3.1. Data Selection and Data Preprocessing
The data analyzed in this study is from ALA Joblist’s database [
19] from 2009 through 2014. According to Applegate’s work, ALA Joblist covers 23% of available academic library positions, ranked only next to Academic Employment Network [
18]. Although directly gathering data from institutions may provide more representative data, it would be much too time-consuming.
The data source, however, brings deviation between the end result of the study and actual job market. For example, Applegate’s work shows that ALA Joblist covers a remarkably higher percentage of job ads from masters (20%) and doctoral (27%) institutions than from associates (0%) and baccalaureate (10%) institutions [
18]. Another subsequent potential limitation is that some job ads posted on ALA Joblist may point to a Web page where the position is more fully described. These Web pages are typically removed from the Web after the position is filled, making the information more difficult to obtain [
20].
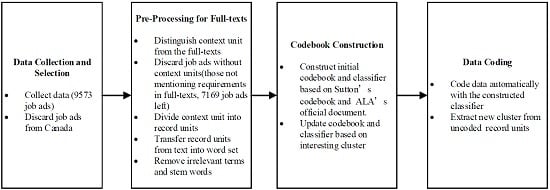
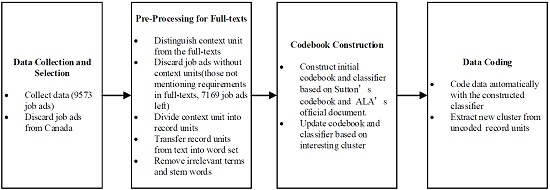
With a total of 9573 job ads posted on ALA Joblist from 1 January 2009 to 25 June 2014, the data include both full-texts and basic information showing brief descriptions. As the first step of the data analysis,
Figure 1 shows the path and procedure of the data processing. After discarding job ads from Canada, there are 9198 job ads left as the total of data records analyzed directly in this study using statistical computing techniques. Their full texts are preprocessed further for content analysis.
Figure 1.
Overview of data processing.
Figure 1.
Overview of data processing.
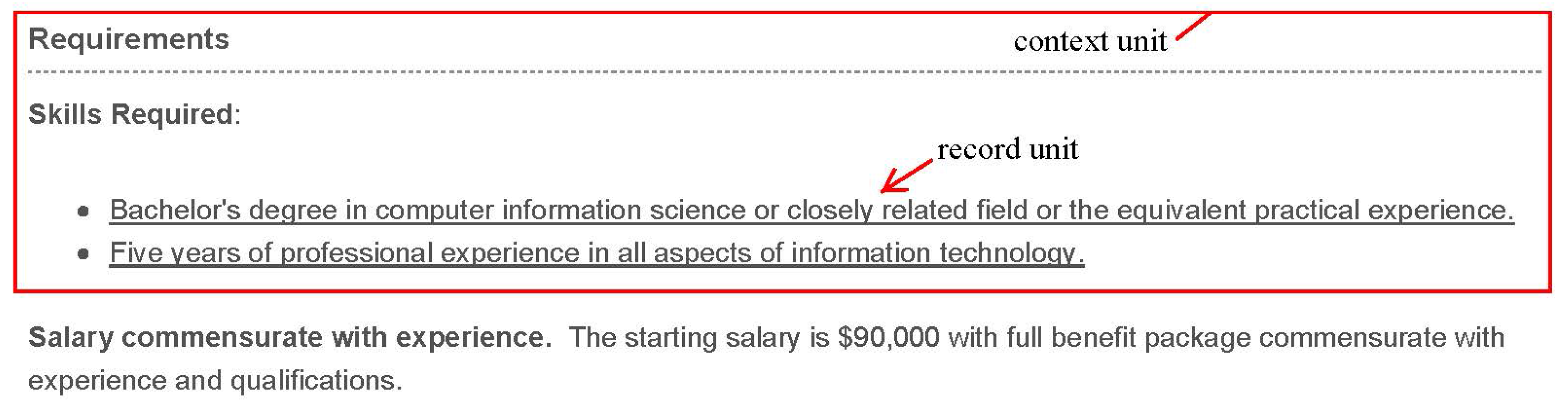
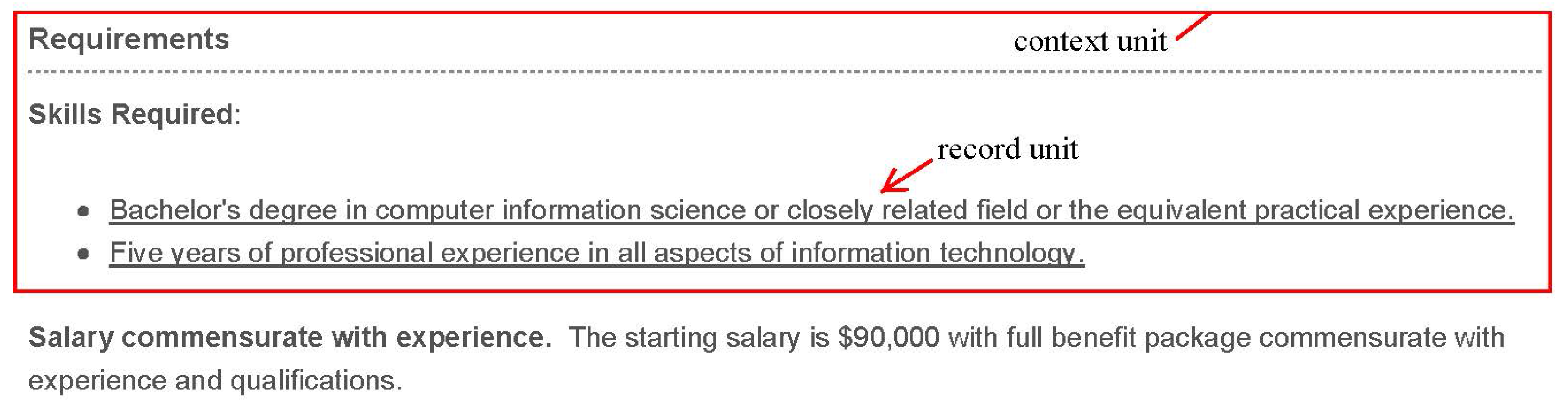
In the preprocessing stage, the authors transition each full-text ad into several record units (see
Figure 2). In his seminal text on content analysis, Krippendorff identifies three separate units of analysis that must be considered in content analysis: sampling units, context units, and recording units [
12]. In this study, sampling units are full-texts of all 9198 job ads; context units are blocks describing requirements; recording units are segments in context units, each of which is supposed to describe a competency. The example for context units and recording units is shown in
Figure 3.
To extract context units from a sampling unit, the authors divide it into sentences and build a rule-based classifier, which is designed to determine whether a sentence belongs to a context unit. For example, a context unit usually begins with a “Required Qualifications:” in a single line and ends before an url link for application (See
Figure 3). The classifier gets a hit rate of 90% and a recall rate of 84% in sentences from 10 randomly picked job ads.
After that, the authors discard job ads without context unit, in which no job requirements are mentioned, and divide the remaining sentences into recording units (recording units may be divided by semicolons). Via this process, the authors try to avoid mixing multiple competencies in one recording unit.
Finally the authors transfer recording units from text into “bag-of-words” (a sparse vector of occurrence counts of words). To unify the form of word set, words are stemmed with toolkit in nltk and irrelevant words (stop words e.g.) are removed.
Figure 2.
Data flow diagram of pre-processing.
Figure 2.
Data flow diagram of pre-processing.
Figure 3.
Example for context unit and record unit.
Figure 3.
Example for context unit and record unit.
3.2. Codebook Construction
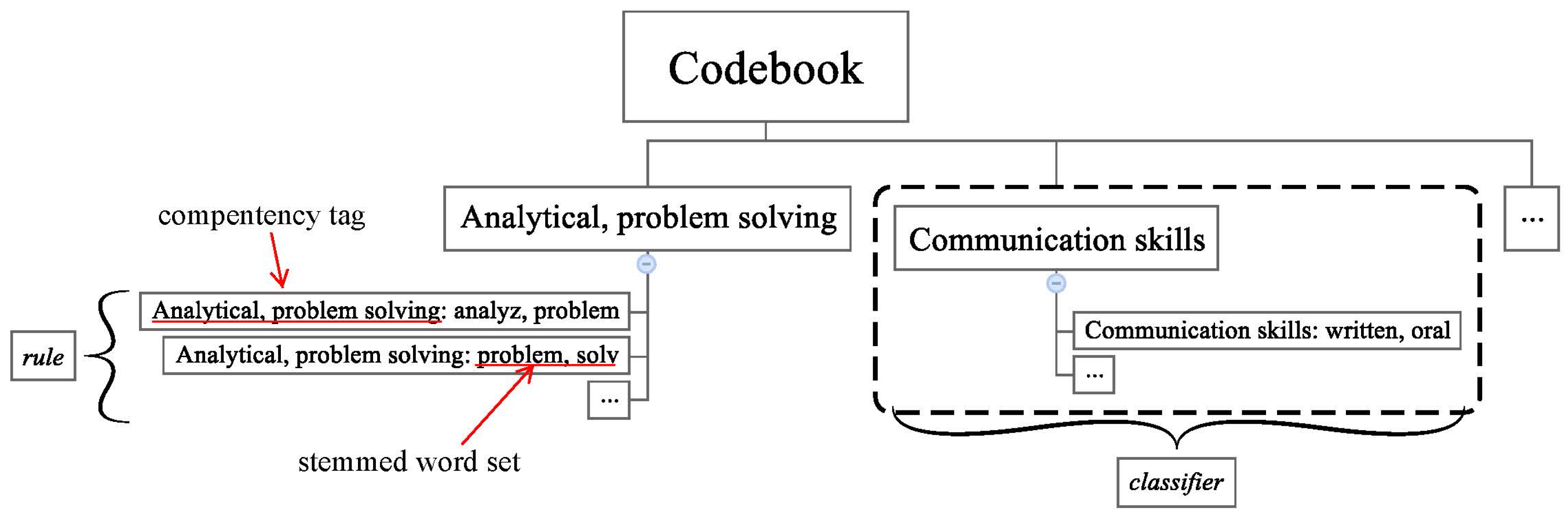
In this study, coding means transforming each job ad into a “bag-of-competencies” (a sparse vector of occurrence of competency tags). As job ads have been transferred into multiple bags of stemmed words (each recording unit corresponds to a bag of stemmed words) in data preprocessing, a codebook in this study is consist of serval rule-based classifiers. Each classifier may judge whether a job ad requests a certain competency. A classifier contains a number of rules, each of which contains a word set and a corresponding competency tag (a competency tag is usually correspo). Different rules belonging to the same classifier contain different word sets and the same competency tag.
Figure 4 shows part of the final codebook in this study. For rule “
Analytical, problem solving skills: analyz; problem”, if “analyz” and “problem” appear in one recording unit (the recording unit has been transferred into a bag of stemmed words) at the same time, it is said that the recording unit meets the rule and we may add a competency tag of
Analytical, problem solving skills to this recording unit. If any recording units in a job ad own a competency tag of “
Analytical, problem solving skills”, it is concluded that the job ad requests a competency of
Analytical, problem solving skills. All classifiers in the codebook will be applied to a job ad in turn to transform it into a bag of competencies.
Figure 4.
Sketch for a part of the final codebook in this study.
Figure 4.
Sketch for a part of the final codebook in this study.
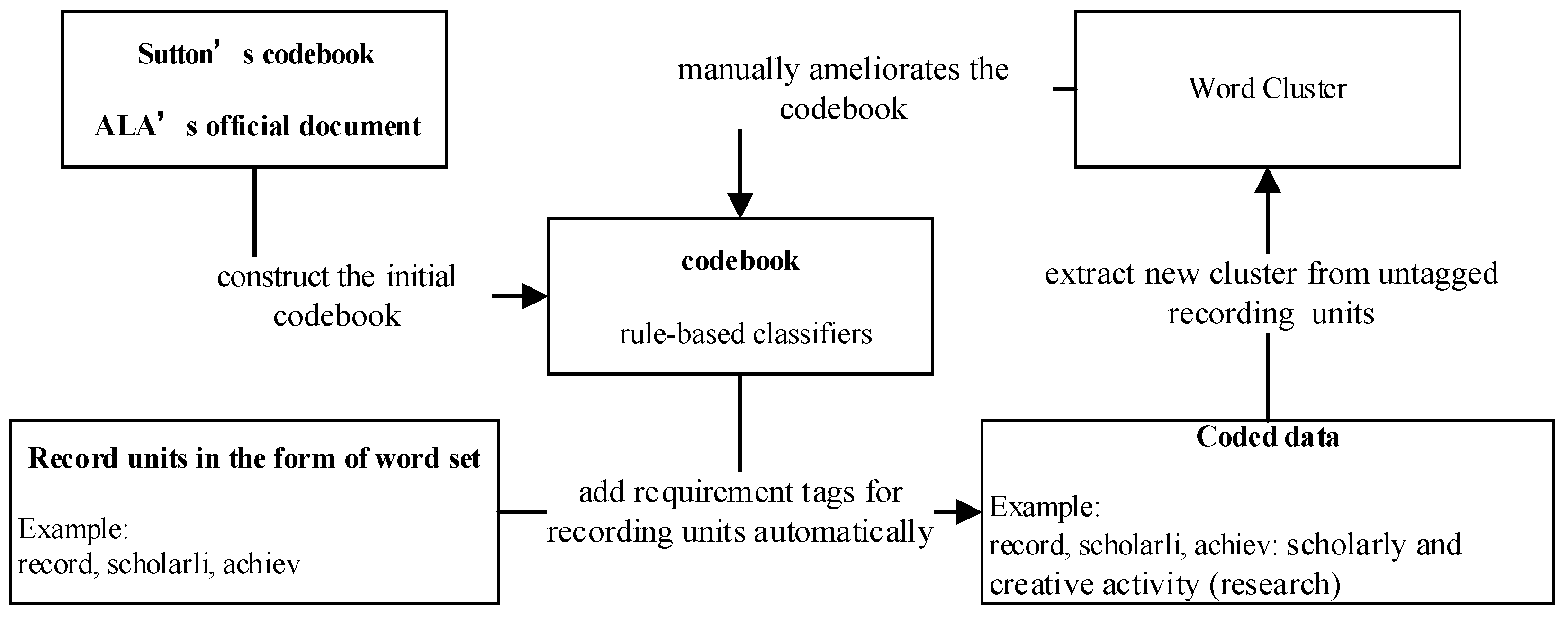
The data flow diagram of the codebook construction is shown in
Figure 5.
ALA’s Core Competences of Librarianship divides core competencies of librarianship into 8 categories:
Foundations of the Profession,
Information Resources,
Organization of Recorded Knowledge and Information,
Technological Knowledge and Skills,
Reference and User Services,
Research,
Continuing Education and Lifelong Learning,
Administration and Management. The authors categorize themes used in Sutton’s codebook following the criterion, and categorize qualifications like second post-graduate degree as
Qualification (see
Table 1). Then, the authors manually construct a competency tag, a detailed explanation and a set of rules for each competency themes according to their samples.
Table 1.
Codebook for competencies. +: the same; -: not exist.
Table 1.
Codebook for competencies. +: the same; -: not exist.
| Category | Theme | Sutton’s Codebook | ALA’s Core Competency |
|---|
| | communication skills | + | 1J |
| | work independently | + | - |
| | analytical, problem solving skills | + | 1I |
| 1 Foundations of the Profession | change, flexibility | + | 1I |
| | collection management | - | 2C |
| | collection development | + | 2B |
| 2 Information Resources | electronic resources | + | - |
| | cataloging | + | 3C |
| 3 Organization of Recorded Knowledge and Information | information management | - | 3B |
| | general technology knowledge | technical/system-related | 4A; 4B; 4C; 4D |
| 4 Technological Knowledge and Skills | database | - | - |
| | programming | - | - |
| 5 Reference and User Services | customer service orientation | customer service | 5A |
| reference | + | 5A |
| 6 Research | scholarly and creative activity (research) | course work | 6A; 6B; 6C |
| 7 Continuing Education and Lifelong Learning | instruction experience | - | - |
| | work collaboratively | + | 8F |
| | leadership | + | 8E |
| 8 Administration and Management | financial skills | acquisitions assessment consortium | 8A |
| | project management experience | - | - |
| 9 Qualification | ALA-accredited Master | - | - |
| second post-graduate degree | - | - |
Figure 5.
Data flow diagram of codebook construction.
Figure 5.
Data flow diagram of codebook construction.
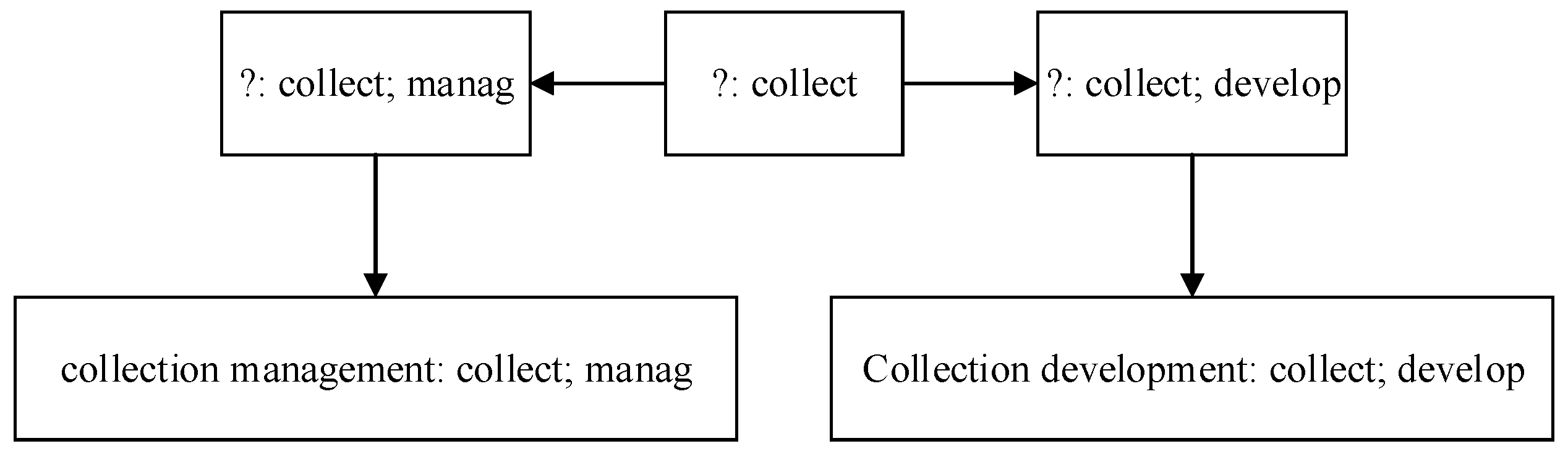
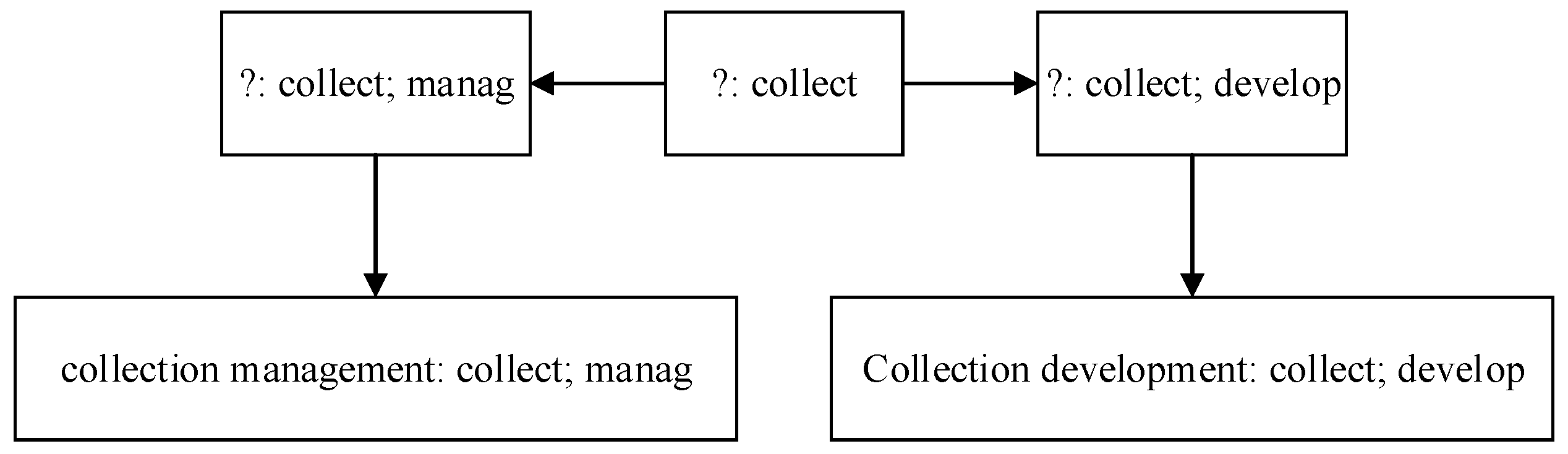
Each rule in the codebook grows from one meaningful stemmed word (like “collect”, which indicates competencies related to “collection”) and one temporary competency tag. However, a rule with only one stemmed word may get a low hit rate. To extend the rule, the authors manually pick other stemmed words one by one, making the rule more accurate. When the rule becomes accurate enough, the competency tag for the rule will be determined (either an existed tag or a new one). Of special note is that the rule may grow in multiple branches (see
Figure 6).
Figure 6.
Example for rule growing.
Figure 6.
Example for rule growing.
The selection of “meaningful stemmed words” is based on an assumption that if a meaningful word or phrase may compose a rule, it will appear much more frequently in recording units belonging to the corresponding theme than in other recording units. After applying a codebook to all recording units, we may add multiple competency tags for each of them. To simplify the definition, we add a special tag called “None” to recording units without any competency tags so that all recording units own at least one tag. Supposing
C (contains
c,
c ...
c) is the set of all competency tags in the codebook,
R stands for all recording units,
R stands for recording units with tag
c. For each stemmed word in all recording units, the authors may calculate n TF-IDF (term frequency-inverse document frequency), each of which responds to a competency tag. Suppose
w is a stemmed word,
RC stands for the number of recording units containing
w and belonging to
R. Define the importance of
w as follows:
Sorting all stemmed words by their importance, the authors pick one of them from the top to optimize the codebook. Once the codebook is changed, we may update the importance of all stemmed words. The iteration is repeated until no obvious new rules can be found.
3.3. The Roles of the Two Specified Codebooks
Simply put, the first codebook (see
Table 2) contains basic job position information drawn from the records of ALA Joblist’s job advertisements, such as job title, location, institution, minimum required degree, and years of work experience. This data is identified as the original supplying basic data elements, which are used to conduct descriptive statistical analysis. Data elements in the sheet are well structured so that the authors can directly analyze them with Excel 2013.
Table 2.
Codebook for basic information of job ads.
Table 2.
Codebook for basic information of job ads.
| Fieldname | Value |
|---|
| Line Item ID | Unique integer |
| Ad Start Date | Date |
| Job Title | Text |
| State | USA States |
| Canada States |
| District of Columbia |
| Not Applicable |
| Org type | Academic Library: Academic/Research (College/University) |
| Public Library: Public Library |
| School Library: School Library/Media Center (K-12); Library and Information Science School |
| Special Library: Association; Publishing; Vendor; Special Library/Corporate; Library Cooperative/System; Museum; Government (Federal/State) Library; Other |
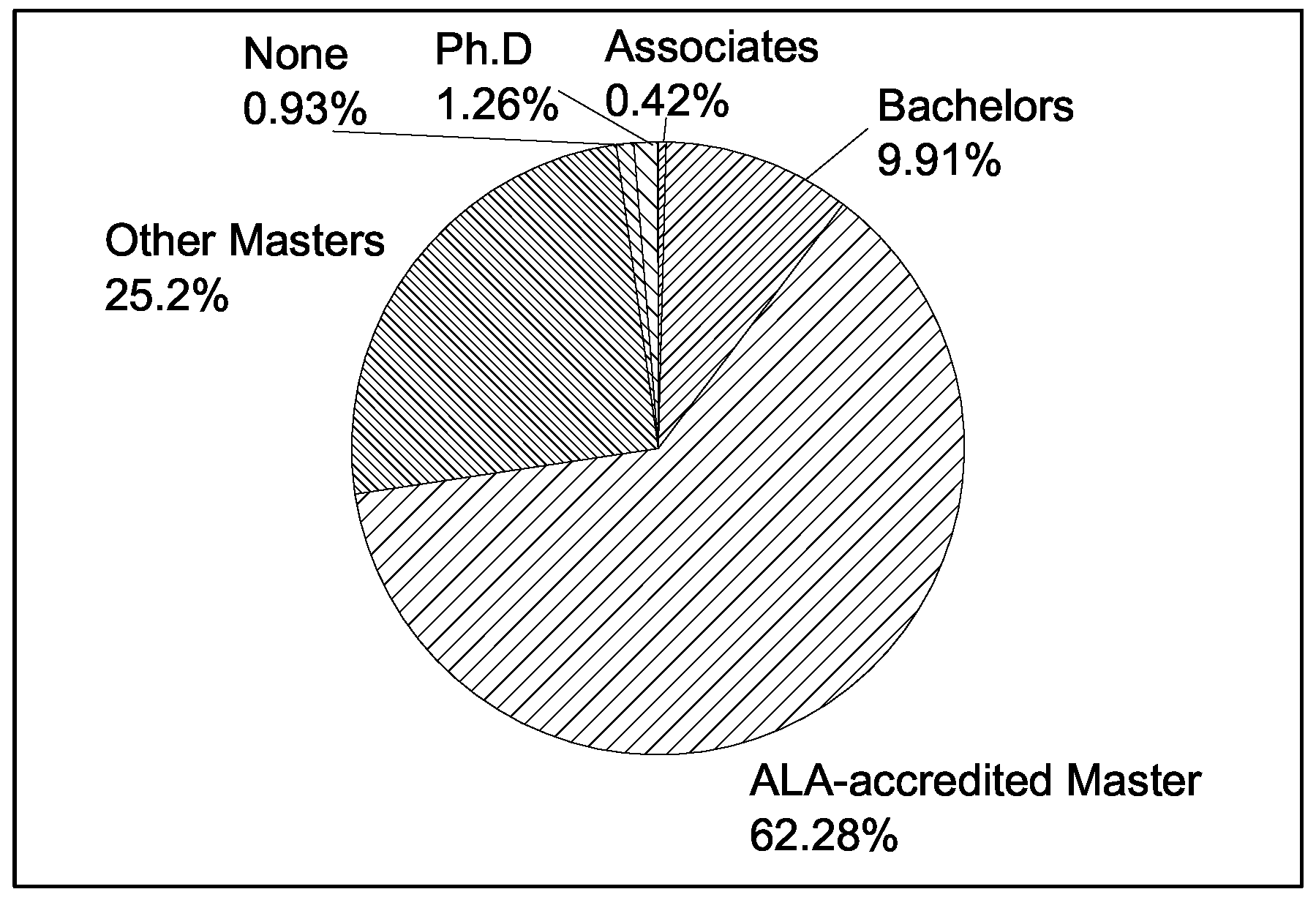
| Minimum Degree | Masters |
| Ph.D |
| Bachelors |
| Associates |
| None |
| Years of Experience category | 5 or more years |
| 2–5 years |
| 1–2 years |
| Less Than 1 year |
| Not Specified |
Table 3.
Most common requirements, 2009–2014 (6890 ads).
Table 3.
Most common requirements, 2009–2014 (6890 ads).
| Category | Theme | Percentage |
|---|
| 1 Foundations of the Profession | Communication skills | 48.88% |
| 8 Administration and Management | project management | 35.03% |
| 8 Administration and Management | work collaboratively | 27.92% |
| 5 Reference and User Services | reference | 19.40% |
| 8 Administration and Management | leadership | 13.61% |
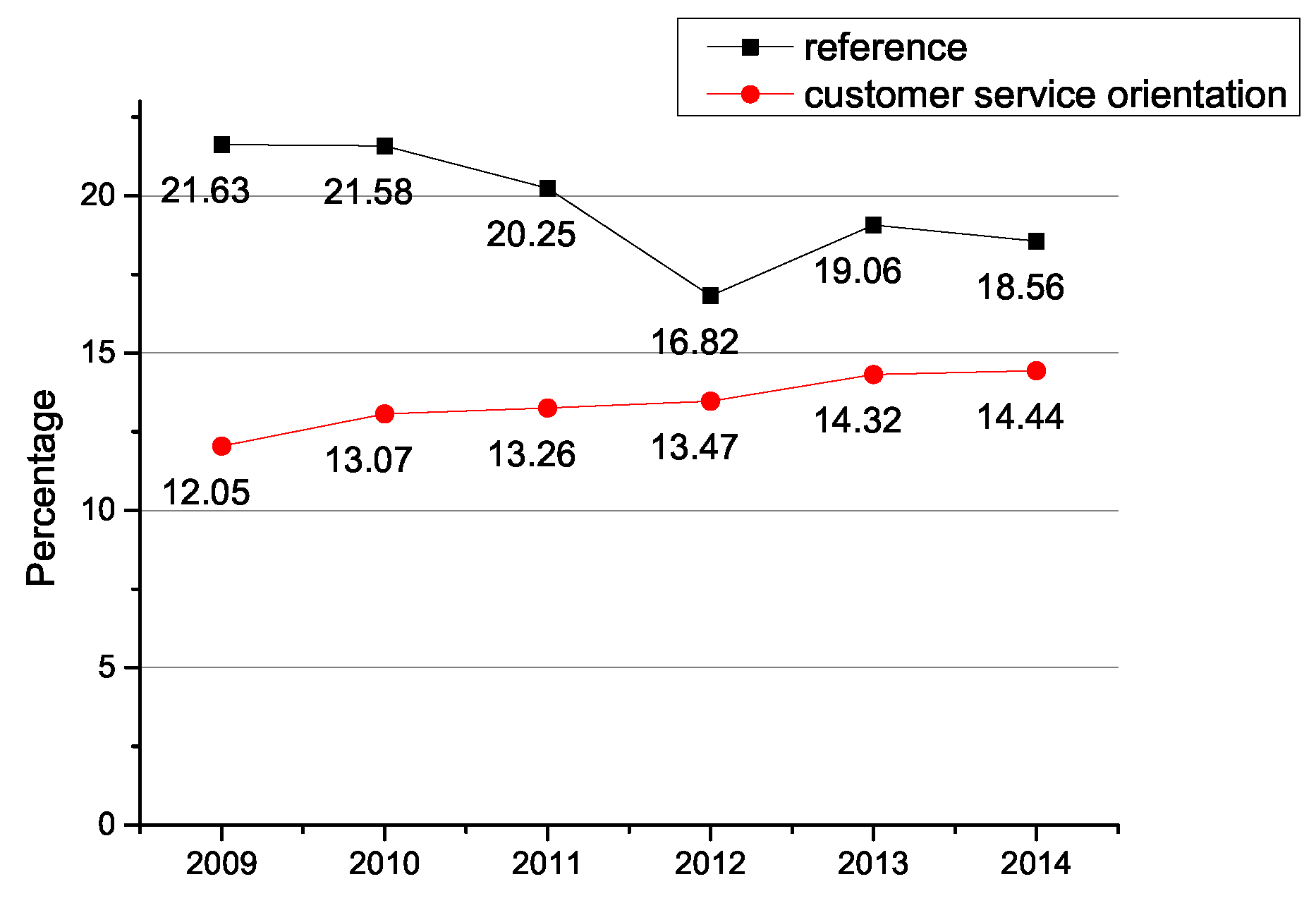
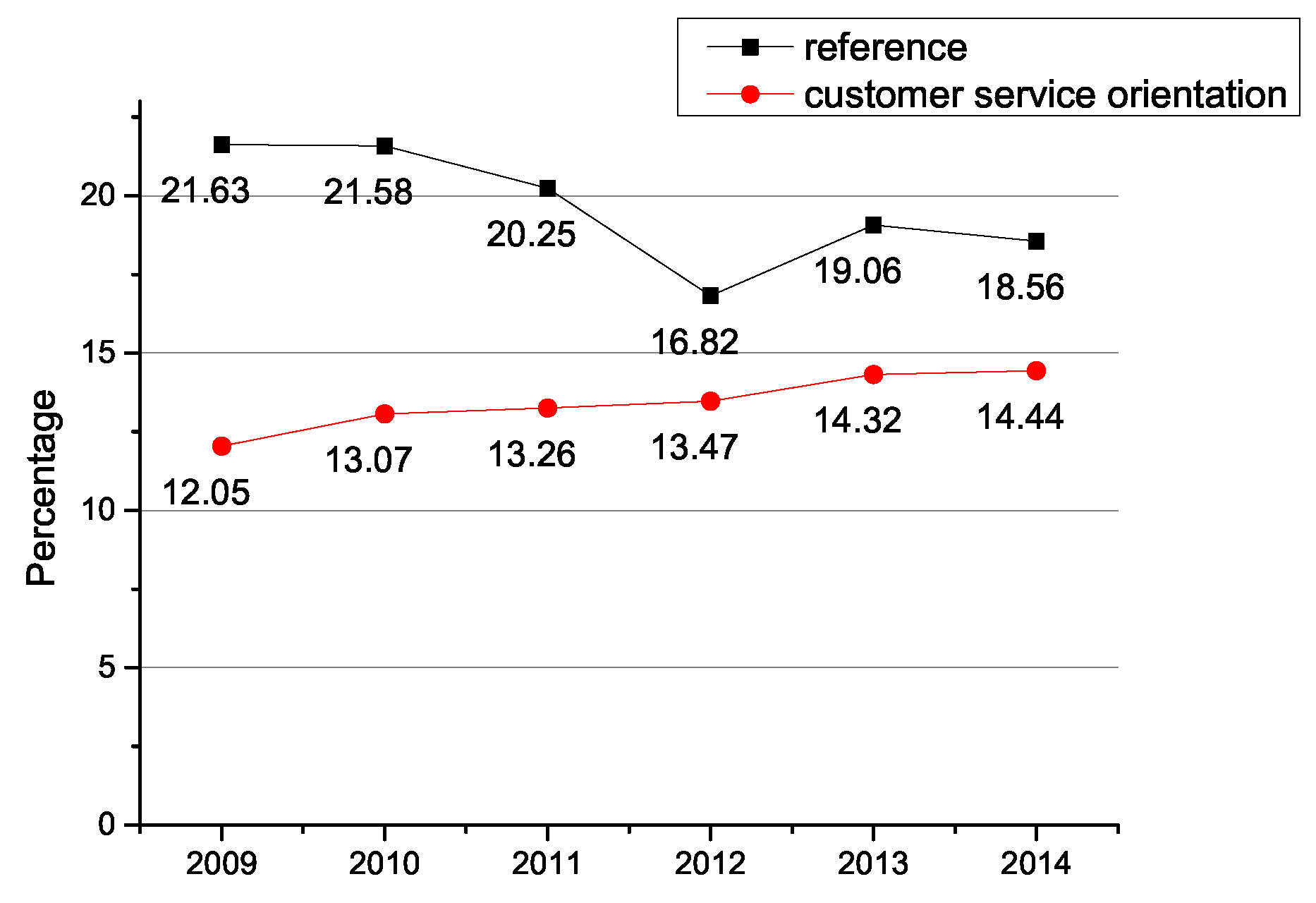
| 5 Reference and User Services | customer service orientation | 13.58% |
| 3 Organization of Recorded Knowledge and Information | cataloging | 13.05% |
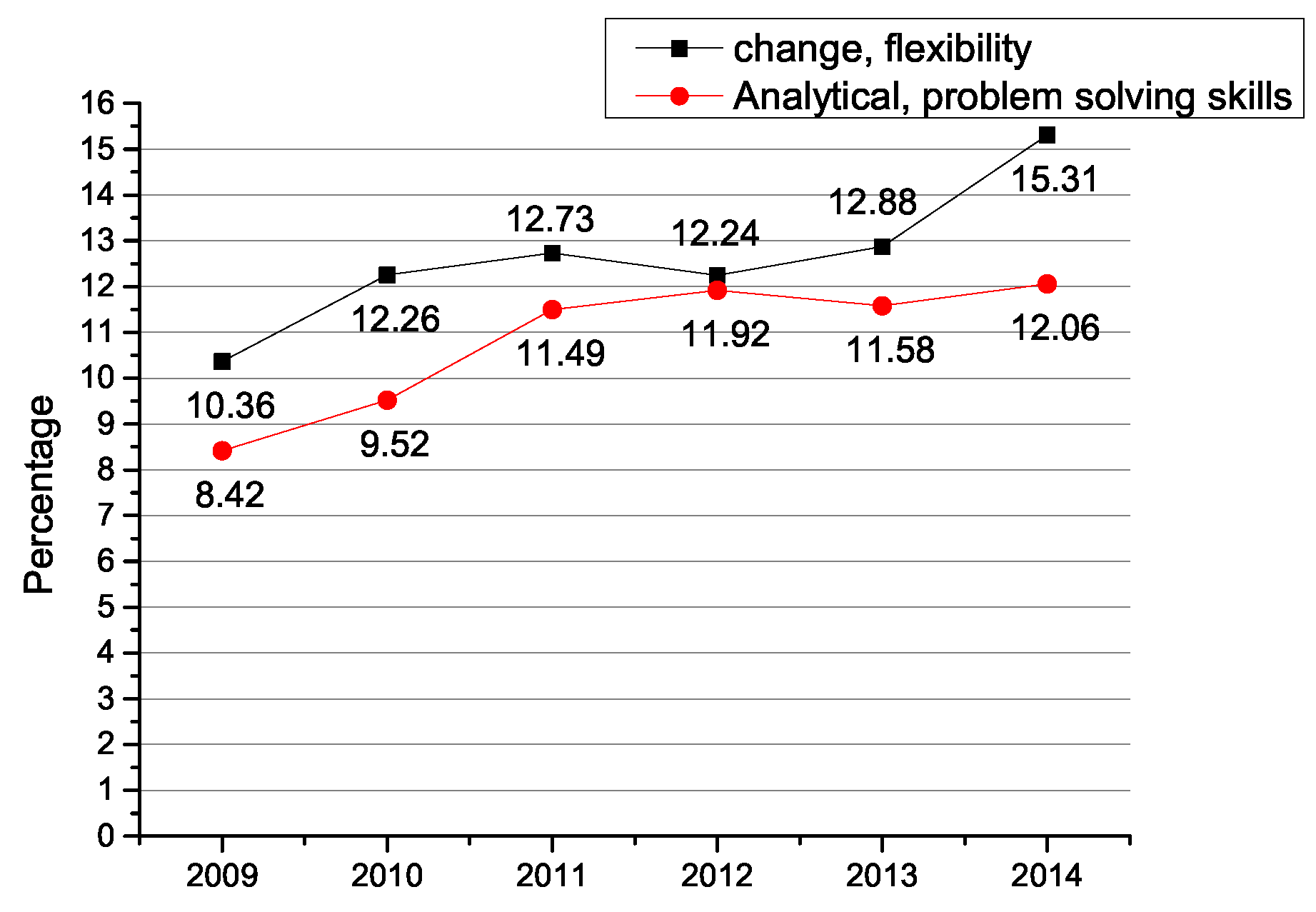
| 1 Foundations of the Profession | change, flexibility | 12.86% |
| 1 Foundations of the Profession | Analytical, problem solving skills | 11.07% |
| 2 Information Resources | collection development | 10.61% |
| 4 Technological Knowledge and Skills | general technological knowledge | 10.22% |
| 2 Information Resources | electronic resources | 10.01% |
| 1 Foundations of the Profession | work independently | 9.75% |
| 8 Administration and Management | financial skills | 9.68% |
| 4 Technological Knowledge and Skills | database | 7.43% |
| 4 Technological Knowledge and Skills | programming | 5.82% |
| 2 Information Resources | collection management | 5.79% |
| 7 Continuing Education and Lifelong Learning | library instruction experience | 5.57% |
| 3 Organization of Recorded Knowledge and Information | information management | 5.08% |
| 6 Research | scholarly and creative activity (research) | 3.41% |
The codebook for competencies is more complex (
Table 1, without key word groups). All job ads are coded with the final codebook constructed in
Section 3.3 to extract the competencies that they request (see
Table 3).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
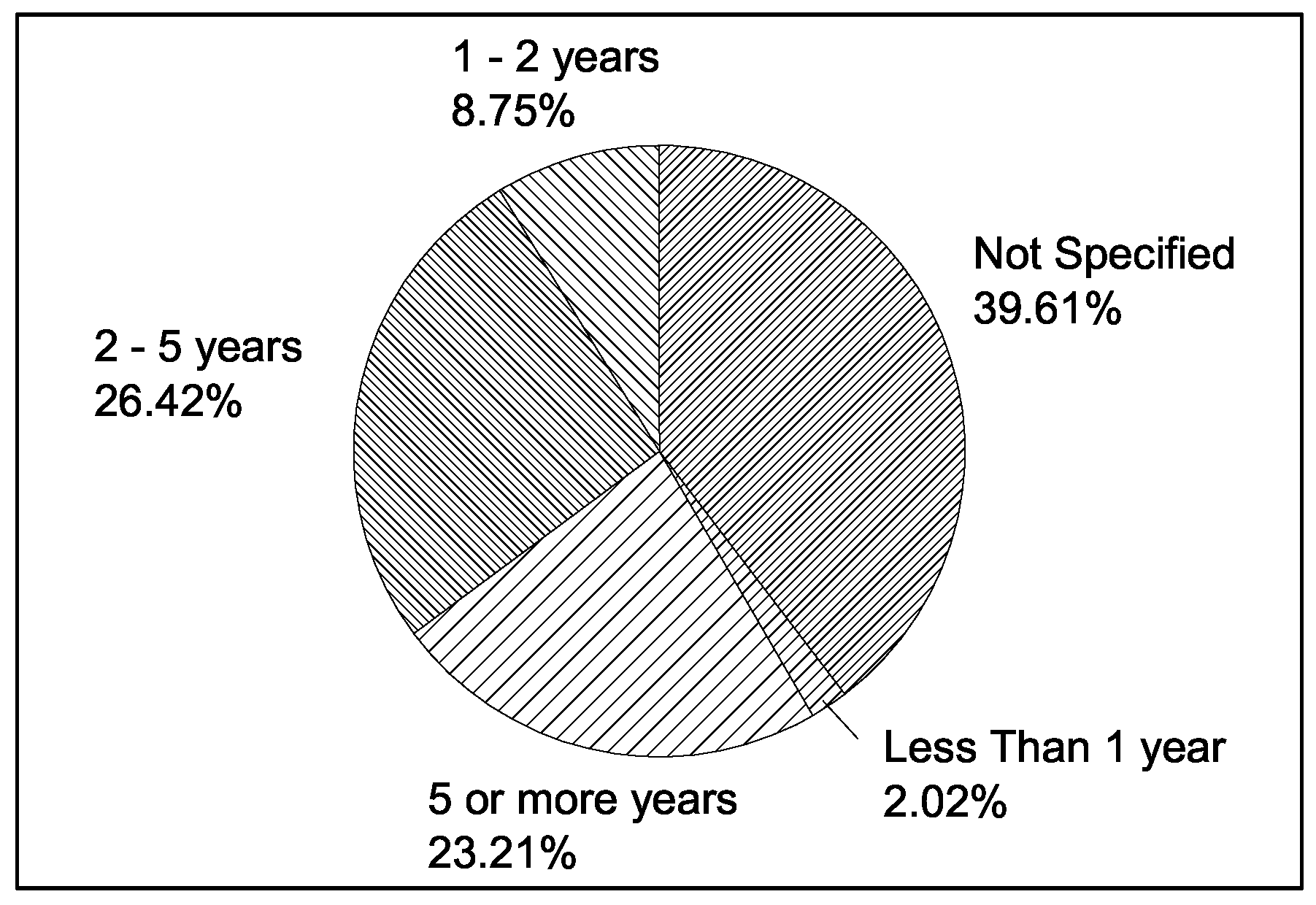{kind=link}
{kind=link}
{kind=link}