
Detection of Dense Citrus Fruits by Combining Coordinated Attention and Cross-Scale Connection with Weighted Feature Fusion


Abstract
:1. Introduction
- Improving the original YOLOv5 network architecture with a visual attention mechanism coordinated attention module (CA) and weighted feature fusion BiFPN;
- Comparing the performance of the improved YOLOv5 with other commonly used object detectors including Faster R-CNN, YOLOv4, and original YOLOv5; and
- Developing a robot fruit detector for precision agriculture applications such as yield estimation and mechanical harvesting, where such a detector can adapt to different varieties of citrus trees and different growth stages under a natural environment.
2. Materials
2.1. Citrus Image Collection
2.2. Image Processing and Augmentation
3. Methods
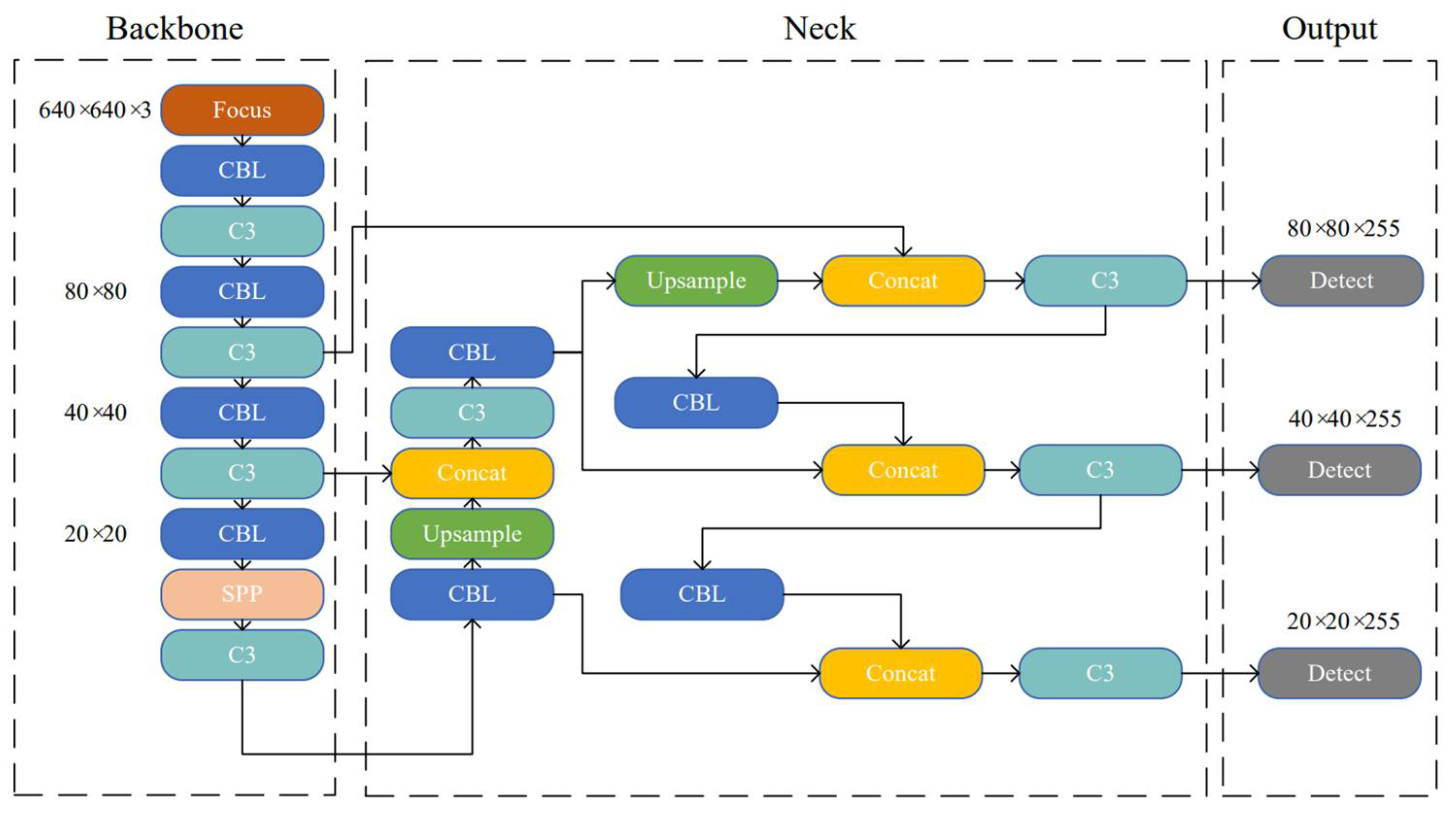
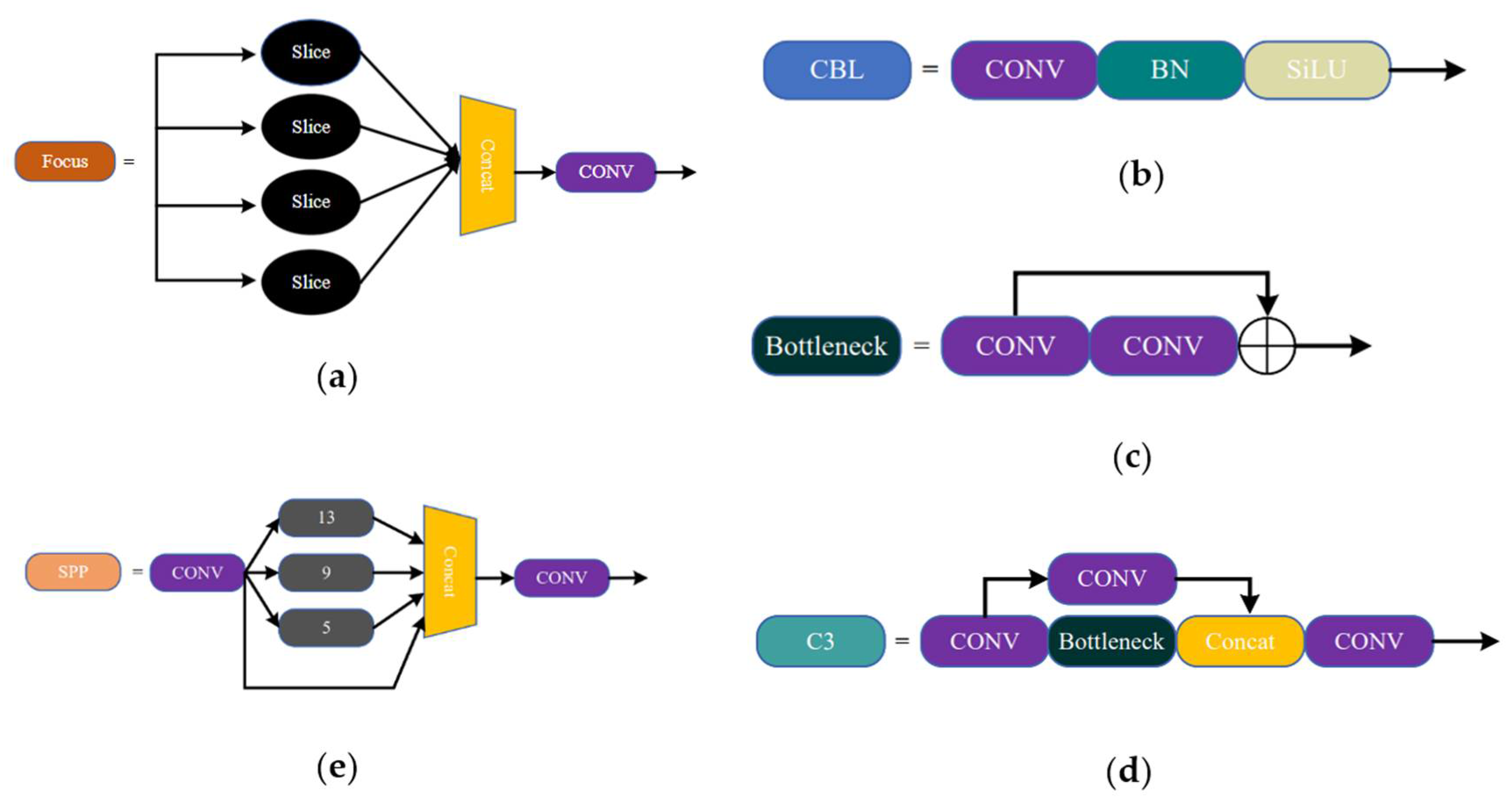
3.1. YOLOv5 Object Detection Network
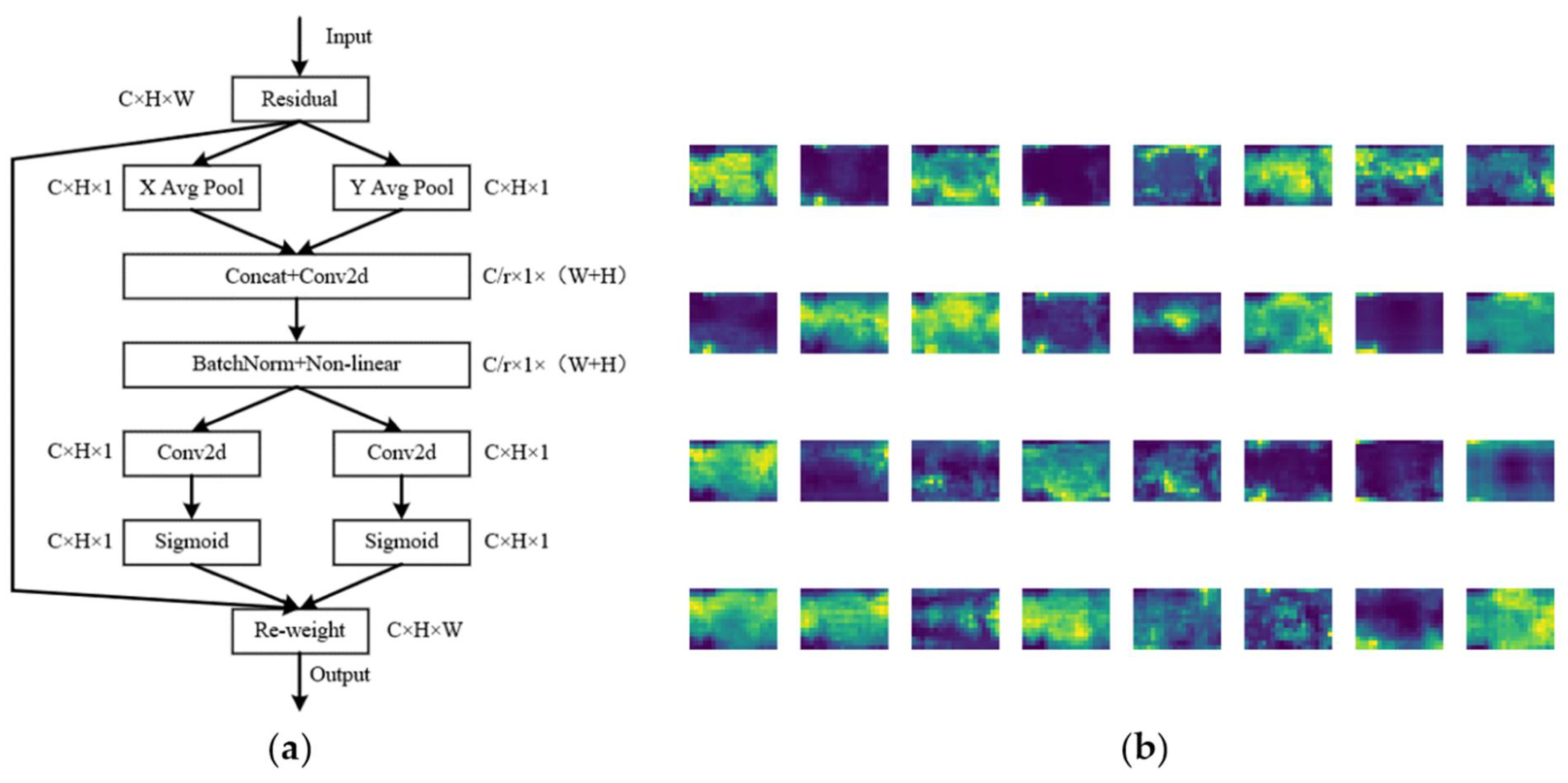
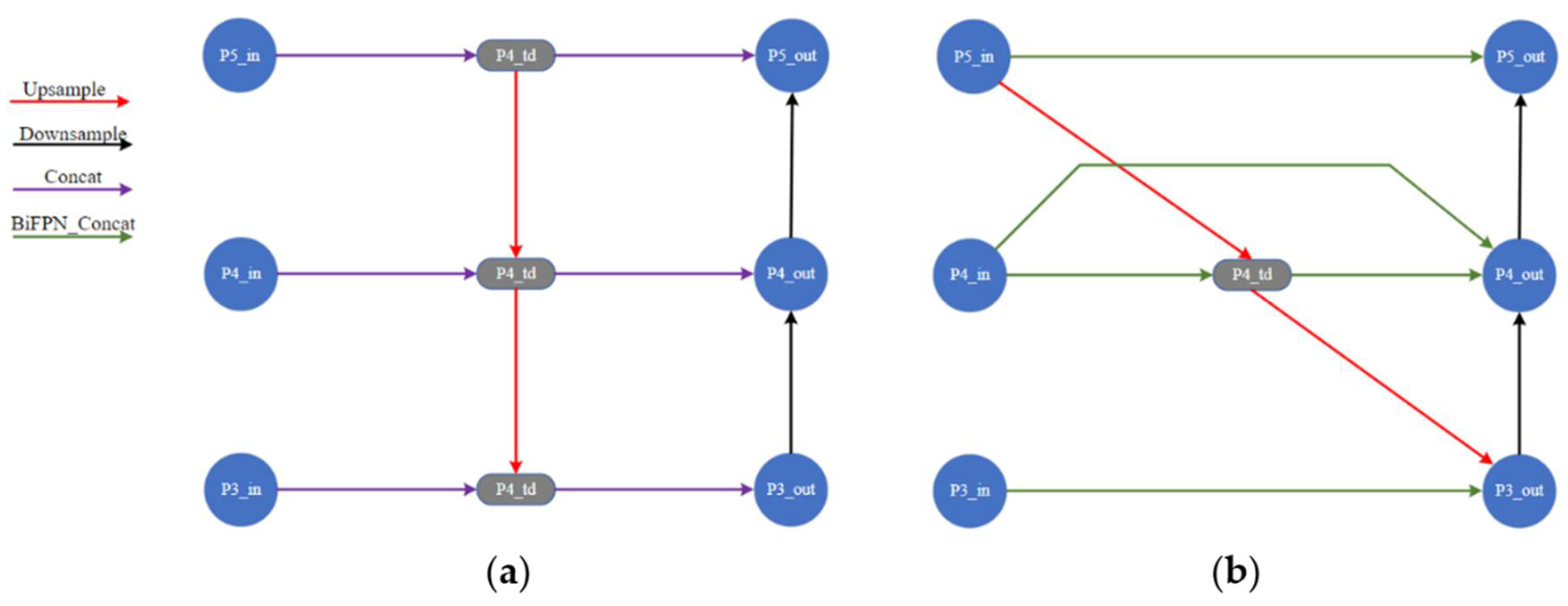
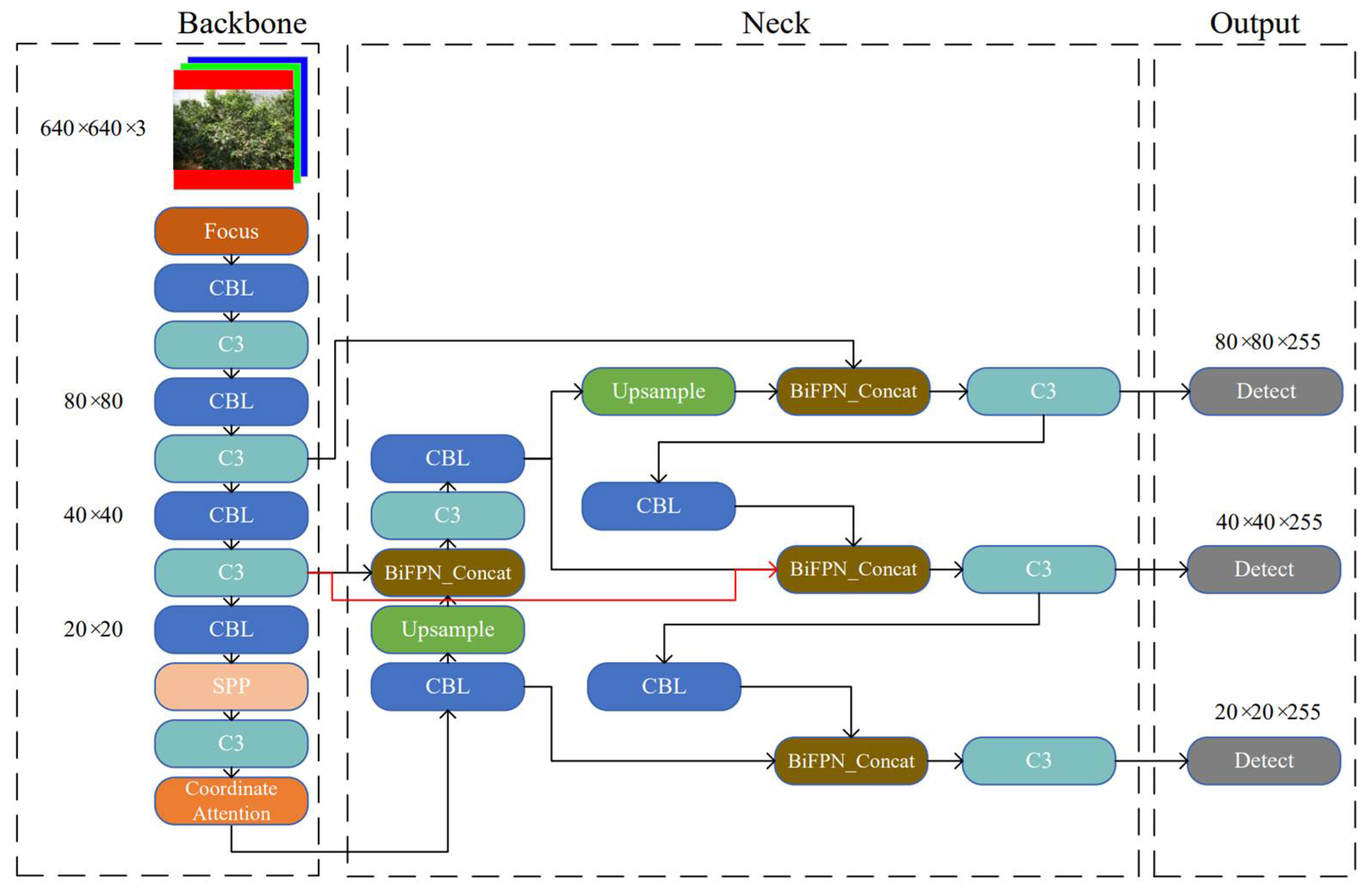
3.2. Improvement to the YOLOv5
3.2.1. Improvement on the Network Structure
3.2.2. Improvement on Loss Function
4. Results
4.1. Experimental Environment
4.2. Evaluation Indicators
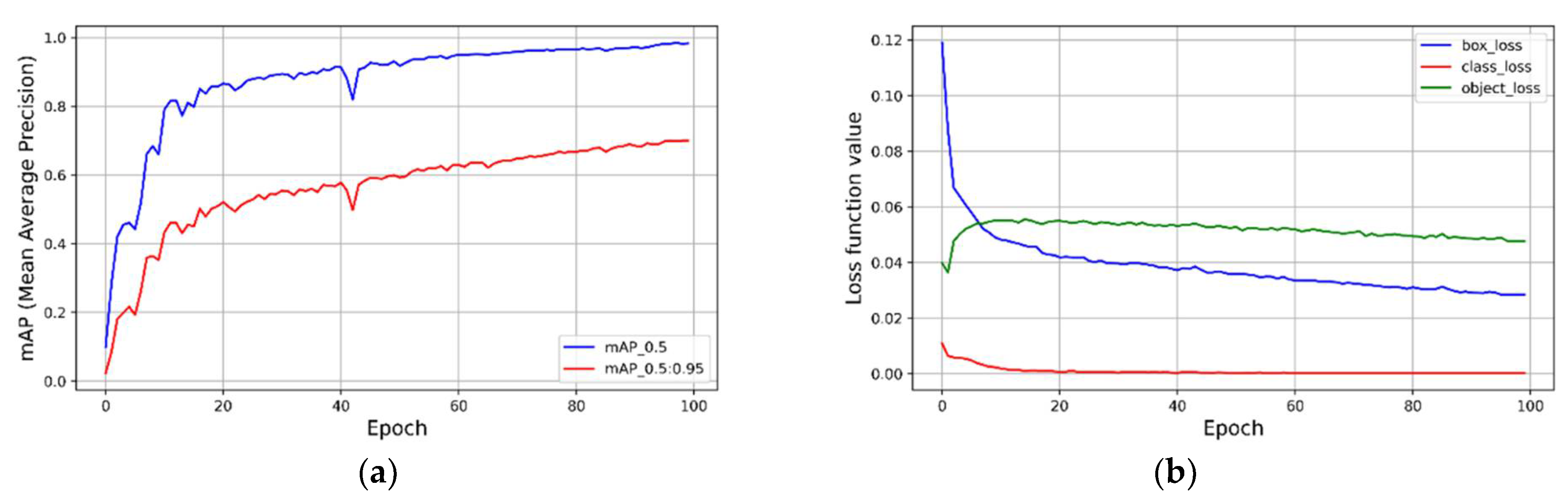
4.3. Experimental Results
5. Discussion
- Comparisons of the improved YOLOv5 model on citrus fruit images at different growth stages were performed to evaluate the fruit recognition accuracy and performance.
- Comparisons of the improved YOLOv5 model with the other three commonly used deep learning-based models were performed on citrus images of the growth period and mature period.
- Testing the generalization of the improved YOLOv5 model by detecting the recognition effect of four different citrus fruits.
5.1. Dense Citrus Detection with the Improved YOLOv5
5.2. Comparison with Other Commonly Used Object Models
5.3. Detection on Different Citrus Varieties
6. Conclusions
- (1)
- Our improvements to the YOLOv5 model included three factors: (I) the latest visual attention mechanism coordinated attention module (CA) was inserted into the backbone network of the original YOLOv51 to recognize small target fruits; (II) the two-way cross-scale connection and weighted feature fusion BiFPN in the neck network were used to replace the PANet multiscale feature fusion network; and (III) the varifocal loss function was used to replace the focal loss function for detecting occluded fruits.
- (2)
- Compared with the original YOLOv5 model, the mAP@0.5 of the improved model was improved by 5.4%, and the inference speed of YOLOv5 for detecting images on the server was 0.019 s, respectively. The results of the experiments on the four varieties of citrus trees showed that our proposed improved model could effectively identify dense small citrus fruits for their entire growth period.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning–Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Tyagi, A.C. TOWARDS A SECOND GREEN REVOLUTION. Irrig. Drain. 2016, 65, 388–389. [Google Scholar] [CrossRef]
- Vasconez, J.P.; Kantor, G.A.; Cheein, F.A.A. Human-robot interaction in agriculture: A survey and current challenges. Biosyst. Eng. 2019, 179, 35–48. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J.P. Image Segmentation for Fruit Detection and Yield Estimation in Apple Orchards. J. Field Robot. 2017, 34, 1039–1060. [Google Scholar] [CrossRef] [Green Version]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K. Sensors and systems for fruit detection and localization: A review. Comput. Electron. Agric. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Liu, T.H.; Ehsani, R.; Toudeshki, A.; Zou, X.J.; Wang, H.J. Detection of citrus fruit and tree trunks in natural environments using a multi-elliptical boundary model. Comput. Ind. 2018, 99, 9–16. [Google Scholar] [CrossRef]
- Vasconez, J.P.; Delpiano, J.; Vougioukas, S.; Cheein, F.A. Comparison of convolutional neural networks in fruit detection and counting: A comprehensive evaluation. Comput. Electron. Agric. 2020, 173, 12. [Google Scholar] [CrossRef]
- Lu, J.; Sang, N. Detecting citrus fruits and occlusion recovery under natural illumination conditions. Comput. Electron. Agric. 2015, 110, 121–130. [Google Scholar] [CrossRef]
- Mahdavifar, S.; Ghorbani, A.A.J.N. Application of deep learning to cybersecurity: A survey. Neurocomputing 2019, 347, 149–176. [Google Scholar] [CrossRef]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P.J.S. Visual-based defect detection and classification approaches for industrial applications—A survey. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef] [Green Version]
- Bersani, M.; Mentasti, S.; Dahal, P.; Arrigoni, S.; Vignati, M.; Cheli, F.; Matteucci, M. An integrated algorithm for ego-vehicle and obstacles state estimation for autonomous driving. Robot. Auton. Syst. 2021, 139, 16. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldu, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Patel, N.; Mukherjee, S.; Ying, L. Erel-net: A remedy for industrial bottle defect detection. In Proceedings of the International Conference on Smart Multimedia, Toulon, France, 24–26 August 2018; pp. 448–456. [Google Scholar]
- Quan, L.Z.; Feng, H.Q.; Li, Y.J.; Wang, Q.; Zhang, C.B.; Liu, J.G.; Yuan, Z.Y. Maize seedling detection under different growth stages and complex field environments based on an improved Faster R-CNN. Biosyst. Eng. 2019, 184, 1–23. [Google Scholar] [CrossRef]
- Li, Z.B.; Li, Y.; Yang, Y.B.; Guo, R.H.; Yang, J.Q.; Yue, J.; Wang, Y.Z. A high-precision detection method of hydroponic lettuce seedlings status based on improved Faster RCNN. Comput. Electron. Agric. 2021, 182, 11. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 Algorithm with Pre- and Post-Processing for Apple Detection in Fruit-Harvesting Robot. Agronomy 2020, 10, 19. [Google Scholar] [CrossRef]
- Ji, W.; Gao, X.X.; Xu, B.; Pan, Y.; Zhang, Z.; Zhao, D. Apple target recognition method in complex environment based on improved YOLOv4. J. Food Process. Eng. 2021, 44, 13. [Google Scholar] [CrossRef]
- Lu, S.; Chen, W.; Zhang, X.; Karkee, M.J.C. Canopy-attention-YOLOv4-based immature/mature apple fruit detection on dense-foliage tree architectures for early crop load estimation. Comput. Electron. Agric. 2022, 193, 106696. [Google Scholar]
- Chen, W.K.; Lu, S.L.; Liu, B.H.; Li, G.; Qian, T.T. Detecting Citrus in Orchard Environment by Using Improved YOLOv4. Sci. Program. 2020, 2020, 13. [Google Scholar] [CrossRef]
- Fu, L.S.; Feng, Y.L.; Wu, J.Z.; Liu, Z.H.; Gao, F.F.; Majeed, Y.; Al-Mallahi, A.; Zhang, Q.; Li, R.; Cui, Y.J. Fast and accurate detection of kiwifruit in orchard using improved YOLOv3-tiny model. Precis. Agric. 2021, 22, 754–776. [Google Scholar] [CrossRef]
- Gai, R.; Chen, N.; Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Lawal, M.O. Tomato detection based on modified YOLOv3 framework. Sci. Rep. 2021, 11, 11. [Google Scholar] [CrossRef] [PubMed]
- Lyu, S.; Li, R.; Zhao, Y.; Li, Z.; Fan, R.; Liu, S.J. Green Citrus Detection and Counting in Orchards Based on YOLOv5-CS and AI Edge System. Sensors 2022, 22, 576. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Xiong, J.; Jiao, J.; Xie, Z.; Huo, Z.; Hu, W.J. Citrus fruits maturity detection in natural environments based on convolutional neural networks and visual saliency map. Precis. Agric. 2022. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10705–10714. [Google Scholar]
- Lim, J.-S.; Astrid, M.; Yoon, H.-J.; Lee, S.-I. Small object detection using context and attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Korea, 20–23 April 2021; pp. 181–186. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. Varifocalnet: An iou-aware dense object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Ni, J.; Yan, Z.; Jiang, J.J. TongueCaps: An Improved Capsule Network Model for Multi-Classification of Tongue Color. Diagnostics 2022, 12, 653. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Varieties | Image Resolution (Pixels) | Number of Original Images | Number of Images after Augmentation |
|---|---|---|---|---|
| Citrus | Kumquat | 1280 × 720 | 500 | 4000 |
| Nanfeng tangerine | 1280 × 720 | 400 | 3000 | |
| Fertile tangerine | 1280 × 720 | 300 | 3000 | |
| Shatang tangerine | 1280 × 720 | 300 | 3000 |
| Hyperparameter | Value |
|---|---|
| lr0 | 0.01 |
| lrf | 0.2 |
| momentum | 0.937 |
| weight_decay | 0.0005 |
| iou_t | 0.2 |
| anchor_t | 4.0 |
| fl_gama | 2.0 |
| hsv_h | 0.015 |
| hsv_s | 0.7 |
| hsv_v | 0.4 |
| Method | Parameters (M) | GFLOPS | Average Detection Time/ms | F1 Score | mAP |
|---|---|---|---|---|---|
| YOLOv5n | 1.7 | 4.2 | 8 | 0.75 | 80.2 |
| YOLOv5s | 7.0 | 16.3 | 9 | 0.78 | 83.3 |
| YOLOv5m | 20.8 | 48.0 | 14 | 0.80 | 85.8 |
| YOLOv5l | 46.6 | 114.1 | 19 | 0.81 | 85.4 |
| YOLOv5x | 86.1 | 204.0 | 22 | 0.80 | 87.7 |
| Improved YOLOv5(ours) | 50.9 | 116.5 | 19 | 0.82 | 88.5 |
| Growth Stage | Model | Ground Truth Count | Correctly Identified | Falsely Identified | ||
|---|---|---|---|---|---|---|
| Amount | Rate (%) | Amount | Rate (%) | |||
| Growing | YOLOv5l | 300 | 243 | 81.00 | 10 | 3.3 |
| Ours | 300 | 261 | 87.00 | 3 | 1 | |
| Maturity | YOLOv5l | 281 | 259 | 92.17 | 15 | 5.3 |
| Ours | 281 | 270 | 96.08 | 5 | 1.7 | |
| Model | Growth Stage | F1 Score (%) | Average Detection Time/ms | Accuracy (%) |
|---|---|---|---|---|
| Faster R-CNN | Growing stage | 86.24 | 350 | 0.84 |
| YOLOv4 | Growing stage | 87.52 | 25 | 0.92 |
| YOLOv51 | Growing stage | 92.45 | 19 | 0.93 |
| Improved YOLOv5(ours) | Growing stage | 94.49 | 19 | 0.95 |
| Faster R-CNN | Mature stage | 86.48 | 350 | 0.86 |
| YOLOv4 | Mature stage | 87.58 | 25 | 0.92 |
| YOLOv51 | Mature stage | 93.27 | 19 | 0.94 |
| Improved YOLOv5(ours) | Mature stage | 95.13 | 19 | 0.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Li, G.; Chen, W.; Liu, B.; Chen, M.; Lu, S. Detection of Dense Citrus Fruits by Combining Coordinated Attention and Cross-Scale Connection with Weighted Feature Fusion. Appl. Sci. 2022, 12, 6600. https://doi.org/10.3390/app12136600
Liu X, Li G, Chen W, Liu B, Chen M, Lu S. Detection of Dense Citrus Fruits by Combining Coordinated Attention and Cross-Scale Connection with Weighted Feature Fusion. Applied Sciences. 2022; 12(13):6600. https://doi.org/10.3390/app12136600
Chicago/Turabian StyleLiu, Xiaoyu, Guo Li, Wenkang Chen, Binghao Liu, Ming Chen, and Shenglian Lu. 2022. "Detection of Dense Citrus Fruits by Combining Coordinated Attention and Cross-Scale Connection with Weighted Feature Fusion" Applied Sciences 12, no. 13: 6600. https://doi.org/10.3390/app12136600
APA StyleLiu, X., Li, G., Chen, W., Liu, B., Chen, M., & Lu, S. (2022). Detection of Dense Citrus Fruits by Combining Coordinated Attention and Cross-Scale Connection with Weighted Feature Fusion. Applied Sciences, 12(13), 6600. https://doi.org/10.3390/app12136600