1. Introduction
Artificial neural network (ANN) models have been widely used for prediction and forecast in various areas including finance, medicine, power generation, water resources and environmental sciences. Although the basic concept of artificial neurons was first proposed in 1943 [
1], applications of ANNs have blossomed after the introduction of the back-propagation (BP) training algorithm for feedforward ANNs in 1986 [
2], and the explosion in the capabilities of computers accelerated the employment of ANNs. The ANN models have also been used in various coastal and nearshore research [
3,
4,
5,
6,
7,
8,
9,
10].
An ANN model is a data-driven model aiming to mimic the systematic relationship between input and output data by training the network based on a large amount of data [
11]. It is composed of the information-processing units called neurons, which are fully connected with different weights indicating the strength of the relationships between input and output data. Biases are also necessary to increase or decrease the net input of the neurons [
12]. With the randomly selected initial weights and biases, the neural network cannot accurately estimate the required output. Therefore, the weights and biases are continuously modified by the so-called training so that the difference between the model output and target (observed) value becomes small. To train the network, the error function is defined as the sum of the squares of the differences. To minimize the error function, the BP training approach generally uses a gradient descent algorithm [
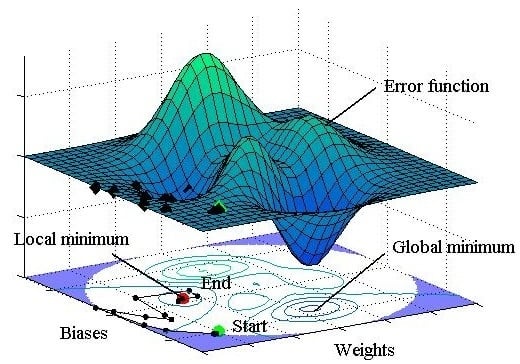
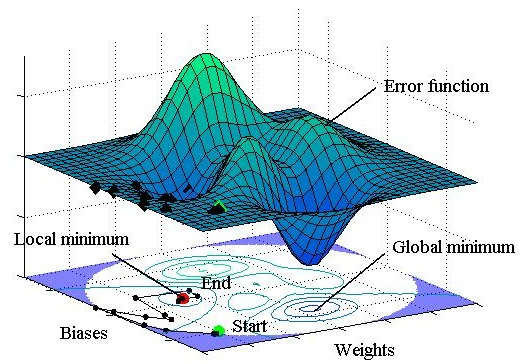
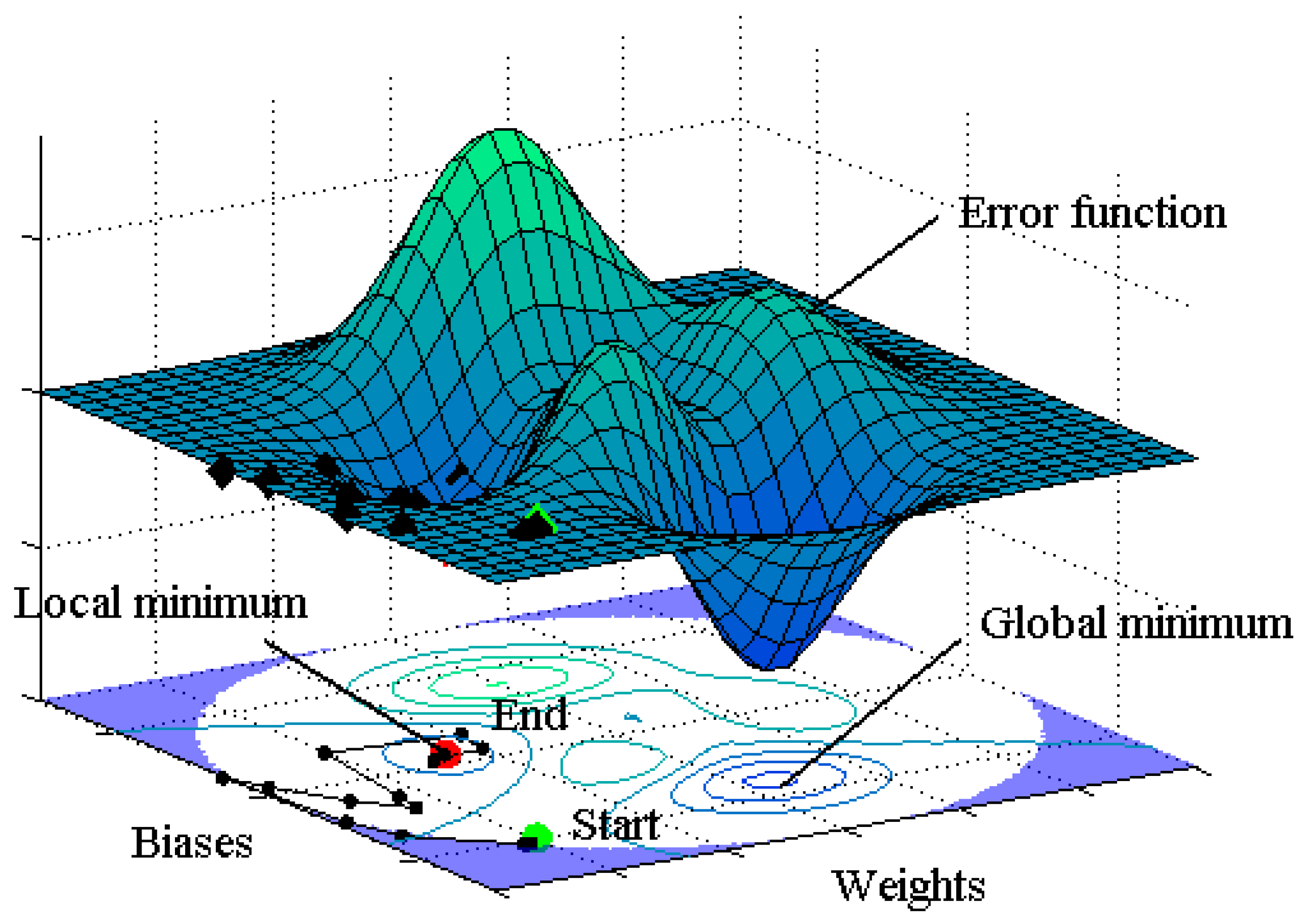
11]. However, it can give a local minimum value of the error function as shown in
Figure 1, and it is sensitive to the initial weights and biases. In other words, the gradient descent method is prone to giving a local minimum or maximum value [
13,
14]. If the initial weights and biases are fortunately selected to be close to the values that give the global minimum of the error function, the global minimum would be found by the gradient method. On the other hand, as expected in most cases, if they are selected to be far from the optimal values as shown by ‘Start’ in
Figure 1, the final destination would be the local minimum that is marked by ‘End’ in the figure. As a consequence of local minimization, most ANNs provide erroneous results.
To find the optimal initial weights and biases that lead into the global minimum of the error function, a Monte-Carlo simulation is often used, which, however, takes a long computation time. Moreover, even if we find the global optimal weights and biases by the simulation, they cannot be reproduced by the general users of the ANN model. Research has been performed to reveal and overcome the problem of local minimization in the ANN model. Kolen and Pollack [
15] demonstrated that the BP training algorithm has large dependency on the initial weights by performing a Monte Carlo simulation. Yam and Chow [
16] proposed an algorithm based on least-squares methods to determine the optimal initial weights, showing that the algorithm can reduce the model’s dependency on the initial weights. Recently, genetic algorithms have been applied to find the optimal initial weights of ANNs and to improve the model accuracy [
17,
18,
19]. Ensemble methods have also been implemented to enhance the accuracy of the model. They are also shown to overcome the dependency of the ANN model not only on the initial weights but also on training algorithms and data structure [
20,
21,
22,
23].
In this study, we employ the harmony search (HS) algorithm to find the near-global optimal initial weights of ANNs. It is a music-based metaheuristic optimization algorithm developed by Geem
et al. [
24] and has been applied to many different optimization problems such as function optimization, design of water distribution networks, engineering optimization, groundwater modeling, model parameter calibration,
etc. The structure of the HS algorithm is much simpler than other metaheuristic algorithms. In addition, the intensification procedure conducted by the HS algorithm encourages speeding up the convergence by exploiting the history and experience in the search process. Thus, the HS algorithm in this study is expected to efficiently find the near-global optimal initial weights of the ANN. We develop an HS-ANN hybrid model to predict the stability number of armor stones of a rubble mound structure, for which a great amount of experimental data is available and thus several pieces of research using ANN models have been performed previously. The developed HS-ANN model is compared with the conventional ANN model without the HS algorithm in terms of the capability to find the global minimum of an error function. In the following section, previous studies for estimation of stability number are described; then, the HS-ANN model is developed in
Section 3; the performance of the developed model is described in
Section 4; and, finally, major conclusions are drawn in
Section 5.
2. Previous Studies for Estimation of Stability Number
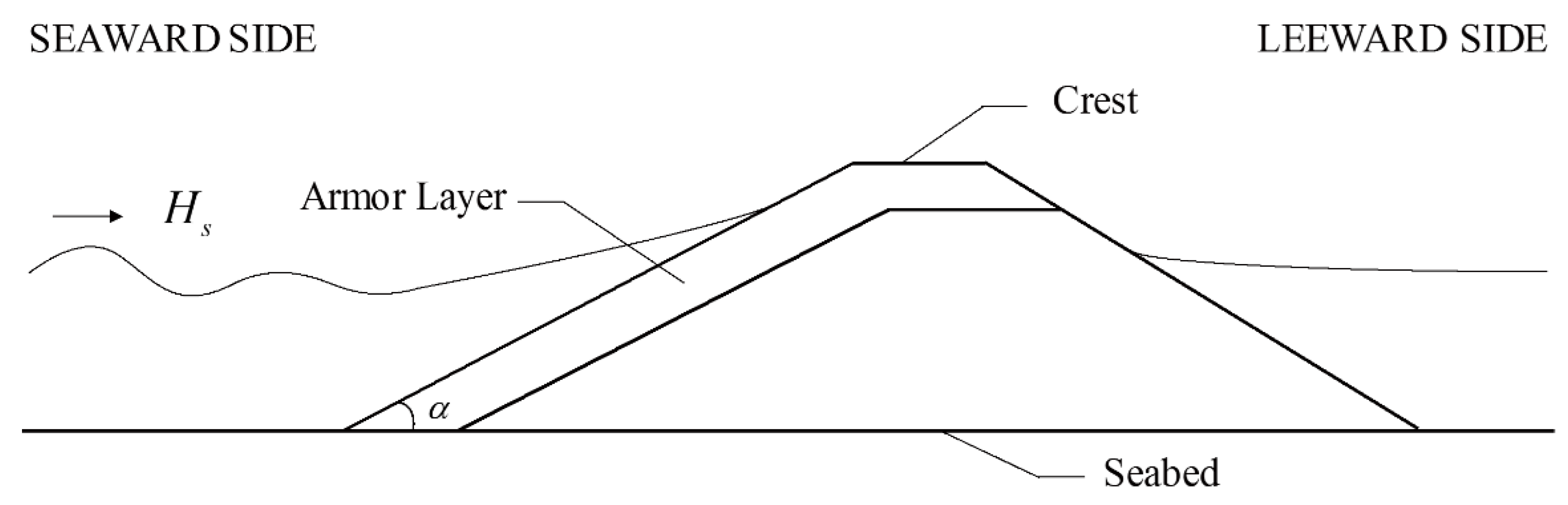
A breakwater is a port structure that is constructed to provide a calm basin for ships and to protect port facilities from rough seas. It is also used to protect the port area from intrusion of littoral drift. There are two basic types of breakwater: rubble mound breakwater and vertical breakwater. The cross section of a typical rubble mound breakwater is illustrated in
Figure 2. To protect the rubble mound structure from severe erosion due to wave attack, an armor layer is placed on the seaward side of the structure. The stability of the armor units is measured by a dimensionless number, so-called stability number, which is defined as
where
is the significant wave height in front of the structure,
is the relative mass density,
and
are the mass densities of armor unit and water, respectively, and
is the nominal size of the armor unit. As shown in Equation (1), the stability number is defined as the ratio of the significant wave height to the size of armor units. A larger stability number, therefore, signifies that the armor unit with that size is stable against higher waves, that is, the larger the stability number, the more stable the armor units against waves.
To estimate the stability number, it is required to determine the relationship between the stability number and other variables which would describe the characteristics of waves and structure. Hudson [
25] proposed an empirical formula:
where
is the angle of structure slope measured from horizontal, and
is the stability coefficient which depends on the shape of the armor unit, the location at the structure (
i.e., trunk or head), placement method, and whether the structure is subject to breaking wave or non-breaking wave. The Hudson formula is simple, but it has been found to have a lot of shortcomings.
To solve the problems of the Hudson formula, Van der Meer [
26] conducted an extensive series of experiments including the parameters which have significant effects on armor stability. Based on the experimental data, empirical formulas were proposed by Van der Meer [
26,
27] as follows:
where
is the surf similarity parameter based on the average wave period,
,
is the critical surf similarity parameter indicating the transition from plunging waves to surging waves,
is the permeability of the core of the structure,
is the number of waves during a storm, and
(where
is the eroded cross-sectional area of the armor layer) is the damage level which is given depending on the degree of damage, e.g., onset of damage or failure.
On the other hand, with the developments in machine learning, various data-driven models have been developed based on the experimental data of Van der Meer [
26]. A brief summary is given here only for the ANN models. Mase
et al. [
3] constructed an ANN by using randomly selected 100 experimental data of Van der Meer [
26] for training the network. The total number of experimental data excluding the data of low-crested structures was 579. In the test of the ANN, they additionally used the 30 data of Smith
et al. [
28]. They employed six input variables:
,
,
,
,
, and the spectral shape parameter
, where
is the water depth in front of the structure. Kim and Park [
6] followed the approach of Mase
et al. [
3] except that they used 641 data including low-crested structures. Since, in general, the predictive ability of an ANN is improved as the dimension of input variables increases, they split the surf similarity parameter into structure slope and wave steepness, and the wave steepness further into wave height and period. Note that the surf similarity parameter
consists of structure slope, wave height and period as shown in its definition below Equation (3), where
is the wave steepness. They showed that the ANN gives better performance as the input dimension is increased. On the other hand, Balas
et al. [
9] used principal component analysis (PCA) based on 554 data of Van der Meer [
26] to develop hybrid ANN models. They created four different models by reducing the data from 544 to 166 by using PCA or by using the principal components as the input variables of the ANN.
Table 1 shows the correlation coefficients of previous studies, which will be compared with those of the present study later.
3. Development of an HS-ANN Hybrid Model
3.1. Sampling of Training Data of ANN Model
The data used for developing an ANN model is divided into two parts: the training data for training the model and the test data for verifying or testing the performance of the trained model. The training data should be sampled to represent the characteristics of the population. Otherwise, the model would not perform well for the cases that had not been encountered during the training. For example, if a variable of the training data consists of only relatively small values, the model would not perform well for large values of the variable because the model has not experienced the large values and vice versa. Therefore, in general, the size of the training data is taken to be larger than that of the test data. In the previous studies of Mase
et al. [
3] and Kim and Park [
6], however, only 100 randomly sampled data were used for training the models, which is much smaller than the total number of data, 579 or 641. This might be one of the reasons why the ANN models do not show superior performance compared with the empirical formula (see
Table 1).
To overcome this problem, the stratified sampling method is used in this study to sample 100 training data as in the previous studies while using the remaining 479 data to test the model. The key idea of stratified sampling is to divide the whole range of a variable into many sub-ranges and to sample the data so that the probability mass in each sub-range becomes similar between sample and population. Since a number of variables are involved in this study, the sampling was done manually. There are two kinds of statistical tests to evaluate the performance of stratified sampling,
i.e., parametric and non-parametric tests. Since the probability mass function of each variable in this study does not follow the normal distribution, the chi-square (
) test is used, which is one of the non-parametric tests. The test is fundamentally based on the error between the assumed and observed probability densities [
29]. In the test, each of the range of the
observed data is divided into
sub-ranges. In addition, the number of frequencies (
) of the variable in the
th sub-range is counted. Furthermore, the observed frequencies (
) and the corresponding theoretical frequencies (
) of an assumed distribution are compared. As the total sample points
tends to
, it can be shown [
30] that the quantity,
, approaches the
distribution with
degree of freedom, where
is the number of parameters in the assumed distribution.
is set to zero for non-normal distribution. The observed distribution is considered to follow the assumed distribution with the level of significance
if
where
indicates the value of the
distribution with
degree of freedom at the cumulative mass of
. In this study, a 5% level of significance is used.
Table 2 shows the input and output variables in the ANN model. The surf similarity parameter was split into
,
, and
as done by Kim and Park [
6]. The peak period,
, was used instead of
because it contains the information about spectral peak as well as mean wave period. The neural network can deal with qualitative data by assigning the values to them. The permeability coefficients of impermeable core, permeable core, and homogeneous structure are assigned to 0.1, 0.5, and 0.6, respectively, as done by Van der Meer [
27]. On the other hand, the spectral shapes of narrowband, medium-band (
i.e., Pierson-Moskowitz spectrum), and wideband are assigned to 1.0, 0.5, and 0, as done by Mase
et al. [
3]. To perform the chi-square test, the range of each variable was divided into eight to 11 sub-ranges. The details of the test can be found in the thesis of Lee [
31]. Here, only the residual chart calculated based on Equation (4) is presented in
Table 3. Some variables are well distributed over the whole range, whereas some varies among a few sub-ranges (e.g.,
0.1, 0.5, or 0.6).
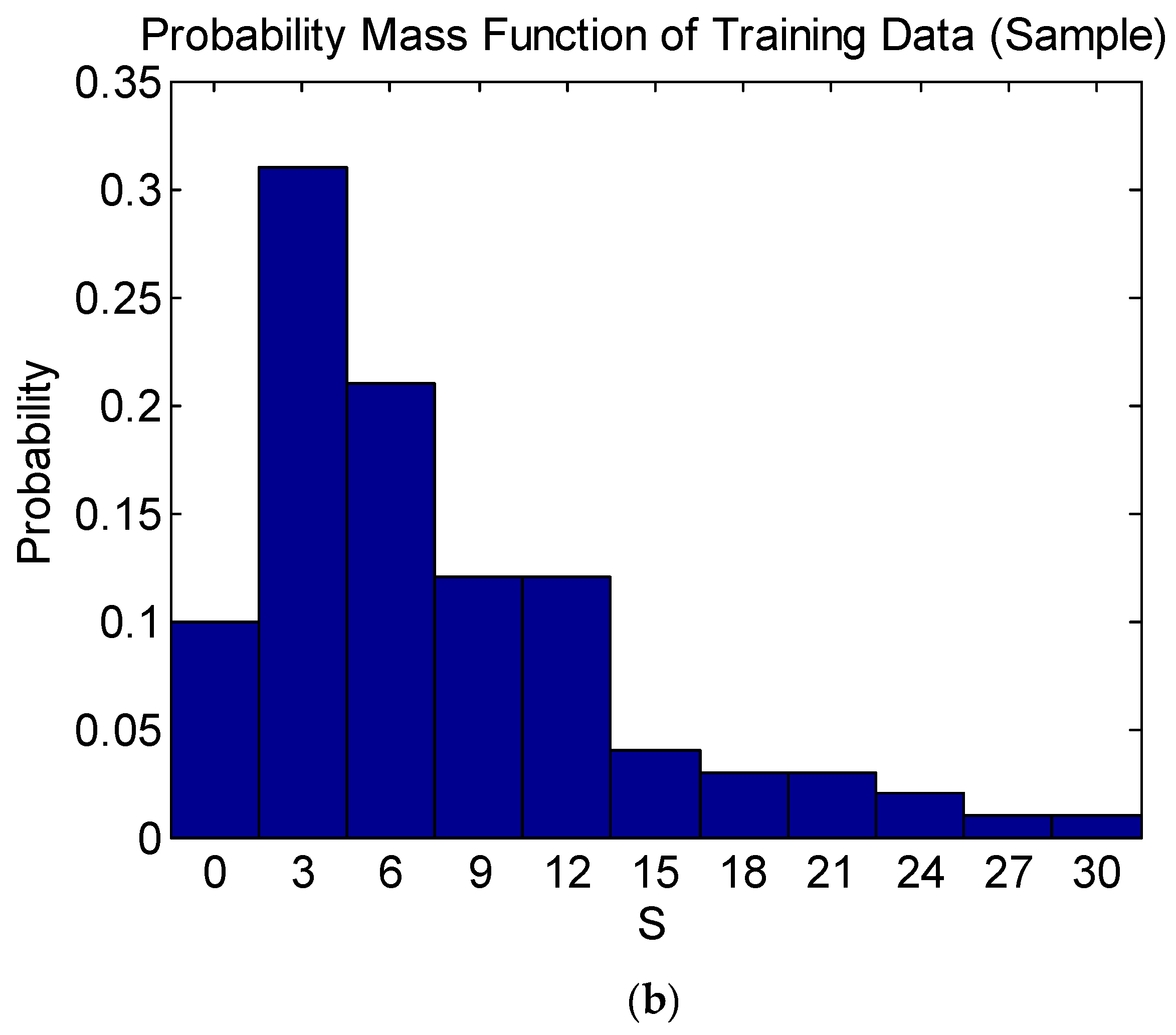
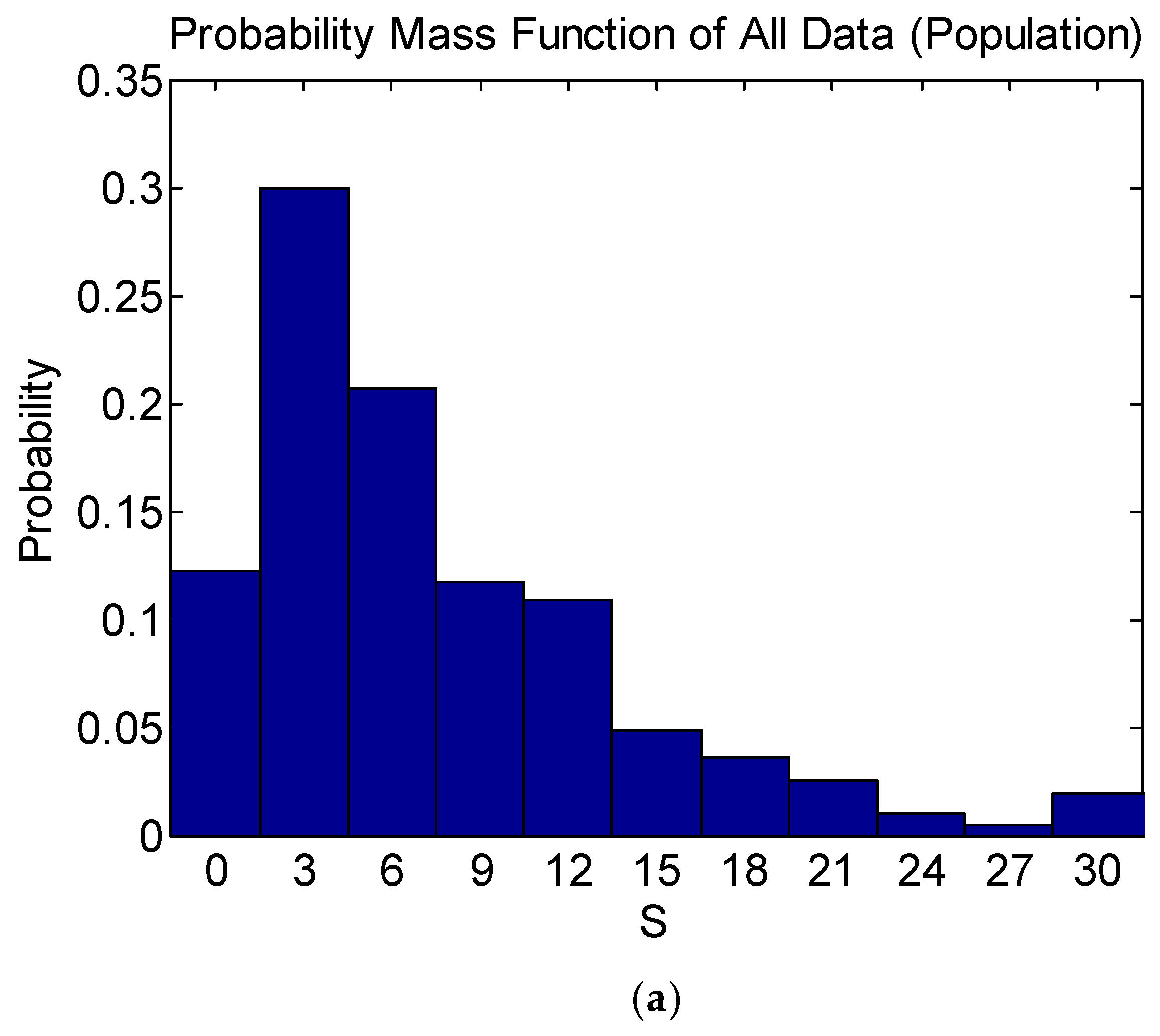
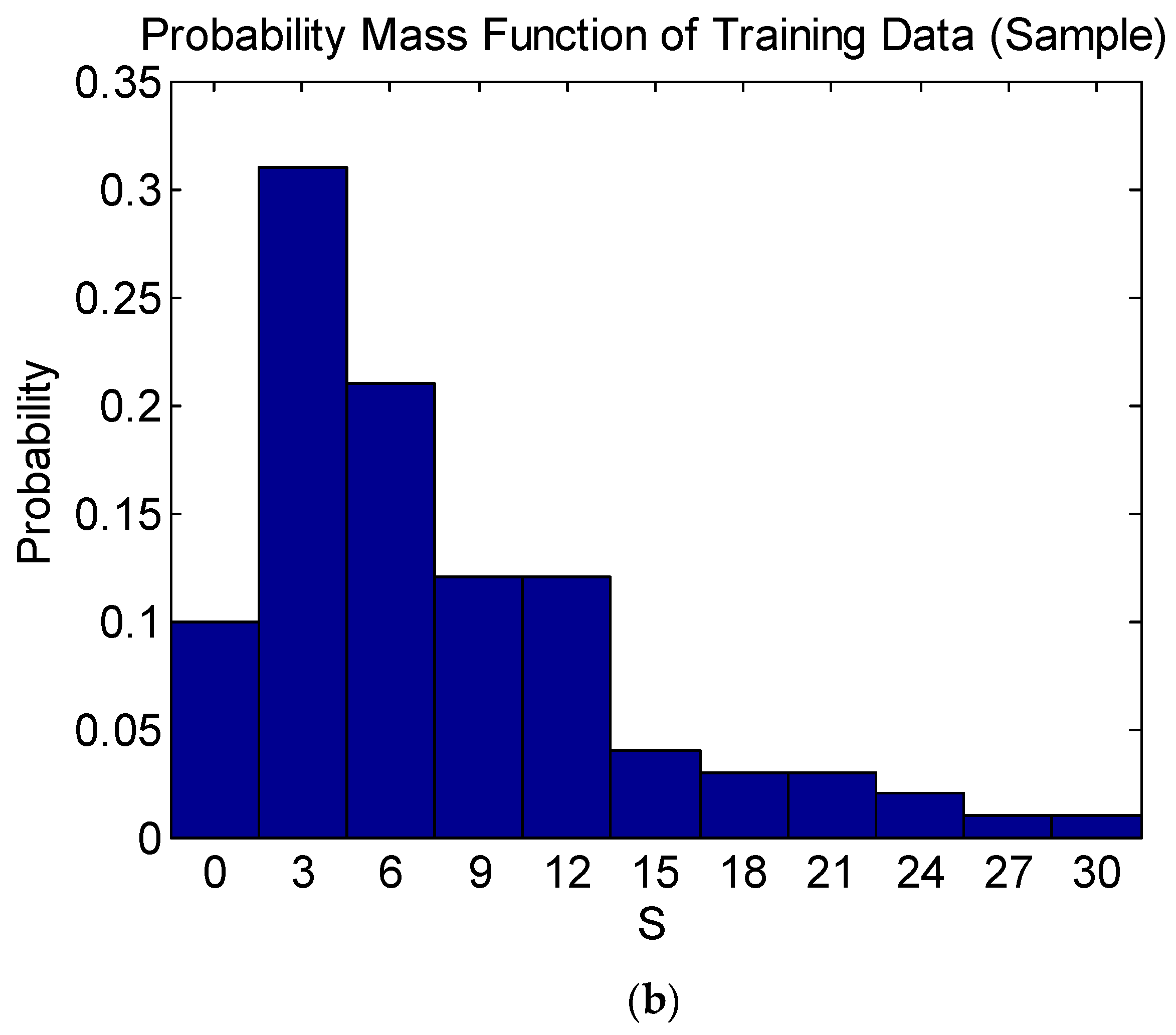
Table 3 shows that Equation (4) is satisfied for all the variables, indicating that the probability mass function of each variable of the training data is significant at a 5% level of significance. As an example, the probability mass functions of the training data and population of the damage level
are compared in
Figure 3, showing that they are in good agreement.
3.2. ANN Model
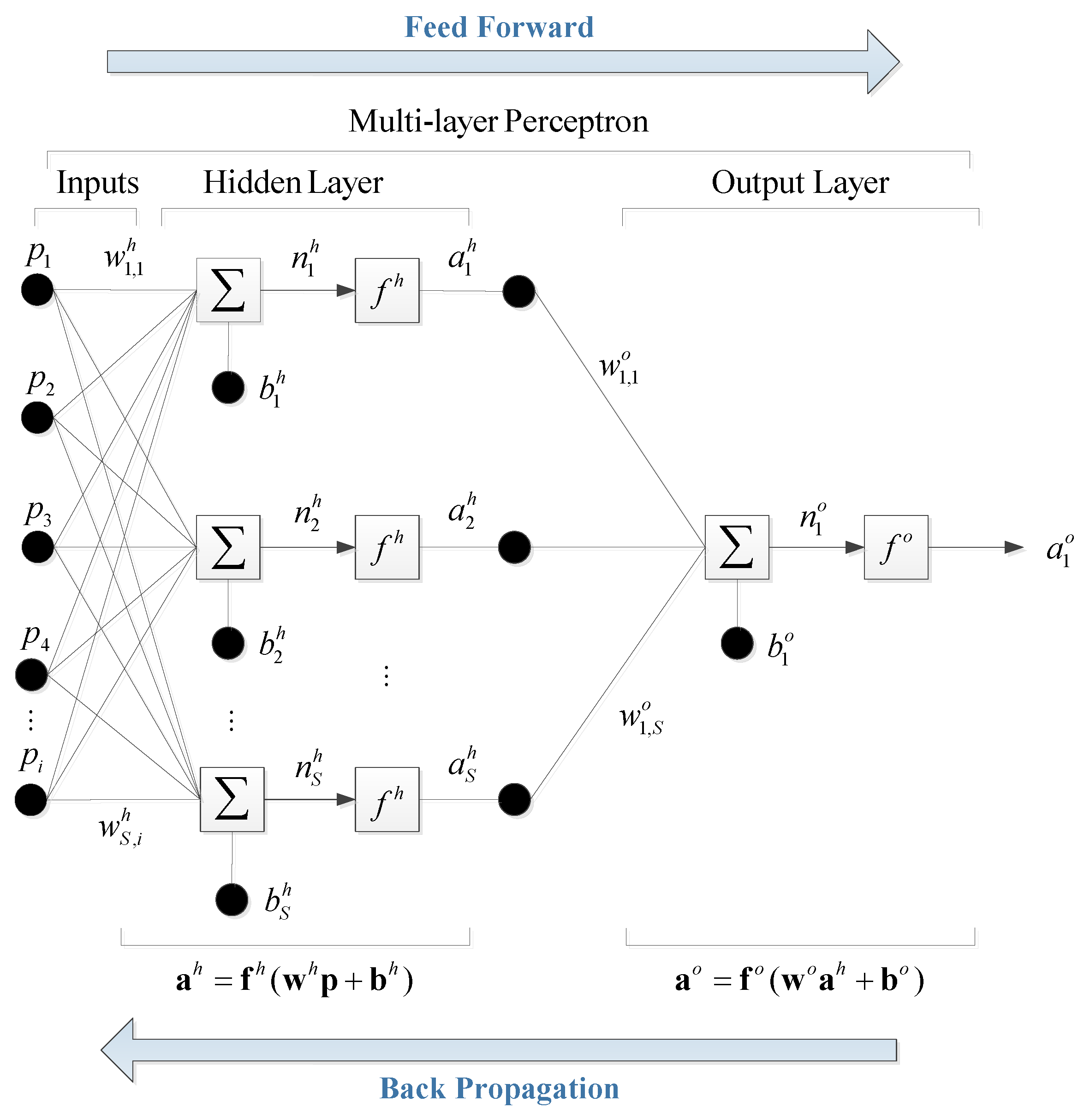
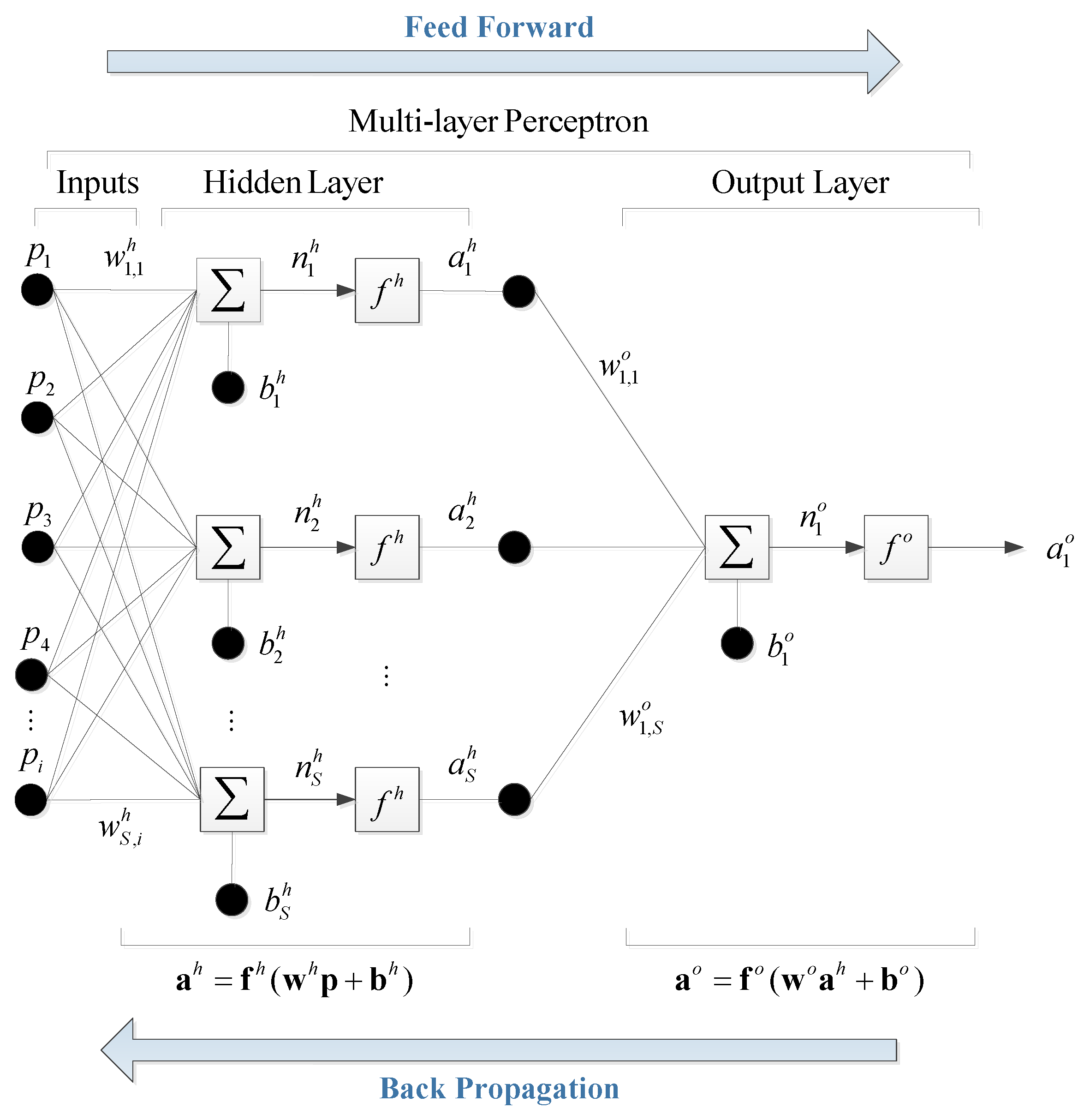
The multi-perceptron is considered as an attractive alternative to an empirical formula in that it imitates the nonlinear relationship between input and output variables in a more simplified way. The model aims to obtain the optimized weights of the network using a training algorithm designed to minimize the error between the output and target variables by modifying the mutually connected weights. In this study, the multi-perceptron with one hidden layer is used as shown in
Figure 4, where
is the number of input variables.
Firstly, for each of the input and output variables, the data are normalized so that all of the data are distributed in the range of [min, max] = [–1, 1]. This can be done by subtracting the average from the data values and rescaling the resulting values in such a way that the smallest and largest values become
and 1, respectively. Secondly, the initial weights in the hidden layer are set to have random values between
and 1, and the initial biases are all set to zero. The next step is to multiply the weight matrix by the input data,
, and add the bias so that
where
and
are the number of input variables and hidden neurons, respectively, and
,
and
are the input variable, bias, and weight in the hidden layer, respectively. The subscripts of the weight
are written in such a manner that the first subscript denotes the neuron in question and the second one indicates the input variable to which the weight refers. The
calculated by Equation (5) is fed into an activation function,
, to calculate
. Hyperbolic tangent sigmoid function is used as the activation function so that
In the output layer, the same procedure as that in the hidden layer is used except that only one neuron is used so that
and the linear activation function is used to calculate
so that
The neural network with the randomly assigned initial weights and biases cannot accurately estimate the required output. Therefore, the weights and biases are modified by the training to minimize the difference between the model output and target (observed) values. To train the network, the error function is defined as
where
denotes a norm, and
is the target value vector to be sought. To minimize the error function, the Levenberg-Marquardt algorithm is used, which is the standard algorithm of nonlinear least-squares problems. Like other numeric minimization algorithms, the Levenberg-Marquardt algorithm is an iterative procedure. It necessitates a damping parameter
, and a factor
that is greater than one. In this study,
and
were used. If the squared error increases, then the damping is increased by successive multiplication by
until the error decreases with a new damping parameter of
for some
. If the error decreases, the damping parameter is divided by
in the next step. The training was stopped when the epoch reached 5000 or the damping parameter was too large for more training to be performed.
3.3. HS-ANN Hybrid Model
To find the initial weights of the ANN model that lead into the global minimum of the error function, in general, a Monte Carlo simulation is performed, that is, the training is repeated many times with different initial weights. The Monte Carlo simulation, however, takes a great computational time. In this section, we develop an HS-ANN model in which the near-global optimal initial weights are found by the HS algorithm.
The HS algorithm consists of five steps as follows [
32].
Step 1. Initialization of the algorithm parameters
Generally, the problem of global optimization can be written as
where
is an objective function,
is the set of decision variables, and
is the set of possible ranges of the values of each decision variable, which can be denoted as
for discrete decision variables satisfying
or
for continuous decision variables. In addition,
is the number of decision variables and
is the number of possible values for the discrete variables. In addition, HS algorithm parameters exist that are required to solve the optimization problems: harmony memory size (HMS, number of solution vectors), harmony memory considering rate (HMCR), pitch adjusting rate (PAR) and termination criterion (maximum number of improvisation). HMCR and PAR are the parameters used to improve the solution vector.
Step 2. Initialization of harmony memory
The harmony memory (HM) matrix is composed of as many randomly generated solution vectors as the size of the HM, as shown in Equation (11). They are stored with the values of the objective function,
, ascendingly:
Step 3. Improvise a new harmony from the HM
A new harmony vector,
, is created from the HM based on assigned HMCR, PAR, and randomization. For example, the value of the first decision variable
for the new vector can be selected from any value in the designated HM range,
. In the same way, the values of other decision variables can be selected. The HMCR parameter, which varies between 0 and 1, is a possibility that the new value is selected from the HM as follows:
The HMCR is the probability of selecting one value from the historic values stored in the HM, and the value (1-HMCR) is the probability of randomly taking one value from the possible range of values. This procedure is analogous to the mutation operator in genetic algorithms. For instance, if a HMCR is 0.95, the HS algorithm would pick the decision variable value from the HM including historically stored values with a 95% of probability. Otherwise, with a 5% of probability, it takes the value from the entire possible range. A low memory considering rate selects only a few of the best harmonies, and it may converge too slowly. If this rate is near 1, most of the pitches in the harmony memory are used, and other ones are not exploited well, which does not lead to good solutions. Therefore, typically is recommended.
On the other hand, the HS algorithm would examine every component of the new harmony vector,
, to decide whether it has to be pitch-adjusted or not. In this procedure, the PAR parameter which sets the probability of adjustment for the pitch from the HM is used as follows:
The pitch adjusting procedure is conducted only after a value is selected from the HM. The value (1−PAR) is the probability of doing nothing. To be specific, if the value of PAR is 0.1, the algorithm will take a neighboring value with
probability. For example, if the decision for
in the pitch adjustment process is Yes, and
is considered to be
, then the
kth element in
, or the pitch-adjusted value of
, is changed into
where
m is the neighboring index,
,
is the value of
,
is an arbitrarily chosen distance bandwidth or fret width for the continuous variable, and
is a random number from uniform distribution with the range of
. If the pitch-adjusting rate is very low, because of the limitation in the exploration of a small subspace of the whole search space, it slows down the convergence of HS. On the contrary, if the rate is very high, it may cause the solution to scatter around some potential optima. Therefore,
is used in most applications. The parameters HMCR and PAR help the HS algorithm to search globally and locally, respectively, to improve the solution.
Step 4. Evaluate new harmony and update the HM
This step is to evaluate the new harmony and update the HM if necessary. Evaluating a new harmony means that the new harmony (or solution vector) is used in the objective function and the resulting functional value is compared with the solution vector in the existing HM. If the new harmony vector gives better performance than the worst harmony in the HM, evaluated in terms of the value of objective function, the new harmony would be included in the harmony memory and the existing worst harmony is eliminated from the harmony memory. In this study, the mean square error function is used as the objective function for both HS optimization and ANN training.
Step 5. Repeat Steps 3 and 4 until the termination criterion is satisfied
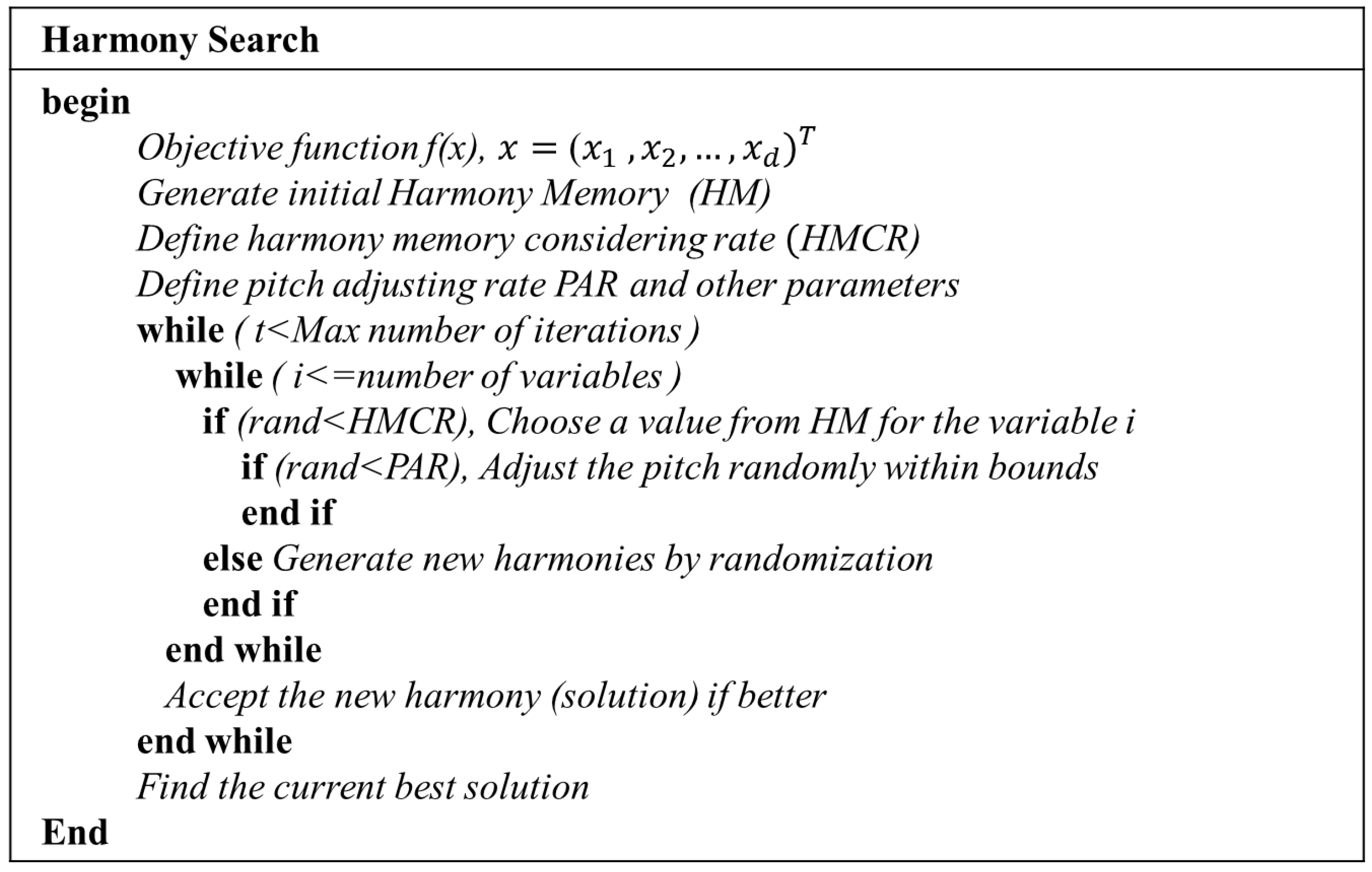
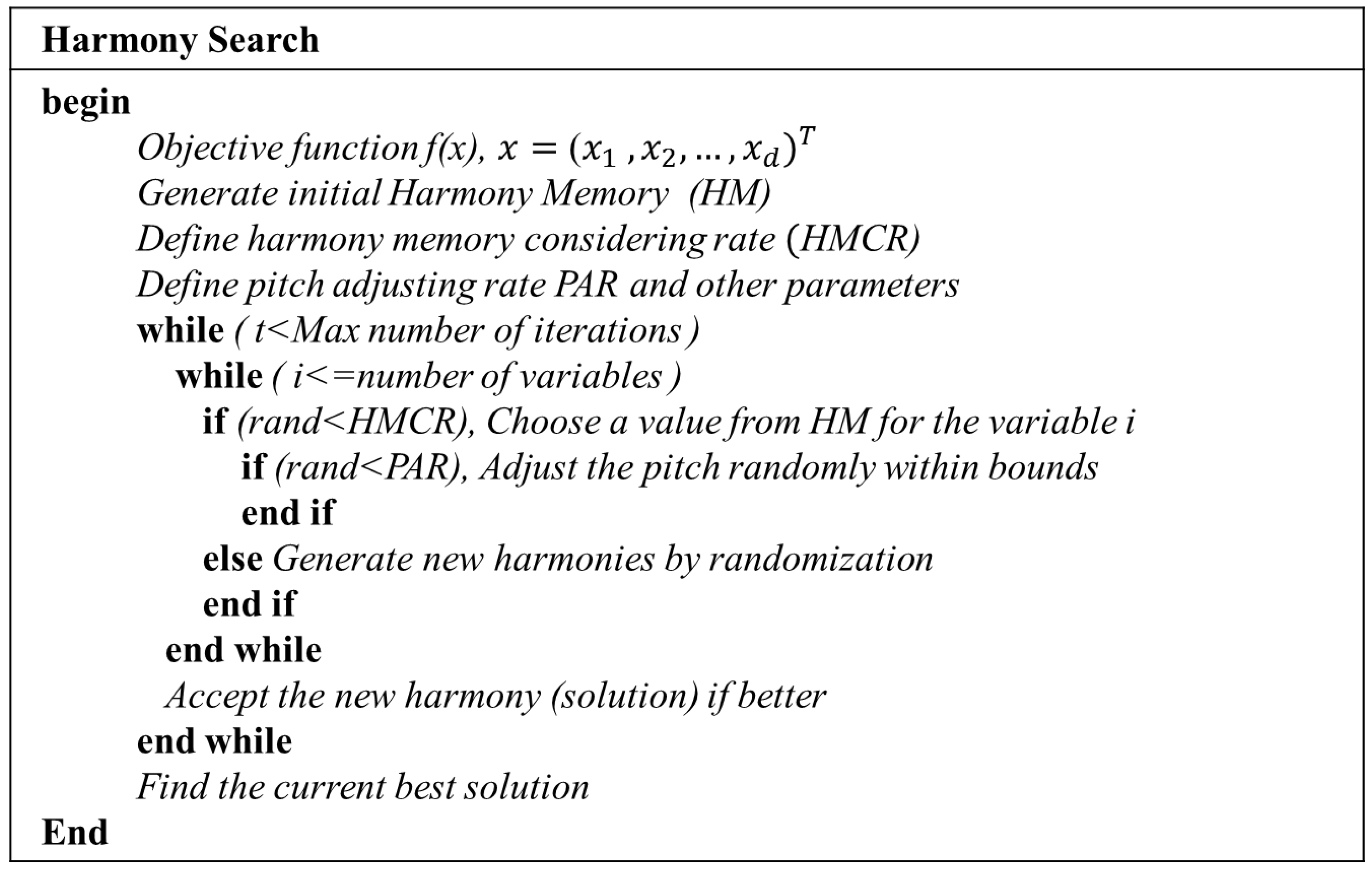
The iterations are terminated if the stop criterion is satisfied. If not, Steps 3 and 4 would be repeated. The pseudo-code of the HS algorithm is given in
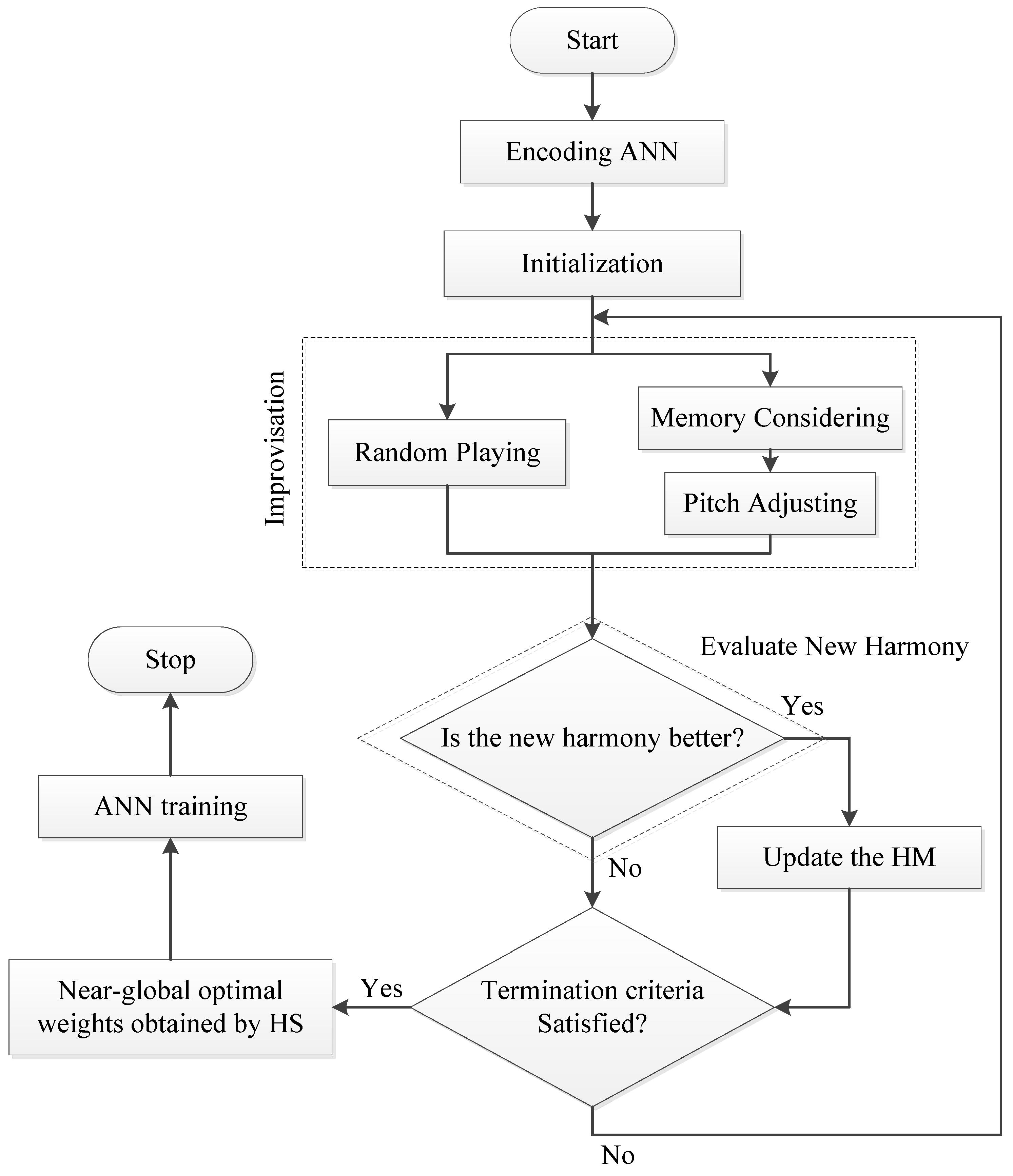
Figure 5. The initial weights optimized by the HS algorithm are then further trained by a gradient descent algorithm. This method is denoted as an HS-ANN model, and it can be expressed as the flow chart in
Figure 6.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}