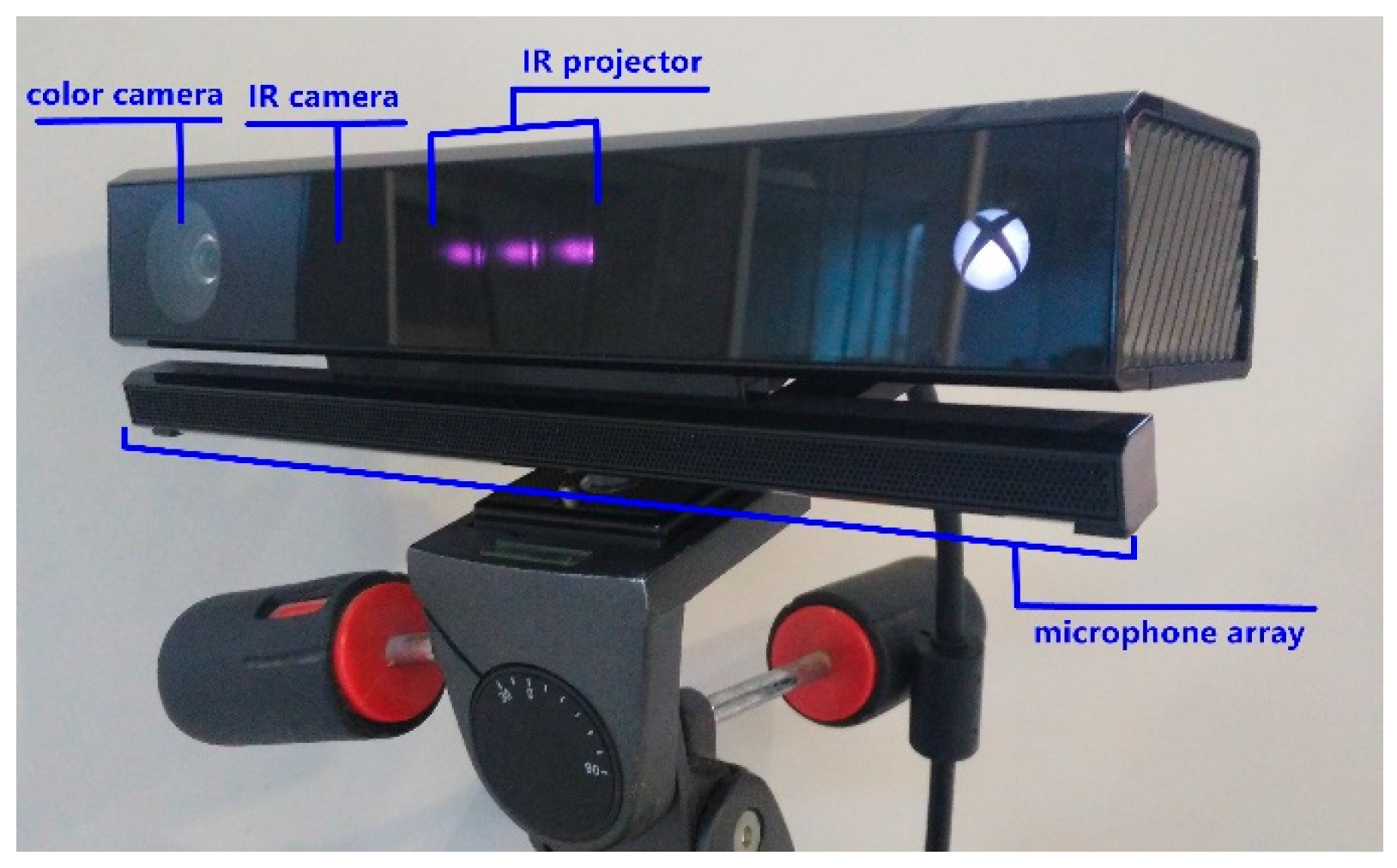
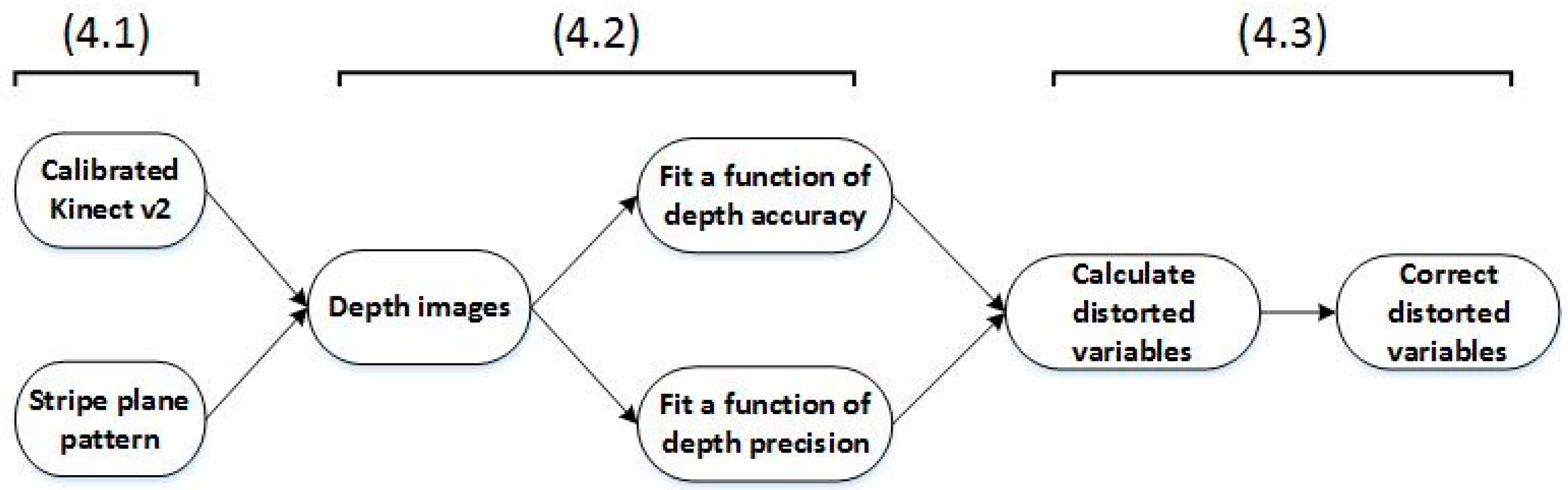
4.1. Calibrate the Kinect v2 and Prepare the Stripe Plane Pattern
In this paper, we equipped our computer with the Ubuntu 14.04 operating system and libfreenect2 [
26], which is the driver for the Kinect v2. Then we printed a chessboard calibration pattern (5 × 7 × 0.03) [
18] on A4 paper. Additionally, we used two tripods, one for holding the calibration pattern, and another one for holding the Kinect v2 sensor to calibrate the color, infrared, sync, and depth successively at two distances: 0.9 m and 1.8 m. It is noted that the pinhole camera model is used to explain the corresponding parameters of calibrating the Kinect v2 under different reflectivity.
Actually, there is a possible geo-referencing problem in our post-rectification method. However, in a short distance, the camera can be conducted perfectly orthogonally. Even in the worst condition there is an incidence angle of approximately 8° in its frame edges, which is equivalent to an error of 0.13% for the reflectance value. Therefore, the performance of our proposed algorithm is not affected.
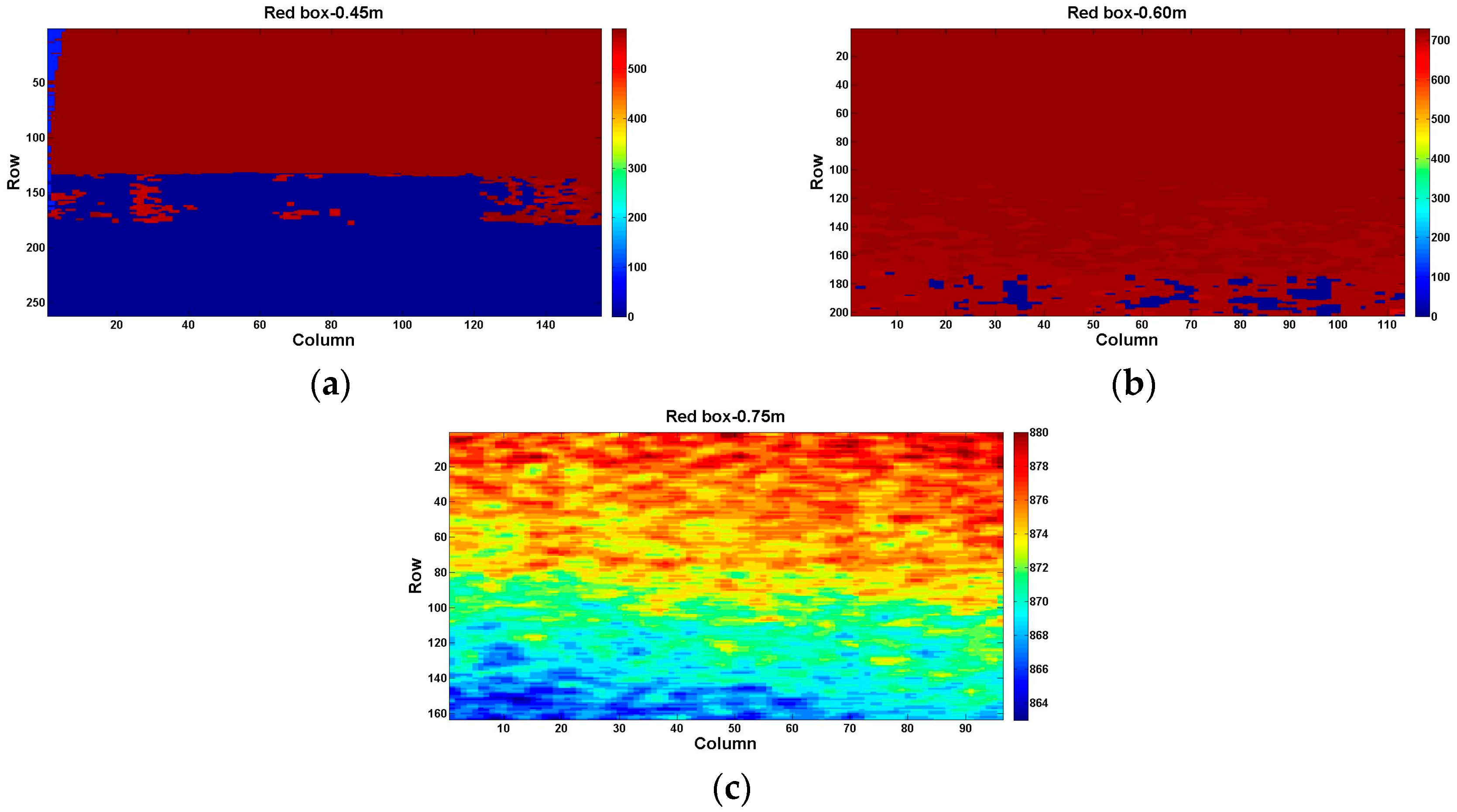
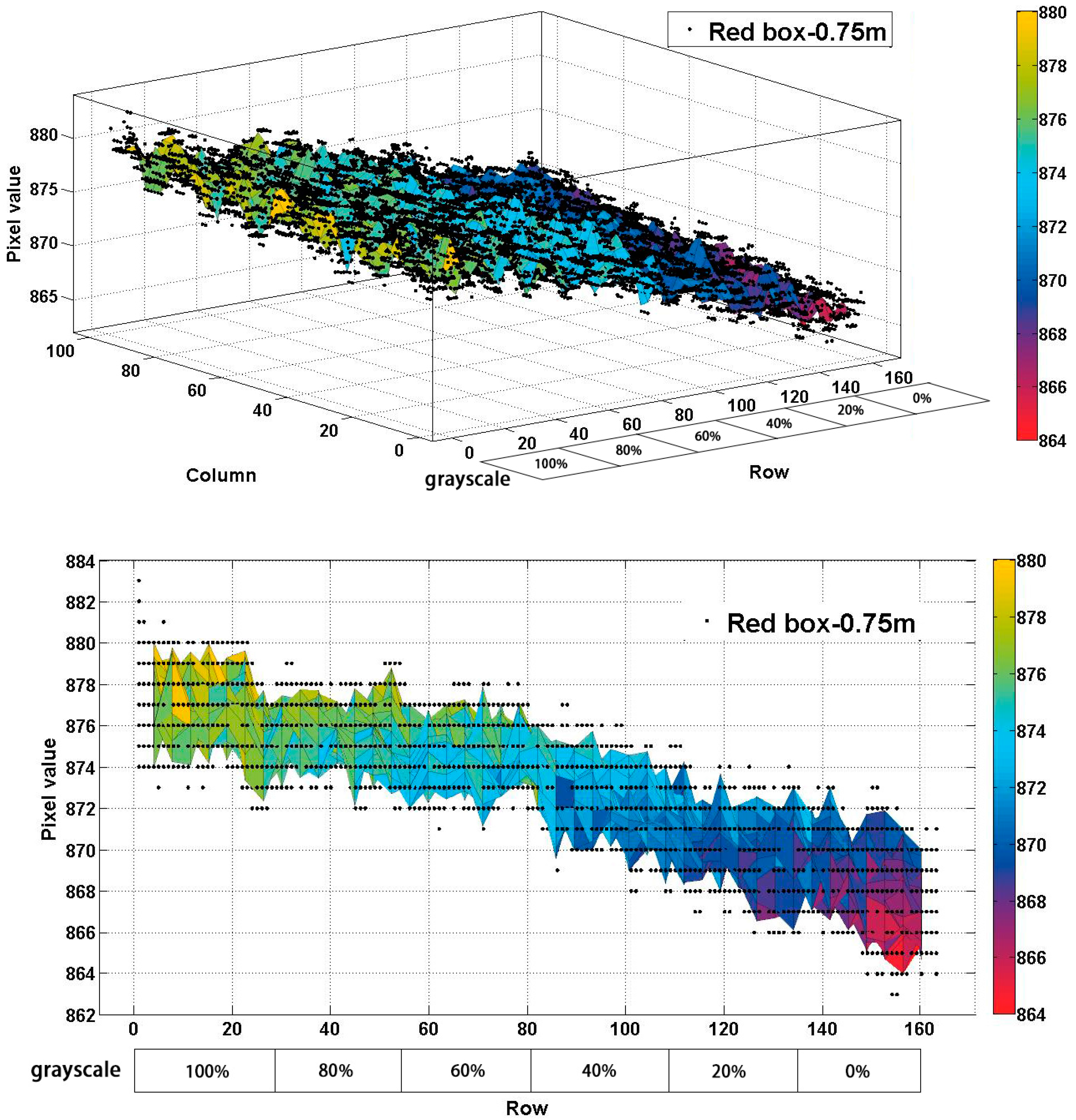
We firstly designed and utilized a stripe plane pattern with different grayscales to investigate the relationship of reflectivity and measured depth. The squared panel divided the gray values into six levels of 100% black, 80% black, 60% black, 40% black, 20% black, and 0% black (white). In the stripe plane pattern, the top strip is printed with 0.0013, decreasing in five steps to 0.9911 (white) from top to bottom with the same size (
Figure 4a). This approach is inspired by the Ringelmann card that is usually used in the reflectance calibration. It is noted that the panel is calibrated for wavelengths of 827 nm to 849 nm. These wavelengths are the expected range for the Kinect 2. As we know, the reflectivity is related to the wavelength, so we chose a mean value as the estimated reflectance factor when the wavelength is 838 nm, which is shown in
Table 3.
4.2. Capture Depth Images and Fit Functions of Depth Accuracy and Precision, Respectively
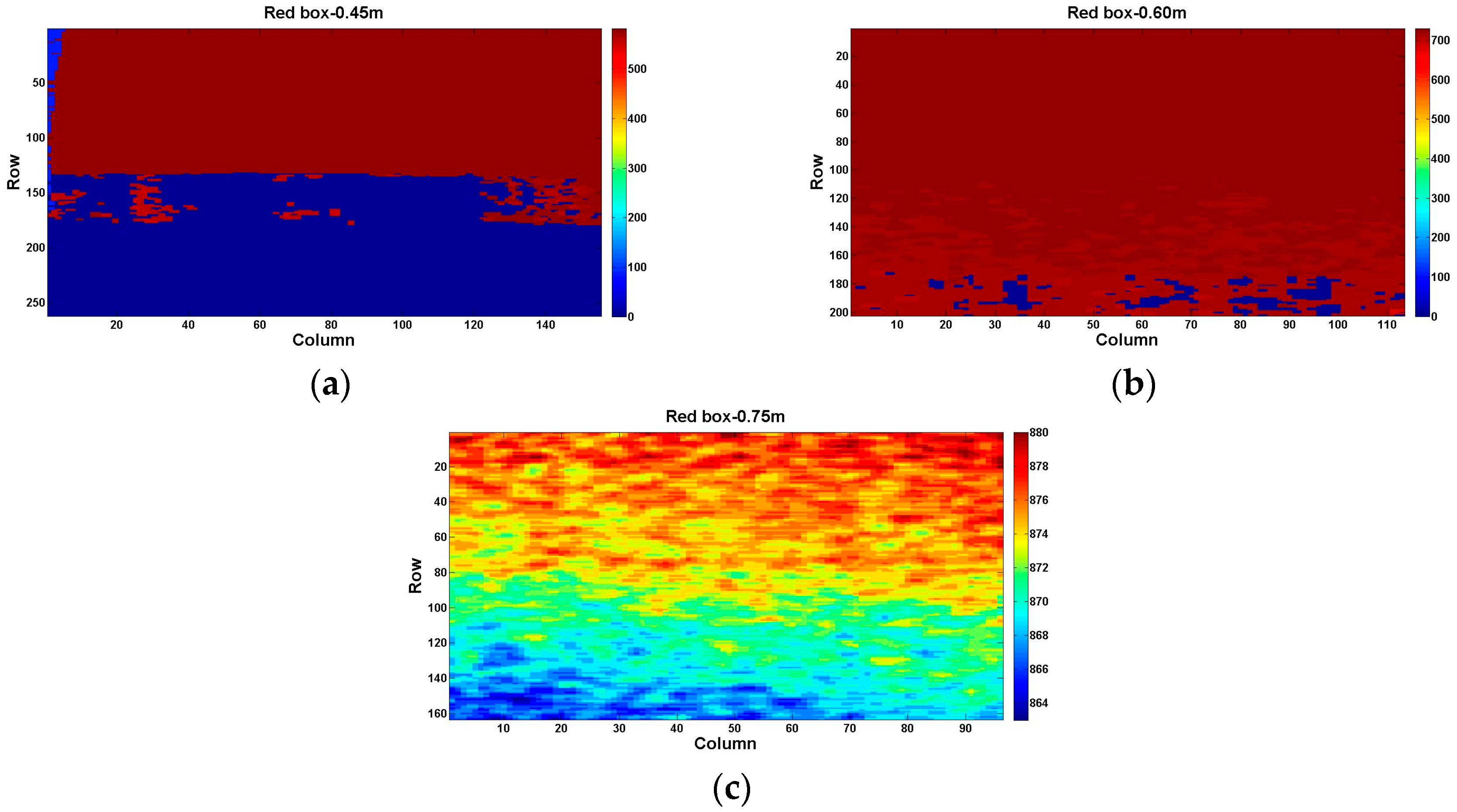
At the same reflectivity, we took the grayscale of 80% black at different distances in the operative measuring range as an example. The region to be studied is presented in
Figure 4c with a yellow box.
We fixed the calibrated Kinect v2 sensor to a stable tripod, and mounted the stripe plane pattern to the other tripod. As shown in
Figure 5, the front panel of the Kinect v2 sensor and the stripe plane pattern are always maintained in parallel, both perpendicular to the ground, using a large triangular rule to guarantee alignment. The stripe plane pattern is progressively moved away from the Kinect v2 sensor in the operative measuring range with a step length of
x meters (less than 0.20 m). Therefore,
L sets of depth images of the yellow box region are captured. One set contains
N (no less than 1) depth images.
Step 1: we calculate a mean depth image and an offset matrix of each set of depth images:
where
L is the quantity of the depth image sets of the yellow box region captured,
i is the sequence number of sets, and
N is the quantity of depth images that each set contains,
j the sequence number of depth images of each set.
Mij is every depth image of each set, and
Mi is the calculated mean depth image of each set. The ground truth matrix is expressed as
Mgi (measured by the flexible ruler). Then we obtain an offset matrix
Moi for each distance.
Step 2: we average pixel values of each offset matrix
Moi:
where
R is the number of rows of each yellow box region of each offset matrix
Moi that varies with different distances,
p the sequence number of the rows, and
C is the number of columns of each yellow box region of each offset matrix
Moi,
q the sequence number of the columns. In the offset matrix
Moi, each pixel value offset to the ground truth in the yellow box is represented as
mpq.
mi is the expectation of each offset matrix
Moi.
Step 3: based on Equations (4) and (5), we compute the standard deviation
si of the offset matrix
Moi for each distance:
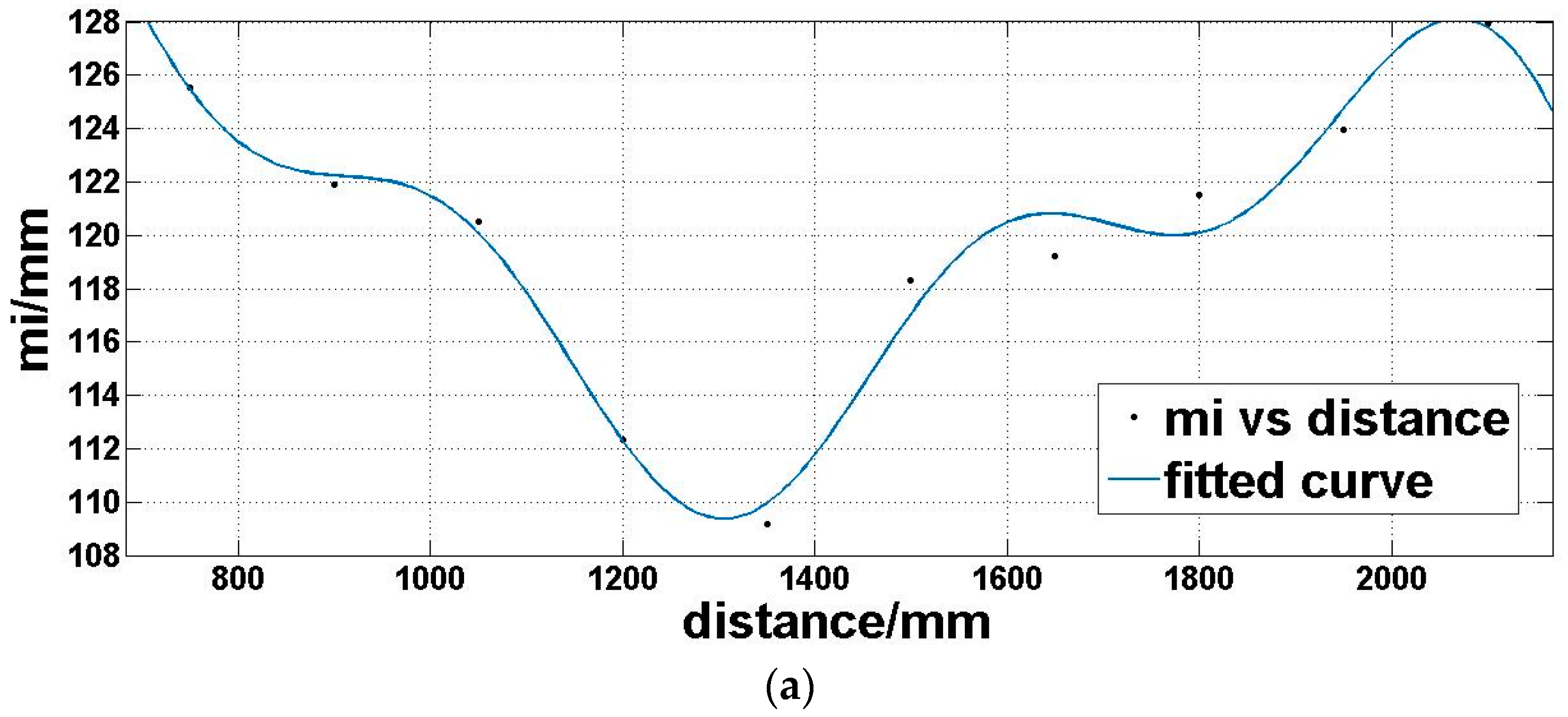
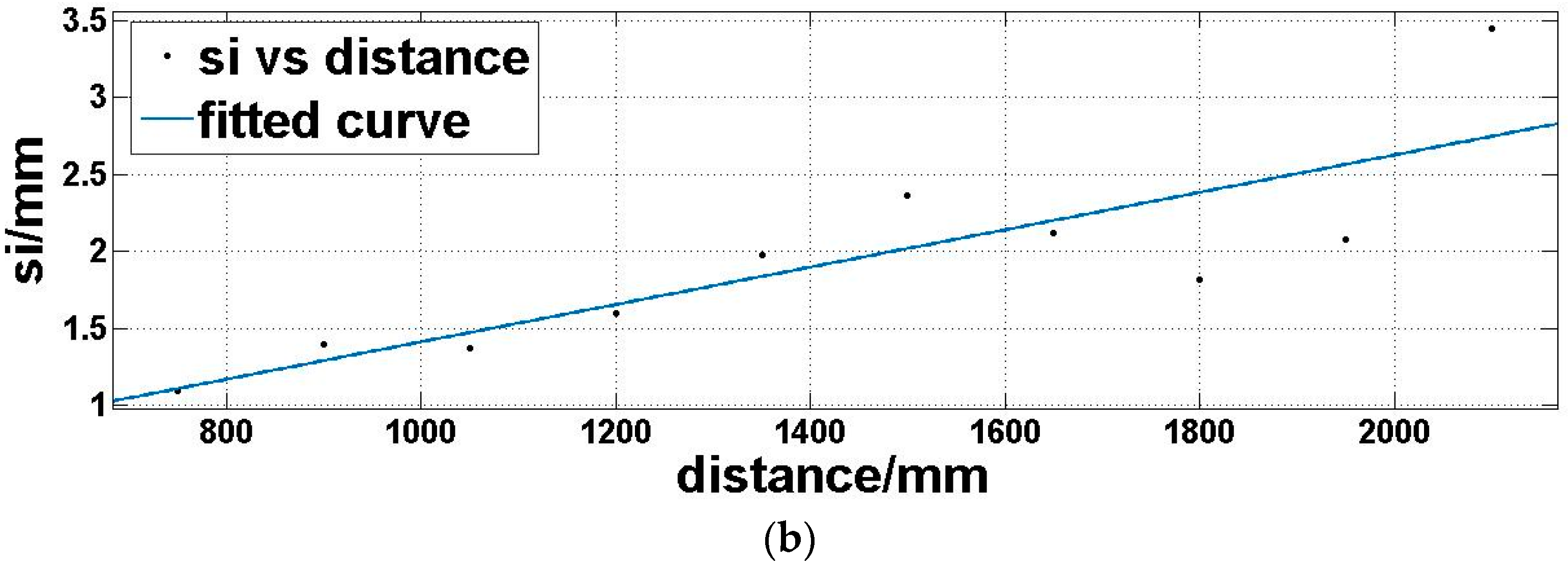
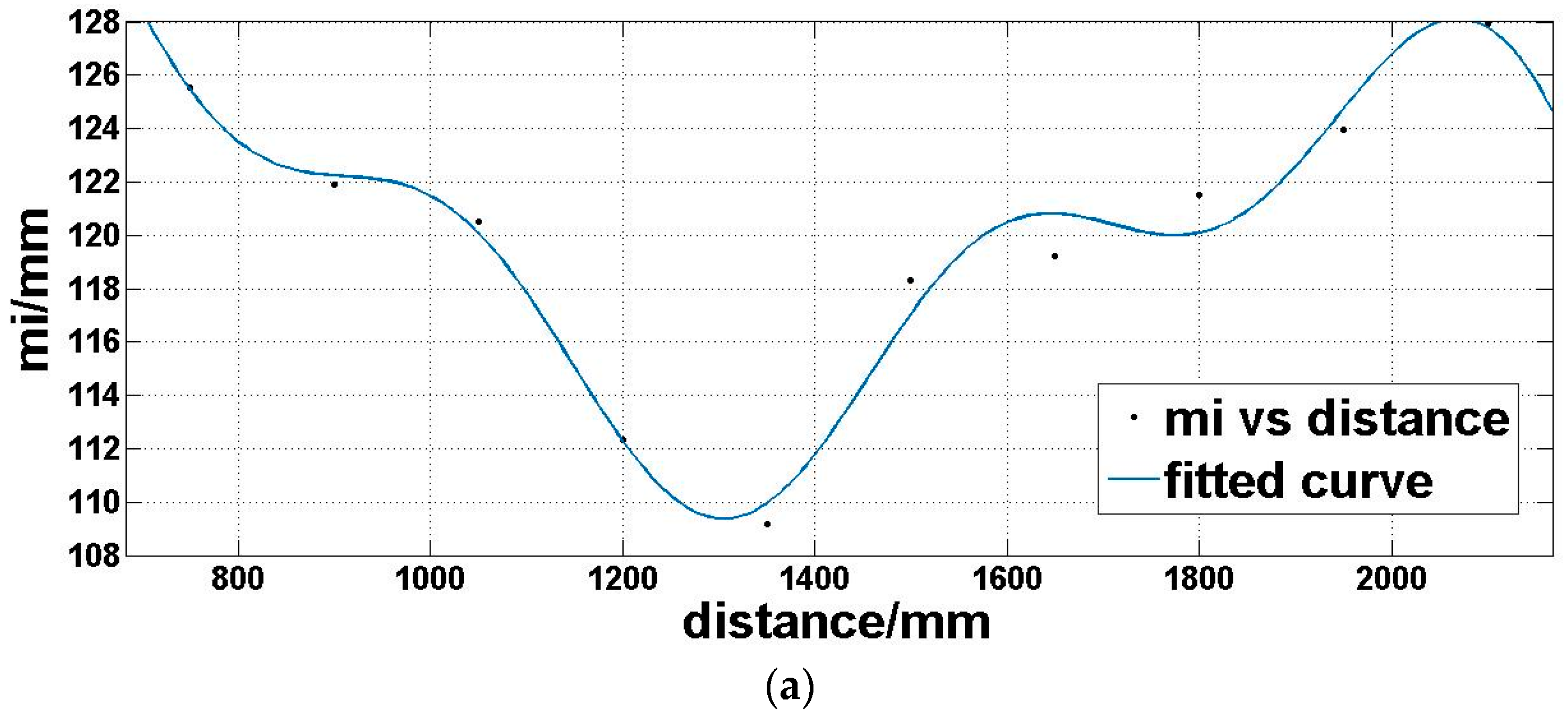
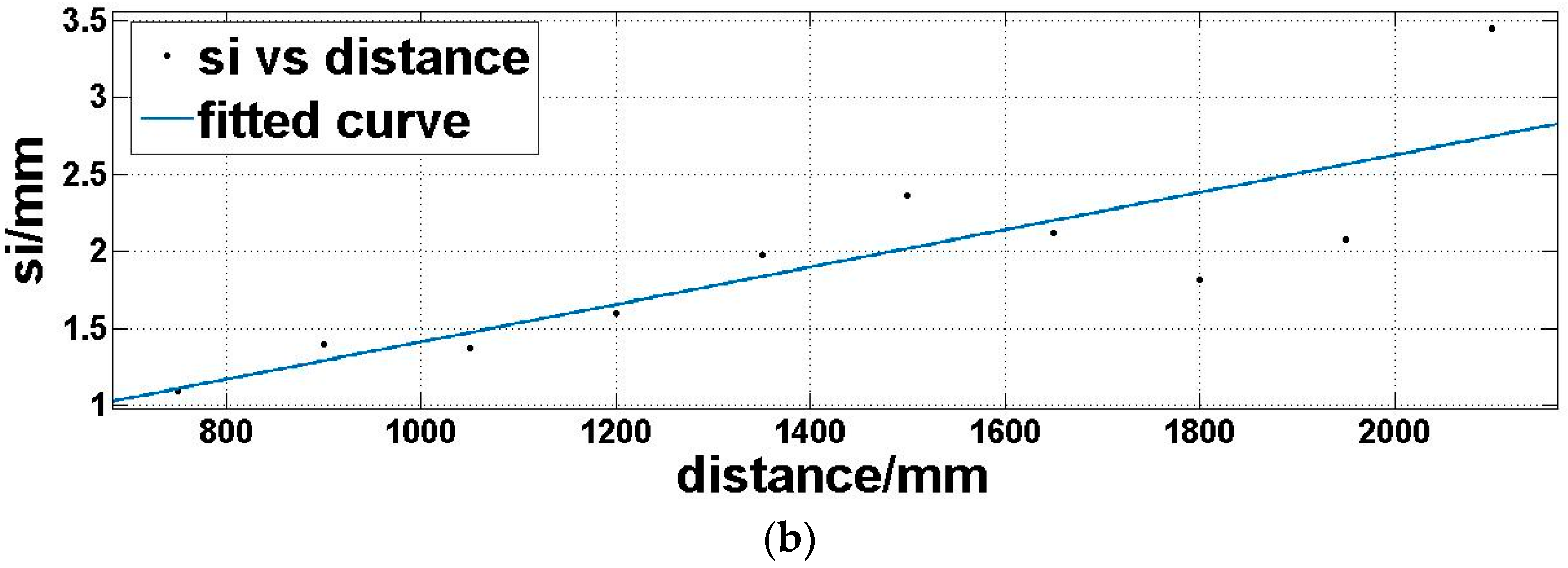
Step 4: we utilize a fitting function three-term sum of sine (Equation (7)) to model the expectation of the offset matrix
Moi (Figure 8a) and a linear polynomial (Equation (8)) to model the standard deviation of the offset matrix
Moi (Figure 8b), which is dependent on the above analysis:
where
d is the distance,
md is the offset expectation corresponding to the distance,
sd is the offset standard deviation corresponding to the distance.
a1,
a2,
a3,
b1,
b2,
b3,
c1,
c2, and
c3 are coefficients to be determined in Equation (7).
t1 and
t2 are coefficients to be determined in Equation (8).
4.3. Correct Depth Images
For different distances, we correct the depth image based on Equation (7). The corrected yellow box region depth image is:
where
Md is the depth image corresponding to the distance. Then, based on Equations (4)–(6), we can calculate
mcorr and
scorr.
mcorr represents the corrected expectation of the offset matrix and
scorr represents the standard deviation. The depth accuracy of the Kinect v2 is evaluated by the expectation of an offset matrix of the depth image, and the depth precision is evaluated by the standard deviation [
20,
22]. In the next section, we apply the post-rectification approach to RGB-D SLAM [
6] in an indoor environment to prove its real effect.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}