Employing Search Engine Optimization (SEO) Techniques for Improving the Discovery of Geospatial Resources on the Web


Abstract
:1. Introduction
2. Background and Related Work
2.1. Search Engine Optimization (SEO) Techniques for Visibility of Web Resources
2.2. SEO Techniques in Academic Literature
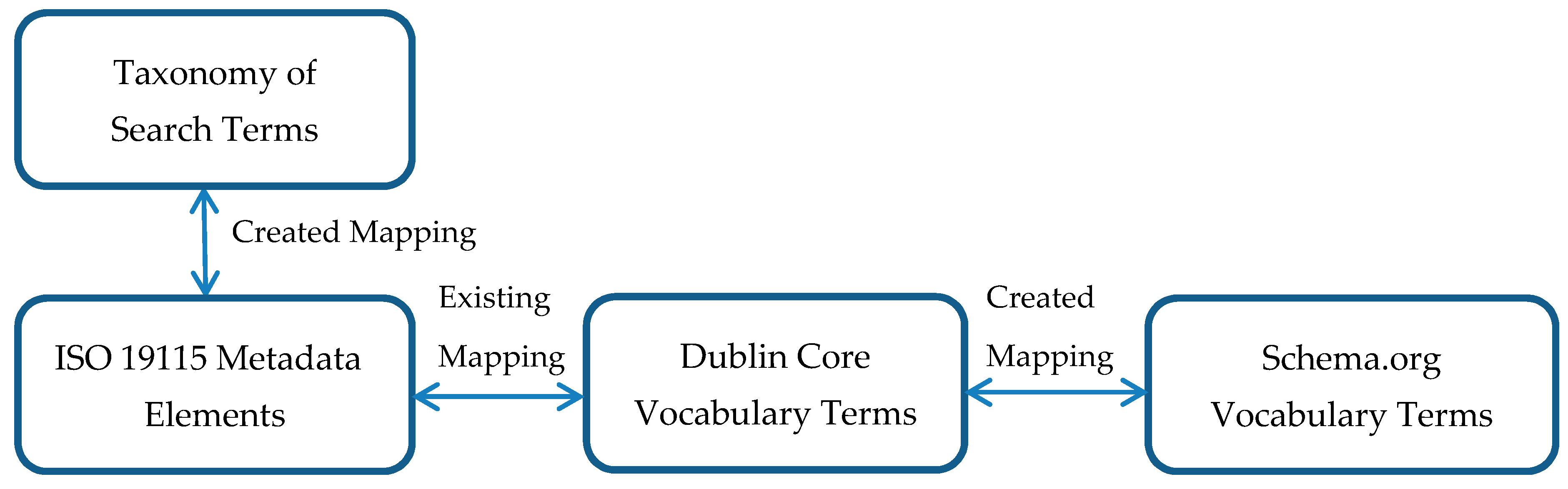
2.3. SEO Techniques with Schema.org and Dublin Core
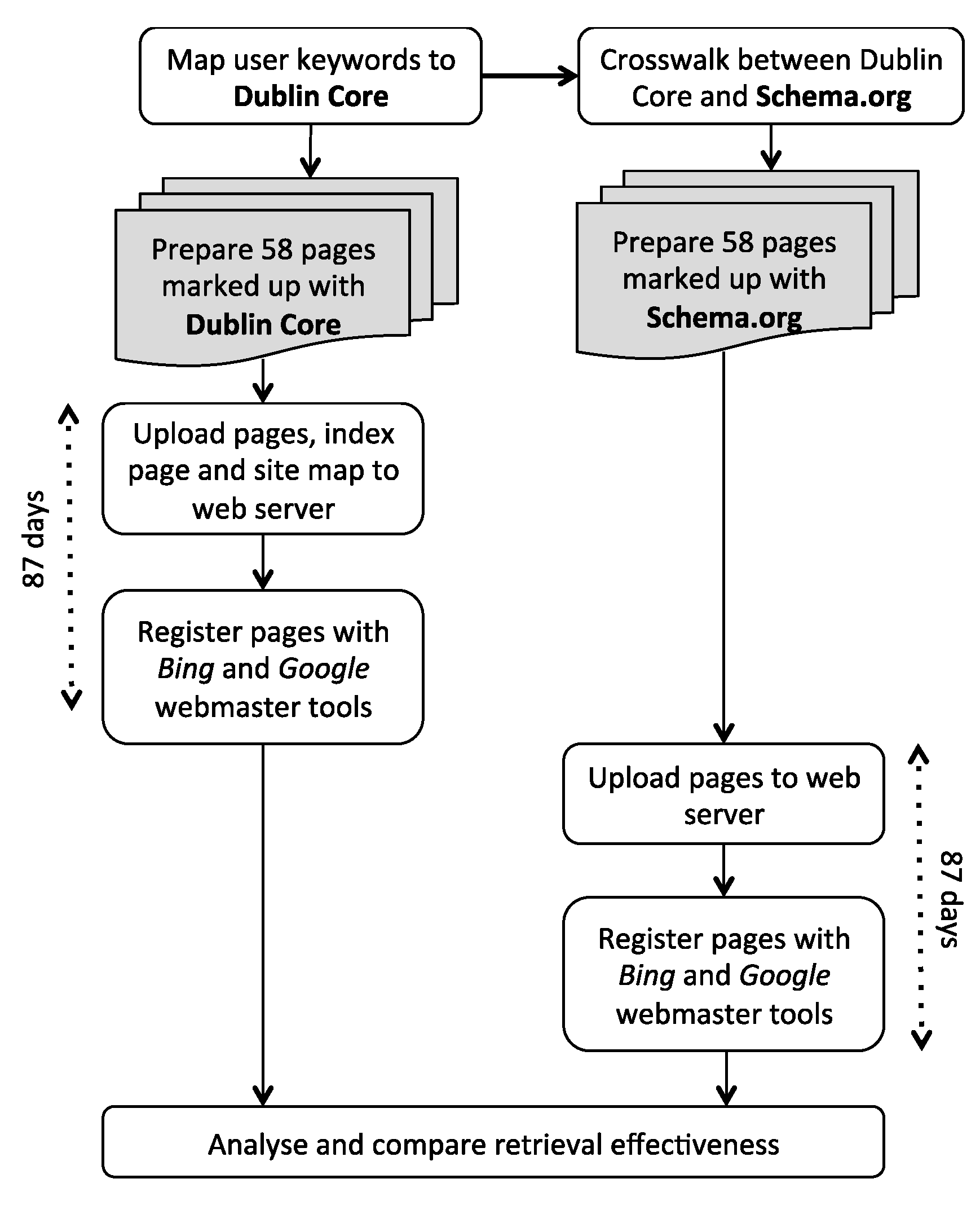
3. Method
3.1. Overview
- Dublin Core: Bing vs. Google
- Schema.org: Bing vs. Google
- Bing: Dublin Core vs. Schema.org
- Google: Dublin Core vs. Schema.org
3.2. Justification for Using Bing, Google, Dublin Core and Schema.org
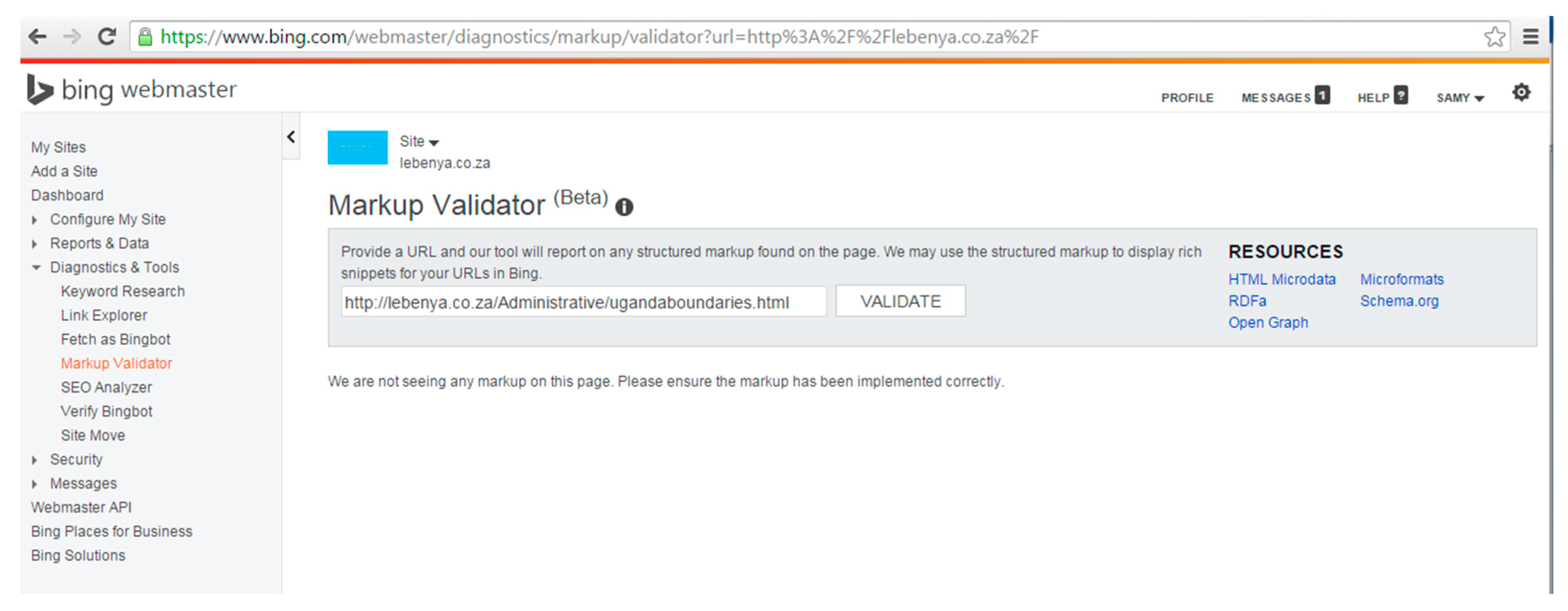
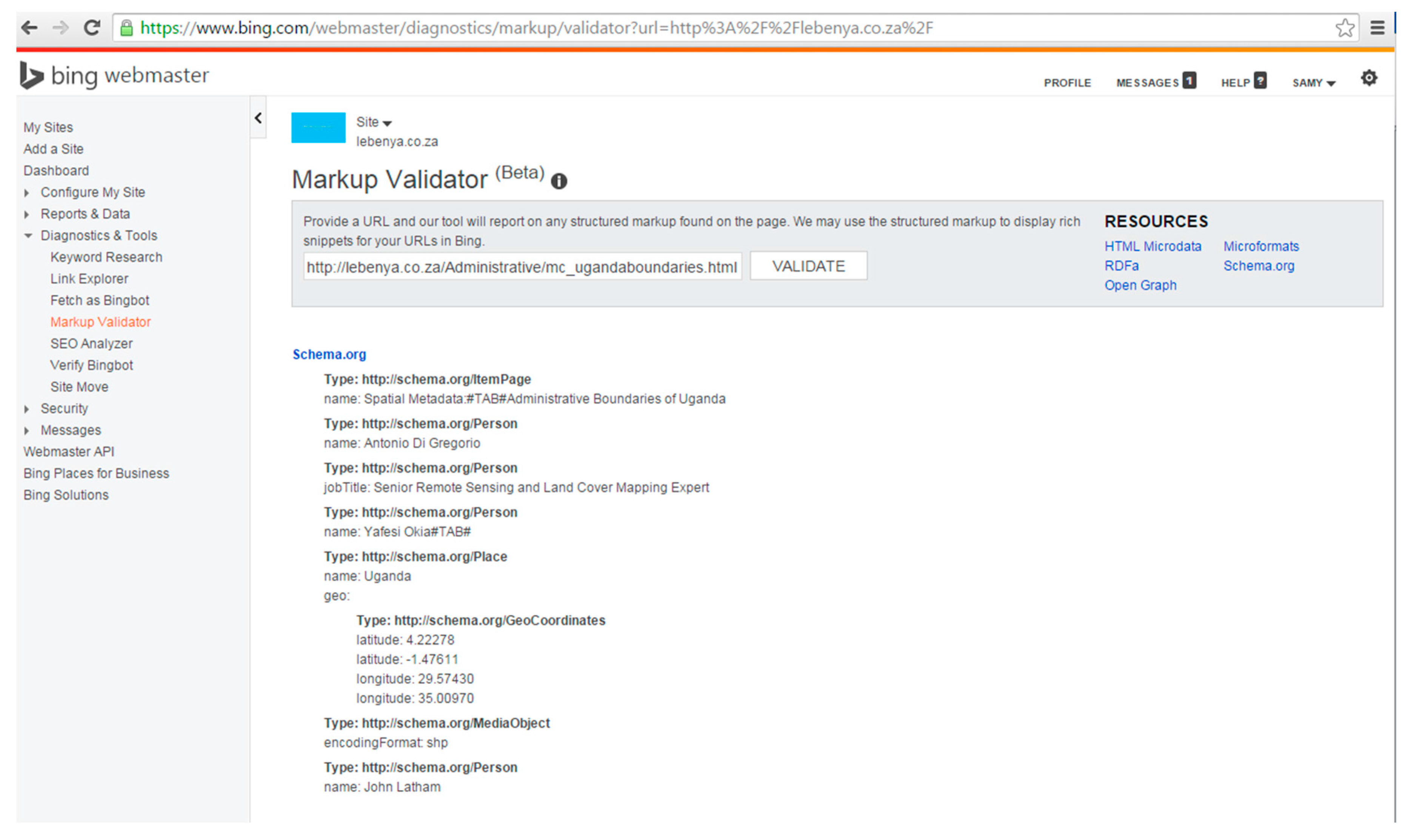
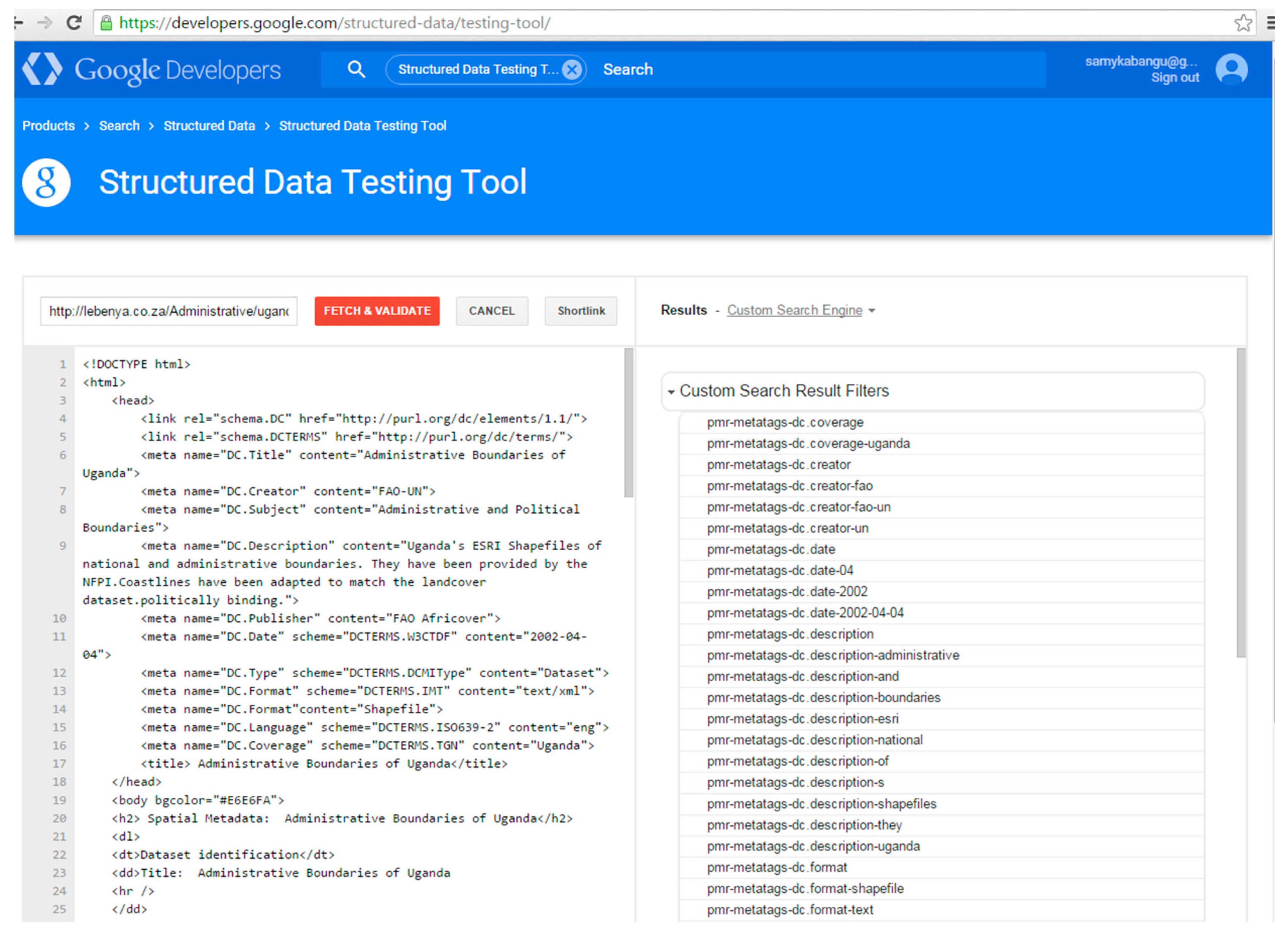
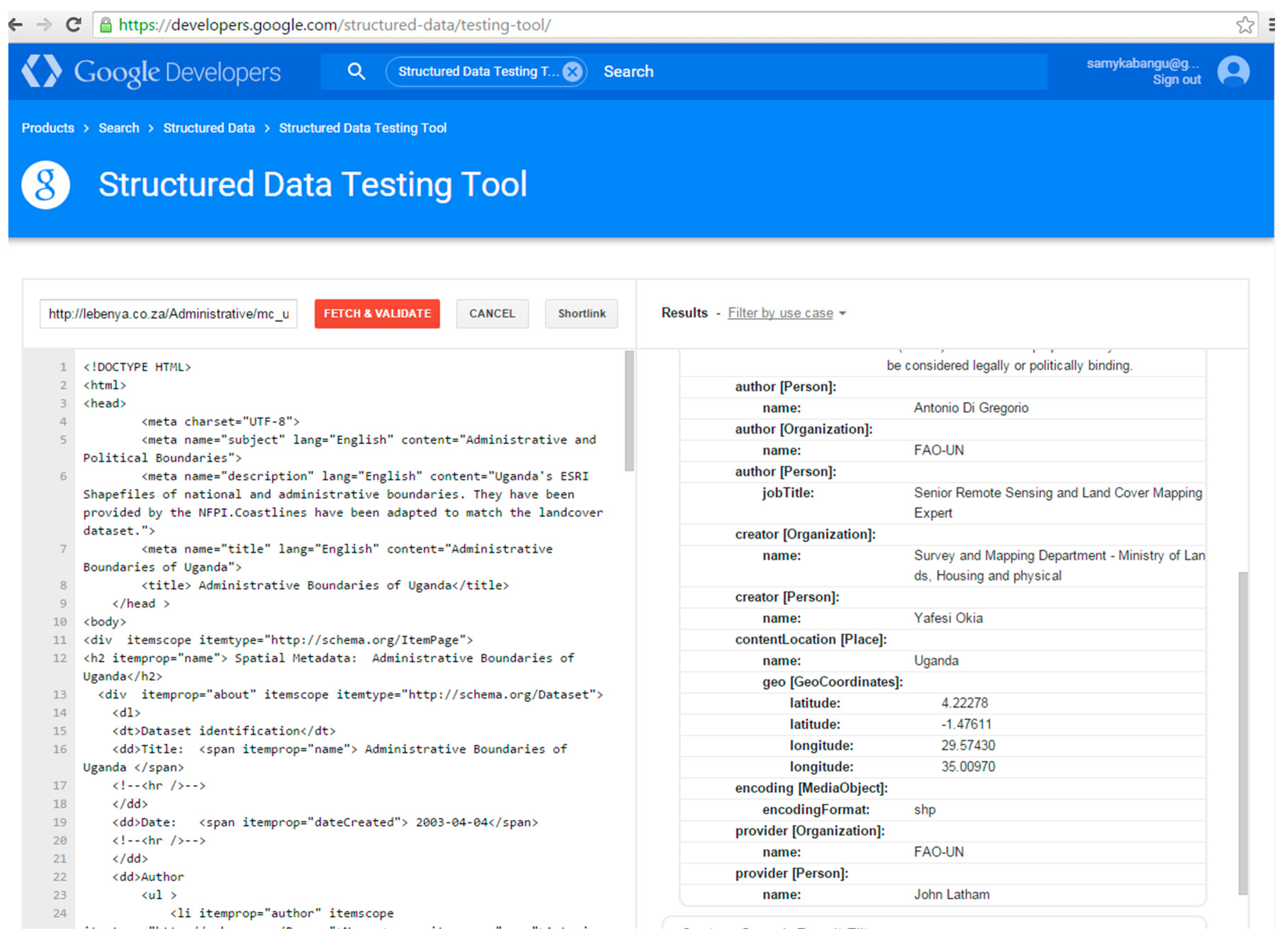
3.3. Method for Marking up Geospatial Metadata
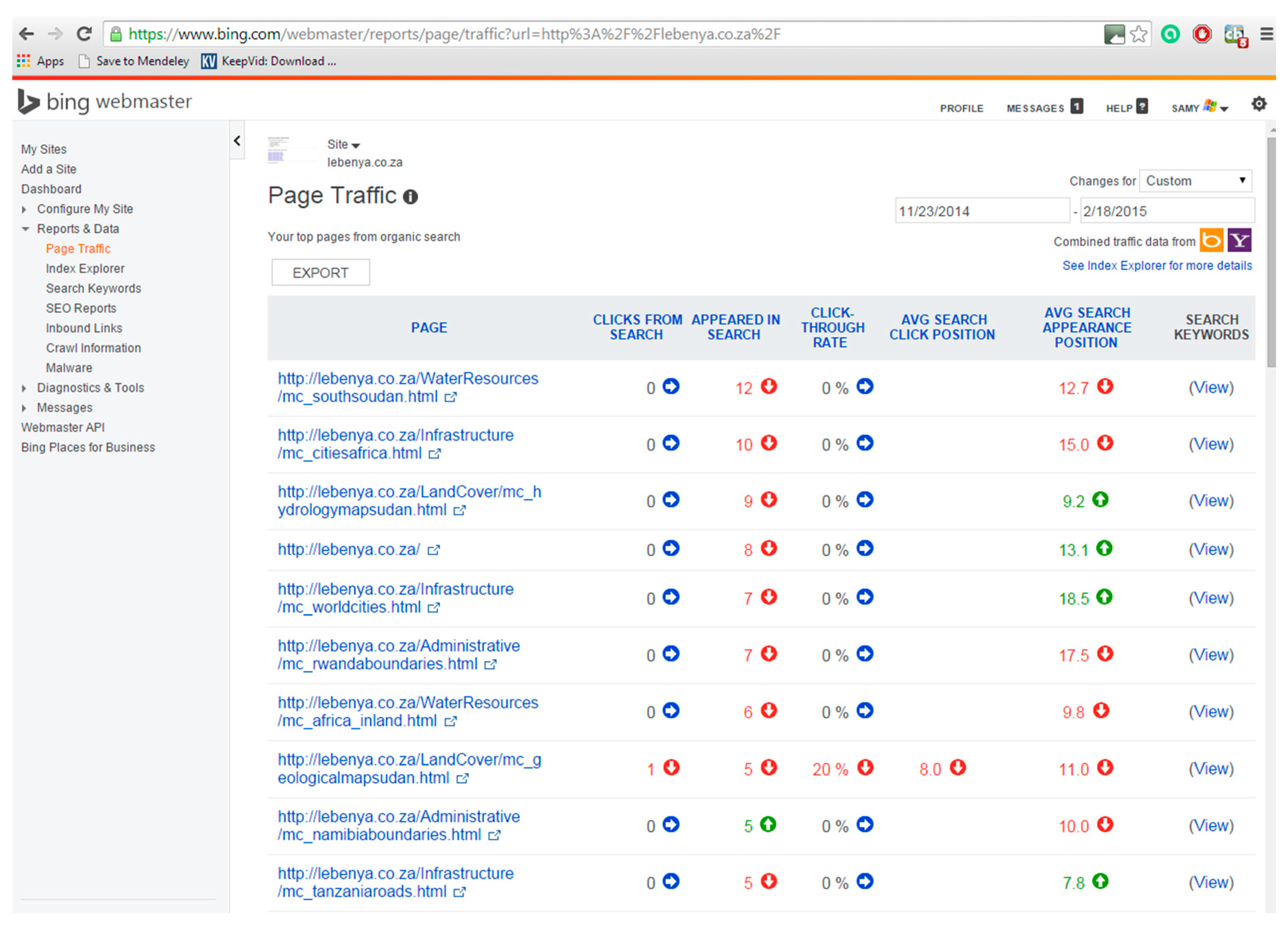
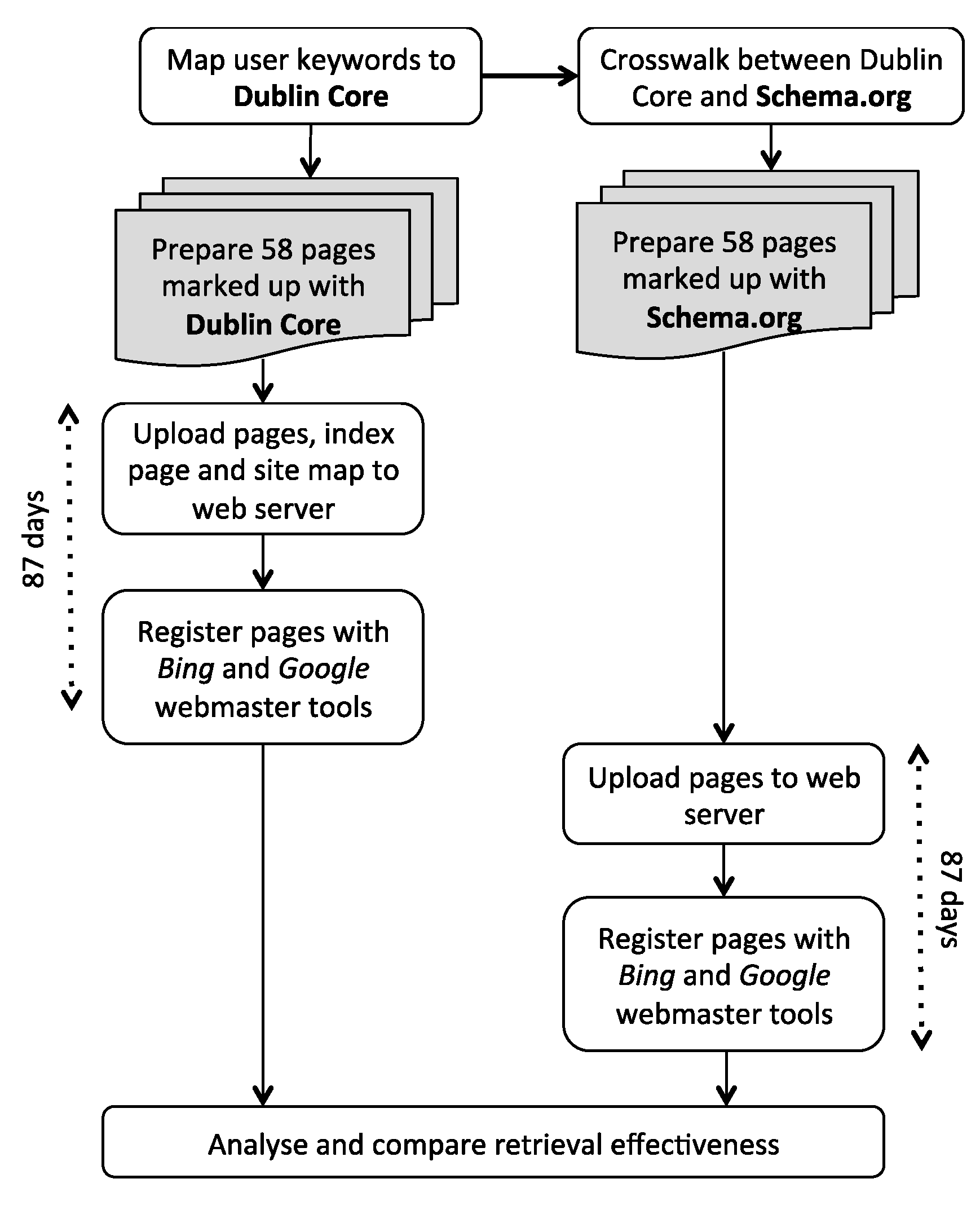
3.4. Method for the Evaluation of Retrieval Effectiveness
4. Results: Retrieval Effectiveness Evaluation
4.1. Relevance-Based Evaluation
4.2. Ranking-Based Evaluation
4.3. Summary of Results
5. Discussion and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Taxonomy of Search Terms Categories | Corresponding ISO 19115 Elements (Adapted from the Long Name) | Corresponding Dublin Core Elements | Corresponding Schema.org Properties (Elements) |
|---|---|---|---|
| Subject (Theme) | Title (Name by which the cited resource is known) | TITLE (A name given to the resource. Typically, a Title will be a name by which the resource is formally known) | NAME (The name of the item) |
| Topic Category (Main theme(s) of the dataset | SUBJECT (The topic of the content of the resource. Typically, a Subject will be expressed as keywords, key phrases, or classification codes that describe a topic of the resource) | ABOUT (The subject matter of the content) | |
| Abstract (Brief narrative summary of the content of the resource(s) | DESCRIPTION (An account of the resource. Description may include but is not limited to; an abstract, table of contents, reference to graphical representation of content or a free-text account of the content) | DESCRIPTION (A description of the item) | |
| Lineage (Detailed description of the level of the source data) | SOURCE (A reference to a resource from which the present resource is derived. The present resource may be derived from the Source resource in whole or part.) | ||
| Location (Spatial Extent) | Geographic Description (Geographic location of the dataset by four coordinates, or geographic identifier) | COVERAGE (The extent or scope of the content of the resource. Coverage will typically include spatial location, geographic coordinates, place name or jurisdiction such as named administrative entity) | Spatial (The range of spatial applicability of a dataset, e.g., for a dataset of New York weather, the state of New York.) |
| SpatialCoverage (indicates areas that the dataset describes: a dataset of New York weather would have spatialCoverage which was the place: the state of New York.) | |||
| Geo (The geo coordinates of the place) | |||
| Geographic Feature Type | Spatial Representation Type (Method used to spatially represent geographic information) | TYPE (The nature or genre of the content of the resource. Type includes terms describing general categories, functions, or aggregation levels for content) | Encoding (A media object that encodes this CreativeWork) |
| Data Model | Resource Format (Provides a description of the format of the resource(s)) | FORMAT (The physical or digital manifestation of the resource. Typically, Format may include the media-type or dimensions of the resource. Format may be used to determine the software, hardware or other equipment needed to display or operate the resource) | MediaObject (A media object, such as an image, video, or audio object embedded in a web page or a downloadable dataset i.e., DataDownload.) |
| FileFormat (Media type, typically MIME format (see IANA site) of the content e.g., application/zip of a Software Application binary.) | |||
| EncodingFormat (mp3, mpeg4, etc.) |
Appendix B. Users’ Search Query Terms as Recorded by the Webmaster Tools Application of Bing.
| wgs nairobi kenya shapefile | yafesi wp-/wp- |
| uganda administrative boundaries shapefile | rail roads of the world |
| geological map of the sudan | geology of uganda |
| www.lefenya.co.za | r fao vail blue ley |
| eugene rurangwa fao | water bodies shapefile |
| political map of namibia site:.za | un dataset shapefile cities |
| gemstone geology map in sudan | bountries oferitrea |
| kenya admin boundaries | boundaries of rwanda |
| rwanda map of roads | somali map site:.za |
| sudan geological map | mil-v-89039 |
| utilization of land title in tanzania -pdf | uganda administrative boundaries |
| tanzania infrastructures shapefiles | rwanda bounding box |
| namibia administrative data shapefile | bounding box africa |
| ++serena.coetzee@up.ac.za | shapefile of africa rivers |
| +serena.coetzee@up.ac.za | water distribution -china “hotmail.com” |
| #NAME? | drc map site:.za |
| shapefile africa countries wgs | megadatauganda |
| hydrology maps sudan | list of rivers in dr congo |
| spatial planning tanzania | map of nigeria and agricultural produce |
| biggest inland water bodies in africa | what east african nation has the most inland bodies of water? |
| ghana map site:.za | hydrological map site:.za |
| hydrological map of sudan wikipedia | map of africa eritrea site:.za |
| vector street maps site:.za | nfpi for africover |
| lebenya | “south sudan” shapefile |
| africas area and population | aaglmru |
| administrative bounderies in kenya | african figures site:.za |
| congo dr site:.za | geological survey maps online site:.za |
| field crop production in botswana | tekleyohannes wp-/wp- |
| shapefile rivers africa | what is cropping patterns for africa |
| uganda towns shapefile | agricultural product in nigeria site:.za |
| hydrological maps site:.za | africa inland lakes shapefiles |
| “http://theacrc.info” site:za | rivers of rwanda |
| geology south west uganda | geological maps online site:.za |
| africa water bodies shapefile | hydrology south africa site:.za |
| congo dr map site:.za | hydrological data site:.za |
| administrative boundaries kenya | namibia shapefile mme |
| rwanda administrative map | namibia shapefile |
| property boundary maps online site:.za | shapefile african rivers |
| ghana grographical extent | statial data site:.za |
| namibia adminstrative boundaries | tanzania leben |
| riversofafrica | map of nigeria showing distributions of common cultivated crops |
| rivers of tanzania | tanzania road map site:.za |
| dr congo map site:.za | rwanda administrative boundaries |
| www. sudan mc.com | yafesi okia linkedin |
| kenya towns | +land land resources use site:.za |
| cropping patterns in east africa |
References
- Nebert, D. (Ed.) Developing Spatial Data Infrastructures: The SDI Cookbook, Version 2.0, 2004. Available online: http://gsdiassociation.org/images/publications/cookbooks/SDI_Cookbook_GSDI_2004_ver2.pdf (accessed on 1 June 2017).
- Lopez-Pellicer, J.F.; Béjar, R.; Zarazaga-Soria, F. Providing Semantic Links to the Invisible Geospatial Web. In Notes in Geoinformatics Research, 1st ed.; Prensas Universitarias de Zaragoza: Zaragoza, Spain, 2012. [Google Scholar]
- Vockner, B.; Mittlböck, M. Geo-Enrichment and Semantic Enhancement of Metadata Sets to Augment Discovery in Geoportals. ISPRS Int. J. Geo-Inf. 2014, 3, 345–367. [Google Scholar] [CrossRef]
- Nebert, D.; Whiteside, A.; Vretanos, P.P. (Eds.) OpenGIS® Catalogue Services Specification. Open Geospatial Consortium (OGC), 2007. Available online: http://www.opengeospatial.org/standards/cat (accessed on 5 May 2017).
- Lopez-Pellicer, J.F.; Florczyk, J.A.; Nogueras-Iso, J.; Muro-Medrano, P.; Zarazaga, J.F. Exposing CSW catalogues as Linked Data. In Geospatial Thinking, Lecture Notes in Geoinformation and Cartography (LNG&C); Painho, M., Santos, M.Y., Pundt, H., Eds.; Springer: Berlin, Germany, 2010; pp. 183–200. [Google Scholar]
- Hou, D.; Chen, J.; Wu, H. Discovering Land Cover Web Map Services from the Deep Web with JavaScript Invocation Rules. ISPRS Int. J. Geo-Inf. 2016, 5, 105. [Google Scholar] [CrossRef]
- Huang, C.; Chang, H. GeoWeb Crawler: An Extensible and Scalable Web Crawling Framework for Discovering Geospatial Web Resources. ISPRS Int. J. Geo-Inf. 2016, 5, 136. [Google Scholar] [CrossRef]
- Purcell, K. Search and Email Still Top the List of Most Popular Online Activities: Two Activities Nearly Universal among Adult Internet Users, Pew Research Center’s Internet & American Life Project, 2011. Available online: http://www.pewinternet.org/2011/08/09/search-and-email-still-top-the-list-of-most-popular-online-activities/ (accessed on 4 May 2017).
- McGee, M. By the Numbers: Twitter vs. Facebook vs. Google Buzz, Search Engine Land, 2010. Available online: http://searchengineland.com/by-the-numbers-twitter-vs-facebook-vs-google-buzz-36709 (accessed on 1 March 2015).
- Cahill, K.; Chalut, R. Optimal Results: What Libraries Need to know about Google and Search Engine Optimization. Ref. Libr. 2009, 50, 234–247. [Google Scholar] [CrossRef]
- Ochoa, E. An Analysis of the Application of Selected Search Engines Optimization (SEO) Techniques and their Effectiveness on Google’s Search Ranking Algorithm. Master’s Thesis, California State University, Long Beach, CA, USA, May 2012. [Google Scholar]
- Swati, P.; Pawar, B.V.; Patil, A.S. Search Engine Optimization: A study. Res. J. Comput. Inf. Technol. Sci. 2013, 1, 10–13. [Google Scholar]
- Onaifo, D.; Rasmussen, D. Increasing libraries’ content findability on the web with search engine optimization. Libr. Hi Tech 2013, 31, 87–108. [Google Scholar] [CrossRef]
- Mustafa, R.; Naawaz, M.S.; Lali, M.I. Search engine optimization techniques to get high score in SERP’s using recommended guidelines. Sci. Int. 2015, 27, 5079–5086. [Google Scholar]
- Meta Tags that Google Understands. Available online: https://support.google.com/webmasters/answer/79812?hl=en (accessed on 22 December 2014).
- Malaga, R.A. Search Engine Optimization-Black and White Hat Approaches. Adv. Comput. 2010, 78, 1–39. [Google Scholar]
- Zhang, J.; Dimitroff, A. The impact of webpage content characteristics on webpage visibility in search engine results (Part I). Inf. Process. Manag. 2005, 41, 665–690. [Google Scholar] [CrossRef]
- Zhang, J.; Dimitroff, A. The impact of metadata implementation on webpage visibility in search engine results (Part II). Inf. Process. Manag. 2005, 41, 691–715. [Google Scholar] [CrossRef]
- Krutil, J.; Kudelka, M.; Snasel, V. Web page classification based on Schema.org collection. In Proceedings of the Fourth International Conference on Computational Aspects of Social Networks (CASoN), Sao Carlos, Brazil, 21–23 November 2012. [Google Scholar]
- Dublin Core Metadata Initiative. Available online: http://dublincore.org/ (accessed on 15 November 2013).
- Harper, C.A. Dublin Core Metadata Initiative: Beyond the element set. Inf. Stand. Q. Winter 2010, 22, 1. Available online: http://www.niso.org/publications/isq/free/FE_DCMI_Harper_isqv22no1.pdf (accessed on 1 June 2017). [CrossRef]
- Beall, J. The Death of Metadata. Ser. Libr. 2008, 51, 55–74. [Google Scholar] [CrossRef]
- Google Search Engine Optimization Starter Guide. Available online: http://static.googleusercontent.com/media/www.google.com/en//webmasters/docs/search-engine-optimization-starter-guide.pdf (accessed on 1 November 2014).
- Zhang, J.; Dimitroff, A. Internet search engines’ reponse to metadata Dublin Core implementation. J. Inf. Sci. 2004, 30, 310–320. [Google Scholar] [CrossRef]
- Weibel, S.L. An Introduction to Metadata for Geographic Information. In World Spatial Metadata Standards, 1st ed.; Moellering, H., Aalders, H.J.G.L., Crane, A., Eds.; Elsevier Ltd.: Oxford, UK, 2005; pp. 493–513. [Google Scholar]
- Katumba, S.; Coetzee, S. Enhancing the online discovery of geospatial data through taxonomy, folksonomy and semantic annotations. S. Afr. J. Geomat. 2015, 4, 339–350. [Google Scholar] [CrossRef]
- Nogueras-Iso, J.; Zarazaga-Soria, F.J.; Lacasta, J.; Bejar, R.B.; Muro-Medrano, P.R. Metadata standard interoperability: Application in the geo-graphic information domain. Comput. Environ. Urban Syst. 2004, 28, 611–634. [Google Scholar] [CrossRef]
- Ali, R.; Sufyan Beg, M.M. An overview of web search evaluation methods. Comput. Electr. Eng. 2011, 37, 835–848. [Google Scholar] [CrossRef]
- Croft, B.; Metzler, D.; Strohman, T. Search Engines: Information Retrieval in Practice, 1st ed.; Addison-Wesley Publishing Company: Boston, MA, USA, 2009; pp. 308–338. [Google Scholar]
- Can, F.; Nuray, R.; Sevdik, A.B. Automatic performance evaluation of web search engines. Inf. Process. Manag. 2004, 40, 495–514. [Google Scholar] [CrossRef]
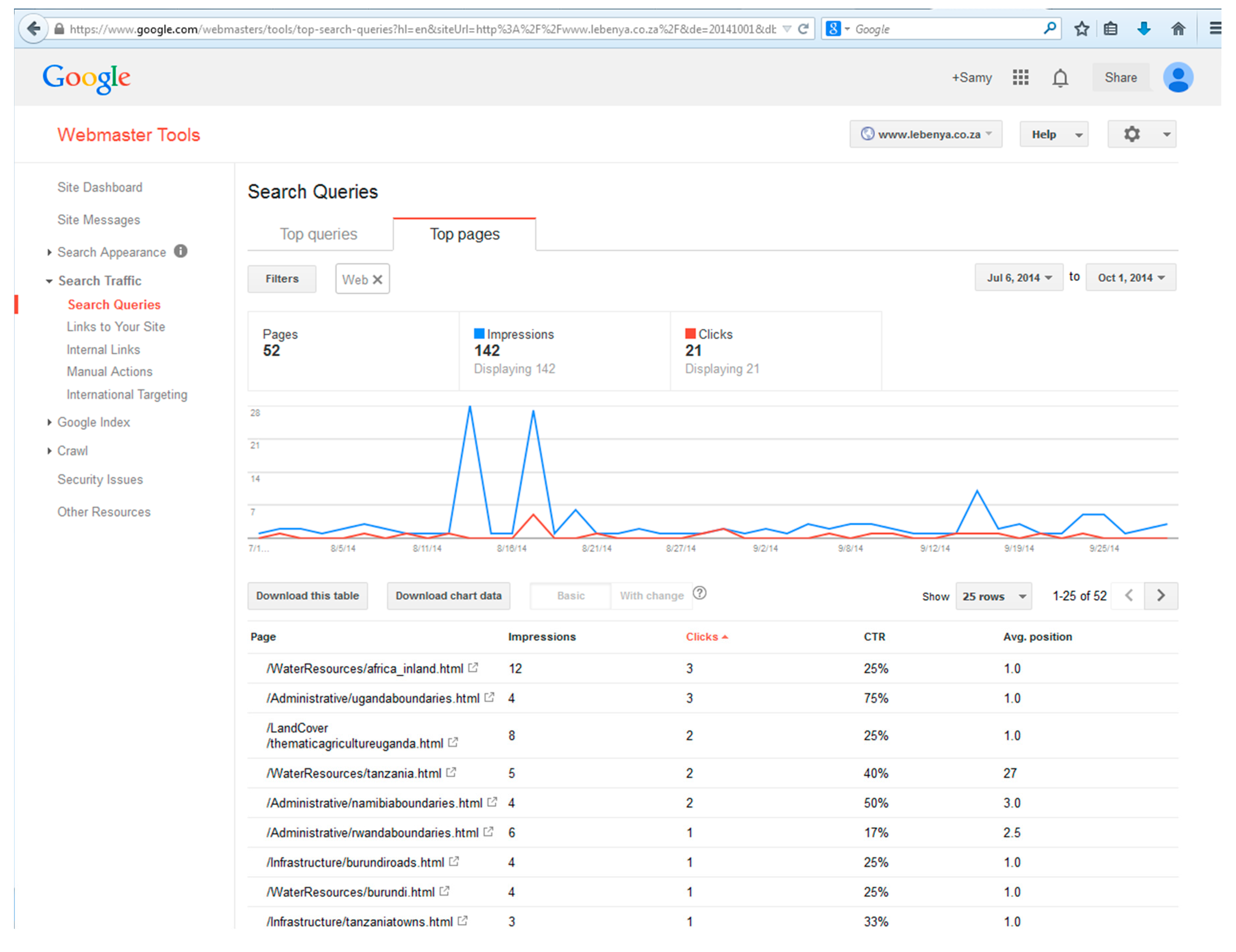
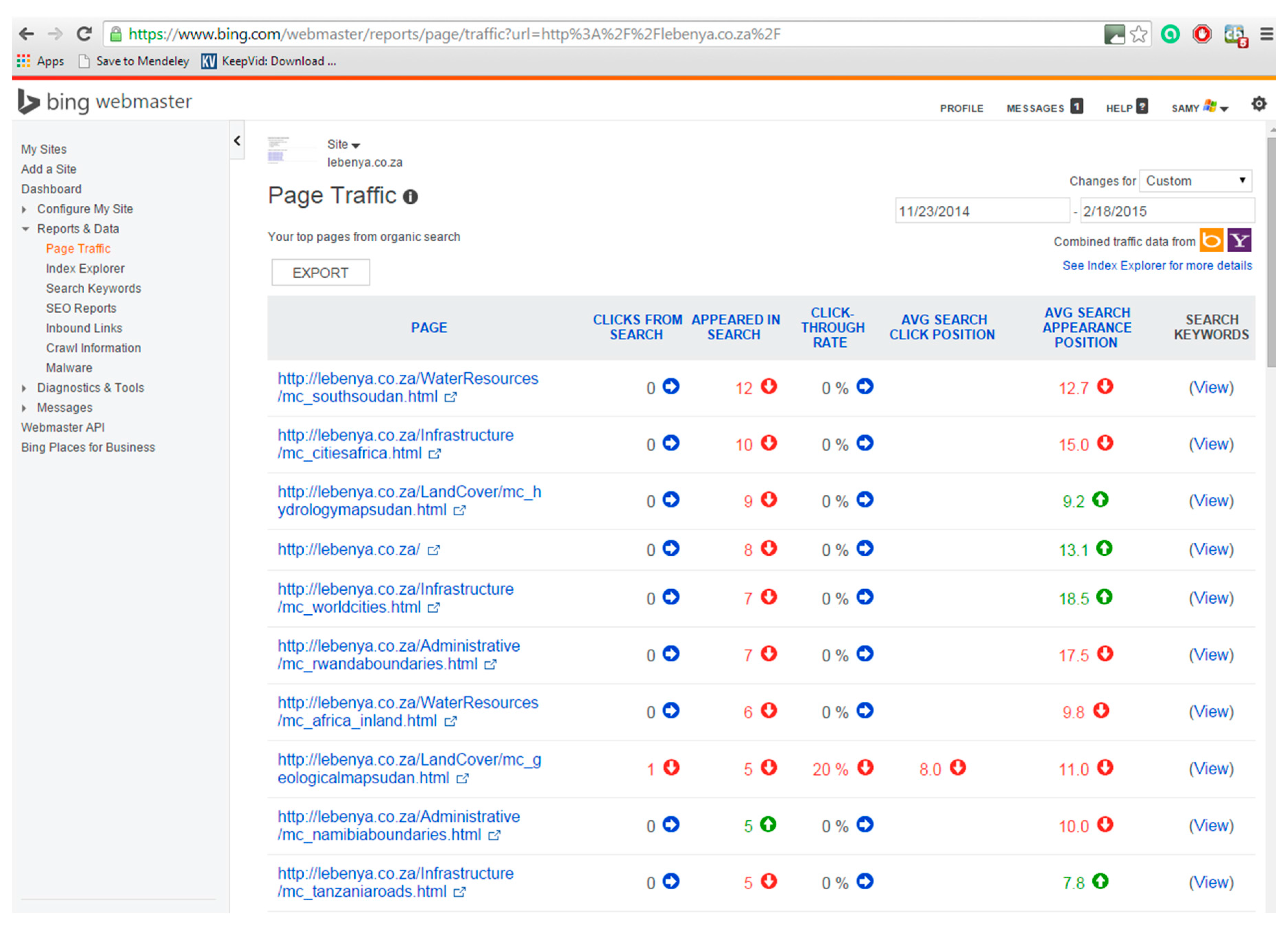
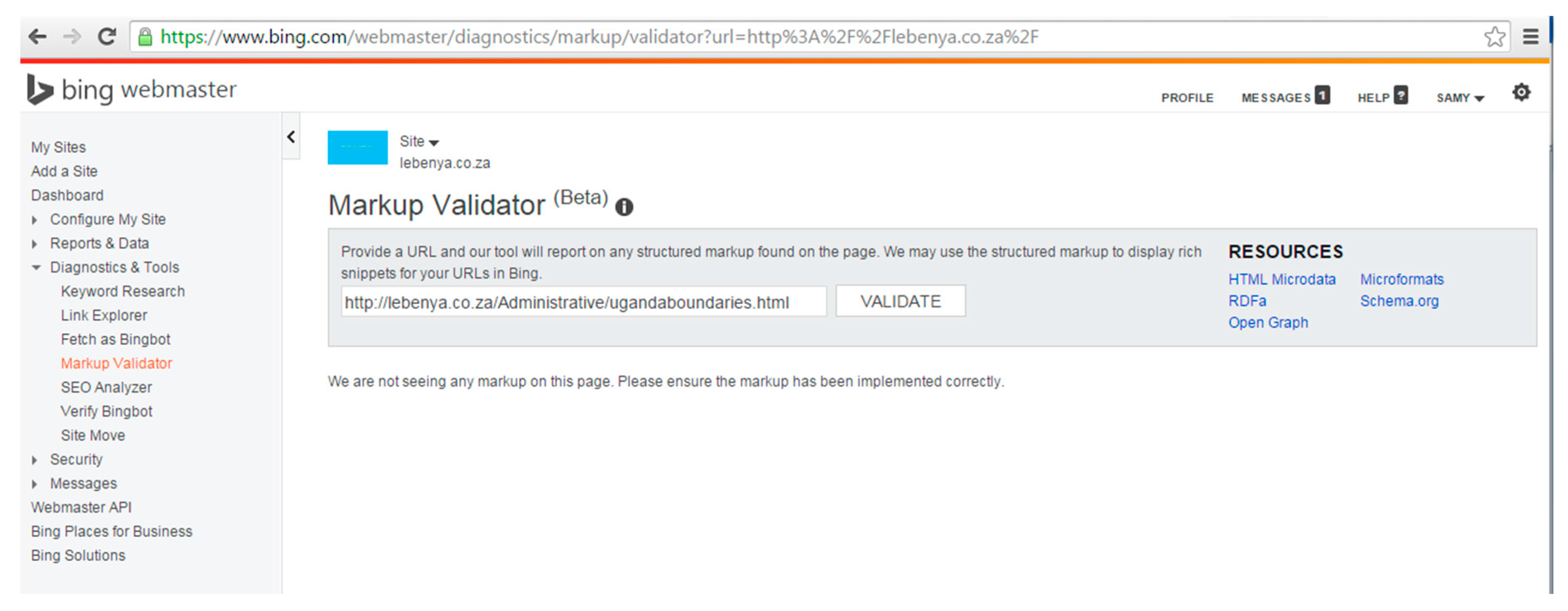
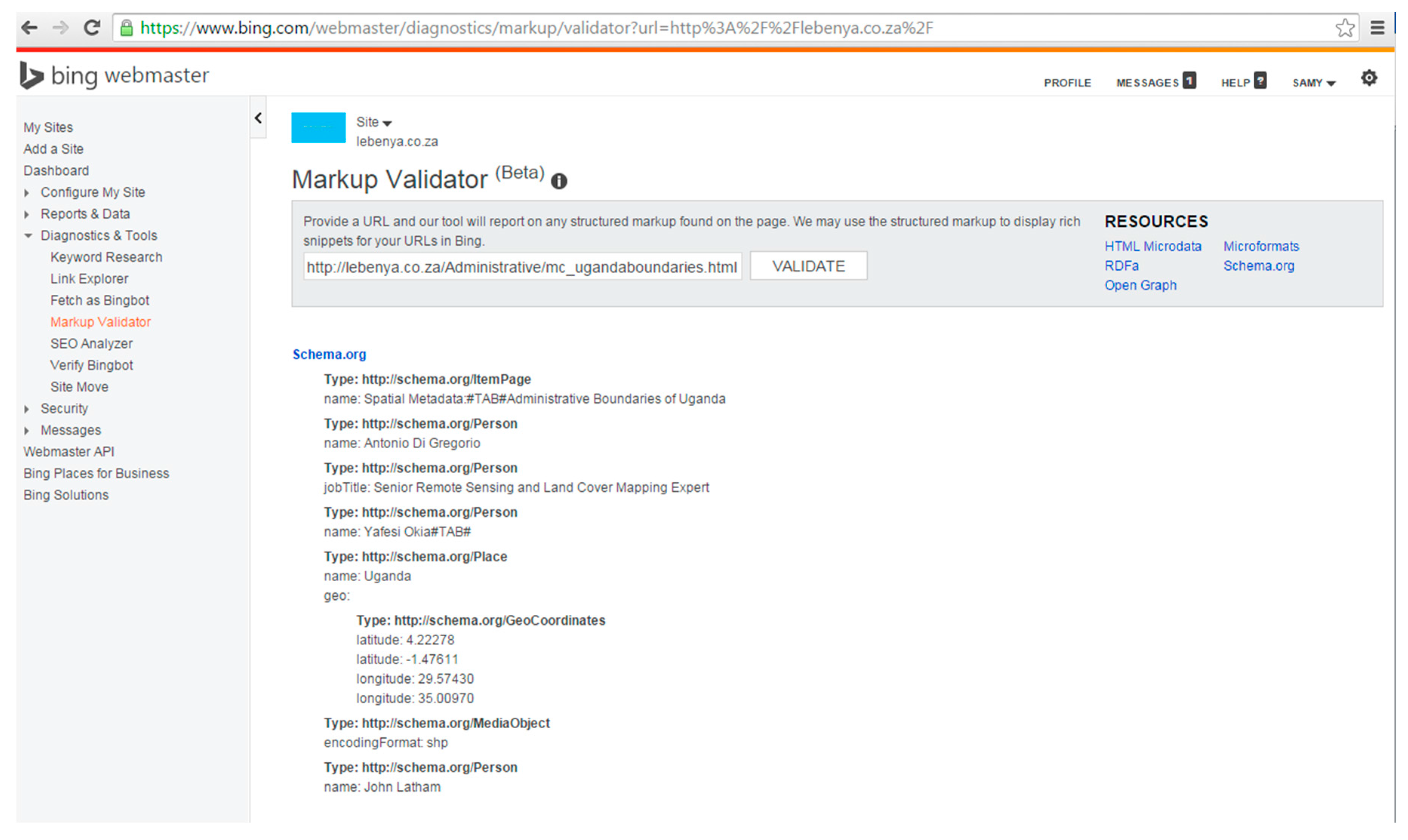
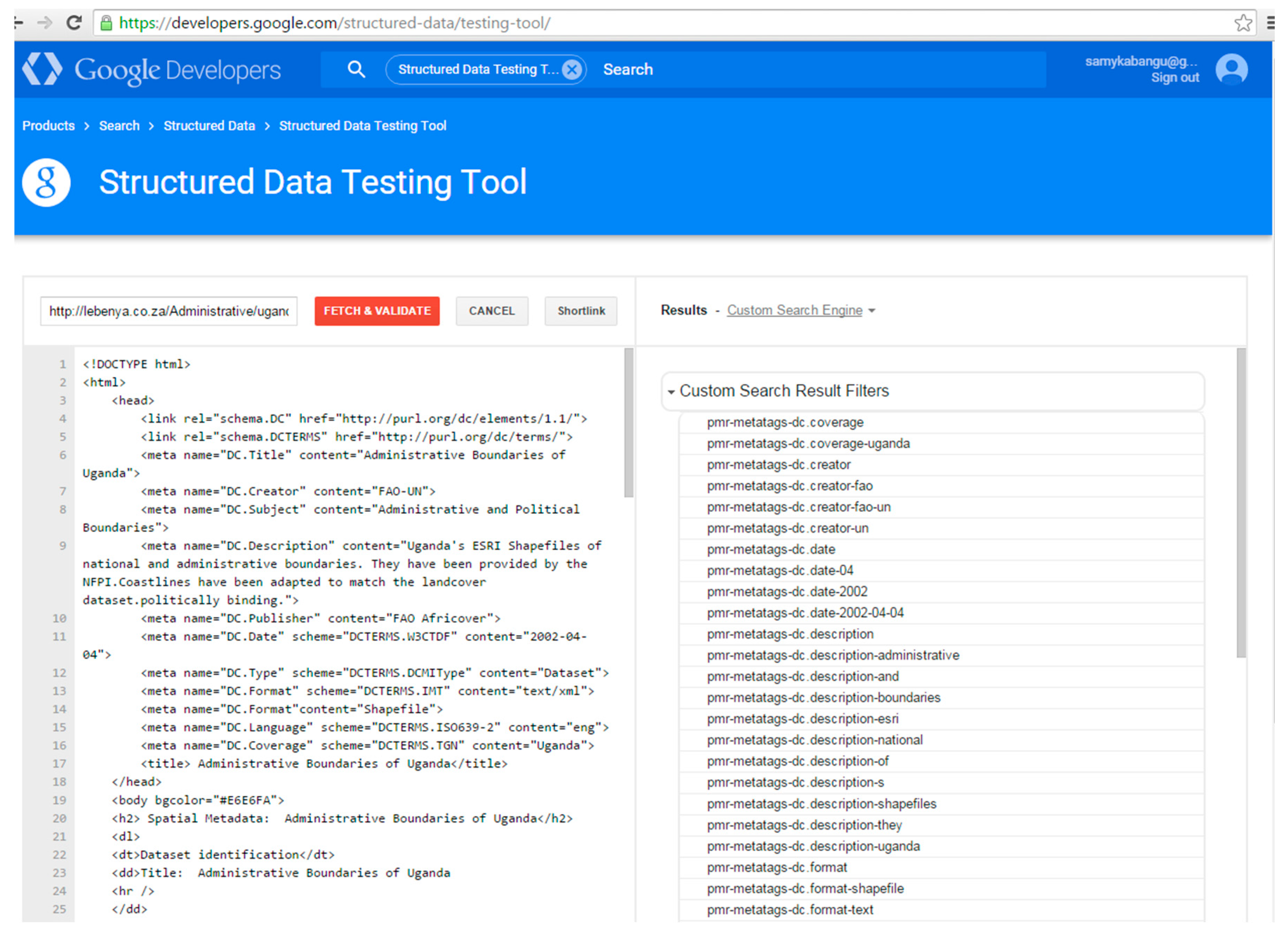
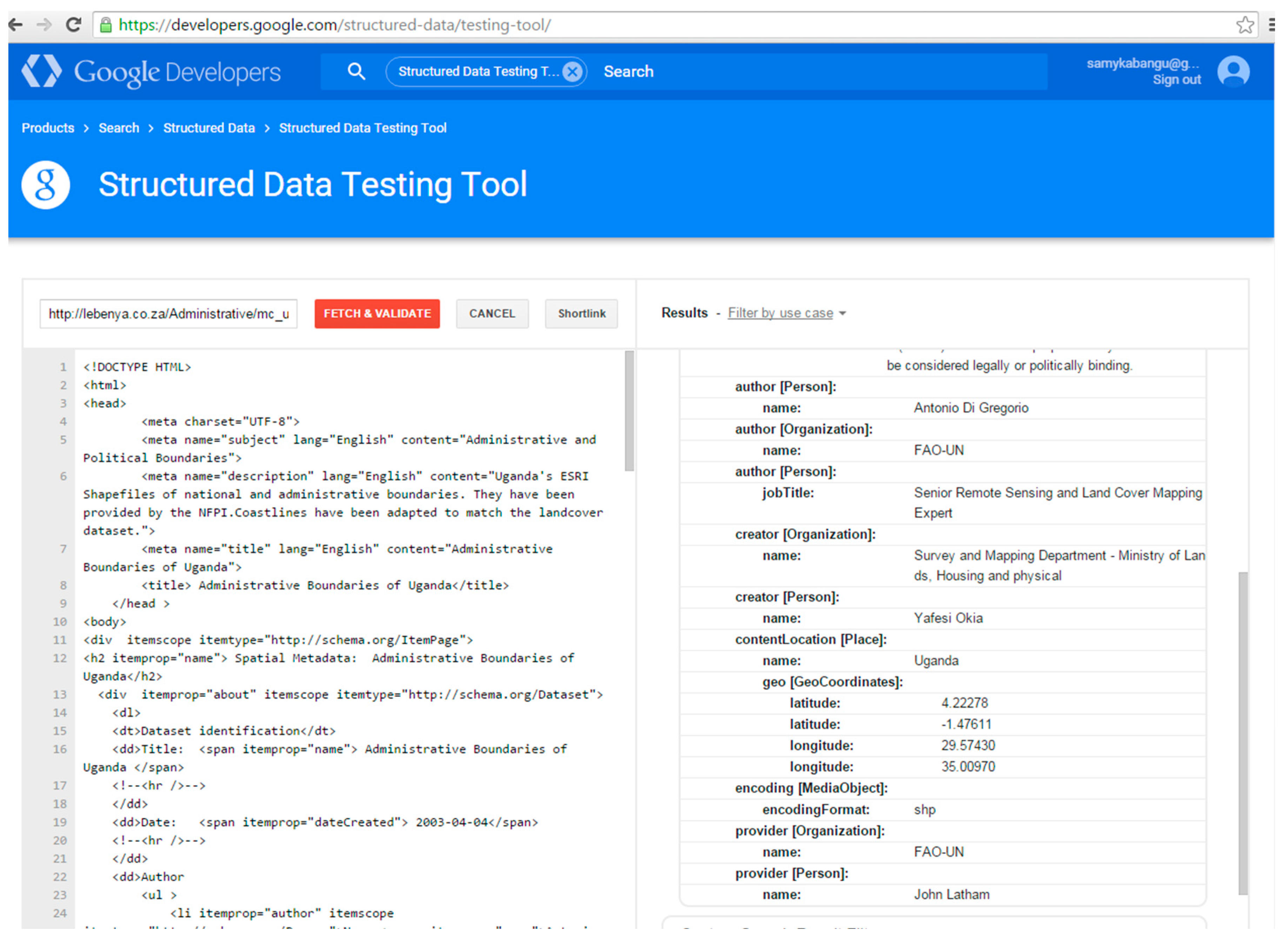

| Taxonomy | Subject (Theme): Road Network |
|---|---|
| ISO 19115 | Dataset title: Roads of Egypt |
| Dublin Core Vocabulary | TITLE: Roads of Egypt <head> <link rel = “schema.DC” href = http://purl.org/dc/elements/1.1> <link rel = “schema.DCTERMS” href =http://purl.org/dc/terms”/> <meta name = “DC.Title” content = “Roads of Egypt” lang = “en”> … </head> |
| Schema.org Vocabulary | NAME: Roads of Egypt <body> <div itemscope itemtype=“http://schema.org/ItemPage”> <h2 itemprop=“name”> Roads of Egypt</h2> … </div> </body> |
| Measure | Description |
|---|---|
| Rank | The average position of a page (URL) in the search results. The lower the average position, the higher its rank and visibility. |
| Recall | The ratio of the number of relevant pages retrieved (included in the search results) to the total number of relevant pages in the web server (58 for this research). |
| Bing | |||
|---|---|---|---|
| Dublin Core | Number of retrieved relevant pages | 15 | 49 |
| Number of relevant pages | 58 | 58 | |
| Recall | 0.26 | 0.84 | |
| Schema.org | Number of retrieved relevant pages | 39 | 45 |
| Number of relevant pages | 58 | 58 | |
| Recall | 0.67 | 0.78 | |
| Rank | Bing | ||
|---|---|---|---|
| Dublin Core | Mean average position | 744.5 | 163.1 |
| Standard deviation of the average position | 436.4 | 363.5 | |
| Minimum position | 1 | 1 | |
| Maximum position * | 1000 | 1000 | |
| Schema.org | Mean average position | 338.2 | 227.1 |
| Standard deviation of the average position | 466.4 | 419.1 | |
| Minimum position | 2 | 1 | |
| Maximum position * | 1000 | 1000 |
| Bing vs. Google | n | Mean Rank | Sum of Ranks | |
|---|---|---|---|---|
| Dublin Core | Bing rank < Google rank | 47 | 27.06 | 1272 |
| Bing rank > Google rank | 4 | 13.50 | 54 | |
| Bing rank = Google rank | 7 | |||
| 58 | ||||
| Schema.org | Bing rank < Google rank | 42 | 25.98 | 1091 |
| Bing rank > Google rank | 11 | 30.91 | 340 | |
| Bing rank = Google rank | 5 | |||
| 58 |
| Dublin Core vs. Scheman.org | n | Mean Rank | Sum of Ranks | |
|---|---|---|---|---|
| Bing | Dublin Core rank < Schema.org rank | 35 | 21.59 | 755.50 |
| Dublin Core rank > Schema.org rank | 8 | 23.81 | 190.50 | |
| Dublin Core rank = Schema.org rank | 15 | |||
| 58 | ||||
| Dublin Core rank < Schema.org rank | 12 | 13.25 | 159 | |
| Dublin Core rank > Schema.org rank | 15 | 14.6 | 219 | |
| Dublin Core rank = Schema.org rank | 31 | |||
| 58 |
| Relevance-based evaluation of retrieval effectiveness | Vocabulary | Dublin Core | Google recall > Bing recall |
| Schema.org | Google recall > Bing recall | ||
| Search engine | Bing | Schema.org recall > Dublin Core recall | |
| Dublin Core recall > Schema.org | |||
| Ranking-based evaluation of retrieval effectiveness | Vocabulary | Dublin Core | Google visibility > Bing visibility |
| Schema.org | Google visibility > Bing visibility | ||
| Search engine | Bing | Schema.org visibility > Dublin Core visibility | |
| Schema.org visibility = Dublin Core visibility |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Katumba, S.; Coetzee, S. Employing Search Engine Optimization (SEO) Techniques for Improving the Discovery of Geospatial Resources on the Web. ISPRS Int. J. Geo-Inf. 2017, 6, 284. https://doi.org/10.3390/ijgi6090284
Katumba S, Coetzee S. Employing Search Engine Optimization (SEO) Techniques for Improving the Discovery of Geospatial Resources on the Web. ISPRS International Journal of Geo-Information. 2017; 6(9):284. https://doi.org/10.3390/ijgi6090284
Chicago/Turabian StyleKatumba, Samy, and Serena Coetzee. 2017. "Employing Search Engine Optimization (SEO) Techniques for Improving the Discovery of Geospatial Resources on the Web" ISPRS International Journal of Geo-Information 6, no. 9: 284. https://doi.org/10.3390/ijgi6090284
APA StyleKatumba, S., & Coetzee, S. (2017). Employing Search Engine Optimization (SEO) Techniques for Improving the Discovery of Geospatial Resources on the Web. ISPRS International Journal of Geo-Information, 6(9), 284. https://doi.org/10.3390/ijgi6090284