doi.org/10.3390/ijgi7010037
Chicago/Turabian StyleMa, Chunyong, Yu Zhang, Anni Wang, Yuan Wang, and Ge Chen. 2018. "Traffic Command Gesture Recognition for Virtual Urban Scenes Based on a Spatiotemporal Convolution Neural Network" ISPRS International Journal of Geo-Information 7, no. 1: 37. https://doi.org/10.3390/ijgi7010037