Abstract
Fuzzy vector signature (FVS) is a new primitive where a fuzzy (biometric) data w is used to generate a verification key , and, later, a distinct fuzzy (biometric) data (as well as a message) is used to generate a signature . The primary feature of FVS is that the signature can be verified under the verification key only if w is close to in a certain predefined distance. Recently, Seo et al. proposed an FVS scheme that was constructed (loosely) using a subset-based sampling method to reduce the size of helper data. However, their construction fails to provide the reusability property that requires that no adversary gains the information on fuzzy (biometric) data even if multiple verification keys and relevant signatures of a single user, which are all generated with correlated fuzzy (biometric) data, are exposed to the adversary. In this paper, we propose an improved FVS scheme which is proven to be reusable with respect to arbitrary correlated fuzzy (biometric) inputs. Our efficiency improvement is achieved by strictly applying the subset-based sampling method used before to build a fuzzy extractor by Canetti et al. and by slightly modifying the structure of the verification key. Our FVS scheme can still tolerate sub-linear error rates of input sources and also reduce the signing cost of a user by about half of the original FVS scheme. Finally, we present authentication protocols based on fuzzy extractor and FVS scheme and give performance comparison between them in terms of computation and transmission costs.
1. Introduction
Biometric information (e.g., fingerprint, iris, face, vein) has been used for user authentication [1,2,3,4,5] because of its uniqueness and immutability. Due to these properties, such biometric information can be used in place of a user secret key in an authentication system. When using biometric information as a security key, the user is not required to memorize or securely store anything to authenticate, which makes the process much more convenient and user-friendly. However, since biometric information is noisy and non-uniformly distributed, it differs greatly from what is known about cryptographic secret keys. In general, a secret key of an authentication system is largely set to be a uniformly random string of fixed length. Until now, a large body of research has been conducted to bridge this gap and enable biometric information to be used as a secret key in a cryptographic way.
To overcome the problem of noisy secret keys, researchers proposed the fuzzy extractor and fuzzy signature as two types of biometric cryptosystems. Comprised of two algorithms, Gen and Rep, a fuzzy extractor [6] is able to generate a uniformly random string of fixed length (i.e., a secret key) from fuzzy (biometric) data. The generation algorithm Gen takes as input sample f fuzzy (biometric) data w to generate a secret key r together with helper data p. The reproduction algorithm Rep takes as input another sample of fuzzy (biometric) data close to w and p to reproduce r. If the difference between w and is less than a minimal threshold value, Rep can generate the same secret key r. On the other hand, consisting of three algorithms, KG, Sign, and Vrfy, the fuzzy signature [7] generates a signature by using fuzzy (biometric) data itself as a signing key. The key generation algorithm KG takes as input sample of fuzzy (biometric) data w to generate a verification key . The signing algorithm Sign takes as input another sample of biometric information to generate a signature . The verification algorithm Vrfy takes as input and and succeeds in verification if w and are close to within a fixed threshold.
Biometric cryptosystems are generally considered secure when each sample of fuzzy (biometric) data is used only once. However, in reality, a user may use the same biometric source (e.g., right index fingerprint) to authenticate their accounts for several applications as a matter of expediency. Since similar biometric information is used multiple times, a new security notion is required to guarantee both the privacy of the fuzzy (biometric) data at hand and the reusable security of biometric cryptosystems in this situation. In 2004, Boyen [8] introduced the reusability of a fuzzy extractor, which ensures no entropy loss to the secret key or biometric source even when relevant pairs of helper data or keys from similar forms of biometric information are revealed. Since then, many researchers have focused on studying this fuzzy extractor with reusability (a.k.a. reusable fuzzy extractor).
In order for a reusable fuzzy extractor to be widely used in practice, it should be able to tolerate more than a certain level of errors inherent in fuzzy (biometric) data. For example, iris readings have the average error rate of 20–30% [9,10,11]. A number of studies have proposed constructions that tolerate linear fraction of errors [8,12,13,14,15], but these schemes impose a strong requirement on the distribution of fuzzy (biometric) data, namely: (1) the distribution must have sufficiently high min-entropy (“Y” in High min-entropy in Table 1), or (2) any difference between two distinct biometric readings cannot significantly decrease the min-entropy of the fuzzy (biometric) data (“” in Source Distribution in Table 1). Unfortunately, both of these expectations are somewhat unrealistic.

Table 1.
Comparison with reusable biometric cryptosystems.
Canetti et al. [17] relaxed these conditions, only requiring a subset of samples to have sufficient average min-entropy for given subset indices, and proposed a reusable fuzzy extractor that would tolerate a sub-linear fraction of errors. The construction is contingent on the existence of a powerful tool called digital locker, which is a non-standard assumption. Other reusable biometric cryptosystems [16,19] did not require either unrealistic requirements on the biometric distribution or contain non-standard assumptions, but they only tolerated a logarithmic fraction of errors.
Recently, a new primitive called fuzzy vector signature (FVS) [20] was proposed based on bilinear maps (i.e., pairings), which improved the error tolerance rate without any additional requirements on the distribution of biometric information. This scheme tolerates a sub-linear fraction of errors and also is based on standard assumptions, like the external Diffie-Hellman (XDH). It is also claimed to be reusable, but no formal proof for reusability was provided in Reference [20]. In this paper, we introduce the formal security model for reusability of fuzzy vector signature (FVS) and prove that our proposed scheme is reusable in the reusability model. By more strictly applying the subset-based sampling method [17], our scheme is also more efficient than Reference [20] from the perspective of the user and the authentication server. Specifically, it reduces not only the size of the signature and verification key but also the number of pairing operations required for verification. Section 5 outlines a detailed performance comparison.
1.1. Related Work
Reusable Fuzzy Extractor. The concept of a fuzzy extractor and secure sketch was first proposed by Dodis et al. [6]. Following this, Boyen et al. [8] introduced the notion of reusability, meaning that additional keys could be securely generated for any helper data, which is required to regenerate the key, even if the helper data or key pairs were exposed. Wen et al. [14] subsequently proposed a reusable fuzzy extractor based on the Decisional Diffie-Hellman (DDH) problem, which can tolerate a linear size of errors. However, their scheme requires that, for any two distinct readings of the same source, the differences between them should not leak significant information about the source—a requirement that is too strict, as each component of fuzzy (biometric) data is non-uniformly distributed. In response to this, Wen et al. [15] proposed a DDH-based reusable fuzzy extractor to remove the requirement [14] by changing the source distribution. Apart from these studies, Wen et al. [13] also proposed a reusable fuzzy extractor that allowed a linear fraction of errors based on the Learning with Errors (LWE) assumption [22]. However, their schemes [13,14,15] used a secure sketch as a method for controlling noise of data. A secure sketch is used for recovering w from if w and are close to within a fixed distance, but it nevertheless causes a small leakage of biometric information. Therefore, when considering reusability scenarios, it is noted that these schemes require an input source to have sufficiently high min-entropy to avoid brute-force attack even after security loss.
On the other side of the spectrum are reusable fuzzy extractors that did not suggest using secure sketches. Canetti et al. [17] proposed a reusable fuzzy extractor that is constructed using the subset-based sampling technique instead of a secure sketch to control a noisy data source. This scheme relied on the use of a digital locker to generate helper data. However, even if a digital locker was simply instantiated with a hash function, the size of helper data would increase significantly (e.g., about 0.8 GB to achieve an error tolerance rate of ). Cheon et al. [18] modified this scheme [17] to reduce the size of the helper data, but in turn, the computational cost for Rep increased significantly. Alamélou et al. [12] also improved [17] and suggested a fuzzy extractor that achieved a linear fraction of errors. However, they also used a digital locker and this scheme had an unrealistic requirement that each component of a fuzzy (biometric) source had to have significant min-entropy. Apon et al. [16] modified a non-reusable fuzzy extractor [23] based on the LWE assumption into a reusable one. However, their scheme can tolerate only a logarithmic fraction of errors due to the time-consuming process of reproducing a key even with a small number of errors.
Fuzzy Signature. The concept of a fuzzy signature was proposed by Takahashi et al. [7]. The fuzzy signature does not need helper data, unlike the fuzzy extractor, because it only requires a valid correlation between two input fuzzy (biometric) data relevant to a verification key and a signature, which can be achieved using a linear sketch. However, in Reference [7], a strong assumption was required that input fuzzy (biometric) data should be uniformly distributed, which is then relaxed in Reference [24]. Afterwards, Yasuda et al. announced that a linear sketch of fuzzy extractors [7,24] is vulnerable to recovery attacks [25]. In Reference [26], the merge of Reference [7,24], Takahashi et al. proposed two instantiations of a fuzzy signature secure against recovery attacks. In 2019, Tian et al. first introduced the notion of reusability in a fuzzy signature [19]. To construct a reusable fuzzy signature, they adopted a reusable fuzzy extractor in Reference [16]. Consequently, the reusability is limited only to the generation of verification keys, ignoring the privacy of signatures.
Fuzzy Vector Signature. Seo et al. first proposed a fuzzy vector signature [20] following the subset-based sampling method of Reference [17]. The fuzzy vector signature requires the signing parameter like helper data in fuzzy extractor, to be reusable, but the size of the signing parameter is much smaller than that of helper data in Reference [17]. In addition, a fuzzy vector signature can tolerate sub-linear errors, while a reusable fuzzy signature [19] can only tolerate logarithmic errors. However, the size of verification key in Reference [20] is still huge, which results in high computational costs for verification. In addition, security models for reusability are incomplete as in Reference [19], and, as a result, no formal proof of reusability is provided.
1.2. Source Distributions
A source distribution of reusable biometric cryptosystems can be categorized into four types, according to correlation between two repeating readings, as in Table 1.
“” implies that the hamming distance between and is less than a threshold value t, where W is an input source. Since is randomly chosen by an adversary, may not be included in W, which is a little far from reality. Especially in Reference [16,19], additional assumptions were made that W should be a small error distribution of Learning with Errors (LWE) problem and both w and should be in W to tolerate logarithmic errors.
“” implies that, for any two distinct readings and in W, holds where m is a minimum level of security. In other words, the difference between and (i.e., ) should not leak too much information of even if is correlated to , which is a strong requirement for the input source.
“” implies that any two distinct readings are arbitrarily correlated, which would be the most realistic assumption. However, as a trade-off, schemes based on this distribution require additional assumptions on the input source. For example, in Reference [17,18], any subset of should have high min-entropy even if indices are exposed, and, in Reference [12], each component should have a high min-entropy even if other components are exposed.
Unlike the above three types, a previous fuzzy vector signature [20] used a -block source in Reference [21], although following the subset concept in Reference [17] for construction. -block source means that for input sources , i-th source has a high min-entropy even though readings are set to , i.e., for all where k is a minimum level of security. Namely, are not correlated. However, since fuzzy (biometric) data from the same source must be correlated, it is inappropriate to use the -block source when considering reusability.
1.3. Contribution
In this paper, we propose a new fuzzy vector signature (FVS) scheme based on a subset concept in Reference [17] to deal with noise in fuzzy (biometric) data. In consequence, our scheme is reusable and can tolerate sub-linear errors without any additional requirements, such as sufficiently high min-entropy of the input source. Compared to the previous fuzzy vector signature [20], we eliminated redundant parts in both verification key and signature by trying a new approach to security proofs, which in turn improved the efficiency of the scheme. For instance, for 80-bit security with error tolerance rates, we reduce the size of the signing parameter by , from 48 KB to 32 KB, the signature by , from 32 KB to 16 KB, and a verification key by , from GB to GB, where the length of the fuzzy (biometric) data is bits. Additionally, we reduce the number of pairing operations in verification by up to from to .
We also provide the formal security models to reflect reusability of the privacy of the verifier and signer (i.e., VK-privacy and SIG-privacy, respectively) and the unforgeability of the signature (i.e., Reusability). And we prove these properties on the assumption that the repeating readings of fuzzy (biometric) data are arbitrarily correlated, which is more realistic than the -block source used in Reference [20]. In addition, we analyze the performance of our FVS scheme in terms of transmission and computational costs by comparing it with previous reusable biometric cryptosystems [17,18,20]. In particular, a signature can be generated in 155 ms on the signer’s side, which is almost twice as fast as in Reference [20] (for more details, see Section 5).
2. Preliminaries
2.1. Notation
Let be the security parameter and denote a polynomial in variable . We use the acronym “PPT“ to indicate probabilistic polynomial-time. Let be a fuzzy (biometric) space with metric space and be a set of arbitrary alphabet. We denote as the process of sampling w according to a random variable W such that . Let be a fuzzy vector of length n. We denote string concatenation with the symbol “,” and U represents an arbitrary random distribution.
2.2. Hamming Distance Metric
A metric space is a set with a non-negative integer distance function dis: . The elements of are vectors in for some alphabet sets . For any , the hamming distance dis is defined as the number of components in which w and differ.
2.3. Min-Entropy
Let X and Y be random variables. The min-entropy of X is defined as . For conditional distributions, the average min-entropy of X given Y is defined by . For a given source , we say that X is a source with -entropy ℓ-samples if
where and ℓ are determined by the security parameter .
2.4. Statistical Distance
The statistical distance between random variables X and Y with the same domain is defined by
2.5. Universal Hash Function
A collection of hash functions is -universal if for any such that , it holds that .
Lemma 1.
(Reference [6]) Let be random variables. Then,
- (a)
- For any , the conditional entropy is at least with a probability of at least over the choice of b.
- (b)
- If B has at most possible values, then . In particular, .
Lemma 2.
(Reference [27]) Let be any two jointly distributed random variables and Z has at most possible values. Then, for any it holds that .
Lemma 3.
Let be a family of universal hash functions , and let be a joint distribution such that for and . Then, the distribution , where , is -close to the uniform distribution over .
Proof.
Proof of Lemma 3 is in Appendix A. □
2.6. Discrete Logarithm Assumption
Let be a group of prime order q, and let g be a generator of . For any PPT algorithm , we define the advantage of , denoted by , in solving the discrete logarithm (DL) problem as follows:
We say that the DL assumption holds in if, for all PPT algorithms and any security parameter , for some negligible function .
2.7. Bilinear Maps
Let be groups of some prime order q and a bilinear map (or pairing) over be admissible if it satisfies the following properties:
- Bilinear: The map is bilinear if for all .
- Non-degenerate: .
- Computable: There is an efficient algorithm to compute for all .
Our fuzzy vector signature is constructed using a Type-3 pairing where and there is no known efficiently computable isomorphism between and .
2.8. External Diffie-Hellman (XDH) Assumption
Let , be groups with prime order q and be generators of , , respectively. The XDH problem in is defined as follows: given and with a Type-3 pairing, the goal of an adversary is to distinguish whether T is either or random R. For any PPT algorithm , the advantage in solving the XDH problem in is defined as
We say that an XDH assumption holds in if, for any PPT algorithm , the advantage is negligible for .
3. Definitions
3.1. Syntax of Fuzzy Vector Signature
Let be a fuzzy (biometric) space with the Hamming distance metric and w is a sample of random variable . A fuzzy vector signature (FVS) scheme [20] is defined by three algorithms (Setup, Sign, Verify) as follows:
- Setup: The setup algorithm takes as input the security parameter , a sample of fuzzy (biometric) data , the length n of w, the number d of subsets, the number ℓ of elements included into each subset, and the maximum number t of errors that can be tolerated. It generates a signing parameter and verification key corresponding to w. Here, is said to be the error tolerance rate.
- Sign: The signature generation algorithm takes as input a signing parameter , a sample of fuzzy (biometric) data of length n, and a message m. It generates a signature corresponding to .
- Verify: The verification algorithm takes as input a verification key , a signature , and a message m. If a signature is valid under the condition that , it outputs 1; otherwise 0.
Correctness. Let be the probability that the Verify algorithm outputs 0, and let dis for two sample of fuzzy (biometric) data . For the signing parameter and the verification key , if ←Sign, then Verify.
3.2. Security Models
We considered three security notions for FVS security: VK-privacy, SIG-privacy, and reusability.
3.2.1. VK-Privacy
VK-privacy blocks an adversary from obtaining any information about fuzzy input data w from a verification key . In other words, the adversary cannot distinguish between a real and a random R. We say that an FVS scheme is VK-private if the advantage that any PPT adversary wins against the challenger in the following game for any is negligible in :
- Setup: selects target correlated random variables and gives these to .
- Generation: samples . runs Setup for , and chooses random R. chooses one of the modes, real or random experiment. For any , if the mode is real, gives ; otherwise .
- Distinguishing: For k, outputs a bit that, respectively, represents a real or random experiment.
Definition 1 (VK-privacy.).
An FVS scheme is VK-private if, for any PPT adversary against VK-privacy, there exists a negligible function such that
3.2.2. SIG-Privacy
SIG-privacy means that an adversary cannot ascertain any information on fuzzy input data from a signature . The adversary cannot distinguish between a valid signature and a signature corresponding to a uniformly random fuzzy data u without a corresponding verification key. We say that an FVS scheme is SIG-private if the advantage that any PPT adversary wins against the challenger in the following game for is negligible in :
- Setup: selects target correlated random variables and gives it to . chooses . Then, runs Setup for and Setup, . sends and to .
- Query: issues a random variable correlated with , a message , and an index of the signing parameter . chooses correlated with , runs Sign, and gives the resulting signature to .
- Challenge: issues a message . obtains and selects a bit at random. If , sends to . Otherwise, selects a random input u from a uniformly random distribution U, obtains , and gives to .
- Guess: outputs its guess . If , wins the game.
Definition 2 (SIG-privacy.).
An FVS scheme is SIG-private if, for any PPT adversary against SIG-privacy, there exists a negligible function such that
3.2.3. Reusability
Reusability means that an adversary cannot generate a valid signature without knowing the target input source of data, even if the adversary is given verification keys and signing parameters correlated with the target input data. In addition, the adversary can get valid signatures that are verified with the target verification key or other (correlated) verification keys via signing oracles. We say that an FVS scheme is reusable if the advantage that any PPT adversary wins against the challenger in the following game is negligible in :
- Setup: selects correlated random variables and gives it to . chooses and runs Setup for . Then, gives to .
- Signing query: issues a random variable correlated with , a message , and an index of the signing parameter . chooses correlated with , and runs Sign. sends the resulting signature to .
- Output: outputs such that was not the output of queried. If Verify for some , wins the game.
Definition 3 (Reusability).
An FVS scheme is reusable in chosen message attacks if, for any PPT adversary making at most signature queries, there is a negligible function such that
4. Fuzzy Vector Signature
4.1. Construction
Let be a bilinear group, where and are generators. Let be a (biometric) space with the Hamming distance metric, and let be a random variable that is the user source. Given W, we consider two fuzzy (biometric) samples such that . In this section, we present our FVS scheme that consists of the following three algorithms: Setup, Sign, and Verify.
- Setup For a security parameter , the setup algorithm generates a bilinear group , and picks a hash function . The setup algorithm generates a signing parameter () as follows:
- Pick random elements for and set for .
- Generate a random element .
- Output .
Let n be the length of a fuzzy (biometric) data w, and d be the number of entire subsets, ℓ be the number of elements included in each subset, and t be the maximum number of errors among n elements, indicating an error tolerance rate. Given a fuzzy (biometric) data , the setup algorithm generates a verification key as follows:- Randomly select a set where for .
- Set a subset of a vector w for .
- Select random elements for .
- Set for .
The verification key is given by- .
- Sign. To sign a message m under fuzzy (biometric) data , the signing algorithm generates a signature as follows:
- Choose random elements .
- Set for .
- Set .
- Set .
- Set
- Set .
- Output .
- Verify. To verify a signature , , , on a message m under the verification key , …, , , …, , the verification algorithm proceeds as follows:
- Set for .
- Set .
- While for :
- (1)
- Compute .
- (2)
- If , .
If , output 0. - Otherwise, set and .
- If , output 1; otherwise 0.
4.2. Setting the Number of Subsets
Let be the probability that the Verify algorithm outputs 0, meaning that it fails to verify a signature using . Thus, if is set, then a signer would produce a signature two times with overwhelming probability of generating a valid signature. Following [17], we show that the number d of subsets is determined by setting the value . Given , we assume that our FVS scheme wants to tolerate at most t errors among n elements. During verification, the probability that is at least for each . Thus, the probability that the Verify algorithm outputs 0 is at most , meaning that no (biometric) vector matches the vector corresponding with . If we set the failure probability as
the approximation gives the relations, such as . Consequently, we obtain the relation
as required to determine the number d of subsets.
4.3. Correctness
Assume that dis. Then, the probability that for any is at least . In this case, since because of , we can derive the probability that the Verify algorithm outputs 0 as
by the above approximation. As a result, if dis, Verify.
4.4. Security
Theorem 1.
If is a family of sources over with α-entropy ℓ-samples, then the FVS scheme is VK-private for such a .
Proof.
Before proving the VK-privacy, we first prove that a family of functions generating the partial verification key is a -universal hash function for a fixed . In our FVS scheme, given a vector as input, the function is defined as follows:
where is a randomly chosen exponent . Since is raised for each input, it is easy to see that two outputs of the function could be equal with probability . Thus, it holds that for two distinct inputs and , ; thus, is -universal.
Next, we prove that a verification key corresponding with is almost close to uniform distribution based on Lemma 3. After that, we extend the result to the case of a polynomial number of verification keys. Let be a random variable of a source with -entropy ℓ-samples. If , we see that is a joint distribution of d subsets of such that for random sets of indices . In addition, as mentioned above, each function is a -universal hash function with respect to a distinct .
By Lemma 2(a), if a random set of indices is set to be , then with a probability of at least . Let be a random variable for a set of indices for and let be a sample of . By a similar proof A1 (proof of Lemma 3), we obtain the following result:
where shows negligible probability determined by a security parameter. As a result, if , we have
For , we can show that , similarly as in the above process.
Let for some samples (), and let = be random samples chosen from . Because of the above inequality, under the assumption that , we see via Lemma 2.3 that, for any () and , the statistical distance between and is less than .
We can extend the above result of a single verification key to correlated random variables . Let be a joint distribution of d subsets for . If , the statistical distance between , …, , …, and is less than for any where and for uniformly random . □
Theorem 2.
If the FVS scheme is VK-private and the XDH assumption holds in , the FVS scheme is SIG-private in the random oracle model.
In reality, if verification keys and signatures were to become revealed to an adversary, we would have to prove that it is infeasible for the adversary to glean any information on the fuzzy (biometric) data from the signatures. As mentioned above, however, we prove from Theorem 4.1 that the VK-privacy holds, meaning that it is difficult for the adversary to get some information on the fuzzy data from verification keys. In addition, the setup algorithm chooses a new signing parameter each time a verification key is generated for each fuzzy data. Thus, it is sufficient to show that a signature generated under a fixed does not reveal any information about a challenged fuzzy data.
To do this, a simulator chooses a challenge sample along with other correlated samples. For the length n of , we create the following sequence of games where is used for generating a challenge signature:
In Game 0, the challenge signature is generated for the original as in a real game, whereas in Game n the challenge signature is generated for a random vector and thus does not have any information on the original . For proving the SIG-privacy, it is sufficient to show that it is infeasible for the adversary to distinguish between Game and Game under the DDH problem.
Lemma 4.
Under the XDH assumption in , it is infeasible to distinguish between Game -1) and Game α.
Proof.
Given an XDH instance , a challenger interacts with an adversary who tries to break the the SIG-privacy of our FVS scheme.
- Setup. chooses samples , , …, , where those correlated distributions are from . In particular, for a sample corresponding to , sets for randomly chosen values . For each , generates for as follows:
- -
- Choose random values and in .
- -
- Set .
- -
- Select d sets of random indices such that .
- -
- Set a subset for .
- -
- Choose at random in .
- -
- Set .
For the target , chooses in , and sets and , under the implicit setting of . then sets ) and gives along with for to . - Signing queries. issues a pair of a correlated distribution with , , …, , an index of signing parameter , and a message m. Then, chooses a sample correlated with . performs the ordinary signature generation algorithm by taking as inputs.
- Challenge. sends a message to . In particular, we use a non-interactive zero-knowledge (NIZK) simulator to generate two elements without knowing the witness. generates a challenge signature as follows:
- -
- Set for and .
- -
- Set .
- -
- Set .
- -
- Set .
- -
- Obtain using the NIZK simulator.
sends to . - Guess. outputs a guess in response to the challenge signature.
If , then interacts with in Game , because . Otherwise, becomes a random element, in which case is in Game . Therefore, depending on the ability of , is able to solve the given XDH problem. □
Theorem 3.
If the FVS is VK-private and SIG-private and the DL assumption holds in , the FVS scheme is reusable in random oracle model.
The proof for Theorem 4.3 is almost the same as the proof for unforgeability in Reference [20], but the difference resides in the fact that an adversary in our reusability proof is given verification keys and signatures that correspond to correlated fuzzy (biometric) data. In other words, even if such correlated fuzzy data is reused, our proof shows that it is difficult for the adversary to generate a valid signature with (unknown) target fuzzy data. To prove reusability, we need the VK-privacy and SIG-privacy to guarantee that the verification keys and signatures exposed to the adversary do not reveal any information about the fuzzy data. At this point, there are two strategies we anticipate that the adversary might take in their forgery. The first is that the adversary would guess from a certain distribution W and then generate a signature on the input . However, as long as W is assumed to be a distribution with -entropy ℓ-samples and is sufficiently large with respect to the security parameter, such a strategy can be successful with negligible probability only.
The other strategy is to reuse a previous signature without changing the fuzzy data embedded into it. More specifically, there are two prongs to this strategy. One is to re-randomize the previous signature by raising a new random exponent into the elements , , and . Thus, the discrete logarithm of such elements becomes , where s was chosen by a signer and is now selected by an adversary. The important point is that the adversary still cannot know the exact discrete logarithm , which is then the witness necessary for generating the other signature elements as an NIZK proof as it relates to . However, generating such an NIZK proof equates to breaking the statistical soundness of proving the equality of discrete logarithms [28] in regard to the unknown witness. Thus, the probability that the adversary would succeed is at most , where is the number of H-oracle queries, which is also negligible. Now, the remaining case is to reuse the previous signature as it is and simply reconstruct a new proof . Fortunately, this case can be reduced to the forgery of a one-time multi-user Schnorr signature [29], which is provably secure under the DL assumption. In our proof, a slight variant of the one-time multi-user Schnorr signature proves the equality of discrete logarithms rather than proving knowledge. In line with this, the variant is also provably unforgeable [30,31] against chosen-message attacks in a multi-user setting (MU-SUF-CMA). Based on the variant we use, we show that, under the DL assumption, it is difficult for the adversary to succeed in the remaining case.
Proof.
A simulator uses an adversary (which breaks the reusability of the FVS scheme) as a subroutine to forge a signature in the one-time multi-user Schnorr signature scheme. Let for the number of signature queries. Given independent public keys of the one-time multi-user Schnorr signature scheme, interacts with as follows:
- Setup. gives correlated random variables , of which each is in . samples and runs Setup to obtain a signing parameter and a verification key for . In the setup algorithm, and are selected uniformly at random in . gives to .
- Signing queries. For , issues signing queries with input, namely a random variable correlated with , …, , an index of signing parameter , and a message . responds to the query as follows:
- -
- Choose a sample correlated with from .
- -
- Generate for , and set .
- -
- Query to the signing oracle of the one-time multi-user Schnorr signature scheme, meaning a signing query on a message under the j-th public key, and receive .
- -
- Set and give to .
- Output. outputs , . checks if for any , and finds such that . After finding the index j corresponding with the -th query, checks if Verify, , outputs 1. If it does, outputs a forgery of the one-time multi-user Schnorr signature scheme as follows:
- -
- Set .
- -
- Output .
It follows that, as longs as breaks the reusability of the FVS scheme, then can break the MU-SUF-CMA security of the Schnorr signature scheme. Indeed, if Verify, , = 1, this means that is the valid signature of the message under the -th public key .
Since it is clearly proven that the variant of the one-time multi-user Schnorr signature scheme is MU-SUF-CMA secure under the DL assumption in the random oracle model [29], the reusability of our FVS scheme can also be proven in the random oracle model under the DL problem. □
5. Performance Analysis
Our FVS scheme is constructed using the subset-based sampling method of the re-usable fuzzy extractor [17], which does not require fuzzy (biometric) input data to have sufficiently high min-entropy and can still tolerate a sub-linear fraction of errors. Generally, biometric data sources are non-uniformly and uniquely distributed from person to person; thus, it is not easy to expect that such biometric data will have high min-entropy. Nevertheless, most reusable fuzzy extractors [8,13,14,15] based on secure sketches require source data with high min-entropy because a secure sketch is known to cause an entropy loss of a biometric input data. For comparison, we focus on fuzzy extractors [17,18] that do not rely on secure sketches, and therefore not require a high min-entropy source. A reusable fuzzy extractor suggested by Reference [12] is not based on a secure sketch and tolerates a linear fraction of errors, but it uses a so-called pseudoentropic isometry that requires each biometric input data component to have high min-entropy. This requirement is also far from realistic biometric information. A reusable fuzzy extractor suggested by Apon et al. [16] is constructed based on the hardness of Learning with Errors (LWE) problems, where biometric data is injected into the part with LWE errors. In that case, such biometric data must follow a certain error distribution (e.g., Gaussian) in order to ensure the security of LWE problems. This reveals a limitation in its real-world application potential. Furthermore, the LWE-based fuzzy extractor [16] requires a time-consuming reproducing algorithm, where another sample of biometric data is subtracted from an LWE instance that was previously created per each component, and then a randomly chosen linear system is expected to be solved. A problem arises if any error components in the chosen linear system are not 0, at which point a new linear system must be randomly reselected until achieving success. The same problem is found in the reusable fuzzy signature [19] that follows the LWE-based fuzzy extractor technique. To mitigate the reproducing problem, [16,19] should be limited to dealing with only a logarithmic size of errors.
Eventually, we compare our FVS scheme with previous fuzzy extractors [17,18] and the original FVS scheme [20], which all follow the subset-based sampling technique [17]. We specifically consider authentication protocols where a fuzzy extractor or an FVS scheme is instantiated to authenticate a user using biometric data. During protocol executions, we compare our proposed scheme with existing schemes in terms of storage or transmission costs and computational costs on the part of the user. In regards to the fuzzy extractor, we assume that a digital signature scheme is additionally provided. As usual, an authentication protocol consists of two phases; enrollment and authentication. In the enrollment phase, a user is registered with an authentication server by sending an identity , a verification key , and helper data . In each authentication phase, a user receives helper data from the server, recovers a secret key for signature generation using their biometric data, and returns a signature in response to a challenge message R sent by the server. Figure 1 and Figure 2 present two authentication protocols in more detail.
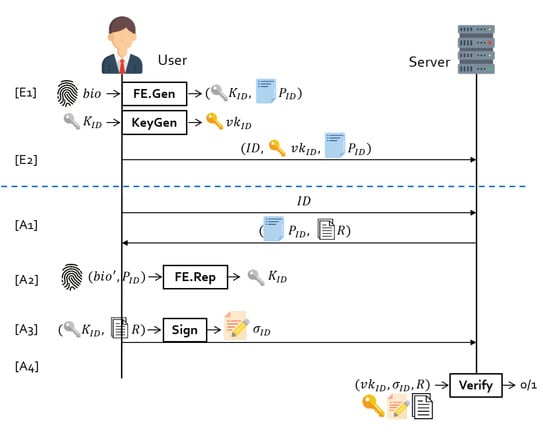
Figure 1.
Authentication with a fuzzy extractor.
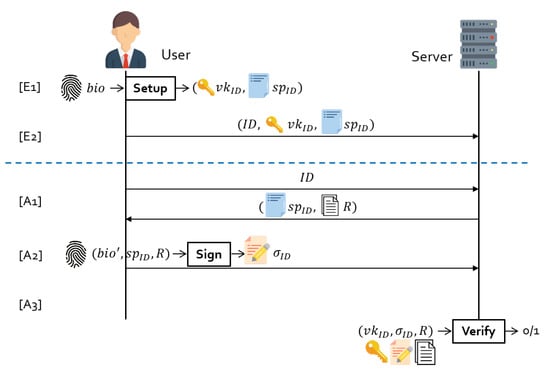
Figure 2.
Authentication with our fuzzy vector signature (FVS).
5.1. Storage or Transmission Costs
In the authentication phase, helper data is needed to generate a signing key from user biometric data. There are two options through which the user obtains an . The first way is to store it in their own personal device, and the other is to receive it from the server for each instance of authentication. The first method can reduce the amount of transmission, while carrying a personal storage device. Conversely, the second one does not require a personal device, while the server sends out a huge amount of transmission, and it has the advantage in that the user authentication can work on secure devices that are shared by multiple users. For comparison purposes, we present the size of as the storage or transmission cost in Table 2.
Table 2.
Comparison of storage or transmission costs with helper data.
Let n be the dimension of biometric data, d be the number of subsets, ℓ be the number of elements in each subset, and t be the maximum number of errors among n elements. With fuzzy extractors [17,18], helper data consists of an information set, a nonce, and an output of a hash function per subset. To begin, the number d of subsets is obtained via in Reference [17], whereas d is computed as in Reference [18], where for -threshold scheme [32]. In this case, the information set per subset has ℓ indices which are represented by bits. When using SHA-256 as the hash function, we set the size of a nonce to be sufficient at bits. As a result, the whole size of is about for 512, 1024, and 2048 cases, which, as shown in Table 2, becomes huge when setting as an error tolerance rate and . On the other hand, with FVS schemes, the number of subsets is determined by following [17], but helper data consists of only a signing parameter , regardless of the number of subsets. Indeed, in Figure 3, in Reference [20] is elements in , whereas in ours is elements in . When taking the Type-3 pairing [33] at the 100-bit security level, the size of elements in and is 256 bits. For , 1024, and 2048 cases, Table 2 shows that the size of the FVS schemes are overwhelmingly smaller than that of the fuzzy extractors. Compared to Reference [20], our FVS scheme obtains a slightly shorter size of with the same parametrization. Regarding the signature size, the in our scheme consists of elements in plus 2 elements in that are transmitted to the server. When taking the Type-3 paring and again, the amount of transmission is about KB. is the the probability that verification fails, and we expect the user to run step [A2] of the authentication protocols twice, during which the transmission cost of becomes about 32 KB.

Figure 3.
Comparison between previous and our construction.
5.2. Computation Cost
For the fuzzy extractor, we considered the computational cost required for obtaining a signing key by running the algorithm that takes as input helper data and a biometric data . This is the step for [A2] in Figure 1. We assume that a reproduced value from is straightforwardly used as the singing key corresponding with the verification key . If a hash function H, such as SHA-256, is used as a digital locker [17], is locked with for a positive integer s, where is the set of biometric data corresponding to a subset i among n components. Therefore, with a new , the unlocking algorithm needs to perform a hash computation plus an XOR operation per each subset i until is obtained. Consequently, the algorithm in Reference [17] must compute operations as a worst case scenario. Since [18] also requires solving a -secret sharing scheme, the algorithm chooses a set of shares among m unlocked values and then solves a secret-sharing scheme, leading to performing additional operations. In contrast, the FVS scheme needs to run the algorithm to generate a signature by taking . This is the step for [A2] in Figure 2. In our FVS scheme, the algorithm needs exponentiations in for the dimension n of biometric data. Compared to Reference [20], the signing operation is reduced by about half, which is shown in Table 3.
Table 3.
Comparison of computational costs necessary for signature generation.
In order to measure the actual amount of calculation, we considered how much computation the user should perform by substituting the numbers in Table 2 directly. For instance, let and . The fuzzy extractor by Canetti et al. [17] must complete operations, and when setting , the fuzzy extractor by Cheon et al. [18] needs to compute approximately operations—which still seems to be a burdensome amount of calculation to perform on a personal device. To compare, when considering ms for an exponentiation in [34], the algorithm in ours takes about ms. Since , the user is required to run the step [A2] of the authentication protocols twice, such that the algorithm, which is computed by the user, takes about 310 ms.
5.3. Implementation
We implemented our fuzzy vector signature as a C program to measure actual time consumption. All implementations are performed on an Intel Core i7-8700k with 8GB RAM running Ubuntu 18.04 LTS, and GNU GCC version 7.5.0 is used for the compilation. For implementation, we selected the BLS12381 curve that offer around a 128-bit security level and a SHA-256 for a hash function. In a BLS12381 curve, the size of a element of and are 192 bit and 384 bit, respectively. Our implementation codes are available to https://github.com/Ilhwan123/FVS.
For each error rate 5% and 10%, we measured the time consumption required for running our scheme several times. Table 4 presents parameter setting, storage size, and time required for each algorithm, which is the results of our implementation. Compared with Table 2, the size of the group element is 192 bits, which is less than 256 bits. Therefore, the size of a signing parameter is smaller. However, this depends on the curve type, so it can be different depending on which curve is selected.
Table 4.
Implementation results of FVS using BLS12381 curve in case of error tolerance rate : 12.5%, the number of components in each subset : 80, and the number of subsets : 15,268 with .
Note that, if signature verification fails in the parameter setting in Table 4, the total verification time takes about 56 s.
6. Conclusions
In this paper, we presented an FVS scheme improved upon across all aspects of efficiency and security that is, more strictly speaking, based on the subset-based sampling method [17]. Compared to the original FVS scheme [20], we reduced the size of the signing parameter and the verification key to approximately two-thirds their original sizes and cut the signature size by about half. In addition, we reduced the number of pairings necessary for signature verification to about two-thirds the original number.
We prove that our FVS scheme is VK-private and SIG-private, meaning that the verification key and signatures generated using user correlated fuzzy (biometric) data do not reveal any information about the fuzzy input data. Additionally, instead of the unforgeability of Reference [20], we define the reusuability property which guarantees that a user is able to reuse their fuzzy correlated (biometric) data to generate polynomially-many verification keys, all while still making it infeasible for an adversary to forge a signature without any fuzzy (biometric) data. Under the reusability notion, we can prove that our FVS scheme is reusable, assuming that our FVS scheme is {VK, SIG}-private and the DL assumption holds.
In the remote authentication protocol of our FVS scheme, a user must receive the signing parameter and transmit a signature in response to a random challenge message. The primary advantage of FVS-based (biometric) authentication is that the transmission cost, including the signing parameter and signature, is determined only by the number of dimensions with respect to the fuzzy (biometric) data, not by the number of entire subsets. Thus, unlike the authentication protocol with a fuzzy extractor, the transmission cost between the user and the authentication server becomes remarkably smaller. However, the disadvantage of our FVS-based authentication scheme is that the server is required to perform pairing operations by the number of entire subsets, which is the worst case scenario. Such a burden may be somewhat alleviated by utilizing the computing power of the server in parallel, but it could be more desirable to build a new FVS scheme that supports efficient batch verification operations in the future.
Author Contributions
Conceptualization, J.H.P.; Formal analysis, I.L., and D.H.L.; methodology, I.L., and M.S.; validation, M.S., and J.H.P.; writing—original draft preparation, I.L.; writing—review and editing, M.S., and J.H.P.; supervision, D.H.L.; project administration, D.H.L.; All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Institute for Information & communications Technology Promotion (IITP) grant funded by the Korea government (MSIT) (No.2016-6-00600, A Study on Functional Encryption: Construction, Security Analysis, and Implementation).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Lemma 3
Proof.
Let and be q independent and uniform distributions over V. Let , , ⋯, , and , , ⋯, , , , , ⋯, , be two distributions for . By mathematical induction, we prove that D and are -close for .
For , Lemma 2 shows that with a probability of at least over the sample of , it holds that
In this case, the leftover hash lemma [35] implies that the two distributions and are -close.
Next, assuming that the above lemma holds for , we show that the case for i also holds. Lemma 2 shows that, with a probability of at least over the sample of ←, it holds that
Similarly, the leftover hash lemma [35] shows that the two distributions and are -close. It follows that , which concludes the proof of Lemma 3. □
References
- Bruce, V.; Young, A. Understanding face recognition. Br. J. Psychol. 1986, 77, 305–327. [Google Scholar] [CrossRef] [PubMed]
- Daugman, J. How iris recognition works. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 21–30. [Google Scholar] [CrossRef]
- Ding, Y.; Zhuang, D.; Wang, K. A study of hand vein recognition method. In Proceedings of the IEEE International Conference Mechatronics and Automation; 2005; Volume 4, pp. 2106–2110. [Google Scholar] [CrossRef]
- Jain, A.; Ross, A.; Prabhakar, S. An Introduction to Biometric Recognition. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 4–20. [Google Scholar] [CrossRef]
- Maltoni, D.; Maio, D.; Jain, A.K.; Prabhakar, S. Handbook of Fingerprint Recognition; Springer: London, UK, 2009; ISBN 978-1-84882-254-2. [Google Scholar]
- Dodis, Y.; Reyzin, L.; Smith, A. Fuzzy extractors: How to generate strong keys from biometrics and other noisy data. In Proceedings of the Advances in Cryptology (EUROCRYPT 2004), Interlaken, Switzerland, 2–6 May 2004; pp. 523–540. [Google Scholar] [CrossRef]
- Takahashi, K.; Matsuda, T.; Murakami, T.; Hanaoka, G.; Nishigaki, M. A signature scheme with a fuzzy private key. In Proceedings of the 13th International Conference on Applied Cryptography and Network Security, New York, NY, USA, 2–5 June 2015; pp. 105–126. [Google Scholar] [CrossRef]
- Boyen, X. Reusable Cryptographic Fuzzy Extractors. In Proceedings of the 11th ACM Conference on Computer and Communications Security, Washington, DC, USA, 25–29 October 2004; pp. 82–91. [Google Scholar] [CrossRef]
- Daugman, J. Probing the Uniqueness and Randomness of IrisCodes: Results From 200 Billion Iris Pair Comparisons. Proc. IEEE 2006, 94, 1927–1935. [Google Scholar] [CrossRef]
- Desoky, A.I.; Ali, H.A.; Abdel-Hamid, N.B. Enhancing iris recognition system performance using templates fusion. Ain Shams Eng. J. 2012, 3, 133–140. [Google Scholar] [CrossRef]
- Hollingsworth, K.P.; Bowyer, K.W.; Flynn, P.J. Improved Iris Recognition through Fusion of Hamming Distance and Fragile Bit Distance. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2465–2476. [Google Scholar] [CrossRef] [PubMed]
- Alamélou, Q.; Berthier, P.E.; Cachet, C.; Cauchie, S.; Fuller, B.; Gaborit, P.; Simhadri, S. Pseudoentropic Isometries: A New Framework for Fuzzy Extractor Reusability. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, Incheon, Korea, 4–8 June 2018; pp. 673–684. [Google Scholar] [CrossRef]
- Wen, Y.; Liu, S. Reusable Fuzzy Extractor from LWE. In Proceedings of the Australasian Conference on Information Security and Privacy 2018, Wollongong, Australia, 11–13 July 2018; pp. 13–27. [Google Scholar] [CrossRef]
- Wen, Y.; Liu, S.; Han, S. Reusable Fuzzy Extractor from the Decisional Diffie—Hellman Assumption. Des. Codes Cryptogr. 2018, 86, 2495–2512. [Google Scholar] [CrossRef]
- Wen, Y.; Liu, S. Robustly Reusable Fuzzy Extractor from Standard Assumptions. In Proceedings of the Advances in Cryptology (ASIACRYPT 20180, Brisbane, Australia, 2–6 December 2018; pp. 459–489. [Google Scholar] [CrossRef]
- Apon, D.; Cho, C.; Eldefrawy, K.; Katz, J. Efficient, Reusable Fuzzy Extractors from LWE. In Proceedings of the International Conference on Cyber Security Cryptography and Machine Learning, Be’er Sheva, Israel, 29–30 June 2017; pp. 1–18. [Google Scholar] [CrossRef]
- Canetti, R.; Fuller, B.; Paneth, O.; Reyzin, L.; Smith, A. Reusable fuzzy extractors for low-entropy distributions. In Proceedings of the Advances in Cryptology (EUROCRYPT 2016), Vienna, Austria, 8–12 May 2016; pp. 117–146. [Google Scholar] [CrossRef]
- Cheon, J.; Jeong, J.; Kim, D.; Lee, J. A Reusable Fuzzy Extractor with Practical Storage Size: Modifying Canetti et al.’s Construction. In Proceedings of the Australasian Conference on Information Security and Privacy 2018, Wollongong, Australia, 11–13 July 2018; pp. 28–44. [Google Scholar] [CrossRef]
- Tian, Y.; Li, Y.; Deng, R.H.; Sengupta, B.; Yang, G. Lattice-Based Remote User Authentication from Reusable Fuzzy Signature. Cryptology ePrint Archive: Report 2019/743. Available online: https://eprint.iacr.org/2019/743 (accessed on 24 June 2019).
- Seo, M.; Hwang, J.Y.; Lee, D.H.; Kim, S.; Kim, S.; Park, J.H. Fuzzy Vector Signature and Its Application to Privacy-Preserving Authentication. IEEE Access 2019, 7, 69892–69906. [Google Scholar] [CrossRef]
- Boneh, D.; Raghunathan, A.; Segev, G. Function-Private Identity-Based Encryption: Hiding the Function in Functional Encryption. In Proceedings of the Advances in Cryptology (CRYPTO 2013), Santa Barbara, CA, USA, 18–22 August 2013; pp. 461–478. [Google Scholar] [CrossRef]
- Regev, O. On Lattices, Learning with Errors, Random Linear Codes, and Cryptography. In Proceedings of the Thirty-Seventh Annual ACM Symposium on Theory of Computing (STOC 2005), Baltimore, MA, USA, 22–24 May 2005; pp. 84–93. [Google Scholar] [CrossRef]
- Fuller, B.; Meng, X.; Reyzin, L. Computational Fuzzy Extractors. In Proceedings of the advances in Cryptology (ASIACRYPT 2013), Bangalore, India, 1–5 December 2013; pp. 174–193. [Google Scholar] [CrossRef]
- Matsuda, T.; Takahashi, K.; Murakami, T.; Hanaoka, G. Fuzzy Signatures: Relaxing Requirements and a New Construction. In Proceedings of the Applied Cryptography and Network Security (ACNS 2016), London, UK, 19–22 June 2016; pp. 97–116. [Google Scholar] [CrossRef]
- Yasuda, M.; Shimoyama, T.; Takenaka, M.; Abe, N.; Yamada, S.; Yamaguchi, J. Recovering Attacks Against Linear Sketch in Fuzzy Signature Schemes of ACNS 2015 and 2016. In Proceedings of the Information Security Practice and Experience, Melbourne, Australia, 13–15 December 2017; pp. 409–421. [Google Scholar] [CrossRef]
- Takahashi, K.; Matsuda, T.; Murakami, T.; Hanaoka, G.; Nishigaki, M. Signature schemes with a fuzzy private key. In Int. J. Inf. Secur. 2019, 18, 581–617. [Google Scholar] [CrossRef]
- Vadhan, S.P. Pseudorandomness. Found. Trends Theor. Comput. Sci. 2012, 7, 1–336. [Google Scholar] [CrossRef]
- Bernhard, D.; Pereira, O.; Warinschi, B. How Not to Prove Yourself: Pitfalls of the Fiat-Shamir Heuristic and Applications to Helios. In Proceedings of the Advances in Cryptology (ASIACRYPT 2012), Beijing, China, 2–6 December 2012; pp. 626–643. [Google Scholar] [CrossRef]
- Kiltz, E.; Masny, D.; Pan, J. Optimal security proofs for signatures from identification schemes. In Proceedings of the Advances in Cryptology (CRYPTO 2016), Santa Barbara, CA, USA, 14–18 August 2016; pp. 33–61. [Google Scholar] [CrossRef]
- Boneh, D.; Boyen, X. Short Signatures Without Random Oracles. In Proceedings of the Advances in Cryptology (EUROCRYPT 2004), Interlaken, Switzerland, 2–6 May 2004; pp. 56–73. [Google Scholar] [CrossRef]
- Boneh, D.; Shen, E.; Waters, B. Strongly Unforgeable Signatures Based on Computational Diffie-Hellman. In Proceedings of the Public Key Cryptography (PKC 2006), New York, NY, USA, 24–26 April 2006; pp. 229–240. [Google Scholar] [CrossRef]
- Kurihara, J.; Kiyomoto, S.; Fukushima, K.; Tanaka, T. A New (k,n)-Threshold Secret Sharing Scheme and Its Extension. In Proceedings of the Information Security 2008, Taipei, Taiwan, 15–18 September 2008; pp. 455–470. [Google Scholar] [CrossRef]
- ISO/IEC 15946-5:2017. Information Technology-Security Techniques-Cryptographic Techniques Based on Elliptic Curves—Part 5: Elliptic Curve Generation; International Organization for Standardization: Geneva, Switzerland, 2017. [Google Scholar]
- Bos, J.W.; Costello, C.; Naehrig, M. Exponentiating in Pairing Groups. In Proceedings of the Selected Areas in Cryptography (SAC 2013), Coimbra, Portugal, 18–22 March 2013; pp. 438–455. [Google Scholar] [CrossRef]
- HÅstad, J.; Impagliazzo, R.; Levin, L.A.; Luby, M. A Pseudorandom Generator from Any One-Way Function. SIAM J. Comput. 1999, 28, 1364–1396. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).