1. Introduction
As explicitly stated in the Abstract, the algebraic code-excited linear-prediction (ACELP)-based speech coding technique [
1,
2,
3,
4,
5,
6] has the double advantage of low bit rate and high speech quality. Accordingly, it is most widely used in speech communication systems, and adopted in many speech codec standards, such as G.723.1, G.729 [
1] in International Telecommunication Union (ITU), adaptive multi-rate narrowband (AMR-NB) [
2] and wideband (AMR-WB) [
3], and in the codec for enhanced voice services (EVS) [
4,
5] in the 3rd Generation Partnership Project (3GPP). Among such standards, the AMR-WB speech codec with a 16 kHz sampling rate is applied to modern mobile communication systems as a way to improve the speech quality in handheld devices, e.g., smartphones. The AMR-WB codec [
3,
6,
7,
8] is a multi-mode speech codec with nine wideband speech coding modes with bitrates of 23.85, 23.05, 19.85, 18.25, 15.85, 14.25, 12.65, 8.85 and 6.6 kbps. The ACELP-based coding technique is developed as an excellent speech coding technique, but a price paid is a high computational complexity required in the AMR-WB codec. Using the AMR-WB speech codec, the speech quality of a smartphone can be improved but at the cost of high power consumption on a smartphone battery.
A vector quantization (VQ) of immittance spectral frequency (ISF) coefficients [
9,
10,
11,
12,
13] occupies the second largest part of the total computation load required in the AMR-WB encoder. The VQ structure in AMR-WB adopts a combination of split VQ (SVQ) and multi-stage VQ (MSVQ) techniques, referred to as split-multistage VQ (S-MSVQ), to quantize the 16-order ISF coefficients. Conventionally, VQ conducts a full search to ensure that a codeword is best matched with an arbitrary input vector, but the full search requires an enormous computational load. Thus, a continuous effort has been made to simplify the search complexity of an encoding process in a great volume of published studies [
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25]. These approaches are further classified into three types in terms of the way the complexity is simplified, including the tree-structured VQ (TSVQ) techniques [
14,
15,
16], the TIE-based approaches [
18,
19,
20] and the equal-average equal-variance equal-norm nearest neighbor search (EEENNS) based algorithms [
21,
22,
23,
24,
25].
A TIE algorithm was proposed in [
18] as a solution to a VQ-based image coding problem in the aspect of computational load reduction. Improved versions of TIE approaches are presented in [
19,
20] to downsize a search space, giving rise to further reduction in computational load. However, there exists a high correlation between ISF coefficients of neighboring frames in AMR-WB, that is, ISF coefficients evolve smoothly over successive frames. This feature benefits TIE-based VQ encoding, according to which a remarkable computational load reduction is demonstrated, while a moving average (MA) filter is required to smooth the data in advance of VQ encoding of ISF coefficients. As a consequence of data smoothing, the high correlation feature is gone, resulting in a poor performance in computational load reduction. On the other hand, an EEENNS algorithm was derived from equal-average nearest neighbor search (ENNS) and equal-average equal-variance nearest neighbor search (EENNS) approaches. The EEENNS algorithm, as opposed to TIE-based approaches, uses three significant features of a vector, i.e., mean value, variance, and norm, as a three-level elimination criterion to reject impossible codewords.
In view of this, a TIE algorithm equipped with a dynamic and an intersection mechanism, DI-TIE for short, is presented as an efficient way to quantize the ISF coefficients in AMR-WB. Both mechanisms are designed in a way that recursively enhances the performance of the TIE algorithm. On the other hand, a major motivation behind this paper is to meet the energy saving requirement on handheld devices for an extended operation time period.
This paper is outlined as follows. The ISF coefficient quantization in AMR-WB is described in
Section 2.
Section 3 presents the DI-TIE search algorithm for ISF quantization. Experimental results are demonstrated and discussed in
Section 4. This work is summarized at the end of this paper.
2. ISF Coefficient Quantization in AMR-WB
In AMR-WB, a linear prediction analysis is made as follows. As the first step, a speech frame of 20 ms is applied to evaluate linear predictive coefficients (LPC), which are then converted into ISF coefficients. Subsequently, quantized ISF coefficients are obtained following a vector quantization process, which is detailed below.
2.1. Linear Prediction Analysis
In a linear prediction, a Levinson-Durbin algorithm is used to compute the 16th order LPC,
ai, of a linear prediction filter, defined as
Subsequently, the LPC parameters are converted into the immittance spectral pair (ISP) coefficients for the purposes of parametric quantization and interpolation. The ISP coefficients are defined as the roots of the following two polynomials
and
are symmetric and antisymmetric polynomials, respectively. It can be proven that all the roots of such two polynomials lie and alternate successively on a unit circle in the
z-domain. Also,
has two roots at
z = 1 (
ω = 0) and
z = −1 (
ω = π). Such two roots are eliminated by introducing the following polynomials, with eight and seven conjugate roots respectively on the unit circle, expressed as
where the coefficients
qi are referred to as the ISPs in the cosine domain and
a [
16] is the last predictor coefficient. A Chebyshev polynomial is used to solve (4) and (5). Finally, derived from the ISP coefficients, 16th order ISF coefficients
ωi can be obtained by taking the transformation
ωi = arccos(
qi).
2.2. Quantization of ISF Coefficients
Before a quantization process, a mean-removed and a first order MA filtering are performed on the ISF coefficients to obtain a residual ISF vector, that is,
where
z(
n) and
p(
n) respectively denote the mean-removed ISF vector and the predicted ISF vector at frame
n by a first order MA prediction, defined as
where
is the quantized residual vector at the previous frame.
Subsequently, S-MSVQ is performed on
r(
n). As presented in
Table 1 and
Table 2, S-MSVQ is categorized into two types in terms of the bit rate of the coding modes. In stage 1,
r(
n) is split into two subvectors, namely, a 9-dimensional subvector
r1(
n) associated with codebook CB1 and a 7-dimensional subvector
r2(
n) associated with codebook CB2, for VQ encoding. As a preliminary step of stage 2, the quantization error vectors are split into three subvectors for the 6.60 kbps mode or five for the modes with bitrates between 8.85 and 23.85 kbps, symbolized as
, respectively. For instance,
r(2)1,1–3 in
Table 1 represents the subvector split from the 1st to the 3rd components of
r1, and then VQ encoding is performed thereon over codebook CB11 in stage 2. Likewise,
r(2)2,4–7 stands for the subvector split from the 4th to the 7th components of
r2, after which VQ encoding is performed over codebook CB22 in stage 2. Finally, a squared error ISF distortion measure, that is, Euclidean distance, is used in all the quantization processes.
3. DI-TIE Search Algorithm for ISF Quantization
DI-TIE is presented as a two-stage search algorithm, i.e., a dynamic mechanism as the first stage and an intersection mechanism as the second. For the sake of discussion, a TIE algorithm is firstly stated as follows. As presented in [
18], a codeword captured from the preceding frame is treated as a reference codeword
cr in the current frame. Subsequently, the Euclidean distance between an input vector
x and
cr, symbolized as
d(
cr,
x), is evaluated. A set, composed of all the codewords
ci satisfying the condition
, is referred to as a candidate search group (CSG), denoted by
CSG(
cr) and formulated as
where
CNum represents the total number of codewords.
CSG(
cr) is the search space over which a current codebook search is performed. In addition, a lookup table listing all the codewords sorted by the Euclidean distance is prebuilt for the TIE search algorithm.
The dynamic mechanism refers to a mechanism exclusively developed to downsize a search space dynamically. With N(cr) representing the number of candidate codewords contained in CSG(cr), the aim is to find a way to reduce the value of N(cr). For this sake, each candidate codeword in CSG(cr), ck, 1 ≤ k ≤ N(cr), is treated in turn as a reference codeword. For instance, ck at k = 1, represented as , is initially appointed a reference codeword, according to which CSG(ck) and N(ck) are found directly in the lookup table, and merely one time evaluation of d(ck, x) is required each time CSG(ck) is determined. Thus, if the updated CSG(ck) satisfies the condition N(ck) < N(cr) – k, the search space can be downsized, and then move forward to stage 2. Otherwise, the above-stated mechanism is repeatedly performed on the rest of ck until the end.
In stage 2, intersection of the sets
CSG(
cr) and
CSG(
ck) is performed, in an attempt to locate the optimal codeword that lies in each CSG, and in an effort to downsize the search space for search performance improvement.
CSG(
cr) is updated as
The
N(
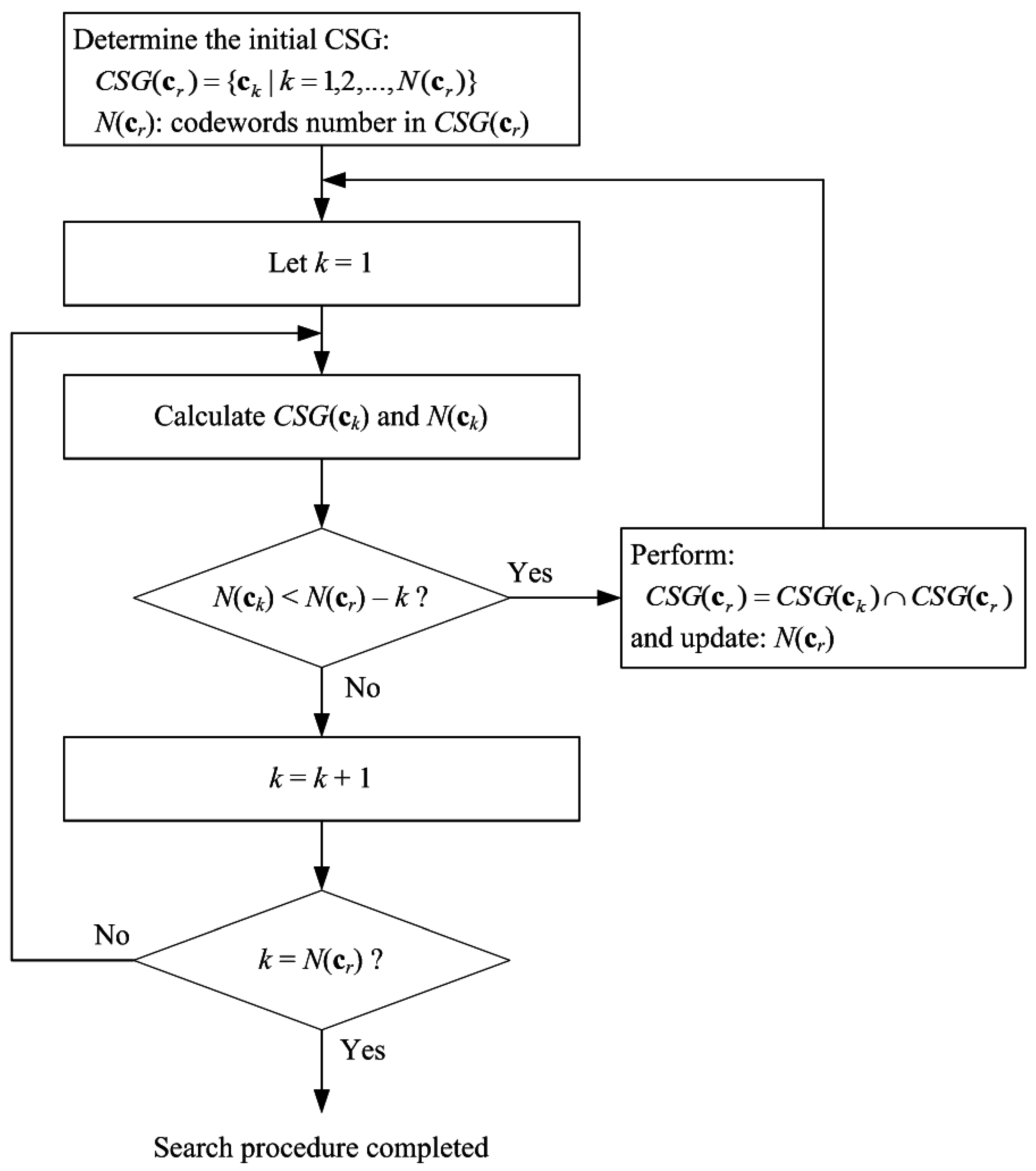
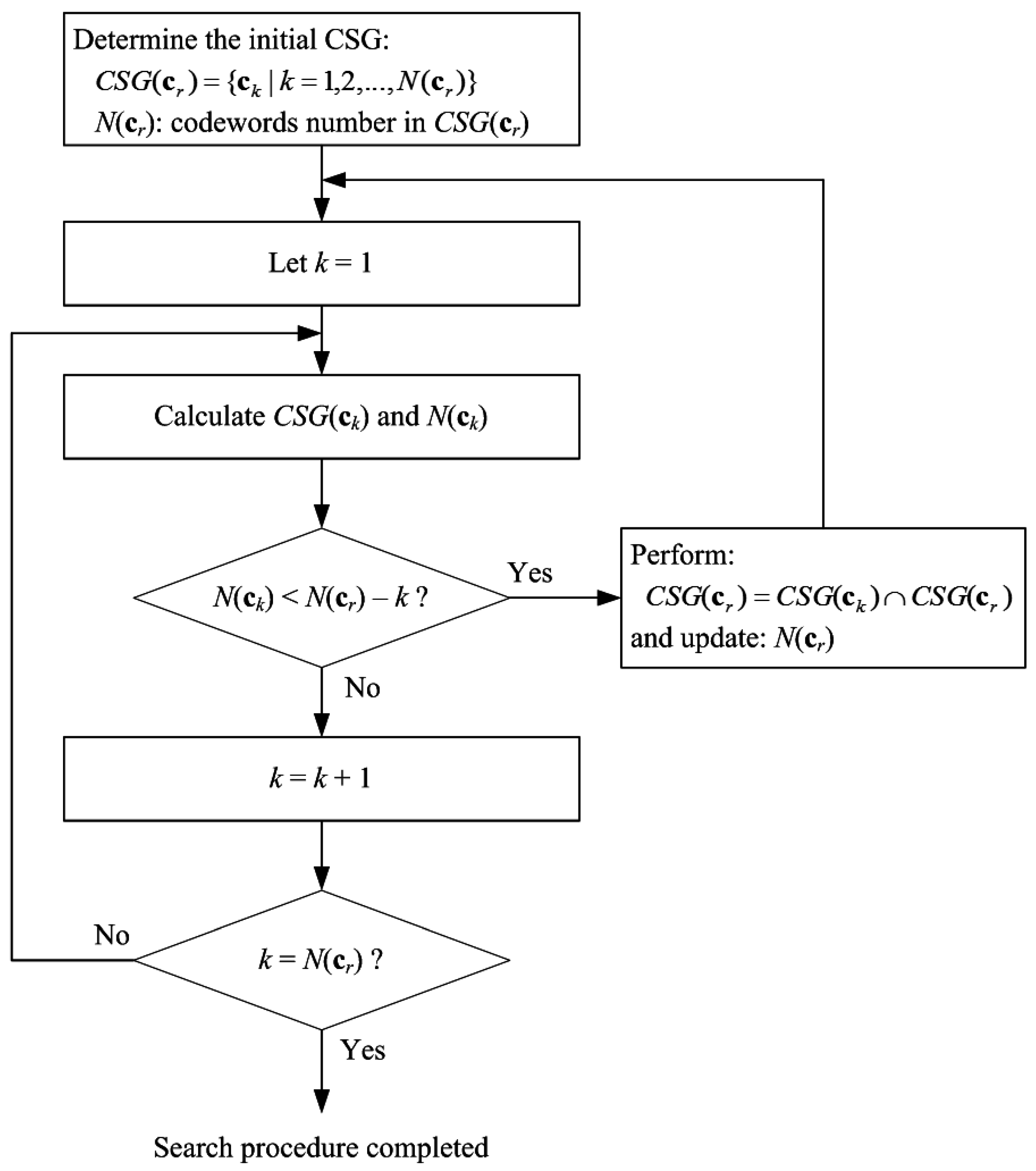
cr) and the reference codeword are updated until a search task is done. The DI-TIE search algorithm is illustrated as a flowchart in
Figure 1, and is described below.
| Algorithm 1: Search procedure of DI-TIE |
- Step 1.
Build a TIE lookup table. - Step 2.
Compute the Euclidean distance d( cr, x), and then determine the initial search space according to (8), that is,
where ck and N( cr) denote the codewords and the number thereof in CSG( cr), respectively. - Step 3.
Starting at k = 1, assign ck as a new reference codeword, compute d(ck, x), and then determine CSG(ck) and N(ck). - Step 4.
if (N(ck) < N(cr) − k), then perform the set intersection operation in (9), update N(cr), let k = 1, and repeat Step 3. Otherwise, let k = k + 1, and then repeat Step 3 and Step 4, until k = N(cr).
|
4. Experimental Results
A performance comparison is made among the presented DI-TIE, a typical TIE [
18], a multiple TIE (MTIE) [
20] and an EEENNS. Since TIE-based and EEENNS VQ codebook searches are conducted, a 100% search accuracy is obtained by such four algorithms as compared with a full search approach. For this sake, performance is compared in terms of search complexity. The test objects are those selected out of a Chinese language speech database, containing 1694 syllables out of 50 sentences for a duration over 445 s and 22,244 frames.
Table 3 gives a comparison on the average number of searches for coding modes with bitrates between 8.85 and 23.85 kbps, while
Table 4 lists a comparison on the percentage complexity reduction with the search load required in a full search algorithm as a benchmark. An observation in
Table 3 and
Table 4 reveals two findings. Firstly, DI-TIE is found to provide a remarkable search complexity reduction, relative to its counterparts. Secondly, the percentage complexity reduction is found to have a strong dependence on the codebooks over which a codeword search is carried out, particularly in the case of TIE, and it must be noted that DI-TIE is found to outperform EEENNS.
Taking the codebook CB22 as an instance, the complexity reduction is well maintained at 60.26% in the case of DI-TIE, while plunges to 13.85% and 8.77% in the cases of MTIE and TIE, respectively. This might be due to the reason that CB22 contains a great number of similar codewords, that is, they are very close to each other. Thus, it is respectively required to search a great number of codewords over the search space in MTIE and TIE. In contrast, the search space in DI-TIE is efficiently downsized in such a way that a high search performance can be maintained over codebooks.
Furthermore,
Table 5 gives a comparison on the average number of searches for the 6.60 kbps mode, and
Table 6 gives a complexity reduction comparison with the full search as a benchmark. The performance superiority of DI-TIE is demonstrated again over EEENNS, MTIE and TIE, particularly in the CB21 case, a finding in agreement with
Table 3 and
Table 4.
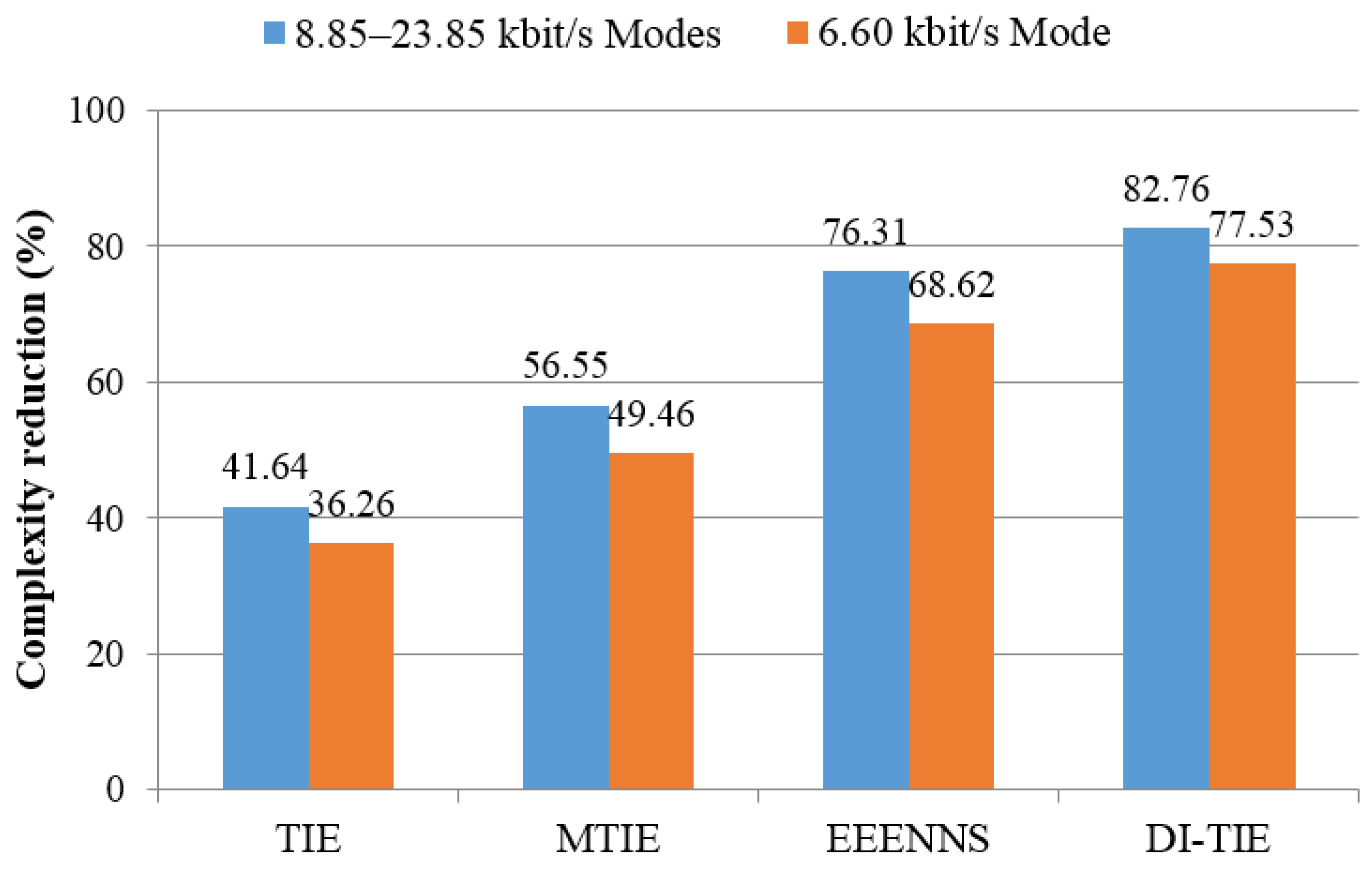
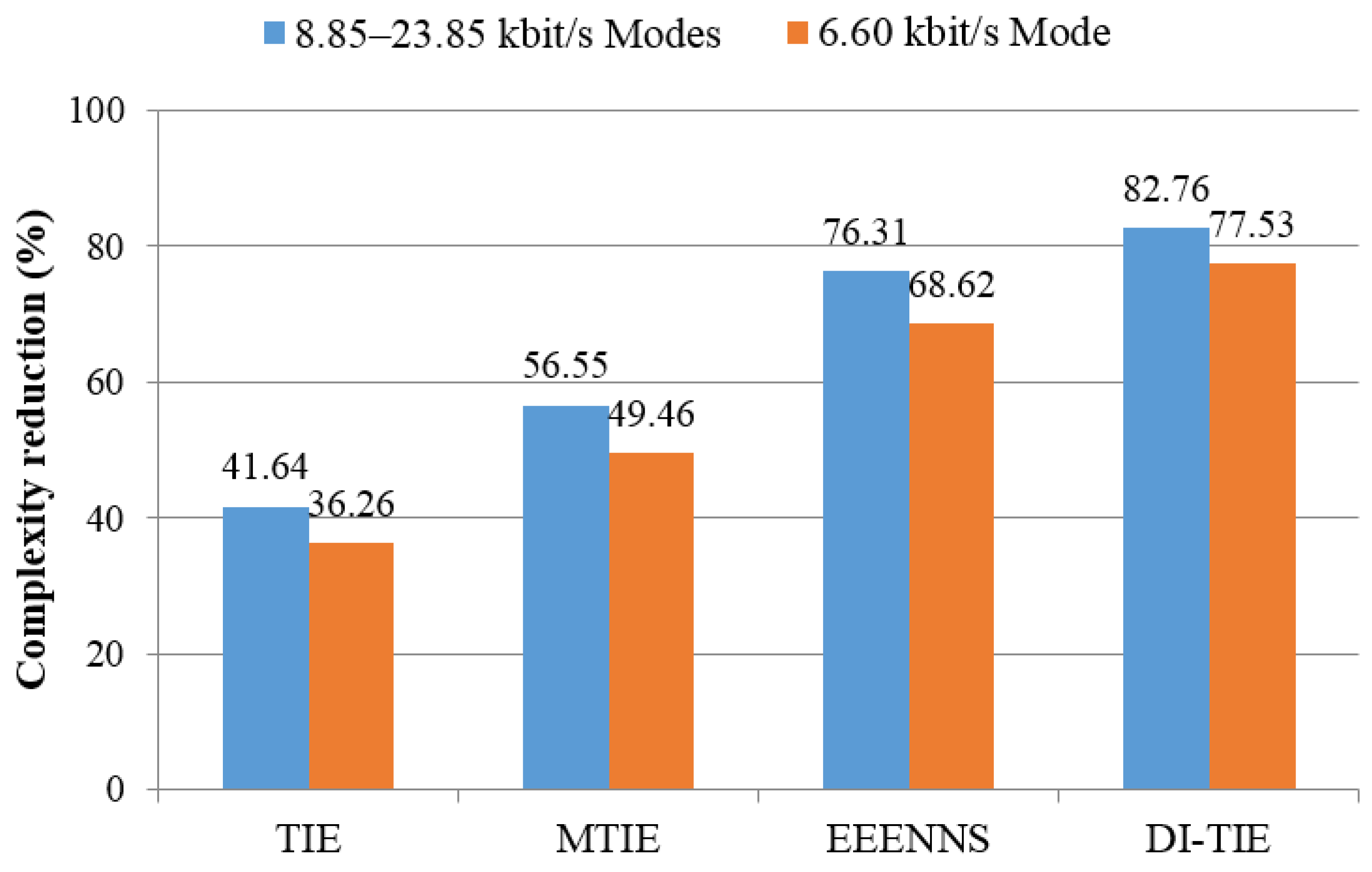
Table 7 gives an overall performance comparison with the full search as a benchmark, and is presented as well as a bar graph in
Figure 2. The overall performance refers to the total search load, defined as the sum of the average number of searches multiplied by the vector dimension in each codebook. As clearly indicated in
Figure 2, this proposal is experimentally validated as a superior candidate relative to the EEENNS and the TIE-based counterparts.
5. Conclusions and Future Work
This paper presents a DI-TIE algorithm for ISF vector quantization in the AMR-WB speech codec. As a result, the search complexity is as expected reduced to a great extent, but without a deterioration in the speech coding quality. This complexity reduction superiority is seen when it is applied to a codeword search over five codebooks in the 6.6 kbps mode, and over seven codebooks in the remaining eight modes. In terms of overall complexity reduction, this presented DI-TIE algorithm is validated again by experimental means as superior to TIE, MTIE and EEENNS search approaches.
Furthermore, this improved AMR-WB speech codec can be adopted to improve the VoIP performance on a smartphone. As a consequence, the energy efficiency requirement is achieved for an extended operation time period due to computational load reduction.
As scheduled, the presented search algorithm will be employed to handle VQ codebook search tasks required in speech, audio and video codecs for the purpose of further computational load reduction in the very near future. This move is expected to achieve a tremendous improvement in real-time audio/video compression and transmission in embedded systems.



{kind=link}
{kind=link}