
BoT2L-Net: Appearance-Based Gaze Estimation Using Bottleneck Transformer Block and Two Identical Losses in Unconstrained Environments
Abstract
:1. Introduction
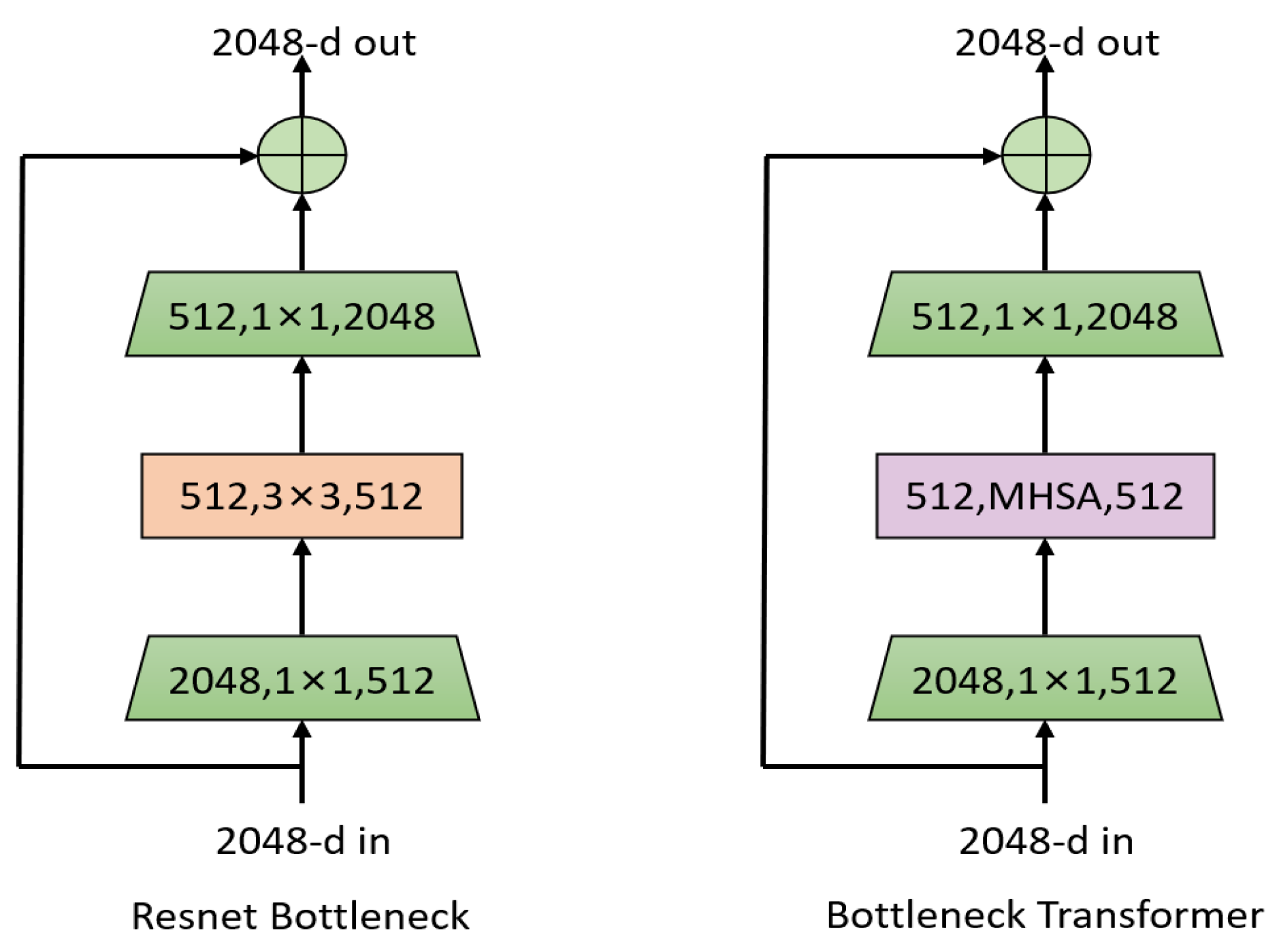
- This paper proposes a gaze estimation network designed to operate in unconstrained environments. The network utilizes Bottleneck Transformer blocks to introduce self-attention, allowing it to be connected to Transformer. This design results in better overall capture capabilities while also requiring fewer parameters.
- We employ two identical loss functions to predict pitch and yaw angles. By combining the cross-entropy loss function with the MSE loss function, the resulting combined loss function achieves a lower angle error in the network.
- Further, we conduct a verification and comparison of the mean angular error of our model on the Gaze360 and MPIIGaze testing sets. Our results demonstrate that our model has a lower mean angular error and can accurately estimate gaze in unconstrained environments.
2. Related Work
2.1. Gaze Estimation Methods
2.1.1. Model-Based Gaze Estimation
2.1.2. Appearance-Based Gaze Estimation
2.2. Transformer
3. Method
3.1. Bottleneck Transformer
3.2. Loss Function
3.3. BoT2L-Net
3.4. Dataset
4. Experiment
4.1. Setup
4.1.1. Data Preprocessing
4.1.2. Training
4.2. Evaluation and Results
5. Prediction in Unconstrained Environments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, W.; Shen, J.; Dong, X.; Borji, A.; Yang, R. Inferring salient objects from human fixations. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1913–1927. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Shen, J. Deep visual attention prediction. IEEE Trans. Image Process. 2017, 27, 2368–2378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, Y.; Dong, Y.; Wu, J.; Sun, Z.; Shi, Z.; Yu, J.; Gao, S. Gaze prediction in dynamic 360 immersive videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5333–5342. [Google Scholar]
- Yu, H.; Cai, M.; Liu, Y.; Lu, F. First-and third-person video co-analysis by learning spatial temporal joint attention. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Hempel, T.; Al-Hamadi, A. Slam-based multistate tracking system for mobile human-robot interaction. In Proceedings of the Image Analysis and Recognition: 17th International Conference, ICIAR 2020, Póvoa de Varzim, Portugal, 24–26 June 2020; pp. 368–376. [Google Scholar]
- Strazdas, D.; Hintz, J.; Khalifa, A.; Abdelrahman, A.A.; Hempel, T.; Al-Hamadi, A. Robot systemassistant (RoSA): Towards intuitive multi-modal and multi-device human-robot interaction. Sensors 2022, 22, 923. [Google Scholar] [CrossRef] [PubMed]
- D’Mello, S.; Olney, A.; Williams, C.; Hays, P. Gaze tutor: A gaze-reactive intelligent tutoring system. Int. J. Hum.-Comput. Stud. 2012, 70, 377–398. [Google Scholar] [CrossRef] [Green Version]
- Jiang, M.; Zhao, Q. Learning visual attention to identify people with autism spectrum disorder. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3267–3276. [Google Scholar]
- Hennessey, C.; Noureddin, B.; Lawrence, P. A single camera eye-gaze tracking system with free head motion. In Proceedings of the 2006 Symposium on Eye Tracking Research & Applications, San Diego, CA, USA, 27–29 March 2006; pp. 87–94. [Google Scholar]
- Yoo, D.H.; Chung, M.J. A novel non-intrusive eye gaze estimation using cross-ratio under large head motion. Comput. Vis. Image Underst. 2005, 98, 25–51. [Google Scholar] [CrossRef]
- Huang, M.X.; Li, J.; Ngai, G.; Leong, H.V. Screenglint: Practical, in-situ gaze estimation on smartphones. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 2546–2557. [Google Scholar]
- Biswas, P. Appearance-based gaze estimation using attention and difference mechanism. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3143–3152. [Google Scholar]
- Cheng, Y.; Huang, S.; Wang, F.; Qian, C.; Lu, F. A coarse-to-fine adaptive network for appearance-based gaze estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 10623–10630. [Google Scholar]
- Chen, Z.; Shi, B.E. Appearance-based gaze estimation using dilated-convolutions. In Proceedings of the Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 309–324. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-based gaze estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 4511–4520. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Mpiigaze: Real-world dataset and deep appearance-based gaze estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 162–175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kellnhofer, P.; Recasens, A.; Stent, S.; Matusik, W.; Torralba, A. Gaze360: Physically unconstrained gaze estimation in the wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6912–6921. [Google Scholar]
- Zhang, X.; Park, S.; Beeler, T.; Bradley, D.; Tang, S.; Hilliges, O. Eth-xgaze: A large scale dataset for gaze estimation under extreme head pose and gaze variation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 365–381. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. It’s written all over your face: Full-face appearance-based gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Venice, Italy, 22–29 October 2017; pp. 51–60. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Singapore, 29–30 March 2021. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. In Proceedings of the International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2020; pp. 579–589. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 16519–16529. [Google Scholar]
- Zhu, Z.; Ji, Q. Eye gaze tracking under natural head movements. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; pp. 918–923. [Google Scholar]
- Schneider, T.; Schauerte, B.; Stiefelhagen, R. Manifold alignment for person independent appearance-based gaze estimation. In Proceedings of the IEEE/CVF International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 1167–1172. [Google Scholar]
- Huang, Q.; Veeraraghavan, A.; Sabharwal, A. Tabletgaze: Dataset and analysis for unconstrained appearance-based gaze estimation in mobile tablets. Mach. Vis. Appl. 2017, 28, 445–461. [Google Scholar] [CrossRef]
- Cheng, Y.; Lu, F.; Zhang, X. Appearance-based gaze estimation via evaluation-guided asymmetric regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 100–115. [Google Scholar]
- Yu, Y.; Liu, G.; Odobez, J.M. Deep multitask gaze estimation with a constrained landmark-gaze model. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, Z.; Shi, B.E. Towards High Performance Low Complexity Calibration in Appearance Based Gaze Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 1174–1188. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Zhao, R.; Su, H.; Ji, Q. Generalizing eye tracking with bayesian adversarial learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11907–11916. [Google Scholar]
- Fischer, T.; Chang, H.J.; Demiris, Y. Rt-gene: Real-time eye gaze estimation in natural environments. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 334–352. [Google Scholar]
- Cheng, Y.; Zhang, X.; Lu, F.; Sato, Y. Gaze estimation by exploring two-eye asymmetry. IEEE Trans. Image Process. 2020, 29, 5259–5272. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Narasimhan, K.; Salimans, T. Improving Language Understanding by Generative Pre-Training. Open AI. Available online: https://openai.com/research/language-unsupervised (accessed on 11 June 2018).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Liu, Y.; Zhang, Y.; Wang, Y.; Hou, F.; Yuan, J.; Tian, J.; Zhang, Y.; Shi, Z.; Fan, J.; He, Z. A survey of visual transformers. arXiv 2021, arXiv:2111.06091. [Google Scholar] [CrossRef]
- Cordonnier, J.B.; Loukas, A.; Jaggi, M. On the relationship between self-attention and convolutional layers. In Proceedings of the 8rd International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Studying Stand Alone Self-Attention in Vision Models. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar]
- Funes Mora, K.A.; Monay, F.; Odobez, J.M. EYEDIAP: A database for the development and evaluation of gaze estimation algorithms from RGB and RGB-D cameras. In Proceedings of the Symposium on Eye Tracking Research and Applications, Safety Harbor, FL, USA, 22–31 March 2014; pp. 255–258. [Google Scholar]
- Smith, B.A.; Yin, Q.; Feiner, S.K.; Nayar, S.K. Gaze locking: Passive eye contact detection for human-object interaction. In Proceedings of the 26th Annual ACM Symposium on User Interface Software and Technology, St. Andrews, UK, 8–11 October 2013; pp. 271–280. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5203–5212. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Output | ResNet-50 | BoT2L-Net |
|---|---|---|---|
| C1 | 2 | 2 | |
| C2 | 3 × 3 maxpool, stride 2 | ||
| C3 | |||
| C4 | |||
| C5 | |||
| Average pool 1000-d fc | Average pool 512-d fc 90-d fc | ||
| params |
| Method | MPIIFaceGaze |
|---|---|
| MPIIGaze [16] | 5.4° |
| AR-Net [27] | 5.0° |
| Full-Face [19] | 4.8° |
| Dilated-Net [14] | 4.8° |
| GEDD-Net [29] | 4.5° |
| FAR-Net [32] | 4.3° |
| CA-Net [13] | 4.1° |
| AGE-Net [12] | 4.09° |
| Bot2L-Net (ours) | 3.97° |
| Method | Front 180° | Front Facing |
|---|---|---|
| Full-Face [19] | 14.99° | N/A |
| Dilated-Net [14] | 13.73° | N/A |
| RT-Gene [31] | 12.26° | N/A |
| CA-Net [13] | 12.20° | N/A |
| Gaze360 (LSTM) [17] | 11.40° | 11.10° |
| Bot2L-Net (ours) | 11.53° | 9.59° |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Zhou, J.; Wang, L.; Yin, Y.; Wang, Y.; Ding, Z. BoT2L-Net: Appearance-Based Gaze Estimation Using Bottleneck Transformer Block and Two Identical Losses in Unconstrained Environments. Electronics 2023, 12, 1704. https://doi.org/10.3390/electronics12071704
Wang X, Zhou J, Wang L, Yin Y, Wang Y, Ding Z. BoT2L-Net: Appearance-Based Gaze Estimation Using Bottleneck Transformer Block and Two Identical Losses in Unconstrained Environments. Electronics. 2023; 12(7):1704. https://doi.org/10.3390/electronics12071704
Chicago/Turabian StyleWang, Xiaohan, Jian Zhou, Lin Wang, Yong Yin, Yu Wang, and Zhongjun Ding. 2023. "BoT2L-Net: Appearance-Based Gaze Estimation Using Bottleneck Transformer Block and Two Identical Losses in Unconstrained Environments" Electronics 12, no. 7: 1704. https://doi.org/10.3390/electronics12071704