Research Front Detection and Topic Evolution Based on Topological Structure and the PageRank Algorithm



Abstract
:1. Introduction
2. Related Works
2.1. Research front Detection and Topic Evolution
2.2. Related Algorithms Used in this Study
3. The Proposed Research Front Detection and Topic Evolution Method
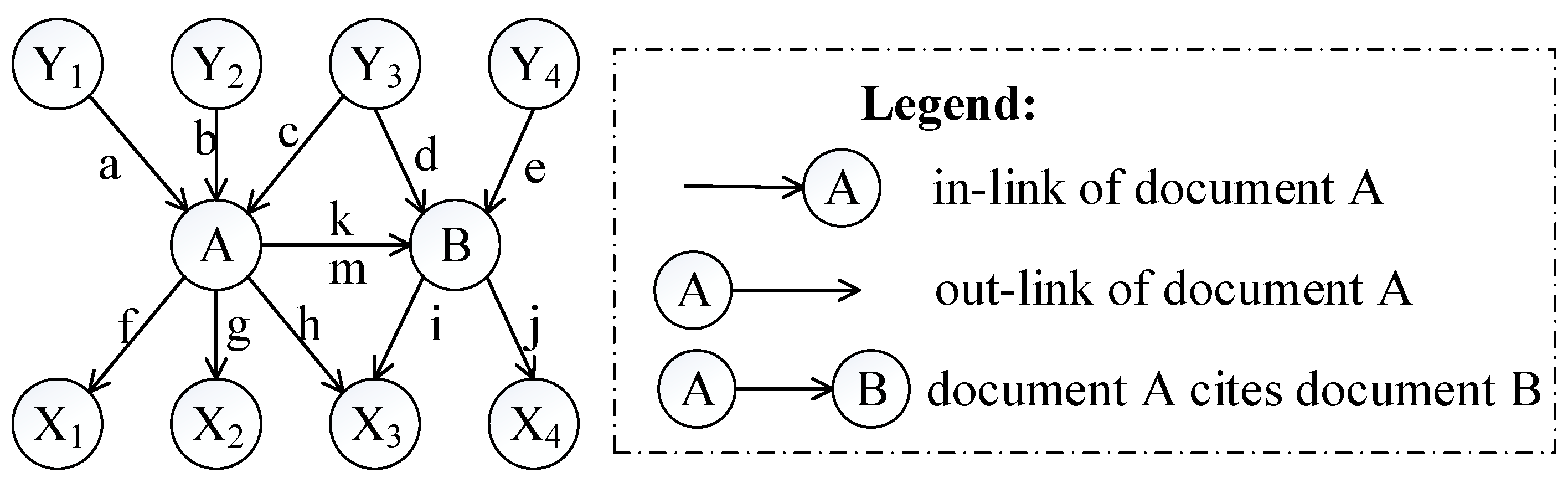
3.1. Notations
| A/B | scientific documents A or B in case study |
| p/q | clusters p or q in this study |
| |p/q| | number of scientific documents in the clusters p or q |
| NA | number of scientific documents in the cluster which contains document A |
| t | length of time window |
| d | damping factor introduced in the PageRank algorithm, which is set as 0.85 in this study |
| Ccite(A/B) | collection of scientific documents that cite documents A or B |
| Ccited(A/B) | collection of scientific documents that are cited by documents A or B |
| P(A/B) | rank value of documents A or B in the cluster |
| Nin(A/B) | in-degree of documents A or B, which equals the number of scientific documents that cite documents A or B |
| Nout(A/B) | out-degree of documents A or B, which equals the number of scientific documents that are cited by documents A or B |
| Ncluster(B) | number of scientific documents that are cited by document B and belong to the same cluster with document B |
| Nci(p,q) | number of citations between clusters q and p |
| H(var) | function that returns the value of variable var if var is not equal to zero, otherwise it returns positive infinity. |
| Hin(A,B) | function that returns Nin(A) if document B cites document A, returns Nin(B) if document A cites document B, and returns positive infinity if documents A and B have no direct citation relationship |
| Hout(A,B) | function that returns Nout(A) if document A cites document B, returns Nout(B) if document B cites document A, and returns positive infinity if documents A and B have no direct citation relationship |
| Sco(A,B) | similarity between documents A and B based on relative co-citation [25] |
| Sbi(A,B) | similarity between documents A and B based on relative bibliographic coupling [25] |
| S(A,B) | similarity between documents A and B based on the traditional approach that combines relative co-citation and bibliographic coupling [10] |
| similarity between documents A and B based on extended co-citation | |
| similarity between documents A and B based on extended bibliographic coupling | |
| similarity between documents A and B based on our proposed approach | |
| Scluster(p,q) | similarity between clusters p and q |
| F(p,x) | enhanced frequency of keyword x in the cluster p, which is based on our proposed approach |
| δ(A,x) | binary parameter, with 1 representing that document A contains keyword x, and 0 otherwise |
3.2. Scientific Document Clustering
3.3. Clustering Theme Detection
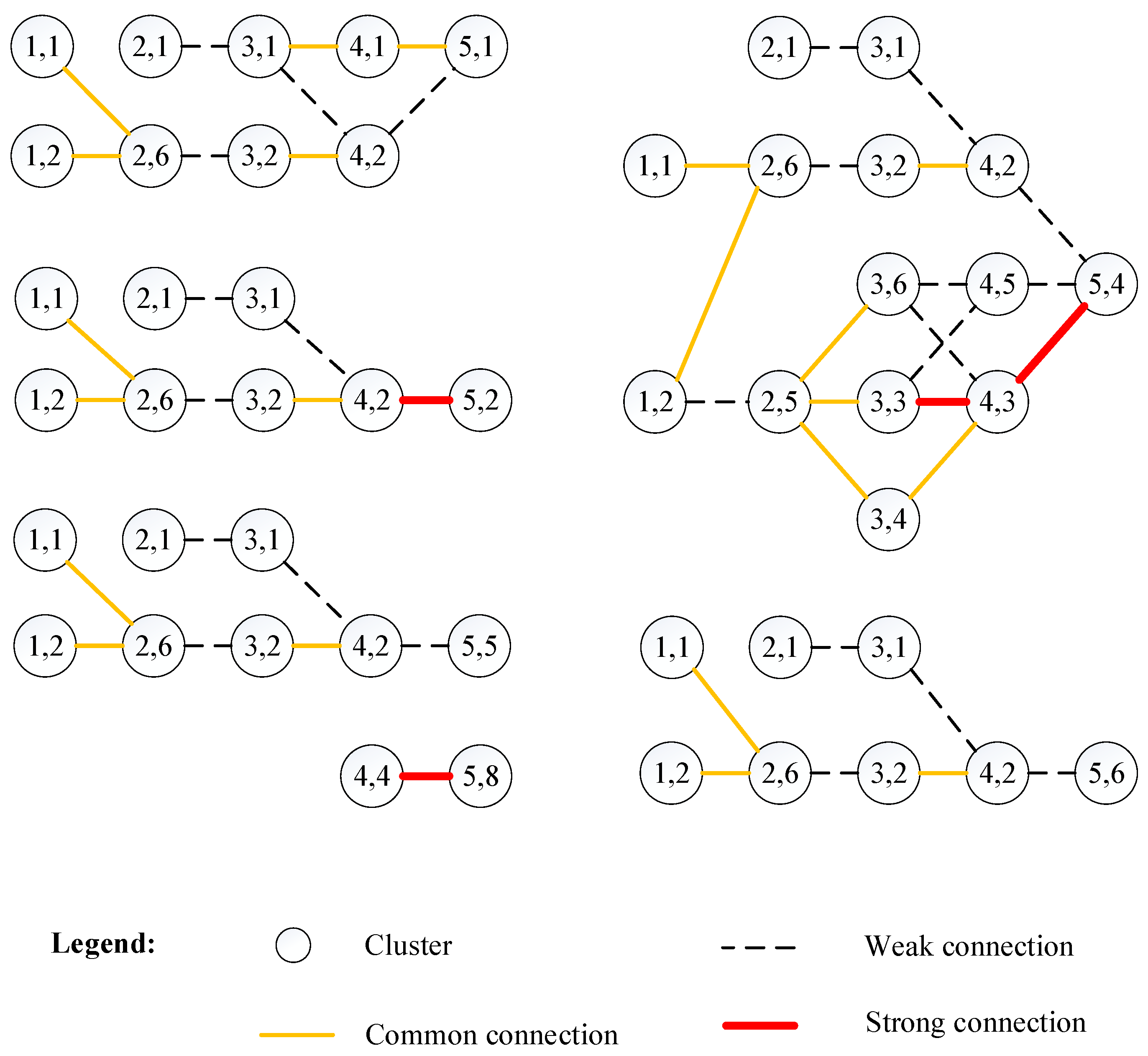
3.4. Research front Detection and Topic Evolution
4. Case Study and Experiments
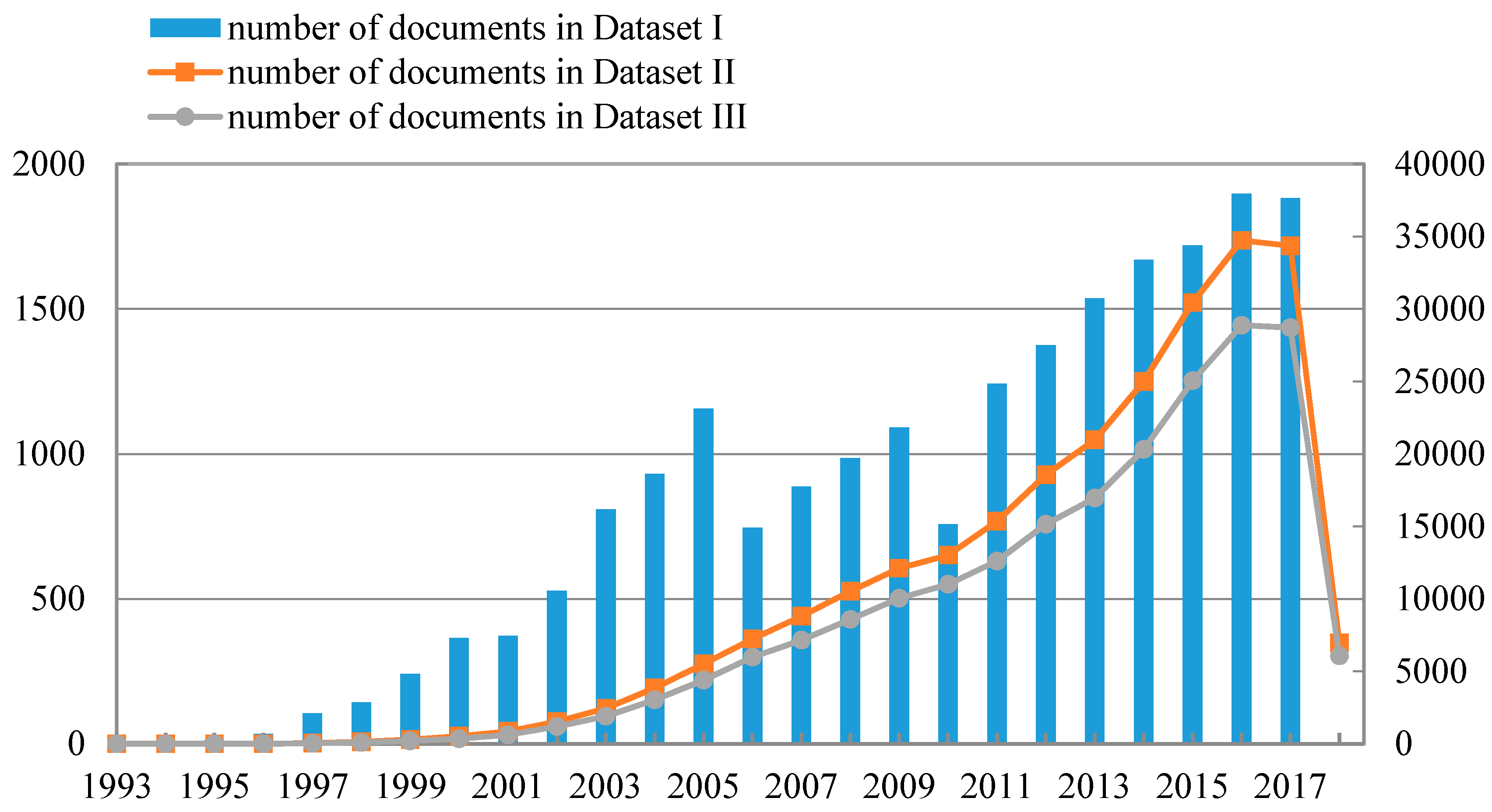
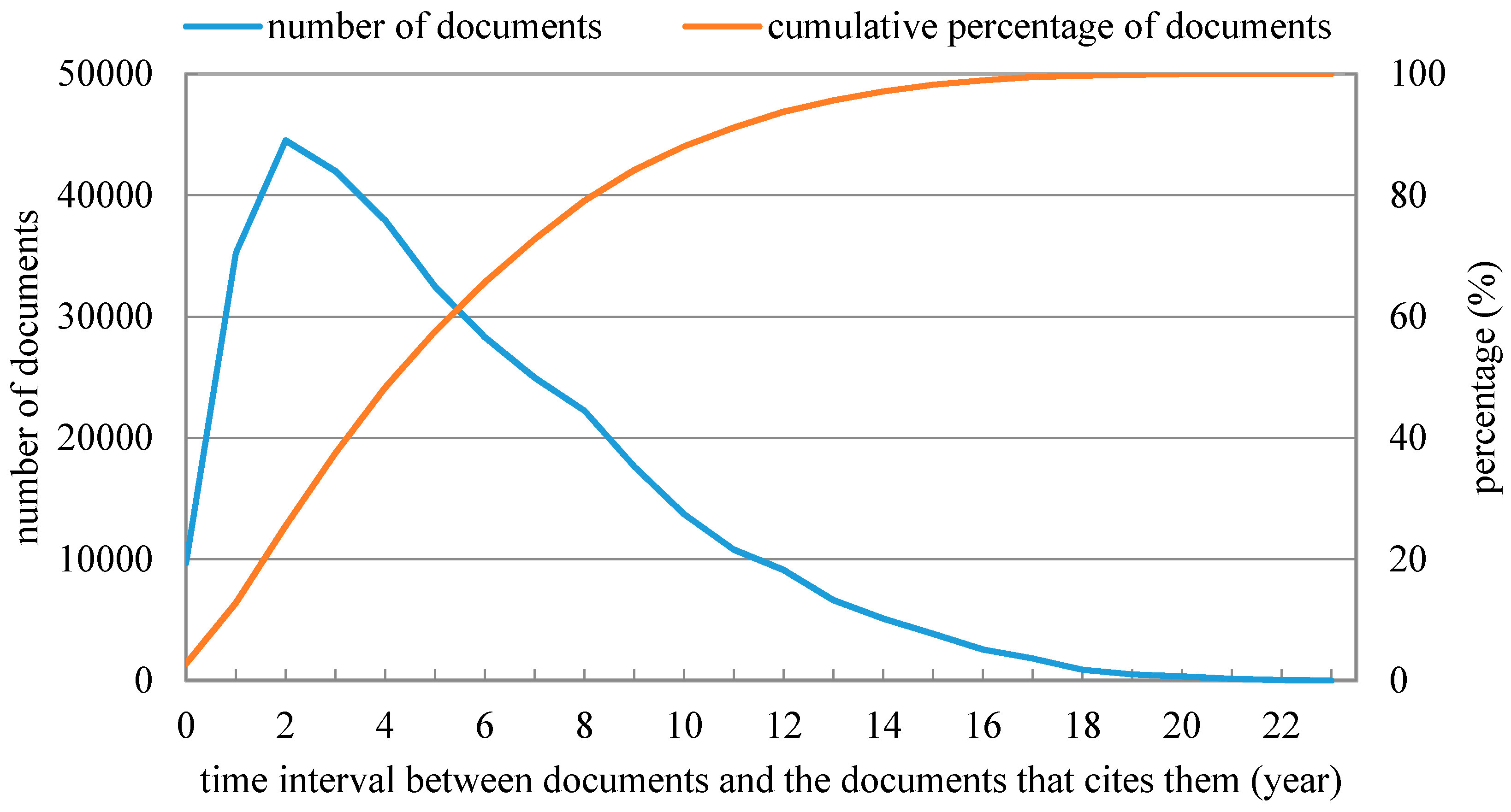
4.1. Dataset
4.2. Data Preprocessing
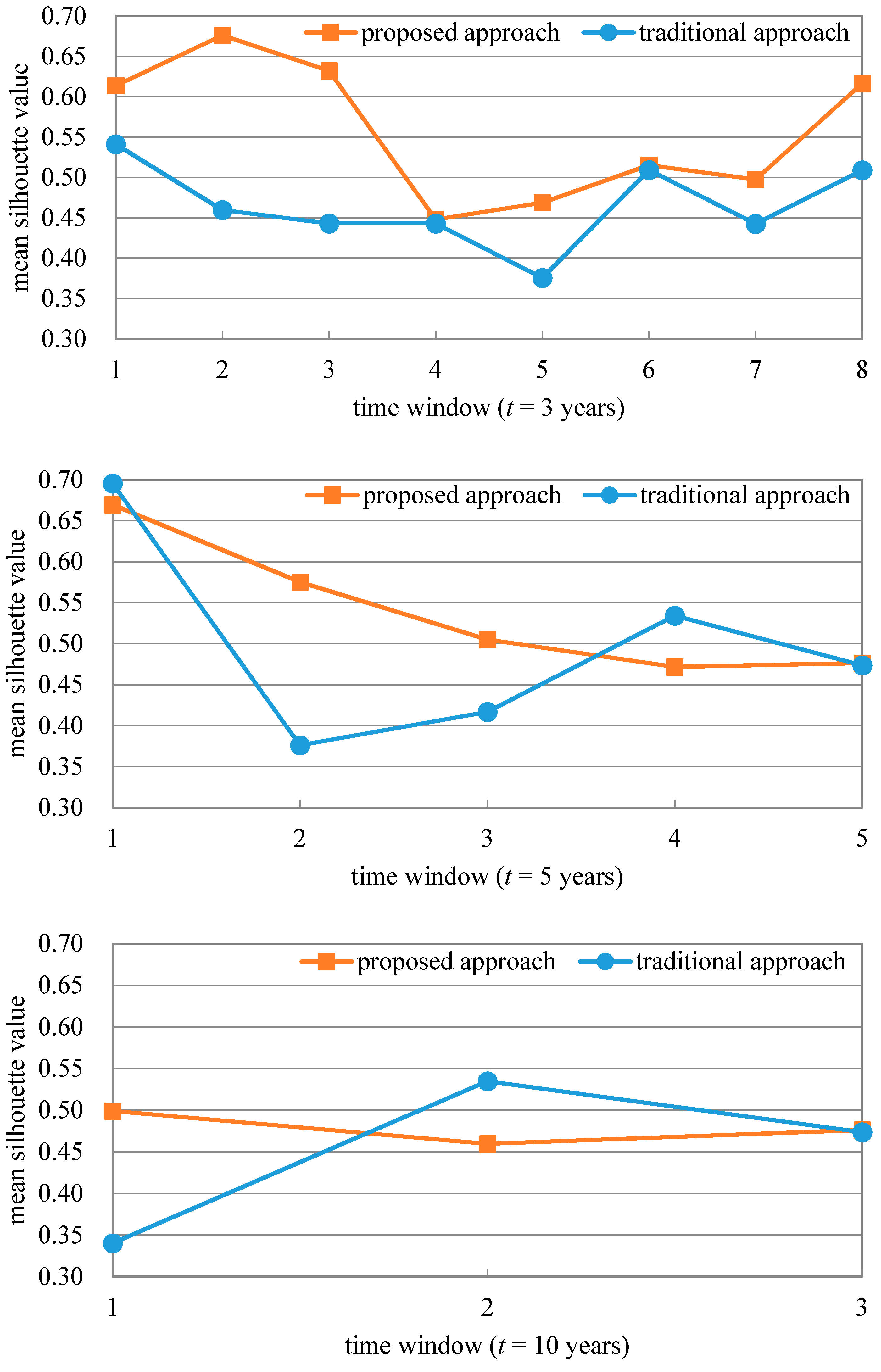
4.3. Experimental Design and Evaluation Index
4.4. Experiment Results
4.4.1. Scientific Document Clustering
4.4.2. Clustering Theme Detection
4.4.3. Research front Detection and Topic Evolution
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Window | Cluster (Size) | Clustering Theme |
|---|---|---|
| 1993–1997 | Cluster 1 (35) | Neural network; uncertainty; prediction |
| Cluster 2 (31) | Association rule; knowledge discovery; clustering | |
| Cluster 3 (19) | Knowledge discovery; machine learning; rule | |
| 1998–2002 | Cluster 1 (325) | Protein; identification; neural network |
| Cluster 2 (207) | Neural network; knowledge discovery; decision tree | |
| Cluster 3 (163) | Neural network; machine learning; genetic algorithm | |
| Cluster 4 (151) | Knowledge discovery; rough set; machine learning | |
| Cluster 5 (146) | Association rule; knowledge discovery; pattern | |
| Cluster 6 (136) | Decision tree; machine learning; knowledge discovery | |
| 2003–2007 | Cluster 1 (1597) | Clustering analysis; bioinformatics; gene expression |
| Cluster 2 (747) | Decision tree; machine learning; neural network | |
| Cluster 3 (373) | Association rule; sequential pattern; knowledge discovery | |
| Cluster 4 (344) | Association rule; knowledge discovery; frequent itemset | |
| Cluster 5 (303) | Rough set; feature selection; genetic algorithm | |
| Cluster 6 (224) | Sequential pattern; association rule; knowledge discovery | |
| Cluster 7 (115) | Knowledge discovery; prediction; neural network | |
| 2008–2012 | Cluster 1 (1830) | Clustering analysis; identification; bioinformatics |
| Cluster 2 (1617) | Support vector machine; decision tree; prediction | |
| Cluster 3 (566) | Association rule; pattern; knowledge discovery | |
| Cluster 4 (232) | Privacy; security; k-anonymity | |
| Cluster 5 (200) | Sequential pattern; association rule; knowledge discovery | |
| 2013–2017 | Cluster 1 (2117) | Clustering analysis; social network; big data |
| Cluster 2 (1750) | Support vector machine; prediction; neural network | |
| Cluster 3 (1544) | Identification; gene expression; bioinformatics | |
| Cluster 4 (930) | Association rule; sequential pattern; knowledge discovery | |
| Cluster 5 (517) | Machine learning; prediction; decision tree | |
| Cluster 6 (460) | Prediction; educational data mining; design | |
| Cluster 7 (249) | Rough set; attribute reduction; approximation | |
| Cluster 8 (189) | Differential privacy; k-anonymity; big data |

References
- Chen, C. Citespace II: Detecting and visualizing emerging trends and transient patterns in scientific literature. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 359–377. [Google Scholar] [CrossRef]
- Wu, Y.; Jin, X.; Xue, Y.Z. Evaluation of research topic evolution in psychiatry using co-word analysis. Medicine 2017, 96, e7349. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Jiang, T.; Ma, F. Collective dynamics in knowledge networks: Emerging trends analysis. J. Informetrics 2013, 7, 425–438. [Google Scholar] [CrossRef]
- Fujita, K.; Kajikawa, Y.; Mori, J.; Sakata, I. Detecting research fronts using different types of weighted citation networks. J. Eng. Technol. Manag. 2014, 32, 129–146. [Google Scholar] [CrossRef]
- Chen, B.; Tsutsui, S.; Ding, Y.; Ma, F. Understanding the topic evolution in a scientific domain: An exploratory study for the field of information retrieval. J. Informetr. 2017, 11, 1175–1189. [Google Scholar] [CrossRef]
- Boyack, K.W.; Klavans, R. Co-citation analysis, bibliographic coupling, and direct citation: Which citation approach represents the research front most accurately? J. Assoc. Inf. Sci. Technol. 2010, 61, 2389–2404. [Google Scholar] [CrossRef]
- Glänzel, W.; Thijs, B. Using ‘core documents’ for detecting and labelling new emerging topics. Scientometrics 2012, 91, 399–416. [Google Scholar] [CrossRef]
- Yu, D.J.; Wang, W.R.; Zhang, S.; Zhang, W.Y.; Liu, R.Y. Hybrid self-optimized clustering model based on citation links and textual features to detect research topics. PLoS ONE 2017, 12, e0187164. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Wang, X.G.; Zhao, D.L.; Tang, X.O. Graph degree linkage: Agglomerative clustering on a directed graph. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 428–441. [Google Scholar]
- Bichteler, J.; Iii, E.A.E. The combined use of bibliographic coupling and cocitation for document retrieval. J. Am. Soc. Inf. Sci. 1980, 31, 278–282. [Google Scholar] [CrossRef]
- Shubankar, K.; Singh, A.P.; Pudi, V. A frequent keyword-set based algorithm for topic modeling and clustering of research papers. In Proceedings of the 3rd Conference on Data Mining and Optimization, Putrajaya, Malaysia, 28–29 June 2011; pp. 96–102. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Kim, J.; Lee, E. Understanding review expertise of developers: A reviewer recommendation approach based on latent dirichlet allocation. Symmetry Basel 2018, 10, 114. [Google Scholar] [CrossRef]
- Kim, M.; Gupta, B.B.; Rho, S. Crowdsourcing based scientific issue tracking with topic analysis. Appl. Soft Comput. 2018, 66, 506–511. [Google Scholar] [CrossRef]
- Qiao, S.; Han, A. A way to construct evolution model of scientific papers based on the seed document and OLDA models. In Proceedings of the 2013 International Conference on Mechatronic Science, Electric Engineering and Computer, Shenyang, China, 20–22 December 2013; pp. 900–903. [Google Scholar]
- Morris, S.A.; Yen, G.; Wu, Z.; Asnake, B. Time line visualization of research fronts. J. Am. Soc. Inf. Sci. Technol. 2003, 54, 413–422. [Google Scholar] [CrossRef]
- Clauset, A.; Newman, M.E.; Moore, C. Finding community structure in very large networks. Phys. Rev. E 2004, 70, 066111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual web search engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E.J. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newman, M.E.J. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- dos Santos, C.K.; Evsukoff, A.G.; de Lima, B.S.L.P. Cluster analysis in document networks. In Proceedings of the Conference on Data Mining Protection, Univ Cadiz, Cadiz, Spain, 26–28 May 2008; pp. 95–104. [Google Scholar]
- Chen, P.; Xie, H.; Maslov, S.; Redner, S. Finding scientific gems with google’s PageRank algorithm. J. Informetr. 2007, 1, 8–15. [Google Scholar] [CrossRef]
- Nykl, M.; Campr, M.; Jezek, K. Author ranking based on personalized PageRank. J. Informetr. 2015, 9, 777–799. [Google Scholar] [CrossRef]
- Yu, D.J.; Wang, W.R.; Zhang, S.; Zhang, W.Y.; Liu, R.Y. A multiple-link, mutually reinforced journal-ranking model to measure the prestige of journals. Scientometrics 2017, 111, 521–542. [Google Scholar] [CrossRef]
- Egghe, L.; Rousseau, R. Co-citation, bibliographic coupling and a characterization of lattice citation networks. Scientometrics 2002, 55, 349–361. [Google Scholar] [CrossRef]
- Boyack, K.W.; Newman, D.; Duhon, R.J.; Klavans, R.; Patek, M.; Biberstine, J.R. Clustering more than two million biomedical publications: Comparing the accuracies of nine text-based similarity approaches. PLoS ONE 2011, 6, e18029. [Google Scholar] [CrossRef] [PubMed]
- Dehdarirad, T.; Villarroya, A.; Barrios, M. Research trends in gender differences in higher education and science: A co-word analysis. Scientometrics 2014, 101, 273–290. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Janssens, F.; Glänzel, W.; Moor, B.D. A hybrid mapping of information science. Scientometrics 2008, 75, 607–631. [Google Scholar] [CrossRef]
- Bafna, P.; Pramod, D.; Vaidya, A. Document clustering: TF-IDF approach. In Proceedings of the International Conference on Electrical, Electronics, and Optimization Techniques, Palnchur, India, 3–5 March 2016; pp. 61–66. [Google Scholar]





| Example | Relative Co-Citation | Relative Bibliographic Coupling | Extended Co-Citation | Extended Bibliographic Coupling | Traditional Approach | Our Proposed Approach | |
|---|---|---|---|---|---|---|---|
| (1) |  | 1/3 | 1/3 | 1/2 | 1/2 | 1/3 | 1/2 |
| (2) |  | 1/4 | 1/4 | 7/12 | 7/12 | 1/4 | 7/12 |
| (3) |  | 1/4 | 1/4 | 5/12 | 5/12 | 1/4 | 5/12 |
| (4) |  | 1/5 | 1/5 | 1/2 | 1/2 | 1/5 | 1/2 |
| Cluster (Size) | Clustering Theme |
|---|---|
| Cluster 1 (2117) | Clustering analysis; social network; big data |
| Cluster 2 (1750) | Support vector machine; prediction; neural network |
| Cluster 3 (1544) | Identification; Gene expression; Bioinformatics |
| Cluster 4 (930) | Association rule; sequential pattern; knowledge discovery |
| Cluster 5 (517) | Machine learning; prediction; decision tree |
| Cluster 6 (460) | Prediction; educational data mining; design |
| Cluster 7 (249) | Rough set; attribute reduction; approximation |
| Cluster 8 (189) | Differential privacy; k-anonymity; big data |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Zhang, S.; Zhang, W.; Yang, S.; Shen, Y. Research Front Detection and Topic Evolution Based on Topological Structure and the PageRank Algorithm. Symmetry 2019, 11, 310. https://doi.org/10.3390/sym11030310
Xu Y, Zhang S, Zhang W, Yang S, Shen Y. Research Front Detection and Topic Evolution Based on Topological Structure and the PageRank Algorithm. Symmetry. 2019; 11(3):310. https://doi.org/10.3390/sym11030310
Chicago/Turabian StyleXu, Yangbing, Shuai Zhang, Wenyu Zhang, Shuiqing Yang, and Yue Shen. 2019. "Research Front Detection and Topic Evolution Based on Topological Structure and the PageRank Algorithm" Symmetry 11, no. 3: 310. https://doi.org/10.3390/sym11030310
APA StyleXu, Y., Zhang, S., Zhang, W., Yang, S., & Shen, Y. (2019). Research Front Detection and Topic Evolution Based on Topological Structure and the PageRank Algorithm. Symmetry, 11(3), 310. https://doi.org/10.3390/sym11030310