
Cloud-Based Parameter-Driven Statistical Services and Resource Allocation in a Heterogeneous Platform on Enterprise Environment



Abstract
:1. Introduction
2. Statistical Data and Information Mining Model for a Heterogeneous Platform
2.1. Statistical Data Mining Model
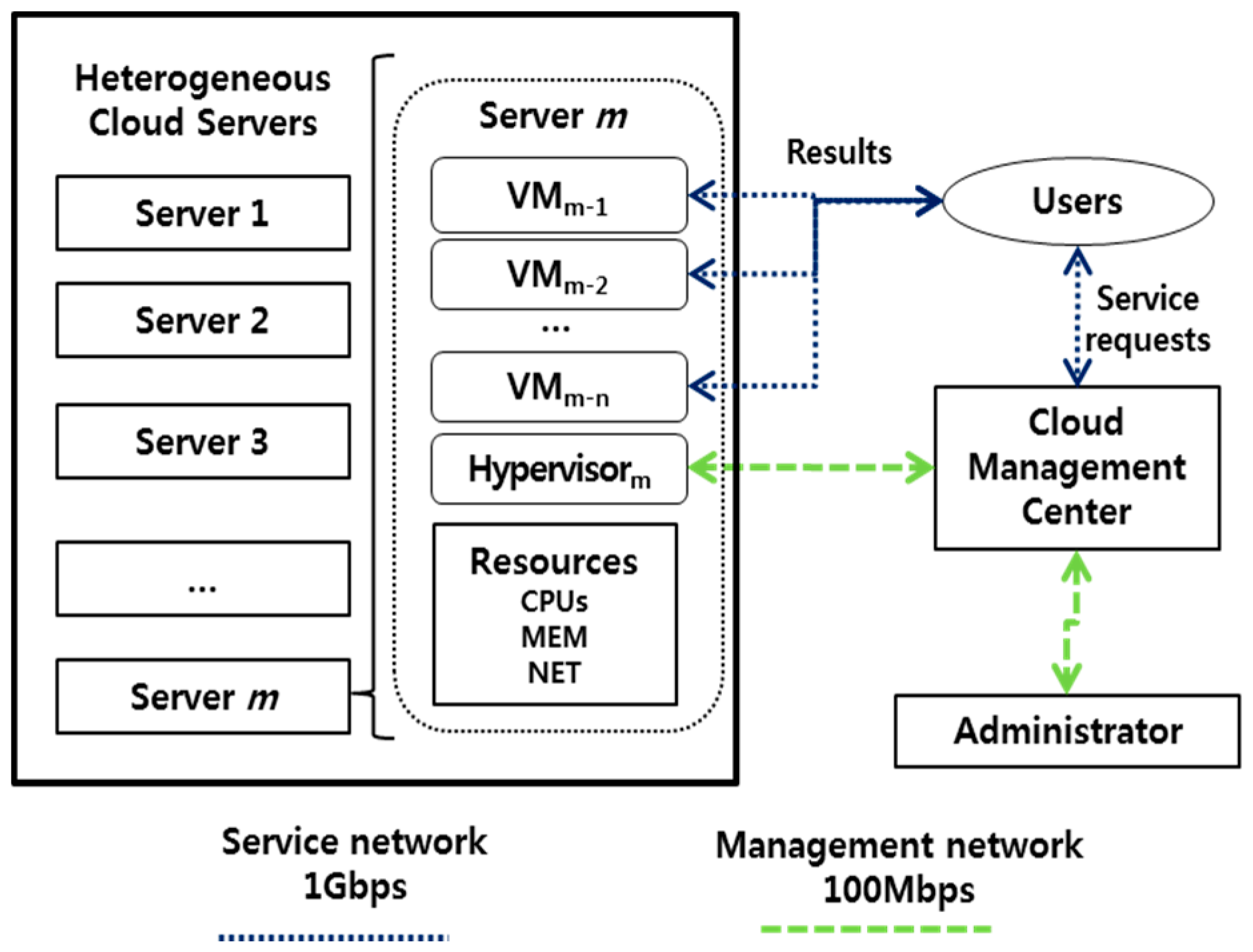
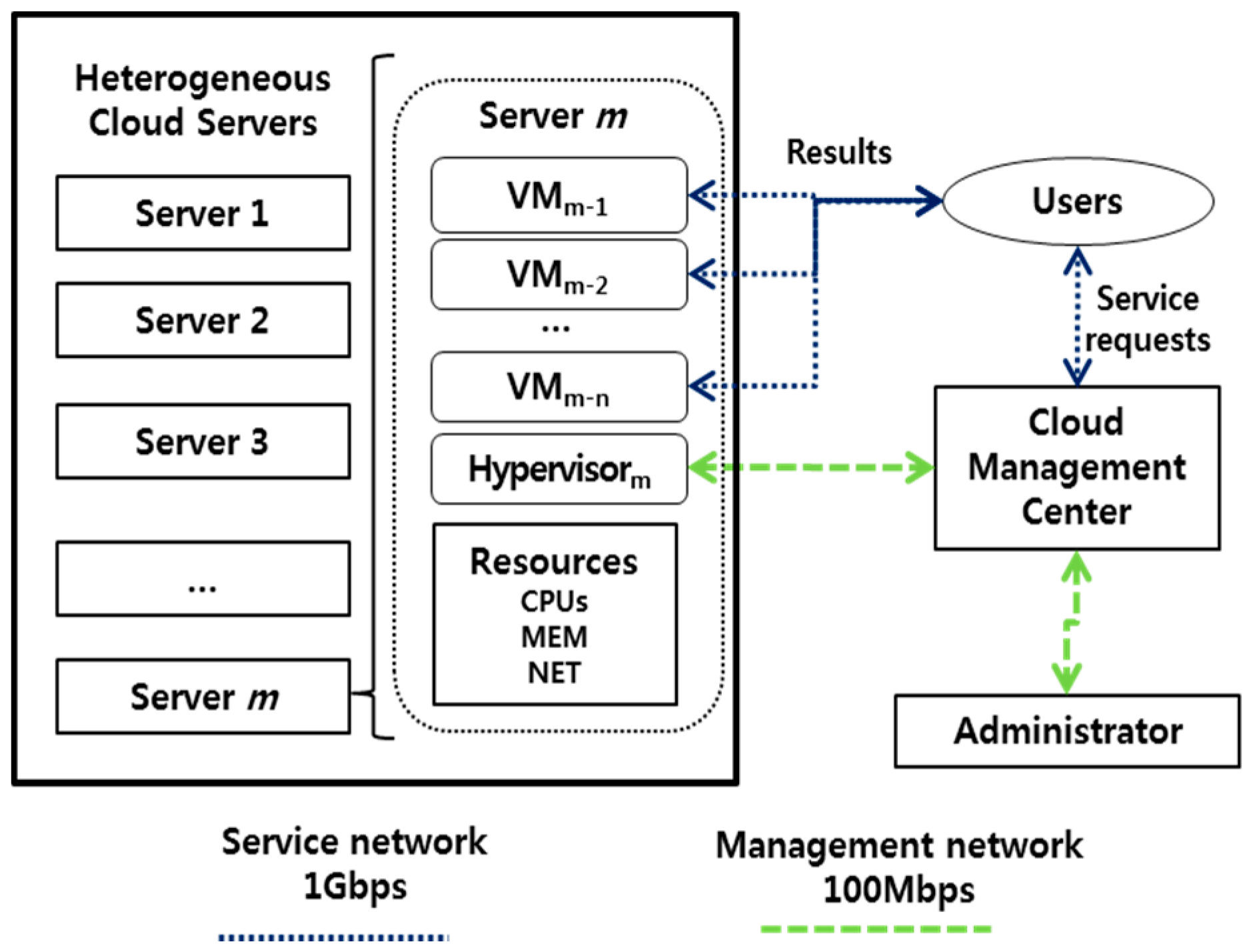
2.2. Cloud Computing for a Heterogeneous Platform
3. Cloud-Based Statistical Analysis
3.1. Data Analysis
3.2. Parameter Classification
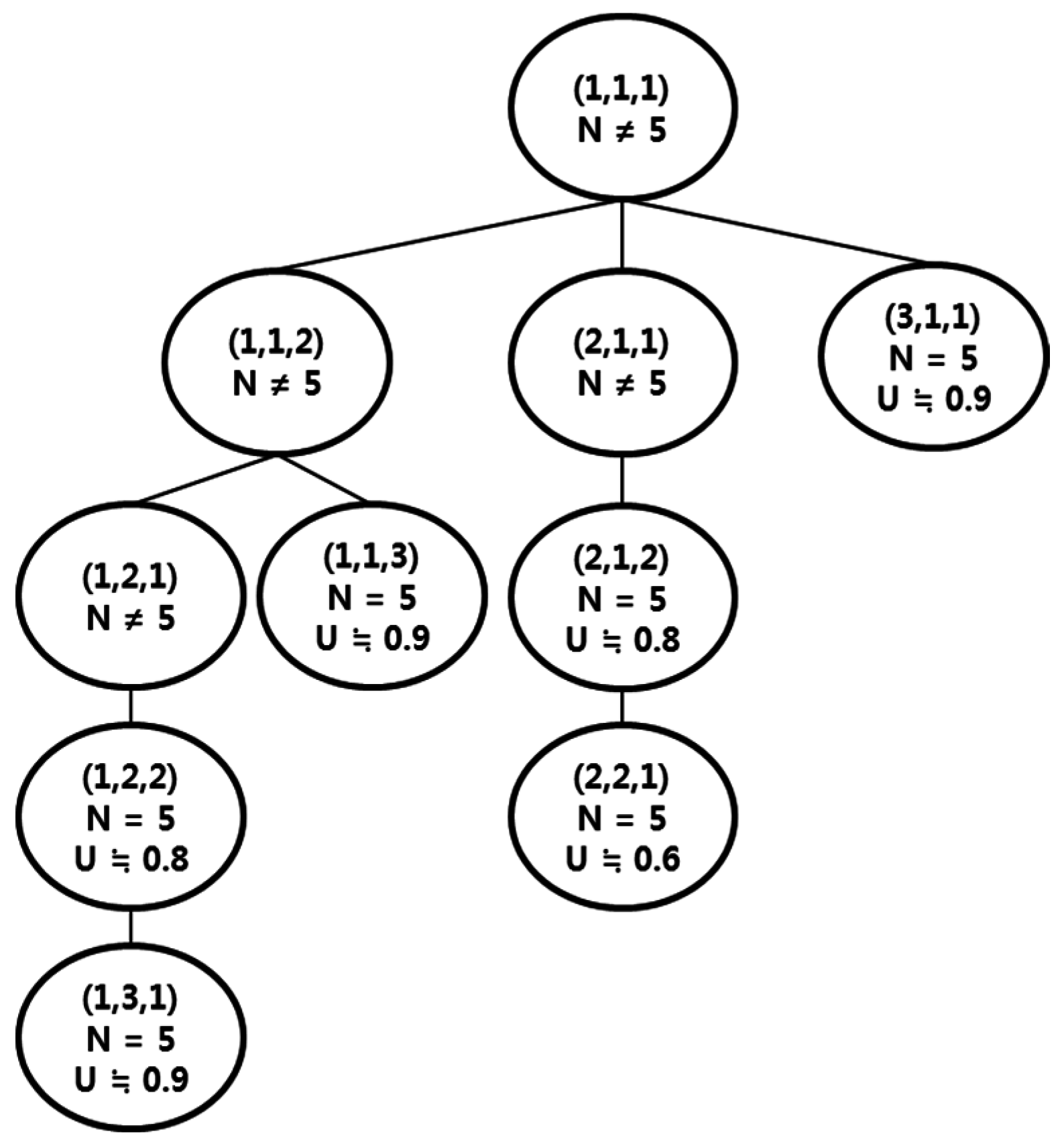
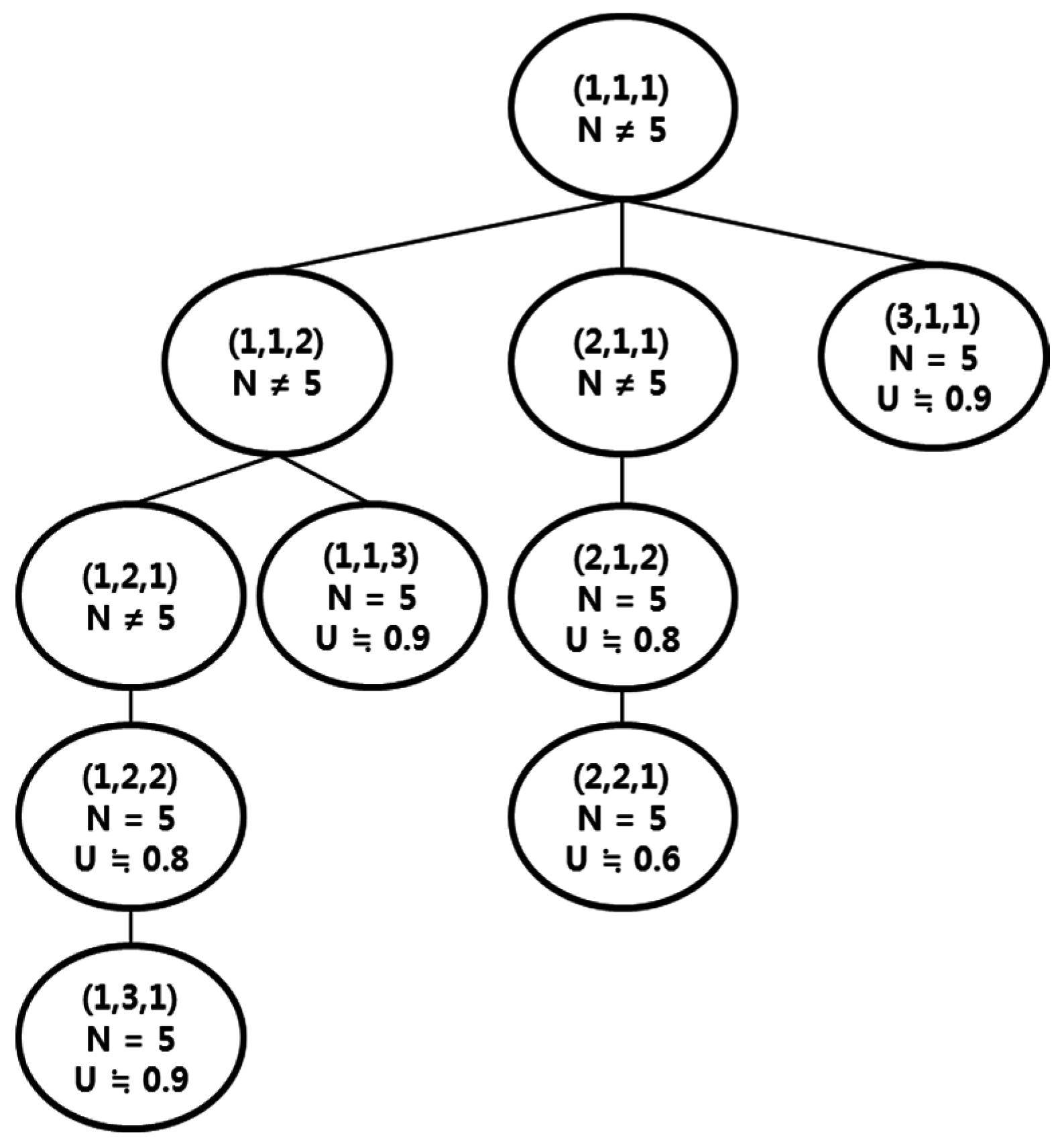
4. Resource Allocation Method
5. Services and Performance
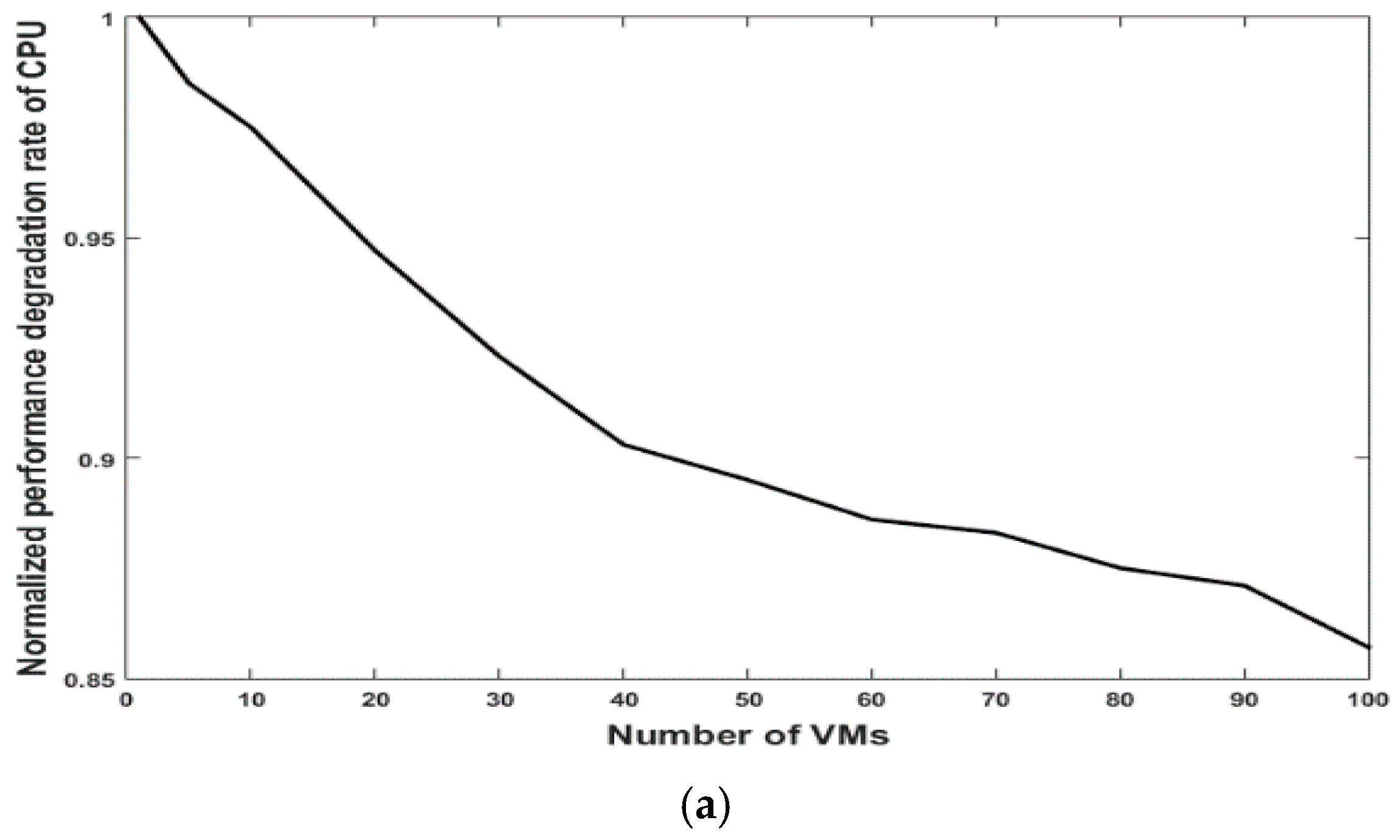
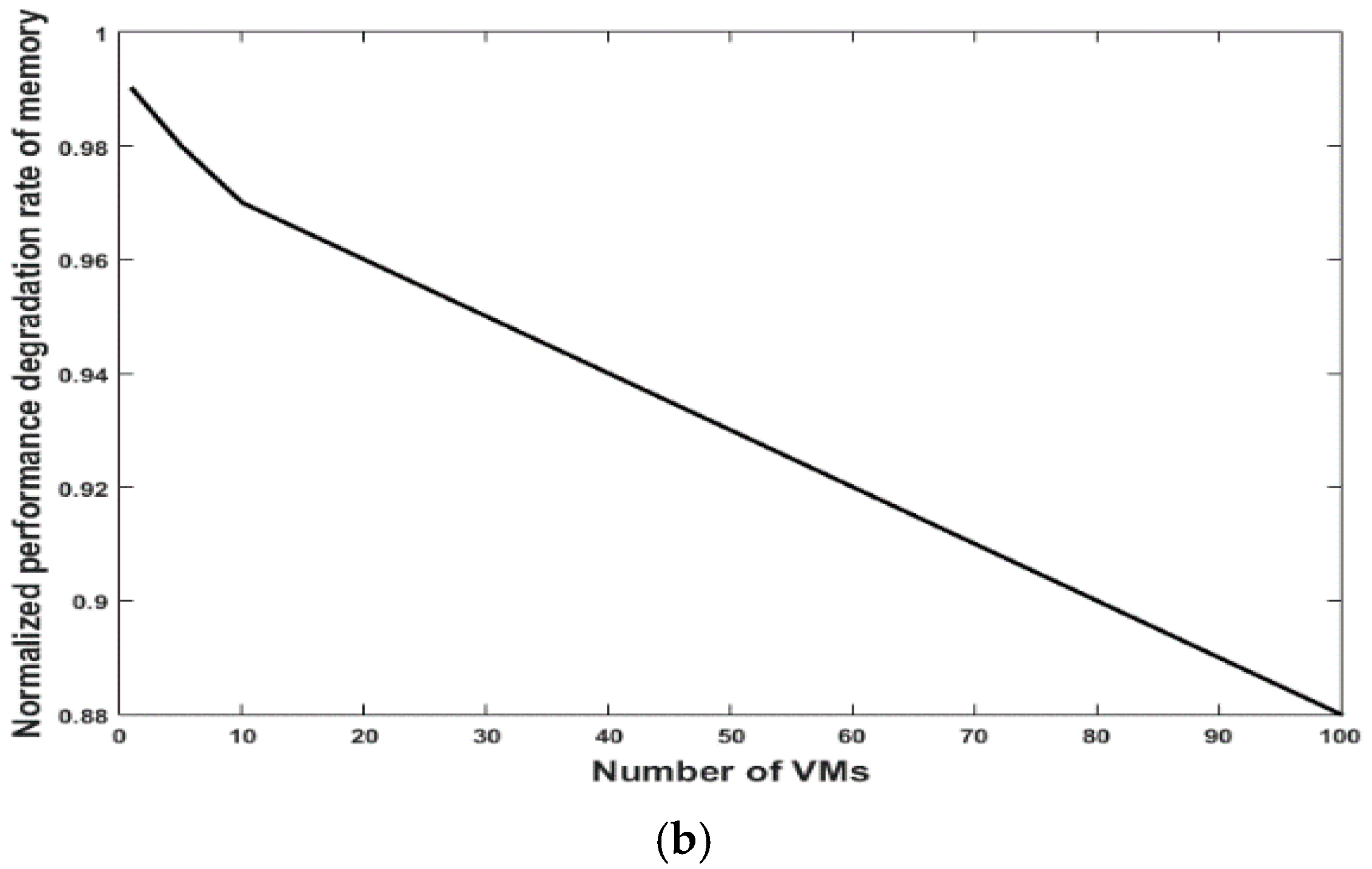
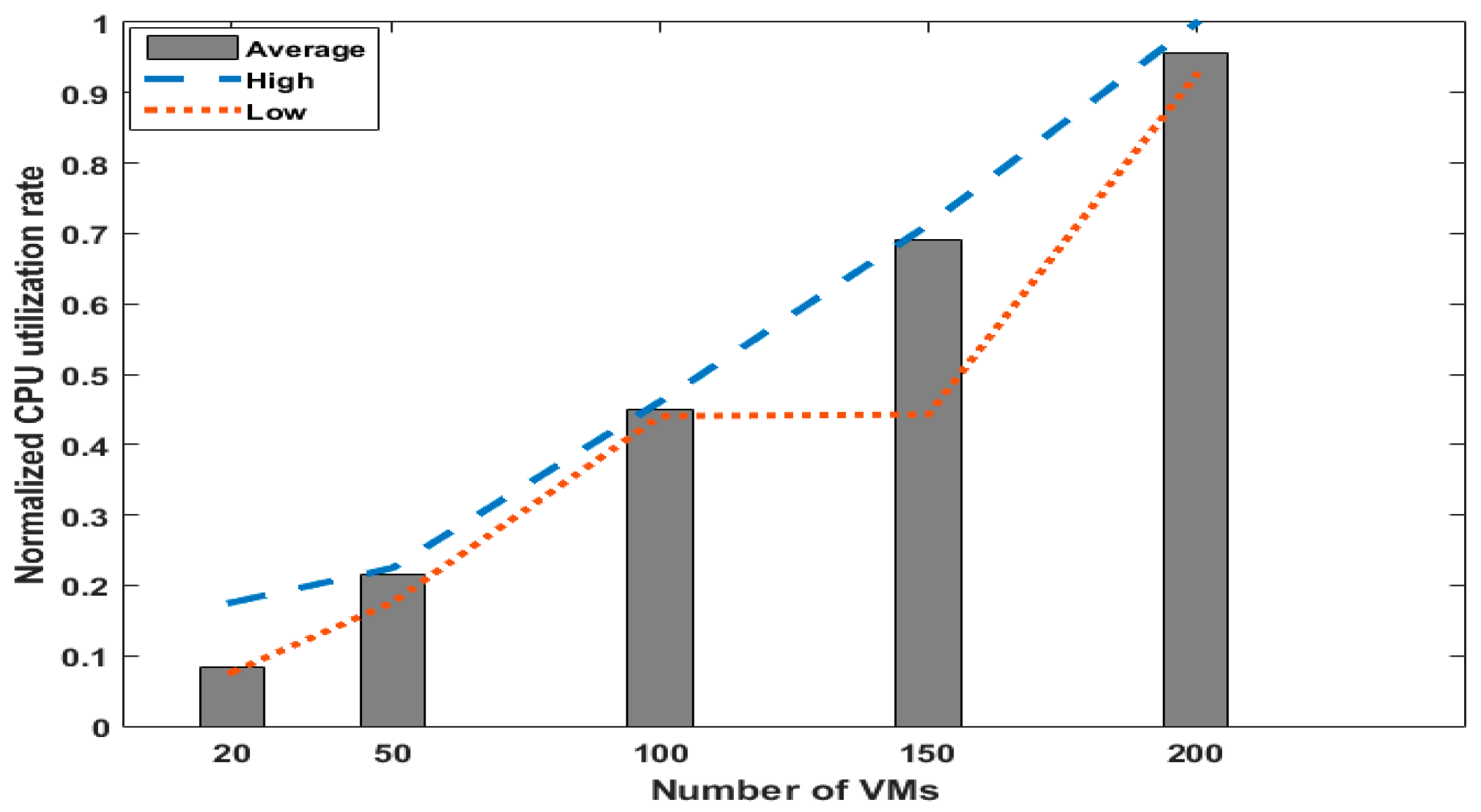
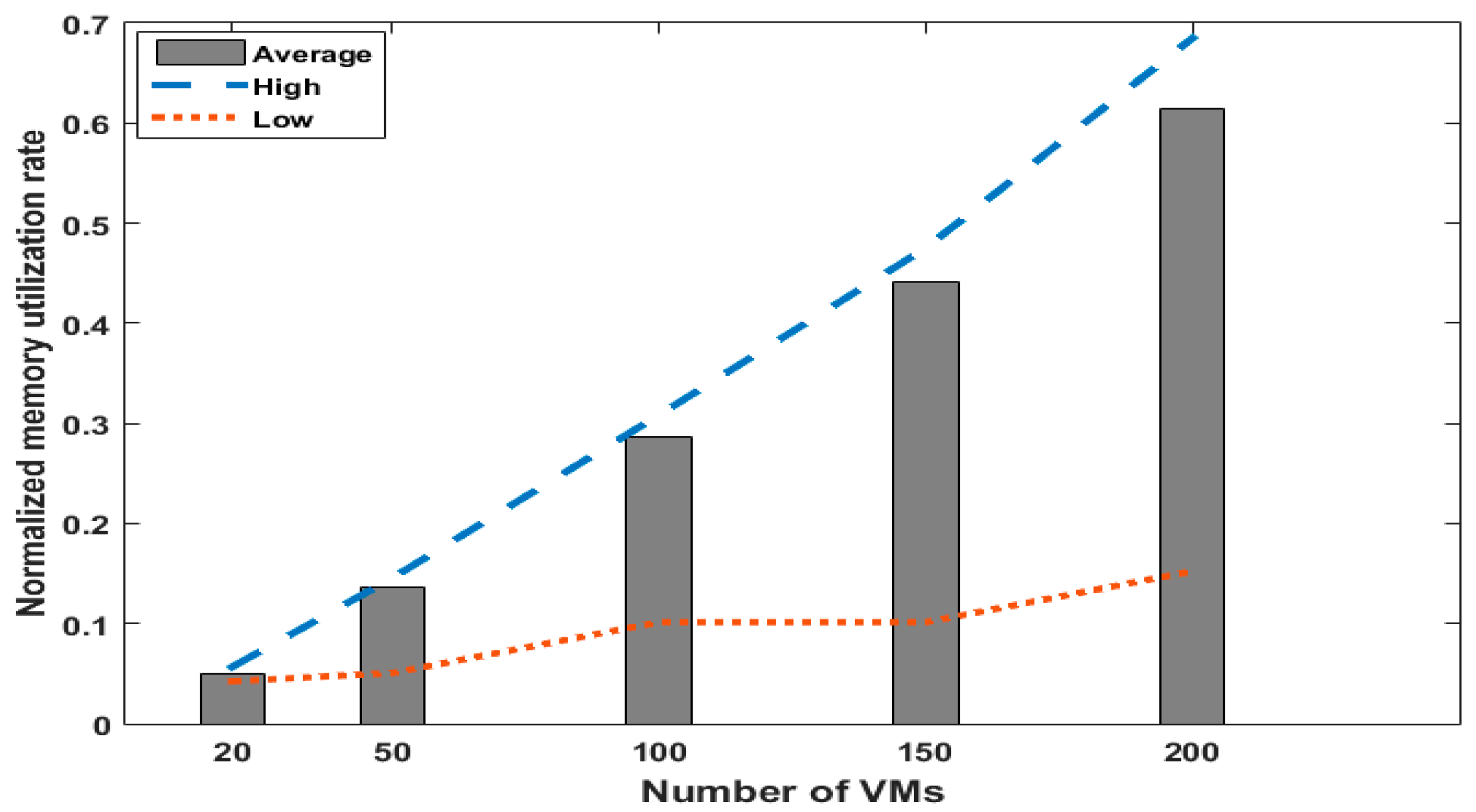
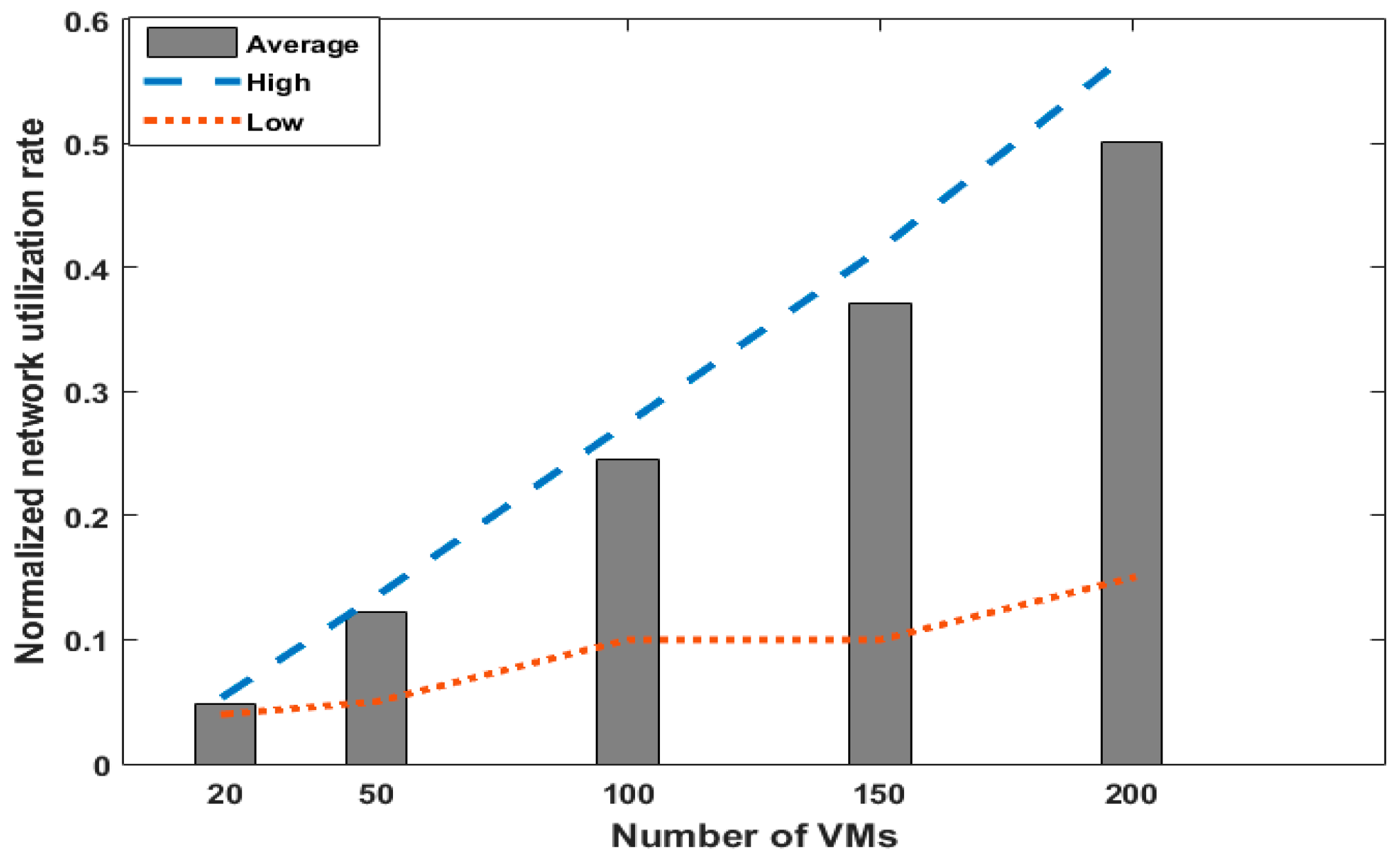
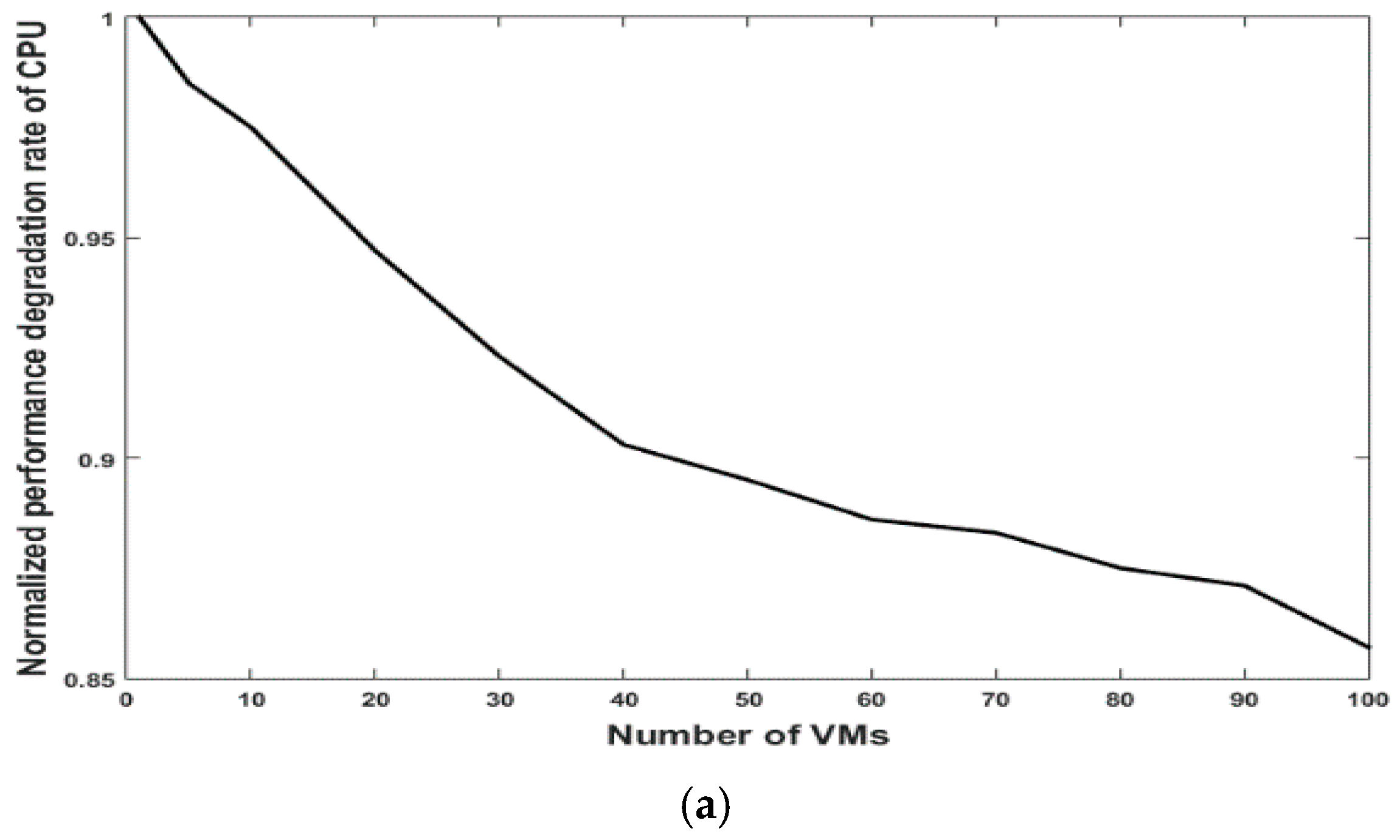
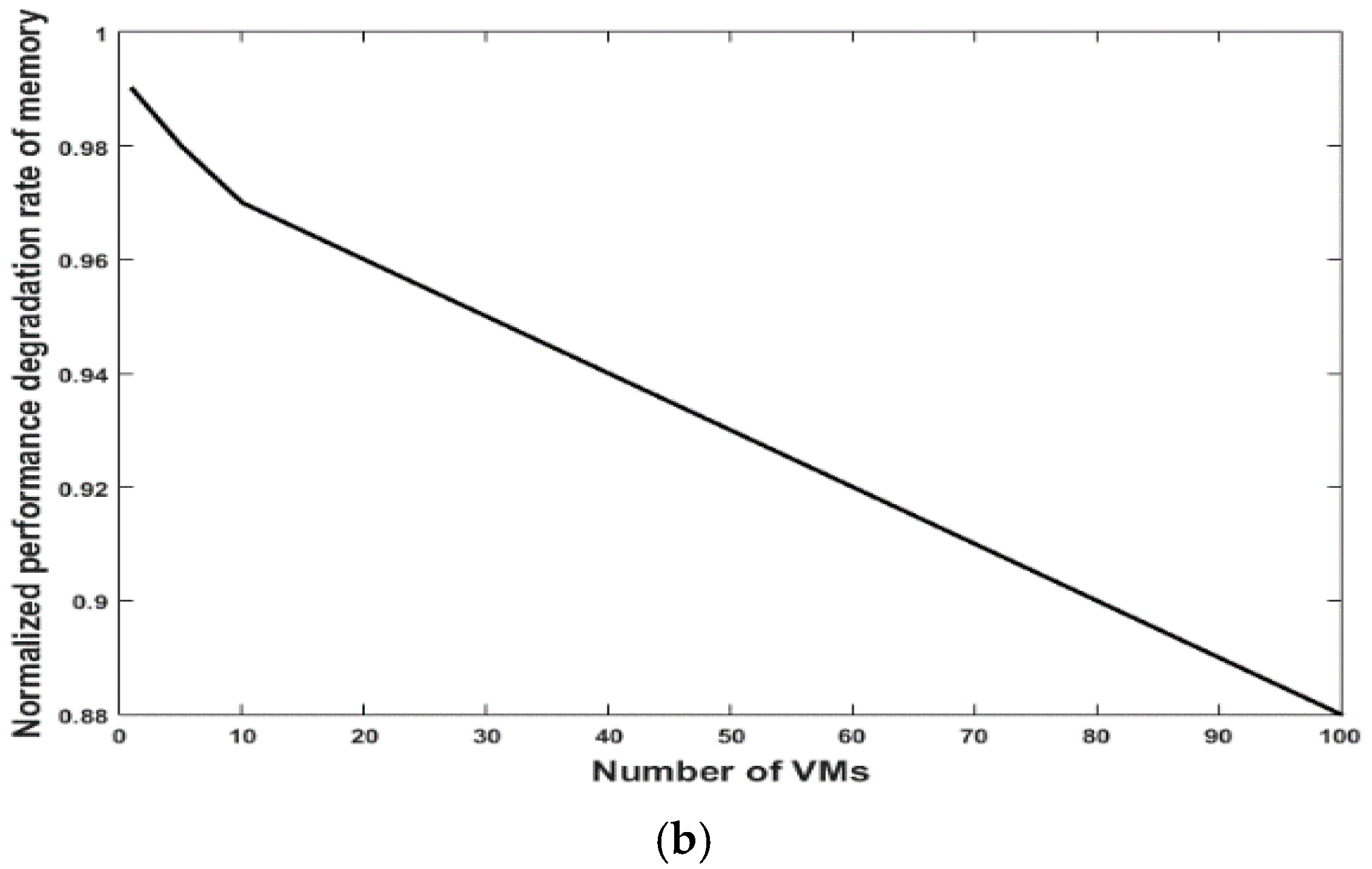
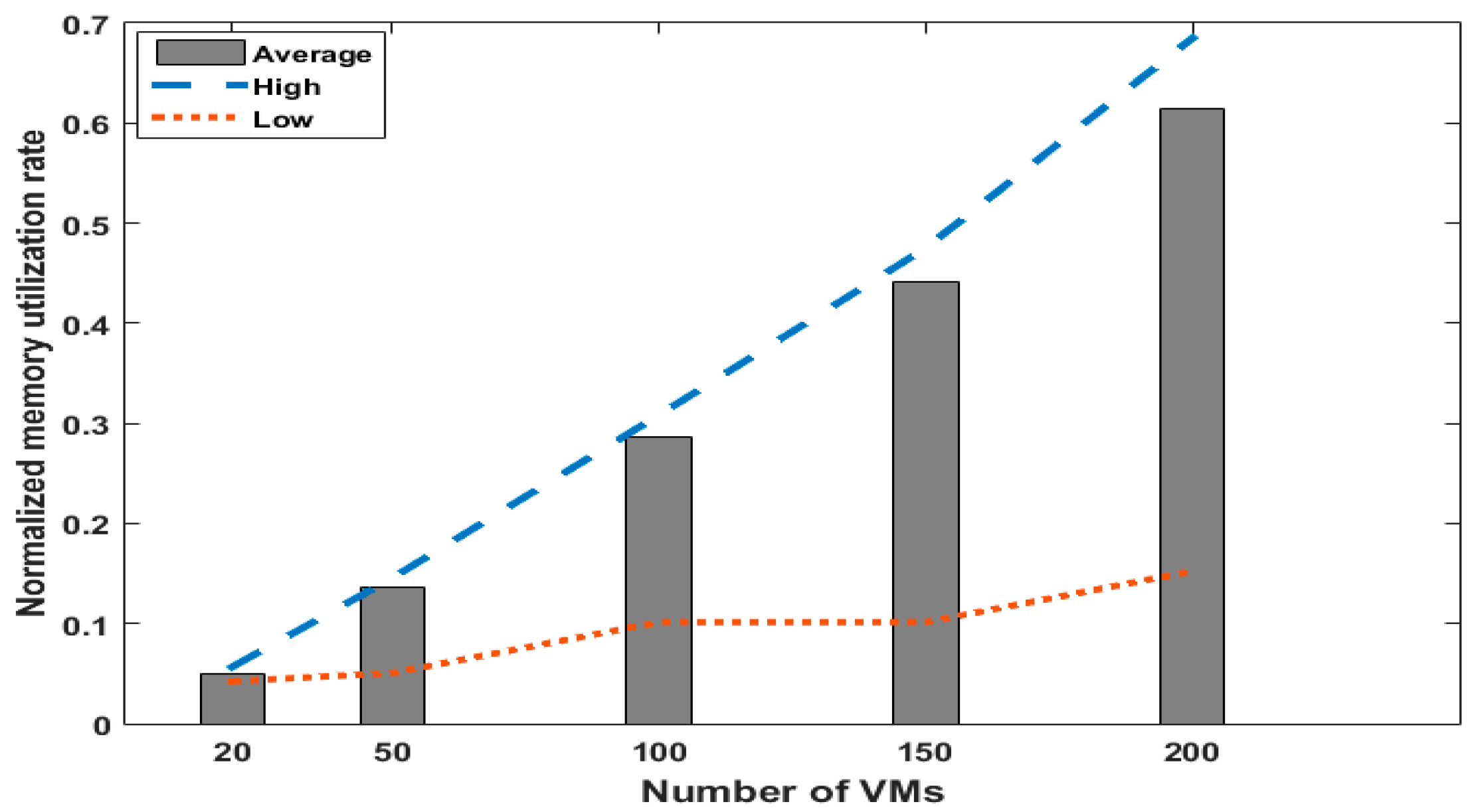
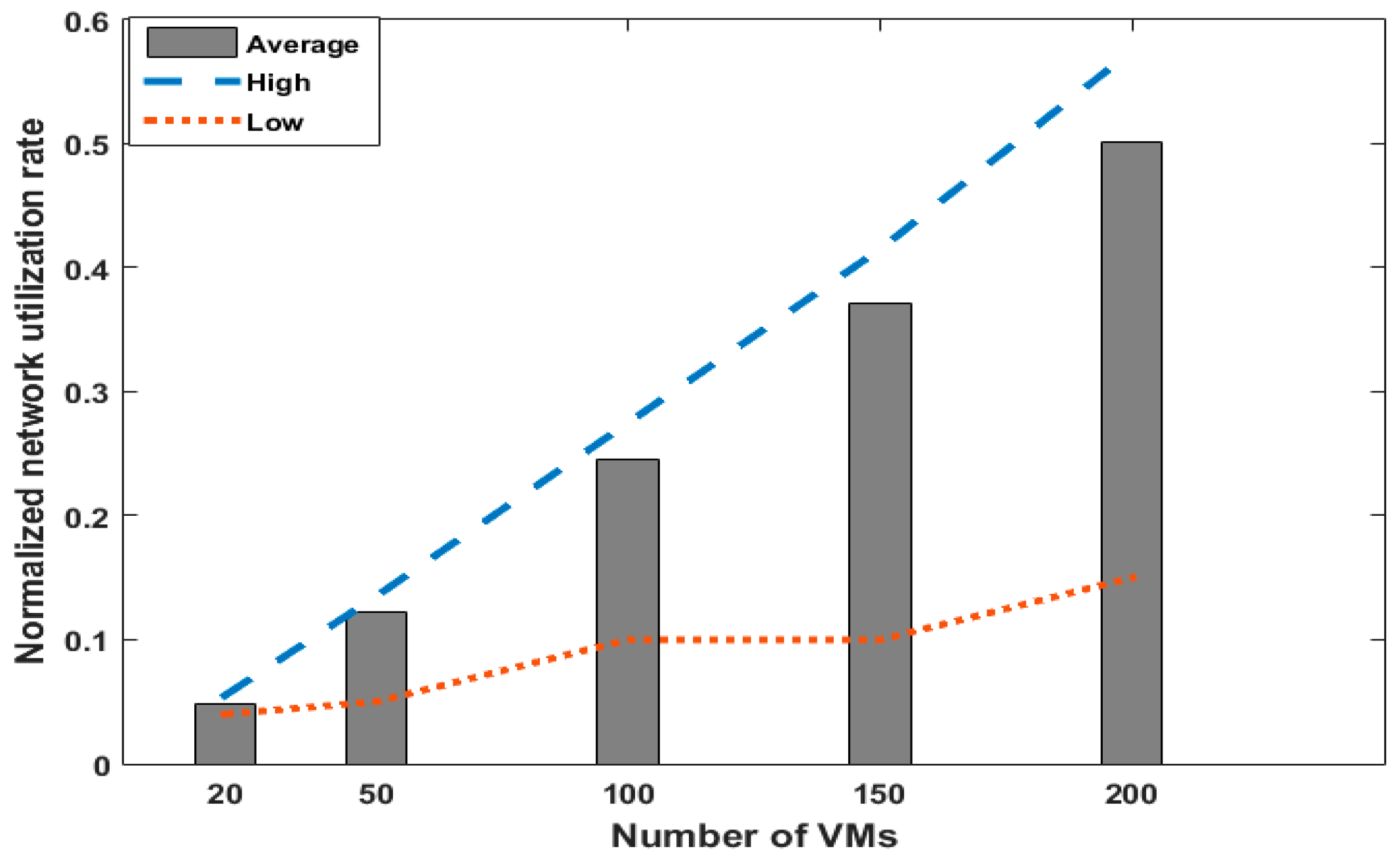
5.1. Performance Issue
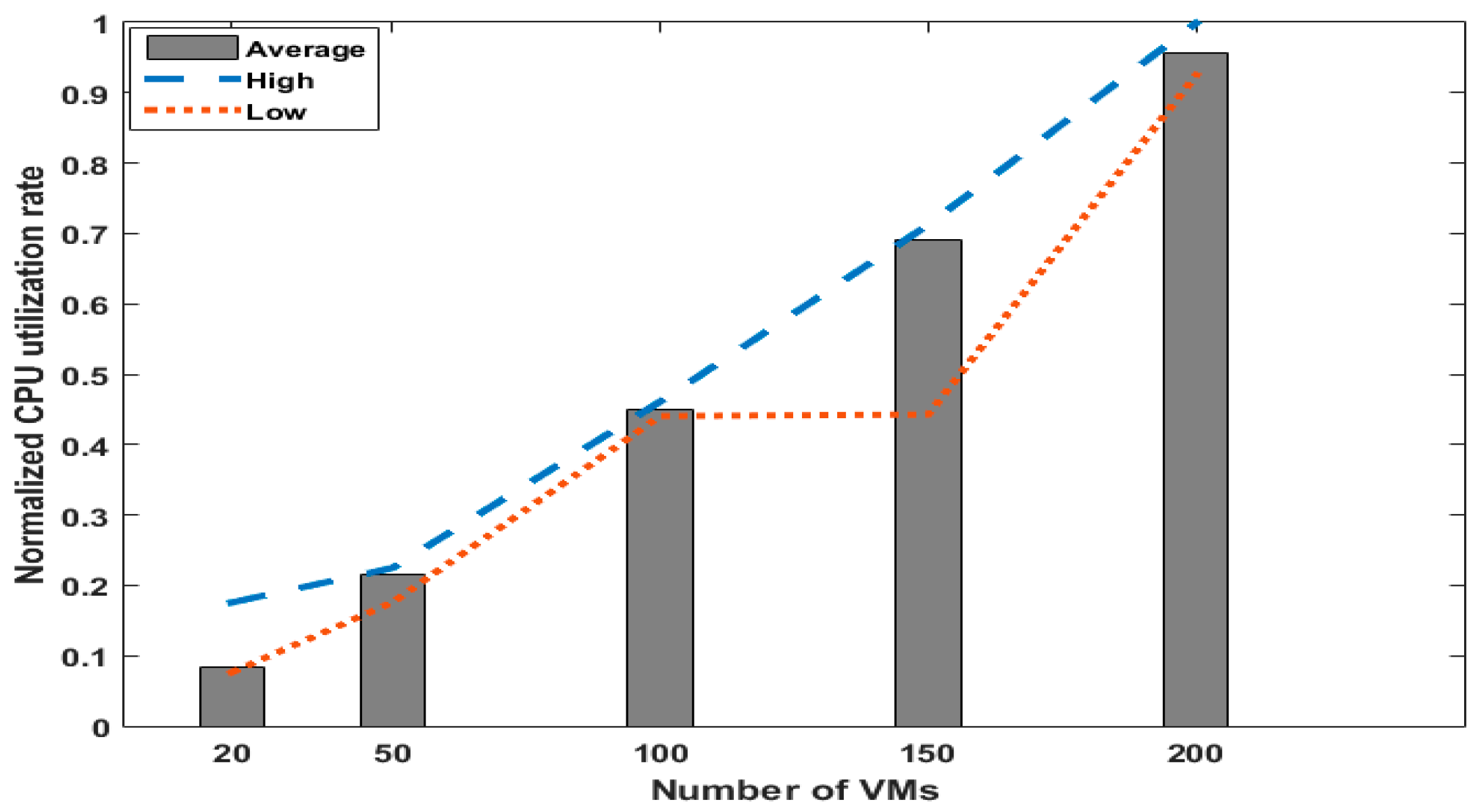
5.2. Results
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zeithaml, V.A.; Parasuraman, A.; Malhotra, A. Service Quality Delivery through Web Sites: A Critical Review of Extant Knowledge. J. Acad. Mark. Sci. 2002, 30, 362–375. [Google Scholar] [CrossRef]
- Kleinberg, J.M. Authoritative soxszurces in a hyperlinked environment. J. ACM 1999, 46, 604–632. [Google Scholar] [CrossRef]
- Felton, J.; Mitchella, J.; Stinsona, M. Web-based student evaluations of professors: The relations between perceived quality, easiness and sexiness. Assess. Eval. High. Educ. 2004, 29, 91–108. [Google Scholar] [CrossRef]
- Alsaadi, E.; Abdallah, T. Internet of things: Features, challenges, and vulnerabilities. Int. J. Adv. Comput. Sci. Inform. Technol. 2015, 4, 1–13. [Google Scholar]
- Rajamony, R.; Elnozahy, M. Measuring Client-Perceived Response Times on the WWW. In USITS; IBM Austin Research Laboratory: Austin, TX, USA, 2001. [Google Scholar]
- Gurak, L.J.; Logie, J. Internet Protests, from Text the Web. In Cyberactivism: Online Activism in Theory and Practice; MCcaughey, M., Ayers, M.D., Eds.; Routledge: London, UK, 2003. [Google Scholar]
- Piccoli, G.; Brohman, M.K.; Watson, R.T.; Parasuraman, A. Net-Based Customer Service Systems: Evolution and Revolution in Web Site Functionalities. Decis. Sci. 2014, 35, 423–455. [Google Scholar] [CrossRef]
- Jeong, T.; Lee, J.; Yoo, S.; Lee, W. Statistical Analysis for Information and Data Mining based on Parameter Classification. In Proceedings of the 7th International Conference on Internet (ICONI 2005), Kuala Lumpur, Malaysia, 13–16 December 2015.
- Tan, F.B.; Tung, L.L.; Xu, Y. A study of web-designers’ criteria for effective business-to-consumer (B2C) websites using the repertory grid technique. J. Electron. Commer. Res. 2009, 10, 165–170. [Google Scholar]
- Velte, T.; Velte, A.; Elsenpeter, R. Cloud Computing: A Practical Approach; McGraw-Hill: New York, NY, USA, 2010. [Google Scholar]
- Dillon, T.; Chen, W.; Chang, E. Cloud Computing: Issues and Challenges. In Proceedings of the IEEE International Conference on AINA, Perth, Australia, 20–23 April 2010.
- Chang, B.R.; Tsai, H.-F.; Chen, C.-M. Empirical Analysis of Server Consolidation and Desktop Virtualization in Cloud Computing. Math. Probl. Eng. 2013, 2013. [Google Scholar] [CrossRef]
- Yang, X.; Xie, N.; Wang, D.; Jiang, L. Study on Cloud Service Mode of Agricultural Information Institutions. In Proceedings of the Springer CCTA, Beijing, China, 18–20 September 2013.
- Choi, B. Effective Transmission method for High-Quality DaaS (Desktop as a Service) on Mobile Environments. Adv. Sci. Technol. Lett. SERSC 2014, 46, 48–51. [Google Scholar]
- Calyam, P.; Rajagopalan, S.; Seetharam, S.; Selvadhurai, A.; Salah, K.; Ramnath, R. Design and Verification of Virtual Desktop Cloud Resource Allocations. Elsevier Commun. Netw. Cloud 2014, 68, 110–122. [Google Scholar] [CrossRef]
- Escherich, M.; Kitagawa, M. Market Trends: Worldwide. In Desk-Based PCs Are Battling on 2012; Gartner: Stamford, CT, USA, 2012. [Google Scholar]
- Atwal, R.; Shiffler, G.; Vasquez, R. Forecast Analysis: PC Forecast Assumptions. In Worldwide 2011–2015 4Q11 Update Gartner; Gartner: Stamford, CT, USA, 26 January 2012. [Google Scholar]
- Donepudi, H.; Bhavineni, B.; Galloway, M. Designing a Web-Based Graphical Interface for Virtual Machine Management. In Information Technology: New Generations; Springer: Cham, Switzerland, 2016; pp. 401–411. [Google Scholar]
- Brecher, C.; Obdenbusch, M.; Herfs, W. Towards Optimized Machine Operations by Cloud Integrated Condition Estimation. In Machine Learning for Cyber Physical Systems; Springer: Berlin/Heidelberg, Germany, 2016; pp. 23–31. [Google Scholar]
- Guru, S.; Hanigan, I.C.; Nguyen, H.A.; Burns, E.; Stein, J.; Blanchard, W.; Lindenmayer, D.; Clancy, T. Development of a cloud-based platform for reproducible science: A case study of an IUCN Red List of Ecosystems Assessment. Ecol. Inform. 2016. [Google Scholar] [CrossRef]
- Pandi, K.M.; Somasundaram, K. Energy Efficient in Virtual Infrastructure and Green Cloud Computing: A Review. Indian J. Sci. Technol. 2016, 9. [Google Scholar] [CrossRef]
- Xu, X.C. Design Considerations for Reliable Data Transmission and Network Separation. Appl. Mech. Mater. 2015, 738, 1146–1149. [Google Scholar] [CrossRef]
- Calheiros, R.; Ranjan, R.; Beloglazov, A.; Rose, C.; Buyya, R. CloudSim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Softw. Pract. Exp. 2010, 41, 24–50. [Google Scholar] [CrossRef]
- Garg, S.; Buyya, R. NetworkCloudSim: Modelling Parallel Applications in Cloud Simulations. In Proceedings of the IEEE International Conference on UCC, Melbourne, VIC, Australia, 5–8 December 2011.
- Kliazovich, D.; Bouvry, P.; Audzevich, Y.; Khan, S. GreenCloud: A Packetlevel Simulator of Energy-aware Cloud Computing Data Centers. J. Supercomput. 2010, 62, 1263–1283. [Google Scholar] [CrossRef]
- Network Simulator 2. Available online: http://www.isi.edu/nsnam/ns (accessed on 9 November 2015).
- Jrad, F.; Tao, J.; Streit, A. Simulation-based Evaluation of an Intercloud Service Broker. In Proceeding of the Conference on Cloud Computing, GRIDs, and Virtualization, Nice, France, 22–27 July 2012.
- Castane, G.; Nunez, A.; Carretero, J. iCanCloud: A Brief Architecture Overview. In Proceeding of the IEEE International Symposium on Parallel and Distributed Processing with Applications, Madrid, Spain, 10–13 July 2012.
- Casanova, H.; Legrand, A.; Quinson, M. SimGrid: A Generic Framework for Large-Scale Distributed Experiments. In Proceeding of the IEEE International Conference on Computer Modeling and Simulation, Cambridge, UK, 1–3 April 2008.
- Buyya, R.; Manzur, M. GridSim: A Toolkit for the Modeling and Simulation of Distributed Resource Management and Scheduling for Grid Computing. Concurr. Comput. Pract. Exp. 2002, 14, 1175–1220. [Google Scholar] [CrossRef]
- Jeong, T. Theoretical and Linearity Analysis for Pressure Sensors and Communication System Development. Int. J. Distrib. Sens. Netw. 2014, 10. [Google Scholar] [CrossRef]
- Graziano, C. A Performance Analysis of Xen and KVM Hypervisors for Hosting the Xen Worlds Project; Master of Science, Iowa State University: Ames, IA, USA, 2011. [Google Scholar]
- OpenSSL. Available online: https://www.openssl.org/ (accessed on 31 July 2016).
- Kivity, A.; Kamay, Y.; Laor, D.; Lublin, U.; Ligouri, A. KVM: The Linux Virtual Machine Monitor. In Proceedings of the Linux Symposium, Ottawa, ON, Canada, 27–30 June 2007; pp. 225–230.
- Li, P. Selecting and using virtualization solutions: Our experiences with VMware and VirtualBox. J. Comput. Sci. Coll. 2010, 25, 11–17. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria Classification | Comply with the Criteria (%) | Do Not Comply with the Criteria (%) | No Data (%) |
|---|---|---|---|
| Query Service with Image Use (600 × 400 pixels or smaller) | 78% | 13% | 9% |
| Loading of Images (Use no more than three images per page) | 14% | 84% | 2% |
| Loading of Images (No more than four colors per page) | 98% | 2% | |
| Images (Indicate emphasis with bright color) | 15% | 85% | |
| Scripts (Not using Java script) | 12% | 88% | |
| Way of Expression (Display text on the page first while graphics is loading) | 79% | 21% | |
| Search box (Use or not) | 59% | 41% | |
| News information (Use or not) | 90% | 10% | |
| Web mail (Use or not) | 2% | 98% | |
| Segmented Order (Break up content with topics and sub-topics, headings, or horizontal lines, or use headers) | 73% | 27% | |
| Links (Make links within a document descriptive) | 58% | 42% | |
| Lines (Use horizontal line at the bottom of page) | 34% | 66% | |
| Single Fonts (Avoid using multiple fonts) | 96% | 4% | |
| Letter Size (Not use all capital letters) | 97% | 3% | |
| White Space (Use or not) | 86% | 14% | |
| Page Length (No single pages) | 30% | 70% |
| Service Parameters | N (#) | Mean | Std. Deviation | Std. Error Mean |
|---|---|---|---|---|
| PIC_SIZE | 84 | 0.9762 | 0.15337 | 0.01673 |
| IM_3 | 99 | 0.1414 | 0.35022 | 0.03520 |
| N_BG_COL | 100 | 1.8700 | 0.97084 | 0.09708 |
| BG | 100 | 0.8100 | 0.39428 | 0.03943 |
| BG_BLACK | 100 | 0.1200 | 0.32660 | 0.03266 |
| FON_COL | 100 | 0.2500 | 0.43519 | 0.04352 |
| FONT_3 | 100 | 0.0300 | 0.17145 | 0.01714 |
| BR_COL | 100 | 0.1600 | 0.36845 | 0.03685 |
| JAVA_SC | 97 | 0.8866 | 0.31873 | 0.03236 |
| BEF_GRP | 100 | 0.7900 | 0.40936 | 0.04094 |
| SEAR_BOX | 100 | 0.5900 | 0.49431 | 0.04943 |
| CUR_EVEN | 100 | 0.9000 | 0.30151 | 0.03015 |
| WEB_MAIL | 100 | 0.0200 | 0.14071 | 0.01407 |
| SEPAR | 100 | 0.7300 | 0.44620 | 0.04462 |
| LINK | 100 | 0.5800 | 0.49604 | 0.04960 |
| HOR_LINE | 100 | 0.3400 | 0.47610 | 0.04761 |
| MUL_FONT | 100 | 0.9700 | 0.17145 | 0.01714 |
| CAP_LETT | 100 | 0.0200 | 0.14071 | 0.01407 |
| SEP_SPA | 100 | 0.8700 | 0.33800 | 0.03380 |
| LG_PAGE | 100 | 1.8300 | 0.68246 | 0.06825 |
| Servers | Server Specifications | Hypervisor |
|---|---|---|
| Server #1 | CPU: 2.7 GHz, 24 cores RAM: 396 GB Network: 1 GB | Linux (KVM) [33] |
| Server #2 | CPU: 2.7 GHz, 20 cores RAM: 396 GB Network: 1 GB | Linux (KVM) [33] |
| Server #3 | CPU: 2.7 GHz, 4 cores RAM: 32 GB Network: 1 GB | Windows (Virtual Box) [34] |
| Servers and Resources | d(Ni) | ||||
|---|---|---|---|---|---|
| a3 | a2 | a1 | a0 | ||
| Server #1 (i = 1) | CPU | −6.9 × 10−7 | 1.1 × 10−4 | −7.3 × 10−3 | 0.9 |
| MEM | 4.0 × 10−9 | 7.3 × 10−7 | 5.4 × 10−3 | 0.9 | |
| Server #2 (i = 2) | CPU | −2.0 × 10−7 | 4.5 × 10−5 | −3.9 × 10−3 | 1.0 |
| MEM | −6.8 × 10−8 | 1.2 × 10−5 | −1.6 × 10−3 | 0.9 | |
| Server #3 (i = 3) | CPU | 1.2 × 10−2 | −1.0 × 10−1 | 3.2 × 10−2 | 1.0 |
| MEM | 5.9 × 10−8 | −1.3 × 10−5 | 1.6 × 10−3 | 1.0 | |
| # of Total VMs | Optimal Distribution of VMs | ||
|---|---|---|---|
| Server #1 | Server #2 | Server #3 | |
| 20 | 8 | 11 | 1 |
| 50 | 22 | 27 | 1 |
| 100 | 43 | 55 | 2 |
| 150 | 65 | 83 | 2 |
| 200 | 82 | 115 | 3 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Jeong, T. Cloud-Based Parameter-Driven Statistical Services and Resource Allocation in a Heterogeneous Platform on Enterprise Environment. Symmetry 2016, 8, 103. https://doi.org/10.3390/sym8100103
Lee S, Jeong T. Cloud-Based Parameter-Driven Statistical Services and Resource Allocation in a Heterogeneous Platform on Enterprise Environment. Symmetry. 2016; 8(10):103. https://doi.org/10.3390/sym8100103
Chicago/Turabian StyleLee, Sungju, and Taikyeong Jeong. 2016. "Cloud-Based Parameter-Driven Statistical Services and Resource Allocation in a Heterogeneous Platform on Enterprise Environment" Symmetry 8, no. 10: 103. https://doi.org/10.3390/sym8100103
APA StyleLee, S., & Jeong, T. (2016). Cloud-Based Parameter-Driven Statistical Services and Resource Allocation in a Heterogeneous Platform on Enterprise Environment. Symmetry, 8(10), 103. https://doi.org/10.3390/sym8100103