
Top-N Recommender Systems Using Genetic Algorithm-Based Visual-Clustering Methods

Abstract
:
1. Introduction
2. Methodology
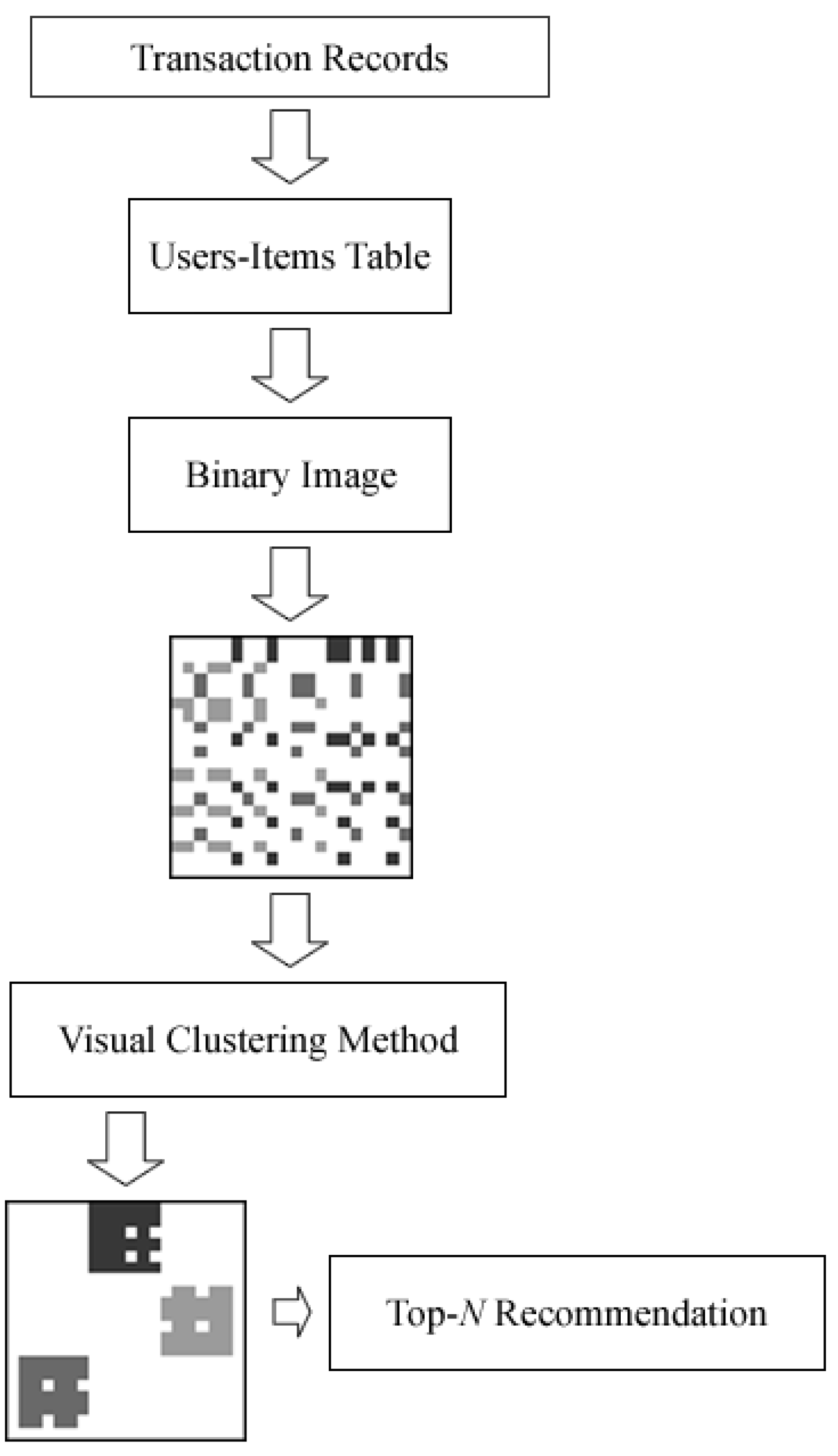
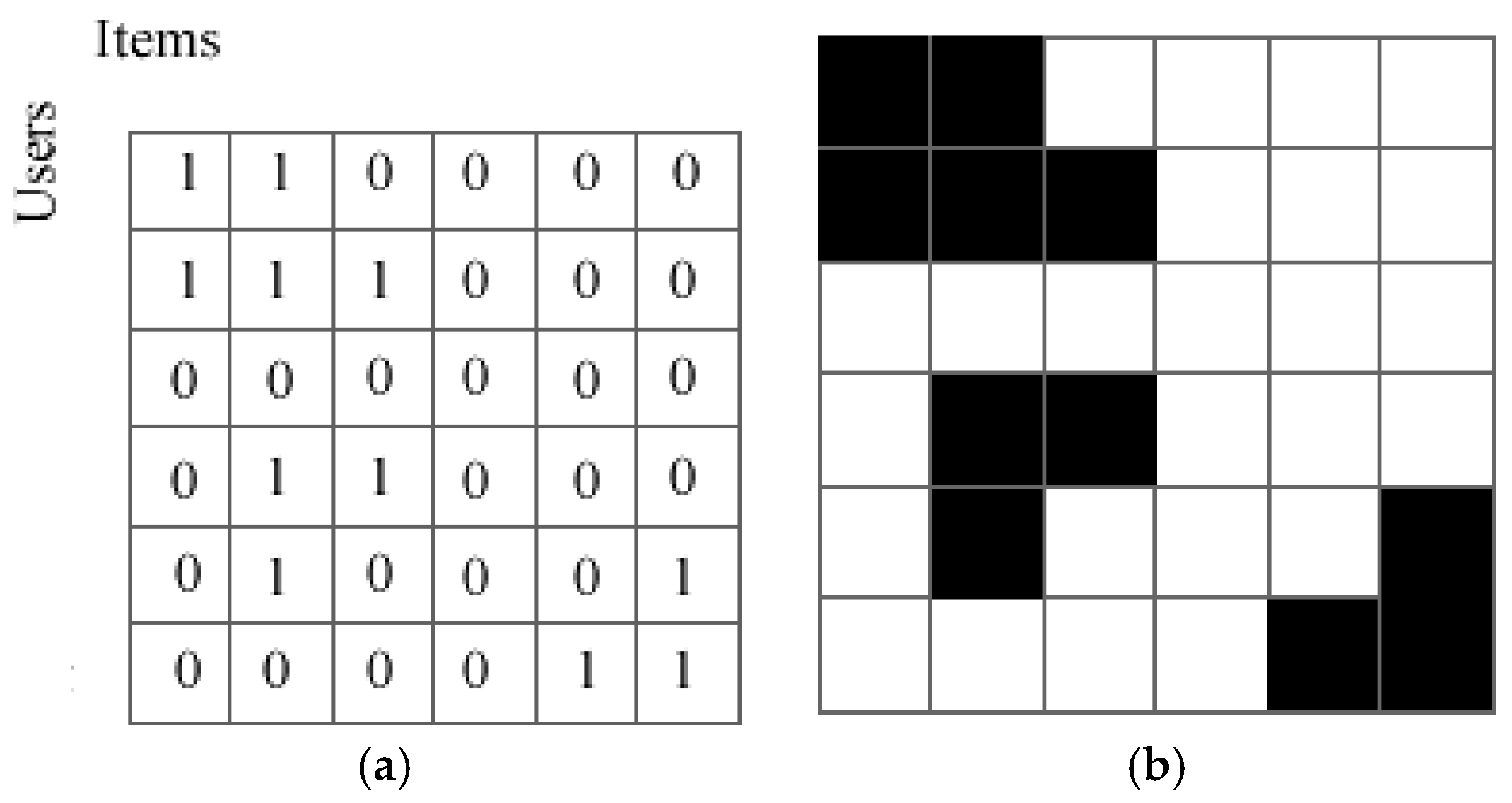
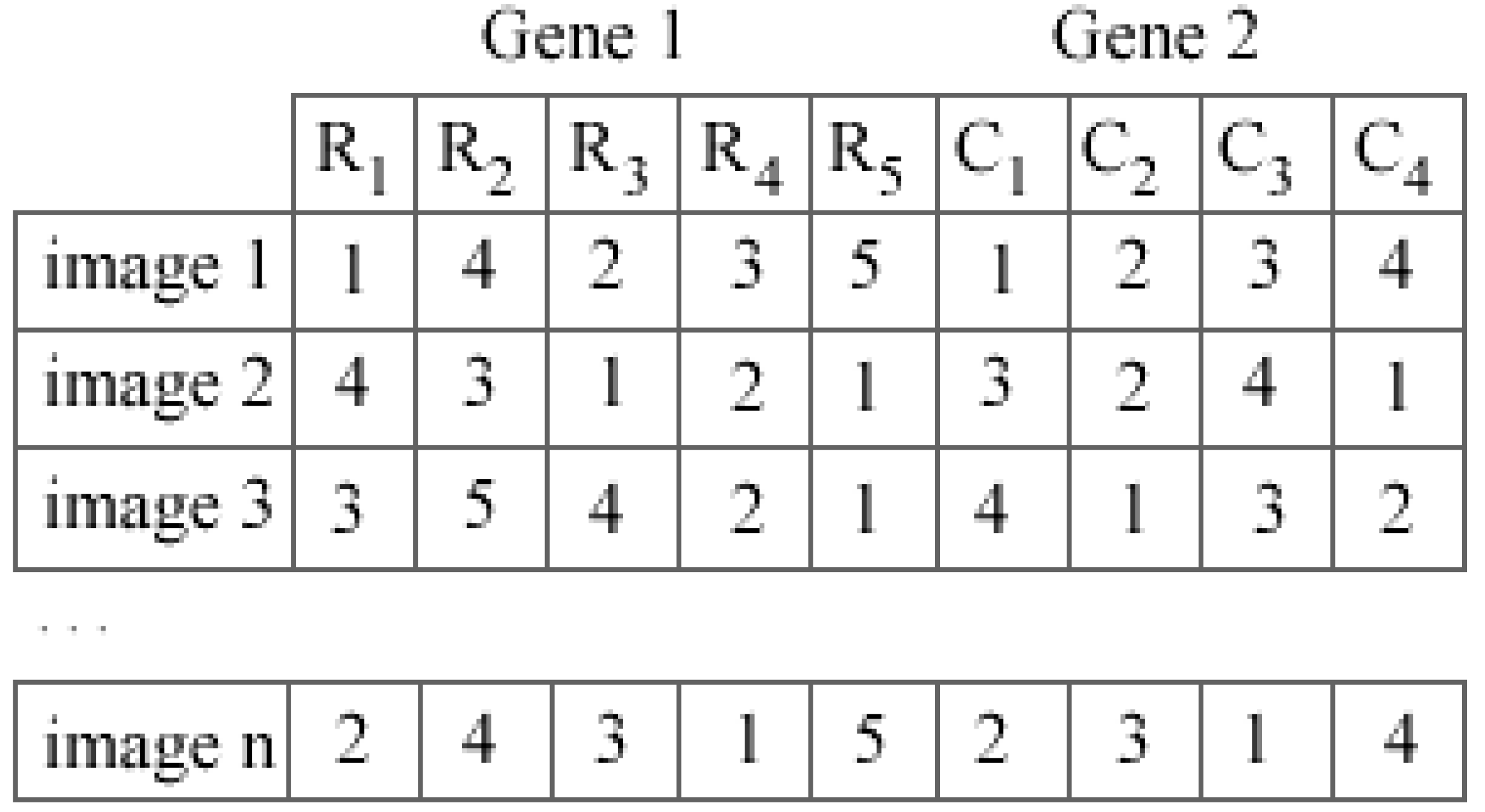
2.1. Proposed Genetic Algorithm-Based Visual-Clustering Method
2.2. Recommendation Engine
2.3. Evaluation Measures
3. Experimental Framework
3.1. Data Descriptions
3.2. Parameter Setting
3.3. Cross-Validation
4. Experimental Results and Discussion
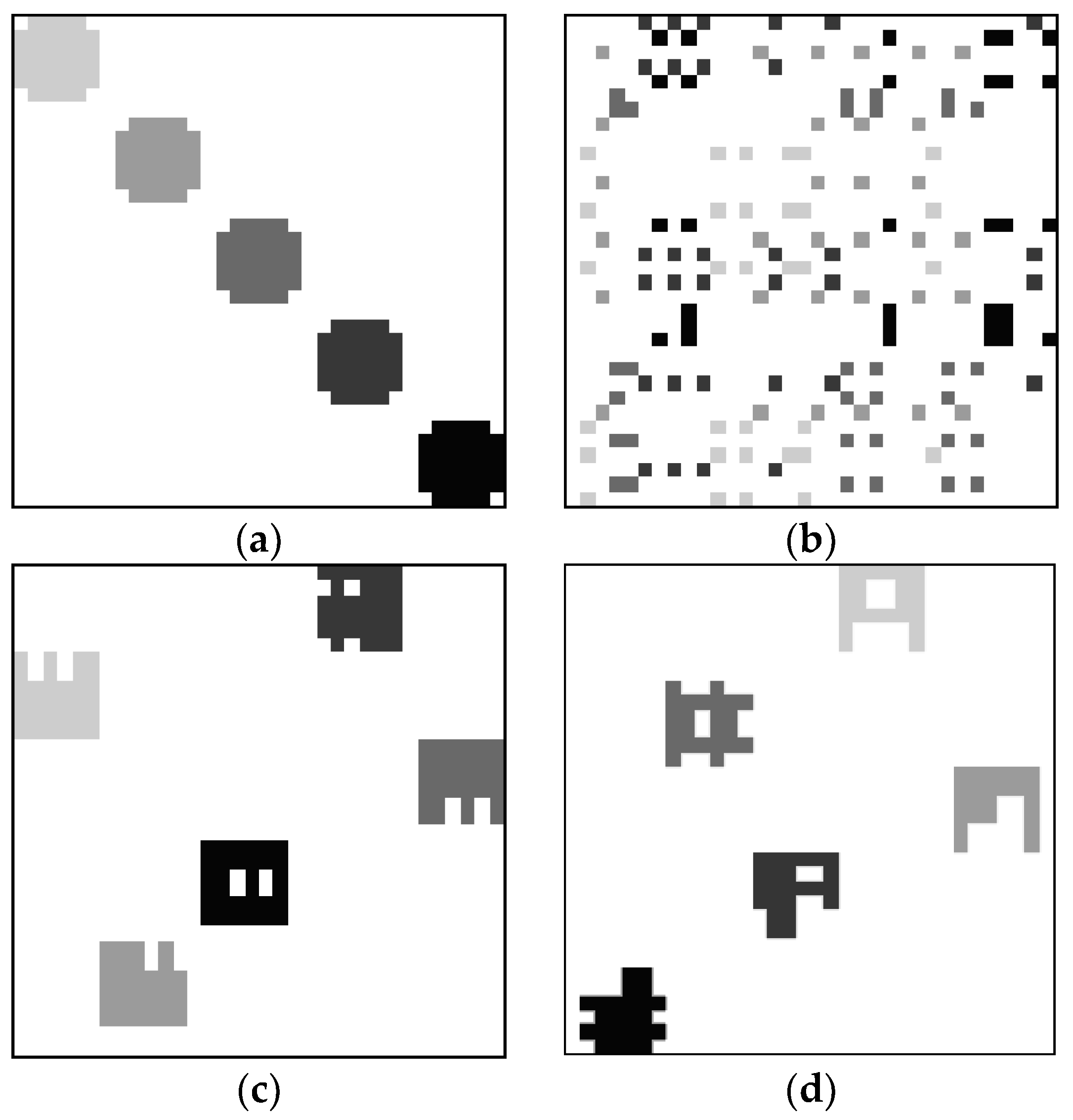
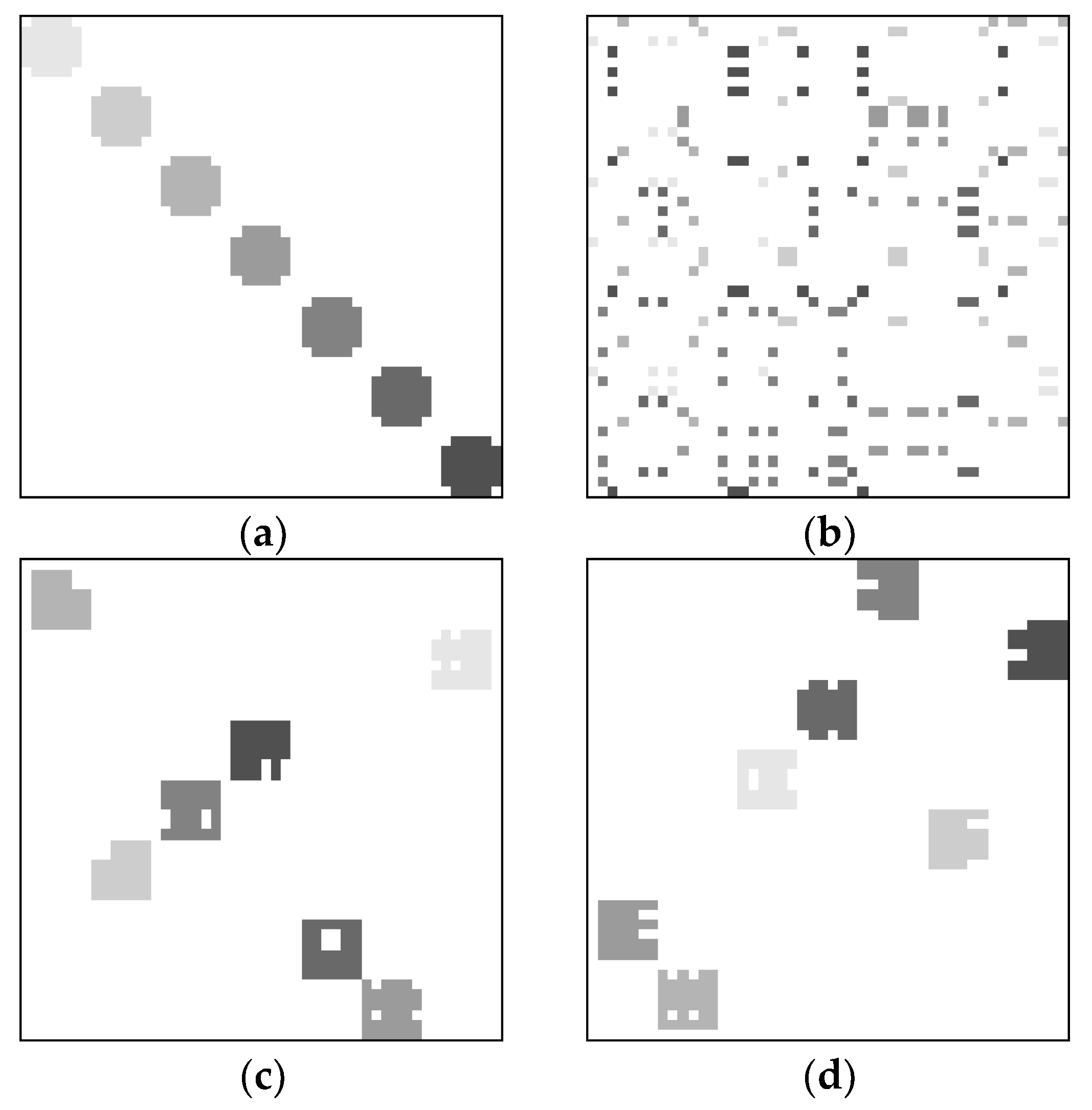
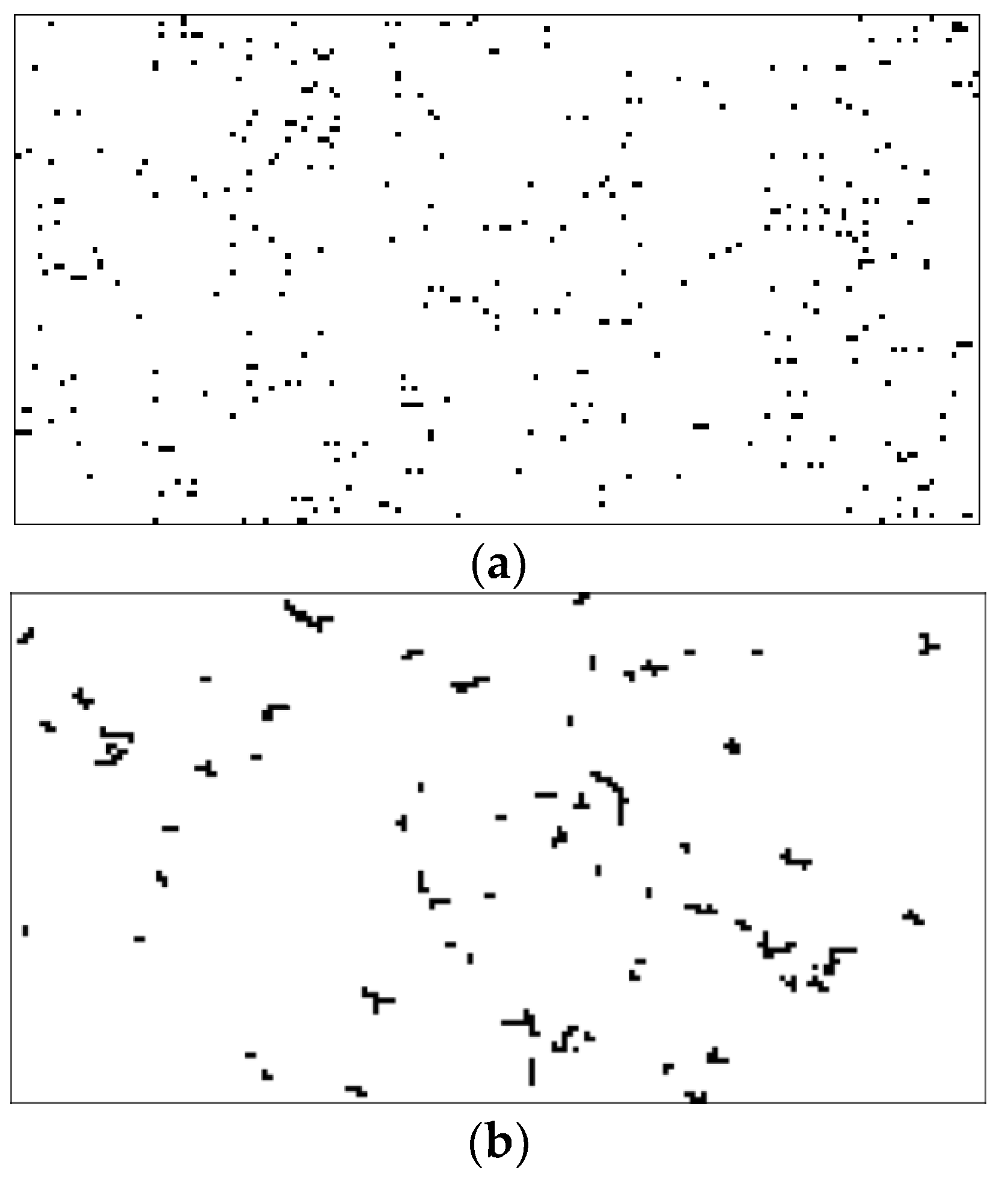
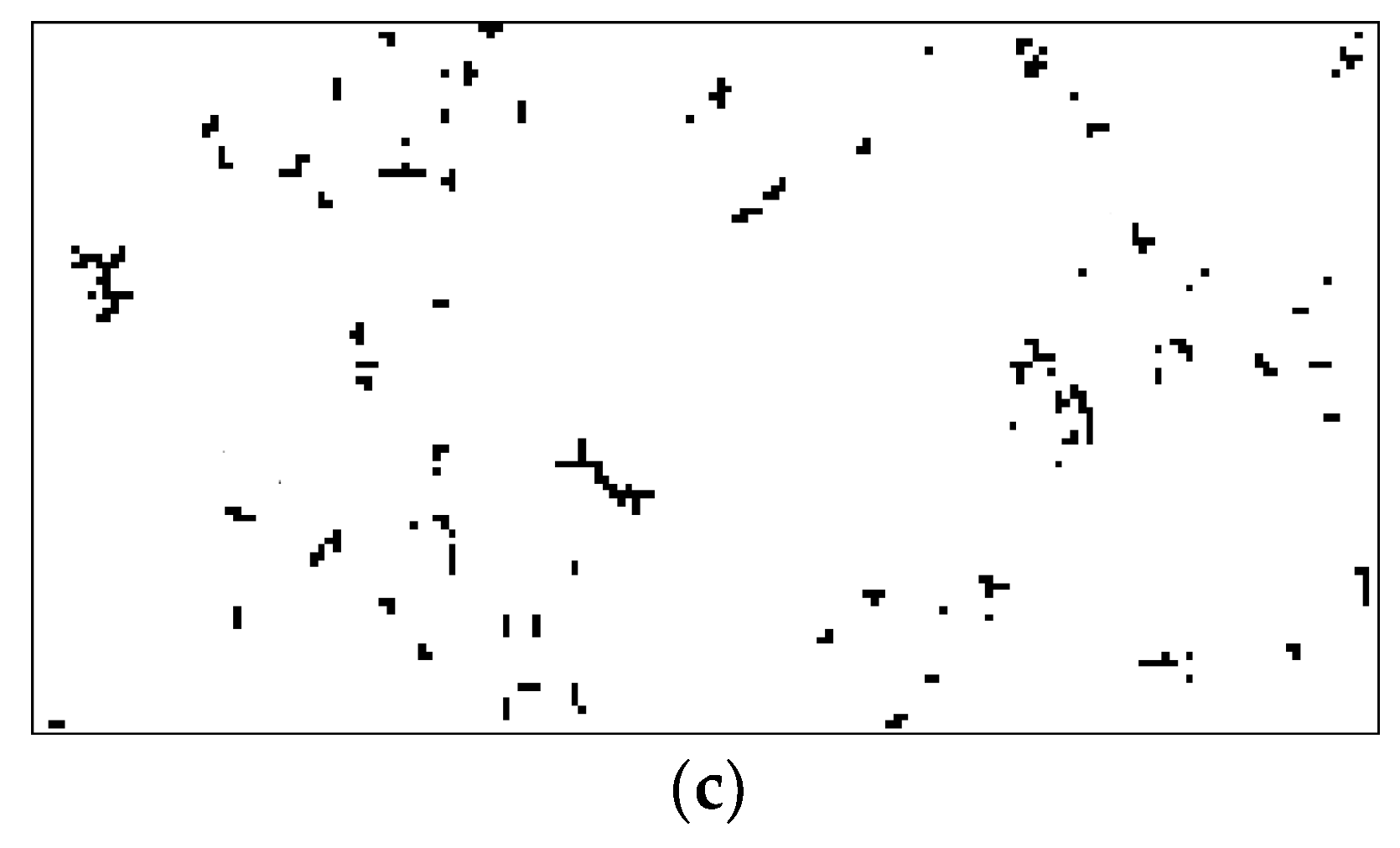
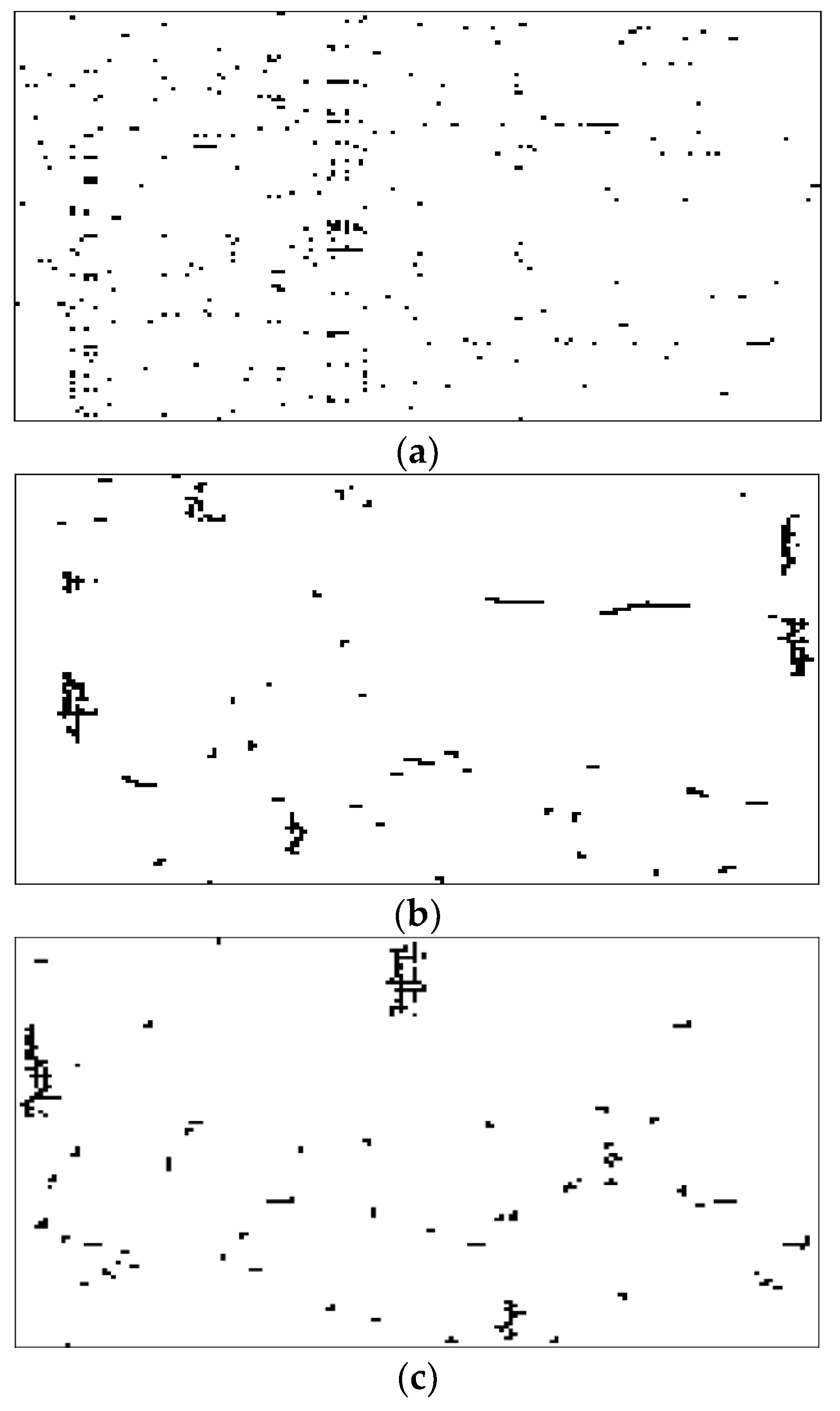
4.1. Clustering Results
4.1.1. Clustering Results on Synthetic Data Sets
4.1.2. Clustering Results on Real-World Data Sets
4.2. Top-5 Recommendation Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lops, P.; Gemmis, M.; de Semeraro, G. Content-based Recommender Systems: State of the Art and Trends. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P.B., Eds.; Springer US: New York, NY, USA, 2011. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Melville, P.; Mooney, R.J.; Nagarajan, R. Content-boosted collaborative filtering for improved recommendations. In Proceedings of the Eighteenth National Conference on Artificial Intelligence, Edmonton, AB, Canada, 28 July–1 August 2002.
- Salter, J.; Antonopoulos, A. Cinema screen recommender agent: Combining collaborative and content-based filtering. IEEE Intell. Syst. 2006, 21, 35–41. [Google Scholar] [CrossRef]
- Zhang, F.; Chang, H. A collaborative filtering algorithm employing genetic clustering to ameliorate the scalability issue. In Proceedings of the IEEE International Conference on e-Business Engineering, Shanghai, China, 24–26 October 2006.
- Gong, S. Joining case-based reasoning and item-based collaborative filtering in recommender systems. In Proceedings of the Second International Symposium on Electronic Commerce and Security 2009, Nanchang, China, 22–24 May 2009.
- Linden, G.; Smith, B.; York, J. Amazon.com recommendations item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Bogdanova, G.; Georgieva, T. Using error-correcting dependencies for collaborative filtering. Data Knowl. Eng. 2008, 66, 402–413. [Google Scholar] [CrossRef]
- Yakut, I.; Polat, H. Arbitrarily distributed data-based recommendations with privacy. Data Knowl. Eng. 2012, 72, 239–256. [Google Scholar] [CrossRef]
- Adomavicius, G.; Kwon, Y. New recommendation techniques for multicriteria rating systems. IEEE Intell. Syst. 2007, 22, 48–55. [Google Scholar] [CrossRef]
- Weng, S.-S.; Liu, M.-J. Feature-based recommendations for one-to-one marketing. Expert Syst. Appl. 2004, 26, 493–508. [Google Scholar] [CrossRef]
- Lee, Y.-H.; Hu, P.J.-H.; Cheng, T.-H.; Hsieh, Y.-F. A cost-sensitive technique for positive-example learning supporting content-based product recommendations in B-to-C e-commerce. Decis. Support Syst. 2012, 53, 245–256. [Google Scholar] [CrossRef]
- Kagie, M.; van Wezel, M.; Groenen, P.J.F. A graphical shopping interface based on product attributes. Decis. Support Syst. 2008, 46, 265–276. [Google Scholar] [CrossRef]
- Dai, Y.; Ye, H.; Gong, S. Personalized recommendation algorithm using user demography information. In Proceedings of the Second International Workshop on Knowledge Discovery and Data Mining 2009, Moscow, Russia, 23–25 January 2009.
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Analysis of recommendation algorithms for e-Commerce. In Proceedings of the 2nd ACM conference on Electronic commerce, Minneapolis, MN, USA, 17–20 October 2000.
- Luo, X.; Liu, H.; Gou, G.; Xia, Y.; Zhu, Q. A parallel matrix factorization based recommender by alternating stochastic gradient decent. Eng. Appl. Artif. Intell. 2012, 25, 1403–1412. [Google Scholar] [CrossRef]
- Choi, K.; Yoo, D.; Kim, G.; Suh, Y. A hybrid online-product recommendation system: combining implicit rating-based collaborative filtering and sequential pattern analysis. Electron. Commer. Res. Appl. 2012, 11, 309–317. [Google Scholar] [CrossRef]
- Kim, H.-N.; Ha, I.; Lee, K.-S.; Jo, G.-S.; El-Saddik, A. Collaborative user modeling for enhanced content filtering in recommender systems. Decis. Support Syst. 2011, 51, 772–781. [Google Scholar] [CrossRef]
- Blanco-Fernandez, Y.; Lopex-Nores, M.; Pazos-Arias, J.J.; Garcia-Duque, J. An improvement for sementics-based recommender systems grounded on attaching temporal information on ontologies and user profiles. Eng. Appl. Artif. Intell. 2011, 24, 1385–1397. [Google Scholar] [CrossRef]
- Moreno, A.; Vallas, A.; Isern, D.; Marin, L.; Barras, J. SigTur/E-Destination: Ontology-based personalized recommendation of tourism and leisure activities. Eng. Appl. Artif. Intell. 2013, 26, 633–651. [Google Scholar] [CrossRef]
- Kim, H.-N.; Ji, A.-T.; Ha, I.; Jo, G.-S. Collaborative filtering based on collaborative tagging for enhancing the quality of recommendation. Electron. Commer. Res. Appl. 2010, 9, 73–83. [Google Scholar] [CrossRef]
- Piramuthu, S.; Kapoor, G.; Zhou, W.; Mauw, S. Input online review data and related bias in recommender systems. Decis. Support Syst. 2012, 53, 418–424. [Google Scholar] [CrossRef]
- Symeonidis, P.; Tiakas, E.; Manolopoulos, Y. Transitive Node Similarity for Link: Prediction in Social Networks with Positive and Negative Links. In Proceedings of the Fourth ACM Conference on Recommender Systems, RecSys 2010, Barcelona, Spain, 26–30 September 2010.
- Yang, X.; Steck, H.; Liu, Y. Circle-based Recommendation in Online Social Networks. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 2012, Beijing, China, 12–16 August 2012.
- Jahrer, M.; Töscher, A.; Legenstein, R. Combining Predictions for Accurate Recommender Systems. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 2010, Washington, DC, USA, 25–28 July 2010.
- Good, N.; Schafer, J.B.; Konstan, J.A.; Borchers, A.; Sarwar, B.; Herlocker, J.; Riedl, J. Combining collaborative filtering with personal agents for better recommendations. In Proceedings of the Sixteenth National Conference on Artificial Intelligence and the Eleventh Innovative Applications of Artificial Intelligence Conference Innovative Applications of Artificial Intelligence, Orlando, FL, USA, 18–22 July 1999.
- Leroy, V.; Cambazoglu, B.B.; Bonchi, F. Cold Start Link Prediction. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 2010, Washington, DC, USA, 25–28 July 2010.
- Park, S.-T.; Chu, W. Pairwise Preference Regression for Cold-start Recommendation. In Proceedings of the Third ACM Conference on Recommender Systems, RecSys 2009, New York, NY, USA, 22–25 October 2009.
- Weng, L.T.; Xu, Y.; Li, Y.; Nayak, R. Exploiting Item Taxonomy for Solving Cold-Start Problem in Recommendation Making. In Proceedings of the 2008 20th IEEE International Conference on Tools with Artificial Intelligence, Dayton, OH, USA, 3–5 November 2008.
- Cao, Y.; Li, Y. An intelligent fuzzy-based recommendation system for consumer electronic products. Expert Syst. Appl. 2007, 33, 230–240. [Google Scholar] [CrossRef]
- Park, Y.-J.; Chang, K.-N. Individual and group behavior-based customer profile model for personalized product recommendation. Expert Syst. Appl. 2009, 36, 1932–1939. [Google Scholar] [CrossRef]
- Kim, H.-N.; El-Saddik, A.; Jo, G.-S. Collaborative error-reflected models for cold-start recommender systems. Decis. Support Syst. 2011, 51, 519–531. [Google Scholar] [CrossRef]
- Yu, L.; Pan, R.; Li, Z. Adaptive Social Similarities for Recommender Systems. In Proceedings of the Fifth ACM Conference on Recommender Systems, RecSys 2011, Chicago, IL, USA, 23–27 October 2011.
- Jamali, M.; Ester, M. A Matrix Factorization Technique with Trust Propagation for Recommendation in Social Networks. In Proceedings of the Fourth ACM Conference on Recommender Systems, RecSys 2010, Barcelona, Spain, 26–30 September 2010.
- Zhang, Y.; Cao, B.; Yeung, D.-Y. Multi-Domain Collaborative Filtering. In Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence (UAI2010), Catalina Island, CA, USA, 8–11 July 2010.
- Si, S.; Shin, D.; Dhillon, I.S.; Parlett, B.N. Multi-Scale Spectral Decomposition of Massive Graphs. In Proceedings of the Advances in Neural Information Processing Systems 27, Montréal, QC, Canada, 8–13 December 2014.
- Karatzoglou, A.; Amatriain, X.; Baltrunas, L.; Oliver, N. Multiverse Recommendation: N-dimensional Tensor Factorization for Context-aware Collaborative Filtering. In Proceedings of the Fourth ACM Conference on Recommender Systems, RecSys 2010, Barcelona, Spain, 26–30 September 2010.
- Luo, Y.; Hu, J.; Wei, X. Blog Recommender Based on Hypergraph Modeling Clustering Algorithm. In Proceedings of the 2013 Fourth World Congress on Software Engineering, WCSE 2013, Hong Kong, China, 3–4 December 2013; pp. 231–235.
- Marung, U.; Theera-Umpon, N.; Auephanwiriyakul, S. Visual clustering method using genetic algorithm and image manipulation. In Proceedings of the 2011 International Symposium on Intelligent Signal Processing and Communications Systems, Chiang Mai, Thailand, 7–9 December 2011.
- Linqi, L.; Li, C. Hybrid personalized recommended model based on genetic algorithm. In Proceedings of the 4th International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 12–14 October 2008.
- Kim, K.-J.; Ahn, H. A recommender system using GA k-means clustering in an online shopping market. Expert Syst. Appl. 2008, 34, 1200–1209. [Google Scholar] [CrossRef]
- Dorn, C.; Skopik, F.; Schall, D.; Dustdar, S. Interaction mining and skill-dependent recommendations for multi-objective team composition. Data Knowl. Eng. 2011, 70, 866–891. [Google Scholar] [CrossRef] [PubMed]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization, and Machine Learning; Addison-Wesley Publishing: Boston, MA, USA, 1989. [Google Scholar]
- Karypis, G. Evaluation of item-based top-N recommendation algorithms. In Proceedings of the Tenth International Conference on Information and Knowledge management, McLean, VA, USA, 6–11 November 2000.
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Lin, P.; Yang, F.; Yu, X.; Xu, Q. Personalized e-commerce recommendation based on ontology. In Proceedings of the International Conference on Internet Computing in Science and Engineering 2008, Harbin, China, 28–29 January 2008.
- Thaiherbs-Thaimassage Shop. Available online: http://www.thaiherbs-thaimassage.com/ (accessed on 1 October 2015).
- Li, C.; Liang, C.-Y. Cold-start eliminating method of collaborative filtering based on n-sequence access analytic logic. Syst. Eng. Theory Pract. 2012, 7, 1537–1545. [Google Scholar]
- Vargas-Govea, B.; Gonzalez-Serna, J.B.; Ponce-Medellan, R. Effects of relevant contextual features in the performance of a restaurant recommender system. In Proceedings of the Workshop on Context-Aware Recommender Systems, Chicago, IL, USA, 23 October 2011.
- Domingues, M.A.; Jorge, A.M.; Soares, C. Using contextual information as virtual items on top-N recommender systems. In Proceedings of the Workshop on Context-Aware Recommender Systems, New York, NY, USA, 25 October 2009.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| I | Chromosome | Fitness | Pi |
|---|---|---|---|
| 1 | 1 4 2 3 5 | 1 2 3 4 | 0.10 | 0.075 |
| 2 | 4 3 1 2 5 | 3 2 4 1 | 0.62 | 0.466 |
| 3 | 3 5 4 1 2 | 4 1 3 2 | 0.39 | 0.293 |
| 4 | 2 4 3 1 5 | 2 3 1 4 | 0.22 | 0.166 |
| Method | One Item | Two Items | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | |
| UB | 0.03 ± 0.01 | 0.07 ± 0.02 | 0.04 ± 0.01 | 0.05 ± 0.02 | 0.11 ± 0.05 | 0.07 ± 0.02 |
| IB | 0.04 ± 0.02 | 0.07 ± 0.04 | 0.05 ± 0.02 | 0.04 ± 0.02 | 0.11 ± 0.05 | 0.06 ± 0.03 |
| FB | 0.02 ± 0.01 | 0.03 ± 0.01 | 0.02 ± 0.01 | 0.01 ± 0.01 | 0.05 ± 0.03 | 0.02 ± 0.01 |
| VCR1 | 0.05 ± 0.03 | 0.08 ± 0.04 | 0.06 ± 0.05 | 0.07 ± 0.05 | 0.11 ± 0.06 | 0.09 ± 0.05 |
| VCR-UB1 | 0.04 ± 0.03 | 0.08 ± 0.05 | 0.05 ± 0.04 | 0.06 ± 0.02 | 0.16 ± 0.05 | 0.09 ± 0.03 |
| VCR-IB1 | 0.05 ± 0.04 | 0.12 ± 0.10 | 0.07 ± 0.05 | 0.07 ± 0.03 | 0.19 ± 0.07 | 0.10 ± 0.04 |
| VCR2 | 0.07 ± 0.05 | 0.11 ± 0.10 | 0.09 ± 0.06 | 0.09 ± 0.05 | 0.19 ± 0.07 | 0.12 ± 0.05 |
| VCR-UB2 | 0.05 ± 0.04 | 0.11 ± 0.10 | 0.07 ± 0.05 | 0.05 ± 0.04 | 0.15 ± 0.10 | 0.08 ± 0.05 |
| VCR-IB2 | 0.05 ± 0.04 | 0.11 ± 0.10 | 0.07 ± 0.05 | 0.05 ± 0.03 | 0.17 ± 0.08 | 0.08 ± 0.04 |
| Method | Precision | Recall | F1 |
|---|---|---|---|
| UB | 0.13 ± 0.08 | 0.24 ± 0.15 | 0.17 ± 0.10 |
| IB | 0.09 ± 0.04 | 0.19 ± 0.13 | 0.12 ± 0.06 |
| FB | 0.07 ± 0.03 | 0.16 ± 0.10 | 0.10 ± 0.05 |
| VCR1 | 0.14 ± 0.08 | 0.21 ± 0.12 | 0.16 ± 0.09 |
| VCR-UB1 | 0.15 ± 0.06 | 0.30 ± 0.14 | 0.18 ± 0.10 |
| VCR-IB1 | 0.15 ± 0.07 | 0.28 ± 0.15 | 0.18 ± 0.10 |
| VCR2 | 0.28 ± 0.13 | 0.40 ± 0.17 | 0.33 ± 0.15 |
| VCR-UB2 | 0.18 ± 0.06 | 0.42 ± 0.18 | 0.24 ± 0.08 |
| VCR-IB2 | 0.19 ± 0.06 | 0.44 ± 0.20 | 0.25 ± 0.09 |
| Method | One Restaurant | Two Restaurants | Three Restaurants | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | Precision | Recall | F1 | |
| UB | 0.21 ± 0.11 | 0.19 ± 0.10 | 0.20 ± 0.09 | 0.14 ± 0.04 | 0.17 ± 0.06 | 0.16 ± 0.04 | 0.12 ± 0.08 | 0.16 ± 0.07 | 0.14 ± 0.07 |
| IB | 0.19 ± 0.10 | 0.17 ± 0.08 | 0.18 ± 0.09 | 0.18 ± 0.10 | 0.20 ± 0.11 | 0.19 ± 0.10 | 0.14 ± 0.09 | 0.14 ± 0.08 | 0.14 ± 0.08 |
| FB | 0.14 ± 0.07 | 0.08 ± 0.04 | 0.10 ± 0.05 | 0.12 ± 0.07 | 0.08 ± 0.05 | 0.09 ± 0.06 | 0.12 ± 0.10 | 0.08 ± 0.05 | 0.10 ± 0.07 |
| VCR1 | 0.22 ± 0.07 | 0.38 ± 0.10 | 0.28 ± 0.08 | 0.17 ± 0.08 | 0.25 ± 0.14 | 0.20 ± 0.09 | 0.15 ± 0.04 | 0.20 ± 0.09 | 0.17 ± 0.06 |
| VCR-UB1 | 0.22 ± 0.11 | 0.31 ± 0.13 | 0.26 ± 0.11 | 0.15 ± 0.09 | 0.24 ± 0.14 | 0.18 ± 0.10 | 0.13 ± 0.10 | 0.21 ± 0.12 | 0.16 ± 0.11 |
| VCR-IB1 | 0.20 ± 0.11 | 0.29 ± 0.13 | 0.24 ± 0.11 | 0.19 ± 0.13 | 0.33 ± 0.18 | 0.24 ± 0.14 | 0.14 ± 0.09 | 0.25 ± 0.15 | 0.18 ± 0.10 |
| VCR2 | 0.22 ± 0.10 | 0.34 ± 0.15 | 0.27 ± 0.11 | 0.21 ± 0.06 | 0.32 ± 0.08 | 0.25 ± 0.05 | 0.17 ± 0.06 | 0.25 ± 0.09 | 0.20 ± 0.06 |
| VCR-UB2 | 0.20 ± 0.11 | 0.28 ± 0.16 | 0.23 ± 0.12 | 0.16 ± 0.07 | 0.25 ± 0.12 | 0.20 ± 0.08 | 0.13 ± 0.11 | 0.25 ± 0.15 | 0.17 ± 0.11 |
| VCR-IB2 | 0.20 ± 0.11 | 0.30 ± 0.15 | 0.24 ± 0.12 | 0.19 ± 0.08 | 0.32 ± 0.15 | 0.24 ± 0.10 | 0.15 ± 0.12 | 0.29 ± 0.20 | 0.20 ± 0.13 |
| Method | One Restaurant | Two Restaurants | Three Restaurants | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | Precision | Recall | F1 | |
| UB | 0.36 ± 0.10 | 0.26 ± 0.07 | 0.30 ± 0.12 | 0.33 ± 0.11 | 0.29 ± 0.15 | 0.31 ± 0.12 | 0.28 ± 0.07 | 0.29 ± 0.07 | 0.28 ± 0.07 |
| IB | 0.37 ± 0.12 | 0.25 ± 0.10 | 0.30 ± 0.11 | 0.39 ± 0.07 | 0.33 ± 0.11 | 0.36 ± 0.09 | 0.35 ± 0.07 | 0.39 ± 0.11 | 0.37 ± 0.08 |
| FB | 0.12 ± 0.07 | 0.16 ± 0.07 | 0.14 ± 0.07 | 0.13 ± 0.06 | 0.17 ± 0.10 | 0.15 ± 0.07 | 0.11 ± 0.04 | 0.17 ± 0.11 | 0.13 ± 0.05 |
| VCR1 | 0.40 ± 0.05 | 0.63 ± 0.07 | 0.49 ± 0.05 | 0.40 ± 0.04 | 0.60 ± 0.07 | 0.48 ± 0.04 | 0.38 ± 0.03 | 0.61 ± 0.04 | 0.47 ± 0.03 |
| VCR-UB1 | 0.33 ± 0.05 | 0.46 ± 0.06 | 0.38 ± 0.05 | 0.34 ± 0.05 | 0.53 ± 0.08 | 0.41 ± 0.06 | 0.28 ± 0.03 | 0.40 ± 0.02 | 0.33 ± 0.02 |
| VCR-IB1 | 0.37 ± 0.02 | 0.48 ± 0.03 | 0.42 ± 0.02 | 0.38 ± 0.03 | 0.60 ± 0.05 | 0.47 ± 0.03 | 0.37 ± 0.03 | 0.73 ± 0.05 | 0.49 ± 0.03 |
| VCR2 | 0.42 ± 0.07 | 0.37 ± 0.06 | 0.39 ± 0.06 | 0.41 ± 0.04 | 0.45 ± 0.05 | 0.43 ± 0.04 | 0.38 ± 0.02 | 0.61 ± 0.03 | 0.47 ± 0.02 |
| VCR-UB2 | 0.36 ± 0.05 | 0.55 ± 0.05 | 0.44 ± 0.04 | 0.33 ± 0.05 | 0.54 ± 0.07 | 0.41 ± 0.05 | 0.28 ± 0.03 | 0.53 ± 0.02 | 0.37 ± 0.02 |
| VCR-IB2 | 0.38 ± 0.05 | 0.52 ± 0.07 | 0.44 ± 0.05 | 0.39 ± 0.07 | 0.60 ± 0.11 | 0.47 ± 0.09 | 0.38 ± 0.03 | 0.73 ± 0.04 | 0.50 ± 0.03 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marung, U.; Theera-Umpon, N.; Auephanwiriyakul, S. Top-N Recommender Systems Using Genetic Algorithm-Based Visual-Clustering Methods. Symmetry 2016, 8, 54. https://doi.org/10.3390/sym8070054
Marung U, Theera-Umpon N, Auephanwiriyakul S. Top-N Recommender Systems Using Genetic Algorithm-Based Visual-Clustering Methods. Symmetry. 2016; 8(7):54. https://doi.org/10.3390/sym8070054
Chicago/Turabian StyleMarung, Ukrit, Nipon Theera-Umpon, and Sansanee Auephanwiriyakul. 2016. "Top-N Recommender Systems Using Genetic Algorithm-Based Visual-Clustering Methods" Symmetry 8, no. 7: 54. https://doi.org/10.3390/sym8070054