Adding a Piece to the Puzzle? The Allocation of Figurative Language Comprehension into the CHC Model of Cognitive Abilities


Abstract
:1. Introduction
2. Different Definitions and Models of Figurative Language Comprehension and Problems Resulting from This
3. Modern Conceptualization of Cognitive Abilities
4. Processes Proposed to Be Involved in the Comprehension of Figurative Language
5. Attempting to Integrate Figurative Language Comprehension into the CHC Model
6. Considering Personality for the Comprehension of Figurative Language
7. Different Tests to Measure Figurative Language Comprehension
8. The Present Study
9. Methods
Procedure
10. Sample
11. Instruments
11.1. Comprehension of Figurative Language
11.2. Item Example of the Reverse Paraphrase Test (RPT)
| Item | Translation | |
| Wenn die Aufsichtsperson nicht anwesend ist, verstoßen die anderen gegen die Regeln. | If the supervisor is not present, the others violate the rules. | |
| a. | Ein Hund, der nach zwei Hasen jagt, fängt keinen. | A dog hunting for two rabbits catches none. |
| b. | Wenn der Hund schläft, hat der Wolf gut Schafe stehlen. | When the dog sleeps, the wolf has good sheep stealing. |
| c. | Wer den Hund füttert, dem leckt er die Hände. | Whoever feeds the dog, the dog licks his hands. |
| d. | Zwei Hunde an einem Bein, kommen selten überein. | Two dogs on one leg, rarely agree. |
| e. | Soll der Hund Schläge haben, so hat er Leder gefressen. | If the dog is to have strokes, it has eaten leather. |
| The correct answer is shown in bold. | ||
11.3. Item Example of the Literal Paraphrase Test (LPT)
| Item | Translation | |
| Das am Ende der Straße liegende Hotel war sehr teuer. | The hotel located at the end of the street was very expensive. | |
| a. | Das teure Hotel war am anderen Ende der Straße. | The expensive hotel was at the other end of the street. |
| b. | Das Hotel, das am Ende der Straße liegt, war sehr teuer. | The hotel, which is located at the end of the street, was very expensive. |
| c. | Das Hotel war sehr teuer und lag am anderen Ende der Straße. | The hotel was very expensive and was at the other end of the street. |
| d. | Das teure Hotel lag am anderen Ende der Straße. | The expensive hotel was at the other end of the street. |
| e. | Das Hotel befand sich auf einer teuren Straße. | The hotel was located on an expensive street. |
| The correct answer is shown in bold. | ||
11.4. Item Example of the Proverb Test (PT)
| Item | Translation | |
| Der Medienwissenschaftler Ben Bachmair untersuchte die Fernsehgewohnheiten von Kindern. In den Familien, wo die Eltern häufig vor dem Fernseher hocken, verbringen auch die Kinder mehrere Stunden vor dem Bildschirm. Die aktuelle Studie zeigte, dass es sich dann meist um männerdominierte Familien handelt, in denen Actionfilme geguckt werden, was die Kinder, meist Jungen, übernehmen. | Media scientist Ben Bachmair studied the television habits of children. In families where parents frequently sit in front of the TV, children also spend several hours in front of the screen. The current study showed that these are then mostly male-dominated families where action movies are watched, which the children, mostly boys, take over. | |
| Correct answer | Der Apfel fällt nicht weit vom Stamm. | The apple doesn’t fall far from the tree. |
| The correct answer is shown in bold. | ||
11.5. Item Example of the Proverb–Metaphor Test (PMT)
| Item | Translation | |
| Ist die Katze aus dem Haus, tanzen die Mäuse auf dem Tisch. | When the cat’s away, the mice will play. | |
| a. | Wenn keine Kontrollperson da ist, können die Mäuse machen, was sie wollen. | If there is no control person, the mice can do whatever they want. |
| b. | Wenn Katzen und Mäuse nicht da sind, ist das Haus völlig leer. | When cats and mice are not there, the house is completely empty. |
| c. | Wenn die Katze nicht da ist und aufpasst, kann man machen, was man will. | When the cat is not around and paying attention, you can do whatever you want. |
| d. | Wenn keine Kontrollperson da ist, kann man machen, was man will. | If there is no control person, you can do whatever you want. |
| e. | Katzen fressen Mäuse. Mäuse können daher erst dann tanzen, wenn die Katze das Haus verlassen hat. | Cats eat mice. Therefore, mice can dance only after the cat has left the house. |
| f. | Wenn niemand da ist, kann man alles alleine machen. | When no one is around, you can do everything on your own. |
| The correct answer is shown in bold. | ||
11.6. CHC-Based Cognitive Abilities
11.7. Personality
11.8. Further Tests Not Used in the Current Study
11.9. Planned Missing Data Design
12. Data Analysis
12.1. Statistical Analysis
12.2. Structural Validity
12.3. CFAs for the Three Tests of Figurative Language Comprehension
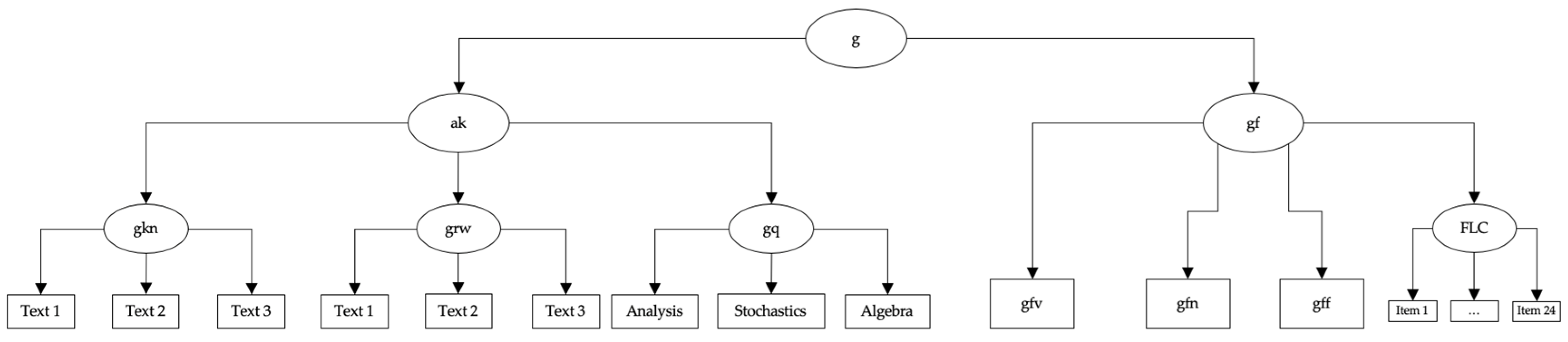
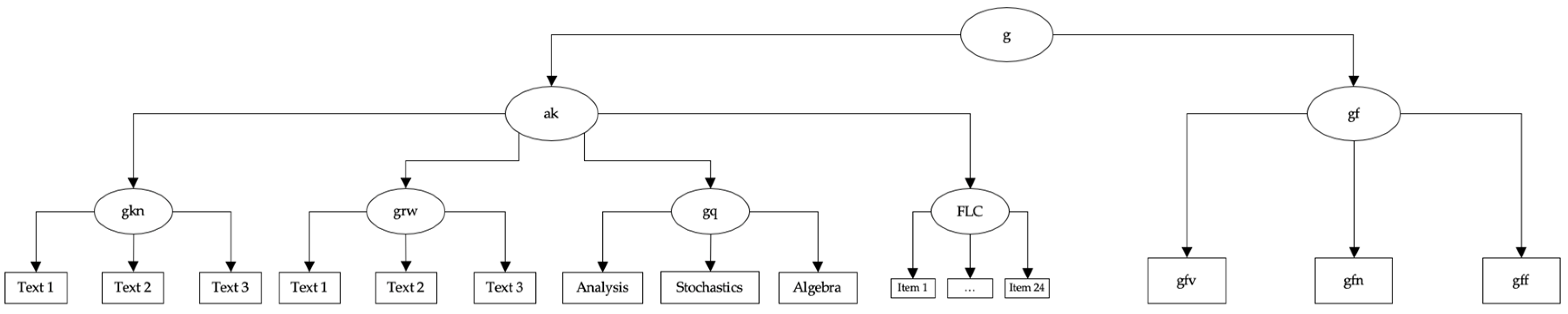
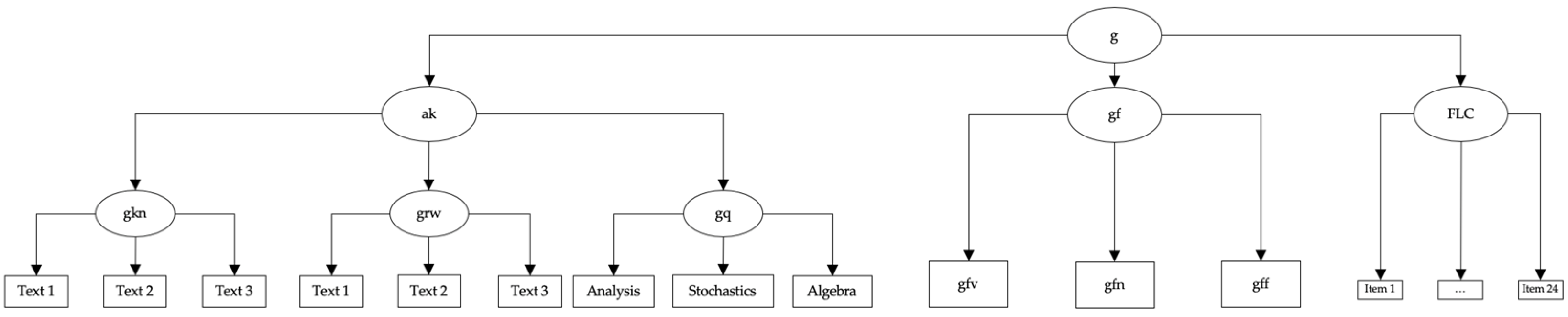
12.4. Theoretical Models for the Three Tests of Figurative Language Comprehension
12.5. Comparison of Different Models for the Allocation of Figurative Language Comprehension
12.6. Convergent and Discriminant Validity and Reliability Evidence
13. Results
13.1. Descriptive Statistics
13.2. Measurement Models for the Three Tests of Figurative Language Comprehension
13.3. Theoretical Models of Figurative Language Comprehension
13.4. Comparison of Different Theoretical Models for the Allocation of Figurative Language Comprehension in the CHC Model
13.5. Correlations with Personality
14. Discussion
14.1. Psychometric Quality of Different Figurative Language Comprehension Operationalizations
14.2. Allocating FLC in the CHC Model of Cognitive Abilities
14.3. How does Figurative Language Comprehension relate to Personality?
14.4. Limitations and Further Research
14.5. Conclusions and Outlook
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ackerman, Phillip L. 1987. Individual Differences in Skill Learning: An Integration of Psychometric and Information Processing Perspectives. Psychological Bulletin 102: 3–27. [Google Scholar] [CrossRef]
- Ackerman, Phillip L. 1996. A Theory of Adult Intellectual Development: Process, Personality, Interests, and Knowledge. Intelligence 22: 227–57. [Google Scholar] [CrossRef]
- Ackerman, Phillip L. 2000. Domain-Specific Knowledge as the ‘Dark Matter’ of Adult Intelligence: Gf/Gc, Personality and Interest Correlates. The Journals of Gerontology Series B: Psychological Sciences and Social Sciences 55: P69–P84. [Google Scholar] [CrossRef] [PubMed]
- Ackerman, Phillip L., and Eric D. Heggestad. 1997. Intelligence, Personality, and Interests: Evidence for Overlapping Traits. Psychological Bulletin 121: 219–45. [Google Scholar] [CrossRef] [PubMed]
- Ackerman, Phillip L., and Eric L. Rolfhus. 1999. The Locus of Adult Intelligence: Knowledge, Abilities, and Nonability Traits. Psychology and Aging 14: 314–30. [Google Scholar] [CrossRef] [PubMed]
- Akaike, Hirotugu. 1974. A New Look at the Statistical Model Identification. IEEE Transactions on Automatic Control 19: 716–23. [Google Scholar] [CrossRef]
- Alexander, Patricia A., and Judith E. Judy. 1988. The Interaction of Domain-Specific and Strategic Knowledge in Academic Performance. Review of Educational Research 58: 375–404. [Google Scholar] [CrossRef]
- Arslan, Ruben C., Matthias P. Walther, and Cyril S. Tata. 2020. formr: A study framework allowing for automated feedback generation and complex longitudinal experience-sampling studies using R. Behavior Research Methods 52: 376–87. [Google Scholar] [CrossRef] [PubMed]
- Barnden, John A. 2010. Metaphor and Metonymy: Making Their Connections More Slippery. Cogl 21: 1–34. [Google Scholar] [CrossRef]
- Barth, Alfred, and Bernd Küfferle. 2001. Die entwicklung eines sprichworttests zur erfassung konkretistischer denkstörungen bei schizophrenen patienten. Nervenarzt 72: 853–58. [Google Scholar] [CrossRef]
- Beaty, Roger E., and Paul J. Silvia. 2013. Metaphorically Speaking: Cognitive Abilities and the Production of Figurative Language. Memory & Cognition 41: 255–67. [Google Scholar] [CrossRef]
- Beier, Margaret E., and Phillip L. Ackerman. 2005. Age, Ability, and the Role of Prior Knowledge on the Acquisition of New Domain Knowledge: Promising Results in a Real-World Learning Environment. Psychology and Aging 20: 341–55. [Google Scholar] [CrossRef]
- Bentler, Peter M. 1990. Comparative Fit Indexes in Structural Models. Psychological Bulletin 107: 238–46. [Google Scholar] [CrossRef]
- Blömeke, Sigrid, Jan-Eric Gustafsson, and Richard J. Shavelson. 2015. Beyond Dichotomies: Competence Viewed as a Continuum. Zeitschrift Für Psychologie 223: 3–13. [Google Scholar] [CrossRef]
- Bohrn, Isabel C., Ulrike Altmann, and Arthur M. Jacobs. 2012. Looking at the brains behind figurative language-A quantitative meta-analysis of neuroimaging studies on metaphor, idiom, and irony processing. Neuropsychologia 50: 2669–83. [Google Scholar] [CrossRef] [PubMed]
- Boukes, Mark, Hajo G. Boomgaarden, Marjolein Moorman, and Claes H. De Vreese. 2015. At Odds: Laughing and Thinking? The Appreciation, Processing, and Persuasiveness of Political Satire: At Odds: Laughing and Thinking? Journal of Communication 65: 721–44. [Google Scholar] [CrossRef]
- Brauer, Kay, Jochen Ranger, and Matthias Ziegler. 2023. Confirmatory Factor Analyses in Psychological Test Adaptation and Development: A Nontechnical Discussion of the WLSMV Estimator. Psychological Test Adaptation and Development 4: 4–12. [Google Scholar] [CrossRef]
- Browne, Michael W., and Robert Cudeck. 1993. Alternative ways of assessing model fit. In Testing Structural Equation Models. Edited by Kenneth A. Bollen and J. Scott Long. Newbury Park: Sage, pp. 136–62. [Google Scholar]
- Brüne, Martin, and Luise Bodenstein. 2005. Proverb comprehension reconsidered—‘Theory of mind’ and the pragmatic use of language in schizophrenia. Schizophrenia Research 75: 233–39. [Google Scholar] [CrossRef]
- Burgers, Christian, Margot Van Mulken, and Peter Jan Schellens. 2012. Verbal Irony: Differences in Usage Across Written Genres. Journal of Language and Social Psychology 31: 290–310. [Google Scholar] [CrossRef]
- Cain, Kate, Jane Oakhill, and Kate Lemmon. 2005. The relation between children’s reading comprehension level and their comprehension of idioms. Journal of Experimental Child Psychology 90: 65–87. [Google Scholar] [CrossRef]
- Callis, Zoe, Paul Gerrans, Dana L. Walker, and Gilles E. Gignac. 2023. The Association between Intelligence and Financial Literacy: A Conceptual and Meta-Analytic Review. Intelligence 100: 101781. [Google Scholar] [CrossRef]
- Campbell, Donald T., and Donald W. Fiske. 1959. Convergent and Discriminant Validation by the Multitrait-Multimethod Matrix. Psychological Bulletin 56: 81–105. [Google Scholar] [CrossRef] [PubMed]
- Carroll, John B. 1993. Human Cognitive Abilities: A Survey of Factor-Analytic Studies. Cambridge and New York: Cambridge University Press. [Google Scholar]
- Carroll, John B. 2003. The Higher-Stratum Structure of Cognitive Abilities. In The Scientific Study of General Intelligence. Amsterdam: Elsevier, pp. 5–21. [Google Scholar] [CrossRef]
- Carter, Ronald. 2016. Language and Creativity: The Art of Common Talk, 2nd ed. Routledge Linguistics Classics. London and New York: Routledge. [Google Scholar]
- Cattell, Raymond B. 1943. The Description of Personality: Basic Traits Resolved into Clusters. The Journal of Abnormal and Social Psychology 38: 476–506. [Google Scholar] [CrossRef]
- Cattell, Raymond B. 1987. Intelligence: Its Structure, Growth, and Action. Advances in Psychology 35. Amsterdam: North-Holland. New York: Sole distributors for the U.S.A., Canada. New York: Elsevier Science Pub. Co. [Google Scholar]
- Chiappe, Dan L., and Penny Chiappe. 2007. The role of working memory in metaphor production and comprehension. Journal of Memory and Language 56: 172–88. [Google Scholar] [CrossRef]
- Colom, Roberto, Doreen Bensch, Kai T. Horstmann, Caroline Wehner, and Matthias Ziegler. 2019. Special Issue The Ability–Personality Integration. Journal of Intelligence 7: 13. [Google Scholar] [CrossRef]
- Conner, Tamlin S., and Paul J. Silvia. 2015. Creative Days: A Daily Diary Study of Emotion, Personality, and Everyday Creativity. Psychology of Aesthetics, Creativity, and the Arts 9: 463–70. [Google Scholar] [CrossRef]
- Corts, Daniel P., and Kristina Meyers. 2002. Conceptual Clusters in Figurative Language Production. Journal of Psycholinguistic Research 31: 391–408. [Google Scholar] [CrossRef] [PubMed]
- Cronk, Brian C., and Wendy A. Schweigert. 1992. The Comprehension of Idioms: The Effects of Familiarity, Literalness, and Usage. Applied Psycholinguistics 13: 131–46. [Google Scholar] [CrossRef]
- Cumming, Geoff. 2014. The New Statistics: Why and How. Psychological Science 25: 7–29. [Google Scholar] [CrossRef]
- Danner, Daniel, Beatrice Rammstedt, Matthias Bluemke, Lisa Treiber, Sabrina Berres, Christopher J. Soto, and Oliver P. John. 2016. Die Deutsche Version des Big Five Inventory 2 (BFI-2). Mannheim: GESIS—Leibniz-Institut für Sozialwissenschaften. [Google Scholar] [CrossRef]
- Deary, Ian J., Jian Yang, Gail Davies, Sarah E. Harris, Albert Tenesa, David Liewald, Michelle Luciano, Lorna M. Lopez, Alan J. Gow, Janie Corley, and et al. 2012. Genetic Contributions to Stability and Change in Intelligence from Childhood to Old Age. Nature 482: 212–15. [Google Scholar] [CrossRef]
- Dews, Shelly, and Ellen Winner. 1995. Muting the Meaning A Social Function of Irony. Metaphor and Symbolic Activity 10: 3–19. [Google Scholar] [CrossRef]
- DeYoung, Colin G., Rachael G. Grazioplene, and Jordan B. Peterson. 2012. From Madness to Genius: The Openness/Intellect Trait Domain as a Paradoxical Simplex. Journal of Research in Personality 46: 63–78. [Google Scholar] [CrossRef]
- Drnyei, Zoltn, and Peter Skehan. 2003. Individual Differences in Second Language Learning. In The Handbook of Second Language Acquisition. Edited by Catherine J. Doughty and Michael H. Long. Oxford: Blackwell Publishing Ltd., pp. 589–630. [Google Scholar] [CrossRef]
- Eid, Michael, Christian Geiser, Tobias Koch, and Moritz Heene. 2017. Anomalous Results in G-Factor Models: Explanations and Alternatives. Psychological Methods 22: 541–62. [Google Scholar] [CrossRef] [PubMed]
- Elliot, Andrew J., and Holly A. McGregor. 2001. A 2 × 2 Achievement Goal Framework. Journal of Personality and Social Psychology 80: 501–19. [Google Scholar] [CrossRef] [PubMed]
- Elvevåg, B., K. Helsen, M. De Hert, K. Sweers, and G. Storms. 2011. Metaphor interpretation and use: A window into semantics in schizophrenia. Schizophrenia Research 133: 205–11. [Google Scholar] [CrossRef] [PubMed]
- Filik, Ruth, and Linda M. Moxey. 2010. The On-Line Processing of Written Irony. Cognition 116: 421–36. [Google Scholar] [CrossRef]
- Filik, Ruth, Hartmut Leuthold, Katie Wallington, and Jemma Page. 2014. Testing Theories of Irony Processing Using Eye-Tracking and ERPs. Journal of Experimental Psychology: Learning, Memory, and Cognition 40: 811–28. [Google Scholar] [CrossRef]
- Garcia-Albea, Jose, and Jose Gavilan. 2009. A Discriminant Analysis on Language Comprehension and Theory of Mind in Schizophrenia. Proceedings of the Annual Meeting of the Cognitive Science Society 31. [Google Scholar]
- Gavilán, José M., and José E. García-Albea. 2011. Theory of mind and language comprehension in schizophrenia: Poor mindreading affects figurative language comprehension beyond intelligence deficits. Journal of Neurolinguistics 24: 54–69. [Google Scholar] [CrossRef]
- Gernsbacher, Morton Ann, Boaz Keysar, Rachel R.W. Robertson, and Necia K. Werner. 2001. The Role of Suppression and Enhancement in Understanding Metaphors. Journal of Memory and Language 45: 433–50. [Google Scholar] [CrossRef]
- Gerrig, Richard J., and Raymond W. Gibbs Jr. 1988. Beyond the Lexicon: Creativity in Language Production. Metaphor and Symbolic Activity 3: 1–19. [Google Scholar] [CrossRef]
- Ghisletta, P., J.-F. Bickel, and M. Lovden. 2006. Does Activity Engagement Protect Against Cognitive Decline in Old Age? Methodological and Analytical Considerations. The Journals of Gerontology Series B: Psychological Sciences and Social Sciences 61: P253–P261. [Google Scholar] [CrossRef] [PubMed]
- Gibbs, Raymond W. 1994. The Poetics of Mind: Figurative Thought, Language, and Understanding. Cambridge and New York: Cambridge University Press. [Google Scholar]
- Gibbs, Raymond W. 2000. Irony in Talk Among Friends. Metaphor and Symbol 15: 5–27. [Google Scholar] [CrossRef]
- Gibbs, Raymond W., and Dinara Beitel. 1995. What proverb understanding reveals about how people think. Psychological Bulletin 118: 133–54. [Google Scholar] [CrossRef] [PubMed]
- Gibbs, Raymond W., and Herbert L. Colston. 2007. Irony in Language and Thought: A Cognitive Science Reader. New York: Lawrence Erlbaum Associates. [Google Scholar]
- Gibbs, Raymond W., and Herbert L. Colston. 2012. Interpreting Figurative Meaning. Cambridge and New York: Cambridge University Press. [Google Scholar]
- Giora, Rachel. 2003. On Our Mind. Oxford: Oxford University Press. [Google Scholar] [CrossRef]
- Giora, Rachel, and Ofer Fein. 1999. On understanding familiar and less-familiar figurative language. Journal of Pragmatics 31: 1601–18. [Google Scholar] [CrossRef]
- Giora, Rachel, Ofer Fein, and Tamir Schwartz. 1998. Irony: Grade Salience and Indirect Negation. Metaphor and Symbol 13: 83–101. [Google Scholar] [CrossRef]
- Giora, Rachel, Ofer Fein, Dafna Laadan, Joe Wolfson, Michal Zeituny, Ran Kidron, Ronie Kaufman, and Ronit Shaham. 2007. Expecting Irony: Context Versus Salience-Based Effects. Metaphor and Symbol 22: 119–46. [Google Scholar] [CrossRef]
- Glucksberg, Sam. 2003. The psycholinguistics of metaphor. Trends in Cognitive Sciences 7: 92–96. [Google Scholar] [CrossRef]
- Glucksberg, Sam, and Matthew S. McGlone. 2001. Understanding Figurative Language: From Metaphors to Idioms. Oxford Psychology Series, no. 36; Oxford and New York: Oxford University Press. [Google Scholar]
- Glucksberg, Sam, Matthew S. McGlone, and Deanna Manfredi. 1997. Property attribution in metaphor comprehension. Journal of Memory and Language 36: 50–67. [Google Scholar] [CrossRef]
- Gorham, Donald R. 1956. Use of the Proverbs Test for differentiating schizophrenics from normals. Journal of Consulting Psychology 20: 435–40. [Google Scholar] [CrossRef]
- Graham, John W., Bonnie J. Taylor, Allison E. Olchowski, and Patricio E. Cumsille. 2006. Planned missing data designs in psychological research. Psychological Methods 11: 323–43. [Google Scholar] [CrossRef] [PubMed]
- Grice, Herbert P. 1975. Logic and Conversation. In Speech Acts. Edited by Peter Cole and Jerry L. Morgan. Leiden: BRILL, pp. 41–58. [Google Scholar] [CrossRef]
- Heredia, Roberto R., and Anna B. Cieślicka, eds. 2015. Bilingual Figurative Language Processing. New York: Cambridge University Press. [Google Scholar]
- Horn, John L., and Raymond B. Cattell. 1966. Refinement and Test of the Theory of Fluid and Crystallized General Intelligences. Journal of Educational Psychology 57: 253–70. [Google Scholar] [CrossRef] [PubMed]
- Horstmann, Kai T., Andra Biesok, Katja Witte, Henrik R. Godmann, Karla Fliedner, Lisa Wilm, Larissa Doran, and Matthias Ziegler. 2023. Berliner Studierfähigkeitstest—Psychologie (BSF-P). Psychologische Rundschau 74: 221–38. [Google Scholar] [CrossRef]
- Hu, Li-tze, and Peter M. Bentler. 1999. Cutoff Criteria for Fit Indexes in Covariance Structure Analysis: Conventional Criteria versus New Alternatives. Structural Equation Modeling: A Multidisciplinary Journal 6: 1–55. [Google Scholar] [CrossRef]
- Huang, Li, Francesca Gino, and Adam D. Galinsky. 2015. The Highest Form of Intelligence: Sarcasm Increases Creativity for Both Expressers and Recipients. Organizational Behavior and Human Decision Processes 131: 162–77. [Google Scholar] [CrossRef]
- Johnson, Janice, and Teresa Rosano. 1993. Relation of Cognitive Style to Metaphor Interpretation and Second Language Proficiency. Applied Psycholinguistics 14: 159–75. [Google Scholar] [CrossRef]
- Jorgensen, William L., David S. Maxwell, and Julian Tirado-Rives. 1996. Development and Testing of the OPLS All-Atom Force Field on Conformational Energetics and Properties of Organic Liquids. Journal of the American Chemical Society 118: 11225–36. [Google Scholar] [CrossRef]
- Kan, Kees-Jan, Rogier A. Kievit, Conor Dolan, and Han Van Der Maas. 2011. On the Interpretation of the CHC Factor Gc. Intelligence 39: 292–302. [Google Scholar] [CrossRef]
- Kerbel, Debra, and Pam Grunwell. 1997. Idioms in the classroom: An investigation of language unit and mainstream teachers’ use of idioms. Child Language Teaching and Therapy 13: 113–23. [Google Scholar] [CrossRef]
- Keysar, Boaz. 1989. On the Functional Equivalence of Literal and Metaphorical Interpretations in Discourse. Journal of Memory and Language 28: 375–85. [Google Scholar] [CrossRef]
- Kintsch, Walter. 2000. Metaphor Comprehension: A Computational Theory. Psychonomic Bulletin & Review 7: 257–66. [Google Scholar] [CrossRef]
- Kircher, Tilo, Frederike Stein, and Arne Nagels. 2022. Differences in Single Positive Formal Thought Disorder Symptoms between Closely Matched Acute Patients with Schizophrenia and Mania. European Archives of Psychiatry and Clinical Neuroscience 272: 395–401. [Google Scholar] [CrossRef]
- Kline, Theresa. 2005. Psychological Testing: A Practical Approach to Design and Evaluation. Thousand Oaks: Sage Publications. [Google Scholar]
- Knight, Jacquelyn L., Megan S. Barker, Timothy J. Edwards, Joseph M. Barnby, Linda J. Richards, and Gail A. Robinson. 2023. Mirror Movements and Callosal Dysgenesis in a Family with a DCC Mutation: Neuropsychological and Neuroimaging Outcomes. Cortex 161: 38–50. [Google Scholar] [CrossRef]
- Kuncel, Nathan R., Deniz S. Ones, and Paul R. Sackett. 2010. Individual Differences as Predictors of Work, Educational, and Broad Life Outcomes. Personality and Individual Differences 49: 331–36. [Google Scholar] [CrossRef]
- Lakoff, George, and Mark Johnson. 2003. Metaphors We Live by. Chicago: University of Chicago Press. [Google Scholar]
- Landis, J. Richard, and Gary G. Koch. 1977. An Application of Hierarchical Kappa-type Statistics in the Assessment of Majority Agreement among Multiple Observers. Biometrics 33: 363. [Google Scholar] [CrossRef] [PubMed]
- Lang, Jonas W.B., and Stefan Fries. 2006. A revised 10-item version of the achievement motives scale: Psychometric properties in German-speaking samples. European Journal of Psychological Assessment 22: 216–24. [Google Scholar] [CrossRef]
- Lawes, Mario, Martin Schultze, and Michael Eid. 2020. Making the Most of Your Research Budget: Efficiency of a Three-Method Measurement Design With Planned Missing Data. Assessment 27: 903–20. [Google Scholar] [CrossRef] [PubMed]
- Leyhe, Thomas, Ralf Saur, Gerhard W. Eschweiler, and Monika Milian. 2011. Impairment in Proverb Interpretation as an Executive Function Deficit in Patients with Amnestic Mild Cognitive Impairment and Early Alzheimer’s Disease. Dementia and Geriatric Cognitive Disorders Extra 1: 51–61. [Google Scholar] [CrossRef]
- Li, Lanlan, Jiliang Chen, and Lan Sun. 2015. The Effects of Different Lengths of Pretask Planning Time on L2 Learners’ Oral Test Performance. TESOL Quarterly 49: 38–66. [Google Scholar] [CrossRef]
- Little, Roderick J. A., and Donald B. Rubin. 2020. Statistical Analysis with Missing Data, 3rd ed. Wiley series in probability and statistics; Hoboken: Wiley. [Google Scholar]
- McCarthy, Michael, and Ronald Carter. 2004. There’s Millions of Them”: Hyperbole in Everyday Conversation. Journal of Pragmatics 36: 149–84. [Google Scholar] [CrossRef]
- McGrew, Kevin S. 2009. CHC theory and the human cognitive abilities project: Standing on the shoulders of the giants of psychometric intelligence research. Intelligence 37: 1–10. [Google Scholar] [CrossRef]
- Meade, Adam W., Emily C. Johnson, and Phillip W. Braddy. 2008. Power and Sensitivity of Alternative Fit Indices in Tests of Measurement Invariance. Journal of Applied Psychology 93: 568–92. [Google Scholar] [CrossRef]
- Mitchell, Rachel L.C., and Tim J. Crow. 2005. Right hemisphere language functions and schizophrenia: The forgotten hemisphere? Brain 128: 963–78. [Google Scholar] [CrossRef]
- Nenchev, Ivan, and Christiane Montag. 2023. Novel Proverbs Tests for Schizophrenia [Manuscript in Preparation]. Berlin: Department of Psychiatry and Psychotherapy, Campus Charité Mitte—Universitätsmedizin Berlin, Corporate Member of Freie Universität Berlin, Humboldt-Universität zu Berlin, and Berlin Institute of Health. [Google Scholar]
- Nusbaum, Emily C., Paul J. Silvia, and Roger E. Beaty. 2017. Ha Ha? Assessing Individual Differences in Humor Production Ability. Psychology of Aesthetics, Creativity, and the Arts 11: 231–41. [Google Scholar] [CrossRef]
- Olkoniemi, Henri, Henri Ranta, and Johanna K. Kaakinen. 2016. Individual Differences in the Processing of Written Sarcasm and Metaphor: Evidence from Eye Movements. Journal of Experimental Psychology: Learning, Memory, and Cognition 42: 433–50. [Google Scholar] [CrossRef]
- Ortony, Andrew, ed. 1993. Metaphor and Thought, 2nd ed. Cambridge and New York: Cambridge University Press. [Google Scholar]
- Pereira de Barros, Débora, Ricardo Primi, Fabiano Koich Miguel, Leandro S Almeida, and Ema P Oliveira. 2010. Metaphor Creation: A Measure of Creativity or Intelligence? European Journal of Education and Psychology No 3: 103–15. [Google Scholar] [CrossRef]
- Pfaff, Kerry L., Raymond W. Gibbs, and Michael D. Johnson. 1997. Metaphor in Using and Understanding Euphemism and Dysphemism. Applied Psycholinguistics 18: 59–83. [Google Scholar] [CrossRef]
- Pierce, Russell S., and Dan L. Chiappe. 2009. The roles of aptness, conventionality, and working memory in the production of metaphors and similes. Metaphor and Symbol 24: 1–19. [Google Scholar] [CrossRef]
- Piovan, Cristiano, Laura Gava, and Mara Campeol. 2016. Theory of Mind and social functioning in schizophrenia: Correlation with figurative language abnormalities, clinical symptoms and general intelligence. Rivista di Psichiatria 51: 20–29. [Google Scholar] [CrossRef] [PubMed]
- Revelle, William. 2023. Psych: Procedures for Psychological, Psychometric, and Personality Research. R Package Version 2.3.3. Available online: https://CRAN.R-project.org/package=psych (accessed on 8 August 2023).
- Revelle, William, David M. Condon, Joshua Wilt, Jason A. French, Ashley Brown, and Lorien G. Elleman. 2017. Web and phone based data collection using planned missing designs. In Sage Handbook of Online Research Methods. Edited by Nigel Fielding, Raymond M. Lee and Grant Blank. London: Sage, pp. 578–95. [Google Scholar]
- Roberts, Richard M., and Roger J. Kreuz. 1994. Why Do People Use Figurative Language? Psychological Science 5: 159–63. [Google Scholar] [CrossRef]
- Rolfhus, Eric L., and Phillip L. Ackerman. 1996. Self-Report Knowledge: At the Crossroads of Ability, Interest, and Personality. Journal of Educational Psychology 88: 174–88. [Google Scholar] [CrossRef]
- Rolfhus, Eric L., and Phillip L. Ackerman. 1999. Assessing Individual Differences in Knowledge: Knowledge, Intelligence, and Related Traits. Journal of Educational Psychology 91: 511–26. [Google Scholar] [CrossRef]
- Rosseel, Yves. 2012. Lavaan: An R Package for Structural Equation Modeling. Journal of Statistical Software 48: 1–36. [Google Scholar] [CrossRef]
- Rounds, James, Rong Su, Phil Lewis, and David Rivkin. 2010. O* Net Interest Profiler Short form Psychometric Characteristics: Summary. Raleigh: National Center for O* NET Development. [Google Scholar]
- Rusche, Marianna Massimilla, and Matthias Ziegler. 2022. The Interplay between Domain-Specific Knowledge and Selected Investment Traits across the Life Span. Intelligence 92: 101647. [Google Scholar] [CrossRef]
- Rusche, Marianna Massimilla, and Matthias Ziegler. 2023. Measuring Domain-Specific Knowledge: From Bach to Fibonacci. Journal of Intelligence 11: 47. [Google Scholar] [CrossRef] [PubMed]
- Schipolowski, Stefan, Oliver Wilhelm, and Ulrich Schroeders. 2014. On the Nature of Crystallized Intelligence: The Relationship between Verbal Ability and Factual Knowledge. Intelligence 46: 156–68. [Google Scholar] [CrossRef]
- Schneider, W. Joel, and Kevin S. McGrew. 2013. Cognitive performance models: Individual differences in the ability to process information. In Handbook of Educational Theories. Edited by Beverly Irby, Genevieve Brown, Rafael Laro-Alecia and Shirley Jackson. Charlotte: Information Age, pp. 767–82. [Google Scholar]
- Schneider, W. Joel, and Kevin S. McGrew. 2018. The Cattell-Horn-Carroll theory of cognitive abilities. Contemporary Intellectual Assessment: Theories, Tests, and Issues 2018: 73–163. [Google Scholar]
- Shamay-Tsoory, Simone G., Rachel Tomer, and Judith Aharon-Peretz. 2005. The neuroanatomical basis of understanding sarcasm and its relationship to social cognition. Neuropsychology 19: 288–300. [Google Scholar] [CrossRef]
- Silvia, Paul J. 2015. Intelligence and Creativity Are Pretty Similar After All. Educational Psychology Review 27: 599–606. [Google Scholar] [CrossRef]
- Silvia, Paul J., and Roger E. Beaty. 2012. Making Creative Metaphors: The Importance of Fluid Intelligence for Creative Thought. Intelligence 40: 343–51. [Google Scholar] [CrossRef]
- Silvia, Paul J., Emily C. Nusbaum, Christopher Berg, Christopher Martin, and Alejandra O’Connor. 2009. Openness to Experience, Plasticity, and Creativity: Exploring Lower-Order, High-Order, and Interactive Effects. Journal of Research in Personality 43: 1087–90. [Google Scholar] [CrossRef]
- Simpson, Paul. 1993. Language, Ideology, and Point of View. Interface series; London and New York: Routledge. [Google Scholar]
- Simpson, Paul. 2003. On the Discourse of Satire: Towards a Stylistic Model of Satirical Humour. Linguistic Approaches to Literature 2. Amsterdam: Benjamins. [Google Scholar]
- Sperber, Dan, and Deirdre Wilson. 2002. Pragmatics, Modularity and Mind-reading. Mind & Language 17: 3–23. [Google Scholar]
- Stanley, David. 2021. apaTables: Create American Psychological Association (APA) Style Tables. R Package Version 2.0.8. Available online: https://cran.r-project.org/web/packages/apaTables/apaTables.pdf (accessed on 8 August 2023).
- Stekhoven, Daniel J., and Peter Bühlmann. 2012. MissForest—Non-Parametric Missing Value Imputation for Mixed-Type Data. Bioinformatics 28: 112–18. [Google Scholar] [CrossRef] [PubMed]
- Sutin, Angelina R. 2015. Openness. Edited by Thomas A. Widiger. 1 vol. Oxford: Oxford University Press. [Google Scholar] [CrossRef]
- Sutu, Andreea, Surizaday Serrano, Leah H. Schultz, Joshua J. Jackson, and Rodica Ioana Damian. 2019. Creating through Deviancy or Adjustment? The Link between Personality Profile Normativeness and Creativity. European Journal of Personality 33: 565–88. [Google Scholar] [CrossRef]
- Swineford, Lauren B., Audrey Thurm, Gillian Baird, Amy M. Wetherby, and Susan Swedo. 2014. Social (pragmatic) communication disorder: A research review of this new DSM-5 diagnostic category. Journal of Neurodevelopmental Disorders 6: 1–8. [Google Scholar] [CrossRef]
- Titone, Debra, Georgie Columbus, Veronica Whitford, Julie Mercier, and Maya Libben. 2015. Contrasting Bilingual and Monolingual Idiom Processing. In Bilingual Figurative Language Processing, 1st ed. Edited by Roberto R. Heredia and Anna B. Cieślicka. New York: Cambridge University Press, pp. 171–207. [Google Scholar] [CrossRef]
- Trapp, Stefanie, and Matthias Ziegler. 2019. How Openness Enriches the Environment: Read More. Frontiers in Psychology 10: 1123. [Google Scholar] [CrossRef]
- Trapp, Stefanie, Sigrid Blömeke, and Matthias Ziegler. 2019. The Openness-Fluid-Crystallized-Intelligence (OFCI) Model and the Environmental Enrichment Hypothesis. Intelligence 73: 30–40. [Google Scholar] [CrossRef]
- Uekermann, Jennifer, Patrizia Thoma, and Irene Daum. 2008. Proverb Interpretation Changes in Aging. Brain and Cognition 67: 51–57. [Google Scholar] [CrossRef] [PubMed]
- Unsworth, Nash. 2017. Examining the Dynamics of Strategic Search from Long-Term Memory. Journal of Memory and Language 93: 135–53. [Google Scholar] [CrossRef]
- Von Stumm, Sophie, and Phillip L. Ackerman. 2013. Investment and Intellect: A Review and Meta-Analysis. Psychological Bulletin 139: 841–69. [Google Scholar] [CrossRef]
- Watts, Logan L., Logan M. Steele, and Hairong Song. 2017. Re-Examining the Relationship Between Need for Cognition and Creativity: Predicting Creative Problem Solving Across Multiple Domains. Creativity Research Journal 29: 21–28. [Google Scholar] [CrossRef]
- Weisberg, Robert W. 2006. Expertise and Reason in Creative Thinking: Evidence from Case Studies and the Laboratory. In Creativity and Reason in Cognitive Development, 1st ed. Edited by James C. Kaufman and John Baer. New York: Cambridge University Press, pp. 7–42. [Google Scholar] [CrossRef]
- Zhang, Charlene, and Martin C. Yu. 2022. Planned Missingness: How to and How Much? Organizational Research Methods 25: 623–41. [Google Scholar] [CrossRef]
- Zhang, Jing, and Matthias Ziegler. 2022. Getting Better Scholastic Performance: Should Students Be Smart, Curious, Interested, or Both? Personality and Individual Differences 189: 111481. [Google Scholar] [CrossRef]
- Ziegler, Matthias. 2020. Psychological Test Adaptation and Development—How Papers Are Structured and Why. Psychological Test Adaptation and Development 1: 3–11. [Google Scholar] [CrossRef]
- Ziegler, Matthias, and Dirk Hagemann. 2015. Testing the Unidimensionality of Items: Pitfalls and Loopholes. European Journal of Psychological Assessment 31: 231–37. [Google Scholar] [CrossRef]
- Ziegler, Matthias, Anja Cengia, Patrick Mussel, and Denis Gerstorf. 2015. Openness as a Buffer against Cognitive Decline: The Openness-Fluid-Crystallized-Intelligence (OFCI) Model Applied to Late Adulthood. Psychology and Aging 30: 573–88. [Google Scholar] [CrossRef]
- Ziegler, Matthias, Erik Danay, Moritz Heene, Jens Asendorpf, and Markus Bühner. 2012. Openness, Fluid Intelligence, and Crystallized Intelligence: Toward an Integrative Model. Journal of Research in Personality 46: 173–83. [Google Scholar] [CrossRef]
- Ziegler, Matthias, Titus Schroeter, Oliver Lüdtke, and Lena Roemer. 2018. The Enriching Interplay between Openness and Interest: A Theoretical Elaboration of the OFCI Model and a First Empirical Test. Journal of Intelligence 6: 35. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Variable | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.RPT | 10.92 | 3.20 | ||||||||||||||||||||||
| 2.LPT | 8.89 | 2.07 | .72 ** | |||||||||||||||||||||
| [.69, .75] | ||||||||||||||||||||||||
| 3.PMT | 11.63 | 3.66 | .69 ** | .75 ** | ||||||||||||||||||||
| [.65, .72] | [.72, .77] | |||||||||||||||||||||||
| 4.Extraversion | 3.49 | 0.67 | .00 | .02 | .02 | |||||||||||||||||||
| [−.06, .07] | [−.04, .09] | [−.05, .08] | ||||||||||||||||||||||
| 5.Agreeableness | 3.82 | 0.56 | .03 | .08 * | .08 * | .14 ** | ||||||||||||||||||
| [−.04, .09] | [.01, .14] | [.01, .14] | [.08, .20] | |||||||||||||||||||||
| 6.Conscientiousness | 3.48 | 0.68 | −.10 ** | −.03 | −.01 | .28 ** | .30 ** | |||||||||||||||||
| [−.16, −.04] | [−.09, .04] | [−.07, .06] | [.22, .34] | [.24, .36] | ||||||||||||||||||||
| 7.Negative Emotionality | 2.81 | 0.70 | .02 | .02 | .04 | −.30 ** | −.31 ** | −.34 ** | ||||||||||||||||
| [−.04, .09] | [−.05, .08] | [−.02, .11] | [−.35, −.24] | [−.37, −.25] | [−.40, −.29] | |||||||||||||||||||
| 8.Openness | 3.64 | 0.69 | .24 ** | .19 ** | .24 ** | .30 ** | .19 ** | .07 * | −.05 | |||||||||||||||
| [.17, .30] | [.13, .25] | [.18, .30] | [.24, .36] | [.12, .25] | [.00, .13] | [−.12, .01] | ||||||||||||||||||
| 9.E_Sociability | 3.36 | 0.90 | −.06 | −.03 | −.03 | .86 ** | .09 ** | .12 ** | −.20 ** | .14 ** | ||||||||||||||
| [−.12, .01] | [−.09, .04] | [−.10, .03] | [.84, .88] | [.03, .15] | [.06, .19] | [−.27, −.14] | [.08, .21] | |||||||||||||||||
| 10.A_Compassion | 4.04 | 0.72 | .08 * | .14 ** | .15 ** | .18 ** | .82 ** | .26 ** | −.09 ** | .21 ** | .12 ** | |||||||||||||
| [.02, .14] | [.08, .20] | [.08, .21] | [.12, .24] | [.80, .84] | [.20, .32] | [−.16, −.03] | [.15, .28] | [.06, .18] | ||||||||||||||||
| 11.C_ Organization | 3.62 | 0.98 | −.14 ** | −.05 | −.04 | .14 ** | .18 ** | .84 ** | −.16 ** | −.03 | .05 | .15 ** | ||||||||||||
| [−.20, −.07] | [−.12, .01] | [−.10, .03] | [.08, .20] | [.11, .24] | [.82, .86] | [−.23, −.10] | [−.10, .03] | [−.01, .12] | [.09, .21] | |||||||||||||||
| 12.N_Anxiety | 3.11 | 0.77 | .03 | .05 | .07 * | −.26 ** | −.11 ** | −.19 ** | .85 ** | −.01 | −.19 ** | .07 * | −.06 | |||||||||||
| [−.04, .09] | [−.01, .12] | [.01, .13] | [−.31, −.19] | [−.17, −.05] | [−.25, −.13] | [.83, .87] | [−.08, .05] | [−.26, −.13] | [.00, .13] | [−.12, .01] | ||||||||||||||
| 13.O_Aesthetic Sensitivity | 3.43 | 1.05 | .19 ** | .16 ** | .22 ** | .13 ** | .19 ** | .04 | .05 | .84 ** | .05 | .23 ** | .01 | .09 ** | ||||||||||
| [.13, .25] | [.10, .22] | [.16, .29] | [.07, .20] | [.12, .25] | [−.02, .11] | [−.01, .12] | [.81, .85] | [−.02, .11] | [.16, .29] | [−.06, .07] | [.02, .15] | |||||||||||||
| 14.E_Assertiveness | 3.53 | 0.84 | .06 | .04 | .04 | .79 ** | −.05 | .27 ** | −.23 ** | .26 ** | .49 ** | .04 | .14 ** | −.25 ** | .08 * | |||||||||
| [−.01, .12] | [−.03, .10] | [−.03, .10] | [.76, .81] | [−.11, .02] | [.20, .32] | [−.29, −.17] | [.20, .32] | [.44, .54] | [−.02, .11] | [.07, .20] | [−.31, −.19] | [.01, .14] | ||||||||||||
| 15.A_Respectfulness | 4.17 | 0.64 | .00 | .05 | .04 | .10 ** | .80 ** | .39 ** | −.37 ** | .14 ** | .03 | .56 ** | .25 ** | −.15 ** | .13 ** | .00 | ||||||||
| [−.06, .07] | [−.01, .12] | [−.02, .11] | [.04, .17] | [.78, .83] | [.33, .45] | [−.42, −.31] | [.08, .20] | [−.03, .10] | [.52, .61] | [.19, .31] | [−.22, −.09] | [.06, .19] | [−.06, .07] | |||||||||||
| 16.C_Productiveness | 3.18 | 0.83 | −.06 | −.03 | −.01 | .32 ** | .26 ** | .85 ** | −.37 ** | .13 ** | .17 ** | .21 ** | .51 ** | −.24 ** | .05 | .28 ** | .30 ** | |||||||
| [−.13, .00] | [−.10, .03] | [−.07, .06] | [.26, .38] | [.19, .32] | [.83, .86] | [−.43, −.32] | [.06, .19] | [.11, .24] | [.14, .27] | [.46, .56] | [−.30, −.17] | [−.01, .12] | [.22, .34] | [.24, .36] | ||||||||||
| 17.N_Depression | 2.54 | 0.90 | .06 | .04 | .07 * | −.44 ** | −.29 ** | −.38 ** | .83 ** | −.05 | −.36 ** | −.14 ** | −.22 ** | .57 ** | .05 | −.28 ** | −.29 ** | −.40 ** | ||||||
| [−.00, .13] | [−.02, .11] | [.00, .13] | [−.49, −.39] | [−.35, −.23] | [−.43, −.32] | [.81, .85] | [−.12, .01] | [−.42, −.31] | [−.20, −.07] | [−.28, −.15] | [.53, .62] | [−.02, .11] | [−.34, −.22] | [−.35, −.23] | [−.45, −.34] | |||||||||
| 18.O_Intellectual Curiosity | 3.83 | 0.78 | .30 ** | .23 ** | .26 ** | .28 ** | .10 ** | .05 | −.10 ** | .76 ** | .12 ** | .13 ** | −.06 | −.08 * | .44 ** | .28 ** | .08 * | .15 ** | −.06 | |||||
| [.24, .35] | [.17, .29] | [.20, .32] | [.22, .34] | [.04, .16] | [−.01, .12] | [−.16, −.03] | [.73, .79] | [.06, .19] | [.07, .19] | [−.12, .01] | [−.15, −.02] | [.39, .49] | [.22, .34] | [.02, .15] | [.08, .21] | [−.13, .00] | ||||||||
| 19.E_Energy Level | 3.58 | 0.74 | .02 | .06 | .05 | .80 ** | .33 ** | .31 ** | −.30 ** | .36 ** | .58 ** | .30 ** | .16 ** | −.18 ** | .22 ** | .42 ** | .25 ** | .36 ** | −.45 ** | .30 ** | ||||
| [−.05, .08] | [−.00, .13] | [−.01, .12] | [.77, .82] | [.27, .39] | [.25, .37] | [−.36, −.24] | [.31, .42] | [.53, .62] | [.24, .36] | [.10, .23] | [−.24, −.12] | [.16, .28] | [.37, .47] | [.19, .31] | [.30, .42] | [−.50, −.39] | [.24, .36] | |||||||
| 20.A_Trust | 3.25 | 0.76 | −.02 | −.00 | .00 | .06 | .78 ** | .09 ** | −.31 ** | .09 ** | .06 | .41 ** | .04 | −.18 ** | .10 ** | −.15 ** | .42 ** | .12 ** | −.27 ** | .03 | .25 ** | |||
| [−.09, .04] | [−.07, .06] | [−.06, .07] | [−.01, .12] | [.75, .80] | [.02, .15] | [−.36, −.25] | [.03, .16] | [−.00, .13] | [.36, .46] | [−.03, .10] | [−.24, −.12] | [.03, .16] | [−.21, −.08] | [.36, .47] | [.06, .18] | [−.33, −.21] | [−.03, .10] | [.19, .31] | ||||||
| 21.C_Responsibility | 3.66 | 0.66 | −.03 | .03 | .04 | .25 ** | .34 ** | .80 ** | −.36 ** | .09 ** | .09 ** | .32 ** | .48 ** | −.21 ** | .06 | .27 ** | .47 ** | .62 ** | −.35 ** | .06 | .27 ** | .07 * | ||
| [−.09, .04] | [−.03, .10] | [−.03, .10] | [.19, .31] | [.29, .40] | [.78, .82] | [−.42, −.31] | [.03, .15] | [.02, .15] | [.26, .38] | [.43, .53] | [−.27, −.14] | [−.01, .12] | [.21, .33] | [.41, .52] | [.58, .66] | [−.41, −.29] | [−.01, .12] | [.21, .33] | [.00, .13] | |||||
| 22.N_Emotional Volatility | 2.78 | 0.86 | −.03 | −.05 | −.02 | −.03 | −.37 ** | −.28 ** | .83 ** | −.06 | .05 | −.14 ** | −.12 ** | .59 ** | .00 | −.05 | −.45 ** | −.29 ** | .48 ** | −.10 ** | −.10 ** | −.31 ** | −.34 ** | |
| [−.10, .03] | [−.11, .02] | [−.09, .04] | [−.10, .03] | [−.42, −.31] | [−.34, −.22] | [.81, .85] | [−.13, .00] | [−.01, .12] | [−.21, −.08] | [−.18, −.06] | [.55, .63] | [−.06, .07] | [−.11, .02] | [−.50, −.40] | [−.35, −.23] | [.43, .53] | [−.17, −.04] | [−.17, −.04] | [−.37, −.25] | [−.39, −.28] | ||||
| 23.O_Creative Imagination | 3.66 | 0.80 | .07 * | .06 | .08 * | .34 ** | .13 ** | .06 | −.11 ** | .76 ** | .19 ** | .13 ** | −.04 | −.07 * | .42** | .30 ** | .12 ** | .12 ** | −.14 ** | .41 ** | .37 ** | .08 * | .10 ** | −.06 |
| [.00, .13] | [−.01, .12] | [.02, .15] | [.28, .40] | [.07, .20] | [−.00, .13] | [−.17, −.04] | [.73, .78] | [.12, .25] | [.07, .19] | [−.10, .03] | [−.13, −.00] | [.37, .47] | [.24, .36] | [.05, .18] | [.06, .19] | [−.20, −.07] | [.36, .47] | [.31, .42] | [.01, .14] | [.04, .16] | [−.12, .01] |
| Measurement Model | RPT | LPT | |||
|---|---|---|---|---|---|
| Sample | Sample 1 | Sample 2 | Sample 1 | Sample 1 Adjusted | Sample 2 |
| x2 | 105.386 ** | 100.604 ** | 400.008 *** | 34.186 | 42.012 |
| df | 77 | 77 | 170 | 35 | 35 |
| CFI | .910 | .955 | 1 | 1 | .998 |
| RMSEA | .094 | .065 | .061 | .000 | .019 |
| SRMR | .070 | .054 | .156 | .048 | .037 |
| ω | .93 | .93 | 1 | .96 | .97 |
| Theoretical Model | Mgfm | Mcfm | Mbfm |
|---|---|---|---|
| x2 | 514.972 *** | 364.154 *** | 328.441 *** |
| df | 252 | 251 | 238 |
| CFI | .937 | .973 | .979 |
| RMSEA | .041 | .027 | .025 |
| SRMR | .040 | .033 | .030 |
| AIC | 11,389.644 | 11,164.323 | 11,135.733 |
| BIC | 11,620.637 | 11,400.128 | 11,434.098 |
| ω | .92 | .84 a .88 b | .92 c |
| Theoretical Model | FLC-g | FLC-gf | FLC-ak |
|---|---|---|---|
| x2 | 938.002 *** | 942.560 *** | 951.043 *** |
| df | 575 | 575 | 575 |
| CFI | .939 | .938 | .937 |
| RMSEA | .040 | .040 | .040 |
| SRMR | .049 | .051 | .051 |
| AIC | 20,785.322 | 20,790.157 | 20,798.558 |
| BIC | 21,159.264 | 21,164.098 | 21,172.500 |
| ω | .89 | .89 | .89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biesok, A.; Ziegler, M.; Montag, C.; Nenchev, I. Adding a Piece to the Puzzle? The Allocation of Figurative Language Comprehension into the CHC Model of Cognitive Abilities. J. Intell. 2024, 12, 29. https://doi.org/10.3390/jintelligence12030029
Biesok A, Ziegler M, Montag C, Nenchev I. Adding a Piece to the Puzzle? The Allocation of Figurative Language Comprehension into the CHC Model of Cognitive Abilities. Journal of Intelligence. 2024; 12(3):29. https://doi.org/10.3390/jintelligence12030029
Chicago/Turabian StyleBiesok, Andra, Matthias Ziegler, Christiane Montag, and Ivan Nenchev. 2024. "Adding a Piece to the Puzzle? The Allocation of Figurative Language Comprehension into the CHC Model of Cognitive Abilities" Journal of Intelligence 12, no. 3: 29. https://doi.org/10.3390/jintelligence12030029