A Short-Term Photovoltaic Power Prediction Model Based on the Gradient Boost Decision Tree



Abstract
:1. Introduction
2. GBDT Algorithm
2.1. Gradient Boosting
2.1.1. Problem Restatement
2.1.2. Gradient Descent in Function Space
2.1.3. Gradient Boosting
2.2. Decision Tree
2.3. GBDT
| Algorithm 1 GBDT Model |
| For = 1 to M |
| For j = 1 to k |
| For s = 1 to N |
| End for |
| End for |
| End for |
| End algorithm |
3. PV Model Architecture
3.1. Physical Model
3.2. Input Vector
3.3. Data Pre-Processing
3.4. Error Evaluation
3.5. Flowchart of the Model
4. Case Studies and Simulation Results
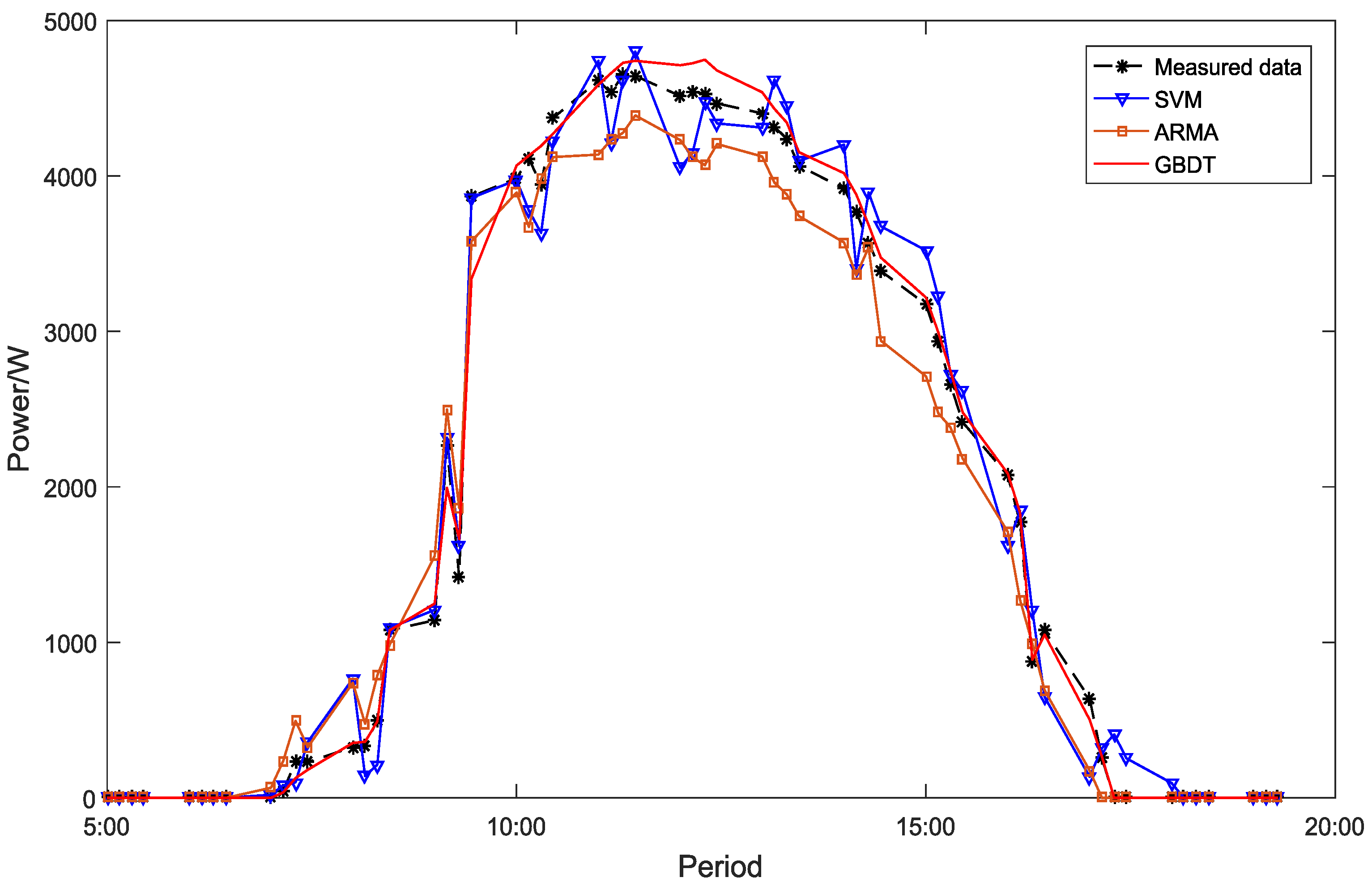
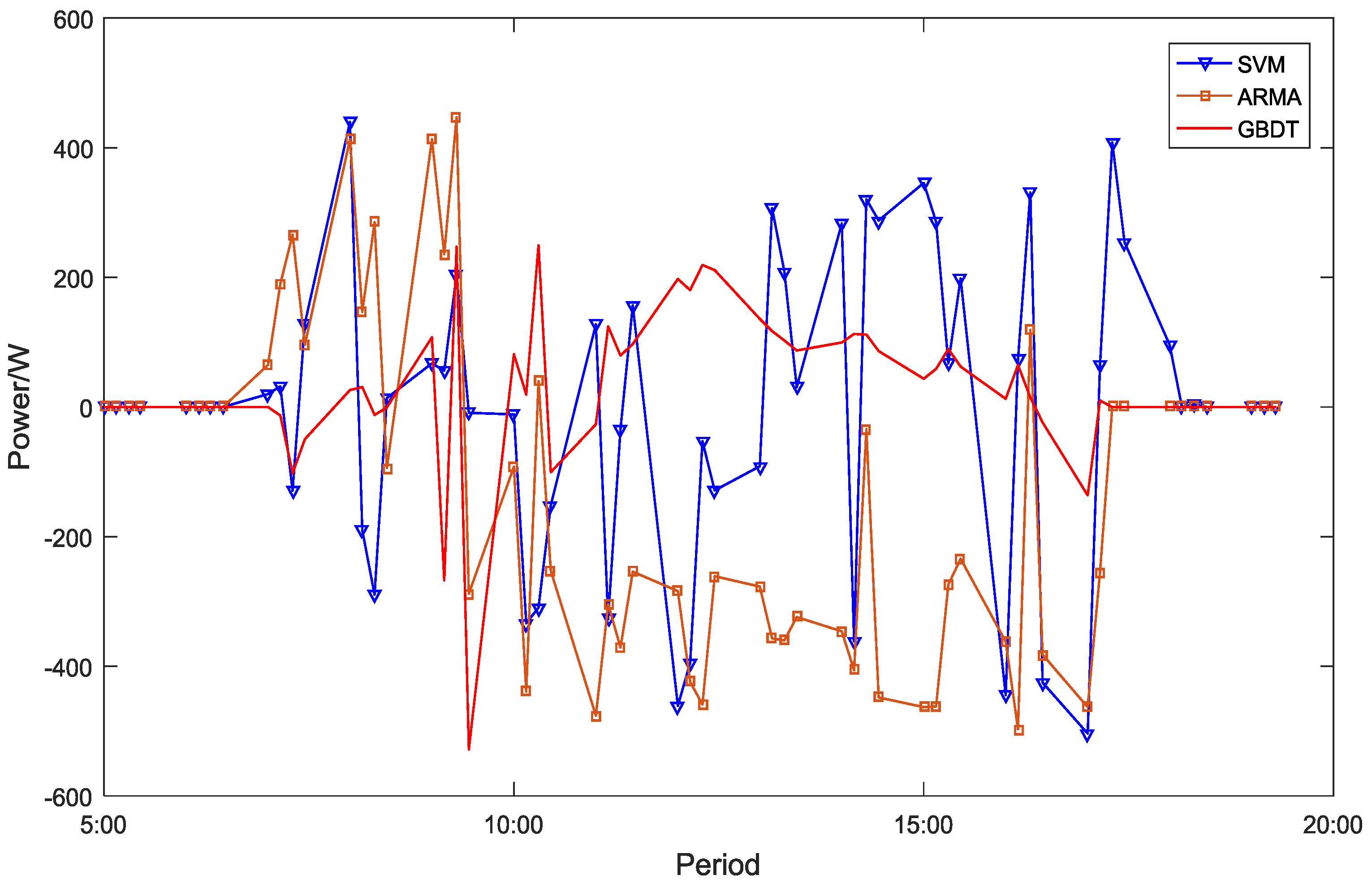
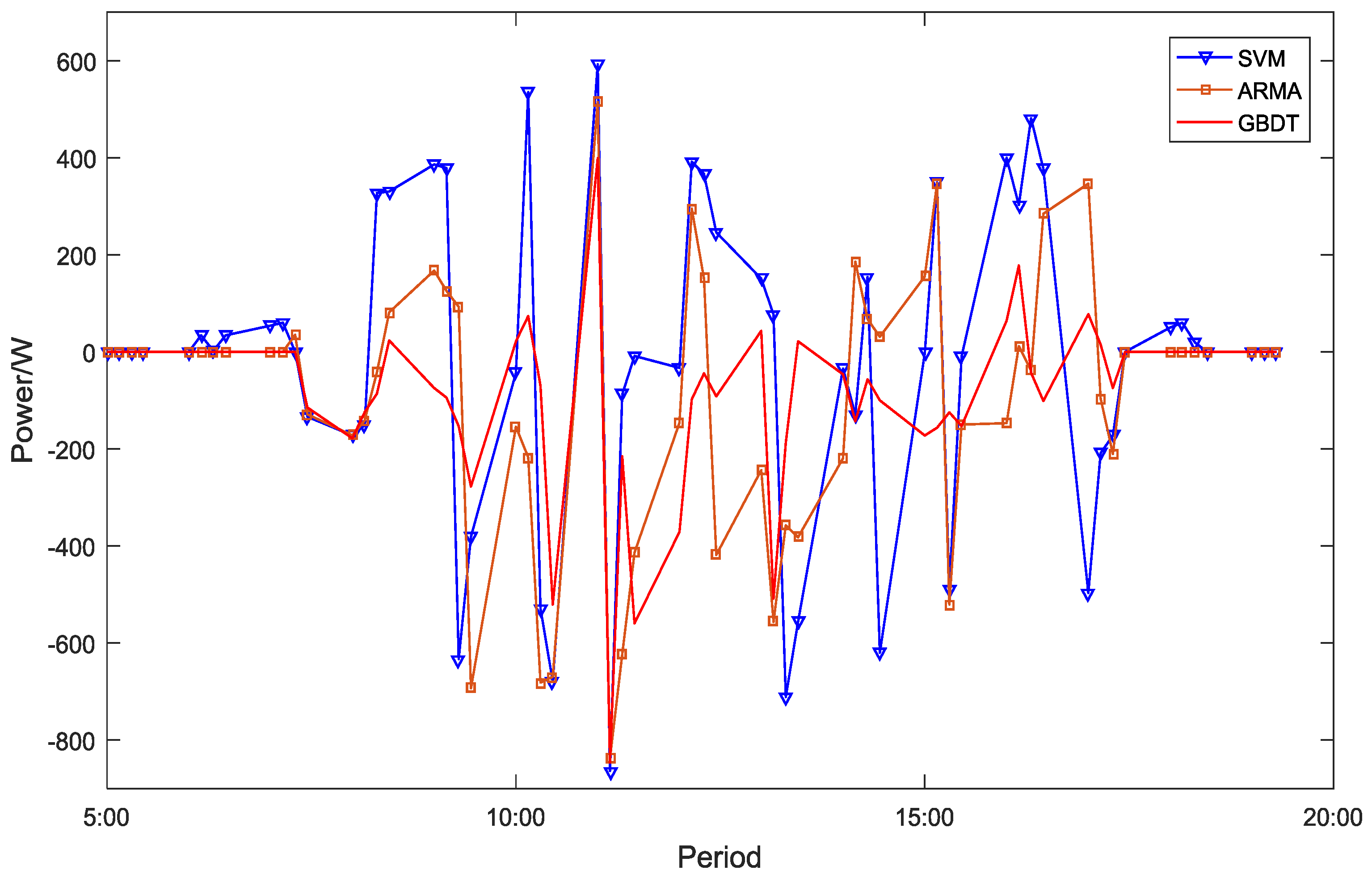
4.1. Accuracy Comparison in a Single Day
4.2. Monthly Average Accuracy Comparison
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Available, N. 2010 Solar Technologies Market Report; Office of Scientific & Technical Information Technical Reports; Energy Efficiency and Renewable Energy: Washington, DC, USA, 2011. [Google Scholar]
- Babaa, S.E.; Armstrong, M.; Pickert, V. Overview of Maximum Power Point Tracking Control Methods for PV Systems. J. Power Energy Eng. 2014, 2, 59–72. [Google Scholar] [CrossRef]
- Kouro, S.; Leon, J.I.; Vinnikov, D.; Franquelo, L.G. Grid-Connected Photovoltaic Systems: An Overview of Recent Research and Emerging PV Converter Technology. IEEE Ind. Electron. Mag. 2015, 9, 47–61. [Google Scholar] [CrossRef]
- Solangi, K.H.; Islam, M.R.; Saidur, R.; Rahim, N.A.; Fayaz, H. A Review on Global Solar Energy Policy. Renew. Sustain. Energy Rev. 2011, 15, 2149–2163. [Google Scholar] [CrossRef]
- Paatero, J.V.; Lund, P.D. Effects of Large-Scale Photovoltaic Power Integration on Electricity Distribution Networks. Renew. Energy 2007, 32, 216–234. [Google Scholar] [CrossRef]
- Aydinalp-Koksal, M.; Ugursal, V.I. Comparison of Neural Network, Conditional Demand Analysis, and Engineering Approaches for Modeling End-use Energy Consumption in the Residential Sector. Appl. Energy 2008, 85, 271–296. [Google Scholar] [CrossRef]
- Wu, Z.; Tazvinga, H.; Xia, X. Demand Side Management of Photovoltaic-battery Hybrid System. Appl. Energy 2015, 148, 294–304. [Google Scholar] [CrossRef]
- Ke, B.R.; Ku, T.T.; Ke, Y.L.; Chuang, C.Y.; Chen, H.Z. Sizing the Battery Energy Storage System on a University Campus With Prediction of Load and Photovoltaic Generation. IEEE Trans. Ind. Appl. 2016, 52, 1136–1147. [Google Scholar]
- Elminir, H.K.; Azzam, Y.A.; Younes, F.I. Prediction of Hourly and Daily Diffuse Fraction Using Neural Network, as Compared to Linear Regression Models. Energy 2007, 32, 1513–1523. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine Learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 105, 569–582. [Google Scholar] [CrossRef]
- Zhu, H.; Li, X.; Sun, Q.; Nie, L.; Yao, J.; Zhao, G. A Power Prediction Method for Photovoltaic Power Plant Based on Wavelet Decomposition and Artificial Neural Networks. Energies 2016, 9, 11. [Google Scholar] [CrossRef]
- Mellit, A.; Pavan, A.M.; Lughi, V. Short-term Forecasting of Power Production in a Large-scale Photovoltaic Plant. Solar Energy 2014, 105, 401–413. [Google Scholar] [CrossRef]
- Yao, Z.; Fei, P.; Shen, Y. Short-term Prediction of Photovoltaic Power Generation Output Based on GA-BP and POS-BP Neural Network. Power Syst. Prot. Control 2015, 43, 83–89. [Google Scholar]
- Shi, J.; Lee, W.J.; Liu, Y.; Yang, Y.; Wang, P. Forecasting Power Output of Photovoltaic Systems Based on Weather Classification and Support Vector Machines. IEEE Trans. Ind. Appl. 2012, 48, 1064–1069. [Google Scholar] [CrossRef]
- Wang, J.; Ran, R.; Song, Z.; Sun, J. Short-Term Photovoltaic Power Generation Forecasting Based on Environmental Factors and GA-SVM. J. Electr. Eng. Technol. 2017, 12, 64–71. [Google Scholar] [CrossRef]
- Malvoni, M.; Giorgi, M.G.D.; Congedo, P.M. Photovoltaic Forecast Based on Hybrid PCA-LSSVM Using Dimensionality Reducted Data. Neurocomputing 2016, 211, 72–83. [Google Scholar] [CrossRef]
- Yang, H.T.; Huang, C.M.; Huang, Y.C.; Pai, Y.S. A Weather-Based Hybrid Method for 1-Day Ahead Hourly Forecasting of PV Power Output. IEEE Trans. Sustain. Energy 2014, 5, 917–926. [Google Scholar] [CrossRef]
- Gala, Y.; Fernández, Á.; Díaz, J.; Dorronsoro, J.R. Hybrid machine learning forecasting of solar radiation values. Neurocomputing 2016, 176, 48–59. [Google Scholar] [CrossRef]
- Chaouachi, A.; Kamel, R.M.; Nagasaka, K. Neural Network Ensemble-Based Solar Power Generation Short-Term Forecasting. J. Adv. Comput. Intell. Intell. Inform. 2011, 14, 69–75. [Google Scholar] [CrossRef]
- Mohammed, A.A.; Aung, Z. Ensemble Learning Approach for Probabilistic Forecasting of Solar Power Generation. Energies 2016, 9, 1017. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Duffy, N.; Helmbold, D. Boosting Methods for Regression. Mach. Learn. 2002, 47, 153–200. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient Boosting Machines, a Tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L.; Friedman, J.H.; Olshen, R.A. CART: Classification and Regression Trees. Biometrics 1984, 40, 358–380. [Google Scholar]
- Sakar, A.; Mammone, R.J. Growing and Pruning Neural Tree Networks. IEEE Trans. Comput. 1993, 42, 291–299. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Riffonneau, Y.; Bacha, S.; Barruel, F.; Ploix, S. Optimal Power Flow Management for Grid Connected PV Systems with Batteries. IEEE Trans. Sustain. Energy 2011, 2, 309–320. [Google Scholar] [CrossRef]
- University of Oregon Solar Radiation Monitoring Laboratory [EB/OL]. Available online: http://solardat.uoregon.edu/SelectDailyTotal.html (accessed on 9 May 2016).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Season | Model | nRMSE | MAPE |
|---|---|---|---|
| April (spring) | GBDT | 0.0719 | 0.1420 |
| SVM | 0.1072 | 0.1783 | |
| ARMA | 0.1143 | 0.1867 | |
| July (summer) | GBDT | 0.0772 | 0.1365 |
| SVM | 0.0957 | 0.1541 | |
| ARMA | 0.1106 | 0.1618 | |
| October (autumn) | GBDT | 0.0703 | 0.1477 |
| SVM | 0.1108 | 0.1732 | |
| ARMA | 0.1229 | 0.1894 | |
| January (winter) | GBDT | 0.0696 | 0.15270.1876 |
| SVM | 0.0985 | ||
| ARMA | 0.1121 | 0.2013 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Li, P.; Ran, R.; Che, Y.; Zhou, Y. A Short-Term Photovoltaic Power Prediction Model Based on the Gradient Boost Decision Tree. Appl. Sci. 2018, 8, 689. https://doi.org/10.3390/app8050689
Wang J, Li P, Ran R, Che Y, Zhou Y. A Short-Term Photovoltaic Power Prediction Model Based on the Gradient Boost Decision Tree. Applied Sciences. 2018; 8(5):689. https://doi.org/10.3390/app8050689
Chicago/Turabian StyleWang, Jidong, Peng Li, Ran Ran, Yanbo Che, and Yue Zhou. 2018. "A Short-Term Photovoltaic Power Prediction Model Based on the Gradient Boost Decision Tree" Applied Sciences 8, no. 5: 689. https://doi.org/10.3390/app8050689
APA StyleWang, J., Li, P., Ran, R., Che, Y., & Zhou, Y. (2018). A Short-Term Photovoltaic Power Prediction Model Based on the Gradient Boost Decision Tree. Applied Sciences, 8(5), 689. https://doi.org/10.3390/app8050689