Abstract
Most of the existing intelligent anti-jamming communication algorithms model sensing, learning, and transmission as a serial process, and ideally assume that the duration of sensing and learning timeslots is very short, almost negligible. However, when the jamming environment changes rapidly, the sensing and learning time can no longer be ignored, and the adaptability of the wireless communication system to the time-varying jamming environment will be significantly reduced. To solve this problem, this paper proposes a parallel Q-learning (PQL) algorithm. In the case of long sensing and learning time, by modeling sensing, learning, and transmission as parallel processes, the time that the transmitter remains silent during sensing and learning is reduced. Aiming at the situation that the PQL algorithm is susceptible to jamming when the jamming changes faster, this paper proposes an intelligent anti-jamming algorithm for wireless communication based on Slot Cross Q-learning (SCQL). In the case of rapid change of jamming channel, the system can sense and learn the jamming patterns in multiple successive jamming periods at the same time in the same timeslot, and use multiple Q-tables to learn the jamming patterns in different jamming periods, so as to achieve the effect of reliable communication in the environment with rapid change of jamming. The simulation results show that the jamming collision rate of the proposed algorithm under the condition of intelligent blocking jamming is equivalent to that of the traditional Q-learning (QL), but the timeslot utilization rate is higher. Compared with PQL, the proposed algorithm has the same slot utilization and lower jamming collision rate. Compared with random frequency hopping (RFH) anti-jamming, the proposed algorithm not only has higher timeslot utilization, but also has lower jamming collision rate.
1. Introduction
With the increasing demand for wireless communication and the proliferation of users, there is a growing strain on spectrum resources, leading to interference between users. Additionally, due to the openness of the wireless channel, malicious jammers can deliberately interfere with wireless communication [1,2,3]. Therefore, to ensure efficient and secure wireless communication, it is crucial to use intelligent anti-jamming methods [4,5,6,7,8,9,10]. The intelligent anti-jamming method is based on real-time sensing of the electromagnetic environment, intelligent anti-jamming decision-making as the core, and dynamic adjustment of communication signal parameters as a means to achieve the purpose of countering malicious jamming and improving transmission reliability. The development of machine learning provides a new research idea for intelligent anti-jamming methods. Reinforcement Learning (RL) is a branch of machine learning that is used to solve the problem that agents can maximize returns or achieve specific goals by learning strategies during the interaction with the environment. Applied to anti-jamming decisions in wireless communication, RL can find the transmission strategy that maximizes the return of communication system. In recent years, effective anti-jamming technologies based on RL have been developed. Bout et al. [11] reviewed the solutions of machine learning-based attack technology in the Internet of Things, and proposed that interference, edge channels, false data injection, and adversarial machine learning attacks are key research directions in the future. Wang et al. [12] used federated learning (FL) technology to propose a secret drive signal transmission scheme based on collaborative interference to solve the problem of eavesdropping attacks when parameter servers sent model data to wireless devices. Wang et al. [13] reviewed the latest developments in Spectrum Sharing (SS) based on machine learning, and described the latest methods to improve the performance of spectrum-sharing communication systems in various important aspects, including ML-based Cognitive Radio networks (CRNs), ML-based database assistance systems, and ML-based communication systems. From the physical layer, the security problem based on an ML algorithm and corresponding defense strategy are proposed, including Primary User Emulation (PUE) attack, spectrum sensing data forgery (SSDF). Spectrum Sensing Data Falsification) attacks, jamming attacks, eavesdropping attacks, and privacy concerns. Slimane et al. [14] proposed a lightweight machine learning technology, LightGBM, to detect deceptive jamming attacks on UAV networks, taking into account the size, weight, and power limitations of UAV application scenarios. Using half of the memory obtains a prediction 21 times faster than Gradient Boost and Random Forest. Zhang et al. [15] proposed an anti-interference algorithm based on Dyna-Q to efficiently establish the optimal transmission path in wireless communication networks under malicious interference environment. According to previous observations on the environment, the Q-table selected the optimal sequential nodes to reduce the packet loss rate and obtained a faster convergence rate than model-free reinforcing learning.
Many anti-jamming algorithms have been proposed for various jamming styles, such as time-domain anti-random impulsive jamming proposed by Han et al. [16], a PQL algorithm developed by Huang et al. [17], and a QL serial structure proposed by Zhang et al. [18]. Moreover, some studies have explored using deep reinforcement learning (DRL) for anti-jamming, such as Li et al.’s [19] cognitive radio network application and Wang et al.’s [20] intelligent transportation system case, as well as Yao et al.’s [21] QL-based anti-jamming strategy for UAV communication systems. However, most of these approaches assume that sensing and learning timeslots are negligible compared to transmission timeslots, which is not always the case in real-world scenarios as the number of communication channels and complexity of jamming patterns increases. As a result, longer times may be required for sensing and learning, reducing available transmission time and resulting in ineffective communication transmission rates.
To improve the timeslot utilization of wireless communication and achieve better communication transmission rates, this paper proposes a parallel timeslot structure for perception, learning, and transmission, and a PQL intelligent anti-jamming method. However, the parallel structure may encounter issues like low slot utilization and high jamming collision rates when the sensing and learning timeslot length surpasses the transmission timeslot length. To overcome this problem, the paper proposes a time SCQL algorithm to reduce ineffective decision-making due to long sensing time and rapid changes in jamming style.
In summary, this paper has the following three contributions:
- Analyzing the influence of different sensing, learning, and transmission timeslot structure distribution on the time utilization and anti-jamming effect of the algorithm.
- Proposing a PQL algorithm to address low slot utilization using limited jamming change speed.
- Proposing a SCQL algorithm to mitigate high jamming collision rates.
The simulation is carried out and compared with other methods. Compared with RFH, the jamming collision rate of PQL and QL can converge to 0 after learning, but the timeslot utilization rate of QL is lower than that of RFH, while the learning rate of PQL proposed in this paper can converge to 1 through learning. PQL has better anti-jamming performance and time utilization than RFH, and has a higher timeslot utilization than QL. As for SCQL, Compared with RFH, the jamming collision rate of SCQL, PQL and QL can converge to 0 after learning, and the timeslot utilization rate of SCQL is higher than all of PQL and QL, while the learning rate of SCQL proposed in this paper can converge to 1 through learning. SCQL has better anti-jamming performance and higher time utilization than RFH, PQL, and QL.
In conclusion, this paper proposes a novel intelligent anti-jamming method to improve the efficiency and security of wireless communication. By integrating parallel timeslot structure, PQL algorithm, and time SCQL algorithm, this anti-jamming method can effectively counter malicious jamming and achieve better communication transmission rates.
This manuscript is structured as follows: Section 2 introduces the system components and problem formulation; Section 3 proposes the intelligent anti-jamming algorithm of wireless communication based on PQL and the intelligent anti-jamming method of wireless communication based on time SCQL; Section 4 presents the simulation results and data analysis of the proposed algorithm. Finally, Section 5 concludes the manuscript.
2. System Components and Problem Formulation
This section introduces the system components and problem formulation. In the system components, the communication system is introduced, which is composed of three subsystems: decision subsystem, Q-learning subsystem, and communication subsystem. In problem formulation, the Q-learning of different timeslot structures is introduced and the calculation formulas of timeslot utilization are given.
2.1. System Components
The communication system components are shown in Figure 1. The whole system includes three subsystems, which are communication subsystem, QL subsystem, and decision subsystem. To facilitate the research, the following assumptions are made [1,9]:
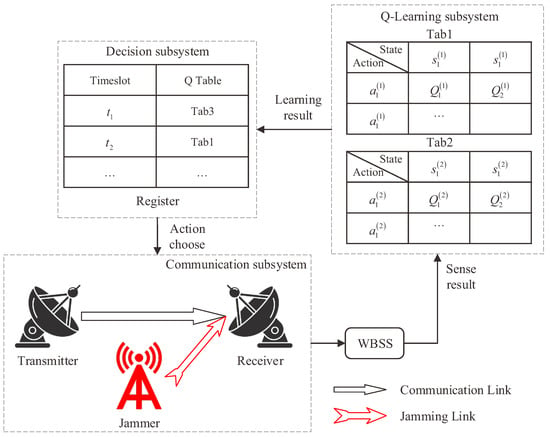
Figure 1.
System Components.
- The communication subsystem contains a transmitter, a receiver, and a jammer. An optional channel is allocated between the transmitter and the receiver. The transmitter has no a priori knowledge about the jamming strategy, but can sense whether there is jamming in all channels at each timeslot using wide-band spectrum sensing technology;
- The jammer can sense the communication probability of each channel in each timeslot of the previous period, and carry out high-power and pressure jamming on the channels with the highest communication probability, and the communication on the jamming channel is bound to fail;
- In the SCQL algorithm, there are multiple Q-tables in the QL subsystem, and different Q-tables are updated alternately with the timeslot. The decision results obtained by learning are stored in the registers of the decision subsystem.
2.2. Problem Formulation
If the spectrum sensing timeslot is denoted as , the learning timeslot is denoted as , the transmission timeslot is denoted as, and the jamming collision rate is denoted as , then the timeslot utilization is as follows [16]:
As shown in Figure 2a, QL anti-jamming communication considers spectrum sensing, learning, and data transmission as a serial process. At the same time, it is considered that the sensing and learning timeslots are very short and almost negligible. Then, according to Equation (1), the timeslot utilization is only related to the jamming collision rate [1].
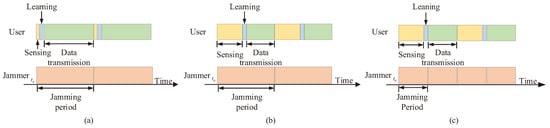
Figure 2.
QL anti-jamming communication timeslot structure diagram. (a) Sensing and learning timeslot is very short; (b) The timeslot of sensing and learning is comparable to the transmission timeslot; (c) The jamming changes rapidly.
However, when the proportion of sensing and learning time in a period is large, the proportion of transmission time will be small. In addition, when the time interval of jamming change is less than the process of sensing, learning, and transmission of wireless communication system, the communication transmission reliability will also decrease significantly.
As shown in Figure 2b, when the timeslot of sensing and learning is equal to the transmission timeslot, the timeslot utilization is as follows:
Obviously, when is large, the timeslot utilization is very low even if the jamming collision rate is 0. In addition, as shown in Figure 2c, when the jamming changes rapidly, the QL anti-jamming algorithm also struggles to meet the anti-jamming requirements.
Therefore, sensing, learning, and data transmission are considered to be carried out simultaneously, forming a parallel structure, as shown in Figure 3a.

Figure 3.
PQL anti-jamming communication timeslot structure diagram. (a) The interference period is similar to the spectrum sensing and learning period; (b) The spectrum sensing and learning period is significantly longer than the jamming period, sacrificing the jamming collision rate; (c) The spectrum sensing and learning period is significantly longer than the interference period, timeslot utilization is sacrificed.
Obviously, by performing spectrum sensing, learning, and data transmission in parallel, the timeslot utilization is greatly improved. However, when facing jamming over a short period and fast change as shown in Figure 3a, or as shown in Figure 3b, the timeslot utilization is guaranteed, but the second half of the transmission is changed due to the jamming, and the jamming collision rate will be greatly improved. As shown in Figure 3c, the jamming collision rate is guaranteed, but the transmitter will be silent for half of the timeslot length with low timeslot utilization. Obviously, this method cannot take into account both timeslot utilization and jamming collision rate [17].
Therefore, in order to reduce the jamming collision rate without reducing the timeslot utilization, SCQL is proposed based on the PQL algorithm in this paper, and its timeslot structure is shown in Figure 4.
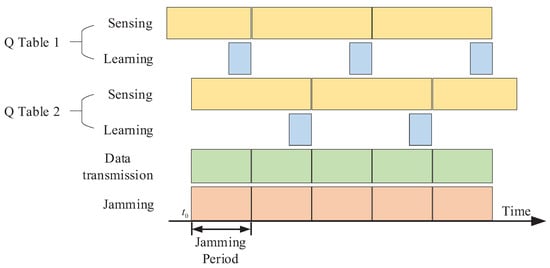
Figure 4.
Timeslot structure of SCQL anti-jamming communication scheme.
By using multiple agents (multiple Q-tables), the jamming of different stages in the same cycle can be learned separately. Therefore, it not only ensures the transmission at all times, improves the timeslot utilization, but also ensures the timeliness of the transmission strategy with the change of jamming, and reduces the jamming collision rate.
This manuscript uses a Markov Decision Process (MDP) [22,23,24] to solve the model.
For quadruples , the state space S can be expressed as follows:
where denotes that the kth jammed channel is channel j, and, at most, N channels can be jammed in the same timeslot.
The action space A can be expressed as follows:
where means that the transmitter chooses to communicate on channel i.
The state transition probability p depends on the jamming and is unknown.
The reward function r is defined as follows:
where represents the reward function of channel i at timeslot t, and the loss is −1 when the message transmission fails. The reward for successful message transmission is 1, and represents the jamming state of each channel at time t, .
QL is used to solve the MDP process. First, the long-term cumulative reward can be expressed as follows:
where is the discount factor, which represents the importance of future rewards, and is the immediate reward value obtained at step t. The goal of QL is to find a policy that maximizes the long-term cumulative reward.
In order to solve the optimal policy, the state value function V and state-action value function Q are defined as follows:
Since it satisfies the MDP model, it can be converted into a recursive form as follows:
where represents the probability of taking action a in state s and the next state is and is the corresponding reward.
According to Bellman’s optimization principle, the optimal value can be obtained as follows:
Therefore, the optimal policy can be obtained as follows:
Since the QL algorithm does not require prior knowledge such as state transition probabilities, its update formula is as follows:
where is the learning rate, if satisfies the condition
Then, the QL algorithm must converge after a finite number of iterations. After the Q-table has converged, the action corresponding to choosing the maximum Q value in each state is the optimal action in that state.
3. Scheme
In this section, we propose an intelligent anti-jamming algorithm for wireless communication, which is based on PQL, as well as the intelligent anti-jamming method based on time SCQL. The algorithm description and complexity, as well as convergence analysis of both PQL and SCQL are provided in this section.
3.1. Algorithm
In order to solve the problem of low slot utilization of serial Q-learning(SQL), a PQL algorithm is proposed. Since sensing, learning, and transmission are carried out simultaneously, the current transmission strategy is given by the sensing and learning results of the previous timeslot, and the current time sensing and learning results are also used to control the transmission of the next timeslot. The algorithm is as follows:
Then, the SCQL algorithm was proposed to solve the problem of high jamming collision rate or low timeslot utilization in the face of faster change of jamming channel in PQL. The core algorithm is as follows:
- Firstly, through a period of observation, the jamming period , perception and learning period are calculated, and the required number of Q-tables N is obtained according to Equation (16).
- The jamming in this jamming period is sensed and the table is updated.
- For timeslot t, if , the optimal action in the next timeslot is obtained by using the table and according to the -greedy strategy, that is, the appropriate communication channel is selected. The -greedy strategy is as follows:where is the exploration probability and satisfies Equation (19).
3.2. Complexity and Convergence Analysis
The computational complexity of Algorithm 1 is in steps 5, 6, and 7. If the single computational complexity is denoted as , , , and, respectively. Then iterate T times to execute steps 5, 6, and 7 of the algorithm and the total algorithm complexity is so the algorithm can obtain the optimal solution in polynomial time.
| Algorithm 1 Parallel Q-learning (PQL) |
|
The computational complexity of Algorithm 2 is in step 5, 6, and 7. If the single computational complexity is denoted as , , , and, respectively. Then iterate T times to execute steps 5, 6, and 7 of the algorithm and the total algorithm complexity is so the algorithm can obtain the optimal solution in polynomial time.
| Algorithm 2 Slotted Cross Q-learning (SCQL) |
|
If the learning factor is a non-negative constant value and the conditions in Equation (15) are satisfied, the Q-learning algorithm will surely converge to the optimal strategy after a finite number of iterations. In this section, the algorithms based on PQL and SCQL are proposed, which are Q-learning in essence and can also converge to the optimal transmission policy.
4. Simulation
This section presents a simulation of the proposed scheme and provides comparisons with other schemes. We compare PQL and SCQL with QL and RFH in terms of the time utilization ratio and jamming collision rate.
4.1. Setting
This section conducts anti-jamming research for intelligent blocking jamming. The basic idea of intelligent blocking jamming is that the jammer chooses the four channels with the highest communication frequency to jam through the communication frequency of each channel in each timeslot for a period of time. The simplified slot-channel diagram of jamming channel in a period is as Figure 5 [16,17].
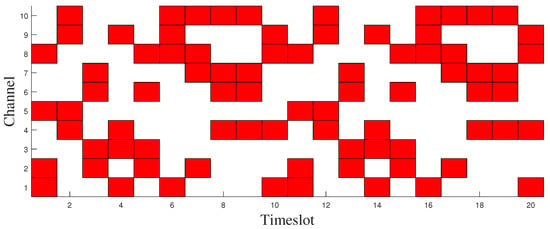
Figure 5.
Timeslot structure of SCQL anti-jamming communication scheme.
The simulation parameter settings are shown in Table 1.

Table 1.
Simulation Parameters.
4.2. Results
Figure 6 shows the comparison between PQL, QL and RFH algorithms in terms of jamming collision rate. In the simulation, the sum of the sensing and learning timeslot lengths is equal to the transmission timeslot length and the jamming timeslot length. It can be seen from the figure that when the algorithm converges, the jamming collision rate of both QL and PQL can be reduced to 0 after the algorithm converges, indicating that for the jamming with slow jamming change speed, both algorithms can effectively learn the jamming strategy and make the correct channel selection action. However, the random frequency hopping strategy randomly selects communication channels in each timeslot, and for each timeslot, 4 channels out of 10 must be jammed, so the jamming collision rate is 0.4.
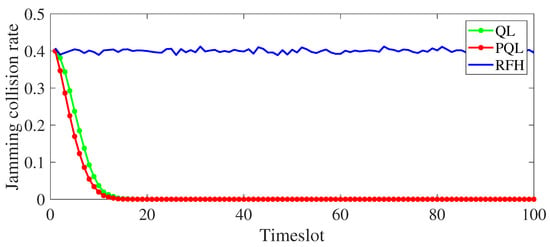
Figure 6.
The comparison diagram of jamming collision rate of three algorithms in the case of short sensing and learning timeslots.
Figure 7 shows the comparison of timeslot utilization between PQL, QL and RFH algorithms when sensing and learning timeslots are short. QL adopts a serial structure to model the sensing, learning, and transmission timeslots, where the length of each timeslot is set to ms, ms, and can be calculated. According to Equation (2), the timeslot utilization is. Therefore, constrained by the structure itself, the maximum timeslot utilization of QL is 1/2. It can also be seen from the figure that when the algorithm converges, the timeslot utilization of QL is 0.5, which is consistent with the theoretical results. PQL models the sensing, learning and transmission timeslots into a parallel structure. When the jamming collision rate is reduced to 0, the slot utilization can reach 100%.
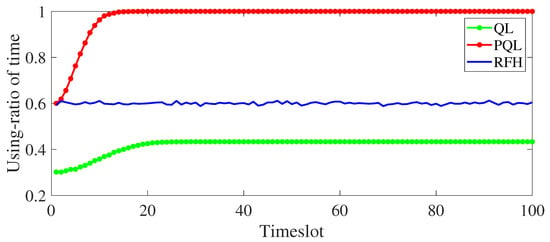
Figure 7.
The comparison of timeslot utilization of the three algorithms in the case of short sensing and learning timeslots.
Figure 8 shows the comparison of timeslot utilization of four algorithms, namely, QL, PQL, SCQL and RFH, in combating intelligent blocking jamming. In the simulation, the sum of the sensing and learning timeslot lengths is twice as long as the transmission timeslot length and the jamming timeslot length, as shown in Figure 8. From the simulation results, we can see that when the algorithm converges, the jamming collision rate of the random frequency hopping strategy is 0.4, and the reason is the same as the previous analysis. The jamming collision rate of PQL is about 0.22. The reason is that the jamming channel changes too fast, and the PQL algorithm experiences the jamming of two timeslots in each transmission timeslot (as shown in Figure 3), but the PQL algorithm only learns the jamming of the former timeslot effectively, which leads to the loss of jamming information of the latter timeslot. It also leads to the increase of jamming collision rate. Because of the serial structure of QL, the communication is stopped whenever the jamming changes, and the communication is carried out on the new channel after the effective learning of the new jamming information, so that the jamming in each sensing and learning timeslot is effectively avoided, so that the jamming collision rate is reduced to 0. The SCQL algorithm establishes multiple Q-tables, and different Q-tables record the jamming encountered in the same sensing and learning timeslot in different jamming timeslots. Thus, each jamming timeslot is effectively learned, so that the jamming collision rate is reduced to 0.
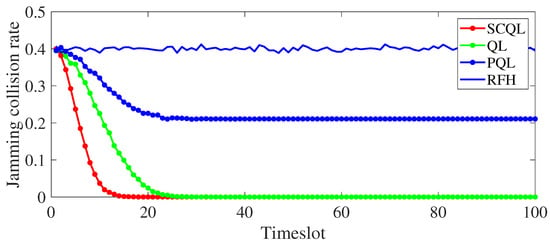
Figure 8.
The comparison diagram of jamming collision rate of four algorithms in the case of long sensing and learning timeslots.
Figure 9 shows the comparison of timeslot utilization of four algorithms, namely traditional QL, PQL, SCQL and RFH, in combating intelligent blocking jamming. Among them, the length of each timeslot is set to, which can be calculated. QL adopts a serial structure to model the sensing, learning, and transmission timeslots. According to Equation (2), the timeslot utilization is. Therefore, limited by the structure itself, the maximum timeslot utilization of QL is 1/3. Due to the PQL model of sensing, learning, and transmission timeslots into a parallel structure, the timeslot utilization has been improved to a certain extent. However, due to the high jamming collision rate, the timeslot utilization can only reach about 78%. By using multiple Q-tables to learn the jamming of different jamming timeslots in the same sensing and learning timeslot, the jamming collision rate is effectively reduced. In addition, the sensing and learning timeslot and the transmission timeslot are parallel and carried out at the same time, so the slot utilization can reach 100%.
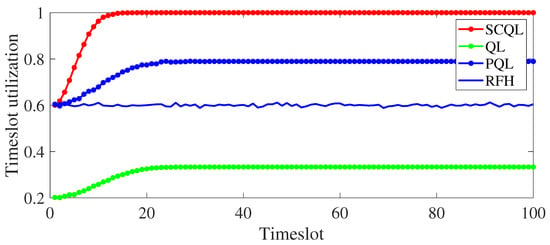
Figure 9.
The comparison of timeslot utilization of the four algorithms in the case of long sensing and learning timeslots.
From the simulation results, it can be seen that due to the blind channel selection strategy, the random frequency hopping algorithm is not ideal timeslot utilization and jamming collision rate, which is the worst anti-jamming effect among the four algorithms. The QL algorithm can achieve low jamming collision rate at the expense of slot utilization because it models sensing, learning, and transmission timeslots as a series structure. The PQL algorithm can effectively improve the slot utilization by modeling the sensing, learning, and transmission timeslots as a parallel structure, but at the cost of high jamming collision rate. SCQL fully considers the advantages and disadvantages of traditional QL and PQL, and adopts a parallel structure and multiple Q-tables to record the jamming of different jamming timeslots in the same sensing and learning timeslot, respectively, so as to achieve the optimal slot utilization and jamming collision rate.
5. Conclusions
Aiming at the problem that the QL algorithm has low slot utilization and is difficult to adapt to the rapid change of jamming, this paper proposes a PQL algorithm, which models the sensing, learning, and transmission timeslots into a parallel structure to improve slot utilization. Aiming at the problem that the adaptability of PQL to rapidly-changing jamming needs to be improved, a SCQL algorithm is proposed. The algorithm can effectively reduce the jamming collision rate by establishing multiple Q-tables to record the jamming behavior of different jamming timeslots in the same sensing and learning timeslot. The simulation results show that although QL can reduce the collision rate of jamming to 0, the utilization of the timeslot is low, and it cannot adapt to fast time-varying jamming. The improved PQL improves the slot utilization, but the jamming collision rate is high. Random frequency hopping, which randomly selects a channel for transmission in each timeslot, is a purely random strategy, so the jamming collision rate and timeslot utilization are not ideal. SCQL can greatly improve the timeslot utilization, while ensuring a very low jamming collision rate, and significantly improving the anti-jamming effectiveness of communication systems. There are more and more attacks targeting machine learning based on intelligent algorithms, in order to protect machine learning systems from these attacks [27,28]. We plan to use adversarial machine learning (AML) [29,30] techniques to solve this problem in the next step. The problem of anti-jamming communication considered in this paper can be modeled as state-to-action mapping, in which data classification errors do occur. In the next step, we plan to conduct adversarial training to reduce data classification errors and improve the robustness of the system.
Author Contributions
Conceptualization, Z.Z., Z.P. and Y.N.; methodology, Z.Z. and Z.P.; software, Z.Z. and B.W.; validation, B.W. and Z.Z.; formal analysis, B.W. and Y.N.; investigation, Z.P. and Y.N.; resources, B.W. and Z.Z.; data curation, B.W. and Z.Z.; writing—original draft preparation, Z.Z. and Z.P.; writing—review and editing, B.W. and Y.N.; visualization, Z.Z., B.W. and Z.P.; supervision, Z.Z. and B.W.; project administration, Y.N. and Z.Z.; funding acquisition, Y.N. and Z.Z. All authors have read and agreed to the published version of the manuscript.
Funding
National Natural Science Foundation of China: U19B2014.
Data Availability Statement
Due to institutional data privacy requirements, our data is unavailable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhou, Q.; Niu, Y.; Xiang, P.; Li, Y. Intra-Domain Knowledge Reuse Assisted Reinforcement Learning for Fast Anti-Jamming Communication. IEEE Trans. Inf. Forensics Secur. 2023. [Google Scholar] [CrossRef]
- Pärlin, K.; Riihonen, T.; Turunen, M.; Nir, V.L.; Adrat, M. Known-Interference Cancellation in Cooperative Jamming: Experimental Evaluation and Benchmark Algorithm Performance. IEEE Wirel. Commun. Lett. 2023. [Google Scholar] [CrossRef]
- Kirk, B.H.; Martone, A.F.; Gallagher, K.A.; Narayanan, R.M.; Sherbondy, K.D. Mitigation of Clutter Modulation in Cognitive Radar for Spectrum Sharing Applications. IEEE Trans. Radar Syst. 2023. [Google Scholar] [CrossRef]
- Chen, X.; Guo, D.; Wu, W. A Robust Detection-Estimation-Navigation Framework with Deep Reinforcement Learning against GPS Jamming. IEEE Access 2020, 8, 131750–131763. [Google Scholar]
- Zhang, H.; Han, X.; Cheng, J.; Lu, Y. A Reconfigurable Bayesian Adaptive Interference Mitigation SIC Receiver With Reinforcement Learning. IEEE Access 2021, 9, 15420–15434. [Google Scholar]
- Shahriar, M.; Lichtman, M.; Poston, J.D.; Amuru, S. Intelligent Anti-jamming Method for LEO Satellite Communication System Based on Reinforcement Learning. AEU—Int. J. Electron. Commun. 2021, 138, 153567. [Google Scholar]
- Yang, T.; Chen, Z.; Cao, G. Q-Learning-Based Dynamic anti-Jamming Transmission Design in Device-to-Device Assisted Vehicular Ad Hoc Networks. IEEE Trans. Intell. Transp. Syst. 2021, 4, 2193–2202. [Google Scholar]
- Li, W.; Chen, H.; Shi, R.; Gao, J. Anti-jamming stochastic gradient descent-based optimization deployment algorithm for wireless sensor networks. IET Wirel. Sens. Syst. 2021, 6, 536–543. [Google Scholar]
- Liu, J.; Xue, Y.; Shen, X. Reinforcement Learning for Active Interference Cancelling with Power Control in mmWave Cellular Networks. IEEE J. Sel. Areas Commun. 2020, 9, 2015–2027. [Google Scholar]
- Luo, Y.; Shi, S.; Ye, F. Anti-interference access control method based on the adaptive Q-learning algorithm for the satellite-IoT network. Comput. Electr. Eng. 2021, 91, 107072. [Google Scholar]
- Bout, E.; Loscri, V.; Gallais, A. How Machine Learning Changes the Nature of Cyberattacks on IoT Networks: A Survey. IEEE Commun. Surv. Tutorials 2022, 1, 248–279. [Google Scholar] [CrossRef]
- Wang, T.; Li, Y.; Wu, Y.; Tony, Q. Secrecy driven Federated Learning via Cooperative Jamming: An Approach of Latency Minimization. IEEE Trans. Emerg. Top. Comput. 2022, 99, 1. [Google Scholar] [CrossRef]
- Wang, Q.; Sun, H.; Hu, R.Q.; Bhuyan, A. When Machine Learning Meets Spectrum Sharing Security: Methodologies and Challenges. IEEE Open J. Commun. Soc. 2022, 3, 176–208. [Google Scholar] [CrossRef]
- Slimane, H.; Benouadah, S.; Khoei, T.; Kaabouch, N. A Light Boosting-based ML Model for Detecting Deceptive Jamming Attacks on UAVs. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022. [Google Scholar]
- Zhang, G.; Li, Y.; Niu, Y.; Zhou, Q. Anti-Jamming Path Selection Method in a Wireless Communication Network Based on Dyna-Q. Electronics 2022, 15, 2397. [Google Scholar] [CrossRef]
- Han, X.; Ma, L.; Wu, M.; Lu, Y.; Wang, S. A time-domain anti-random impulsive interference method based on reinforcement learning for wireless communication. IEEE Trans. Veh. Technol. 2018, 8, 7863–7877. [Google Scholar]
- Huang, L.; Ma, C.; Liang, J.; Xu, G. Parallel Q-learning Based Intelligence Anti-interference Method for Wireless Communication. J. Cent. South Univ. 2021, 4, 1286–1294. [Google Scholar]
- Zhang, Z.; Liu, J.; Xiao, P.; Liu, Y. Slot-cross Q-learning Algorithm for Intelligence Anti-jamming. J. Electron. Inf. Technol. 2015, 6, 1401–1405. [Google Scholar]
- Li, H.; Zhao, S.; Zhang, K.; Jin, D. Deep Reinforcement Learning for Anti-jamming in Cognitive Radio Networks. In Proceedings of the 2020 IEEE International Conference on Communications (ICC), Marrakech, Morocco, 12–14 December 2020; pp. 1–6. [Google Scholar]
- Wang, Q.; Chen, J.; Lin, F.; Meng, F. Reinforcement Learning-Based Anti-jamming Mechanism for Intelligent Transportation Systems. In Proceedings of the 2020 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Tempe, AZ, USA, 11–13 November 2020; pp. 1–6. [Google Scholar]
- Yao, F.; Li, Y.; Fan, T.; Sun, Y. A Q-Learning Based Anti-jamming Strategy for UAVs Communication System. In Proceedings of the 2018 International Wireless Communications and Mobile Computing Conference (IWCMC), Limassol, Cyprus, 25–29 June 2018; pp. 1294–1299. [Google Scholar]
- Su, H.; Pan, M.; Chen, H.; Liu, X. MDP-Based MAC Protocol for WBANs in Edge-Enabled eHealth Systems. Electronics 2023, 12, 947. [Google Scholar] [CrossRef]
- Xing, H.; Xing, Q.; Wang, K. Radar Anti-Jamming Countermeasures Intelligent Decision-Making: A Partially Observable Markov Decision Process Approach. Aerospace 2023, 10, 236. [Google Scholar] [CrossRef]
- Li, W.; Chen, J.; Liu, X.; Wang, X.; Li, Y.; Liu, D.; Xu, Y. Intelligent Dynamic Spectrum Anti-Jamming Communications: A Deep Reinforcement Learning Perspective. IEEE Wirel. Commun. 2022, 99, 1–7. [Google Scholar] [CrossRef]
- Machuzak, S.; Jayaweera, S.K. Reinforcement learning based anti-jamming with wideband autonomous cognitive radios. In Proceedings of the 2016 IEEE/CIC International Conference on Communications in China (ICCC), Chengdu, China, 27–29 July 2016. [Google Scholar]
- Morghare, G.; Bhadauria, S.S. An Effective Approach for Cognitive Radio Wideband Spectrum Compressive Sensing over AWGN/Rayleigh Channels. In Proceedings of the 2023 10th International Conference on Signal Processing and Integrated Networks (SPIN), Delhi, India, 23–24 March 2023; pp. 609–614. [Google Scholar]
- Ebrahimi, M.R.; Li, W.; Chai, Y.; Pacheco, J.; Chen, H. An Adversarial Reinforcement Learning Framework for Robust Machine Learning-based Malware Detection. In Proceedings of the 2022 IEEE International Conference on Data Mining Workshops (ICDMW), Orlando, FL, USA, 28 November–1 December 2022; pp. 567–576. [Google Scholar]
- Sayghe, A.; Anubi, O.M.; Konstantinou, C. Adversarial Examples on Power Systems State Estimation. In Proceedings of the 2020 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 17–20 February 2020; pp. 1–5. [Google Scholar]
- Vaccari, I.; Carlevaro, A.; Narteni, S.; Cambiaso, E.; Mongelli, M. eXplainable and Reliable Against Adversarial Machine Learning in Data Analytics. IEEE Access 2022, 10, 83949–83970. [Google Scholar] [CrossRef]
- Edwards, D.; Rawat, D.B. Quantum Adversarial Machine Learning: Status, Challenges and Perspectives. In Proceedings of the 2020 Second IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Atlanta, GA, USA, 28–31 October 2020; pp. 128–133. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).