CFAM: Estimating 3D Hand Poses from a Single RGB Image with Attention


Abstract
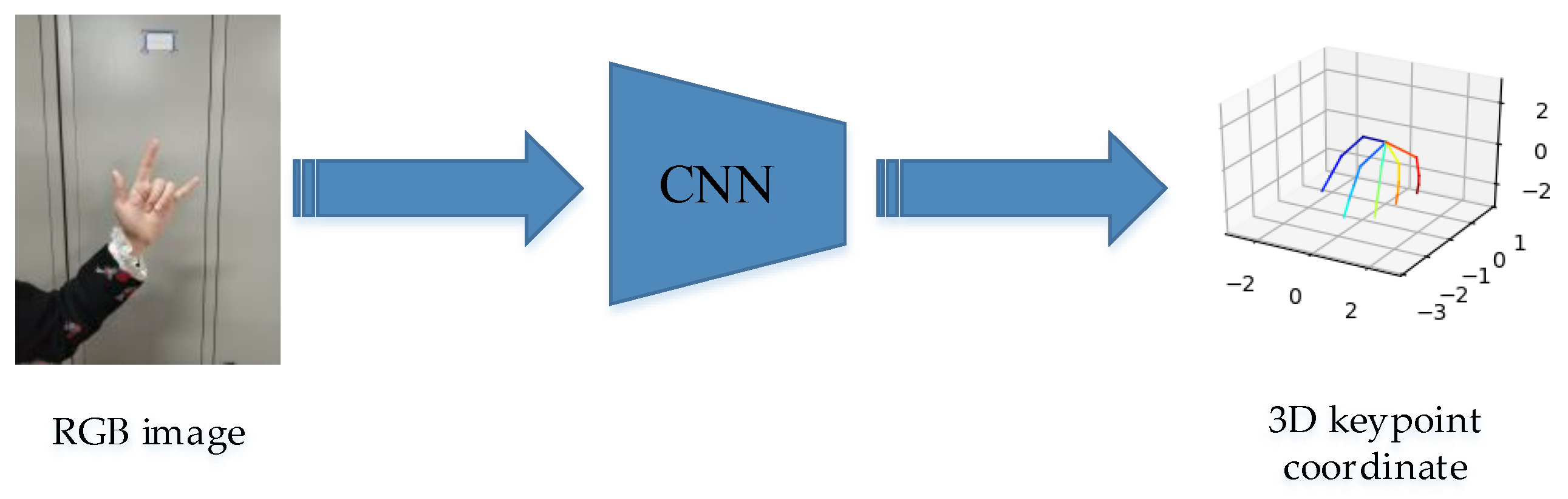
:1. Introduction
2. Related Work
2.1. 3D Hand Pose Estimation Based on Depth Images
2.2. 3D Hand Pose Estimation Based on RGB Images
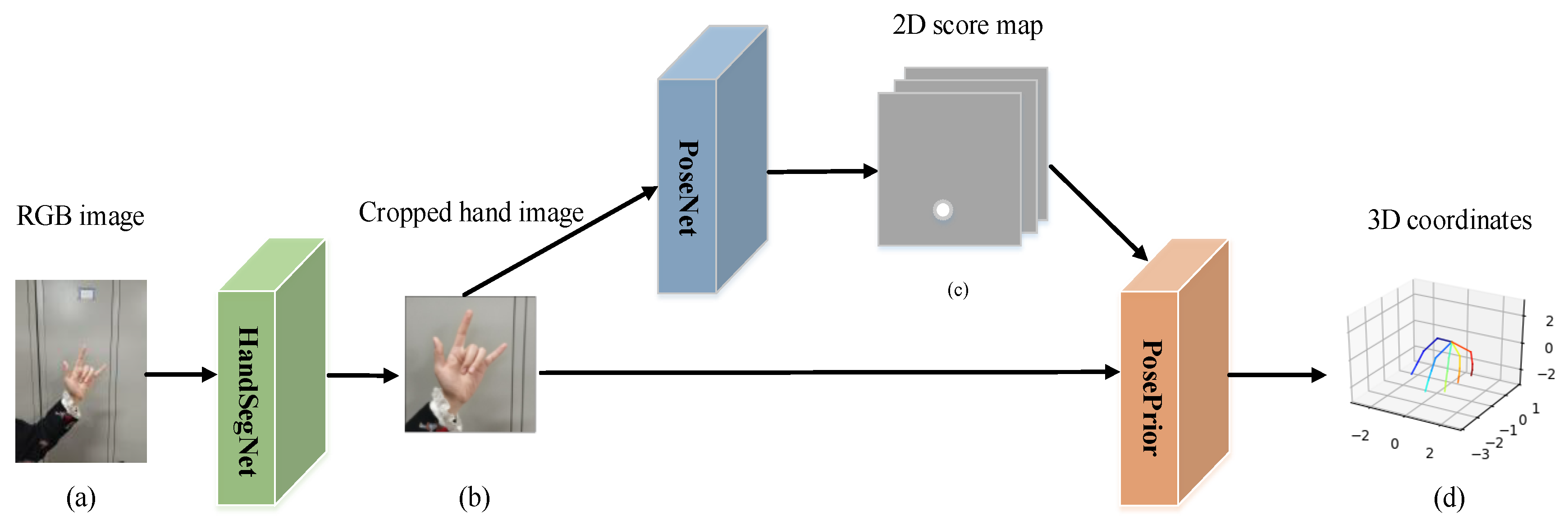
3. Method
3.1. 2D Keypoint Calculation
3.2. 3D Hand Pose Estimation
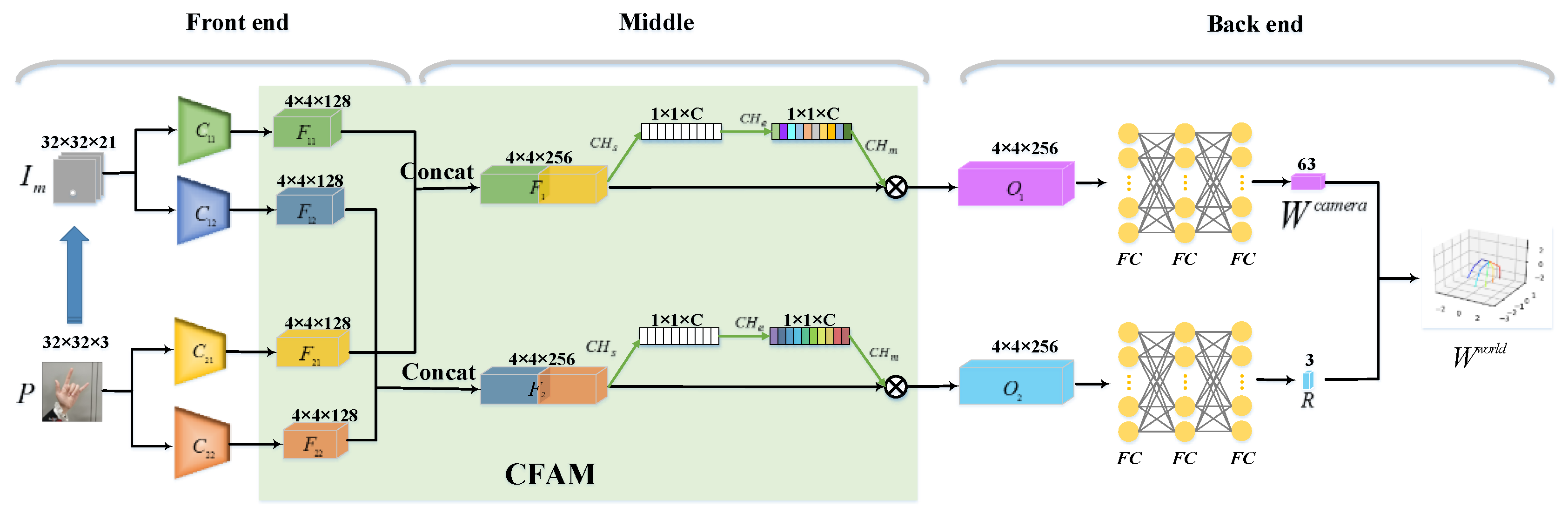
3.3. Channel Fusion Attention Mechanism (CFAM)
3.3.1. The Frontend: A Fusion Model of the Handmask and the Score Maps
3.3.2. The Middle: A Channel Attention Block on the Fused Mode
3.3.3. The Backend: Calculate the World Coordinates of the Keypoints
4. Experiments
4.1. Dataset
4.2. Assessment Criteria
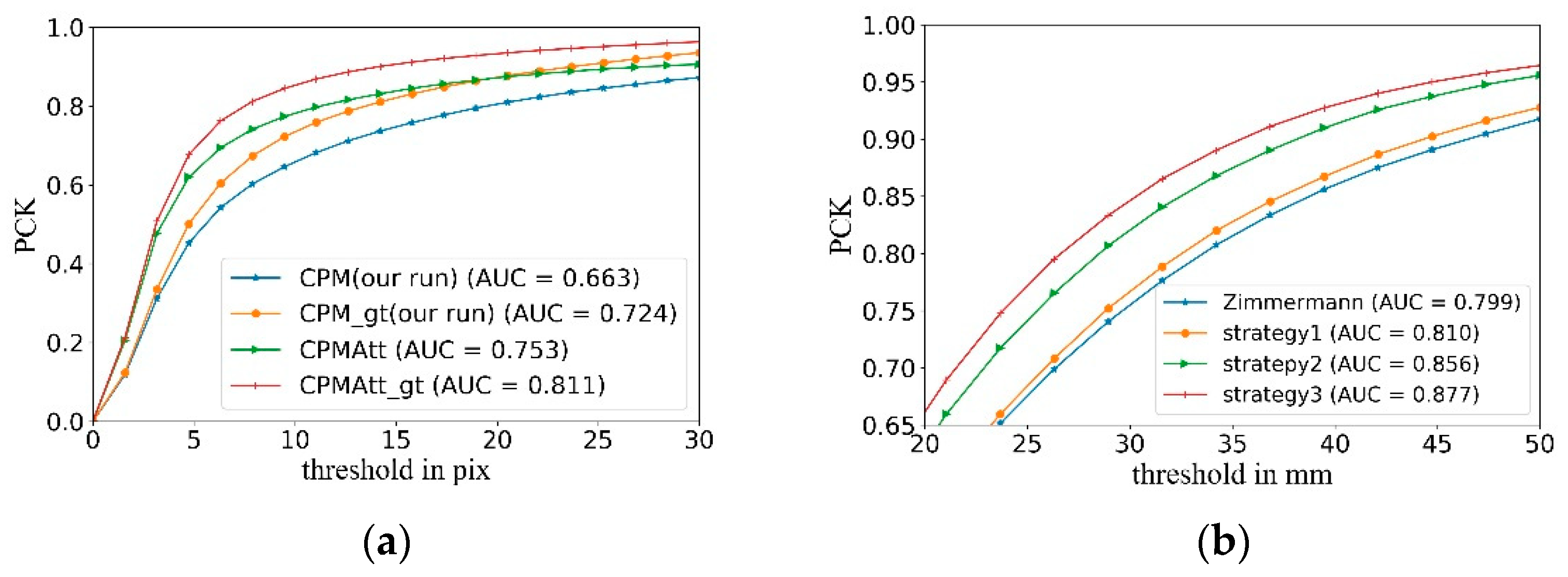
4.3. 2D Score Map Detection
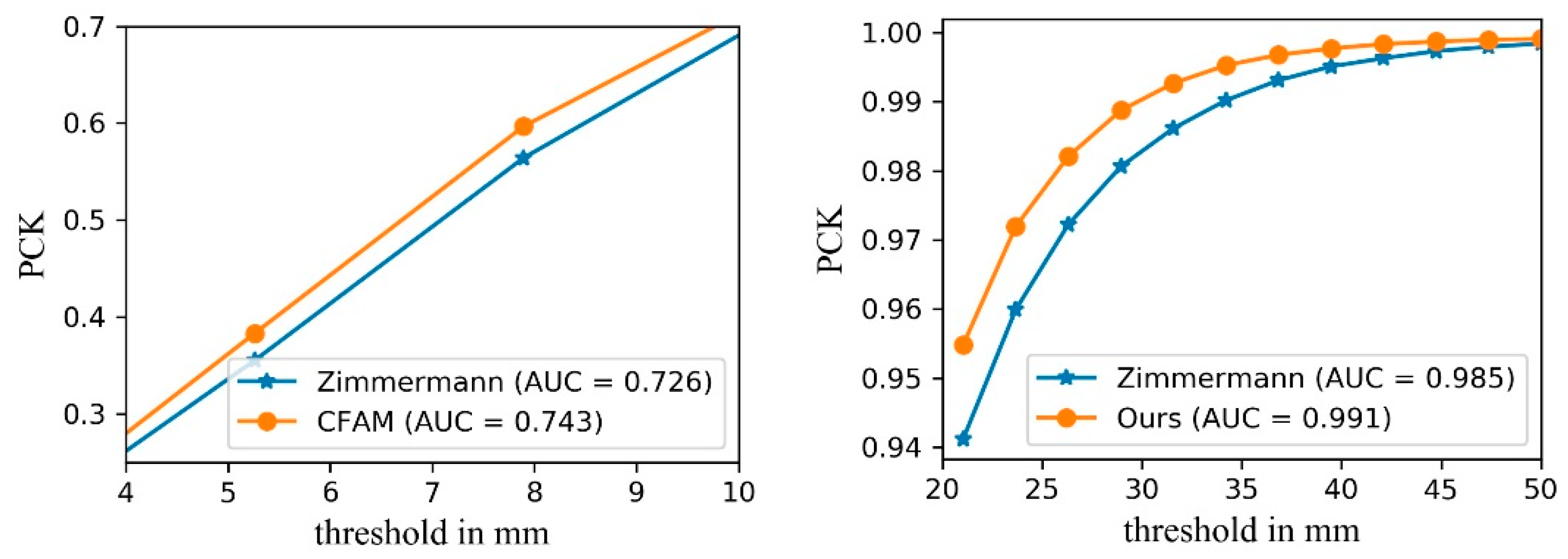
4.4. 3D Hand Pose Estimation with CFAM
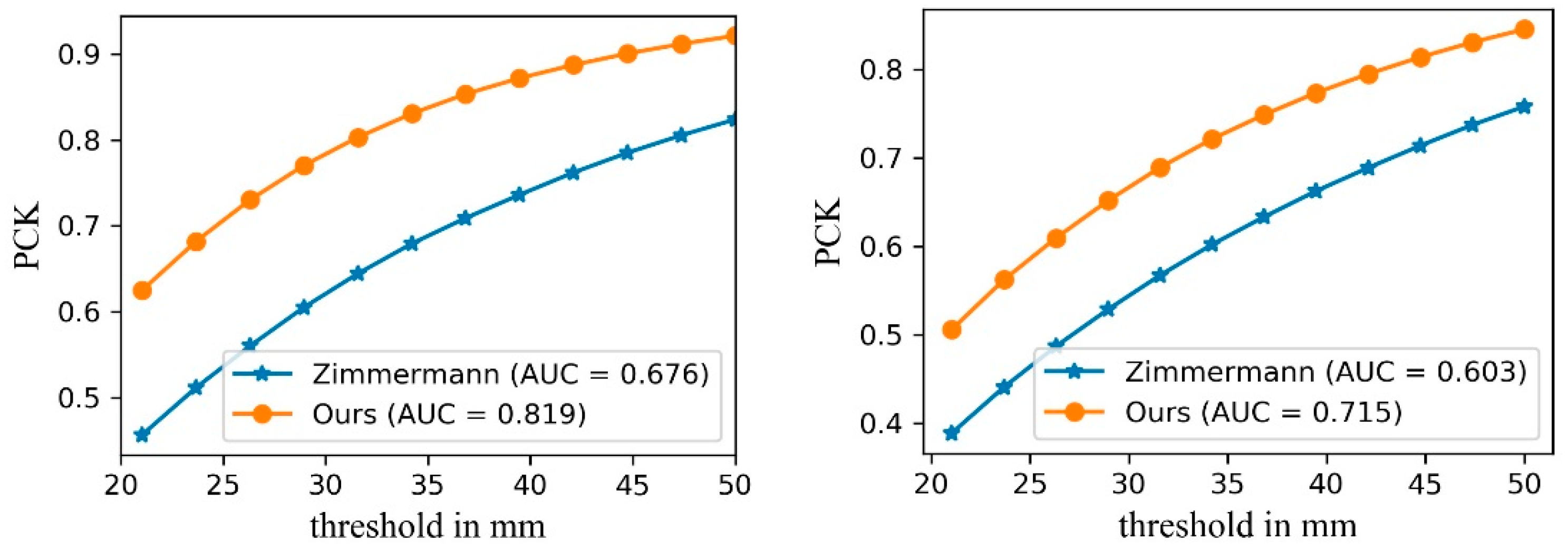
4.5. Estimating 3D Hand Poses from a Single RGB Image
4.6. Comparison with the State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Markus, O.; Paul, W.; Vincent, L. Hands Deep in Deep Learning for Hand Pose Estimation. Comput. Vis. Winter Workshop 2015, 2015, 21–30. [Google Scholar]
- Ayan, S.; Chiho, C.; Karthik, R. Deep Hand Robust Hand Pose Estimation by Computer a Matrix Imputed with Deep Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4150–4158. [Google Scholar]
- Markus, O.; Vincent, L. DeepPrior++: Improving Fast and Accurate 3D Hand Pose Estimation. In Proceedings of the IEEE Internatio-nal Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; pp. 585–594. [Google Scholar]
- Tompson, J.; Stein, M.; Lecun, Y.; Perlin, K. Real-time continuous pose recovery of human hands using convolutional networks. TOG. ACM Trans. Graph. 2014, 33, 169. [Google Scholar] [CrossRef]
- Sun, X.; Wei, Y.; Liang, S.; Tang, X.; Sun, J. Cascaded hand pose regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Edgar, S.-S.; Arnau, R.; Guillem, A.; Carme, T.; Francesc, M.N. Single image 3D human pose estimation from noisy observations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Rhode, Island, 18–20 July 2012; pp. 2673–2680. [Google Scholar]
- Athitsos, V.; Sclaroff, S. Estimating 3d hand pose from a cluttered image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Madison, WI, USA, 18–20 June 2003; Volume 2, p. II-432. [Google Scholar]
- Zhou, X.; Wan, Q.; Zhang, W.; Xue, X.; Wei, Y. Model-based deep hand pose estimation. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence IJCAI, New York, NK, USA, 9–15 July 2016. [Google Scholar]
- Garcia-Hernando, G.; Yuan, S.; Baek, S.; Kim, T.-K. First-person hand action benchmark with RGB-D videos and 3D hand pose annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 409–419. [Google Scholar]
- Zhang, J.; Jiao, J.; Chen, M.; Qu, L.; Xu, X.; Yang, Q. 3d hand pose tracking and estimation using stereo matching. arXiv 2016, arXiv:1610.07214. [Google Scholar]
- Chengde, W.; Thomas, P.; Luc, V.G.; Angela, Y. ETH Zurich Dense 3D Regression for Hand Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Aisha, U.K.; Ali, B. Analysis of Hand Segmentation in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Seungryul, B.; Kwang, I.K.; Kim, T.-K. Augmented Skeleton Space Transfer for Depth-based Hand Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wan, C.; Probst, T.; Gool, L.V.; Yao, A. Crossing Nets: Combining GANs and VAEs with a Shared Latent Space for Hand Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zimmermann, C.; Brox, T. Learning to estimate 3d hand pose from single rgb images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4903–4911. [Google Scholar]
- Wei, S.-E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Spur, A.; Song, J.; Park, S.; Hilliges, O. Cross-modal Deep Variational Hand Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Dibra, E.; Melchior, S.; Balkis, A.; Wolf, T.; Öztireli, C.; Gross, M. Monocular rgb hand pose inference from unsupervised refinable nets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1075–1085. [Google Scholar]
- Mueller, F.; Bernard, F.; Sotnychenko, O.; Mehta, D.; Sridhar, S.; Casas, D.; Theobalt, C. Ganerated hands for real-time 3d hand tracking from monocular rgb. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 22 May 2018; pp. 49–59. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Panteleris, P.; Oikonomidis, I.; Argyros, A. Using a single rgb frame for real time 3d hand pose estimation in the wild. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 436–445. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Name | Kernel | Dimensionality |
|---|---|---|---|
| Input | 32 × 32 × Channel | ||
| 1 | Conv. + ReLU | 3 × 3 | 32 × 32 × 32 |
| 2 | Conv. + ReLU | 3 × 3 | 16 × 16 × 32 |
| 3 | Conv. + ReLU | 3 × 3 | 16 × 16 × 64 |
| 4 | Conv. + ReLU | 3 × 3 | 8 × 8 × 64 |
| 5 | Conv. + ReLU | 3 × 3 | 8 × 8 × 128 |
| 6 | Conv. + ReLU | 3 × 3 | 4 × 4 × 128 |
| ID | Name | Kernel | Dimensionality |
|---|---|---|---|
| 1 | F1i | 4 × 4 × 128 | |
| 2 | F2i | 4 × 4 × 128 | |
| 3 | Concat(1,2) | 4 × 4 × 256 | |
| 4 | Average Pooling | 4 × 4 | 1 × 1 × 256 |
| 5 | FC | 1 × 1 × 32 | |
| 6 | FC | 1 × 1 × 256 | |
| 7 | Sigmoid | 1 × 1 × 256 | |
| 8 | Multiply(3,7) | 4 × 4 × 256 | |
| 9 | FC + ReLU | 512 | |
| 10 | FC + ReLU | 512 | |
| 11 | FC | Output |
| Evaluation Index | CPMAtt | CPMAtt_gt | CPM (Our Run) | CPM_gt (Our Run) |
|---|---|---|---|---|
| AUC (0–30 pix) | 0.753 | 0.811 | 0.663 | 0.724 |
| Median Error (pix) | 3.81 | 3.25 | 5.83 | 5 |
| Mean Error (pix) | 14.49 | 6.26 | 17.04 | 9.14 |
| Evaluation Index | Method | Wrist | Thumb | Index | Middle | Ring | Little |
|---|---|---|---|---|---|---|---|
| Mean Error (pix) | CPMAtt | 24.8 | 13.47 | 13.66 | 13.23 | 14.12 | 15.39 |
| CPMAtt_gt | 4.34 | 8.53 | 7.4 | 4.5 | 5.04 | 6.32 | |
| CPM (our run) | 24.62 | 17.23 | 16.29 | 14.3 | 16.04 | 19.45 | |
| CPM_gt (our run) | 6.11 | 12.2 | 9.59 | 6.1 | 7.65 | 10.89 | |
| Media Error (pix) | CPMAtt | 16.12 | 3.4 | 2.87 | 3.13 | 3.25 | 3.31 |
| CPMAtt_gt | 3.36 | 3.66 | 3.31 | 3.06 | 3.14 | 3.05 | |
| CPM (our run) | 15.97 | 5.84 | 4.67 | 4.59 | 5.59 | 5.93 | |
| CPM_gt (our run) | 4.47 | 6.15 | 4.6 | 4.36 | 4.99 | 5.04 | |
| AUC (0–50 pix) | CPMAtt | 0.44 | 0.75 | 0.77 | 0.8 | 0.78 | 0.75 |
| CPMAtt_gt | 0.86 | 0.76 | 0.79 | 0.85 | 0.83 | 0.8 | |
| CPM (our run) | 0.44 | 0.64 | 0.67 | 0.74 | 0.7 | 0.62 | |
| CPM_gt (our run) | 0.8 | 0.65 | 0.71 | 0.8 | 0.75 | 0.68 |
| Evaluation Index | Zimmermann | Strategy 1 | Strategy 2 | Strategy 3 |
|---|---|---|---|---|
| AUC (0–50 mm) | 0.585 | 0.591 | 0.629 | 0.648 |
| Median Error (mm) | 18.84 | 18.6 | 16.65 | 15.85 |
| Mean Error (mm) | 22.43 | 21.88 | 19.4 | 18.2 |
| Evaluation Index | Methods | Wrist | Thumb | Index | Middle | Ring | Little |
|---|---|---|---|---|---|---|---|
| Mean Error (mm) | Zimmermann [16] | 0.28 | 24.98 | 27.11 | 22.27 | 20.98 | 22.36 |
| Strategy 1 | 0.8 | 24.55 | 25.49 | 21.44 | 20.64 | 22.54 | |
| Strategy 2 | 1.39 | 20.09 | 22.46 | 20.63 | 18.56 | 19.77 | |
| Strategy 3 | 0.21 | 18.88 | 20.95 | 18.83 | 17.35 | 19.47 | |
| Media Error (mm) | Zimmermann [16] | 0.27 | 20.67 | 22.98 | 18.76 | 17.68 | 18.76 |
| Strategy 1 | 0.77 | 20.79 | 21.51 | 18.26 | 17.53 | 19.37 | |
| Strategy 2 | 1.32 | 17.3 | 18.91 | 17.8 | 15.87 | 17.21 | |
| Strategy 3 | 0.2 | 16.56 | 17.81 | 16.32 | 15 | 17.47 | |
| AUC (0–50 mm) | Zimmermann [16] | 0.97 | 0.55 | 0.52 | 0.58 | 0.6 | 0.58 |
| Strategy 1 | 0.97 | 0.55 | 0.53 | 0.6 | 0.61 | 0.57 | |
| Strategy 2 | 0.97 | 0.62 | 0.58 | 0.61 | 0.64 | 0.62 | |
| Strategy 3 | 0.97 | 0.64 | 0.6 | 0.64 | 0.66 | 0.62 |
| STB | Zimmermann [16] | CFAM |
|---|---|---|
| AUC (0–50 mm) | 0.83 | 0.837 |
| Median Error (mm) | 7.3 | 7.06 |
| Mean Error (mm) | 8.47 | 8.07 |
| Evaluation Index | Methods | Wrist | Thumb | Index | Middle | Ring | Little |
|---|---|---|---|---|---|---|---|
| Mean Error (mm) | Zimmermann [16] | 0 | 8.74 | 10.04 | 8.93 | 8.35 | 8.42 |
| CFAM | 0 | 9.02 | 9.1 | 8.68 | 7.76 | 7.79 | |
| Media Error (mm) | Zimmermann [16] | 0 | 7.72 | 8.79 | 7.57 | 6.99 | 7.24 |
| CFAM | 0 | 7.85 | 8.45 | 7.76 | 6.71 | 6.31 | |
| AUC (0–50 mm) | Zimmermann [16] | 0.97 | 0.83 | 0.8 | 0.82 | 0.83 | 0.83 |
| CFAM | 0.97 | 0.82 | 0.82 | 0.83 | 0.84 | 0.84 |
| Datasets | RHD | STB | ||
|---|---|---|---|---|
| Method | Zimmermann [16] | Ours | Zimmermann [16] | Ours |
| AUC (0–50 mm) | 0.48 | 0.561 | 0.823 | 0.824 |
| Median Error (mm) | 24.47 | 19.61 | 7.58 | 7.78 |
| Mean Error (mm) | 30.36 | 24.6 | 8.8 | 8.75 |
| Datasets | Method | Wrist | Thumb | Index | Middle | Ring | Little |
|---|---|---|---|---|---|---|---|
| RHD | Zimmermann [16] | 0 | 24.57 | 28.58 | 25.5 | 24.46 | 25.33 |
| Ours | 0.13 | 18.46 | 20.01 | 18.1 | 16.83 | 18.11 | |
| STB | Zimmermann [16] | 0 | 9.41 | 10.06 | 9.62 | 8.61 | 8.51 |
| Ours | 0 | 9.11 | 9.04 | 10.04 | 8.97 | 8.75 |
| Datasets | Methods | Wrist | Thumb | Index | Middle | Ring | Little |
|---|---|---|---|---|---|---|---|
| RHD | Zimmermann [16] | 0 | 33.81 | 35.55 | 30.33 | 28.5 | 31.2 |
| Ours | 0.14 | 24.2 | 25.7 | 22.35 | 20.65 | 22.48 | |
| STB | Zimmermann [16] | 0 | 8.45 | 8.83 | 8.16 | 7.19 | 7.17 |
| Ours | 0 | 8.24 | 8.29 | 8.79 | 7.89 | 7.62 |
| Datasets | Methods | Wrist | Thumb | Index | Middle | Ring | Little |
|---|---|---|---|---|---|---|---|
| RHD | Zimmermann [16] | 0.97 | 0.47 | 0.41 | 0.46 | 0.48 | 0.45 |
| Ours | 0.97 | 0.58 | 0.54 | 0.59 | 0.61 | 0.58 | |
| STB | Zimmermann [16] | 0.97 | 0.81 | 0.8 | 0.81 | 0.83 | 0.83 |
| Ours | 0.97 | 0.82 | 0.82 | 0.8 | 0.82 | 0.82 |
| Methods | Wrist | Thumb | Index | Middle | Ring | Little | |
|---|---|---|---|---|---|---|---|
| Mean Error (mm) | Zimmermann [16] | 0 | 39.8 | 42.51 | 35.98 | 33.04 | 35.59 |
| Ours | 0.21 | 32.83 | 34.43 | 29.81 | 26.85 | 29.02 | |
| Media Error (mm) | Zimmermann [16] | 0 | 29.46 | 34.66 | 29.8 | 27.98 | 28.7 |
| Ours | 0.2 | 23.51 | 25.35 | 23.08 | 21.05 | 22.68 | |
| AUC (0–50 mm) | Zimmermann [16] | 0.97 | 0.4 | 0.35 | 0.41 | 0.43 | 0.4 |
| Ours | 0.97 | 0.48 | 0.45 | 0.49 | 0.53 | 0.49 |
| Methods | Zimmermann [16] | Ours |
|---|---|---|
| AUC (0–50 mm) | 0.424 | 0.512 |
| Median Error (mm) | 28.69 | 22.04 |
| Mean Error (mm) | 35.61 | 29.14 |
| Methods | AUC (20–50 mm) |
|---|---|
| Dibra [19] (CVPR2018 workshop) | 0.923 |
| Panteleris [23] (2018 WACV) | 0.941 |
| Mueller [20] (CVPR2018) | 0.965 |
| Spur [18] (2018 CVPR) | 0.983 |
| Zimmermann [16] (2017 ICCV) | 0.985 |
| Ours | 0.991 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Jiang, J.; Guo, Y.; Kang, L.; Wei, Y.; Li, D. CFAM: Estimating 3D Hand Poses from a Single RGB Image with Attention. Appl. Sci. 2020, 10, 618. https://doi.org/10.3390/app10020618
Wang X, Jiang J, Guo Y, Kang L, Wei Y, Li D. CFAM: Estimating 3D Hand Poses from a Single RGB Image with Attention. Applied Sciences. 2020; 10(2):618. https://doi.org/10.3390/app10020618
Chicago/Turabian StyleWang, Xianghan, Jie Jiang, Yanming Guo, Lai Kang, Yingmei Wei, and Dan Li. 2020. "CFAM: Estimating 3D Hand Poses from a Single RGB Image with Attention" Applied Sciences 10, no. 2: 618. https://doi.org/10.3390/app10020618
APA StyleWang, X., Jiang, J., Guo, Y., Kang, L., Wei, Y., & Li, D. (2020). CFAM: Estimating 3D Hand Poses from a Single RGB Image with Attention. Applied Sciences, 10(2), 618. https://doi.org/10.3390/app10020618