
A Comparative Study of Two Rule-Based Explanation Methods for Diabetic Retinopathy Risk Assessment




Abstract
:1. Introduction
2. Literature Review
2.1. Methods Based on Measuring the Importance of Features
2.2. Methods Based on Counterfactual Examples
2.3. Methods Focused on Visualisation
3. Preliminaries
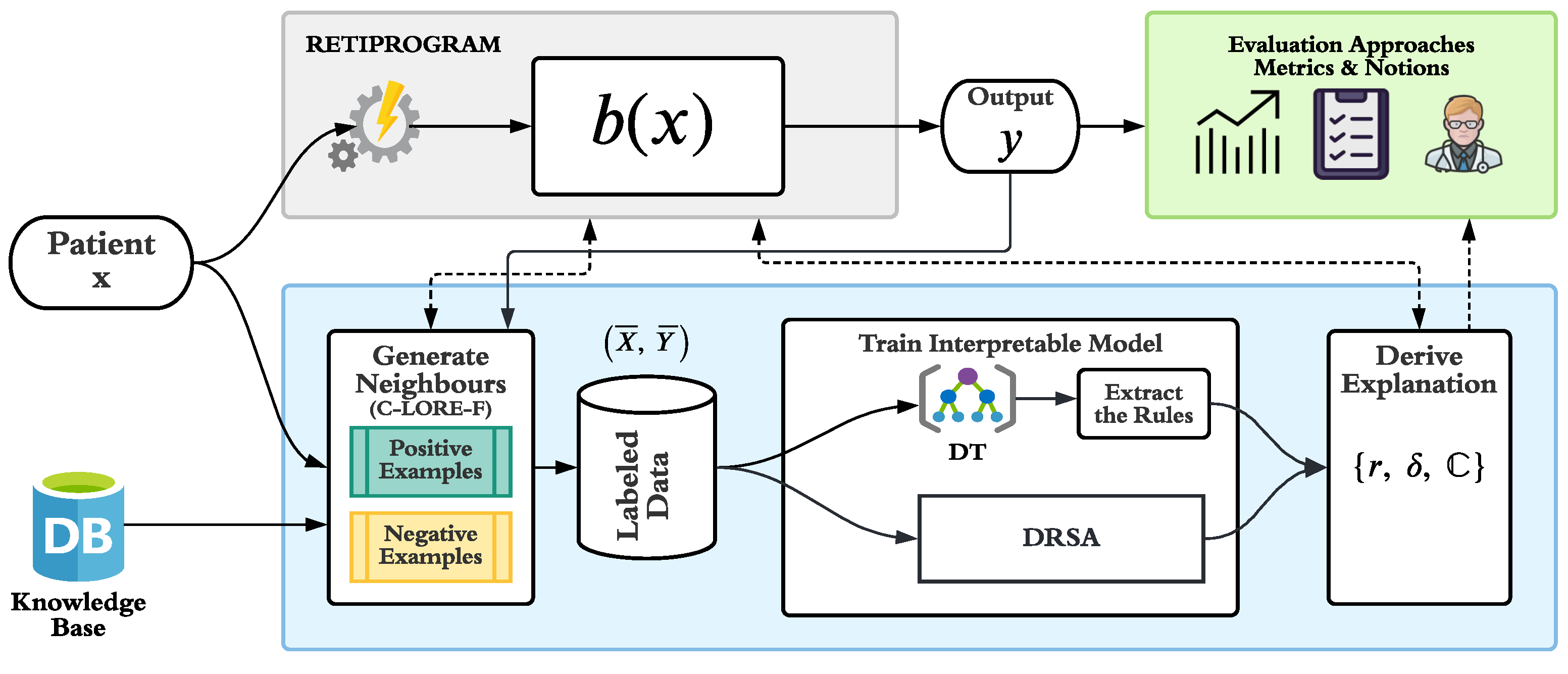
3.1. Contextualised LORE for Fuzzy Attributes (C-LORE-F)
| Algorithm 1:C-LORE-F |
| input :x: an instance to explain, T: an auxiliary set, b: a black-box model, L: maximum level of exploration, and : knowledge base. output: E: the explanation of the decision of b on x 1 ; 2 ; 3 ; 4 ; 5 ; 6 ; 7 ; 8 ; 9 ; 10 |
- Attributes with a fixed value (e.g., sex).
- Attributes whose value increases in time (e.g., age).
- Attributes whose value decreases in time (e.g., years left until retirement).
- Variable attributes, that can change positively and negatively (e.g., weight).
- State Space: the set of all possible examples S.
- Initial State: , where x is the instance of which we want to generate its neighbours and y is the label of this instance obtained by the black-box b.
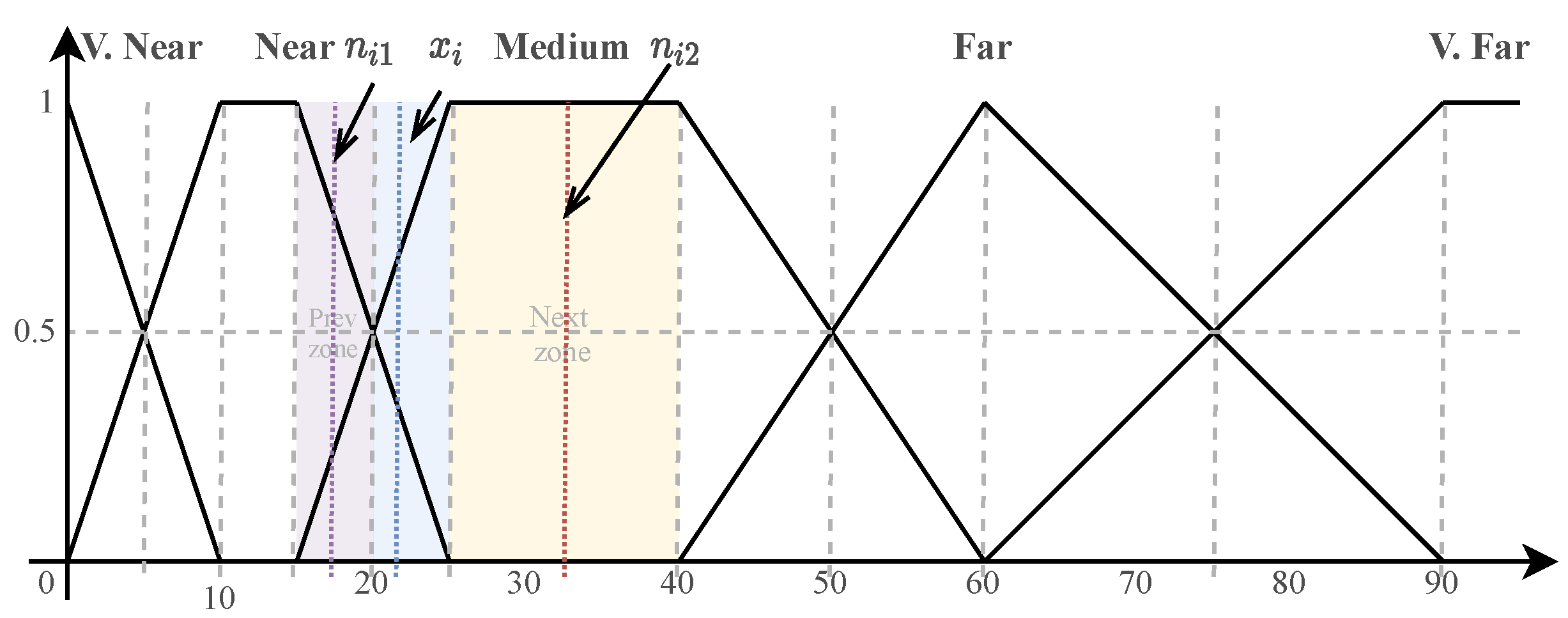
- Actions: Modifications of the value of a single attribute (feature). These actions leverage some contextual information about the feature to make the desired changes to generate new neighbours. In our case, we define two types of actions, next and prev, described later.
- Transition Model: returns a new instance in which the value of a feature is changed by applying all actions.
- Goal Test: We check, for each generated individual, if, according to the black box, it has the same label as the root, y. If that is the case, we generate its neighbours in the same way (i.e., applying one positive/negative change in the value of a single attribute). Otherwise, we have found an individual close to x that belongs to another class; thus, we have reached a boundary of y, and we terminate the search from that instance.
- Path Cost: The path cost of each example is calculated by measuring the HVDM distance between the generated example and x.
3.2. Dominance-Based Rough Set Approach (DRSA)
- ≥ decision rules, providing lower profile descriptions for objects belonging at least to class (so they belong to or a better class, ):IF ≥ AND ≥ AND … ≥ THEN y ≥
- ≤ decision rules, providing upper profile descriptions for objects belonging at most to class (so they belong to or a lower class, ):IF ≤ AND ≤ AND … ≤ THEN y ≤ .
| Algorithm 2:DRSA method |
 |
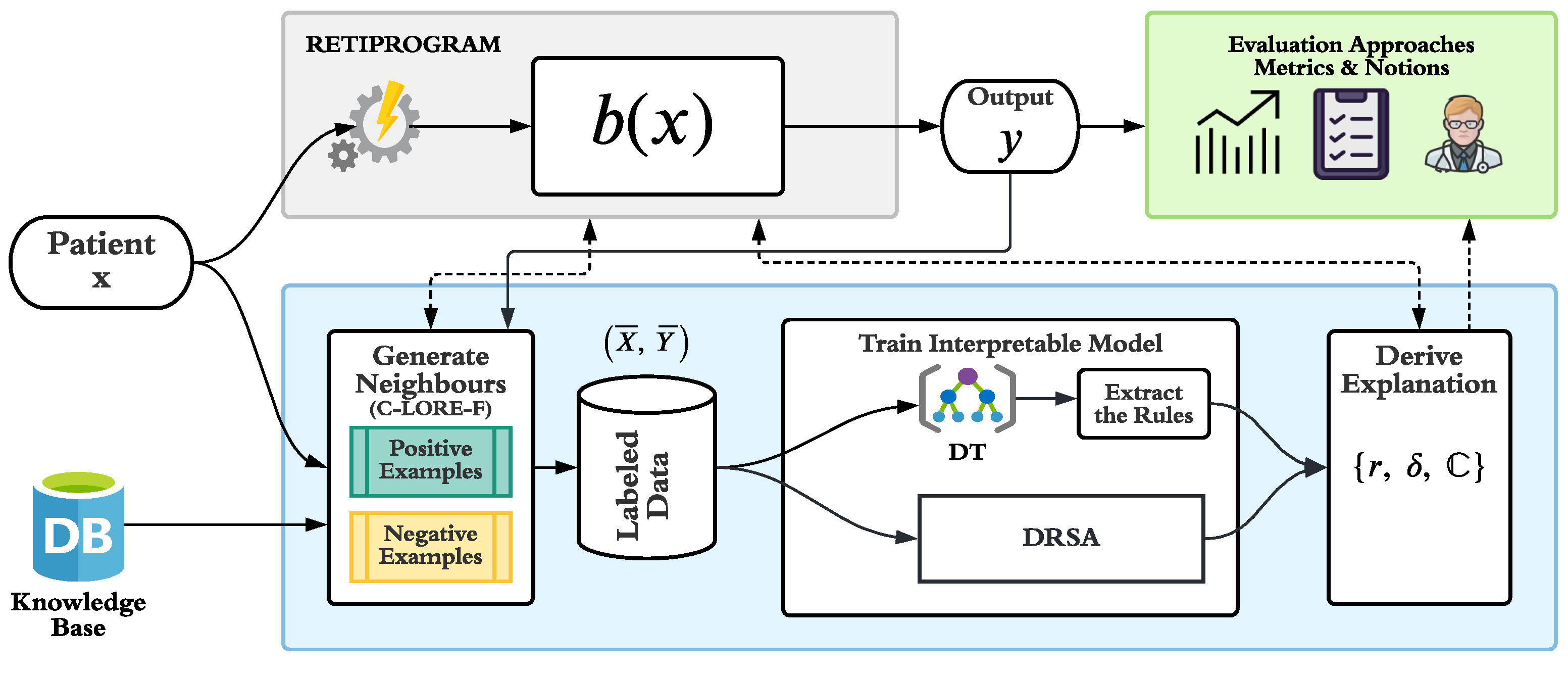
4. Explanation Generation System
- r is the decision rule(s) that covers the instance x. This rule tells which are the necessary conditions to be satisfied by the object for being classified as y, so they indicate the minimal reasons for belonging to that class. When using DRSA, we can have more than one applicable rule with different combinations of conditions.
- is the set of counterfactual rules that lead to an outcome different than the one of x. They indicate the minimal number of conditions that should be simultaneously changed in the object for not being in class y.
- is a set of counterfactual instances that represent examples of objects that belong to a different class and have the minimum changes with respect to the original input object x.
| Algorithm 3:Extraction of counterfactual rules |
 |
5. Experiments and Results
5.1. Experimental Setup
5.2. Evaluation of the Explanation Results
- Hit: this metric computes the similarity between the output of the explanation model and the black-box, b, for all the testing instances. It returns 1 if they are equal and 0 otherwise.
- Fidelity: this metric measures to which extent the explanation model can accurately reproduce the black-box predictor for the particular case of instance x. It answers the question of how good is the explanation model at mimicking the behaviour of the black-box by comparing its predictions and the ones of the black-box on the instances that are neighbours of x, which are in .
- l-Fidelity: it is similar to the fidelity; however, it is computed on the subset of instances from covered by the explanation rule(s), r. It is used to measure to what extent this rule is good at mimicking the black-box model on similar data of the same class.
- c-Hit: this metric compares the predictions of the explanation model and the black-box model on all the counterfactual instances of x that are extracted from the counterfactual rules in .
- cl-Fidelity: it is also similar to the fidelity; however, it is computed on the set of instances from covered by the counterfactual rules in .
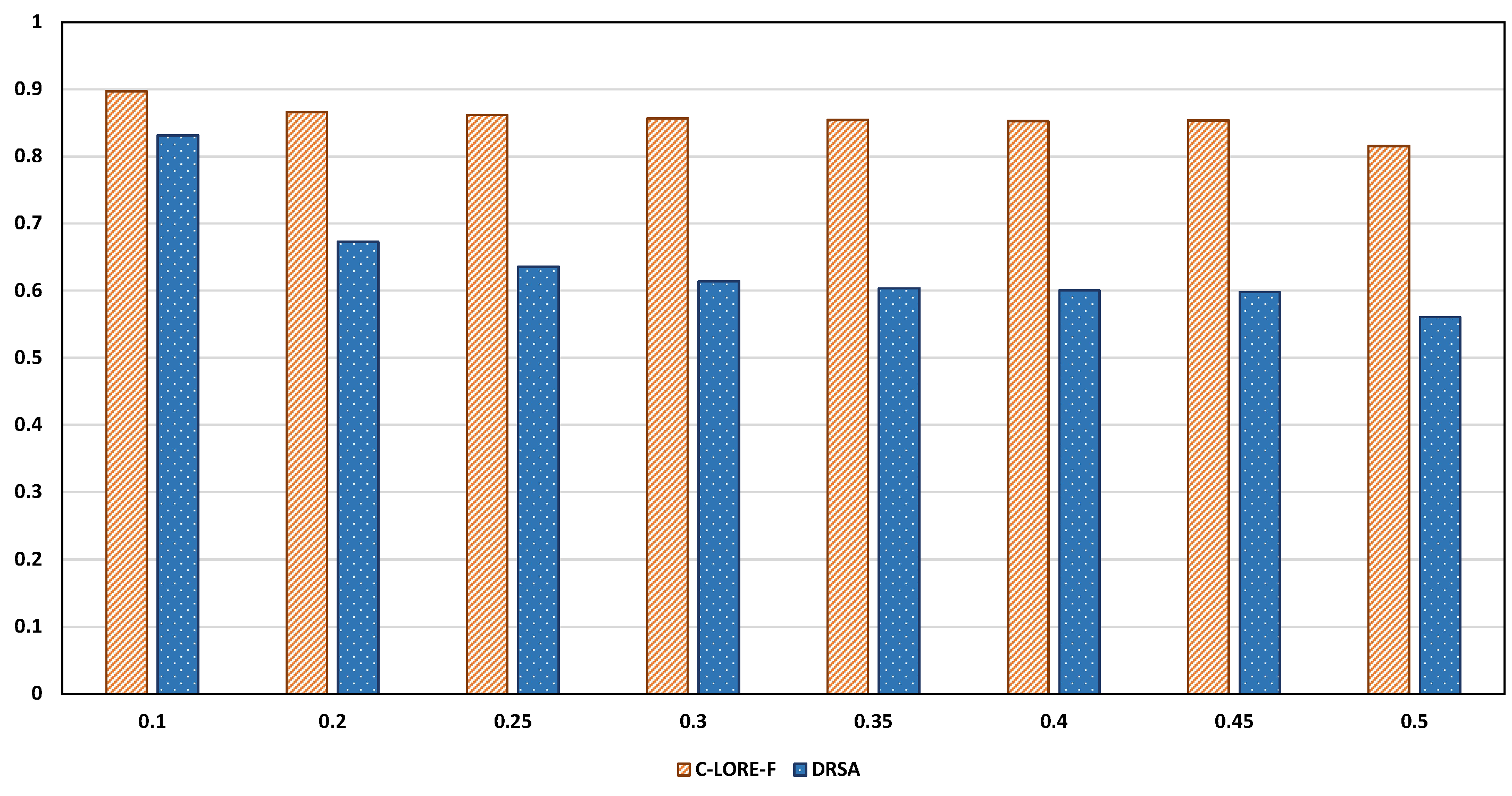
5.3. Evaluating the Locality of the Methods
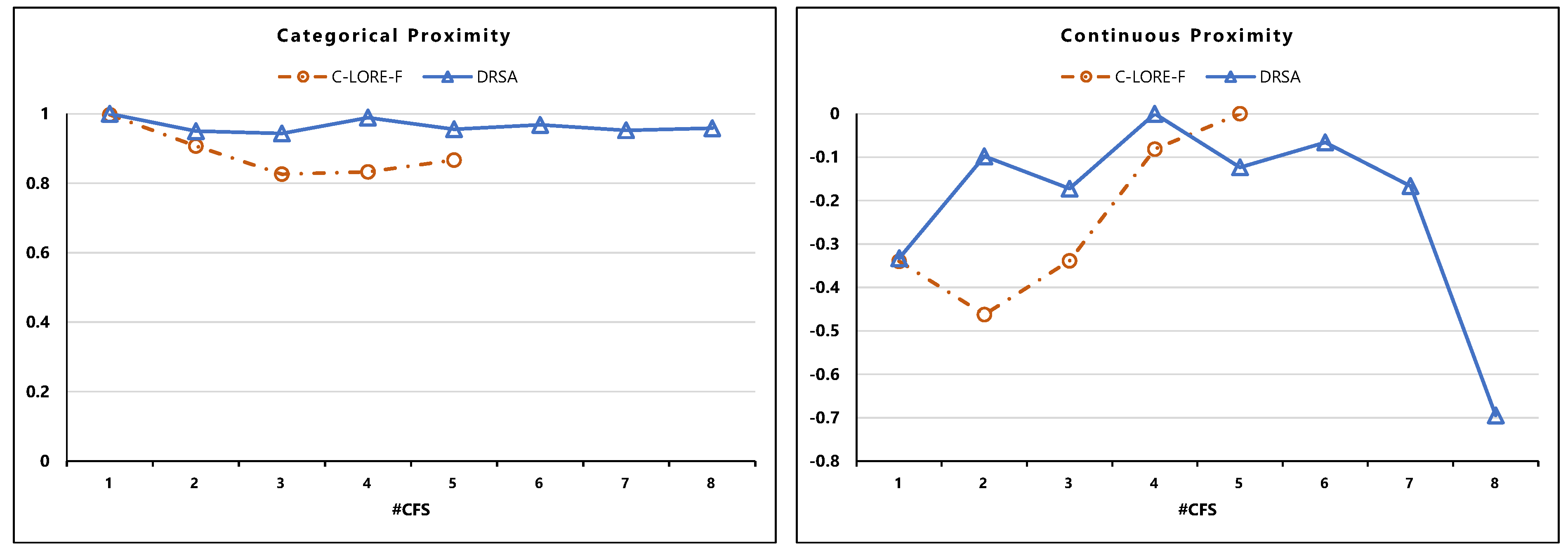
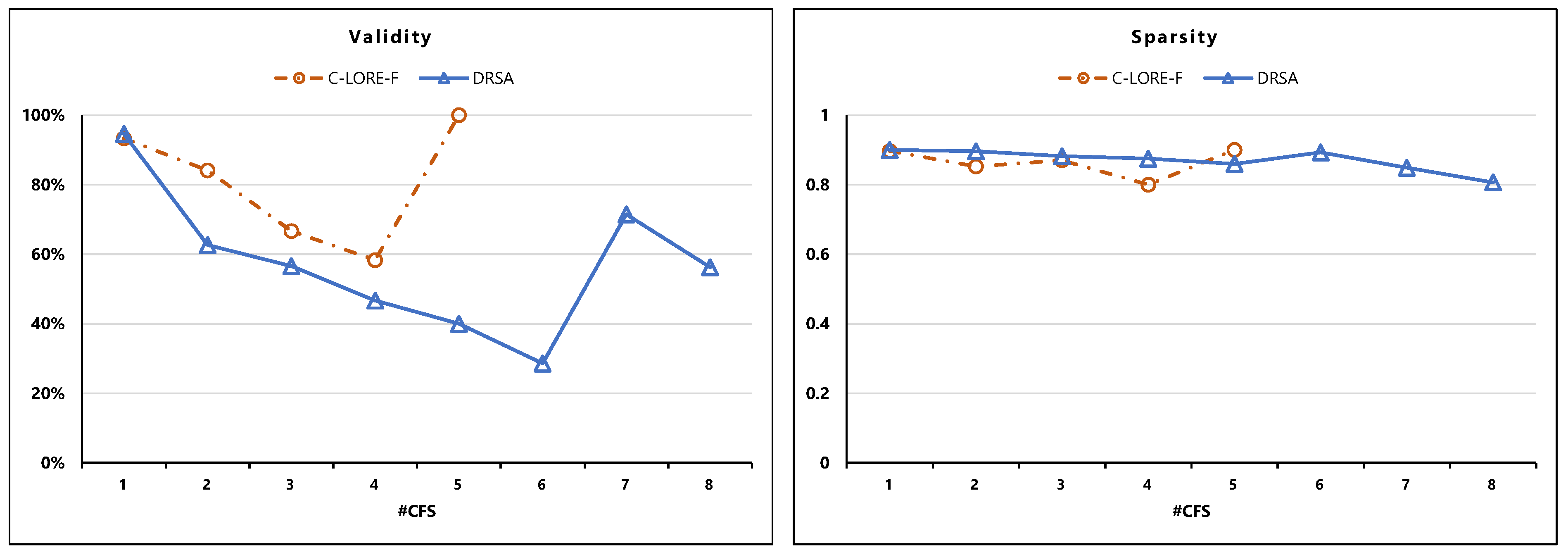
5.4. Evaluation of the Counterfactual Examples
- Validity: is the number of counterfactual examples with a different outcome than the original input, i.e., x, divided by the total number of counterfactual examples.Here refers to the set of returned counterfactual examples and b is the black-box model.
- Proximity: is the mean of feature-wise distances between a counterfactual example c and the original input x. We considered two different proximity measures, the Euclidean distance for the continuous features and the Hamming distance for the categorical ones.
- Sparsity: it measures the average of changes between a counterfactual example and the original input.Here, is the set of features, and is the indicator function.
- Diversity: it is similar to proximity. However, instead of computing the feature-wise distance between the counterfactual example and the original input, we compute it between each pair of counterfactual examples. As in the proximity measure, we considered two different diversity versions, one for the continuous and the other for the categorical features.
5.5. Analysis of Computational Complexity
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DM | Diabetes Mellitus |
| DR | Diabetic Retinopathy |
| NHS | National Health Surveys |
| AI | Artificial Intelligence |
| CDSS | Clinical Decision Support System |
| ML | Machine Learning |
| FDT | Fuzzy Decision Tree |
| FRF | Fuzzy Random Forest |
| LIME | Local Interpretable Model-agnostic Explanations |
| LORE | Local Rule-Based Explanations |
| C-LORE-F | Contextualized LORE for Fuzzy Attributes |
| DRSA | Dominance-based Rough Set Approach |
| HVDM | Heterogeneous Value Difference Metric |
| CKD-EPI | Chronic Kidney Disease Epidemiology index |
References
- Aguiree, F.; Brown, A.; Cho, N.H.; Dahlquist, G.; Dodd, S.; Dunning, T.; Hirst, M.; Hwang, C.; Magliano, D.; Patterson, C.; et al. IDF Diabetes Atlas; International Diabetes Federation: Brussels, Belgium, 2013. [Google Scholar]
- Shaw, J.E.; Sicree, R.A.; Zimmet, P.Z. Global estimates of the prevalence of diabetes for 2010 and 2030. Diabetes Res. Clin. Pract. 2010, 87, 4–14. [Google Scholar] [CrossRef] [PubMed]
- Nair, A.T.; Muthuvel, K.; Haritha, K. Effectual Evaluation on Diabetic Retinopathy. In Information and Communication Technology for Competitive Strategies (ICTCS 2020); Springer: Singapore, 2022; pp. 559–567. [Google Scholar]
- López, M.; Cos, F.X.; Álvarez-Guisasola, F.; Fuster, E. Prevalence of diabetic retinopathy and its relationship with glomerular filtration rate and other risk factors in patients with type 2 diabetes mellitus in Spain. DM2 HOPE study. J. Clin. Transl. Endocrinol. 2017, 9, 61–65. [Google Scholar] [CrossRef] [PubMed]
- Romero-Aroca, P.; Valls, A.; Moreno, A.; Sagarra-Alamo, R.; Basora-Gallisa, J.; Saleh, E.; Baget-Bernaldiz, M.; Puig, D. A clinical decision support system for diabetic retinopathy screening: Creating a clinical support application. Telemed. e-Health 2019, 25, 31–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saleh, E.; Valls, A.; Moreno, A.; Romero-Aroca, P.; Torra, V.; Bustince, H. Learning fuzzy measures for aggregation in fuzzy rule-based models. In International Conference on Modeling Decisions for Artificial Intelligence; Springer: Cham, Switzerland, 2018; pp. 114–127. [Google Scholar]
- Romero-Aroca, P.; Verges-Pujol, R.; Santos-Blanco, E.; Maarof, N.; Valls, A.; Mundet, X.; Moreno, A.; Galindo, L.; Baget-Bernaldiz, M. Validation of a diagnostic support system for diabetic retinopathy based on clinical parameters. Transl. Vis. Sci. Technol. 2021, 10, 17. [Google Scholar] [CrossRef] [PubMed]
- Burkart, N.; Huber, M.F. A Survey on the Explainability of Supervised Machine Learning. J. Artif. Intell. Res. 2021, 70, 245–317. [Google Scholar] [CrossRef]
- Strumbelj, E.; Kononenko, I. An efficient explanation of individual classifications using game theory. J. Mach. Learn. Res. 2010, 11, 1–18. [Google Scholar]
- Krause, J.; Perer, A.; Ng, K. Interacting with predictions: Visual inspection of black-box machine learning models. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 5686–5697. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why Should I Trust You?: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Maaroof, N.; Moreno, A.; Valls, A.; Jabreel, M. Guided-LORE: Improving LORE with a Focused Search of Neighbours. In International Workshop on the Foundations of Trustworthy AI Integrating Learning, Optimization and Reasoning; Springer: Cham, Switzerland, 2020; pp. 49–62. [Google Scholar]
- Maaroof, N.; Moreno, A.; Jabreel, M.; Valls, A. Contextualized LORE for Fuzzy Attributes. In Artificial Intelligence Research and Development; IOS Press: Amsterdam, The Netherlands, 2021; pp. 435–444. [Google Scholar]
- Saleh, E.; Moreno, A.; Valls, A.; Romero-Aroca, P.; de La Riva-Fernandez, S. A Fuzzy Random Forest Approach for the Detection of Diabetic Retinopathy on Electronic Health Record Data. In Artificial Intelligence Research and Development; Frontiers in Artificial Intelligence and Applications; IOS Press: Amsterdam, The Netherlands, 2016; Volume 288, pp. 169–174. [Google Scholar]
- Greco, S.; Matarazzo, B.; Slowinski, R. Rough sets theory for multicriteria decision analysis. Eur. J. Oper. Res. 2001, 129, 1–47. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Molnar, C. Interpretable Machine Learning; Lulu.com: Morrisville, NC, USA, 2020. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. AAAI 2018, 18, 1527–1535. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Martens, D.; Provost, F. Explaining data-driven document classifications. MIS Q. 2014, 38, 73–100. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Pedreschi, D.; Turini, F.; Giannotti, F. Local rule-based explanations of black box decision systems. arXiv 2018, arXiv:1805.10820. [Google Scholar]
- Mothilal, R.K.; Sharma, A.; Tan, C. Explaining machine learning classifiers through diverse counterfactual explanations. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 607–617. [Google Scholar]
- Russell, C. Efficient search for diverse coherent explanations. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 19–31 January 2019; pp. 20–28. [Google Scholar]
- Ming, Y.; Qu, H.; Bertini, E. Rulematrix: Visualizing and understanding classifiers with rules. IEEE Trans. Vis. Comput. Graph. 2018, 25, 342–352. [Google Scholar] [CrossRef] [Green Version]
- Neto, M.P.; Paulovich, F.V. Explainable Matrix—Visualization for Global and Local Interpretability of Random Forest Classification Ensembles. IEEE Trans. Vis. Comput. Graph. 2020, 27, 1427–1437. [Google Scholar] [CrossRef] [PubMed]
- Wilson, D.R.; Martinez, T.R. Improved heterogeneous distance functions. J. Artif. Intell. Res. 1997, 6, 1–34. [Google Scholar] [CrossRef]
- Ruggieri, S. YaDT: Yet another Decision Tree Builder. In Proceedings of the 16th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2004), Boca Raton, FL, USA, 15–17 November 2004; pp. 260–265. [Google Scholar]
- Pawlak, Z. Rough Sets: Theoretical Aspects of Reasoning about Data; Springer Science & Business Media: Dordrecht, The Netherlands, 1991; Volume 9. [Google Scholar]
- Słowiński, R.; Greco, S.; Matarazzo, B. Rough set methodology for decision aiding. In Springer Handbook of Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2015; pp. 349–370. [Google Scholar]
- Błaszczyński, J.; Słowiński, R.; Szeląg, M. Sequential covering rule induction algorithm for variable consistency rough set approaches. Inf. Sci. 2011, 181, 987–1002. [Google Scholar] [CrossRef]
- Błaszczyński, J.; Słowiński, R.; Szeląg, M. Induction of Ordinal Classification Rules from Incomplete Data. In Rough Sets and Current Trends in Computing; Yao, J., Yang, Y., Słowiński, R., Greco, S., Li, X., Mitra, S., Polkowski, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7413, pp. 56–65. [Google Scholar]
- Saleh, E.; Maaroof, N.; Jabreel, M. The deployment of a decision support system for the diagnosis of Diabetic Retinopathy into a Catalan medical center. In Proceedings of the 6th URV Doctoral Workshop in Computer Science and Mathematics; Universitat Rovira i Virgili: Tarragona, Spain, 2020; p. 45. [Google Scholar]
- Blanco, M.E.S.; Romero-Aroca, P.; Pujol, R.V.; Valls, A.; SaLeh, E.; Moreno, A.; Basora, J.; Sagarra, R. A Clinical Decision Support System (CDSS) for diabetic retinopathy screening. Creating a clinical support application. Investig. Ophthalmol. Vis. Sci. 2020, 61, 3308. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 4th ed.; Pearson: London, UK, 2020. [Google Scholar]
- Sani, H.M.; Lei, C.; Neagu, D. Computational complexity analysis of decision tree algorithms. In International Conference on Innovative Techniques and Applications of Artificial Intelligence; Springer: Cham, Switzerland, 2018; pp. 191–197. [Google Scholar]
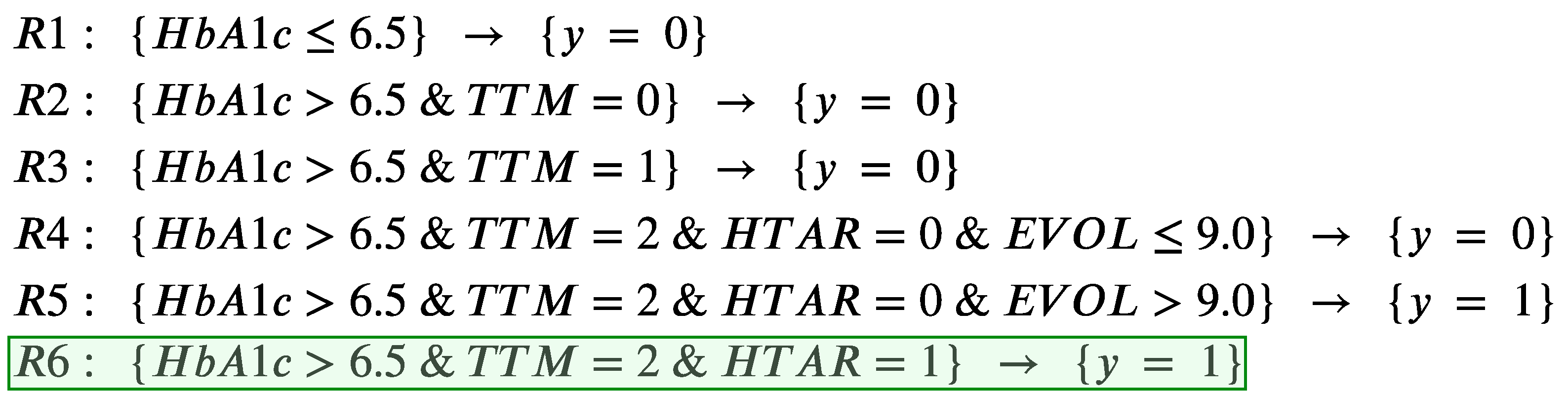



{kind=link}
{kind=link}
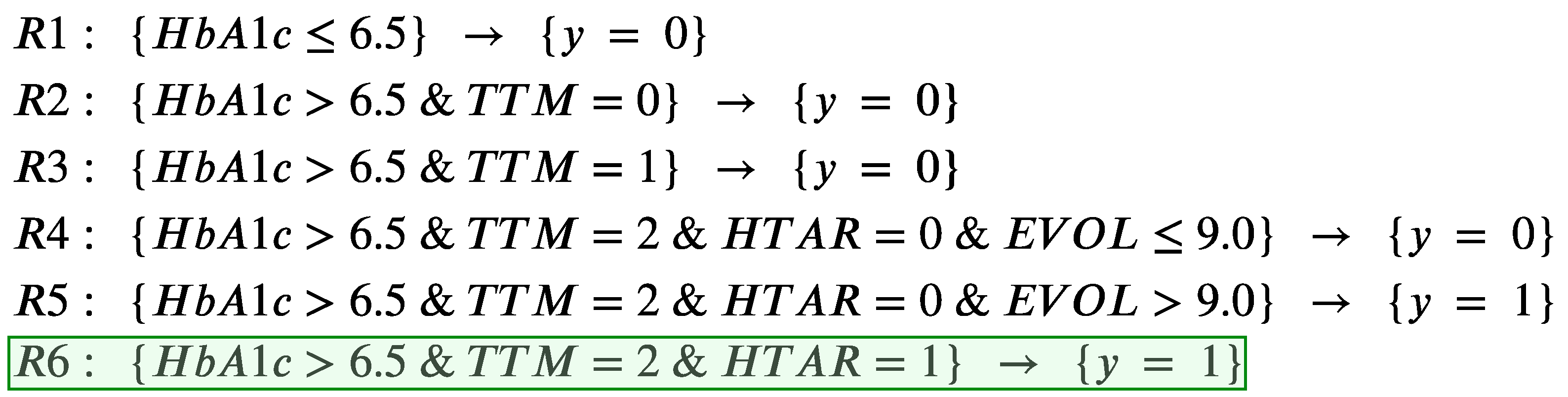{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Age | Sex | EVOL | TTM | HbA1c | CDKEPI | MA | BMI | HTAR |
|---|---|---|---|---|---|---|---|---|
| 71.0 | 1 | 14.0 | 2 | 7.4 | 90.07 | 0.0 | 31.05 | 1 |
| — | — | — | — | 6.5 | — | — | — | — |
| — | — | — | 0 | — | — | — | — | — |
| — | — | — | 1 | — | — | — | — | — |
| Hit | Fidelity | l-Fidelity | cHit | cl-Fidelity | |
|---|---|---|---|---|---|
| C-LORE-F | 1.00 ± 0.00 | 0.99 ± 0.002 | 0.99 ± 0.002 | 0.89 ± 0.290 | 0.88 ± 0.282 |
| DRSA | 0.97 ± 0.152 | 0.831 ± 0.32 | 0.93 ± 0.176 | 0.830 ± 0.315 | 0.83 ± 0.298 |
| Min | Max | Average | |
|---|---|---|---|
| Neighbours Generation | 5.453 | 19.252 | 8.882 |
| C-LORE-F | 0.093 | 1.149 | 0.169 |
| DRSA | 0.125 | 2.556 | 0.386 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maaroof, N.; Moreno, A.; Valls, A.; Jabreel, M.; Szeląg, M. A Comparative Study of Two Rule-Based Explanation Methods for Diabetic Retinopathy Risk Assessment. Appl. Sci. 2022, 12, 3358. https://doi.org/10.3390/app12073358
Maaroof N, Moreno A, Valls A, Jabreel M, Szeląg M. A Comparative Study of Two Rule-Based Explanation Methods for Diabetic Retinopathy Risk Assessment. Applied Sciences. 2022; 12(7):3358. https://doi.org/10.3390/app12073358
Chicago/Turabian StyleMaaroof, Najlaa, Antonio Moreno, Aida Valls, Mohammed Jabreel, and Marcin Szeląg. 2022. "A Comparative Study of Two Rule-Based Explanation Methods for Diabetic Retinopathy Risk Assessment" Applied Sciences 12, no. 7: 3358. https://doi.org/10.3390/app12073358
APA StyleMaaroof, N., Moreno, A., Valls, A., Jabreel, M., & Szeląg, M. (2022). A Comparative Study of Two Rule-Based Explanation Methods for Diabetic Retinopathy Risk Assessment. Applied Sciences, 12(7), 3358. https://doi.org/10.3390/app12073358