
A Novel Local Structure Descriptor for Color Image Retrieval

Abstract
:1. Introduction
- (a)
- We design a new local structure descriptor to simulate human visual perception mechanism. The descriptor combines color, texture, shape and color layout as a whole. The dimensionality of its feature vector is low, which is very appropriate for large-scale image retrieval. The descriptor achieves better accuracy results on standard benchmarks than other descriptors.
- (b)
- The detail experimental research we carried out adds our understanding of the effects of different color space, parameter settings, and gradient operators of the studied descriptor.
2. Related Works
3. Local Structure Descriptors
3.1. Selection and Quantization of Color Space
3.2. Edge Direction Detection
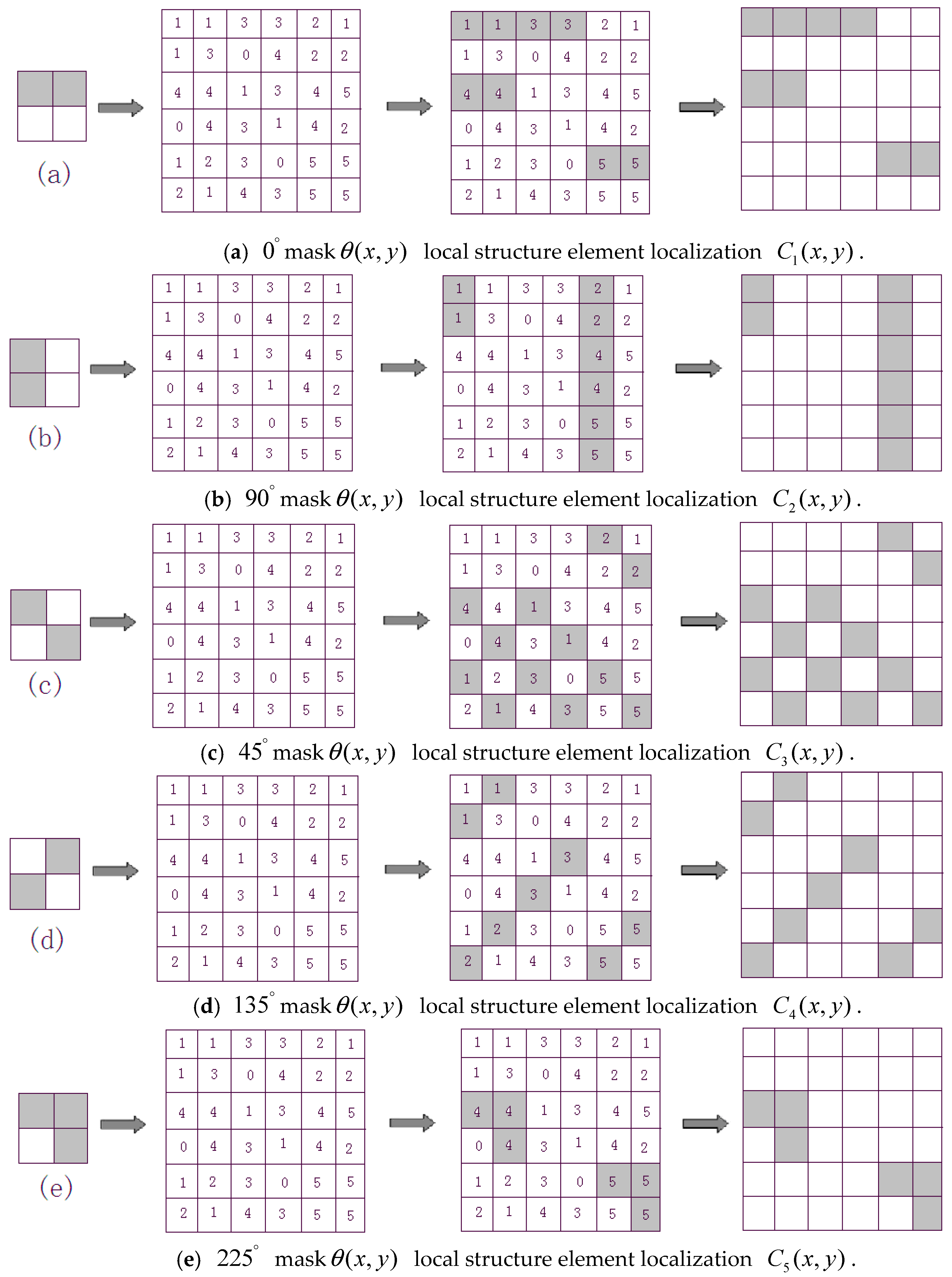
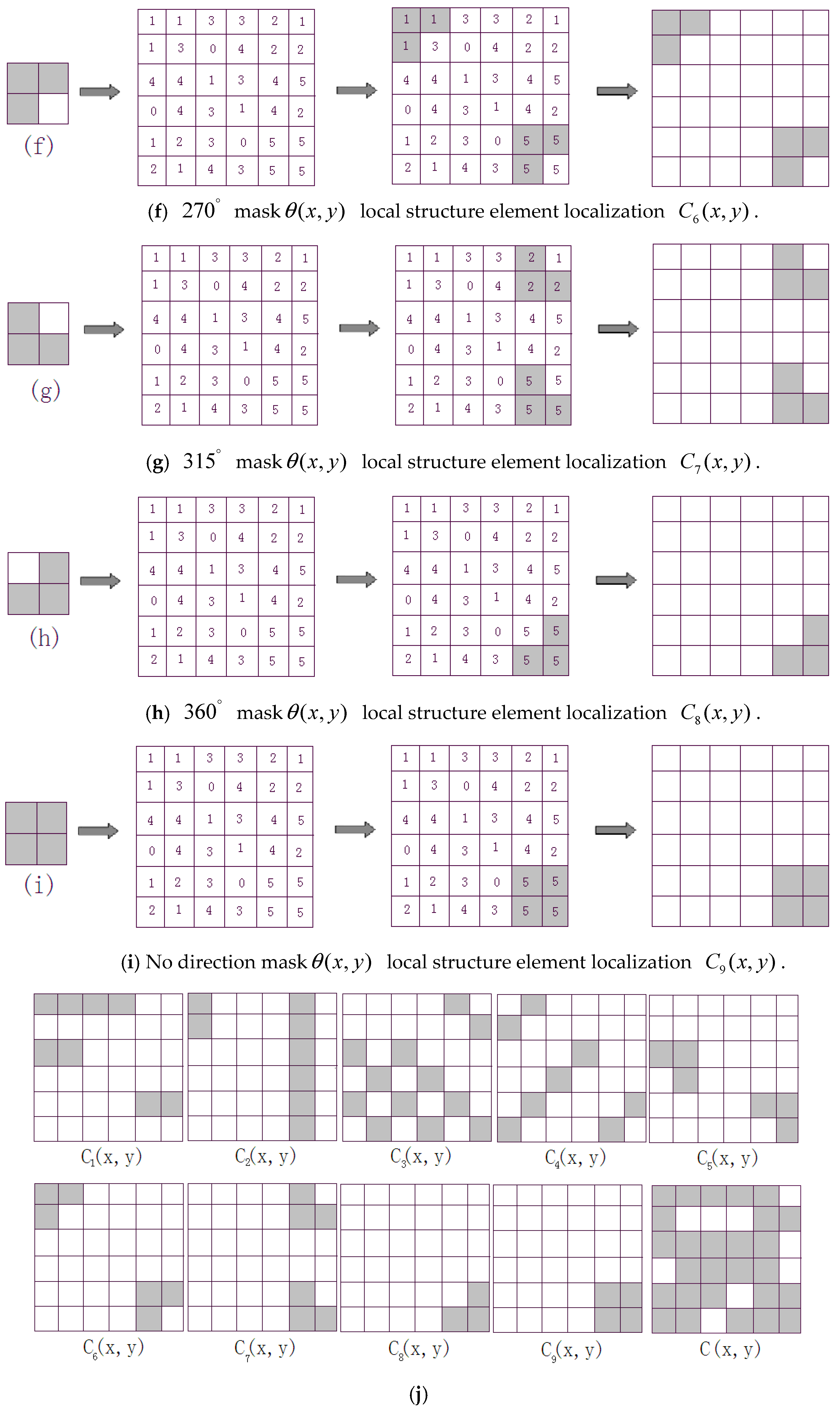
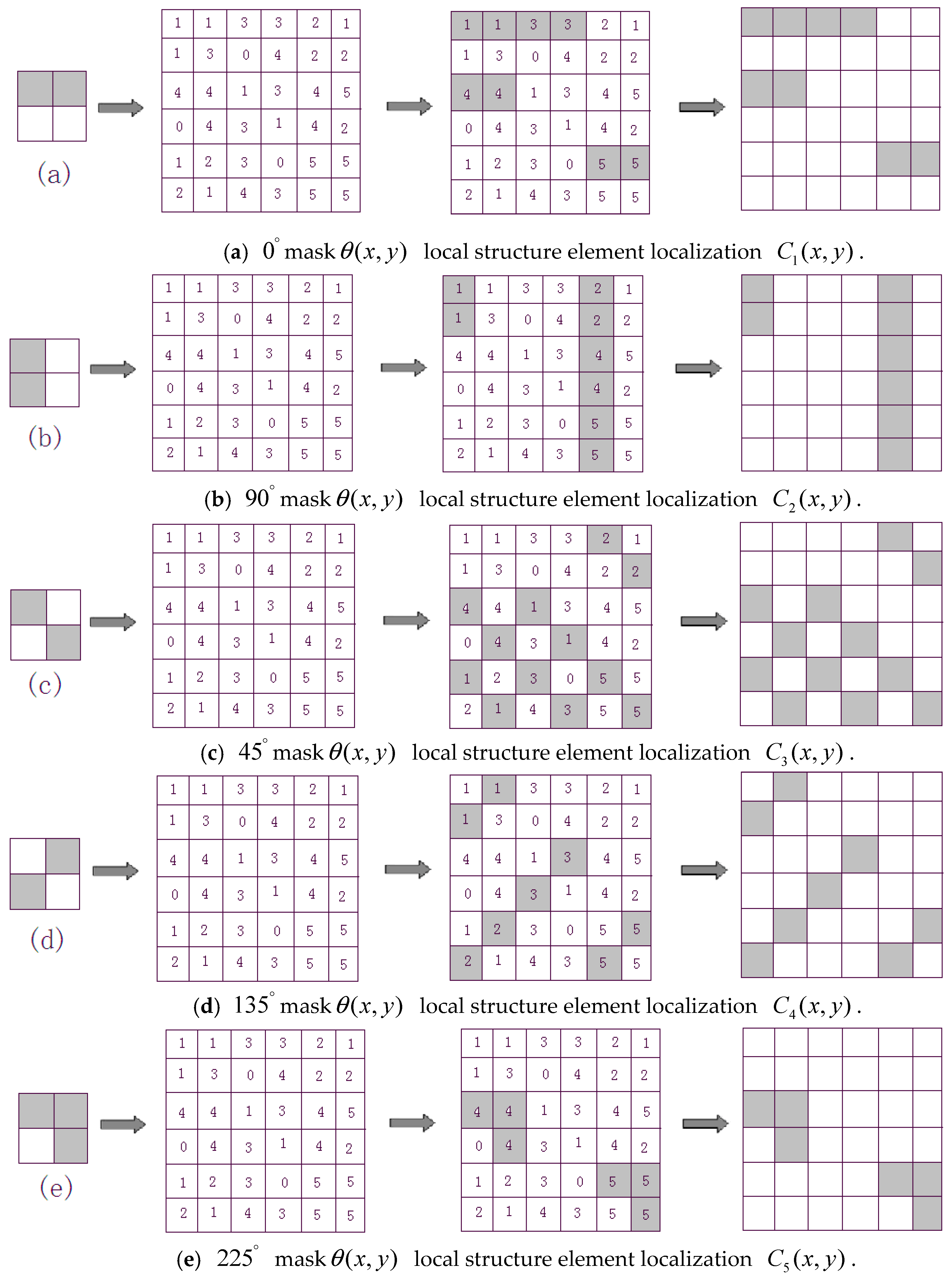
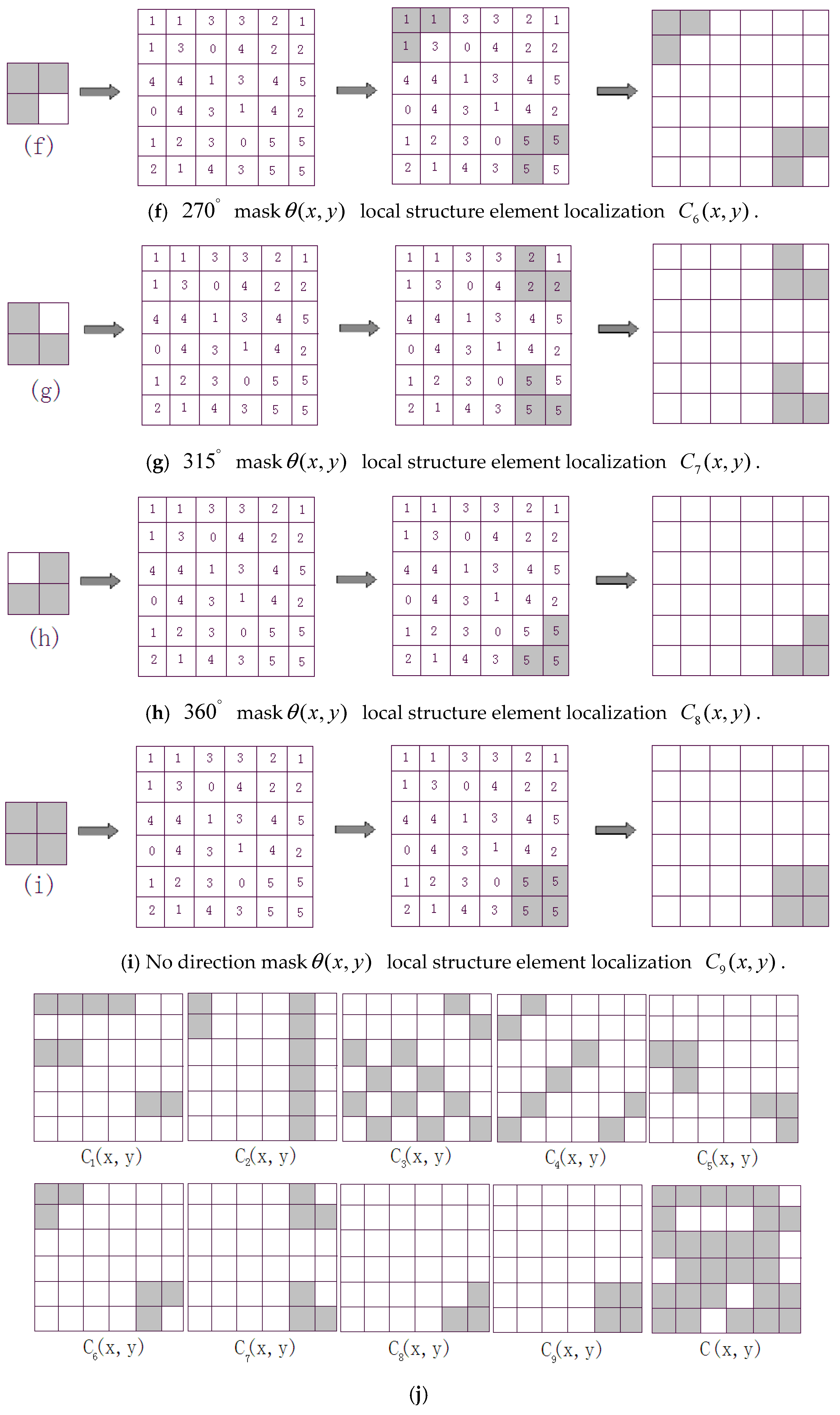
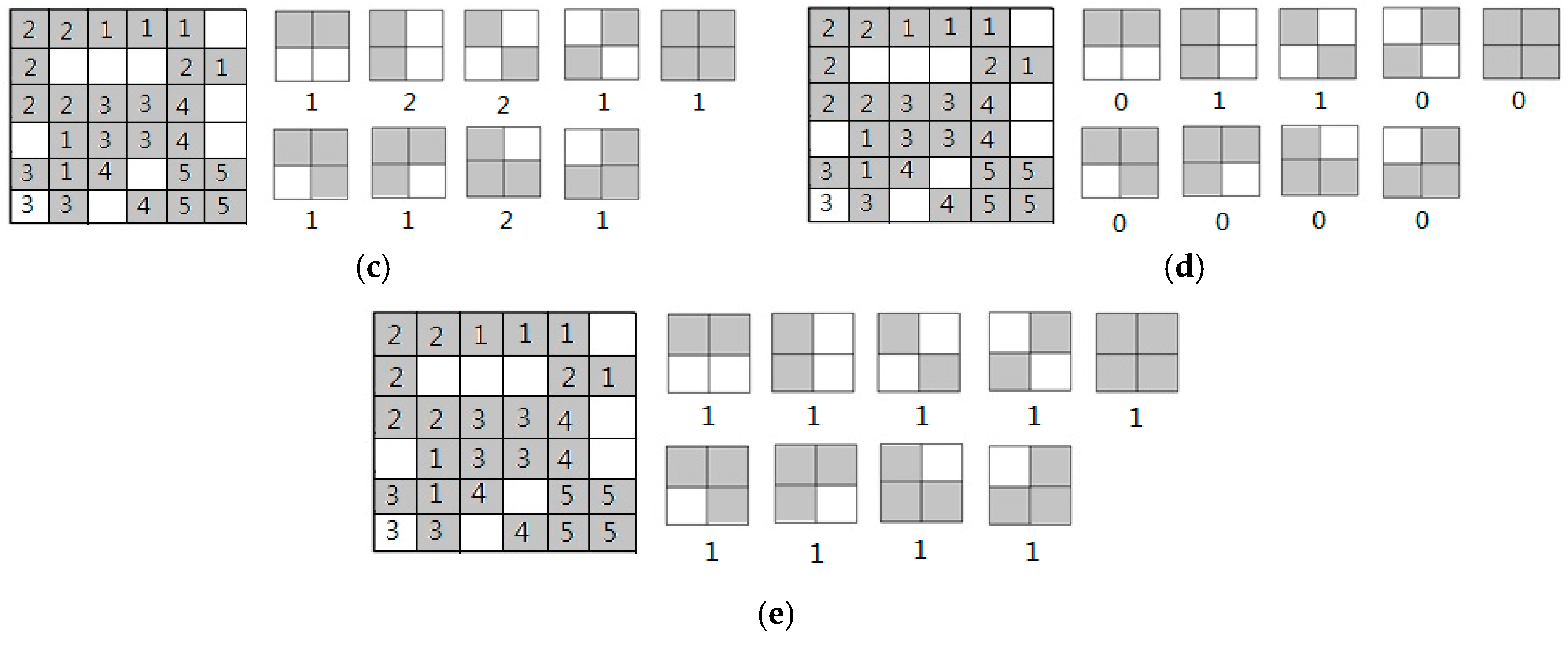
3.3. Definition and Extraction of Local Structure
- (1)
- Beginning from the point (0, 0), we shift 2 × 2 local structure template (a) from top-to-bottom and left-to-right throughout edge direction map with a step length of two pixels along both vertical and horizontal directions. If the values of in the corresponding structure template are equal, the values will be saved, otherwise, the values will be set zero. Then, we will obtain a local structure map .
- (2)
- We use the other eight templates (b), (c), (d), (e), (f), (g), (h) and (i) throughout edge orientation map to conduct the same operations as (1) step, respectively, we will obtain eight local structure maps , , , , , , , .
- (3)
- Using C(x,y) to denote the final local structure map, C(x,y) is obtained by fusing nine local structure maps based on the following rules:
4. Feature Extraction
- (1)
- When , count the number of LSD on nine LSD maps. In particular, when the local structure descriptor that denotes no direction has been counted, the other eight local structure descriptors should be counted again, because no direction means that every direction is possible.
- (2)
- Calculate LSH based on the number of LSD.
5. Similarity Measurement
6. Experiments and Results Analysis
6.1. Image Database
6.2. Performance Measurements
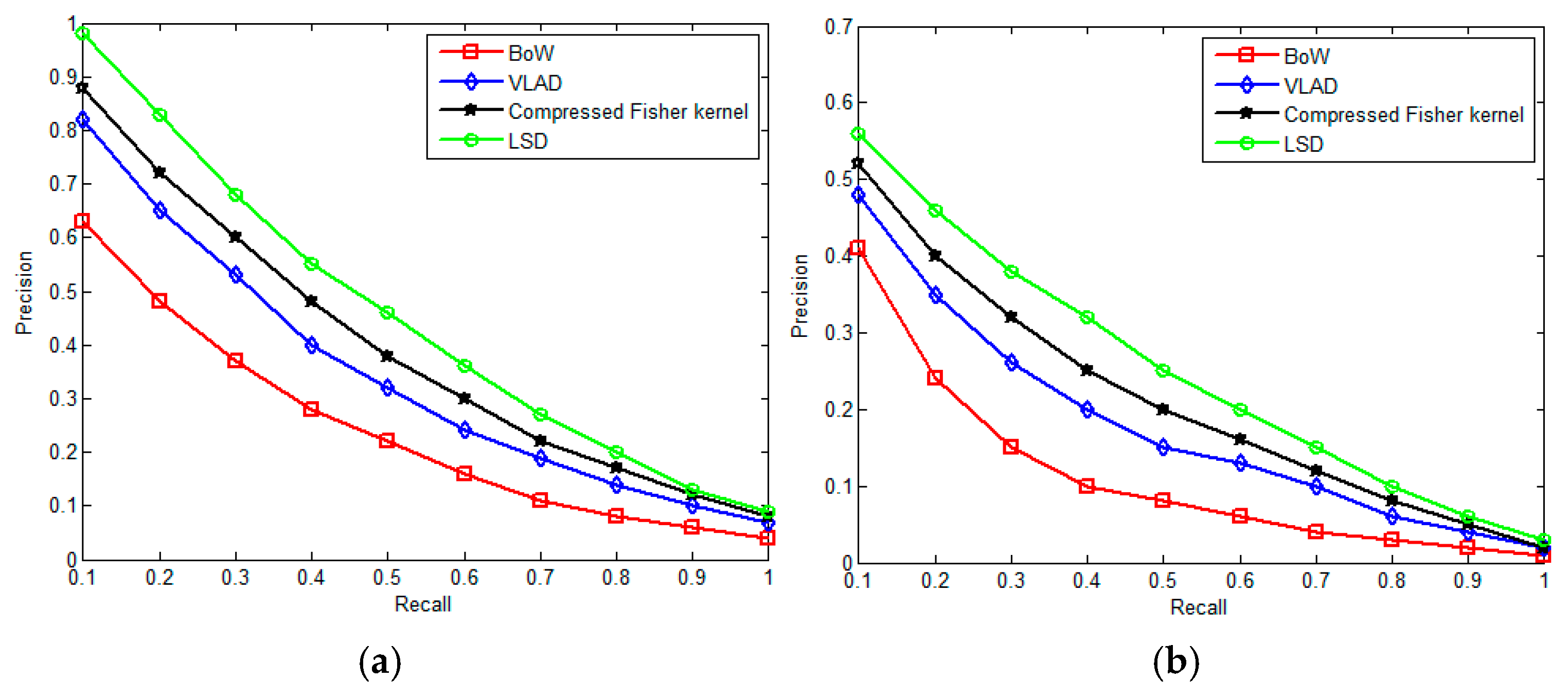
6.3. Retrieval Results
7. Conclusions
Acknowledgments
Conflicts of Interest
References
- Liu, Y.; Zhang, D.; Lu, G.; Ma, W.Y. A survey of content-based image retrieval with high-level semantics. Pattern Recognit. 2007, 40, 262–282. [Google Scholar] [CrossRef]
- Zhang, D.S.; Islam, M.M.; Lu, G.J. A review on automatic image annotation techniques. Pattern Recognit. 2012, 45, 346–362. [Google Scholar] [CrossRef]
- Desimone, R. Visual attention mediated by biased competition in extrastriate visual cortex. Philos. Trans. R. Soc. B 1998, 353, 1245–1255. [Google Scholar] [CrossRef] [PubMed]
- Reily, R.C.O. The what and how of prefrontal cortical organization. Trends Neurosci. 2010, 33, 355–361. [Google Scholar]
- Huang, J.; Kumar, S.R.; Mitra, M. Image indexing using color correlograms. In Proceedings of the 1997 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–19 June 1997; pp. 762–768.
- Quellec, G.; Lamard, M.; Cazuguel, G.; Cochener, B.; Roux, C. Fast wavelet-based image characterization for highly adaptive image retrieval. IEEE Trans. Image Process. 2012, 21, 1613–1623. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2007; pp. 395–398. [Google Scholar]
- Manjunath, B.S.; Ohm, J.R.; Vasudevan, V.V.; Yamada, A. Color and texture descriptors. IEEE Trans. Circuit Syst. Video Technol. 2001, 11, 703–715. [Google Scholar] [CrossRef]
- Mahmoudi, F.; Shanbehzadeh, J. Image retrieval based on shape similarity by edge orientation autocorrelogram. Pattern Recognit. 2003, 36, 1725–1736. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant key points. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Wang, X.Y.; Wang, Z.Y. A novel method retrieval based on structure elements’ descriptor. J. Vis. Commun. Image Represent. 2013, 24, 63–74. [Google Scholar] [CrossRef]
- Liu, G.H.; Yang, J.Y. Content-based image retrieval using color difference histogram. Pattern Recognit. 2013, 46, 188–198. [Google Scholar] [CrossRef]
- Murala, S.; Maheshwari, R.P.; Balasubramanian, R. Local tetra patterns: a new feature descriptor for content-based image retrieval. IEEE Trans. Image Process. 2012, 21, 2874–2886. [Google Scholar] [CrossRef] [PubMed]
- Meng, F.J.; Guo, B.L.; Wu, X.X. Localized Image Retrieval Based on Interest Points. Proced. Eng. 2012, 29, 3371–3375. [Google Scholar]
- Wang, X.Y.; Yang, H.Y.; Li, D.M. A New Content-Based Image Retrieval Technique Using Color and Texture Information. Comput. Electr. Eng. 2013, 39, 746–761. [Google Scholar] [CrossRef]
- Lee, Y.H.; Kim, Y. Efficient image retrieval using advanced SURF and DCD on mobile platform. Multimed. Tools Appl. 2015, 74, 2289–2299. [Google Scholar] [CrossRef]
- Kafai, M.; Eshghi, K.; Bhanu, B. Discrete Cosine Transform Locality-Sensitive Hashes for Face Retrieval. IEEE Trans. Multimed. 2014, 16, 1090–1103. [Google Scholar] [CrossRef]
- Yang, Y.; Nie, F.P.; Xu, D. A Multimedia Retrieval Framework based on Semi-Supervised Ranking and Relevance Feedback. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 723–742. [Google Scholar] [CrossRef] [PubMed]
- Spyromitros-Xioufis, E.; Papadopoulos, S. A Comprehensive Study over VLAD and Product Quantization in Large-Scale Image Retrieval. IEEE Trans. Multimed. 2014, 16, 1713–1728. [Google Scholar] [CrossRef]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1470–1477.
- Jegou, H.; Perronnin, F.; Douze, M.; Sanchez, J.; Perez, P.; Schmid, C. Aggregating local image descriptors into compact codes. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1704–1716. [Google Scholar] [CrossRef] [PubMed]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311.
- Perronnin, F.; Liu, Y.; Sánchez, J.; Poirier, H. Large-scale image retrieval with compressed fisher vectors. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3384–3391.
- Wan, J.; Wang, D.; Hoi, S.C.H.; Wu, P. Deep Learning for Content-Based Image Retrieval: A Comprehensive Study. ACM Int. Conf. Multimed. 2014. [Google Scholar] [CrossRef]
- Ng, J.Y.-H.; Yang, F.; Davis, L.S. Exploiting Local Features from Deep Networks for Image Retrieval. In Proceedings of the IEEE International Conference on Vision and Pattern Recognition, Deep Vision Workshop, Boston, MA, USA, 7–12 June 2015; pp. 53–61.
- Zhang, R.; Lin, L.; Zhang, R.; Zuo, W.; Zhang, L. Bit-Scalable Deep Hashing with Regularized Similarity Learning for Image Retrieval and Person Re-identification. IEEE Trans. Image Process. 2015, 24, 4766–4779. [Google Scholar] [CrossRef] [PubMed]
- Lin, K.; Yang, H.-F.; Hsiao, J.-H.; Chen, C.-S. Deep Learning of Binary Hash Codes for Fast Image Retrieval. In Proceedings of the IEEE International Conference on Vision and Pattern Recognition, Deep Vision Workshop, Boston, MA, USA, 7–12 June 2015; pp. 27–35.
- Jegou, H.; Douze, M.; Schmid, C. Hamming embedding and weak geometric consistency for large scale image search. In Computer Vision—ECCV 2008; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5302, pp. 304–317. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Color Quantization Level | Texture Orientation Quantization Level | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | |||||||||||
| 6 | 12 | 18 | 24 | 30 | 36 | 6 | 12 | 18 | 24 | 30 | 36 | |
| 128 | 93.43 | 93.32 | 93.13 | 92.82 | 92.91 | 93.12 | 9.40 | 9.38 | 9.36 | 9.32 | 9.33 | 9.35 |
| 64 | 92.50 | 92.42 | 91.86 | 91.97 | 91.99 | 92.25 | 9.28 | 9.27 | 9.21 | 9.22 | 9.22 | 9.25 |
| 32 | 89.85 | 90.06 | 89.50 | 89.41 | 89.64 | 89.66 | 8.96 | 8.97 | 8.90 | 8.91 | 8.94 | 8.93 |
| 16 | 82.12 | 82.63 | 82.38 | 82.55 | 82.22 | 82.35 | 8.02 | 8.12 | 8.09 | 8.11 | 8.04 | 8.05 |
| Color Quantization Level | Texture Orientation Quantization Level | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | |||||||||||
| 6 | 12 | 18 | 24 | 30 | 36 | 6 | 12 | 18 | 24 | 30 | 36 | |
| 192 | 99.05 | 98.91 | 98.73 | 98.44 | 98.69 | 98.56 | 10.31 | 10.30 | 10.28 | 10.25 | 10.27 | 10.26 |
| 128 | 99.09 | 98.57 | 98.85 | 98.73 | 98.60 | 98.49 | 10.33 | 10.26 | 10.28 | 10.28 | 10.25 | 10.24 |
| 108 | 98.88 | 98.54 | 98.46 | 98.72 | 98.72 | 98.16 | 10.18 | 10.12 | 10.12 | 10.16 | 10.15 | 10.09 |
| 72 | 98.20 | 98.24 | 98.30 | 98.45 | 98.54 | 98.12 | 10.06 | 10.05 | 10.08 | 10.09 | 10.14 | 10.05 |
| Datasets | Performance | Gradient Operator | ||||
|---|---|---|---|---|---|---|
| Proposed Operator | Sobel | Robert | LOG | Prewitt | ||
| Corel-1000 | Precision (%) | 98.20 | 97.83 | 97.15 | 96.21 | 97.52 |
| Recall (%) | 10.06 | 9.96 | 9.98 | 9.81 | 9.95 | |
| Corel-10000 | Precision (%) | 52.26 | 51.85 | 51.54 | 51.18 | 51.62 |
| Recall (%) | 5.87 | 5.75 | 5.73 | 5.68 | 5.74 | |
| Datasets | Performance | Distance or Similarity Measurement | ||
|---|---|---|---|---|
| Euclidian | Histogram Intersection | |||
| Corel-1000 | Precision (%) | 98.20 | 98.21 | 76.88 |
| Recall (%) | 10.06 | 10.06 | 9.72 | |
| Corel-10000 | Precision (%) | 52.26 | 52.26 | 30.42 |
| Recall (%) | 5.87 | 5.87 | 3.16 | |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, Z. A Novel Local Structure Descriptor for Color Image Retrieval. Information 2016, 7, 9. https://doi.org/10.3390/info7010009
Zeng Z. A Novel Local Structure Descriptor for Color Image Retrieval. Information. 2016; 7(1):9. https://doi.org/10.3390/info7010009
Chicago/Turabian StyleZeng, Zhiyong. 2016. "A Novel Local Structure Descriptor for Color Image Retrieval" Information 7, no. 1: 9. https://doi.org/10.3390/info7010009
APA StyleZeng, Z. (2016). A Novel Local Structure Descriptor for Color Image Retrieval. Information, 7(1), 9. https://doi.org/10.3390/info7010009