Layer-Edge Patterns Exploration and Presentation in Multiplex Networks: From Detail to Overview via Selections and Aggregations


Abstract
:1. Introduction
- An interactive exploration and analysis model that tightly couples topological structure and high-level patterns;
- a multi-force directed method specially for multiplex networks visualization, which realizes the balanced layout of nodes in multi-layer topology by considering the attraction from the center of the community and the cross-layer attraction from the counterpart node, and then the similar communities between layers can be identified quickly;
- two kinds of high-level patterns, of which the visual representations are, respectively, designed by a metaphor familiar to users—that is, the similar pattern representation based on the area-proportional Venn diagrams and the interaction pattern representation based on the directed arrow, which are convenient for non-expert users to obtain the abstract of interested regions;
- views association, enabling users to gain insights through the creation of selection of interest (layer, sub-graph, region, etc.), and produce high-level infographic-style views simultaneously.
2. Related Work
3. Theory and Methods
3.1. Model of Multiplex Networks
3.2. Tasks for Multiplex Networks Visual Analysis
3.3. Analysis Model from Detial to Overview
- Multi-style interaction methods—the user can directly operate the visual element and select the layer (or group) of interest;
- the ability to view detailed information and aggregated high-level patterns simultaneously with a familiar metaphor.
3.4. Topological Structure View
3.4.1. Community Detection
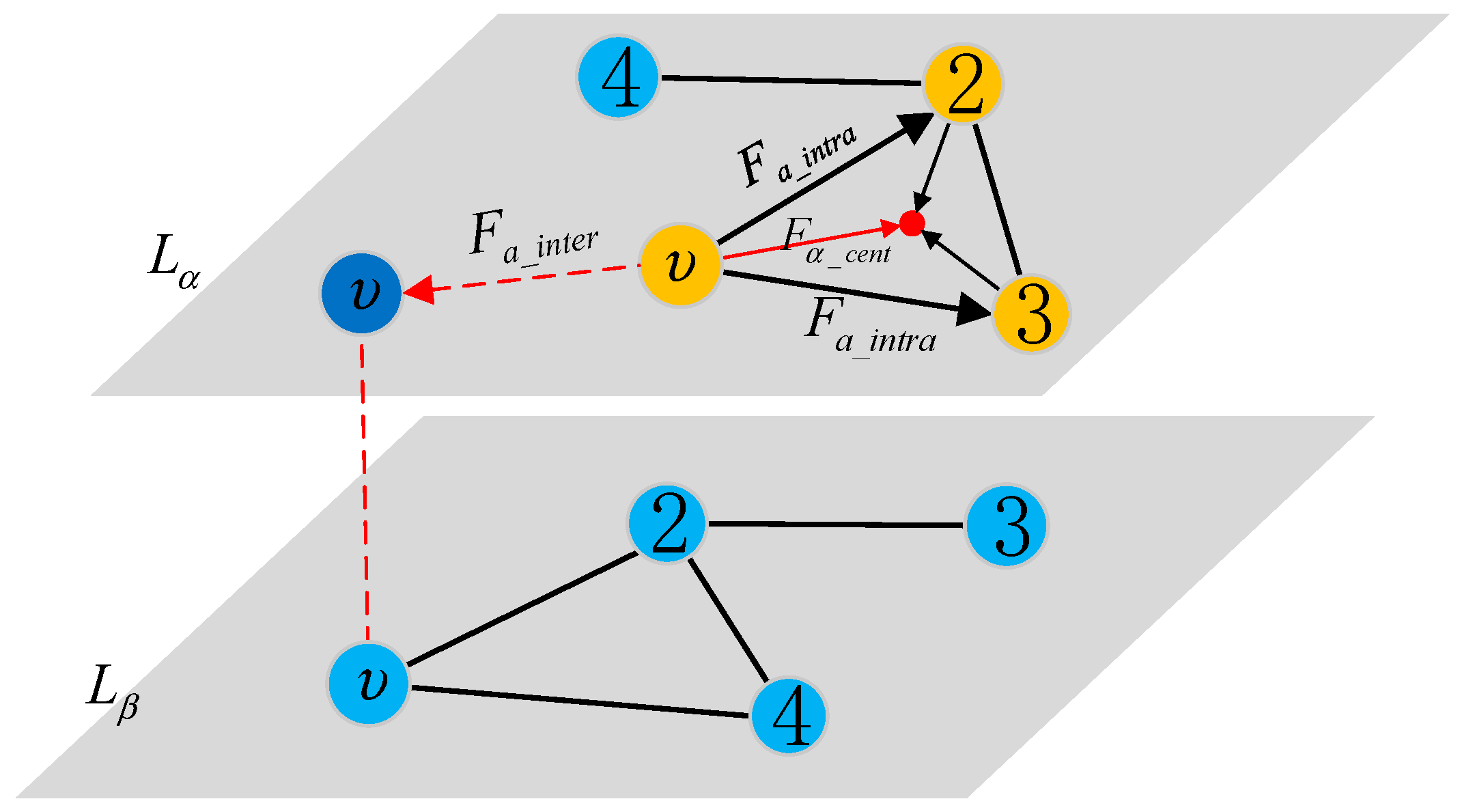
3.4.2. Multi-Force Directed Model
3.4.3. Iterative Algorithm Based on Simulated Annealing
3.5. High-Level Infographic-Style View
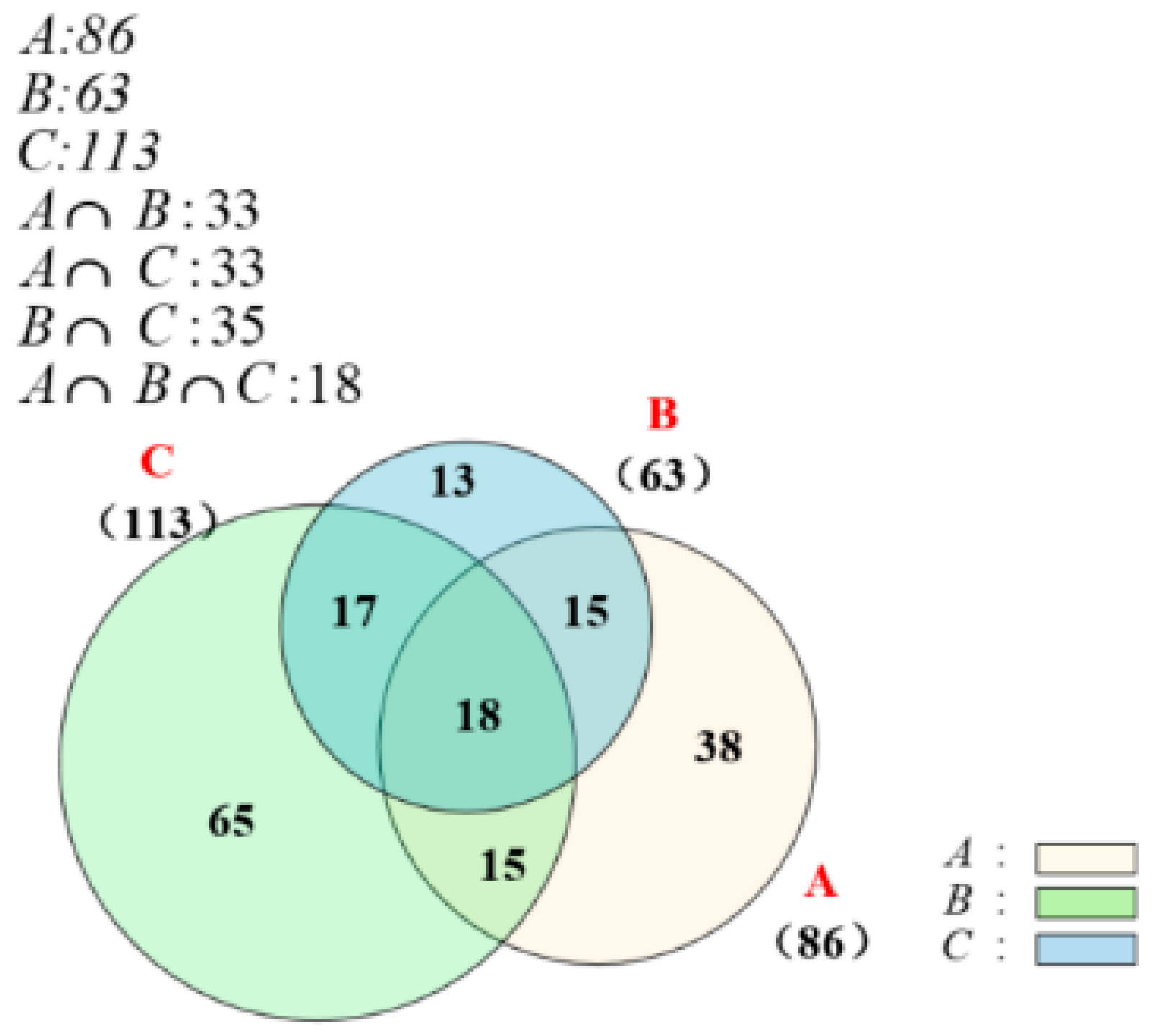
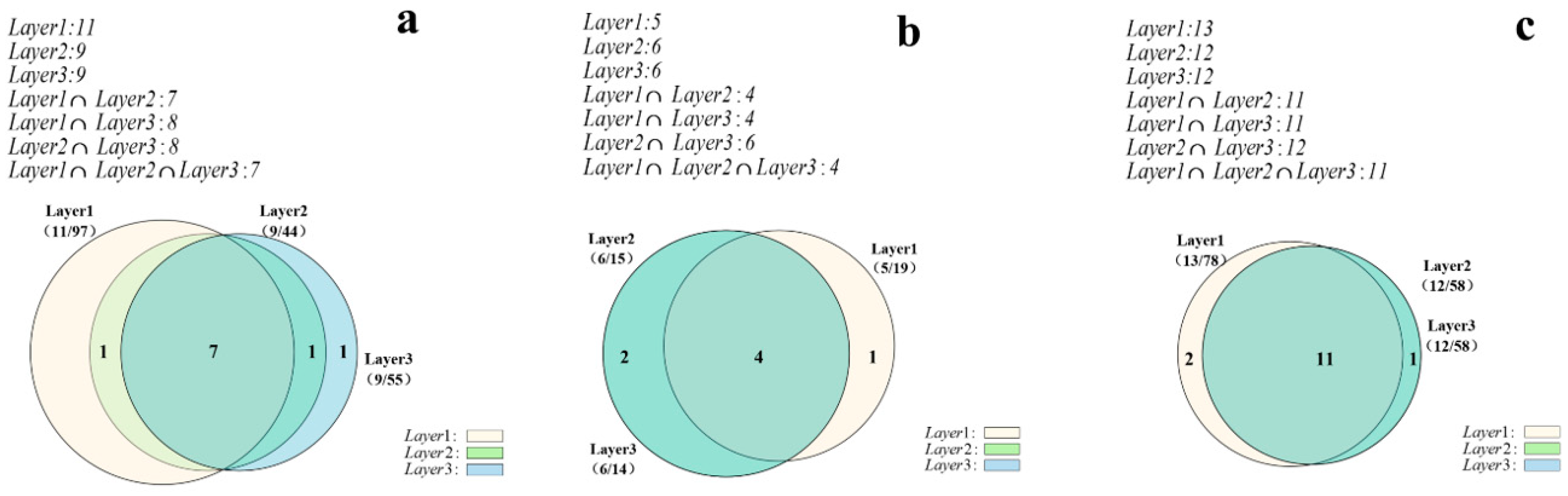
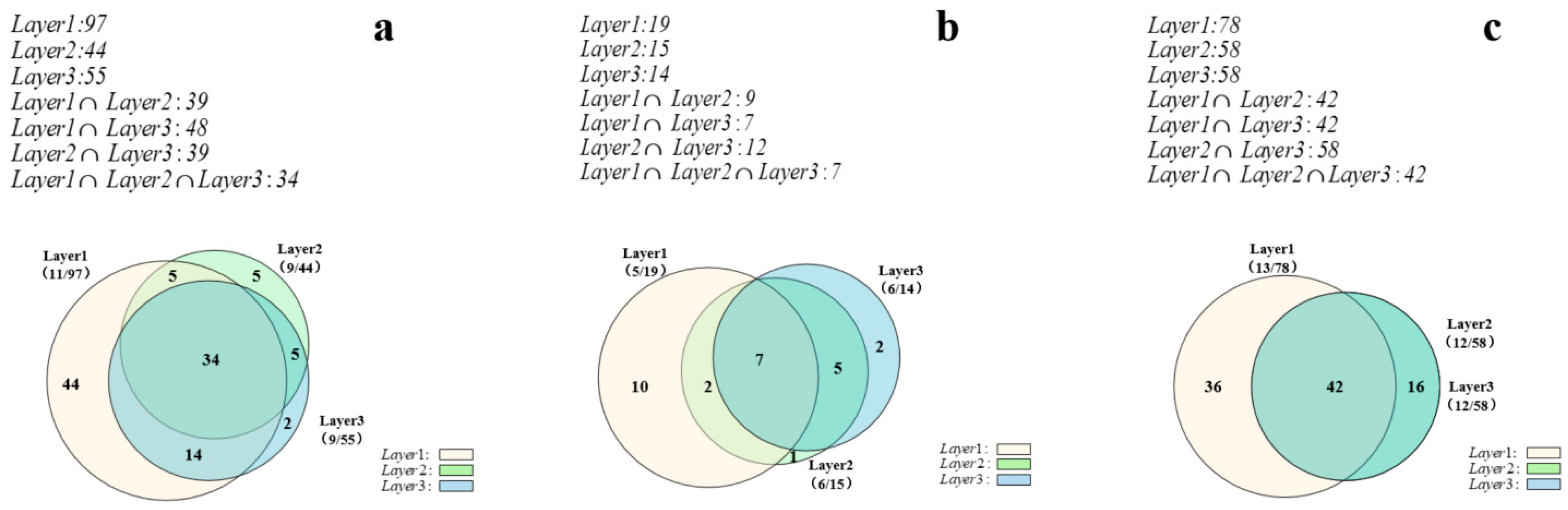
3.5.1. Similarity Pattern Representation
- Step1:
- Count the coordinates of the intersection of N rings and sort them clockwise to determine the centroid coordinates of the overlapping polygons .
- Step2:
- Calculate the size of the convex N-gon, , i.e., the sum of the sizes of N triangles by the formula (12) according to the centroid coordinates and the coordinates of two adjacent intersection points.
- Step3:
- Calculate the size of each arc region with the formula (13) by selecting the angles between two adjacent intersection points. Then the sum of the sizes of the N arc regions can be calculated.
- Step4:
- Calculate the sizes of N ring overlap areas by Formula (11).
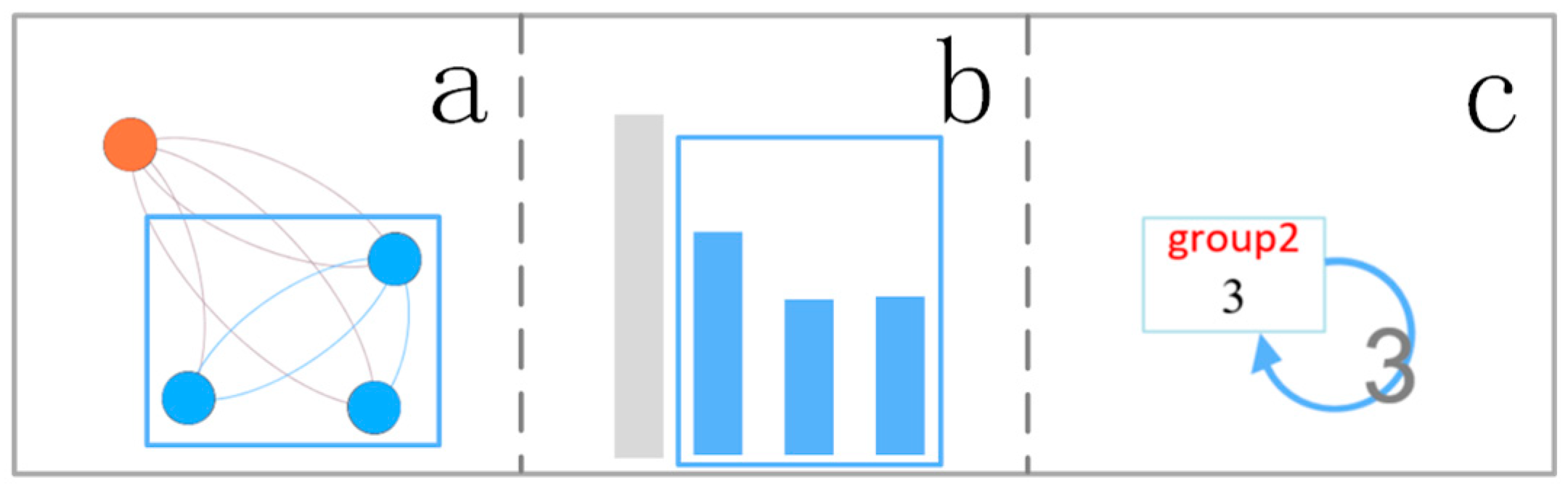
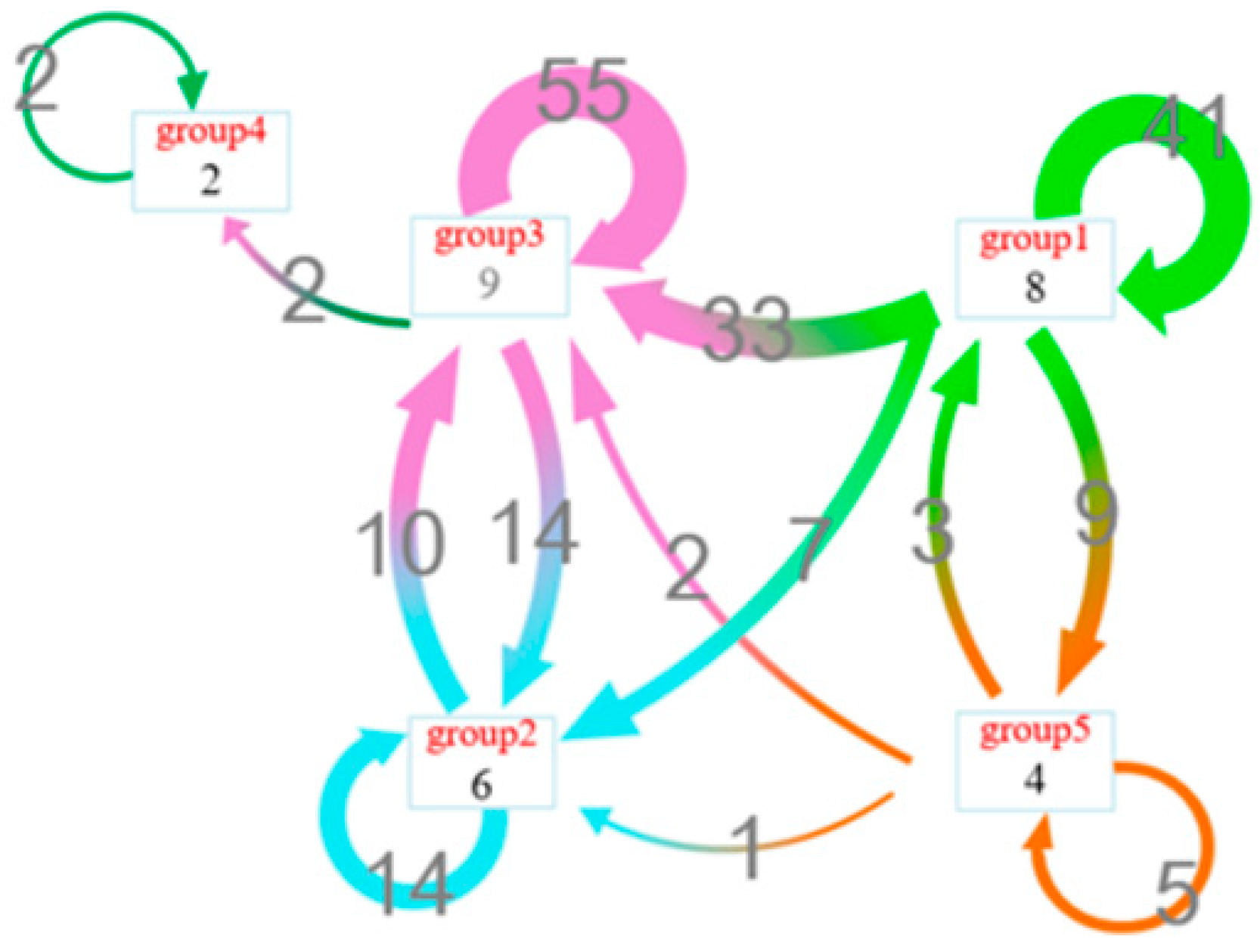
3.5.2. Interaction Pattern Representation
- Each box container represents a selected area which is coded in the same color as the selection rectangular. Inside of the container, as shown in Figure 3b, is the node degree distribution of each area. The user can click on the box container to zoom in and display the internal information of the container. The histogram of the degree distribution of the internal nodes in each area is shown in Figure 3c. The containers can also display information such as node overlap degree, node activation degree, and node importance ranking in other forms of bubble chart, histogram, or ring chart.
- All the intra-edges of the area are displayed as a self-circulating directed arrow; all the inter-edges are shown as a directed arrow between the box containers and coded with a gradient of the colors of the starting area and the target area. The width of the arrow is proportional to the sum of the number of edges associated with the selected area.
3.6. Interaction and Views Association
3.6.1. Sharing of Underlying Data
3.6.2. Filtering by Node Attribute
4. Case Study
4.1. Multiplex Networks Data
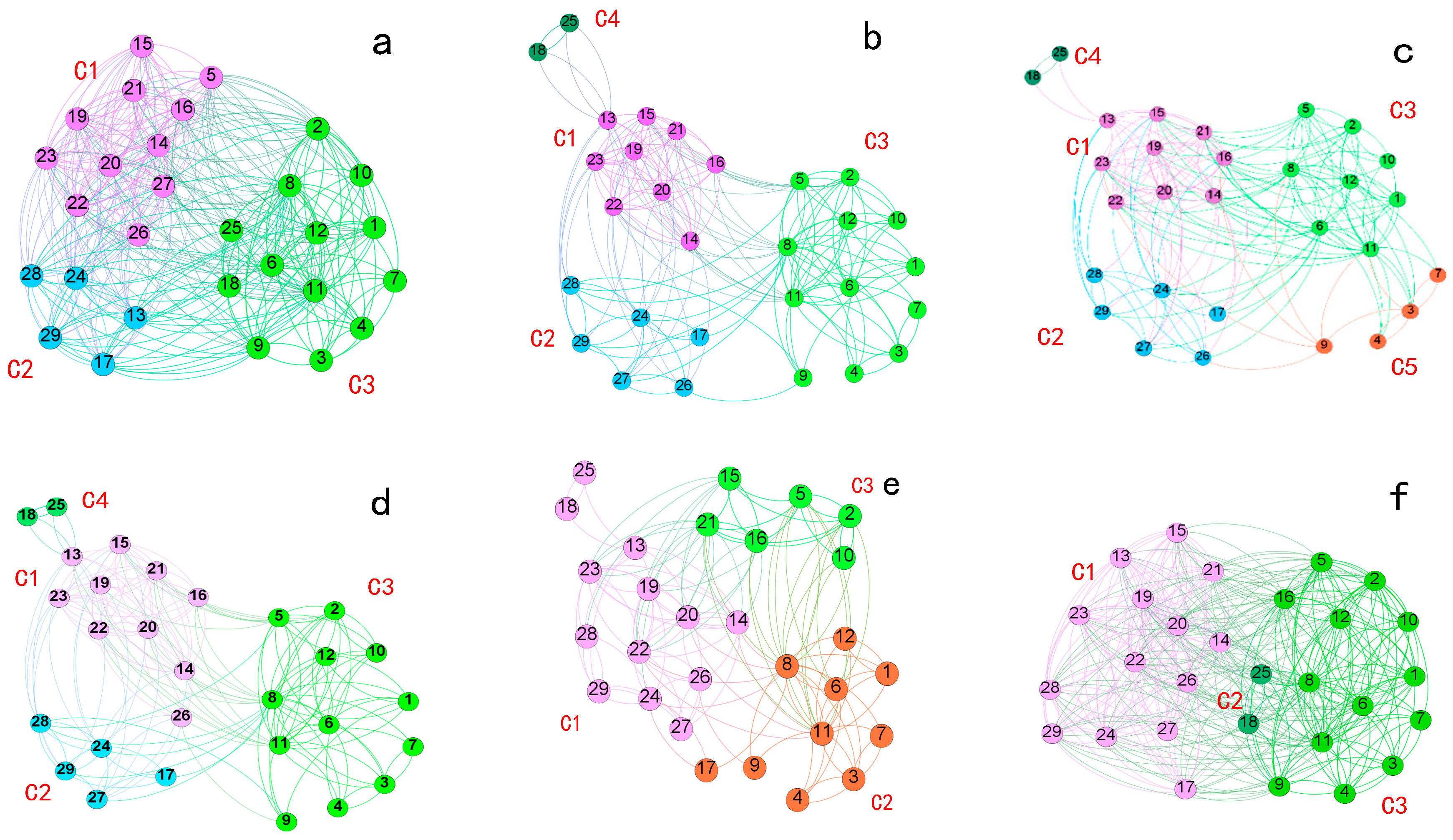
4.2. TopolView Analysis
- Displaying the details of the nodes and edges in the network layer through the node-link diagrams, revealing the community composition in every network layer.
- Assisting users in perceiving the difference of the inter-layer structure on the intuitive, evaluating and predicting the distribution of the nodes and the edges in network, which facilitate users to find the layer (or sub-graph, region, etc.) and nodes of interest to further explore their interests.
- Supporting selection between multiple layout algorithms, which can be used to carry out deeper research on node automatic layout algorithm for multiplex network.
4.3. Similarity Pattern Analysis
4.4. Interaction Pattern Analysis
5. Discussions and Limitations
5.1. Discussions
5.2. Limitations and Future Directions
- This paper mainly provides an automatic layout method specially for multiplex networks visualization. However, the computational complexity of repulsion calculation is still large, and it is time-consuming to lay out large-scale nodes. The novel layout methods should take quadtrees, multidimensional scaling analysis, and many other methods into consideration to speed up node position calculation. Some other kinds of community detection algorithms can also be applied to effectively support the comparison analysis of the multi-layer structure.
- In terms of similarity pattern representation, the area-proportional circular Venn diagrams do better in visual perception. However, when the number of input sets is larger than six, the layout and size calculations will not be accurate. It is not suitable for the representation of the relationship between a larger number of sets. Since the specific analysis focuses more on the two- or three-layer comparison, the method in this paper basically meets the requirements.
- This article provides the necessary selection and filtering methods to basically satisfy users’ freedom to select the node elements of the specified area. However, the region selection requires community partitioning and force-directed layout in advance to cluster nodes that belong to a same community. Considering the scalability of the system, there is still a need for multiple styles of interaction to support freewill exploration.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dickison, M.E.; Magnani, M.; Rossi, L. Multilayer Social Networks, 1st ed.; Cambridge University Press: Cambridge, UK, 2016; pp. 5–10. [Google Scholar]
- Cardillo, A.; Zanin, M.; Gómez-Gardeñes, J.; Romance, M.; García, A.J.; Boccaletti, S. Modeling the multi-layer nature of the European air transport network: Resilience and passengers re-scheduling under random failures. Eur. Phys. J. Spec. Top. 2013, 215, 23–33. [Google Scholar] [CrossRef]
- Domenico, M.D.; Nicosia, V.; Arenas, A.; Latora, V. Structural reducibility of multilayer networks. Nat. Commun. 2015, 6, 6864. [Google Scholar] [CrossRef] [PubMed]
- Kivelä, M.; Arenas, A.; BartheIemy, M.; Gleeson, J.P.; Moreno, Y.; Porter, M.A. Multilayer networks. J. Complex Netw. 2014, 2, 203–271. [Google Scholar] [CrossRef]
- Boccaletti, S.; Bianconi, G.; Criado, R. The structure and dynamics of multilayer networks. Phys. Rep. 2014, 544, 1–122. [Google Scholar] [CrossRef]
- Rossi, L.; Magnani, M. Towards effective visual analytics on multiplex and multilayer networks. Chaos Solitons Fractals 2015, 72, 68–76. [Google Scholar] [CrossRef]
- Piskorec, M.; Sluban, B.; Smuc, T. MultiNets: Web-Based Multilayer Network Visualization. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Part III; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Bourqui, R.; Ienco, D.; Sallaberry, A.; Poncelet, P. Multilayer Graph Edge Bundling. In Proceedings of the IEEE Pacific Visualization Symposium, Taipei, Taiwan, 19–22 April 2016; pp. 184–188. [Google Scholar]
- Domenico, M.D.; Porter, M.A.; Arenas, A. MuxViz: A tool for multilayer analysis and visualization of networks. J. Complex Netw. 2015, 3, 159–176. [Google Scholar] [CrossRef]
- Redondo, D.; Sallaberry, A.; Poncelet, P.; Zaidi, F.; Ienco, D. Layer-centered approach for multigraphs visualization. In Proceedings of the IEEE International Conference on Information Visualisation, Barcelona, Spain, 22–24 July 2015; pp. 50–55. [Google Scholar]
- Herman, I.; Melançon, G.; Marshall, M.S. Graph visualization and navigation in information visualization: A survey. IEEE Trans. Vis. Comput. Graph. 2000, 6, 24–43. [Google Scholar] [CrossRef]
- Kamada, T.; Kawai, S. An algorithm for drawing general undirected graphs. Inf. Process. Lett. 1989, 31, 7–15. [Google Scholar] [CrossRef]
- Fruchterman, T.M.J.; Reingold, E.M. Graph drawing by force-directed placement. Softw. Pract. Exp. 1991, 21, 1129–1164. [Google Scholar] [CrossRef]
- Zhao, R.Q.; Wu, Y.; Chen, X. An Algorithm for Large-scale Social Network Community Detection and Visualization. J. Comput.-Aided Des. Comput. Graph. 2017, 29, 328–336. [Google Scholar]
- Shneiderman, B. The eyes have it: A task by data type taxonomy for information visualizations. In Proceedings of the IEEE Symposium on Visual Languages, Washington, DC, USA, 3–6 September 1996; pp. 336–343. [Google Scholar]
- Ham, F.V.; Perer, A. Search, Show Context, Expand on Demand: Supporting Large Graph Exploration with Degree-of-Interest. IEEE Trans. Vis. Comput. Graph. 2009, 15, 953–960. [Google Scholar]
- Lam, F.; Lalansingh, C.M.; Babaran, H.E. VennDiagramWeb: A web application for the generation of highly customizable Venn and Euler diagrams. BMC Bioinform. 2016, 17, 401–409. [Google Scholar] [CrossRef] [PubMed]
- Micallef, L. Visualizing Set Relations and Cardinalities Using Venn and Euler Diagrams; University of Kent: Canterbury, UK, 2013; pp. 5–10. [Google Scholar]
- Pirooznia, M.; Nagarajan, V.; Deng, Y. GeneVenn—A web application for comparing gene lists using Venn diagrams. Bioinformation 2007, 1, 420–422. [Google Scholar] [CrossRef]
- Heberle, H.; Meirelles, G.V.; da Silva, F.R.; Telles, G.P.; Minghim, R. InteractiVenn: A web-based tool for the analysis of sets through Venn diagrams. BMC Bioinform. 2015, 16, 169–176. [Google Scholar] [CrossRef] [PubMed]
- Kestler, H.A.; André, M.; Gress, T.M.; Buchholz, M. Generalized Venn diagrams: A new method of visualizing complex genetic set relations. Bioinformatics 2005, 21, 1592–1595. [Google Scholar] [CrossRef] [PubMed]
- Wilkinson, L. Exact and approximate area-proportional circular Venn and Euler diagrams. IEEE Trans. Vis. Comput. Graph. 2011, 18, 321–331. [Google Scholar] [CrossRef]
- Gurarie, E.; Andrews, R.D.; Laidre, K.L. A novel method for identifying behavioural changes in animal movement data. Ecol. Lett. 2010, 12, 395–408. [Google Scholar] [CrossRef]
- Zeng, W.; Fu, C.W.; Arisona, S.M.; Qu, H. Visualizing Interchange Patterns in Massive Movement Data. Comput. Graph. Forum 2013, 32, 271–280. [Google Scholar] [CrossRef]
- Liu, S.; Floriani, L.D. Multivariate Network Exploration and Presentations. Computer 2015, 48, 6. [Google Scholar] [CrossRef]
- Brehmer, M.; Munzner, T. A multi-level typology of abstract visualization tasks. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2376–2385. [Google Scholar] [CrossRef]
- Saket, B.; Simonetto, P.; Kobourov, S. Group-level graph visualization taxonomy. arXiv, 2014; arXiv:1403.7421. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. 2008, 10, 155–168. [Google Scholar] [CrossRef]
- Gach, O.; Hao, J.K. Improving the Louvain Algorithm for Community Detection with Modularity Maximization. In Proceedings of the International Conference on Artificial Evolution (Evolution Artificielle), Bordeaux, France, 21–23 October 2013; Springer International Publishing: Cham, Switzerland, 2013; pp. 145–156. [Google Scholar]
- Fortunato, S.; Barthelemy, M. Resolution limit in community detection. Proc. Natl. Acad. Sci. USA 2007, 104, 36–41. [Google Scholar] [CrossRef] [PubMed]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An open source software or exploring and manipulating networks. In Proceedings of the International AAAI Conference on Weblogs and Social Media, San Jose, CA, USA, 17–20 May 2009; pp. 361–362. [Google Scholar]
- Conde-Céspedes, P.; Marcotorchino, J.F.; Viennet, E. Comparison of Linear Modularization Criteria Using the Relational Formalism, an Approach to Easily Identify Resolution Limit. In Advances in Knowledge Discovery and Management; Springer International Publishing: Cham, Switzerland, 2017; pp. 101–120. [Google Scholar]
- Campigotto, R.; Céspedes, P.C.; Guillaume, J.L. A generalized and adaptive method for community detection. arXiv, 2014; arXiv:1406.2518. [Google Scholar]
- Nelder, J.A.; Mead, R. A simplex method for function minimization. Commput. J. 1965, 7, 308–313. [Google Scholar] [CrossRef]
- Vickers, M.; Chan, S. Representing Classroom Social Structure; Victoria Institute of Secondary Education: Melbourne, Australia, 1981; Available online: http://deim.urv.cat/~alephsys/data.html (accessed on 20 December 2018).
- Chen, C.H.; Härdle, W.; Unwin, A. Handbook of Data Visualization (Springer Handbooks of Computational Statistics); Springer: Berlin/Heidelberg, Germany, 2008; pp. 217–241. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task 1: Single-Layer Analysis |
| Task 1.1: Structure component in terms of group of a given layer (Layer-Group Level) |
| Task 1.1.1: Number and distribution of nodes in groups of a given layer (Group-Node Level) |
| Task 1.1.2: Number and distribution of edges in groups of a given layer (Group -Edge Level) |
| Task 1.2: Number of nodes of a given layer (Layer-Node Level) |
| Task 1.3: Number of edges of a given layer (Layer-Edge Level) |
| Task 2: Multi-Layer Analysis |
| Task 2.1: Comparison between two or more given layers (Layer Level) |
| Task 2.1.1: Comparison in terms of group between two or more given layers (Layer-Group Level) |
| Task 2.1.2: Comparison in terms of the number and distribution of overlap nodes between two or more given layer (Layer-Node Level) |
| Task 2.1.3: Comparison in terms of the number and distribution of overlap edges between two or more given layer (Layer-Edge Level) |
| Task 2.2: Comparison in given groups between two or more given layers (Group Level) |
| Task 2.2.1: Comparison in terms of number and distribution of overlap nodes in given groups between two or more given layers (Group-Node Level) |
| Task 2.2.2: Comparison in terms of number and distribution of overlap edges in given groups between two or more given layers (Group-Edge Level) |
| Name | Single-Layer Visual Analysis | Multi-Layer Visual Analysis | ||||
|---|---|---|---|---|---|---|
| LA | HIP | Interaction | LA | HIP | Interaction | |
| Gephi [36] | ★★★★★ | ★★★★ | ★★★★★ | ★ | ★ | ★ |
| Multired [3] | ★★★ | ★ | ★ | ★★ | ★ | ★ |
| Multinets [7] | ★★★ | ★ | ★ | ★★ | ★ | ★ |
| MuxViz9 | ★★★ | ★★★ | ★★★ | ★★ | ★★ | ★★★ |
| Prototype proposed | ★★★ | ★★★ | ★★★★ | ★★★ | ★★★ | ★★★ |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Wu, L.; Yu, S.; Li, K. Layer-Edge Patterns Exploration and Presentation in Multiplex Networks: From Detail to Overview via Selections and Aggregations. Electronics 2019, 8, 387. https://doi.org/10.3390/electronics8040387
Zhang X, Wu L, Yu S, Li K. Layer-Edge Patterns Exploration and Presentation in Multiplex Networks: From Detail to Overview via Selections and Aggregations. Electronics. 2019; 8(4):387. https://doi.org/10.3390/electronics8040387
Chicago/Turabian StyleZhang, Xitao, Lingda Wu, Shaobo Yu, and Kang Li. 2019. "Layer-Edge Patterns Exploration and Presentation in Multiplex Networks: From Detail to Overview via Selections and Aggregations" Electronics 8, no. 4: 387. https://doi.org/10.3390/electronics8040387