1. Introduction
Deep Neural Networks (DNNs) have shown major state-of-the-art developments in several technology domains, especially speech recognition [
1] and computer vision, specifically in image-based object recognition [
2,
3]. Convolutional neural networks have shown an outstanding performance and reliable results on object detection and recognition, which are beneficial in real-world applications. Simultaneously, there is a great deal of progress in visual recognition tasks, which leads to remarkable advancements in virtual reality (VR by Oculus) [
4], augmented reality (AR by HoloLens) [
5] and smart wearable devices. We urge that it is the right time to put these two pieces together and empower the smart portable devices with modern recognition systems.
Currently, machine learning methods have [
6] turned out to be a core solution to understand the scenes. Most importantly, deep learning has set a benchmark on numerous popular datasets [
7,
8]. Earlier methods have employed convolution networks (CNN/convnets) for semantic segmentation [
9,
10] in which every pixel is labeled with a class of its enclosing region or object. Some of semantic segmentation methods [
11,
12,
13,
14,
15] turned out to be a significant tool for image recognition and scene understanding. It offers a great deal of support for understanding the scenes that frequently vary in appearance and pose. Scene understanding becomes an important research problem, as it can be employed to assess scene geometry and object support relationships, as well. It also has a wide range of applications, varying from autonomous driving to robotic interaction.
Earlier approaches of semantic segmentation are based on Fully-Convolution Neural Networks (FCNs) [
16,
17] and have a number of critical limitations. The first issue is the inconsistent labeling, which emerges from the network’s predefined fixed-size receptive field. In such a situation, the label prediction is carried out only with local information for large objects that leads to an inconsistent labeling for some objects. Furthermore, small objects are often ignored and classified as background. Secondly, the object details are either lost or smooth due to too coarse feature maps while inputting to the deconvolution (De-Conv) layer. The scene understanding methods [
18], which employed the low-level visual features maps, did not offer a substantial performance. Third, the fully-connected layers of the traditional VGG-16 network hold about 90 percent of the parameters of the entire network. This situation leads to a huge number of trainable parameters that requires extra storage and training time. Our motivation for this research is to design a CNN architecture with skip-architecture (mitigating the first problem) and low resolution features mapping (mitigating the second problem) for pixel-wise classification. This architecture will offer an accurate boundary localization and delineation. The next key idea behind this research is to design an efficient architecture that is both space and time efficient. For this purpose, we have discarded the fully-connected layers of the VGG-16 in the encoder architecture of the CNN design. It enables us to train the CNN using the relevant training set and Stochastic Gradient Descent (SGD) [
19] optimization. With a negligible performance loss, we have significantly dropped a number of trainable parameters (mitigating the third problem). The CSSA is a core segmentation engine, which is intended to perform the pixel-wise semantic segmentation for road scene understanding applications like ADAS. The proposed design is intended to have the ability to model appearance (road, building), shape (cars, pedestrians) and recognizing the spatial-relationship (context) among different classes, such as roads and side walks.
Recently, ADAS turned out to be one of the key research areas in visual recognition, which demands various methods and tools to improve and enhance the driving experience. A key aspect of ADAS is to facilitate the driver with the latest surrounding information. These days, critical sensors for production-grade ADAS include sonar, radar and cameras. For long-range detection, ADAS typically utilizes radar, whereas nearby detection is performed through sonar. Recently, computer vision- and CNN-based systems can play a significant role in the pedestrian detection, lane detection and redundant object detection at moderate distances. The radar technology has performed significantly well for detecting vehicles with a deficiency in differentiating between different metal objects. This can register false positives on any metal objects, such as a small tin can. Moreover, sharp bends can make localization difficult for the radar technology. On the other hand, the sonar utility is compromised at high and slow speed, as well as it has a limited working distance of about two meters. In contrast to sonar and radar, cameras offer a richer set of features at lower costs. With a great deal of advancements in computer vision and deep learning, cameras could replace the other sensors for the driving assistance system. Video-based ADAS is intended to provide assistance to drivers in different road conditions [
20]. In typical road scenes, most of the input pixels belong to large classes, such as buildings and roads, and thus, the network must generate a smooth segmentations. Designing a DNN engine that has the capability to delineate and segment moving and other objects based on their shapes despite their small sizes is needed. Therefore, it is significant to keep boundary details in the extracted image representation. From a computational perspective, it is essential for the network to be effective in terms of both computation time and memory during inference. The CSSA is aimed at offering an enhanced performance for the driving assistance system in different road and light conditions. By offering an improved boundary delineation and fast visual segmentation results, the proposed design could be an efficient choice for visual ADAS. The proposed system is trained and tested for the performance of road scene segmentation into 11 classes of interest for the road driving scenario.
The key objective of this research is to propose a more enhanced and efficient CNN model. We have experimented with a number of activation functions (e.g., ReLU, Exponential Linear Units (ELU), PReLU, Maxout, Tanh), pooling methods (e.g., Avg, Max, stochastic), Batch Normalization (BN) methods and dropout units. We have also experimented with a reduced version of the proposed network. After a detailed analysis, the well-performing units are implemented in our final larger version of the proposed network, which is trained over road scene datasets. The proposed network architecture is stable, easy to manage and performs efficiently over all pervious benchmark results. We evaluate the performance of the CSSA on both CamVid and the Pascal VOC-12 datasets.
The remainder of the paper is organized as follows. The first part of this paper presents the related work and an overview of the proposed architecture. The next section is about the system’s working algorithm and architecture. Later, we present the experimentation and related training details. The last section is dedicated to the results and their analysis for the proposed system.
2. Related Work
Convolutional networks have been employed successfully for object detection and classification [
3,
21]. Current models offer methods to classify either a single object’s label for a bounding box of a few objects or a whole input window in each scene. The CNNs have also been applied to a wide diversity of other tasks, e.g., stereo-depth [
22], pose estimation [
23], instance segmentation [
24], and much more [
25,
26]. In such research methodologies, CNNs are either applied to discover local features or to produce descriptors of discrete proposal regions.
Recently, the Fully-Convolutional Network (FCN) [
17] has brought a breakthrough to semantic segmentation. It has offered a powerful approach to enhance the power of CNNs by offering inputs of arbitrary size. The proposed network demonstrates remarkable performance on the PASCAL VOC-12 benchmark dataset. A number of outstanding approaches have been presented to enhance and improve the overall efficiency and performance of CNNs. Initially, this idea was used to extend the classic LeNet [
27] for digit string recognition. Matan et al. [
28] employed Viterbi decoding methods to extract outputs from limited one-dimensional input strings. Later, Wolf and Platt [
29] improved this idea to expand CNN outputs with a new model of two-dimensional maps. This model was used to detect the four corners of a postal address block. These outstanding developments in FCN have established the strong base for future developments in CNNs for detection. Ning et al. [
30] offered a coarse multiclass segmentation CNN for C-Elegans tissues having FCN inference. The proposed network by Chen et al. [
16] attains denser score maps within the FCN architecture to predict pixel-wise labels, as well as refine the label map by means of the fully-connected Conditional Random Field (CRF) [
31]. Later developments in FCN involve semantic pixel labeling that was initially proposed by Shotton et al. named TextonForest [
18] and random forest-based classifiers [
6]. Emerging progress in FCN and pixel-wise segmentation has offered a huge success in object recognition for an entire image.
There are numerous semantic segmentation techniques that are based on classification such as [
12,
32], which offered methods to classify multi-scale superpixels into predefined categories. These studies have also combined the classification results for pixel-wise labeling. A number of algorithms [
10,
33,
34] classify the region proposals and improve the labels in the image-level segmentation map to attain the absolute segmentation. In semantic pixel-wise segmentation [
35] or SfM appearance [
36], feature extraction has been explored for the CamVid [
37] road scene understanding test. In order to improve the accuracy of the network, the classifier’s per-pixel noise predictions were smoothed by pair-wise or higher order CRF [
38].
Using the encoder and decoder to enhance the performance is now a key trend in designing the CNN architectures. The idea was initially presented by Ranzato et al. [
39] with an unsupervised feature learning architecture. Noh et al. [
15] proposed a deconvolution network, which is composed of deconvolution and un-pooling layers, that offers segmentation masks and pixel-wise class labels for the PASCAL VOC-12 dataset [
7]. This work has offered one of the initial successful implementations of deconvolution and un-pooling. With a significant success with encoder-decoder architectures so far, recent CNNs, like SegNet [
40] and Bayesian-SegNet [
41], have been proposed with a core segmentation engine for whole image pixel-wise segmentation. These are initial models that can be trained end-to-end in one step because of their low parameterization.
Recently, ADAS has turned out to be one of the key research areas and demands various methods and tools to improve and enhance the driving experience. Using computer vision and neural networks in ADAS, we can enhance the performance of the auto driving system to a great extent. CSSA is an attempt to harness the CNN power for ADAS, and it offers a more reliable and cost-effective solution. Recently, a number of research works [
42,
43,
44] has offered outstanding solutions, as well as set a baseline for our proposed system.
4. CSSA Architecture
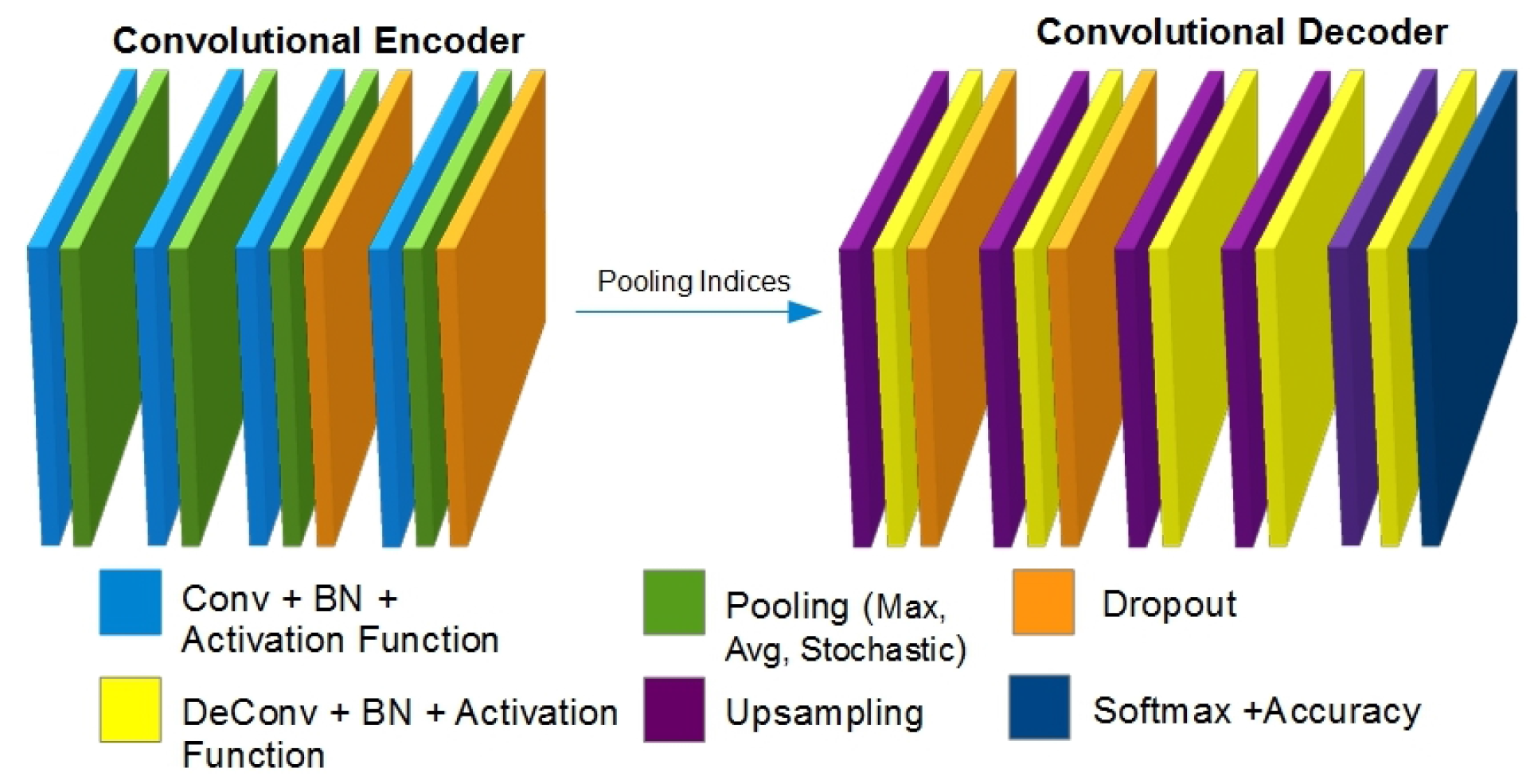
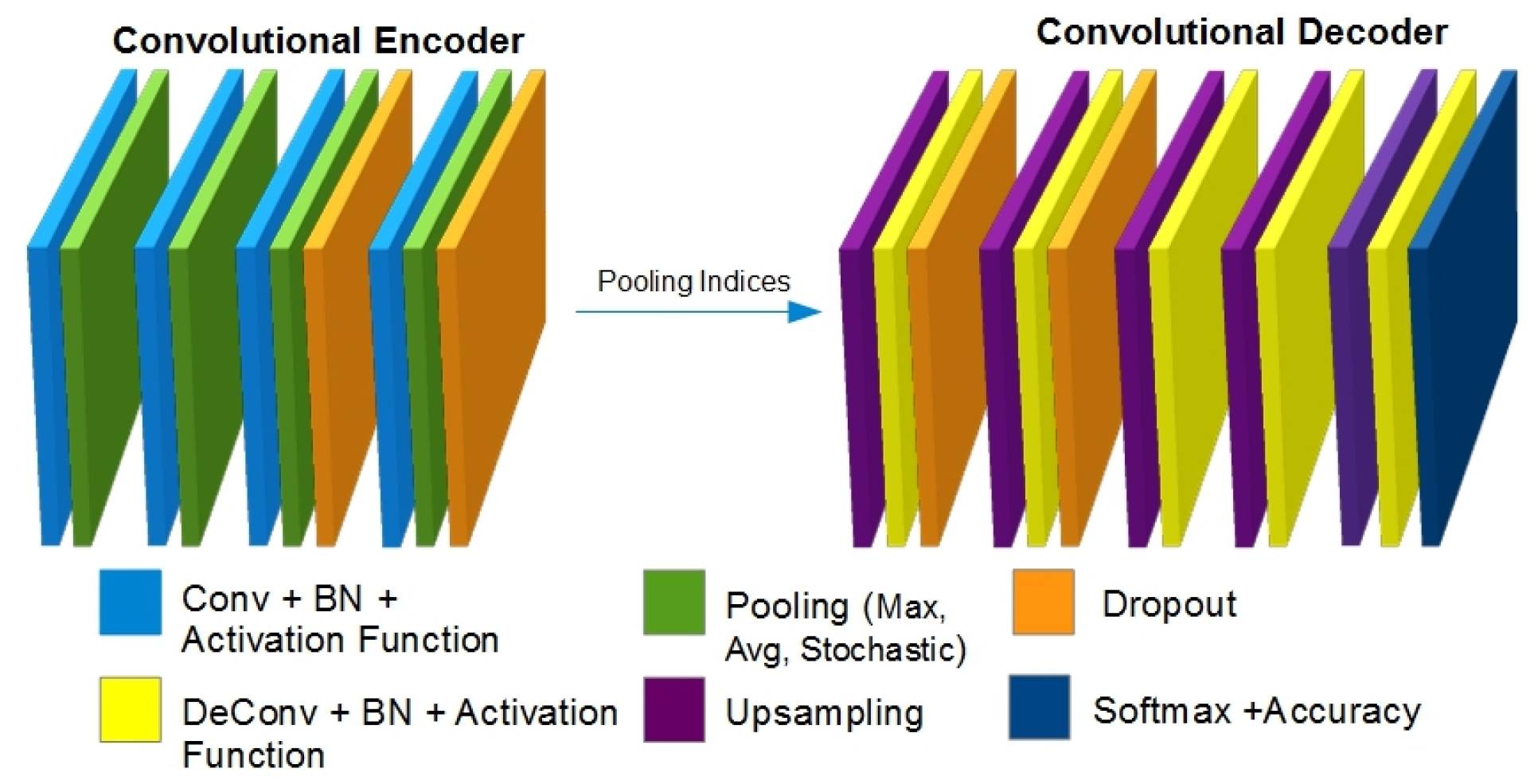
To devise an enhanced and improved architecture, we have initially proposed a smaller version of the original network. This small version is a complete working model with a reduced number of layers. The idea is to perform experiments on the reduced version and to transfer high performance units (pooling methods, activation techniques) to the extended version.
Figure 1 shows the initial base model (reduced version) of the proposed architecture. It is named the Basic Testing CNN Model (BTCM). It is based on encoder-decoder networks, which are presented separately with an image input and a corresponding image output with pixel-wise semantic segmentation.
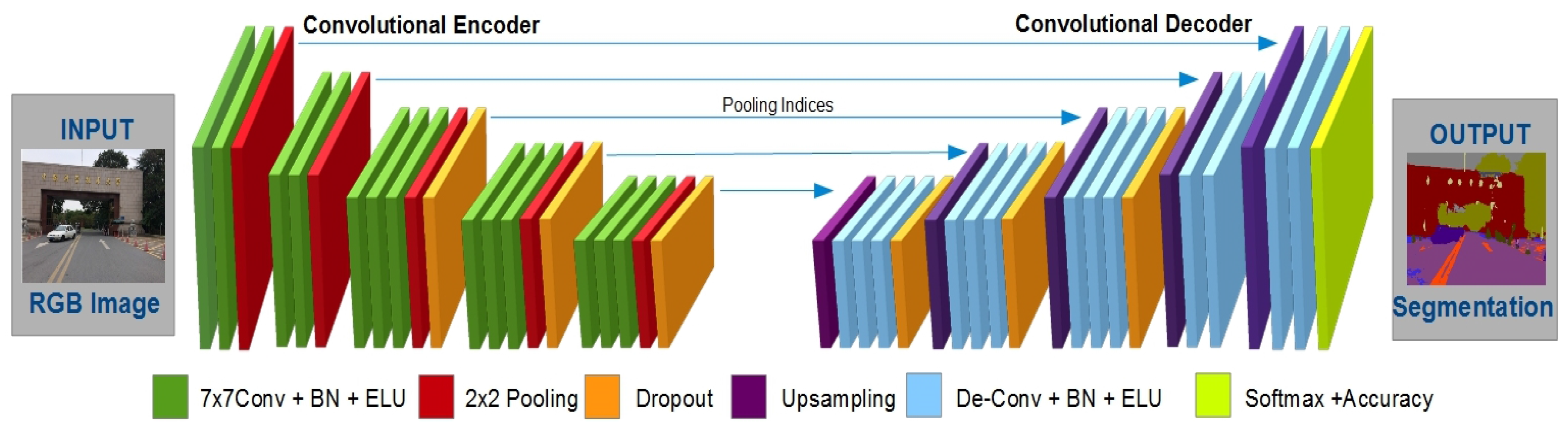
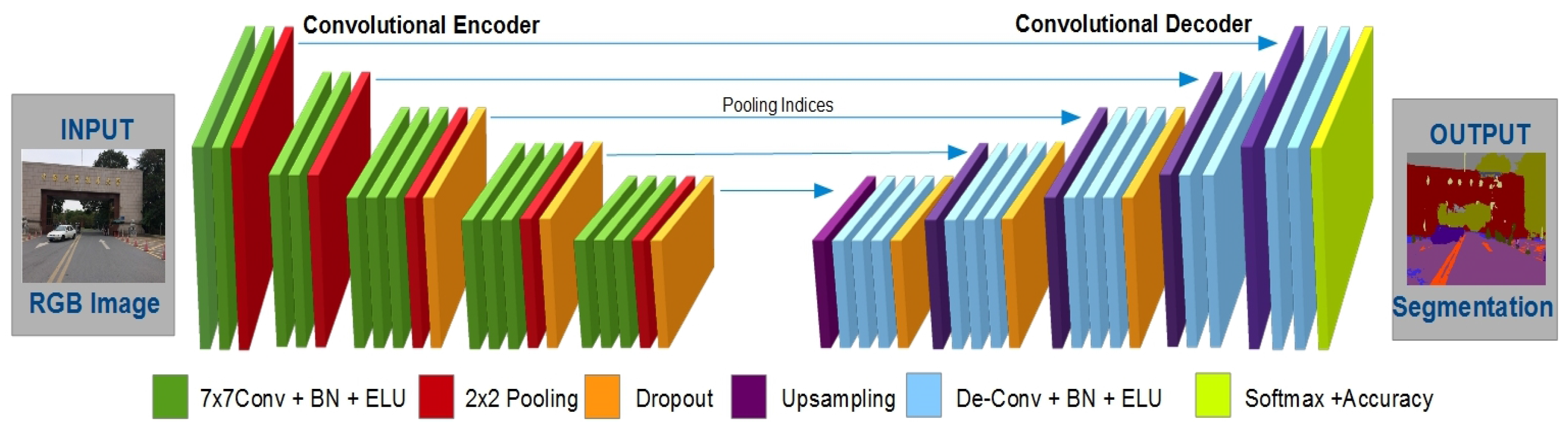
The proposed architecture is a pixel-wise semantic segmentation engine, which is based on two decoupled encoding and decoding FCNs. The aforementioned encoder is based on the initial 13 convolution layers of the VGG-16 [
47] network followed by the batch normalized [
46] layer, an activation function, the pooling layer and dropout [
48] units. Each layer in the proposed CNN is represented by a triplet
, where
I is a set of tensors, and each element
I =
is the input tensor for the
l-th layer of CNN.
W represents the set of tensors, where each element in this set
W =
is the
k-th weight filter in the
l-th CNN layer. Additionally,
is the number of weight filters in the
l-th layer of the proposed CNN. Here, * represents a convolutional operation with its operands
and
, where
∈
in which
c,
and
represent channels, width and height, respectively.
∈
, where
and
. The decoder network is based on up-sampling layers, de-convolution layers, activation functions, batch normalized layers, dropout layers and a multi-class soft-max classifier layer. The whole architecture is based on an encoder-decoder relation where every decoder corresponds to a pooling unit of the encoder. Thus, the decoder CNN possesses 13 de-convolution layers. The decoder feeds its computations to a multi-class soft-max classifier to output the class probabilities intended for every pixel independently.
The network starts its training with an input image and proceeds through the network to final layers. The encoder performs convolution with a set filter banks to yield feature maps, and then, the batch normalization operation is performed. Later, Exponential Linear Units (ELU) [
49] carry out activations. Then, the max-pooling operation is performed with a
window size and stride-rate of two. In this way, the resultant image is sub-sampled by a factor of two. Whereas numerous pooling layers can offer more translation invariance for robust classification tasks, there is an unnecessary loss of spatial resolution of the feature maps. An image with increasingly lossy boundary details is not useful for segmentation tasks. Therefore, for semantic segmentation, boundary delineation is so important. Hence, there is a need for capturing and storing the boundary information in the encoder feature maps prior to the sub-sampling operation. However, due to memory constraints, it is not possible to store all encoder feature maps. The ultimate solution is to store only the max-pooling indices. The locations of every max-pooling feature-map are memorized using two bits for every
pooling window. It is a very efficient solution to keep a large amount of feature maps. This solution offers a great deal of storage efficiency for the encoder, and we can get rid of the
and
layers.
Next, the decoder up-samples or un-pools the input feature map(s) in the decoder network. It utilizes the memorized max-pooling indices from the corresponding encoder’s feature map(s). This step generates sparse feature maps, which are later convolved with a trainable decoder filter bank to generate dense feature maps. The batch normalization is also applied over those maps. Finely, the high dimensional feature map(s) representation is fed to a trainable soft-max classifier that classifies every pixel independently. It outputs a K (number of classes) channel of image probabilities.
6. Results and Analysis
This section will present the overall assessment for trained models and testing results by well-known segmentation and classification performance training measures, such as Global Accuracy (GA) and Class Average Accuracy (CAA). The GA offers an overall percentage of pixels properly classified in the dataset, while CAA is used to assess the predictive accuracy mean of the entire classes. Proposed tests were performed on BTCM with comparatively less training iterations. The proposed network is limited to run for a maximum of 10,000 training transactions to test the ultimate reduction in loss and enhancement in accuracy; whereas the final version of the proposed CNN is trained for 40,000 iterations.
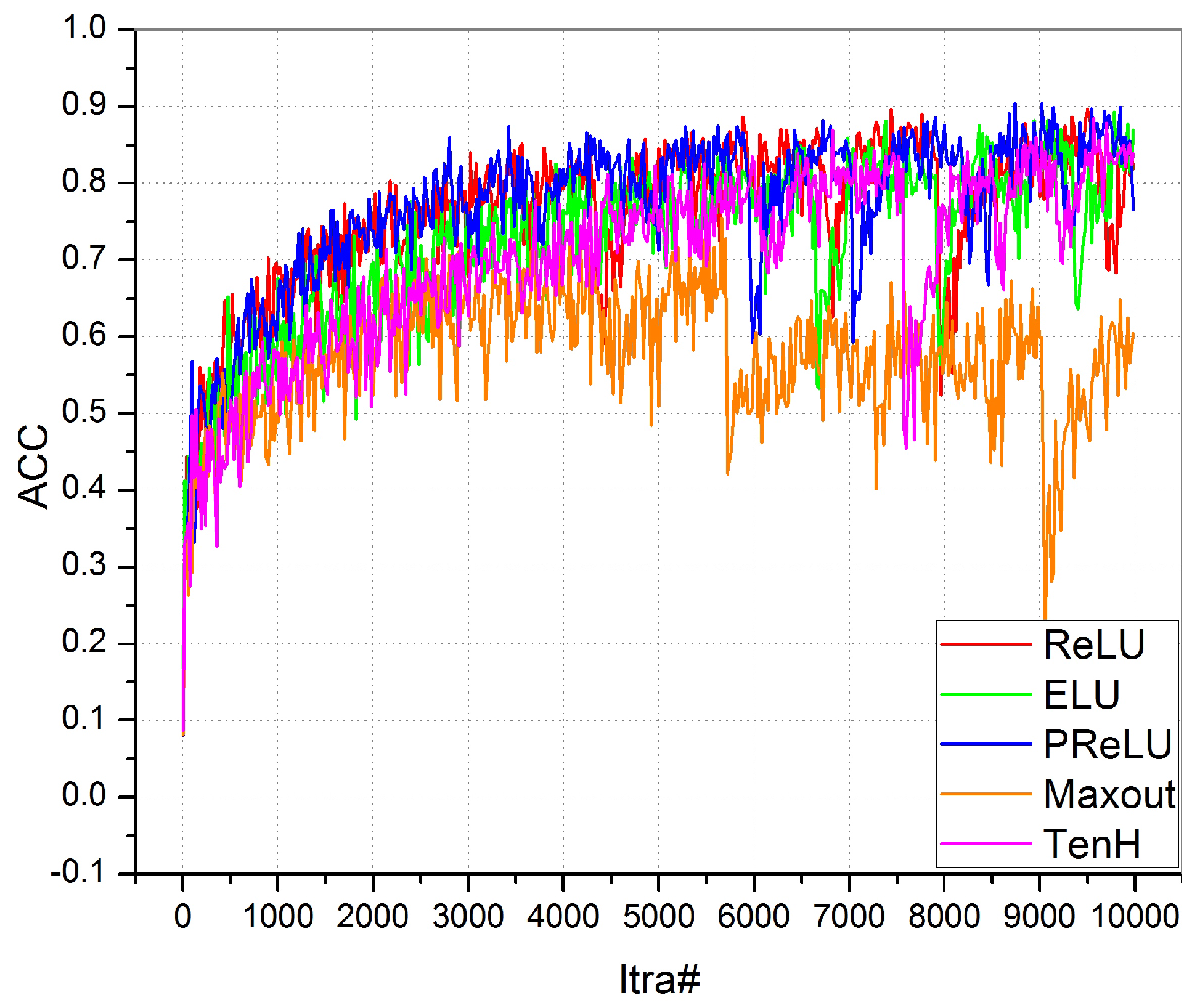
Test 1: Different kinds of tests are performed on BTCM. The proposed model is used for the training efficiency of different activation functions. We have tested for ReLU, ELU, PReLU, Maxout and Tanh. The final outcomes showed that ELU and PReLU are performing better and offer enhanced outcomes. It is assessed that the PReLU performs well throughout the training process, but accuracy declines at the end of the training process, as shown in
Figure 3. The ELU converged to the ultimate peak till the end of the training process.
The Exponential Linear Unit (ELU) with
is:
The ELU hyperparameter manages the given value to which an ELU saturates for negative net-inputs. ELUs reduce the chances of vanishing gradient effect as Leaky ReLUs (LReLUs) and ReLUs do. The problem of the vanishing gradient is eased because the positive part of these functions is the identity; hence, their derivative is one and not contractive. However, sigmoid and tanh activation functions are contractive nearly everywhere. Contrary to ReLUs, ELUs offer negative values, which can push the mean of the activations very near to zero. The closer to zero, the faster the learning by the activation function, as this brings the gradient closer to the natural gradient. ELUs saturate to a negative value when the argument value gets smaller. Saturation means a small derivative that decreases the variation, as well as the information that is transferred to the next layer. Consequently, the representation is both of low-complexity and noise-robust.
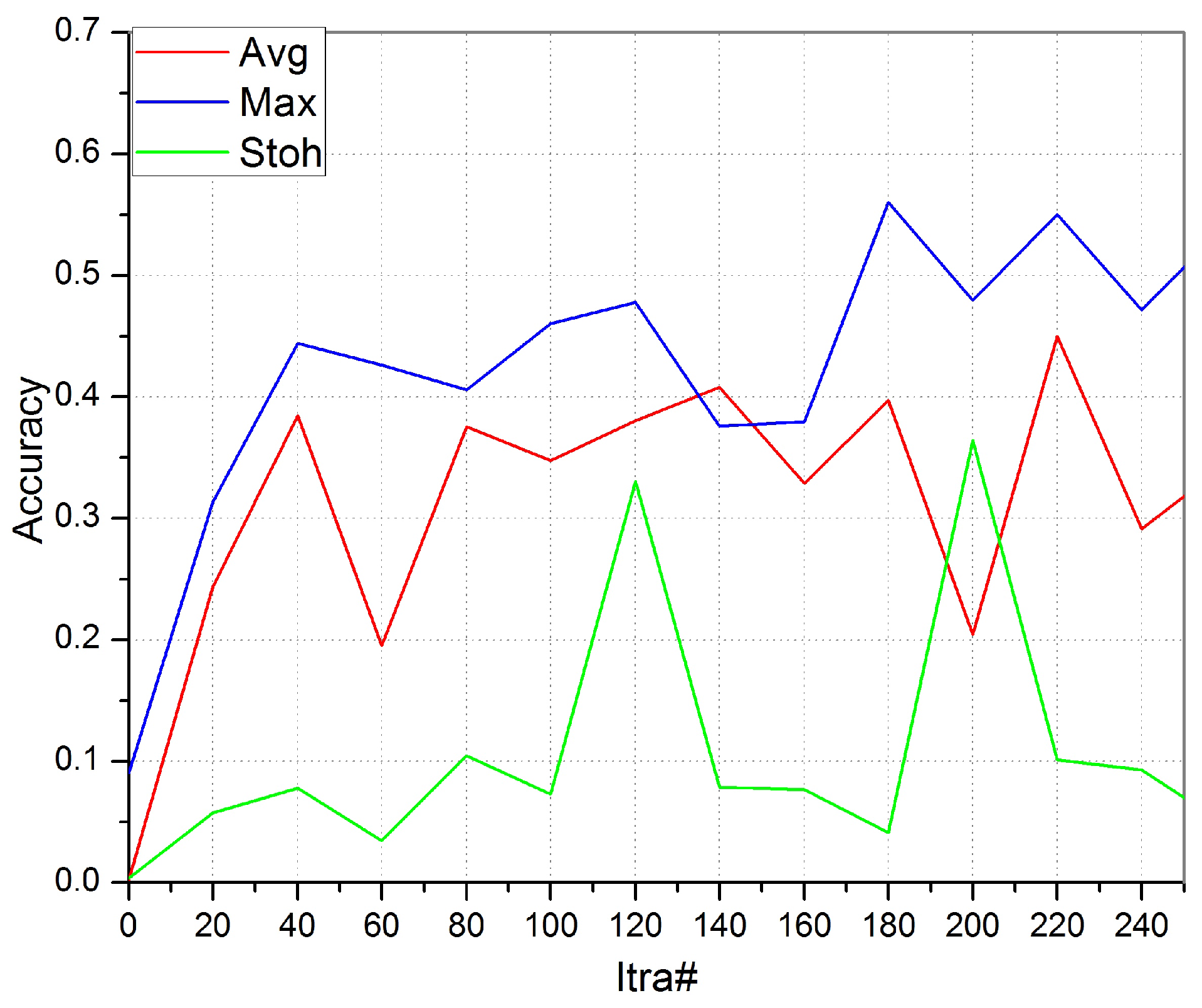
Test 2: In Test 2, the BTCM is tested for different pooling techniques (average, max and stochastic). The final outcomes have shown that the max pooling method is outperforming all existing methods.
Figure 4 shows that the max pooling training accuracy is converging quickly as compared to other methods. The CSSA final version will be trained with the max pooling units.
Test 3: Batch normalization layers offer us a higher accuracy and faster learning at the expense of additional computations and trainable parameters. This leads the learning process to become slower. To assess network performance and train it in a faster way, we have removed BN layers and try to train the network; though, the outcomes are not really encouraging.
Figure 5 shows the final outcomes of the proposed model. The initial loss is too high, and it reduces down too slowly; whereas, the accuracy is improving slowly, and there is no considerable increase in it after a number of training iterations. According to Schilling [
53], besides a certain amount of computational complexity, there are out-weighed benefits attained by introducing the batch normalization unit. It is further mentioned that by reducing the batch size, we can efficiently reduce the batch normalization-associated overheads. It can also be achieved by sparsely distributing normalization layers throughout the CNN architecture. Therefore, the final version of CSSA is trained with sparse BN layers and a small batch size. We set the batch size limit to 12 to avoid BN-associated overheads.
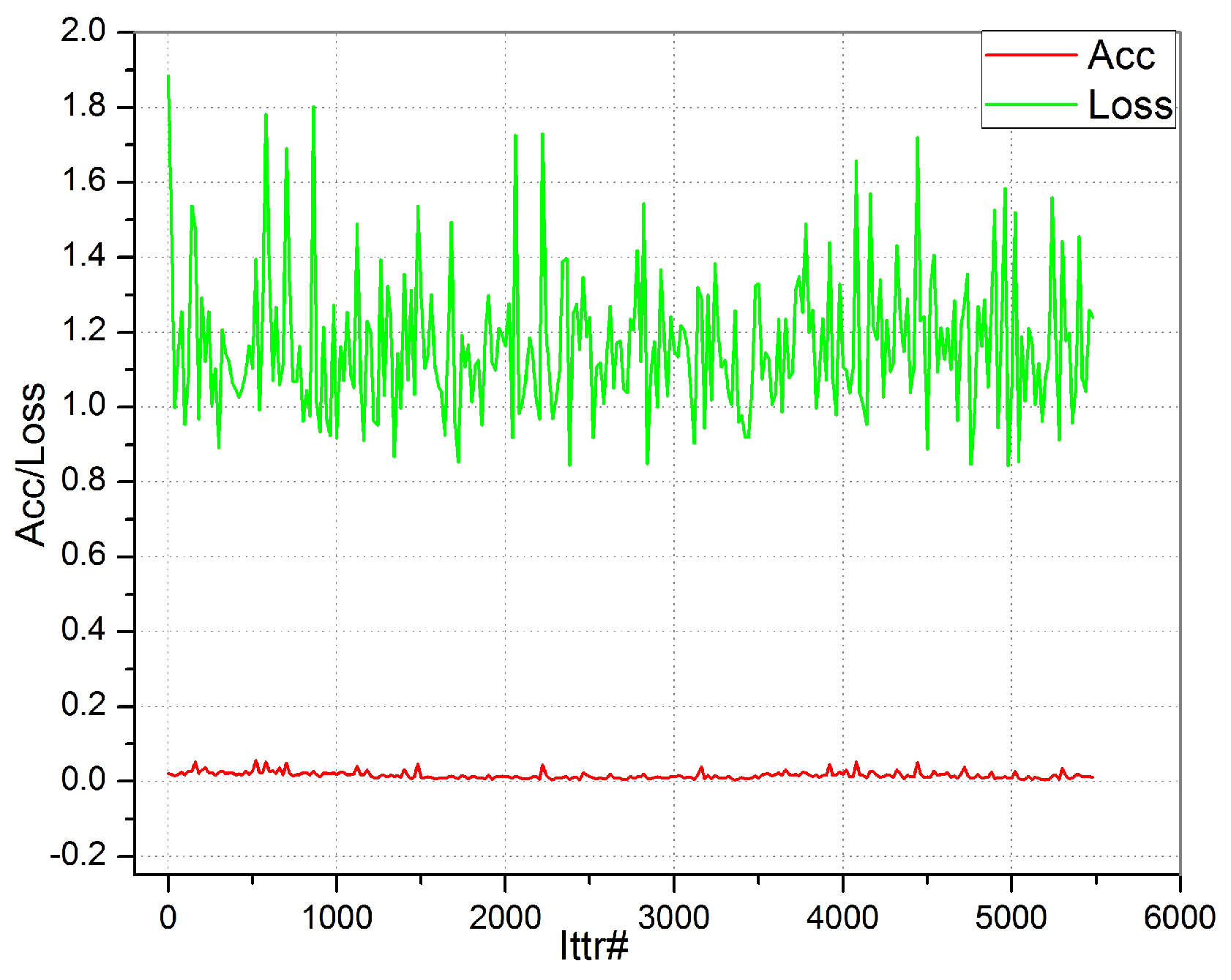
Test 4: To simplify the CNN pipeline, we propose Springenberg et al.’s [
54] inspired BTCM and train it. The results are shown in
Figure 6. It shows a very poor training outcome, where the accuracy remains close to zero, and loss stays higher than one. The outcomes are really discouraging, so this BTCM design is discarded from further analysis. The hypothesis to eliminate the pooling layer for the sake of network simplicity is not successful due to the whole network getting degraded through consecutive convolutions. Therefore, for the final CSSA experimentation, we eliminate the current BTCM and continue with max pooling units.
Test 5: The CSSA is a VGG-16-based model. Its architecture is shown in
Table 1. It is composed of the best performing ELU activation function, the max pooling unit and BN layer. The aforementioned whole network is based on an encoder-decoder arrangement, which is trained end-to-end over the Pascal VOC-12 and CamVid datasets.
The final results are assessed with benchmark results, and it is noticed that the proposed network out-performer with an improved ELU activation function and other units.
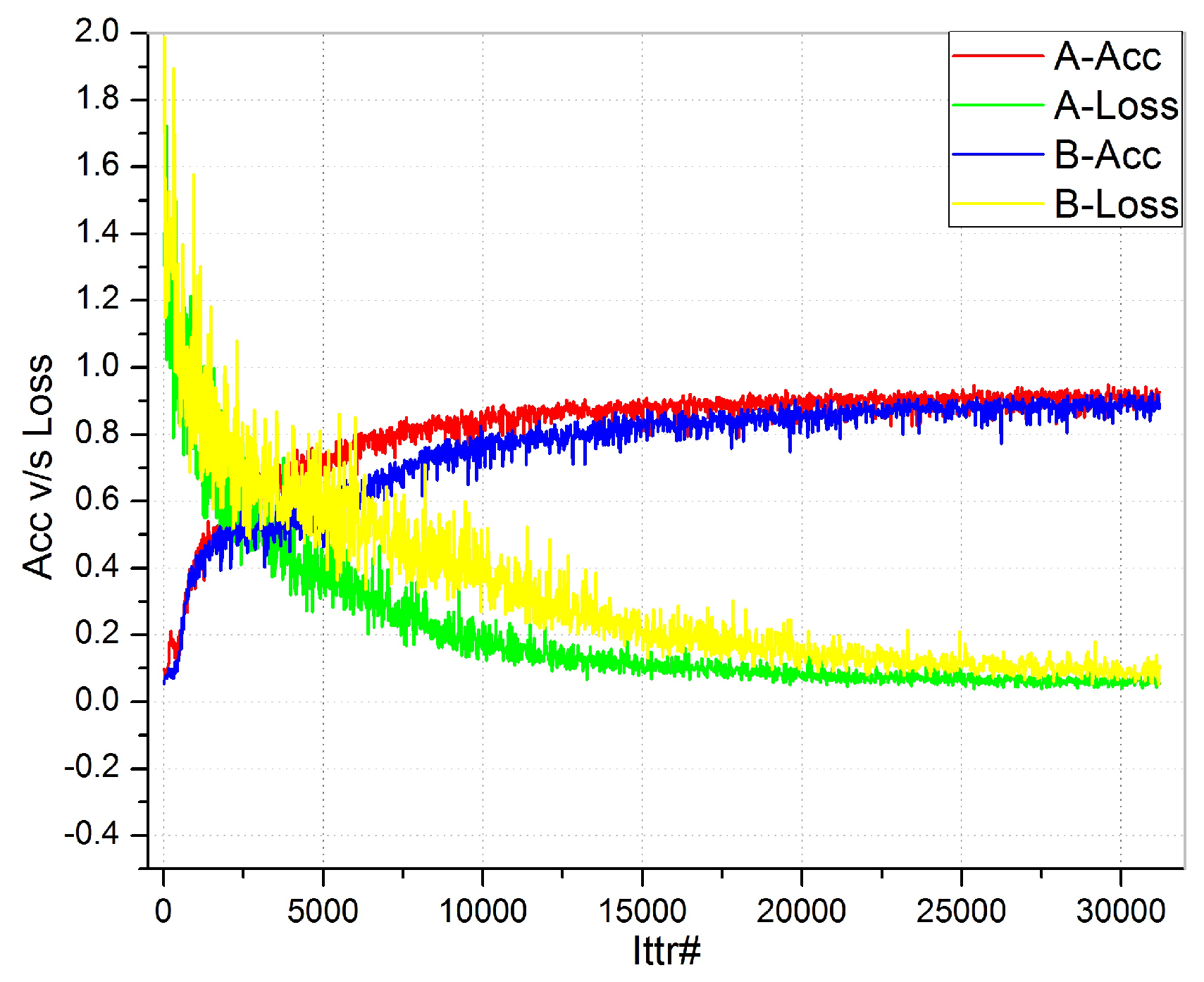
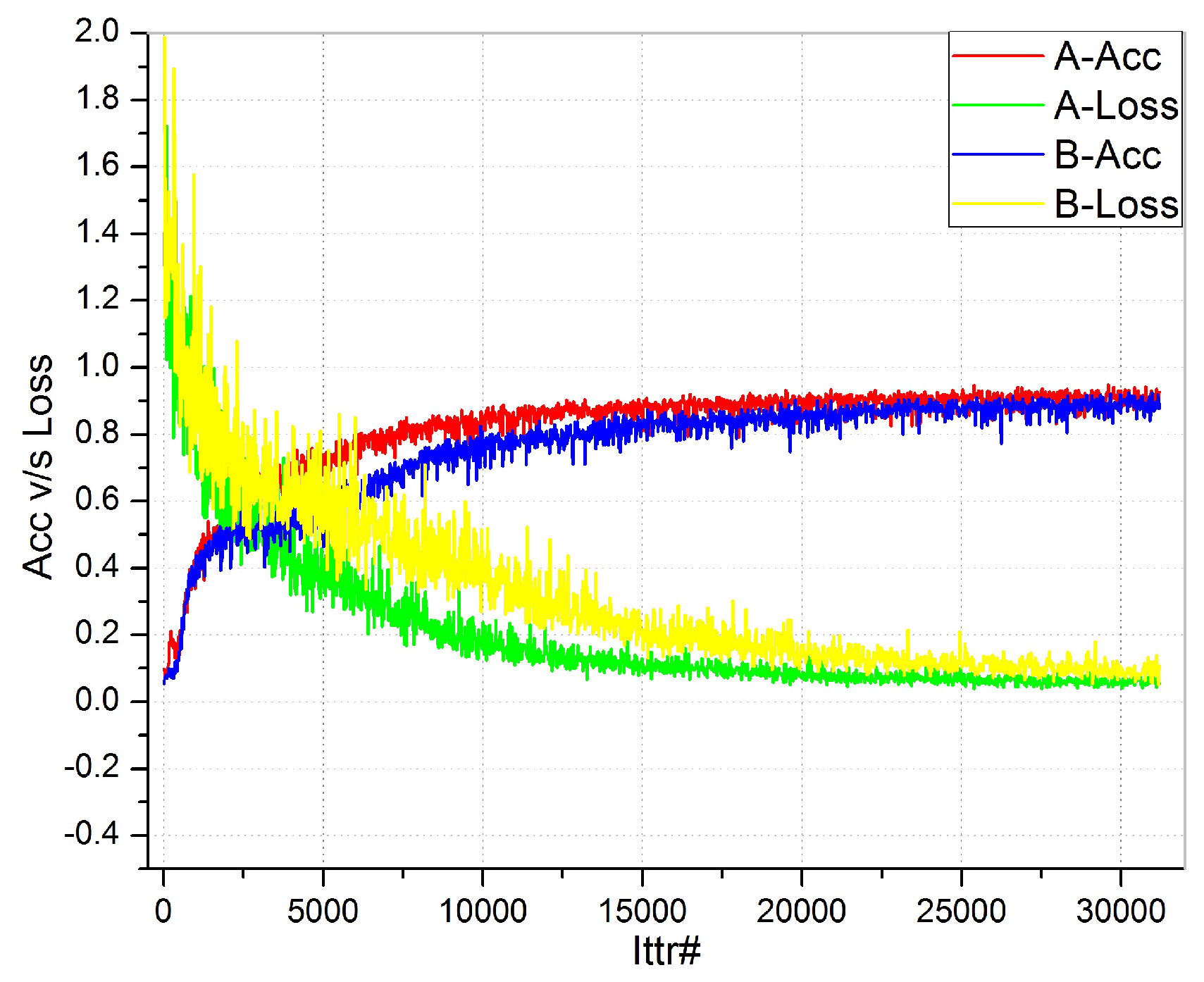
Figure 7 shows the accuracy vs. loss comparison of our proposed network. The “
x-axis” shows the number of training iterations, while the “
y-axis” shows the training accuracy and loss. We set a low learning rate that helps us to reduce training loss very slowly. After analyzing the curves, it can be claimed that our proposed network achieves a good learning rate, as the “red” accuracy curve moves smoothly, and finally, it attains the best performance. A similar smoothness is achieved with the “green” loss curve. It can be observed that the loss is gradually decreasing and accuracy is improving alongside, until they become constant. It is the ultimate performance of the CSSA network. “A” is the proposed network, while “B” is SegNet, which is used as the benchmark result for analysis. It can be clearly observed that the proposed network is performing well with perfect converging loss and accuracy curves as compared to its counterpart.
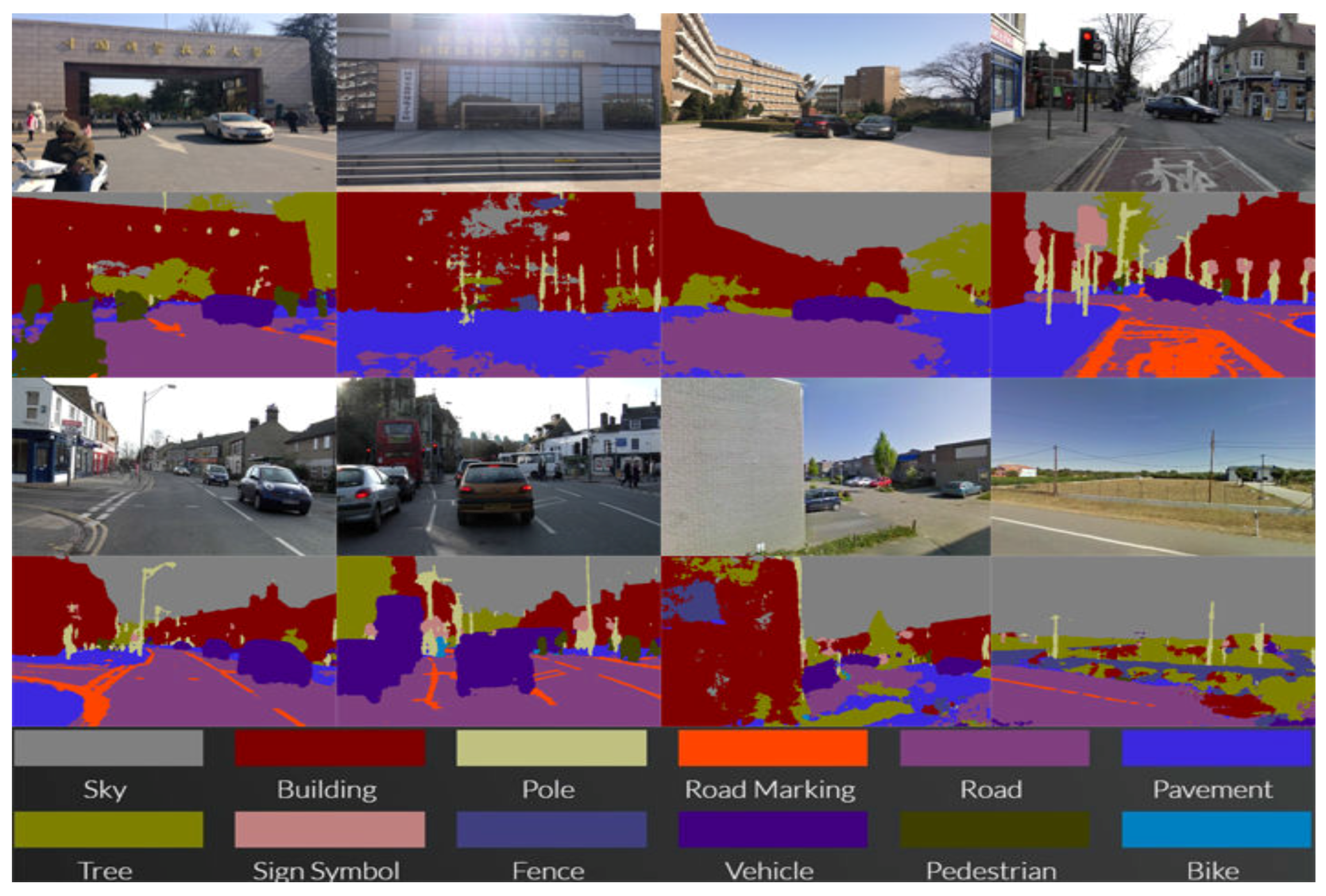
Figure 8 shows different road-scene training and testing set images and their corresponding results. The resultant images show clear boundary delineation among different object. It also shows a significantly efficient result regarding the detection of objects in a given image.
Table 2 shows quantitative results on the CamVid dataset. Our proposed CSSA results are compared with other popular benchmark results. The road scene detection process comprises 11 road scene categories. The proposed CSSA outperforms over all other methods. There is a great deal of improvement in class average accuracy and global accuracy for the smaller classes.
The Pascal VOC-12 [
7] segmentation dataset is composed of the segmentation of a few salient object classes with usually a variable background class. It is different from earlier segmentation for road scene understanding benchmarks, which need to learn both classes and their spatial context.
Table 3 presents the Pascal VOC-12 segmentation challenge results in comparison with established benchmark results. The proposed CSSA is intended for road scene understanding; therefore, we do not intend to benchmark this experiment to attain the top rank in the Pascal VOC-12 segmentation challenge. Therefore, the CSSA is not trained by using multi-stage training [
17] or post-processing, which uses CRF-based methods [
15,
16]. The CSSA network is trained end-to-end without any other assistance, and
Table 3 presents the resultant performance. Early best-performing benchmark networks are either very large [
15] and/or they use a CRF (such as [
66] use Recurrent Neural Networks (RNNs)). In contrast, the key object behind CSSA implementation is to reduce the number of trainable parameters and improve overall inference time without other aids. We have reported results in terms of class average accuracy and the size of the network.
There is little loss recorded in the performance due to dropping fully-connected layers. However, this reduces the size of CSSA and offers us the capability to train the network end-to-end. Although it may be argued that bigger and denser CNNs can have outstanding performance, it is at the cost of increased memory requirements and longer inference time. This kind of architecture also leads to a complex training mechanism. Due to such kinds of bottlenecks, bigger and denser CNNs are not appropriate for real-time applications, such as road scene understanding. Therefore, the CSSA could be a preferred choice for the ADAS architecture.
According to a report by [
67], during 1990–2010, 54 million people were injured in roadside accidents. About 1.4 million deaths occurred since 2013, and in 68,000 cases, the victims were children less than five years old. In all of these cases, 93 percent of crashes were due to driver error/ human factors. Thus, to avoid such situations, there is a new technology-based ADAS solution, which is the ultimate choice. Since the initiation of the autonomous vehicles grand challenges by DARPA [
68], there has been an explosion in research for designing and developing of driving assistance systems. A number of automakers have initiated vehicle ADAS to mitigate driver stress and fatigue to offer additional safety features. However, self-driving cars are over promised and under delivered so far. Society of Automotive Engineers (SAE) [
69] has proposed five levels of vehicle automation in which we still stand on Level 3. The key reason is the lack of efficient technology and expensive solutions. These days, headway sensors (short range and long radars) are used in cars for ADAS. However, these solutions are expensive and prone to some of road conditions (corners, narrow turns, etc.). However, some vision-based applications, such as the “German Traffic Sign Recognition System” by Stallkamp et al. [
70], have attained 99 percent accuracy. These kinds of achievements had opened new horizons for vision-based applications for road scene understanding and ADAS. From traffic sign detection [
71] to pedestrian detection [
72], CNNs are offering a great deal of support and capability to attain the SAE five-level goals in the near future. The proposed CSSA is a small step toward achieving this great goal. It offers a higher accuracy rate for 11 road objects. This CNN could be trained and transformed according to any image size and requirements. It is a low cost and efficient solution for ADAS, will offer a more efficient performance and could be adopted as the video component for the ADAS toolkit. To enhance the potential performance of the proposed system, a larger road scene dataset is needed. By using existing sensors, such as mm-accurate GPS and LiDAR [
44], and calibrating them with cameras, a more comprehensive video dataset could be created. This dataset will contain the labeled lane-markings and annotated vehicles with location and relative speed. In this way, a labeled dataset with diverse driving situations (snow, rain, day, night, etc.) could be created. Training the proposed CNN on such a dataset would offer a robust ADAS support system.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}