
A Feature Selection Method for Large-Scale Network Traffic Classification Based on Spark



Abstract
:1. Introduction
2. Related Work
3. The Parallel Computing Framework
3.1. Hadoop-MapReduce
3.2. Spark
4. FSMS
4.1. The Filter Methods for Feature Selection Based on Fisher Score
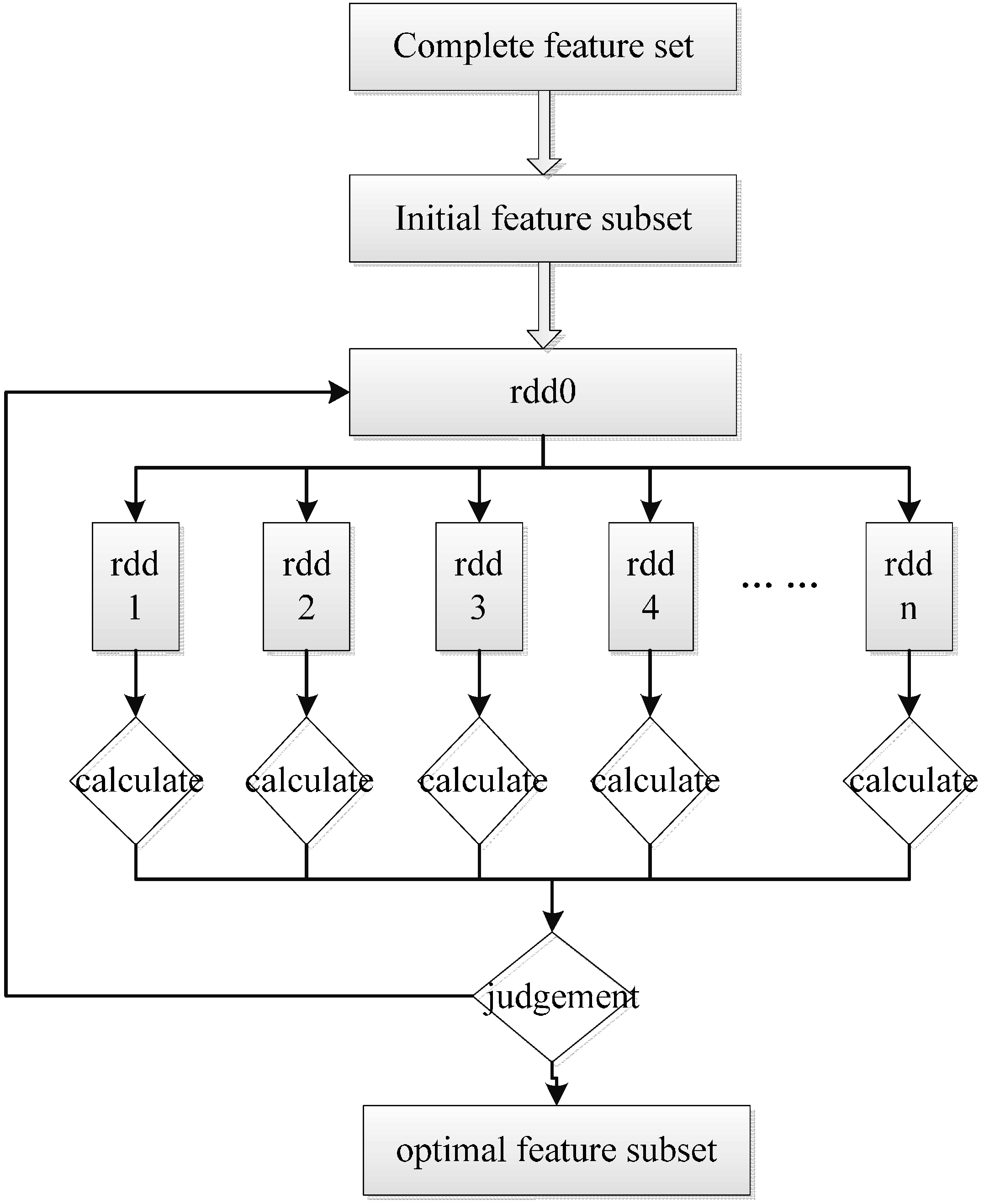
4.2. The Wrapper Feature Selection Methods Base on the SFS Strategy
- The classification accuracy of each feature in is obtained separately by the classification model .
- The feature achieving the highest accuracy is added into and eliminated from .
- Each feature in is combined with all the features in separately, and then obtains their own classification accuracy by the classification model .
- The corresponding feature of the highest accuracy in is added into and eliminated from .
- Steps 3 and 4 are repeated until the stopping criterion is reached.
4.3. The Realization of FSMS
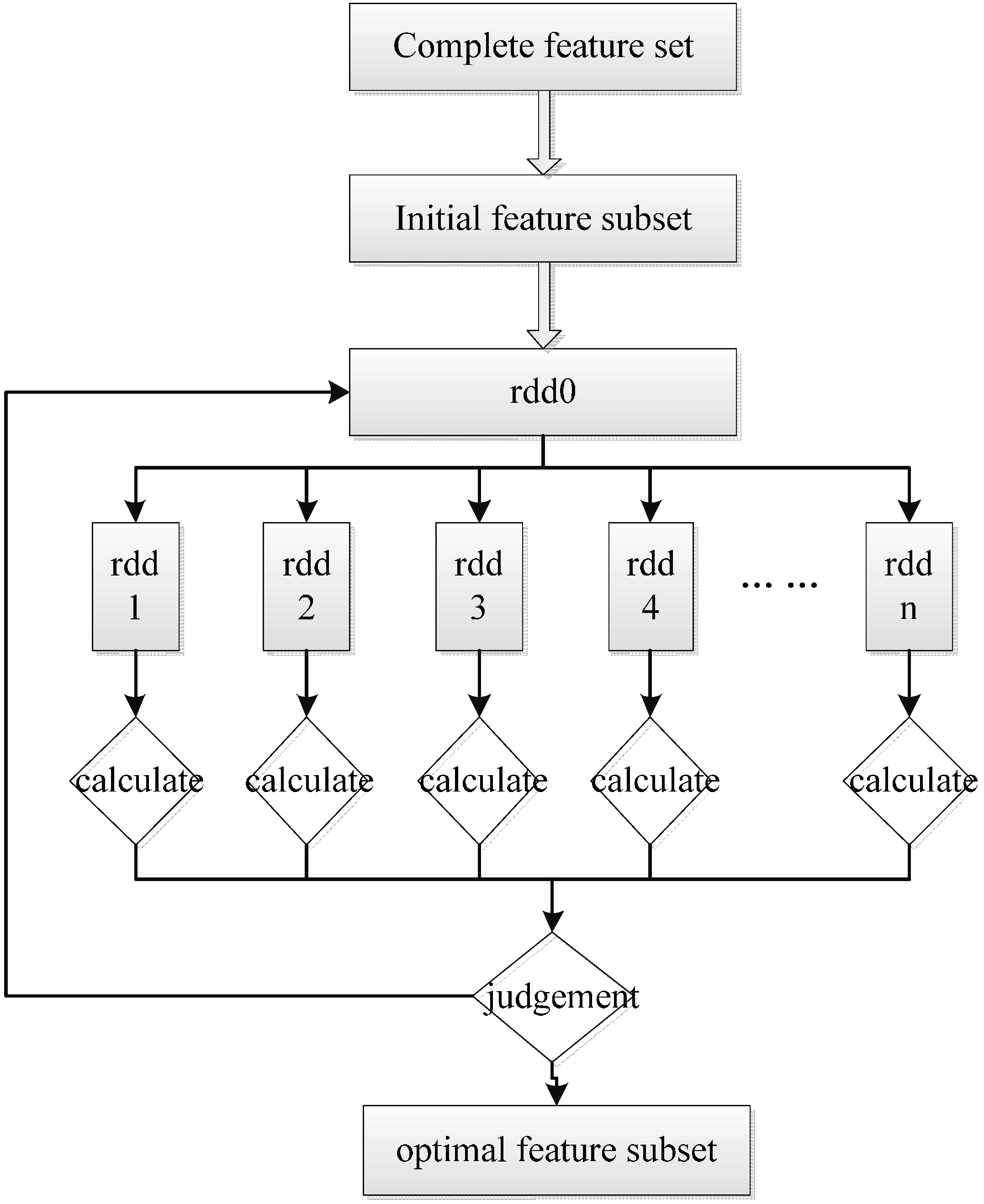
| The Algorithm of FSMS: |
| input: complete feature set ; |
| output: optimal feature set Z; |
| //-------------------------------------------Phase 1: Filter Process-------------------------------------------- |
|
| //-------------------------------------------Phase 2: Wrapper Process------------------------------------------ |
|
5. The Experiment Design and the Result Analysis
5.1. The Setup of Experimental Environment and Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Application Type | Count |
|---|---|---|
| WWW | http, https | 328,091 |
| imap, pop2/3, smtp | 28,567 | |
| BULK | ftp-Control, ftp-Pasv, ftp-Data | 11,539 |
| SERVICES | X11, dns, ident, ldap, ntp | 2099 |
| DATABASE | postgres, sqlnet oracle, ingres | 2648 |
| P2P | KaZaA, BitTorrent, GnuTella | 2094 |
| ATTACK | worm, virus | 1793 |
| MUITIMEDIA | Windows Media Player, Real | 1152 |
| Dataset | Data1 | Data2 | Data3 | Data4 | Data5 | Data6 |
|---|---|---|---|---|---|---|
| Instances count | 24,000 | 192,000 | 288,000 | 384,000 | 480,000 | 576,000 |
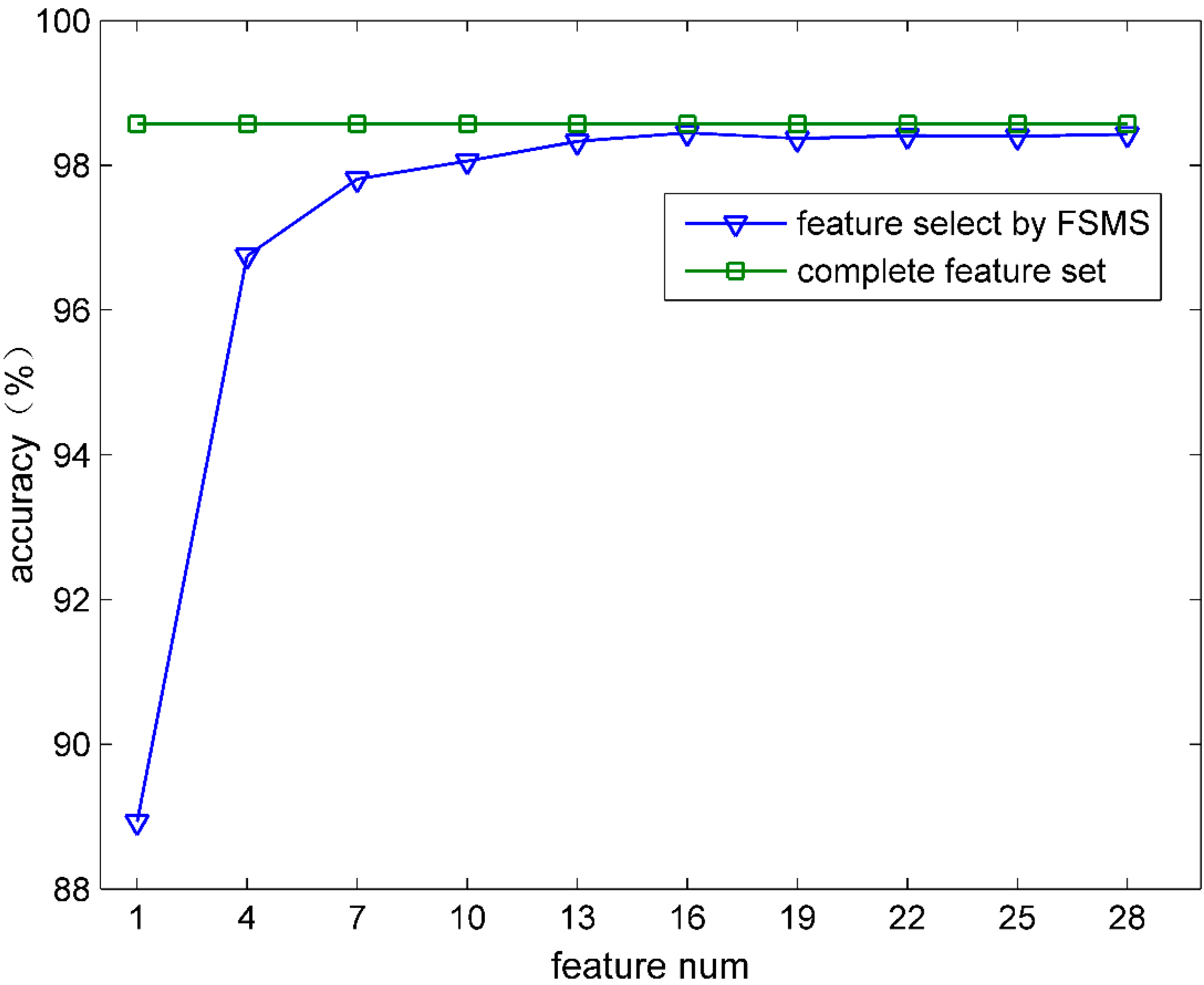
5.2. The Feature Selection Effectiveness
5.2.1. The Classification Accuracy

5.2.2. The Amount of Classification Computation

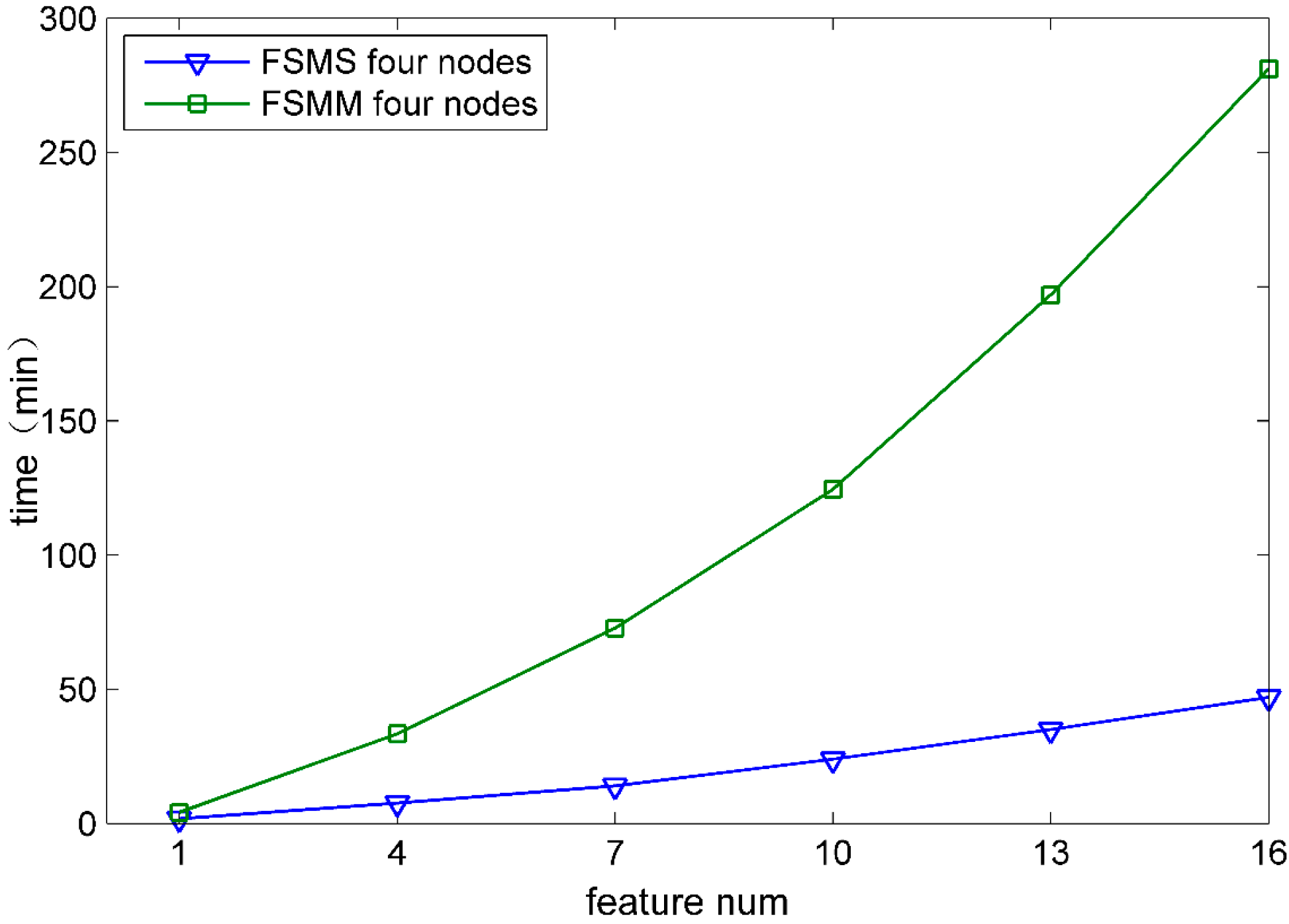
5.3. The Efficiency of Feature Selection
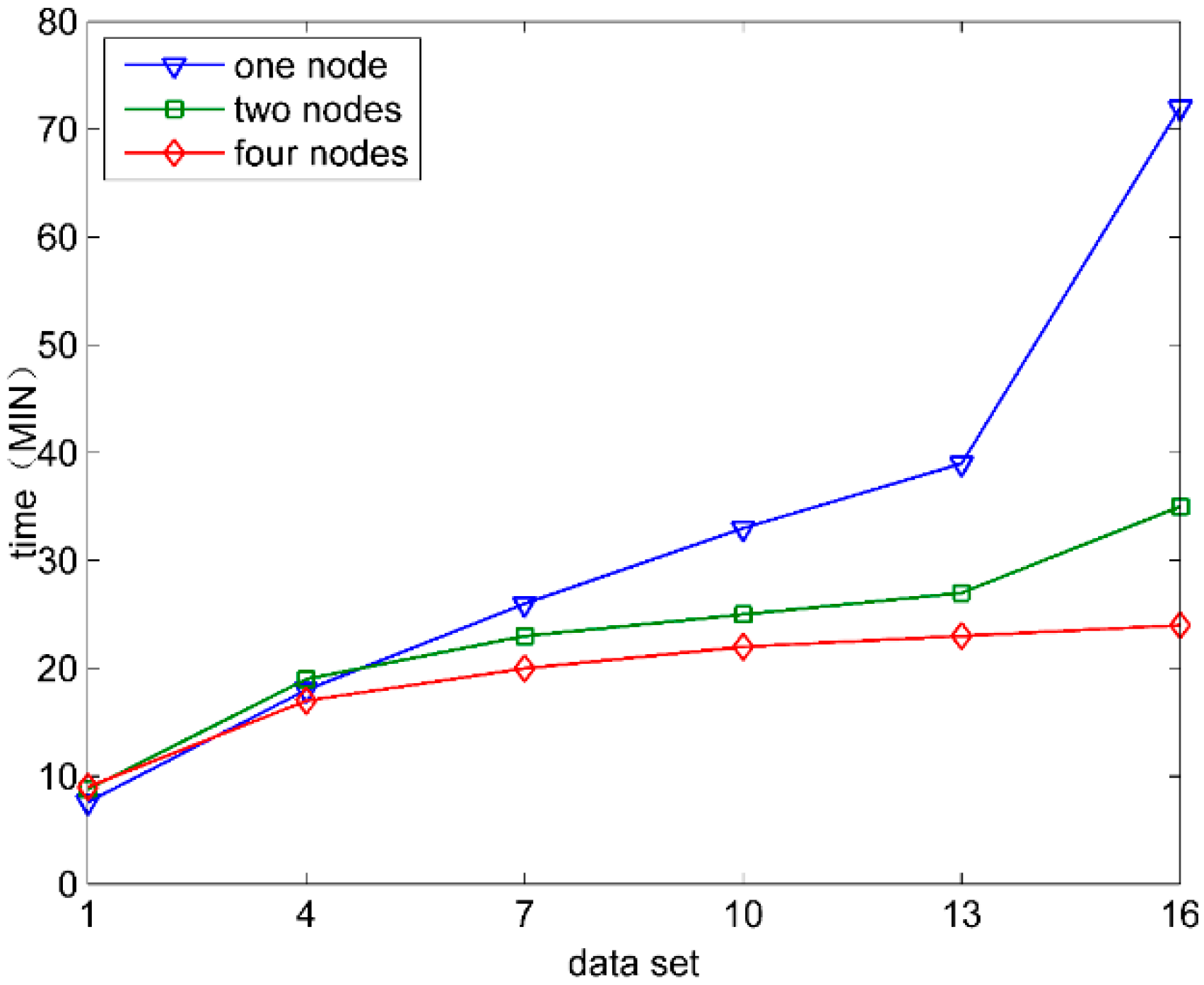
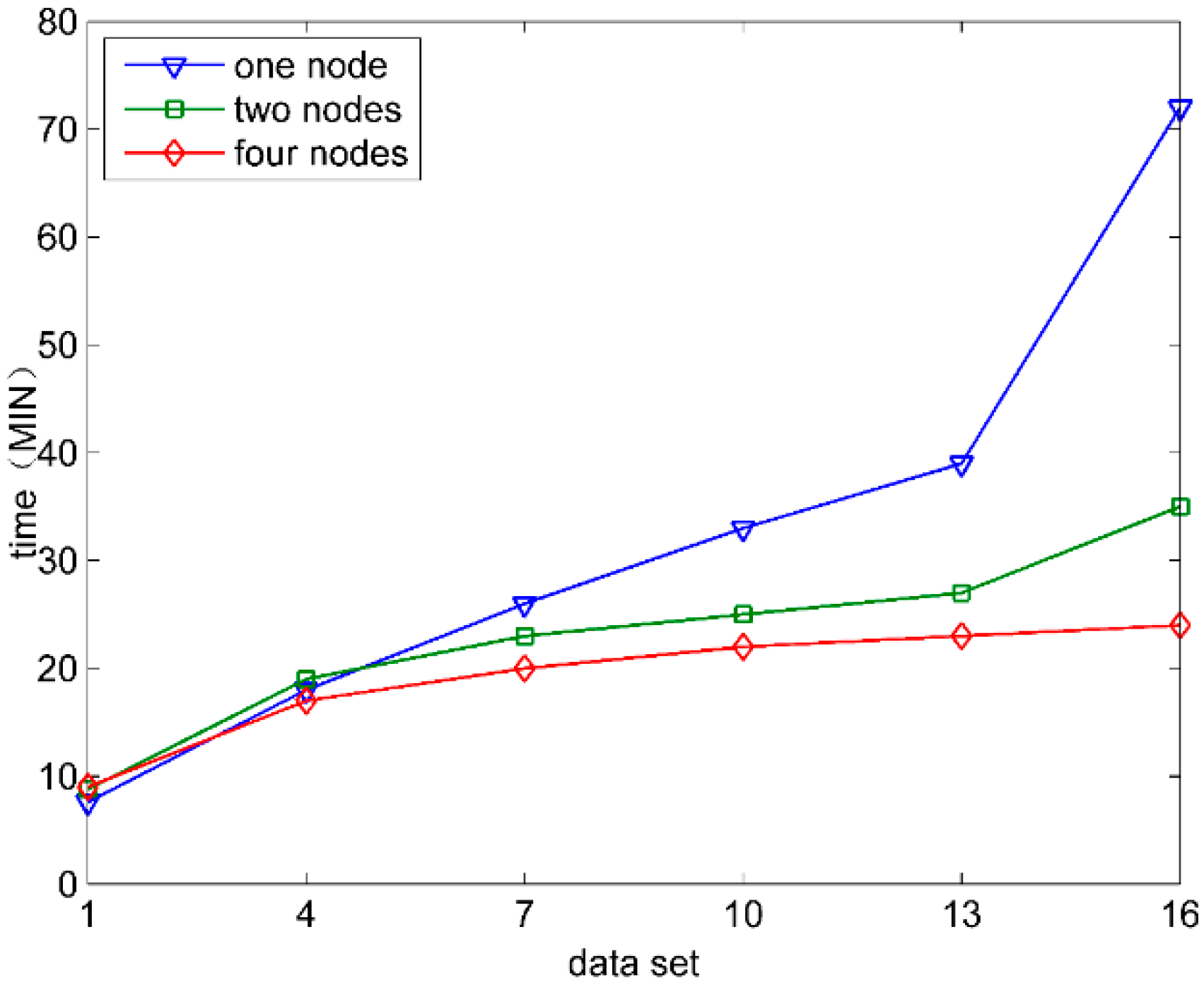
5.3.1. The Velocity of Feature Selection

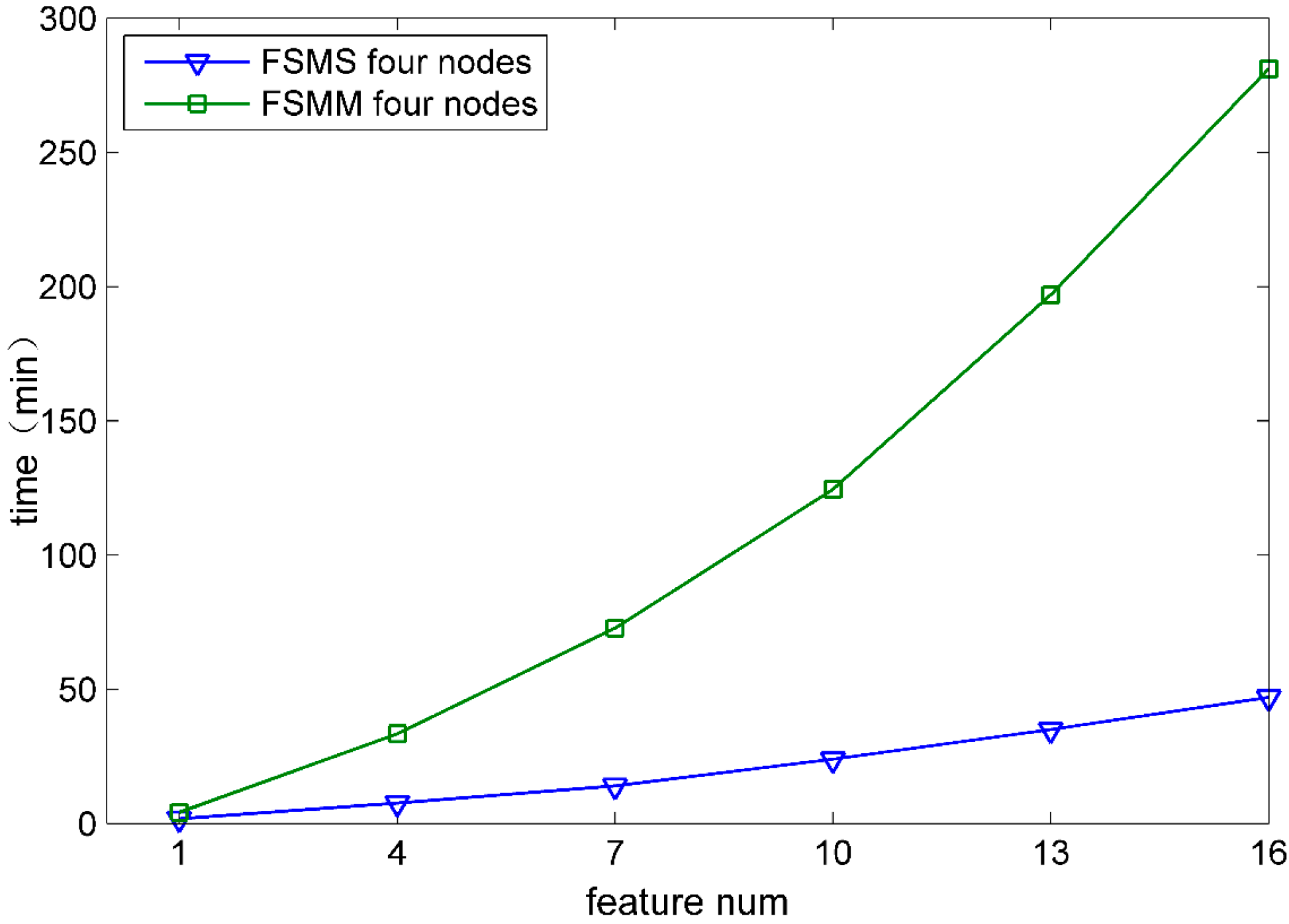
5.3.2. The Parallel Computing Effectiveness

6. Conclusions
Acknowledgements
Author Contributions
Conflicts of Interest
References
- Soysal, M.; Schmidt, E.G. Machine learning algorithms for accurate flow-based network traffic classification: Evaluation and comparison. Perform. Eval. 2010, 67, 451–467. [Google Scholar] [CrossRef]
- Fahad, A.; Tari, Z.; Khalil, I.; Habib, I.; Alnuweiri, H. Toward an efficient and scalable feature selection approach for internet traffic classification. Comput. Netw. 2013, 57, 2040–2057. [Google Scholar] [CrossRef]
- Crone, S.F.; Kourentzes, N. Feature selection for time series prediction—A combined filter and wrapper approach for neural networks. Neurocomputing 2010, 73, 1923–1936. [Google Scholar] [CrossRef] [Green Version]
- De Donato, W.; Pescapé, A.; Dainotti, A. Traffic Identification Engine: An Open Platform for Traffic Classification. IEEE Netw. 2014, 28, 56–64. [Google Scholar]
- Xu, M.; Zhu, W.; Xu, J.; Zheng, N. Towards Selecting Optimal Features for Flow Statistical Based Network Traffic Classification. In Proceedings of the 17th Asia-Pacific Network Operations and Management Symposium (APNOMS), Busan, Korea, 19–21 August 2015; pp. 479–482.
- Dainotti, A.; Pescapé, A.; Sansone, C. Early Classification of Network Traffic through Multi-classification. In Traffic Monitoring and Analysis; Domingo-Pascual, J., Shavitt, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 122–135. [Google Scholar]
- Jing, R.; Zhang, C. A Novel Feature Selection Method for the Conditional Information Entropy Model. In Proceedings of the 3rd International Conference on Artificial Intelligence and Computational Intelligence(AICI 2011), Taiyuan, China, 24–25 September 2011; pp. 598–605.
- Wang, Y. Fisher scoring: An interpolation family and its Monte Carlo implementations. Computational Stat. Data Anal. 2010, 54, 1744–1755. [Google Scholar] [CrossRef]
- Wang, P.; Sanin, C.; Szczerbicki, E. Prediction based on Integration of Decisional DNA and a Feature Selection Algorithm relief-F. Cybern. Syst. 2013, 44, 173–183. [Google Scholar] [CrossRef]
- Rodrigues, D.; Pereira, L.A.M.; Nakamura, R.Y.M.; Costa, K.A.P.; Yang, X.S.; Souza, A.N.; Papa, J.P. A wrapper approach for feature selection based on bat algorithm and optimum-path forest. Expert Syst. Appl. 2014, 41, 2250–2258. [Google Scholar] [CrossRef]
- Chuang, L.-Y.; Yang, C.-H.; Li, J.C.; Yang, C.-H. A hybrid BPSO-CGA approach for gene selection and classification of microarray data. J. Comput. Biol. 2012, 19, 68–82. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.H.; Wu, Z.Q.; Jiang, J.M. A novel feature selection approach for biomedical data classification. J. Biomed. Inform. 2010, 43, 15–23. [Google Scholar] [CrossRef] [PubMed]
- Dainotti, A.; Pescapé, A.; Claffy, K.C. Issues and Future Directions in Traffic Classification. IEEE J. Mag. 2012, 25, 35–40. [Google Scholar] [CrossRef]
- Szabó, G.; Veres, A.; Malomsoky, S.; Gódor, I.; Molnár, S. Traffic Classification over Gbit Speed with Commodity Hardware. IEEE J. Commun. Softw. Syst. 2010, 5. Available online: http://hsnlab.tmit.bme.hu/molnar/files/jcss2010.pdf (accessed on 15 February 2016). [Google Scholar]
- Sun, Z.Q.; Li, Z. Data intensive parallel feature selection method study. In Proceedings of 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 2256–2262.
- Li, J.Z.; Meng, X.R.; Wen, J. An improved method of SVM-BPSO feature selection based on cloud model. IAES Telkomnika Indones. J. Electr. Eng. 2014, 12, 3979–3986. [Google Scholar] [CrossRef]
- Long, Y. Network Traffic Classification Method Research Based on Cloud Computing and Ensemble Learning. Ph.D. Thesis, Guilin University of Electronic Technology, Guilin, China, June 2015. [Google Scholar]
- Srirama, S.N.; Batrashev, O.; Jakovits, P.; Vainikko, E. Scalability of parallel scientific applications on the cloud. Sci. Program. 2011, 19, 91–105. [Google Scholar] [CrossRef]
- Srirama, S.N.; Jakovits, P.; Vainikko, E. Adapting scientific computing problems to clouds using MapReduce. Future Gener. Comput. Syst. 2012, 28, 184–192. [Google Scholar] [CrossRef]
- Apache Spark. Available online: http://spark.apache.org (accessed on 14 February 2016).
- Moore, A.; Zuev, D. Discriminators for Use in Flow-based Classification; Queen Mary and Westfield College: London, UK, 2005; pp. 1–13. [Google Scholar]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Ke, W.; Tao, X. A Feature Selection Method for Large-Scale Network Traffic Classification Based on Spark. Information 2016, 7, 6. https://doi.org/10.3390/info7010006
Wang Y, Ke W, Tao X. A Feature Selection Method for Large-Scale Network Traffic Classification Based on Spark. Information. 2016; 7(1):6. https://doi.org/10.3390/info7010006
Chicago/Turabian StyleWang, Yong, Wenlong Ke, and Xiaoling Tao. 2016. "A Feature Selection Method for Large-Scale Network Traffic Classification Based on Spark" Information 7, no. 1: 6. https://doi.org/10.3390/info7010006
APA StyleWang, Y., Ke, W., & Tao, X. (2016). A Feature Selection Method for Large-Scale Network Traffic Classification Based on Spark. Information, 7(1), 6. https://doi.org/10.3390/info7010006