1. Introduction
Due to the rapid development and popularity of the Internet, cloud computing has become an indispensable and highly demanded application service [
1]. In order to meet the greater storage requirements of Big Data, the system will continue to upgrade and expand its capabilities, resulting in a large number of heterogeneous servers, storage, and related equipment in a cloud computing environment.
The server type of cloud computing can be classified into three service types: Software as a Service (SaaS), Platforms as a Service (PaaS), and Infrastructure as a Service (IaaS) [
2,
3,
4]. In SaaS, the frequently used software and programs are provided by the Internet vendor, such as Gmail and Google Maps [
5]. In PaaS, a platform for users is provided for programs, such as the Google APP Engine, one kind of PaaS platform. In the last type of service, the IaaS, the user can rent the hardware resources to build their own framework, such as a Cloud server [
2,
3,
4,
6]. No matter what kind of cloud service is applied to the cloud computing network, there is a common character: each cloud server has different capabilities and computing abilities. According to the reason above, there is a need for an efficient scheduling algorithm that can dispatch tasks to the appropriate cloud server, which is an important challenge in current cloud computing environments.
Basically, in the traditional cloud clustering architecture, the system only considers the heterogeneity of tasks while executing scheduling procedures and ignores the heterogeneity of tasks which come from different platforms, and its categories are not distinguishable by nodes. Therefore, heterogeneous tasks have become major flaws in traditional cloud architectures. In addition, cloud service types are very diverse. As a result, the cloud computing environment becomes complicated and the reliability is greatly reduced. So, the scheduling of cloud environments is more difficult.
Therefore, the Three-Layer Cloud Dispatching (TLCD) architecture is proposed to handle the scheduling problem while heterogeneous nodes and tasks exist in the cloud system at the same time. For the first layer, a Category Assignment Cluster (CAC) [
7,
8] layer was proposed to reduce the task delay and the overloading by classifying the heterogeneous tasks. In the CAC layer, the various tasks can be classified into three types according to the IaaS, SaaS, and PaaS categories. Subsequently, the homogeneous tasks can be dispatched to the corresponding service category clusters in the following layer.
In the second layer, called the Cluster Selection (CS) layer, the homogenous tasks can be assigned to appropriate clusters by the Cluster Scheduling Algorithm (CSA) to enhance the reliability of the system. Besides this, the cost and completion time of task scheduling can be reduced in this layer. Finally, tasks can be dispatched to service nodes by the scheduling algorithm in the third layer, the Server Nodes Selection (SNS) layer. In this layer, an Advanced Cluster Sufferage Scheduling (ACSS) algorithm is proposed to enhance resource utilization and to achieve load balancing [
2,
3,
9,
10,
11].
The rest of this paper is organized as follows.
Section 2 illustrates the previous works on scheduling algorithms. Subsequently, the details of the TLCD architecture are shown in
Section 3 and examples are given in
Section 4. Finally,
Section 5 gives the conclusions of this paper.
2. Materials and Methods
So far, many scheduling algorithms been proposed for various application scenarios [
12,
13,
14]. For example, in [
12], the authors propose an energy-efficient adaptive resource scheduler architecture for providing real-time cloud services to Vehicular Clients. The main contribution of the proposed protocol is maximizing the overall communication-plus-computing energy efficiency while meeting the application-induced hard Quality of Service (QoS) [
14] requirements on the minimum transmission rates, maximum delays, and delay jitters. In [
14], the authors propose a joint computing-plus-communication optimization framework exploiting virtualization technologies to ensure users the QoS, to achieve maximum energy savings, and to attain green cloud computing goals in a fully distributed fashion. Basically, these proposed algorithms and architectures can help with rethinking the design of scheduling algorithms in depth.
Generally, there are two types of scheduling algorithm can be provided based on the time of scheduling, namely, the real-time type and the batch type. Basically, the received tasks are immediately assigned to cloud server nodes in the real-time type. Conversely, in the batch type, the received tasks are accumulated for a period of time and subsequently dispatched to cloud server nodes. A scheduling algorithm of the batch type can obtain better performance than one of the real-time type. This is because the assignment results of all tasks can be considered in a batch-based scheduling algorithm [
11,
15,
16].
So far, many scheduling algorithms [
2,
3,
9,
10,
11,
15,
17] have been proposed to dispatch the task to cloud server nodes in the cloud computing network, such as the Min-Min [
9,
10,
15,
17], Max-Min [
9,
15,
17], Sufferage [
2,
9,
11,
17], and MaxSufferage algorithms [
2,
3,
9,
15]. However, these algorithms only consider the factor of the expected completion time (
ECT) without considering the load status of the server node. Therefore, the performance is not as good as expected, and the minimum completion time cannot be obtained.
For example, in the Min-Min algorithm, the task i with the minimum ECT of the unassigned tasks T is called min_ECT. Subsequently, the task which has minimum ECT can be elected and dispatched to corresponding server node. Then, the task which is newly matched is eliminated from a set T and the procedure is repeated until all tasks are dispatched. Under this circumstance, the workload will easy to unbalance while there are too many tasks waiting to be scheduled.
In the Max-Min algorithm, the
ECT is also to be used for dispatching tasks. Conversely, the task with overall maximum
ECT in Max-Min algorithm is always to be selected to assign; thus, the overall
ECT will be increased significantly [
9,
15,
17]. Besides this, both of above algorithms easily cause higher-capacity server nodes to be assigned more tasks than lower-capacity server nodes. The workloads of cloud server nodes are unbalanced and inefficient. Therefore, an improvement algorithm, the Sufferage algorithm [
1,
17,
18,
19], was proposed to reduce the workloads of the cloud server nodes. In the Sufferage algorithm, the Sufferage Value (
SV), which is calculated by the second earliest
ECT minus the earliest
ECT, is used as an estimated factor to dispatch the task. Then, the task which has largest
SV value can be selected and dispatched to the corresponding cloud server node which has minimum
ECT. However, the Sufferage algorithm cannot obtain efficient performance when the number of waiting tasks is very large.
Therefore, the MaxSufferage algorithm [
3], which is improved from the Sufferage algorithm, has three phases to solve the above problem. At first, the SV values of all tasks need to be calculated in the
SVi calculation phase. Subsequently, in the
MSVi calculation phase, the second earliest
ECT of task
i which has the maximum
SV value will be elected as the MaxSufferage Value (
MSV) value. In the final phase, the task dispatch phase, task
i which has maximum
SV can be dispatched to corresponding server node
j when the
ECTij of server node
j is less than
MSVi. Conversely, task
i with maximum
ECTij value can be dispatched to server node
j. However, in this algorithm, the large tasks are easily dispatched to low-capability server nodes under the heterogeneous environments.
For solving the problem above, the Advanced MaxSufferage (AMS) algorithm [
20] is proposed to improve this drawback of the MaxSufferage algorithm. However, the AMS only considers the task scheduling of service nodes, regardless of the cluster and type of service. As a result, an incremental algorithm is proposed to solve the scheduling service types, clusters, and service nodes simultaneously. In addition, all tasks can be dispatched to the appropriate server nodes in the cloud computing network even if the server nodes are in a heterogeneous environment.
Subsequently, our algorithm is described and explained as follows.
3. Three-Layer Cloud Dispatching Architecture
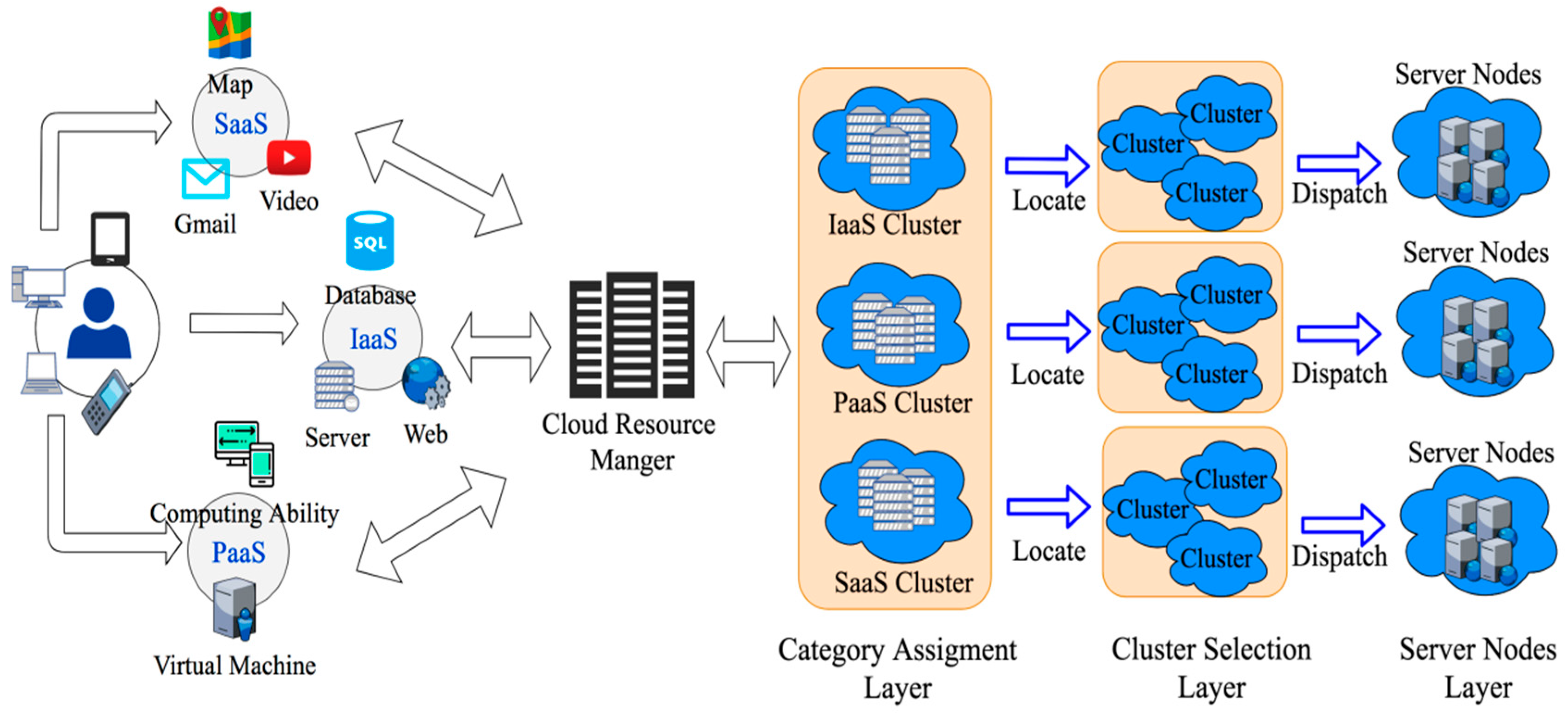
The traditional dispatch algorithm of cluster architecture does not dispatch tasks by the capacity of clusters, which may cause the drawbacks of task delay, low reliability, and high makespan. Therefore, a Three-Layer Cloud Dispatching (TLCD) architecture and related scheduling algorithm are proposed for application to cluster-based cloud environments, as shown in
Figure 1. Before introducing the detail of the proposed protocol, all notation and their descriptions as used in the algorithm are organized in
Table 1.
In the cloud computing environment, improving the accuracy of cloud service search is challenging [
7]. Thus, to improve the overall performance, the first thing in the proposed protocol is identifying cloud service categories. Based on [
7], the system will randomly select a cloud service task as the core task of the first cluster. After that, the similarities between this randomly selected cloud service task and other cloud service tasks will be calculated. Here, all cloud service tasks which have larger similarity scores than the predefined threshold will be added to the first cluster. Then these tasks will be removed from the candidate set of cloud service tasks. At this time, the system will continue to select another core task randomly from the remaining cloud service tasks to generate a second cloud cluster. Again, the system will apply a similar selection process to add similar cloud service tasks to this cluster. The selection process will repeat until all cloud service tasks are categorized into a cluster. After identifying and categorizing the tasks, all classified tasks will continuously be executed in the proposed TLCD architecture. The details of TLCD are shown as follows.
3.1. Category Assignment Cluster Layer
The traditional cluster architecture collects and distributes tasks to the cluster by way of cloud resource managers. However, the allocation process may be affected by cluster heterogeneity, causing the task to be insignificant in terms of scheduling. This is because that the tasks are allocated to an idle cluster by cloud resource managers. Therefore, the scheduling result is not ideal. This will increase the complexity of the cloud computing system.
Besides this, the diversity of tasks increases the delay in processing time. To reduce the delay and the complexity of scheduling, the heterogeneity task can be classified into different categories according to demand defined in the Category Assignment Cluster (CAC) layer [
7,
8]. The category cloud clusters can be divided into three types: SaaS, PaaS, and IaaS. Through these three categories of classification, the difficulty of scheduling heterogeneous tasks and scheduling delays can be reduced.
3.2. Cluster Selection Layer
After completing the classification of the category assignment cluster layer, the classified tasks can be dispatched to the corresponding category cluster. Subsequently, a Cluster Selection Algorithm (CSA) is proposed to assign the tasks to appropriate clusters by using the factors of Reliability (
Ri), Cost (
Ci), and MakeSpan (
Mi) [
3,
21], as shown in Equations (1)–(3). MakeSpan is the length of time to complete a task. Basically, when the MakeSpan value increases, the system will need longer operation time. Due to the similarity of the fault tolerance of clusters, the computing power will increase as the Reliability gets higher. Therefore, we need to focus on clusters’ computing power [
3,
21]. Finally, the cost factor is defined as the cost needed for a task to be sent and responded to. When taking these three factors into account, tasks can be assigned to suitable clusters and the system efficiency can be enhanced. In addition, users and service providers can customize those three factors based on their own requirements. According to the above description, in the following example, we customize the Reliability (
Ri) and Cost (
Ci), and arrange the tasks to the suitable clusters. The reliability and the cost of assignment
i are expressed by
and
respectively. Moreover, the makespan of assignment
i is expressed by
Subsequently, we propose an example to explain Algorithm 1. In Line (4) of Algorithm 1, we arrange the combination of tasks in all clusters. The cluster will choose an appropriate task combination and then help the node to adjust these tasks. Furthermore, Lines (5) to (8) are proposed to check if the and of each assignment i agree with Ri ≥ Tr && Ci ≥ Tc. Then, among those assignments, the one with the smallest Mi is scheduled. If there are more than two eligible groups, we compare Ri and Mi and choose Ai as the combination of the highest reliability and the least time.
In CSA, users can customize the quality of services by reliability, cost, and MakeSpan factors. Thus, algorithms can meet the requirements of various users and can enhance the efficiency of job scheduling. Subsequently, an example is shown to explain the CSA algorithm and the related assumptions are shown in
Table 2.
| Algorithm 1. Cluster Selection Algorithm |
1: for total tasks N
2: for total clusters L
3: get , and of each cluster k
4: Arrange all tasks in the cluster and assign the number of
5: for calculating the , and of the assignment
6: if && in assignment then is candidate assignment
7: end for
8: choose the smallest in candidate assignment
9: end for
10: end for
11:End |
We assumed that there are 10 tasks need to be sent to 3 cloud clusters; the process is the following:
Step 1: Tr and Tc are set by the user. In this example, Tr and Tc are 22 and 260, respectively.
Step 2: Calculate Ri, Ci, and Mi of each allocation combination.
According to
Table 2, assignment A
1 assigns five tasks to Cluster 1, two tasks to Cluster 2 and three tasks to Cluster 3. We used Equations (1)–(3) to calculate the average of
Ri,
Ci, and
Mi, and the results are
;
= 242;
.
The same procedure is followed for the other assignments, too.
Step 3: Select the schedule that meets the condition of Ri ≥ 22 and Ci < 260; Here, A1, A2, and A6 are selected.
Step 4: According to the conditions of Step 3, we choose A1 with the highest reliability and smallest MakeSpan. Since the result of assignment A1 is better than others, assignment A1 is elected as the combination to dispatch in this example.
The above procedure is the most suitable solution when the MakeSpan is the main concern. However, when the reliability is the main concern, the MakeSpan and Cost become the masking factors to filter out the schedule with the best reliability. After finished the CSA layer, the tasks can be dispatched to the corresponding clusters in the cloud cluster section layer. Subsequently, the appropriate server nodes need to be elected to complete the task in the next layer.
3.3. Server Nodes Selection Layer
After finishing the first two layers, the homogeneous tasks can be dispatched to homogeneous cloud clusters. However, the cloud workload can be unbalanced when a large number of tasks exits due to inappropriate task assignment. Based on the reasons above, this paper proposed a novel algorithm, the Advanced Cluster Sufferage Scheduling (ACSS), to solve the drawback of the MaxSufferage algorithm [
12,
17,
18], especially in the heterogeneous environment. In ACSS, each task can be assigned to the appropriate server nodes by
Sj which is calculated from the average
ECT of the server node to reduce the influence of inappropriate assignment. The notation and details of the ACSS algorithm are shown in
Table 3 and Algorithm 2.
In general, there are three phases in the ACSS algorithm. At first, the (the earliest expected completion time) and (the second earliest expect completion time) of the Sj are found in order to calculate the SV value in the SVj calculation phase; the detailed process is shown in Lines (8) and (9) in the ACSS algorithm. Then, the MSV value will be set to the second earliest ECT value of task i in the second phase, which is called the MSVi calculation phase, while task i has the maximum SV value among all SV values.
In the final phase, the task dispatching phase, task
i will be dispatched to
Sj while
MSVi >
ECTij and
EECTi >
AECTj of
Sj. Conversely, when
EECTi <
AECTj, task
i can be dispatched to server node
j where the
ECTi is approximate to
AECTj and the
ECTi needs to be larger than
AECTj. As a result, the main concept is different from those of previous algorithms; the detail of the algorithm is shown in Line (11) and (12) of Algorithm 2.
| Algorithm 2. Advanced Cluster Sufferage Scheduling |
1: for all unassigned tasks i
2: for all server nodes
3:
4: do scheduling for all job assignments
5: mark all server nodes as unassigned;
6: for each task i in
7: find server node that gives the earliest completion time;
8: calculate the Sufferage Value ();
9: If the maximum value of has two or even more the same
then choose the assignment to with maximum;
else the assignment i with maximum can be compared to other ;
10: end if;
11: If ()
then the task i with maximum ECT can be dispatched to server nodes ;
12: else if () && ()
then the task i can be dispatched to server nodes ;
13: else if () && ()
then assignment task i can be
dispatched to server nodes ;
14: end if;
15: end for
16: end do
17: end for
18:
19:
20: end for
21:End |
Based on the procedure above, the completion time and load balancing of the workload can be reduced efficiently in the heterogeneous cloud computing network. For the security issue, we can employ a Message Authentication Code (MAC) algorithm [
18,
22] with a session key to confirm that the message truly comes from the sender and has not been modified. Subsequently, the example is provided to help understanding of the ACSS algorithm in the server node selection layer.
4. Example and Comparison Results
In this section, there are four heterogeneous environments that can be discussed, such as HiHi (High heterogeneity task, High heterogeneity server node), LoLo, HiLo, and LoHi [
8,
19]. In general, HiHi is the most complex case among all of environments. As a result, an example of task assignment including four server nodes and twelve tasks is discussed under the HiHi heterogeneous environment. At first, the
SV value and the
MSV value can be calculated in the
SVj calculation phase and the
MSVi calculation phase separately. Subsequently, the
AECTj of
Sj is calculated in the task dispatching phase. In addition, the related parameters of the HiHi environment are shown in
Table 4.
4.1. The SVi Calculation Phase
Step 1. List the expected execution times for all tasks
i on
Sj, as shown in
Table 3.
Step 2. Calculate the SV value for each task. For example, the
SV value of Task
a is equal to
SEECTi minus
EECTi, which is 23526 − 22345 = 1181, and the same procedures will be executed for tasks
b to
l to calculate the
SV values. The calculation results are shown in
Table 5.
4.2. The MSVi Calculation Phase
Step 1. The second earliest
ECT value of task
i can be selected as the
MSV value while task
i has the maximum
SVi value among all
SV values. As shown in
Table 6, the task with the largest
SVi value is task
g; thus, the second earliest
ECT (here, it is 21486) of
ECTaB is selected as the
MSV value.
4.3. The Task Dispatching Phase
Basically, there are three cases that need to be discussed in different heterogeneous environments, and the cases are illustrated and discussed as follows, step by step.
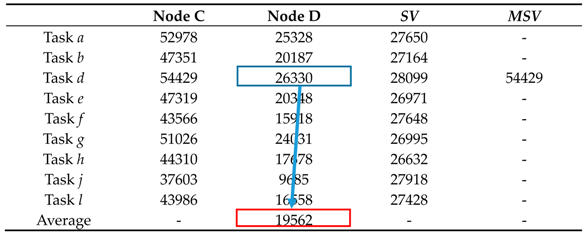
Case 1.MSVi > ECTij of Sj and EECTi > AECTj of Sj
Compare the
MSV value found in the
MSVi calculation phase with the earliest expected completion time of other tasks. Task
i can be dispatched to the appropriate server node
j while
MSVi >
ECTij of
Sj and
EECTi >
AECTj of
S. Therefore, task
d is dispatched to Node D while
MSVi >
ECTdD and
ECTdD >
AECTj in
Table 7 and
Table 8.
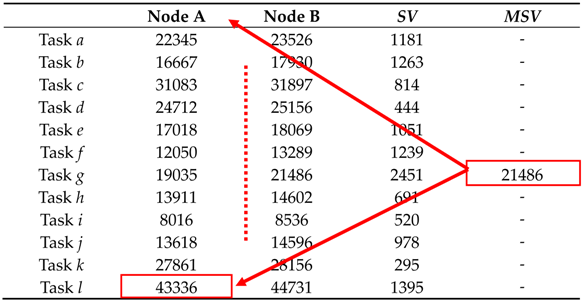
Case 2.MSVi < ECTij of Sj
Compare the
MSV value found in the
MSVi calculation phase with the earliest expected completion time of other tasks. Task
i with maximum
ECT can be dispatched to appropriate server node
j when
MSVi <
ECTij of server node
j. Therefore, task
l is assigned to Node A in
Table 9 because its
ECTlA is greater than the
MSV value (43336 > 21486).
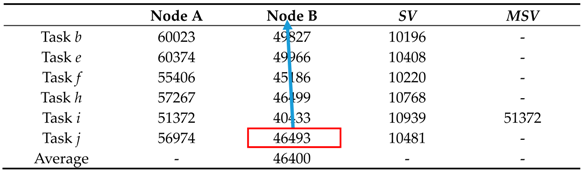
Case 3.MSVi > ECTij of Sj and EECTi < AECTj of Sj
Compare the MSV value found in the
MSVi calculation phase with the earliest expected completion time of other tasks. Task
i in
Table 10 will be dispatched to server node
j where the
ECTi is approximate to
AECTj and the
ECTi is larger than
AECTj under the conditions that
MSVi >
ECTij and
EECTi <
AECTj of
Sj. Therefore, task
j is assigned to Node B in
Table 11 because
ECTjB is bigger than and closer to
AECTB.
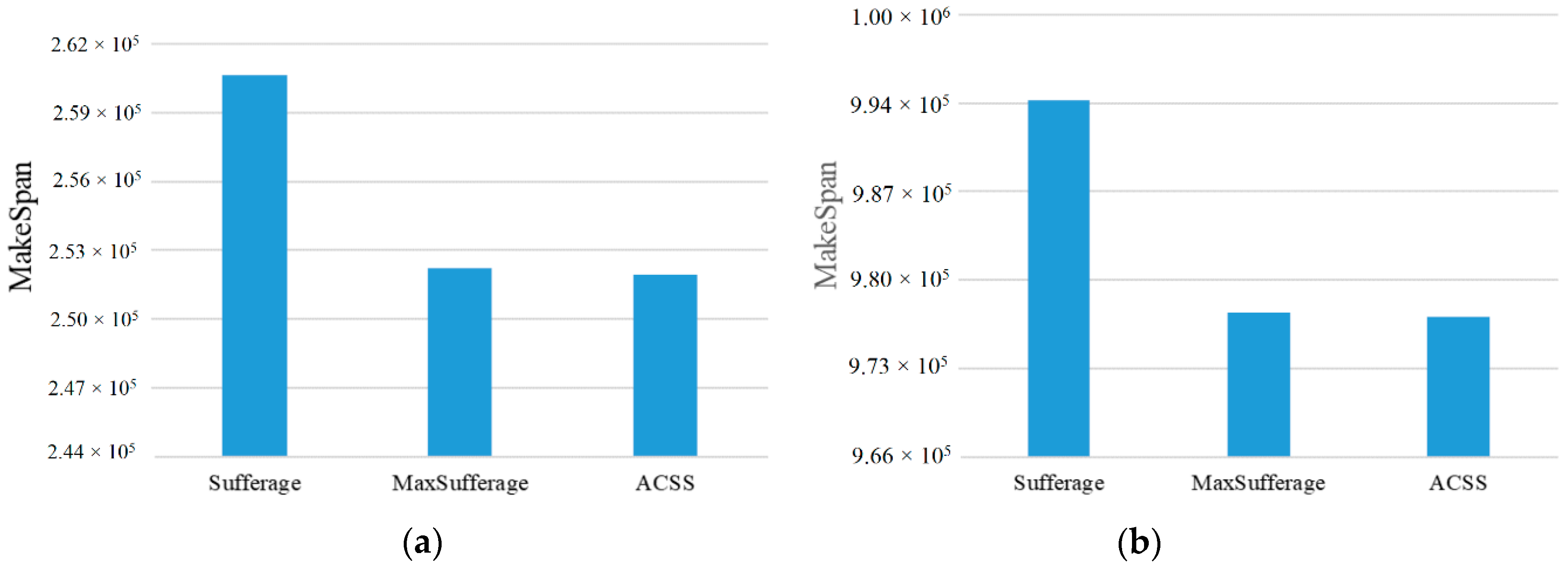
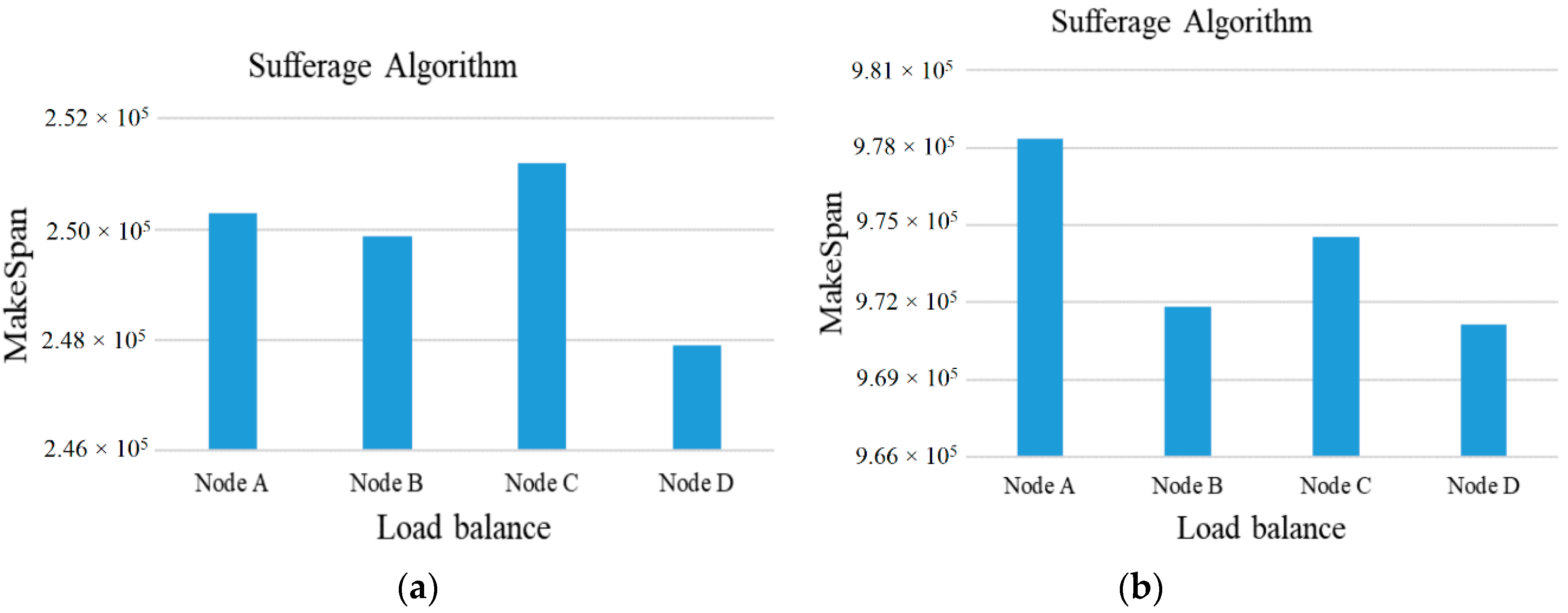
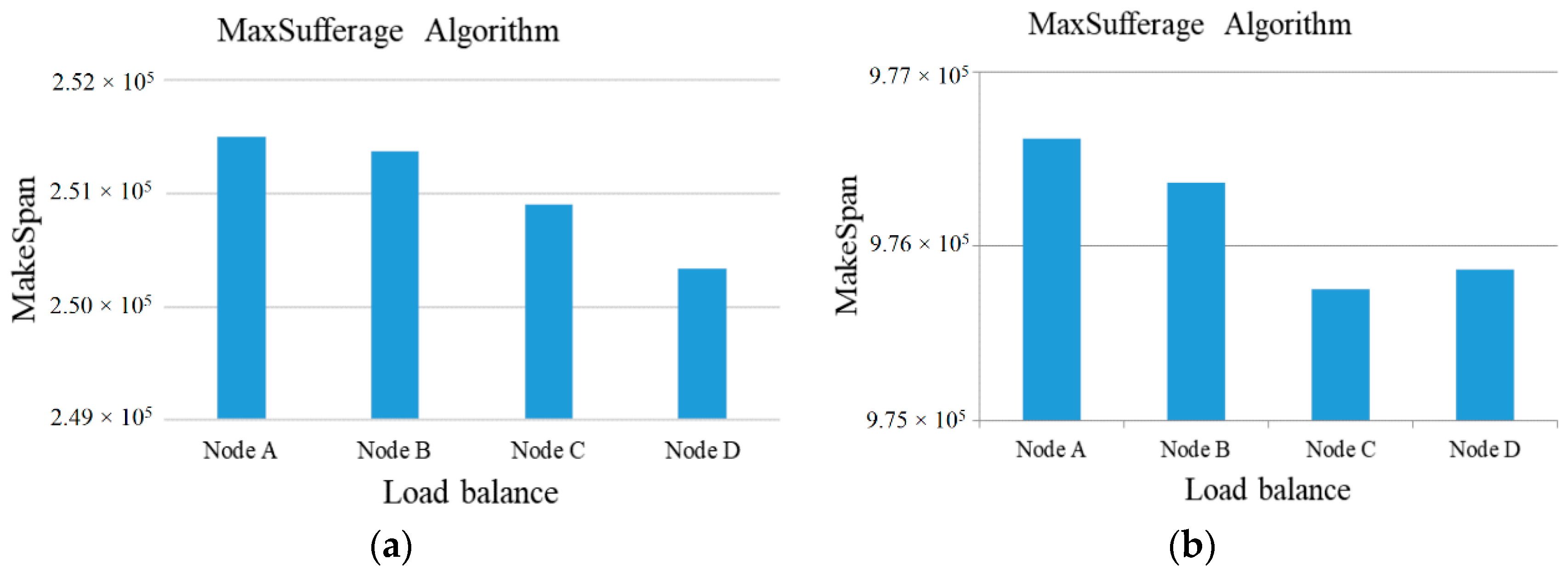
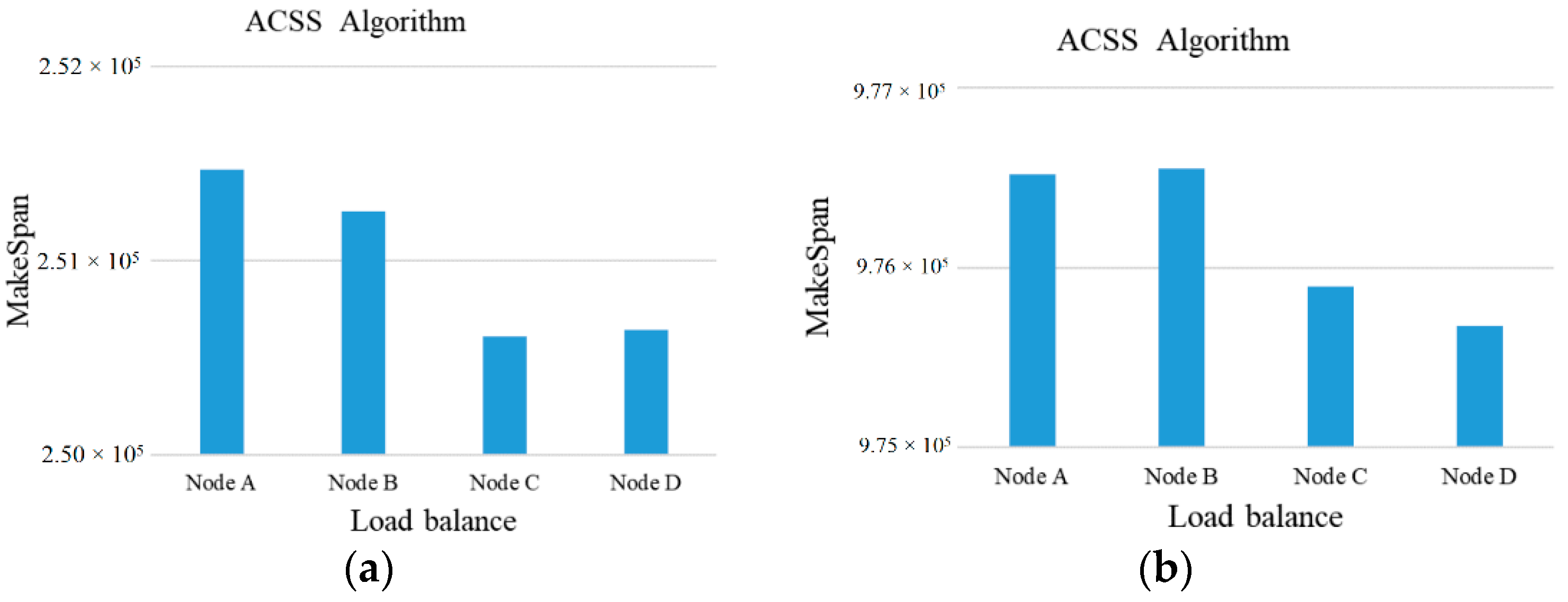
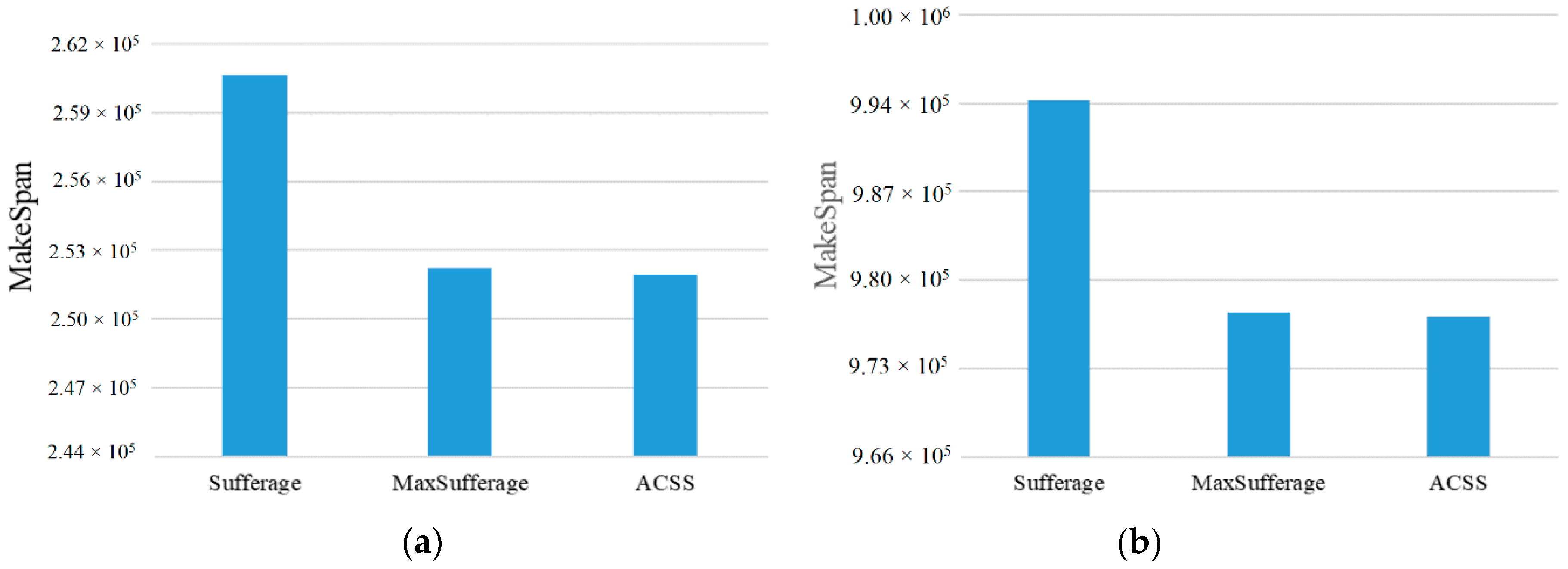
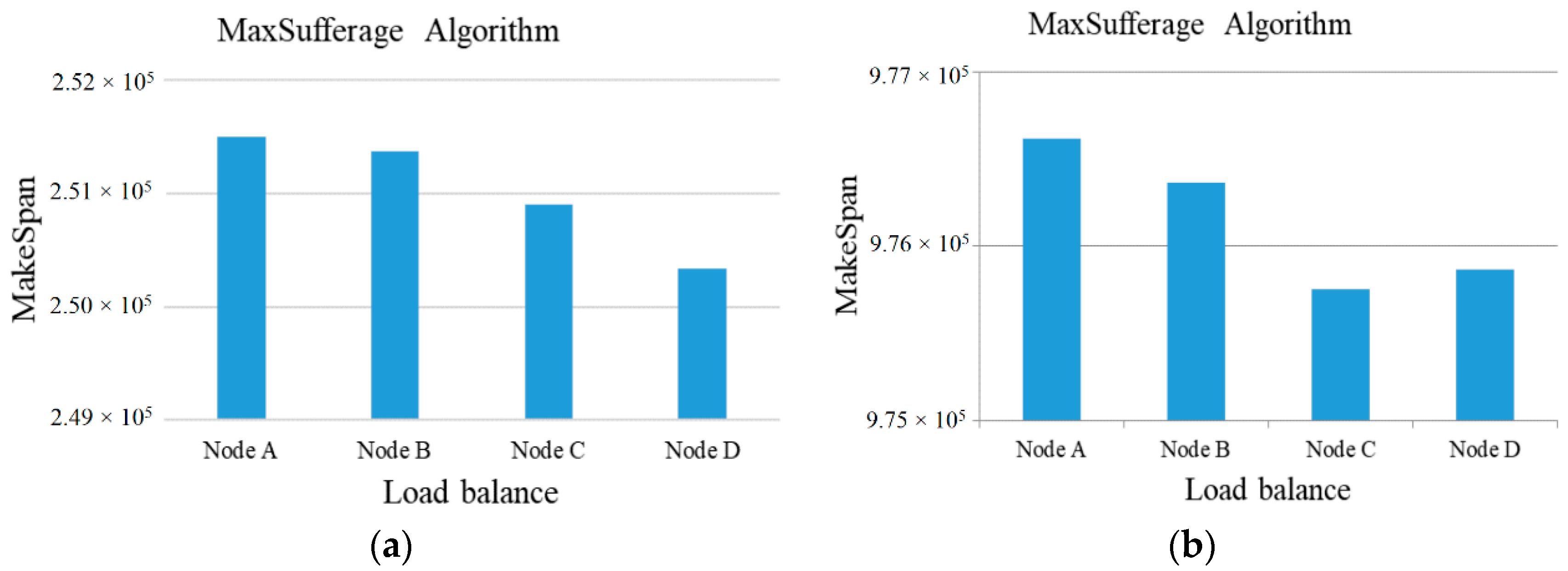
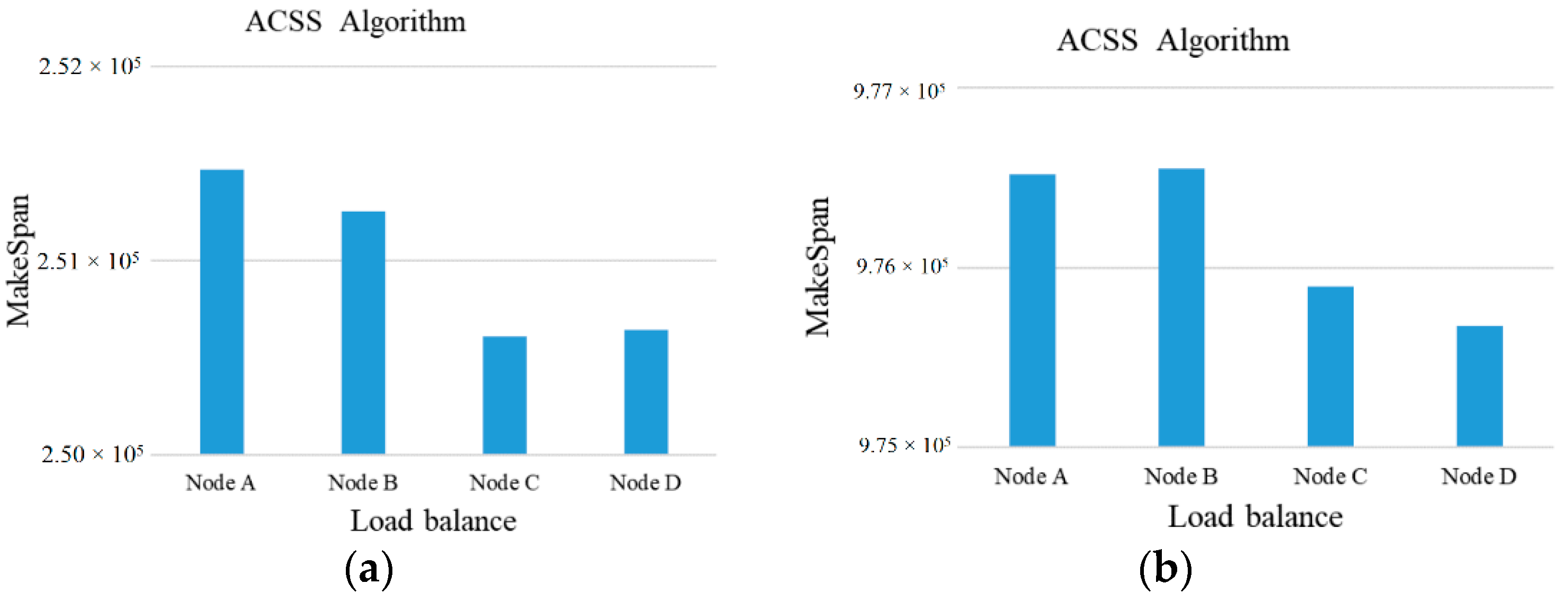
Subsequently, the above examples can be simulated in our experiment. At first, the number of tasks is set to 50 to 100 and the computing ability of the 5 cloud server nodes is set to {500~1000} units to adapt to the high-heterogeneity environment. Besides this, the comparisons of MakeSpan and load balancing among the Sufferage, MaxSufferage, and ACSS algorithms are simulated 50 times and the average value of makespan is taken, as shown in
Figure 2,
Figure 3,
Figure 4 and
Figure 5. In
Figure 2, the proposed algorithm has a better MakeSpan than the others, especially in the large tasks environment. In addition, the load balancing index can be defined by
rmin/
rmax, where
rmin is the shortest completed task time of all tasks and
rmax is the longest completed task time of all tasks [
1,
15].
In general, the value of the load balancing index is a number between 0 and 1, with 0 being the worst load balance and 1 being the optimal load balance.
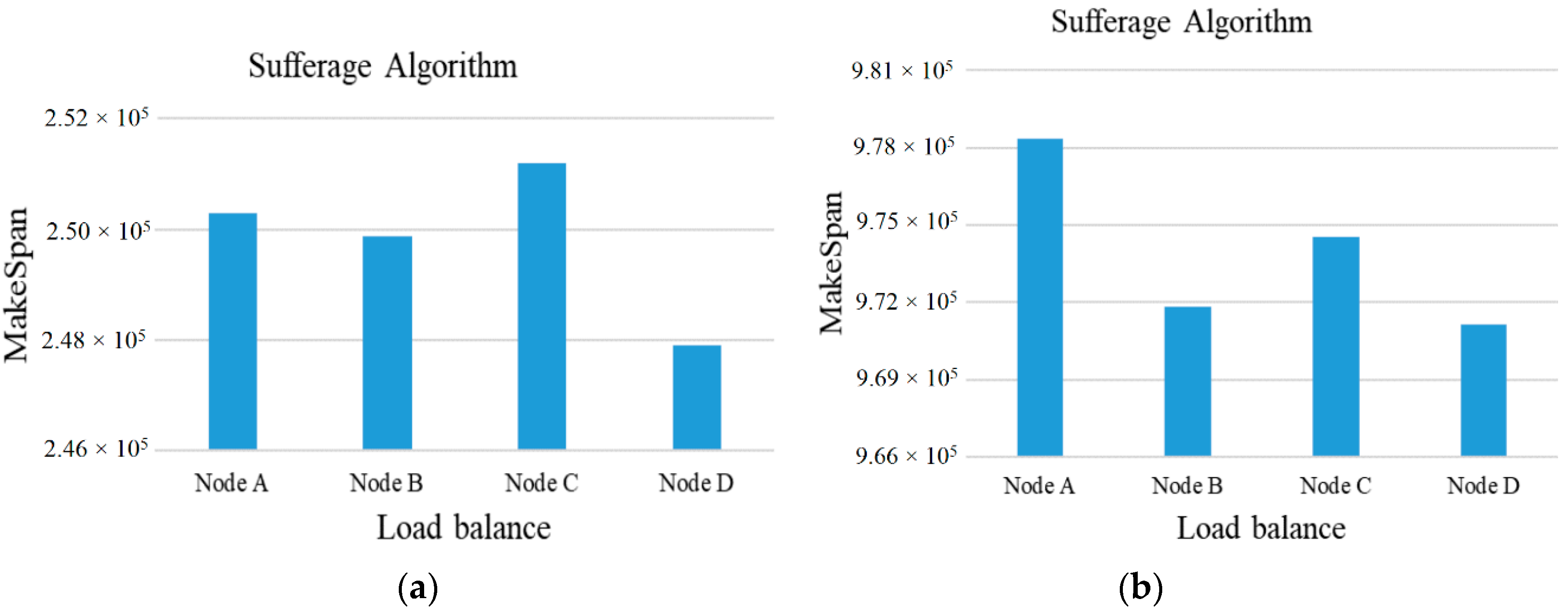
As shown in
Figure 3,
Figure 4 and
Figure 5, the ACSS algorithm can obtain the best load balancing index (0.88) over Sufferage (0.87) and MaxSufferage (0.83). Because the ACSS algorithm uses the distribution of the average value, the MakeSpan of each node can achieve similar results. However, MaxSufferage completed time is better than that of Sufferage, but the load balancing results are similar. This is because MaxSufferage did not consider the load status of the node during the selection of tasks. As a result, the proposed ACSS algorithm can obtain the best results of complete time and load balance among these algorithms even if the heterogeneous cloud computing network is complex.
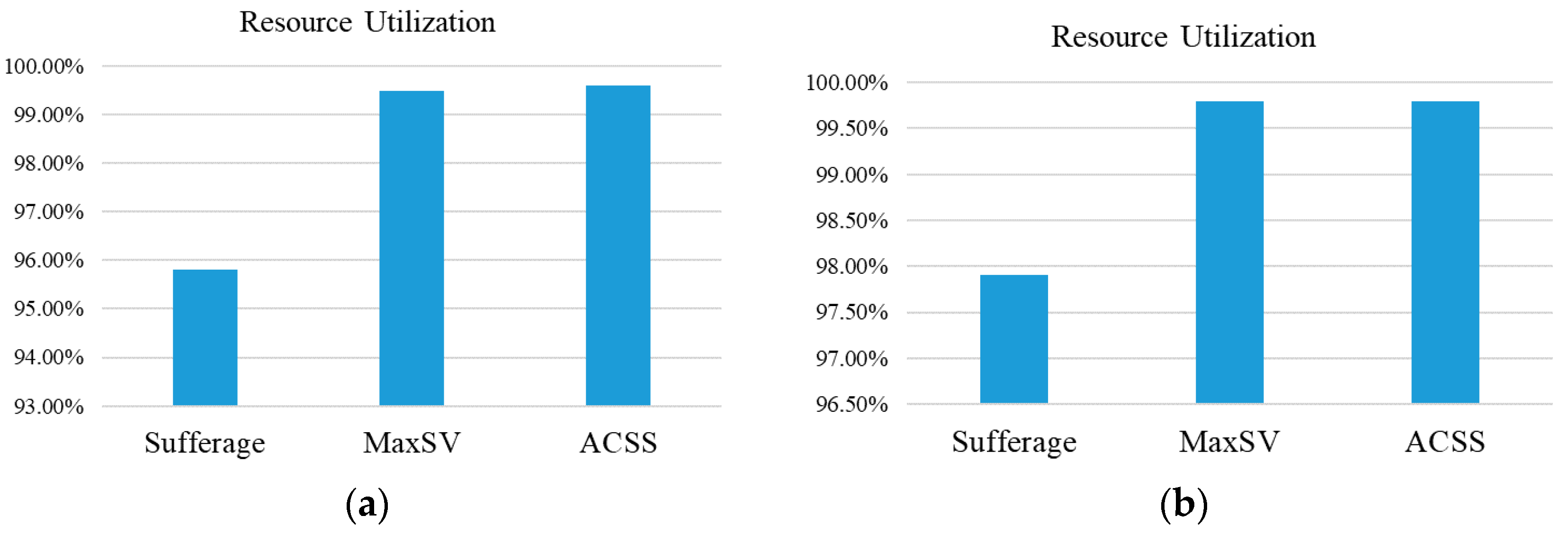
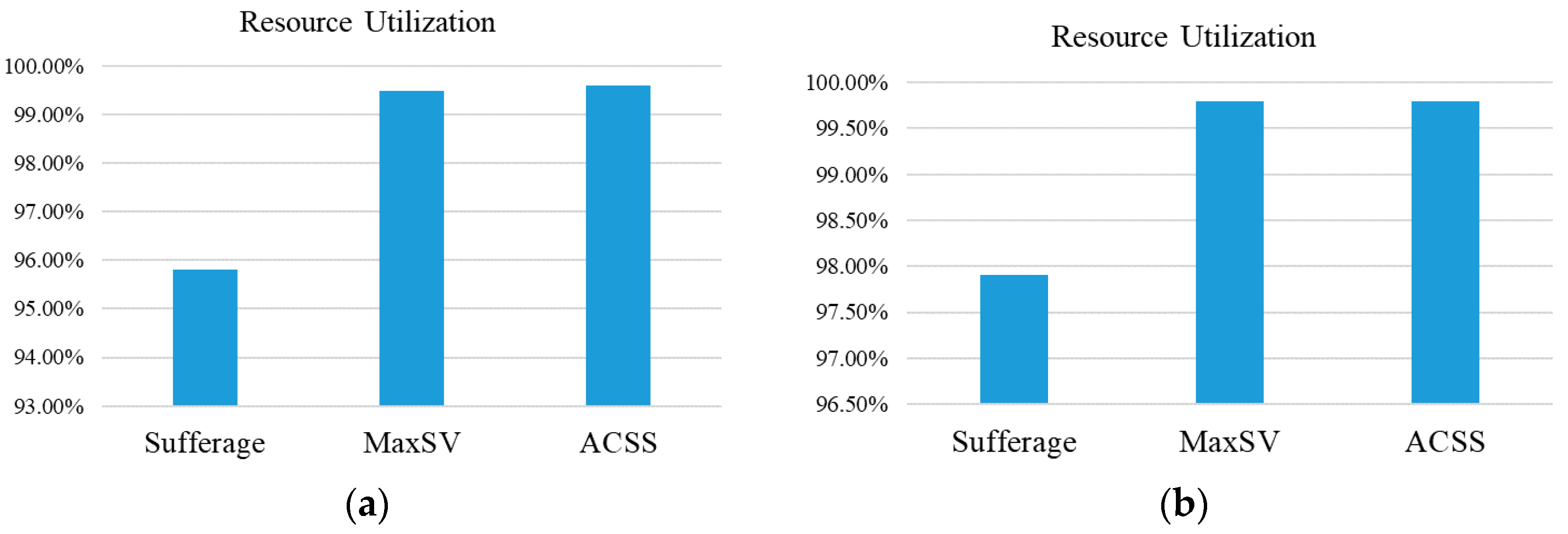
Besides this, the formula
is used to calculate the ratio of resource utilization to show whether the use of resource in this paper is maximized. In factor
RU, the
represents the total expected completion time by virtual machine
j,
N represents the number of virtual machines, and
m represents the final completion time of the virtual machine. The related ratio results of resource utilization are shown in
Figure 6. In
Figure 6, the ratio of resource utilization of ACCS can reach 89%, and this result is better than for other algorithms. This is because that the average value is used to consider the allocation status of nodes in the ACSS algorithm.
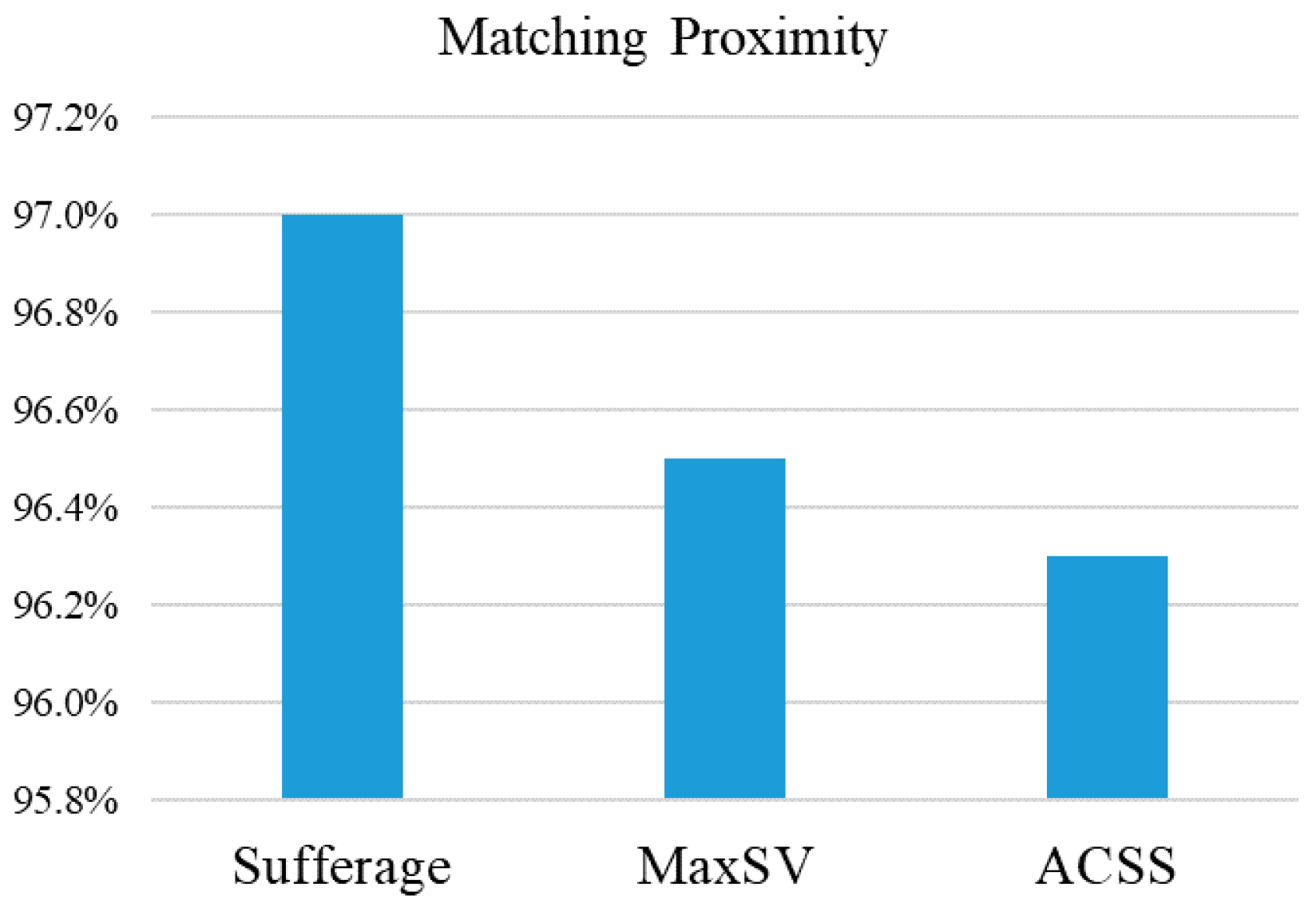
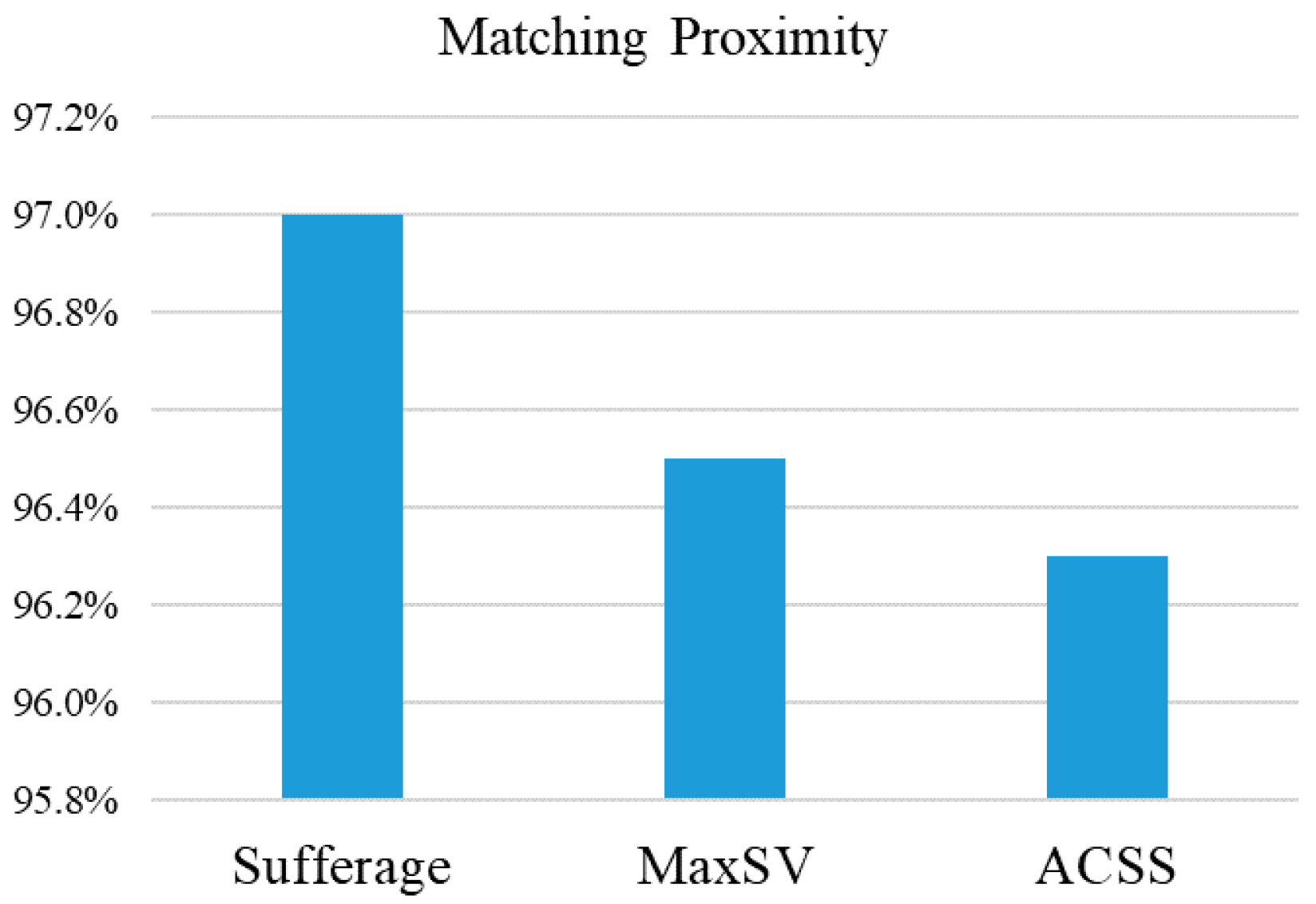
Subsequently, the parameter of matching proximity [
11] is used to evaluate the degree of proximity of various scheduling algorithms. In
Figure 7, the MET (Minimum Execution Time) and ECT (Expected Computing Time) are used to estimate whether the task can be quickly matched. A large value for matching proximity means that a large number of tasks are assigned to the machine that executes them faster, as expressed by
As show in
Figure 7, the matching ratio of the three algorithms is close to 1. These three algorithms have good matching efficiency. Subsequently, the performance and complexity of algorithms can be compared in
Table 12. The results of the comparison table show that ACSS can obtain the best performance among all algorithms in evaluation factors including makespan, load balance, resource utilization, and matching proximity. Based on [
9], the Big O notation is used to estimate the complexity of these algorithms. Then, the results of complexity of MaxSufferage and ACSS are O(
n2rm) because parameter
r indicates that the alternative condition is selected when the condition of (
MSVi >
ECTij) && (
EECTi <
AECTij of
Sj) is satisfied. As a result, the complexity of the ACC algorithm is approximately equal to that of the Sufferage algorithm.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}