Evolutionary Conservation and Expression Patterns of Neutral/Alkaline Invertases in Solanum


Abstract
:1. Introduction
2. Materials and Methods
2.1. Identification of CIN Genes in Solanum
2.2. Multiple Sequence Alignment and Phylogenetic Analysis
2.3. Conserved Motifs and Gene Structure of CIN Genes
2.4. Mapping CIN Members on Chromosomes
2.5. Tissue-Specific Expression of CINs in Tomato and Potato
2.6. Expression Profiling of CINs in Response to Different Stresses
2.7. Plant Materials and Stress Treatment
2.8. Total RNA Extraction and Quantitative Real-Time PCR (qRT-PCR)
3. Results and Discussion
3.1. Conservation in CIN Gene Family: Gene Number, Sequence Length, and Molecular Weight
3.2. Potential Functional Conservation: Four Key Amino Acid Residues
3.3. Evolutionary Conservation of CIN Genes Based on Phylogenetic Relationship
3.4. Conservation in CIN Motif Compositions and Gene Structures
3.5. Strong Observed Collinearity in CIN Gene Family
3.6. Cross-Species Transcript Profiling Reveals High Constitutive Expression of CIN Genes in S. lycopersicum and S. tuberosum
3.7. Expression Profiles of CIN Genes under Different Stress Conditions
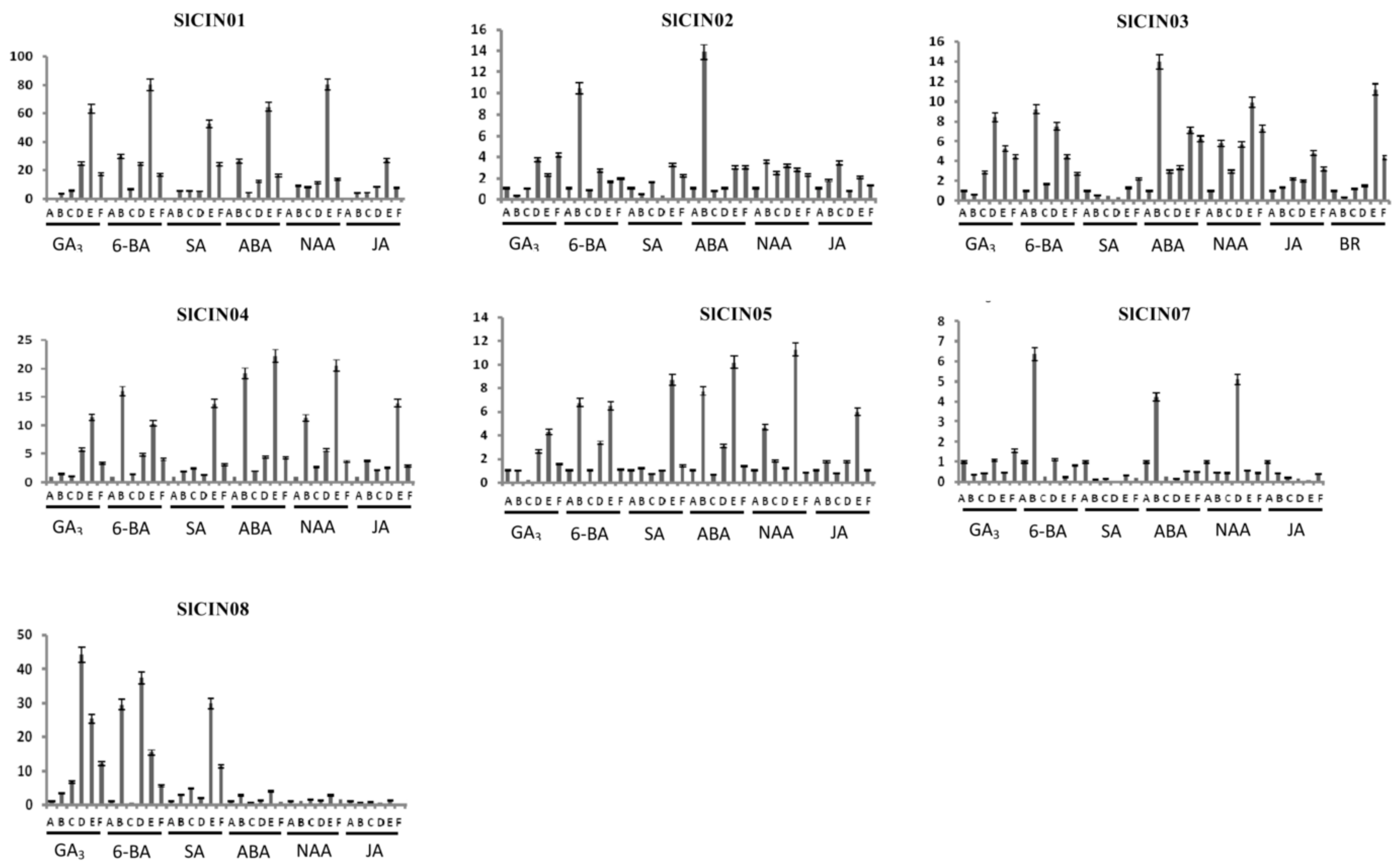
3.8. Expression profiles of tomato CIN genes in response to phytohormones with qRT-PCR
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Vargas, W.A.; Salerno, G.L. The Cinderella story of sucrose hydrolysis: Alkaline/neutral invertases, from cyanobacteria to unforeseen roles in plant cytosol and organelles. Plant Sci. 2010, 178, 1–8. [Google Scholar] [CrossRef]
- Avigad, G.; Dey, P.M. Carbohydrate metabolism: Storage carbohydrates. In Plant Biochemistry; Dey, P.M., Harborne, J.B., Eds.; Academic Press San Diego: San Diego, CA, USA, 1997; pp. 143–204. [Google Scholar]
- Ruan, Y.L.; Jin, Y.; Yang, Y.J.; Li, G.J.; Boyer, J.S. Sugar input, metabolism, and signaling mediated by invertase: Roles in development, yield potential, and response to drought and heat. Mol. Plant. 2010, 3, 942–955. [Google Scholar] [CrossRef] [PubMed]
- Koch, K. Sucrose metabolism: Regulatory mechanisms and pivotal roles in sugar sensing and plant development. Curr. Opin. Plant Biol. 2004, 7, 235–246. [Google Scholar] [CrossRef] [PubMed]
- Hummel, M.; Rahmani, F.; Smeekens, S.; Hanson, J. Sucrose-mediated translational control. Ann. Bot. 2009, 104, 1–7. [Google Scholar] [CrossRef]
- Ruan, Y.L. Sucrose metabolism: Gateway to diverse carbon use and sugar signaling. Annu. Rev. Plant Biol. 2014, 65, 33–67. [Google Scholar] [CrossRef]
- Smeekens, S. Sugar-induced signal transduction in plants. Annu. Rev.Plant Physiol. Plant Mol. Biol. 2000, 51, 49–81. [Google Scholar] [CrossRef]
- Rolland, F.; Moore, B.; Sheen, J. Sugar sensing and signaling in plants. Plant Cell. 2002, 14, S185–S205. [Google Scholar] [CrossRef]
- Coleman, H.D.; Yan, J.; Mansfield, S.D. Sucrose synthase affects carbon partitioning to increase cellulose production and altered cell wall ultrastructure. Proc. Natl. Acad. Sci. USA 2009, 106, 13118–13123. [Google Scholar] [CrossRef]
- Roitsch, T.; Gonzàlez, M.C. Function and regulation of plant invertases: Sweet sensations. Trends Plant Sci. 2004, 9, 606–613. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Ruan, Y.L. Critical roles of vacuolar invertase in floral organ development and male and female fertilities are revealed through characterization of GhVIN1-RNAi cotton plants. Plant Physiol. 2016, 171, 405–423. [Google Scholar] [CrossRef] [PubMed]
- Barratt, D.H.; Derbyshire, P.; Findlay, K.; Pike, M.; Wellner, N.; Lunn, J.; Feil, R.; Simpson, C.; Maule, A.J.; Smith, A.M. Normal growth of Arabidopsis requires cytosolic invertase but not sucrose synthase. Proc. Natl. Acad. Sci. USA 2009, 106, 13124–13129. [Google Scholar] [CrossRef] [PubMed]
- Sturm, A. Invertases Primary structures, functions, and roles in plant development and sucrose partitioning. Plant Physiol. 1999, 121, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Salerno, G.L.; Curatti, L. Origin of sucrose metabolism in higher plants: When, how and why? Trends Plant Sci. 2003, 8, 63–69. [Google Scholar] [CrossRef]
- Vargas, W.; Cumino, A.; Salerno, G.L. Cyanobacterial alkaline/neutral invertases: Origin of sucrose hydrolysis in the plant cytosol? Planta 2003, 216, 951–960. [Google Scholar]
- Goetz, M.; Guivarćh, A.; Hirsche, J.; Bauerfeind, M.A.; González, M.C.; Hyun, T.K.; Eom, S.H.; Chriqui, D.; Engelke, T.; Großkinsky, D.K.; et al. Metabolic control of tobacco pollination by sugars and invertases. Plant Physiol. 2017, 173, 984–997. [Google Scholar] [CrossRef]
- Swarbrick, P.J.; Lefert, P.S.; Scholes, J.D. Metabolic consequences of susceptibility and resistance (race-specific and broad-spectrum) in barley leaves challenged with powdery mildew. Plant Cell Environ. 2006, 29, 1061–1076. [Google Scholar] [CrossRef]
- Liu, Y.H.; Ruan, Y.L. Cell wall invertase promotes fruit set under heat stress by suppressing ROS-independent cell death. Plant Physiol. 2016, 172, 163–180. [Google Scholar] [CrossRef]
- Qi, X.; Wu, Z.; Li, J.; Mo, X.; Wu, S.; Chu, J.; Wu, P. AtCYT-INV1, a neutral invertase, is involved in osmotic stress-induced inhibition on lateral root growth in Arabidopsis. Plant Mol. Biol. 2007, 64, 575–587. [Google Scholar] [CrossRef]
- Welham, T.; Pike, J.; Horst, I.; Flemetakis, E.; Katinakis, P.; Kaneko, T.; Sato, S.; Tabata, S.; Perry, J.; Parniske, M.A. A cytosolic invertase is required for normal growth and cell development in the model legume, Lotus Japonicus. J. Exp. Bot. 2009, 60, 3353–3365. [Google Scholar] [CrossRef]
- Gao, J.; van Kleeff, P.J.; Oecking, C.; Li, K.W.; Erban, A.; Kopka, J.; Hincha, D.K.; de Boer, A.H. Light modulated activity of root alkaline/neutral invertase involves the interaction with 14-3-3 proteins. Plant J. 2014, 80, 785–796. [Google Scholar] [CrossRef]
- Xie, J.; Cai, K.; Hu, H.X.; Jiang, Y.L.; Yang, F.; Hu, P.F.; Cao, D.D.; Li, W.F.; Chen, Y.; Zhou, C.Z. Structural analysis of the catalytic mechanism and substrate specificity of Anabaena alkaline invertase InvA reveals a novel glucosidase. J. Biol. Chem. 2016, 291, 25667–25677. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Hu, H.X.; Cai, K.; Yang, F.; Jiang, Y.L.; Chen, Y.; Zhou, C.Z. Structural and enzymatic analyses of Anabaena heterocyst-specific alkaline invertase InvB. FEBS Lett. 2018, 592, 1589–1601. [Google Scholar] [CrossRef] [PubMed]
- Wan, H.J.; Wu, L.; Yang, Y.; Zhou, G.; Ruan, Y.L. Evolution of sucrose metabolism: The dichotomy of invertases and beyond. Trends Plant Sci. 2018, 23, 163–177. [Google Scholar] [CrossRef] [PubMed]
- Nonis, A.; Ruperti, B.; Pierasco, A.; Canaguier, A.; Adam-Blondon, A.F.; Gaspero, G.; Vizzotto, G. Neutral invertases in grapevine and comparative analysis with Arabidopsis, poplar and rice. Planta 2008, 229, 129–142. [Google Scholar] [CrossRef]
- Shen, L.B.; Yao, Y.; He, H.; Qin, Y.L.; Liu, Z.J.; Liu, W.X.; Qi, Z.Q.; Yang, L.J.; Cao, Z.M.; Yang, Y. Genome-wide identification, expression, and functional analysis of the alkaline/neutral invertase gene family in pepper. Int. J. Mol. Sci. 2018, 19, E224. [Google Scholar] [CrossRef]
- Yao, S.G.; Kodama, R.; Wang, H.; Ichii, M.; Taketa, S.; Yoshida, H. Analysis of the rice SHORT-ROOT5 gene revealed functional diversification of plant neutral/alkaline invertase family. Plant Sci. 2009, 176, 627–634. [Google Scholar] [CrossRef]
- Liu, S.; Lan, J.; Zhou, B.; Qin, Y.; Zhou, Y.; Xiao, X.; Yang, J.; Gou, J.; Qi, J.; Huang, Y. HbNIN2, a cytosolic alkaline/neutral-invertase, is responsible for sucrose catabolism in rubber-producing laticifers of Hevea brasiliensis (para rubber tree). New Phytol. 2015, 206, 709–725. [Google Scholar] [CrossRef]
- Hall, T.A. BioEdit: A user-friendly biological sequence alignment editor and analysis program for Windows 95/98/NT. Nucl. Acids Symp. Ser. 1999, 41, 95–98. [Google Scholar]
- Larkin, M.A.; Blackshields, G.; Brown, N.P.; Chenna, R.; McGettigan, P.A.; McWilliam, H.; Valentin, F.; Wallace, I.M.; Wilm, A.; Lopez, R.; et al. Clustal W and Clustal X version 2.0. Bioinformatics 2007, 23, 2947–2948. [Google Scholar] [CrossRef]
- Kumar, S.; Stecher, G.; Tamura, K. MEGA7: Molecular evolutionary genetics analysis version 7.0 for bigger datasets. Mol. Biol. Evol. 2016, 33, 1870–1874. [Google Scholar] [CrossRef]
- Chen, C.; Chen, H.; He, Y.; Xia, R. TBtools, a Toolkit for Biologists integrating various biological data handling tools with a user-friendly interface. bioRxiv 2018, 289660. [Google Scholar]
- Liu, R.H.; Meng, J.L. MapDraw: A microsoft excel macro for drawing genetic linkage maps based on given genetic linkage data. Hereditas (Beijing) 2003, 25, 317–321. [Google Scholar]
- Gu, Z.; Cavalcanti, A.; Chen, F.C.; Bouman, P.; Li, W.H. Extent of gene duplication in the genomes of Drosophila, nematode, and yeast. Mol. Biol. Evol. 2002, 19, 256–262. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Zhang, X.; Yue, J.X.; Tian, D.; Chen, J.Q. Recent duplications dominate NBS-encoding gene expansion in two woody species. Mol. Genet. Genomics 2008, 280, 187–198. [Google Scholar] [CrossRef] [PubMed]
- Howe, E.; Holton, K.; Nair, S.; Schlauch, D.; Sinha, R.; Quackenbush, J. MeV: MultiExperiment viewer. In Biomedical Informatics for Cancer Research; Ochs, M., Casagrande, J., Davuluri, R., Eds.; Springer: Boston, MA, USA; Berlin, Germany, 2010; pp. 267–277. [Google Scholar]
- Livak, K.J.; Schmittgen, T.D. Analysis of relative gene expression data using real-time quantitative PCR and the 2 -△△ct method. Methods 2001, 25, 402–408. [Google Scholar] [CrossRef]
- Tunca, D.; Bilge, K. Automatic identification of highly conserved family regions and relationships in genome wide datasets including remote protein sequences. PLoS ONE 2013, 8, e75458. [Google Scholar]
- Murayama, S.; Handa, H. Genes for alkaline/neutral invertase in rice: alkaline/neutral invertases are located in plant mitochondria and also in plastids. Planta 2007, 225, 1193–1203. [Google Scholar] [CrossRef]
- Hirakawa, H.; Shirasawa, K.; Miyatake, K.; Nunome, T.; Negoro, S.; Ohyama, A.; Yamaguchi, H.; Sato, S.; Isobe, S.; Tabata, S.; et al. Draft genome sequence of eggplant (Solanum melongena L): The representative Solanum species indigenous to the old world. DNA Res. 2014, 21, 649–660. [Google Scholar]
- Hou, Y.B.; Lin, S.J. Distinct gene number-genome size relationships for eukaryotes and non-eukaryotes: Gene content estimation for dinoflagellate genomes. PLoS ONE 2009, 4, e6978. [Google Scholar] [CrossRef] [Green Version]
- Nakano, T.; Suzuki, K.; Fujimura, T.; Shinshi, H. Genome-wide analysis of the ERF gene family in Arabidopsis and rice. Plant Physiol. 2006, 140, 411–432. [Google Scholar] [CrossRef] [Green Version]
- Ji, X.; Van, E.W.; Van, L.A.; Cheng, S.; Bennett, J. Structure, evolution, and expression of the two invertase gene families of rice. J. Mol. Evol. 2005, 60, 615–634. [Google Scholar] [CrossRef] [PubMed]
- Zhao, T.; Rens, H.; Suzanne, D.B.; Gerco, C.A.; Burg, H.A.; Schranz, M.E. Phylogenomic synteny network analysis of MADS-Box transcription factor genes reveals lineage-specific transpositions, ancient tandem duplications, and deep positional conservation. Plant Cell 2017, 29, 1278–1292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.P.; Tang, H.B.; Jeremy, D.D.; Tan, X.; Li, J.P.; Wang, X.Y.; Lee, T.; Jin, H.Z.; Barry, M.; Guo, H.; et al. MCScanX: A toolkit for detection and evolutionary analysis of gene synteny and collinearity. Nucleic Acids Res. 2012, 40, e49. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dewey, C.N. Positional orthology: Putting genomic evolutionary relationships into context. Brief Bioinform. 2011, 12, 401–412. [Google Scholar] [CrossRef]
- Lv, J.; Havlak, P.; Putnam, N.H. Constraints on genes shape long-term conservation of 887 macro-synteny in metazoan genomes. BMC Bioinform. 2011, 12, S11. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Gerstein, M.; Snyder, M. RNA-Seq: A revolutionary tool for transcriptomics. Nat. Rev. Genet. 2009, 10, 57–63. [Google Scholar] [CrossRef]
- Lu, T.; Zhang, G.; Sun, L.; Wang, J.; Hao, F. Genome-wide identification of CBL family and expression analysis of CBLs in response to potassium deficiency in cotton. Peer J. 2017, 5, e3653. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.Y.; Li, K.; Li, H.P.; Song, C.P.; Miao, Y.C. The Glutathione peroxidase gene family in Gossypium hirsutum: Genome-wide identification, classification, gene expression and functional analysis. Sci. Rep. 2017, 7, 44743. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Lu, T.; Miao, W.; Sun, L.; Tian, M.; Wang, J.; Hao, F. Genome-wide identification of ABA receptor PYL family and expression analysis of PYLs in response to ABA and osmotic stress in Gossypium. Peer J. 2017, 5, e4126. [Google Scholar] [CrossRef] [Green Version]
- Sun, Q.; Wang, G.H.; Zhang, X.; Zhang, X.R.; Qiao, P.; Long, L.; Yuan, Y.L.; Cai, Y.F. Genome-wide identification of the TIFY gene family in three cultivated Gossypium species and the expression of JAZ genes. Sci. Rep. 2017, 7, 42418. [Google Scholar] [CrossRef]
- Liu, L.Y.; Li, N.; Yao, C.P.; Meng, S.S.; Song, C.P. Functional analysis of the ABA-responsive protein family in ABA and stress signal transduction in Arabidopsis. Chin. Sci. Bull. 2013, 58, 3721–3730. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.W.; Guo, H.L.; Li, X.; Huang, L.L.; Zhang, B.N.; Pang, X.B.; Liu, B.Y.; Ma, L.Q.; Wang, H. Two type III polyketide synthases from Polygonum cuspidatum: Gene structure, evolutionary route and metabolites. Plant Biotech. Rep. 2013, 7, 371–381. [Google Scholar] [CrossRef]
- Xia, X.; Zhang, H.M.; Offler, C.E.; Patrick, J.W. Enzymes contributing to the hydrogen peroxide signal dynamics that regulate wall labyrinth formation in transfer cells. J. Exp. Bot. 2019. [Google Scholar] [CrossRef] [PubMed]
- Akashi, H. Gene expression and molecular evolution. Curr. Opin. Genet. Dev. 2001, 11, 660–666. [Google Scholar] [CrossRef]
- Wright, S.I.; Yau, C.B.; Looseley, M.; Meyers, B.C. Effects of gene expression on molecular evolution in Arabidopsis thaliana and Arabidopsis lyrata. Mol. Biol. Evol. 2004, 21, 1719–1726. [Google Scholar] [CrossRef]
- Duret, L.; Mouchiroud, D. Determinants of substitution rates in mammalian genes, expression pattern affects selection intensity but not mutation rate. Mol. Biol. Evol. 2000, 17, 68–74. [Google Scholar] [CrossRef] [Green Version]
- Hao, F.; Zhao, S.; Dong, H.; Zhang, H.; Sun, L.; Miao, C. Nia1 and Nia2 are involved in exogenous salicylic acid-induced nitric oxide generation and stomatal closure in Arabidopsis. J. Integr. Plant Biol. 2010, 52, 298–307. [Google Scholar] [CrossRef]
- Xu, L.H.; Wang, W.Y.; Guo, J.J.; Qin, J.; Shi, D.Q.; Li, Y.L.; Xu, J. Zinc improves salt tolerance by increasing reactive oxygen species scavenging and reducing Na+ accumulation in wheat seedlings. Biol. Plant. 2014, 58, 751–757. [Google Scholar] [CrossRef]
- Wang, P.T.; Liu, H.; Hua, H.J.; Wang, L.; Song, C.P. A vacuole localized β-glucosidase contributes to drought tolerance in Arabidopsis. Chinese Sci. Bull. 2011, 56, 3538–3546. [Google Scholar] [CrossRef] [Green Version]
- Qi, J.; Song, C.P.; Wang, B.; Zhou, J.; Kangasjärvi, J.; Zhu, J.K.; Gong, Z. Reactive oxygen species signaling and stomatal movement in plant responses to drought stress and pathogen attack. J. Integr. Plant Biol. 2018, 60, 805–826. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gene Name | Sequence ID | Chromosome Location | ORF Length (bp) | Intron Number | Protein Length (AA) | MW (KDA) |
|---|---|---|---|---|---|---|
| StCIN01 | PGSC0003DMC400017548 | ch04:70796961..70817020 | 1710 | 3 | 570 | 65.2 |
| StCIN02 | PGSC0003DMC400004942 | ch01:78428855..78437323 | 1857 | 5 | 619 | 70.5 |
| StCIN03 | PGSC0003DMC400046100 | ch11:39906240..39914966 | 1923 | 5 | 641 | 72.6 |
| StCIN04 | PGSC0003DMC400016331 | ch11:13671979..13682038 | 1605 | 3 | 535 | 60.9 |
| StCIN05 | PGSC0003DMC400002890 | ch01:87159564..87165074 | 1704 | 3 | 568 | 64.9 |
| StCIN06 | PGSC0003DMC400045302 | ch06:46659148..46666904 | 1653 | 3 | 551 | 62.8 |
| StCIN07 | PGSC0003DMC400033886 | ch11:5045582..5054168 | 1965 | 5 | 655 | 73.6 |
| StCIN08 | PGSC0003DMC400023170 | ch01:37066183..37073554 | 2034 | 5 | 678 | 76.6 |
| SlCIN01 | Solyc04g081440.3.1 | ch04:65414803..65419467 | 1710 | 3 | 570 | 65.2 |
| SlCIN02 | Solyc01g100810.3.1 | ch01:90737614..90743352 | 1959 | 5 | 653 | 74.5 |
| SlCIN03 | Solyc11g067050.3.1 | ch11:52804241..52807353 | 1923 | 5 | 672 | 76.2 |
| SlCIN04 | Solyc06g065210.4.1 | ch06:40659646..40663785 | 1653 | 3 | 551 | 62.8 |
| SlCIN05 | Solyc11g020610.3.1 | ch11:11747788..11752875 | 1656 | 3 | 552 | 62.6 |
| SlCIN06 | Solyc01g111100.4.1 | ch01:97477472..97482570 | 1704 | 3 | 568 | 64.9 |
| SlCIN07 | Solyc11g007270.2.1 | ch11:1652454..1656955 | 2010 | 6 | 670 | 75.2 |
| SlCIN08 | Solyc01g058010.3.1 | ch01:64953319..64958618 | 1518 | 3 | 641 | 72.6 |
| SpeCIN01 | Sopen04g035050.1 | ch04:76047959..76052613 | 1710 | 3 | 570 | 65.2 |
| SpeCIN02 | Sopen01g044310.1 | ch01:101216445..101222621 | 1758 | 5 | 586 | 66.6 |
| SpeCIN03 | Sopen11g026760.1 | ch11:62559567..62563895 | 1923 | 5 | 641 | 72.6 |
| SpeCIN04 | Sopen06g023710.1 | ch06:51117483..51123347 | 1653 | 3 | 551 | 62.8 |
| SpeCIN05 | Sopen11g021020.1 | ch11:48314836..48320989 | 1656 | 3 | 552 | 62.7 |
| SpeCIN06 | Sopen01g023510.1 | ch01:71411679..71418653 | 1908 | 5 | 635 | 72.9 |
| SpeCIN07 | Sopen11g003160.1 | ch11:1750266..1756318 | 1965 | 5 | 655 | 73.5 |
| SpeCIN08 | Sopen01g053160.1 | ch01:108318819..108324218 | 1236 | 2 | 412 | 47.3 |
| SpiCIN01 | Sopim04g081440.0.1 | 1710 | 3 | 570 | 65.2 | |
| SpiCIN02 | Sopim01g100810.0.1 | 1959 | 5 | 653 | 74.5 | |
| SpiCIN03 | Sopim11g067050.0.1 | 1923 | 5 | 641 | 72.5 | |
| SpiCIN04 | Sopim06g065210.0.1 | 1653 | 3 | 551 | 62.8 | |
| SpiCIN05 | Sopim11g020610.0.1 | 1605 | 3 | 535 | 60.9 | |
| SpiCIN06 | Sopim01g111100.0.1 | 1815 | 5 | 605 | 69.1 | |
| SpiCIN07 | Sopim11g007270.0.1 | 1965 | 5 | 655 | 73.5 | |
| SpiCIN08 | Sopim01g058010.0.1 | 1518 | 3 | 641 | 72.6 | |
| SmCIN01 | Sme2.5_00505.1_g00017.1 | 1710 | 3 | 570 | 65.1 | |
| SmCIN02 | Sme2.5_03894.1_g00007.1 | 1980 | 5 | 660 | 75.2 | |
| SmCIN03 | Sme2.5_02773.1_g00004.1 | 1569 | 5 | 523 | 59.3 | |
| SmCIN04 | Sme2.5_05261.1_g00002.1 | 1236 | 2 | 412 | 47.3 | |
| SmCIN05 | Sme2.5_01346.1_g00001.1 | 1914 | 9 | 673 | 76.1 | |
| SmCIN06 | Sme2.5_07789.1_g00007.1 | 1908 | 7 | 636 | 72.1 | |
| SmCIN07 | Sme2.5_00977.1_g00009.1 | 1641 | 3 | 547 | 61.9 | |
| SmCIN08 | Sme2.5_24471.1_g00001.1 | 810 | 6 | 294 | 34.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, L.; Guo, Q.; Chai, S.; Cheng, Y.; Ruan, M.; Ye, Q.; Wang, R.; Yao, Z.; Zhou, G.; Li, Z.; et al. Evolutionary Conservation and Expression Patterns of Neutral/Alkaline Invertases in Solanum. Biomolecules 2019, 9, 763. https://doi.org/10.3390/biom9120763
Pan L, Guo Q, Chai S, Cheng Y, Ruan M, Ye Q, Wang R, Yao Z, Zhou G, Li Z, et al. Evolutionary Conservation and Expression Patterns of Neutral/Alkaline Invertases in Solanum. Biomolecules. 2019; 9(12):763. https://doi.org/10.3390/biom9120763
Chicago/Turabian StylePan, Luzhao, Qinwei Guo, Songlin Chai, Yuan Cheng, Meiying Ruan, Qingjing Ye, Rongqing Wang, Zhuping Yao, Guozhi Zhou, Zhimiao Li, and et al. 2019. "Evolutionary Conservation and Expression Patterns of Neutral/Alkaline Invertases in Solanum" Biomolecules 9, no. 12: 763. https://doi.org/10.3390/biom9120763