Abstract
For the characterization of the kidney segmentation task, this paper proposes a self-supervised kidney segmentation method based on multi-scale feature fusion and residual full attention, named MRFA-Net. In this study, we introduce the multi-scale feature fusion module to extract multi-scale information of kidneys from abdominal CT slices; additionally, the residual full-attention convolution module is designed to handle the multi-scale information of kidneys by introducing a full-attention mechanism, thus improving the segmentation results of kidneys. The Dice coefficient on the Kits19 dataset reaches 0.972. The experimental results demonstrate that the proposed method achieves good segmentation performance compared to other algorithms, effectively enhancing the accuracy of kidney segmentation.
1. Introduction
The kidneys are vital visceral organs in the urinary system that filter waste and excess substances from the blood, expelling them from the body through urine to prevent toxin accumulation, thus performing metabolic functions. Simultaneously, they regulate electrolyte balance by controlling the levels of ions such as sodium, potassium, calcium, and phosphate in the blood. They assist in blood pressure regulation by adjusting the blood volume and secreting hormones like renin, which aids in regulating blood vessel constriction and fluid balance [1]. It is evident that the kidneys play a crucial role in maintaining endocrine balance and stabilizing blood pressure [2]. Once the kidneys are damaged, it poses a serious threat to overall health [3]. According to the survey, more than 850 million people worldwide suffer from kidney disease [4], and by 2021, the number of chronic kidney disease patients in China will reach 120 million [5]. This indicates that kidney diseases have become a prevalent and significant threat to people’s health [6].
For the treatment of kidney diseases, such as nephritis and chronic kidney disease, it is essential to localize and determine the specific lesion locations within the kidneys for effective diagnosis and treatment. With the continuous advancement of medical technology, computed tomography (CT) has become a primary imaging modality for doctors to diagnose and locate kidney-related issues. Because it can utilize X-ray and computer processing technology to generate cross-sectional images, CT scanning provides high-resolution images of the kidneys, displaying internal structures and abnormalities. Doctors can accurately locate the kidneys and assess the position, size, and morphology of lesions using CT scans, providing crucial evidence for diagnosis and treatment. However, most CT images currently require manual identification by experienced medical experts. This manual identification process is not only time-consuming and labor-intensive but is also susceptible to subjective factors, leading to the possibility of misdiagnosis [7].
The emergence of deep-learning methods addresses the shortcomings of manual approaches. Deep learning, as a powerful machine-learning technology, possesses the capability to autonomously extract various features and patterns without extensive human intervention [8,9]. Automatic segmentation methods based on deep learning play a crucial role in medical image analysis. They learn features of kidney images through extensive training data, enabling more accurate segmentation, thereby effectively improving the efficiency of image segmentation and diagnosis for physicians, reducing the occurrence of missed diagnoses and misdiagnoses. Medical image segmentation is a critical step in medical image analysis, aiming to extract regions of interest from the entire image to identify lesion areas and facilitate diagnosis. In particular, in abdominal CT images, automatic kidney segmentation technology can efficiently detect the kidneys. Through automatic kidney segmentation, the kidney portions in CT images can be accurately delineated and presented to medical personnel. This can enhance the early detection and diagnostic accuracy of kidney diseases, providing better treatment plans and care for patients.
However, kidney segmentation faces numerous challenges. Patients with different kidney diseases may exhibit various kidney lesions, resulting in morphological, dimensional, and other feature diversities within the segmented kidney target areas. This further complicates the segmentation task. Additionally, compared to natural images, medical images often have less pronounced gradient variations, especially in abdominal CT images, where the grayscale values between different soft tissues are similar, causing minimal differences in grayscale values between tissues [10]. This is specifically evident in abdominal CT images where the boundaries between the kidneys and adjacent organs are usually unclear, further increasing the difficulty of kidney segmentation [11].
To address the aforementioned issues, the paper proposes a kidney segmentation method based on multi-scale feature fusion and residual full attention (MRFA-Net). The method first utilizes a multi-scale feature fusion module based on the feature pyramid, integrating deep feature information into shallow feature maps to optimize the feature representation across different network layers. Then, it employs residual convolution modules with full-attention mechanisms to address attention deficits, further capturing semantic features corresponding to the kidneys. Experimental results on the publicly available Kits19 dataset [12] demonstrate the effectiveness of the proposed kidney segmentation method. The specific contributions are as follows:
- To achieve precise segmentation of the kidney region, an efficient kidney segmentation method is proposed. The classic ResNeXt50 network [13] is utilized for downsampling, extracting multi-scale information containing kidneys at different network layers, and integrating deep feature information into shallow feature maps. The multi-scale fusion features contain rich texture and semantic features, addressing the problem of blurry kidney contours in abdominal CT images and optimizing feature representations at different network layers;
- Utilizing residual full-attention convolutional modules to recalibrate multi-scale features can expand the information contained in features and further fit features to improve the output results. Adopting a multi-path parallel approach to obtain four sets of average segmentation outputs enhances the segmentation performance of the model. The model addresses the problem of large variations in kidney position by introducing a complete attention mechanism to handle multi-scale fusion features and obtain correlated features between different features, thereby resolving attention deficits;
- Excellent segmentation results are achieved on the Kits19 dataset, with a Dice coefficient of 0.972 for kidney segmentation. Compared to other kidney models, this performance is superior, demonstrating outstanding segmentation capability, particularly surpassing the classic U-Net [14] model by 5.3%.
2. Related Works
Currently, medical image segmentation methods mainly fall into two categories: traditional image segmentation and deep-learning-based semantic segmentation. Many scholars both domestically and internationally have conducted a series of studies in the field of medical image segmentation, proposing various models and methods for kidney segmentation tasks.
Traditional medical image segmentation relies on the inherent features of the images. For instance, Pohle et al. [15] utilized traditional methods such as adaptive region growing for segmenting kidney organs. Berlgherbi et al. [16] employed the watershed method to segment markers extracted from kidney image gradients and morphological reconstruction operations. Rusinek et al. [17] proposed a method to track kidney boundaries in slice subsets using thresholding and morphological techniques for segmentation. Traditional image segmentation methods rely on shallow features such as grayscale and texture to accomplish segmentation tasks. However, the information contained in images extends beyond these features, making it challenging for traditional methods to effectively leverage deeper image features. Therefore, relying solely on traditional methods proves challenging in achieving satisfactory kidney segmentation results.
With the development of computer technology, medical image processing methods based on deep learning, especially convolutional neural networks (CNNs), have achieved significant success [18,19]. Many scholars have made outstanding contributions in the field of kidney segmentation by utilizing deep learning. Cruz et al. [20] proposed a coarse-to-fine image segmentation strategy, initially using AlexNet [21] to extract the region of interest (ROI) from kidney CT images and then employing the U-Net network for segmentation, thereby reducing segmentation errors. Xie et al. [22] utilized the ResNeXt network combined with group convolution and depth-wise separable convolution operations, improving the U-Net network and proposing the SERU model, effectively reducing parameters and computational load and increasing algorithm speed. Additionally, the SE module [23] was employed to calculate weights, improving segmentation results. Although the coarse-to-fine segmentation strategy proposed by these two methods has to some extent improved segmentation accuracy, aiming to narrow down the detection area of the kidneys, it fails to address the issue of boundary blurring during kidney segmentation. Feng et al. [24] introduced a model that integrates the generative adversarial network (GAN) [25] supervision mechanism into the U-Net network, enhancing the segmentation performance and achieving good results. Although this method partially reduces under-segmentation and over-segmentation in images with unclear edges between the kidneys and background noise, it overlooks the inconsistent variations in the size and position of kidney organs in abdominal CT images. Khan et al. [26] proposed the Camofocus method, in which the foreground and background regions of the target are effectively segmented under the action of the feature split and modulation (FSM) module, and then a context refinement module (CRM) is designed to refine the multiscale feature representation.
The aforementioned models have certain limitations in kidney segmentation, overlooking the challenge of small and diverse shapes of kidney organs, as well as the low contrast and fuzzy boundaries of kidney organs in abdominal CT images. To address the issue of fuzzy kidney organ boundaries, existing models often use multi-scale feature maps extracted from different network layers for multi-path segmentation. However, shallow feature maps suffer from a lack of semantic information, resulting in suboptimal accuracy when directly used for segmentation. In this study, we propose a kidney segmentation method based on multi-scale feature fusion and residual complete attention. This approach optimizes the feature-extraction process using the feature pyramid concept, integrating deep semantic information into shallow features, to solve the problem of boundary ambiguity in kidney segmentation. We design a residual complete attention convolutional module to process the multi-scale feature fusion map, taking into account the unique characteristics of varying kidney shapes and positions during kidney CT data extraction, using full attention to eliminate attention deficit problems has addressed the issue of inconsistent variations in kidney positioning, ultimately improving segmentation accuracy.
3. Materials and Methods
To address the issue of the varying size and position of the kidneys in abdominal CT slices and to accommodate the spatial feature dependencies among organs for the kidney segmentation task, our network architecture model (as shown in Figure 1) utilizes the first five layers of the ResNeXt50 network as feature-extraction layers. We employ a method of integrating shallow layers with deep layers to extract multi-scale information about the kidneys. Considering the connections between various organs in the abdomen, we design residual full-attention convolution modules to process the multi-scale information of the kidneys and extract semantic information from the features for better feature representation. The model primarily consists of two modules: the multi-scale feature fusion module and the residual full-attention convolution module.
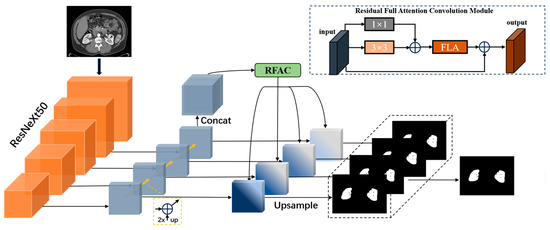
Figure 1.
The structure of the MRFA-Net network model. RFAC module stands for residual full-attention convolutional module, while FLA represents the full-attentional mechanism used in this paper.
The network input first undergoes feature extraction through the downsampling part of the multidimensional feature module fusion. Then, it goes through upsampling to obtain unified dimensional structural features and, based on these multidimensional features, proceeds through residual full-topic clustering to obtain key information regarding the spatial and channel dimensions of the fused module features. Finally, using the integrated learning multi-path unit concept on the features extracted after upsampling, four sets of segmentation outputs are obtained. These four outputs are averaged to produce the final output result, enhancing the segmentation performance of the model, next we will introduce each module separately.
3.1. Multi-Scale Feature Fusion Architecture
To tackle segmentation tasks for small targets like kidneys, a common approach is to use image pyramids, enhancing the detection capability by transforming the target at multiple scales. However, this method results in significant computational overhead and struggles to effectively fuse semantic information across different scales. In this study, we adopted the concept of feature pyramid networks (FPN) [27]. The FPN not only overcomes the computational complexity of image pyramid methods but also extracts features at different scales. This allows us to generate multi-scale feature representations, with each scale possessing robust semantic information, thereby improving the accurate segmentation efficiency for the kidney region.
This module employs the ResNeXt50 network structure for feature extraction, enhancing network expressive capability with a multi-branch structure distinct from the ResNet50 network. Residual connections and multi-layer processing are applied to the feature maps of each branch after grouped convolution, extracting higher-level kidney feature representations. We divide the module (as shown in Figure 2) into five different stages based on the slice size requirements, and the last feature layer in each stage is selected as the corresponding level feature in the network hierarchy. During the upsampling process, we use the output of the deepest layer (Layer 4) of the feature-extraction network as input without further 1 × 1 convolution to change channel numbers. The size of the upsampled feature map is adjusted to match the size of the corresponding feature map in the previous layer, and they are added together for feature fusion output. The shallow feature information from lateral connections is added together to obtain multi-scale kidney features. In this process, bilinear interpolation was used for two-fold upsampling because it produces smooth transitions, is computationally simple and efficient, and largely overcomes the discontinuities associated with nearest-neighbor interpolation. The quality of the scaled image is high, preserving the details of the image. It is worth noting that compared to using deconvolution for upsampling, if the parameters are not properly configured, the output feature maps may exhibit significant instability in the form of checkerboard artifacts [28]. Therefore, bilinear interpolation is preferred. To prevent aliasing, a 3 × 3 convolution is applied to the output, ensuring feature stability. Finally, the four feature maps are concatenated, resulting in a multi-scale feature map that integrates spatial and channel information. This feature map has the same size as the processed Layer 4 and a channel count equal to the sum of the four feature maps.
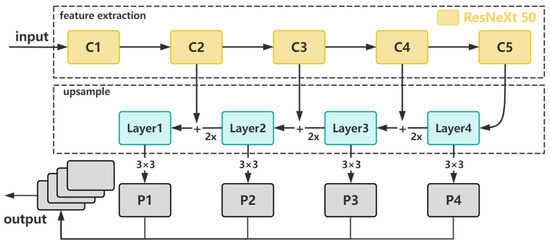
Figure 2.
The structure of multi-scale feature fusion module.
3.2. RFAC Architecture
3.2.1. Full-Attention Mechanism
In recent years, non-local self-attention methods have become widely applied in medical image segmentation models. These methods utilize self-attention mechanisms to explore channel dependencies and spatial relationships among features. However, this approach tends to overlook feature dependencies in other dimensions, leading to incomplete attention. Moreover, hybrid attention methods can only retain some advantages brought by a single attention type and fail to address the issue of incomplete attention. To avoid this problem, we have adopted a full-attention approach (Figure 3), utilizing a single attention map to capture both channel and spatial attention. This better reflects the relationships between different semantic features. This method effectively addresses the problem of attention deficiency and allows for more accurate kidney segmentation.
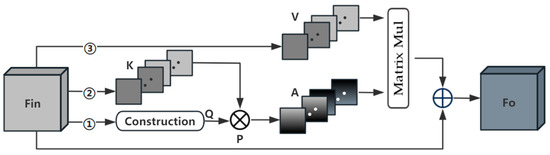
Figure 3.
The process of calculating full attention. Each of the three paths has the same construction step, forming global context Q by construction.
The full-attention operation has three computational branches, each path is shown in Figure 4. Firstly, the feature is input into the bottom Path 1, and and are obtained through two parallel paths. each path contains a global average pooling layer and a linear layer, and the pooling windows of the two paths are and , respectively, which helps to obtain richer information about the contextual prior and maintains the spatial consistency in the computation of the channel relations. Afterwards, and are repeated to form a global prior representing the horizontal direction and representing the vertical direction, which will be used to realize the spatial interactions in the corresponding dimensions. Furthermore, we cut along the dimension and along the dimension, followed by merging these two sets of slices in order to form the global context . In the same way, we can generate feature maps .
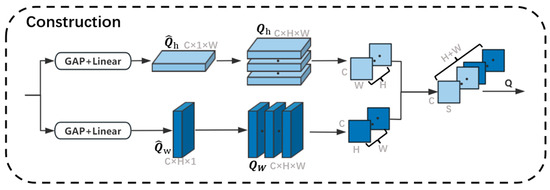
Figure 4.
The process for constructing global context information. GAP stands for a global average pooling layer. Linear stands for a linear layer. Because H is equal to W, we use the letter ‘S’ to represent the merged dimension.
This enables each spatial location to receive a global a priori feature response from the same row and the same column through the operation , which named . The operation is defined as follows:
We then perform a matrix multiplication between and to update each channel map by the generated complete attention, multiply it by the scale parameter α, and perform an element-by-element summation operation with the input feature map to obtain the final output as follows:
Full attention helps to improve the discrimination of kidney features by constructing a global context in order to introduce spatial interactions into the channel attention maps, thus enabling the capture of full attention in a single attention map with more comprehensive contextual information.
3.2.2. RFAC Module
The primary objective of this section is to enhance the segmentation performance of kidney organs by understanding the connections between different organs in abdominal CT images. The model initially extracts concatenated multi-scale information features; however, further extraction of information from these features is required. The obtained features are divided into spatial position dimensions and channel dimensions of the feature map. In typical scenarios, convolutional neural networks need to stack multiple convolutions to capture dependencies across a global scope. However, this approach increases the network depth and model complexity, and it is less efficient for capturing dependencies between spatially distant positions. Each channel dimension corresponds to a semantic information class, mapping to a class of image features in the original image. All feature classes share the same weights in the channel dimension, expressing them with equal importance in the model. However, we aim to assign higher importance to the image features corresponding to kidney organs. Using identical channel weights does not favor highlighting the importance of critical features.
To address the above two problems, the residual full-attention convolution RFAC module (Figure 5) is designed in this paper to highlight important semantic features in both the spatial and channel dimensions. The result is shown in the dashed box in Figure 5. The input of RFAC needs to go through a 1 × 1 convolution to map the output feature channel to the specified dimension, then go through a 1 × 1 convolution and a 3 × 3 convolution and obtain the sum of the two features, after that, go through the full-attention network to re-calibrate its spatial and channel features and use a residual path to fuse the original features with the full-attention features to obtain the output features of the RFAC module. The 3 × 3 convolution extracts the nonlinear features, and the residual path ensures that the model does not have the problem of gradient vanishing. The above process can be summarized as
where denotes a multilevel full-attention convolution operation, and denotes an input feature. is a convolution matrix used to linearly map the original input, which is equivalent to a residual path. is a convolution matrix used to perform feature extraction on the input features, and denotes a full-attention operation.

Figure 5.
The structure of the residual full-attention convolution module.
3.3. Loss Function
The cross-entropy loss function is applicable in most semantic segmentation scenarios and can be used to measure the difference between the model output and the real label, i.e., the cross-entropy between the predicted probability distribution and the actual label. The kidney segmentation task is a binary classification task, which labels the foreground (kidney) as 1 and the background as 0. We output the model output as a value between (0, 1) after the sigmoid function, which can be regarded as the probability of predicting a kidney. The formula is as follows:
where is the true label (0 or 1) and is the probability of the model output.
3.4. Evaluation Criteria
In this experiment, the Dice coefficient, which is most commonly used in the field of medical image processing as a measure of the model, is often used to assess the degree of overlap between the prediction and the real labels, and its value is in the range of [0, 1], with 1 denoting a complete overlap and 0 denoting no overlap. The higher the Dice coefficient, the better the prediction overlap with the real labels, which means a better performance of the model. The formula is as follows:
where is the true label and is the probability of the model output.
3.5. Experimental Preparation
3.5.1. Dataset
The dataset is an open-source dataset from the Medical Image Computing and Computer Assisted Intervention Society (MICCAI) kidney tumor segmentation challenge (KiTS19), an open-source dataset that provides preoperative arterial-phase abdominal CT images of 210 patients with contour labels of whole kidneys and kidney tumors. All patients were in a supine position for image acquisition. The height and width of the images originated from the left anterior aspect of the patient, and the image size was 512 × 512 in most cases, but the 160th case had an image size of 796 × 512. Layer thicknesses ranged from 1 to 5 mm, and the number of scanned slices varied, from tens to hundreds of slices.
3.5.2. Preprocessing
To cooperate with the network training, it is necessary to preprocess the original image. From the above basic information, the dataset can be set to an HU value of (−200, 200); at this time the window width is 400, the window position is 50 and will be scaled to 512 for both the images x and y, and through interpolation the z-direction of the spacing value will be from the original value to 1 mm, so that the kidney part of the imaging is clear, which is conducive to highlighting the boundary of the kidneys. The contrast before and after dataset processing is shown in Figure 6. To prepare the kidney segmentation region, the dataset is now taken for slicing processing, and the slice size is selected as 512 × 512 × 64, to expand the training sample capacity, improve the model generalization ability, and prevent the occurrence of overfitting; the data normalization accelerates the training speed of the network, thus speeding up the convergence of the network.
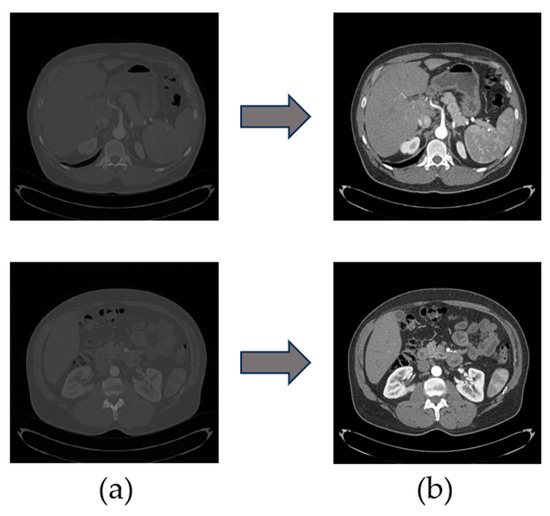
Figure 6.
(a) An image of an abdominal CT slice from the original dataset; (b) An image of an abdominal CT slice after preprocessing.
To avoid the situation that the data of the same case are divided into the training set and the test set at the same time, which causes the data similarity to be too large, we randomly divided the data into training data, validation data, and test data in a ratio of 8:1:1 according to each case as the basic unit. The training set contains 189 cases with a total of 3744 CT slices; the test set contains 21 cases with a total of 416 CT slices. The training set is further divided into 168 cases with 3328 CT slices for training data and 21 cases with 416 CT slices for validation data. This ensures that each set of data is independent of each other and there is no crossover.
3.5.3. Model Pre-Training
The hardware configuration used in this experiment is a Xeon(R) Platinum 8255C processor with 2.5 GHz, an Nvidia GeForce RTX 3090 series graphics card with 24 GB of memory, Ubuntu 20.04 as the operating system, and the software platform includes the GPU parallel computing architecture CUDA v11.3, as well as the Python v3.8-based Pytorch v1.11.0 deep-learning framework. The software platform includes the GPU parallel computing architecture CUDA v11.3 and the Pytorch v1.11.0 deep-learning framework based on the Python v3.8 programming language. The spe-cific hyperparameter settings for this experiment are shown in Table 1. Upon parti-tioning the dataset, we conducted a five-fold cross-validation experiment and selected the optimal model from the five-fold cross-validation for testing on the test set. To prevent overfitting, we employed the early-stopping technique to control the iteration termination. The model training halts when the evaluation metric on the validation set does not improve.

Table 1.
Hyperparameter settings for model pre-training.
4. Experimental Results and Analysis
4.1. Validation of Attention Mechanisms
In this paper, the residual full-attention convolution module is employed to process the multi-scale sliced feature information extracted from the first half of the model to accomplish the feature optimization and extraction tasks. The selection of attention mechanisms in the FRAC module is compared with the existing more outstanding and widely used non-local attention mechanisms, and the three major categories of attention mechanisms involved in the test are spatial attention (S), channel attention (C), and spatial–channel hybrid attention (C + S), and the parameters and model structure are kept consistent, and the results are shown in the following Table 2.
Table 2.
Comparative test results for attentional decision making.
The MRFA model, without attention mechanism processing, achieves a Dice score of 93.6% in kidney segmentation tasks. Single-channel attention methods and spatial attention methods are not suitable for handling the multi-scale fusion feature part of this model. This may be because the number of channels in the multiscale fusion feature to be processed is 3840. At this point, the main information of the model lies in the spatial position information of the feature map and the semantic features carried by the channel dimension. A singular attention mechanism consolidates feature information from other dimensions, lacking mutual feature responses. DANet, combining spatial and channel-mixed attention, achieved a better performance, with an improvement of approximately 2.7%, but retained only partial benefits. Among them, FLANet performed the best, as it can obtain feature responses from all other channel maps and their corresponding spatial positions for each channel map, addressing the issue of attention deficiency. Based on the above analysis, FLANet is selected as the mechanism for the attention part of the RFAC module in subsequent experiments.
4.2. Validation of Module Structure
Based on the full-attention module, we tested the impact of RFAC blocks with different structures on feature-extraction ability, primarily examining five structures as illustrated in Figure 7. The test results are shown in Table 3. Among them, the effect of the base and adding a res path is not much different, because the 1 × 1 convolution is equivalent to linear mapping in nature, and its role is equivalent to the res path. Analyzing the experimental results of adding the attention mechanism in different locations, we can see that adding in the external effect is better, and adding the residual path after the attention module reduces the possible gradient disappearance problem.
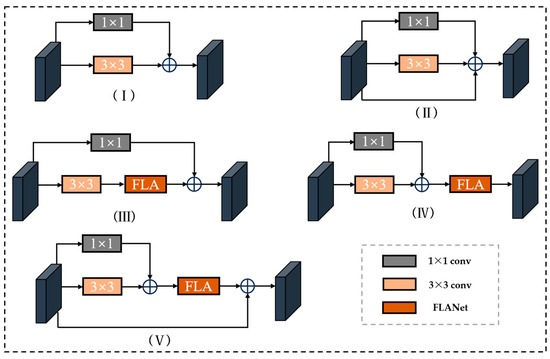
Figure 7.
(I) Base residual convolution block (Base); (II) Add residual path (+res); (III) add attention module internally (+FAin); (Ⅳ) externally add attention module (+FAout); (V) add attention and residual path (+FAout + res).
Table 3.
Test results of RFAC module structure.
4.3. Ablation Experiments and Visualization Results
In this section, we analyze the experimental results for the multi-scale feature fusion part, as well as the RFAC part of the visualization, as shown in Figure 8. It can be found that the kidney segmentation visualization results in (III) are quite different from the gold standard. And (IV) optimizes the expression of kidney features by fusing kidney features of different scales, which solves the problem of ambiguous kidney boundaries to some extent. Due to the addition of the RFAC module, (V) can not only better segment the outer boundary of the kidney but can also well segment the inner hollow region of the kidney compared to (IV).
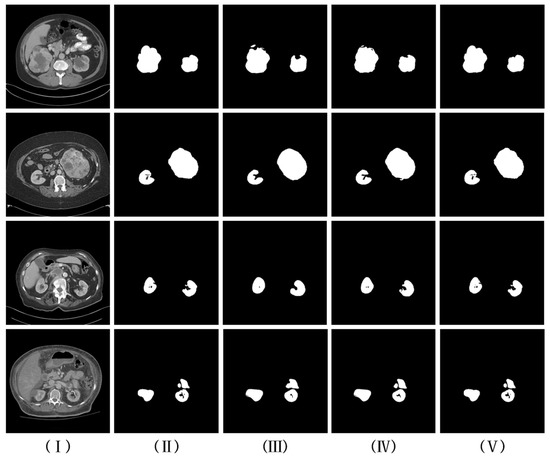
Figure 8.
Visual comparison of kidney segmentation results. (I,II) are CT slices and corresponding labels, respectively; (III) experimental results are from the RFAC model without multi-scale feature fusion and using the base version of the RFAC module; (IV) multi-scale feature fusion is added based on (III); and (V) an experimentally refined RFAC module is used based on (IV).
4.4. Comparative Test Results and Analyses
To further verify the effectiveness of this method in the kidney segmentation task, methods in the field of kidney organ segmentation, as well as methods in the field of medical image segmentation, are selected for comparison in this experiment, which contain classical segmentation algorithms including FCN, U-Net, etc., the improved U-Net algorithm in the field of kidney segmentation, and the MsAUNet algorithm that adopts a similar method of multiscale feature fusion as in this paper, as well as the 3D U-Net algorithm and Hybrid V-Net algorithm which are better known in the field of 3D kidney segmentation. The comparative experimental results are presented in the Table 4. The kidney segmentation results obtained using the method proposed in this paper are significantly higher than those of two classical segmentation algorithms. Compared to FR2PattU-Net and MsAUNet, which also employ multi-scale fusion, our method demonstrates a slight advantage in terms of the Dice coefficient. Both MsAUNet and FR2PattU-Net utilize feature pyramid networks and attention mechanisms. However, there may be issues of attention deficiency in these methods. In such cases, the main information of the model lies in the spatial positional information of the feature maps rather than the semantic features carried by the channel dimensions. Since channel attention coefficients are typically less than 1, applying channel attention can further weaken the expression of feature map information. Therefore, our segmentation results outperform those of existing methods in the kidney segmentation domain. Given that our 2D model achieves results similar to 3D methods in the context of kidney segmentation, it indicates that our method exhibits strong competitiveness in liver segmentation tasks.
Table 4.
Comparison of experimental test results.
5. Conclusions
Aiming at the problem of segmentation of the kidney, this paper presents an automatic kidney segmentation method called MRFA-Net. By introducing a multi-scale feature fusion module to extract rich texture and semantic features, it addresses the issue of unclear boundaries when segmenting kidneys. However, traditional multi-scale models, despite combining deep semantic features and shallow texture features, do not consider the relationship between features. Therefore, we designed a residual full-attention convolution module to handle the multi-scale information of kidneys and capture the relevant features between different scales, improving the output results and addressing the challenges posed by variations in kidney size and position.
Experimental results on the KITS19 public dataset demonstrate that the proposed segmentation method outperforms existing 2D kidney segmentation methods in terms of accuracy and robustness. The Dice coefficient of the proposed model is 0.972, with a slight difference compared to the more mature 3D kidney segmentation model Hybrid V-Net+, indicating the practicality of our approach. Additionally, the attention mechanism used in the RFAC module exhibits a stronger performance compared to existing attention mechanisms, significantly enhancing the efficiency of kidney segmentation. Finally, ablation experiments confirm the outstanding medical image segmentation performance of the proposed network. While this study has addressed some challenges in abdominal CT image kidney segmentation algorithms and made significant progress, future research could integrate three-dimensional models to obtain more accurate segmentation results while considering resource consumption.
Author Contributions
Conceptualization, J.C. and S.D.; data curation, D.S.; formal analysis, H.F.; funding acquisition, D.S.; investigation, D.S.; methodology, J.C. and S.D.; project administration, D.S.; resources, D.S.; software, J.C. and S.D.; supervision, H.F. and D.S.; validation, J.C.; visualization, J.C.; writing—original draft, J.C.; writing—review and editing, J.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China (NNSF) under Grant No. 62266025.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available from the corresponding
author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Young, J.H.; Klag, M.J.; Muntner, P.; Whyte, J.L.; Pahor, M.; Coresh, J. Blood pressure and decline in kidney function: Findings from the Systolic Hypertension in the Elderly Program (SHEP). J. Am. Soc. Nephrol. 2002, 13, 2776–2782. [Google Scholar] [CrossRef]
- Vaziri, N.D. Silva’s diagnostic renal pathology. Kidney Int. 2010, 77, 939–940. [Google Scholar] [CrossRef][Green Version]
- Xia, J. Research Progress of Renal Function Assessment by CT. Guangxi Med. 2023; 45, 77–81. [Google Scholar]
- Jager, K.J.; Kovesdy, C.; Langham, R.; Rosenberg, M.; Jha, V.; Zoccali, C. A single number for advocacy and communication-worldwide more than 850 million individuals have kidney diseases. Nephrol. Dial. Transpl. 2019, 34, 1803–1805. [Google Scholar] [CrossRef]
- Guo, J.; Lin, X.; Cai, W.; Pan, B. Study on the incidence of chronic kidney disease in a specific region. Prim. Med. Forum 2021, 25, 2. [Google Scholar]
- Bellomo, G. The Relationship Between Uric Acid, Allopurinol, Cardiovascular Events, and Kidney Disease Progression: A Step Forward. Am. J. Kidney Dis. 2015, 65, 525–527. [Google Scholar] [CrossRef]
- Li, X.; Zhang, S.; Wang, X.; Wang, X. Evaluation of artificial intelligence combined with low-dose CT of the lung in the diagnosis of novel coronavirus pneumonia. China Med. Equip. 2021, 18, 180–183. [Google Scholar]
- Nadimi-Shahraki, M.H.; Taghian, S.; Mirjalili, S.; Abualigah, L. Binary Aquila Optimizer for Selecting Effective Features from Medical Data: A COVID-19 Case Study. Mathematics 2022, 10, 1929. [Google Scholar] [CrossRef]
- Rezaeijo, S.M.; Nesheli, S.J.; Serj, M.F.; Birgani, M.J.T. Segmentation of the Prostate, Its Zones, Anterior Fibromuscular Stroma, and Urethra on the MRIs and Multimodality Image Fusion Using U-Net Model. Quant. Imaging Med. Surg. 2022, 12, 4786–4804. [Google Scholar] [CrossRef]
- Shehata, M.; Mahmoud, A.; Soliman, A.; Khalifa, F.; Ghazal, M.; Abou El-Ghar, M.; El-Melegy, M.; El-Baz, A. 3D kidney segmentation from abdominal diffusion MRI using an appearance-guided deformable boundary. PLoS ONE 2018, 13, e0200082. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, N.; Sun, X.; Zhang, Y.; Huo, L. Construction and application of a web-side 3D organ model visualization system containing anatomical differences in Chinese population. J. Anat. 2019, 50, 7. [Google Scholar]
- Heller, N.; Sathianathen, N.; Kalapara, A.; Walczak, E.; Moore, K.; Kaluzniak, H.; Rosenberg, J.; Blake, P.; Rengel, Z.; Oestreich, M. The kits19 challenge data: 300 kidney tumor cases with clinical context, ct semantic segmentations, and surgical outcomes. arXiv 2019, arXiv:190400445. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015), Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Pohle, R.; Toennies, K.D. A New Approach for Model-Based Adaptive Region Growing in Medical Image Analysis. In Proceedings of the 9th International Conference on Computer Analysis of Images and Patterns (CAIP 2001), Warsaw, Poland, 5–7 September 2001; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Belgherbi, A.; Hadjidj, I.; Bessaid, A. Morphological segmentation of the kidneys from abdominal ct images. J. Mech. Med. Biol. 2014, 14, 1450073. [Google Scholar] [CrossRef]
- Rusinek, H.; Lim, J.C.; Wake, N.; Seah, J.M.; Botterill, E.; Farquharson, S.; Mikheev, A.; Lim, R.P. A semi-automated “blanket” method for renal segmentation from non-contrast T1-weighted MR images. Magn. Reson. Mater. Phys. Biol. Med. 2016, 29, 197–206. [Google Scholar] [CrossRef]
- Anwar, S.M.; Majid, M.; Qayyum, A.; Awais, M.; Alnowami, M.; Khan, M.K. Medical image analysis using convolutional neural networks: A review. J. Med. Syst. 2018, 42, 226. [Google Scholar] [CrossRef]
- Elyan, E.; Vuttipittayamongkol, P.; Johnston, P.; Martin, K.; McPherson, K.; Jayne, C.; Sarker, M.K. Computer vision and machine learning for medical image analysis: Recent advances, challenges, and way forward. Artif. Intell. Surg. 2022, 2, 24–25. [Google Scholar] [CrossRef]
- da Cruz, L.B.; Araújo, J.D.; Ferreira, J.L.; Diniz, J.O.; Silva, A.C.; de Almeida, J.D.; de Paiva, A.C.; Gattass, M. Kidney segmentation from computed tomography images using deep neural network. Comput. Biol. Med. 2020, 123, 103906. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Xie, X.; Li, L.; Lian, S.; Chen, S.; Luo, Z. SERU: A cascaded SE-ResNeXT U-Net for kidney and tumor segmentation. Concurr. Comput. Pract. Exp. 2020, 32, e5738. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Feng, W.; Liu, J.; Guan, Z.; He, Z.; Chen, G.; Dai, Y. Renal Ultrasound Image Segmentation Based on U-Net and Generative Adversarial Nets. In Proceedings of the 2022 7th Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Tianjin, China, 1–3 July 2022. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B. Generative adversarial nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Khan, A.; Khan, M.; Gueaieb, W.; El Saddik, A.; De Masi, G.; Karray, F. CamoFocus: Enhancing Camouflage Object Detection With Split-Feature Focal Modulation and Context Refinement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–10 January 2024; pp. 1434–1443. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Disstill 2016, 1, e3. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Song, Q.; Mei, K.; Huang, R. AttaNet: Attention-augmented network for fast and accurate scene parsing. In Proceedings of the AAAI Conference on Artificial Intelligence, Hongkong, China, 2–9 February 2021; Volume 35, pp. 2567–2575. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Song, Q.; Li, J.; Li, C.; Guo, H.; Huang, R. Fully attentional network for semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentatio. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- Sun, P.; Mo, Z.; Hu, F.; Liu, F.; Mo, T.; Zhang, Y.; Chen, Z. Kidney tumor segmentation based on FR2PAttU-Net model. Front. Oncol. 2022, 12, 853281. [Google Scholar] [CrossRef]
- Chattopadhyay, S.; Basak, H. Multi-scale attention u-net (msaunet): A modified u-net architecture for scene segmentation. arXiv 2020, arXiv:200906911. [Google Scholar]
- George, Y. A coarse-to-fine 3D U-Net network for semantic segmentation of kidney CT scans. In International Challenge on Kidney and Kidney Tumor Segmentation; Springer: Berlin/Heidelberg, Germany, 2021; pp. 137–142. [Google Scholar]
- Türk, F.; Lüy, M.; Barışçı, N. Kidney and renal tumor segmentation using a hybrid V-Net-Based model. Mathematics 2020, 8, 1772. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).