
Synthetic Data Generation to Speed-Up the Object Recognition Pipeline




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Works
3. Research Methodology
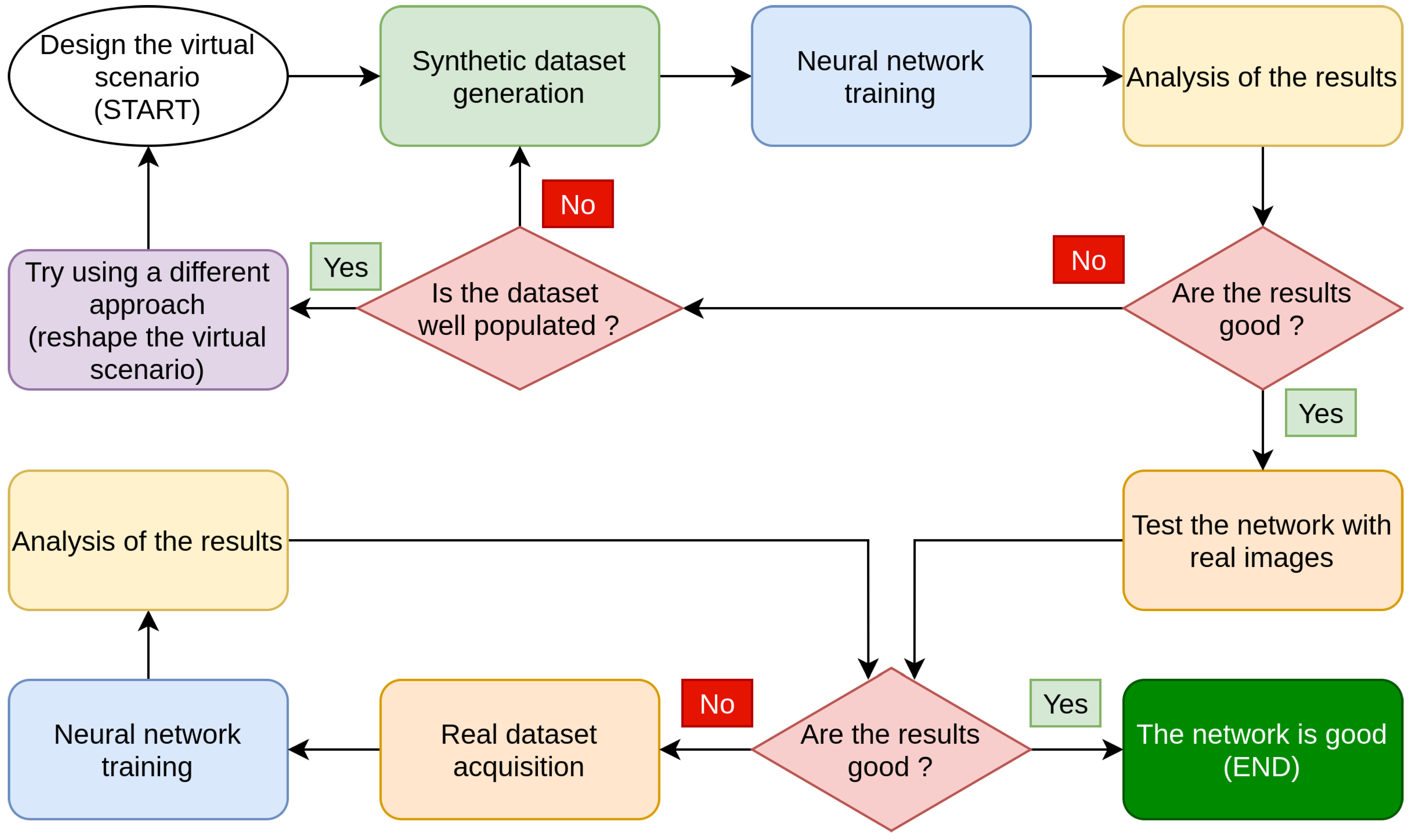
3.1. Experimental Protocol
3.2. Our Proposed Pipeline
4. Discussion of Results
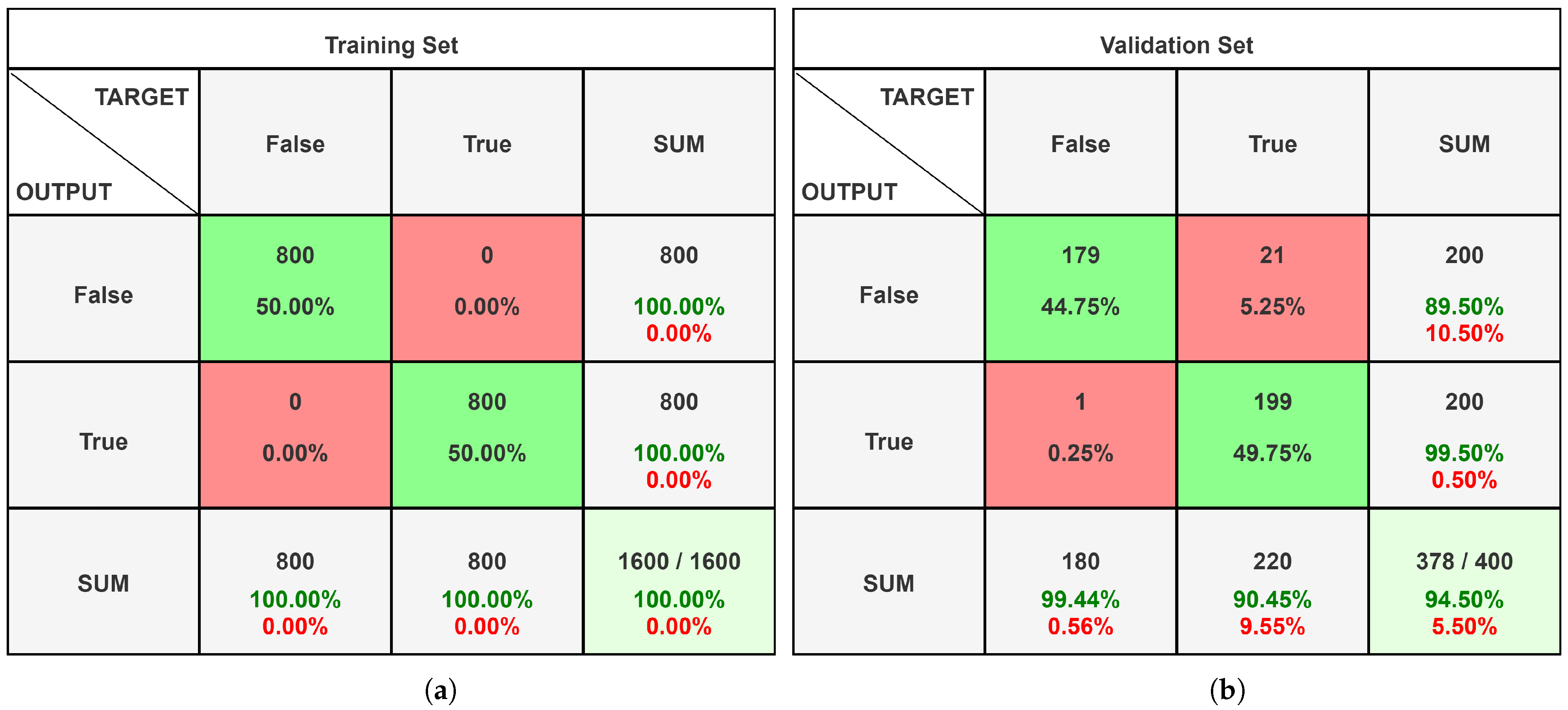
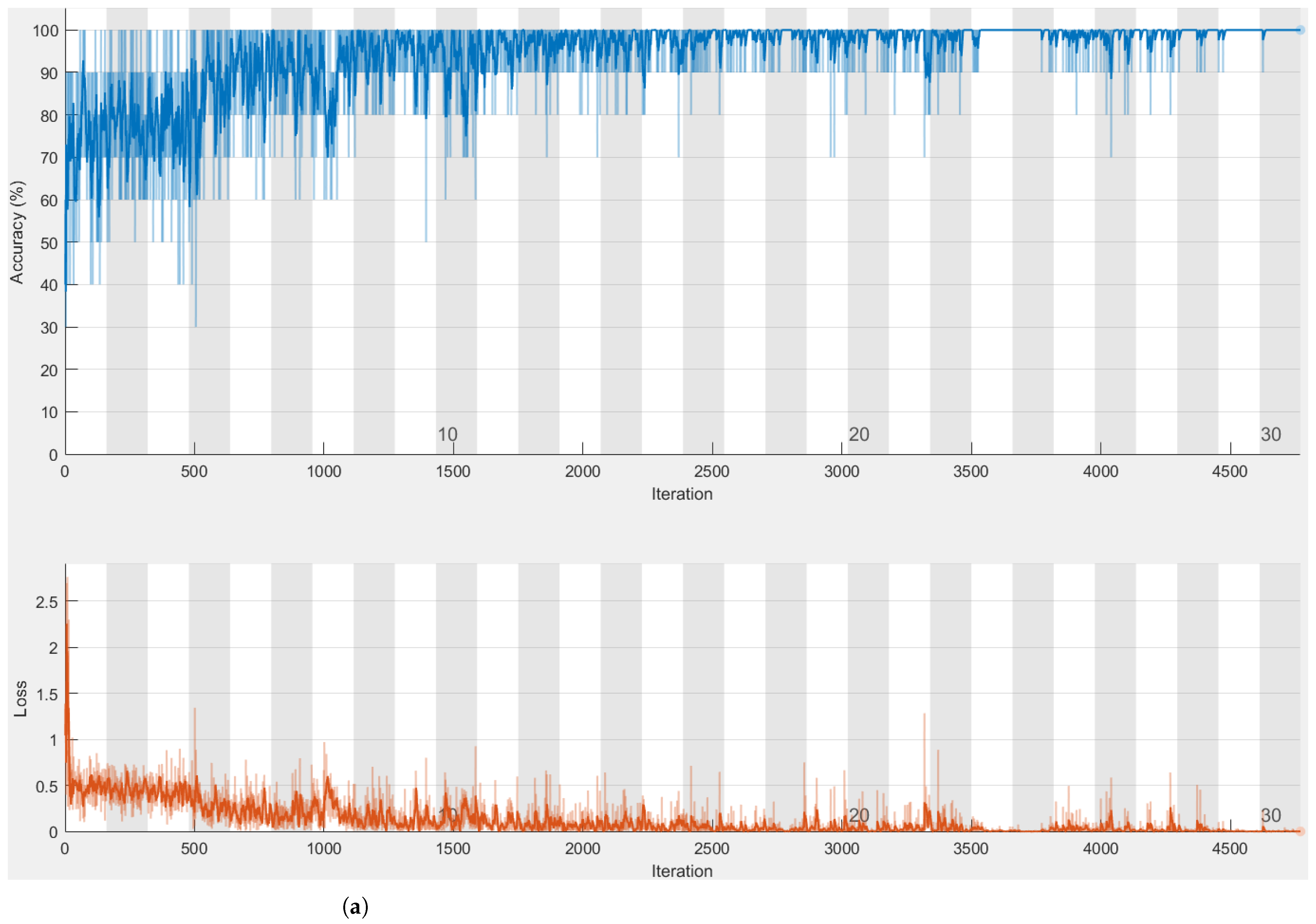
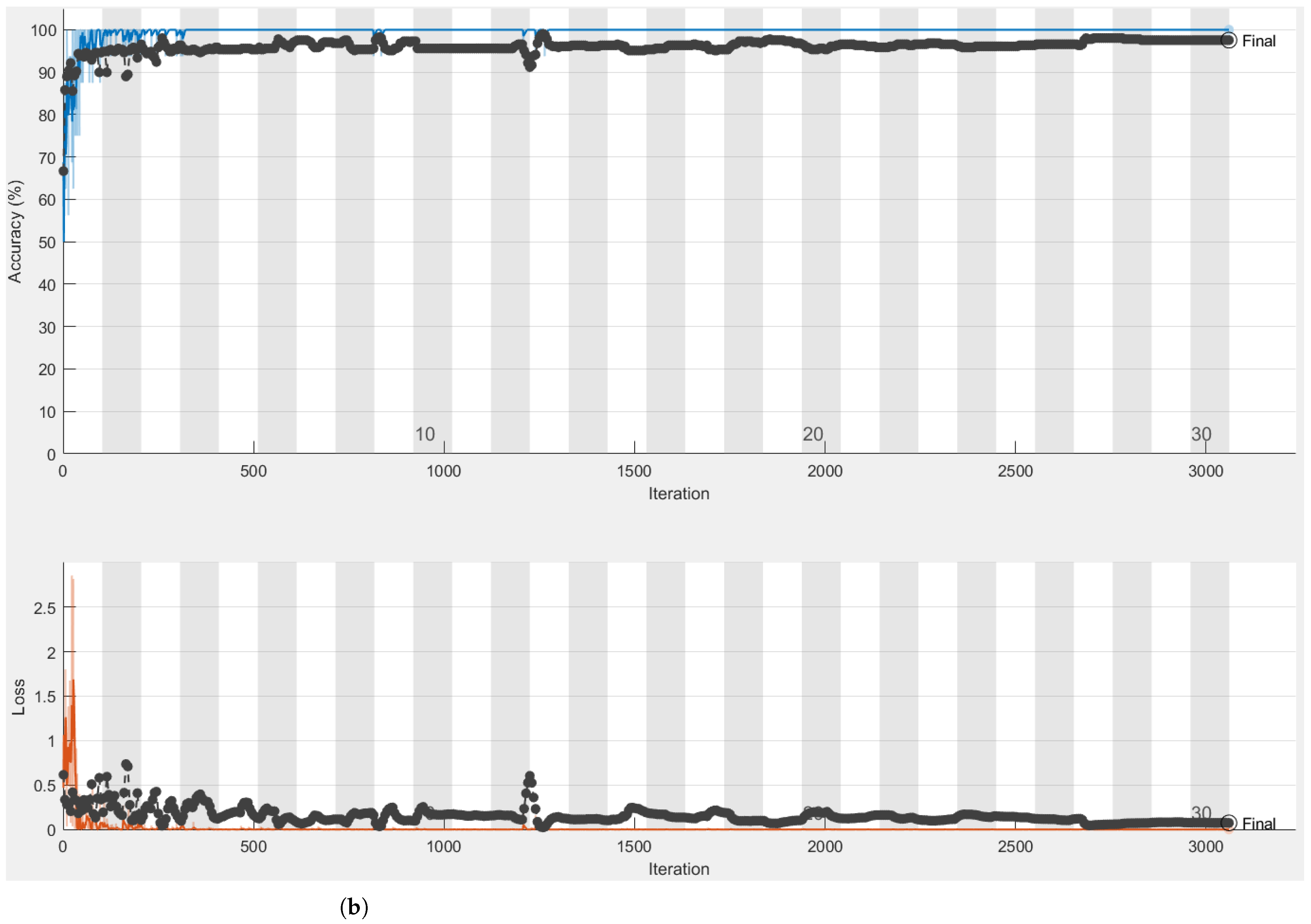
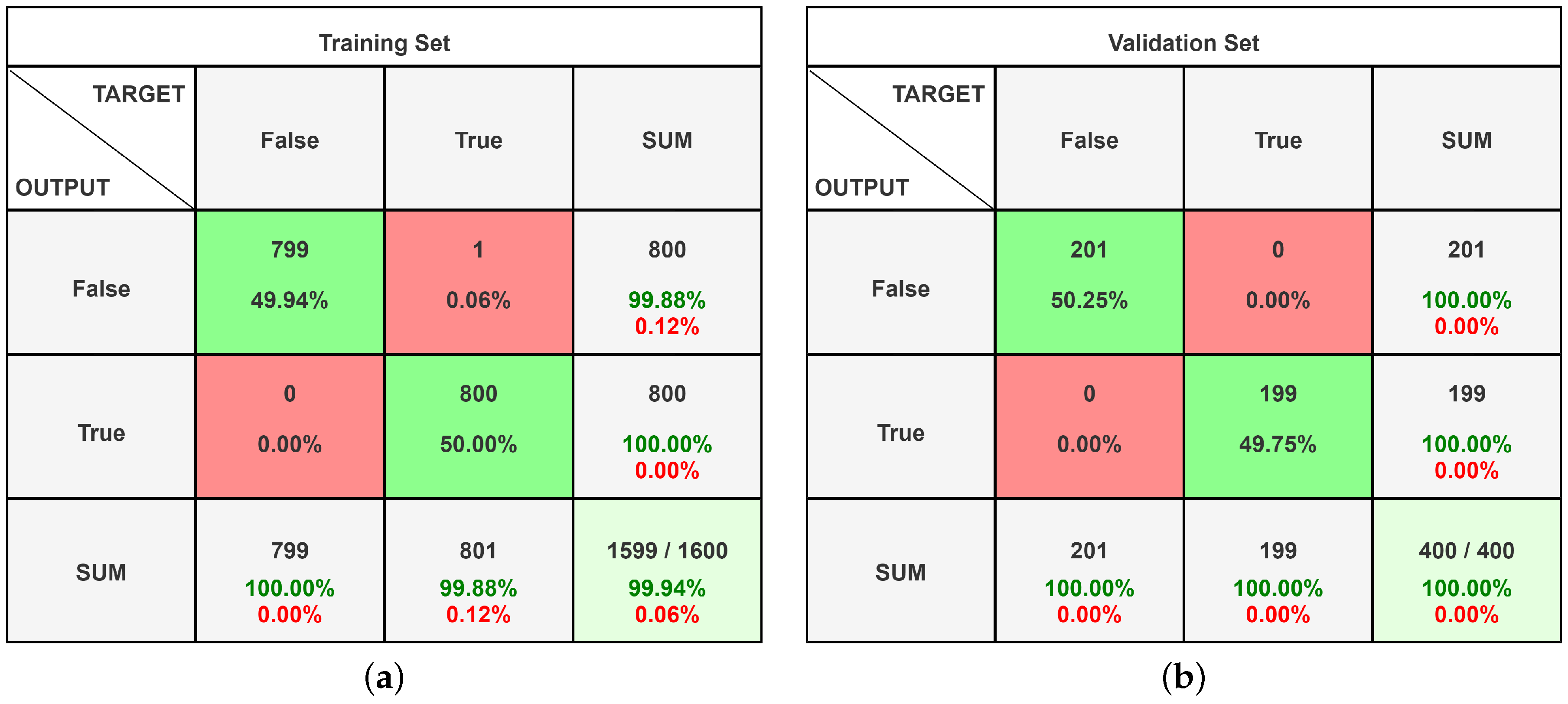
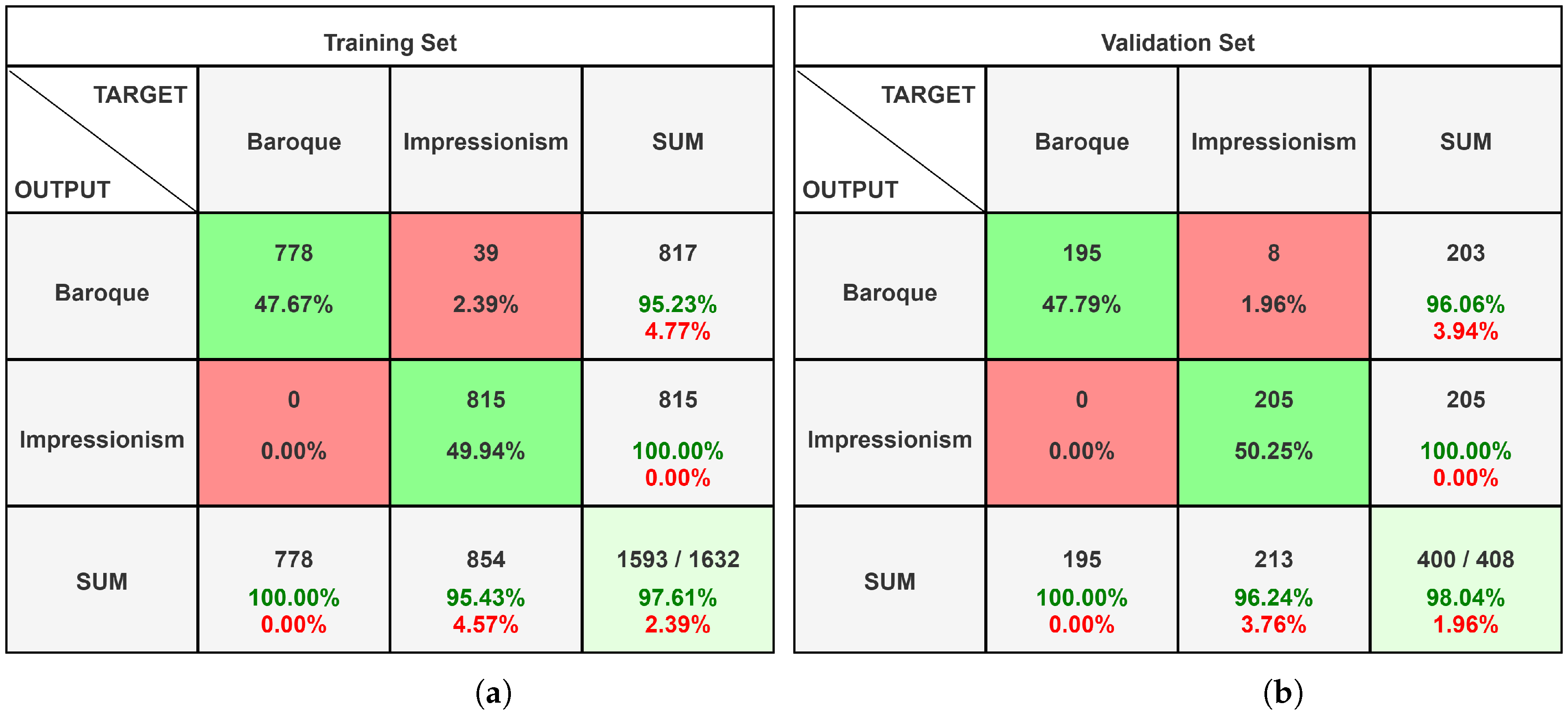
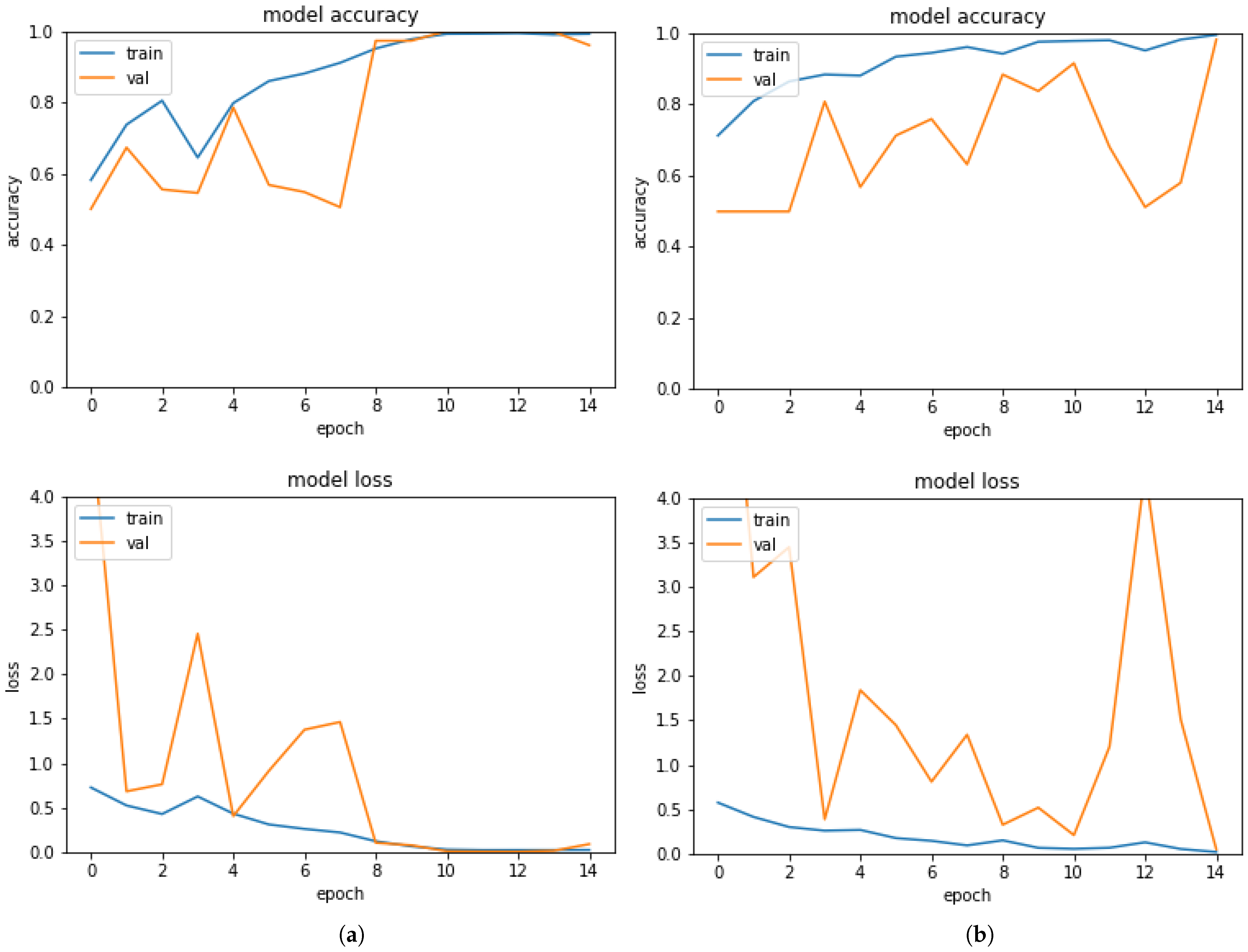
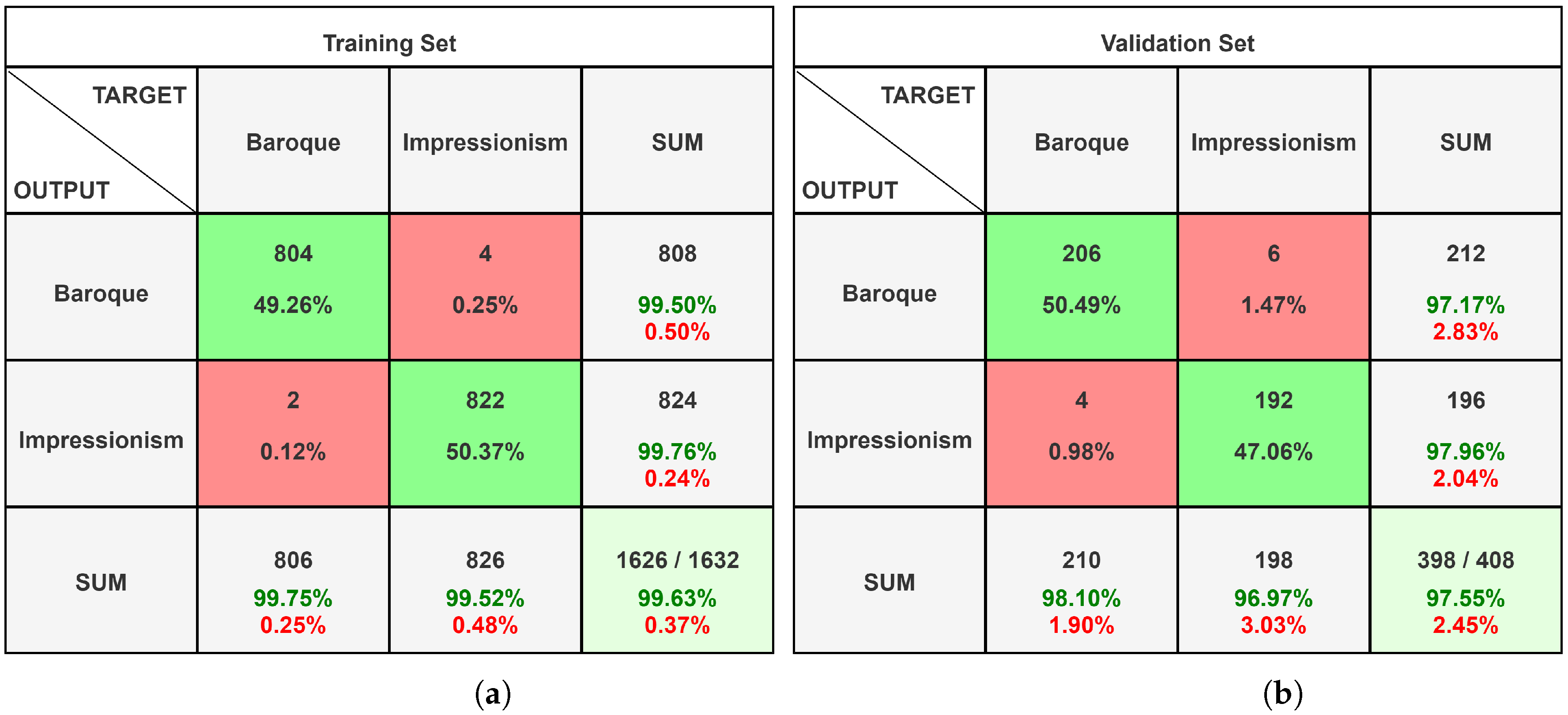
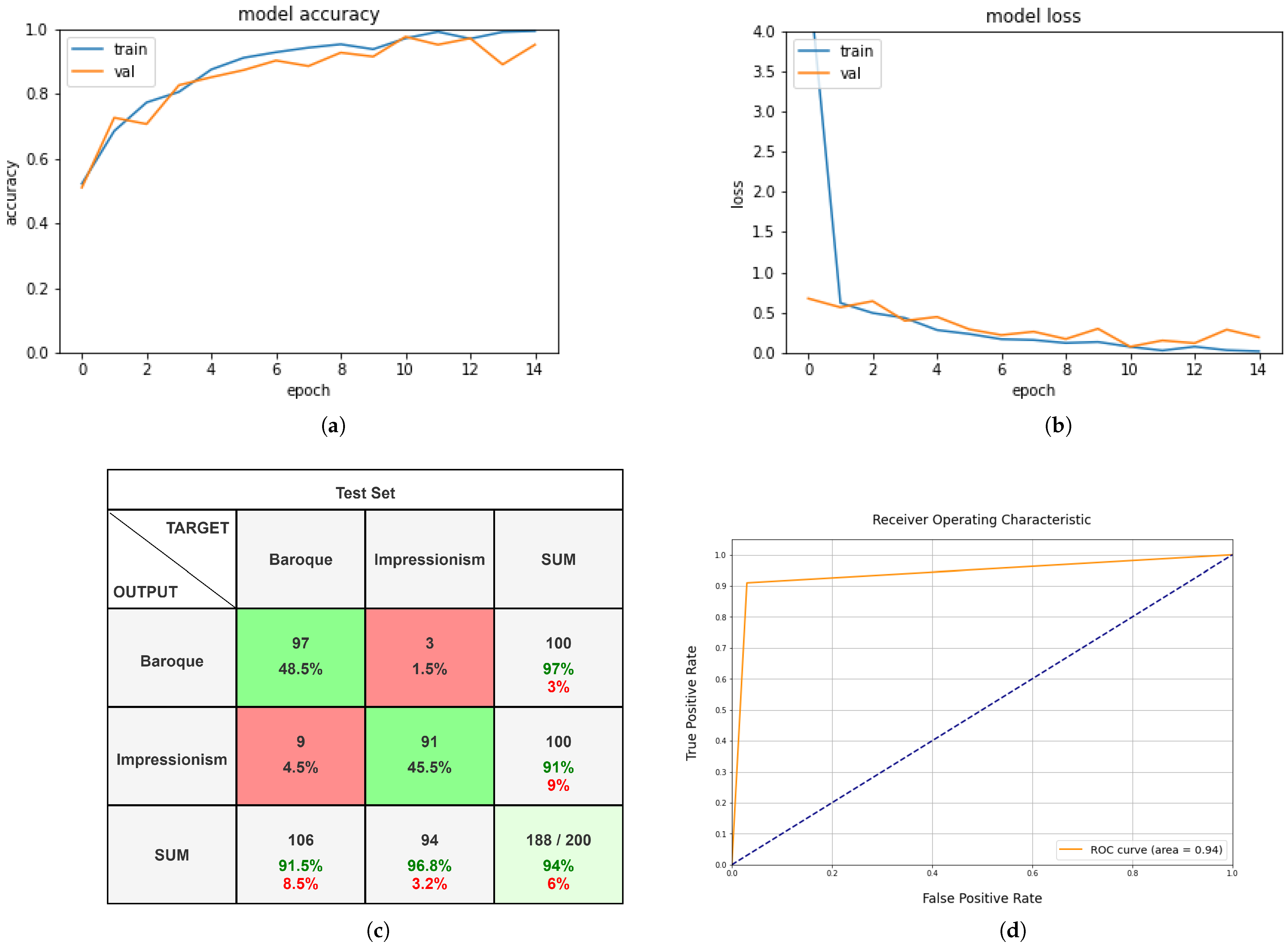
4.1. Alexnet
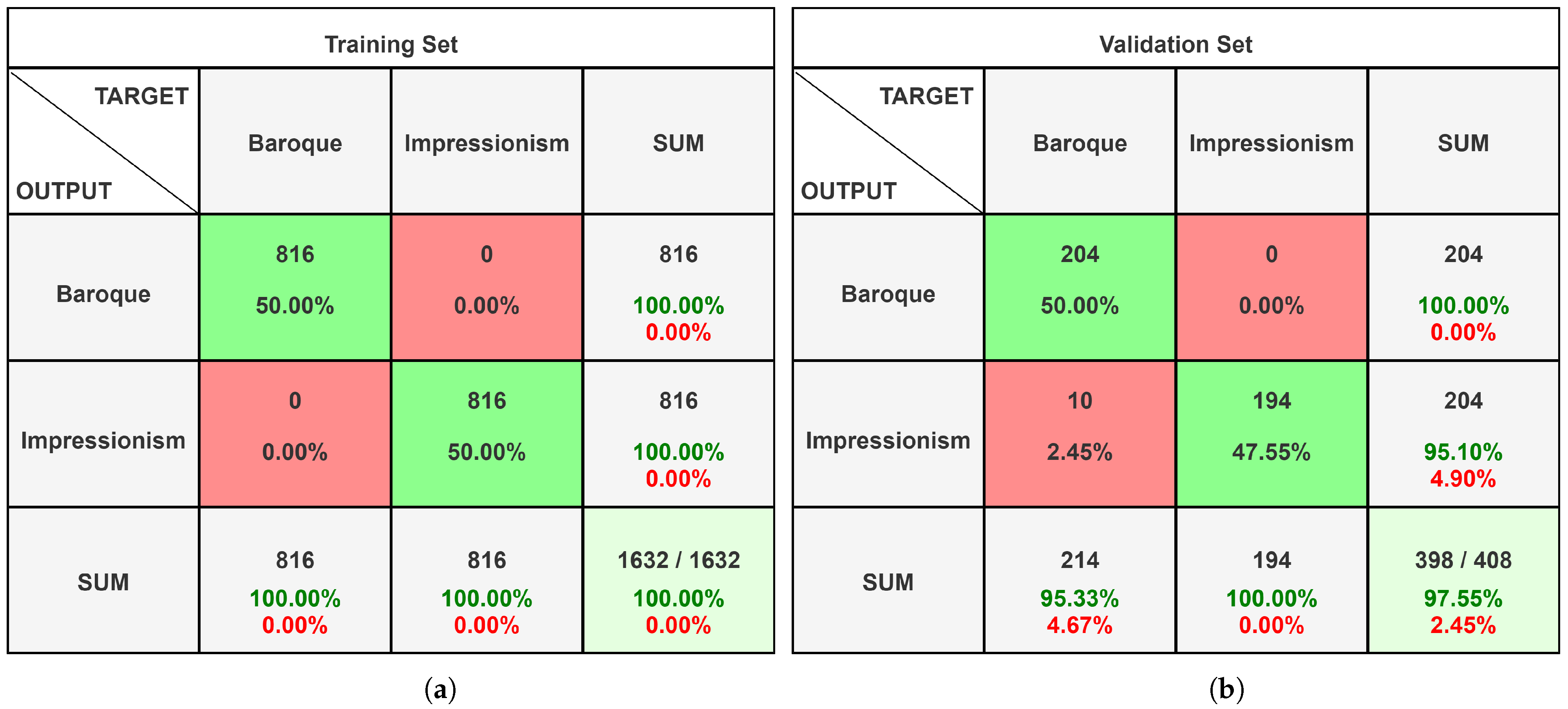
4.2. InceptionResNet-V2
4.3. Custom Convolutional Neural Network
5. Best Practices Generating a Synthetic Dataset in Virtual Environments
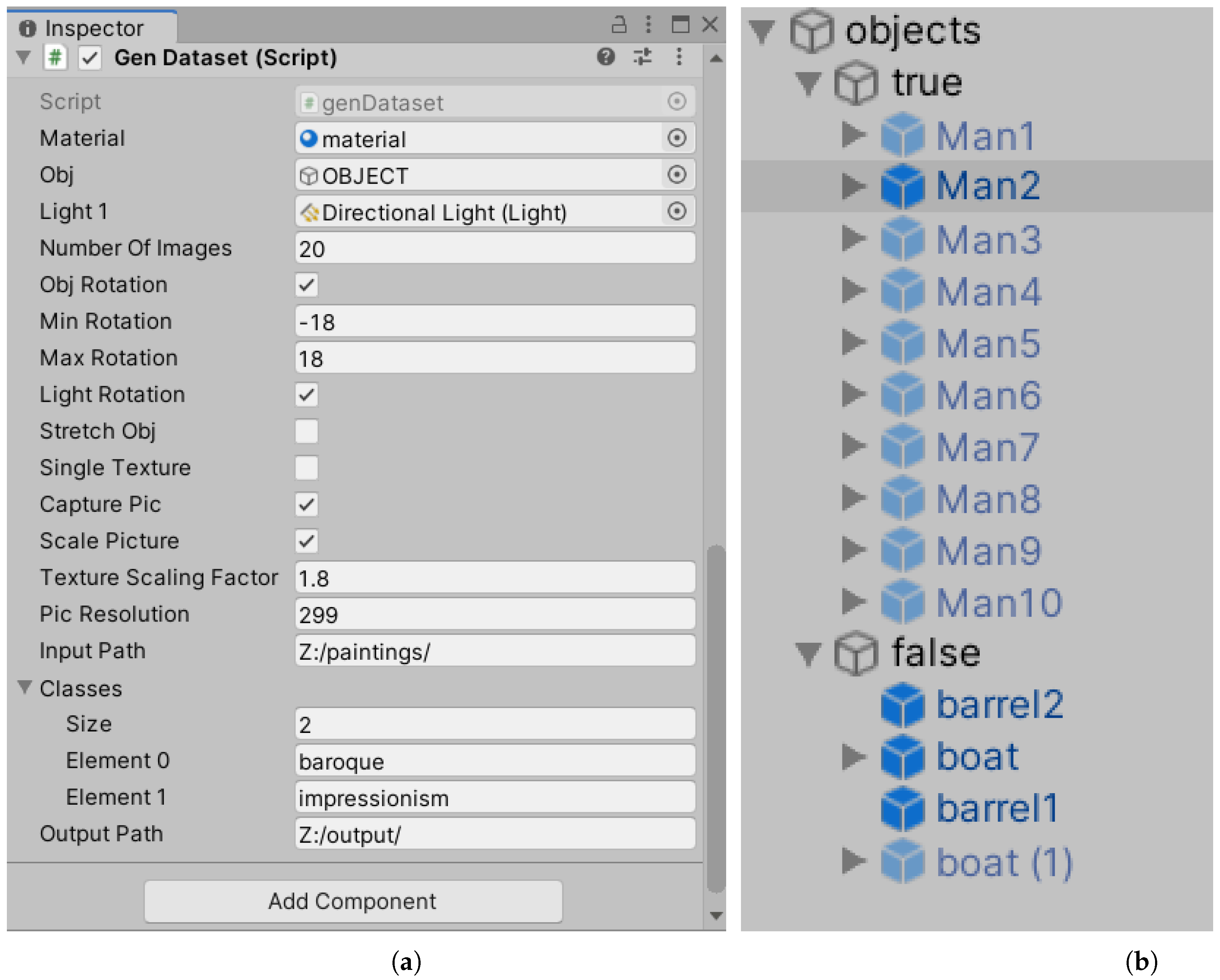
5.1. Representation of the Synthetic Scenario
- Random rotation of the object: we produce three random integers that are contained in the minimum and maximum rotation ranges that we previously established and assign them as coefficients of the object’s X, Y, and Z rotations.
- Changing the scene’s global lighting: We produce three random integers that represent the potential rotations of the light in the scene. It is critical to establish the ranges of the three variables accurately to guarantee that the representation obtained is believable. A picture with illumination from the bottom up, or even directly into the viewer’s eyes, for example, would be unusual. As a result, we recommend trying until the appropriate outcome is obtained. These numbers are then allocated as light rotation coefficients once they are formed. It is also possible to produce a random value that alters the light’s intensity and hue.
- Acquisition of image: to store a photograph of the scene, generate a rectangle that overlaps the user interface starting at the coordinates of (0, 0) and finishing at the coordinates of (Screen.width, Screen.height), then extract the RGB values of the pixels included inside the rectangle.
- Scaling the image: after we have gotten the RGB values, we need to scale the image to fit the size requirements of the neural network we are going to utilise. For example, if we are creating a dataset to train the InceptionResNetV2 network, we may scale the photos directly in Unity3D to 299 × 299 resolution.
- Saving the image: once the pixels are captured and resized, the image must be saved to a file system, for example, in the PNG format. During the saving step, we propose distinguishing the objects using an identifying name and an incremental integer that is used to create the saved file’s name, such as "impressionism_0000X.png".
5.2. Dataset for the Classification of Images Representing Objects
- Restore the scene to its original state by hiding all items on the scene, except the sea, the camera, and the sunlight at the start of each new iteration.
- Make a random number of the objects active (and so display them within the scene) while producing pictures of the class true/false.
- Alter the location of the objects: for each object in the scene, we generate three random numbers (X, Y, and Z) from the range of coordinates that the camera can frame and update the position of this object to the produced coordinates.
- Change the rotation of objects: for each object in the scene, we produce three random integers (X, Y, and Z) that are within the desired rotation interval and realistically match the class to be formed. Then, using the provided values, rotate the item under examination.
- Modify the lighting of the scene as described in point 2 in the previous list.
- Acquire the scene image as specified in the preceding list’s point 3.
- Resize the image to the size acceptable by the neural network we wish to test, as explained in the preceding list’s point 4.
- Save the picture to the file system as stated in point 5 from the preceding list, be sure to give each image a name that allows you to identify the class to which it belongs.
6. Conclusions and Future Works
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| GAN | Generative Adversarial Network |
| RAN | Recurrent Adversarial Network |
| UV | The u,v graphic coordinates |
| VR | Virtual Reality |
| ROC | Receiver Operating Characteristic |
| NN | Neural Network |
References
- Wu, F.Y. Remote sensing image processing based on multi-scale geometric transformation algorithm. J. Discret. Math. Sci. Cryptogr. 2017, 20, 309–321. [Google Scholar] [CrossRef]
- Wolberg, G. Geometric Transformation Techniques for Digital Images: A Survey, Columbia University Computer Science Technical Reports CUCS-390-88; Department of Computer Science, Columbia University: New York, NY, USA, 21 December 2011. [CrossRef]
- Arce-Santana, E.R.; Alba, A. Image registration using Markov random coefficient and geometric transformation fields. Pattern Recognit. 2009, 42, 1660–1671. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Ekstrom, M.P. Digital Image Processing Techniques; Academic Press: Cambridge, MA, USA, 2012; Volume 2. [Google Scholar]
- Kwak, H.; Zhang, B.T. Generating images part by part with composite generative adversarial networks. arXiv 2016, arXiv:1607.05387. [Google Scholar]
- Wang, X.L.; Gupta, A. Generative image modeling using style and structure adversarial networks. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2016; pp. 318–319. [Google Scholar]
- Zhang, C.; Feng, Y.; Qiang, B.; Shang, J. Wasserstein generative recurrent adversarial networks for image generating. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 242–247. [Google Scholar]
- Im, D.J.; Kim, C.D.; Jiang, H.; Memisevic, R. Generating images with recurrent adversarial networks. arXiv 2016, arXiv:1602.05110. [Google Scholar]
- Frid-Adar, M.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. Synthetic data augmentation using GAN for improved liver lesion classification. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 289–293. [Google Scholar]
- Santucci, F.; Frenguelli, F.; De Angelis, A.; Cuccaro, I.; Perri, D.; Simonetti, M. An immersive open source environment using godot. In Proceedings of the International Conference on Computational Science and Its Applications, Cagliari, Italy, 1–4 July 2020; pp. 784–798. [Google Scholar]
- Benedetti, P.; Perri, D.; Simonetti, M.; Gervasi, O.; Reali, G.; Femminella, M. Skin Cancer Classification Using Inception Network and Transfer Learning. In Proceedings of the International Conference on Computational Science and Its Applications, Cagliari, Italy, 1–4 July 2020; pp. 536–545. [Google Scholar]
- Biondi, G.; Franzoni, V.; Gervasi, O.; Perri, D. An Approach for Improving Automatic Mouth Emotion Recognition. In Computational Science and Its Applications—ICCSA 2019; Misra, S., Gervasi, O., Murgante, B., Stankova, E., Korkhov, V., Torre, C., Rocha, A.M.A., Taniar, D., Apduhan, B.O., Tarantino, E., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 649–664. [Google Scholar]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef]
- Bellinger, C.; Corizzo, R.; Japkowicz, N. Remix: Calibrated resampling for class imbalance in deep learning. arXiv 2020, arXiv:2012.02312. [Google Scholar]
- Aggarwal, C.C. An introduction to outlier analysis. In Outlier Analysis; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–34. [Google Scholar]
- Kubat, M.; Holte, R.; Matwin, S. Learning when negative examples abound. In Proceedings of the 9th European Conference on Machine Learning, Prague, Czech Republic, 23–25 April 1997; pp. 146–153. [Google Scholar]
- Kubat, M.; Matwin, S. Addressing the curse of imbalanced training sets: One-sided selection. ICML Citeseer 1997, 97, 179–186. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Part B 2008, 39, 539–550. [Google Scholar]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. SMOTEBoost: Improving prediction of the minority class in boosting. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Cavtat-Dubrovnik, Croatia, 22–26 September 2003; pp. 107–119. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Liu, X.Y. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Trans. Knowl. Data Eng. 2005, 18, 63–77. [Google Scholar] [CrossRef]
- Ting, K.M. An instance-weighting method to induce cost-sensitive trees. IEEE Trans. Knowl. Data Eng. 2002, 14, 659–665. [Google Scholar] [CrossRef]
- Sun, Y.; Kamel, M.S.; Wong, A.K.; Wang, Y. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit. 2007, 40, 3358–3378. [Google Scholar] [CrossRef]
- Perri, D.; Simonetti, M.; Lombardi, A.; Faginas-Lago, N.; Gervasi, O. Binary classification of proteins by a machine learning approach. In Proceedings of the International Conference on Computational Science and Its Applications, Cagliari, Italy, 1–4 July 2020; pp. 549–558. [Google Scholar]
- Perri, D.; Simonetti, M.; Lombardi, A.; Faginas-Lago, N.; Gervasi, O. A new method for binary classification of proteins with Machine Learning. In Proceedings of the International Conference on Computational Science and Its Applications, Cagliari, Italy, 13–16 September 2021; pp. 388–397. [Google Scholar]
- Meyer, G.W. Wavelength selection for synthetic image generation. Comput. Vis. Graph. Image Process. 1988, 41, 57–79. [Google Scholar] [CrossRef]
- Spindler, A.; Geach, J.E.; Smith, M.J. AstroVaDEr: Astronomical variational deep embedder for unsupervised morphological classification of galaxies and synthetic image generation. Mon. Not. R. Astron. Soc. 2021, 502, 985–1007. [Google Scholar] [CrossRef]
- Perri, D.; Simonetti, M.; Tasso, S.; Gervasi, O. Learning Mathematics in an Immersive Way. In Software Usability; IntechOpen: London, UK, 2021. [Google Scholar]
- Prokopenko, D.; Stadelmann, J.V.; Schulz, H.; Renisch, S.; Dylov, D.V. Unpaired synthetic image generation in radiology using gans. In Workshop on Artificial Intelligence in Radiation Therapy; Springer: Berlin/Heidelberg, Germany, 2019; pp. 94–101. [Google Scholar]
- Kuo, S.D.; Schott, J.R.; Chang, C.Y. Synthetic image generation of chemical plumes for hyperspectral applications. Opt. Eng. 2000, 39, 1047–1056. [Google Scholar] [CrossRef][Green Version]
- Simonetti, M.; Perri, D.; Amato, N.; Gervasi, O. Teaching math with the help of virtual reality. In Proceedings of the International Conference on Computational Science and Its Applications, Cagliari, Italy, 1–4 July 2020; pp. 799–809. [Google Scholar]
- Svoboda, D.; Ulman, V. Generation of synthetic image datasets for time-lapse fluorescence microscopy. In Proceedings of the International Conference Image Analysis and Recognition, Aveiro, Portugal, 25–27 June 2012; pp. 473–482. [Google Scholar]
- Borkman, S.; Crespi, A.; Dhakad, S.; Ganguly, S.; Hogins, J.; Jhang, Y.C.; Kamalzadeh, M.; Li, B.; Leal, S.; Parisi, P.; et al. Unity Perception: Generate Synthetic Data for Computer Vision. arXiv 2021, arXiv:2107.04259. [Google Scholar]
- Al-Masni, M.A.; Al-Antari, M.A.; Park, J.M.; Gi, G.; Kim, T.Y.; Rivera, P.; Valarezo, E.; Choi, M.T.; Han, S.M.; Kim, T.S. Simultaneous detection and classification of breast masses in digital mammograms via a deep learning YOLO-based CAD system. Comput. Methods Programs Biomed. 2018, 157, 85–94. [Google Scholar] [CrossRef]
- Lan, W.; Dang, J.; Wang, Y.; Wang, S. Pedestrian detection based on YOLO network model. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018; pp. 1547–1551. [Google Scholar]
- Laroca, R.; Severo, E.; Zanlorensi, L.A.; Oliveira, L.S.; Gonçalves, G.R.; Schwartz, W.R.; Menotti, D. A robust real-time automatic license plate recognition based on the YOLO detector. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–10. [Google Scholar]
- Wang, W.; Li, Y.; Luo, X.; Xie, S. Ocean image data augmentation in the USV virtual training scene. Big Earth Data 2020, 4, 451–463. [Google Scholar] [CrossRef]
- Yun, K.; Yu, K.; Osborne, J.; Eldin, S.; Nguyen, L.; Huyen, A.; Lu, T. Improved visible to IR image transformation using synthetic data augmentation with cycle-consistent adversarial networks. arXiv 2019, arXiv:1904.11620. [Google Scholar]
- Lu, T.; Huyen, A.; Nguyen, L.; Osborne, J.; Eldin, S.; Yun, K. Optimized Training of Deep Neural Network for Image Analysis Using Synthetic Objects and Augmented Reality; SPIE: Bellingham, WA, USA, 2019; p. 10995. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Sharma, S.; Sharma, S.; Athaiya, A. Activation functions in neural networks. Towards Data Sci. 2017, 6, 310–316. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]

















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perri, D.; Simonetti, M.; Gervasi, O. Synthetic Data Generation to Speed-Up the Object Recognition Pipeline. Electronics 2022, 11, 2. https://doi.org/10.3390/electronics11010002
Perri D, Simonetti M, Gervasi O. Synthetic Data Generation to Speed-Up the Object Recognition Pipeline. Electronics. 2022; 11(1):2. https://doi.org/10.3390/electronics11010002
Chicago/Turabian StylePerri, Damiano, Marco Simonetti, and Osvaldo Gervasi. 2022. "Synthetic Data Generation to Speed-Up the Object Recognition Pipeline" Electronics 11, no. 1: 2. https://doi.org/10.3390/electronics11010002
APA StylePerri, D., Simonetti, M., & Gervasi, O. (2022). Synthetic Data Generation to Speed-Up the Object Recognition Pipeline. Electronics, 11(1), 2. https://doi.org/10.3390/electronics11010002