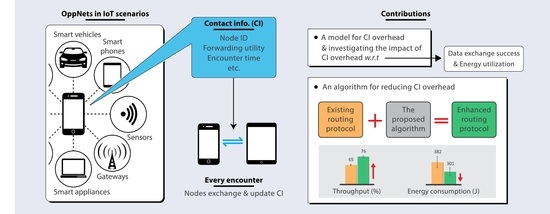
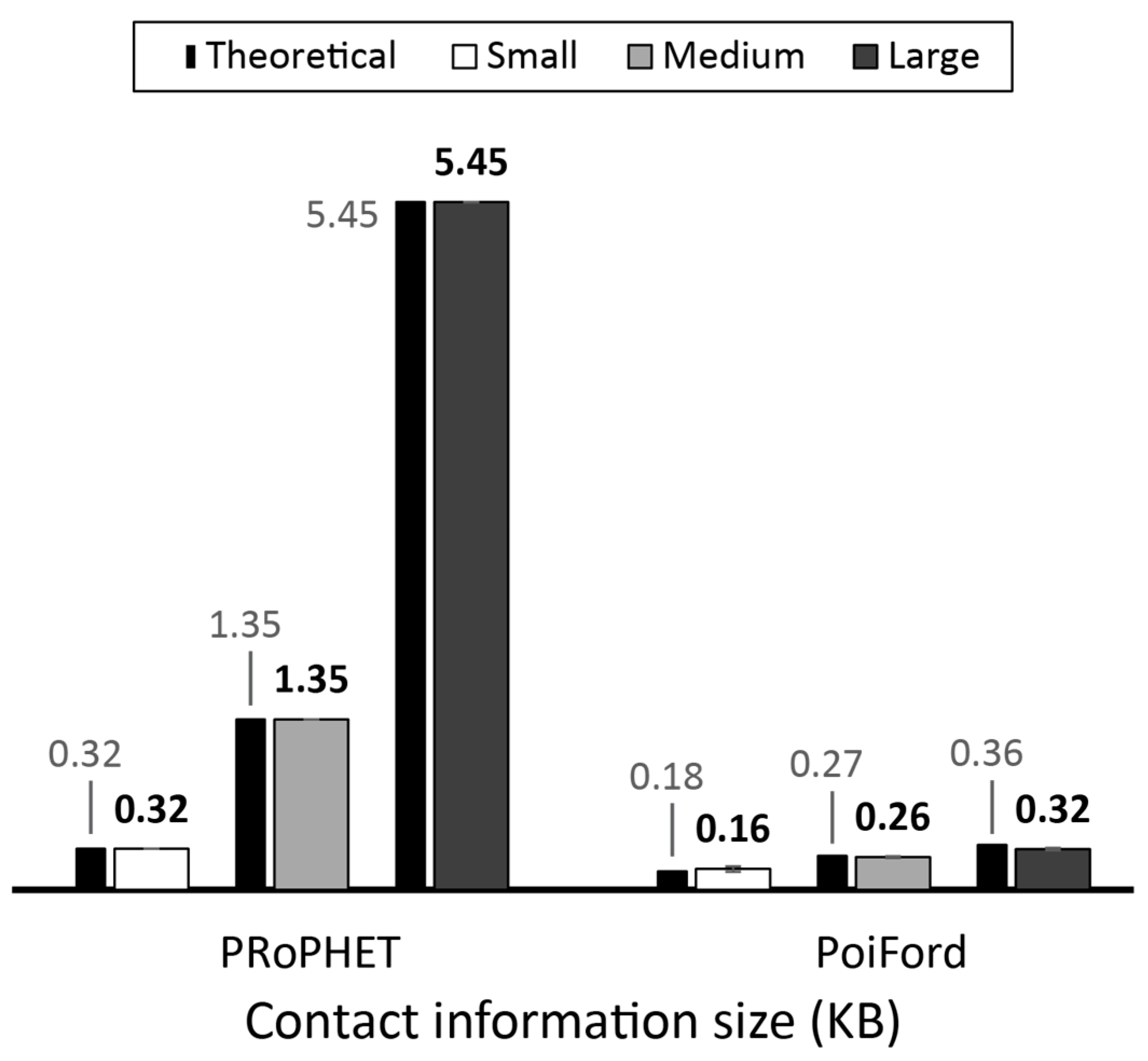
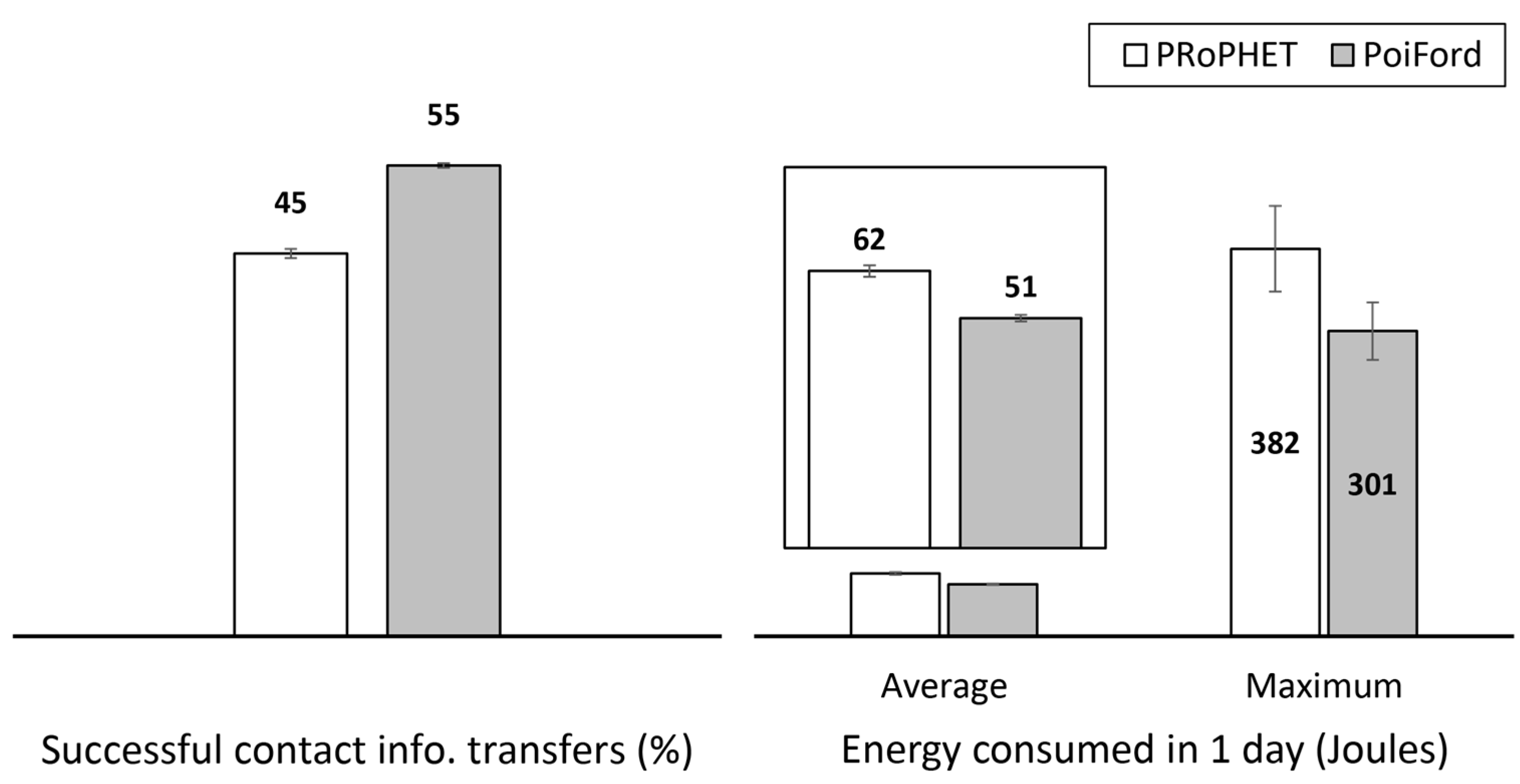
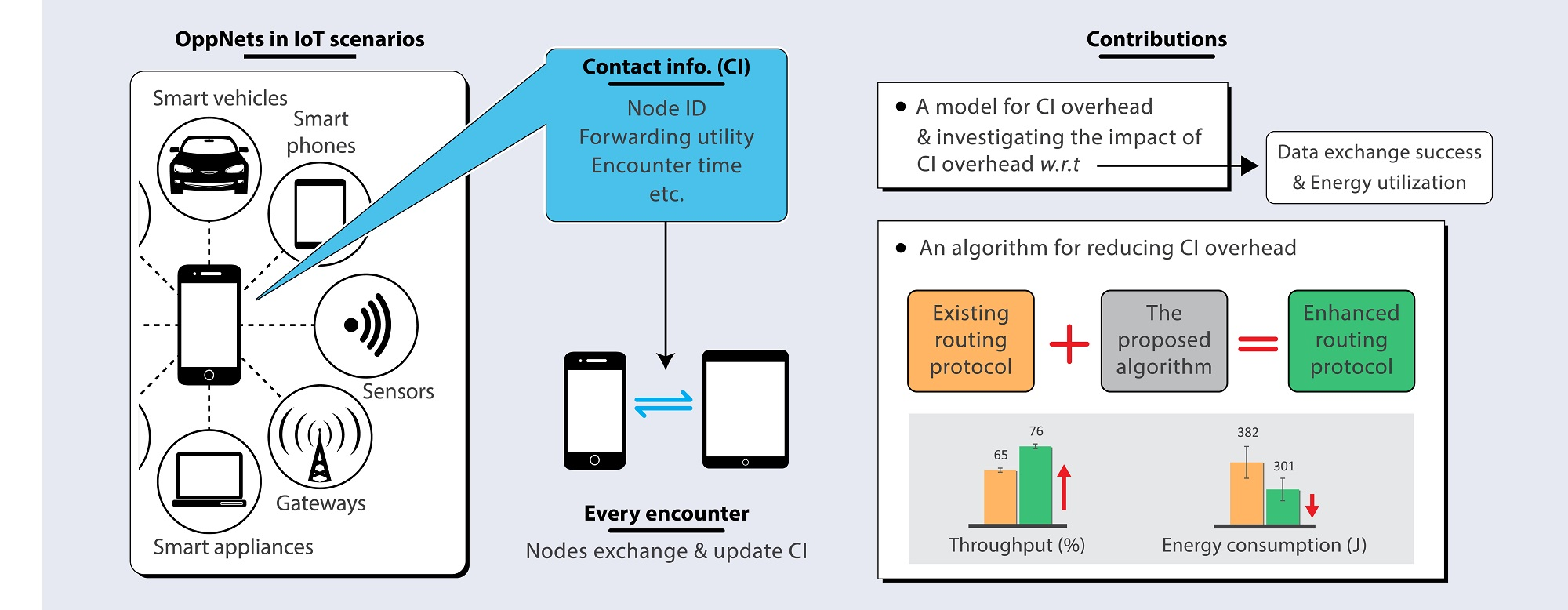
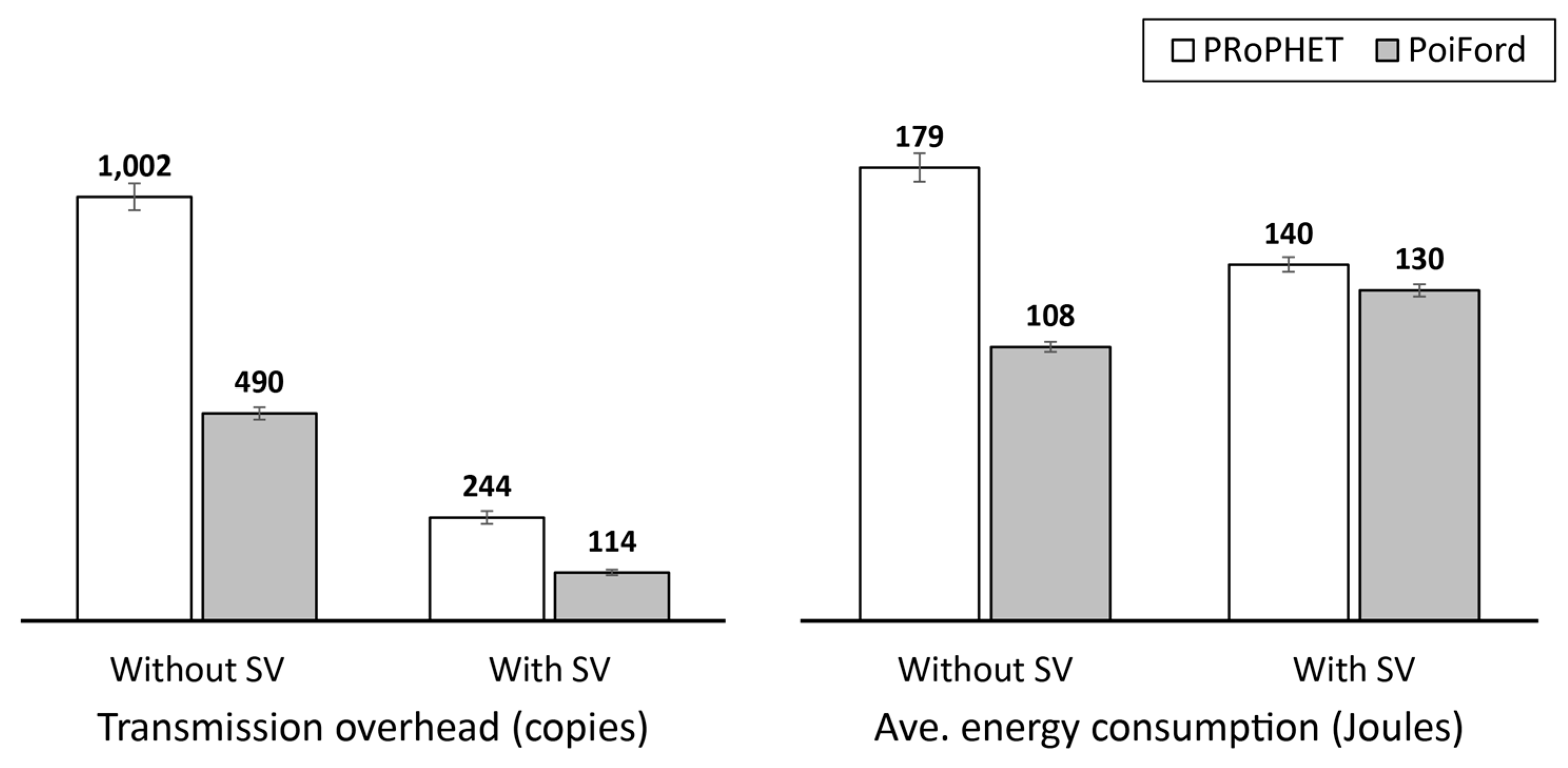
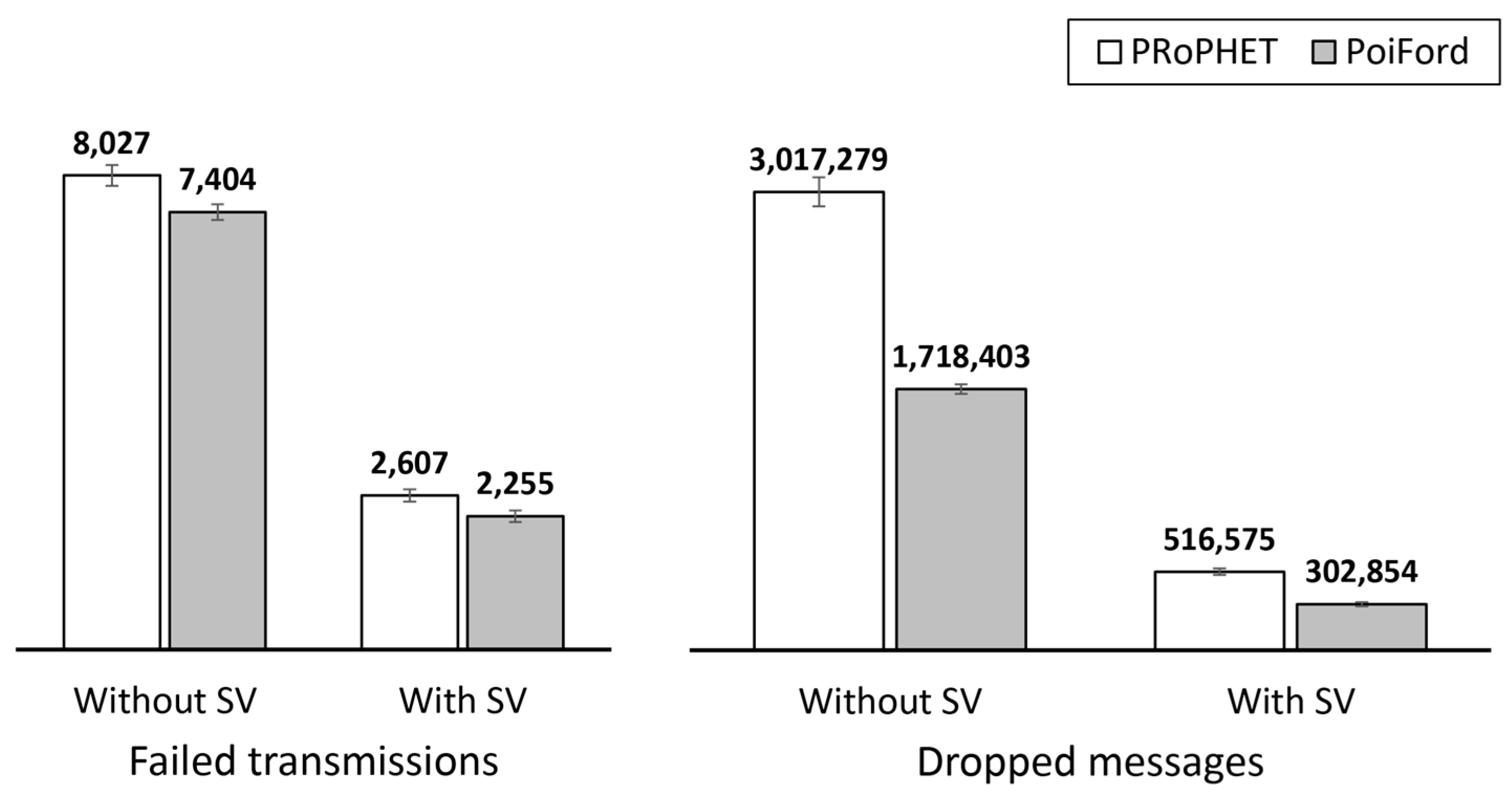
Message forwarding in high node population and dynamicity requires a means of minimizing contact information overhead without throughput degradations. We already learned from a previous study [
47] that it may not be necessary to maintain the history of every encounter in order to realize comparable throughput. The modification of PRoPHET to maintain encounter history for only nodes from the same home-region traded only 11% throughput for about 84% average reduction in contact information maintained at each node. Hence, the challenge in optimizing the trade-off between contact information overhead and throughput lies in: determining which encounters to consider in terms of maintaining encounter history, and which ones to forego; and a forwarding approach that can utilize the available information to carry messages close enough to the destination or to nodes that have recorded their encounter history with the destination. Without a proper understanding of the relationship between node movement and encounter opportunities, important encounters may be neglected and the resulting insufficiency in knowledge may cause throughput degradation. In this section, we present PoiFord, and tackle the following points in the process:
4.1. Overview of PoiFord
Our model in
Section 3 showed that maintaining encounter history about more nodes leads to more contact information overhead, which is in turn directly proportional to the delay incurred in exchanging contact information and the energy utilized in the process. Therefore, less contact information implies less delay and energy consumption. The only problem is how to achieve this without degrading throughput. PoiFord is focused on reducing the amount of encounter history maintained by nodes so that less contact information would be exchanged during encounters. The basic idea behind the approach is as follows. Users often return to their points-of-interest (POIs) in which they may encounter other users that visit the same location regularly. Thus, there is a high chance that most well-connected nodes have at least one mutual POI (e.g., users living in the same house or working in the same office). PoiFord aims to minimize contact information by requiring only nodes that have mutual POIs to maintain encounter history for each other. By limiting information to be maintained only for neighbors with mutual POIs, the problem of existing location-based solutions (i.e., inferring future encounters from location-based information alone) can be addressed while the forwarding ability of nodes that are less connected to the destination can be inferred from location-based information, specifically through spatial locality. That way, nodes moving towards a destination that is located in a shopping mall would carry a message and forward it to a node that has a mutual POI with the destination (i.e., a node whose user works in a shopping mall) to deliver it. Hence, the task of reducing contact information overhead without degrading throughput can be divided into three subtasks:
Determining a node’s significant locations or POIs.
Determining nodes for which to maintain encounter history based on mutual POIs.
Determining a forwarding utility that can deliver messages with the available information.
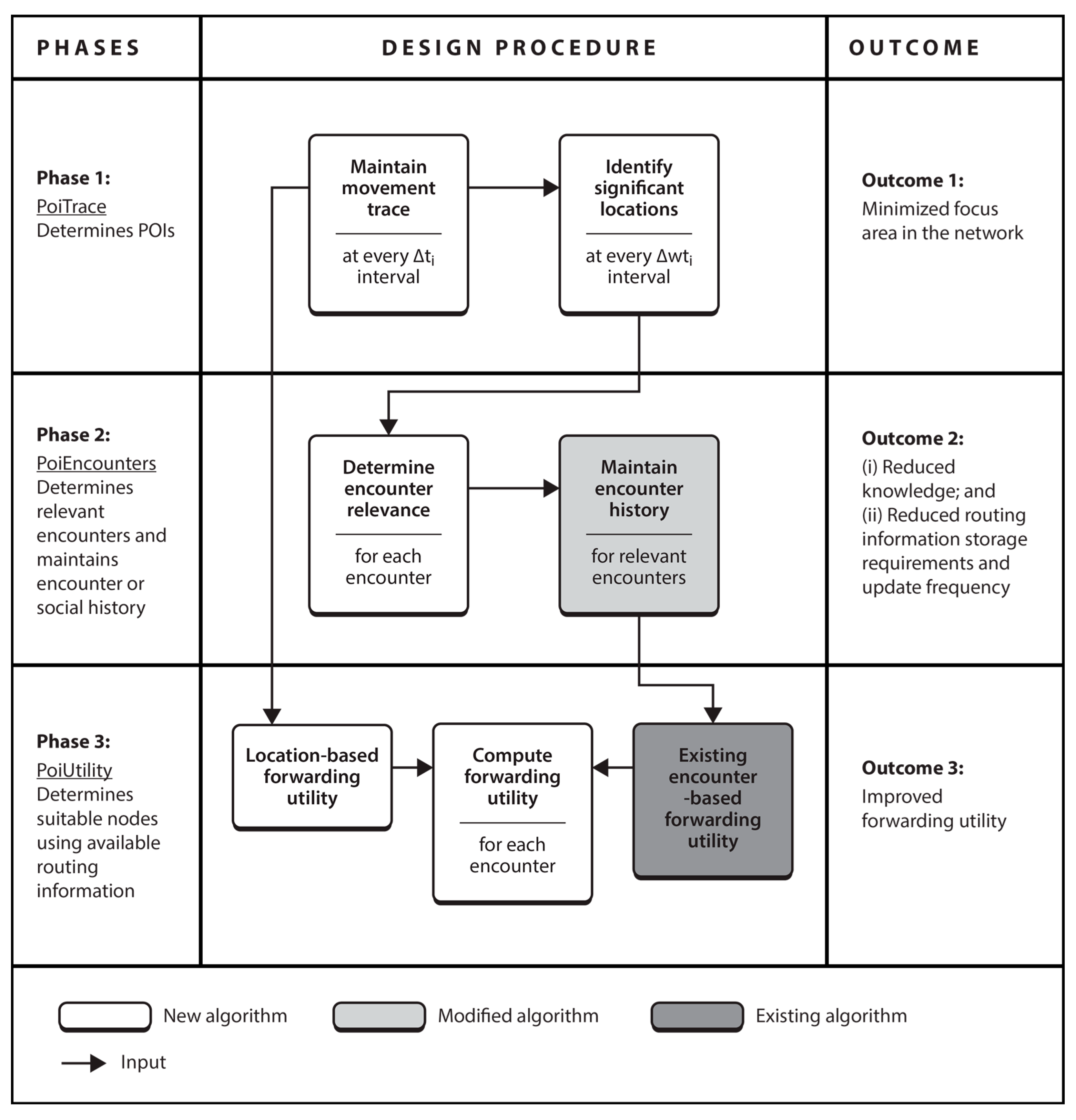
This section overviews PoiFord by presenting the tasks involved in realizing the three subtasks. As shown in
Figure 1, the subtasks are addressed in three phases.
Phase 1. The first phase is concerned with determining POIs. The current location is collected via GPS at fixed intervals and maintained in device memory. From this, significant locations are determined at larger fixed intervals. The major challenge in this phase is how to maintain GPS coordinates from which significant locations can be determined, knowing that the same pair of coordinates may never be recorded twice. To address this, we propose PoiTrace, a mechanism that maintains incoming GPS locations in a location table after converting them to a more stable form we call location references, from which POIs are determined. This minimizes the focus area for each node, as compared to the entire network area.
Phase 2. The second phase is concerned with identifying nodes for which contact information needs to be maintained in the form of encounter history. POI information is included in summary vectors, which nodes first exchange when they encounter each other. This allows nodes to determine relevant encounters with respect to maintaining contact information. Concerned nodes keep record of an encounter only when they have mutual POIs. The major challenge in this phase is how to identify mutual POIs of a node pair, knowing that the likelihood of finding exactly the same set of GPS locations on two nodes is low. To address this, we propose PoiEncounters, a mechanism that seeks for mutual POIs of encountered node pairs, and if they are found, maintains a history of the encounter without any transitive property. This minimizes the amount of contact information and knowledge required to make forwarding decisions. In addition, since nodes are only concerned with relevant encounters, the frequency of updating contact information is reduced. PoiEncounters is flexible in the sense that it can be incorporated into existing encounter-based routing protocols.
Phase 3. The third phase is concerned with determining suitable nodes to forward the message. Without a transitive property, and since nodes maintain encounter history of only relevant encounters, knowledge about the network is limited. Hence, the major challenge in this phase is determining suitable nodes with less knowledge about the network. To address this, we propose PoiUtility, a forwarding utility that determines nodes that either have better chances of delivery or can make better progress towards the destination. The forwarding utility is acquired from two utilities: one that determines suitable relays from the available encounter history; and another that determines nodes capable of carrying the message spatially closer to the destination, in order to compensate for the lack of a transitive property.
The following assumptions are made in the design of PoiFord: (i) each node is a smart mobile device and is equipped with a Global Positioning System (GPS); (ii) nodes are collaborative and willing to participate in routing; and (iii) source nodes have the necessary information for destinations, which are node ID and location-based information in this case.
4.2. PoiFord Design
We present the design of PoiFord by detailing each of the phases presented in
Section 4.1. This section is organized as follows.
Section 4.2.1 presents PoiTrace, a mechanism for locally identifying significant locations (i.e., POIs) from GPS information obtained on the go. With the aid of these POIs,
Section 4.2.2 proposes PoiEncounters, a mechanism for maintaining encounter history that does not increase or become stale in time.
Section 4.2.3 proposes PoiUtility, a forwarding utility based on the obtained location-based information and available encounter history. The forwarding algorithm for PoiFord using the proposed forwarding utility is presented in
Section 4.2.4.
4.2.1. Phase 1: Identification of Significant Locations
Phase 1 presents the design of PoiTrace, for identifying POIs. User movement may reveal multiple significant locations and can be exploited for routing. However, we are interested in investigating how our POI approach can reduce contact information overhead. In order to keep the idea comprehensive, the mechanism proposed here identifies only the two most significant locations, which we refer to as “home” and “work” location. Apart from these locations often corresponding to the actual home and work locations of users, research also shows that most users have at least two most significant locations and regularly commute between them [
59].
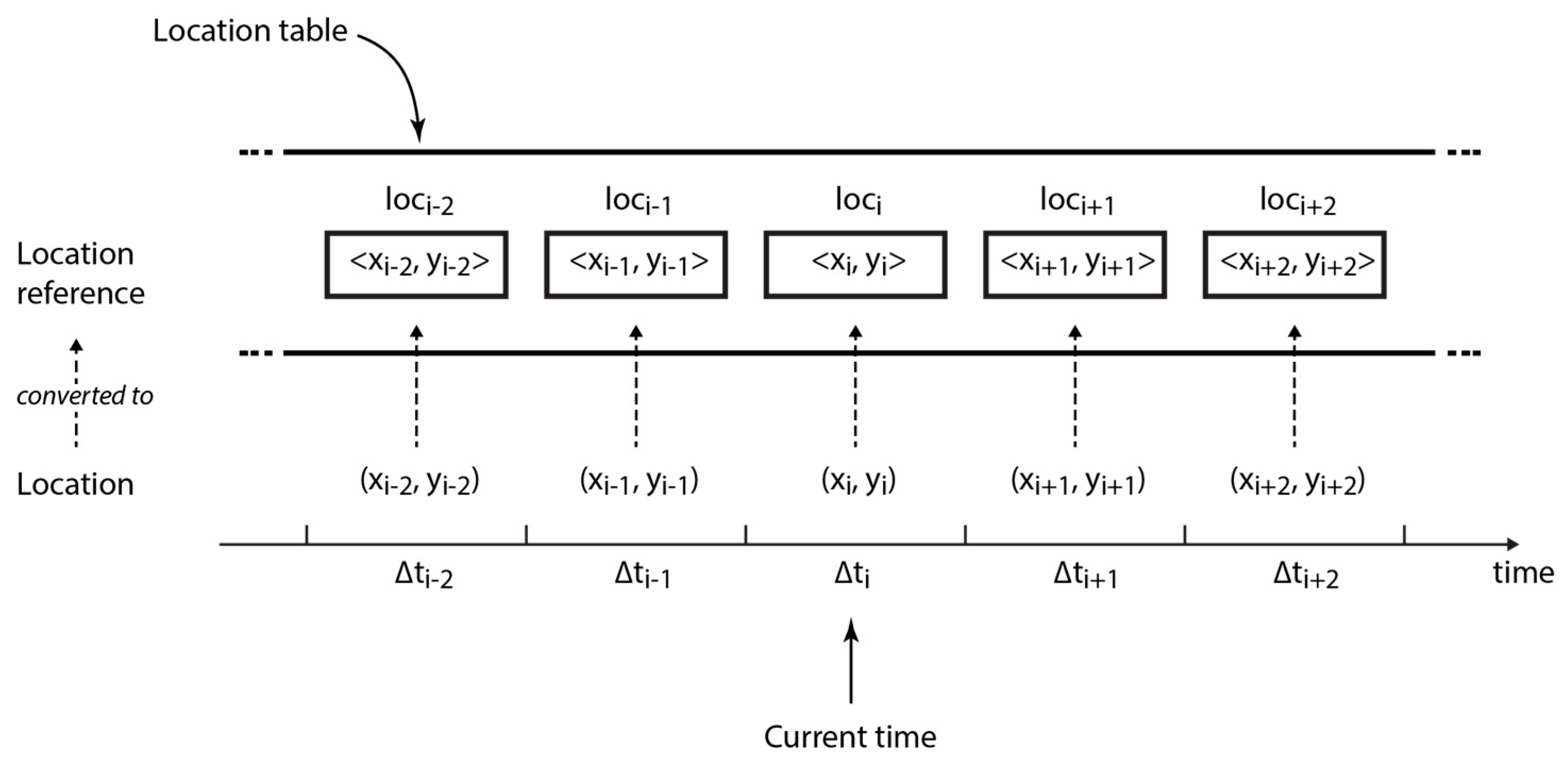
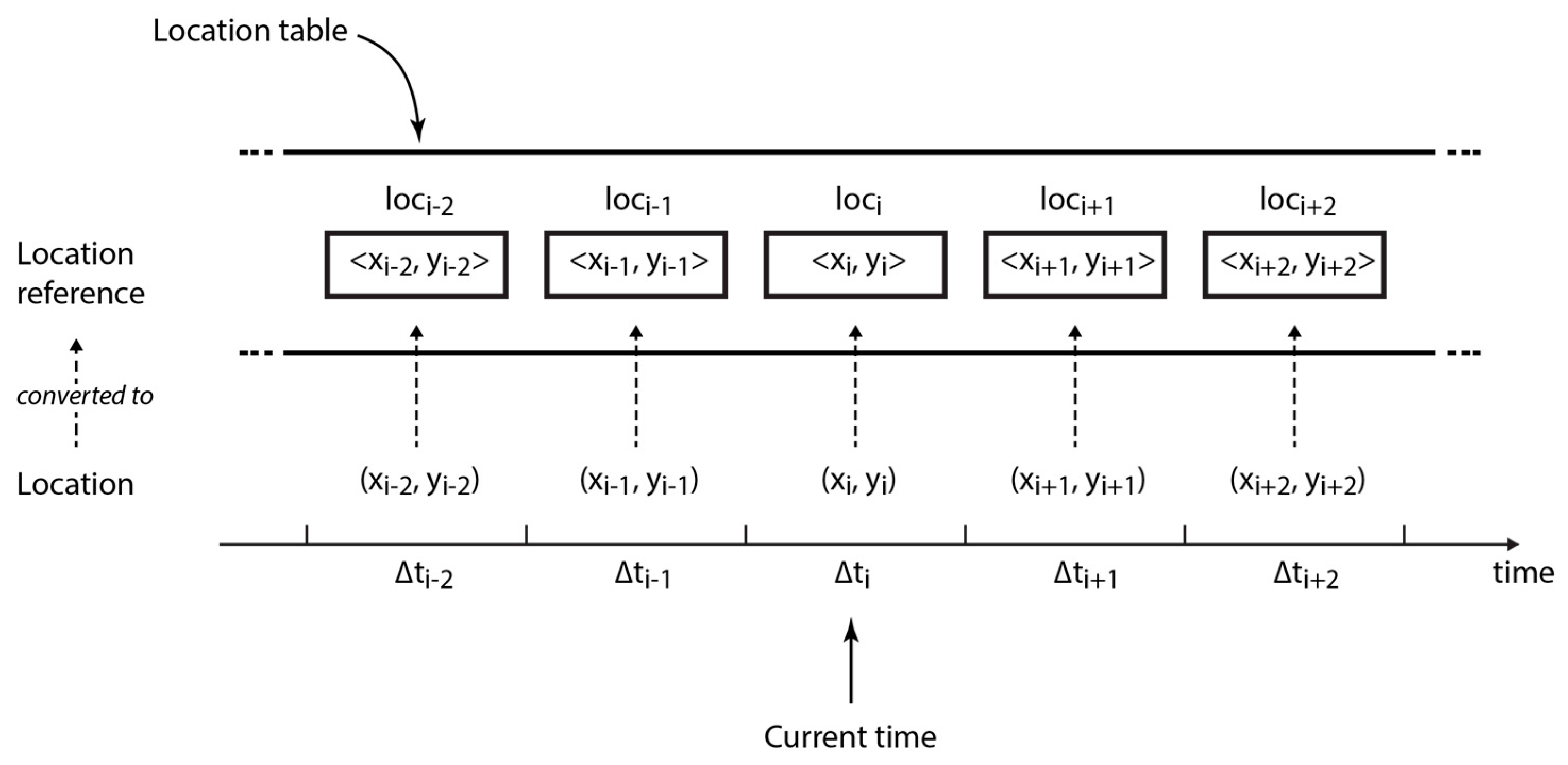
Collecting and recording location information. At every sampling interval , each node collects its current position by GPS in form of latitude and longitude and records it in the corresponding time slot in the location table (cf. Definition 1)—note that PoiFord is fully distributed and does not require synchronization between devices. For example, , the GPS coordinates collected at , the current sampling interval, are recorded in the current time slot as , a location reference. Although GPS is globally available, the signal may not always be reliable in geographically restricted areas (e.g., in buildings and underground locations). In case the signal is too weak or lost, the current position is approximated as the previous record in the location table.
Definition 1 (Location Table). The location table, , which consists of time slots, is a set of elements, each known as a location reference (cf. Equation (6)). Each location reference is a tuple of the format , where () indicates the current time slot. The basic idea behind the algorithm for recording location information is as follows: location references in
should be able to map geographical locations visited for longer periods from user movement, by representing them with circular areas. In order to achieve this, a certain extent of deviation between successive incoming GPS locations is tolerated while acquiring location references. The location reference
for any two locations
and
is the same if the circular areas formed by radius
from both locations intersect. This condition is fulfilled if the Euclidean distance between the two locations
is less than
(cf. Equation (7)).
Hence, if the circular area formed by
from any incoming pair of coordinates
intersects with the circular area formed by
from a previous pair of coordinates
, the corresponding location reference
is formed from the existing coordinates. Otherwise, a location reference
is formed from the incoming coordinates (cf. Equation (8) and
Figure 2).
Algorithm 1 summarizes how is acquired using the current location in the form of latitude and longitude , the previous location references in , and a threshold distance . Consequently, the number of recurrences of a location reference in represents the number of periods in which the user is present in the circular area formed by from location .
| Algorithm 1 The algorithm for recording location information |
![Information 08 00108 i001]() |
Extracting significant locations. Significant locations are identified by more number of recurrences in . At every sampling interval , a node running on PoiFord extracts the two most recurring location references from its location table—where is a constant of the algorithm. These locations represent POIs, and are referred to as the node’s home and work locations, and , respectively. Although incoming GPS coordinates may slightly vary each time the node is in either location, the location reference records only a single pair of approximated coordinates each sampling interval , provided the circular area formed by the incoming pair of coordinates intersects with that of a previous coordinate.
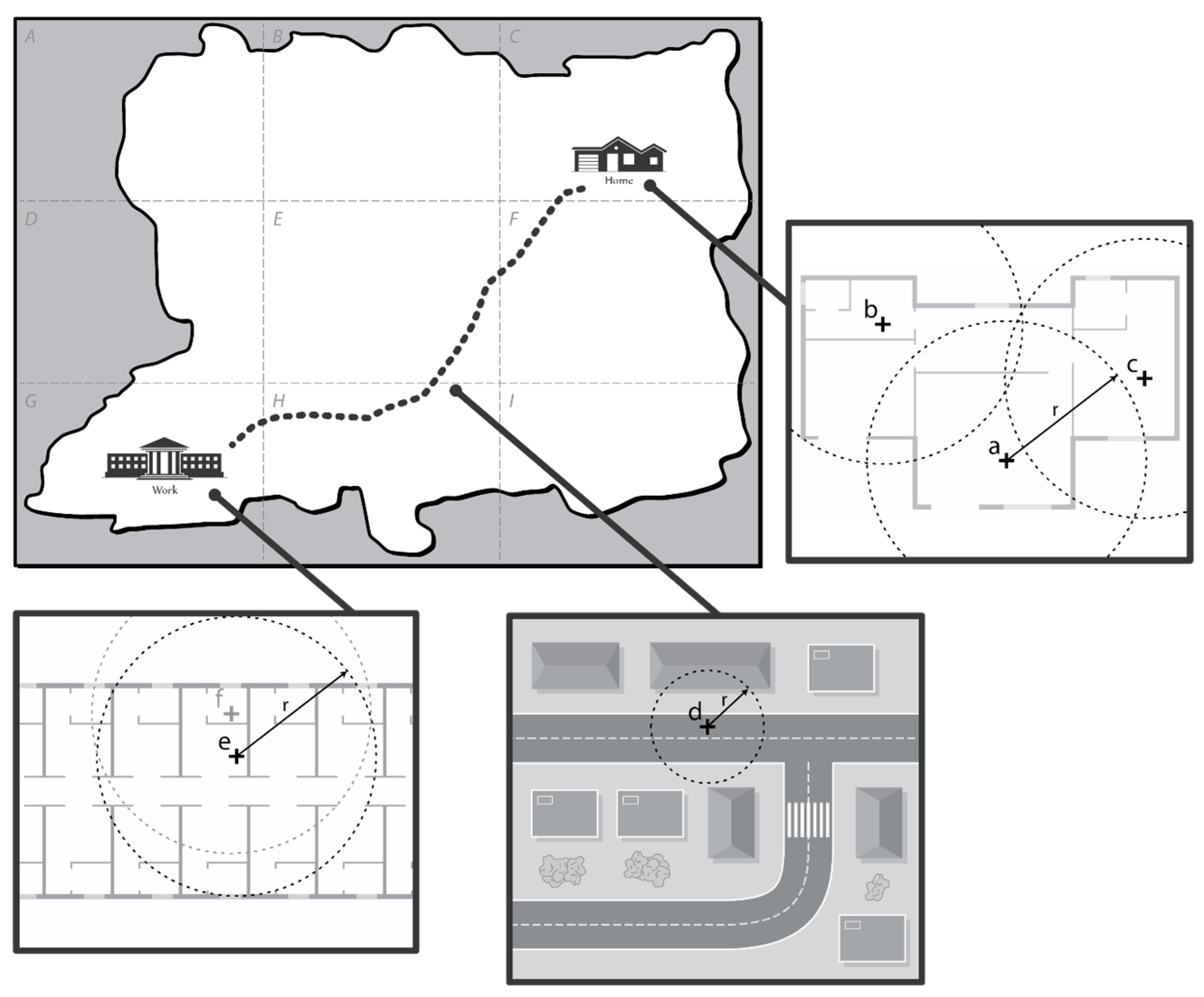
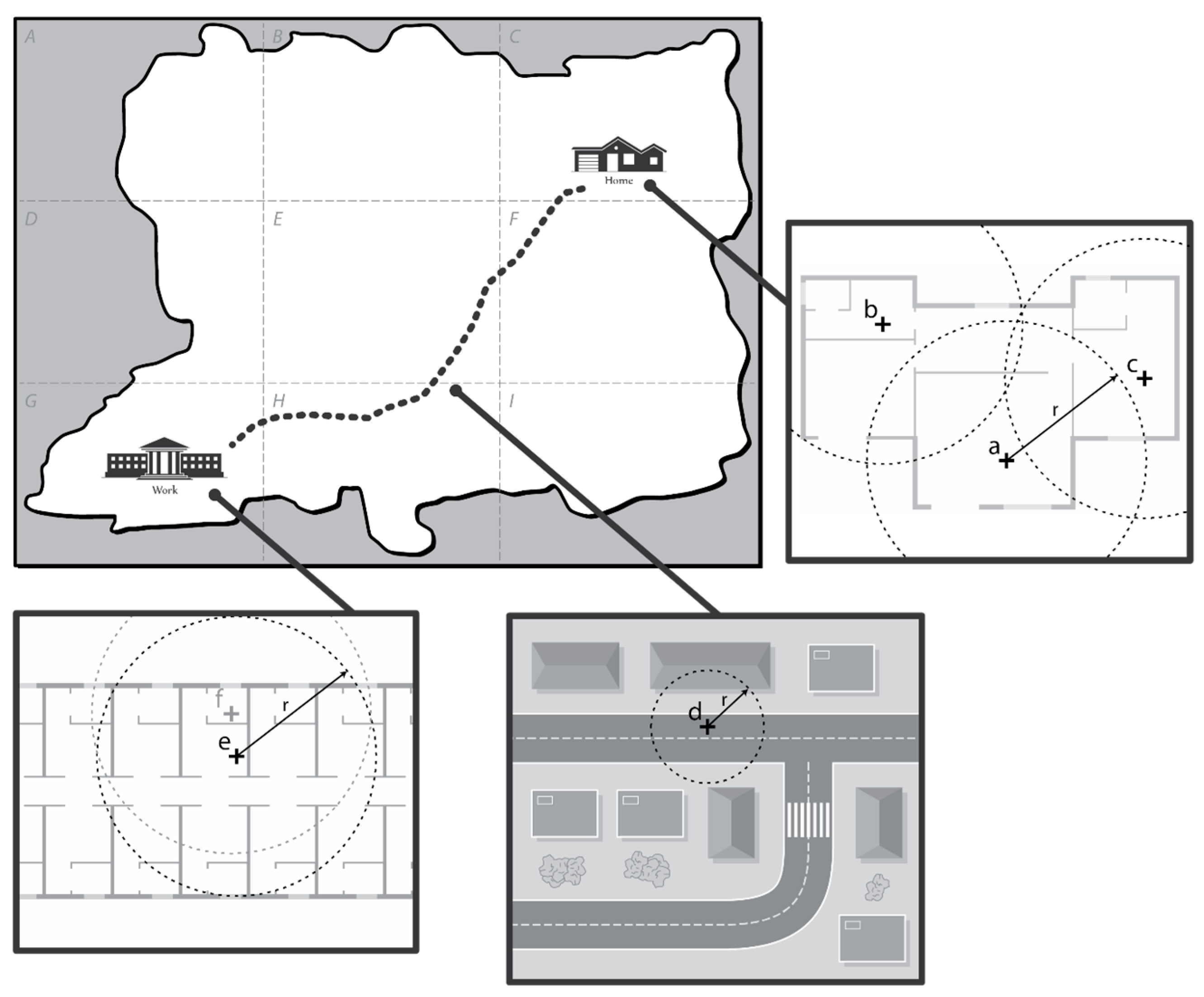
Here, to facilitate understanding, we further explain the working principle of PoiTrace with an example scenario. Consider the map of a fictional city in
Figure 3 which is divided into 9 regions labelled
to
. Charlie, a user in the city, lives in region
and travels to work in region
. The first three GPS readings take place in his house at location
,
, and
. The next reading takes place on his way to work, at location
. The next two readings take place in his office, at location
. and
.
, the GPS reading in location
is recorded as
in the location table. However, as shown in
Table 4, the readings at location
(i.e.,
) and
(i.e.,
) are also recorded as
, instead of
and
, respectively. This is because the circle of radius
formed from these locations intersects with the circle formed from a previous location, i.e., location
. Likewise, the readings at
and
are both recorded as
. After a period of
(here we take
as 6), the two most significant locations of this user become
and
.
4.2.2. Phase 2: Encounter Relevance and Maintaining Encounter History
In this section, we present PoiEncounters, the mechanism for determining relevant encounters and maintaining encounter history using the significant locations identified in the previous section. Without any loss of generality, and to demonstrate how PoiFord can be incorporated into an existing routing protocol, PoiEnconters adopts PRoPHET’s approach for acquiring and computing encounter history, with two major modifications (Note that besides PRoPHET’s, algorithms of other existing encounter-based routing protocols can be utilized. This demonstrates the flexibility of PoiFord). Unlike PRoPHET, which maintains encounter history for every encountered node, encounter history between and , a node pair, is maintained if and only if at least one of the significant locations of ’s intersects with at least one of ’s. Also, PoiEncounters does not utilize the transitive property.
Determining encounter relevance. Upon encounter, two nodes and exchange summary vectors containing their significant locations, which in this case are their home and work locations, as well as the encounter history stored at each node. With this information, each node determines if the circular area of radius formed from either of its significant locations intersect with the circular area formed from either of the other’s. Given their home location as , and their work location , , respectively, each node determines if intersects with or , and if intersects with or . Let represent the coordinates of ’s home or work location, and represent the coordinates of ’s home or work location. If there is an intersection (i.e., if ), maintains/updates its encounter history for , and does the same for . The idea is to find nodes that share the same significant location. (i.e., the diameter of the circle) represents the span of the area of concern, which may either be a living home or an office.
Maintaining and updating encounter history. The encounter history table holds encounter records in the form of node ID and delivery predictability [
39]. Updating the encounter history table is done in two steps. First, each node checks its encounter history table if an encounter history for the other node
already exists. Then the necessary PRoPHET operations are carried out as follows: if a history exists, it is aged based on
, the number of time units elapsed since the last encounter, as shown in Equation (9), where
is the aging constant; otherwise, it is assigned a value of 0.
With this value, the encounter history (or new encounter history if there was a previous encounter) is computed using Equation (10), where
is an initialization constant.
After computing the encounter history for the node pair, the encounter history table is updated by inserting this value (or by replacing the old value if there was a previous encounter). Algorithm 2 summarizes the process of updating the encounter history table when two nodes encounter each other.
| Algorithm 2 The algorithm for updating the encounter history table with PoiEncounters |
![Information 08 00108 i002]() |
4.2.3. Phase 3: Forwarding Utility
In this section, PoiUtility, the forwarding utility for PoiFord is determined using the available encounter history. Since nodes maintain encounter history for only a specific set of nodes (i.e., ones with which they share mutual POIs), neighboring nodes may not have any encounter history with the destination, especially when the destination’s POIs are located in far-away districts. Hence, instead of a transitive property (which tends to increase contact information size with node population as nodes may eventually have to compute and maintain a forwarding utility for every other node in the network), geographical closeness to the destination is used to determine the forwarding ability of a node that has no encounter history with the destination. Encounter history with the destination is only considered when nodes that share a mutual POI with the destination are encountered. Therefore, PoiUtility, the overall forwarding utility, comprises of a location-based utility and an encounter-based utility.
Measuring closeness-to-destination. The information maintained in the encounter history table does not include a transitive property, i.e., a means of computing the likelihood of to deliver a message to the destination through , based on the encounter history of and , and that of and . Hence, the location-based “closeness-to-destination” utility is used to select a node that can take the message closer to the destination, and possibly improve the likelihood of forwarding it to nodes that have an encounter history with the destination. The main conditions are that for each message: (i) the location of the destination node, , denoted by , is known by the source node—e.g., each sensor node can be preconfigured with this information during network initialization (PoiFord is designed for collecting sensed data from sensors—which may either be mobile (e.g., mobile user devices) or static (e.g., sensors deployed along roadsides) to their respective static gateways (e.g., an access point in a shopping mall) in Smart City scenarios. Each sensor node can be preconfigured with the location of the destination node(s) during network initialization. In case a destination node needs to be moved or replaced, the new information can be disseminated to the sources through the network); and (ii) the source node can compute the Euclidean distance from its location, , to the destination node’s location, denoted by . With this information available in the message header, the closeness of a node to the destination, , denoted by , can be determined. The procedure starts by computing as shown in Algorithm 3, which is the centroid of the location references in ’s location table, . In other words, and are the mean values of the and coordinates of every location reference in , respectively. Then is given by the Euclidean distance between and . Note that for a static source node, , , i.e., the closeness-to-destination utility of is equivalent to the Euclidean distance from to the destination node, .
| Algorithm 3 The algorithm for acquiring |
![Information 08 00108 i003]() |
Overall forwarding utility. The overall forwarding utility (i.e., the PoiUtility) of a node is given by summing the weight for encounter history and the weight for closeness-to-destination. The former can be computed for nodes that have an encounter history with the destination node, while the latter can be computed for every node in the network. That way, nodes that do not have an encounter history with the destination node may still have some degree of forwarding utility through the closeness-to-destination weight. This allows them to carry the message spatially closer to the destination node, thereby increasing the chances of encountering and forwarding it to nodes that have a higher likelihood of delivery via the encounter history weight. In order to achieve these weights, encounter history and closeness-to-destination are multiplied by constants
and
, respectively, where
. The sum of both constants equals 1, thereby acting as a slider that decides how much impact each weight has on the overall forwarding utility (cf. Equation (11)).
is much greater than
in order to give more impact to the encounter history weight, so that messages are always directed towards nodes that have encounter history with the destination. To implement this, we select the value of
and
as 0.8 and 0.2, respectively.
The weight for encounter history, denoted by
, at every node
for each known destination node,
, is given by Equation (12), while the weight for closeness-to-destination, denoted by
, is given by Equation (13). From Equation (13),
increases as
reduces, so that a node that often visits locations closer to the location of the destination node presents a higher closeness-to-destination weight. The overall forwarding utility, denoted by
, is given by Equation (14). Note that
is equal to 0 if node
does not have any encounter history with node
, in which case
becomes
.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}