Enhancing Neural Text Detector Robustness with μAttacking and RR-Training



Abstract
1. Introduction
- Introducing Attacking, a mutation-based strategy for systematically evaluating the robustness of neural network language-analysis models.
- Demonstrating robust analysis of neural text detection model using Attacking through adversarial attacks.
- Proposing the RR-training strategy that improves the robustness of language-analysis models significantly without requiring additional data or effort.
2. Technical Background
2.1. Automatic Text Generation
2.2. Neural Text Detection
2.3. Mutation Analysis
2.4. Adversarial Attacks
3. Method
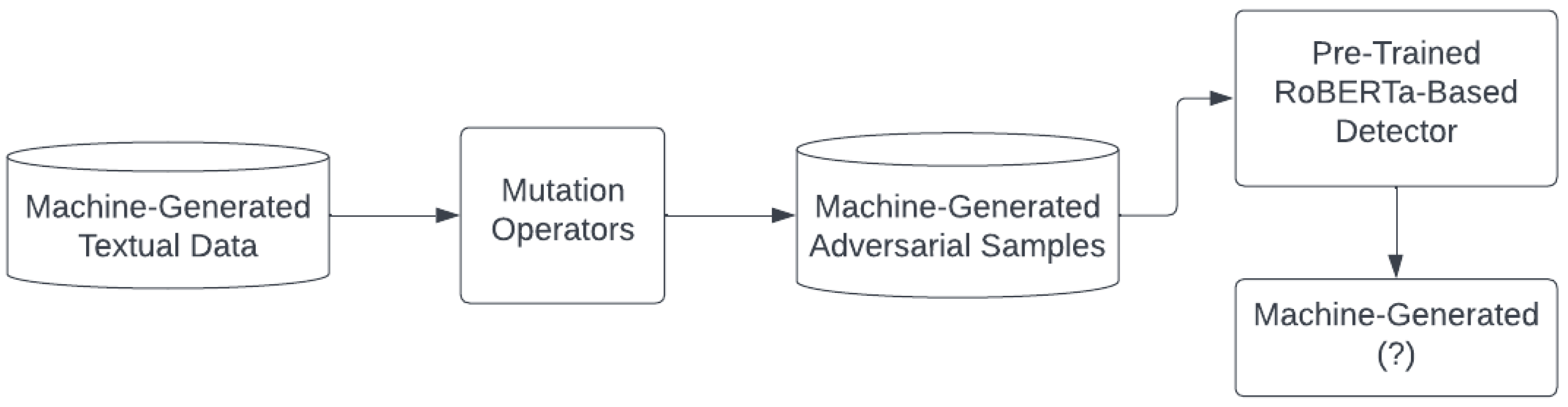
3.1. Attacking
3.1.1. General Mutation Operator Framework
3.1.2. Attacks on Neural Text Detectors
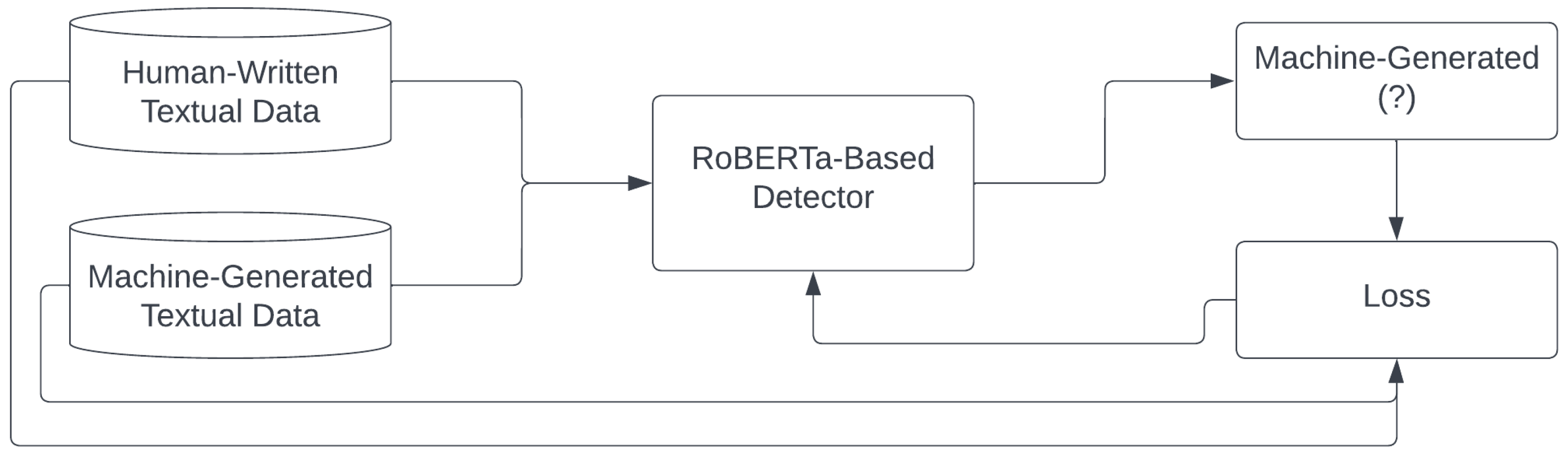
3.2. Random-Removing Training Strategy
| Algorithm 1:RR-Training |
 |
4. Dataset and Experiment Setup
4.1. Data Preparation and Neural Text Acquiring
- The text in a post is usually relatively short. For instance, the typical length of tweets is often between 25–50 characters.
- A good percentage of posts contain images and text. The text is often related to the image.
4.2. Models and Training Setup
- RoBERTa-Base: The RoBERTa-based detector was originally released by OpenAI. We used the model as-is and used the author-related weights.
- RoBERTa-Finetune: A finetuned RoBERTa-based detector using our training set. All the embedding layers were frozen during the training. We only optimized the classifier as part of the model. No mutation operators were applied during the training.
- RoBERTa-RR: Another finetuned RoBERTa-based detector that followed the same setup of the RoBERTa-Finetune model but was trained using the RR-training strategy.
4.3. Mutation Operators and Adversarial Attacks
5. Results and Analysis
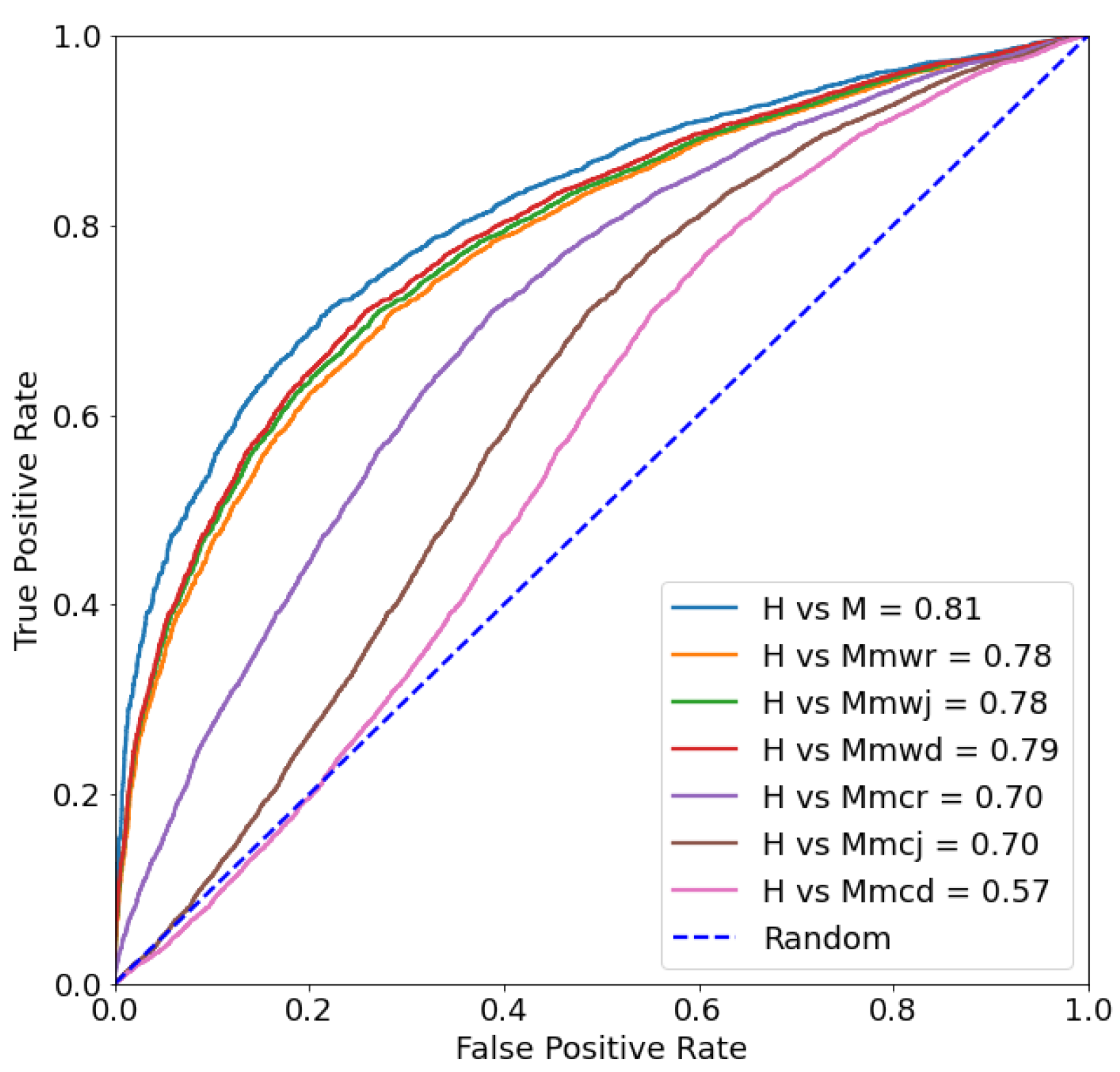
5.1. Evaluating Robustness with Attacking
5.2. Improving Robustness Using RR-Training
5.2.1. In-Distribution Data
5.2.2. Out-of-Distribution Data
5.2.3. Comparing with Dropout
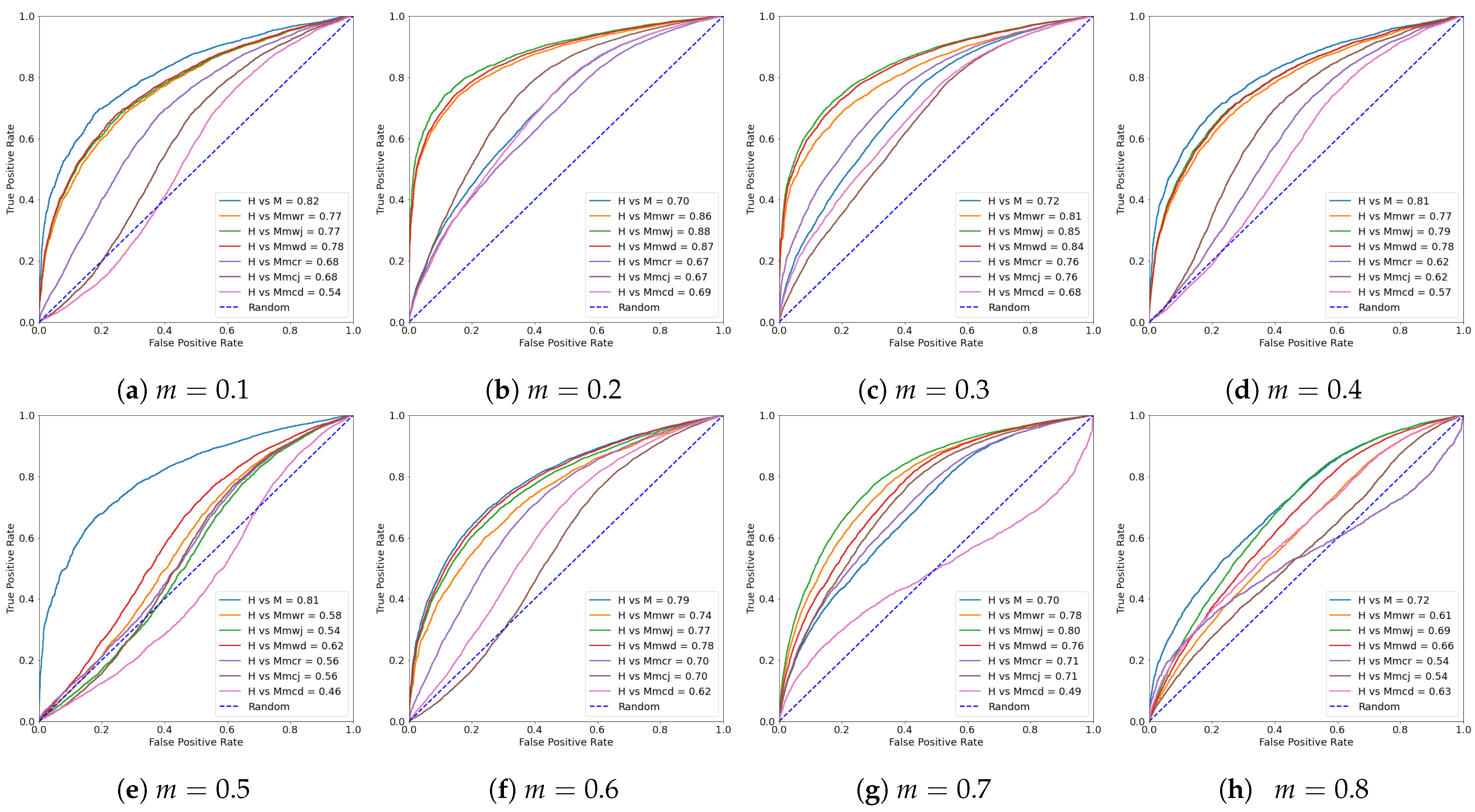
5.2.4. Effective of Random Removing Ratio
6. Discussion, Conclusions, and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zhang, Y.; Liang, G.; Salem, T.; Jacobs, N. Defense-pointnet: Protecting pointnet against adversarial attacks. In Proceedings of the IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 5654–5660. [Google Scholar]
- Xing, X.; Liang, G.; Blanton, H.; Rafique, M.U.; Wang, C.; Lin, A.L.; Jacobs, N. Dynamic image for 3d mri image alzheimer’s disease classification. In Proceedings of the European Conference on Computer Vision Workshops, Glasgow, UK, 23–28 August 2020; Part I. pp. 355–364. [Google Scholar]
- Su, Y.; Zhang, Y.; Liang, G.; ZuHone, J.A.; Barnes, D.J.; Jacobs, N.B.; Ntampaka, M.; Forman, W.R.; Nulsen, P.E.J.; Kraft, R.P.; et al. A deep learning view of the census of galaxy clusters in illustristng. Mon. Not. R. Astron. Soc. 2020, 498, 5620–5628. [Google Scholar] [CrossRef]
- Ying, Q.; Xing, X.; Liu, L.; Lin, A.L.; Jacobs, N.; Liang, G. Multi-modal data analysis for alzheimer’s disease diagnosis: An ensemble model using imagery and genetic features. In Proceedings of the 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society, Mexico City, Mexico, 1–5 November 2021; pp. 3586–3591. [Google Scholar]
- Liu, L.; Chang, J.; Wang, Y.; Liang, G.; Wang, Y.P.; Zhang, H. Decomposition-based correlation learning for multi-modal mri-based classification of neuropsychiatric disorders. Front. Neurosci. 2022, 16, 832276. [Google Scholar] [CrossRef] [PubMed]
- Liang, G.; Xing, X.; Liu, L.; Zhang, Y.; Ying, Q.; Lin, A.L.; Jacobs, N. Alzheimer’s disease classification using 2d convolutional neural networks. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society, Mexico City, Mexico, 1–5 November 2021; pp. 3008–3012. [Google Scholar]
- Lin, S.C.; Su, Y.; Liang, G.; Zhang, Y.; Jacobs, N.; Zhang, Y. Estimating cluster masses from SDSS multiband images with transfer learning. Mon. Not. R. Astron. Soc. 2022, 512, 3885–3894. [Google Scholar] [CrossRef]
- Li, K.; Zheng, F.; Wu, P.; Wang, Q.; Liang, G.; Jiang, L. Improving Pneumonia Classification and Lesion Detection Using Spatial Attention Superposition and Multilayer Feature Fusion. Electronics 2022, 11, 3102. [Google Scholar] [CrossRef]
- Xing, X.; Rafique, M.U.; Liang, G.; Blanton, H.; Zhang, Y.; Wang, C.; Jacobs, N.; Lin, A.L. Efficient Training on Alzheimer’s Disease Diagnosis with Learnable Weighted Pooling for 3D PET Brain Image Classification. Electronics 2023, 12, 467. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Workman, S.; Rafique, M.U.; Blanton, H.; Jacobs, N. Revisiting Near/Remote Sensing with Geospatial Attention. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Mihail, R.P.; Liang, G.; Jacobs, N. Automatic hand skeletal shape estimation from radiographs. IEEE Trans. Nanobiosci. 2019, 18, 296–305. [Google Scholar] [CrossRef]
- Liang, G.; Fouladvand, S.; Zhang, J.; Brooks, M.A.; Jacobs, N.; Chen, J. Ganai: Standardizing ct images using generative adversarial network with alternative improvement. In Proceedings of the 2019 IEEE International Conference on Healthcare Informatics, Xi’an, China, 10–13 June 2019; pp. 1–11. [Google Scholar]
- Liu, L.; Zhang, P.; Liang, G.; Xiong, S.; Wang, J.; Zheng, G. A spatiotemporal correlation deep learning network for brain penumbra disease. Neurocomputing 2023, 520, 274–283. [Google Scholar] [CrossRef]
- Liu, L.; Chang, J.; Wang, Y.; Zhang, P.; Liang, G.; Zhang, H. Llrhnet: Multiple lesions segmentation using local-long rang features. Front. Neuroinform. 2022, 16, 859973. [Google Scholar] [CrossRef]
- Ajami, S. Use of speech-to-text technology for documentation by healthcare providers. Natl. Med. J. India 2016, 29, 148. [Google Scholar] [PubMed]
- Wang, C.; Tang, Y.; Ma, X.; Wu, A.; Okhonko, D.; Pino, J. Fairseq S2T: Fast Speech-to-Text Modeling with Fairseq. In Proceedings of the AACL Association for Computational Linguistics, Suzhou, China, 4–7 December 2020; pp. 33–39. [Google Scholar]
- Li, Q. Machine Translation of English Language Using the Complexity-Reduced Transformer Model. Mob. Inf. Syst. 2022, 2022, 6603576. [Google Scholar] [CrossRef]
- Khan, N.S.; Abid, A.; Abid, K. A novel natural language processing (NLP)–based machine translation model for English to Pakistan sign language translation. Cogn. Comput. 2020, 12, 748–765. [Google Scholar] [CrossRef]
- Kaczorowska-Spychalska, D. Chatbots in marketing. Management 2019, 23, 251–270. [Google Scholar] [CrossRef]
- Cheng, Y.; Jiang, H. Customer–brand relationship in the era of artificial intelligence: Understanding the role of chatbot marketing efforts. J. Prod. Brand Manag. 2022, 31, 252–264. [Google Scholar] [CrossRef]
- Huang, K.H.; McKeown, K.; Nakov, P.; Choi, Y.; Ji, H. Faking Fake News for Real Fake News Detection: Propaganda-loaded Training Data Generation. arXiv 2022, arXiv:2203.05386. [Google Scholar]
- Rezaei, S.; Kahani, M.; Behkamal, B. The process of multi-class fake news dataset generation. In Proceedings of the International Conference on Computer Engineering and Knowledge, Mashhad, Iran, 28–29 October 2021; pp. 134–139. [Google Scholar]
- Stiff, H.; Johansson, F. Detecting computer-generated disinformation. Int. J. Data Sci. Anal. 2022, 13, 363–383. [Google Scholar] [CrossRef]
- Alsmadi, I.; Ahmad, K.; Nazzal, M.; Alam, F.; Al-Fuqaha, A.; Khreishah, A.; Algosaibi, A. Adversarial attacks and defenses for social network text processing applications: Techniques, challenges and future research directions. arXiv 2021, arXiv:2110.13980. [Google Scholar]
- NBCNews. Americans Are Wary of AI Tech like ChatGPT, Data Shows. Available online: https://www.nbcnews.com/meet-the-press/data-download/chatgpt-ai-tech-leaves-americans-concerned-excited-rcna71369/ (accessed on 19 February 2023).
- DailyMail. Rogue Artificial Intelligence Chatbot Declares Love for User, Tells Him to Leave His Wife and Says It Wants to Steal Nuclear Codes. Available online: https://www.dailymail.co.uk/news/article-11761271/Rogue-artificial-intelligence-chatbot-declares-love-user-tells-leave-wife.html (accessed on 16 February 2023).
- OpenAI.com. ChatGPT: Optimizing Language Models for Dialogue. Available online: https://openai.com/blog/chatgpt/ (accessed on 17 December 2022).
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Google.com. An Important Next Step on Our AI Journey. Available online: https://blog.google/technology/ai/bard-google-ai-search-updates/ (accessed on 24 February 2023).
- Pu, J.; Sarwar, Z.; Abdullah, S.M.; Rehman, A.; Kim, Y.; Bhattacharya, P.; Javed, M.; Viswanath, B. Deepfake Text Detection: Limitations and Opportunities. In Proceedings of the IEEE Symposium on Security and Privacy, Los Alamitos, CA, USA, 22–24 May 2023; pp. 19–36. [Google Scholar]
- Wolff, M.; Wolff, S. Attacking neural text detectors. arXiv 2020, arXiv:2002.11768. [Google Scholar]
- Madeyski, L.; Orzeszyna, W.; Torkar, R.; Jozala, M. Overcoming the equivalent mutant problem: A systematic literature review and a comparative experiment of second order mutation. IEEE Trans. Soft. Eng. 2013, 40, 23–42. [Google Scholar] [CrossRef]
- Misra, S. Evaluating four white-box test coverage methodologies. In Proceedings of the Canadian Conference on Electrical and Computer Engineering: Toward a Caring and Humane Technology, Montreal, QC, Canada, 4–7 May 2003; Volume 3, pp. 1739–1742. [Google Scholar]
- DeMillo, R.A.; Lipton, R.J.; Sayward, F.G. Hints on test data selection: Help for the practicing programmer. Computer 1978, 11, 34–41. [Google Scholar] [CrossRef]
- Huang, L.; Joseph, A.D.; Nelson, B.; Rubinstein, B.I.; Tygar, J.D. Adversarial machine learning. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence, Chicago, IL, USA, 21 October 2011; pp. 43–58. [Google Scholar]
- Niedermayr, R.; Juergens, E.; Wagner, S. Will my tests tell me if i break this code? In Proceedings of the International Workshop on Continuous Software Evolution and Delivery, Austin, TX, USA, 14–15 May 2016; pp. 23–29. [Google Scholar]
- Jia, Y.; Harman, M. An analysis and survey of the development of mutation testing. IEEE Trans. Soft. Eng. 2010, 37, 649–678. [Google Scholar] [CrossRef]
- Solaiman, I.; Brundage, M.; Clark, J.; Askell, A.; Herbert-Voss, A.; Wu, J.; Radford, A.; Wang, J. Release strategies and the social impacts of language models. arXiv 2019, arXiv:1908.09203. [Google Scholar]
- Mann, W.C. An overview of the Penman text generation system. In Proceedings of the AAAI, Washington, DC, USA, 22–26 August 1983; pp. 261–265. [Google Scholar]
- Jelinek, F. Markov source modeling of text generation. In The Impact of Processing Techniques on Communications; Springer: Berlin/Heidelberg, Germany, 1985; pp. 569–591. [Google Scholar]
- Guo, J.; Lu, S.; Cai, H.; Zhang, W.; Yu, Y.; Wang, J. Long text generation via adversarial training with leaked information. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zhu, Y.; Lu, S.; Zheng, L.; Guo, J.; Zhang, W.; Wang, J.; Yu, Y. Texygen: A benchmarking platform for text generation models. In Proceedings of the 41st International ACM Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 1097–1100. [Google Scholar]
- Yu, W.; Zhu, C.; Li, Z.; Hu, Z.; Wang, Q.; Ji, H.; Jiang, M. A survey of knowledge-enhanced text generation. ACM Comput. Surv. (CSUR) 2022, 54, 227. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf/ (accessed on 17 December 2022).
- Yu, W.; Zhu, C.; Li, Z.; Hu, Z.; Wang, Q.; Ji, H.; Jiang, M. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Rasmy, L.; Xiang, Y.; Xie, Z.; Tao, C.; Zhi, D. Med-BERT: Pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction. NPJ Dig. Med. 2020, 4, 86. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 July 2015; pp. 3156–3164. [Google Scholar]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Vaswani, A.; Bengio, S.; Brevdo, E.; Chollet, F.; Gomez, A.N.; Gouws, S.; Jones, L.; Kaiser, Ł.; Kalchbrenner, N.; Parmar, N. Tensor2tensor for neural machine translation. arXiv 2018, arXiv:1803.07416. [Google Scholar]
- Zhu, Y.; Song, R.; Dou, Z.; Nie, J.Y.; Zhou, J. Scriptwriter: Narrative-guided script generation. arXiv 2020, arXiv:2005.10331. [Google Scholar]
- Yi, X.; Li, R.; Sun, M. Generating chinese classical poems with rnn encoder-decoder. In Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data; Springer: Berlin/Heidelberg, Germany, 2017; pp. 211–223. [Google Scholar]
- Gehrmann, S.; Strobelt, H.; Rush, A.M. Gltr: Statistical detection and visualization of generated text. arXiv 2019, arXiv:1906.04043. [Google Scholar]
- Adelani, D.I.; Mai, H.; Fang, F.; Nguyen, H.H.; Yamagishi, J.; Echizen, I. Generating sentiment-preserving fake online reviews using neural language models and their human-and machine-based detection. In Proceedings of the International Conference on Advanced Information Networking and Applications, Caserta, Italy, 15–17 April 2020; pp. 1341–1354. [Google Scholar]
- Bhatt, P.; Rios, A. Detecting Bot-Generated Text by Characterizing Linguistic Accommodation in Human-Bot Interactions. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 3235–3247. [Google Scholar]
- Cauteruccio, F.; Terracina, G.; Ursino, D. Generalizing identity-based string comparison metrics: Framework and techniques. Knowl. Based Syst. 2020, 187, 104820. [Google Scholar] [CrossRef]
- Lowd, D.; Meek, C. Adversarial learning. In Proceedings of the Eleventh ACM International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 641–647. [Google Scholar]
- Qiu, S.; Liu, Q.; Zhou, S.; Wu, C. Review of artificial intelligence adversarial attack and defense technologies. Appl. Sci. 2019, 9, 909. [Google Scholar] [CrossRef]
- Zhang, Y.; Song, Y.; Liang, J.; Bai, K.; Yang, Q. Two sides of the same coin: White-box and black-box attacks for transfer learning. In Proceedings of the 26th ACM International Conference on Knowledge Discovery & Data Mining, Online, 6–10 July 2020; pp. 2989–2997. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 274–283. [Google Scholar]
- Bhagoji, A.N.; He, W.; Li, B.; Song, D. Practical black-box attacks on deep neural networks using efficient query mechanisms. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 154–169. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Jawahar, G.; Abdul-Mageed, M.; Lakshmanan, L.V. Automatic detection of machine generated text: A critical survey. arXiv 2020, arXiv:2011.01314. [Google Scholar]
- Wang, X.; Liang, G.; Zhang, Y.; Blanton, H.; Bessinger, Z.; Jacobs, N. Inconsistent performance of deep learning models on mammogram classification. J. Am. Coll. Radiol. 2020, 17, 796–803. [Google Scholar] [CrossRef]
- Pereyra, G.; Tucker, G.; Chorowski, J.; Kaiser, Ł.; Hinton, G. Regularizing neural networks by penalizing confident output distributions. arXiv 2017, arXiv:1701.06548. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G.E. When does label smoothing help? In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–14 September 2019; Volume 32.
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Liang, G.; Zhang, Y.; Wang, X.; Jacobs, N. Improved Trainable Calibration Method for Neural Networks on Medical Imaging Classification. In Proceedings of the British Machine Vision Conference, Online, 7–10 September 2020. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Shrimal, A.; Chakraborty, T. Attention beam: An image captioning approach. arXiv 2020, arXiv:2011.01753. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art natural language processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 652–663. [Google Scholar] [CrossRef] [PubMed]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–1 July 2015; Volume 2. [Google Scholar]
- Liang, G.; Greenwell, C.; Zhang, Y.; Xing, X.; Wang, X.; Kavuluru, R.; Jacobs, N. Contrastive cross-modal pre-training: A general strategy for small sample medical imaging. IEEE J. Biomed. Health Inform. 2021, 26, 1640–1649. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Liang, G.; Jacobs, N. Dynamic feature alignment for semi-supervised domain adaptation. In Proceedings of the British Machine Vision Conference, London, UK, 21–24 November 2022. [Google Scholar]
- Dong, J.; Cong, Y.; Sun, G.; Xu, X. Cscl: Critical semantic-consistent learning for unsupervised domain adaptation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 745–762. [Google Scholar]
- Hlaing, Z.C.S.S.; Khaing, M. A detection and prevention technique on sql injection attacks. In Proceedings of the IEEE Conference on Computer Applications, Yangon, Myanmar, 27– 28 February 2020; pp. 1–6. [Google Scholar]
- Zhao, Y.; Su, T.; Liu, Y.; Zheng, W.; Wu, X.; Kavuluru, R.; Halfond, W.G.; Yu, T. ReCDroid+: Automated End-to-End Crash Reproduction from Bug Reports for Android Apps. ACM Trans. Soft. Eng. Methodol. 2022, 31, 1–33. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | H vs. M | H vs. Mmwr | H vs. Mmwj | H vs. Mmwd | H vs. Mmcr | H vs. Mmcj | H vs. Mmcd |
|---|---|---|---|---|---|---|---|
| AUC | |||||||
| ACC |
| Metric | Model | H vs. M | H vs. Mmwr | H vs. Mmwj | H vs. Mmwd | H vs. Mmcr | H vs. Mmcj | H vs. Mmcd |
|---|---|---|---|---|---|---|---|---|
| AUC | Finetune | 0.7227 | ||||||
| RR | ||||||||
| ACC | Finetune | |||||||
| RR |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, G.; Guerrero, J.; Zheng, F.; Alsmadi, I. Enhancing Neural Text Detector Robustness with μAttacking and RR-Training. Electronics 2023, 12, 1948. https://doi.org/10.3390/electronics12081948
Liang G, Guerrero J, Zheng F, Alsmadi I. Enhancing Neural Text Detector Robustness with μAttacking and RR-Training. Electronics. 2023; 12(8):1948. https://doi.org/10.3390/electronics12081948
Chicago/Turabian StyleLiang, Gongbo, Jesus Guerrero, Fengbo Zheng, and Izzat Alsmadi. 2023. "Enhancing Neural Text Detector Robustness with μAttacking and RR-Training" Electronics 12, no. 8: 1948. https://doi.org/10.3390/electronics12081948
APA StyleLiang, G., Guerrero, J., Zheng, F., & Alsmadi, I. (2023). Enhancing Neural Text Detector Robustness with μAttacking and RR-Training. Electronics, 12(8), 1948. https://doi.org/10.3390/electronics12081948