A Convolution-LSTM-Based Deep Neural Network for Cross-Domain MOOC Forum Post Classification


Abstract
:1. Introduction
- In a forum post, confusion/urgency/sentiment attitude are typically expressed in only one or two sentences, and most sentences do not express these factors. Therefore, a sentence in a positive post shows little difference from one in a negative post, leading to noisy data for classifiers.
- The words/phrases used to express confusion/urgency are quite limited compared with other types of expressions. For example, posts frequently utilize phrases such as “What is”, “How will”, “Is there”, “Am I”, “How long” or “Where do we” to express confusion. Therefore, the set of usefully shared (or common) features in different domains is quite small.
- In different domains, the methods used to express the same attitude are often quite similar. As a result, we encounter an imbalance problem; that is, the shared features are almost exclusively features indicating the positive class. Therefore, only the positive features are shared among different domains, whereas features indicating the negative class in different domains are highly diverse.
- A post communicating confusion might be stated either explicitly or implicitly. Consider the following two real posts on an MOOC forum:Example 1. I understand that if you completed 65% you will get the certificate but where do we download the certificate?Example 2. I have tried to submit a document form of my response, but still nothing happens.Example 1 explicitly clearly expresses confusion related to the procedure to download the certificate. Example 2 is an example of implicit confusion. Recognizing explicit confusion is not difficult, whereas identifying implicit confusion requires deep semantic understanding.
2. Related Works
2.1. NLP in MOOC Research
2.2. Deep Learning in NLP
2.3. Cross-Domain Transfer Learning
3. Definitions
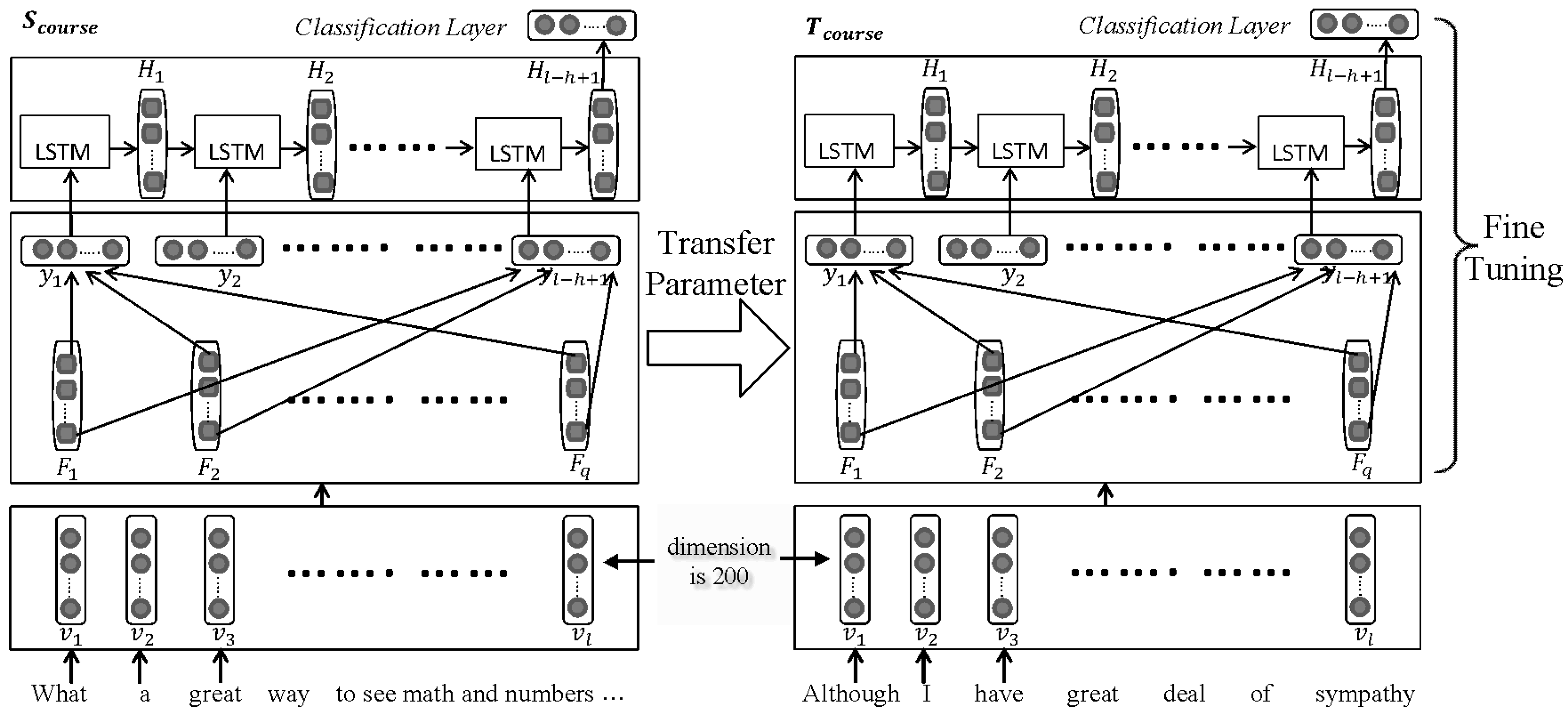
4. Methods
5. Implementation and Evaluation
5.1. Dataset
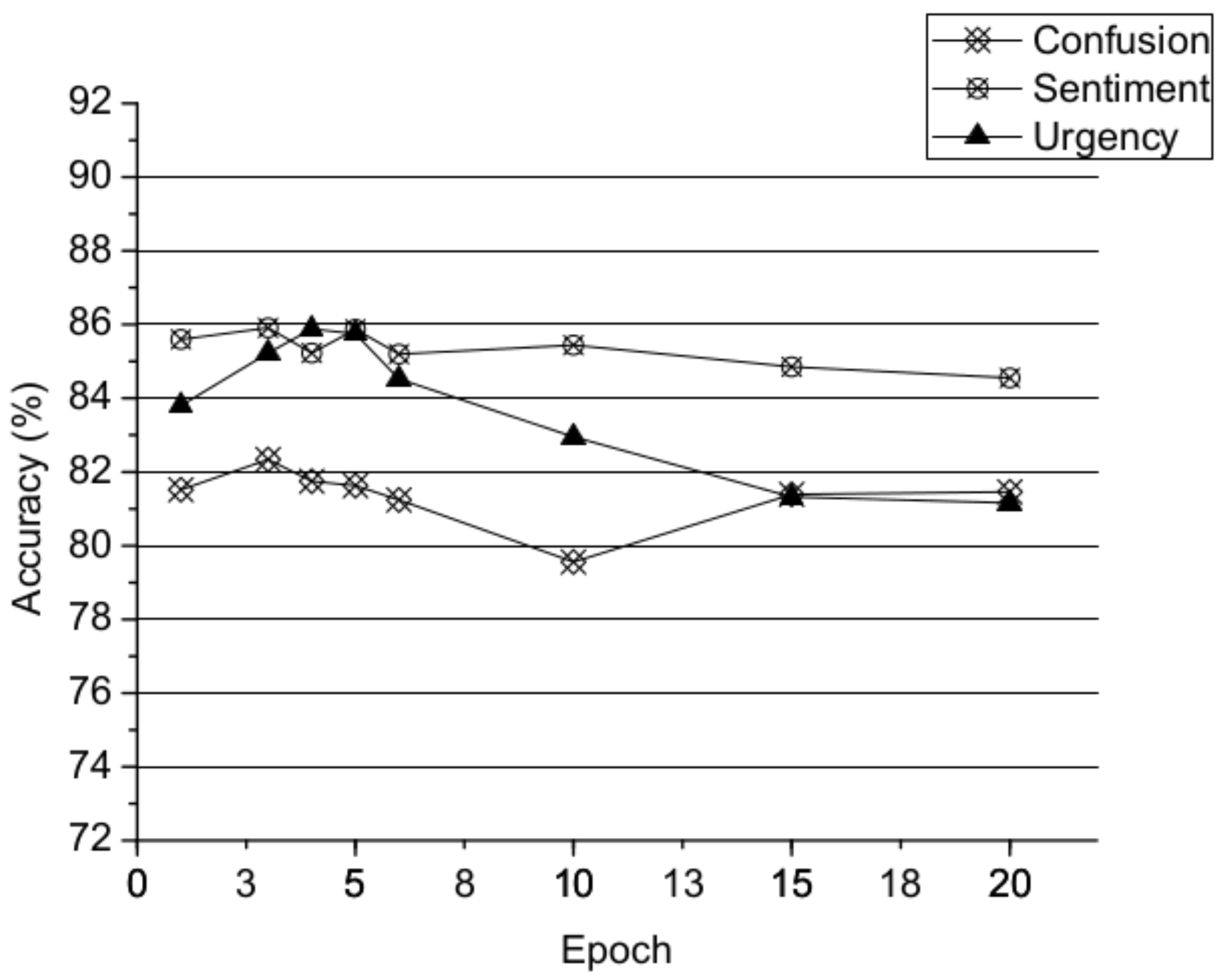
5.2. Experimental Setup
5.3. Baselines
- CNN-NTL: This method is similar to the CNN-TL method mentioned above, but we used to directly predict the unlabeled posts in the target domain without using a transfer scheme.
- CNN-TL: This method uses a model and transfer scheme similar to ConvL, but the layer subsequent to the convolutional layer is a max pooling layer instead of an LSTM layer. The max pooling length is 2.
- LSTM-NTL: This method is similar to the LSTM-TL mentioned above, but we used to directly predict the unlabeled posts in the target domain without using a transfer scheme.
- LSTM-TL: This is a model transfer scheme similar to ConvL, but it has no convolutional layer.
- Consumption intention mining model (CIMM)-TL: CIMM is a CNN-based framework proposed in [21] for mining consumption intention. It consists of a convolutional layer, a max pooling layer and two fully-connected layers. In their study, the authors investigated the possibility of transferring the CIMM mid-level sentence representation learned from one domain to another by adding an adaptation layer. We refer to this method as CIMM-TL. Because framework always performs worse without using transfer learning schema, we do not display CIMM-NTL.
- LM-CNN-LB: LM-CNN-LB is a two-layer convolutional neural network for cross-domain product review sentiment classification proposed in [40].
- ConvL-NTL: This method is the same as ConvL, but we used to directly predict the unlabeled posts in the target domain without using a transfer scheme.
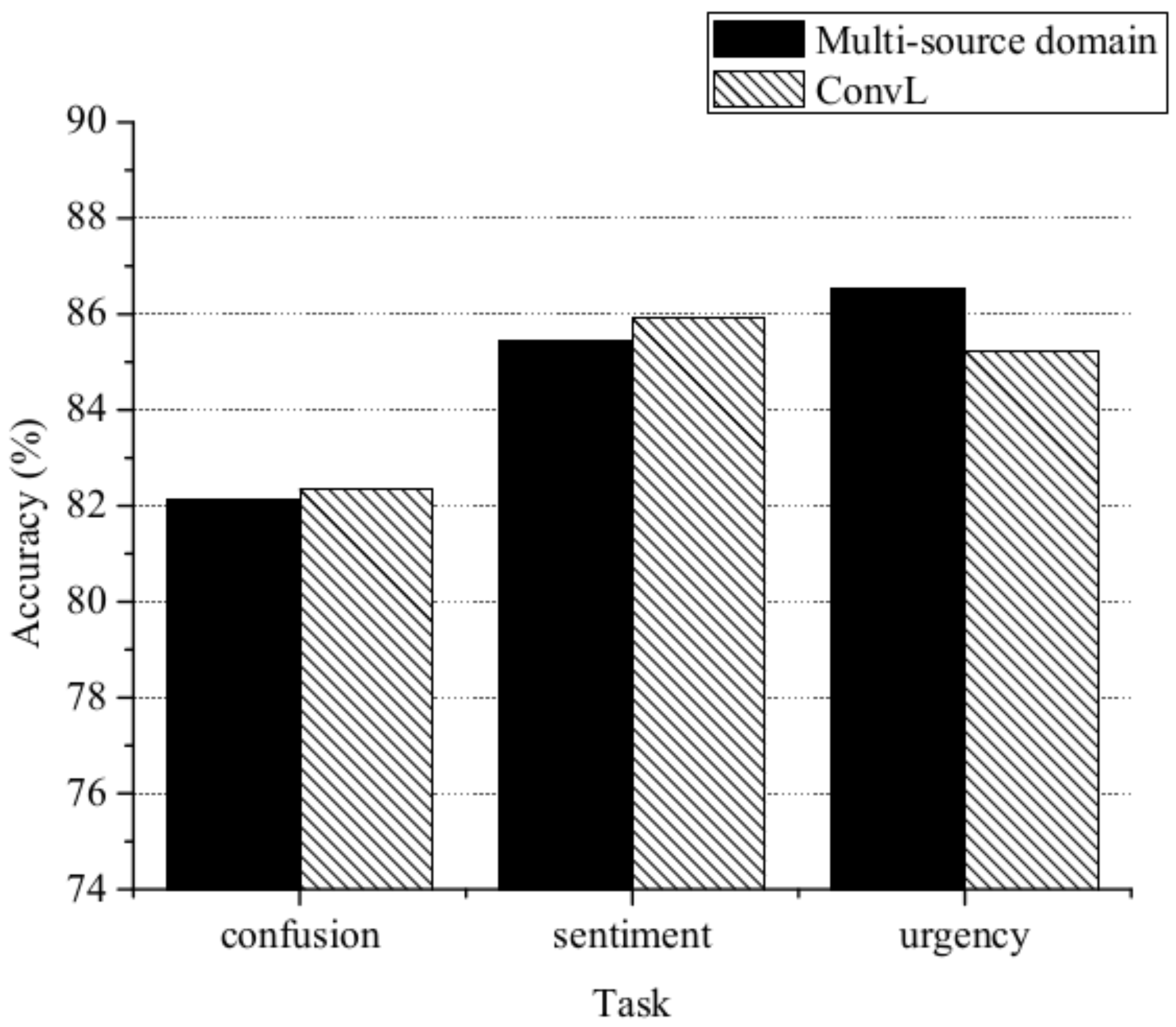
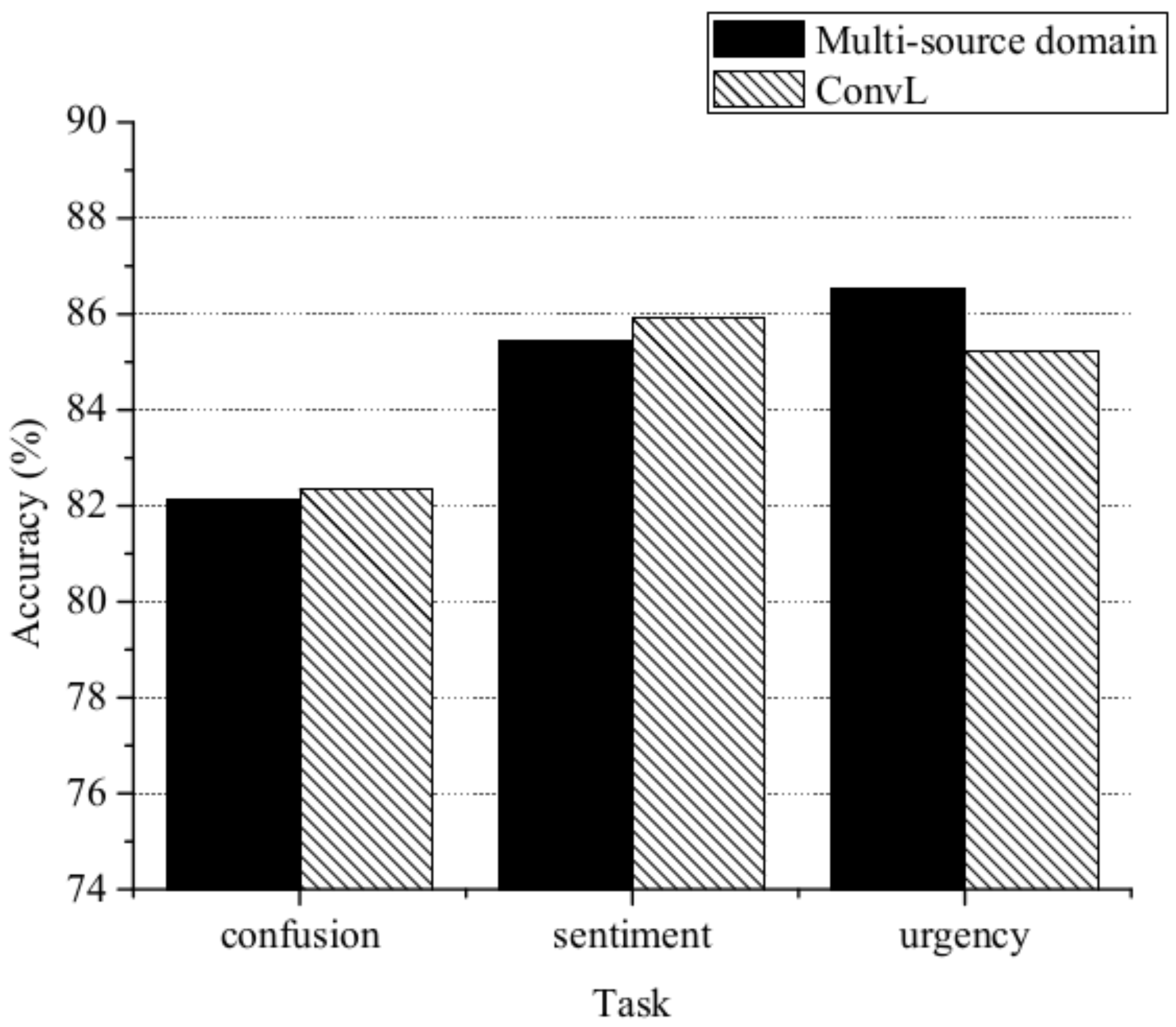
- ConvL: This is the method proposed in this paper. The code is publicly available (https://github.com/wxcmm/NLP).
- ConvL-in domain:This shows the ConvL results of the validation set for training on the source domain. The result can be treated as a higher bound.
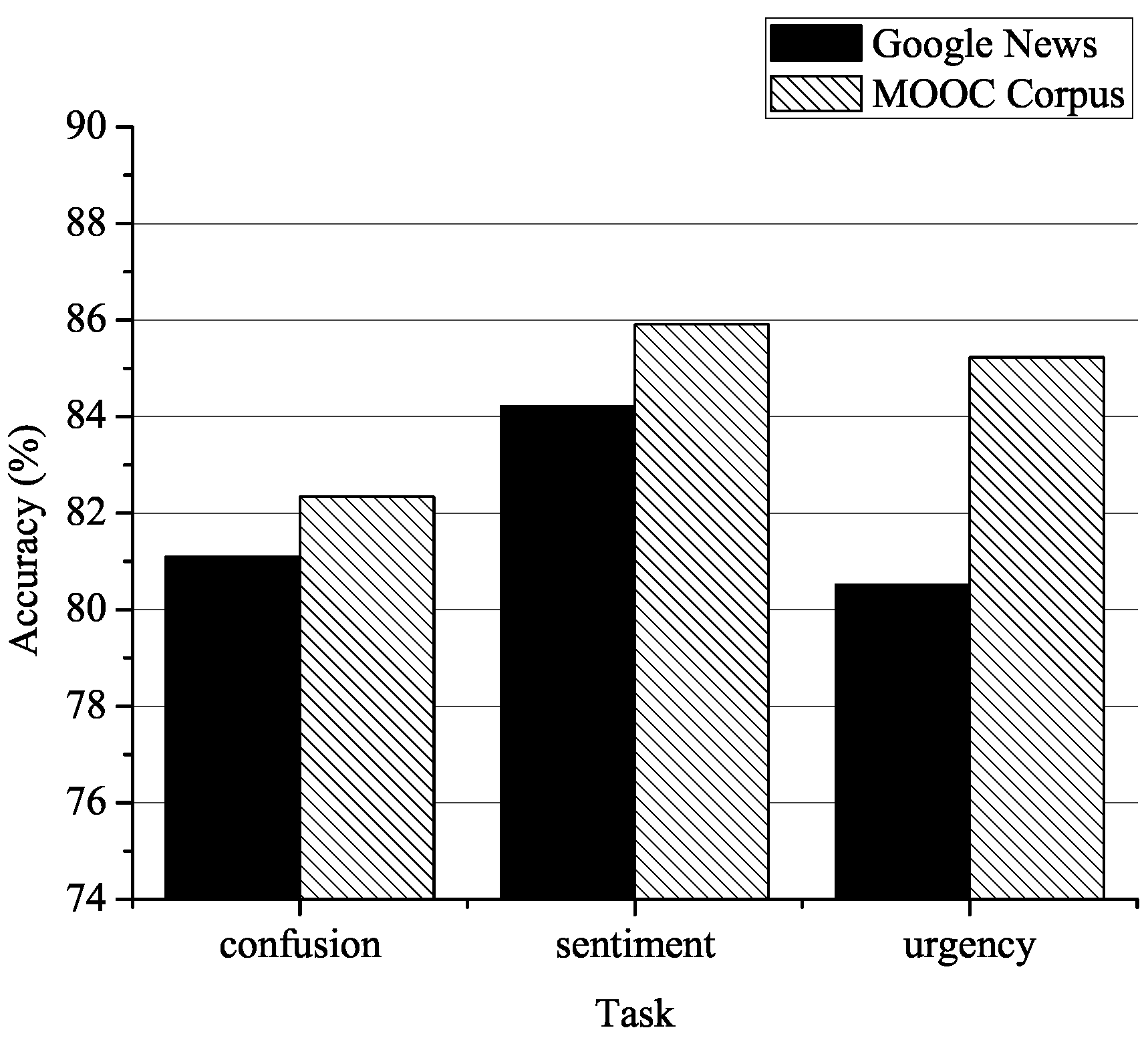
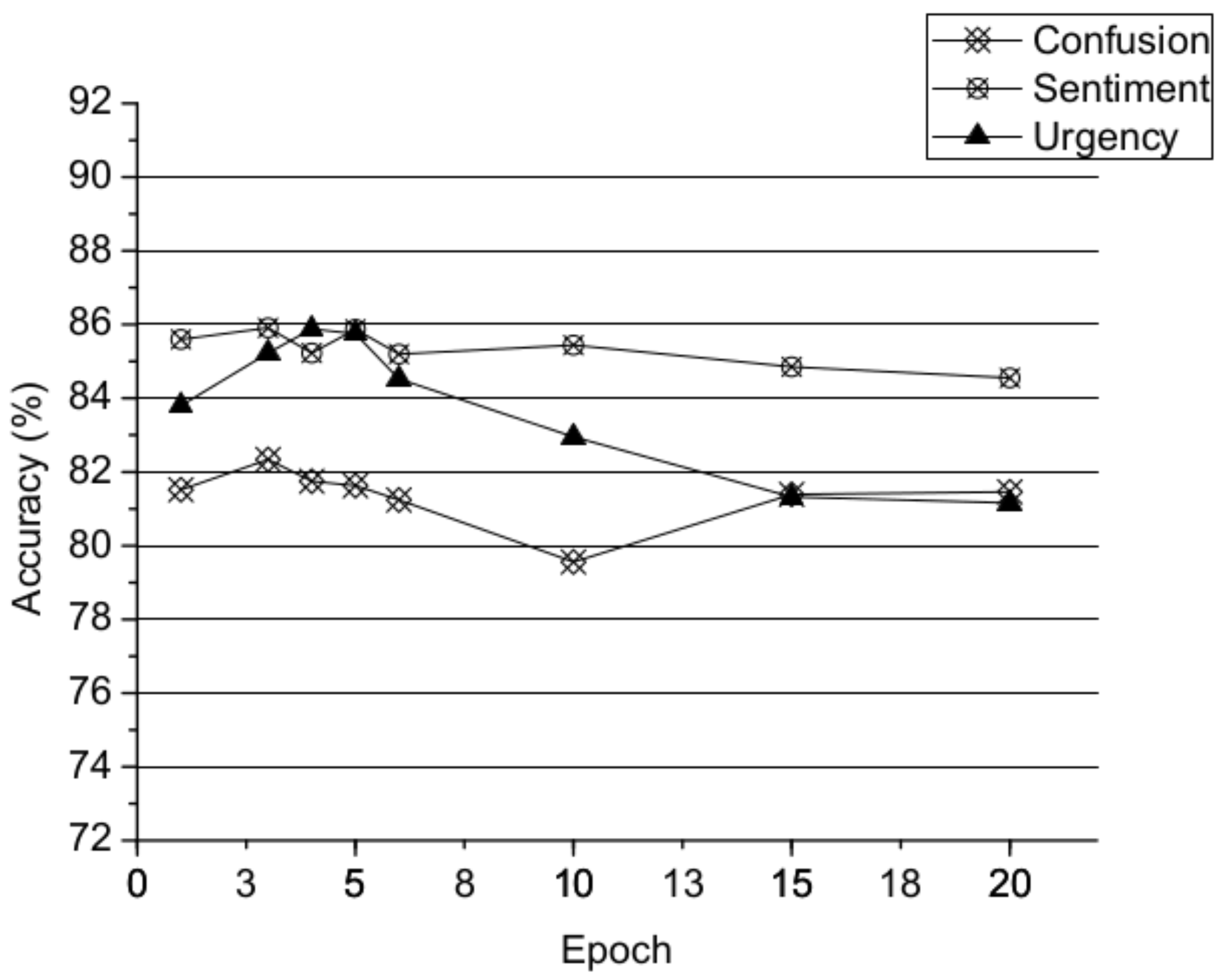
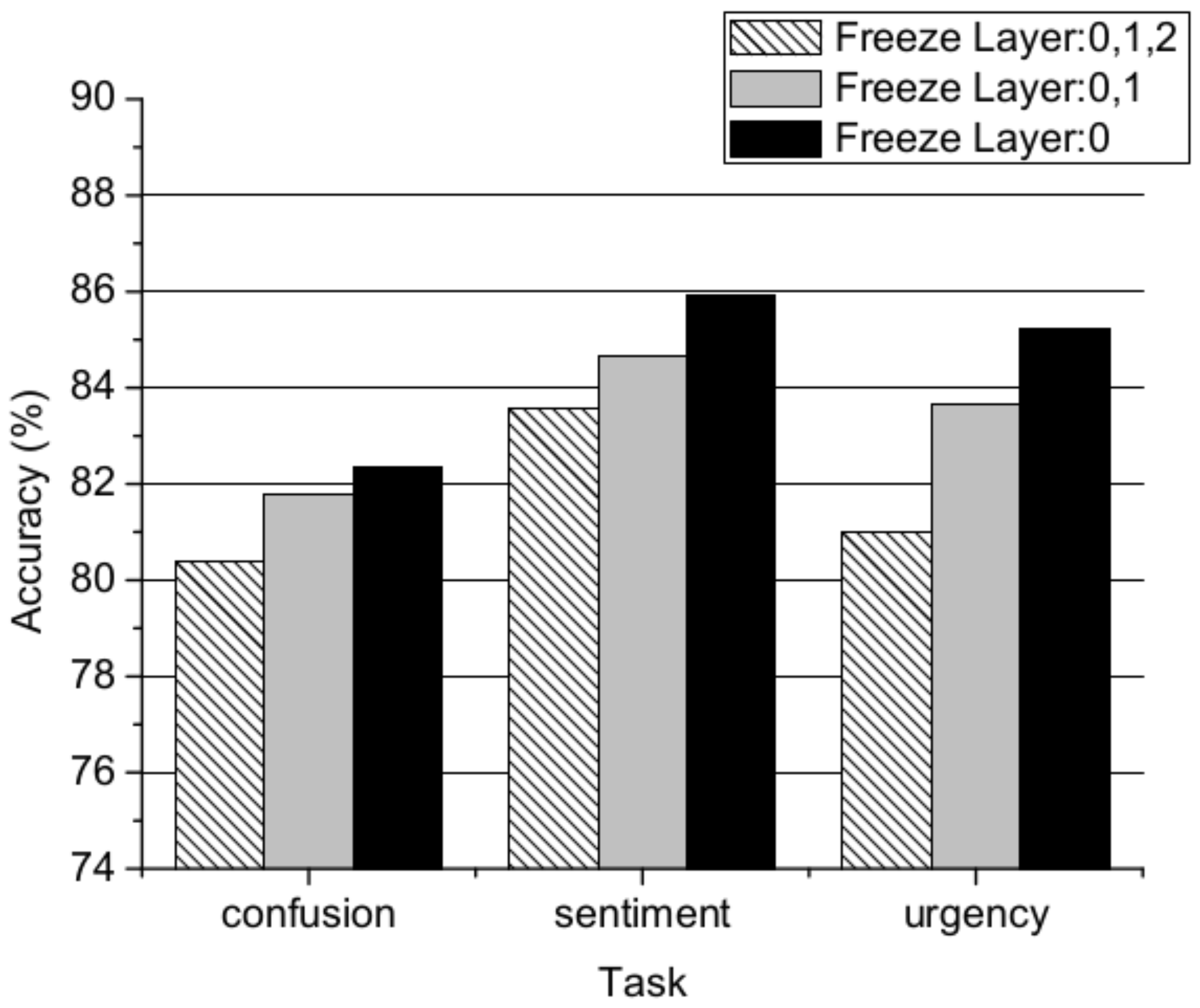
6. Results and Discussion
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| MOOC | Massive open online course |
| CNN | Convolutional neural network |
| LSTM | Long short-term memory |
| NLP | Natural language processing |
References
- Shah, D. Monetization Over Massiveness: Breaking Down MOOCs by the Numbers in 2016. EdSurge. Available online: https://www.edsurge.com/ (accessed on 25 July 2017).
- Rossi, L.A.; Gnawali, O. Language independent analysis and classification of discussion threads in Coursera MOOC forums. In Proceedings of the Information Reuse and Integration, Redwood City, CA, USA, 13–15 August 2014; pp. 654–661. [Google Scholar]
- Bakharia, A. Towards Cross-domain MOOC Forum Post Classification. In Proceedings of the L@S: ACM Conference on Learning at Scale, Edinburgh, Scotland, UK, 25–26 April 2016; pp. 253–256. [Google Scholar]
- Blitzer, J.; McDonald, R.; Pereira, F. Domain adaptation with structural correspondence learning. In Proceedings of the Empirical Methods on Natural Language Processing, Sydney, Australia, 22–23 July 2006; pp. 120–128. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 1st ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2000; pp. 1–1024. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Wen, M.; Howley, I.; Kraut, R.; Rosé, C. Exploring the effect of confusion in discussion forums of massive open online courses. In Proceedings of the L@S: ACM Conference on Learning at Scale, Vancouver, BC, Canada, 14–18 March 2015; pp. 121–130. [Google Scholar]
- Crossley, S.; McNamara, D.S.; Baker, R.; Wang, Y.; Paquette, L.; Barnes, T.; Bergner, Y. Language to Completion: Success in an Educational Data Mining Massive Open Online Class. In Proceedings of the International Conference on Educational Data Mining, Madrid, Spain, 26–29 June 2015. [Google Scholar]
- Robinson, C.; Yeomans, M.; Reich, J.; Hulleman, C.; Gehlbach, H. Forecasting student achievement in MOOCs with natural language processing. In Proceedings of the Conference on Learning Analytics & Knowledge, Edinburgh, UK, 25–29 April 2016; pp. 383–387. [Google Scholar]
- Ramesh, A.; Goldwasser, D.; Huang, B.; Daumé, D., III; Getoor, L. Understanding MOOC discussion forums using seeded LDA. In Proceedings of the Innovative Use of NLP for Building Educational Applications Conference, Baltimore, MD, USA, 22–27 June 2014; pp. 28–33. [Google Scholar]
- Liu, Z.; Liu, S.; Liu, L.; Sun, J.; Peng, X.; Wang, T. Sentiment recognition of online course reviews using multi-swarm optimization-based selected features. Neurocomputing 2016, 185, 11–20. [Google Scholar] [CrossRef]
- Tucker, C.S.; Dickens, B.; Divinsky, A. Knowledge Discovery of Student Sentiments in MOOCs and Their Impact on Course Performance. In Proceedings of the International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Buffalo, New York, NY, USA, 17–20 August 2014; p. V003T04A0288. [Google Scholar]
- Wen, M.; Yang, D.; Rosé, C.P. Sentiment Analysis in MOOC Discussion Forums: What does it tell us? In Proceedings of the International Conference on Educational Data Mining, London, UK, 4–7 July 2014. [Google Scholar]
- Agrawal, A.; Venkatraman, J.; Leonard, S.; Paepcke, A. YouEDU: addressing confusion in MOOC discussion forums by recommending instructional video clips. In Proceedings of the International Conference on Educational Data Mining, Madrid, Spain, 26–29 June 2015. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2016, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. In Proceedings of the Association for Computational Linguistics Conference, Baltimore, MD, USA, 22–27 June 2014; pp. 655–665. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation extraction: Perspective from con-volutional neural networks. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 39–48. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the Conference on Empirical Methods on Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Meng, F.; Lu, Z.; Wang, M.; Li, H.; Jiang, W.; Liu, Q. Encoding source language with convolutional neural network for machine translation. In Proceedings of the Association for Computational Linguistics Conference, Beijing, China, 26–31 July 2015; pp. 20–30. [Google Scholar]
- Ding, X.; Liu, T.; Duan, J.; Nie, J.Y. Mining user consumption intention from social media using domain adaptive convolutional neural network. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), Austin, TX, USA, 25–30 January 2015; pp. 2389–2395. [Google Scholar]
- Chen, H.; Sun, M.; Tu, C.; Lin, Y.; Liu, Z. Neural sentiment classification with user and product attention. In Proceedings of the Conference on Empirical Methods on Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 1650–1659. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for Target-Dependent Sentiment Classification. In Proceedings of the International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 3298–3307. [Google Scholar]
- Kandaswamy, C.; Silva, L.M.; Alexandre, L.A.; Santos, J.M.; de Sá, J.M. Improving deep neural network performance by reusing features trained with transductive transference. In Proceedings of the International Conference on Artificial Neural Networks. A conference of the European Neural Network Society, Hamburg, Germany, 15–19 September 2014; pp. 265–272. [Google Scholar]
- Harel, M.; Mannor, S. Learning from multiple outlooks. In Proceedings of the International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 401–408. [Google Scholar]
- Nam, J.; Kim, S. Heterogeneous defect prediction. In Proceedings of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering, Bergamo, Italy, 30 August–4 September 2015; pp. 508–519. [Google Scholar]
- Huang, J.T.; Li, J.Y.; Yu, D.; Deng, L.; Gong, Y.F. Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7304–7308. [Google Scholar]
- Pan, S.J.; Ni, X.; Sun, J.T.; Yang, Q.; Chen, Z. Cross-domain sentiment classification via spectral feature alignment. In Proceedings of the International World Wide Web Conference, Raleigh, WA, USA, 26–30 April 2010; pp. 751–760. [Google Scholar]
- Zhou, G.; He, T.; Wu, W.; Hu, X.T. Linking heterogeneous input features with pivots for domain adaptation. In Proceedings of the International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1419–1425. [Google Scholar]
- Bollegala, D.; Mu, T.; Goulermas, J.Y. Cross-Domain Sentiment Classification Using Sentiment Sensitive Embeddings. IEEE Trans. Knowl. Data Eng. 2016, 28, 398–410. [Google Scholar] [CrossRef]
- Xia, R.; Zong, C.; Hu, X.; Cambria, E. Feature ensemble plus sample selection: Domain adaptation for sentiment classification. Intell. Syst. 2013, 28, 10–18. [Google Scholar] [CrossRef]
- Huang, X.; Rao, Y.; Xie, H.; Wong, T.; Wang, F. Cross-Domain Sentiment Classification via Topic-Related TrAdaBoost. In Proceedings of the Association for the Advancement of Artificial Intelligence Conference, San Francisco, CA, USA, 4–9 February 2017; pp. 4939–4940. [Google Scholar]
- Li, Y.; Wei, B.; Yao, L.; Chen, H.; Li, Z. Knowledge-based document embedding for cross-domain text classification. In Proceedings of the International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017; pp. 1395–1402. [Google Scholar]
- Bhatt, H.S.; Sinha, M.; Roy, S. Cross-domain Text Classification with Multiple Domains and Disparate Label Sets. In Proceedings of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1641–1650. [Google Scholar]
- Qu, L.; Ferraro, G.; Zhou, L.; Hou, W.; Baldwin, T. Named Entity Recognition for Novel Types by Transfer Learning. In Proceedings of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 899–905. [Google Scholar]
- Zoph, B.; Yuret, D.; May, J.; Knight, K. Transfer learning for low-resource neural machine translation. In Proceedings of the Empirical Methods on Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 1568–1575. [Google Scholar]
- Lu, J.; Behbood, V.; Hao, P.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl. Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Pan, J.; Hu, X.; Li, P.; Li, H.; Li, W.; He, Y.; Zhang, Y.; Lin, Y. Domain adaptation via multi-layer transfer learning. Neurocomputing 2016, 190, 10–24. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Wei, X.C.; Lin, H.F.; Yu, Y.H.; Yang, L. Low-Resource cross-Domain product review sentiment classification based on a CNN with an auxiliary large-Scale corpus. Algorithms. 2017, 10, 81. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Domain adaptation for large-scale sentiment classification: A deep learning approach. In Proceedings of the International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 513–520. [Google Scholar]
- Bengio, Y. Deep learning of representations for unsupervised and transfer learning. In Proceedings of the International Conference on Machine Learning, Edinburgh, Scotland, UK, 26 June–1 July 2012; pp. 17–36. [Google Scholar]
- Mesnil, G.; Dauphin, Y.; Glorot, X.; Rifai, S.; Bengio, Y.; Goodfellow, I.J.; Lavoie, E.; Muller, X.; Desjardins, G.; Warde-Farley, D. Proceedings of the International Conference on Machine Learning, Scotland, UK, 26 June–1 July 2012; pp. 97–110.
- Liu, B.; Huang, M.; Sun, J.; Zhu, X. Incorporating domain and sentiment supervision in representation learning for domain adaptation. In Proceedings of the International Congress On Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1277–1283. [Google Scholar]
- Gani, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2015, 17, 1–35. [Google Scholar]
- Mou, L.; Meng, Z.; Yan, R.; Li, G.; Xu, Y.; Zhang, L.; Jin, Z. How Transferable are Neural Networks in NLP Applications? In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 479–489. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- The Stanford MOOCPosts Data Set. Available online: http://datastage.stanford.edu/StanfordMoocPosts/ (accessed on 17 March 2012).
- Keras, C.F. GitHub. Available online: http://github.com/fchollet/keras (accessed on 25 July 2017).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Confusion | Urgency | Sentiment | |
|---|---|---|---|
| POS | I understand that if you completed 65% you will get the certificate but where do we download the certificate? | I hope any course staff member can help us to solve this confusion asap!!! | This is going to be an awesome course! |
| NEG | I have tried to submit a document form of my response, but still nothing happens. | I am Rana from Egypt, I study dentistry. Happy to be with you. Good luck for everyone. | I get frustrated & at times belittle myself thinking I am stupid :( |
| Domain | Size | Confusion | Urgency | Sentiment | |||
|---|---|---|---|---|---|---|---|
| POS | NEG | POS | NEG | POS | NEG | ||
| EDUC115N/How_to_Learn_Math (Edu) | 9879 | 32% | 68% | 5% | 95% | 83% | 17% |
| SciWrite/Fall2013 (Med) | 5184 | 91% | 9% | 38% | 62% | 75% | 25% |
| StatLearning/Winter2014 (HS) | 3030 | 84% | 16% | 32% | 68% | 94% | 6% |
| Method | Confusion | Sentiment | Urgency |
|---|---|---|---|
| CNN-NTL | 63.35 | 83.52 | 65.90 |
| LSTM-NTL | 62.23 | 83.30 | 78.95 |
| CNN-TL | 81.89 | 83.74 | 79.72 |
| LSTM-TL | 82.25 | 85.88 | 86.13 |
| CIMM-TL | 68.87 | 84.08 | 24.24 |
| LM-CNN-LB | 78.46 | 81.83 | 84.59 |
| ConvL-NTL | 67.52 | 80.91 | 79.99 |
| ConvL | 81.45t | 85.91 | 86.69 |
| ConvL-in domain | 81.88 | 86.08 | 89.14 |
| Ratio of Target Domain Training Data | Accuracy (%) |
|---|---|
| 1/20 | 82.09 |
| 2/20 | 84.49 |
| 3/20 | 84.54 |
| 4/20 | 84.68 |
| ... | ... |
| 10/20 | 85.93 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, X.; Lin, H.; Yang, L.; Yu, Y. A Convolution-LSTM-Based Deep Neural Network for Cross-Domain MOOC Forum Post Classification. Information 2017, 8, 92. https://doi.org/10.3390/info8030092
Wei X, Lin H, Yang L, Yu Y. A Convolution-LSTM-Based Deep Neural Network for Cross-Domain MOOC Forum Post Classification. Information. 2017; 8(3):92. https://doi.org/10.3390/info8030092
Chicago/Turabian StyleWei, Xiaocong, Hongfei Lin, Liang Yang, and Yuhai Yu. 2017. "A Convolution-LSTM-Based Deep Neural Network for Cross-Domain MOOC Forum Post Classification" Information 8, no. 3: 92. https://doi.org/10.3390/info8030092