1. Introduction
In current robot-assisted surgery, the robotic system does not function with any amount of autonomy. Instead, a surgeon remotely controls one or more slaved mechanical arms using a master controller. This is known as teleoperation, which does not represent a truly intelligent/autonomous robotic system. Moreover, the surgeon is encumbered by the need to manipulate the camera as well as the surgical instruments. In this paper, we review autonomous camera control in the context of the next generation of surgical robotics that goes beyond direct slaved control. We envision surgical robotic systems that understand the current task and can evaluate various inputs to intelligently generate movements that aid the surgeon.
Viewpoint control is a key aspect of teleoperation and is conducive for automation. Due to the physical separation of the surgeon from the patient, an indirect view (from a camera), and the indirect manipulation of the remote site, some significant challenges arise that could be aided by automation. The user is removed from the extensive sensory experience of the remote site, which means there is limited visual, auditory, and haptic feedback. This results in a reduced situation awareness and a high mental workload [
1,
2,
3]. Furthermore, it is difficult for the user to obtain optimal camera viewpoints in a dynamic environment or to react effectively to irregular events in the scene due to task overload, latency issues, and complex camera positioning issues. The surgeon has to continually manage the camera position to achieve effective viewpoints through manual control or verbal communication with a second operator. This can lead to errors as well as longer operating times. Therefore, we focus our attention on a robot-controlled camera.
“A Roadmap for U.S. Robotics: From Internet to Robotics” [
4] states that “designing effective and intuitive interfaces for remote users to control telepresence robots is an open challenge.” In addition, the Roadmap points out the need for research that will allow “robots to learn new skills [from observation of humans].” Teleoperating a surgical robot requires the use of indirect visual information that is difficult to manage, which poses many technical and human performance challenges. In particular, the user is expected to control the movement of the camera in addition to the robot’s arms. Camera positioning is a difficult task that can be error-prone and a drain on the user’s resources [
1]. Although camera control research is applicable in many different teleoperation domains, this paper reviews the current state of the art in camera control for telerobotic surgery. It also provides a discussion of potential avenues of research to advance this field and fulfill the unmet need for improved, intelligent camera control [
5].
1.1. Current Surgical Robots
Despite being called “robots,” the robotic surgery systems that have been available for clinical use have lacked any real autonomy. In general, today’s surgical robots act as slaves under the control of the surgeon. For example, the da Vinci Surgical System (Intuitive Surgical, Sunnyvale, CA, USA) is used to perform a variety of minimally invasive procedures, such as prostatectomies. The da Vinci is entirely controlled by the surgeon, who uses hand controls and foot pedals to manipulate a camera arm and several instrument arms.
There are also a number of robots designed specifically to manipulate a laparoscope, such as the AESOP (Intuitive Surgical), EndoAssist [
6] (Armstrong Healthcare, High Wycombe, UK), FreeHand (Freehand 2010 Ltd., Guildford, UK), and ViKY EP (EndoControl, Grenoble, France). These devices employ various forms of control, such as hand control, voice recognition, foot control, and head tracking. Despite the various forms of control, there is still a one-to-one correspondence between the surgeon’s actions and movements of the laparoscope.
Another group of surgical robots is used to execute preprogrammed motions rather than follow the real-time control input from the surgeon. Examples include the neuromate (Renishaw, Gloucestershire, UK), a neurosurgery robot; the ROBODOC (Curexo Technology Corporation, Fremont, CA, USA), an orthopedic robot; and the CyberKnife (Accuray, Sunnyvale, CA, USA), a radiosurgery robot. Although these robots may seem to act independently, they are actually slaves to their rigidly preprogrammed behaviors. Therefore, like the other robots, they lack the intelligence and awareness to be considered autonomous. The surgeon must expend considerable effort to control all of these robots.
1.2. Motivation for Autonomous Camera Research
Open surgery, where the surgical site is directly viewed, provides a clear 3D view and easier access. Surgeons can see the surgical area and surrounding anatomy from the natural viewpoint of their eyes. Open surgery, however, comes with various disadvantages. This includes a larger incision, sometimes more bleeding, more pain for the patient, and sometimes other complications (e.g., adhesions for certain operations) that may be severe enough to require reoperation [
7].
In laparoscopic or robotic surgery, the surgeon views the site through the use of a tool (a laparoscope) that is inserted through a small opening in the patient’s body. The image from the laparoscope is displayed on a monitor located somewhere in the operating room. The laparoscopic view is often quite different from the view during open surgery. The laparoscope provides a magnified image, and the viewing angle varies due to the angle of insertion and the angle of the scope’s lens.
In many cases, the tighter field of view and alternative angle provided by the laparoscope can be better for the surgeon and the patient. For example, during a laparoscopic fundoplication (a surgery that treats acid reflux disease), the scope can easily look directly down on the gastroesophageal junction under the liver, avoiding the need to mobilize the liver. Other advantages of laparoscopic surgery include a smaller incision, less pain, reduced hospital stay, and often a reduced chance of needing a reoperation. Some drawbacks include typically worse depth perception, a smaller field of view (due to the magnification), and the fact that the surgeons have added camera control (either direct or indirect) to their already intensive workload. Note that a stereo/3D laparoscope is sometimes used to improve the depth perception, particularly in robotic surgery.
In a typical laparoscopic procedure, an assistant is needed to control the camera arm. Directing an assistant to control the camera can be challenging (especially with angled scopes) and lead to increased time for accomplishing the operation. Expert camera holders (i.e., those who are also expert surgeons) improve the performance of the surgeon by generally providing a desirable view. In some cases, the camera positioner may even help guide the steps of the operation. This occurs when an attending (teaching) surgeon holds the camera for a resident who is learning to do the procedure. In most cases, however, it is the expert who performs the operation and often struggles because the less experienced and skilled camera holder does not completely understand which view to provide at a given time.
Robotic surgery adds the advantages of motion scaling, tremor filtration, a comfortable interface, the lack of a fulcrum effect, and a wrist at the end of the surgical tool with a greater range of motion than the human wrist. However, it still retains the disadvantages of a reduced field of view and the additional task of controlling a camera arm. Because there is no assistant for the camera arm, the surgeon controls both the tools and the camera. Operations do not flow as smoothly when the surgeon must frequently stop momentarily to change the camera’s viewpoint. Due to the work involved, the surgeon sometimes settles for a suboptimal camera view. The surgeon may also allow the tools to temporarily leave the field of view (due to the effort required to reposition the camera), which can lead to injury to organs outside the field of view.
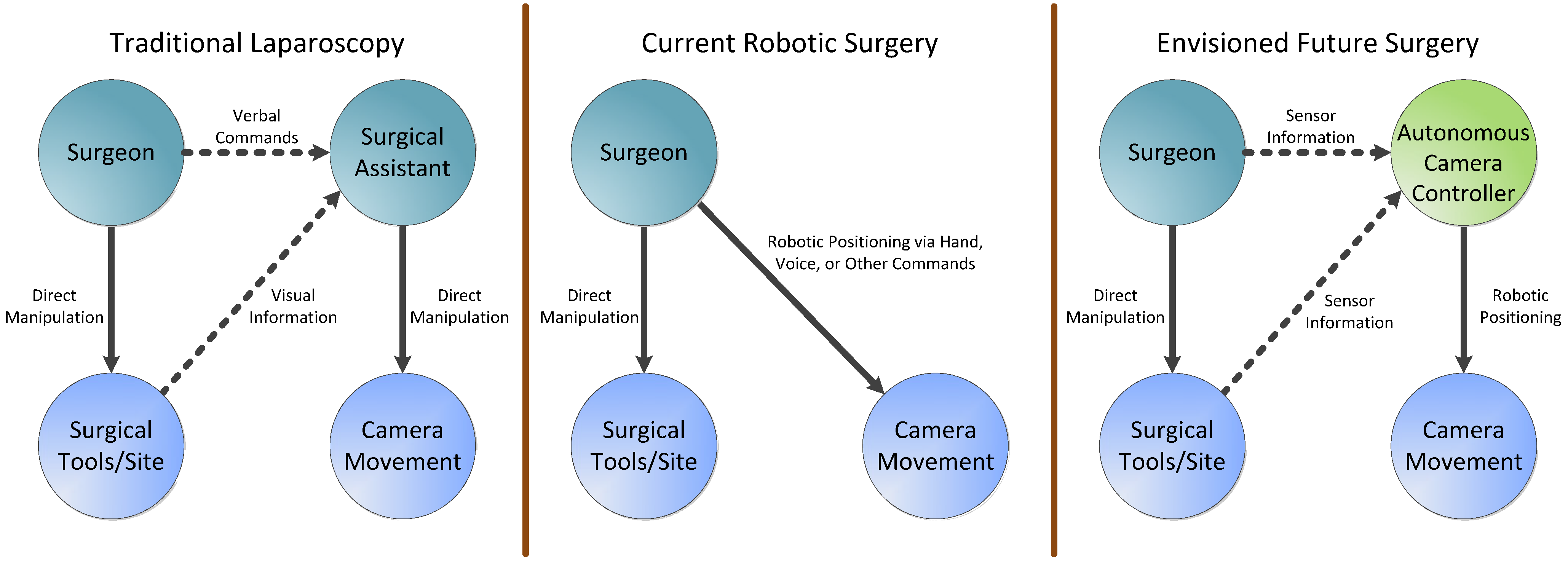
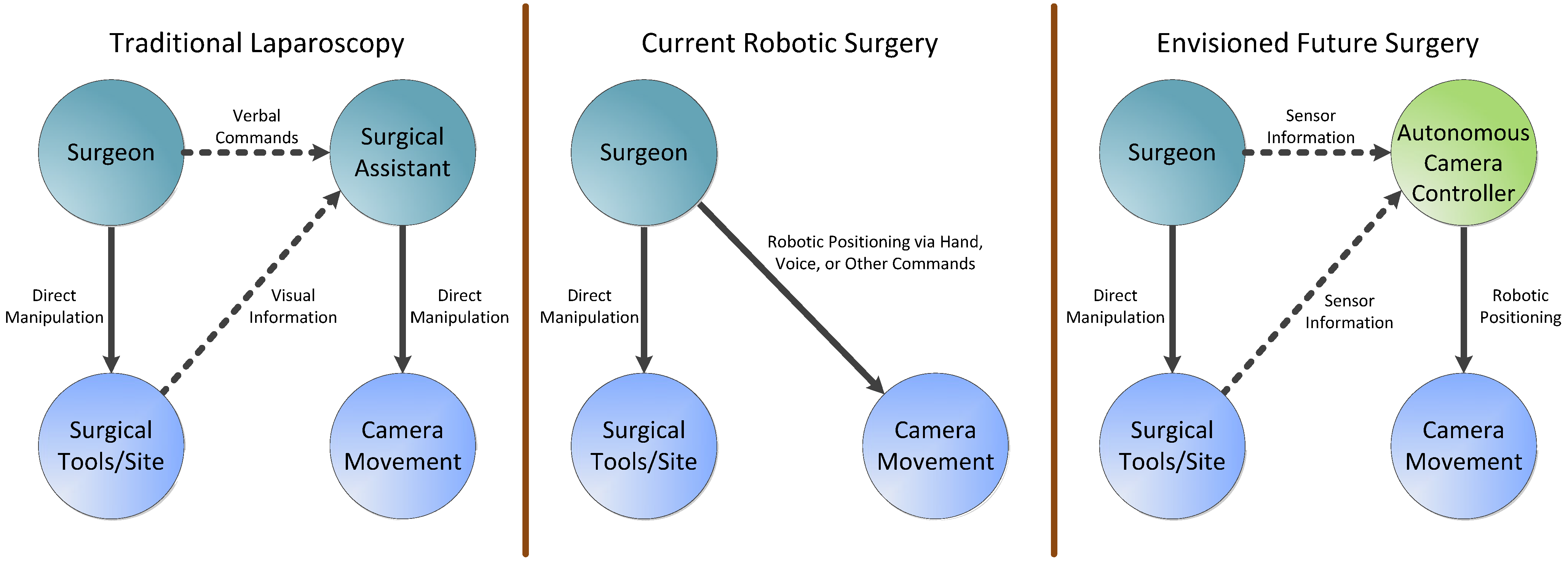
The aforementioned limitations are the motivations for research and development in autonomous camera navigation systems for minimally invasive surgery (both laparoscopic and robotic) and for remote teleoperation in general. With an autonomous camera system, the human camera assistant used in a typical laparoscopy can be eliminated, and the surgeon will not have to manually move the camera arm in a robotic surgery.
Figure 1 demonstrates how an autonomous camera system would differ from current minimally invasive approaches.
Figure 1.
Comparison among the mechanisms used to move the camera in traditional laparoscopy, current robotic surgery, and envisioned future procedures with an autonomous camera control system.
Figure 1.
Comparison among the mechanisms used to move the camera in traditional laparoscopy, current robotic surgery, and envisioned future procedures with an autonomous camera control system.
Some work on optimal visualization for medical robotics was done to ascertain the effects of camera views on surgical tasks using multiple cameras. It was found that using two distinct camera views on different monitors (one zoomed in and one zoomed out) helps both surgeons and non-surgeons perform complex tasks with fewer errors. While not the same as an autonomous camera system, the research showed that efficient camera views are important for surgical performance [
8].
2. Current Research Approaches
Camera navigation can be approached with a reactive, proactive, or combined control strategy. In a reactive system, sensors track data such as surgeon eye gaze or tool position within the field of view, and the camera is moved in direct response to changes in these inputs. With a proactive strategy, a prediction-based approach is used to determine the best camera viewpoint. In this strategy, the system determines the current state of the procedure that is being undertaken and adjusts the camera’s behavior by incorporating preexisting knowledge about the visualization requirements and types of movements needed for the procedure. The knowledge can be represented in different forms, such as simple heuristics or complex statistical models.
Several techniques [
9,
10,
11,
12,
13] for autonomous camera control have been studied in the fields of virtual reality and animation. Some methods rely on reactive techniques where the behavior is related to the dynamic nature of the scene. Higher-level methods of control try to capture expert user knowledge to come up with general-purpose solutions that are often based on simple rules. In these systems, the parameters of the camera movement can be very application- or context-dependent. For example, an expert camera operator might say: “always keep the tools in the camera view.” This information could be translated into a rule-based algorithm, although this rule may not apply to all situations. Currently, these kinds of techniques [
9,
10,
11,
12,
13] are generally designed for computer graphics applications, which are very different from robotic systems operating in the real world. There, the camera views are constrained by physical limitations and are subject to real conditions.
2.1. Techniques for Tracking and Determining Operator Intent
In general, the challenges of teleoperation have been well studied. Dragan
et al. [
14] address the fundamental problem of teleoperation interfaces being limited by the inherent indirectness/remoteness of these systems. Their report discusses intelligent and customizable solutions to the negative aspects of remote operations. They state that the decision on what assistance should be provided to operators must be contextual and dependent upon the prediction of the user’s intent. Their main recommendation is that a robot should learn certain strategies based on examples or even measurements of the movements of a human operator.
2.1.1. Eye Gaze Tracking
Eye tracking technology has its origins in pre-twentieth century studies of basic eye movements, leading to applied research in reading, scene perception, visual search, and other information processing (see Duchowski [
15] for past and contemporary applications). The development of non-invasive techniques such as video-based eye tracking (Morimoto and Mimica [
16], Hansen and Ji [
17]), along with improvements in automatic fixation and saccade detection [
18], have enabled applications for human–computer interaction (see Jacob and Karn [
19] for a review).
In a human–computer interaction context, the user’s point of gaze can be used as an input. For example, it is commonly used as a pointing device (to augment or replace a computer mouse) or to make inferences about the user’s attention or intent. Eye movement has been employed for both direct and indirect input to interactively and automatically change computer interface and camera views. Goldberg and Schryver [
20] developed an offline method for predicting a user’s intended camera zoom level (
i.e., magnification/reduction). An accuracy of 65% was reported when predicting zooming in, zooming out, or no zoom change for simple shapes in a controlled interface environment. Less constrained scenarios, such as complex renderings or video of real scenes, would likely decrease the accuracy. In addition, the algorithm relied on previously recorded eye movement data and could not determine zoom intent in real time, limiting its use to non-interactive evaluations. However, advances in automatic identification of fixations and saccades (e.g., Salvucci and Goldberg [
18]) might enable real-time adaptations.
Hansen
et al. [
21] used eye tracking as direct input to control planar translation and zoom of a gaze-based typing interface. Users fixated on a desired letter to type, and the interface responded by moving that letter toward the center of the screen. Smooth pursuit eye movement to visually track the letter confirmed the user’s intent. Continued tracking as the interface zoomed in on the letter increased system confidence. This sequence culminated in selection of the letter once a threshold zoom level was reached. Events leading to selection of the wrong letter result in the user automatically looking away toward the intended letter. This natural response was utilized to correct errors prior to selection of the wrong letter.
Latif, Sherkat, and Lotfi [
22,
23] proposed a gaze-based interface to both drive a robot and change the on-board camera view. Although the design permitted hands-free teleoperation, a comparison of joystick control, gaze input with dwell-time activation, and gaze input with foot clutch found no statistically significant difference in task completion time, goal achievement, or composite NASA TLX (task load index) scores. Zhu, Gedeon, and Taylor [
24] developed gaze-based automatic camera pan and tilt control that continually repositioned the viewpoint to bring the user’s point of gaze to the center of the video screen. The simple proportional control algorithm only responded to where the user is looking. Both [
22,
23] and [
24] demonstrated how eye movement can be used to control camera viewpoint in real-time, but neither sought to account for how task conditions and scene dynamics may influence optimal viewpoint.
Eye tracking has also been explored for surgical applications. Kwok
et al. [
25] used simultaneous displays of two users’ point of gaze to indicate their respective intents during simulated robotic surgery tasks. Ali
et al. [
26] used eye tracking to automatically center a laparoscopic camera viewpoint at the user’s point of gaze (see
Figure 2). Like [
24], their system did not adapt to the surgical task being performed, although intent prediction [
20] and more sophisticated interaction schemes [
21] using similar eye movement data hint at the possibility of more robust gaze-based automated camera systems. Mylonas
et al. [
27] used a binocular eye-tracking device that was directly integrated into a surgical console for 3D gaze localization. They demonstrated that accurate 3D gaze data can be captured and used to alter scene characteristics.
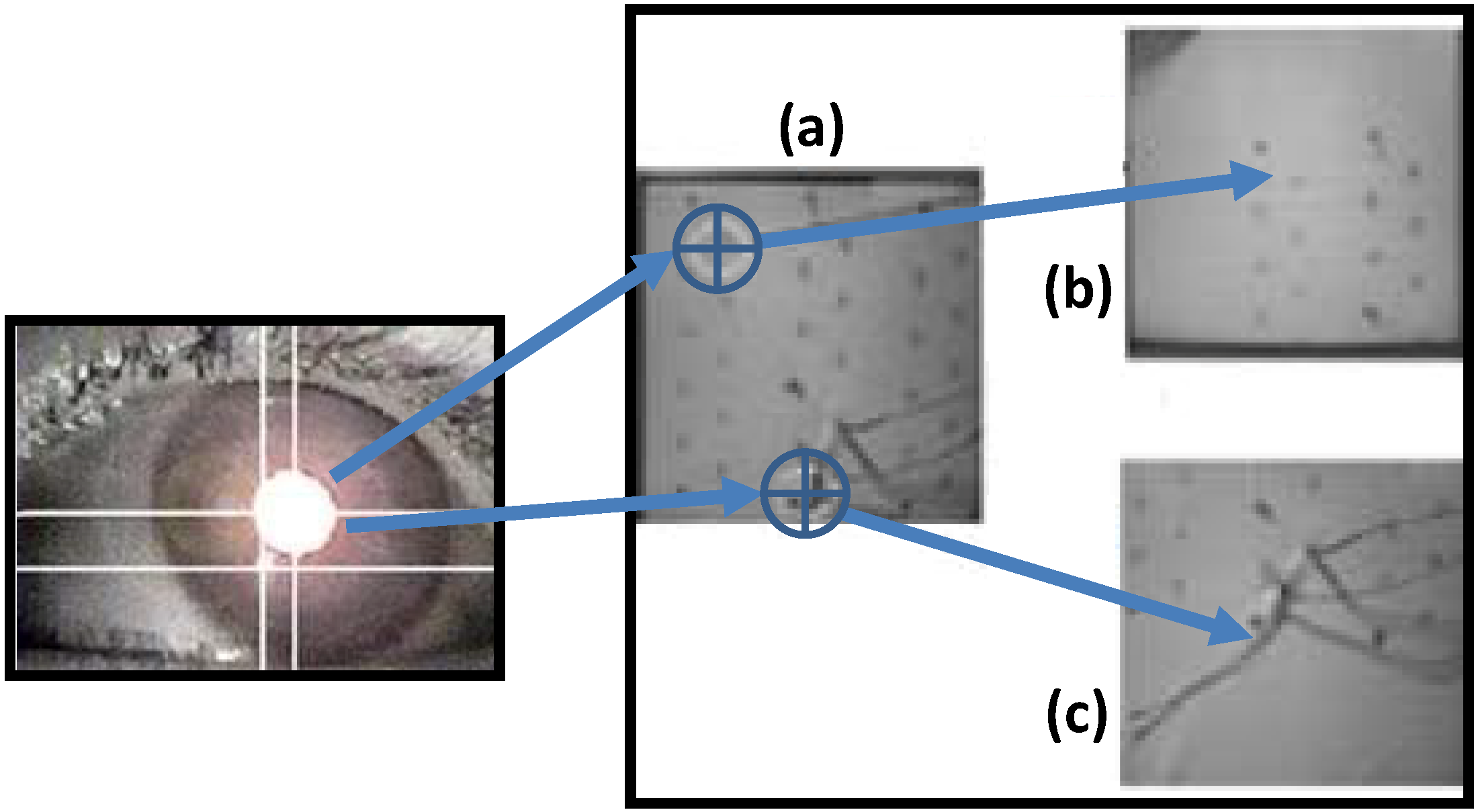
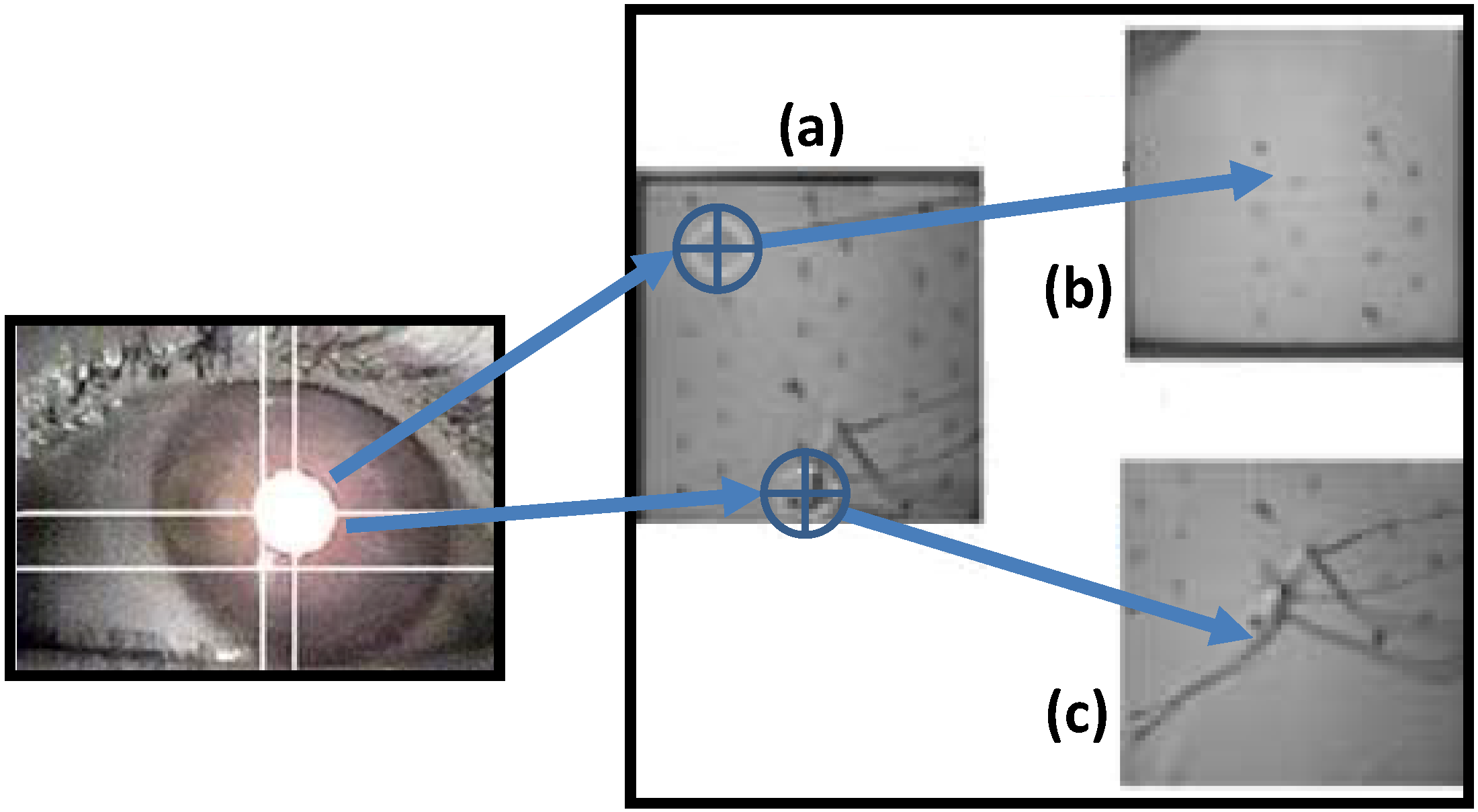
Figure 2.
Diagram showing how a robotic camera arm can center a viewpoint based on eye gaze tracking [
26]. If the eye gaze in (
a) is focused at the top of the image, the camera zooms to that area in image (
b). If the gaze is at the bottom of the image, the camera zooms to the area in image (
c).
Figure 2.
Diagram showing how a robotic camera arm can center a viewpoint based on eye gaze tracking [
26]. If the eye gaze in (
a) is focused at the top of the image, the camera zooms to that area in image (
b). If the gaze is at the bottom of the image, the camera zooms to the area in image (
c).
One weakness of relying solely on eye gaze is that tracking technology remains relatively unreliable. Variations in tracking performance in different environments and between individual users continue to be a challenge for applications. Eye gaze might be useful as one of the components of a system, but researchers should consider multimodal or redundant methods to increase the robustness of the interface.
2.1.2. Instrument Tracking
The teleoperator’s intent is also expressed through any instruments he or she may be using. The operator manipulates instruments in order to achieve desired goals, which indicates that the operator’s intent is closely related to the manner in which the instruments are manipulated. If an intelligent camera control system can ascertain and utilize the dynamic state of the instruments, it can better cooperate with the user.
The state of an instrument includes general properties such as its position, orientation, speed, and acceleration. It also includes instrument-specific properties, such as whether a gripper is open or closed. There are various mechanisms by which a control system can determine these properties. The following subsections describe some of these mechanisms.
2.1.3. Kinematic Tracking
If a system with robotic instrument control is being used, such as the da Vinci Surgical System, kinematic tracking [
28] can generally be used to determine various properties of the instruments. A typical robotic system includes one or more jointed arms that manipulate instruments on behalf of the user. The robot arm includes sensors (like encoders or potentiometers) that can accurately determine the state of each joint. If the fixed properties of the physical structure of the robot arm are known (lengths of links, twists,
etc.), they can be combined with the dynamic joint values to form a mathematical model of the robot arm [
29]. Desired instrument properties, such as the position and orientation of the end-effector, can be computed from this model.
The positional information resulting from kinematic tracking is generally expressed in terms of some coordinate system that is specific to the robot. In order to express this information with respect to some other coordinate system, such as one associated with the view from the camera, a transformation that maps between the two systems must be determined. This transformation can be determined through a registration process. A typical registration process involves finding a number of features (such as predefined reference locations) in both coordinate systems and using an algorithm to compute a transformation between the systems [
28].
2.1.4. Image-Based Tracking
In some applications, such as traditional laparoscopic surgery, there is no robotic instrument manipulation system. In this case, the properties of the instruments must be determined though other mechanisms. Since the systems addressed in this paper would all have a camera, it is logical to use the camera to assess instrument properties [
30].
In addition, there is value in tracking objects in the environment besides the instruments. A basic autonomous camera system could use this information to avoid obstacles or focus on points of interest. A more advanced autonomous system might evaluate how the user interacts with different objects to ascertain the user’s intent or identify the task that is currently being performed.
There are many techniques for tracking objects in a camera image. Objects of interest can be tracked by identifying inherent, distinguishing characteristics of the objects. For example, this could include the shape, color, texture, and movement of the objects. To enhance the tracking, the objects can be modified to make them more recognizable in the camera image. For instance, colored markers or tracking patterns can be affixed to instruments to aid in detection by a computer algorithm [
31,
32,
33].
Depending on the application and environment, image-based tracking techniques may not be sufficient. The resolution of the camera limits accuracy, and most images only contain 2D information. Objects may be occluded, insufficiently lit, or simply not have sufficiently distinguishable features. Moreover, the amount of computer processing required for some image analysis may be prohibitive for real-time applications. For these reasons, it may be necessary to add additional sensing techniques to track the instruments.
2.1.5. Other Tracking Technologies
There are many different types of sensors that can be used to track an instrument or other objects. Optical techniques, such as an infrared tracking system, can locate objects that have infrared markers attached to them. The objects being tracked do not require any wires, but the line of sight from the tracking system to the tracked objects must be kept clear.
A magnetic tracking system can also be used to locate instruments or other objects of interest. Magnetic sensors are affixed to the objects, and a magnetic transmitter emits a field that the sensors can detect. Unfortunately, the presence of objects in the operating room that affect or are affected by magnetic fields may make this technology infeasible for surgery [
34,
35,
36].
Another type of tracking technology is called an inertial measurement unit (IMU). An IMU incorporates multiple sensors, such accelerometers, gyroscopes, and magnetometers, to track the orientation, position, or velocity of an object. An IMU can be relatively small and be designed to transmit data wirelessly. However, these devices experience increasing error over time (especially in position), and some of the sensors may be sensitive to interference from other devices in an operating room.
In summary, beyond the algorithmic and knowledge-based challenges posed, there are some hardware technological barriers that need to be overcome. Better tracking methods that are suitable for use in the operating room are required. As described above, there are limitations to the use of optical, magnetic, and inertial sensors in operating room.
2.2. Gesture/Task Classification
Building on the tracking technologies discussed above, progress has been made in relating basic tool-level data (e.g., tool position, orientation, and motion/dynamics) to more abstract knowledge-based constructs at the surgical task level [
37]. For example, Speidel
et al. [
38] analyzed image data collected from an endoscope, highlighting visual features and key points to identify movement characteristics. Using this technique, they isolated and identified the trajectories, velocities, and shapes of surgical instruments, and then they used a Bayes classifier to predict the next surgical subtask.
Using recorded motions from a da Vinci Surgical System, Murphy [
39] applied linear discriminant analysis to automatically classify seven surgical subtasks. Next, Murphy used this information to characterize skill based on the absence, presence, or order of the surgical gestures. In other work with the da Vinci platform, Lin
et al. [
40] applied an artificial neural network to classify signals into eight ad hoc surgeon gestures. Their study also aimed to automatically determine surgeon skill level. Reiley
et al. [
41] extended the research of Lin
et al. [
40], adding three gestures to Lin’s breakdown (based on surgery observations) for a total of eleven gestures. However, five of their motions were consolidated into one gesture class for processing and analysis.
This body of work shows promise. There were generally acceptable classification accuracies and meaningful outputs. However, further research is required. The employed task breakdowns are ad hoc and potentially idiosyncratic. Future work should start from generally accepted and externally validated task analyses and surgery process models. Regardless, this work is important because it could bridge the gap from low-level signal processing approaches to knowledge-based approaches for camera control. Research is still needed, however, to determine the specific visualization requirements on a task-by-task basis.
In a related topic, Weede
et al. [
42] describe a cognitive robotic system based on closed-loop control. They focus on knowledge acquisition and surgical workflow analysis, and they relate their work to autonomous camera control. They make a clear distinction between automatic systems and autonomous systems. They contend that autonomous systems (unlike automatic systems) must take the environment and task context into account when making decisions. Another fertile area that may lead to insight into cognitive robotics is surgical skills acquisition. Reiley
et al.’s [
43] review paper discusses descriptive statistics based on time and motion analyses for surgical training. They state that developed skill models can also be useful in training robots for building human–robot collaborative systems.
2.4. Existing Methods for Viewpoint Generation in Computer Graphics
While there are existing methods that attempt to address the camera-control problem, they are mostly related to computer graphics/computer gaming [
45,
46,
50,
51]. In a key review paper [
10] of camera control in computer graphics, the authors review a number of state-of-the-art techniques for the yet open research question of camera control. They include constraint-based, potential-field-based, and optimization-based approaches. A very important first conclusion they make is that camera control is difficult, requiring great deal of dexterity. It necessitates the manipulation of seven degrees of freedom: x-position, y-position, z-position, roll, pitch, yaw, and zoom. In addition, the movement speeds and accelerations must be controlled.
Due to the complexity of camera placement, the authors recommend that the next generation of camera control systems not only provide efficient implementations, but also include empirical knowledge gained from experts to extract higher-level properties that will facilitate view aesthetics. Based on this recommendation, we believe that strategies employed by expert users of a telerobotic system also need to be studied in order to incorporate the nuances of their specific application domain. The authors also outline key steps that are taken to reduce the computational complexity.
In a series of papers [
9,
47,
52,
53], Burelli
et al. describe the use of an artificial potential field implementation to control a camera view for virtual/gaming environments. They describe a method that uses particles suspended in an artificial potential field to control both camera position and orientation. A scene’s geometry and three different constraints for each object (visibility, projection size, and viewing angle) are modeled into the system using the notion of potential fields. The papers also discuss the case of under-constrained systems in which several camera poses can satisfy the same requirements. Their solution involves an optimization that allows convergence to the nearest configuration that meets all the constraints. Their implementation, however, is for a gaming environment where the state space of every object in the scene is known.
Hornung [
54] provides a nomenclature that is defined relative to the type of camera view. The author formalizes cinematographic concepts and shows a methodology to transfer this knowledge to the autonomous camera movement domain using techniques in neural networks and artificial intelligence.
Several papers [
13,
55] describe a camera planning algorithm for computer graphics. The developed algorithm allows the user to select certain generic goals, strategies, and presentation methods. The system then uses a genetic algorithm to optimize the camera viewpoints. The authors claim that genetic algorithms work well with ambiguous data values found in camera planning.
Lastly, another active field in which camera path-planning techniques play an important role is virtual endoscopy. Hong
et al. [
56] describe a method that avoids collisions during virtual-reality-guided navigation of the colon. The surfaces of the colon and the centerline of the colon are modeled with potential fields, with the walls being repulsive and the centerline being attractive. This is a promising approach for a real-time viewpoint-generation methodology.
2.5. Existing Autonomous Camera Systems
Various autonomous camera systems have been created for minimally invasive surgery [
26,
30,
31,
33,
57,
58,
59,
60]. For tracking, most of these systems used image processing to identify the position of the tool tips relative to the camera. To move the camera, the systems generally used a limited number of rules to set the camera’s target position and zoom level. For instance, a commonly used rule sets the camera’s target position to the midpoint of two tracked tool tips and alters the zoom level as necessary to keep the tool tips in the camera’s view [
61]. These systems generally are implemented with laparoscopic instruments using image processing to automatically move a camera with no explicit human direction. A camera control algorithm automatically keeps the tools in the view. A system might for instance, zoom in when the tools are brought close together, and zoom out to always keep the tools in the field of view. The advantage of this approach is that no sensors are necessary; making adoption to existing laparoscopic systems easier (see
Figure 3). In general, the testing of the surgical systems was limited to subjective feedback about their performance.
Other methods of tracking the tool tips include using the kinematics of the robot. In these types of systems, the 3D poses of the tools are calculated using the known/measured joint angles, the DH parameters of the system [
29], and a keyhole-based (due to the trocar point of surgical insertion) forward kinematics algorithm [
28]. Once the tools are located in the working region, the camera arm moves to keep the tools within the view of the camera.
Some more recent work has also focused the development of autonomous laparoscopic camera systems. Weede
et al. [
42,
62] have developed a test system that applies a Markov model to predict the motions of the tools so the camera can follow them. The system is trained using data from previous surgical interventions so it can operate more like an expert camera operator. Yu
et al. [
63] propose algorithms for determining how to move the laparoscope from one viewing location to another using kinematic models of a robotic surgery system.
Figure 3.
A test platform for automatic laparoscopic camera movement that tracks the tools via colored markers [
61]. The system automatically centers the camera’s view on the two tools and alters the zoom level (based on the distance between the tools) to ensure both tools are in view at all times.
Figure 3.
A test platform for automatic laparoscopic camera movement that tracks the tools via colored markers [
61]. The system automatically centers the camera’s view on the two tools and alters the zoom level (based on the distance between the tools) to ensure both tools are in view at all times.
3. Potential Future Research Avenues
We envision that successful completion of the several research avenues discussed herein will provide the foundation for intelligent robots that perform automatic camera control in real time. This type of co-robotic system can reduce the cognitive workload of operators, allowing their focus to remain on the primary task. In addition, this technology can reduce the amount of time and the number of personnel required for teleoperations, producing a quantifiable cost savings to society in numerous applications. Moreover, the proposed ideas should help nurture the adoption of medical telerobotic systems in the marketplace by enhancing ease-of-use while reducing costs and errors.
As previously discussed, there are existing methods that attempt to address the camera-control problem. Most are based on reactive techniques, and others are related to computer graphics/computer gaming. Those methods are primarily based on simple virtual environments. They are generally focused on a camera’s position for cinematographic effects and incorporate very little expert knowledge for camera operation.
To advance the field of camera control for surgical applications, there is a need for systems that are (A) capable of generating camera movements that match the quality of domain-specific expert camera operators to assist human partners; (B) able to learn from the knowledge and performance of expert human camera operators; and (C) generalizable for effective application in many different surgical and potentially non-surgical domains (military operations, space exploration, surveillance, border patrol, first response teams, etc.). We propose that the following are important research areas that will help meet those needs: (1) improved tracking methods; (2) algorithms for skills acquisition; (3) knowledge representation; (4) user intent modeling; and (5) methods for evaluation and testing. These areas are summarized in the following subsections.
3.1. Tracking
While there are noteworthy attempts to track surgical instruments through visual, kinematic, and other methods, these techniques give little information about the state of the rest of the scene. Examples of important entities include tissues that are bleeding, a foreign object, etc. It is conceivable that future tracking methods should not only track the instruments, but also be capable of tracking arbitrary objects defined by the user. In addition, as mentioned earlier, current forms of tracking (optical, magnetic, kinematic, etc.) have various limitations. Other methods of tracking need to be developed that are better suited to the operating room and will allow robust tracking of many (potentially ill-defined) objects.
3.2. Algorithms for Skills Acquisition
Gaining a deeper understanding of expert users of a system is essential. Research should be focused on forming a link between expert camera operators and parameters that define how the camera should be moved. There is a potential to use human factors methods, such as cognitive task analysis [
64], to analyze how experts control laparoscopic cameras. This research could involve interviewing expert surgeons to discover and document salient varieties of camera control and their related task contexts. The results could be used to develop better robotic control algorithms that will be more responsive to the surgeon’s needs.
Desired camera movement is dependent on the specific application, which is why research is needed to create fundamental movement algorithms and behaviors that can be generalized among robotic platforms. A generic method of training a robot for autonomous camera movement would be applicable to many different domains (in both surgery and general telerobotics). For instance, camera behavior parameters for a particular laparoscopic surgery could be derived from expert surgical camera operators from that domain. More specifically, the kinematic nuances of the domain could be derived from recordings of movements performed during user operations by a system equipped with various tracking sensors. The recorded movement data could be processed by various statistical and learning algorithms to develop models of how the camera should be moved.
For example, Reiley
et al. and Lin
et al. [
40,
41,
43] describe the automation of skill evaluation, modeling, and capture. In another paper, van den Berg
et al. demonstrated surgical task automation by collecting and learning from human operator data [
65]. In their approach, trajectories of specific movements like knot tying are recorded, learned, and then autonomously executed with enhanced performance in terms of speed and smoothness.
3.3. Knowledge Representation
Research is needed to find effective ways to represent the contents of the working envelope for the camera control algorithms. Generically, this might consist of objects or regions of interest (tools, organs, etc.) and their properties (size, velocity, etc.). The representation should allow the encapsulation of not only the position and orientation of different objects, but also their relative levels of importance. The use of these representations should allow remote viewpoints to be automatically optimized based on a given set of input parameters. This could be accomplished by simulating how the camera would see the objects from different viewpoints and using mathematical optimization to select an effective viewpoint (camera orientation, position, and zoom level). The technical approaches could involve the development of control systems that build on a combination of optimization techniques and a system of representation, such as potential field theory.
In addition, these intelligent systems should allow data and knowledge from experts to be translated into spatial and other descriptive parameters in order to capture the nuances of domain experts. Such a framework should allow different entities have different types of influence on the camera’s viewpoint. By adjusting the parameters of the various entities in the environment, the system’s behavior can be altered to accommodate specific teleoperation applications. Relevant variables, such as object positions/dynamics, sensor inputs, user intentions, and changes in the image could be weighted (based on user inputs) to affect the camera’s movement in domain-specific ways. The goal would be to embed the knowledge of experts into a model that can be used to generate effective camera trajectories for a particular application or task.
3.4. Detecting and Interpreting Operator Intent
To be most effective, an intelligent camera system requires the knowledge of what task(s) the operator is currently performing. Within all of the major research areas described above, one point is clear: moving a camera requires information about what is currently happening in the environment. This information can be used to optimize camera behaviors based on the context and better determine the operator’s intent. It may also help the camera control algorithms handle unfamiliar situations.
Task analysis, a common technique to help chart and organize actions, can be used to categorize and organize data for use in an operator intent classification algorithm. More research into these methods is needed to efficiently establish implementations at the right level of detail to infer operator intent for telerobotic applications. There has been research that detects and segments the intent of a surgeon during robotic surgery [
37,
40], but this work has mainly focused on detecting surgical motions/tasks using complex tracking hardware. An extension of this work would be to use more natural methods of input, such as the video feed. Research that could extract the operator intentions from video would be much more advantageous because it would not require any additional tracking hardware or access to the robot’s hardware. Moreover, it could be more easily applied to laparoscopic surgery, which is much more common than robotic surgery.
3.5. Evaluation and Testing
For the adoption of autonomous camera techniques, especially in the surgical arena, the systems developed for any application area must be thoroughly evaluated. A robust system of evaluating the selected viewpoints should be implemented, as well as ways to assess operator performance on particular tasks. Steinfeld
et al. [
66] provide an overview and analysis of metrics for human–robot interaction performance, and many of these could be easily adapted to measure task performance in robot-assisted camera control in surgical settings. These include aspects of overall task performance time, task performance efficiency, and the mental workload of the human member of the human–robot team. In evaluating the system’s performance, the same tasks should be performed using both an expert human camera operator and the automated system to determine how the system compares to expert human operators. The analysis should consider unbiased metrics and potentially other factors deemed important by the expert users, such as: “are all the important actors in the scene?”, “how much irrelevant information is present?”, and “what level of detail is visible in the target area?”
Finally, clinical trials that test these systems in animal models and human surgical cases should be systematically performed. The U.S. Food and Drug Administration has determined that all technology must be validated for safe and effective use, and surgical equipment is no exception. Recent guidance from the FDA requires that human factors methods be applied during the design phase [
67].
4. Conclusions
Successful completion of the proposed research topics will help provide the foundation for intelligent robots that perform autonomous camera control in real time. We also need standard, usable, and programmable surgical platforms that are sufficiently affordable for use in research and translate well to actual surgical platforms. This will allow mature research to have a streamlined path towards making a direct impact in real surgical robotic applications. The da Vinci Research Kit (DVRK), which is being developed by a consortium of universities and an industry partner (Intuitive Surgical), is an excellent starting point for this kind of research [
68]. In addition, there are other potentially useful platforms, such as the RAVEN I and RAVEN II [
69,
70].
Although the focus of this paper has been on surgical robotics, the gains in this field will also affect remote operations in general. For instance, an astronaut can have eight or more camera views to simultaneously manage in space station operations. Similarly, manual camera control for unmanned military systems can reduce situational awareness under high workload and increase crew size requirements. For each of these examples, camera-related tasks are considerable sources of distraction, diverting users away from what should be the focus of human attention: on-orbit tasks, surveillance, military operations, etc. Autonomous camera control has the potential to enhance the performance of these tasks in ways that are similar to the improvements in surgical applications.



{kind=link}
{kind=link}
{kind=link}