
A Framework for Discovering Evolving Domain Related Spatio-Temporal Patterns in Twitter


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Development of a mining framework: a unified framework is proposed to discover evolving domain-related spatio-temporal patterns in Twitter. Prior knowledge is not required in the new framework.
- Extraction of domain related Twitter events by dynamic query expansion: For the target domain, related tweets can be obtained using a dynamic query expansion strategy. These tweets tagged with geo-location and time information constitute spatio-temporal Twitter events.
- Discovery of evolving spatio-temporal patterns from Twitter events: For the extracted domain related spatio-temporal Twitter events, spatial clusters and outliers are detected by spatial clustering, after which the spatio-temporal patterns are discovered by spatio-temporal clustering as they evolve.
- Experimental evaluation using real Twitter data: The proposed framework was extensively tested for spatio-temporal Twitter events related to ‘civil unrest’ in Mexico. The advantages and effectiveness of the new method are demonstrated by comparing the results with alternative methods and baseline data.
2. Related work
2.1. Twitter Event Extraction
2.2. Cluster, Outlier and Hotspot Detection
3. Motivation and Proposed Strategy
3.1. Motivation
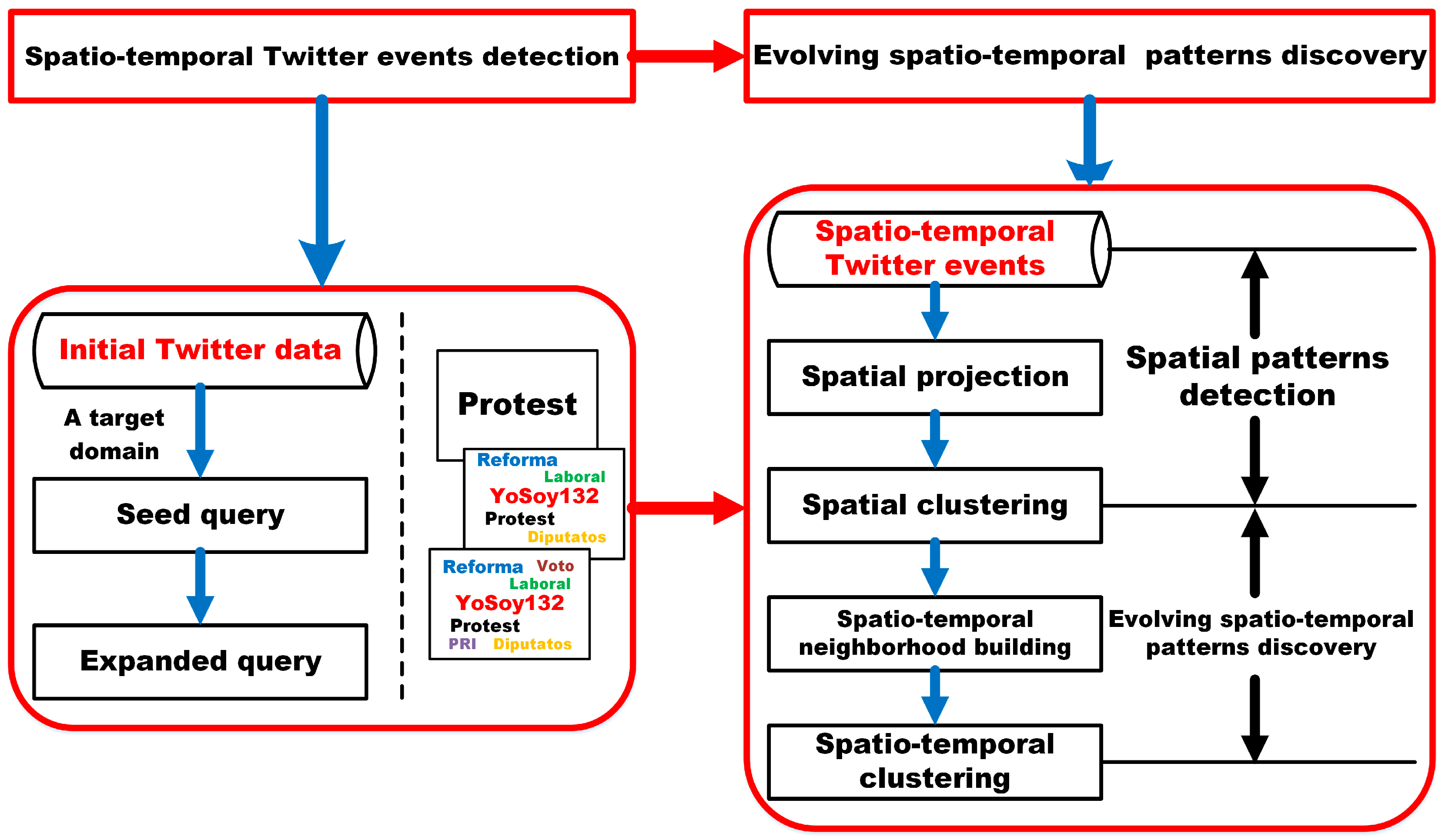
3.2. A New Strategy for Discovering Evolving Domain Related Spatio-Temporal Patterns in Twitter
4. Domain Related Twitter Event Detection
4.1. Basic Definitions
4.2. Dynamic Query Expansion
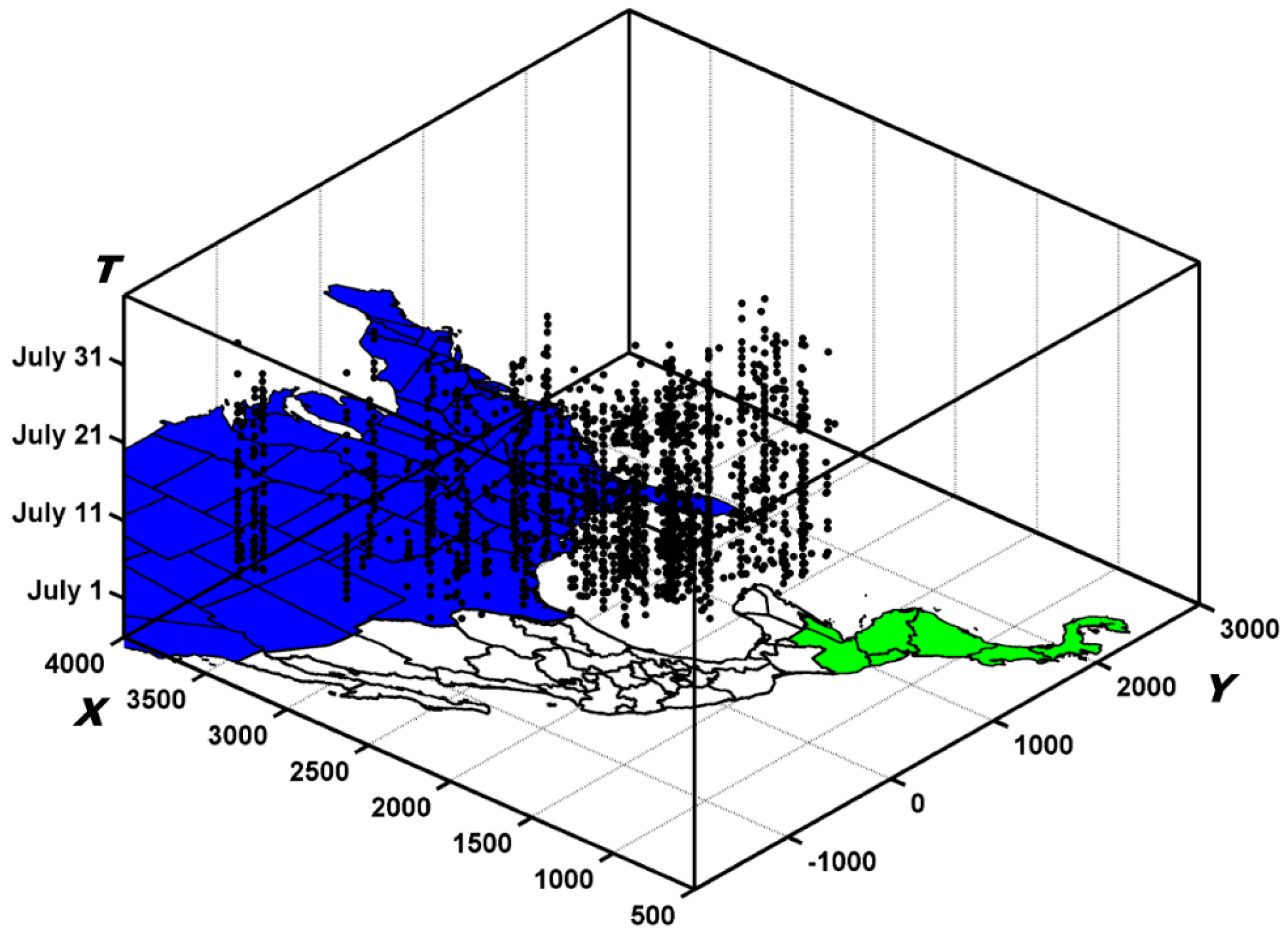
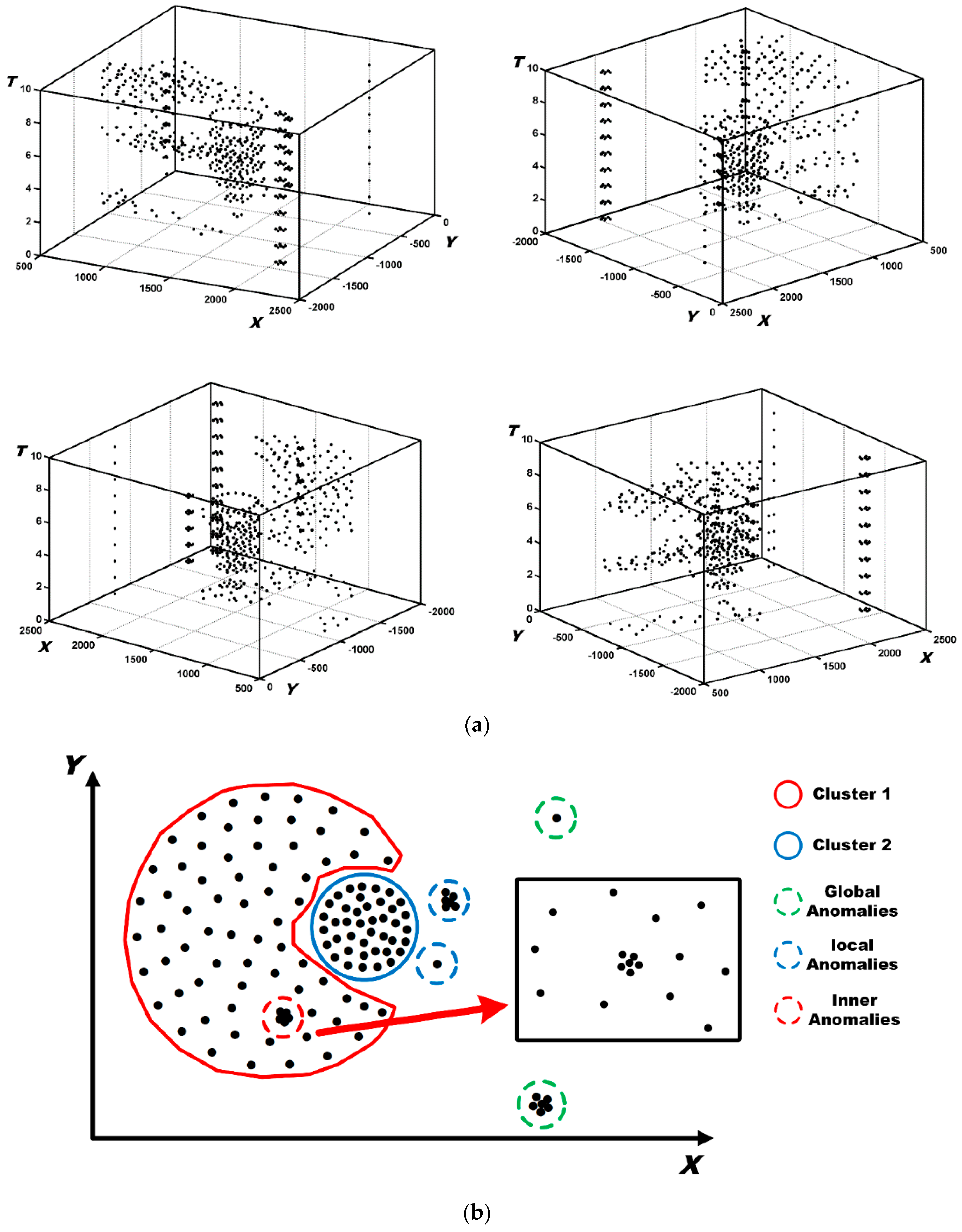
4.3. Spatio-Temporal Twitter Events
5. Evolving Spatio-Temporal Patterns Discovery
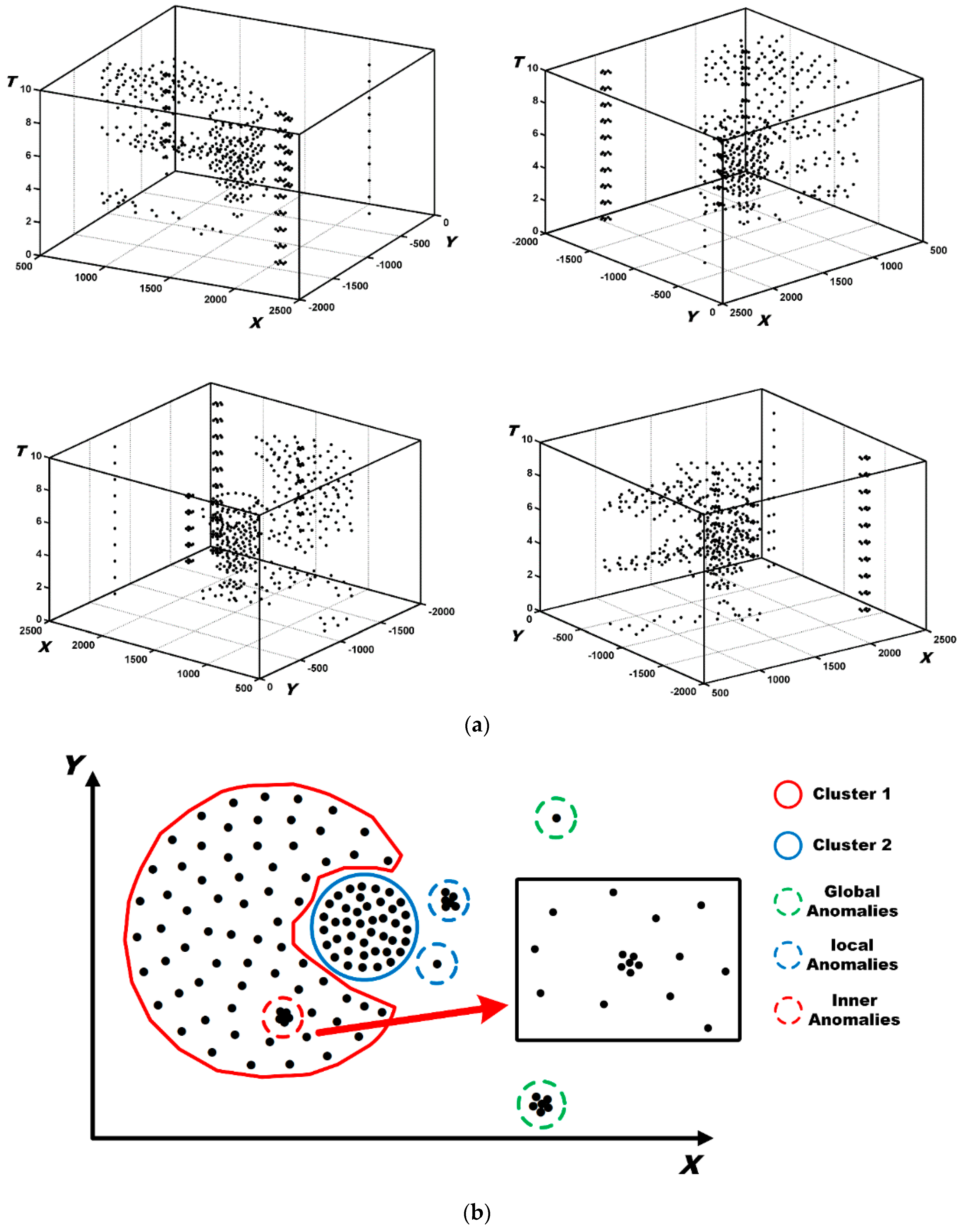
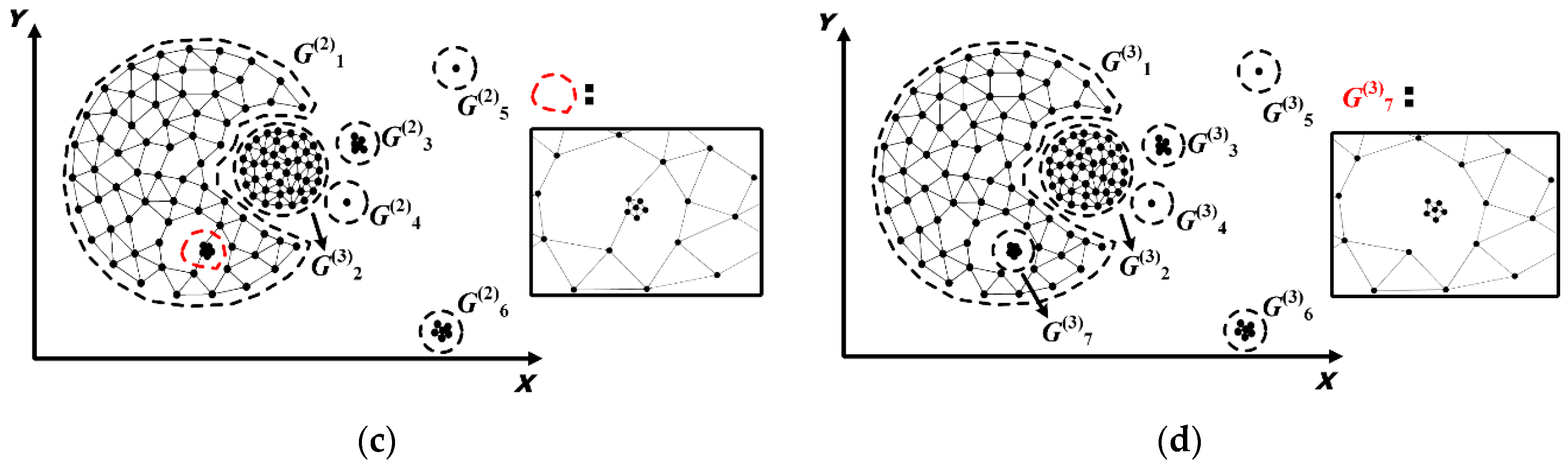
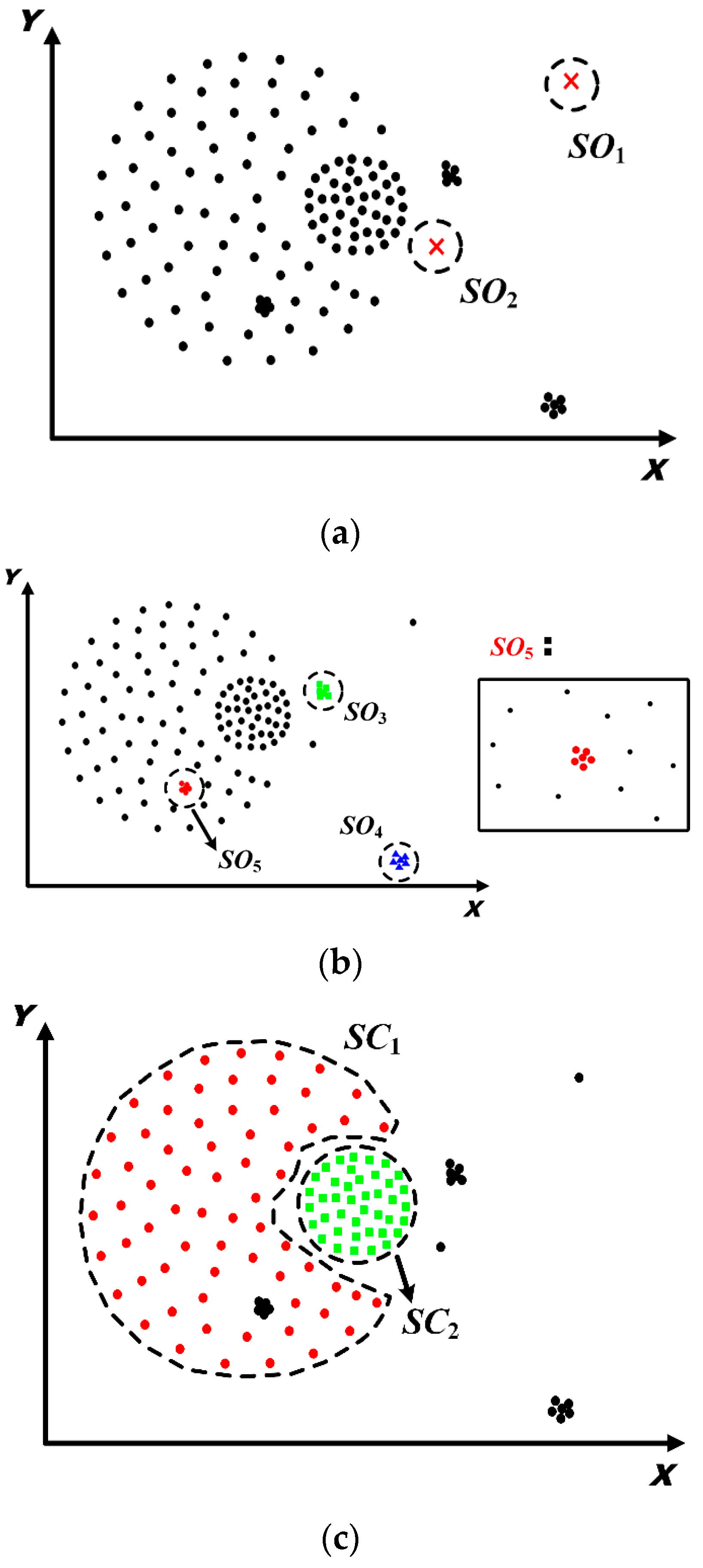
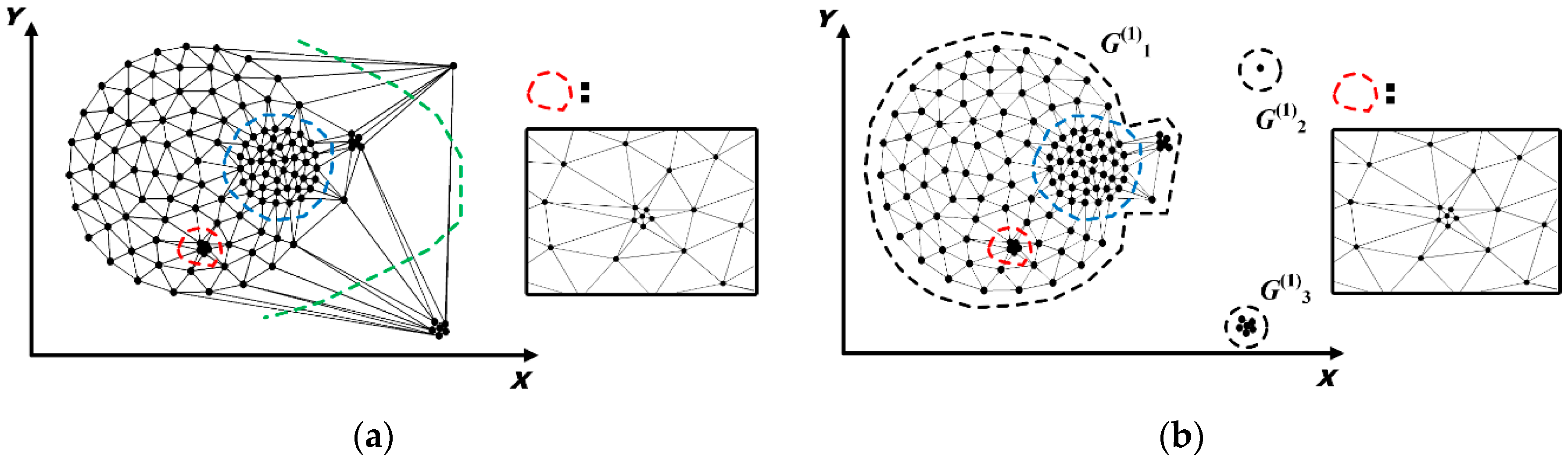
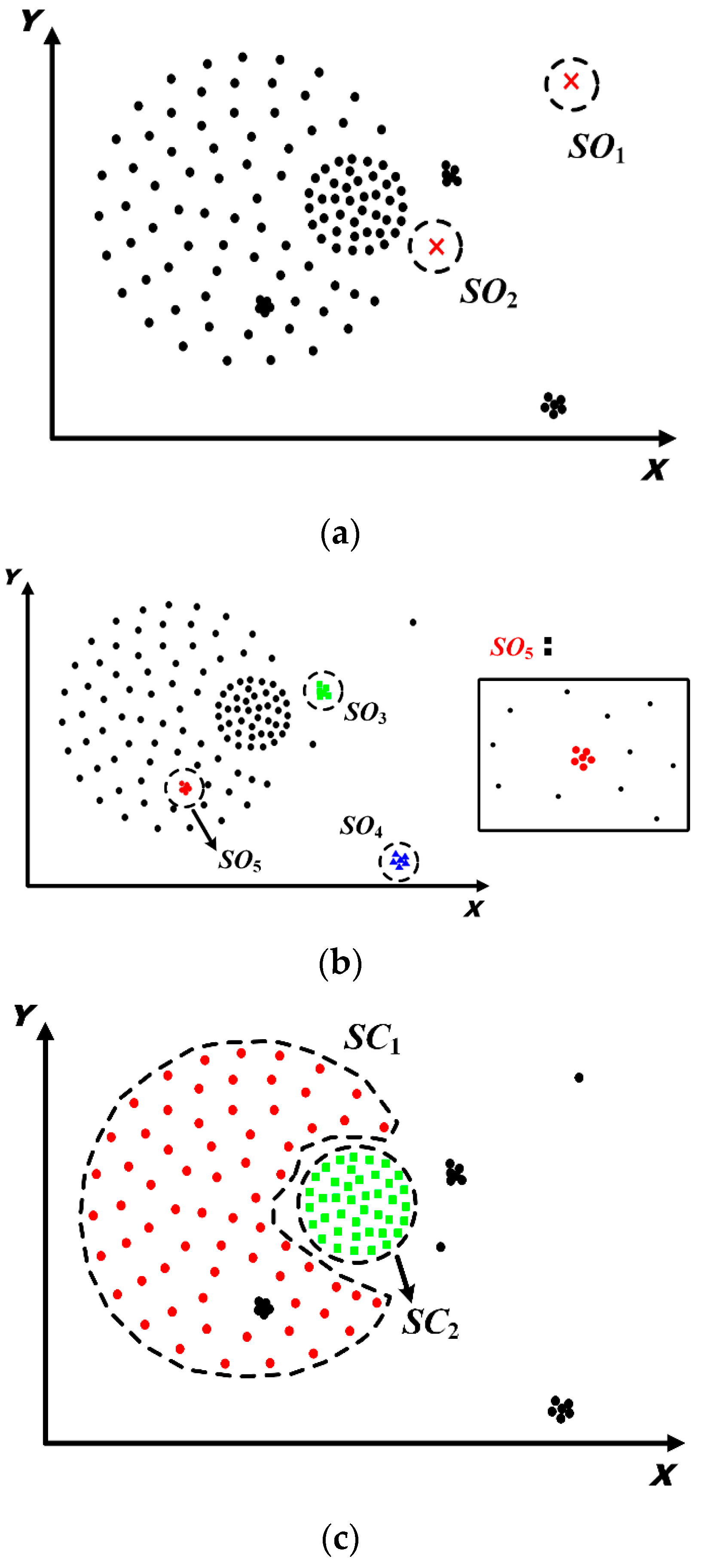
5.1. Spatial Distribution Patterns Detection
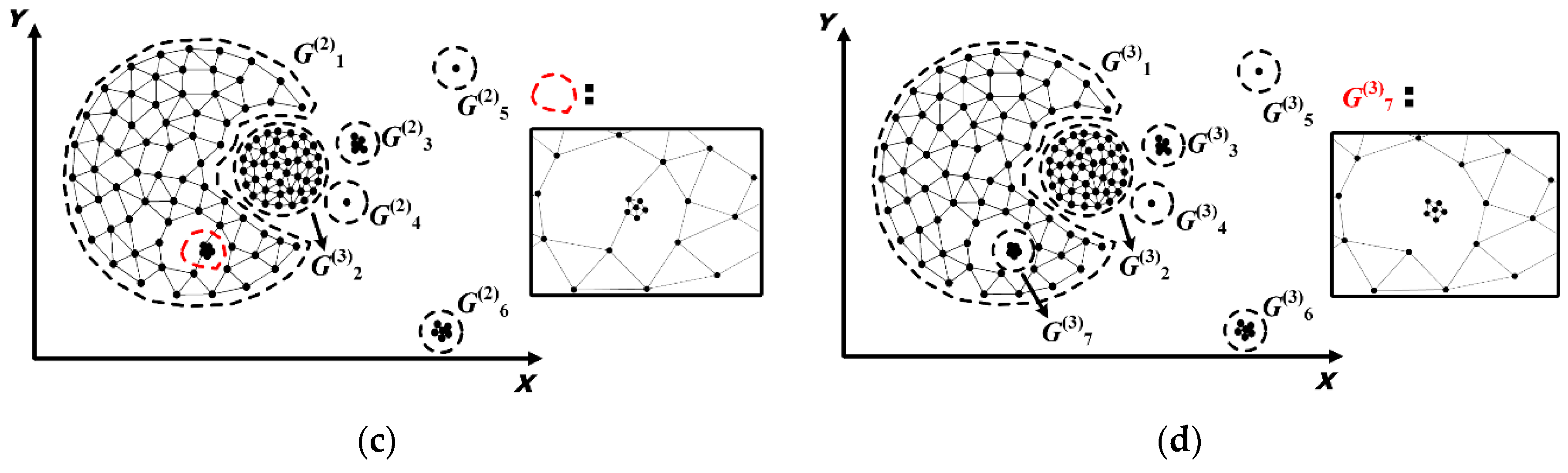
5.1.1. Identification and Removal of I-Long Edges
5.1.2. Identification and Removal of II-Long Edges
5.1.3. Identification and Removal of III-Long Edges
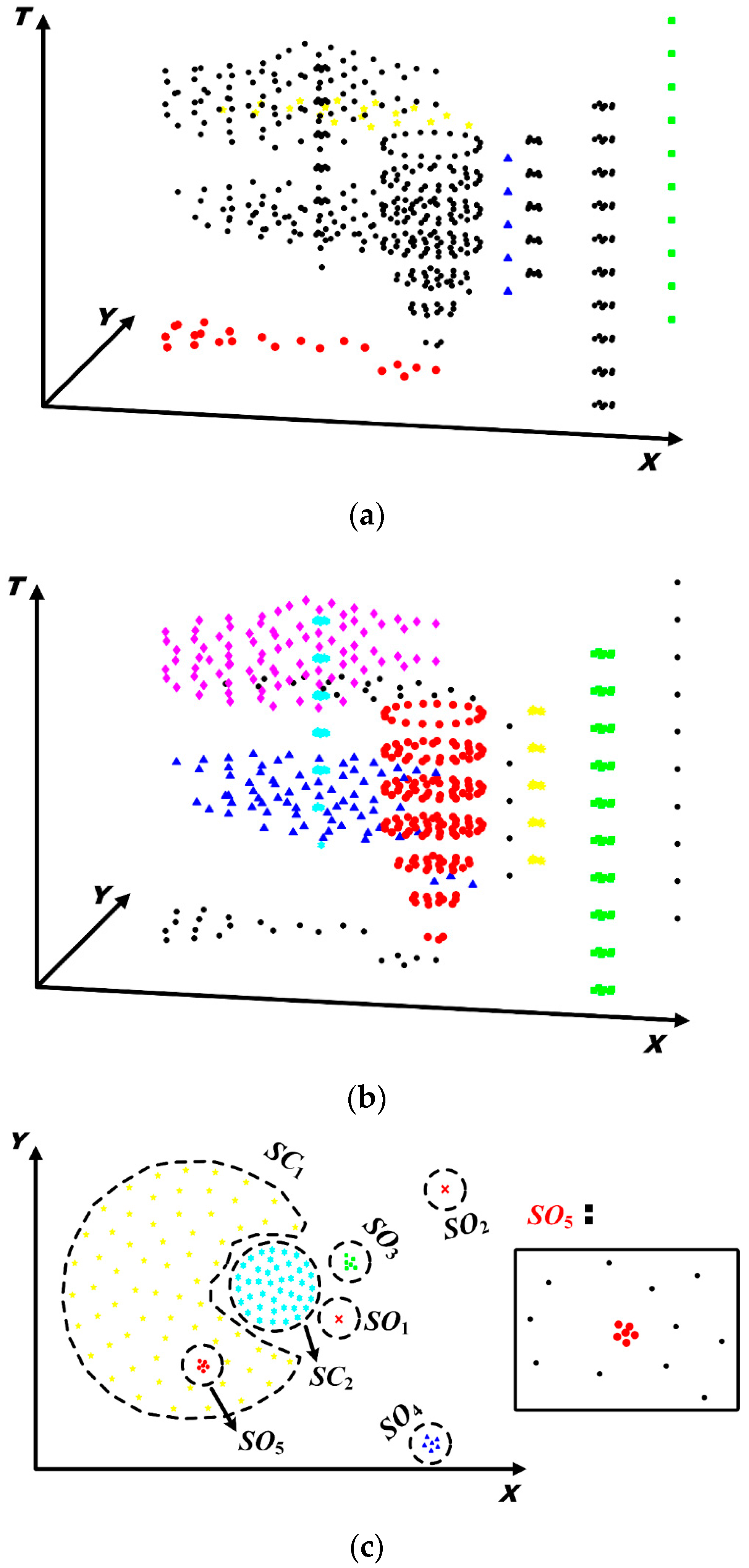
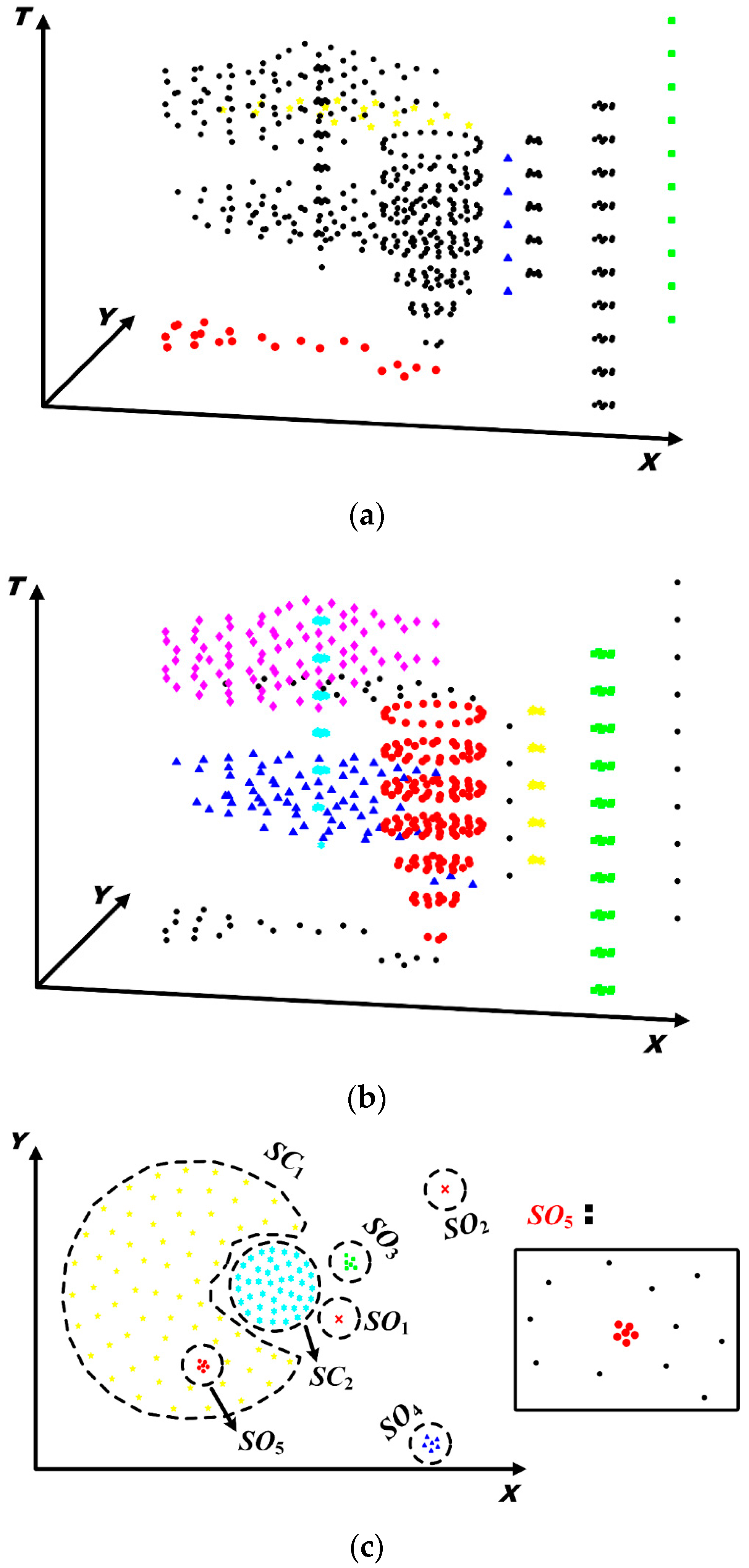
5.1.4. Determination of Spatial Patterns
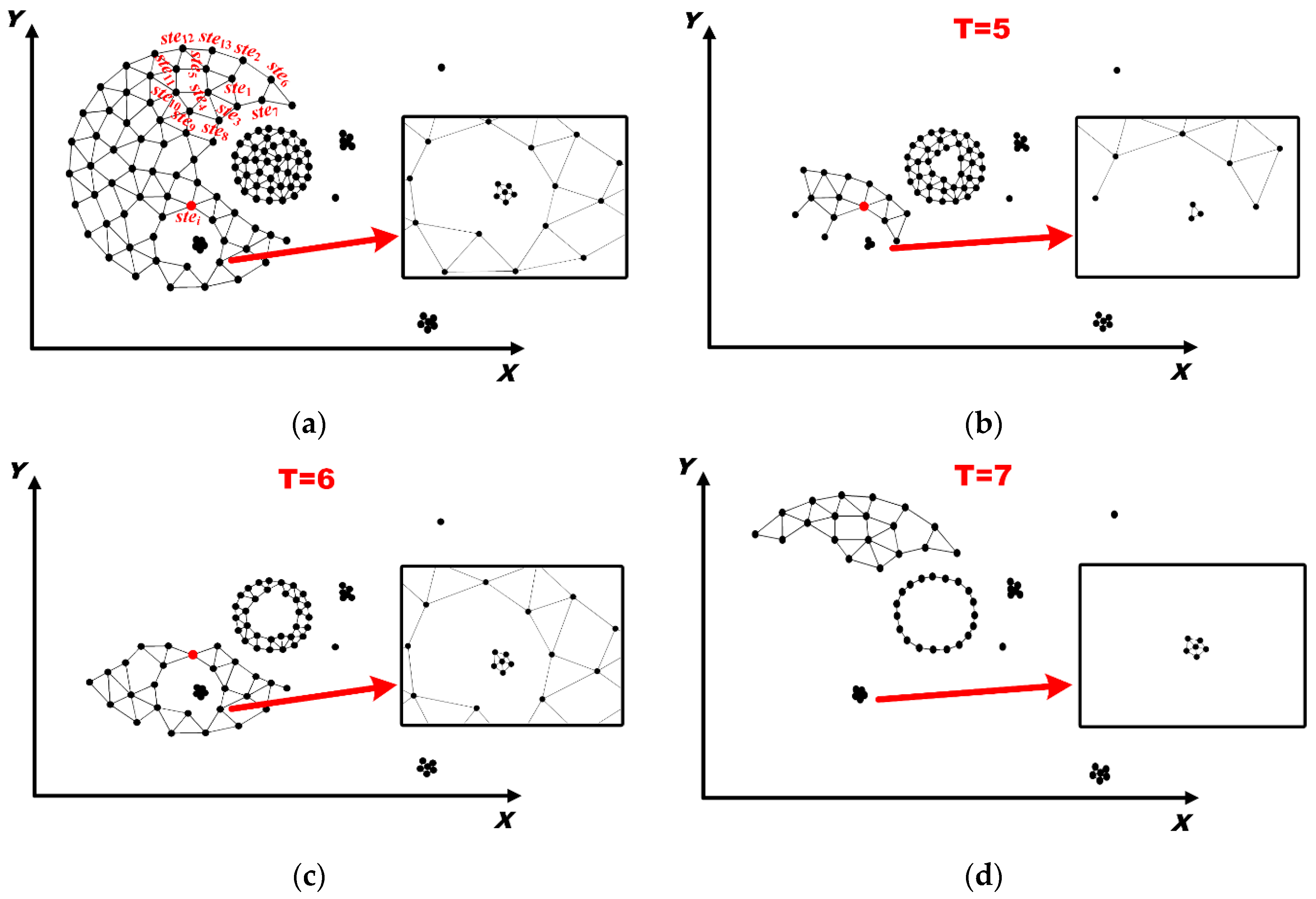
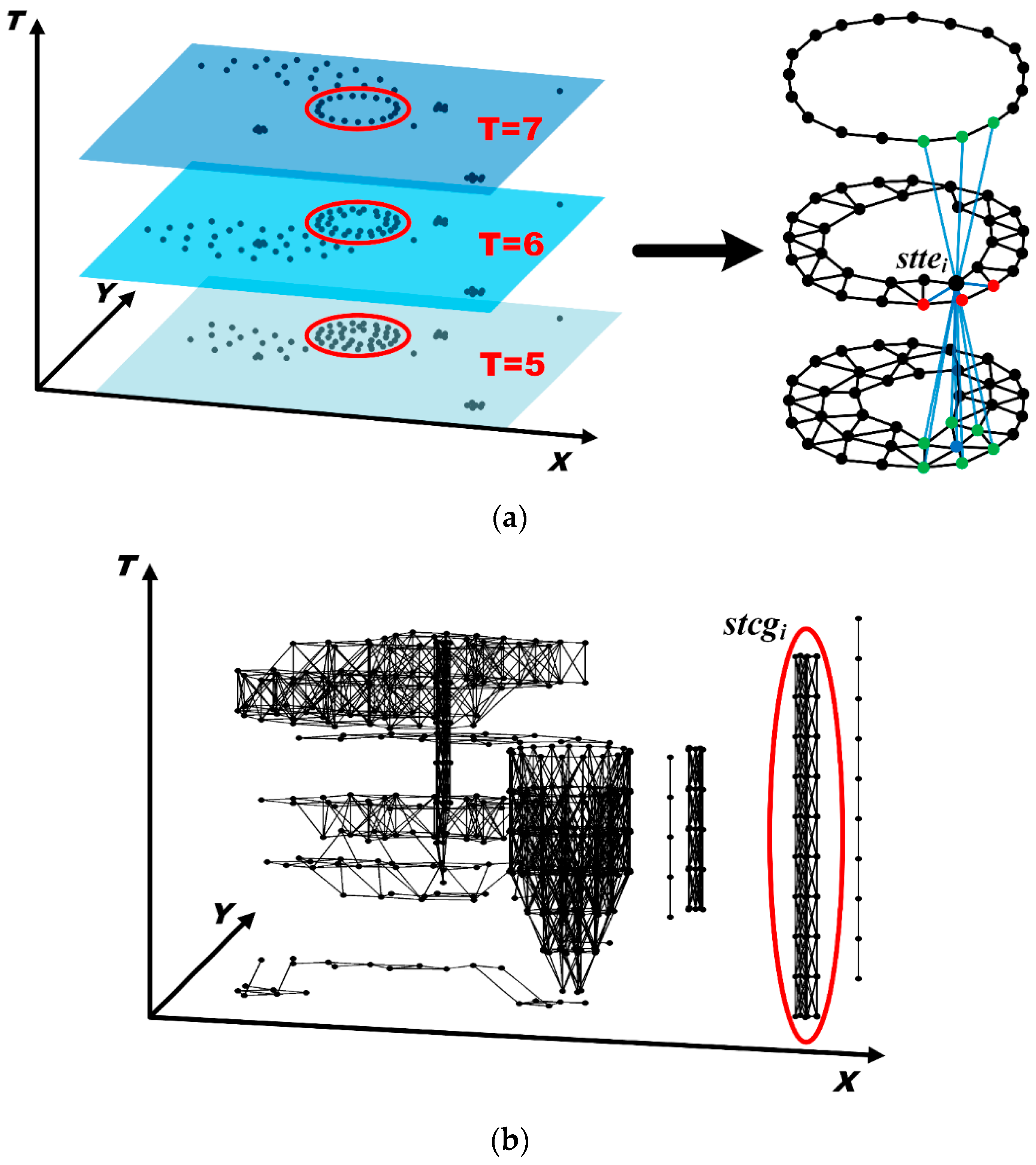
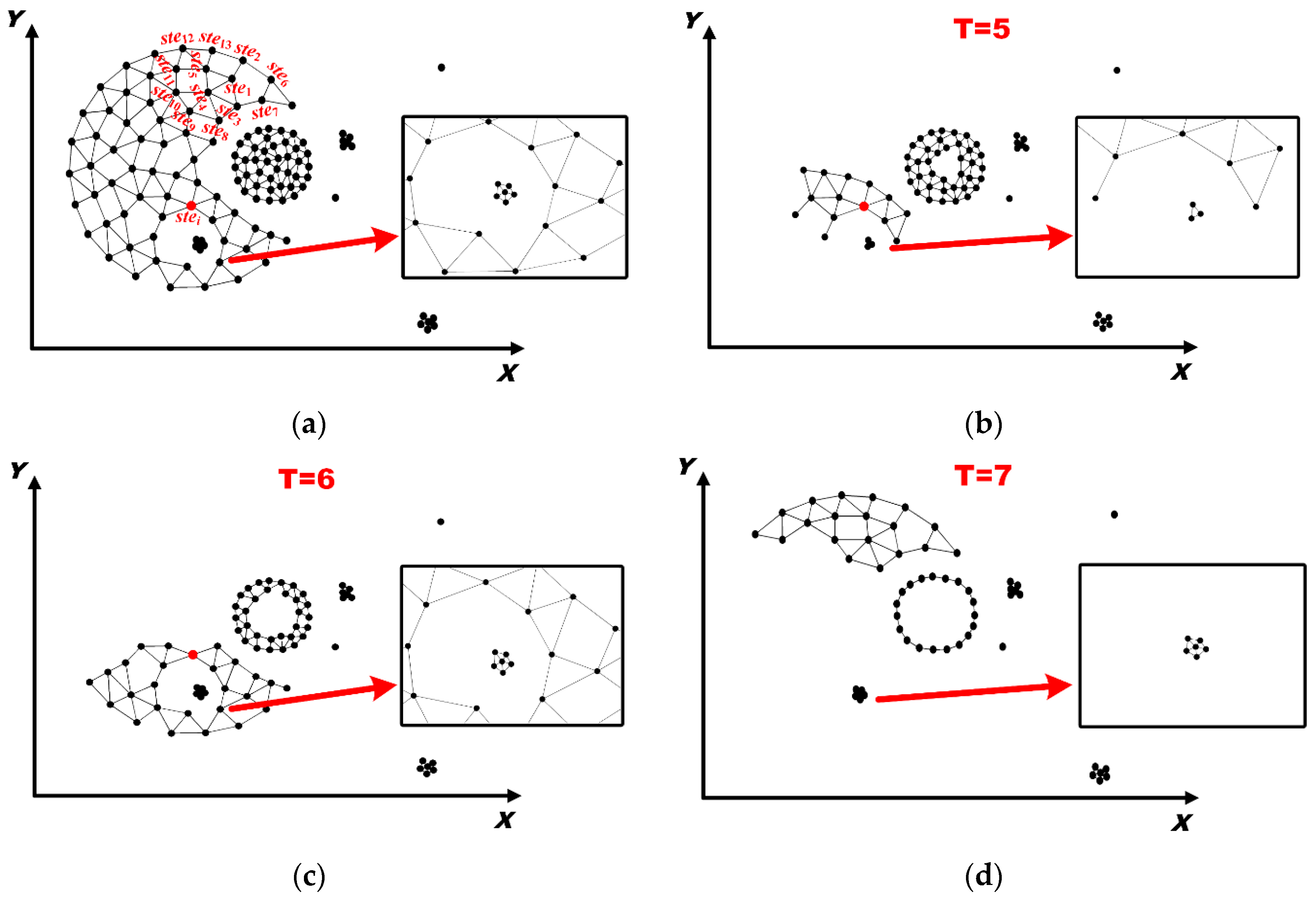
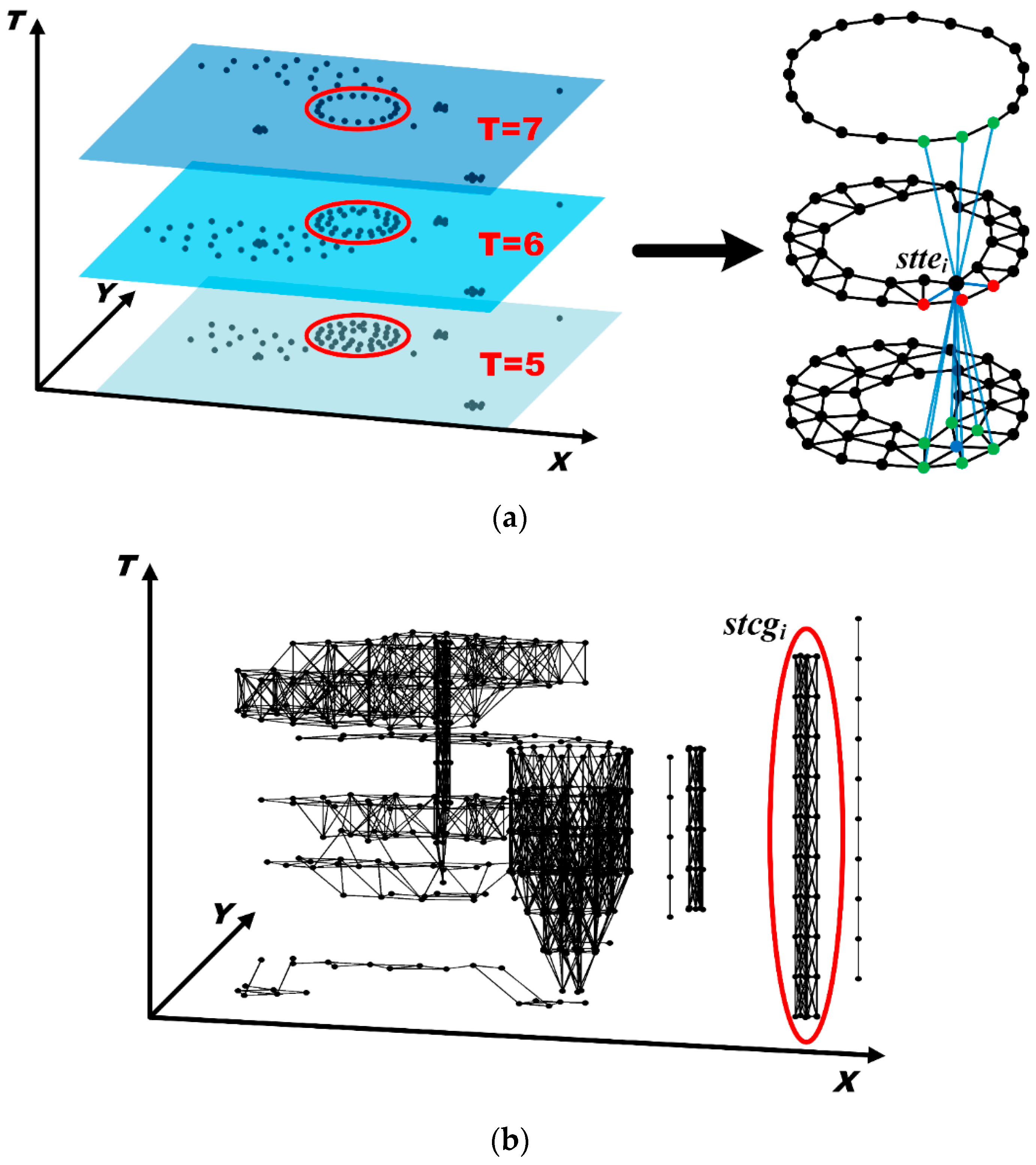
5.2. Discovery of Evolving Spatio-Temporal Patterns
- (i)
- all spatio-temporal Twitter events belonging to SNδ(sttei);
- (ii)
- all spatio-temporal Twitter events belonging to TNε(sttei); and
- (iii)
- all spatio-temporal Twitter events corresponding to spatial Twitter events in SNδ(stei’) with IsOccur_Ttwi(twi∈TWε)=1, where stei’ is the spatial Twitter event of sttei.
5.3. The Evolving_Pattern_Discovery Algorithm
- Input: Spatio-temporal Twitter events STTE, projected spatial Twitter events STE, threshold δ and ε
- Output: Evolving spatio-temporal patterns
- (i)
- Construct the Delaunay triangulation for STE to obtain the initial spatial proximity graph;
- (ii)
- Identify and remove inconsistent long edges, i.e., I-long edges, II-long edges and III-long edges, from the Delaunay triangulation;
- (iii)
- Extract connected sub-graphs and identify spatial clusters and outliers based on the volume of each connected sub-graph.
- (i)
- Determine the spatial neighborhoods of each spatial Twitter event and the spatial neighborhoods of each spatio-temporal Twitter event based on δ;
- (ii)
- Construct time windows based on ε and determine the temporal neighborhoods of each spatio-temporal Twitter event;
- (iii)
- Determine the spatio-temporal neighborhoods of each spatio-temporal Twitter event; and
- (iv)
- Extract spatio-temporal connected graphs based on the spatio-temporal proximity relationships and identify spatio-temporal clusters and outliers based on the volume of each spatio-temporal connected graph.
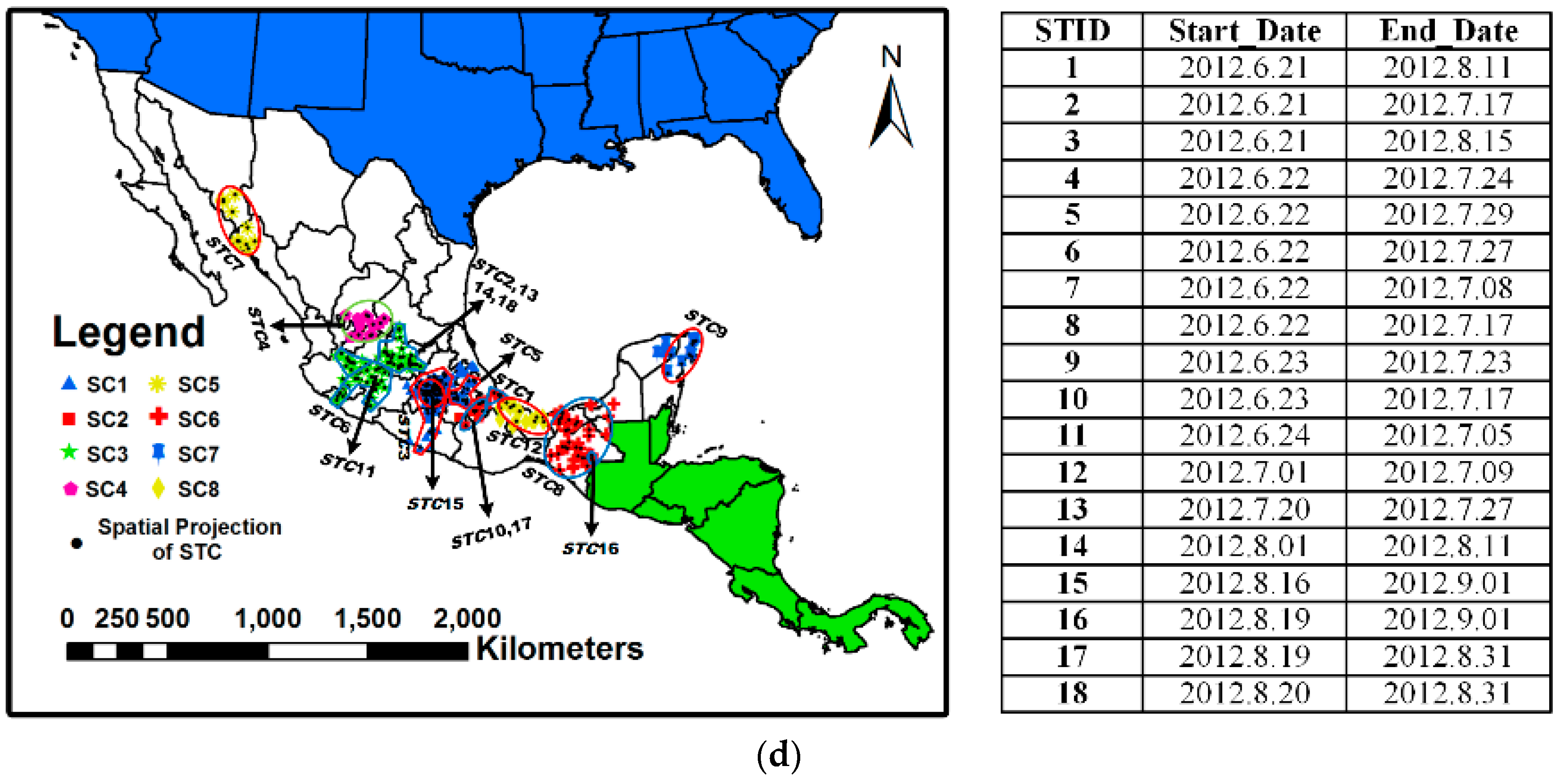
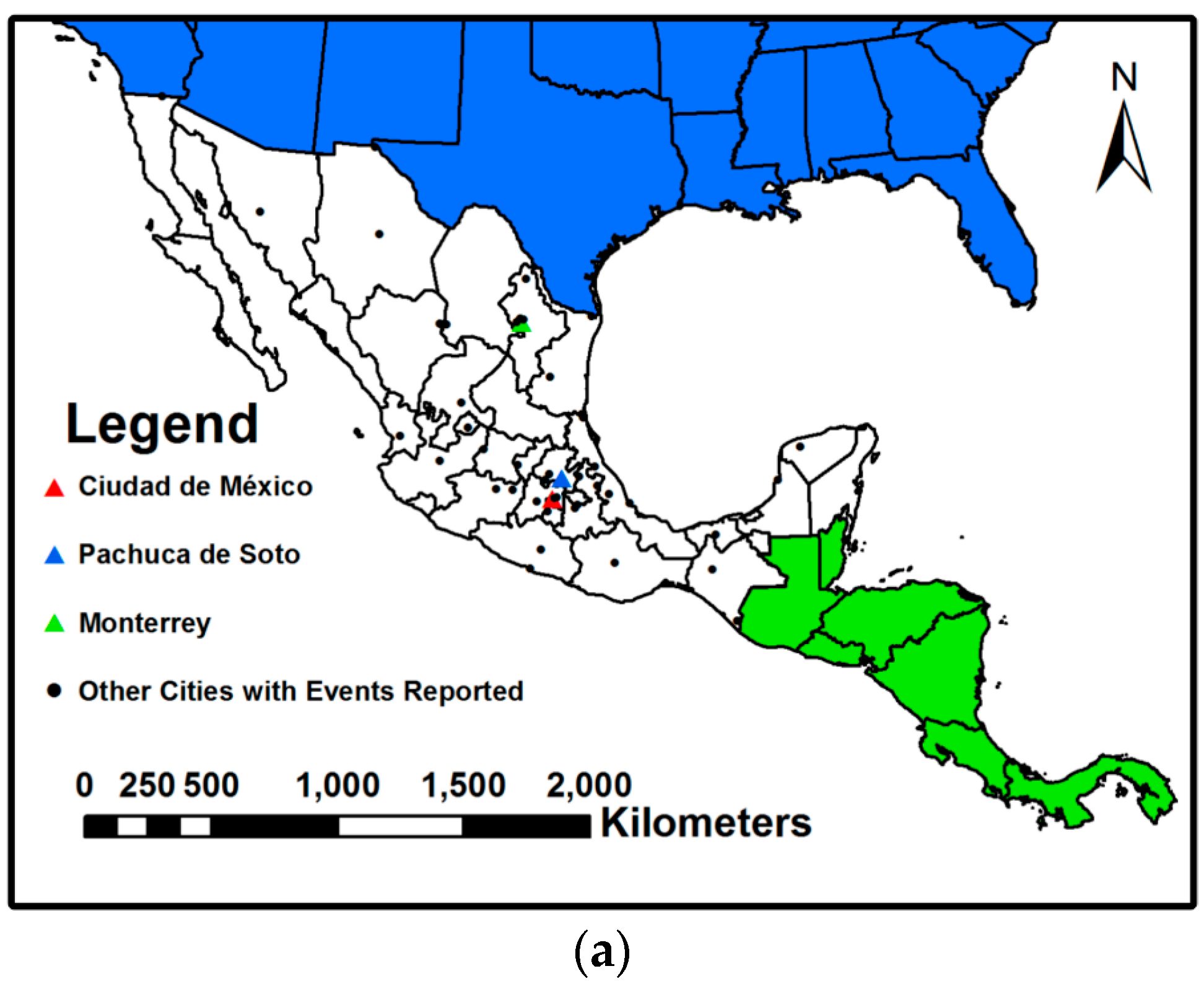
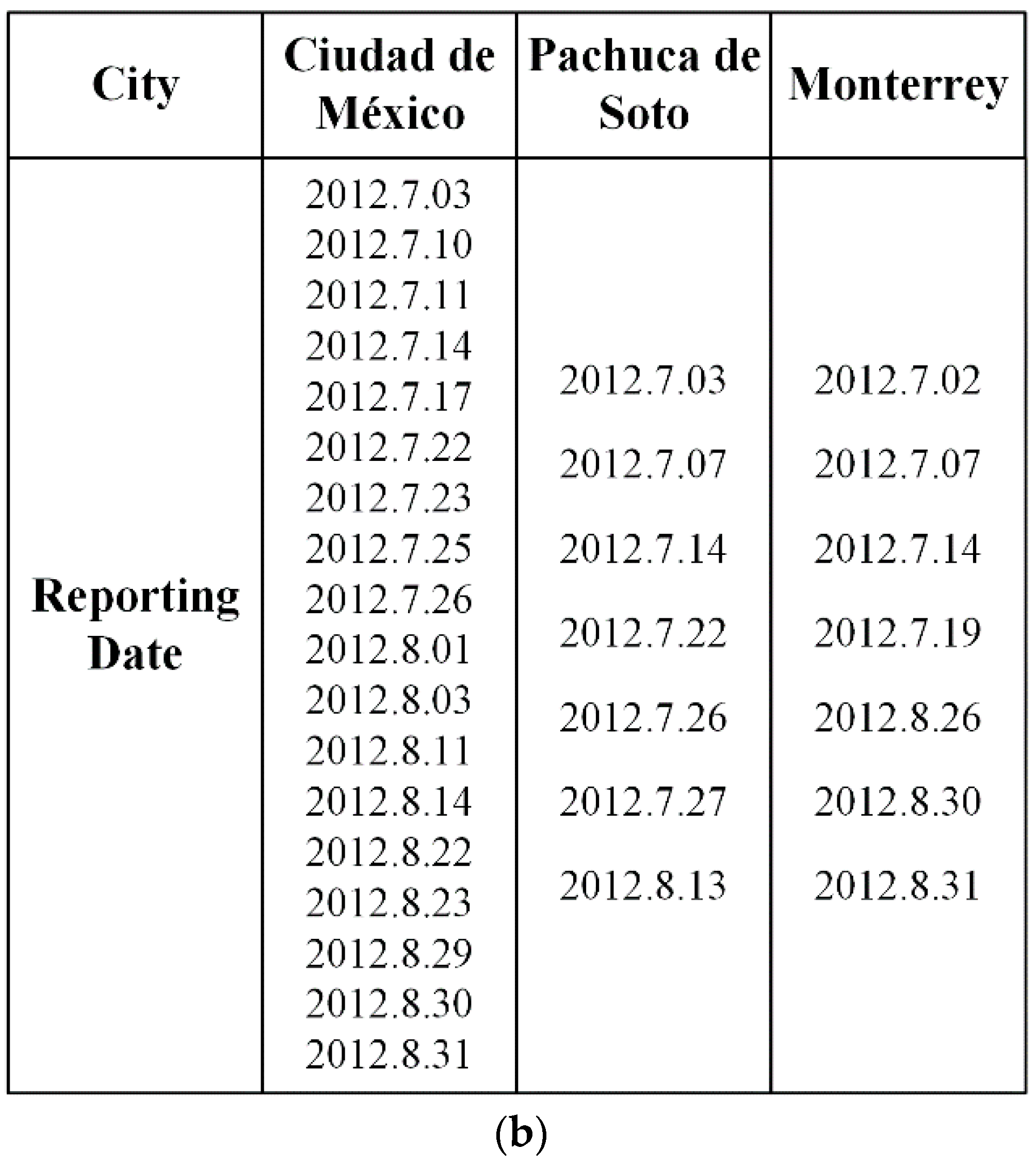
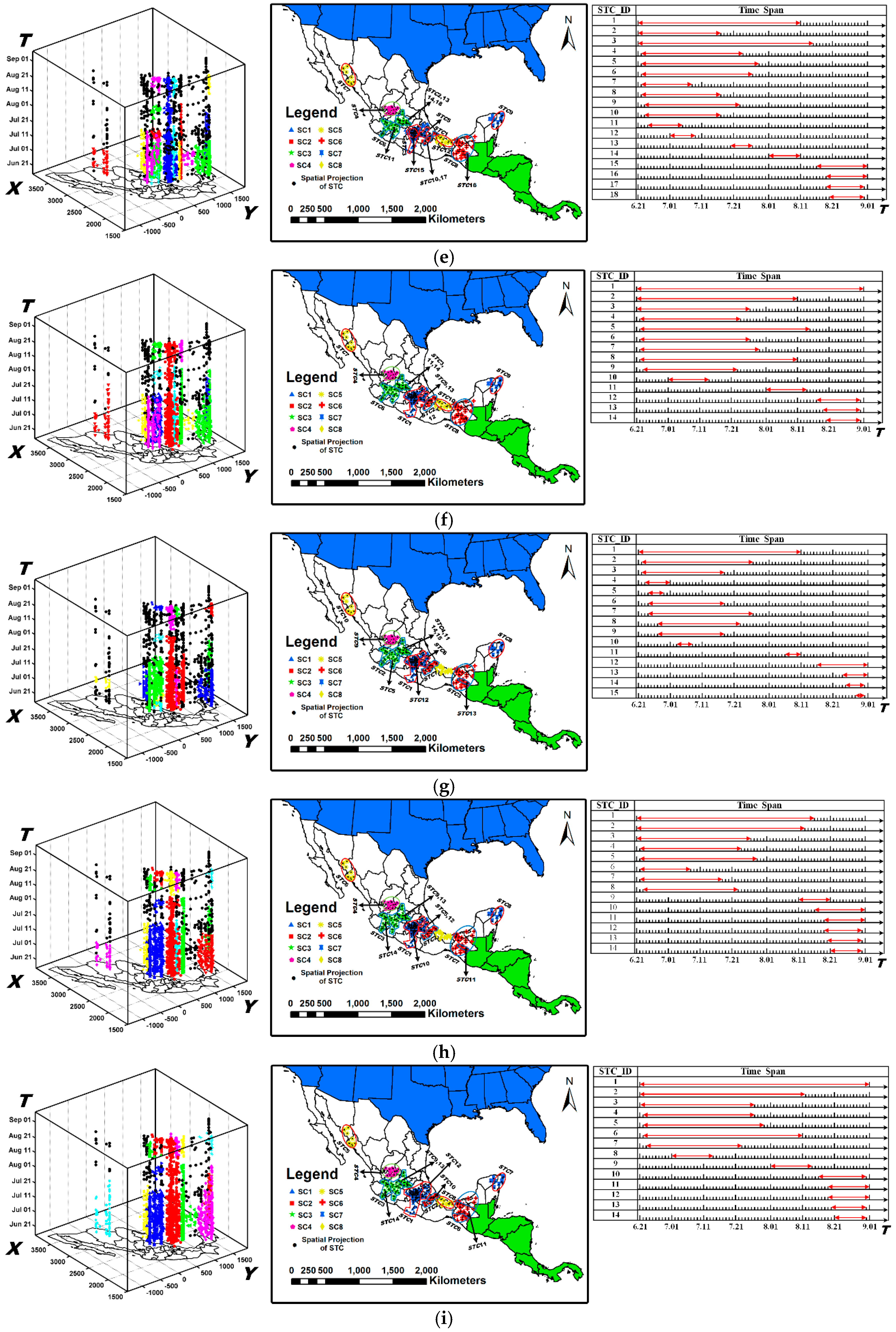
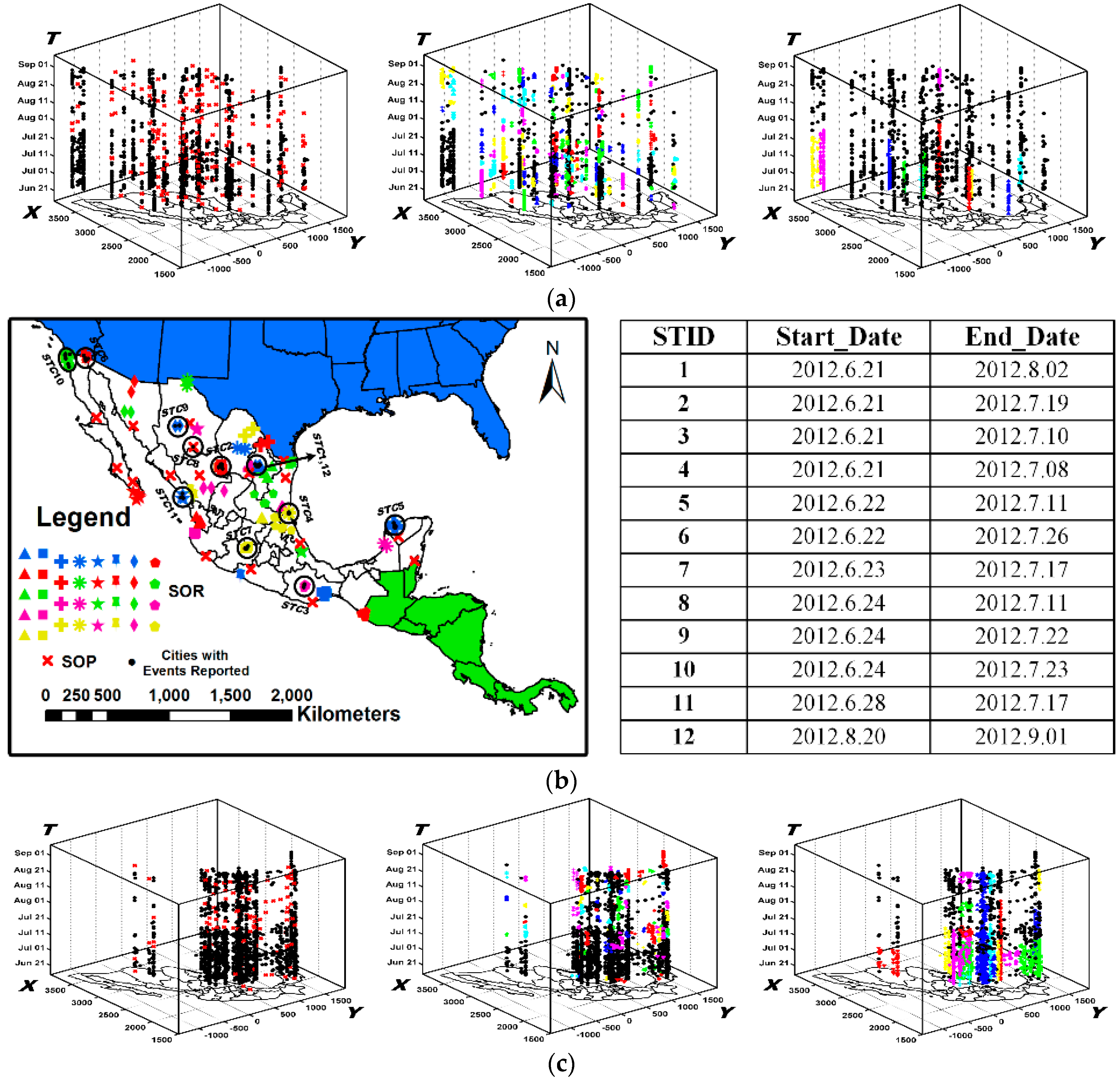
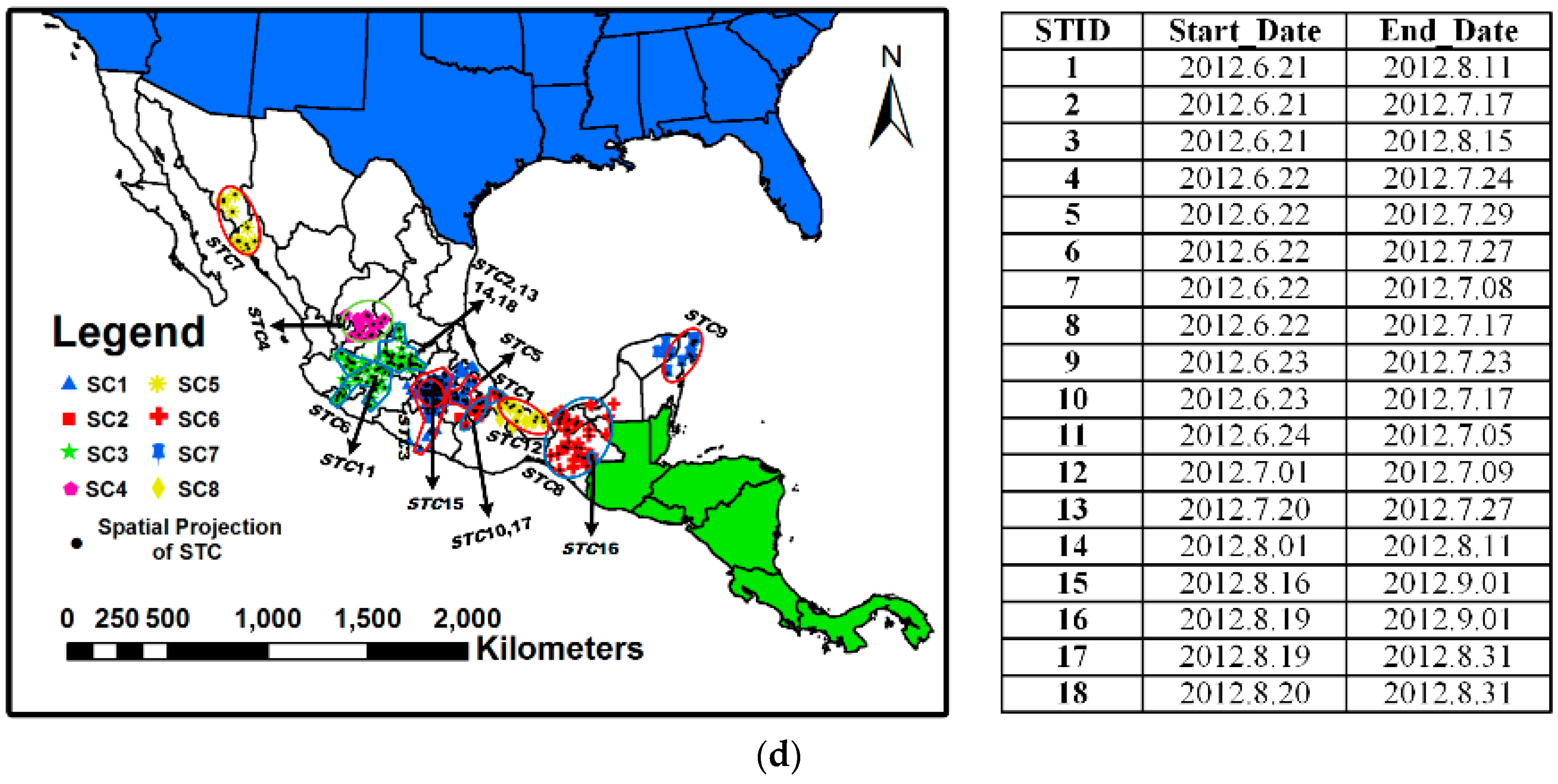
6. Experimental Evaluation and Analysis by Visualization
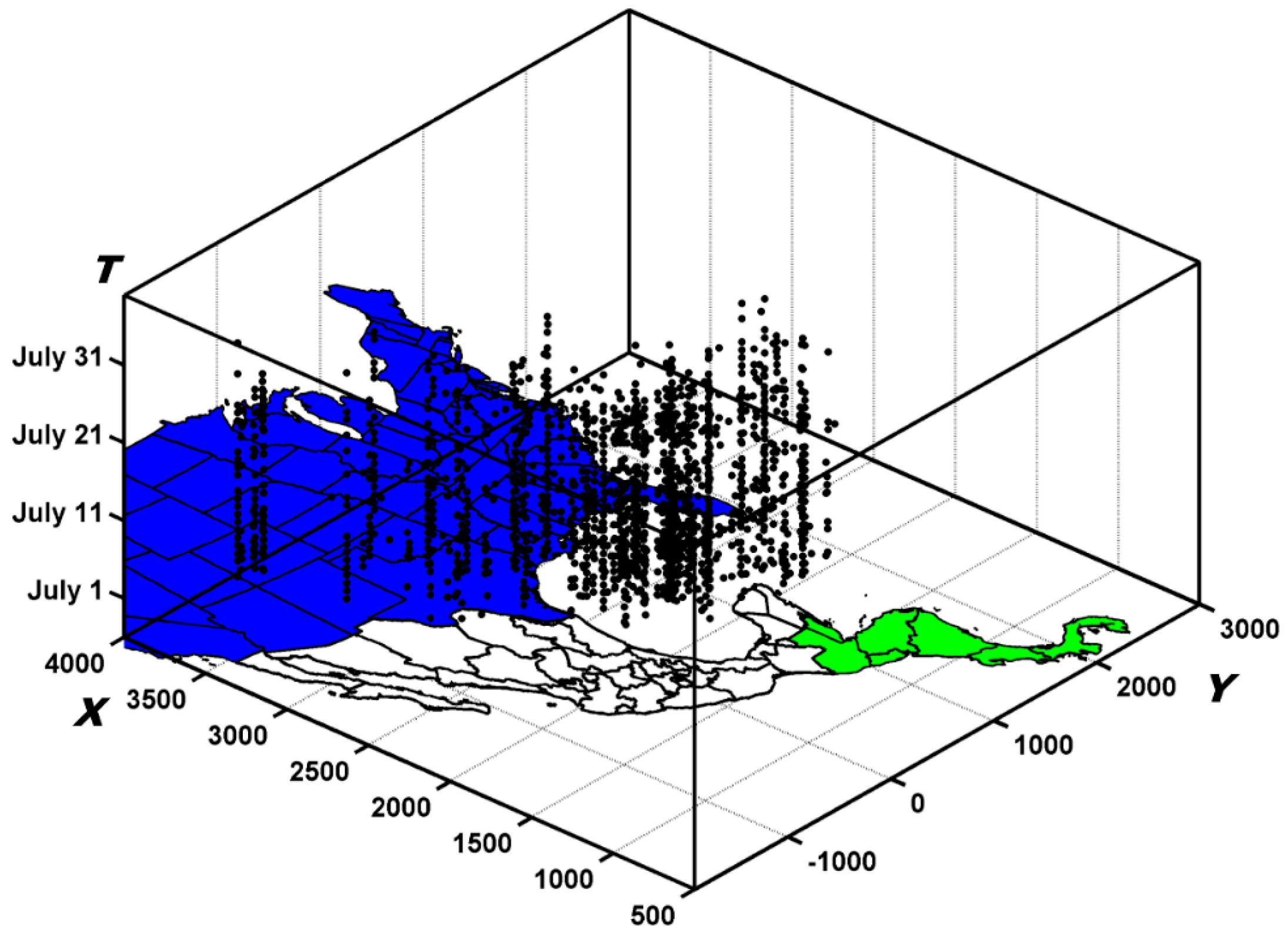
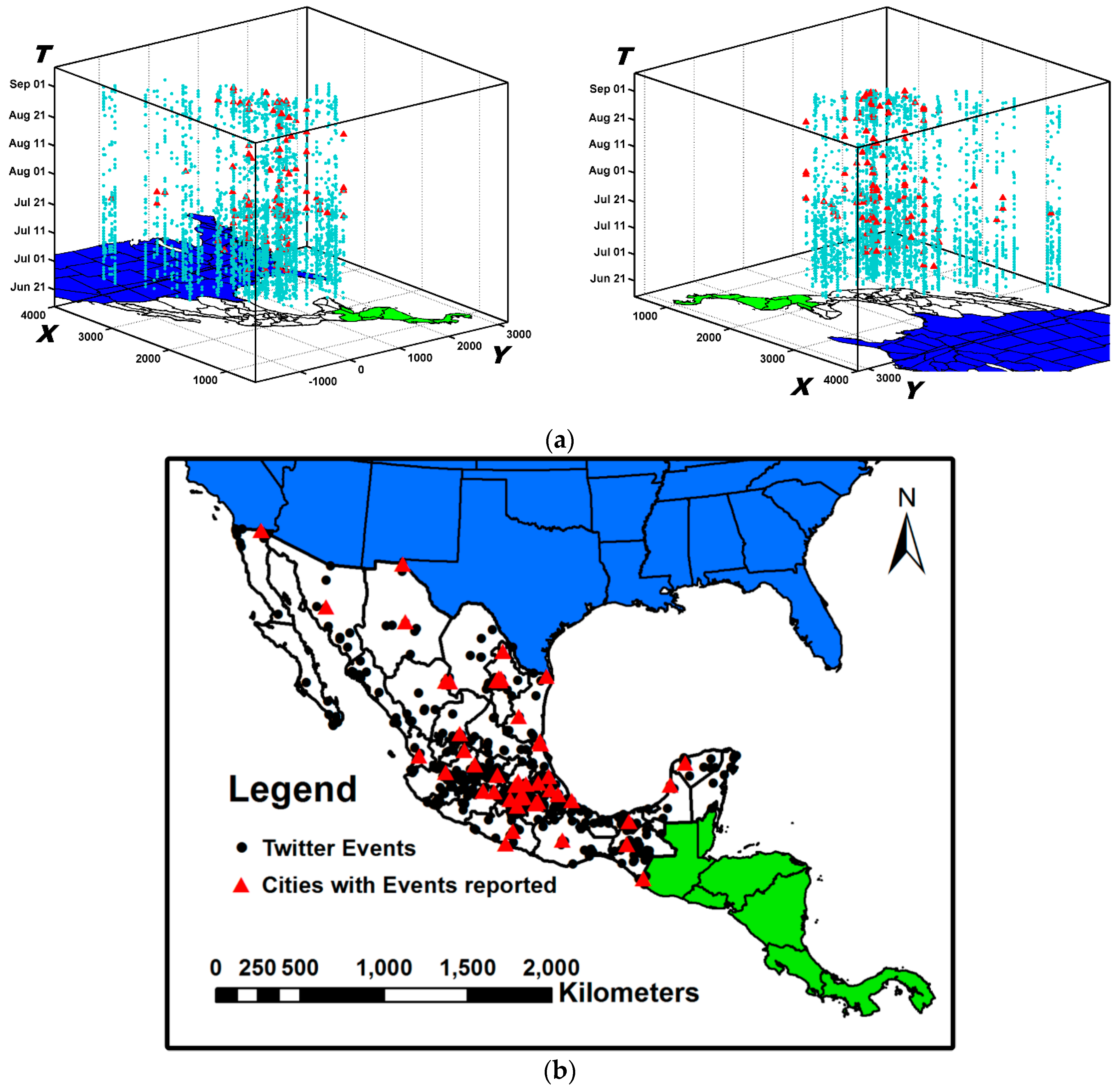
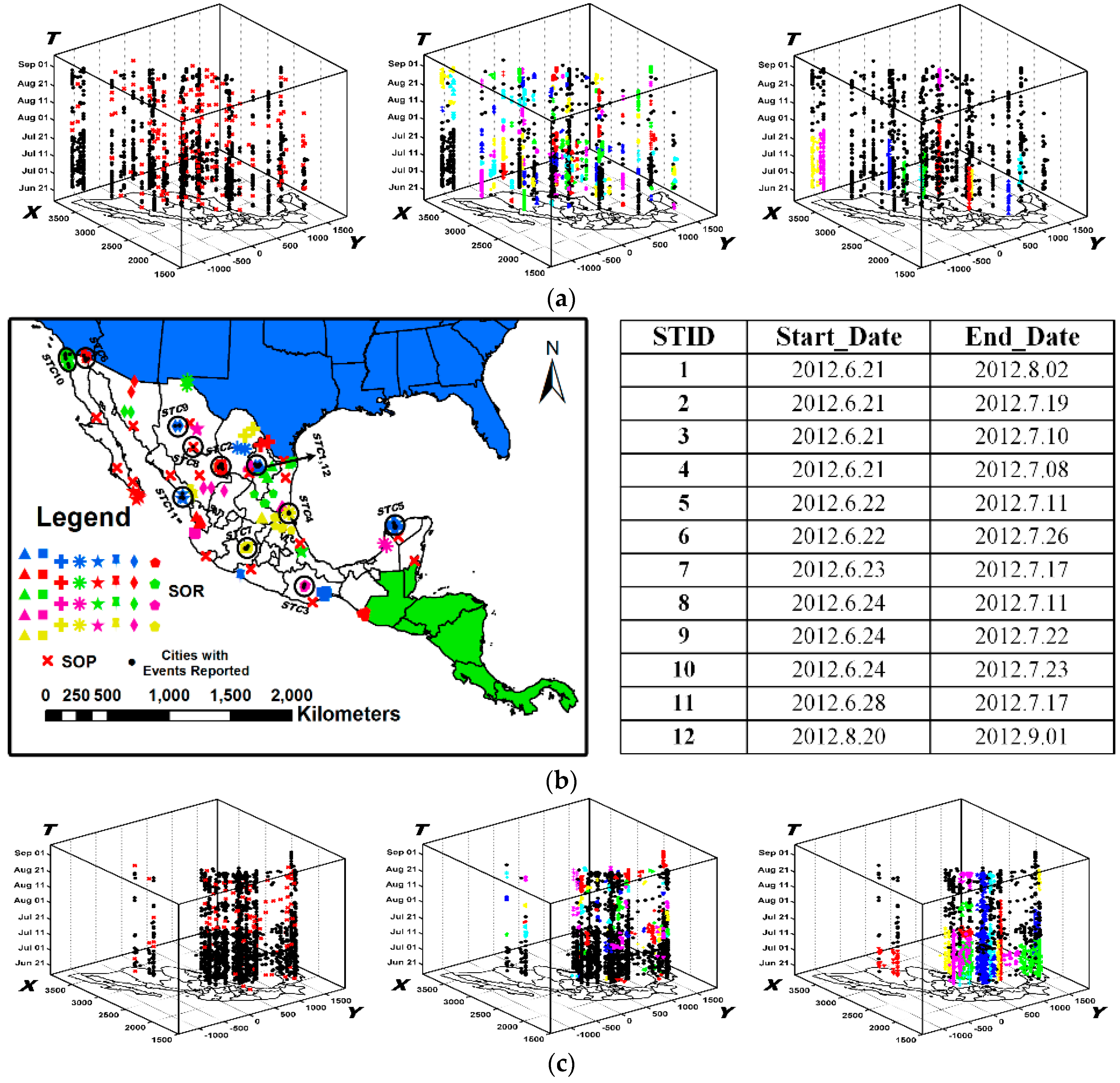
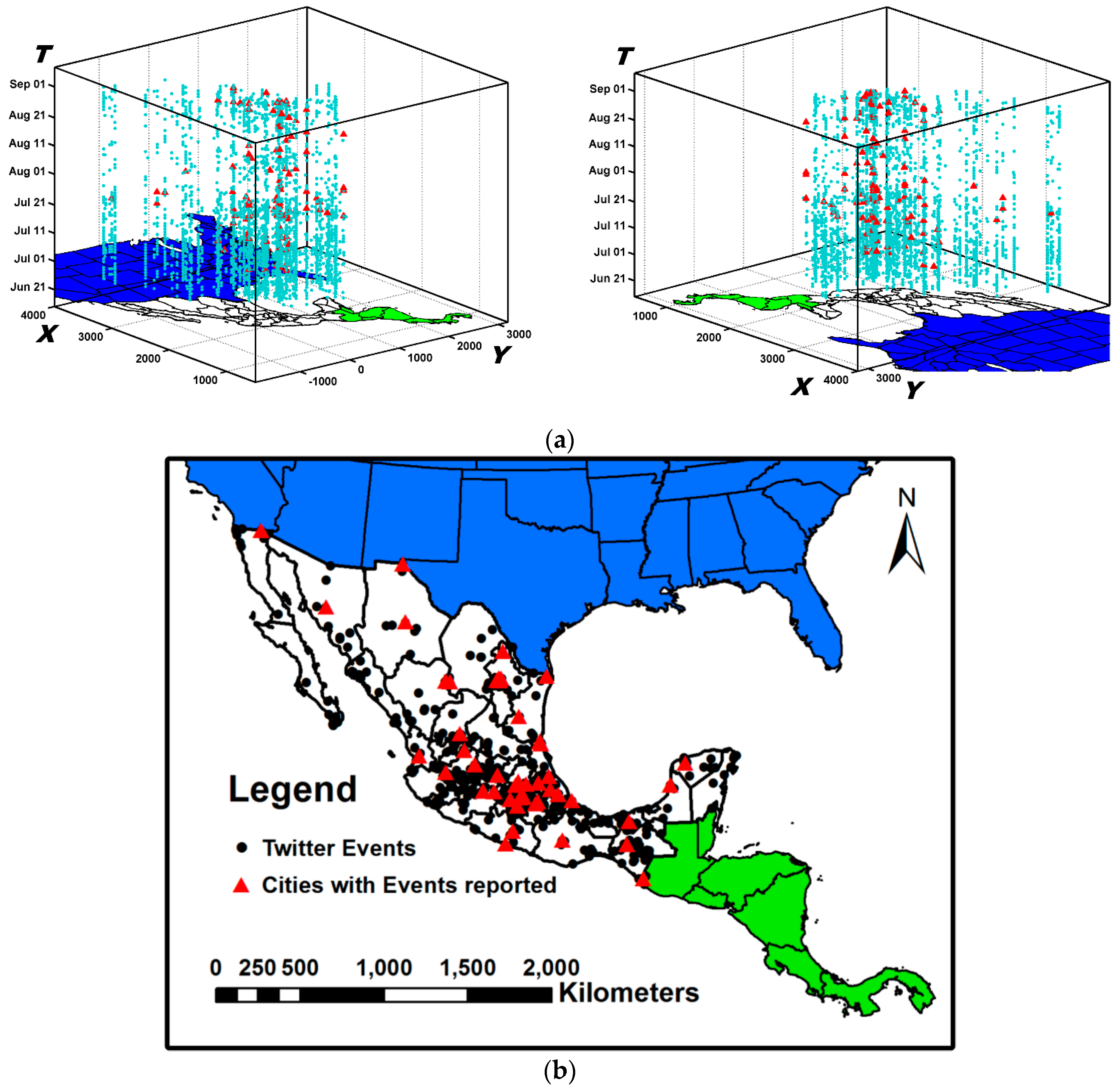
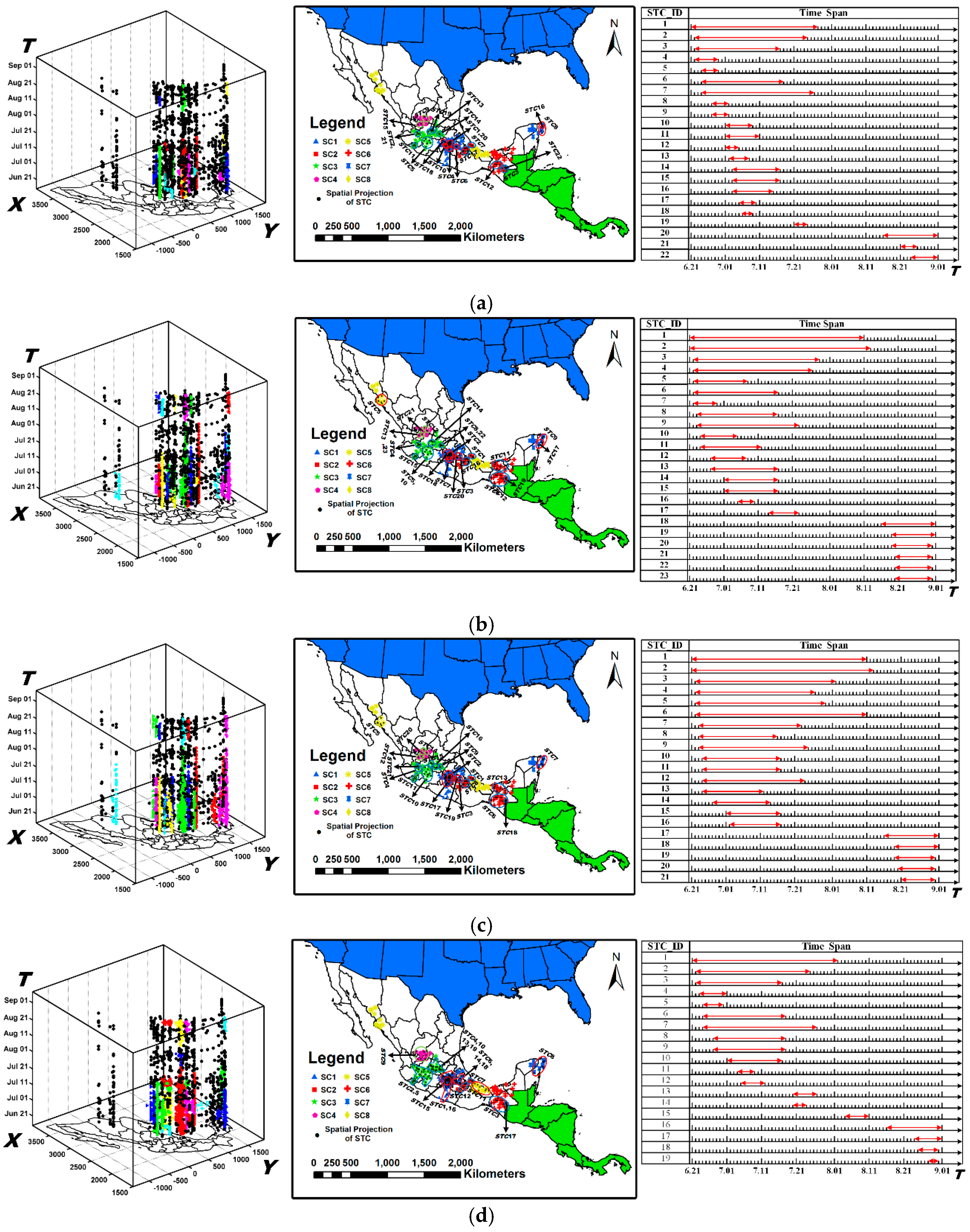
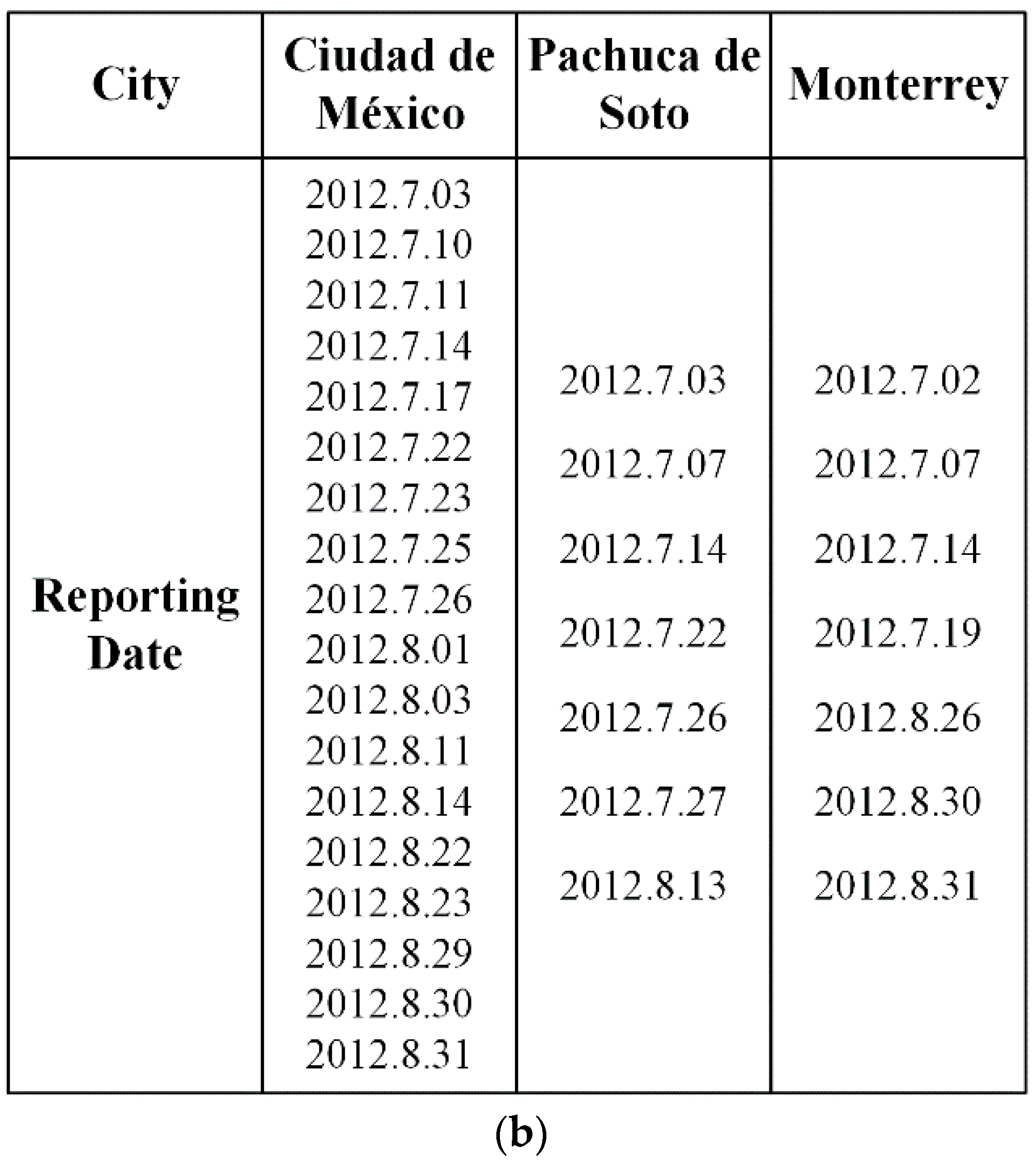
6.1. Dataset and Labels
6.2. Experimental Comparisons
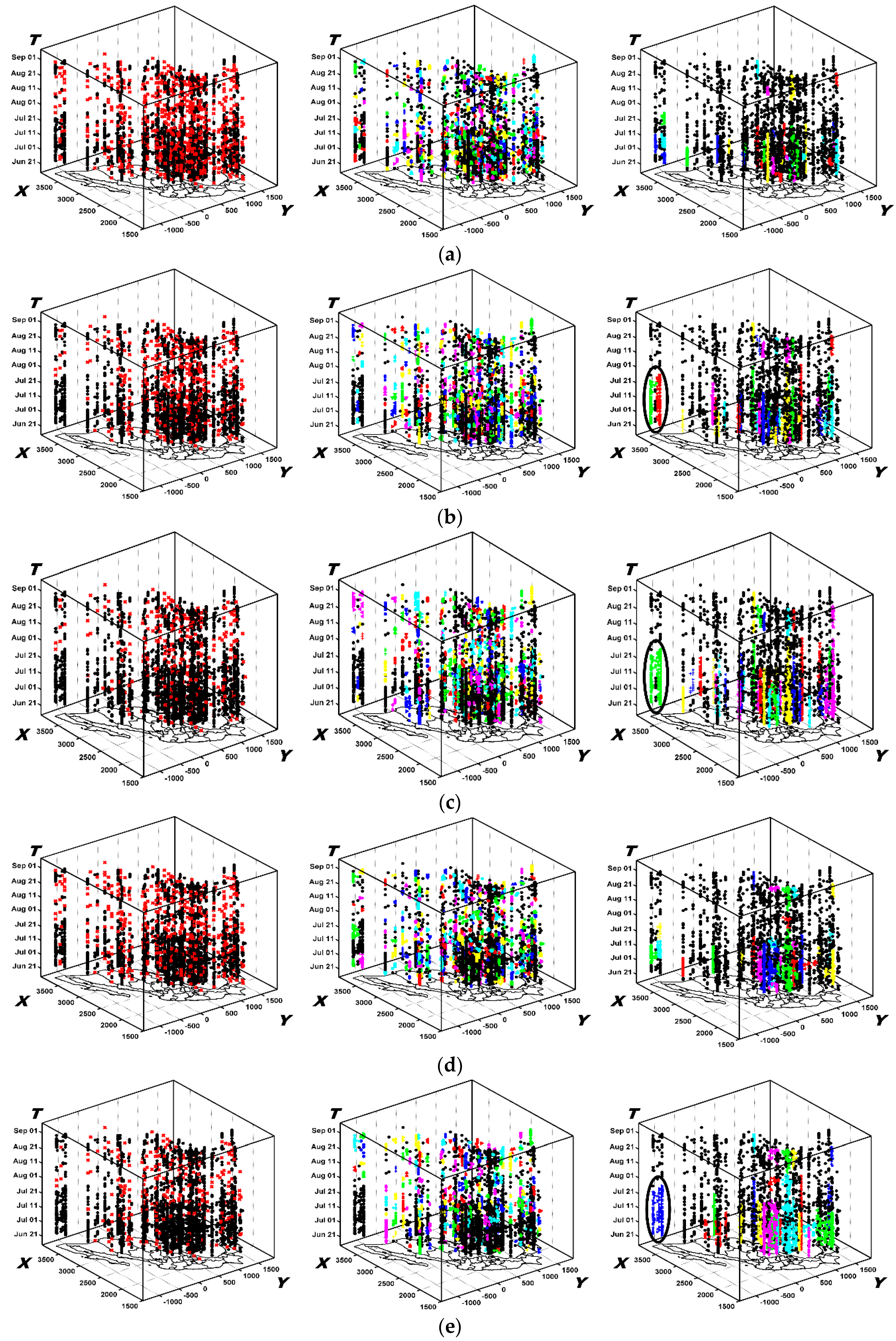
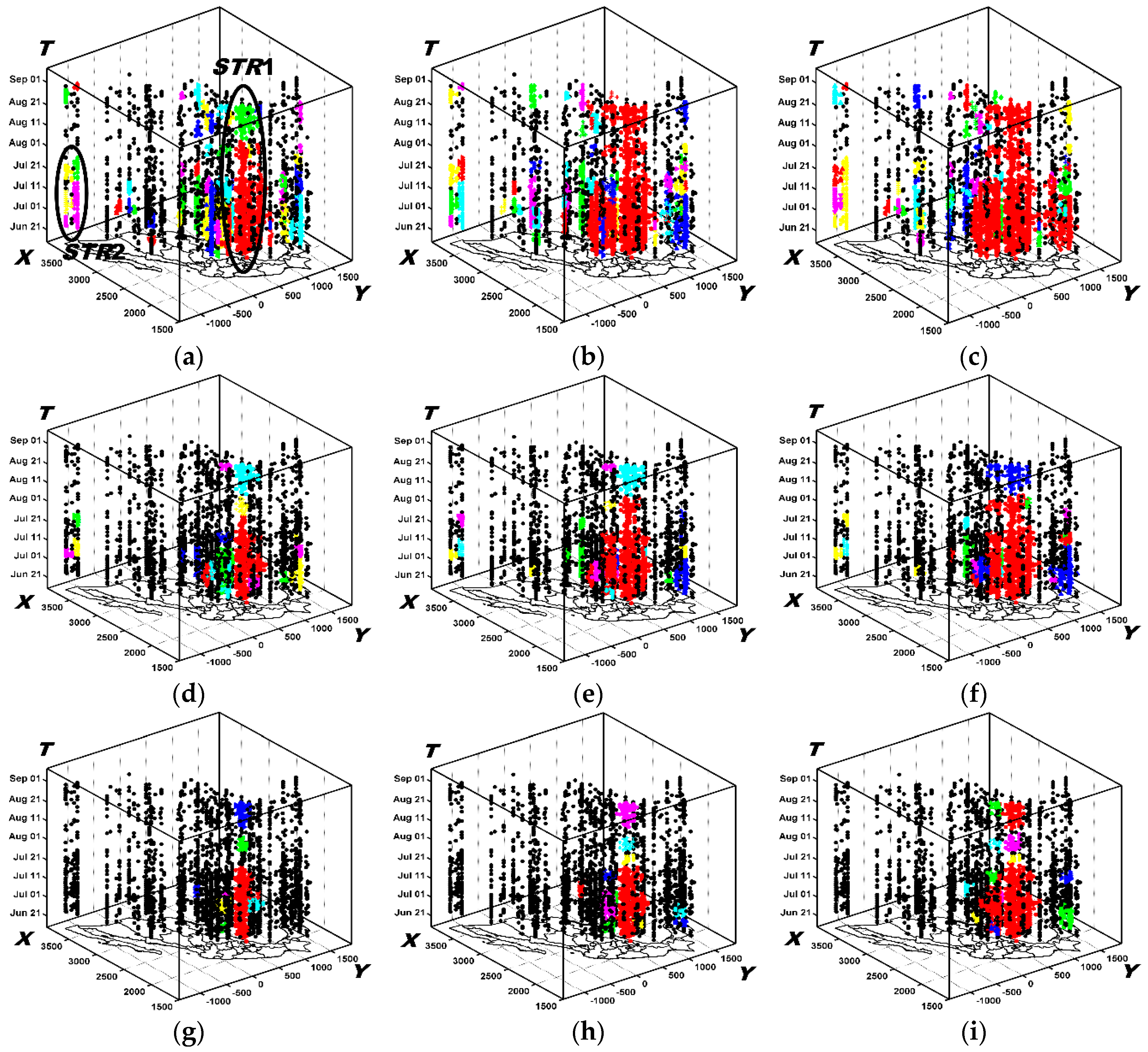
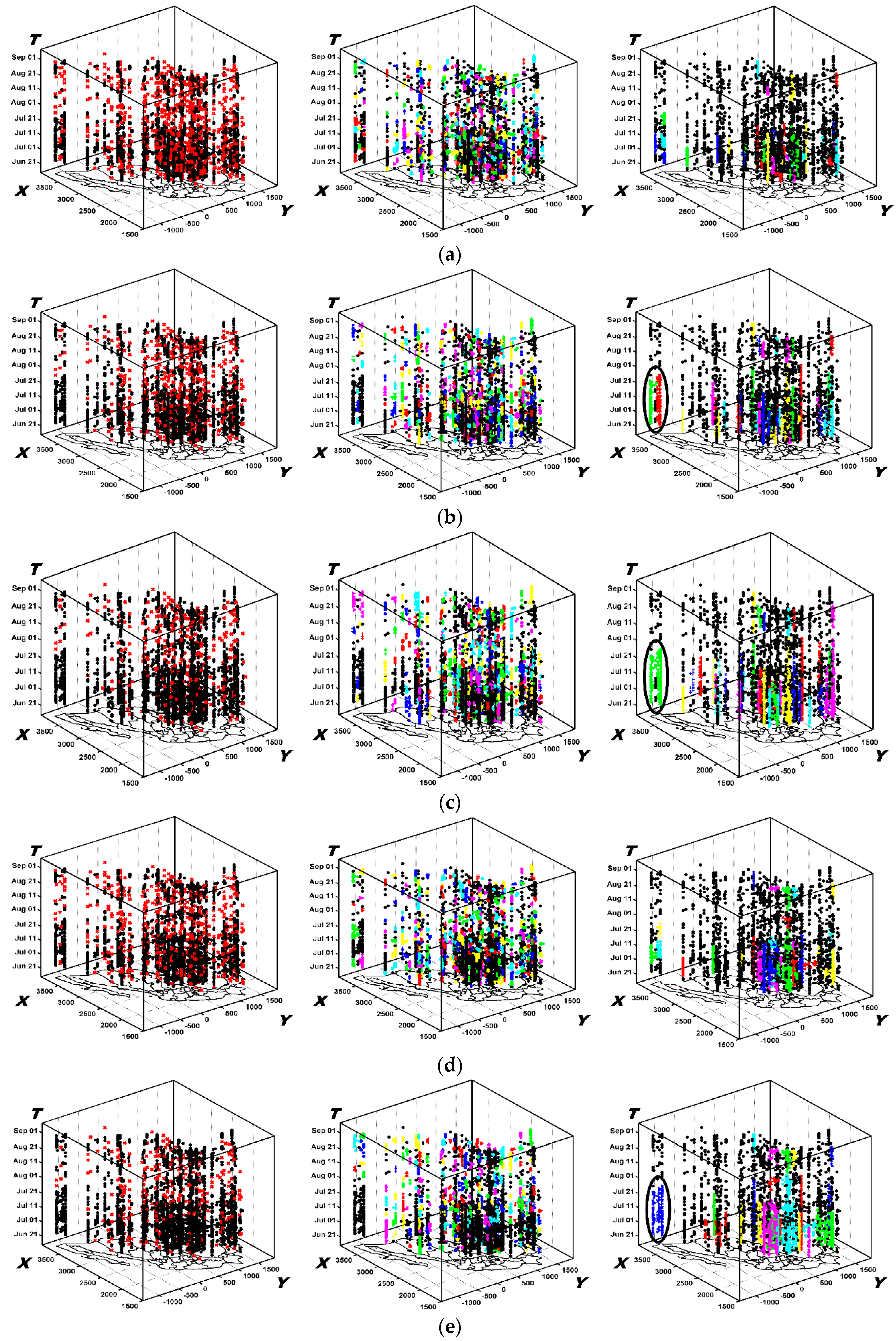
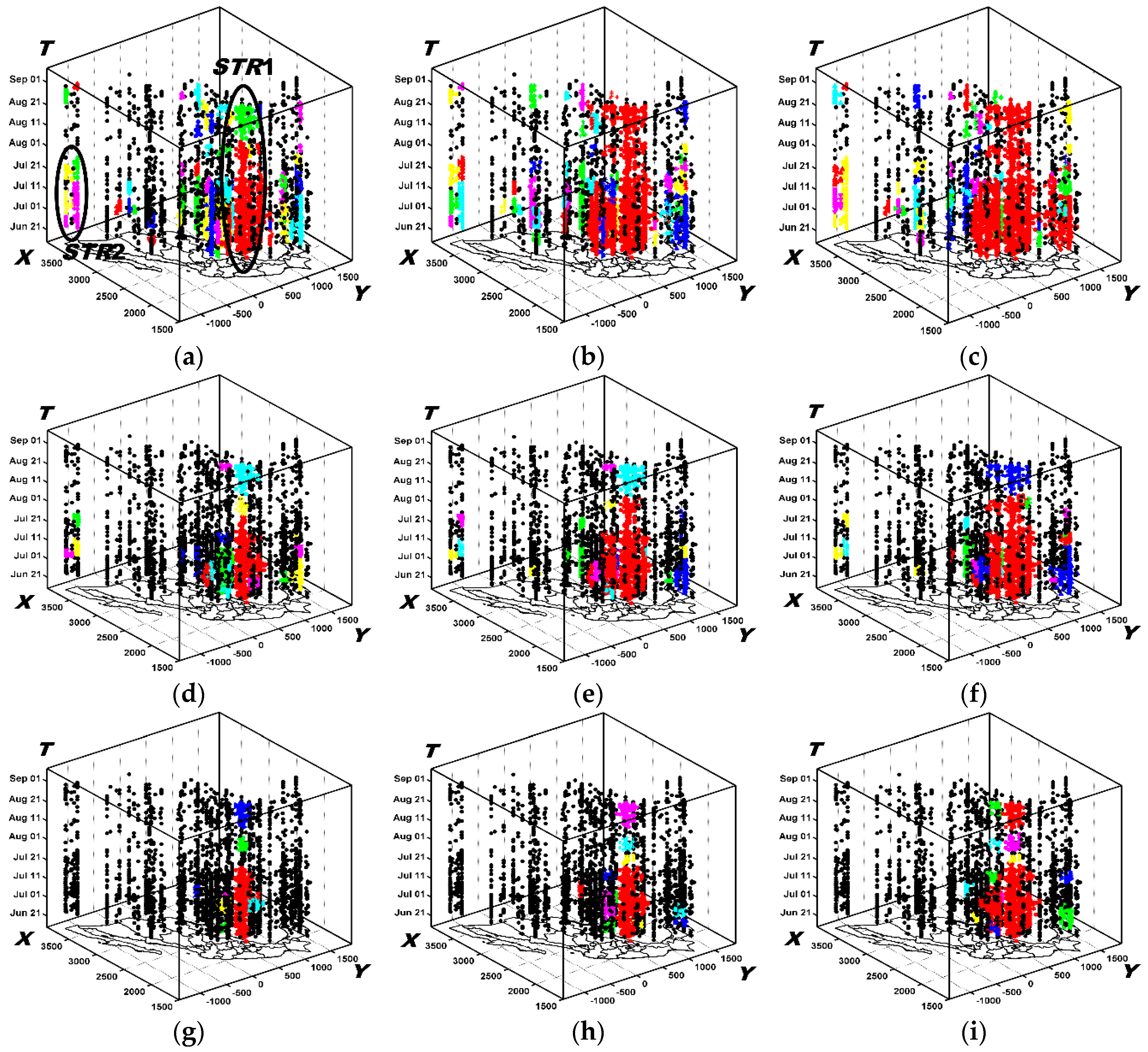
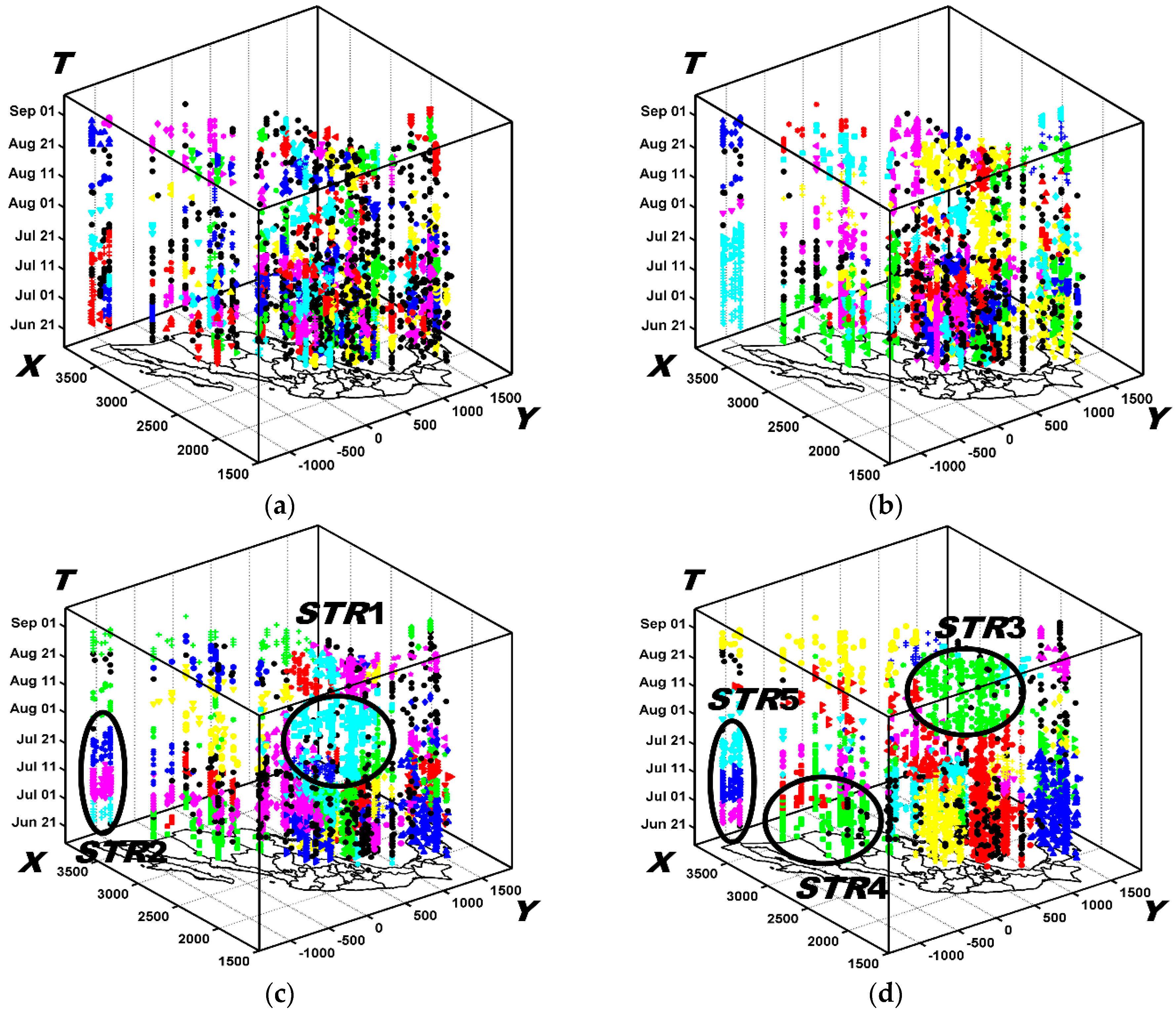
6.2.1. The Results Obtained by the New Method
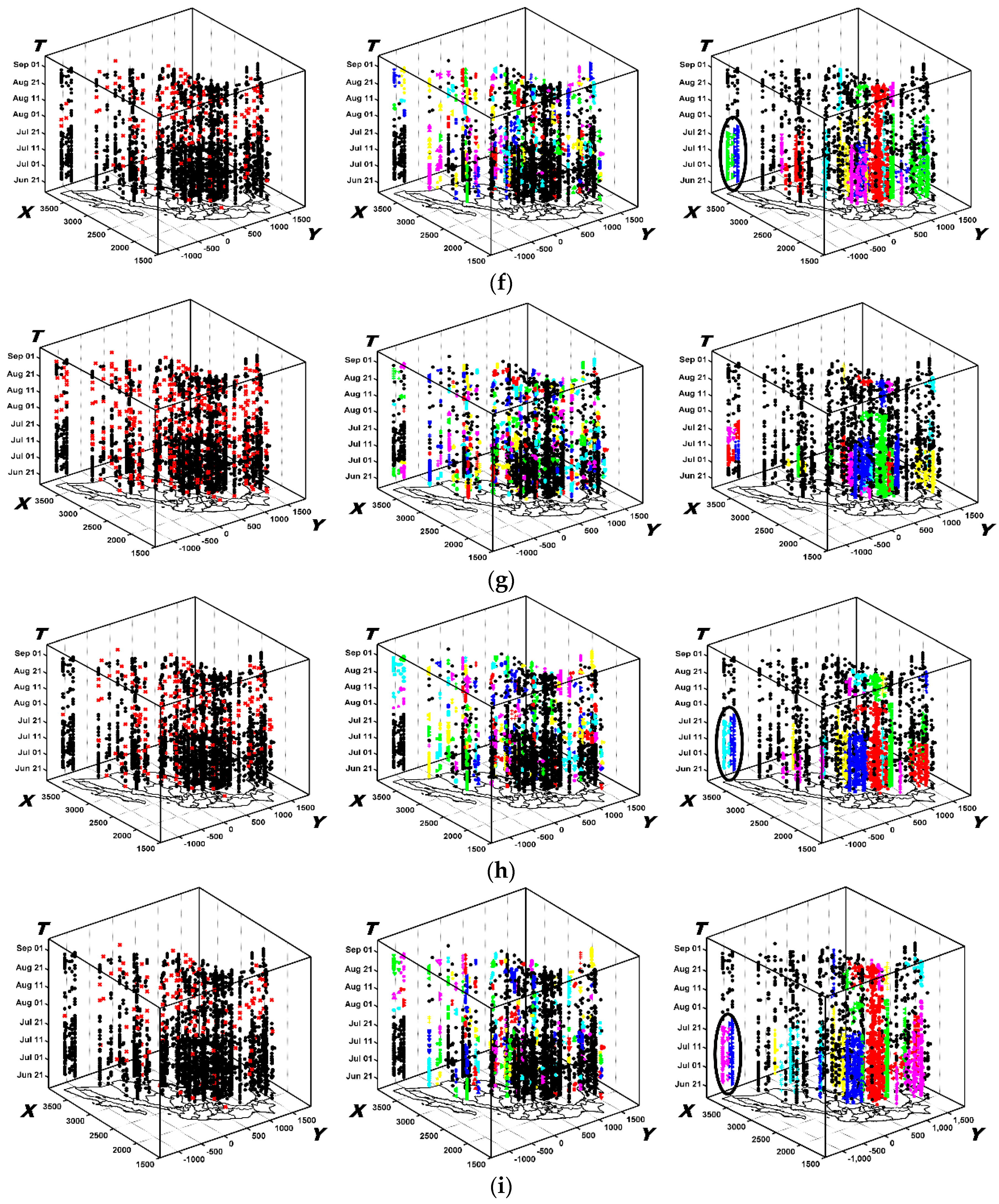
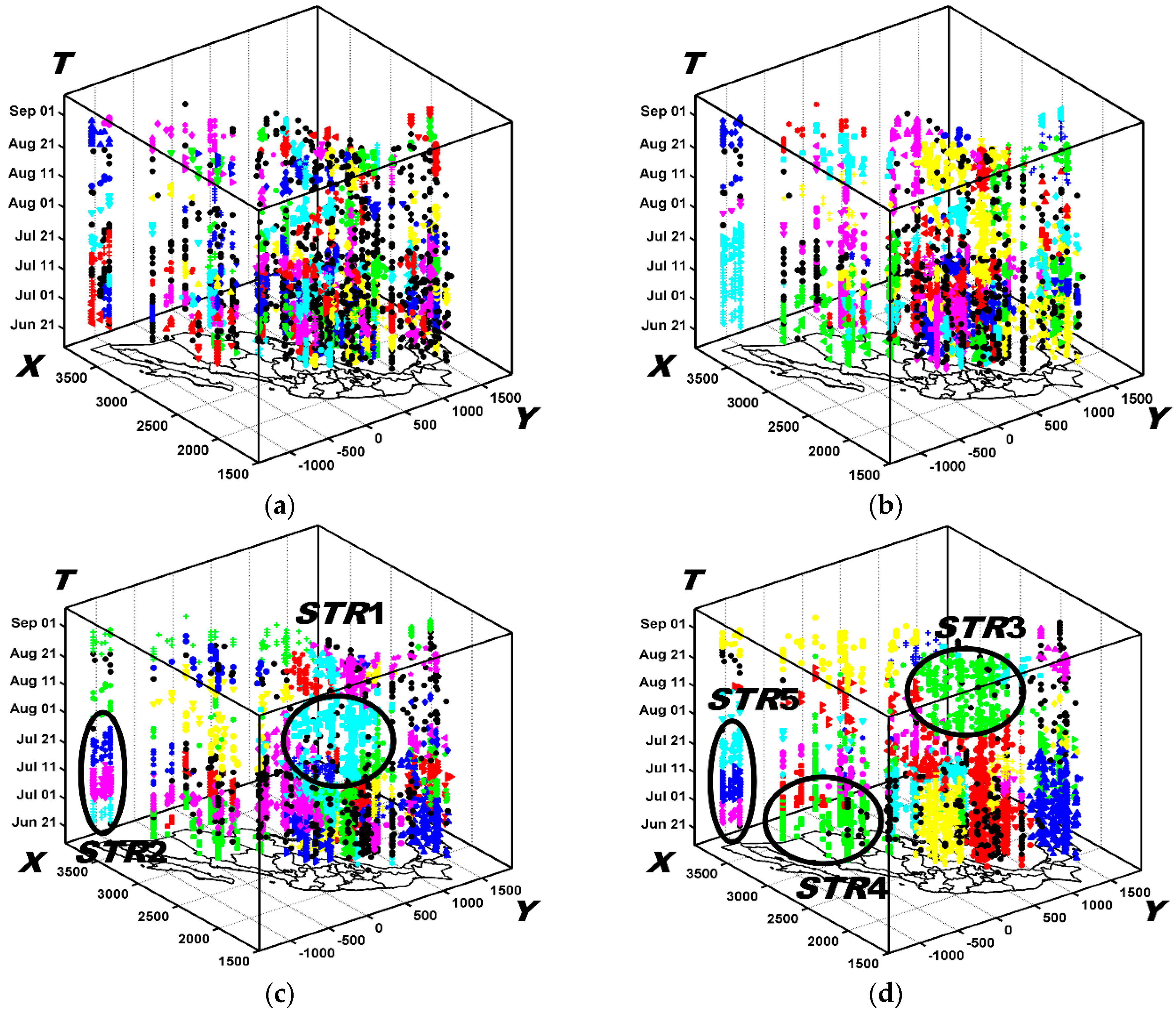
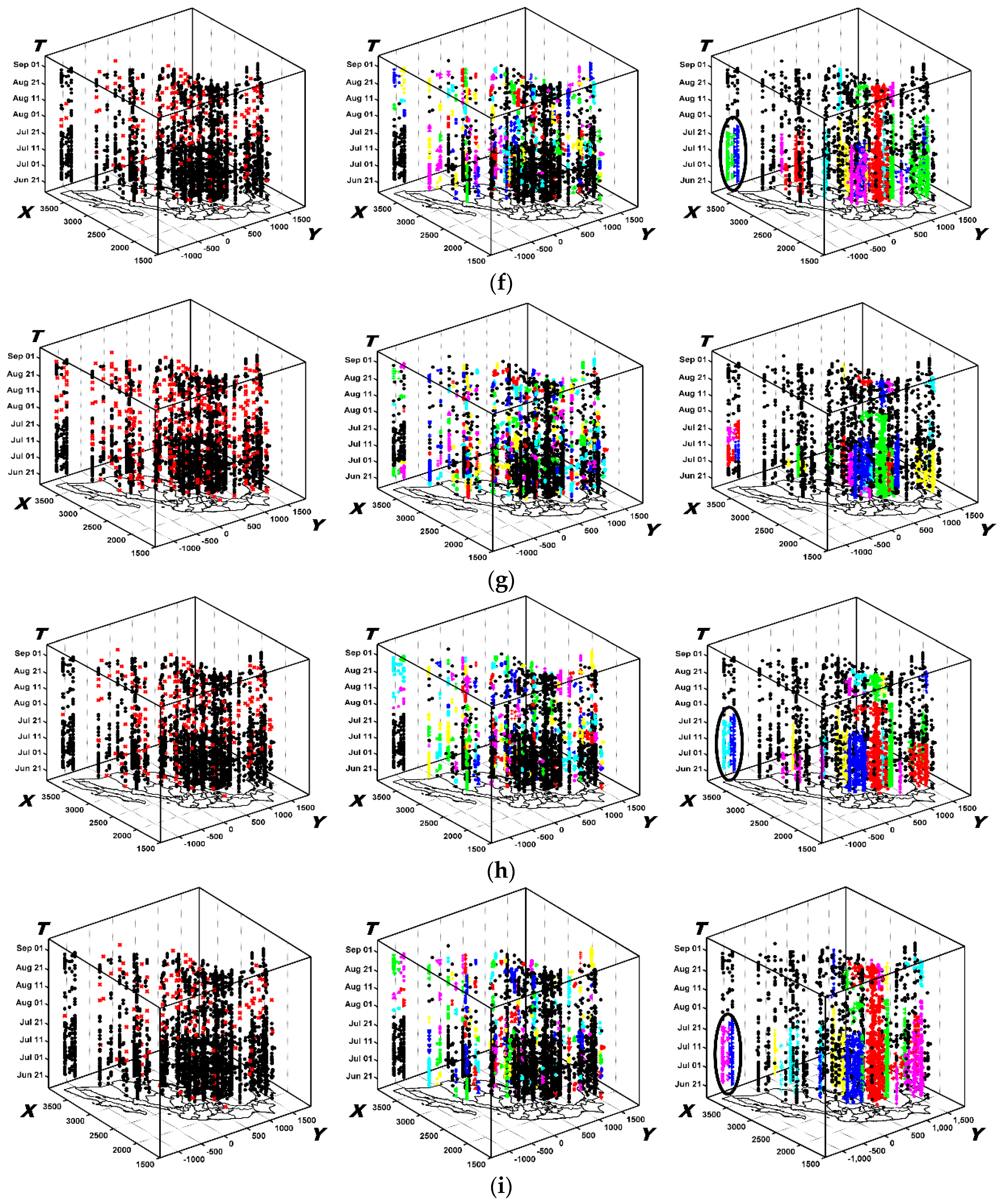
6.2.2. The Results Obtained by ST-DBSCAN
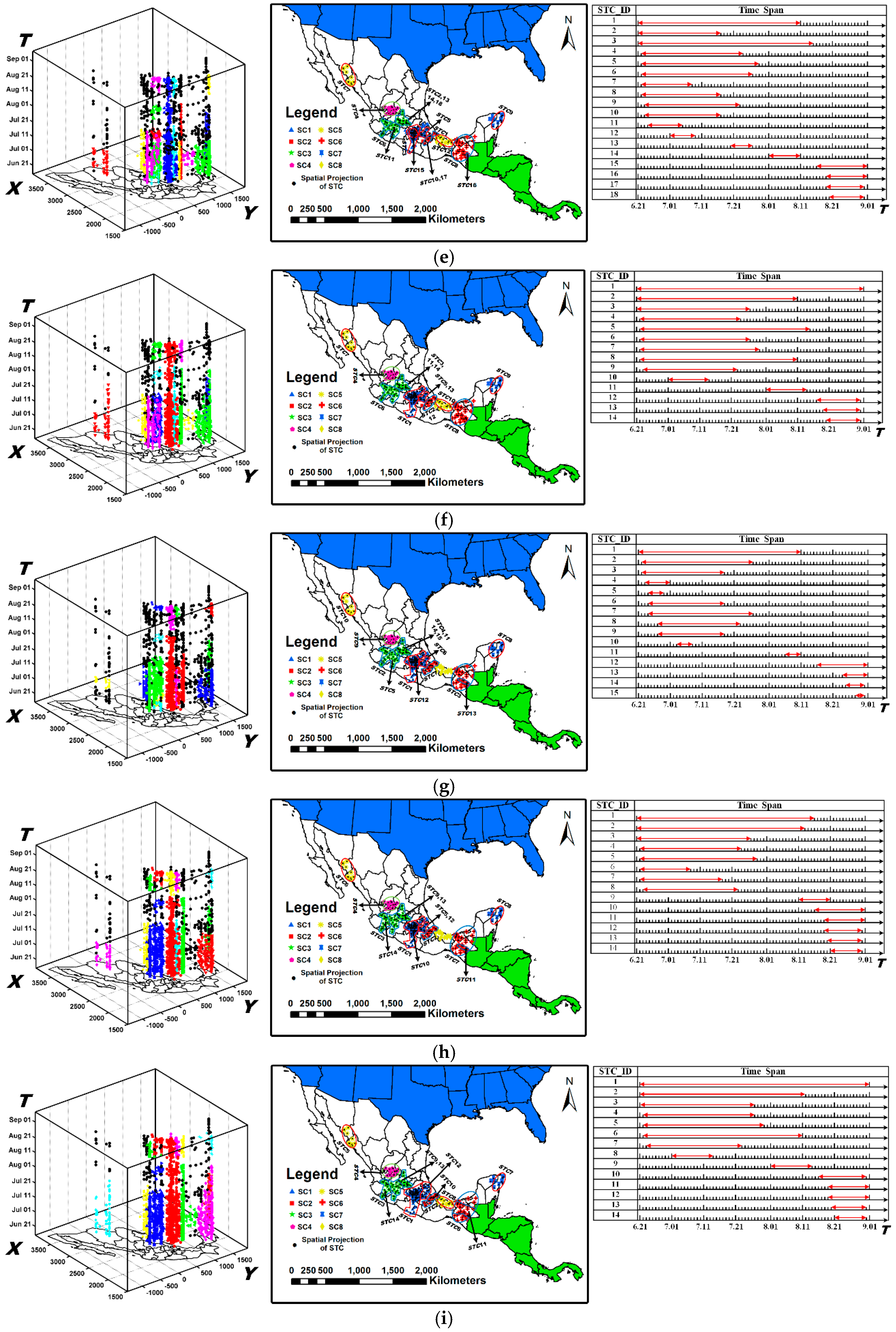
6.2.3. The Results Obtained by STSNN
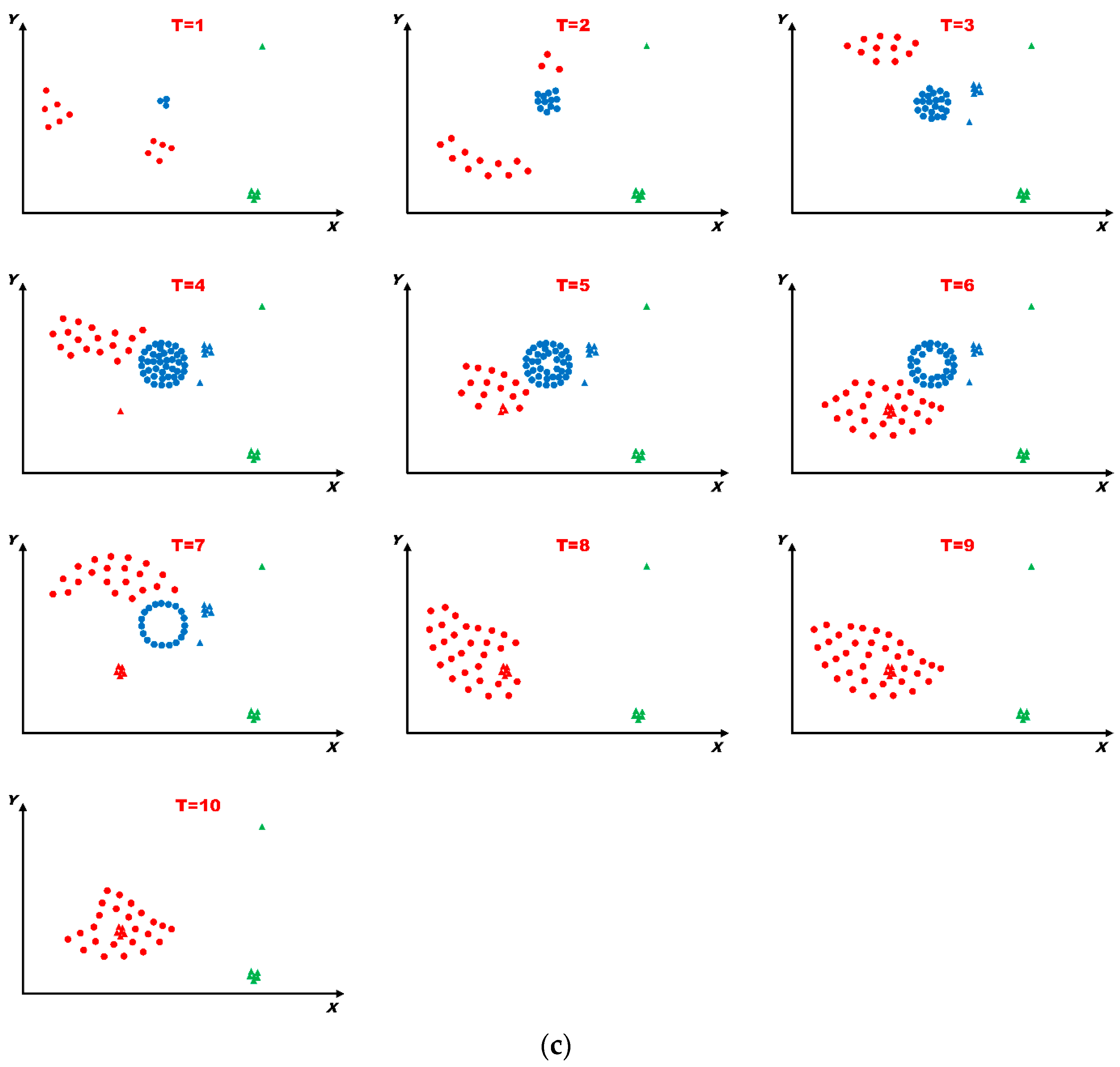
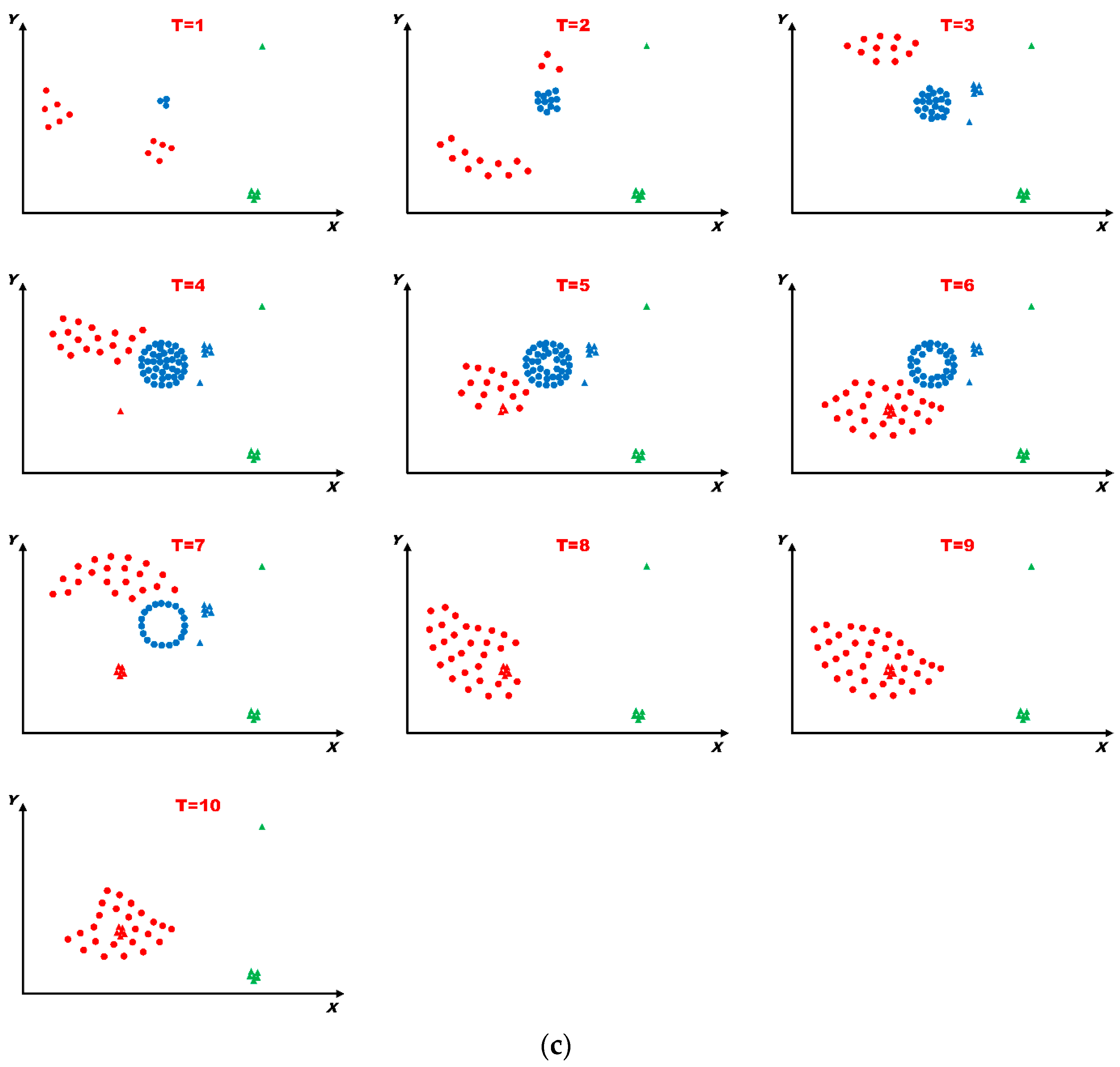
6.3. Analysis of Evolving Spatio-Temporal Patterns
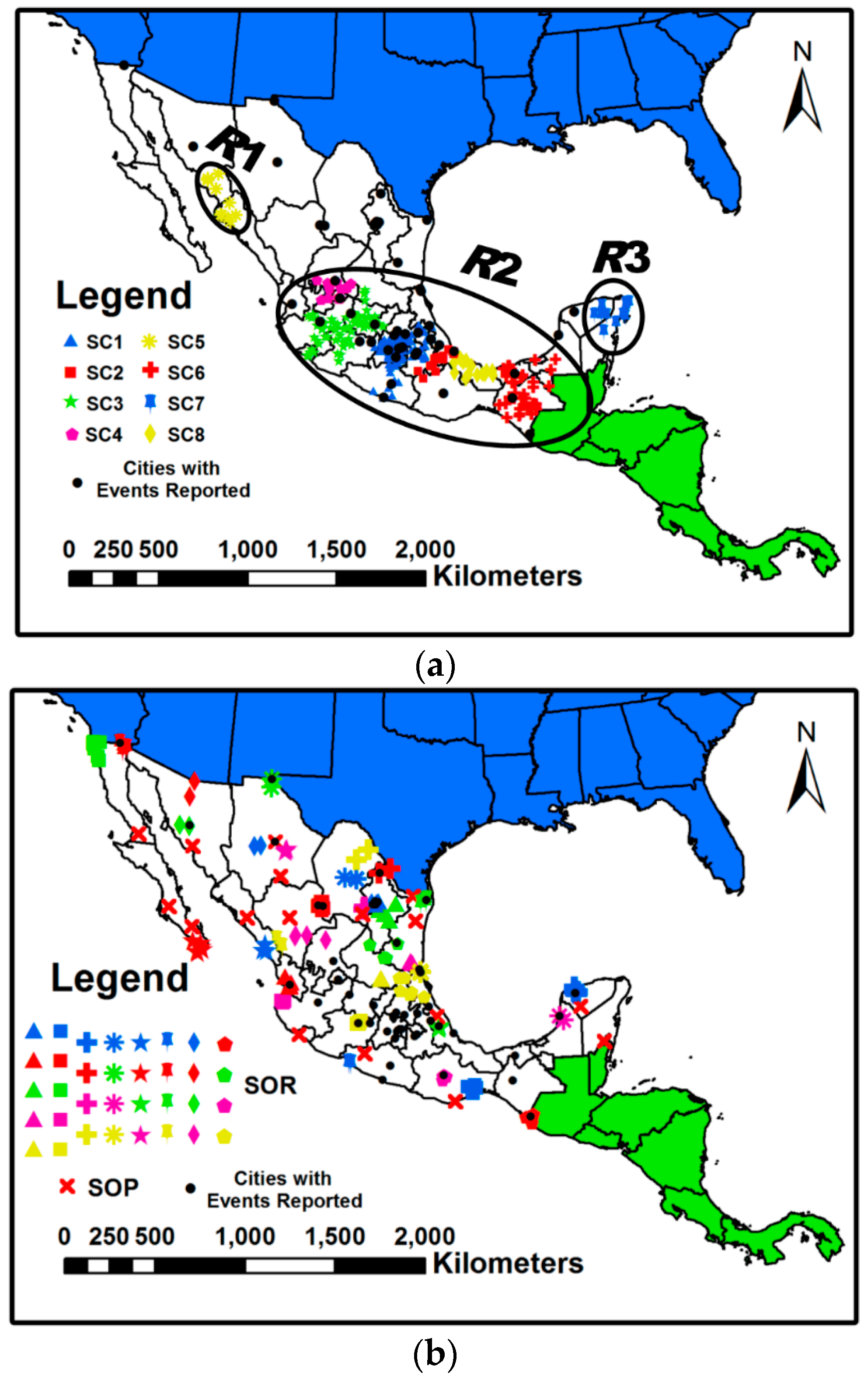
6.3.1. Analysis of Spatio-Temporal Clusters by Our Method
6.3.2. Comparison with Labels
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Java, A.; Song, X.; Finin, T.; Tseng, B. Why we twitter: Understanding microblogging usage and communities. In Proceedings of the 9th WebKDD and 1st SNAKDD 2007 Workshop on Web Mining and Social Network Analysis, San Jose, CA, USA, 12–15 August 2007; pp. 56–65.
- Cheng, A.; Mark, E.; Harshdee, S. Inside Twitter: An in-Depth Look Inside the Twitter World; SYSOMOS: Toronto, ON, Canada, June 2009. [Google Scholar]
- De Albuquerque, J.P.; Herfort, B.; Brenning, A.; Zipf, A. A geographic approach for combining social media and authoritative data towards identifying useful information for disaster management. Int. J. Geogr. Inf. Sci. 2015. [Google Scholar] [CrossRef]
- Heverin, T.; Zach, L. Microblogging for crisis communication: Examination of twitter use in response to a 2009 violent crisis in Seattle-Tacoma, Washington area. In Proceedings of the 7th International ISCRAM Conference, Seattle, WA, USA, 2–5 May 2010.
- Pan, B.; Zheng, Y.; Wilkie, D.; Shahabi, C. Crowd sensing of traffic anomalies based on human mobility and social media. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 334–343.
- Chew, C.; Eysenbach, G. Pandemics in the age of Twitter: Content analysis of Tweets during the 2009 H1N1 outbreak. PLoS ONE 2009, 5, e14118. [Google Scholar] [CrossRef] [PubMed]
- Ramage, D.; Dumais, S.; Liebling, D. Characterizing microblogs with topic models. In Proceedings of the 4th International AAAI Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010; pp. 130–137.
- Markman, V. Unsupervised discovery of fine-grained topic clusters in Twitter posts. Pap. AAAI Workshop Anal. Microtext 2011, WS-11–05, 32–37. [Google Scholar]
- Fujisaka, T.; Lee, R.; Sumiya, K. Detection of unusually crowded places through micro-blogging sites. In Proceedings of 2010 IEEE 24th International Conference on Advanced Information Networking and Applications Workshops, Perth, Australia, 20–23 April 2010; pp. 467–472.
- Lee, R.; Wakamiya, S.; Sumiya, K. Discovery of unusual regional social activities using geo-tagged microblogs. World Wide Web 2011, 14, 321–349. [Google Scholar] [CrossRef]
- Chae, J.; Thom, D.; Bosch, H.; Jang, Y.; Maciejewski, R. Spatiotemporal social media analytics for abnormal event detection an examination using seasonal-trend decomposition. In Proceedings of the 2012 IEEE Conference on Visual Analytics Science and Technology (VAST), Seattle, WA, USA, 14–19 October 2012; pp. 143–152.
- Cheng, T.; Wicks, T. Event detection using Twitter: A spatio-temporal approach. PLoS ONE 2014, 9, e97807. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Chen, F.; Dai, J.; Hua, T.; Lu, C.-T.; Ramakrishnan, N. Unsupervised spatial event detection in targeted domains with applications to civil unrest modeling. PLoS ONE 2014, 9, e110206. [Google Scholar] [CrossRef] [PubMed]
- Bakillah, M.; Li, R.Y.; Liang, S.H. Geo-located community detection in Twitter with enhanced fast-greedy optimization of modularity: The case study of typhoon Haiyan. Int. J. Geogr. Inf. Sci. 2014. [Google Scholar] [CrossRef]
- Liu, Q.; Deng, M.; Bi, J.; Yang, W. A novel method for discovering spatio-temporal clusters of different sizes, shapes and densities in the presence of noise. Int. J. Digit. Earth 2014, 7, 138–157. [Google Scholar] [CrossRef]
- Blei, D.; Ng, A.; Jordan, M. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Signorini, A.; Segre, A.M.; Polgreen, P.M. The use of Twitter to track levels of disease activity and public concern in the US during the influenza A H1N1 pandemic. PLoS ONE 2011, 6, e19467. [Google Scholar] [CrossRef] [PubMed]
- Chakrabarti, D.; Punera, K. Event summarization using tweets. In Proceedings of the 5th International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 66–73.
- Wang, M.; Wang, A.; Li, A. Mining spatial-temporal clusters from geo-database. Lect. Notes Artif. Intell. 2006, 4093, 263–270. [Google Scholar]
- Cheng, T.; Li, Z. A multiscale approach for spatio-temporal outlier detection. Trans. GIS 2006, 10, 253–263. [Google Scholar] [CrossRef]
- Wu, E.; Liu, W.; Chawla, S. Spatio-temporal outlier detection in precipitation data. Knowl. Discov. Sens. Data 2010, 5840, 115–133. [Google Scholar]
- Kulldorff, M.; Heffernan, R.; Hartman, J.; Assunção, R.; Mostashari, F. A space-time permutation scan statistic for disease outbreak detection. PLoS Med. 2005, 2, e59. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, P.; Zhou, D.; Wu, N. VDBSCAN: Varied density based spatial clustering of application with noise. In Proceedings of 2007 International Conference on Service Systems and Service Management, Chengdu, China, 9–11 June 2007; pp. 528–531.
- Weng, J.; Lee, B.S. Event detection in Twitter. In Proceedings of the 5th International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 401–408.
- Estivill-Castro, V.; Lee, I. Argument free clustering for large spatial point-data sets. Comput. Environ. Urban Syst. 2002, 26, 315–334. [Google Scholar] [CrossRef]
- Deng, M.; Liu, Q.; Cheng, T.; Shi, Y. An adaptive spatial clustering algorithm based on Delaunay triangulation. Comput. Environ. Urban Syst. 2011, 35, 320–332. [Google Scholar] [CrossRef]
- Jiang, M.-F.; Tseng, S.-S.; Su, C.-M. Two-phase clustering process for outliers detection. Pattern Recognit. Lett. 2001, 22, 691–700. [Google Scholar] [CrossRef]
- Al-Zoubi, M.B.; Al-Dahoud, A.A.; Yahya, A. New outlier detection method based on fuzzy clustering. WSEAS Trans. Inf. Sci. Appl. 2010, 7, 681–690. [Google Scholar]
- Shi, Y.; Deng, M.; Yang, X.; Liu, Q. Adaptive detection of spatial point event outliers using multilevel constrained Delaunay triangulation. Comput. Environ. Urban Syst. 2016. [Google Scholar] [CrossRef]
- Wang, J.; Ge, Y.; Li, L.; Meng, B.; Wu, J.; Bo, Y.; Du, S.; Liao, Y.; Hu, M.; Xu, C. Spatiotemporal data analysis in geography. Acta Geogr. Sin. 2014, 69, 1326–1345. [Google Scholar]
- Cheng, T.; Adepeju, M. Modifiable temporal unit problem (MTUP) and its effect on space-time cluster detection. PLoS ONE 2014, 9, e100465. [Google Scholar] [CrossRef] [PubMed]
- Huang, Q.; Wong, D.W.S. Modeling and visualizing regular human mobility patterns with uncertainty: An example using Twitter data. Ann. Assoc. Am. Geogr. 2015, 105, 1179–1197. [Google Scholar] [CrossRef]
- Zheng, Y. Methodologies for cross-domain data fusion: An overview. IEEE Trans. Big Data 2015, 1, 16–34. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, H.; Yu, Y. Detecting collective anomalies from multiple spatio-temporal datasets across different domains. In Proceedings of the 23rd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Bellevue, WA, USA, 3–6 November 2015; pp. 1–10.
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Y.; Deng, M.; Yang, X.; Liu, Q.; Zhao, L.; Lu, C.-T. A Framework for Discovering Evolving Domain Related Spatio-Temporal Patterns in Twitter. ISPRS Int. J. Geo-Inf. 2016, 5, 193. https://doi.org/10.3390/ijgi5100193
Shi Y, Deng M, Yang X, Liu Q, Zhao L, Lu C-T. A Framework for Discovering Evolving Domain Related Spatio-Temporal Patterns in Twitter. ISPRS International Journal of Geo-Information. 2016; 5(10):193. https://doi.org/10.3390/ijgi5100193
Chicago/Turabian StyleShi, Yan, Min Deng, Xuexi Yang, Qiliang Liu, Liang Zhao, and Chang-Tien Lu. 2016. "A Framework for Discovering Evolving Domain Related Spatio-Temporal Patterns in Twitter" ISPRS International Journal of Geo-Information 5, no. 10: 193. https://doi.org/10.3390/ijgi5100193
APA StyleShi, Y., Deng, M., Yang, X., Liu, Q., Zhao, L., & Lu, C.-T. (2016). A Framework for Discovering Evolving Domain Related Spatio-Temporal Patterns in Twitter. ISPRS International Journal of Geo-Information, 5(10), 193. https://doi.org/10.3390/ijgi5100193