1. Introduction
Development of 3 dimensional (3D) printing technology has led to the explosive growth of 3D models recently. Hence the 3D printing services are increasing rapidly [
1,
2]. However, copyright infringement of 3D models has become an issue for 3D printing ecosystem of product distribution websites, 3D scanning and design-sharing [
3,
4]. To prevent the copyrighted 3D models from distributing and using illegally, the identification of 3D models remains.
2 dimensional (2D) view-based 3D model identification has a high discriminative property for 3D model representation [
5,
6,
7,
8,
9,
10,
11]. Generally, a 2D view image is a range image obtained from a viewpoint located on a 3D model’s bounding sphere. The identification is implemented by matching the features extracted from the range images. However, the existent approaches suffer from big size of features and slow matching speed. To overcome these problems, we propose an approach using only one range image, which means a panoramic view is used for identification. The panoramic view bridges the gaps between the range images rendered from multiple views. It is obtained by projecting a 3D model onto the surface of a cylinder, which is parallel to a principal axis determined by 3D shape normalization. The purpose of the 3D shape normalization is to normalize 3D models into a canonical coordinate frame to guarantee a unique representation [
12,
13,
14]. Nevertheless, how to determine the principal axes is the keypoint. The most common method is principal component analysis (PCA). However, it is not preferable when 3D models have unobvious orientations or undergo large deformations. If the shape normalization cannot determine the principal axes of a query model as similar as those of original model in database, the identification needs many more range images to match them. Implicit shape representation (ISR) was described in [
13] for normalizing 3D articulated models. However, it has some limitations when some parts of a 3D model are removed or when a 3D model undergoes a large deformation. In this paper, the 3D shape normalization uses a weighted ISR (WISR) to reduce the influence caused by shape deformation and partial removal. It estimates the number of clusters based on rate distortion theory [
15]. It also shows the most representative part for one viewpoint of the six degree of freedom.
After the shape normalization, the model is wrapped by the cylinder to generate a range image. The range image is used for providing features of the model. The feature used in our approach is the scale invariant feature transform (SIFT) descriptor [
16]. The SIFT is generally used to extract geometric transformation invariant local features from images [
17,
18]. It detects interest points called keypoints and assigns orientation information to each keypoint based on local gradient directions. With the SIFT descriptor, object recognition approaches can achieve high performance in feature matching. In this paper, the 3D models are identified by matching the SIFT descriptors of the query model with those in database. In the section of experimental results, we show the comparisons between the precision of identification of the proposed method and those of other methods.
2. Related Work
Several researches have been conducted to group 3D models into corresponding categories by matching the features and comparing the similarities of the models [
5,
6,
7,
8,
9,
10,
11,
14,
19,
20,
21,
22]. The matching and comparison are implemented on a huge dataset containing various models of different poses and shapes. The models are mainly classified into two types: rigid models and non-rigid (deformable) models. Early works are rigid model-based approaches. In this paper, we focus on the identification of non-rigid models.
3D model identification methods are classified into two categories: view-based and model-based methods [
6,
7]. Model based methods include geometric moment [
19], volumetric descriptor [
20], surface distribution [
21], surface geometry [
22]. However, the geometry and topology based methods are generally computationally cost and are fragile to 3D model removal. View-based methods have a high discriminative property for 3D model representation [
5,
6,
7,
8,
9,
10,
11]. A 2D view image is a range image obtained from a viewpoint located on a 3D model’s bounding sphere. After the range image is obtained, image processing technologies are applied to the range image for extracting features. To be invariant against geometrical transformation, researchers proposed shape normalization methods to preprocess the 3D models before extracting the features.
Several view-based methods have been proposed. In Ref. [
9], authors proposed a view based 3D model retrieval method using the SIFT and a bag-of-features approach. The bag-of-features was inspired by the bag-of-words in the text retrieval approach, which classifies documents by histograms of words in the text. The method extracted SIFT features from the range images of the model viewed from dozens of viewpoints located uniformly around the model. The bag-of-features was composed of the SIFT features. The well-known k-means clustering algorithm was applied to the bag-of-features to classify the features and generate visual words. The visual words are integrated in to a histogram and become a feature vector of the model. However, the large number of the range images leads to large capacity of features and slow matching speed.
In [
10,
11], authors proposed 3D model descriptors using the panoramic views which can describe the orientation and position of the model’s surface. In [
10], the panoramic views were obtained by projecting the model to surfaces of cylinders parallel to three principal axes. The principal axes were obtained by using continuous PCA and normal PCA. For each cylinder, the coefficients of 2D discrete Fourier transform and 2D discrete wavelet transform were extracted to generate the 3D shape descriptors. However, these descriptors are not suitable for distinguishing the 3D models well. In [
11], the exes were perpendicular to the surfaces of a dodecahedron generated around the model. Three panoramic views were obtained from each axis. The other two panoramic views were obtained from additional two axes which are orthogonal to each other and to the principal axis. Then, the SIFT features were extracted to generate the 3D model descriptors. However, because of using dozens of panoramic views, the method leads to large capacity of features and slow matching speed.
In [
8], authors normalized the model with the PCA and extracted 18 views from the vertices of a bounding 32-hedron of the model. The 3D model descriptors were composed of 2D Zernike moments, 2D Krawtchouk moments and coefficients of Fourier transform. However, the PCA is fragile to partial removed and deformed models, which means the PCA can’t extract the same axes from the deformed and removed models as those of original models. Hence, the different axes lead to different views and descriptors. Eventually, the method can’t identify the deformed and partial removed versions of the original models.
In [
13], authors proposed a shape normalization method for 3D volumetric models using ISR. The ISR is a set of minimum Euclidean distance values between the surface of the model and the voxels inside the surface. It is invariant to translation and rotation. The method computed an initial center of the model with the ISR and voxels inside the model. It also computed an initial principal axis with the PCA. Then the center and three principal axes were iteratively upgraded based on implicit intensity value and principal axis dependent weight function. Finally, the method translated, rotated and scaled the model with the final center, principal axes and a scale factor which was computed with the ISR.
In [
23], the competition results of SHREC 2015 range scans based 3D shape retrieval were presented. The best performance was achieved by a SIFT based cross-domain manifold ranking method. However the precision was about 70%. In [
24], the results of the SHREC 2015 Track: Non-rigid 3D shape retrieval were presented. The best performance was achieved by a method of super vector-local statistical features. However, the local statistical feature extraction and matching is time consuming. The matching time is over 50 s for 907 models [
25].
In [
26], authors proposed a view-based 3D model retrieval method using bipartite graph matching and multi-feature collaboration. The complement descriptors were extracted from the interior region and contour of 3D models. The employed three types of features: Zernike moments, bag of visual words descriptor and Fourier descriptor to construct bipartite graphs. However, because of using various types of features, it is time consuming.
In [
27], the discriminative information of 2D projective views were learned for 3D model retrieval. The dissimilarity between discriminative ability and view’s semantic is investigated by classification performance. An effective and simple measurement is used to study the discriminative ability. The discriminative information is used for view set matching with a reverse distance metric. Various features were employed to boost the retrieval method. However, each model was represented by 216 views. The feature size is too large. The querying time is 1.7 s for 330 models. It is also time consuming.
In 2015, five leading feature extraction algorithms: SIFT, speeded-up robust features, binary robust independent elementary features, binary robust invariant scalable keypoints and Fast retina keypoint, were used to generate keypoint descriptors of radiographs for classification of bone age assessment [
28]. After comparing the five algorithms, the SIFT was found to perform best based on precision. In 2016, a survey was presented to evaluate various object recognition methods based on local invariant features from a robotics perspective [
29]. The evaluation results reported that the best performing keypoint descriptor is the SIFT and it is very robust to real-world conditions. Based on the previous research results on pattern recognition and computer vision, we decide to extract the SIFT descriptors as the features of 3D models.
3. 3D Shape Normalization Using WISR
3D shape normalization is a process of adjusting the orientation, location, and size of a given 3D model into a canonical coordinate frame. A 3D model is usually composed of a main body part and branch parts (e.g., arms and legs). To reduce the effect caused by the deformation or abscission of branch parts when determining the principal axes, we increase the weight of the main body part. The procedure of weight calculation requires three steps. The first step is automatically estimating the number of clusters based on rate distortion theory [
15]. With the clustering method, we can distinguish the main body part and the branch parts. However, different 3D models have different shapes and topologies that lead to different main body and branch parts. Therefore, a method of automatically estimating the number of clusters is required. The second step is performing the k-means algorithm with the estimated number and calculating the distance among cluster centers. The third step is calculating the number of points inside each cluster sphere. Generally, the number of points inside a main body part is greater than that of a branch part. Thus the weight is obtained based on the number of points.
First of all,
random points
are generated inside the surface of a model. A measure of cluster dispersion called distortion
is defined as Equation (1). It is derived from Mahalanobis distance.
where
is the covariance and
is the closest center to a given point
. The cluster centers are obtained by using the k-means algorithm. We iteratively fit
clusters to the points
. Therefore, there are
distortions
corresponding to
clusters. Each
denotes cluster dispersion of
clusters. After evaluating the distortions with 1 to
partitions, the
is transformed as follows
where
is the dimension of the points, thus
is equal to 3. The
is a transform power motivated by asymptotic reasoning. The number of clusters is set to be
. The
is the ideal number of clusters. Then the k-means algorithm is performed to partition the
into
clusters. The points near the boundaries of clusters interfere with the relation between the points and the main body and branch parts. Therefore, we only consider the points inside a sphere with a specific radius. First we compute a distance
between two cluster centers as follows:
Then we can obtain distances. The radius is defined as . The weight of each cluster is the number of nearest points within the radius from each center. The nearest points set of the th cluster center is defined as .
The weight
of cluster
is the the number of the elements in the
. The ISR is defined as
, which is the minimum Euclidean distance from
to vertices
on the surface of the model. The
is applied to the ISR of nearest points of cluster center
to produce WISR as follows
The points nearest to the cluster center inside a main body are much more than those inside a branch. Therefore, the weight of the main body will be increased, whereas that of the branch will be decreased. To reduce the influence of surface deformation of main body, we quantize the WISR and delete some values which are less than a specified threshold. We use search-based optimization of Otsu’s criterion to find 5 thresholds
. We delete the values of
by setting them to be 0, if they are less than
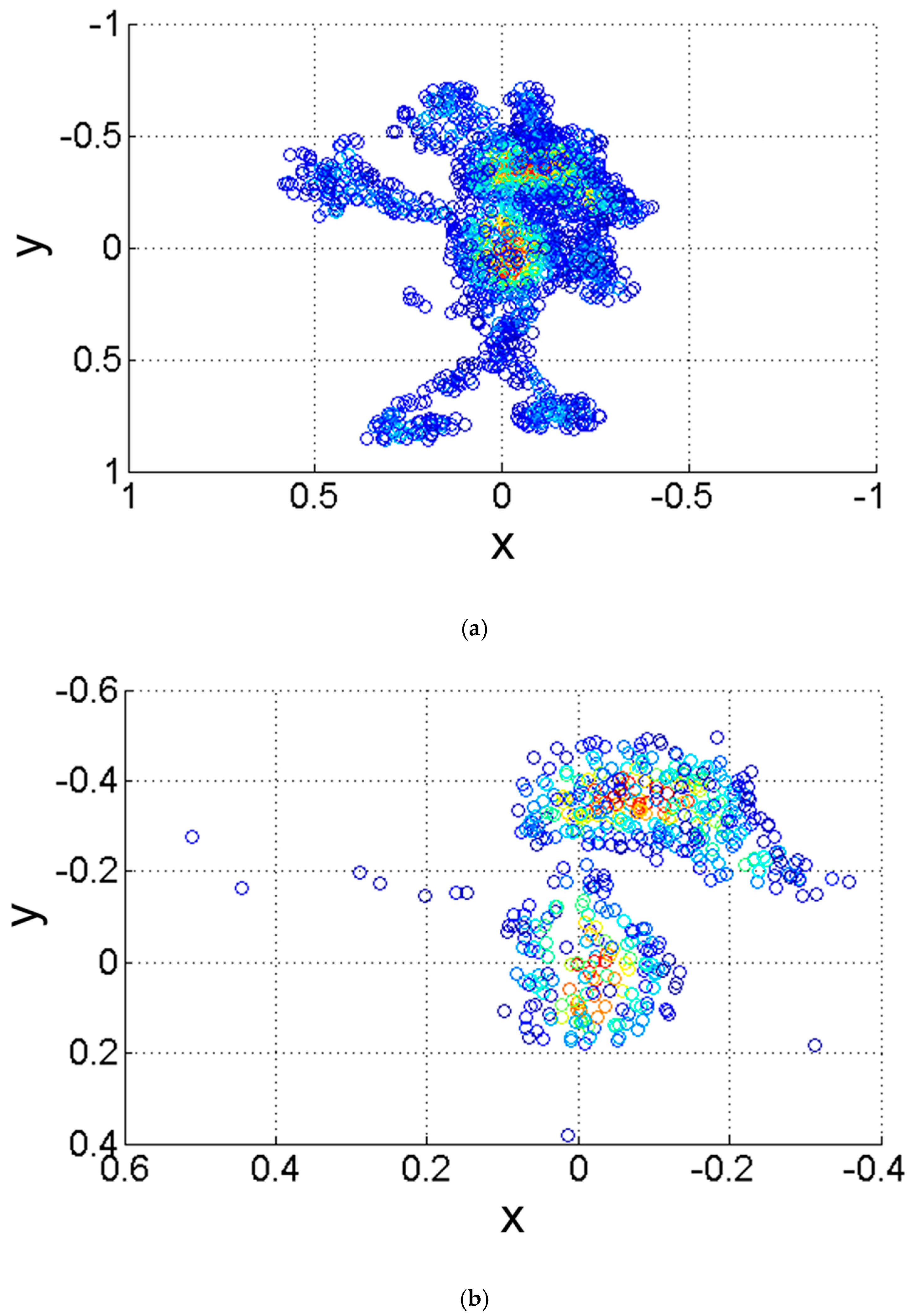
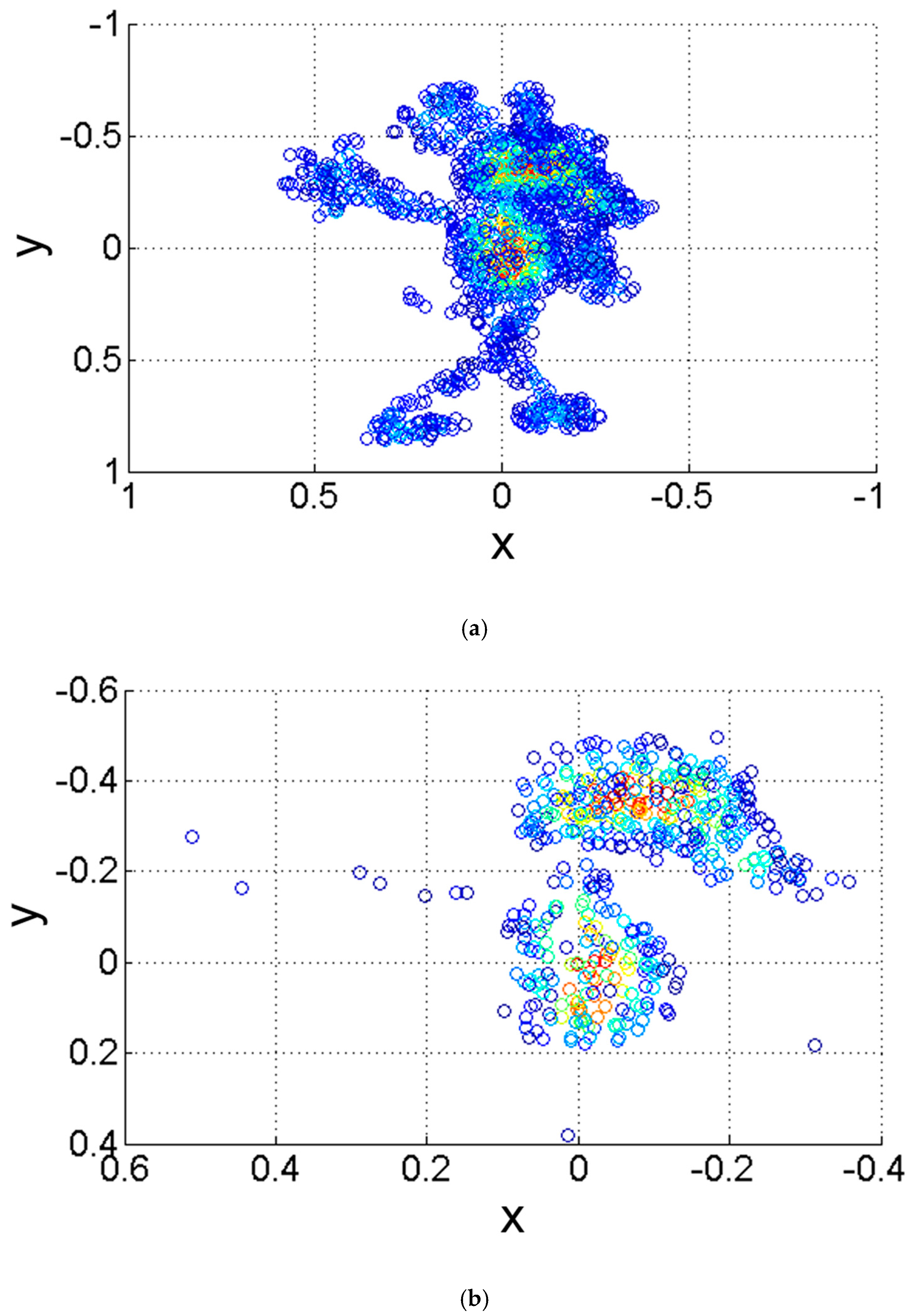
. The ISR and WISR of a mouse model are shown in
Figure 1. To illustrate their salient characteristic more clearly, the figures are shown in
xy-plane.
The principal axes are calculated by singular value decomposition. The points
corresponding to the existing
are selected for analyzing the principal axes. The center of gravity of a model is defined as
It is moved to the origin of coordinate to solve the normalization of translation. It represents the weighted average of all points in a model. It is much closer to the center of main body than conventional barycenter. To normalize a model size, a scale factor is defined as follows
It is based on the volume of the model and is effective in normalizing the 3D model size. Finally, the 3D model is normalized by achieving scaling, translation, and rotation with respect to the scale factor, center, and principal axes.
4. Panoramic View Generation
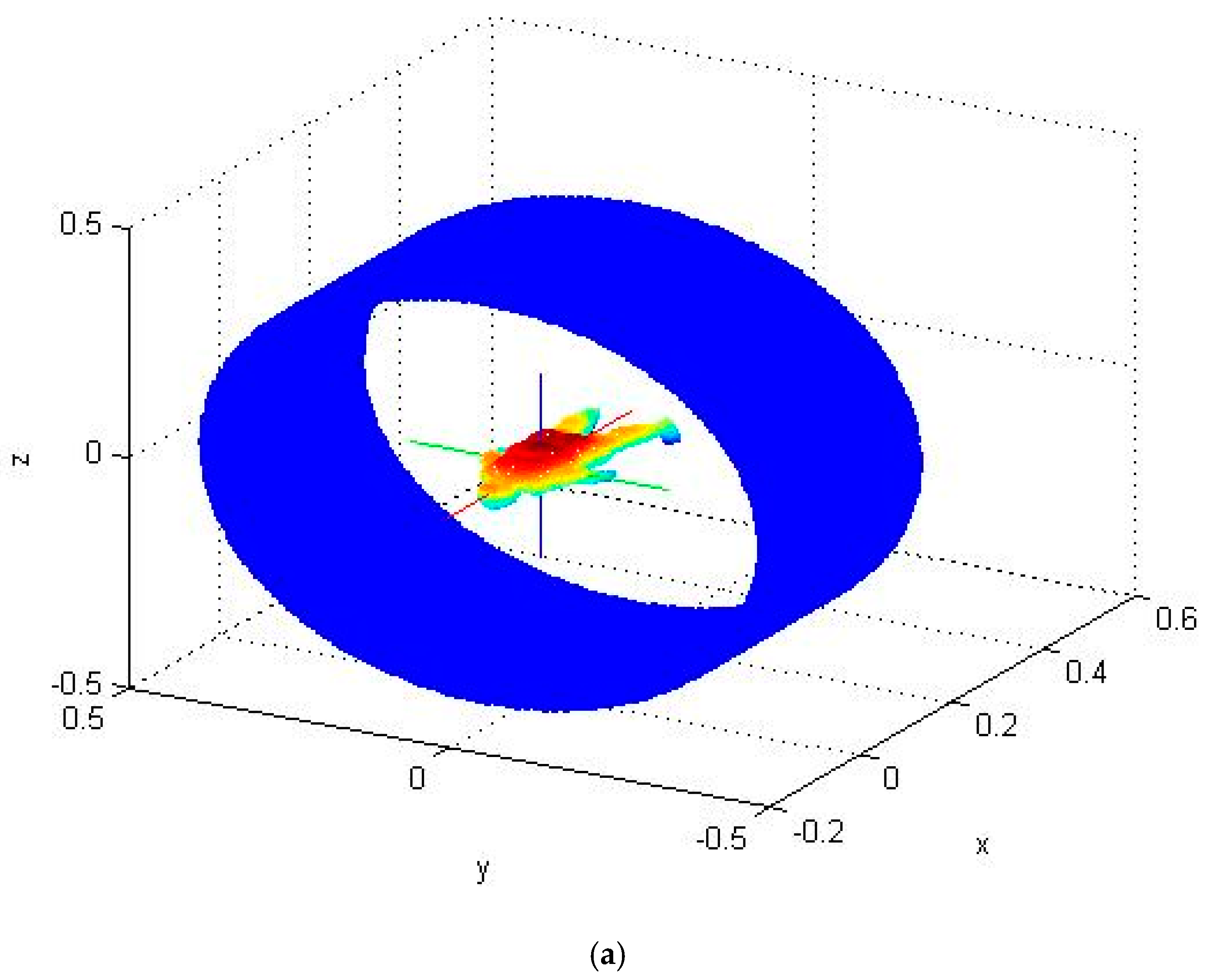
Once the shape normalization has been done, one panoramic view will be generated. First, a cylinder is generated around a 3D model as shown in
Figure 2a. Its center and axis are the center and the first principal axis of the model. Its radius is defined as
. Its height is the height of the model. We sample the axis of the cylinder with a sample rate
. Each sample point of the axis is a center of a cross section of the cylinder. For each cross section,
rays are emanated from each center to the surface of the cylinder. Thus, the degree between each ray is
. Each ray may have more than 1 intersection with the surface of the model. The distance
from a center to the furthest intersection of the ray is mapped to a value in the range of
for representing one pixel in the
range image. After generating the panoramic view, SIFT descriptors are extracted from the panoramic view and stored as the feature of the model.
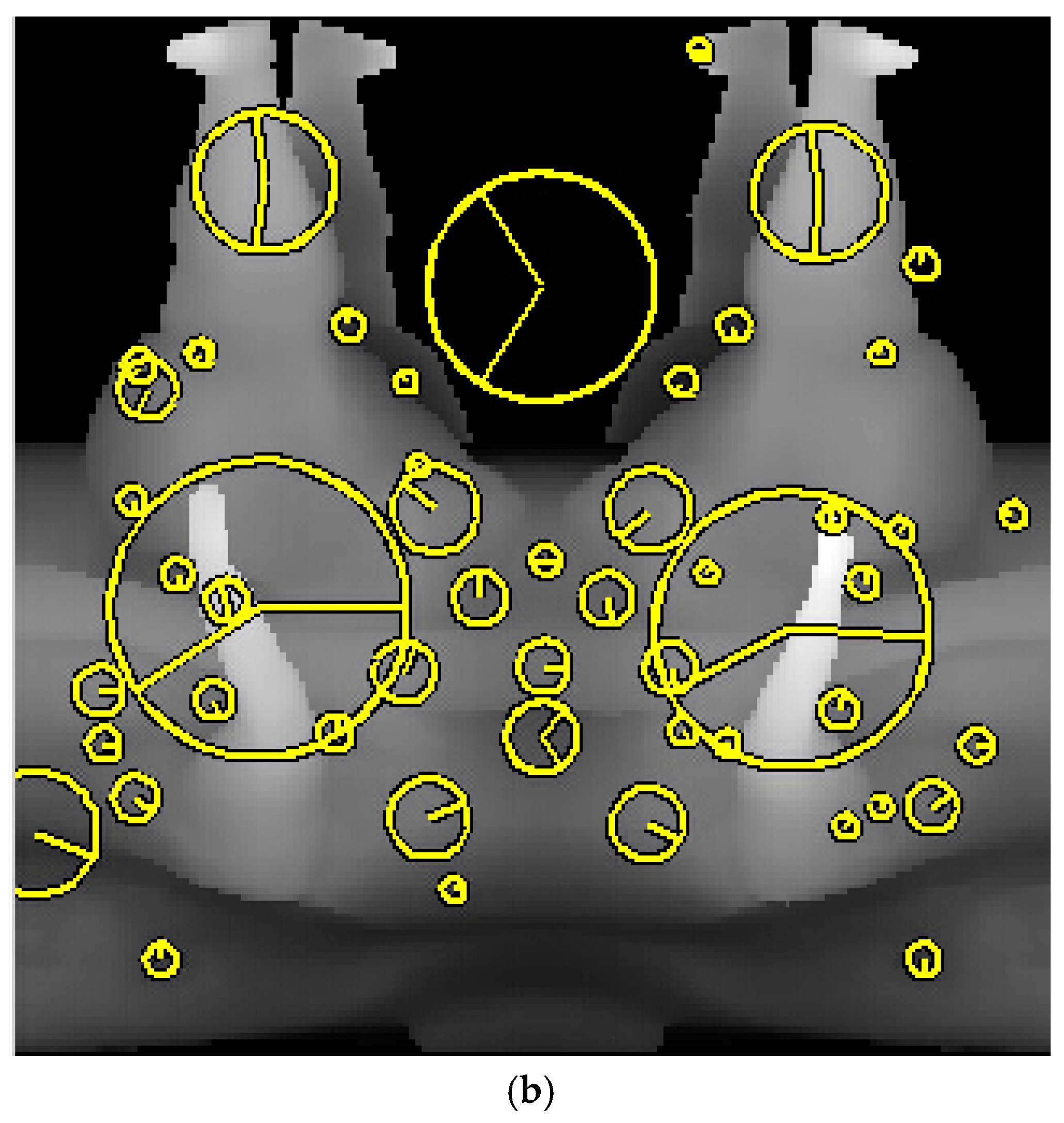
Figure 2b shows the SIFT descriptors of panoramic view-based range image.
The matching procedure of the SIFT descriptors uses the Euclidean distance as in [
16]. Suppose the SIFT descriptor of a query model is
and that of a model in database is
. The distance
between the two descriptor is given by
A keypoint with the least distance value is defined as a matched keypoint. We match the keypoints of the query model to those of the models in the database and obtain the number of matched keypoints. Finally, we identify the model with the maximum number of matched keypoints as the original model of the query model.
5. Experimental Results
In this section, some experimental results about the shape normalizations are shown first. To achieve high precision of 3D model identification, how to accurately normalize the shapes of the models is of great significance in practice.
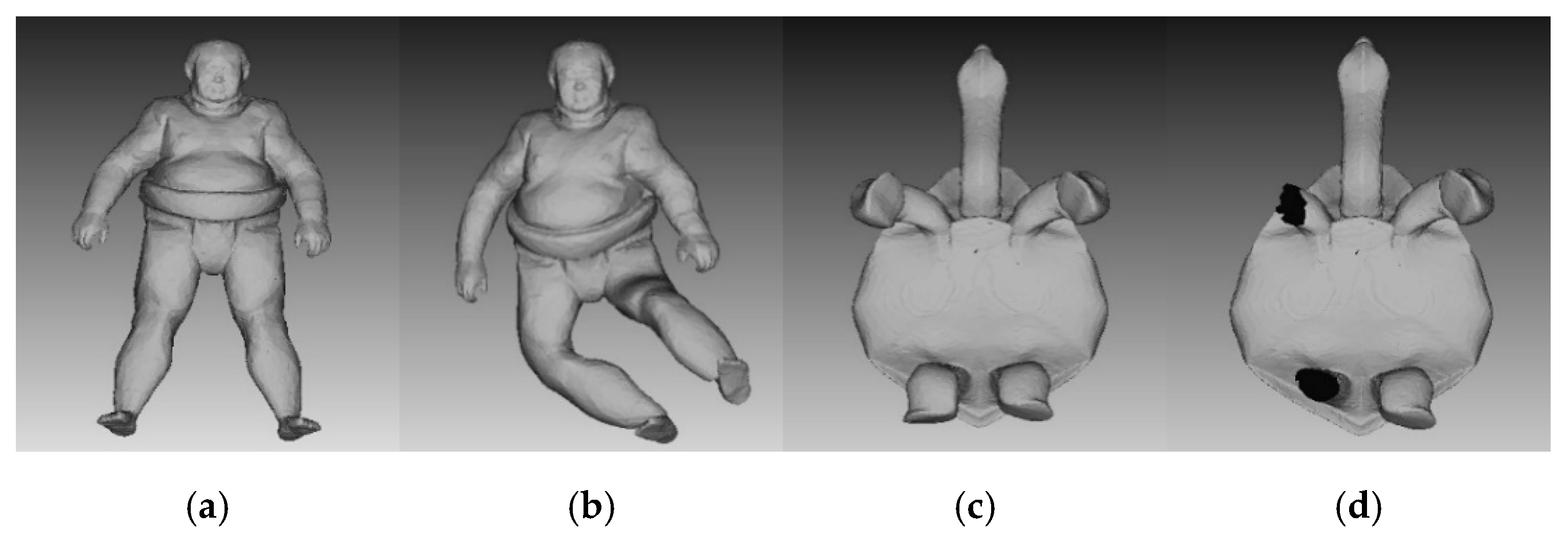
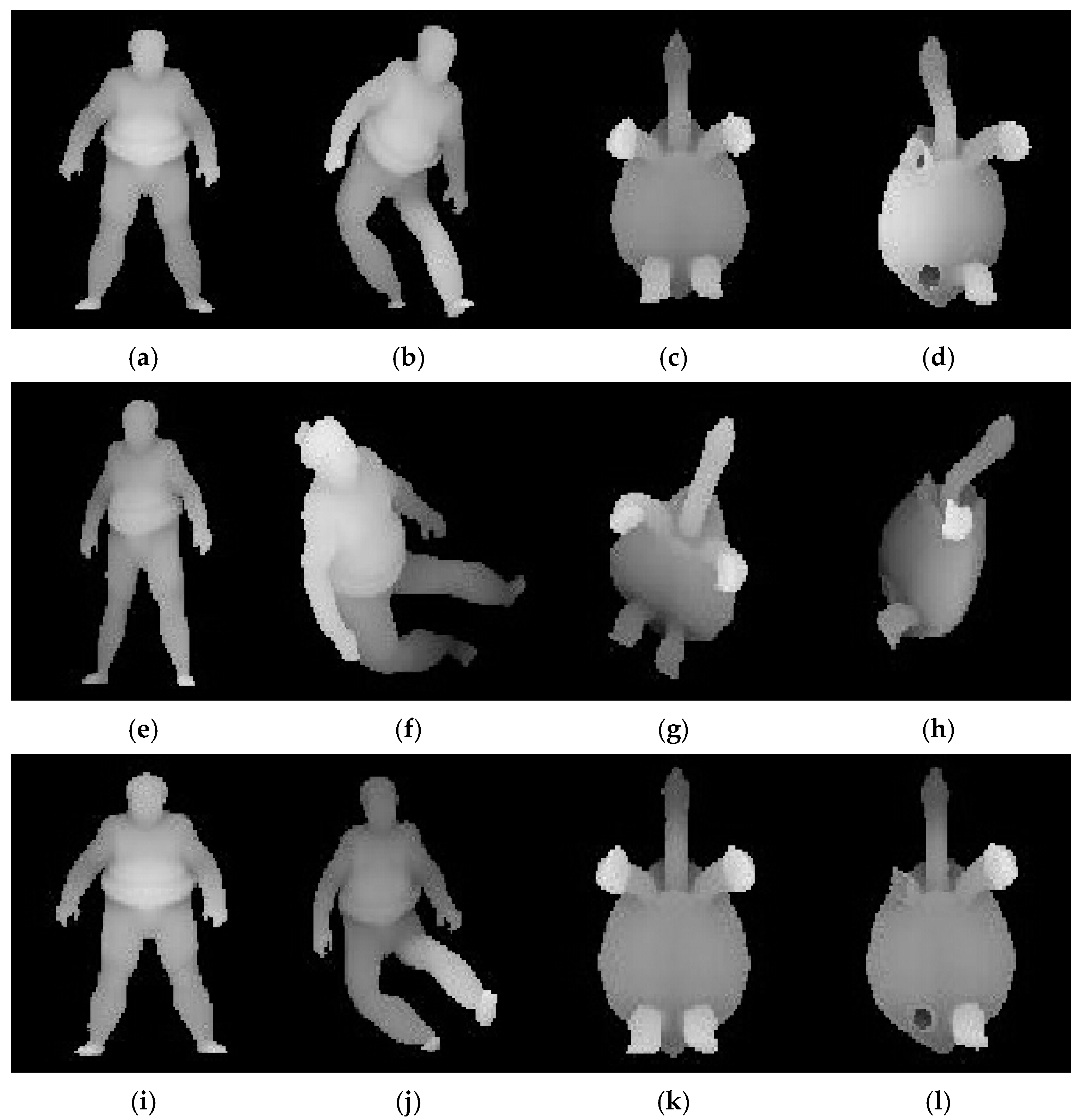
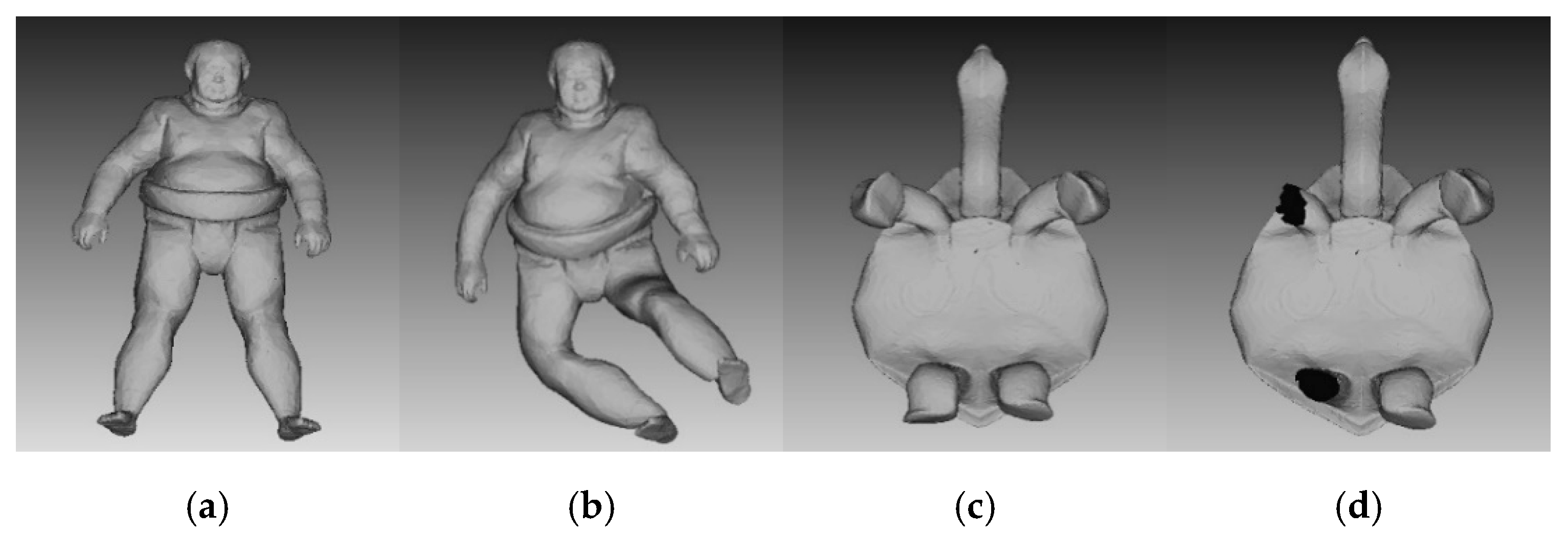
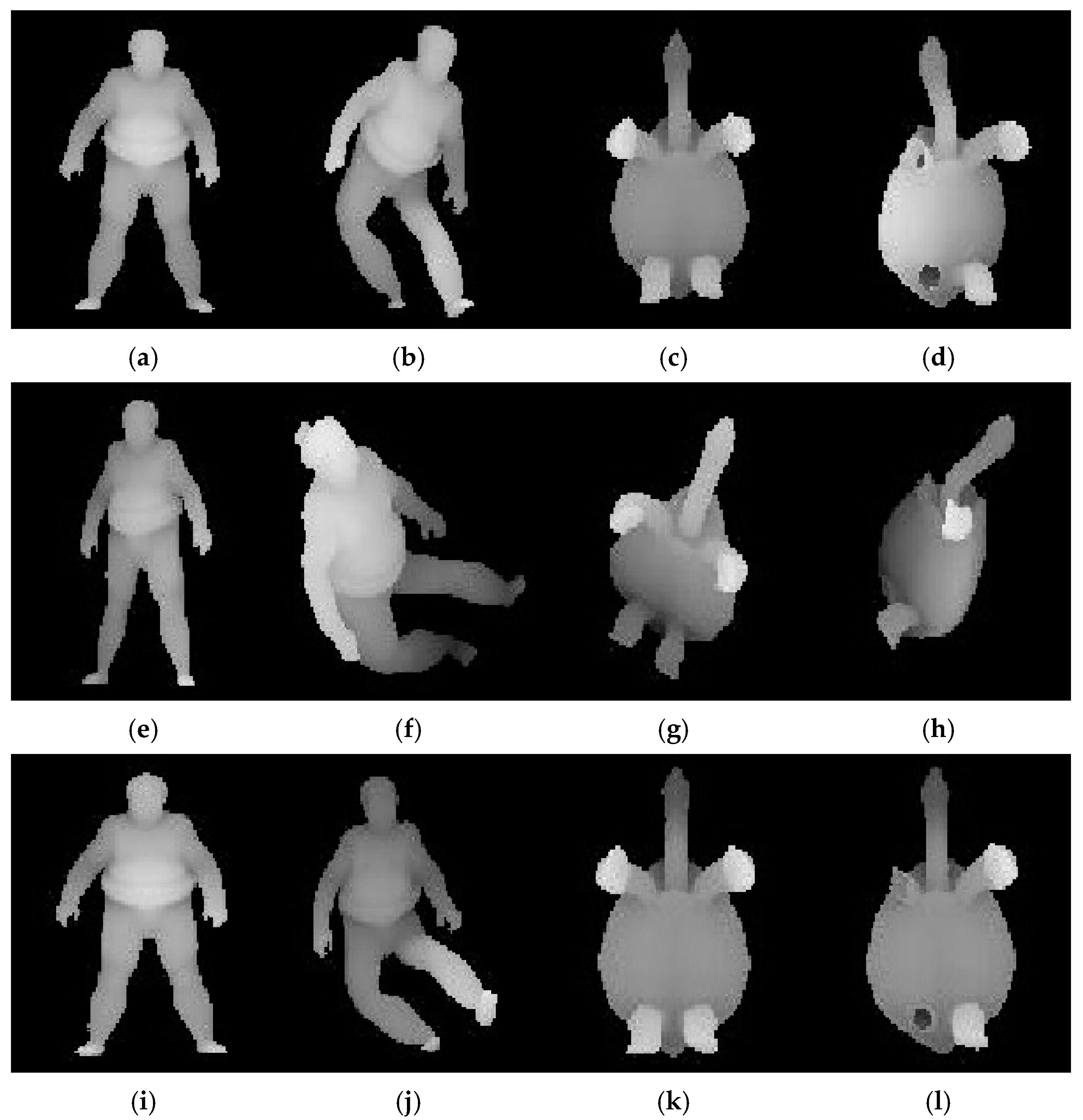
Figure 3a,c are original sumotori and tortoise models.
Figure 3b is deformed version of sumotori model by articulating around its joints in different ways.
Figure 3d is partially removed version of tortoise model. There is a certain extent of difference between the original models and deformed and removed models. If we extract 6 range images from each view point of six degree of freedom, we can obtain 24 possible poses of a 3D model [
8]. We only selected the most representative range image from all possible poses of a model.
Figure 4a–l show the range images which have the most representative surface of the models using PCA, ISR, and WISR, respectively. The main body and face in
Figure 4b are oblique.
Figure 4d shows left side of the model.
Figure 4f,h show the range images were viewed obliquely from above. Both
Figure 4j,l show their fronts to a view point, which means the deformed and removed models were well normalized using WISR.
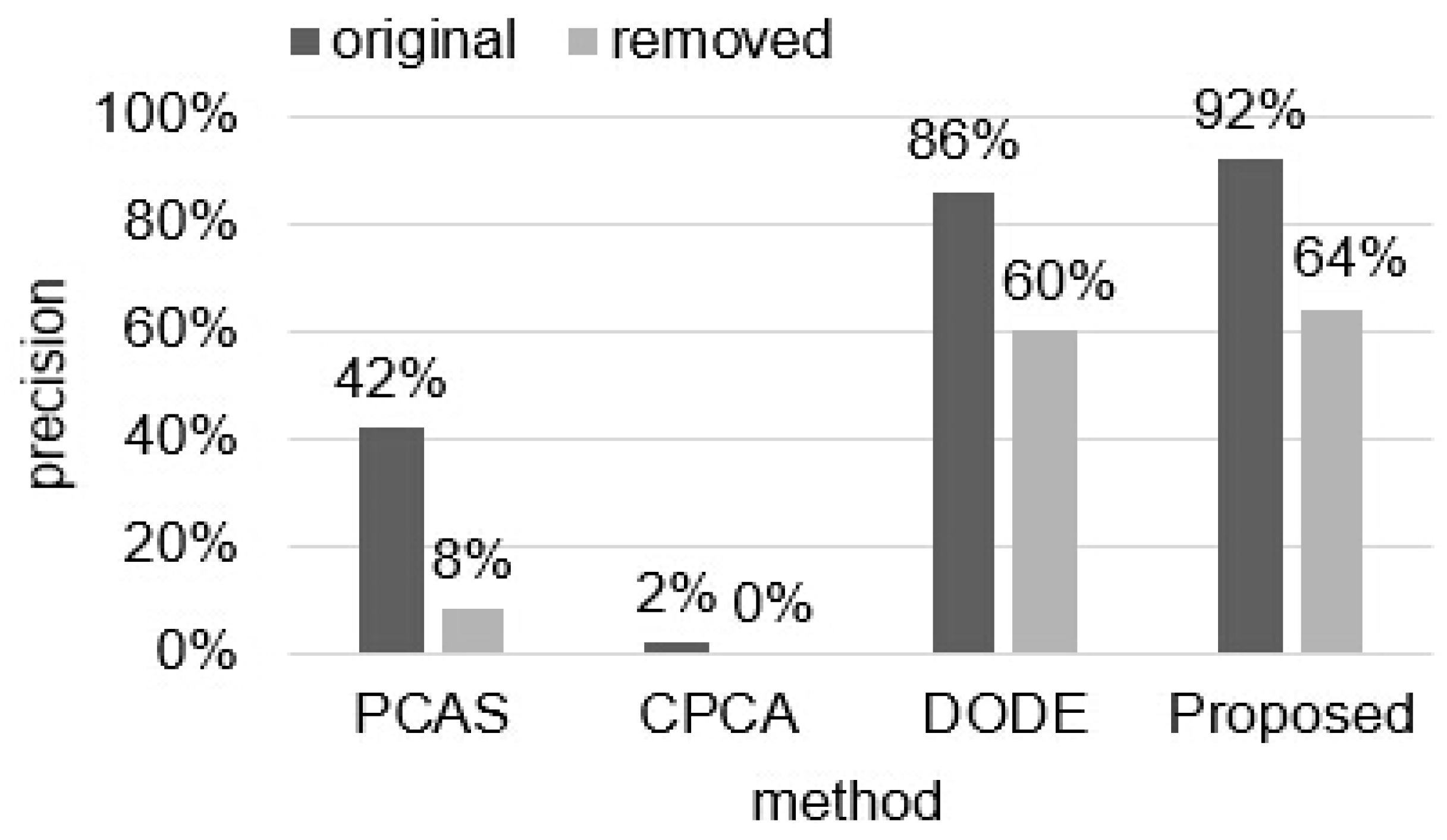
We evaluated the proposed identification method with 1200 non-rigid 3D models in SHREC 2015 benchmark. The models consist of 24 deformed versions of 50 classes. We selected one model for each class to compose 50 query models. We also experimented with the other 3D model identification methods: combination of PCA and SIFT (PCAS) [
9], that of continuous PCA, normal PCA, 2D discrete Fourier transform, and 2D discrete wavelet transform (CPCA) [
10], and that of dodecahedron and SIFT (DODE) [
11]. Two types of experiments were performed to evaluate the performances of the methods. First one is to identify the 50 original query models. Then we removed some parts of the models such as arms and legs. Second experiment is to identify the 50 partially removed query models. The percentage of removal ranges from 6.1% to 33.6%. The average percentage is 13.8%. We set the range of the number of clusters from 1 to 10, which means the 𝐾 is set to 10. Both the sample rate
and the number of rays
are set to be 180. We performed the experiments on an IBM compatible computer with a 3.4 GHz CPU and a 4 GB random-access memory. The average feature size and matching time of the corresponding method for 1200 models are shown in
Table 1. Because of using only one range image, the proposed method provides small size of feature and fast matching speed.
Figure 5 shows the precision of identification for each method. Although the feature size is greatly reduced, the precision is still greater than those of the other 3 methods even with the removed versions.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}