
Enhancement of Two-Dimensional Barcode Restoration Based on Recurrent Feature Reasoning and Structural Fusion Attention Mechanism

Abstract
1. Introduction
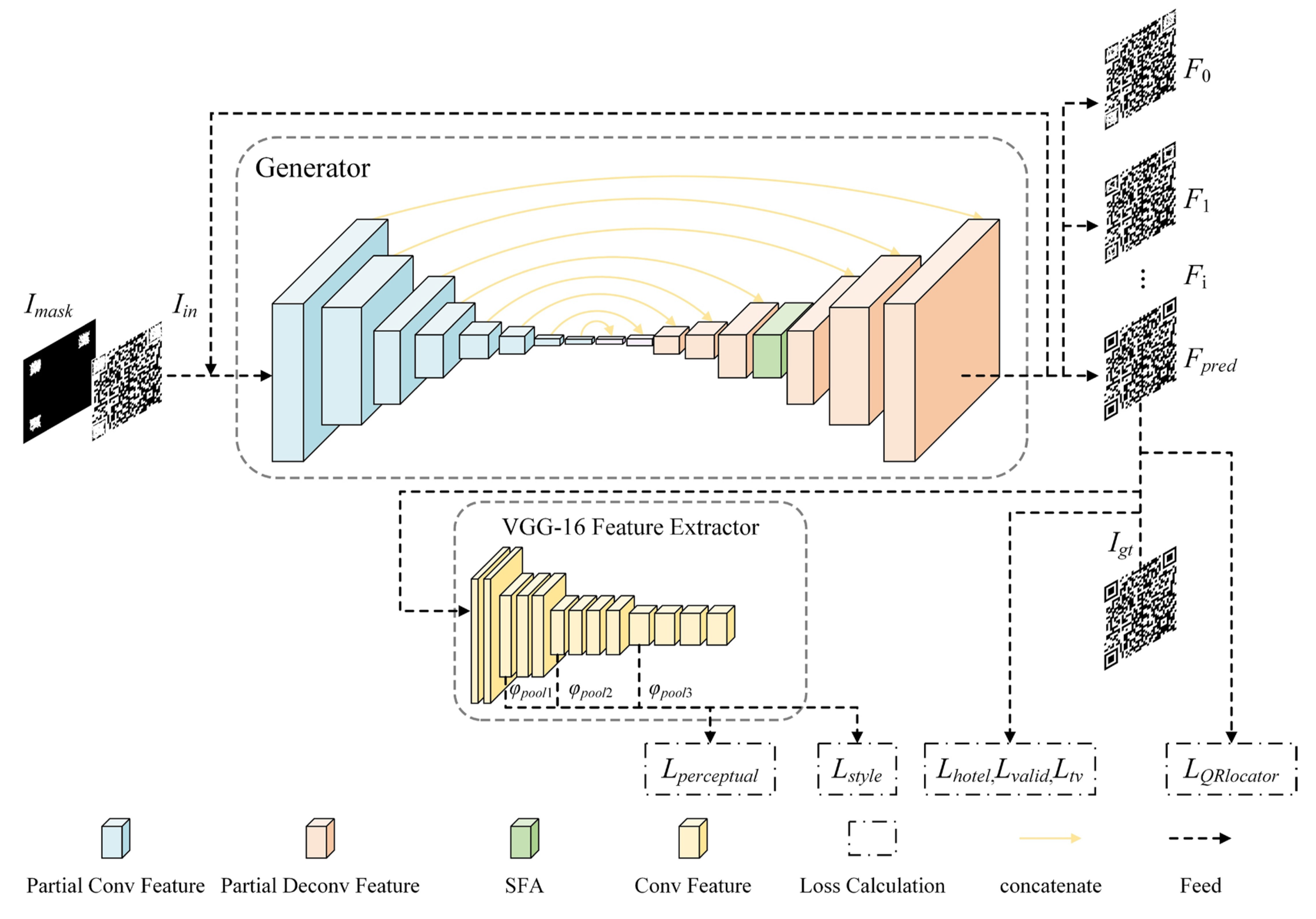
2. Method
2.1. Recurrent Feature Reasoning Network
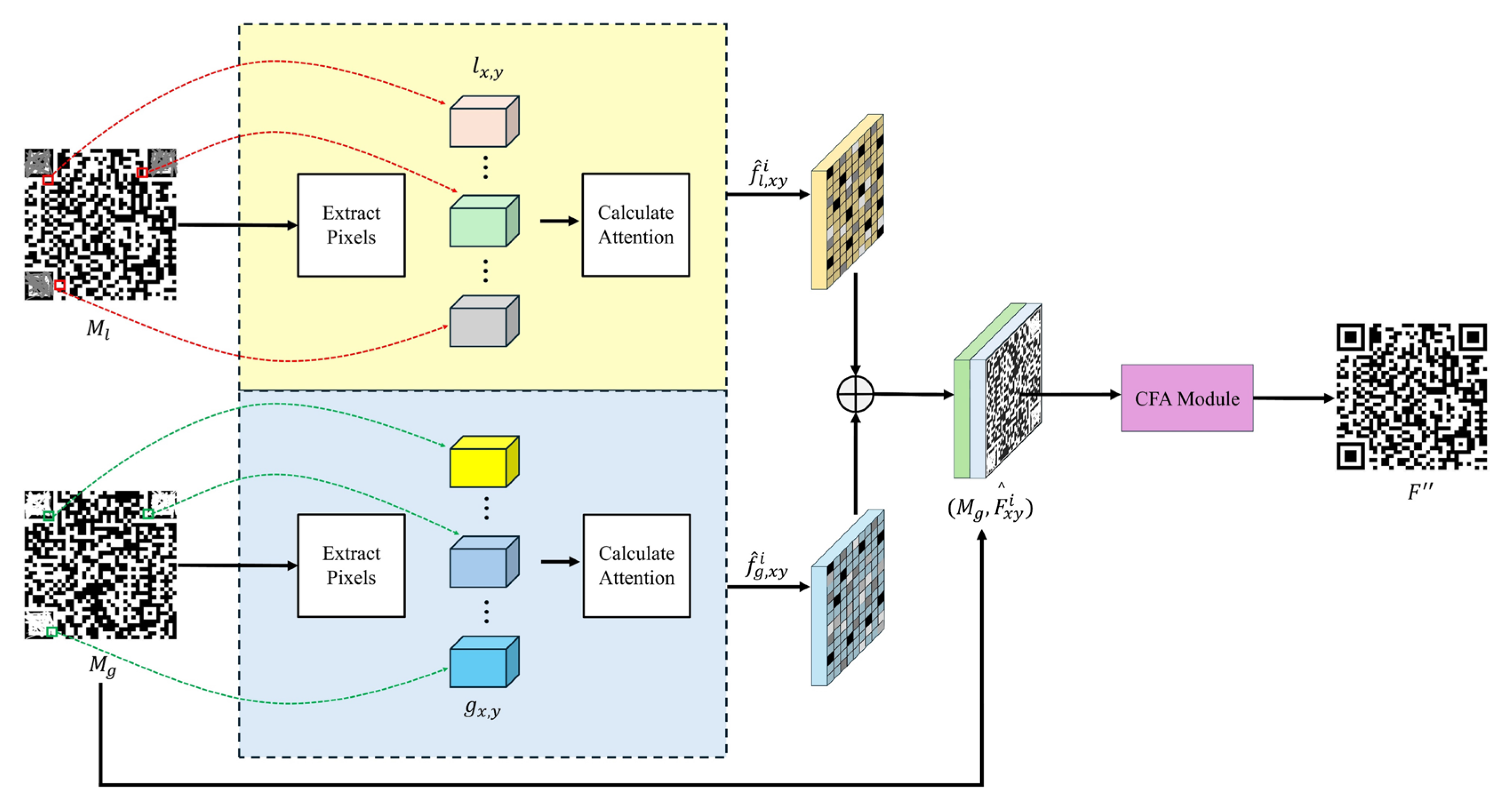
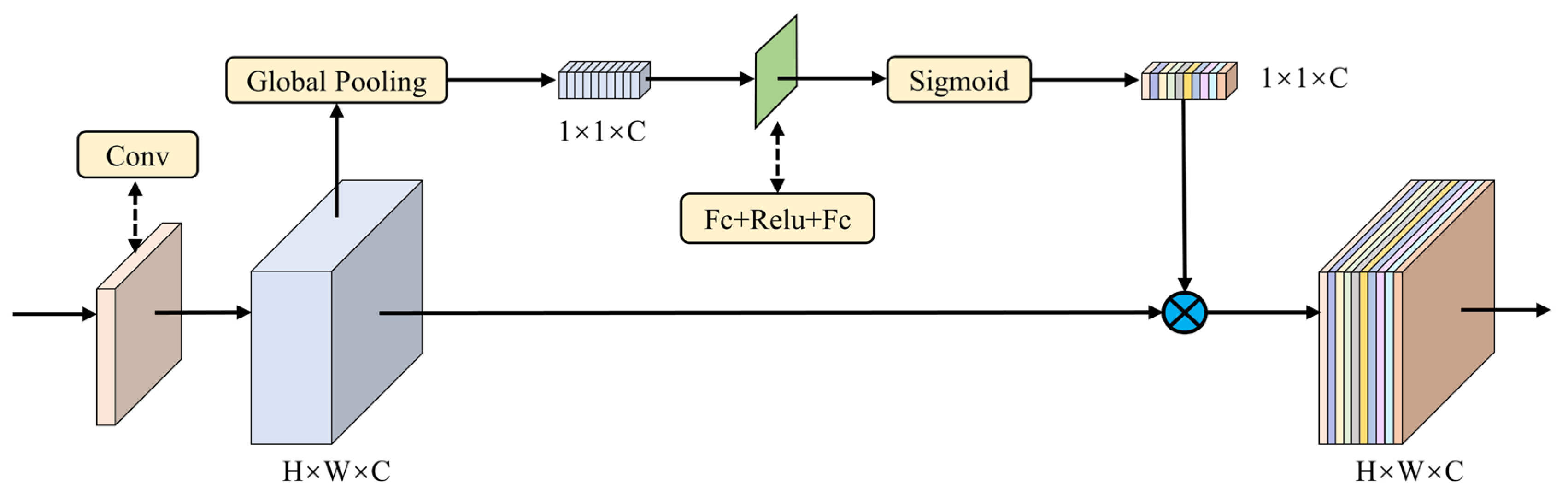
2.2. SFA Mechanism
2.3. Loss Function
3. Experimental Results and Analysis
3.1. Original 2D Barcode Images
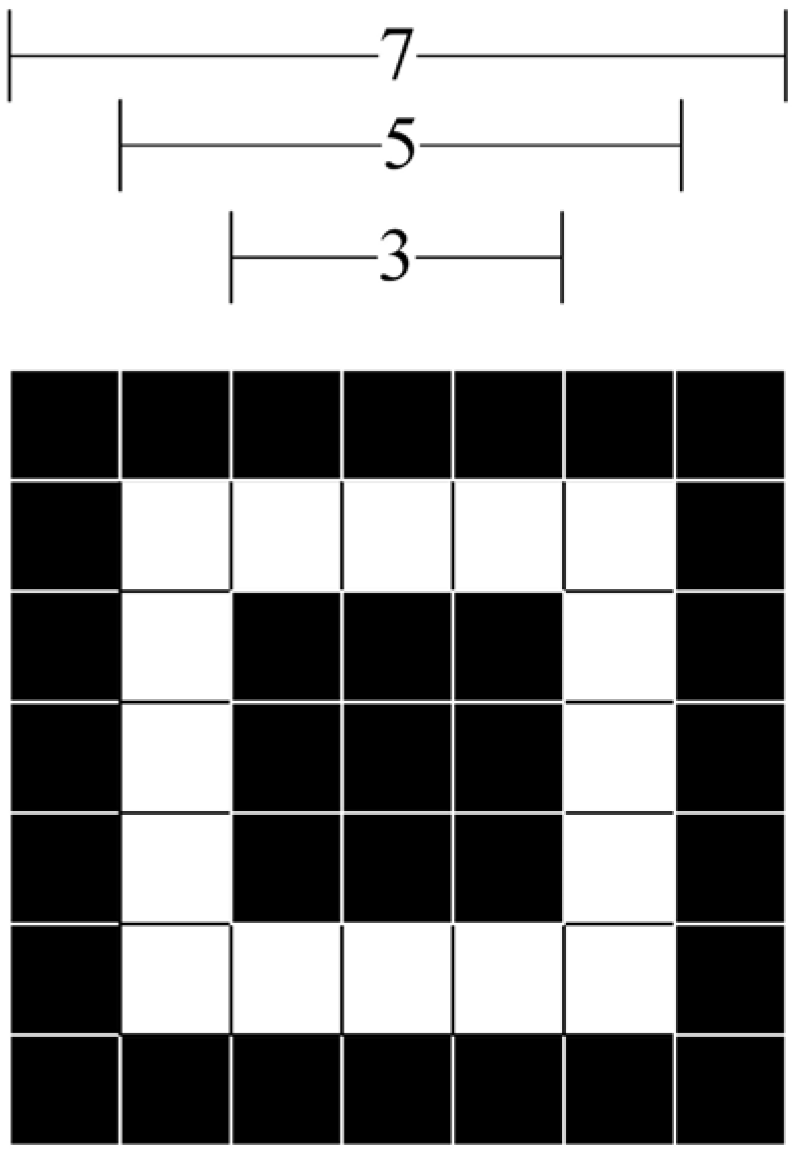
3.2. Irregular Mask of the Locator Region
3.3. Training Parameter Settings
3.4. Evaluation Metrics
3.5. Comparison Models
3.6. Experimental Analysis
4. Discussion
- Practical applications: The proposed 2D barcode restoration method can significantly improve the readability and visual quality of damaged codes, which is critical for industries like retail and logistics. This leads to smoother transactions and better inventory management. Furthermore, considering the potential damage to barcodes carrying electronic device information, this method could resolve barcode detection challenges in electronics manufacturing.
- Future directions in 2D barcode repair: In this research, the focus was put on repairing structural damage in standard 2D barcodes. However, the varied uses of 2D codes call for the study of specific types like data matrix. Future studies should explore these variants using algorithms like transformers for better data section repair. This aligns with the goal of enhancing structural integrity and developing repair methods for diverse codes used across different industries.
- Consideration of external factors: In real-world environments, external factors such as lighting conditions, blurriness, and skew can significantly affect the restoration results of 2D barcodes. This study acknowledges these challenges and suggests incorporating image enhancement and preprocessing techniques to mitigate their effects. Future research should pay attention to enhancing model robustness against these variables, which ensures the practical applicability of the proposed 2D barcode restoration method in diverse conditions. Additionally, collecting electronic device-specific barcode damage datasets will improve our repair techniques, boosting the robustness and practical use of the restoration method in electronics.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Czuszynski, K.; Ruminski, J. Interaction with medical data using QR-codes. In Proceedings of the 2014 7th International Conference on Human System Interactions (HSI), Lisbon, Portugal, 16–18 June 2014; IEEE: Piscataway, NJ, USA; 2014; pp. 182–187. [Google Scholar] [CrossRef]
- Singh, S. QR code analysis. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2016, 6, 89–92. [Google Scholar]
- Bai, H.; Zhou, G.; Hu, Y.; Sun, A.; Xu, X.; Liu, X.; Lu, C. Traceability technologies for farm animals and their products in China. Food Control 2017, 79, 35–43. [Google Scholar] [CrossRef]
- Petrova, K.; Romaniello, A.; Medlin, B.D.; Vannoy, S.A. QR codes advantages and dangers. In Proceedings of the 13th International Joint Conference on e-Business and Telecommunications, Lisbon, Portugal, 26–28 July 2016; SCITEPRESS—Science and Technology Publications: Setbal, Portugal, 2016; pp. 112–115. [Google Scholar] [CrossRef]
- Xiong, J.; Zhou, L. QR code detection and recognition in industrial production environment based on SSD and image processing. In Proceedings of the International Conference on Algorithms, High Performance Computing, and Artificial Intelligence (AHPCAI 2023), Yinchuan, China,, 18–19 August 2023; SPIE: Bellingham, DC, USA, 2023; pp. 640–644. [Google Scholar] [CrossRef]
- Jin, J.; Wang, K.; Wang, W. Research on correction and recognition of QR code on cylinder. In Proceedings of the 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 18–20 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1485–1489. [Google Scholar] [CrossRef]
- Tribak, H.; Zaz, Y. QR code recognition based on principal components analysis method. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 241–248. [Google Scholar] [CrossRef]
- Cao, Z.; Li, J.; Hu, B. Robust hazy QR code recognition based on dehazing and improved adaptive thresholding method. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1112–1117. [Google Scholar] [CrossRef]
- Belussi, L.F.F.; Hirata, N.S.T. Fast component-based QR code detection in arbitrarily acquired images. J. Math. Imaging Vis. 2013, 45, 277–292. [Google Scholar] [CrossRef]
- Chen, R.; Zheng, Z.; Pan, J.; Yu, Y.; Zhao, H.; Ren, J. Fast blind deblurring of QR code images based on adaptive scale control. Mob. Netw. Appl. 2021, 26, 2472–2487. [Google Scholar] [CrossRef]
- Ohbuchi, E.; Hanaizumi, H.; Hock, L.A. Barcode readers using the camera device in mobile phones. In Proceedings of the 2004 International Conference on Cyberworlds, Tokyo, Japan, 18–20 November 2004; IEEE: Piscataway, NJ, USA, 2004; pp. 260–265. [Google Scholar] [CrossRef]
- Ciążyński, K.; Fabijańska, A. Detection of QR-codes in digital images based on histogram similarity. Image Process. Commun. 2015, 20, 41–48. [Google Scholar] [CrossRef]
- Gaur, P.; Tiwari, S. Recognition of 2D barcode images using edge detection and morphological operation. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 1277–1282. [Google Scholar]
- Lopez-Rincon, O.; Starostenko, O.; Alarcon-Aquino, V.; Galan-Hernandez, J.C. Binary large object-based approach for QR code detection in uncontrolled environments. J. Electr. Comput. Eng. 2017, 2017, 4613628. [Google Scholar] [CrossRef]
- Yi, J.; Xiao, Y. Efficient localization of multitype barcodes in high-resolution images. Math. Probl. Eng. 2022, 2022, 5256124. [Google Scholar] [CrossRef]
- Chen, R.; Huang, H.; Yu, Y.; Ren, J.; Wang, P.; Zhao, H.; Lu, X. Rapid detection of multi-QR codes based on multistage stepwise discrimination and a compressed MobileNet. IEEE Internet Things J. 2023, 10, 15966–15979. [Google Scholar] [CrossRef]
- Zhang, J.; Min, X.; Jia, J.; Zhu, Z.; Wang, J.; Zhai, G. Fine localization and distortion resistant detection of multi-class barcode in complex environments. Multimed. Tools Appl. 2021, 80, 16153–16172. [Google Scholar] [CrossRef]
- Jia, J.; Zhai, G.; Ren, P.; Zhang, J.; Gao, Z.; Min, X.; Yang, X. Tiny-BDN: An efficient and compact barcode detection network. IEEE J. Sel. Top. Signal Process. 2020, 14, 688–699. [Google Scholar] [CrossRef]
- Chen, R.; Zheng, Z.; Yu, Y.; Zhao, H.; Ren, J.; Tan, H.-Z. Fast restoration for out-of-focus blurred images of QR code with edge prior information via image sensing. IEEE Sens. J. 2021, 21, 18222–18236. [Google Scholar] [CrossRef]
- Zheng, J.; Zhao, R.; Lin, Z.; Liu, S.; Zhu, R.; Zhang, Z.; Fu, Y.; Lu, J. EHFP-GAN: Edge-enhanced hierarchical feature pyramid network for damaged QR code reconstruction. Mathematics 2023, 11, 4349. [Google Scholar] [CrossRef]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2536–2544. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Shi, C.; Yan, Z.; Li, X.; Kong, B.; Lyu, S.; Zhu, B.; Lv, J.; Yin, Y.; et al. DE-GAN: Domain embedded GAN for high quality face image inpainting. Pattern Recognit. 2022, 124, 108415. [Google Scholar] [CrossRef]
- Jo, Y.; Park, J. SC-FEGAN: Face editing generative adversarial network with user’s sketch and color. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1745–1753. [Google Scholar] [CrossRef]
- Liu, H.; Wan, Z.; Huang, W.; Song, Y.; Han, X.; Liao, J. PD-GAN: Probabilistic diverse GAN for image inpainting. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 9371–9381. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Yang, C.; Lu, X.; Lin, Z.; Shechtman, E.; Wang, O.; Li, H. High-resolution image inpainting using multi-scale neural patch synthesis. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 6721–6729. [Google Scholar] [CrossRef]
- Yan, Z.; Li, X.; Li, M.; Zuo, W.; Shan, S. Shift-Net: Image inpainting via deep feature rearrangement. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Wang, N.; Ma, S.; Li, J.; Zhang, Y.; Zhang, L. Multistage attention network for image inpainting. Pattern Recognit. 2020, 106, 107448. [Google Scholar] [CrossRef]
- Yan, S.; Zhang, X. PCNet: Partial convolution attention mechanism for image inpainting. Int. J. Comput. Appl. 2022, 44, 738–745. [Google Scholar] [CrossRef]
- Ran, C.; Li, X.; Yang, F. Multi-step structure image inpainting model with attention mechanism. Sensors 2023, 23, 2316. [Google Scholar] [CrossRef]
- Li, P.; Chen, Y. Research into an image inpainting algorithm via multilevel attention progression mechanism. Math. Probl. Eng. 2022, 2022, 8508702. [Google Scholar] [CrossRef]
- Liu, J.; Gong, M.; Tang, Z.; Qin, A.K.; Li, H.; Jiang, F. Deep Image Inpainting with Enhanced Normalization and Contextual Attention. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6599–6614. [Google Scholar] [CrossRef]
- Li, J.; Wang, N.; Zhang, L.; Du, B.; Tao, D. Recurrent feature reasoning for image inpainting. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 7757–7765. [Google Scholar] [CrossRef]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.-C.; Tao, A.; Catanzaro, B. Image Inpainting for Irregular Holes Using Partial Convolutions. In Proceedings of the Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 89–105. [Google Scholar] [CrossRef]
- Zeng, Y.; Fu, J.; Chao, H.; Guo, B. Aggregated contextual transformations for high-resolution image inpainting. IEEE Trans. Vis. Comput. Graph. 2023, 29, 3266–3280. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Yang, H.; Huang, D. Image inpainting via conditional texture and structure dual generation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 14134–14143. [Google Scholar] [CrossRef]
- Quan, W.; Zhang, R.; Zhang, Y.; Li, Z.; Wang, J.; Yan, D.M. Image inpainting with local and global refinement. IEEE Trans. Image Process. 2022, 31, 2405–2420. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Masked | Masked_QR | AOT | Ctsdg | LGNet | Ours | |
|---|---|---|---|---|---|---|
| DR | 0.15–0.3 | 0 | 94.2 | 100 | 100 | 100 |
| 0.3–0.45 | 0 | 85 | 100 | 100 | 100 | |
| 0.45–0.6 | 0 | 73.2 | 99.4 | 100 | 100 | |
| 0.6–0.75 | 0 | 57.6 | 95.4 | 100 | 100 | |
| 0.75–0.9 | 0 | 30.6 | 77 | 99.2 | 100 | |
| PSNR | 0.15–0.3 | - | 30.1812 | 37.5892 | 49.4136 | 42.2146 |
| 0.3–0.45 | - | 27.8653 | 35.1785 | 47.7835 | 42.0115 | |
| 0.45–0.6 | - | 26.3334 | 32.7296 | 46.7099 | 41.8028 | |
| 0.6–0.75 | - | 25.1479 | 30.4123 | 45.9290 | 41.6074 | |
| 0.75–0.9 | - | 23.8428 | 27.6531 | 45.3759 | 41.4301 | |
| SSIM | 0.15–0.3 | - | 0.9917 | 0.9954 | 0.9999 | 0.9933 |
| 0.3–0.45 | - | 0.9881 | 0.9933 | 0.9998 | 0.9932 | |
| 0.45–0.6 | - | 0.9852 | 0.9914 | 0.9998 | 0.9931 | |
| 0.6–0.75 | - | 0.9827 | 0.9893 | 0.9998 | 0.9930 | |
| 0.75–0.9 | - | 0.9799 | 0.9866 | 0.9997 | 0.9927 | |
| L1 | 0.15–0.3 | - | 0.0079 | 0.0055 | 0.0037 | 0.0052 |
| 0.3–0.45 | - | 0.0081 | 0.0063 | 0.0053 | 0.0053 | |
| 0.45–0.6 | - | 0.0084 | 0.0073 | 0.0065 | 0.0056 | |
| 0.6–0.75 | - | 0.0091 | 0.0087 | 0.0076 | 0.0057 | |
| 0.75–0.9 | - | 0.0098 | 0.0109 | 0.0084 | 0.0061 |
| Masked | Masked_PDF417 | AOT | Ctsdg | LGNet | Ours | |
|---|---|---|---|---|---|---|
| DR | 0.15–0.3 | 0 | 28.8 | 40.6 | 91.6 | 99.6 |
| 0.3–0.45 | 0 | 2.2 | 10.8 | 89.4 | 99.6 | |
| 0.45–0.6 | 0 | 0 | 1.4 | 84.8 | 99.4 | |
| 0.6–0.75 | 0 | 0 | 0.2 | 82.0 | 98.8 | |
| 0.75–0.9 | 0 | 0 | 0 | 79.2 | 98.2 | |
| PSNR | 0.15–0.3 | - | 27.8765 | 33.0291 | 44.8567 | 37.0854 |
| 0.3–0.45 | - | 25.7306 | 29.8826 | 42.8767 | 35.8876 | |
| 0.45–0.6 | - | 24.4085 | 27.3056 | 41.6536 | 34.7828 | |
| 0.6–0.75 | - | 23.4243 | 25.3089 | 40.7608 | 33.8335 | |
| 0.75–0.9 | - | 22.6673 | 23.6422 | 39.9429 | 33.0167 | |
| SSIM | 0.15–0.3 | - | 0.9916 | 0.9915 | 0.9999 | 0.9849 |
| 0.3–0.45 | - | 0.9870 | 0.9875 | 0.9998 | 0.9834 | |
| 0.45–0.6 | - | 0.9828 | 0.9836 | 0.9998 | 0.9818 | |
| 0.6–0.75 | - | 0.9790 | 0.9797 | 0.9997 | 0.9802 | |
| 0.75–0.9 | - | 0.9758 | 0.9760 | 0.9997 | 0.9786 | |
| L1 | 0.15–0.3 | - | 0.0511 | 0.0028 | 0.0065 | 0.0069 |
| 0.3–0.45 | - | 0.0551 | 0.0049 | 0.0095 | 0.0078 | |
| 0.45–0.6 | - | 0.0559 | 0.0077 | 0.0120 | 0.0086 | |
| 0.6–0.75 | - | 0.0563 | 0.0110 | 0.0141 | 0.0093 | |
| 0.75–0.9 | - | 0.0571 | 0.0147 | 0.0159 | 0.0099 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, J.; Chen, J. Enhancement of Two-Dimensional Barcode Restoration Based on Recurrent Feature Reasoning and Structural Fusion Attention Mechanism. Electronics 2024, 13, 1873. https://doi.org/10.3390/electronics13101873
Yi J, Chen J. Enhancement of Two-Dimensional Barcode Restoration Based on Recurrent Feature Reasoning and Structural Fusion Attention Mechanism. Electronics. 2024; 13(10):1873. https://doi.org/10.3390/electronics13101873
Chicago/Turabian StyleYi, Jinwang, and Jianan Chen. 2024. "Enhancement of Two-Dimensional Barcode Restoration Based on Recurrent Feature Reasoning and Structural Fusion Attention Mechanism" Electronics 13, no. 10: 1873. https://doi.org/10.3390/electronics13101873
APA StyleYi, J., & Chen, J. (2024). Enhancement of Two-Dimensional Barcode Restoration Based on Recurrent Feature Reasoning and Structural Fusion Attention Mechanism. Electronics, 13(10), 1873. https://doi.org/10.3390/electronics13101873