
Hiding and Extracting Important Information in Encrypted Images by Using the Transformation of All Possible Permutations and VQ Codebook




Abstract
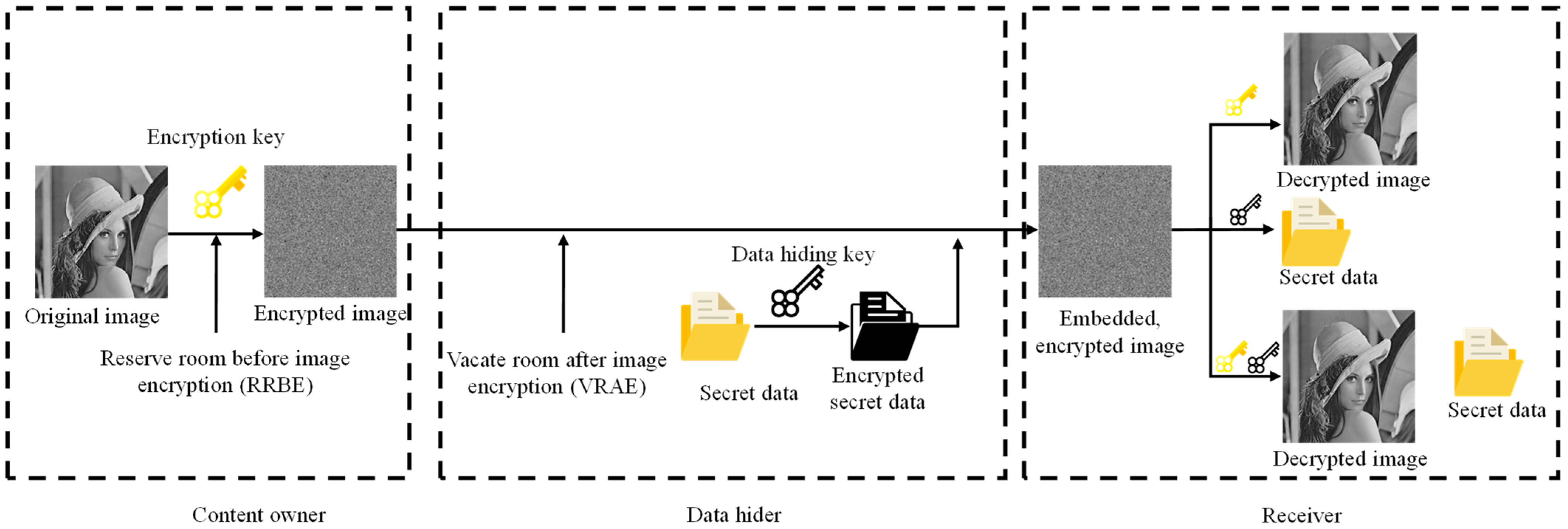
:1. Introduction
1.1. Background Introduction
1.2. Literature Review
2. Related Works
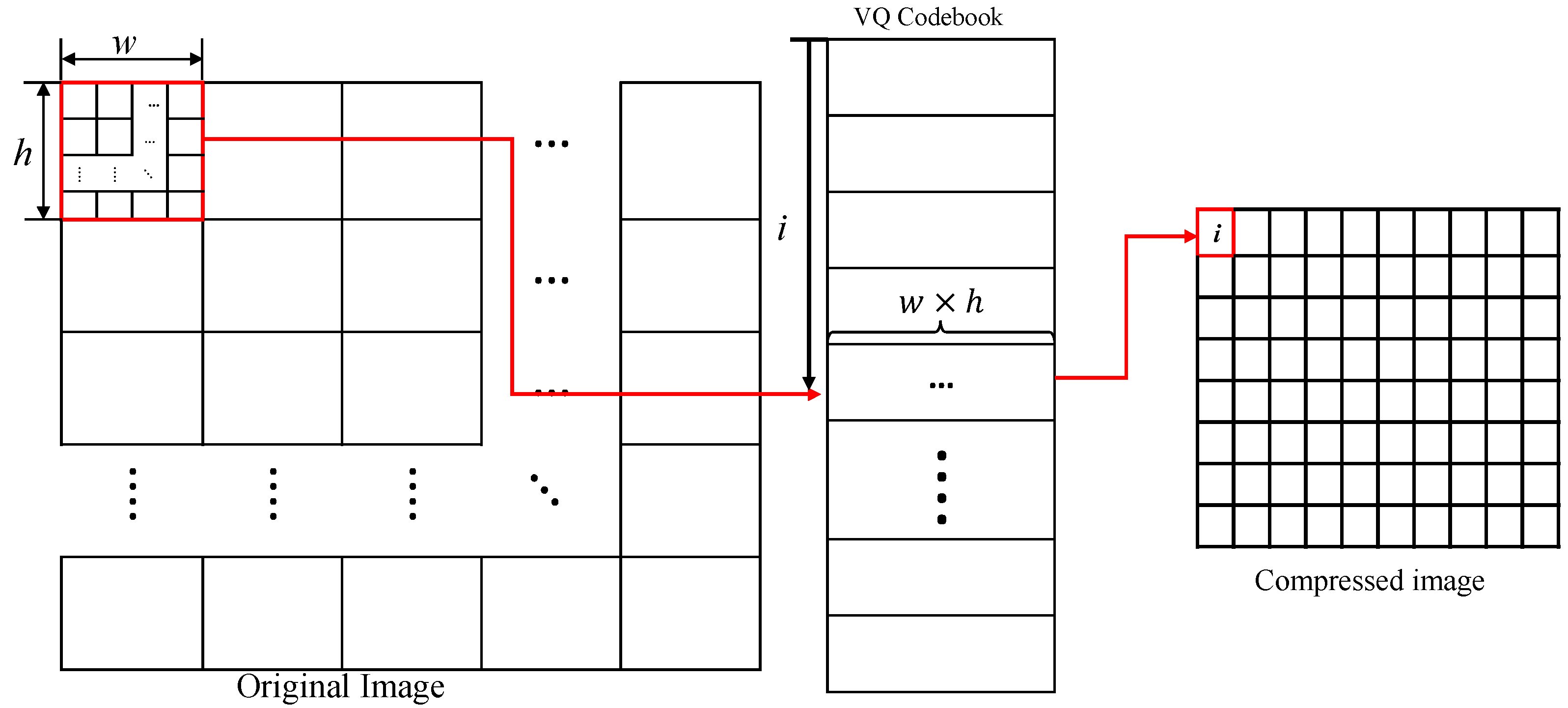
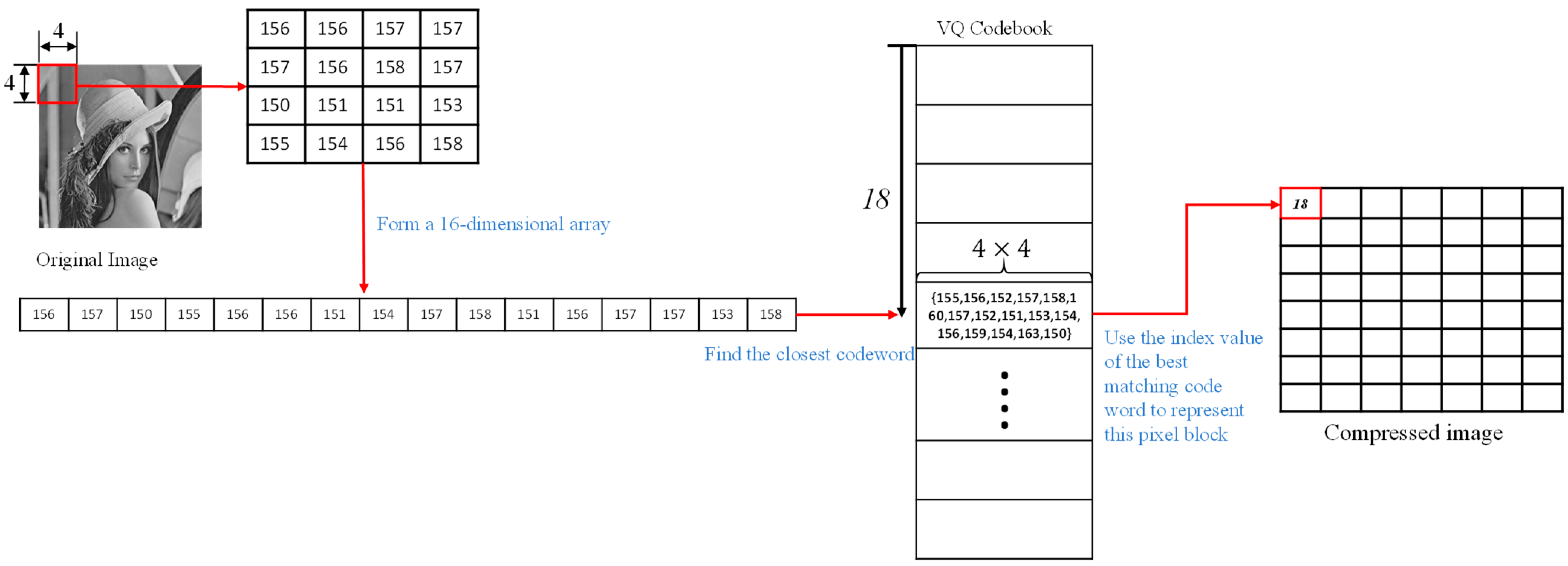
2.1. Vector Quantization (VQ)
2.2. Panchikkil et al.’s Method
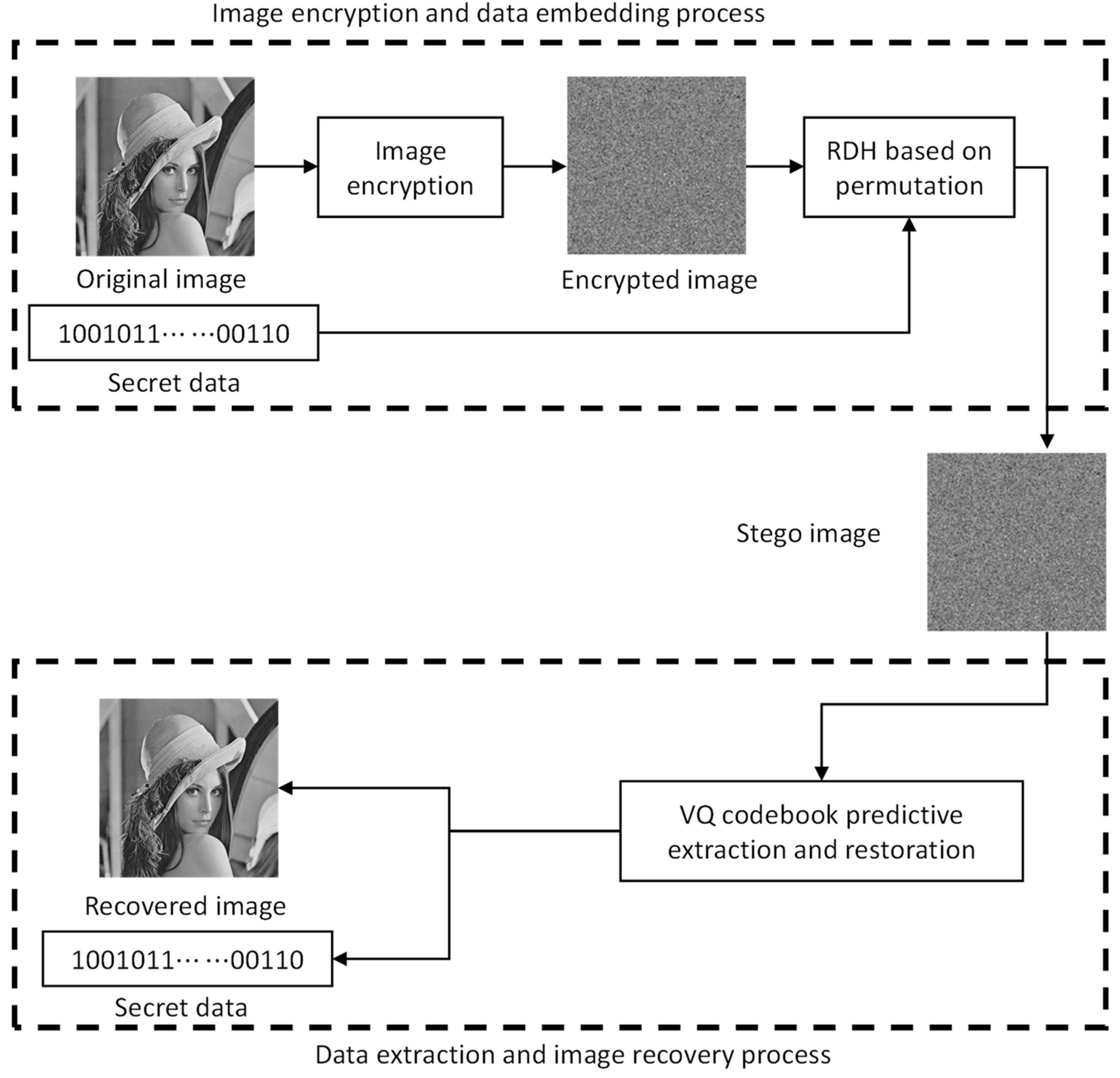
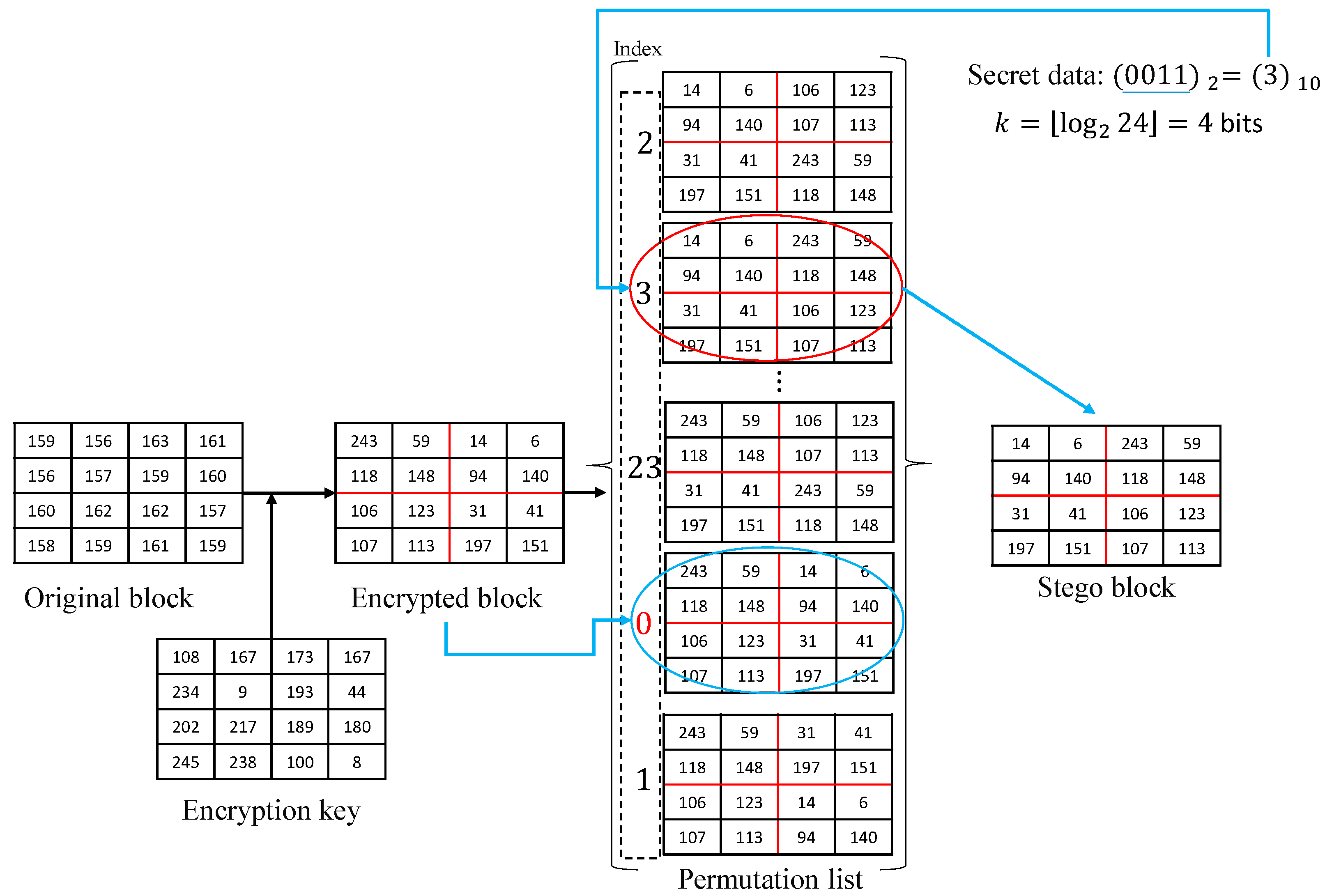
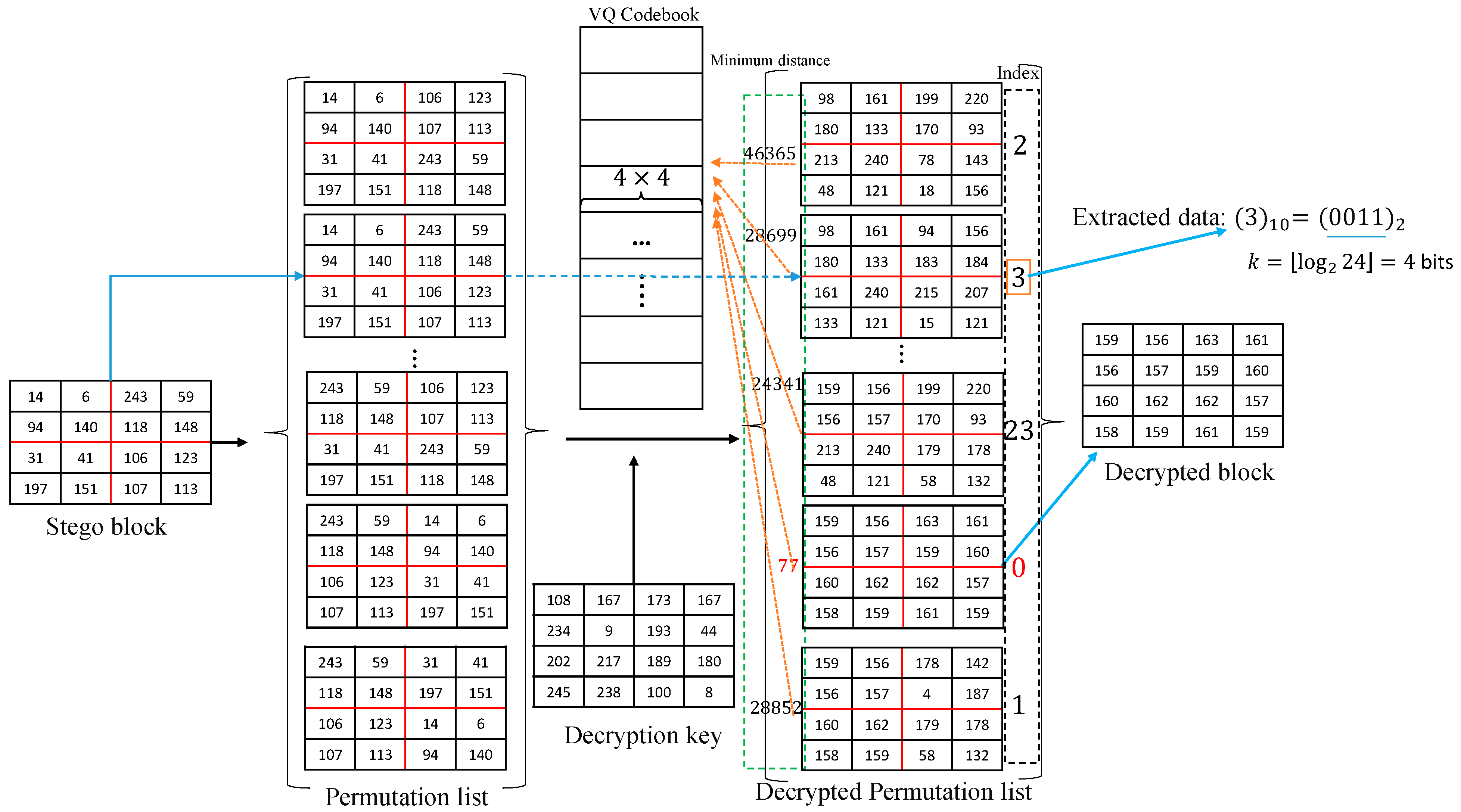
3. Proposed Scheme
3.1. The Image Encryption
3.2. The Data Embedding Phase
3.3. The Data Extraction and Image Recovery Phase
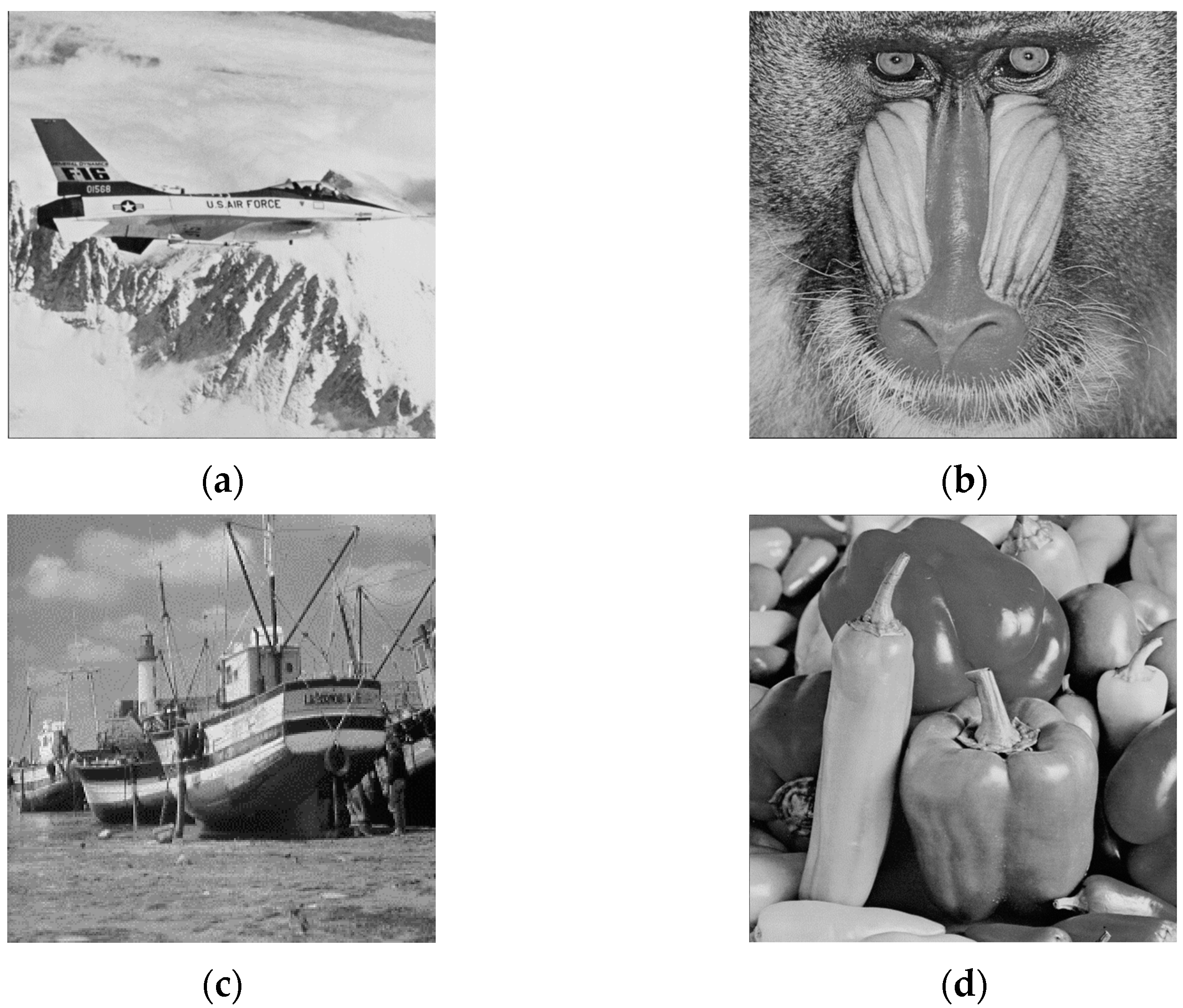
4. Experimental Results
4.1. Performances of Our Proposed Schemes
4.2. Execution Results and Security Analysis
4.3. Comparison with State-of-the-Art Schemes
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, G.; Mao, Y.; Chui, C.K. A symmetric image encryption scheme based on 3D chaotic cat maps. Chaos Solitons Fractals 2004, 21, 749–761. [Google Scholar] [CrossRef]
- Chang, C.-C. Adversarial Learning for Invertible Steganography. IEEE Access 2020, 8, 198425–198435. [Google Scholar] [CrossRef]
- Chi, H.; Chang, C.-C.; Liu, Y. An SMVQ compressed data hiding scheme based on multiple linear regression prediction. Connect. Sci. 2021, 33, 495–514. [Google Scholar] [CrossRef]
- Gray, R. Vector quantization. IEEE ASSP Mag. 1984, 1, 4–29. [Google Scholar] [CrossRef]
- Chi, H.-X.; Horng, J.-H.; Chang, C.-C. Reversible Data Hiding Based on Pixel-Value-Ordering and Prediction-Error Triplet Expansion. Mathematics 2021, 9, 1703. [Google Scholar] [CrossRef]
- Chang, C.-C.; Li, C.-T.; Shi, Y.-Q. Privacy-Aware Reversible Watermarking in Cloud Computing Environments. IEEE Access 2018, 6, 70720–70733. [Google Scholar] [CrossRef]
- Chang, C.C.; Liu, Y.; Nguyen, T.S. A Novel Turtle Shell Based Scheme for Data Hiding. In Proceedings of the 2014 Tenth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Kitakyushu, Japan, 27–29 August 2014; pp. 89–93. [Google Scholar] [CrossRef]
- Das, S.; Muhammad, K.; Bakshi, S.; Mukherjee, I.; Sa, P.K.; Sangaiah, A.K.; Bruno, A. Lip biometric template security framework using spatial steganography. Pattern Recognit. Lett. 2019, 126, 102–110. [Google Scholar] [CrossRef]
- Mohammadi, A.; Nakhkash, M.; Akhaee, M.A. A High-Capacity Reversible Data Hiding in Encrypted Images Employing Local Difference Predictor. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2366–2376. [Google Scholar] [CrossRef]
- Shiu, C.-W.; Chen, Y.-C.; Hong, W. Encrypted image-based reversible data hiding with public key cryptography from difference expansion. Signal Process. Image Commun. 2015, 39, 226–233. [Google Scholar] [CrossRef]
- Zhang, X.; Long, J.; Wang, Z.; Cheng, H. Lossless and Reversible Data Hiding in Encrypted Images With Public-Key Cryptography. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 1622–1631. [Google Scholar] [CrossRef]
- Panchikkil, S.; Manikandan, V.M.; Zhang, Y.-D. A convolutional neural network model based reversible data hiding scheme in encrypted images with block-wise Arnold transform. Optik 2022, 250, 168137. [Google Scholar] [CrossRef]
- Wang, X.; Chang, C.-C.; Lin, C.-C.; Chang, C.-C. Reversal of pixel rotation: A reversible data hiding system towards cybersecurity in encrypted images. J. Vis. Commun. Image Represent. 2022, 82, 103421. [Google Scholar] [CrossRef]
- Agrawal, S.; Kumar, M. Mean value based reversible data hiding in encrypted images. Optik 2017, 130, 922–934. [Google Scholar] [CrossRef]
- Li, M.; Li, Y. Histogram shifting in encrypted images with public key cryptosystem for reversible data hiding. Signal Process. 2017, 130, 190–196. [Google Scholar] [CrossRef]
- Zhang, X. Reversible Data Hiding in Encrypted Image. IEEE Signal Process. Lett. 2011, 18, 255–258. [Google Scholar] [CrossRef]
- Hong, W.; Chen, T.-S.; Wu, H.-Y. An Improved Reversible Data Hiding in Encrypted Images Using Side Match. IEEE Signal Process. Lett. 2012, 19, 199–202. [Google Scholar] [CrossRef]
- Zhang, X. Separable Reversible Data Hiding in Encrypted Image. IEEE Trans. Inf. Forensics Secur. 2012, 7, 826–832. [Google Scholar] [CrossRef]
- Bhardwaj, R.; Aggarwal, A. An improved block based joint reversible data hiding in encrypted images by symmetric cryptosystem. Pattern Recognit. Lett. 2020, 139, 60–68. [Google Scholar] [CrossRef]
- Huang, F.; Huang, J.; Shi, Y.-Q. New Framework for Reversible Data Hiding in Encrypted Domain. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2777–2789. [Google Scholar] [CrossRef]
- Xiong, L.; Xu, Z.; Shi, Y.-Q. An integer wavelet transform based scheme for reversible data hiding in encrypted images. Multidimens. Syst. Signal Process. 2018, 29, 1191–1202. [Google Scholar] [CrossRef]
- Chen, Y.-C.; Shiu, C.-W.; Horng, G. Encrypted signal-based reversible data hiding with public key cryptosystem. J. Vis. Commun. Image Represent. 2014, 25, 1164–1170. [Google Scholar] [CrossRef]
- Puteaux, P.; Puech, W. A Recursive Reversible Data Hiding in Encrypted Images Method With a Very High Payload. IEEE Trans. Multimed. 2021, 23, 636–650. [Google Scholar] [CrossRef]
- Xie, X.-Z.; Chang, C.-C.; Chen, K. A High-Embedding Efficiency RDH in Encrypted Image Combining MSB Prediction and Matrix Encoding for Non-Volatile Memory-Based Cloud Service. IEEE Access 2020, 8, 52028–52040. [Google Scholar] [CrossRef]
- Yu, C.; Zhang, X.; Li, G.; Zhan, S.; Tang, Z. Reversible data hiding with adaptive difference recovery for encrypted images. Inf. Sci. 2022, 584, 89–110. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Images | Block Size | (bpp) | PSNR (dB) | SSIM | (%) |
|---|---|---|---|---|---|
| Airplane | 4 × 4 | 0.2866 | 36.3807 | 0.9956 | 0.0044 |
| 8 × 8 | 0.0716 | 46.2754 | 0.9997 | 0.0002 | |
| 16 × 16 | 0.0179 | 35.8955 | 0.9977 | 0.0029 | |
| 32 × 32 | 0.0045 | Inf | 1 | 0 | |
| Baboon | 4 × 4 | 0.2866 | 30.0085 | 0.9813 | 0.0206 |
| 8 × 8 | 0.0716 | 46.1674 | 0.9997 | 0.0005 | |
| 16 × 16 | 0.0179 | Inf | 1 | 0 | |
| 32 × 32 | 0.0045 | Inf | 1 | 0 | |
| Boat | 4 × 4 | 0.2866 | 34.3157 | 0.9913 | 0.0090 |
| 8 × 8 | 0.0716 | 36.3722 | 0.9976 | 0.0022 | |
| 16 × 16 | 0.0179 | 40.1909 | 0.9994 | 0.0010 | |
| 32 × 32 | 0.0045 | Inf | 1 | 0 | |
| Peppers | 4 × 4 | 0.2866 | 35.8851 | 0.9927 | 0.0078 |
| 8 × 8 | 0.0716 | 46.5244 | 0.9997 | 0.0002 | |
| 16 × 16 | 0.0179 | 38.2135 | 0.9994 | 0.0010 | |
| 32 × 32 | 0.0045 | Inf | 1 | 0 |
| Images | Block Size | (bpp) | PSNR (dB) | SSIM | (%) |
|---|---|---|---|---|---|
| Airplane | 4 × 4 | 0.2866 | 42.4206 | 0.9987 | 0.0018 |
| 8 × 8 | 0.0716 | 47.9849 | 0.9998 | 0.0002 | |
| 16 × 16 | 0.0179 | Inf | 1 | 0 | |
| 32 × 32 | 0.0045 | Inf | 1 | 0 | |
| Baboon | 4 × 4 | 0.2866 | 34.8421 | 0.9938 | 0.0081 |
| 8 × 8 | 0.0716 | 47.1214 | 0.9997 | 0.0002 | |
| 16 × 16 | 0.0179 | Inf | 1 | 0 | |
| 32 × 32 | 0.0045 | Inf | 1 | 0 | |
| Boat | 4 × 4 | 0.2866 | 36.0354 | 0.9960 | 0.0037 |
| 8 × 8 | 0.0716 | 36.1620 | 0.9976 | 0.0022 | |
| 16 × 16 | 0.0179 | Inf | 1 | 0 | |
| 32 × 32 | 0.0045 | Inf | 1 | 0 | |
| Peppers | 4 × 4 | 0.2866 | 39.0904 | 0.9975 | 0.0024 |
| 8 × 8 | 0.0716 | Inf | 1 | 0 | |
| 16 × 16 | 0.0179 | 38.4969 | 0.9991 | 0.0001 | |
| 32 × 32 | 0.0045 | Inf | 1 | 0 |
| Images | Block Size | (bpp) | PSNR (dB) | SSIM | (%) |
|---|---|---|---|---|---|
| Airplane | 4 × 4 | 0.9562 | 28.0438 | 0.9573 | 0.0992 |
| 8 × 8 | 0.2391 | 35.6202 | 0.9958 | 0.0071 | |
| 16 × 16 | 0.0598 | 34.0751 | 0.9960 | 0.0059 | |
| 32 × 32 | 0.0149 | 36.8924 | 0.9987 | 0.0031 | |
| Baboon | 4 × 4 | 0.9562 | 20.8189 | 0.7899 | 0.3775 |
| 8 × 8 | 0.2391 | 36.5928 | 0.9966 | 0.0073 | |
| 16 × 16 | 0.0598 | Inf | 1 | 0 | |
| 32 × 32 | 0.0149 | Inf | 1 | 0 | |
| Boat | 4 × 4 | 0.9562 | 26.3119 | 0.9261 | 0.1343 |
| 8 × 8 | 0.2391 | 31.2961 | 0.9901 | 0.0146 | |
| 16 × 16 | 0.0598 | 34.9084 | 0.9967 | 0.0068 | |
| 32 × 32 | 0.0149 | Inf | 1 | 0 | |
| Peppers | 4 × 4 | 0.9562 | 27.8656 | 0.9552 | 0.0745 |
| 8 × 8 | 0.2391 | 35.5764 | 0.9957 | 0.0063 | |
| 16 × 16 | 0.0598 | 33.3352 | 0.9952 | 0.0088 | |
| 32 × 32 | 0.0149 | 31.1752 | 0.9933 | 0.0156 |
| Images | Block Size | (bpp) | PSNR (dB) | SSIM | (%) |
|---|---|---|---|---|---|
| Airplane | 4 × 4 | 0.9562 | 28.7802 | 0.9658 | 0.0874 |
| 8 × 8 | 0.2391 | 38.0761 | 0.9979 | 0.0049 | |
| 16 × 16 | 0.0598 | 46.1583 | 0.9997 | 0.0001 | |
| 32 × 32 | 0.0149 | 36.5631 | 0.9984 | 0.0117 | |
| Baboon | 4 × 4 | 0.9562 | 21.7144 | 0.8130 | 0.4152 |
| 8 × 8 | 0.2391 | 39.0186 | 0.9980 | 0.0054 | |
| 16 × 16 | 0.0598 | Inf | 1 | 0 | |
| 32 × 32 | 0.0149 | Inf | 1 | 0 | |
| Boat | 4 × 4 | 0.9562 | 26.6285 | 0.9297 | 0.1337 |
| 8 × 8 | 0.2391 | 31.9629 | 0.9918 | 0.0122 | |
| 16 × 16 | 0.0598 | 35.2929 | 0.9967 | 0.0068 | |
| 32 × 32 | 0.0149 | Inf | 1 | 0 | |
| Peppers | 4 × 4 | 0.9562 | 28.8480 | 0.9645 | 0.0754 |
| 8 × 8 | 0.2391 | 40.0998 | 0.9984 | 0.0032 | |
| 16 × 16 | 0.0598 | 37.8925 | 0.9986 | 0.0020 | |
| 32 × 32 | 0.0149 | 37.4123 | 0.9987 | 0.0039 |
| Images | Original Image | Encrypted Image | Block Size | Embedded Encrypted Image | |
|---|---|---|---|---|---|
| 4 Sub-Blocks | 8 Sub-Blocks | ||||
| Airplane | 6.7059 | 7.9994 | 4 × 4 | 7.9994 | 7.9994 |
| 8 × 8 | 7.9994 | 7.9994 | |||
| 16 × 16 | 7.9994 | 7.9994 | |||
| 32 × 32 | 7.9994 | 7.9994 | |||
| Baboon | 7.3579 | 7.9992 | 4 × 4 | 7.9992 | 7.9992 |
| 8 × 8 | 7.9992 | 7.9992 | |||
| 16 × 16 | 7.9992 | 7.9992 | |||
| 32 × 32 | 7.9992 | 7.9992 | |||
| Boat | 7.1914 | 7.9994 | 4 × 4 | 7.9994 | 7.9994 |
| 8 × 8 | 7.9994 | 7.9994 | |||
| 16 × 16 | 7.9994 | 7.9994 | |||
| 32 × 32 | 7.9994 | 7.9994 | |||
| Peppers | 7.5944 | 7.9993 | 4 × 4 | 7.9993 | 7.9993 |
| 8 × 8 | 7.9993 | 7.9993 | |||
| 16 × 16 | 7.9993 | 7.9993 | |||
| 32 × 32 | 7.9993 | 7.9993 | |||
| Average | 7.2124 | 7.9993 | / | 7.9993 | 7.9993 |
| Images | Horizontal Correlation | Vertical Correlation | ||||||
|---|---|---|---|---|---|---|---|---|
| Original Image | Encrypted Image | Embedded Encrypted Image | Original Image | Encrypted Image | Embedded Encrypted Image | |||
| 4 Sub-Blocks | 8 Sub-Blocks | 4 Sub-Blocks | 8 Sub-Blocks | |||||
| Airplane | 0.9606 | −0.0043 | 0.0031 | 0.0040 | 0.9584 | 0.0032 | 0.0025 | −0.0012 |
| Baboon | 0.8667 | −0.0048 | −0.0044 | −0.0039 | 0.7498 | 0.0032 | −0.0032 | 0.0022 |
| Boat | 0.9383 | −0.0026 | 0.0030 | −0.0025 | 0.9715 | 0.0045 | 0.0040 | −0.0022 |
| Peppers | 0.9730 | 0.0030 | 0.0025 | −0.0022 | 0.9762 | 0.0026 | 0.0013 | 0.0015 |
| Images | Horizontal Correlation | Vertical Correlation | ||||||
|---|---|---|---|---|---|---|---|---|
| Original Image | Encrypted Image | Embedded Encrypted Image | Original Image | Encrypted Image | Embedded Encrypted Image | |||
| 4 Sub-Blocks | 8 Sub-Blocks | 4 Sub-Blocks | 8 Sub-Blocks | |||||
| Airplane | 0.9606 | −0.0043 | −0.0028 | 0.0039 | 0.9584 | 0.0032 | −0.0034 | −0.0028 |
| Baboon | 0.8667 | −0.0048 | −0.0036 | −0.0033 | 0.7498 | 0.0032 | 0.0025 | −0.0022 |
| Boat | 0.9383 | −0.0026 | 0.0016 | 0.0012 | 0.9715 | 0.0045 | −0.0047 | −0.0032 |
| Peppers | 0.9730 | 0.0030 | 0.0039 | 0.0025 | 0.9762 | 0.0026 | 0.0011 | 0.0016 |
| Images | Horizontal Correlation | Vertical Correlation | ||||||
|---|---|---|---|---|---|---|---|---|
| Original Image | Encrypted Image | Embedded Encrypted Image | Original Image | Encrypted Image | Embedded Encrypted Image | |||
| 4 Sub-Blocks | 8 Sub-Blocks | 4 Sub-Blocks | 8 Sub-Blocks | |||||
| Airplane | 0.9606 | −0.0043 | 0.0021 | −0.0041 | 0.9584 | 0.0032 | 0.0036 | −0.0025 |
| Baboon | 0.8667 | −0.0048 | 0.0029 | −0.0032 | 0.7498 | 0.0032 | −0.0030 | 0.0032 |
| Boat | 0.9383 | −0.0026 | −0.0018 | 0.0025 | 0.9715 | 0.0045 | −0.0031 | −0.0038 |
| Peppers | 0.9730 | 0.0030 | 0.0031 | −0.0027 | 0.9762 | 0.0026 | −0.0026 | 0.0029 |
| Images | Horizontal Correlation | Vertical Correlation | ||||||
|---|---|---|---|---|---|---|---|---|
| Original Image | Encrypted Image | Embedded Encrypted Image | Original Image | Encrypted Image | Embedded Encrypted Image | |||
| 4 Sub-Blocks | 8 Sub-Blocks | 4 Sub-Blocks | 8 Sub-Blocks | |||||
| Airplane | 0.9606 | −0.0043 | −0.0044 | 0.0036 | 0.9584 | 0.0032 | −0.0037 | 0.0021 |
| Baboon | 0.8667 | −0.0048 | 0.0039 | −0.0030 | 0.7498 | 0.0032 | 0.0034 | 0.0038 |
| Boat | 0.9383 | −0.0026 | −0.0035 | 0.0031 | 0.9715 | 0.0045 | −0.0039 | −0.0056 |
| Peppers | 0.9730 | 0.0030 | 0.0048 | −0.0039 | 0.9762 | 0.0026 | −0.0018 | 0.0017 |
| Images | Block Size | [12] | 4 Sub-Blocks | 8 Sub-Blocks |
|---|---|---|---|---|
| Airplane | 4 × 4 | 0.1563 | 0.2866 | 0.9562 |
| 8 × 8 | 0.0547 | 0.0716 | 0.2391 | |
| 16 × 16 | 0.0176 | 0.0179 | 0.0598 | |
| 32 × 32 | 0.0054 | 0.0045 | 0.0149 | |
| Baboon | 4 × 4 | 0.1563 | 0.2866 | 0.9562 |
| 8 × 8 | 0.0547 | 0.0716 | 0.2391 | |
| 16 × 16 | 0.0176 | 0.0179 | 0.0598 | |
| 32 × 32 | 0.0054 | 0.0045 | 0.0149 | |
| Boat | 4 × 4 | 0.1563 | 0.2866 | 0.9562 |
| 8 × 8 | 0.0547 | 0.0716 | 0.2391 | |
| 16 × 16 | 0.0176 | 0.0179 | 0.0598 | |
| 32 × 32 | 0.0054 | 0.0045 | 0.0149 | |
| Peppers | 4 × 4 | 0.1563 | 0.2866 | 0.9562 |
| 8 × 8 | 0.0547 | 0.0716 | 0.2391 | |
| 16 × 16 | 0.0176 | 0.0179 | 0.0598 | |
| 32 × 32 | 0.0054 | 0.0045 | 0.0149 |
| Images | Block Size | [12] | Codebook Size = 64 | Codebook Size = 128 | ||
|---|---|---|---|---|---|---|
| 4 Sub-Blocks | 8 Sub-Blocks | 4 Sub-Blocks | 8 Sub-Blocks | |||
| Airplane | 4 × 4 | 0 | 0.0044 | 0.0992 | 0.0018 | 0.0874 |
| 8 × 8 | 0 | 0.0002 | 0.0071 | 0.0002 | 0.0049 | |
| 16 × 16 | 0 | 0.0029 | 0.0059 | 0 | 0.0001 | |
| 32 × 32 | 0 | 0 | 0.0031 | 0 | 0.0117 | |
| Baboon | 4 × 4 | 0.0004 | 0.0206 | 0.3775 | 0.0081 | 0.4152 |
| 8 × 8 | 0 | 0.0005 | 0.0073 | 0.0002 | 0.0054 | |
| 16 × 16 | 0 | 0 | 0 | 0 | 0 | |
| 32 × 32 | 0 | 0 | 0 | 0 | 0 | |
| Boat | 4 × 4 | 0.0004 | 0.0090 | 0.1343 | 0.0037 | 0.1337 |
| 8 × 8 | 0 | 0.0022 | 0.0146 | 0.0022 | 0.0122 | |
| 16 × 16 | 0 | 0.0010 | 0.0068 | 0 | 0.0068 | |
| 32 × 32 | 0 | 0 | 0 | 0 | 0 | |
| Peppers | 4 × 4 | 0.0001 | 0.0078 | 0.0745 | 0.0024 | 0.0754 |
| 8 × 8 | 0 | 0.0002 | 0.0063 | 0 | 0.0032 | |
| 16 × 16 | 0 | 0.0010 | 0.0088 | 0.0001 | 0.0020 | |
| 32 × 32 | 0 | 0 | 0.0156 | 0 | 0.0039 | |
| Images | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| [10] | [11] | [12] | [14] | [15] | [16] | [17] | [18] | [21] | [22] | Proposed | |
| Airplane | 0.0039 | 0.0039 | 0.0030 | 0.0020 | 0.0040 | 0.0080 | 0.0080 | 0.0039 | 0.0400 | 0.0547 | 0.2391 |
| Baboon | 0.0039 | 0.0039 | 0.0010 | 0.0020 | 0.0040 | 0.0080 | 0.0080 | 0.0039 | 0.0400 | 0.0547 | 0.2391 |
| Boat | 0.0039 | 0.0039 | 0.0030 | 0.0020 | 0.0040 | 0.0080 | 0.0080 | 0.0039 | 0.0400 | 0.0547 | 0.2391 |
| Peppers | 0.0039 | 0.0039 | 0.0030 | 0.0020 | 0.0040 | 0.0080 | 0.0080 | 0.0039 | 0.0400 | 0.0547 | 0.2391 |
| Average | 0.0039 | 0.0039 | 0.0025 | 0.0020 | 0.0040 | 0.0080 | 0.0080 | 0.0039 | 0.0400 | 0.0547 | 0.2391 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chi, H.-X.; Chang, C.-C.; Wang, X.; Lin, C.-C. Hiding and Extracting Important Information in Encrypted Images by Using the Transformation of All Possible Permutations and VQ Codebook. Electronics 2022, 11, 3475. https://doi.org/10.3390/electronics11213475
Chi H-X, Chang C-C, Wang X, Lin C-C. Hiding and Extracting Important Information in Encrypted Images by Using the Transformation of All Possible Permutations and VQ Codebook. Electronics. 2022; 11(21):3475. https://doi.org/10.3390/electronics11213475
Chicago/Turabian StyleChi, Heng-Xiao, Chin-Chen Chang, Xu Wang, and Chia-Chen Lin. 2022. "Hiding and Extracting Important Information in Encrypted Images by Using the Transformation of All Possible Permutations and VQ Codebook" Electronics 11, no. 21: 3475. https://doi.org/10.3390/electronics11213475
APA StyleChi, H.-X., Chang, C.-C., Wang, X., & Lin, C.-C. (2022). Hiding and Extracting Important Information in Encrypted Images by Using the Transformation of All Possible Permutations and VQ Codebook. Electronics, 11(21), 3475. https://doi.org/10.3390/electronics11213475