Programming Protocol-Independent Packet Processors High-Level Programming (P4HLP): Towards Unified High-Level Programming for a Commodity Programmable Switch

Abstract
:1. Introduction
- Inspired by the high-level synthesize [20] in Verilog programming and prior works [3,4,21], this paper proposes a domain-specific language (DSL), E-Domino, an enhanced version of Domino [4] that extends the grammar of Domino with loops, conditional statements, stateful atoms, and external functions. Also, E-Domino is C-like; thus, it is easy to use and lowers the learning curve.
- This paper devises P4HLPc (Programming Protocol-Independent Packet Processors High-Level Programming compiler), which automatically generates P4 programs from E-Domino programs. The generated P4 programs are eligible for programmable switches. P4HLPc removes the barrier between high-level programming and low-level primitives. P4HLPc comes with four fundamental techniques: loop unrolling, TBA (branch transform algorithm), atom template, and joint compiling.
2. Background
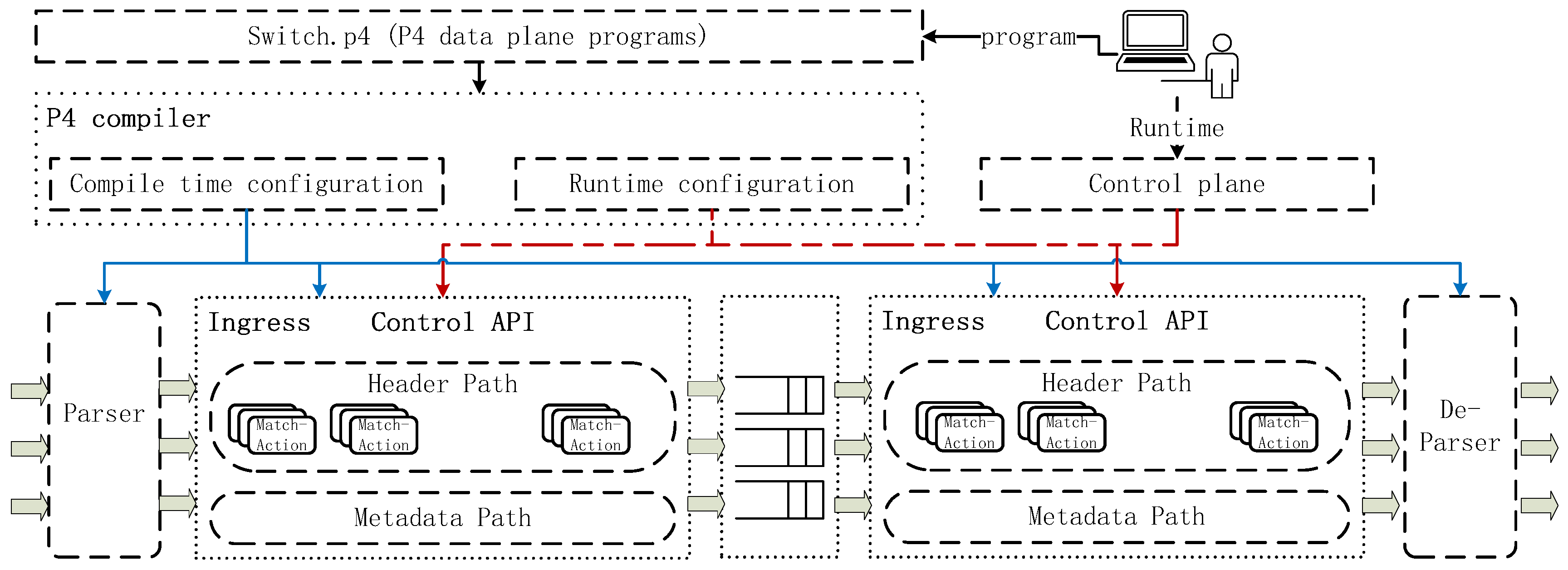
2.1. Programmable Switches
2.2. Restrictions
- Simple operations. Each stage can only perform simple operations. Only primitive arithmetic is allowed in each stage, e.g., addition and subtraction; Branching on conditions of other registers is too costly to implement; There is no loop in P4 language.
- Limited concurrent memory access. Each stage can access a few memory locations of different register arrays but only one location of a register array. For the SpaceSaving algorithm [14], finding the minimum value within an array is impossible.Also, two or more stages cannot access the same memory location. The packets are processed in different stages; read and write operations are paralleled. This restriction avoids the read after write and write after write hazards of different stages.
- Limited stages. As the number of pipeline stages increases, the latency scales linearly and causes poor performance to real-time traffic. Thus, the number of stages in a pipeline is finite.
3. E-Domino Design
3.1. E-Domino by Example
| Algorithm 1: PRECISION heavy hitter algorithm. |
 |
3.2. E-Domino Grammar
4. P4HLPc Design
4.1. Unroll the Loops
4.2. Control Flows
4.3. Stateful Processing
4.4. Stateless Processing
| Algorithm 2: Branch transform algorithm. |
 |
4.5. External Functions
4.6. Outputs
| Algorithm 3: Compiling algorithm. |
 |
5. Results
5.1. E-Domino
5.2. P4HLPc
5.3. Testbed Results
6. Related Works
7. Discussion
- P4HLP defines programs in the high-level language E-Domino, which hides the hardware details of programmable switches. This abstraction relieves programmers from concerns about hardware restrictions but may contribute to infeasible programs on real machines or programs that are low-efficiency, despite being feasible. For example, P4HLP supports the hash parallel algorithm which needs to recirculate every packet in order to update the smallest register slot. Some algorithms may require too many specific hardware resources in one stage, making the other resources in the stage unavailable for other modules. This question may account for external functions that consume match resources. P4HLP warns programmer when algorithm halves the throughput or consumes too many resources.
- P4HLP may fail to generate some programs that originally violate the RMT restrictions thus cannot be mapped to RMT architecture through optimizing techniques. We may find these algorithms and explore possible manual optimizing methods.
- P4HLPc does not optimize P4 programs. Currently we leave optimization to a P4 compiler. Future works can be done in either P4HLPc or a P4 compiler to optimize the pipeline implementation. We may combine P4HLPc with a P4 compiler to generate the optimized hardware configuration directly from E-Domino language, compared with the current two step workflow: First, compile the E-Domino program to the P4 program, and then compile the P4 to the target.
- P4HLP may support more emerging ASIC such as XPA that varies tiny in specific primitives, with minor modifications to E-Domino grammar.
8. Materials and Methods
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| P4HLP | Programming Protocol-Independent Packet Processors High-Level Programming |
| SDN | software-defined network |
| P4 | Programming Protocol-independent Packet Processors |
| P4HLP | P4 high-level programming |
| P4HLPc | P4 high-level programming compiler |
| DSL | domain-specific language |
| HH | heavy hitter |
| RAP | Randomized Admission Policy |
| PRECISION | Probabilistic RECirculation admisSION |
| APIs | Application Programming Interfaces |
| P4HLPc | Programming Protocol-Independent Packet Processors High-Level Programming compiler |
| Thrift-RPC | Thrift Remote Procedure Call |
| ALU | Arithmetic Logic Units |
| E-Domino | Enhanced version of Domino |
| BTA | branch transform algorithm |
| RMT | reconfigurable match-action tables |
| SALU | stateful arithmetic logic unit |
| ASIC | application specific integrated circuit |
| XPA | Cavium XPliant Packet Architecture |
| PISA | protocol-independent switch rchitecture |
| eFDD | extended forwarding decision diagram |
| SNAP | Stateful Network-Wide Abstractions for Packet Processing |
| RAW | Read-Add-Write |
| PRAW | Predicated Read-Add-Write |
| IfElseRAW | IfElse Read-Add-Write |
| Nested | Nested IfElse Read-Add-Write |
| PU | Paired Updates |
| PO | Paired Output |
| SCC | strongly connected component |
| DNF | disjunctive normal form |
| CC | conjunctive clauses |
| RPN | reverse Polish notation |
| CNF | conjunctive normal form |
| DC | disjunction clause |
| SRAM | Static Random Access Memory |
| TCAM | Ternary Content Addressable Memory |
| VLIW | Very long instruction word |
| FPGA | Field Programmable Gate Arrays |
| ILP | integer linear program |
| IR | intermediate representation |
| INT | in-band network telemetry |
| QSFP | quad small form-factor pluggable |
| DPDK | data plane development kit |
References
- ONF. Software-Defined Networking (SDN) Definition; ONF: Menlo Park, CA, USA, 2019. [Google Scholar]
- P4 Language Consortium. 2019. Available online: https://p4.org/ (accessed on 15 June 2019).
- Arashloo, M.T.; Koral, Y.; Greenberg, M.; Rexford, J.; Walker, D. SNAP: Stateful network-wide abstractions for packet processing. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianopolis, Brazil, 22–26 August 2016; pp. 29–43. [Google Scholar]
- Sivaraman, A.; Cheung, A.; Budiu, M.; Kim, C.; Alizadeh, M.; Balakrishnan, H.; Varghese, G.; McKeown, N.; Licking, S. Packet transactions: High-level programming for line-rate switches. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianopolis, Brazil, 22–26 August 2016; pp. 15–28. [Google Scholar]
- Barefoot. Barefoot Tofino: World’s Fastest P4-Programmable Ethernet Switch ASICs; Barefoot: Santa Clara, CA, USA, 2019. [Google Scholar]
- Intel. Intel FlexPipe; Intel: Santa Clara, CA, USA, 2019. [Google Scholar]
- Cavium. Cavium and XPliant Introduce a Fully Programmable Switch Silicon Family Scaling to 3.2 Terabits per Second; Cavium: San Jose, CA, USA, 2019. [Google Scholar]
- Cisco. 2019. Available online: https://www.cisco.com/c/en/us/products/collateral/switches/nexus-3000-series-switches/datasheet-c78-740836.html (accessed on 20 July 2019).
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming protocol-independent packet processors. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Ben-Basat, R.; Chen, X.; Einziger, G.; Rottenstreich, O. Efficient measurement on programmable switches using probabilistic recirculation. In Proceedings of the 2018 IEEE 26th International Conference on Network Protocols (ICNP), Cambridge, UK, 24–27 September 2018; pp. 313–323. [Google Scholar]
- Sivaraman, A.; Subramanian, S.; Alizadeh, M.; Chole, S.; Chuang, S.T.; Agrawal, A.; Balakrishnan, H.; Edsall, T.; Katti, S.; McKeown, N. Programmable packet scheduling at line rate. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianopolis, Brazil, 22–26 August 2016; pp. 44–57. [Google Scholar]
- Chazelle, B.; Kilian, J.; Rubinfeld, R.; Tal, A. The Bloomier filter: An efficient data structure for static support lookup tables. In Proceedings of the Fifteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, New Orleans, LA, USA, 11–14 January 2004; pp. 30–39. [Google Scholar]
- Sinha, S.; Kandula, S.; Katabi, D. Harnessing TCP’s burstiness with flowlet switching. In Proceedings of the 3rd ACM Workshop on Hot Topics in Networks (Hotnets-III), San Diego, CA, USA, 15–16 November 2004. [Google Scholar]
- Metwally, A.; Agrawal, D.; El Abbadi, A. Efficient computation of frequent and top-k elements in data streams. In Proceedings of the International Conference on Database Theory, Edinburgh, UK, 5–7 January 2005; pp. 398–412. [Google Scholar]
- Sivaraman, V.; Narayana, S.; Rottenstreich, O.; Muthukrishnan, S.; Rexford, J. Smoking out the heavy-hitter flows with hashpipe. arXiv 2016, arXiv:1611.04825. [Google Scholar]
- Basat, R.B.; Einziger, G.; Friedman, R.; Kassner, Y. Randomized admission policy for efficient top-k and frequency estimation. In Proceedings of the IEEE INFOCOM 2017-IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Yang, T.; Jiang, J.; Liu, P.; Huang, Q.; Gong, J.; Zhou, Y.; Miao, R.; Li, X.; Uhlig, S. Elastic sketch: Adaptive and fast network-wide measurements. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 561–575. [Google Scholar]
- Huang, Q.; Lee, P.P.; Bao, Y. Sketchlearn: Relieving user burdens in approximate measurement with automated statistical inference. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 576–590. [Google Scholar]
- P4 Group. Specification for the P4Runtime Control-Plane API; GitHub: San Francisco, CA, USA, 2019. [Google Scholar]
- Xilinx. Vivado Design Hub—High-Level Synthesis (C Based); Xilinx: San Jose, CA, USA, 2019. [Google Scholar]
- Shahbaz, M.; Feamster, N. The case for an intermediate representation for programmable data planes. In Proceedings of the 1st ACM SIGCOMM Symposium on Software Defined Networking Research, Santa Clara, CA, USA, 17–18 June 2015; p. 3. [Google Scholar]
- Bosshart, P.; Gibb, G.; Kim, H.S.; Varghese, G.; McKeown, N.; Izzard, M.; Mujica, F.; Horowitz, M. Forwarding metamorphosis: Fast programmable match-action processing in hardware for SDN. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 99–110. [Google Scholar] [CrossRef]
- Cisco. Cisco Data Center Switches; Cisco: San Jose, CA, USA, 2019. [Google Scholar]
- HUAWEI. HUAWEI Data Center Switches; HUAWEI: Shenzhen, China, 2019. [Google Scholar]
- P4 Language Consortium. P4-14 Specification; ONF: Menlo Park, CA, USA, 2019. [Google Scholar]
- P4 Group. P4 Prototype Compiler; GitHub: San Francisco, CA, USA, 2019. [Google Scholar]
- ONF. P4 and P4Runtime Technical Introduction and Use Cases; ONF: Menlo Park, CA, USA, 2019. [Google Scholar]
- P4 Group. Packet Test Framework; GitHub: San Francisco, CA, USA, 2019. [Google Scholar]
- Apache. Apache Thrift; Apache: Wakefield, MA, USA, 2019. [Google Scholar]
- Hang, Z.; Shi, Y.; Wen, M.; Quan, W.; Zhang, C. SWAP: A sliding window algorithm for in-network packet measurement. In Proceedings of the 3rd International Conference on High Performance Compilation, Computing and Communications, Xi’an, China, 8–10 March 2019; pp. 84–89. [Google Scholar]
- Wikipedia DNF. Disjunctive Normal Form. 2019. Available online: https://en.wikipedia.org/wiki/Disjunctive_normal_form (accessed on 20 July 2019).
- Wikipedia CNF. Conjunctive Normal Form. 2019. Available online: https://en.wikipedia.org/wiki/Conjunctive_normal_form (accessed on 20 July 2019).
- Wikipedia RPN. Reverse Polish Notation. 2019. Available online: https://en.wikipedia.org/wiki/Reverse_Polish_notation (accessed on 20 July 2019).
- Kohler, E.; Morris, R.; Chen, B.; Jannotti, J.; Kaashoek, M.F. The Click modular router. ACM Trans. Comput. Syst. (TOCS) 2000, 18, 263–297. [Google Scholar] [CrossRef]
- Jose, L.; Yan, L.; Varghese, G.; McKeown, N. Compiling packet programs to reconfigurable switches. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI 15), Oakland, CA USA, 4–6 May 2015; pp. 103–115. [Google Scholar]
- Zheng, P.; Benson, T.; Hu, C. P4visor: Lightweight virtualization and composition primitives for building and testing modular programs. In Proceedings of the 14th International Conference on Emerging Networking EXperiments and Technologies, Heraklion, Greece, 4–7 December 2018; pp. 98–111. [Google Scholar]
- Hang, Z. P4HLP Repository; GitHub: San Francisco, CA, USA, 2019. [Google Scholar]
- Emmerich, P.; Gallenmüller, S.; Raumer, D.; Wohlfart, F.; Carle, G. Moongen: A scriptable high-speed packet generator. In Proceedings of the 2015 Internet Measurement Conference, Tokyo, Japan, 28–30 October 2015; pp. 275–287. [Google Scholar]
- Libmoon. Libmoonm, a Library for Fast and Flexible Packet Processing with DPDK and LuaJIT; GitHub: San Francisco, CA, USA, 2019. [Google Scholar]
- DPDK Project. DPDK, the Data Plane Development Kit that Consists of Libraries to Accelerate Packet Processing Workloads Running on a Wide Variety of CPU Architectures; DPDK: Dover, DE, USA, 2019. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Derivations | Literals |
|---|---|
| Entry No. | Match Field | Action Parameter |
|---|---|---|
| 1 | (0x00 & 0xfe) | 2 |
| 2 | (0x00 & 0xfc) | 4 |
| 3 | (0x00 & 0xf8) | 8 |
| 4 | (0x00 & 0xf0) | 16 |
| 5 | (0x00 & 0xe0) | 32 |
| 6 | (0x00 & 0xc0) | 64 |
| 7 | (0x00 & 0x80) | 128 |
| 8 | (0x00 & 0x00) | 256 |
| Type | Description | Resources |
|---|---|---|
| Read/Write | Read a single register to field/ write a field to a single register. | ALU_lo_1/ Update_lo_1_value |
| RAW | Add field to a single register. | ALU_lo_1, Update_lo_1_value |
| PRAW | Predicated RAW | ALU_lo_1, Condition_lo Update_lo_1, Update_lo_1_value |
| IfElseRAW | Two PRAWs, each conditional RAW according to predication is true or false. | Low Slice, Update_lo_value |
| Nested | Two PRAWs, each conditional RAW according to combination of two predications. | Condition_hi Low Slice, Update_lo_value |
| PU | Two Nested, and updates two registers. | entire black box |
| PO | Same as PU, but write two fields | entire black box, Low Slice of another black box |
| Method | Type | E-Domino Program | Tofino Program | Delay |
|---|---|---|---|---|
| Tables | bool_op | if(ethernet.dst == 0xC0A80164 and ethernet.src== 0xC0A80165) | if(ethernet.dst == 0xC0A80164) if(ethernet.src== 0xC0A80165) | 0 |
| if(ethernet.dst == 0xC0A80164 or ethernet.src== 0xC0A80165) | reads{ethernet.dst: ternary; ethernet.src: ternary;} | 0 | ||
| rel_op | if (ipv4.ttl < metadata.ttl) | reads{ ipv4.ttl: exact; metadata.ttl: exact;} | 0 | |
| if (ipv4.ttl >= metadata.ttl) | 0 | |||
| if (ipv4.ttl == metadata.ttl) | 0 | |||
| primi- tives | rel_op | if () | subtract(); if( & 0x8000 !=0) | 1 |
| if () | substrct(); if( & 0x8000 ==0) | 1 | ||
| if () | xor(); if(==0) | 1 | ||
| bin_op | if ( rel_op value) | subtract(); if( rel_op ); | 2 | |
| if (⌃ rel_op value) | bitxor(); if ( rel_op ) | 2 | ||
| if ( rel_op ) | shift_left(); if ( rel_op ) | 2 | ||
| un_op | if ( rel_op value) | subtract(); if( rel_op value); | 2 | |
| if (⌃ rel_op value) | bitxor(); if ( rel_op value) | 2 |
| Algorithm | Application | Atom | # of Stages, # of Atoms | E-Domino LOC | P4 LOC | Time (s) |
|---|---|---|---|---|---|---|
| Bloom filter | Distinct flows | Read/Write | 1, 3 | 14 | 116 | 0.21 |
| Flowlet | Flowlet Domain name system tunnel detection Time to live change tracking Phishing/spam detection | PU | 1, 1 | 15 | 102 | 0.18 |
| Space Saving | Heavy hitter detection Per-flow Frequency Cardinality estimation | - | not feasible | |||
| HashPipe | PO | 4, 8 | 25 | 371 | 0.33 | |
| RAP | IfElseRAW | 4, 8 | 60 | 365 | 0.39 | |
| PRECISION | IfElseRAW | 4, 8 | 60 | 365 | 0.39 | |
| Elastic sketch | Per-flow frequency Heavy hitter detection Heavy changers Cardinality estimation Frequency distribution and entropy | Nested | 4, 4 | 44 | 241 | 0.42 |
| SketchLearn | PRAW | 8, 32 | 16 | 767 | 0.72 | |
| No. | Phase | Cold Start | Policy Change | Topo Change | |
|---|---|---|---|---|---|
| 1 | unroll loops | ✓ | ✓ | × | |
| 2 | generate eFDDs | ✓ | ✓ | × | |
| 3 | stateful processing | ✓ | ✓ | × | |
| 4 | stateless processing | ✓ | ✓ | × | |
| 5 | generate SCC | ✓ | ✓ | × | |
| 6 | generate exernal functions | tables | ✓ | × | × |
| entries | ✓ | ✓ | × | ||
| 7 | routing | tables | ✓ | × | × |
| entries | ✓ | × | ✓ | ||
| Resource | Base Line | Bloom Filter | Flowlet | HashPipe | RAP | PRECISION | Elestic Sketch | SketchLearn |
|---|---|---|---|---|---|---|---|---|
| Match Crossbar | 50.13% | 2.84% | 1.47% | 17.33% | 12.60% | 11.02% | 5.87% | 7.28% |
| Hash Bits | 32.35% | 14.21% | 2.38% | 37.25% | 29.76% | 27.30% | 2.32% | 7.14% |
| SRAM | 29.79% | 5.60% | 2.26% | 46.67% | 35.41% | 34.68% | 12.51% | 50.33% |
| TCAM | 28.47% | 0% | 0% | 2.84% | 38.62% | 37.83% | 0% | 1.31% |
| VLIW Actions | 34.64% | 3.48% | 1.67% | 13.96% | 9.56% | 7.59% | 5.48% | 11.31% |
| Stateful ALUs | 15.63% | 0.06% | 0.04% | 16.67% | 16.67% | 16.67% | 75.00% | 66.67% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hang, Z.; Wen, M.; Shi, Y.; Zhang, C. Programming Protocol-Independent Packet Processors High-Level Programming (P4HLP): Towards Unified High-Level Programming for a Commodity Programmable Switch. Electronics 2019, 8, 958. https://doi.org/10.3390/electronics8090958
Hang Z, Wen M, Shi Y, Zhang C. Programming Protocol-Independent Packet Processors High-Level Programming (P4HLP): Towards Unified High-Level Programming for a Commodity Programmable Switch. Electronics. 2019; 8(9):958. https://doi.org/10.3390/electronics8090958
Chicago/Turabian StyleHang, Zijun, Mei Wen, Yang Shi, and Chunyuan Zhang. 2019. "Programming Protocol-Independent Packet Processors High-Level Programming (P4HLP): Towards Unified High-Level Programming for a Commodity Programmable Switch" Electronics 8, no. 9: 958. https://doi.org/10.3390/electronics8090958