1. Introduction
In the current century, the smartphones and other communication devices have been an important part of human life, where it is impossible to have social communications without them [
1,
2]. One of the principal parts in these smartphones is the signal processing platform. This part has an important role in the telecommunication and audio signal processing. Denoising and dereverberation are two main sections in the signal processing and enhancement platforms, which is the aim of this article, to increase the performance of speech enhancement algorithms [
3]. Increasing the number of sensors improves the accuracy of denoising algorithms due to the spatial spectrum extension by providing the proper information. The definition of accuracy in the enhancement algorithms is how the enhanced signal is closer to the original signal with a high level of noise elimination and less distortion. Therefore, the speech enhancement is the main part in such applications as: hearing aid systems, mobile communication, speaker localization and tracking, speech recognition, voice activity detection (VAD), speaker identification, etc. The denoising algorithms should be implemented in a way to keep the speech intelligibility in an acceptable range and to remove a high level of noise and reverberation. Then, the signal-to-noise ratio (SNR) cannot be the only specific factor for comparing the speech enhancement methods. The qualitative criteria such as: perceptual evaluation of speech quality (PESQ) [
4], mean opinion score (MOS) [
5], and short-time objective intelligibility (STOI) [
6] are very useful to show the performance of denoising methods in comparison with other previous works along with quantitative criteria such as: overall SNR and segmental SNR (SegSNR) [
7]. The performance of the denoising algorithms is calculated by considering the qualitative and quantitative criteria at the same time, which are the proper measurements for comparison with other previous works.
In recent years, many of the single and multi-channel methods have been proposed for speech enhancement. The single-channel methods are still challenging strategies for the speech enhancement due to the limited information. The traditional speech enhancement methods such as the Wiener filter (WF) and distributed multichannel WF (DB-MWF) [
8,
9], spectral subtraction [
10,
11], and statistical-model-based [
12,
13] have superior performances in stationary noisy environments but the stability and accuracy of these methods are strongly decreased in non-stationary noisy conditions. However, existing noise estimation methods such as minima-controlled recursive averaging [
14,
15] and minimum statistics [
11,
16] follow the stationary noise energy. However, they do not have the ability to follow the non-stationary noise energy. For example, the method proposed in [
16] is presented to estimate the power spectral density (PSD) of a non-stationary noise signal. This method can be considered in combination with any speech enhancement algorithm, which requires the noise PSD estimation. The presented method follows the spectral minima in each frequency band by minimizing conditional mean square error (MSE) criteria in each time frame, which develops the optimal smoothing parameter for recursive smoothing of the PSD of the noisy speech signal. Therefore, an unbiased noise estimator is presented based on the optimally smoothed PSD estimation and the analysis of the statistics of spectral minima. Therefore, the noise estimation accuracy in some methods [
15,
16] is affected when the noise is non-stationary. A group of speech enhancement methods are proposed based on a priori information of speech signals such as the auto-regressive hidden Markov model (ARHMM) [
17,
18,
19]. The noise and speech signals are modeled as an auto-regressive (AR) process in these methods. In addition, the hidden Markov model (HMM) is implemented for modeling the prior information of speech and noise features. For example, the methods in [
18,
19] are considered for modeling the speech and noise spectrum shape. Therefore, the spectrum gain is calculated instead of the whole spectrum for the speech and noise signals. The noise-spectrum gain estimation is adapted by the fast variations of the signal energy, which is known as non-stationary noise.
Masoud and Sina [
20] proposed a novel method based on the normalized fractional of the two-channel least mean square (LMS) algorithm for enhancing the speech signal. The presented algorithm is known as fractional LMS, which is obtained by considering the fractional terms in the calculation of filter coefficients of the standard LMS algorithm. The normalization is a proper strategy to improve the performance of the LMS algorithm. Therefore, a normalization step is implemented on the fractional LMS in order to promote the performance of the enhancement method. The proposed two-channel method has a higher performance in terms of the MSE criteria in comparison with other works. Pagula and Kishore [
21] proposed a recursive least square (RLS)-based adaptive filter for the application of speech enhancement. The segmentation step is considered for the microphone signals to provide a better stationary of the speech signals. In the following, the adaptive filter coefficients are calculated based on the modified version of the RLS method. The filter coefficients are calculated in a way to have the least distortion in the enhanced speech signals. The presented method has a high performance in the presence of white noise for a different range of SNRs. Qi et al. [
22] proposed a method for estimation of the short-time linear prediction parameters of the Wiener filter. In the presented work, a speech signal spectrum modeling is proposed based on the prior information of the speech linear prediction in order to model the noise as same as the speech signal. The difference between the proposed method with other previous works is the use of multiplicative update rule for better estimation of the coefficients. Tavakoli et al. [
23] introduced a framework for the speech enhancement based on an ad-hoc microphone array. A subarray is considered for coherence calculation in the speech signal. A coherence measurement is proposed based on the speech quality in the entrance of the array in order to select the subarrays in the local speech enhancements, when more than one subarray is used. The proposed method is evaluated based on quantitative and qualitative criteria such as: array gains, speech distortion ratio, PESQ, and STOI to show the superiority of the algorithm. Shimada et al. [
24] proposed an unsupervised speech enhancement method based on the non-negative matrix factorization and sub-band beamforming for robust speech recognition against the noise. In the recent years, the minimum variance distortionless response (MVDR) beamforming is widely used to achieve the speech enhancement because this method properly works when there are steering vectors for the speech signal and spatial covariance matrix for the noise. In the presented algorithm, an unsupervised method decomposes each time-frequency bin to the sum of the noise and signal by implementing the multi-channel non-negative matrix factorization (MNMF). The presented method estimates the spatial covariance matrix (SCM) for the signal and noise by the use of spectral noise and speech features. In this paper, the online MVDR beamforming is proposed via an adaptive update for the MNMF parameters. Kavalekalam et al. [
25] proposed a speech enhancement model-based method to increase the speech perception for auditory earphones applications. In the proposed method, a binaural speech enhancement framework is introduced, which is implemented by a speech production approach. The proposed speech enhancement framework is based on a Kalman filter, which is presented to use the speech production dynamic in the procedure of the speech enhancement. The Kalman filter needs to have an estimation from the short time predictor (STP) of clean speech, noise, and the pitch estimation of the clean speech. A binaural method for STP parameters estimation is proposed in this paper with a directional pitch predictor based on the harmonic model and maximum likelihood (ML) criteria for pitch features estimations. These parameters are calculated just based on 2-microphones signals equivalent to human ears. Botinhao et al. [
26] proposed a simultaneous noise-reverberation enhancement method for text-to-speech (TTS) systems. The recorded voices in noisy-reverberant environments affects the quality of the TTS systems. A simple way is to increase the quality of the prerecorded speech signals for the TTS training system by speech enhancement methods such as: noise suppression and dereverberation algorithms. Then, a recurrent neural network is considered in this paper for the speech enhancement. The neural network is trained by parallel data of clean speech and recorded speech with low quality. The low quality speech signal is obtained by the addition of environmental noise and convolution between the room impulse response and the clean speech. The separated neural networks are trained by only-noise, only-reverberation, and noisy-reverberant data. The quality of the training data with a low quality speech signal is highly improved by the use of this neural network. Wang et al. [
27] proposed a model-based method for speech enhancement in modulation domain by the use of a Kalman filter. The proposed predictor models the estimated amplitude spectral dynamically from the speech and noise to calculate the minimum mean square error (MMSE) of the speech amplitude spectrum taking into account that the noise and speech are additive in the complex plane. The stationary Gaussian model is proposed to consider the dynamic noise amplitude as same as the dynamic speech amplitude, which is a mixture of Gaussian models that the centers are located in a complex plane.
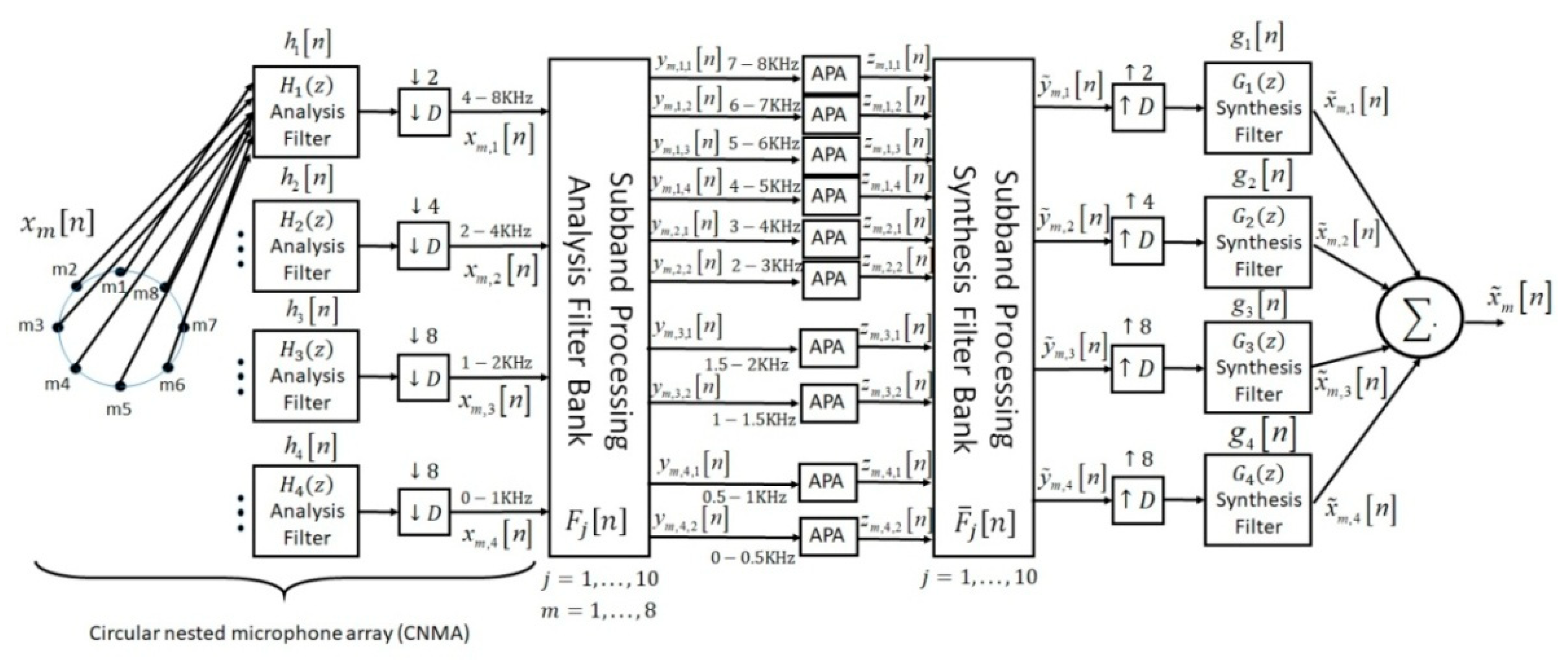
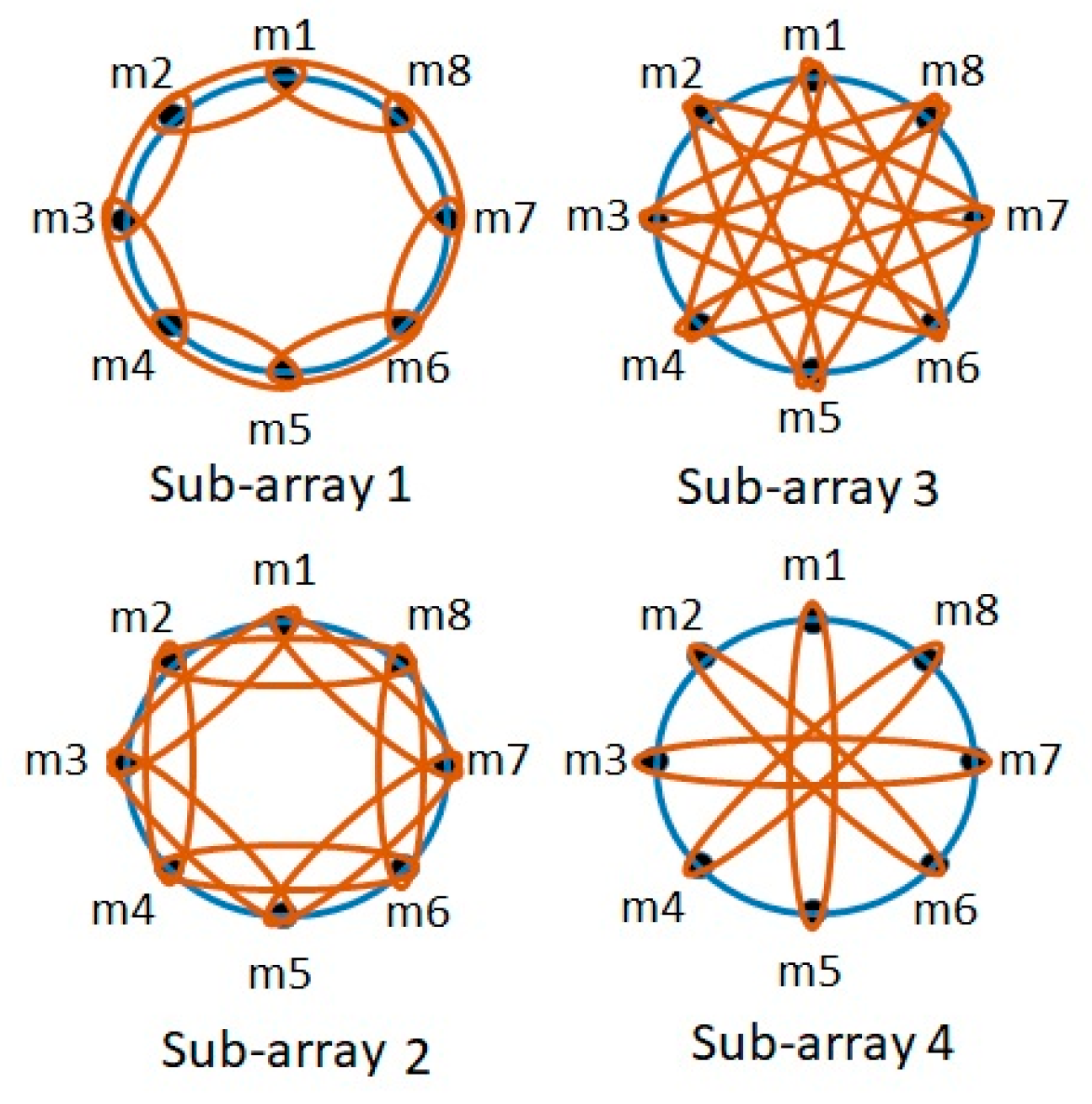
In our article, a multi-channel speech enhancement method is introduced based on the proposed circular nested microphone array in combination with the sub-band affine projection algorithm (CNMA-SBAPA). A nested microphone array increases the accuracy of the speech enhancement methods by increasing the information. Nevertheless, spatial aliasing is one of the challenges when microphone arrays are used. Firstly, a uniform circular nested microphone array (CNMA) is proposed for eliminating the spatial aliasing. Additionally, the array dimensions are designed in a way to be applicable in the real conditions. The speech components are variable in frequency bands. Therefore, a sub-band processing method is considered for speech signals. This method provides the high frequency resolution in low speech frequency components. Finally, the affine projection algorithm (APA), as an adaptive method for the speech enhancement, is implemented on sub-band signals from the circular nested microphone array (NMA). Since each APA block is implemented on a sub-band with specific information, the accuracy and speed of convergence are increased in this condition. In the last step, the synthesis filters are used to generate the enhanced speech signal. The proposed system with sub-band APA is compared by the quantitative (segmental SNR), qualitative (PESQ, MOS, and STOI) criteria, and speed of convergence with the least mean square (LMS), traditional APA, recursive least square (RLS), distributed multichannel Wiener filter (DB-MWF), and multichannel nonnegative matrix factorization-minimum variance distortionless response (MNMF-MVDR) algorithms on real and simulated data under white and colored noisy conditions. The results show the superiority of the proposed system in comparison with other previous works in all environmental conditions.
Section 2 shows the microphone signal model and the proposed uniform circular nested microphone array.
Section 3 includes the proposed sub-band algorithm with analysis and synthesis filter banks in combination with the sub-band APA. The results on real and simulated data are discussed in
Section 4.
Section 5 includes some conclusions.
3. The Proposed Multiresolution Sub-band-APA for the Speech Enhancement
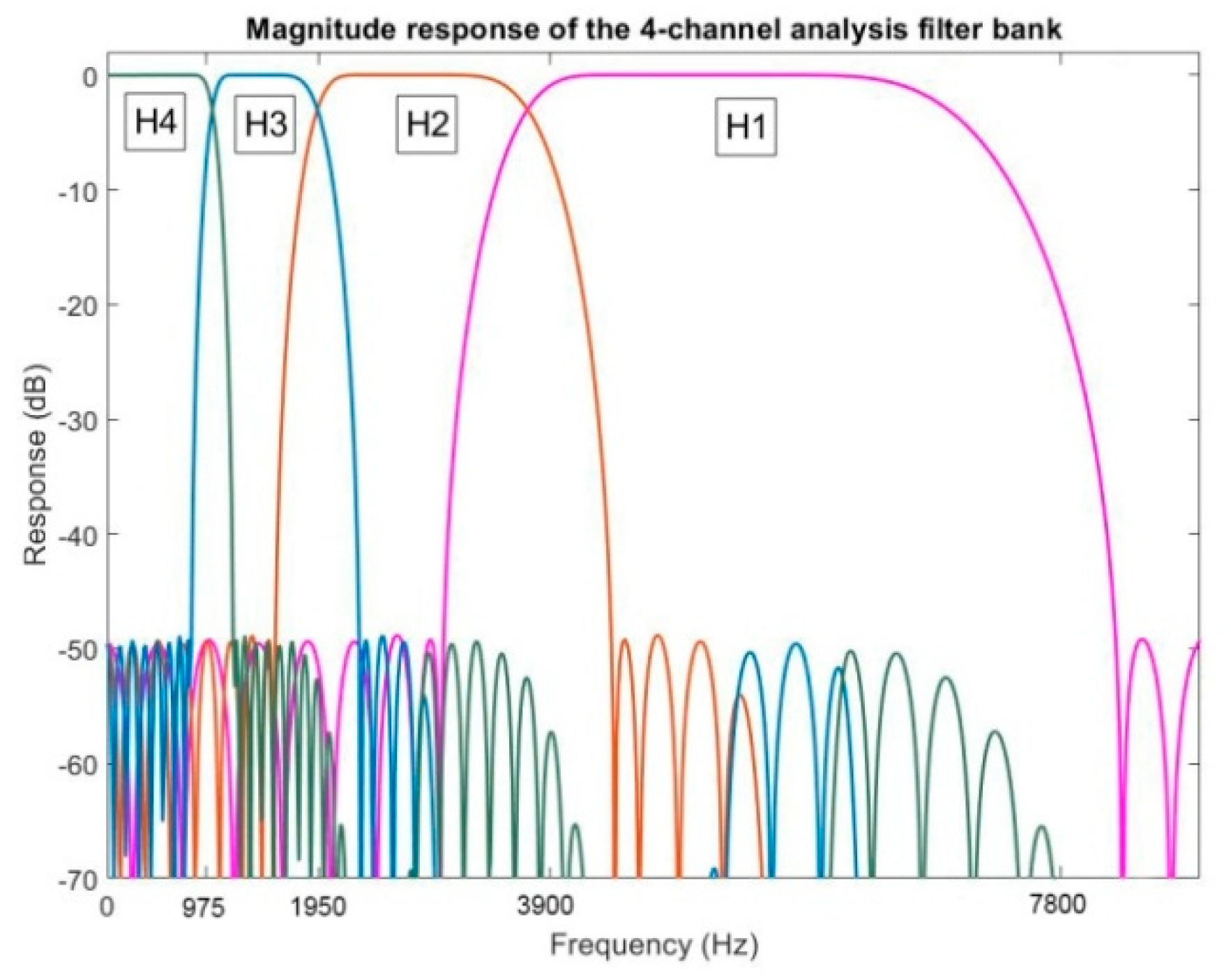
Speech is a wideband and non-stationary signal, where each frequency band has different information. This feature for the speech signal provides the conditions to evaluate the speech spectrum components by considering different frequency resolution. For example, speech information is condensed at the lower part of the spectrum. Therefore, the accuracy of the speech enhancement algorithm is increased by a focus to low frequency components. In this article, a specific sub-band processing along with a filter bank was proposed for paying more attention to lower frequencies by the use of filters with narrower bandwidths.
Table 2 shows the information to design and implement this analysis filter bank. There is still not any certain rule for selecting the number of frequency bands. Of course, by having narrower band filters in low frequencies, we have more frequency resolution, but the concern is the computational complexity. In other hands, adding each more filter means entering more microphone pairs and more calculations. Based on the experiments, this number of frequency bands prepares enough performance and acceptable level of complexity.
As seen, the filter bandwidth is smaller in low frequencies in comparison with high frequencies. This property increases the frequency resolution for low frequencies. The most important benefit in sub-band processing is the noise estimation from the silent part of the speech signal in each sub-band. Since in the proposed denoising method, the noise estimation is required as an input for the enhancement algorithm. Therefore, the more accurate and stationary noise estimation is obtained by sub-band processing of the speech signal, which increases the denoising algorithm performance. If
is considered as an input signal for the
m-th microphone, the analysis filter output for the CNMA is expressed as:
where
is the analysis filter output and
is the impulse response for this filter. Therefore, the spatial aliasing is eliminated from each microphone pairs of CNMA by the use of analysis filters, which are designed specifically for each subarray. In the following, the microphone signals are entered to the proposed analysis filter bank for the sub-band processing. As shown in
Table 2, each microphone signal is divided into 10 sub-bands. These numbers of sub-bands were selected based on our experiments in order to provide a proper efficiency and with low computational complexity, by preparing a high frequency resolution in low frequencies. Therefore, the output of the proposed analysis filter bank is expressed as:
where
is the impulse response for each sub-band filter in the analysis filter bank and
is the output of the analysis filter bank for the
j-th sub-bands and
m-th microphone. The signals
are the sub-band microphone signals for the proposed sub-band-APA algorithm. In the following, the sub-band-APA (SBAPA) algorithm along with the circular nested microphone array (CNMA-SBAPA) is proposed for the speech enhancement. Adaptive filters as an important tool in digital signal processing have been utilized for many years in such application as: speech signal enhancement, system identification, localization and tracking, etc. In adaptive filters, the coefficients change periodically to be adapted based on the time varying features of the noise, and this property increases the performance of the denoising system in comparison with normal methods. In addition, these filters are non-linear and homogeneous since their features are dependent on the input signal. The adaptive filters have the following advantages: low delay and better tracking in non-stationary conditions [
30]. These advantages are very important in dereverberation, denoising, time delay estimation, channel equalization, and speaker tracking applications. In these applications, low delay and robustness against of non-stationary noisy and reverberant conditions are important parameters to improve the performance of the proposed systems. The existence of the reference signal, which is hidden in the filter coefficient estimations, defines the system performance.
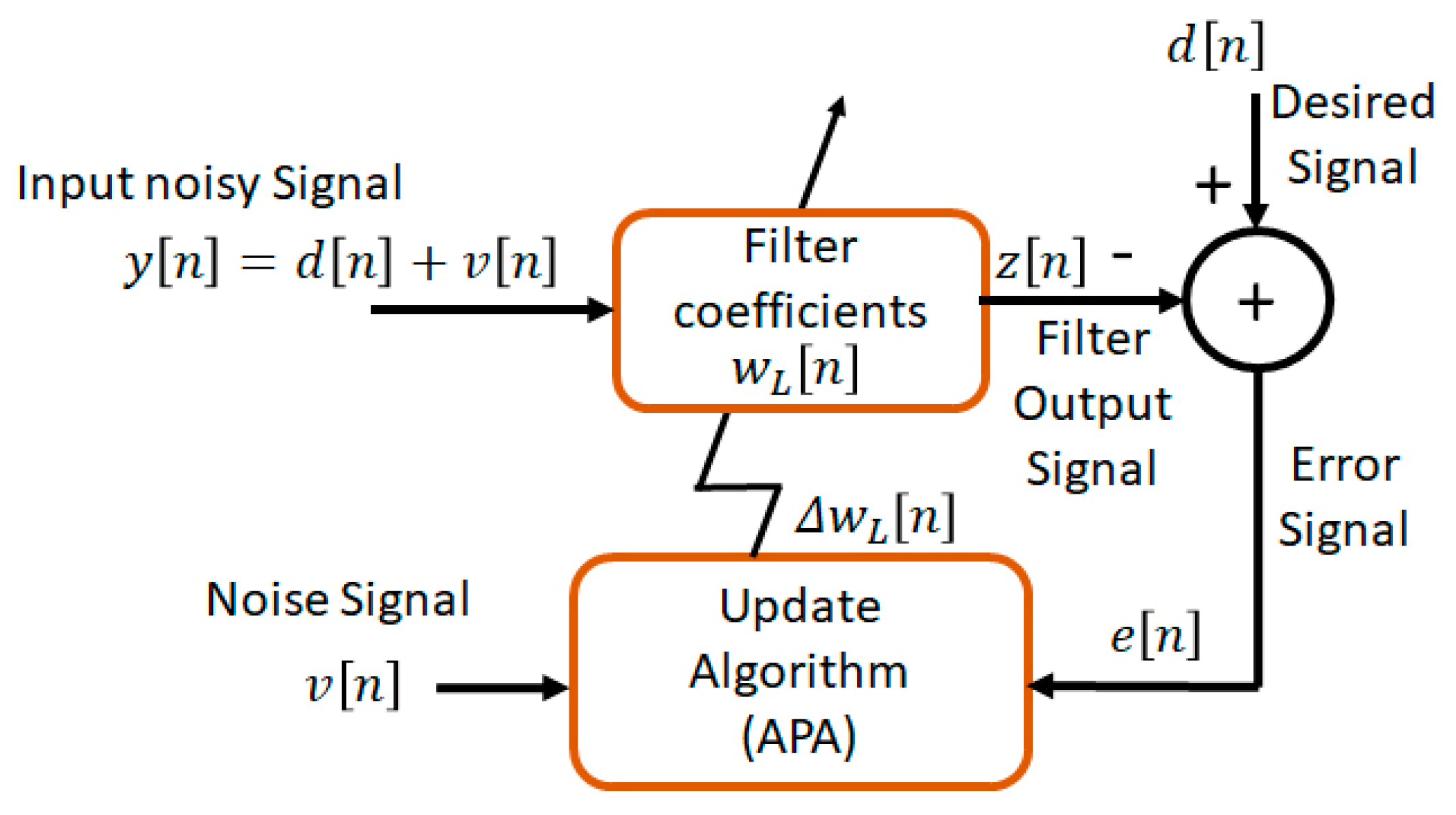
Figure 5 shows the general structure of the adaptive filter in denoising applications.
We change the notation for input signal in adaptive filter (
) to
for simplifying the mathematical expressions. An adaptive filter is expressed as follows [
31]:
where
n is the time index,
is the adaptive filter output, and
is the adaptive filter coefficients with length
L. The update algorithm in
Figure 5 is considered as a principal part for an adaptive filter, which is the APA in this article. The main idea for an adaptive filter is to minimize the error signal
to make the output of the filter as similar as the desired signal.
The input signal
for the adaptive filter is considered as the summation of the noise (
v[
n]) and desired signal (
d[
n]), which is described as:
The adaptive filter has a FIR structure, namely the filter is designed based on the limited number of coefficients in the time domain. For a filter with order of
L, the filter coefficients are defined as:
The error signal or cost function is defined as the difference between estimated and desired signal, namely:
As shown in Equation (6), the output of the adaptive filter
is defined as the convolution between the filter coefficients
and the input signal
, where
is considered as the input of the adaptive filter, namely:
In addition, the adaptive filter coefficients change during the time, which is written as:
where
is defined as the correction factor for the filter coefficients. The adaptive filter produces the correction factor based on the input and error signal. In
Figure 5, several algorithms can be considered for updating the filter coefficients. The APA is one of the fastest and most efficient methods for this purpose. The AP algorithms were introduced to improve the speed of convergence in the gradient-based algorithms, especially when the input signal has a non-stationary spectrum. It is because the speed of convergence is decreased in the case of non-stationary and constraint spectrums [
30].
Filter update equation is one of the most important features in the AP algorithms, which uses N vectors of the input data to update the filter coefficients instead of using one vector of the input data, i.e., the normalized least mean square (NLMS). Therefore, more information was considered in the time for accurately updating the filter coefficients. Thus, the AP algorithm is known as an improved and extended version of the NLMS method or it can be expressed mathematically as a constraints minimization problem, which is expressed as follows.
The variation for
L filter coefficients during the two consecutive times is given by:
We minimized Equation (13) under
N constraints, which are shown in Equation (14) to extend the adaptive filter algorithm.
where
N constraints are defined as follows:
where
is the vector of
N last sample from the input signal and
is the desired signal, see
Figure 5. The proposed solution formulates the update algorithm for AP, which is expressed as:
where:
and
is a vector of size
which is written as:
The vector
is the desired signal with size
namely:
The general format for AP algorithm is obtained by rewriting Equation (15) as:
If
is considered as
, then:
and the signal
is expressed as:
As shown in Equation (19), the
N required vectors to update the adaptive filter are not necessarily to be the last data vectors. Therefore, several versions of AP algorithms are defined based on the way to select the input data and parameters in Equation (19). There are some developed algorithms based on these parameters selections such as: the NLMS along with the orthogonal correction factor (OCF-NLMS) [
32], the partial rank affine projection algorithm (PRAPA) [
33], and the standard APA [
34] whose parameters are
. If
parameter differs to 0, the APA algorithm is extended to APA with regularization (R-APA) [
35], where the update equation for the filter coefficients is a specific case of the Levenberg Marquardt regularized APA (LMR-APA) algorithm [
36].
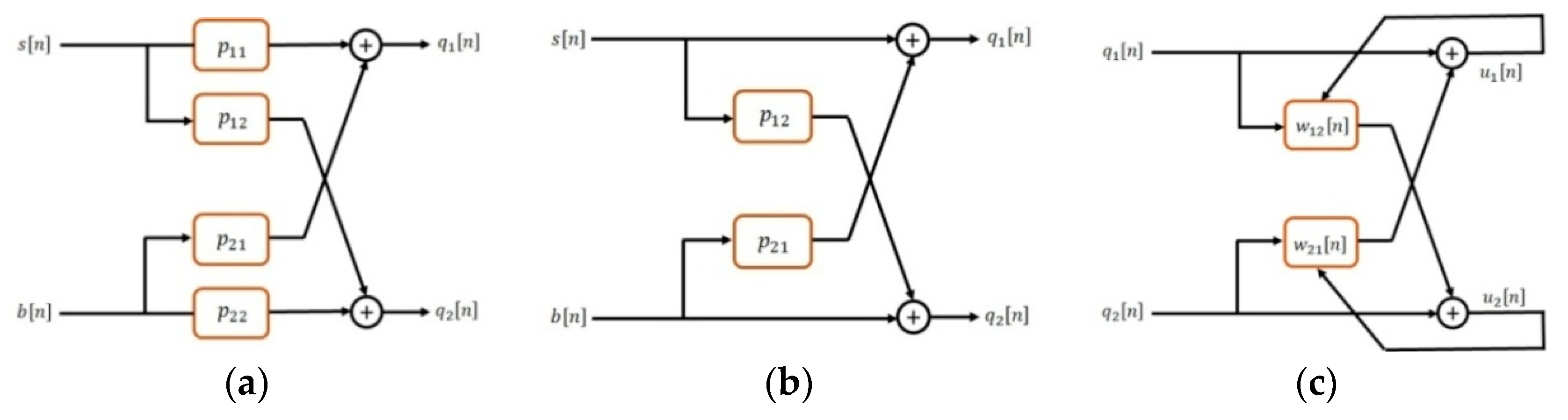
The introduced AP algorithm contains one input signal. Since pairs of microphones are used in the proposed CNMA, the AP algorithm is generalized to a two-microphone version [
37]. Firstly, the generalization of a two-microphone structure is defined, where each microphone contains the mixing speech and noise signal, which is expressed as (see
Figure 6a):
where
represents the source signals,
is the microphone signals,
L is the impulse response length, and
are the impulse responses between the microphone and sources. These impulse responses are considered as linear time-invariant (LTI) systems. Two source signals
are selected as the speech signal
and noise signal
. It is assumed that the speech and noise signals are independent, which means
where
E denotes to expected value. Then, the noise and speech signals are uncorrelated. Based on the general structure, which is shown in
Figure 6a, the microphone signals
and
are expressed as follows:
In addition,
and
represent the impulse responses for direct path, and
and
are cross-coupling for the channels between the sources and microphones. The presented model is simplified by considering
which is shown in
Figure 6b as:
Therefore, the microphone signals are generated based on the impulse responses between the source and microphones, noise, and speech signals. The structure in
Figure 6c was proposed to retrieve the source signal from the received noisy signals
and
. The proposed structure provides the conditions to retrieve the original signal by the use of adaptive filters
and
. The signals
and
for the two-microphone structure are defined as follows:
where in Equations (27) and (28),
and
are the adaptive filters for eliminating the noise of microphone signal
and the speech of microphone signal
, respectively. Signals
and
are rewritten by replacing Equations (25) and (26) to Equations (27) and (28) as:
Two adaptive filters and are required to retrieve the original speech signal from the noisy signals and . There is just a unique structure for adaptive filters and as and to retrieve the enhanced speech of noisy signals and . This structure requires a VAD for preparing the noise estimation from the silent part of the recorded signals.
The AP algorithm is generalized to a two-microphone structure based on the obtained Equation (19) for updating the filter coefficients. The AP algorithm is the generalized version of the two-microphone NLMS [
38], which is shown in
Figure 6c for adaptive speech enhancement algorithm. Therefore, the adaptive filter coefficients
and
for two-microphone APA are expressed as:
where
and
are defined as
and
. The matrices of the two-microphone signals
and
have dimensions
where
L is the adaptive filter length and
N is the projection order. The two parameters
and
are the step sizes, which control the convergence of adaptive filters
and
. These parameters should be selected in the range [0,2] to assure the convergence of AP algorithm. If
N is selected as 1, the AP algorithm is converted to the NLMS method.
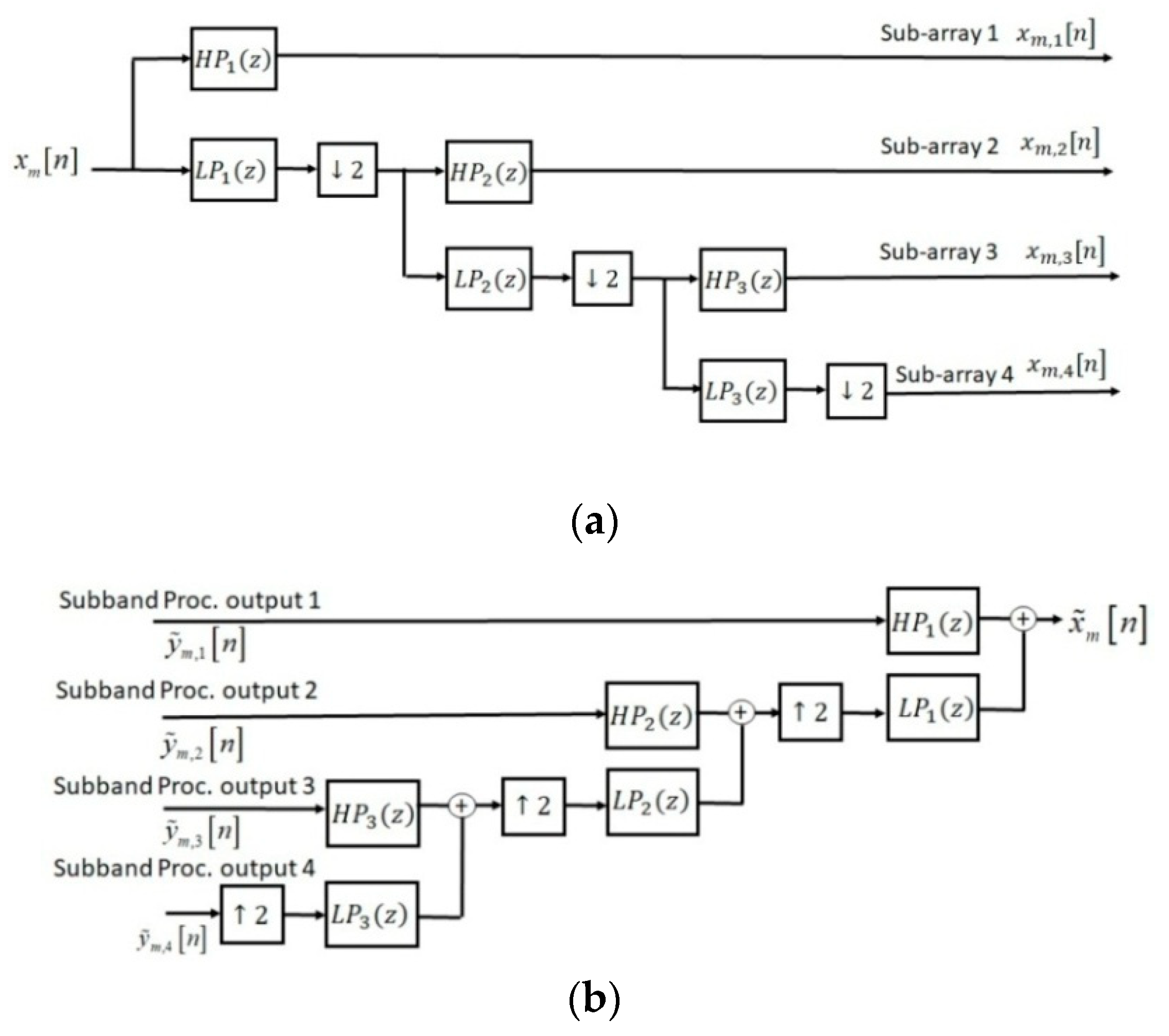
The proposed sub-band APA not only increased the accuracy of the speech enhancement algorithm, but also the speed of convergence was improved (Table 6 in the results section) in the implementations because the noise was estimated separately for each sub-band and it was stationary on narrow bandwidths. Then, the SBAPA was implemented on generated sub-bands by the analysis filters in
Figure 3. As shown in
Figure 1, a symmetrical synthesis filter bank and synthesis filters related to the nested microphone array were implemented for the reconstruction the final enhanced signal. The synthesis filters as similar as the analysis filters were implemented based on the tree structure in
Figure 3b. Finally, all sub-band signals were summed to generate the final enhanced signal. In the next section, the performance of the proposed CNMA-SBAPA was compared with other previous works.
4. Results and Discussion
The experiments in order to evaluate the performance of the proposed method were implemented on the real and simulated data. The TIMIT dataset was considered for the simulated data, where the data collection MDAB0 by four continuous sentences SX139, SX229, SX319, and SX409 were selected as a male speaker in the simulations [
39]. This dataset includes short sentences for testing and training the algorithms. The tones and frequency components are two different parameters in the speech signal. There are pitch and speech spectrum components for the speakers. It is important to work with male or female signals for the algorithms, which works with the pitch parameter. Since this parameter changes highly based on the gender. Since we consider the speech spectrum, then the issue to use the male or female speakers does not change the results. Therefore, 12.5 s male-speech signal is used for implementations and experiments. A voice activity detector is implemented to detect the silence part of the speech signal [
40], and the noise spectrum is estimated of these parts for the proposed SBAPA.
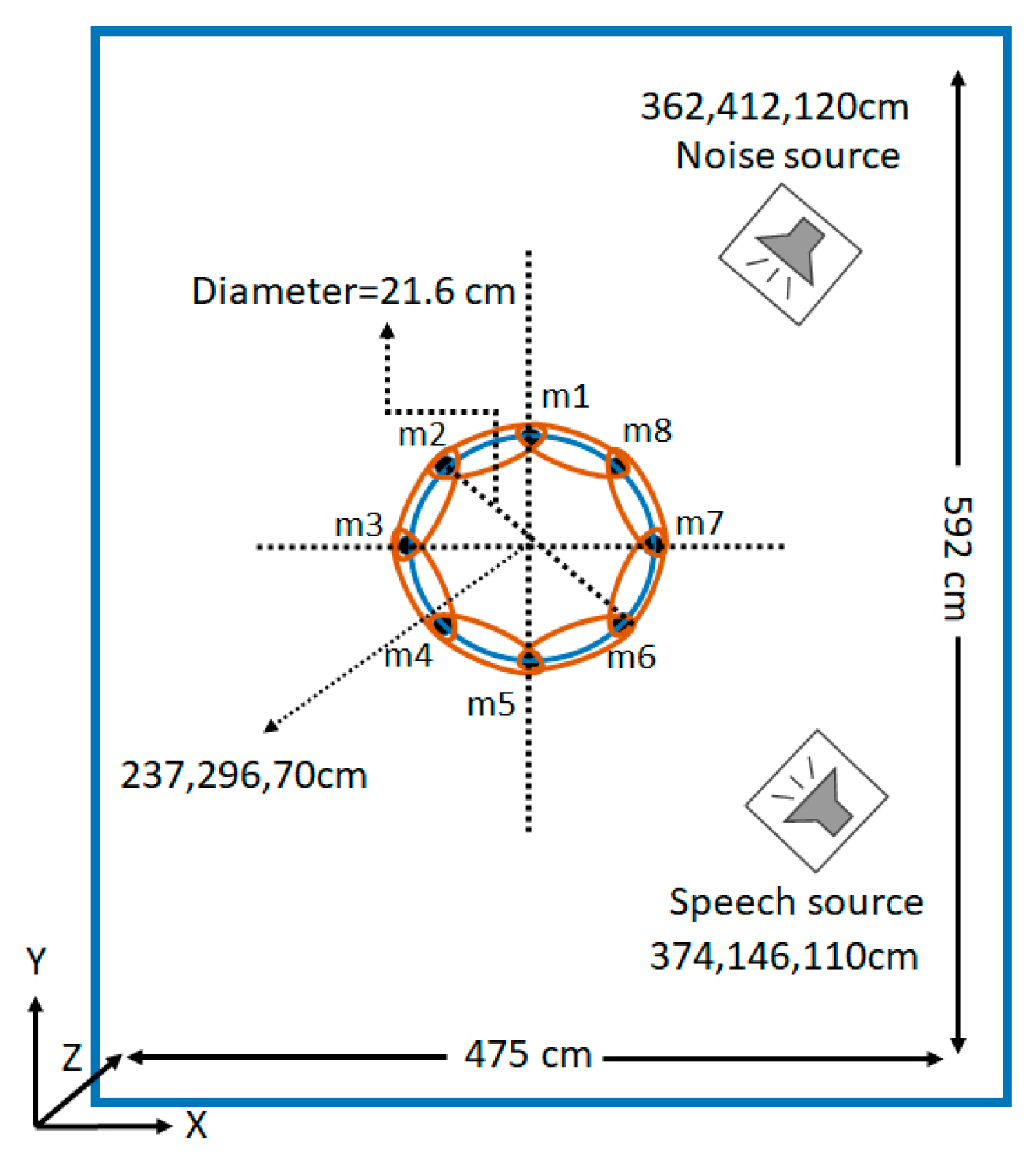
Figure 7 shows the simulated room with the location of speakers and microphone array. The inter-microphone distances
for the simulated data was selected based on the designed array. A speaker and a steered noise source were considered in the simulations. The room dimensions, speaker, and noise source locations were selected as 475,592,420cm, 374,146,110cm, and 362,412,120cm, respectively. These dimensions and locations were considered the same as the real room recording conditions. In addition, the proposed algorithm was implemented on real data to evaluate the real effect of the noise and reverberation on the performance. For this purpose, the real speech signal was recorded in the speech processing laboratory at Fondazione Bruno Kessler (FBK), Trento, Italy.
Figure 8 shows a view of the recording room at FBK. Two electronic speakers were used instead of the human and noise source in the process of data recording. In addition,
Figure 8 shows the position of the circular NMA in the center of the room. We were able to consider the minimum inter-microphone distance in the real conditions with our setup (see
Figure 8) as
because of the microphone dimension, electronic board, and the microphone shield. Additionally, each microphone had a cross section, where in the real conditions it was about 0.7 cm. It means it is hard to measure the exact distance between two microphones and it has some errors. Since all cross sections in a microphone are areas for a sound recording, then, based on all limitations, we were forced to have this inter-microphone distance for real data implementation even with a few millimeters difference with the mathematical calculations. Therefore, the differences in the results of our proposed method for the real and simulated data were for this an issue. In the real condition, there are always some inaccuracy factors for the measurements. We found the center of the room and the microphones were located on the table based on the primary measurements. All microphones were connected to the sound recording system, which uses parallel acquisition for all microphone channels. All channel acquisitions were synchronized and there was not any delay between recorded signals in different microphones or channels. The phase error based on the recording condition was very low and was even close to zero based on the audio recording system. In the real room, the table did not make any direct reflection. All the reflected waves from the table will cross to the walls and ceiling firstly, and since all of them were covered with curtains and sound absorption panels, the indirect reflections to the microphones were very few. Both speakers were connected to the two computers for playing the speech and noise with a sampling frequency of
. The microphone, sound, and noise sources were selected in the simulations with exactly the same real conditions for the results to be comparable in these two conditions.
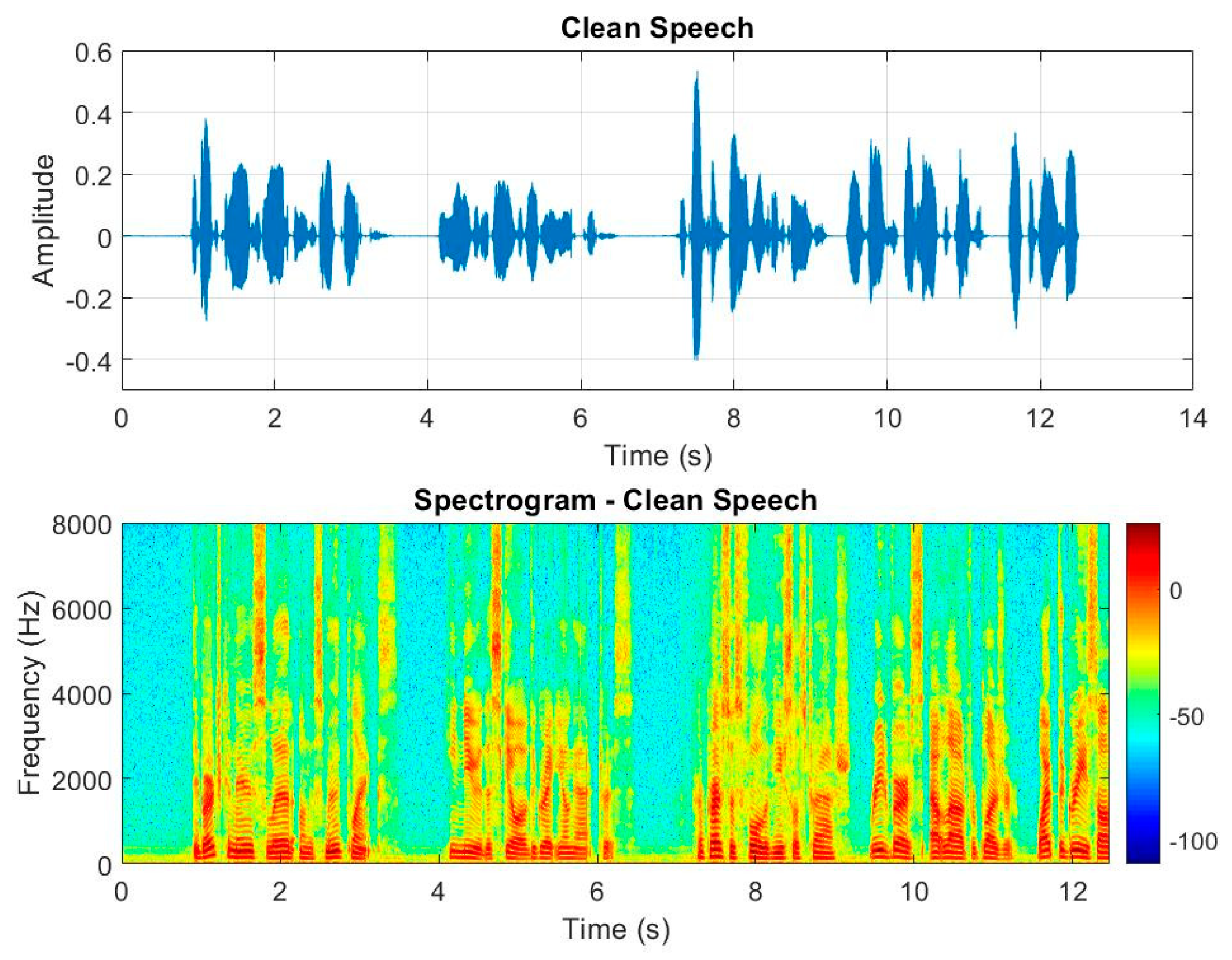
Figure 9 shows the time-domain and spectrum of the male speech signal.
The reverberation effect was considered in the experiments to provide the simulation conditions similar to the real scenarios. The image model was implemented in the simulations to produce the reverberation effect similar to the real conditions [
41]. The image model produced the room impulse response between the source and microphone by considering the speaker position, microphone location, sampling frequency, room dimension, room reflection coefficients, impulse response length, and reverberation time. The received signal to the microphone was simulated by the convolution between the generated impulse response by the image method and the source signal. The impulse response was generated for the noise and speech sources because both receive the same effect of the room reverberation. In addition, noise was additive with the speech signal in the microphone positions. The room reverberation time was selected as
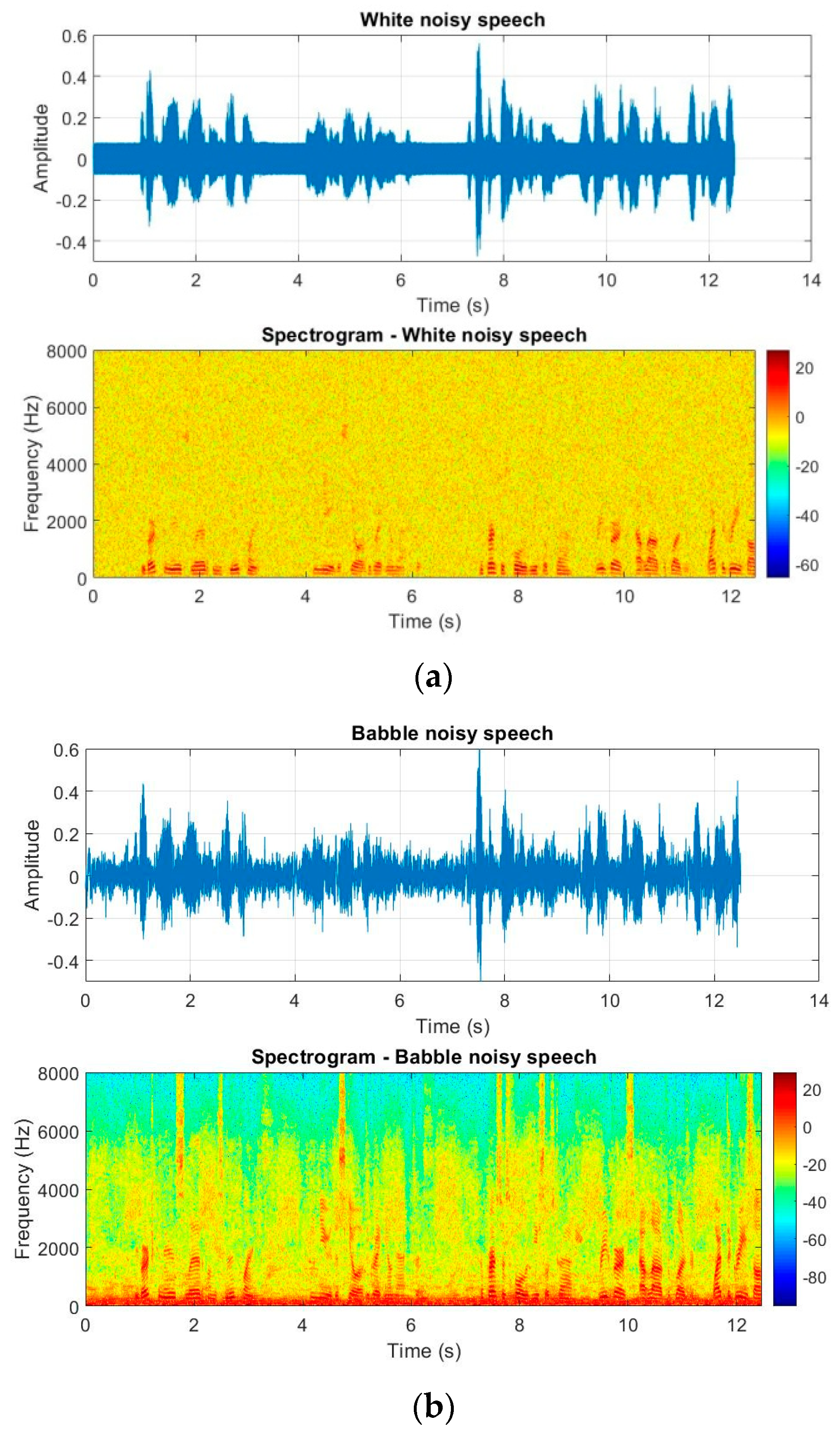
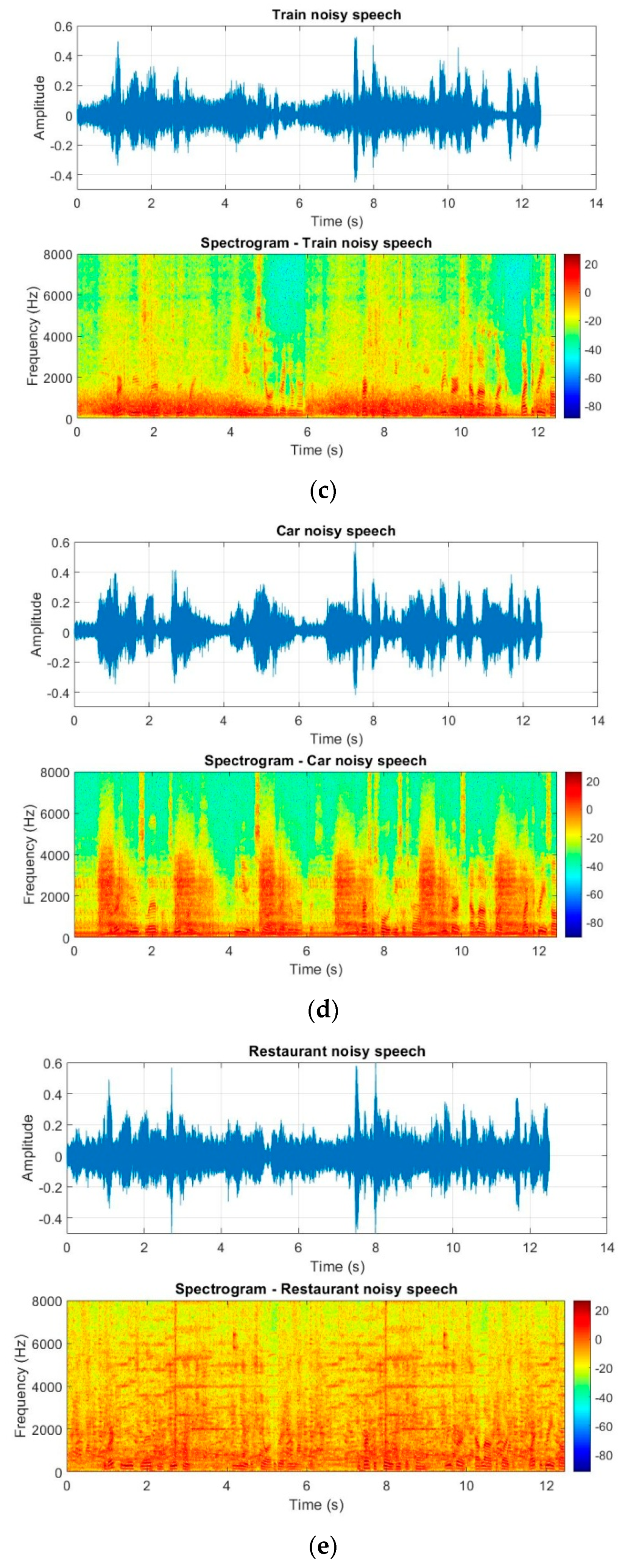
which was considered for a room with a low level of reverberation to be the same as the real conditions. To generate the noisy signal, five types of noise were considered for the simulated and real data such as white noise, babble noise, train noise, car noise, and restaurant noise.
Figure 10 shows the time-domain and spectrum for these noisy signals according to a SNR = 0 dB. The noise signal duration was 12.5 s, the same as the speech signal.
The Hamming window with a length of 30 ms was selected for signal blocking to keep the stationarity of the signal in the short time. The projection order was considered as N = 4 to keep the computational complexity in an acceptable range in addition to a proper accuracy of the algorithm. Additionally, the step sizes were chosen as and to provide the fast convergence for the proposed SBAPA in the real-time implementations. The evaluations in this article were implemented by the use of MATLAB software version 2019b on a PC with processor Inter Core i7-7700k, 4.20 GHz, and with 32GB RAM to be able to implement the proposed algorithm in the real-time conditions.
The proposed SBAPA in combination with a proposed circular nested microphone array (CNMA-SBAPA) was compared with the LMS [
20], traditional APA [
31], RLS [
21], DB-MWF [
9], and MNMF-MVDR [
24] algorithms. These methods were compared because all of them are based on the adaptive filters and multi-channel beamforming as a main category for comparison. There are many methods for comparison with the proposed algorithm but the comparison should be based on the common theme in implementations. Therefore, the adaptive filter-based algorithms were selected for this comparison. The qualitative and quantitative criteria were considered to show the superiority of the proposed method in comparison with other previous works. For this purpose, the SegSNR [
7], PESQ [
4], MOS [
5], and STOI [
6] criteria were selected for the comparison. The SegSNR is a quantitative criterion, which shows the improvement in the enhanced signal due to the percentage of the noise power elimination from the noisy signal, namely:
where
and
are the clean and enhanced speech signals, respectively. The variable
Q is the mean averaging value of the SNR for the output signal. The variable
R is the number of only-speech frames and
is a speech detector, which is 1 for only-speech frames and 0 for only-noise frames. Therefore, the SegSNR is appropriate to show the speech enhancement performance. Many of the speech enhancement algorithms eliminate some part of the speech signals in addition to the noise frames, which decreases the speech perception for the enhanced signals. Then, three well-known qualitative criteria are considered in the evaluations. The first one is the PESQ, which is defined based on the standard ITU-T P.862 for qualitative evaluations of speech signals in mobile stations [
4,
42]. In fact, the PESQ criteria is used in the numerical representation of qualitative evaluations for enhanced speech signals. The defined range for this criteria is [−0.5 4.5], where −0.5 and 4.5 show the lowest and highest quality of the enhanced speech, respectively. Additionally, the results were compared with the MOS score criteria. These are qualitative criteria in telecommunication systems that represent the clarity, perception, and intelligibility of the enhanced signal. The MOS criteria are defined based on the standard ITU-T P.800 [
5,
43] in telecommunication systems. The evaluation results based on the MOS criteria was implemented by the use of some volunteers, by listening to the enhanced signal, where 1 and 5 are the lowest and highest scores in this criteria, respectively.
Table 3 shows the defined scores for the MOS criteria in the evaluations.
Finally, the last qualitative criteria for evaluations is the STOI. This criteria predicts the intelligibility of humans based on a series of cases. The speech intelligibility measurement is based on the existence of a series of pre-assumptions, but if the noisy signal is processed based on the time-frequency weighting, the final results are not trustable. The STOI is an objective intelligibility measurement, which represents the highest convolution value by the intelligibility of both noisy and weighted time-frequency noisy signals. In addition, the lowest and highest scores for the STOI criteria are 0 and 1, which represent the best and the worst enhancement performance, respectively.
Firstly, the proposed method was evaluated on the white noise and then, the other colored noise were considered in the experiments. The proposed CNMA-SBAPA was evaluated on real and simulated data in comparison with the LMS, traditional APA, RLS, DB-MWF, and MNMF-MVDR algorithms.
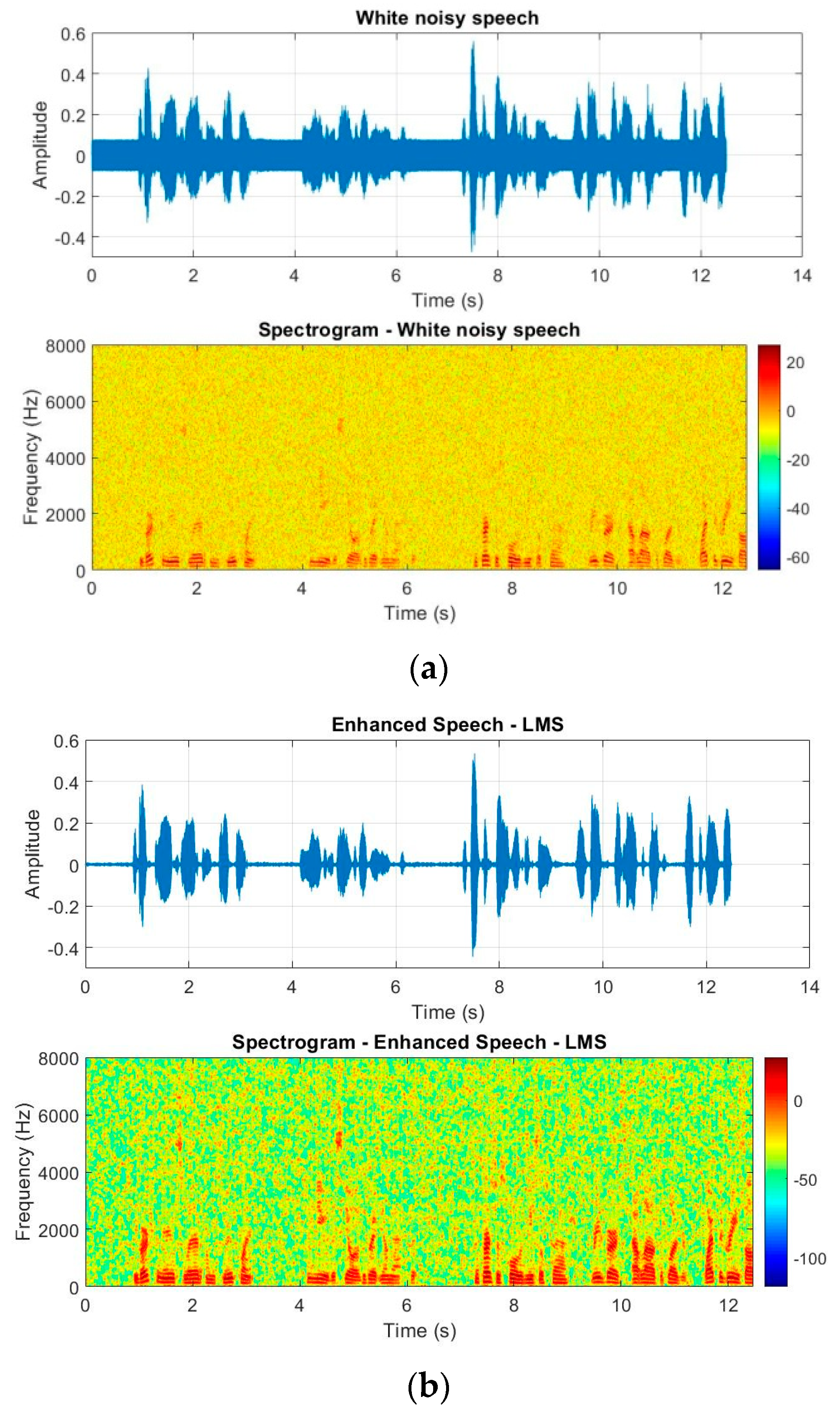
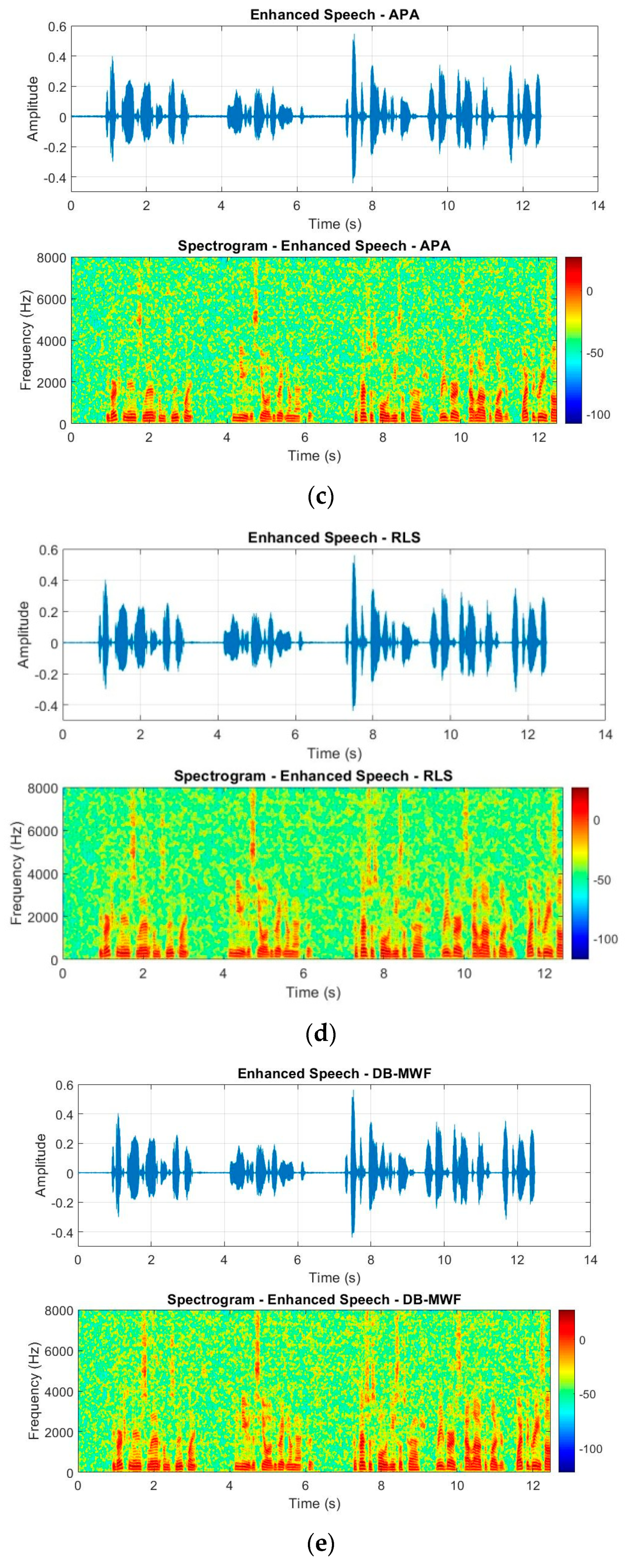
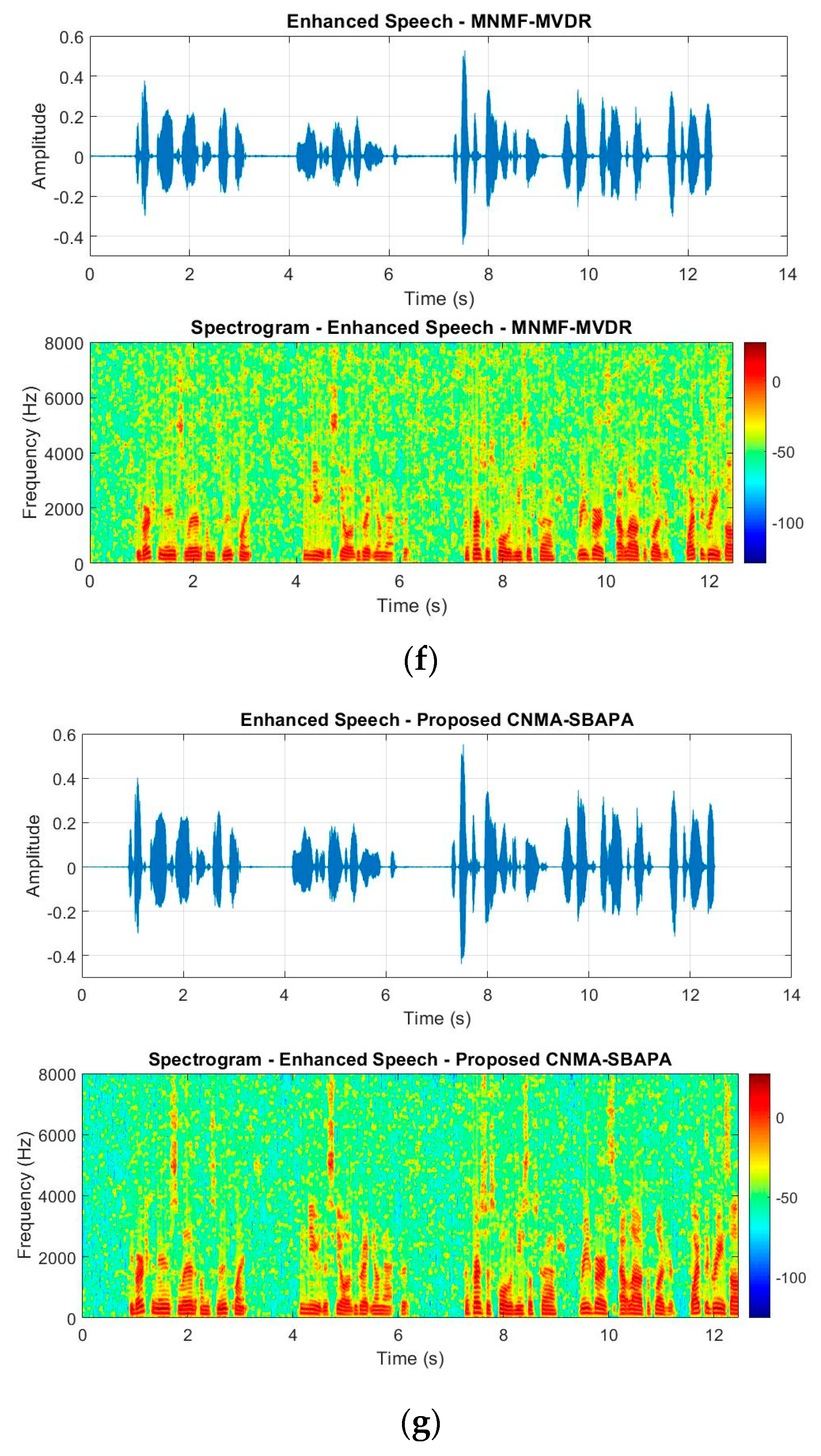
Figure 11 shows the time-domain and spectrum for the noisy and enhanced signals in the presence of white noise for SNR = 0 dB. As seen in these figures, the proposed CNMA-SBAPA method decreased more level of the noise with less distortion in comparison with other works. However, the numerical values are necessary for comparison. In the following, the experiments were evaluated with quantitative and qualitative criteria.
In the following, the proposed method was compared by numerical criteria with other previous works.
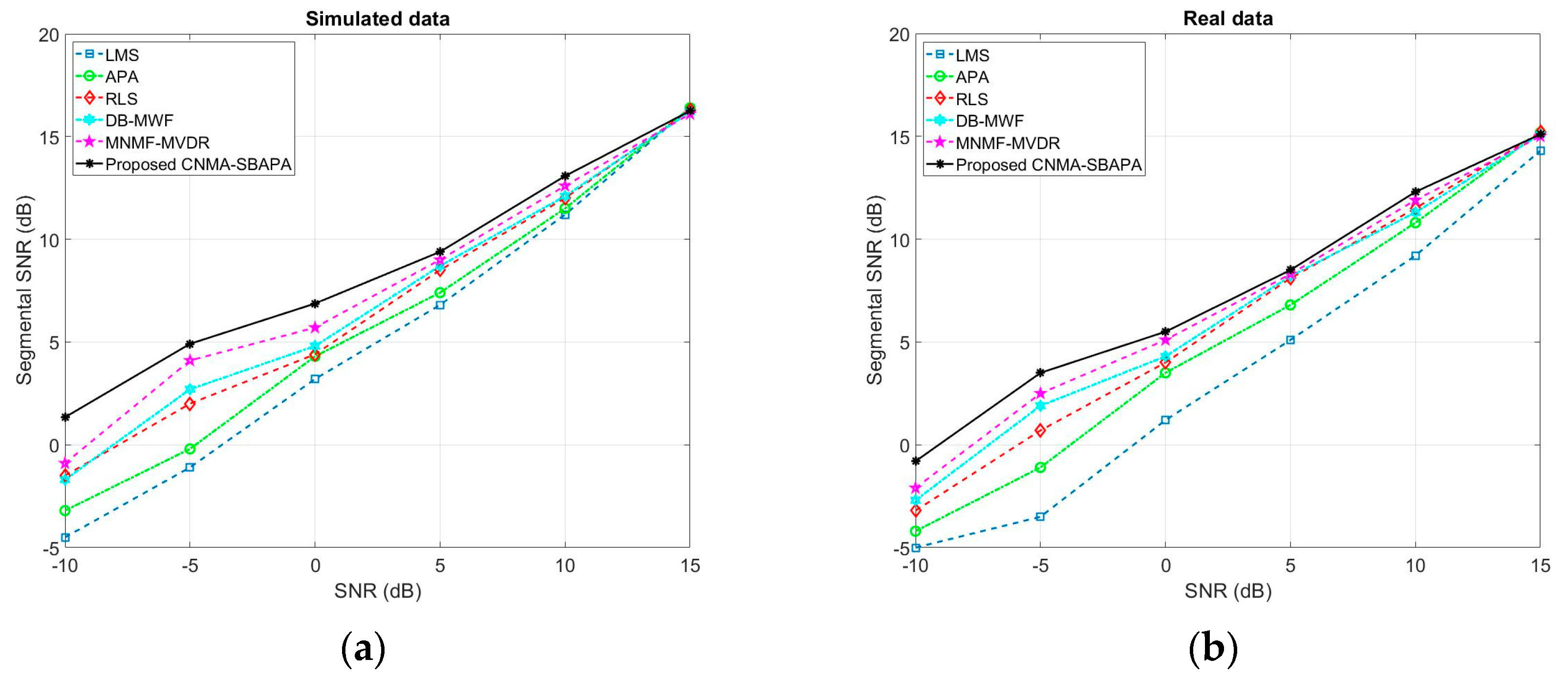
Figure 12 shows the SegSNR results in SNRs [−10, −5, 0, 5, 10, and 15] dB for the proposed CNMA-SBAPA in comparison with the LMS, traditional APA, RLS, DB-MWF, and MNMF-MVDR for real and simulated data in the presence of white noise. As seen, the proposed method had a superior performance in different ranges of SNRs in comparison with the rest of the works, namely a better noise elimination was reached via the proposed algorithm. For example, the proposed method enhanced the noisy speech signal with SNR = −10 dB to SegSNR = 1.35 dB in comparison with SegSNR = −4.58 dB in LMS, SegSNR = −3.21 dB in APA, SegSNR = −1.57 dB in RLS, SegSNR = −1.68 dB in DB-MWF, and SegSNR = −0.94 dB in MNMF-MVDR. Nevertheless, the quantitative criteria are not enough to properly evaluate a method, and both quantitative and qualitative criteria should be considered in the evaluations.
In addition, the proposed method was compared with previous works by qualitative criteria such as the PESQ, MOS, and STOI. We used 20 volunteers, where they listened first to the clean signal by the headset to have an idea of an excellent signal with a rating of 5 in the MOS scale and a noisy signal (before enhancement), which is the worst option in the MOS scale with a rating of 1. Then, the enhanced signal in a different range of SNRs were played for them, and they were asked to select a rate between 1 and 5 based on the
Table 3.
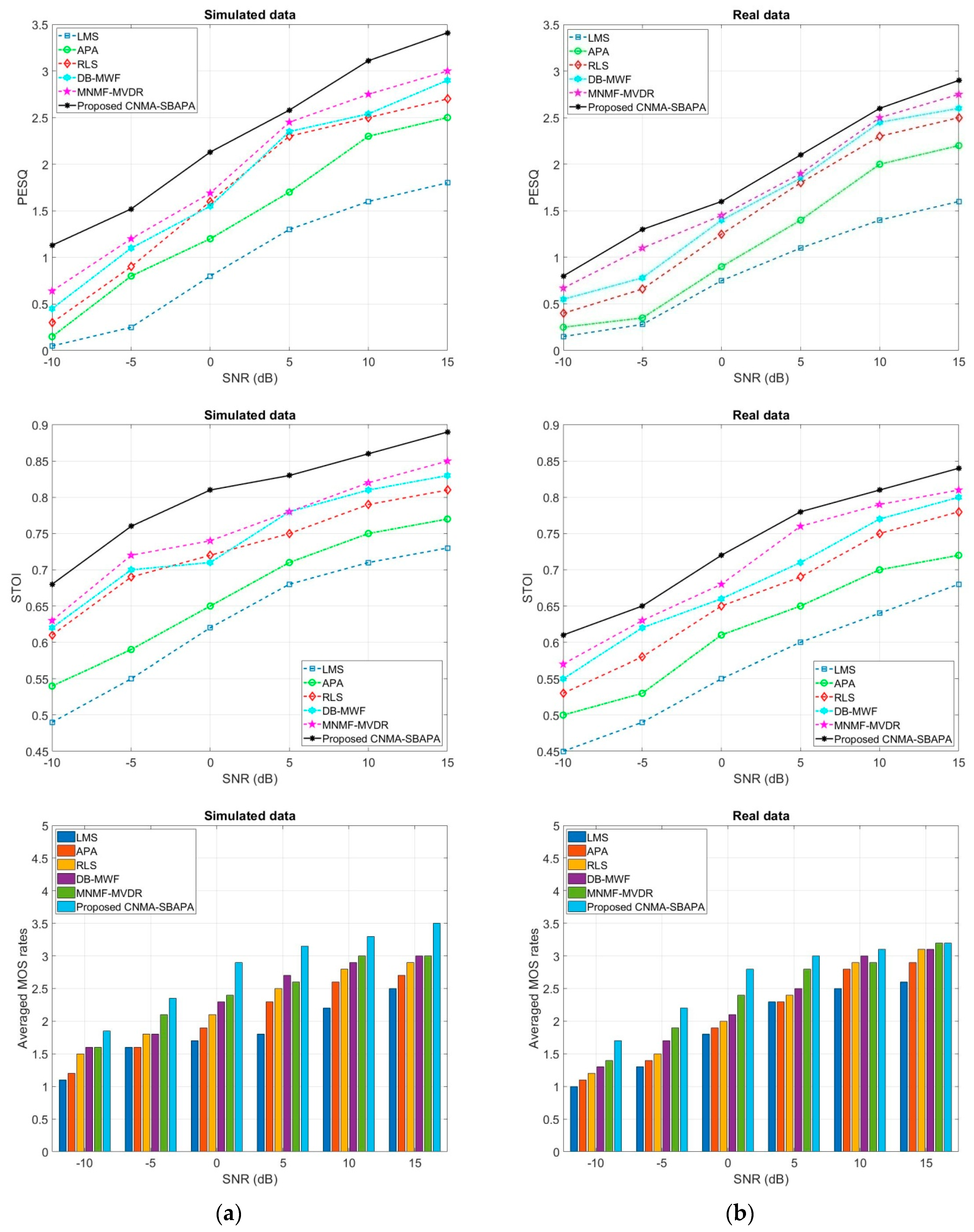
Figure 13 shows the PESQ, STOI, and averaged MOS criteria for the enhanced signal by the proposed method in comparison with previous works on real and simulated data for different ranges of SNRs in the presence of white noise. As seen, the proposed method had the best performance in comparison with previous works. For example, the PESQ score was 3.41 in the proposed method in comparison to 1.82 in LMS, 2.51 in APA, 2.73 in RLS, 2.93 in DB-MWF, and 3.1 in MNMF-MVDR, for SNR = 15 dB for simulated data. In addition, the STOI criteria was 0.89 in the proposed method in comparison to 0.73 in LMS, 0.77 in APA, 0.81 in RLS, 0.83 in DB-MWF, and 0.85 in MNMF-MVDR, for SNR = 15 dB. The other criteria for comparison was the average MOS rate, which was 3.5 in the proposed method in comparison to 2.5 in LMS, 2.7 in APA, 2.9 in RLS, 3.0 in DB-MWF, and 3.0 in MNMF-MVDR, for SNR = 15 dB. Therefore, the proposed method was superior for enhancing the noisy signals by considering both quantitative (
Figure 12) and qualitative (
Figure 13) criteria in comparison to previous works in the presence of white noise. In addition, the proposed method was implemented on colored noises to show the reliability of the results. For this purpose, the proposed method was evaluated on babble, train, car, and restaurant noises for the real and simulated data and for SNR ranges [−10, −5, 0, 5, 10, and 15] dB.
Table 4 and
Table 5 show the results on the simulated and real data, respectively. As seen from the numbers in these tables, the proposed method had better results in most cases in comparison with traditional methods, which present the reliability of the proposed method in colored noisy conditions. Some of the methods had slightly better results in specific cases, for example in SNR = 15 dB, which cannot be generalized to all cases. In addition, the SegSNR values are shown in these tables to present better comparison with qualitative criteria.
Finally,
Table 6 presents the speed of convergence for the proposed method in comparison with other previous works for all white and colored noises in seconds (the required time for convergence based on the configuration of the used PC) on the real data. As shown, the proposed method has a higher speed of convergence in comparison with other algorithms. The main reason for this high speed of convergence is the sub-band processing, because this multiresolution processing provides stationary noise in each frequency band, which is an important factor in the speed of convergence. When the noise is closer to stationary conditions, the speed of convergence is increased in adaptive filter-based algorithms. As clearly shown in this table, the speed of convergence in white noisy conditions was higher than the colored noisy scenarios. Therefore, the proposed CNMA-SBAPA method had superiority for the speech enhancement in comparison with LMS, traditional APA, RLS, DB-MWF, and MNMF-MVDR algorithms based on the quantitative SegSNR and qualitative PESQ, MOS, and STOI criteria, as well as the speed of convergence.
5. Conclusions
Speech enhancement is an important application in the signal processing for smart meeting rooms. The aim of speech enhancement is denoising, dereverberation, or denoising–dereverberation at the same time. The speech enhancement is implemented as a pre-processing step to produce the proper signal in such an application as speaker localization, tracking, speech recognition, text-to-speech, estimation the number of speakers, etc. The speech enhancement algorithms are divided into the single and multi-channels methods. The single-channel algorithms are challenging in the speech enhancement processes because of the lack of suitable information in the denoising procedure. In contrast, the multi-channel algorithms increase the enhancement accuracy due to having more information but the computational complexity is increased. In this article, a multi-channel speech enhancement method was proposed based on the microphone array. The microphone array increased the accuracy in the enhanced algorithms based on the increasing of information, but the spatial aliasing decreased the efficiency because of inter-microphone distances. In this article, a uniform circular nested microphone array was proposed for the speech enhancement algorithms. This nested array was designed in a way that the microphones were located at specific distances to eliminate the spatial aliasing, in combination with analysis filters to provide the proper information for the speech enhancement algorithms. In addition, the speech information is different in various frequency bands. Therefore, the specific sub-band processing was proposed to have especial attention to the speech spectrum components. The frequency bands were designed to have the maximum resolution in low frequency components. In the following, the APA was implemented on all frequency bands, which was obtained by the sub-band processing and circular nested microphone array. The projection factor (N=4) was considered for the CNMA-SBAPA in order to keep the computational complexity in an acceptable range along with the superior accuracy. Finally, the synthesis filter bank was implemented on the sub-band signals and the enhanced signal was generated by the summation through all sub-bands. The proposed algorithm was compared with the LMS, traditional APA, RLS, DB-MWF, and MNMF-MVDR methods on the real and simulated data for white and colored noises under the SNRs range [−10,−5,0,5,10, and 15]dB. In all conditions the proposed method had a superior accuracy in comparison with previous works. In addition, the proposed method was compared based on the speed of convergence with previous works, which it was much faster among all the other algorithms. Since the proposed enhancement algorithm was implemented on stationary signals, where its benefit was increasing the speed of convergence in adaptive filters.
One of the future works is reducing the size of the array and decreasing the number of microphones (without having a high effect on the quality) to be applicable for smartphone applications. Even the type of the microphones is important. In this article, we used a high quality microphone, which provides the signals with proper amplitude from the environment. The use of normal microphones in smartphones is another challenge, which could be an area for future work. Another area for future work is to find the best numbers of sub-bands to provide the maximum performance and lowest computational complexity, where the numbers of sub-bands will not be fixed and it should be adaptive based on the speech components.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}