1. Introduction
Adult spinal deformity (ASD) is a broad diagnosis referring to stable asymptomatic curves and disabling deformities in the spine that contribute to pain, weakness, and low health-related quality of life (HRQOL). Although ASD is quite common, the variation and unique pattern of each spinal deformity make reproducible measurement difficult. Previous studies investigating the correlation between radiographic appearances and clinical symptoms yielded rather low predictive power due to highly variable health status [
1]. Little correlation between radiographic assessment and questionnaire scores was found for adolescent idiopathic scoliosis [
2]. However, in 2005, Glassman et al. showed that sagittal plane balance is the most reliable predictor of clinical symptoms in adults with spinal deformity [
3]. Even mild positive sagittal balance results in destructive spinal deformity, clinical symptoms of which deteriorate linearly [
4]. Therefore, a surgical plan for restoring sagittal balance is crucial in all spinal reconstructive surgeries [
3].
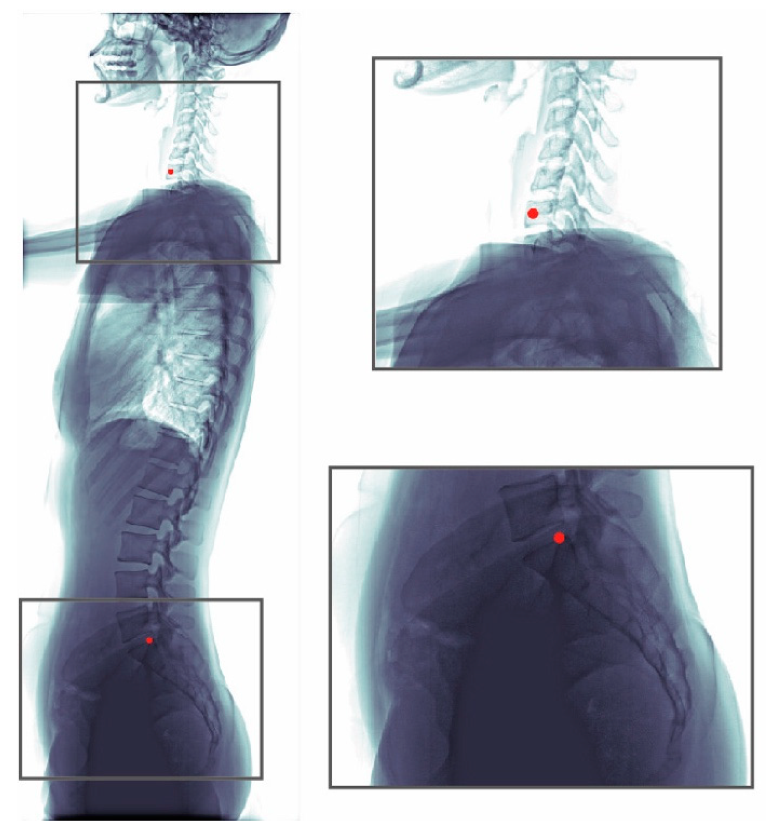
Parameters to describe the sagittal alignment of the spine include the sagittal vertical axis (SVA), thoracic kyphosis, lumbar lordosis, pelvic incidence, pelvic tilt, and sacral slope. SVA, which is the most commonly used measure of the sagittal plane, is obtained from standing lateral radiographs and is defined as the horizontal distance between two landmarks: the center of C7 vertebral body and the posterior superior aspect of the S1 vertebral body. According to Schwab’s classification based on Jean Dubousset‘s cone of economy, the realignment of the spine should aim to meet the criteria of SVA < 50 mm to alleviate sensations of falling over [
5]. Consequently, formulating a patient-specific surgical plan requires SVA measurement both preoperatively and postoperatively, using whole-spine lateral radiographs. However, manual SVA estimation on radiographs is rather inconvenient due to lack of easy-to-use tools. To solve this issue, we propose using deep-learning models for fully automatic estimation of SVA.
A well-known family of deep-learning models is the convolutional neural networks (CNNs). CNNs have drawn considerable attention since 2012, as they were found to outperform traditional image processing algorithms on image classification tasks [
6]. Since then, CNNs have been increasingly used for medical image analysis [
7,
8]. A CNN is primarily made of stacked convolution layers, which can be regarded as a series of learnable feature extractors designed for acquiring low-to-high-level features of an image. In general, basic image features, such as blob of colors or edges of different orientations, are learnable by the shallow convolution layers. On the other hand, complex image features, such as appearances of objects, are learnable by the deep convolution layers [
9]. Therefore, well-trained convolution layers can be used to extract informative features that are useful for landmark localization or other specific tasks [
10,
11].
Automatic SVA estimation can generally be regarded as the task of landmark localization, as SVA was defined as the horizontal difference between two anatomical landmarks. In this study, we investigated the performance of ResUNet [
12] for automatic vertebrae localization on radiographs. ResUNet is a variant of CNN. Its UNet-like structure [
13] combines the contextual information produced by deep layers and better location information produced by shallow layers, allowing better utilization of low- and high-level features. In addition, the encapsulated residual blocks [
14] of ResUNet enable better flow of information and can avoid performance deterioration as the network goes deeper. ResUNet has been used for cell segmentation from biomedical images [
12] and road extraction from satellite images [
15]. To the best of our knowledge, our study is the first to utilize ResUNet for anatomical landmark localization.
Some previous works use CNN for vertebrae segmentation or localization. For example, for 3D CT and MR images, Lessmann et al. [
16] used a 3D UNet-like model for vertebrae segmentation. In addition, Wimmer et al. [
17] used 3D CNN for vertebrae localization. There were also studies on radiographs: for biplanar radiographs, including A-P and lateral view, Gallbusera et al. [
18] used a database collected using the EOS™ imaging system [
19] and trained CNN models for each of the landmarks. For lateral spine radiographs, Al Arif et al. [
20] applied a UNet model for the localization of cervical vertebral centers.
In this study, we applied ResUNet on plain lateral spine radiographs. Although our algorithm is similar to the one in [
20], there are some major differences. First, we did not split images into patches, as patching leads to extra pre- and post-processing steps, and the correlation between landmarks of different patches will be ignored completely. However, if patching was not performed, the large image size would lead to insufficient amount of RAM on GPU. To alleviate this issue, we used a small batch size (batch size = 2) and replaced the widely used batch normalization with the group normalization [
21] in our network. Group normalization is known to perform well even when the batch size is small, as it does not perform normalization along the batch axis. Secondly, we let probability maps of landmarks to be predicted separately. Thus, predictions were not on the same map and further post-processing steps involving separation and identification of the landmarks can be eliminated.
Our main contribution in this paper is three-fold. Firstly, we validated that automatic SVA estimation on lateral spine radiography is feasible using the current deep-learning techniques. The procedure of 10-fold cross-validation was applied to validate the effectiveness of the constructed SVA estimator (ResUNet). Secondly, modern networks often take the Gaussian heatmaps centering at landmark locations as the targets of regression [
22,
23,
24]. In this study, we experimented also the use of exponential heatmaps for model selection. Our experiments suggested that, when the heatmap function was narrow, the exponential heatmaps can be more easily learned, as compared with the Gaussian heatmaps. Thirdly, we compared the estimates between ResUNet and human experts of different seniority. The results show that they were in excellent agreement.
2. Materials and Methods
2.1. Data Preparation
We collected 990 whole spine lateral radiographs from 990 patients who had degenerative changes or deformities in the spine from January 2012 to September 2018 at Chang Gung Memorial Hospital, Linkou, Taiwan. The collected radiographs were from different X-ray scanners and the mean pixel resolution was . Poor-quality images such as those with poor image contrast and positioning errors were excluded. Among the collected radiographs, 13% (128) of the images are of children (age < 12), 42% (414) of the images are of young adults (age 13–18) and 45% (448) of the images are of adults (age > 18). Overall, 77% (765) of the images do not have an implant, while 23% (225) do. In the group without implants (765), 56% (428) of the patients have scoliosis, while 44% (337) of patients have degenerative change. In the group with implants (229), 76% (170) of the implants extend from thoracic to lumbar, 21% (48) of the implants extend from lumbar to sacral, 2% (5) of the implants only involve lumbar, and 1% (2) of the implants only involve thoracic. Pediatric and young adult patients diagnosed of scoliosis were enrolled in this study. In terms of sacral morphology, this cohort displayed various degrees of physiological sacral fusions, as well as pathology resulting from scoliosis. The images were anonymized, and standard research protocols were followed. This study was approved by the Institutional Ethical Committee (IRB number: 201801651B0 (1809270049)).
The whole dataset (990 images) was annotated by one senior resident orthopedic surgeon. This surgeon has more than five years of experience for manual measurement of spine parameters. When a difficult case was encountered, the surgeon discussed with an experienced spine surgeon to reach a consensus. This annotated dataset was used for model training and evaluation. An annotated radiograph can be seen in
Figure 1. We used a custom written MATLAB GUI program for annotation.
In addition, an experienced radiologist and a junior resident physiciane also provided their annotations for a subset of the dataset (99 images), which were randomly selected from the 990 images. Hence, three human annotations (senior/junior resident orthopedic surgeon, and radiologist) can be found for this subset of data and the consistency between our model and human experts can be examined further.
2.2. Gaussian and Exponential Heatmaps
A Gaussian heatmap centering at
can be defined as:
where
is a pixel location of an image (on i-th column and j-th row),
is the human-annotated landmark location, σ is a hyperparameter that controls the width of the Gaussian, and c is the scaling constant, which was fixed to be a large constant (at the order of
) so that the heatmap pixels close to landmark locations were more salient and easier to learn.
Representing landmark locations using heatmaps is beneficial. First, the regression of a heatmap was considered as an easier task as compared to the regression of x and y values, as the latter requires the learning of a highly non-linear function that maps all image pixels into two values only. Secondly, after normalization, the predicted heatmap is more informative, as it can be interpreted as a predicted probability map for the location of a landmark.
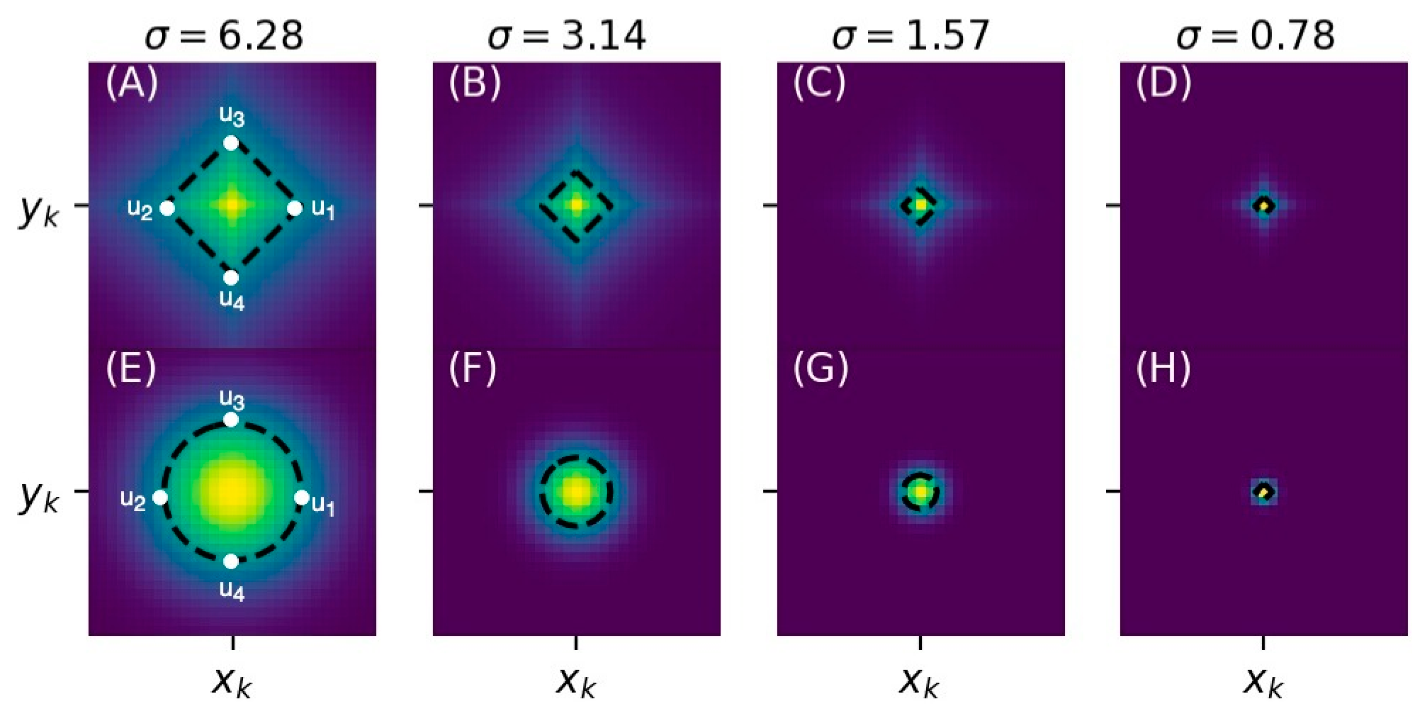
However, to determine , we need to select manually. The value of is often set as a small value because wide Gaussians may introduce high uncertainties to the prediction of landmark locations. However, if the Gaussian is not wide enough, features which are useful for prediction but outside the narrow region of Gaussian may have the chance to be ignored, as we simply let the model to predict zeros at the locations of those features.
To overcome this issue, we propose the use of exponential heatmaps for landmark localization. An exponential heatmap
centering at
can be defined as:
where
is the human-annotated landmark location,
is a hyperparameter that controls the decay rate of the exponential function, and c is the scaling constant as defined in the Gaussian heatmap. For the purpose of comparison, we let
so that both
and
reach to the same half maxima at
and
, as shown in
Figure 2.
Compared to the Gaussian heatmap , the proposed exponential heatmap has a sharper peak centering at the landmark location. As a result, the predicted locations of landmarks can be less uncertain. Furthermore, decays more slowly (especially when the pixels are close to and ), which leads to a wider region of heatmap pixels that should be predicted nonzero. In this case, useful features that lie within the non-zero zone are easier to detect and can be used as a clue for easier localization of landmarks.
2.3. Model Architecture
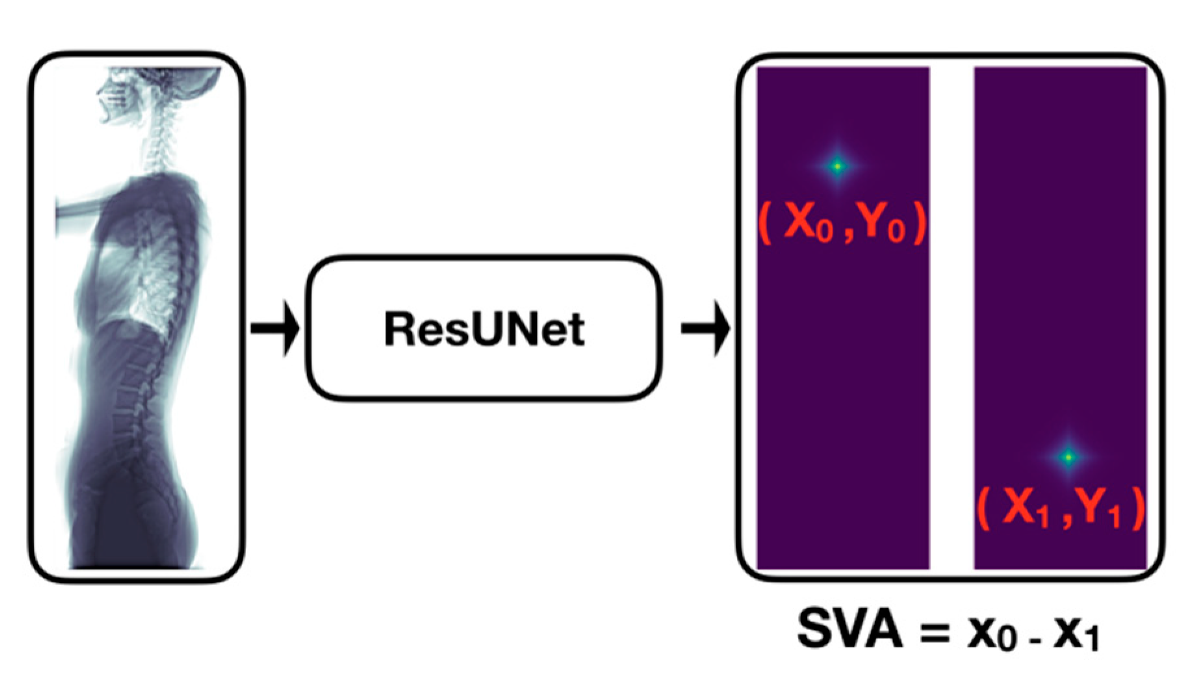
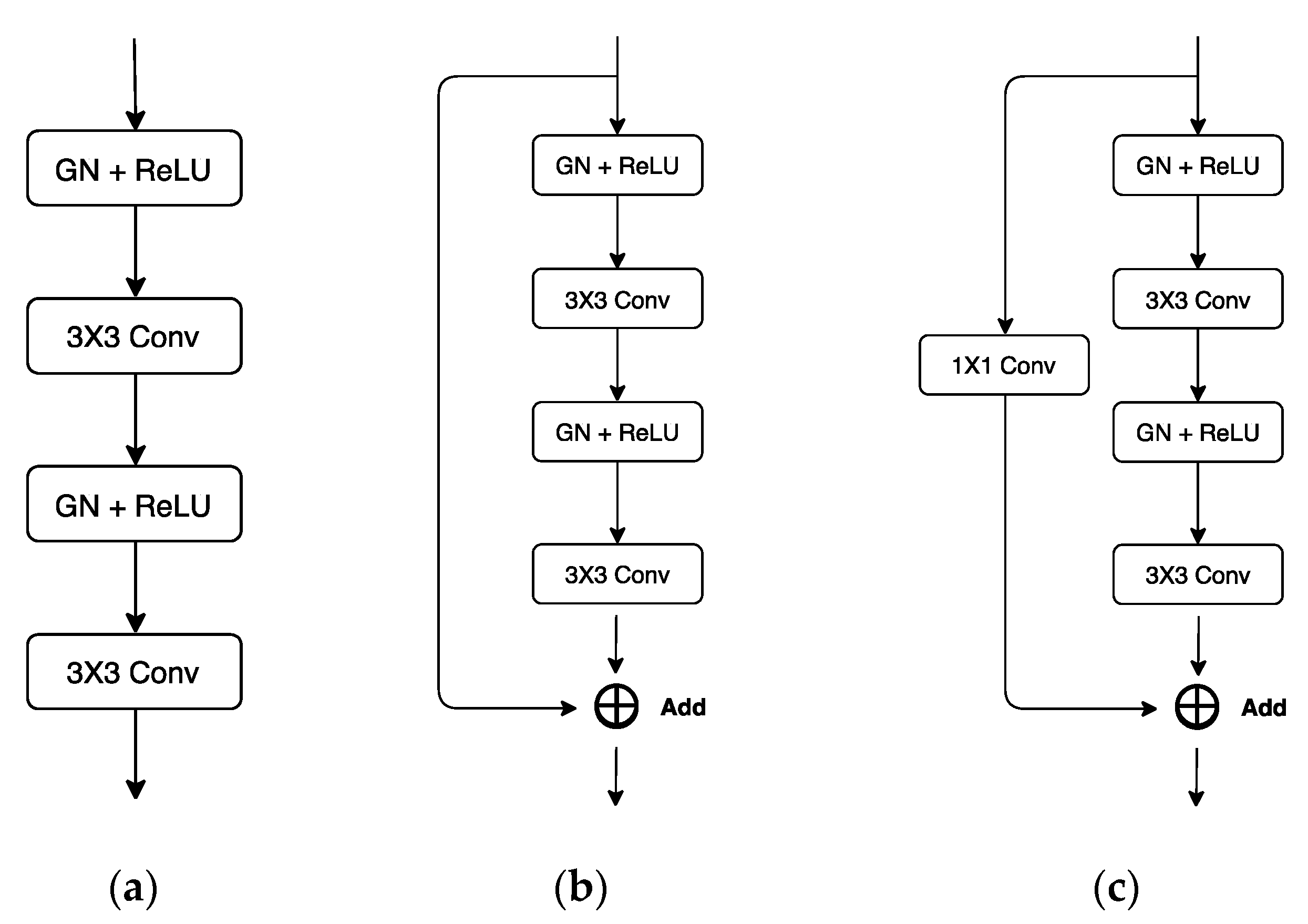
Our automatic SVA estimator (
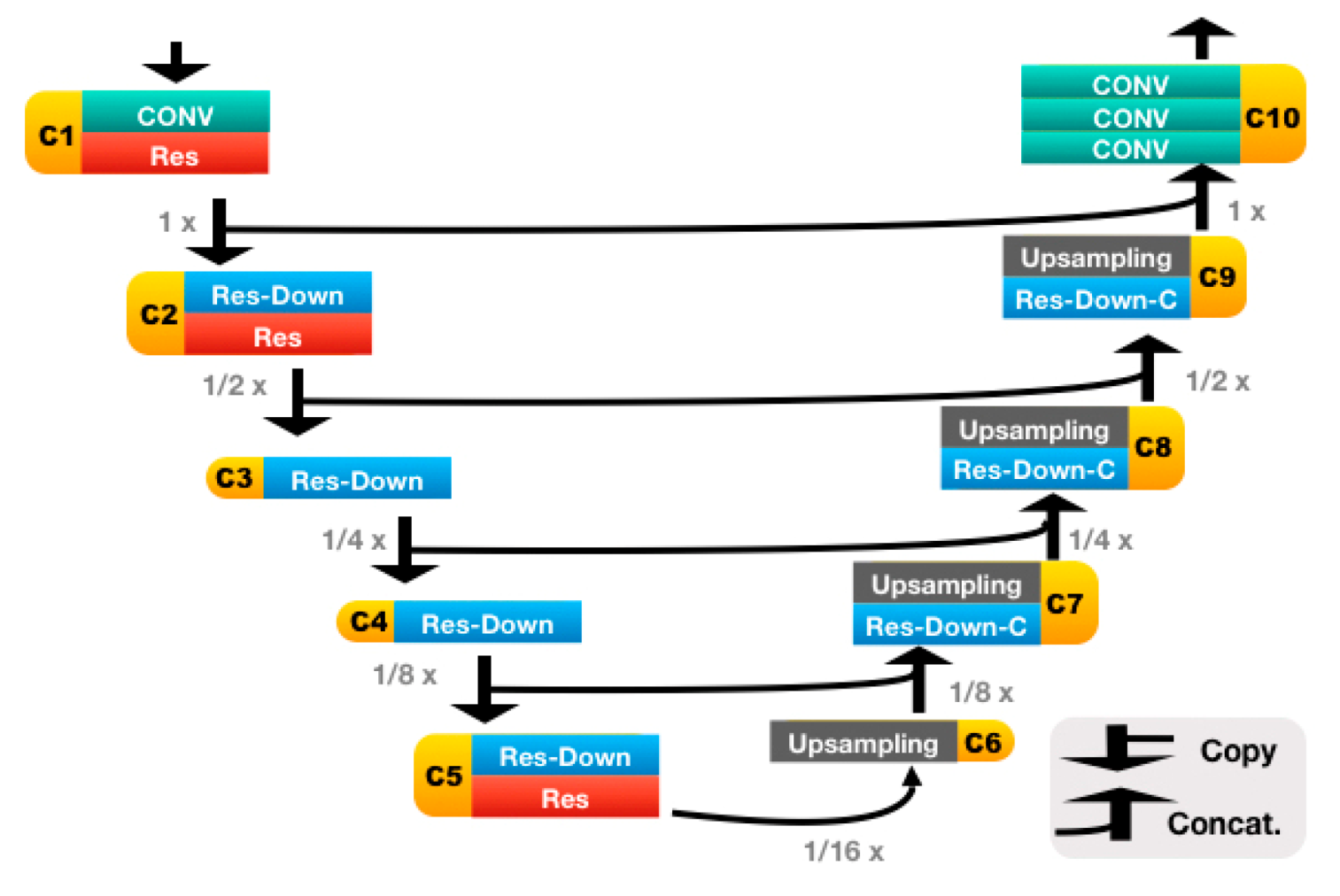
Figure 3) was based on a 31-layer ResUNet (
Figure 4), which was composed of the head convolutional layers (C1), the downsampling path (C2–C5), upsampling path (C6–C9), and the tail convolutional layers (C10). In the downsampling path, both height and width of the feature maps were reduced by half four times. This process was then reversed during the upsampling path, and two heatmaps of landmarks were predicted immediately after C10.
The details of the ResUNet architecture are further illustrated in
Figure 5 and
Table 1. It is worth mentioning that, if the C7 center and the posterior corner of the sacrum were to be predicted on the same heatmap, then we would have to cope with landmark extraction and identification. For the former, we would have to, e.g., fit a Gaussian mixture model (which is rather complex) and regard the locations of the fitted Gaussian centers as the landmark locations. For the latter, we perhaps would have to assume that the one above is the landmark of C7, and the one below is the landmark of sacrum, as the extracted landmarks are indistinguishable.
In this work, all landmarks were predicted on separate heatmaps, i.e., the landmarks were separated and distinguishable from the very beginning. Thus, all we need to do was fit an exponential or a Gaussian function to each of the heatmaps and then regarded the obtained center of the fitted function as the estimated location of its corresponding landmark.
2.4. Image Preprocessing and Augmentation
Before training, all radiographs were downsized to and then padded to . The padding procedure was crucial, as the radiographs were randomly rotated (angle ) during training, and the vertebrae part of the body should not be missing after rotation.
During training, techniques of data augmentation were applied to the radiographs in order to prevent CNNs from adapting to images of certain scales, orientations, and types of noise. The applied techniques were random scaling (scale ), random rotation (angle ), and random Gaussian blur (strength ).
2.5. Details of Experiments
We trained a 31-layer ResUNet for the localization of the C7 center and the posterior corner of the sacrum. For model selection, the experimented hyperparameters for fine-tuning were heatmaps of different types (Gaussian and exponential) and sizes (
). Furthermore, the procedure of 10-fold cross-validation was followed to test the effectiveness of the constructed models. For a schematic description about how the procedure of 10-fold cross-validation was performed, please refer to
Figure S1.
Two GPUs were used for training (NVIDIA Tesla V100), and the batch size was set to 2 per GPU (therefore, the total batch size was 4). For the procedure of group normalization, the number of groups was set to 32. In addition, mean squared error was chosen as our loss function, which was minimized using stochastic gradient descent (SGD) with Nesterov momentum (momentum = 0.9). To eliminate the effect of overfitting, L2 regularization (strength = 10−5) was also added to the loss function.
During training, the learning rate was initially set to 0.01 and was then reduced by half on epoch 100. The number of training epochs was set to 120 and the final model was obtained from the checkpoint that performed the best on the validation data after epoch 80. The elapsed time of an experiment of 10-fold cross-validation was approximately 50 h. We used TensorFlow v1.12 and its Estimator API for model construction and training.
3. Results
We used absolute error of SVA and detection rate of landmarks to evaluate model performance. To obtain errors in pixels, we converted the predicted locations of landmarks back to the resolution of the original (unresized and unpadded) image and then calculated the pixel errors using locations of the true and predicted landmarks. The pixel errors were then converted to mm using the scaling factor recorded in each radiograph. We chose to represent errors in mm because scaling factor is different between radiographs and number of pixels would not be a universal standard.
3.1. Median Absolute Error of SVA
The median absolute error (MAE) of SVA is defined as:
where N stands for number of samples.
and
stand for the i-th true and predicted SVA, respectively.
As MAE is insensitive to outliers, we also report the number of outliers (>10 mm) for absolute errors. The results of various hyperparameter settings are shown in
Table 2.
Our results indicated that, when narrow Gaussian heatmaps were used (), the performance of SVA estimator became highly unstable (standard deviation > 10 mm). These results suggest that has to be fine-tuned carefully when choosing Gaussian heatmaps as the regressing targets.
To further investigate the quality of landmark localization, we also calculated the detection rate of the C7 center and the posterior corner of the sacrum, respectively. The results are shown in the following section.
3.2. Detection Rate of Landmarks
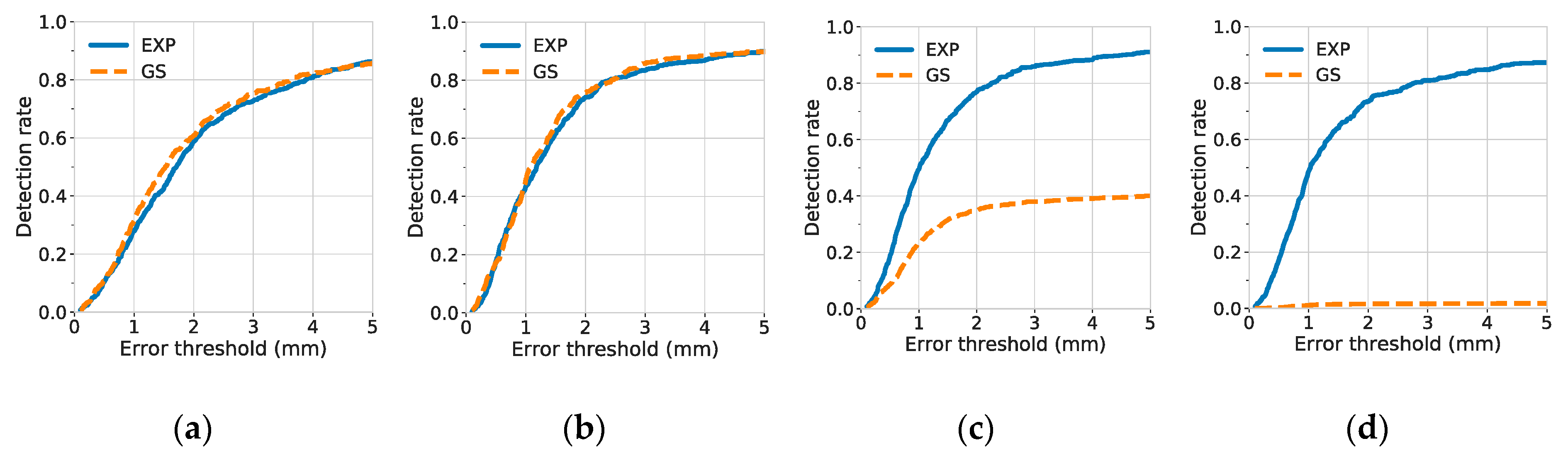
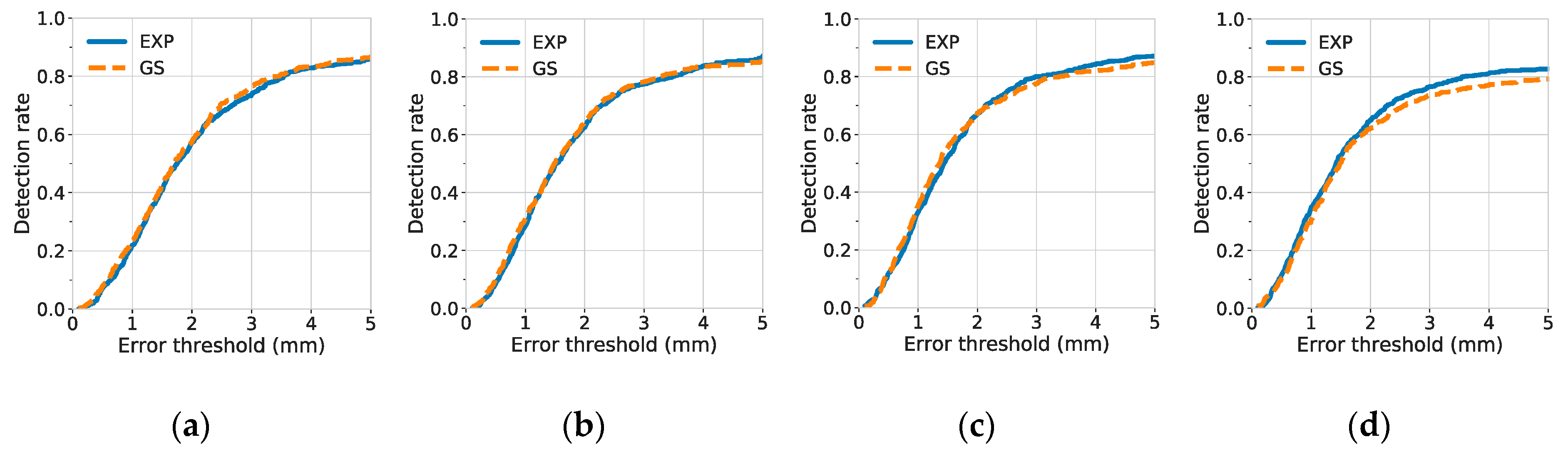
A landmark was considered to be detected when the distance between the true and predicted landmark locations was under some acceptable error threshold. To investigate the quality of predicted landmark locations, the detection rate was plotted against different degrees of error thresholds, as shown in
Figure 6 (for the C7 center) and
Figure 7 (for the posterior corner of the sacrum).
The results of detection rates indicate that the C7 center was difficult to be localized when narrow Gaussian heatmaps were used (). A possible reason is that there were few or no distinct features near the center of the vertebra. The distinct features, such as the vertebrae borders, were not included in the highlighted, non-zero region of the narrow Gaussian and were therefore difficult to be utilized for better localization of landmarks. By contrast, at small , the exponential function has not only a narrow region at its center, but also a rather extended region at its tail. Hence, for the exponential function, even if the distinct features were not inside the narrow region, they may still be discovered and utilized, if they were contained within the non-zero, extended tail region.
In contrast to models trained with narrow Gaussian heatmaps, models trained with narrow exponential heatmaps achieved the best performance for the detection of the C7 center. At
, the 1-mm and 5-mm detection rate of the C7 center reached 0.496 ± 0.023 and 0.911 ± 0.012, respectively, as shown in
Table 3.
Additionally, we used fixed narrow heatmap function (
) and compared the 5-mm detection rate of models trained with different model complexity (31-layer ResUNet and 12-layer UNet) and different types of heatmaps (Gaussian and exponential). The results are shown in
Table 4. Our results suggest that, when the model complexity was fixed, replacing the Gaussian heatmap with the exponential heatmap leads to a better and a more stable performance (the standard deviation has decreased by an order of magnitude). The 5-mm detection rate of C7 increased from 0.045 to 0.842, when a 12-layer UNet was used, and increased from 0.401 to 0.911, when a 31-layer ResUNet was used. These results indicate that the exponential heatmaps were easier to learn at
, regardless of the model complexity. Furthermore, when the heatmap type was fixed, replacing a 12-layer UNet with a 31-layer ResUNet led to significant improvements for the localization of the C7 center. This indicated that the extra skip-connections and convolutional layers of the 31-layer ResUNet were effective at
.
3.3. Analysis of Inter-Rater Reliability
To further compare the SVA estimates between ResUNet and human experts, or the SVA estimates between human experts only, we calculated the intra-class correlation coefficient (ICC). With ICC, the agreement between any two estimators can be tested. Our ICC scores were calculated by two-way-random effects model with absolute agreement. For the evaluation of ICC, 99 radiographs from one fold of 10-fold cross-validation were used.
We report the ICC scores and their 95% confidence intervals in
Table 5. The ICC scores were evaluated for four participants, including a 31-layer ResUNet (
, heatmap type = exponential), a junior resident orthopedic surgeon, a senior resident orthopedic surgeon, and a radiologist. Our results show that the ICC scores derived from any pair of the four participants were all >0.9, indicating a high agreement among the four participants.
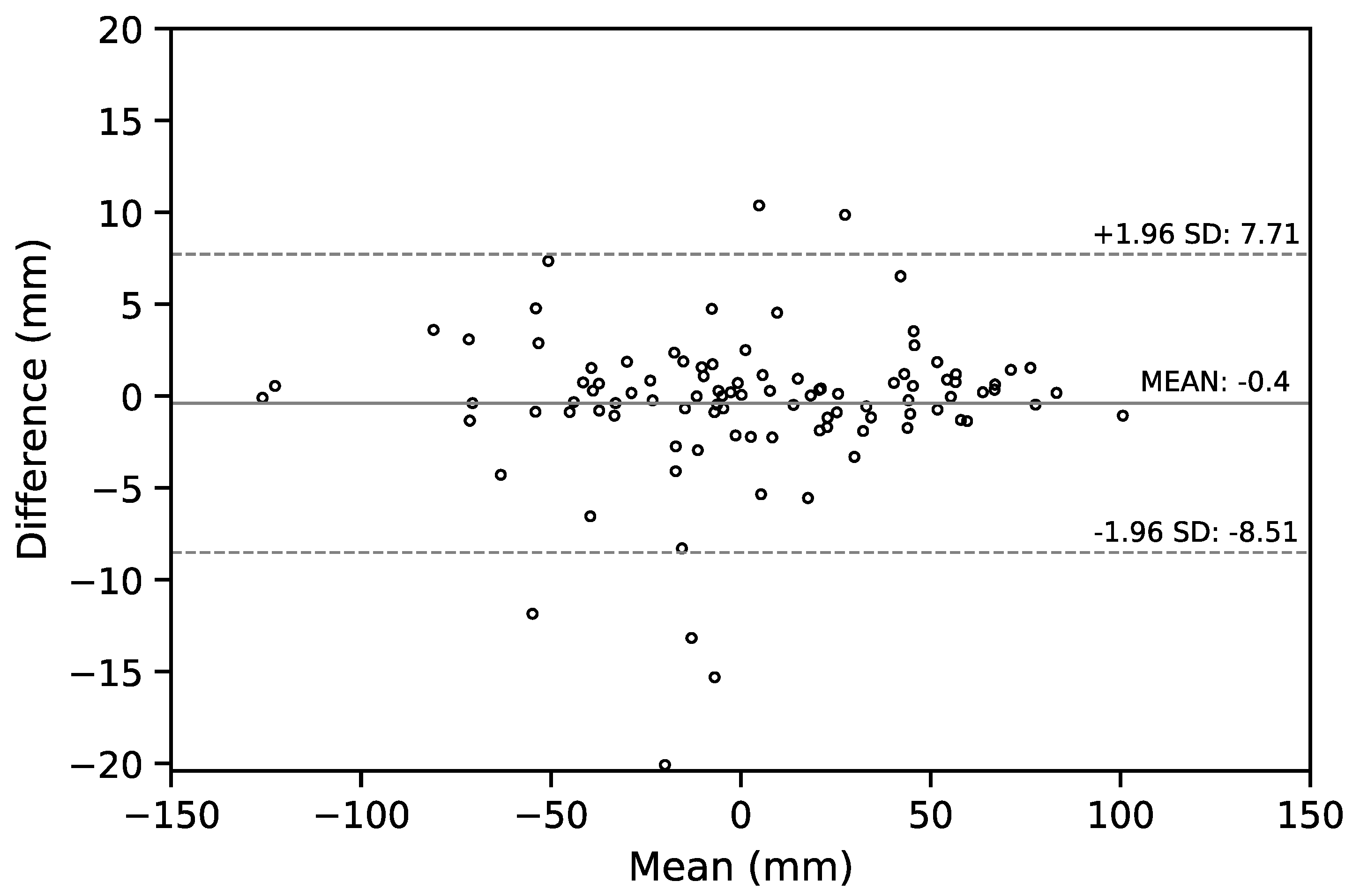
We also report the Bland–Altman (B-A) plot for the SVA values estimated by the senior resident orthopedic surgeon and the ResUNet model in
Figure 8. The median absolute difference and the mean difference of these two set of estimates was
mm and
mm, respectively. For a comparison between doctors, the B-A plot for the SVA values estimated by the senior and the junior resident orthopedic surgeons is shown in
Figure 9. The median absolute difference, and the mean difference of these two set of estimates was
mm and
mm, respectively.
4. Discussion
Sagittal balance is a primary issue for clinical assessment of spine. There are several important morphological indicators of the alignment of spine and pelvis, including sagittal vertical axis (SVA), lumbar lordosis, pelvic incidence, pelvic tilt, and sacral slope. Among them, SVA is the most common parameter used for the evaluation of overall spinal alignment, which represents the sagittal curvature of the spine [
25]. SVA can be used to determine the relationship between the spine and pelvis, and has a normal range. Yukawa et al. [
26] reported the average value of 3.1 ± 12.6 mm for the SVA of 626 asymptomatic volunteers, and SVA may steadily increase from ages of 30 to 70 years.
Although SVA may change with aging, it remains a reliable sagittal spinopelvic parameter for the assessment of spine alignment. Several authors have demonstrated high inter-rater reliability of SVA measurement by the intra-class correlation coefficient (ICC). Kyrölä et al. [
27] reported the ICC score of 0.99 (95% CI: 0.98, 1.00) for SVA in unselected adults with degenerative spine disorders. In a previous study, Katzman et al. [
28] also showed a high ICC score of 0.93 (95% CI: 0.83, 0.97) in older adults with hyperkyphosis.
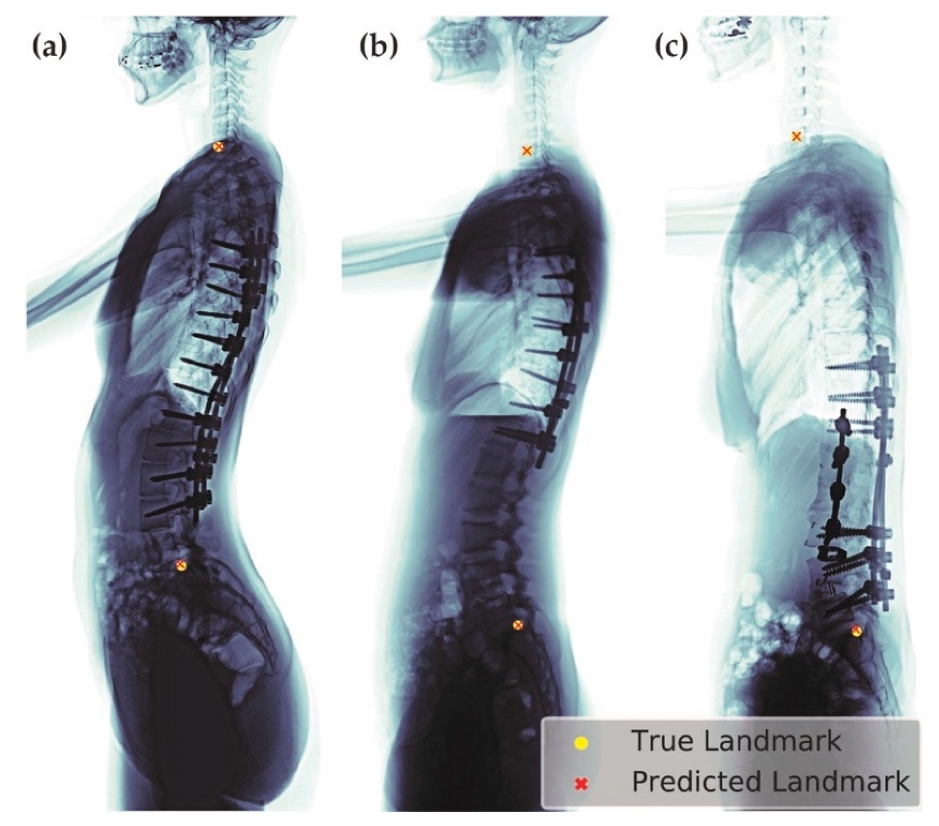
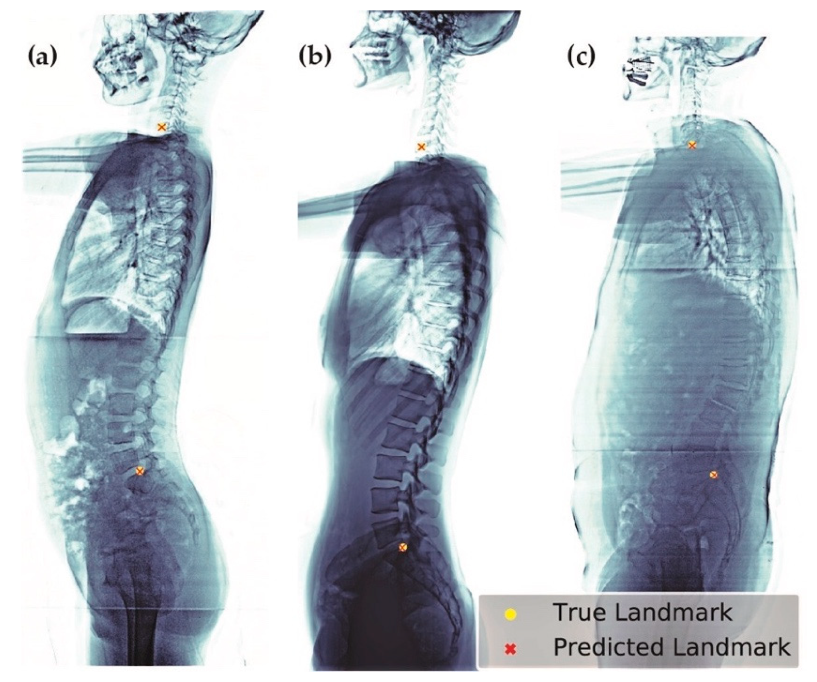
We selected the best model (
, heatmap type = exponential) based on the absolute error of SVA. This model can be applied to patients of different age groups and with various clinical conditions, including patients with or without implants (
Figure 10), having scoliosis, or degenerative changes (
Figure 11).
The hyperparameter, , which controls the width of the heatmap function, plays an important role for model selection. In our experiments, we showed that the exponential heatmap allows the model to keep its performance and stability, when is small. This is potentially helpful when many landmarks exist. In that situation, fine-tuning values for each heatmap is very time-consuming and a heatmap function whose resulting performance is less sensitive to may be beneficial.
In this study, the inter-rater reliability of ResUNet and human experts was also examined. We classified the ICC scores similarly to the criteria introduced by Aubin and Kuklo et al. [
29,
30], i.e. ICC values greater than 0.90 indicate excellent reliability, values between 0.70 and 0.89 indicate good reliability, values between 0.50 and 0.69 indicate moderate reliability, values between 0.25 and 0.49 indicate low reliability, and values less than 0.24 indicate poor reliability. To the best of our knowledge, this study is the first to compare the inter-rater reliability between ResUNet and human experts, and obtained an excellent reliability with the range of ICC values from 0.946 to 0.993.
Using the ResUNet-based framework, the inference time was approximately 0.2 s per image (using one NVIDIA Tesla V100). Due to its short inference time and minimal labor requirement, the automated SVA estimator can be used as an SVA screener for either preoperative or postoperative patients. Nevertheless, recently, abundant important spinal parameters have been proposed and share the same importance as SVA, either at the coronal aspect or lateral aspect. Based on the success of this ResUNet-based SVA estimator, we would like to extend this robust deep learning method to other parameters in the future.
This study has some limitations. Firstly, the outline of vertebrae is slightly torched, as the X-ray was emitted from a single source of radiation. If, for example, the EOS™ X-ray machine [
19] can be utilized, then the resulting outline of vertebrae, as well as the landmark locations predicted by our experts, may be more accurate. Secondly, when the selected CV model (
= 1.57, heatmap type = exponential) was used for predicting the entire dataset (990 images), we found 68 (6.9%) images were with large SVA absolute error (>10 mm). Among these 68 images, there were 33 and 17 images whose predictions were suspected to be influenced by numerical variation of mobile vertebrae (NVMV), and the occlusion of C7 or sacrum, respectively. In the former case, we found it difficult (for both human experts and for ResUNet) to predict the sacral point when confronting with cases of NVMV, or variable sacral fusion, by using the lateral plain radiographs only. NVMV is not uncommon in Chinese adults. In the study of Yan et al. [
31], it was shown that 9.6% of patients have the condition of NVMV. We expect our model to handle patients with NVMV better, once more NVMV images are gathered and learned. In the latter case, by using the plain radiography, the C7 vertebral body was sometimes severely occluded by radiopaque areas around the shoulder, e.g., the clavicle, scapula, and humeral head, which may increase the difficulty for the algorithm to learn. By contrast, our human experts were generally able to infer the location of C7 body by observing the context of vertebrae and imagine the alignment of them.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}