Power Spectral Deviation-Based Voice Activity Detection Incorporating Teager Energy for Speech Enhancement

Abstract
:1. Introduction
2. Review of Teager Energy
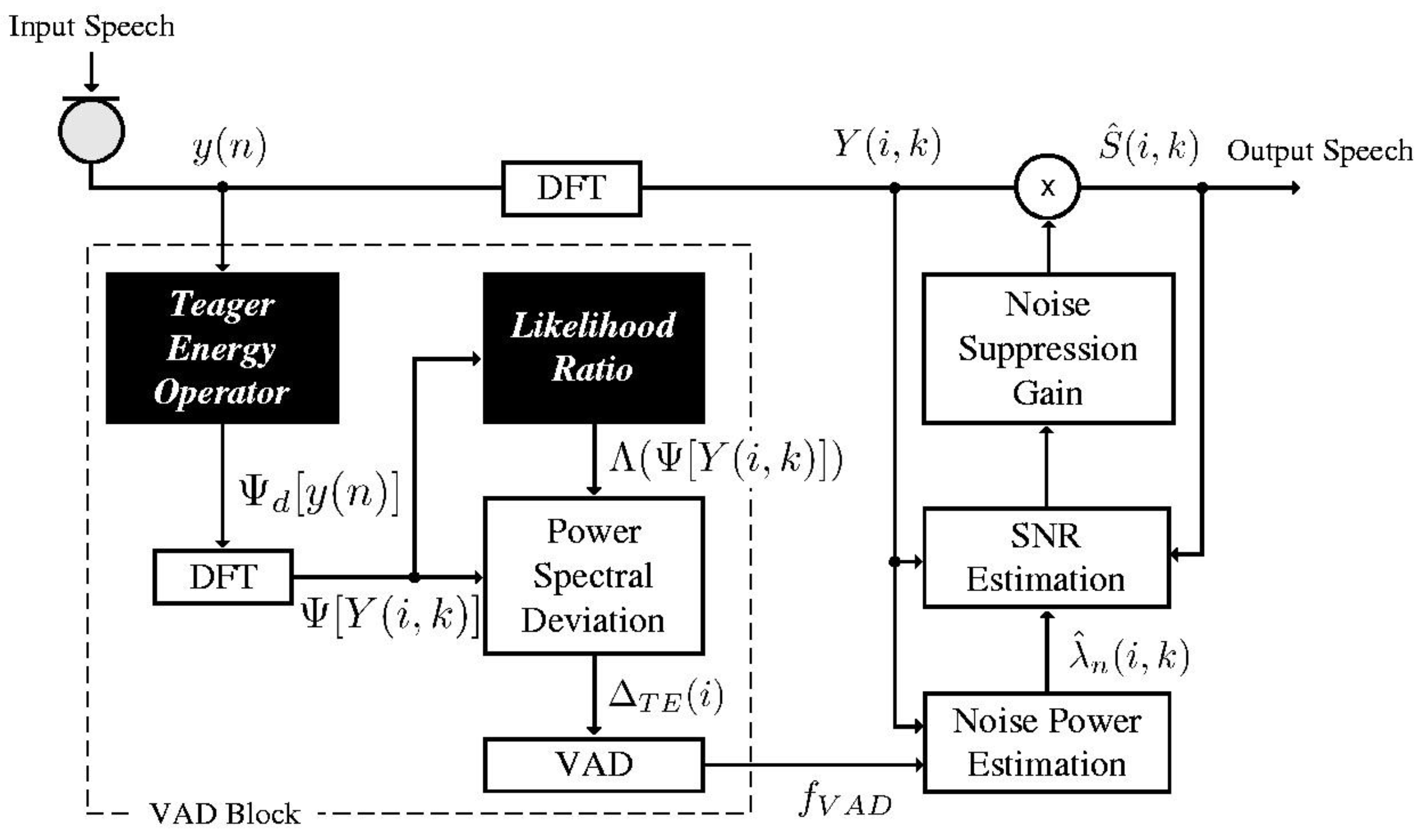
3. Proposed VAD Algorithm Based on the Power Spectral Deviation of Teager Energy
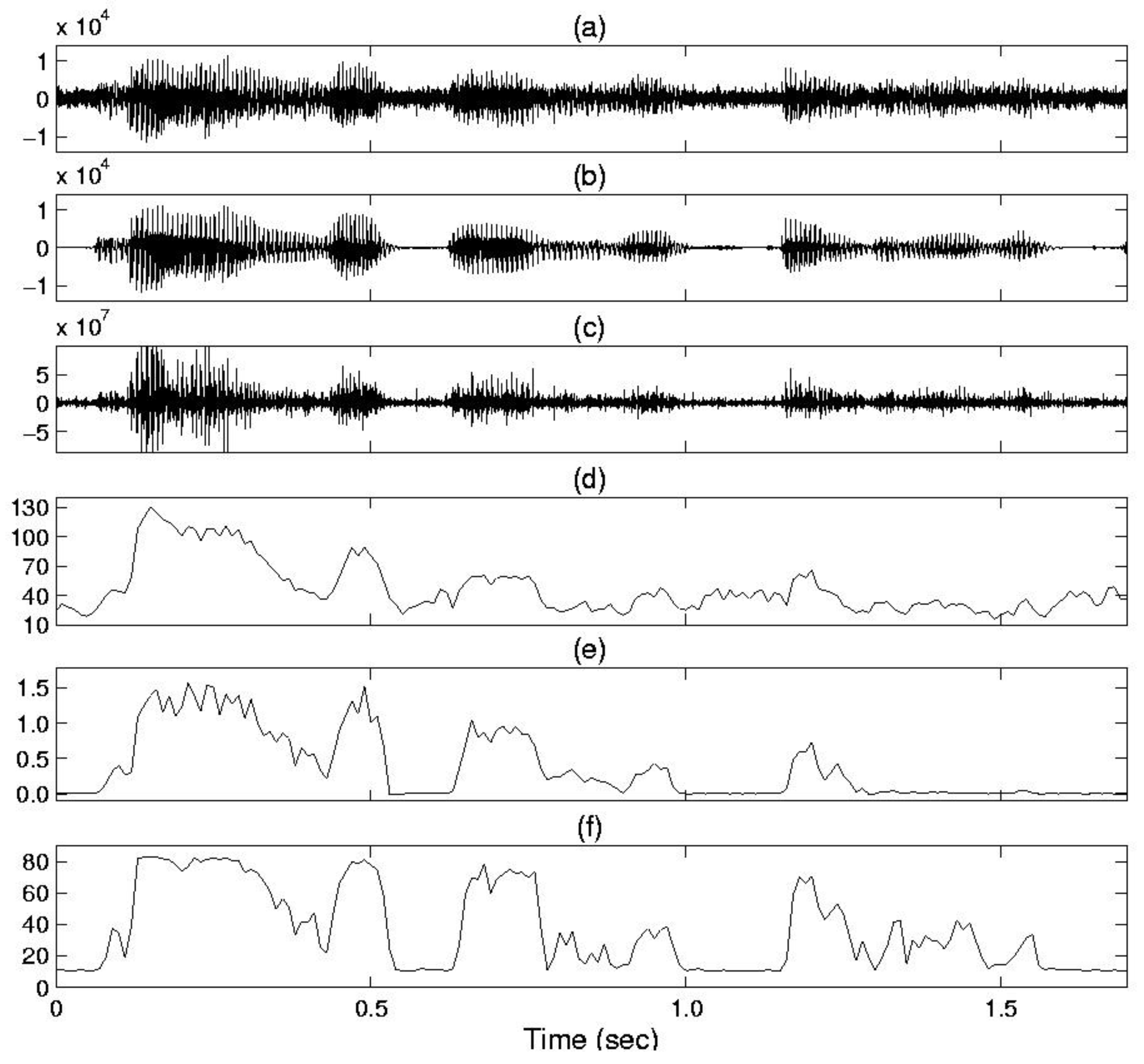
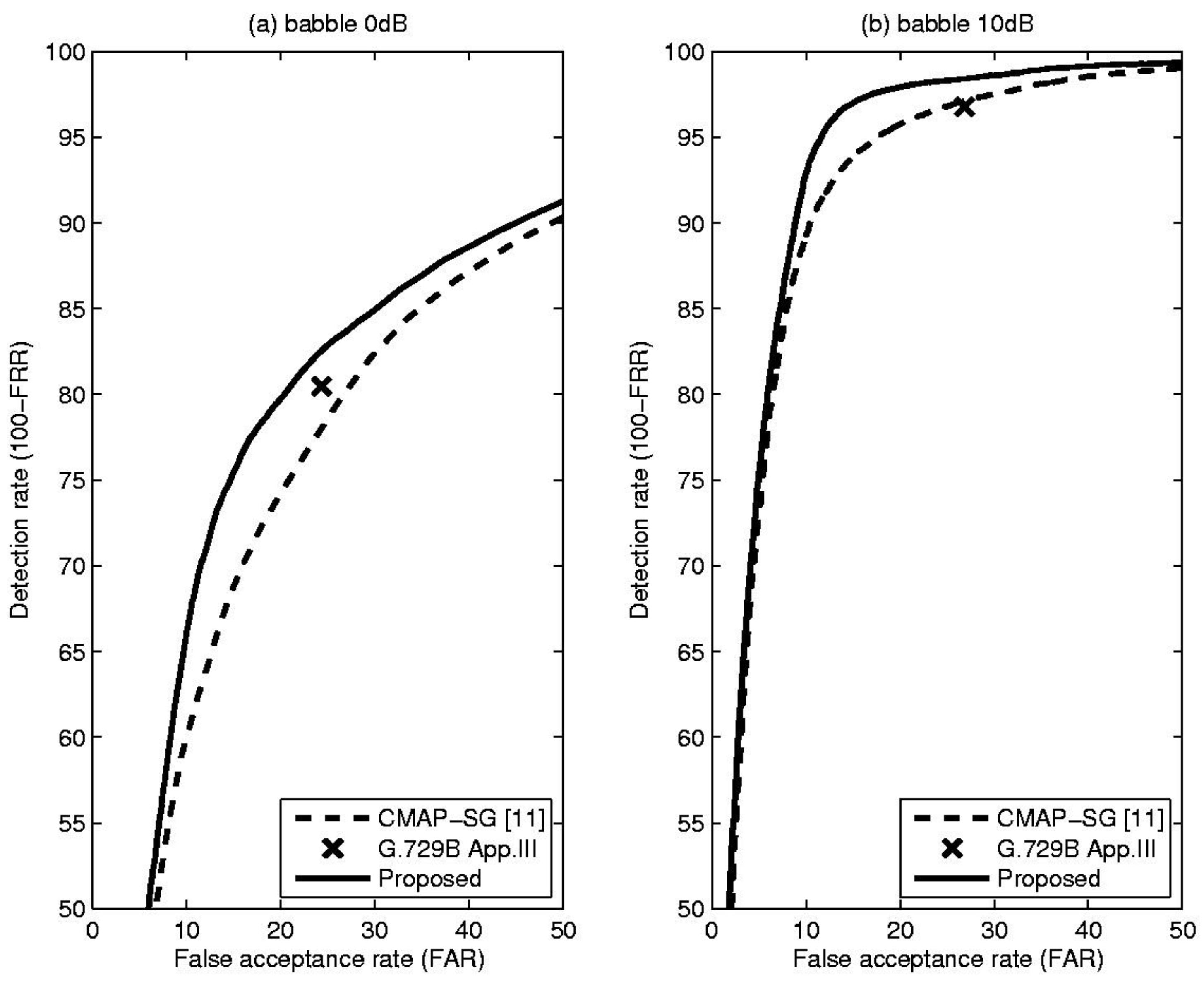
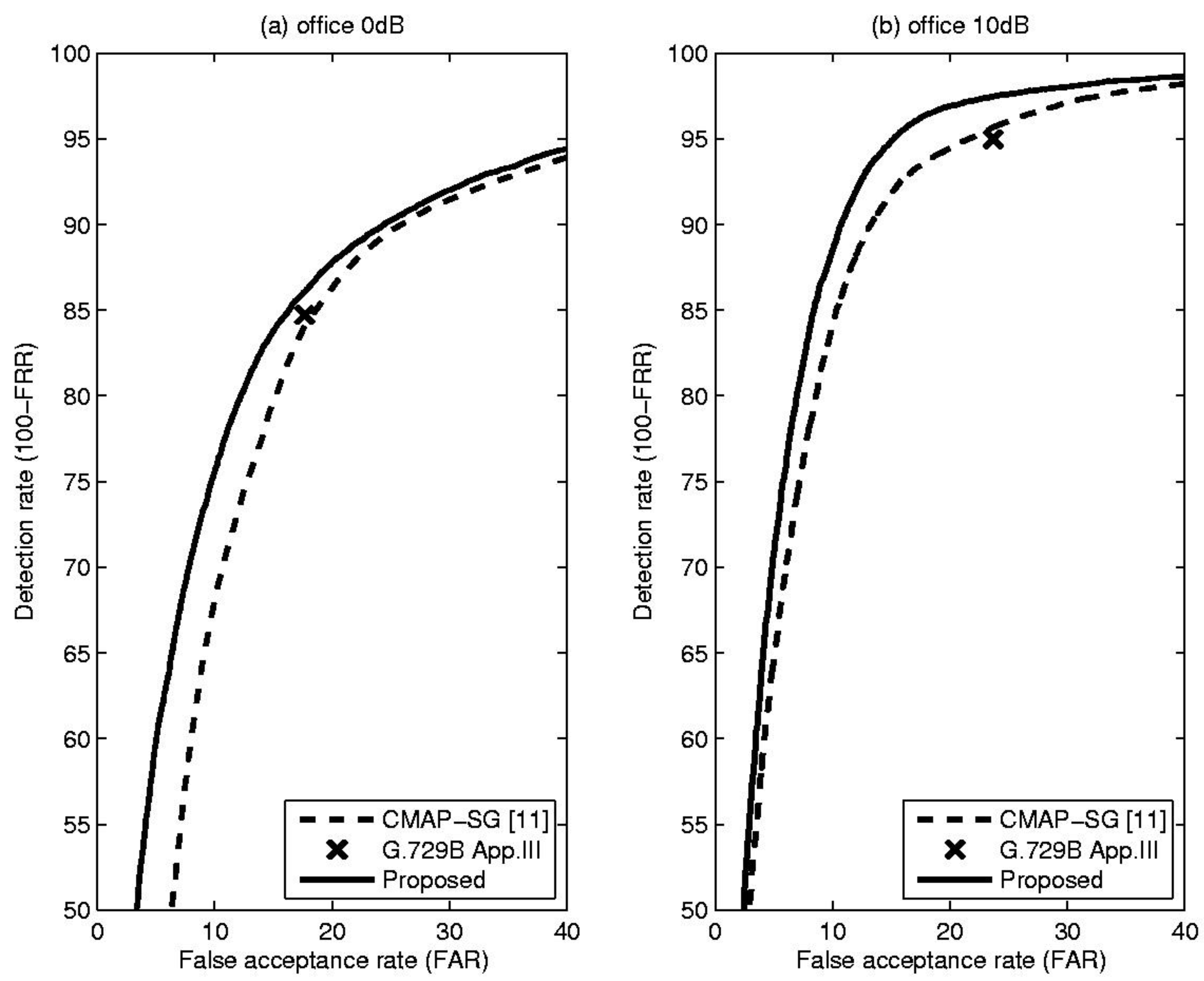
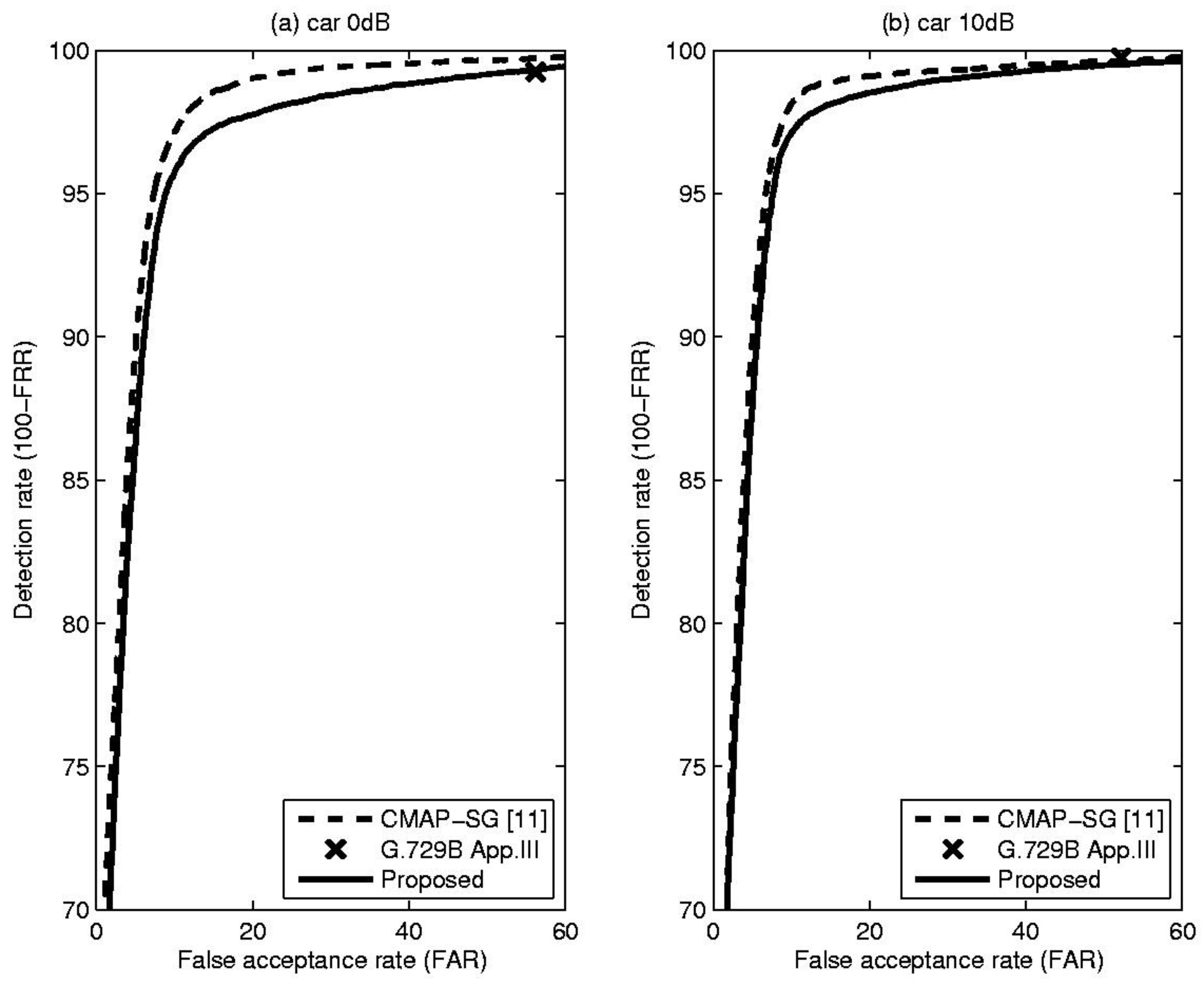
4. Experiments and Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Karray, L.; Mokbel, C.; Monne, J. Solutions for robust speech/non-speech detection in wireless environment. In Proceedings of the IEEE 4th Workshop, Interactive Voice Technology for Telecommunications Applications IVITA’98, Torino, Italy, 29–30 September 1998; pp. 166–170.
- TIA/EIA/IS-127. Enhanced Variable Rate Codec, Speech Service Option 3 for Wideband Spread Spectrum Digital Systems, 1996.
- Sohn, J.; Kim, N.S.; Sung, W. A statistical model-based voice activity detection. IEEE Signal Process. Lett. 1999, 6, 1–3. [Google Scholar] [CrossRef]
- Jabloun, F.; Cetin, A.E.; Erzin, E. Teager energy based feature parameters for speech recognition in car noise. IEEE Signal Process. Lett. 1999, 6, 259–261. [Google Scholar] [CrossRef]
- Chen, S.-H.; Wu, H.-T.; Chang, Y.; Truong, T.K. Robust voice activity detection using perceptual wavelet-packet transform and Teager energy operator. Pattern Recognit. Lett. 2007, 28, 1327–1332. [Google Scholar] [CrossRef]
- Evangelopoulos, G.; Maragos, P. Multiband modulation energy tracking for noisy speech detection. IEEE Trans. ASLP 2006, 14, 2024–2038. [Google Scholar] [CrossRef]
- McAualy, R.J.; Malpass, M.L. Speech enhancement using a soft-decision noise suppression filter. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 137–145. [Google Scholar] [CrossRef]
- Kim, N.S.; Chang, J.-H. Spectral enhancement based on global soft decision. IEEE Signal Process. Lett. 2000, 7, 108–110. [Google Scholar]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum mean-square error short-time spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 1109–1121. [Google Scholar] [CrossRef]
- Ramirez, J.; Segura, J.C. An effective subband OSF-based VAD with noise reduction for robust speech recognition. IEEE Trans. Speech Audio Process. 2005, 13, 1119–1129. [Google Scholar] [CrossRef]
- Kim, S.K.; Chang, J.H. Voice activity detection based on conditional MAP criterion incorporating the spectral gradient. Signal Process. 2012, 92, 1699–1705. [Google Scholar] [CrossRef]
- ITU-T. Appendix III: G.729 Annex B Enhancement in Voice-Over-IP Applications-Option 2, 2005.
- ITU-T. Recommendation P.862, Perceptual Evaluatioon of Speech Quality (PESQ), an Objective Method for end-to-end Speech Quality Assessment of Narrowband Telephone Networks and Speech Codecs, 2001.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environments | CMAP-SG | G.729B App. III | Proposed | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Noise | SNR (dB) | TER | FRR | FAR | TER | FRR | FAR | TER | FRR | FAR |
| Babble | 0 | 22.76 | 27.70 | 17.95 | 21.55 | 19.54 | 24.34 | 19.52 | 22.58 | 16.69 |
| 5 | 16.86 | 18.15 | 15.02 | 16.24 | 7.43 | 28.50 | 15.04 | 17.03 | 14.50 | |
| 10 | 10.09 | 8.97 | 11.28 | 13.11 | 3.23 | 26.86 | 8.30 | 4.89 | 11.79 | |
| 15 | 8.21 | 7.16 | 10.42 | 12.45 | 1.67 | 27.47 | 7.53 | 4.51 | 10.24 | |
| Office | 0 | 16.94 | 13.68 | 21.47 | 16.28 | 15.28 | 17.66 | 15.32 | 15.90 | 15.27 |
| 5 | 15.78 | 11.93 | 21.13 | 14.87 | 9.13 | 22.87 | 12.07 | 9.63 | 14.53 | |
| 10 | 10.84 | 6.79 | 16.48 | 12.84 | 5.03 | 23.70 | 9.77 | 6.87 | 12.84 | |
| 15 | 8.16 | 2.81 | 15.57 | 12.11 | 2.61 | 25.35 | 8.02 | 5.36 | 11.05 | |
| Car | 0 | 6.02 | 1.83 | 11.85 | 23.94 | 0.75 | 56.23 | 6.82 | 5.07 | 8.78 |
| 5 | 5.62 | 1.78 | 10.94 | 22.44 | 0.56 | 52.91 | 6.53 | 4.39 | 8.65 | |
| 10 | 5.51 | 1.69 | 10.82 | 21.97 | 0.25 | 52.21 | 6.11 | 2.96 | 9.84 | |
| 15 | 5.34 | 1.60 | 10.53 | 20.34 | 0.17 | 48.41 | 5.86 | 2.84 | 8.94 | |
| Environments | PESQ | ||
|---|---|---|---|
| Noise | SNR (dB) | CMAP-SG [11] | Proposed |
| Office | 0 | 1.848 0.013 | 1.891 0.016 |
| 5 | 2.193 0.009 | 2.225 0.012 | |
| 10 | 2.556 0.006 | 2.583 0.008 | |
| 15 | 2.841 0.004 | 2.859 0.006 | |
| Babble | 0 | 1.982 0.018 | 2.055 0.023 |
| 5 | 2.362 0.016 | 2.425 0.022 | |
| 10 | 2.674 0.009 | 2.711 0.011 | |
| 15 | 2.965 0.008 | 2.997 0.009 | |
| Car | 0 | 3.152 0.002 | 3.151 0.002 |
| 5 | 3.443 0.001 | 3.439 0.002 | |
| 10 | 3.694 0.001 | 3.692 0.001 | |
| 15 | 3.944 0.001 | 3.941 0.001 | |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.-K.; Kang, S.-I.; Park, Y.-J.; Lee, S.; Lee, S. Power Spectral Deviation-Based Voice Activity Detection Incorporating Teager Energy for Speech Enhancement. Symmetry 2016, 8, 58. https://doi.org/10.3390/sym8070058
Kim S-K, Kang S-I, Park Y-J, Lee S, Lee S. Power Spectral Deviation-Based Voice Activity Detection Incorporating Teager Energy for Speech Enhancement. Symmetry. 2016; 8(7):58. https://doi.org/10.3390/sym8070058
Chicago/Turabian StyleKim, Sang-Kyun, Sang-Ick Kang, Young-Jin Park, Sanghyuk Lee, and Sangmin Lee. 2016. "Power Spectral Deviation-Based Voice Activity Detection Incorporating Teager Energy for Speech Enhancement" Symmetry 8, no. 7: 58. https://doi.org/10.3390/sym8070058