1. Introduction
Nowadays, there are many applications [
1,
2], such as image transmission, acquisition, compression, enhancement and analysis, that require an efficient and accurate algorithm for image quality assessment (IQA). Generally, the IQA methods can be separated into two major classes: subjective assessment and objective assessment. As the final evaluation criterion of an image, the subjective assessment is mainly conducted by the pretrained human observers, which is time-consuming and labour-intensive. Hence, more and more researchers are devoted to the development of objective IQA methods that can automatically evaluate the image quality. One trend is to develop full reference IQA (FR–IQA) algorithms when the pristine reference image is available. For example, Kim et al. [
3] utilized the difference of gradients between the source and distorted images to evaluate the image quality. Zhang et al. [
4] proposed a novel feature similarity (FSIM) index which combines the phase information with image gradient magnitudes for FR–IQA. Xue et al. [
5] presented the gradient magnitude similarity deviation (GMSD) and achieved impressive accuracy. However, these FR–IQA methods evaluate image quality by using the pristine reference images, which are usually unavailable.
To overcome the above-mentioned limitation, many no-reference IQA (NR–IQA) methods [
6,
7,
8,
9] have been proposed. Early NR–IQA methods assume that the assessed images are influenced by one or multiple types of known distortions, for example, ringing, blockiness or compression, and meanwhile, the IQA models are designed for these known distortions. Hence, the application field of these approaches is very limited. The blind IQA (BIQA) is a new trend of NR–IQA research, and it does not need to know the distortion types. Most existing BIQA methods are opinion-aware [
10,
11,
12,
13], which trains a regression model from numerous training images (source and distortion images) with the homologous human subjective scores. Specifically, the features are first obtained from the training images, and then both feature vectors and corresponding human subjective scores are employed to train a regression model. In the test stage, the feature vector of an image is fed into the trained regression model to generate the quality score. In [
12], Li et al. utilized several perceptually relevant image features for the opinion-aware BIQA task. The features contain the entropy and mean value of phase congruency image, and the entropy and gradient of the distorted image. Mittal et al. [
14] proposed the blind/referenceless image spatial quality evaluator (BRISQUE) to assess image quality. In [
15], Zhang and Chandler proposed an efficient NR–IQA algorithm using a log-derivative statistical model of natural scenes. Xue et al. [
16] combined the normalized gradient magnitude (GM) with the Laplacian of Gaussian (LOG) features to learn a regression model. There are two main drawbacks of opinion-aware BIQA. Firstly, the approach requires a large amount of distorted images to learn the regression model. In practice, however, it is a challenging task to collect enough training images to cover all kinds of distortions. Secondly, since the image distortion types are diverse and there may be several interacting distortions contained in one image, the opinion-aware BIQA models have a weak generalization ability. This means that the image quality scores are often inaccurate when the model learned from one database is directly applied to another one.
Recently, many researchers have turned to the attractive and challenging study of the opinion-unaware BIQA methods, which only use the pristine naturalistic images to train a model. The opinion-unaware BIQA methods are independent of the distorted images and relevant subjective quality scores, and therefore they possess more potential to deliver higher generalization capability than the opinion-aware ones. In [
17], the quality score is described as a simple distance metric between the distorted image and the model statistic. Xue et al. [
18] proposed the quality-aware clustering scheme to assess the quality levels of image patches. Zhang et al. [
19] proposed the integrated local natural image quality evaluator (IL–NIQE) to predict image quality for opinion-unaware BIQA tasks. Firstly, they utilize five types of features to obtain the feature vectors of pristine naturalistic images, that is, the mean-subtracted contrast normalized (MSCN)-based features, MSCN product-based features, gradient-based features, log-Gabor response-based features and color-based features. Secondly, they use the feature vectors of pristine images to train a MVG model. Then, each patch in the test image is utilized to train a MVG model, and the parameters of the MVG model are compared with the trained MVG model to generate a quality score for the local patch. Finally, the overall quality score is computed by using the average pooling strategy. However, the average pooling lacks discrimination because the contributions of the patches are equally treated, whatever their importances are.
In this paper, we propose a novel approach for opinion-unaware BIQA.
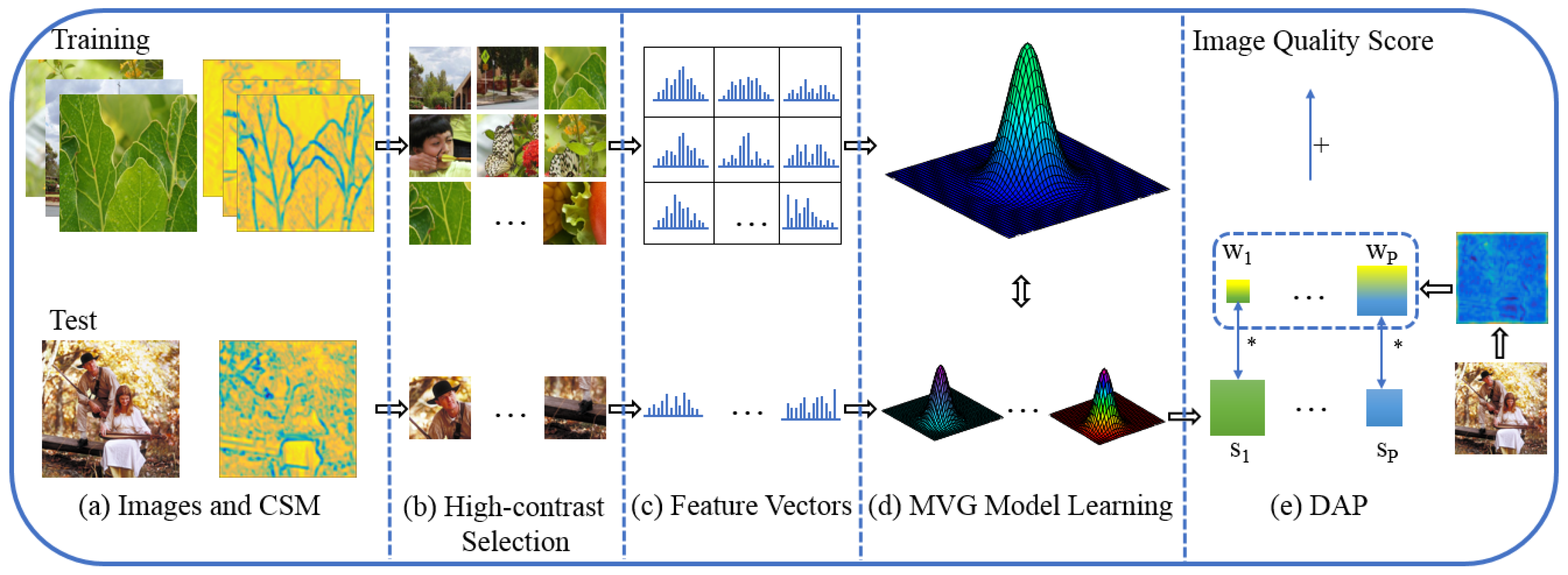
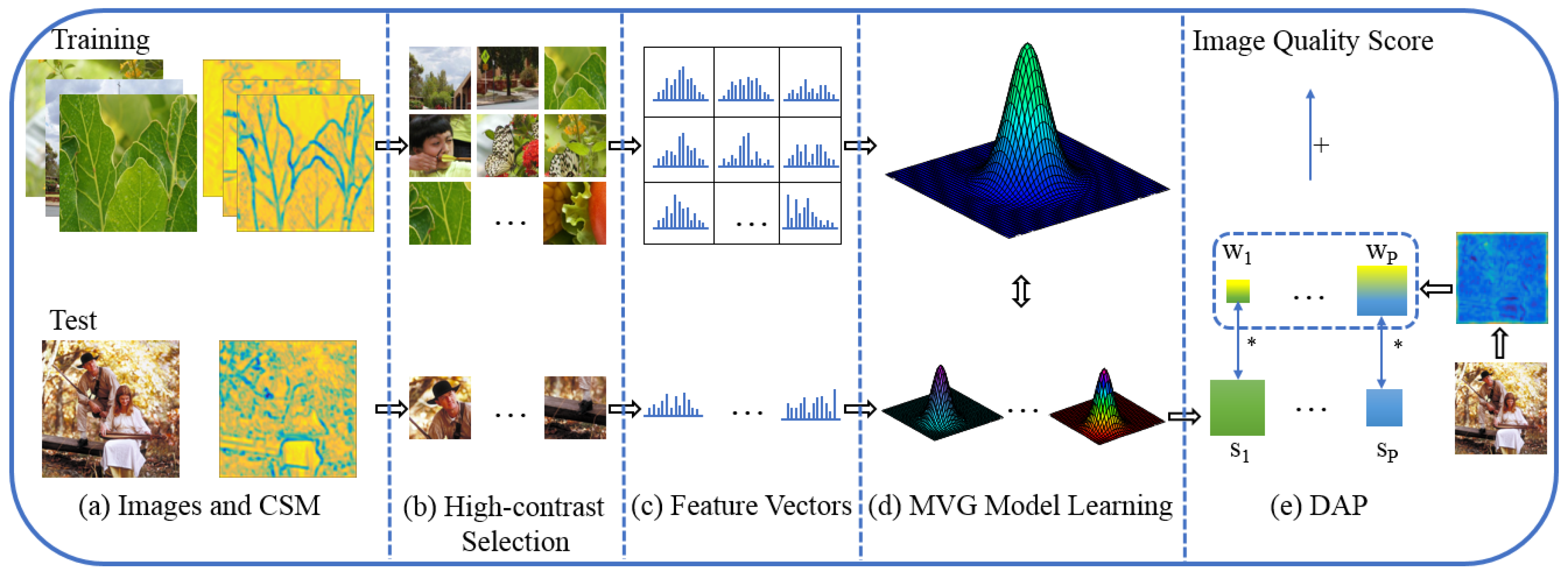
Figure 1 illustrates the procedure of the proposed approach. Firstly, we utilize the convolutional maps of a pretrained convolutional neural network (CNN) for high-contrast patch selection. The convolutional activations represent the structural and textural features, and therefore the selection process could choose the salient patches and drop the meaningless ones for the subsequent assessment. Then, we utilize these selected patches of pristine images to train a pristine multivariate Gaussian (PMVG) model. In the test stage, each high-contrast patch in the test image is fitted by a test MVG (TMVG) model, and the local quality score is obtained by comparing with the PMVG. Finally, the deep activation pooling (DAP) is proposed to aggregate these local quality scores into an overall image quality score. We employ the convolutional summing map (CSM) computed from the convolutional layer to learn the aggregating weights. Specifically, each selected high-contrast patch is mapped to the corresponding activation-response region, and all the activation responses in the corresponding region are added as the aggregating weight. Hence, the proposed DAP could automatically obtain the aggregating weights by learning the importance of local quality scores from the CSM.
In summary, the major contributions of this paper are: (1) We use the high-contrast patches chosen based on convolutional activations to train the PMVG and TMVG models, which captures the primary structural and textural information of images and obtains more accurate PMVG and TMVG models; (2) we compute local quality scores based on the PMVG and TMVG models, and propose the DAP to automatically learn the aggregating weights of local quality scores from CSM, which produces more accurate overall quality score.
2. Approach
In this section, we first describe the convolutional summing map (CSM) of VGG-19 [
20], which is utilized for selecting high-contrast patches and learning pooling weights. Afterwards, we present the high-contrast selection processing and the DAP strategy.
2.1. Convolutional Summing Map
In the convolutional layer of a CNN, the filters traverse the image in a sliding-window manner to generate convolutional maps. The convolutional maps can be regarded as a tensor with the size of , which possesses N convolutional maps with width W and height H. Typically, the top-left (bottom-right) activation response in a convolutional map is generated by the top-left (bottom-right) part of the input image. Each activation response in a convolutional map describes a local part of the input image, and the high responses indicate the salient parts. Hence, we utilize the convolutional maps for high-contrast patch selection and pooling weight learning.
In this paper, we choose the widely-used VGG-19 [
20] as the CNN model, and its architecture is listed in
Table 1. The VGG-19 network contains five convolutional building blocks. The first and second convolutional building blocks both contain two convolutional layers. There are four convolutional layers in the third, fourth and fifth convolutional building blocks. All the receptive fields are the size of 3 × 3. Both the convolution stride and the spatial padding are set to 1 pixel. Max-pooling is implemented by a 2 × 2 pixel window, with stride 2 after convolutional building blocks. The last convolutional building block is followed by three fully-connected (FC) layers: the first two have 4096 channels each, and the third has 1000 channels.
The convolutional maps in the convolutional layer could describe the important features and spatial structural information [
21,
22]. To further capture the complete spatial response information, we add all the convolutional maps of one convolutional layer to obtain the convolutional summing map (CSM), which could build the relationship between the spatial structure and the activation responses. Let
denote the activation response of CSM at position
in the
l-th convolutional layer:
where
denotes the activation response of the
n-th convolutional map at position
in the
l-th convolutional layer and
N is the number of the convolutional maps in the
l-th convolutional layer. The shallow convolutional layers usually contain structural and textural local features, which are very important for BIQA. In the experiment, we present a detailed description of how to select CSM in
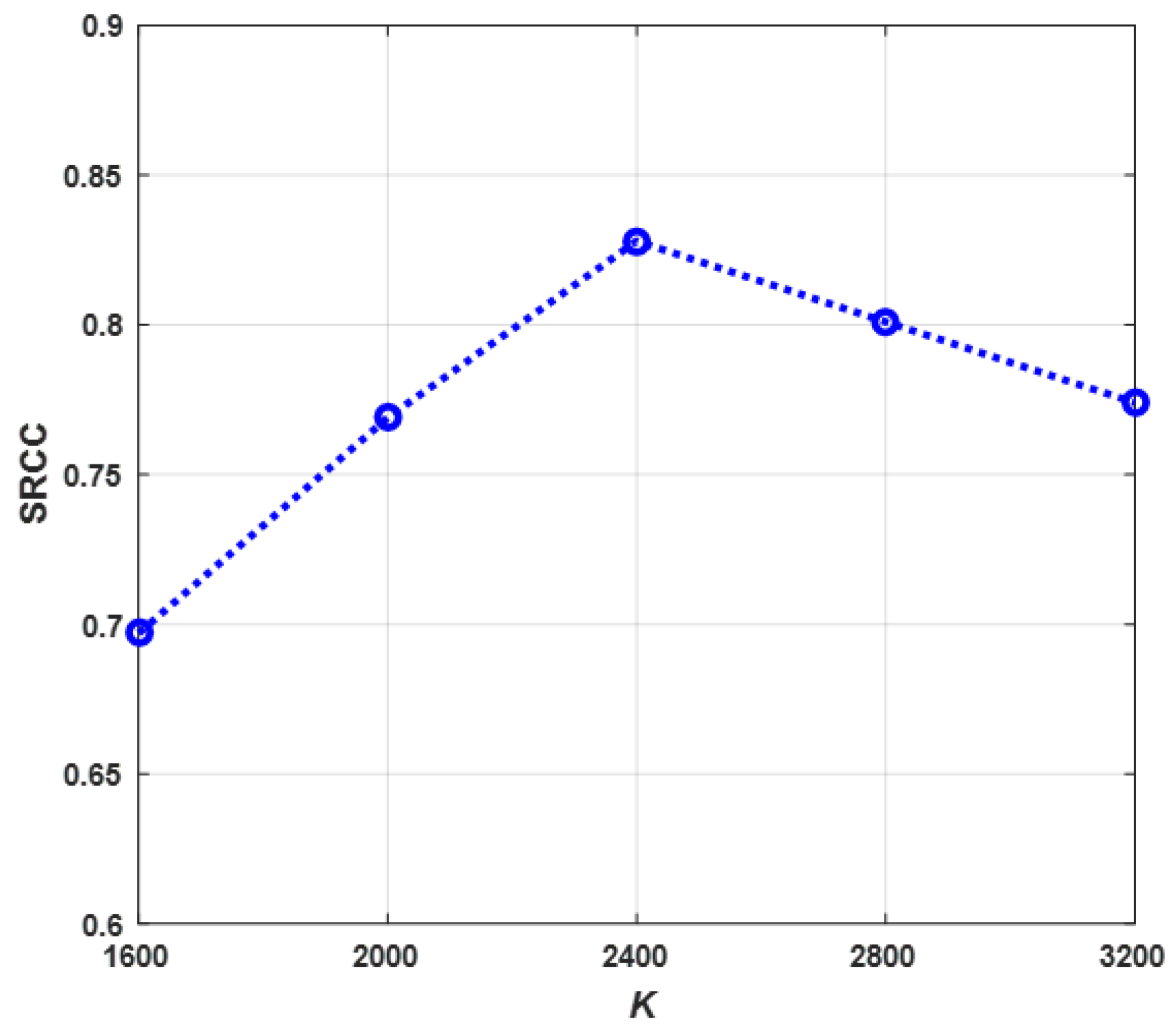
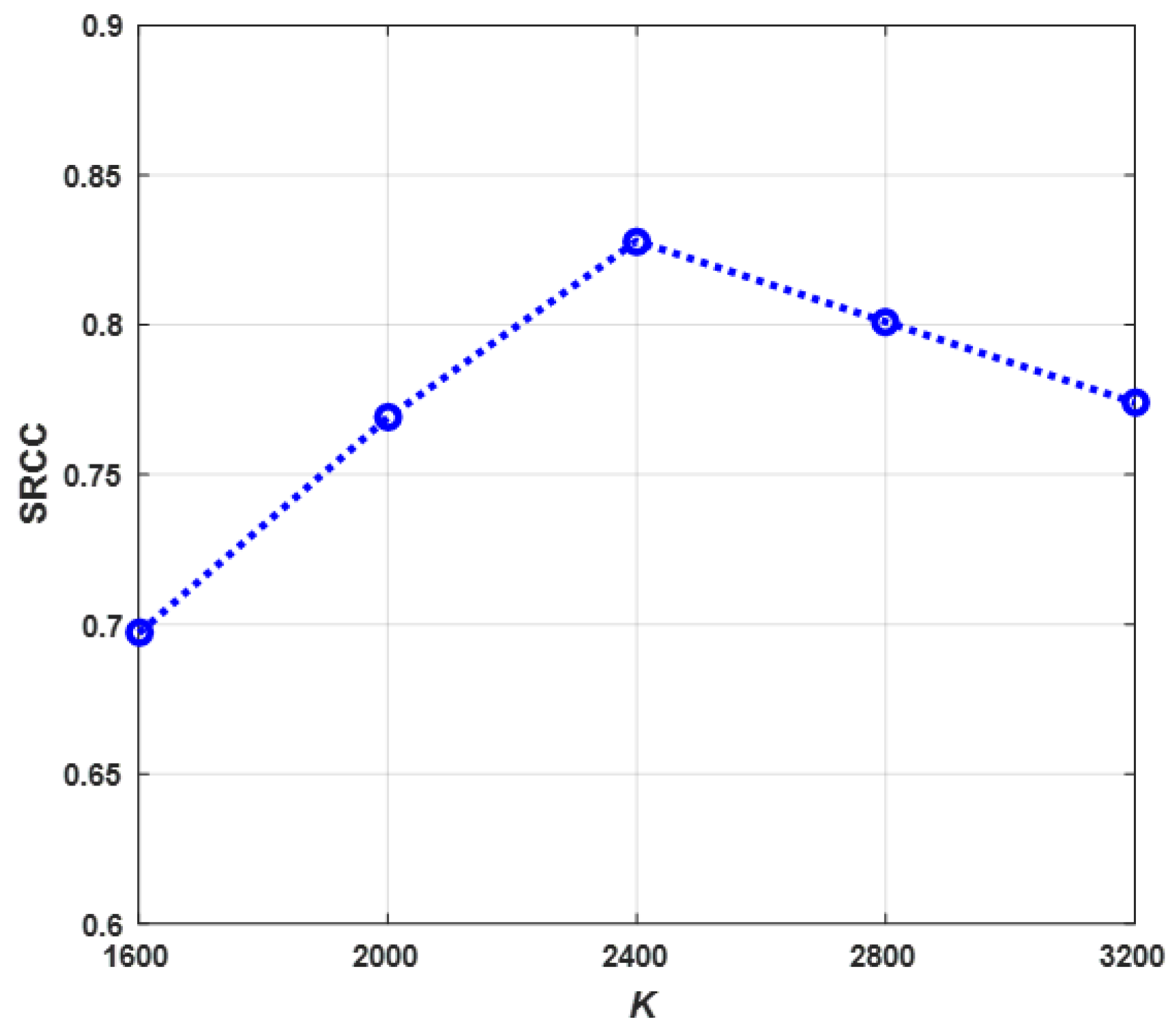
Section 3.2. In this paper, we utilize the CSM in the 4th convolutional layer for selecting high-contrast patches, and the CSM in the 7th convolutional layer for learning pooling weights.
2.2. High-Contrast Patch Selection
The local image information plays a profound role in the task of BIQA. Although the patches in an image could describe the local information, not all the patches are useful for the overall perception of image quality. Furthermore, the patch contrast reflects the image’s structural information, which is sensitive to the image distortions and closely correlated with the image perceptual quality. When an image is subjected to quality degradations, the image structure is violated and the structural damage degree increases with the quality degradation level. Hence, we propose to select the high-contrast patches for the subsequent BIQA.
To discover the high-contrast and meaningful patches, we utilize the CSM to build the relationship between the original image and the corresponding convolutional activations. Concretely, we first transmit the original image to the VGG-19 network and obtain the CSM in the 4th convolutional layer, as shown in
Figure 2b. From
Figure 2b, we can see that those salient positions mainly distribute in the structural parts, and the values can reflect the importance of the local structure information. Hence, we propose the local weighted variance
to reflect the contrast of the activation response at position
in the 4th convolutional layer:
where
defines a unit-volume Gaussian weighting window, and
denote the activation response of the CSM at position
in the 4th convolutional layer. Here,
is the mean value of local activation responses:
To obtain the contrast in the activation-response region
, we sum up all the local weighted variance within it:
The higher the value of
is, the stronger the contrast of the activation-response region is. Hence, we take the value of
as the criterion of high-contrast patch selection. The procedure of high-contrast patch selection is shown in
Figure 2. Firstly, based on the
, the high-contrast activation-response regions (the green rectangles in
Figure 2b) in CSM are selected. Then, the selected high-contrast activation-response regions are mapped to the corresponding input image patches (the yellow rectangles in
Figure 2a) so as to obtain the high-contrast patches. As a result, the useful patches are retained and the meaningless ones are abandoned.
2.3. Deep Activation Pooling
Suppose that
F is a set of
D-dimensional local features extracted from the
K-selected high-contrast patches of pristine images, that is,
, where
is the
D-dimensional feature vector of the
k-th high-contrast patch. Based on these features, we learn a powerful opinion-unaware BIQA model. As shown in
Figure 1d, in the training stage, we learn a PMVG model from the selected high-contrast patches. In the test stage, each selected high-contrast patch is fitted by a TMVG model, and then the TMVG model is compared with the PMVG model to obtain the local quality score of the patch. Finally, we utilize the proposed DAP to aggregate all the local quality scores to obtain the overall quality score. The specific procedure is listed as follows:
(a) We utilize a set of high-quality pristine images to train a PMVG model [
19]. We first choose the CSM in the 4th convolutional layer of the VGG-19 network to select
K high-contrast patches from the 90 pristine images using the high-contrast selection method mentioned in
Section 2.2. Then, we extract the features for each selected high-contrast patch. Finally, based on the feature set
F of the high-contrast patches, we apply the standard maximum likelihood estimation to learn a PMVG distribution:
where
and
represent the mean vector and the covariance matrix of
F, respectively.
(b) Given a test image, we first resize the test image to the size of the pristine images, and then the high-contrast patch selection strategy is performed to obtain a set of patches. Each patch is represented as a feature vector, and each feature vector is fitted by a TMVG model. The learned TMVG model for the
p-th patch
where
P is the number of the selected high-contrast patches of a test image) is denoted as
. We compare the TMVG model of the
p-th patch with the PMVG model to obtain the local quality score
for the
p-th patch. The procedure of learning the TMVG model for each patch is extremely costly. For simplicity, the quality score
is computed using the following formula:
where
is the feature vector of the
p-th patch and
is the covariance matrix computed from all the selected patches in the test image. Note that all the patches for one test image share the same
.
(c) As we know, the contribution of each local quality score to the overall quality score is different. To emphasize the important patch scores and suppress the inessential ones, we propose the novel DAP method to obtain the overall quality score of the test image. Each activation response in the CSM describes a local part of the input image, and the high responses indicate the salient parts. We use the CSM in the 7th convolutional layer of the VGG-19 network to learn a weight for each local quality score. The weight of each local quality score is computed by adding all activation responses in the relevant activation-response region, as shown in the green rectangle of
Figure 3.
is the weight of the
p-th patch and it is formulated as:
where
represents the activation-response region and
is the activation response of the CSM at position
in the 7th convolutional layer. Let
represent the weight set and
be a set of local quality scores. The overall quality score of the test image
can be obtained by:
The superiorities of our method lie in: (1) The proposed method could retain the primary structural and textual information and abandon the meaningless ones by performing the high-contrast selection; (2) the proposed DAP could automatically obtain the aggregating weights by learning the importance of local quality scores from the CSM, and therefore it overcomes the shortcomings of traditional average pooling and obtains more accurate overall quality score.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}